

DS博客作业04--图
0.展示PTA总分

1.本周学习总结
1.1总结图内容
1.1.0图的基本概念
图的分类
-
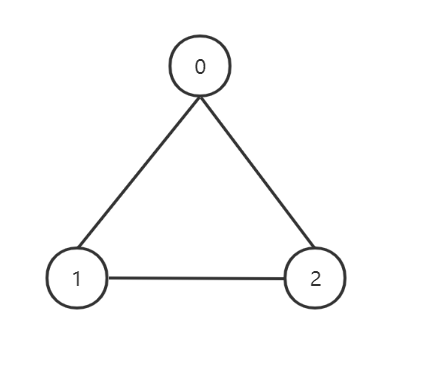
无向图
在一张图中,如果顶点之间的边没有方向(即输入时代表边的顶点对是无序的,比如输入(1,0)与(0,1)是一个意思),则称图G为无向图。如:
![]()
-
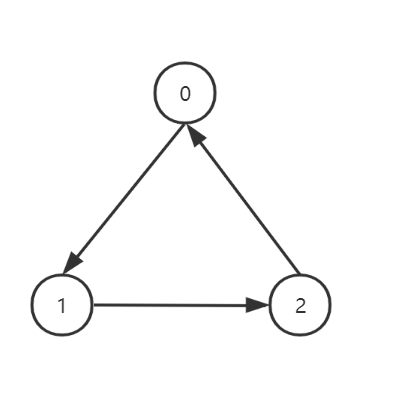
有向图
在一张图中,如果顶点之间的边有方向(即输入时代表边的顶点式有序的,这时输入(1,0)和(0,1)是不同的),则称图G为无向图。如:
![]()
图的基本术语 -
端点和邻接点
- 对于无向图,若输入一条边的信息为(i,j),那么则称顶点i与顶点j为端点,i和j互为邻接点。
- 同理。对于有向图,当输入的边的信息为(i,j)时,那么称顶点i为起始顶点,顶点j为终止顶点,i和j也互为邻接点。
- 即若两个顶点之间有边连通,则这两个顶点互为邻接点。
-
顶点的度、入度和出度
- 对于无向图,一个顶点有几条边,那么这个顶点的度就为多少。如图,点0,1,2的度均为2。
![]()
- 对于有向图,对于其中一个顶点来说,以该顶点为起始顶点的边的数目,称为改顶点的出度,这些边称为该顶点的出边;以该顶点为终止顶点的边的数目,称为该顶点的入度,这些边称为该顶点的入边。如图,点1,2,3的入度都为1,出度也都为1。
![]()
- 对于无向图,一个顶点有几条边,那么这个顶点的度就为多少。如图,点0,1,2的度均为2。
-
完全图
- 对于有n个顶点的无向图来说,有n*(n-1)/2条边的称为完全无向图。
- 对于有n个顶点的有向图来说,有n*(n-1)条边的称为完全有向图。
-
稠密图和稀疏图
- 对于一张有n个顶点的图来说,当它的边数越接近其所对应的完全图(有向和无向)时,称其为稠密图;反之,当这张图的边数远小于其所对应的完全图的边数时,称其为稀疏图。
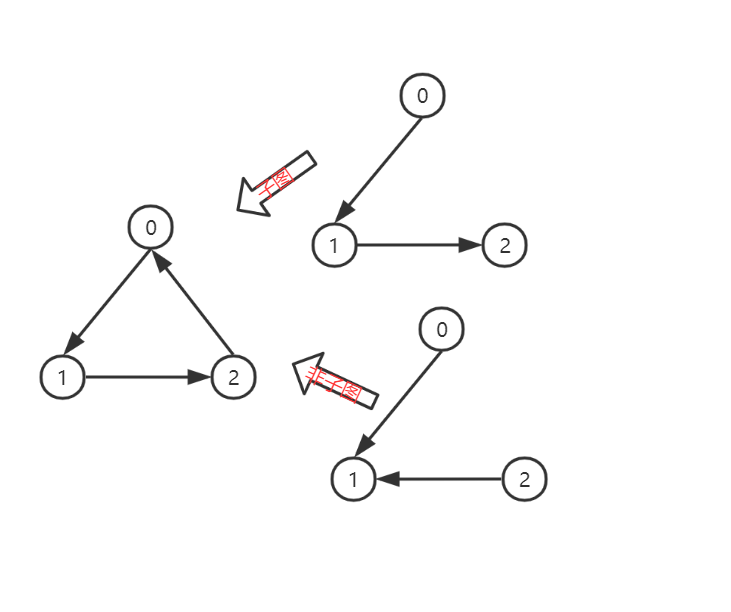
-子图
