

python笔记2--lxml.etree爬取html内容
前言
本篇继续lxml.etree学习,在线访问接口,通过接口返回的html,解析出想要的text文本内容
环境准备:
python3.7
lxml
requests
定位目标
爬取我的博客首页https://www.cnblogs.com/canglongdao/侧边个人基本信息。
打开fiddler抓包,刷新我的博客首页。抓取到的接口地址如下图。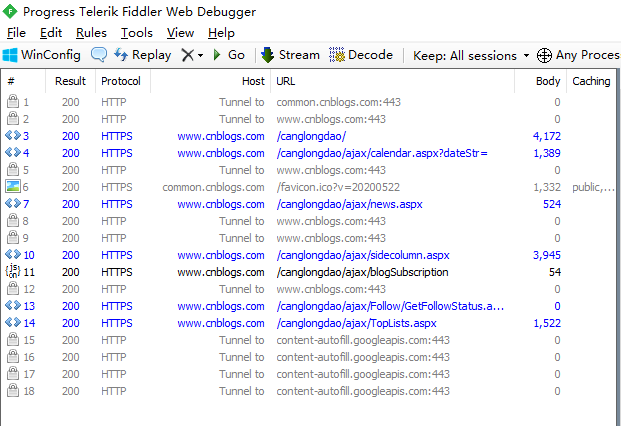
找到该接口地址https://www.cnblogs.com/canglongdao/ajax/news.aspx

# coding:utf-8
import requests
from lxml import etree
import urllib3
urllib3.disable_warnings()
url="https://www.cnblogs.com/canglongdao/ajax/news.aspx"
r=requests.get(url,verify=False)
#print(r.text)
a=etree.HTML(r.content.decode("utf-8"))
b=a.xpath("//*[@id='profile_block']")
#打印提取到的结果
r=etree.tostring(b[0],encoding="utf-8",pretty_print=True)
print(r.decode("utf-8"))
运行结果

提取内容
# coding:utf-8
import requests
from lxml import etree
import urllib3
urllib3.disable_warnings()
url="https://www.cnblogs.com/canglongdao/ajax/news.aspx"
r=requests.get(url,verify=False)
#print(r.text)
a=etree.HTML(r.content.decode("utf-8"))
b=a.xpath("//*[@id='profile_block']")
t0=b[0].xpath("text()") #获取当前节点文本元素
print(t0)
t00=t0[::2]
print(t00)
t1=b[0].xpath('a')#定位a标签的位置
print(t1)
#打印结果
for i,j in zip(t00,t1):
ii=i.replace('\n','').replace(' ','')#去掉i中的所有\n,空格
jj=j.text.replace('\n','').replace(' ','')
print(ii,jj)
运行结果
['\n 昵称:\n ', '\n ', '\n 园龄:\n ', '\n ', '\n 粉丝:\n ', '\n ', '\n 关注:\n ', '\n ', '\n ', '\n '] ['\n 昵称:\n ', '\n 园龄:\n ', '\n 粉丝:\n ', '\n 关注:\n ', '\n '] [<Element a at 0x163596090c8>, <Element a at 0x16359609048>, <Element a at 0x1635961ba08>, <Element a at 0x1635961b248>] 昵称: 星空6 园龄: 1年7个月 粉丝: 8 关注: 3
总结
1.获取当前节点标签名称.tag
print(b[0].tag) div
2.获取当前节点文本
print(b[0].text) 昵称:
3.获取当前节点元素全部属性dict
print(b[0].attrib)
{'id': 'profile_block'}
4.获取当前节点某个属性
print(b[0].get("id"))
profile_block
5.所有子节点
for i in b[0].iter():
print(i.text)
昵称:
星空6
None
1年7个月
None
8
None
3
None
getFollowStatus('fe2d40f4-c531-49cf-1c8d-08d666411c36');
6.获取当前节点下全部文本
print(b[0].xpath('text()'))
['\n 昵称:\n ', '\n ', '\n 园龄:\n ', '\n ', '\n 粉丝:\n ', '\n ', '\n 关注:\n ', '\n ', '\n ', '\n ']
7.获取本节点和子节点所有文本信息
print(b[0].xpath('.//text()'))
['\n 昵称:\n ', '\n 星空6\n ', '\n ', '\n 园龄:\n ', '\n 1年7个月\n ', '\n ', '\n 粉丝:\n ', '\n 8\n ', '\n ', '\n 关注:\n ', '\n 3\n ', '\n ', '\n ', "getFollowStatus('fe2d40f4-c531-49cf-1c8d-08d666411c36');", '\n ']
8.获取父节点
print(b[0].getparent().tag) div
# coding:utf-8
import requests
from lxml import etree
import urllib3
urllib3.disable_warnings()
url="https://www.cnblogs.com/canglongdao/ajax/news.aspx"
r=requests.get(url,verify=False)
#print(r.text)
a=etree.HTML(r.content.decode("utf-8"))
b=a.xpath("//*[@id='profile_block']")
print(b[0].tag) #div
print(b[0].text)#昵称:
print(b[0].attrib)#{'id': 'profile_block'}
print(b[0].get("id"))#profile_block
for i in b[0].iter():
print(i.text)
print(b[0].xpath('text()'))
print(b[0].xpath('.//text()'))
print(b[0].getparent().tag)
越努力,越幸运!!!
good good study,day day up!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号