

Python接口自动化(九) cookie登录,session保持,参数关联接口
cookie登录博客园,session保持,发布新博客,报错:{'errors': ['用户账号不匹配,请备份未提交的内容并检查当前登录账号'], 'type': 0}
import requests
import json
import datetime
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"
}
s=requests.session()
r=s.get("https://account.cnblogs.com/signin",headers=headers)
print(s.cookies)
coo=requests.cookies.RequestsCookieJar()
coo.set(".CNBlogsCookie","01149DC9D6D99F7CF64E77F182E602D4D3E577805A6E19097DBE74781BCE1116B43AAC32FB4F3E866D817F4D5F02262D1A923DCB04E0862237105BE89816C7DCFC143A247B072098B3EB913561395BA569B0BF3A")
coo.set(".Cnblogs.AspNetCore.Cookies","CfDJ8K5MrGQfPjpFvRyctF-QEQey8RTgWroJyR6U7XUE7o4QQl25nXngPbGcFUWC1ffclANZ_jDxB8ZeQVT4CC0k80e5KMVHEDqUtR3dM3yY8CWWDcWxt12wMStbmBY-cNDtU9ec9lSSuLYVQaJbs8sOFuoyN8YYrSeotQhp4TBWJh_uHYo6SArUbgiv1rC0pCdQlhpbVOzN6l3Qu0r-6Ykq5d-NDRI0_Z6cmffdsEXXZVmWttl5gv6u7phqvImHwOwXfblxSdeWUVk3lMGK9SySG4Ob4IvMquKVWp0PQ2hzLnCnkGwTe97swBWcCZQN-vTDkiHTb-pMj9SI_4AzbUvbbCeh_REKR1BffLxkfPSK3QDRy0xtLrkPe_imc0RSdiPhuS2bZJlvtXP4vAfZuQe6LDemeUfU4alBrjL_oc-4-BanQo0bpaTGbdT6QSlQOW_J1U4pSeiR-FjWdaMGdh9AIOoiS-PCplUVkHcs12HXreS0Iqr-MO5cIjKJZ0WaXhI87HKqJUEKGI6bbJegZBe-hkObRrdVhLGLYudesvnZesXlrtc0FV0EyQ_tvL4dmwJgDw")
coo.set("_ga","GA1.2.2037565914.1593676341")
coo.set("_gid","GA1.2.84103295.1595812422")
coo.set("SyntaxHighlighter","python")
coo.set("UM_distinctid","1738ece2b12328-0ca09f0cdf82e7-4353761-1fa400-1738ece2b13435")
s.cookies.update(coo)
print(s.cookies)
s.get("https://i.cnblogs.com/posts?cateId=1588084")
rs1=s.get("https://i.cnblogs.com/api/posts/-1")
rs1.encoding="utf-8"
print(rs1.text)
#ISO格式时间
#ddata={"postType":1,"accessPermission":0,"title":"测试7727","postBody":"<p>good good study</p>","inSiteCandidate":False,"inSiteHome":False,"isPublished":True,"displayOnHomePage":True,"isAllowComments":True,"includeInMainSyndication":True,"isPinned":False,"isOnlyForRegisterUser":False,"isUpdateDateAdded":False,"datePublished":str(datetime.datetime.utcnow().isoformat())[:-3]+'Z',"isMarkdown":False,"isDraft":True,"changePostType":False,"blogId":0,"removeScript":False,"changeCreatedTime":False,"canChangeCreatedTime":False}
ddata={"id":"","postType":1,"accessPermission":0,"title":"绿萝","url":"","postBody":"<p>哈哈哒</p>","categoryIds":"","inSiteCandidate":False,"inSiteHome":False,"siteCategoryId":"","blogTeamIds":"","isPublished":False,"displayOnHomePage":True,"isAllowComments":True,"includeInMainSyndication":True,"isPinned":False,"isOnlyForRegisterUser":False,"isUpdateDateAdded":False,"entryName":"","description":"","tags":"","password":"","datePublished":str(datetime.datetime.utcnow().isoformat())[:-3]+'Z',"isMarkdown":False,"isDraft":True,"autoDesc":"","changePostType":False,"blogId":0,"author":"","removeScript":False,"ip":"","changeCreatedTime":False,"canChangeCreatedTime":False}
hd={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36",
"Content-Type":"application/json"
}
rs2=s.post("https://i.cnblogs.com/api/posts",data=json.dumps(ddata),headers=hd)
print(rs2.json())
OPMS项目,新增简历,修改状态,参数关联,修改状态
提取id,一直在纠结有没有这种操作,虽然尝试失败了,还是留一个记号吧;re.findall(消毒液(.+?)data-id="(.+?)")