- 若有两个图G1,G2,它们所对应的边分别是N1与E1,N2与E2,如果N2与E2分别为N1与E1的子集,则称G2为G1的子图。(注:有向图还需要注意边的方向),如图所示:
-
路径和路径长度
- 在一张图中,从一个顶点到另一个顶点称为一条路径。
- 一条路径上经过的边的数目称为路径长度。
-
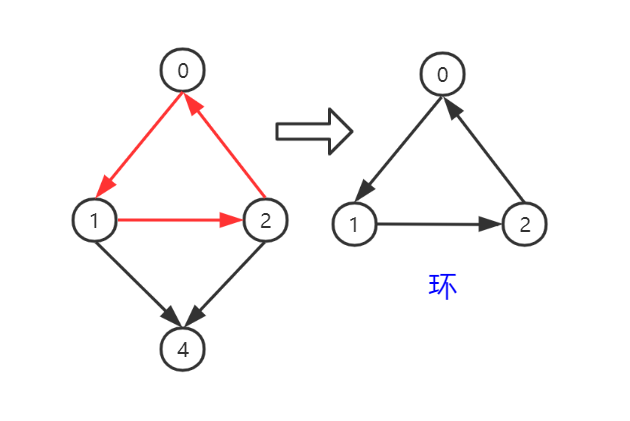
回路或环
- 当走完一条路径后,该路径的起始点和终止点为同一个顶点,那么这一条路径就被称为回路或环。
![]()
- 当走完一条路径后,该路径的起始点和终止点为同一个顶点,那么这一条路径就被称为回路或环。
-
连通、连通图和连通分量
- 对于图,若从一顶点到另一顶点有路径,则这两个顶点是连通的。
- 如果一张图中任意两个顶点均连通,则称为连通图,否则,这张图即为非连通图。
- 在图中,其极大连通子图被称为该图的连通分量。非连通图拥有至少两个连通分量,而连通图只有一个连通分量。就是其本身。
- PS:因为有向图的路径是有序的。所以在判断有向图是否为连通图时应该更加注意
-
权和网
- 一张图中的每一条边都可以附带上一个数值,称为权,通俗来说,我们都叫他边的权值。权值可以表示一个顶点到其邻接点的距离,花费等等。
- 由带权的边构成的图称为带权图,也可以叫做网。
- 通常情况下,一条边都是附带一个权值,但是在一些特殊的题目中,边的权值有可能不止一个,因此在处理这类问题时我们需要多花一些心思。
1.1.1图存储结构
图的存储结构主要有两种:邻接矩阵和邻接表。
邻接矩阵存储结构
邻接矩阵主要时利用二维数组构造矩阵用于存储顶点与顶点之间关系,如是否有边,边上带的权值为多少等等。
- 存储方式
若一个图带有n个顶点,则这个图的邻接矩阵A即为n阶方阵。
若不是带权图,输入(i,j)->顶点i和顶点j有边
1.图为无向图:
A[i][j]=A[j][i]=1;
其余:A[i][j]=A[j][i]=0;
2.图为有向图:
A[i][j]=1;
其余:A[i][j]=A[j][i]=0;
若为带权图,输入(i,j,w)->顶点i和顶点j有边,边的权值为w