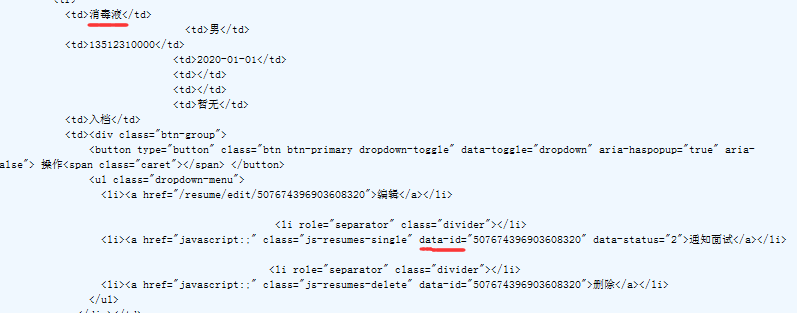
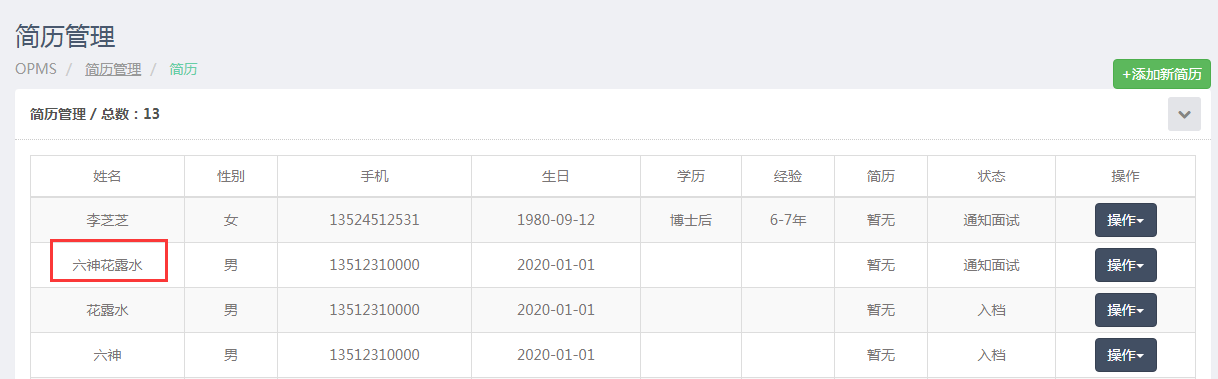
查看页面和fiddler抓包,发现新增的一直位于第2个,好吧,那提取id后,取第二个值就好了,ids[1]
import requests
import json
import re
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"
}
s=requests.session()
r=s.get("http://47.98.106.11:8088/login",headers=headers)
print(s.cookies)
coo=requests.cookies.RequestsCookieJar()
coo.set("beegosessionID","b6c11a0024f4da43ed61f33f2f0d35a3")
s.cookies.update(coo)
print(s.cookies)
rs1=s.get("http://47.98.106.11:8088/project/manage")
rs1.encoding="utf-8"
#print(rs1.text)
data1={
"realname":"六神花露水",
"phone":"13512310000",
"sex":"1",
"birth":"2020-01-01",
"status":"1",
"id":"0"
}
rs2=s.post("http://47.98.106.11:8088/resume/add",data=data1,headers=headers)
print(rs2.json())
#提取id
rs3=s.get("http://47.98.106.11:8088/resume/manage",headers=headers)
ids=re.findall(r"data-id=\"(.+?)\"\>删除",rs3.text)
print(ids)
print(ids[1])
#修改状态
data4={
"status":"2",
"id":ids[1]
}
rs4=s.post("http://47.98.106.11:8088/resume/ajax/status",data=data4,headers=headers)
print(rs4.json())
越努力,越幸运!!!
good good study,day day up!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号