1.图为无向图:
A[i][j]=A[j][i]=1;->i≠j
A[i][j]=A[j][i]=0;->i=j
其余:∞;->顶点之间没有边
2.图为有向图:
A[i][j]=1;->i≠j
A[i][j]=0;->i=j
其余:∞;->顶点之间没有边
-
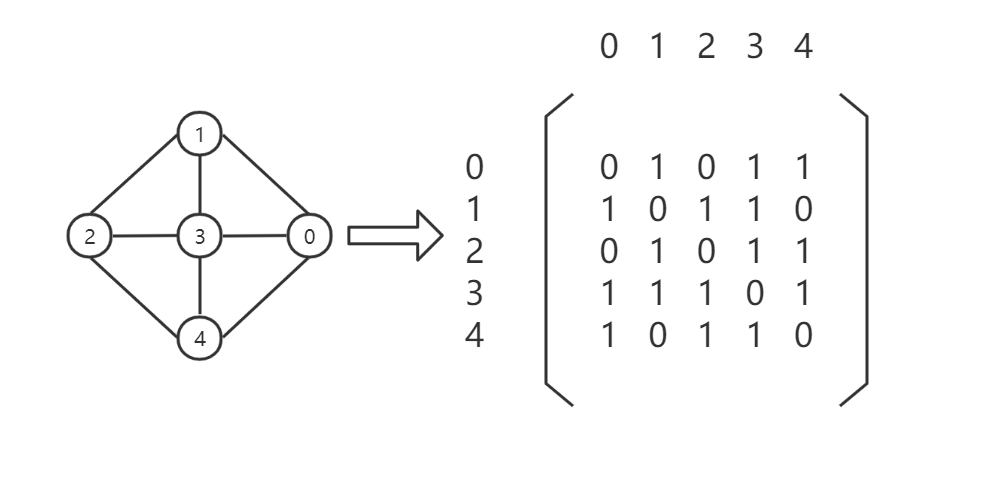
无向图的邻接矩阵存储:
![]()
-
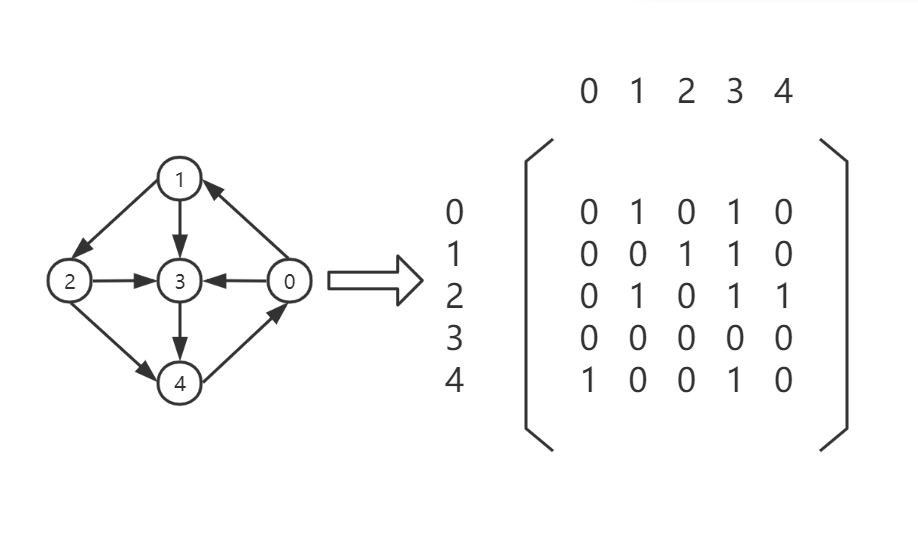
有向图的邻接矩阵存储:
![]()
-
PS:可以发现,无向图的邻接矩阵沿A[i][i]对角线对称,而有向图则不会出现对称的现象。
-
结构体定义:
#define MAXV <最大顶点个数>
typedef struct
{ int no; //顶点编号
InfoType info; //顶点其他信息
} VertexType; ->声明顶点的类型
typedef struct //图的定义
{ int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,边数
VertexType vexs[MAXV]; //存放顶点信息
} MatGraph; ->声明邻接矩阵的类型
邻接表存储结构
邻接表存储主要是运用链表的结构来对每个顶点的邻接点进行存储,但是在使用的使用需要将顺序分配与链式分配相结合来对图的信息进行储存。
- 存储方法
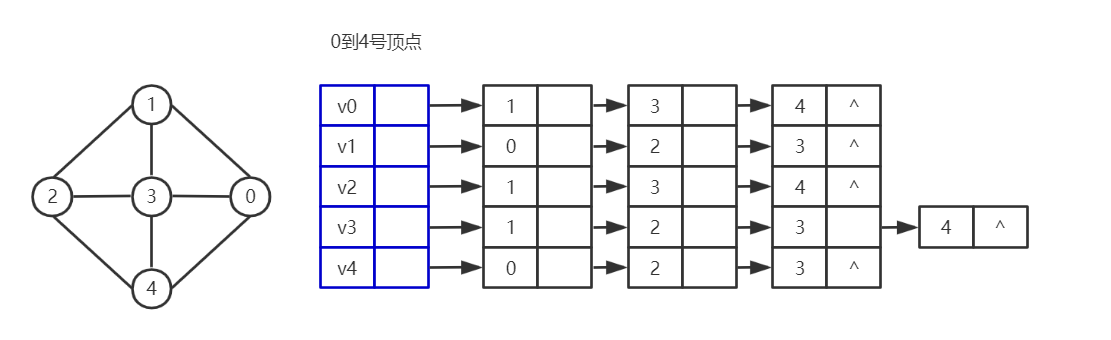
如图,分别以每个顶点作为表头结点建立一条单链表,表头结点后方的结点即为表头结点的邻接点。表头结点的信息可以利用数组的下标进行储存。
![]()
- 带权图的邻接表储存
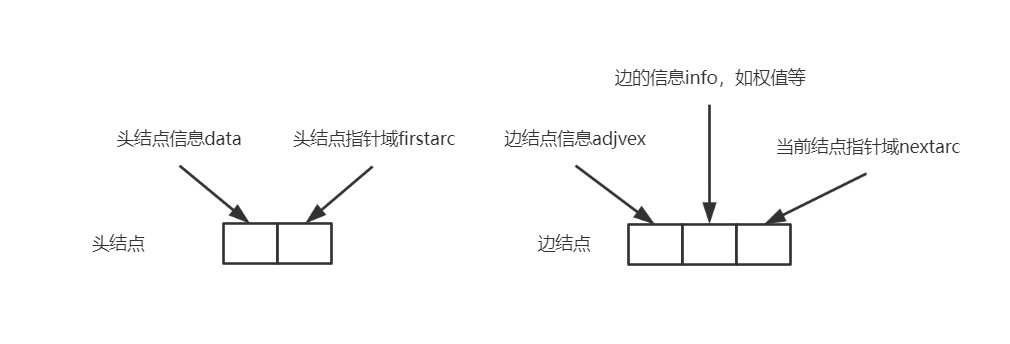
在运用邻接表的同时,我们需要同时对边的权值这样的信息进行保存,我们首先对结点进行新的定义,如图:
![]()
这样,我们在创建邻接表的时候也可以将边的信息一并储存。如图,这是一个带权图的邻接表存储:
![]()
- 结构体定义:
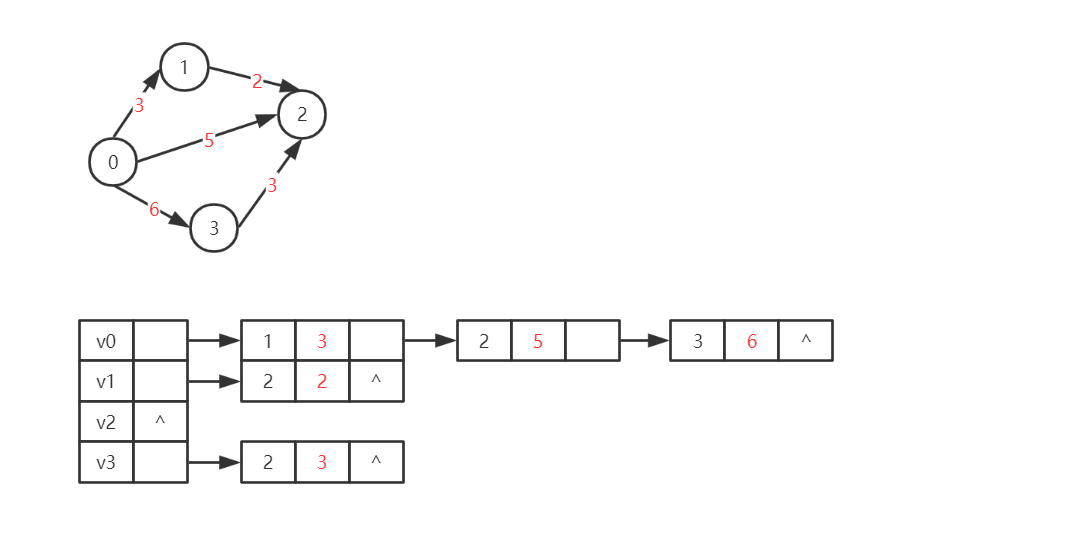
typedef struct ANode
{ int adjvex; //该边的终点编号
struct ANode *nextarc; //指向下一条边的指针
InfoType info; //该边的权值等信息
} ArcNode; ->声明边结点的类型
typedef struct Vnode
{ Vertex data; //顶点信息
ArcNode *firstarc; //指向第一条边
} VNode; ->声明头结点的类型
typedef struct
{ VNode adjlist[MAXV] ; //邻接表
int n,e; //图中顶点数n和边数e
} AdjGraph; ->声明邻接表的类型
1.1.2图遍历及应用。
图的遍历概念
从给定的图中某一点出发,沿着图的边对图的每个顶点进行访问,这个过程中对图中的所有顶点均只访问一次,直至访问完图中的所有结点。->按照遍历的顺序得到的图中顶点的序列称为图的遍历序列。
搜索方法的分类
- 根据遍历方法的不同,图的遍历一共有两种方法:
- 深度优先遍历->也称DFS
- 广度优先遍历->也称BFS
DFS和BFS
- 深度优先遍历(DFS)
- 过程:
(1) 从给定的某一点出发,先对出发点进行访问
(2) 在当前顶点的所有邻接点中选择一个未曾访问过的顶点,对其进行访问,之后重复(1)(2)步骤,直至图中的所有顶点全部被访问完 - 算法思路
(1)由上述过程可以看出,若当前结点已访问且其邻接点也均已访问,这是若是图中的所有顶点未曾全部访问。那么这个时候就需要类似倒退的操作,倒退至存在邻接点未曾访问的顶点进行另一条路径结点的访问,这里可以使用栈的后进先出的操作;同时,由上述的重复步骤操作可以看出,需要在使用栈的操作或者采用递归来进行实现。
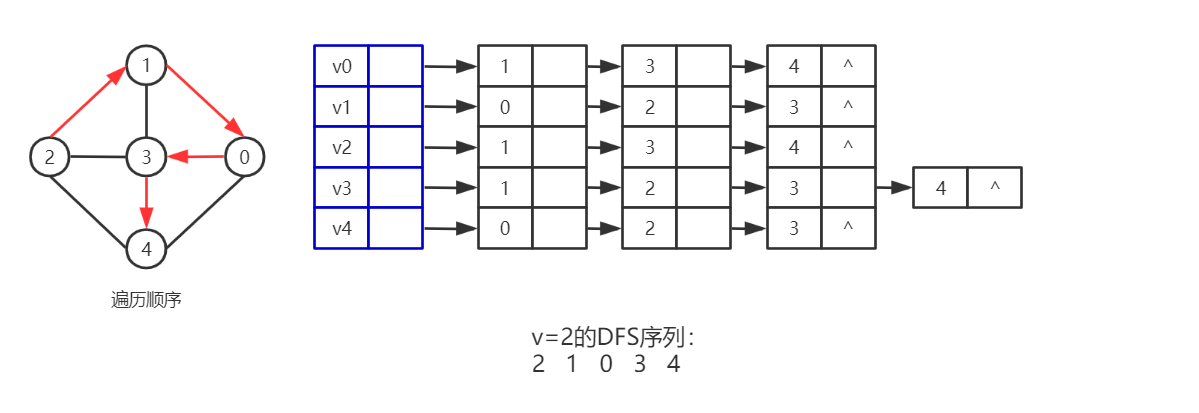
(2)为了确保已经访问过的结点不再访问,我们利用结点的编号定义一个visited[]全局数组来进行判断,开始时将数组初始化为0,待到访问到某一个结点i时,将该结点对应的visited[i]值改为1,表示该顶点已被访问过。 - 遍历过程,如图,从2号顶点开始进行遍历
![]()
- DFS的思路:距离初始顶点越远的顶点越先访问
- 代码实现(采用邻接表)
- 过程:
void DFS(AdjGraph *G,int v)
{ ArcNode *p; int w;
visited[v]=1; //置已访问标记
printf("%d ",v); //输出被访问顶点的编号
p=G->adjlist[v].firstarc; //p指向顶点v的第一条边的边头结点
while (p!=NULL)
{ w=p->adjvex;
if (visited[w]==0)
DFS(G,w); //若w顶点未访问,递归访问它
p=p->nextarc; //p指向顶点v的下一条边的边头结点
}
}
- 广度优先遍历(BFS)
-
过程
(1)从给定的初始顶点出发,接着访问所有当前结点未曾访问过的邻接点
(2)按照上述邻接点的顺序,再一次访问每一个顶点的所有未曾访问过的邻接点
(3)重复上述步骤,直至图中所有与初始点有路径连通的顶点全都被访问过 -
算法思路
(1)其实依照上述方法,不难看出,广度优先遍历的遍历过程与之前学习的二叉树的层次遍历十分类似,遍历所有邻接点与遍历二叉树结点的所有左右孩子及其的相似,因此,我们在处理树的层次遍历时使用的解法在这里也可以用同样的思路通过队列来实现。
(2)与深度优先遍历一样,广度优先遍历同样需要使用visited[]数组来对顶点是否被访问过进行判断。 -
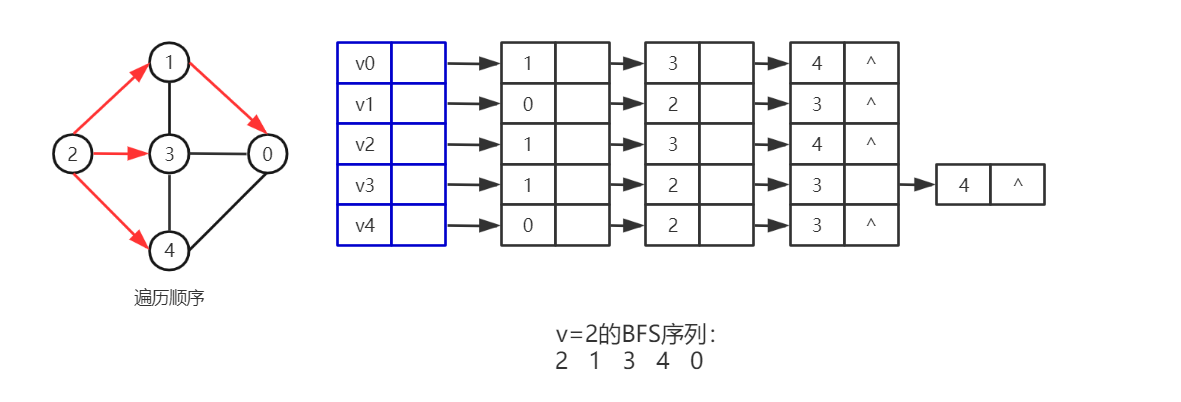
遍历过程,如图,从2号顶点开始进行遍历
![]()
-
BFS思路,距离初始顶点越近的顶点越先访问
-
代码实现
-
void BFS(AdjGraph *G,int v)
{ int w, i;
ArcNode *p;
SqQueue *qu; //定义环形队列指针
InitQueue(qu); //初始化队列
int visited[MAXV]; //定义顶点访问标记数组
for (i=0;i<G->n;i++)
visited[i]=0; //访问标记数组初始化
printf("%2d",v); //输出被访问顶点的编号
visited[v]=1; //置已访问标记
enQueue(qu,v);
while (!QueueEmpty(qu)) //队不空循环
{ deQueue(qu,w); //出队一个顶点w
p=G->adjlist[w].firstarc; //指向w的第一个邻接点
while (p!=NULL) //查找w的所有邻接点
{ if (visited[p->adjvex]==0) //若当前邻接点未被访问
{ printf("%2d",p->adjvex); //访问该邻接点
visited[p->adjvex]=1; //置已访问标记
enQueue(qu,p->adjvex); //该顶点进队
}
p=p->nextarc; //找下一个邻接点
}
}
printf("\n");
}
非连通图的遍历
由于有非连通图的存在,上述的遍历若是运用在非连通图中,只能遍历完初始给定顶点所在的连通分量,而无法遍历至所有的结点,因此,需要定义一个多次调用DFS()或者BFS()的函数
- DFS
void DFS1(AdjGraph *G)
{ int i;
for (i=0;i<G->n;i++) //遍历所有未访问过的顶点
if (visited[i]==0)
DFS(G,i);
}
- BFS
void BFS1(AdjGraph *G)
{ int i;
for (i=0;i<G->n;i++) //遍历所有未访问过的顶点
if (visited[i]==0)
BFS(G,i);
}
图遍历的应用
- 判断图是否连通
- 查找图路径
- 查找最短路径
具体分析如下:
判断图是否连通
要检查一张图是否连通,我们首先想到的是使用遍历来进行判断。有上述内容可知,非连通图在单次遍历的时候,并不会遍历完全部结点。因此,我们采用深度遍历方法,先将visited[]数组初始化为0,之后遍历图。遍历结束后根据visited[]数组的值来判断是否遍历完全图。若所有结点对应的visited[]数组值都为1,该图就是一个连通图,反之,为非连通图。
- 代码实现:
int visited[MAXV];
bool Connect(AdjGraph *G) //判断无向图G的连通性
{ int i;
bool flag=true;
for (i=0;i<G->n;i++) //visited数组置初值
visited[i]=0;
DFS(G,0); //调用前面的中DSF算法,从顶点0开始深度优先遍历
for (i=0;i<G->n;i++)
if (visited[i]==0)
{ flag=false;
break;
}
return flag;
}
如何查找图路径
查找图路径,我们利用的是DFS算法。
- 基础思路:从给定顶点进行DFS遍历,直至搜索到目标顶点时停止,即代表两点之间存在路径。这时,我们可以定义一个函数用于递归判断,最后返回
flase或者true来进行怕判断是否有路径。代码如下:
void ExistPath(AGraph *G,int u,int v,bool &has)
{ //has表示u到v是否有路径,初值为false
int w; ArcNode *p;
visited[u]=1; //置已访问标记
if (u==v) //找到了一条路径
{ has=true; //置has为true并结束算法
return;
}
p=G->adjlist[u].firstarc; //p指向顶点u的第一个相邻点
while (p!=NULL)
{ w=p->adjvex; //w为顶点u的相邻顶点
if (visited[w]==0) //若w顶点未访问,递归访问它
ExistPath(G,w,v,has);
p=p->nextarc; //p指向顶点u的下一个相邻点
}
}
- 上述代码只用于判断是否有路径存在,如果我们需要得到路径,思路和上面的差不多,定义一个path数组用于存储初始顶点和目标顶点之间的路径,当寻找到目标顶点是输出即可,但这只能得到一条路径。我们继续改进代码,若是需要得到所有路径。大致步骤如图:
![]()
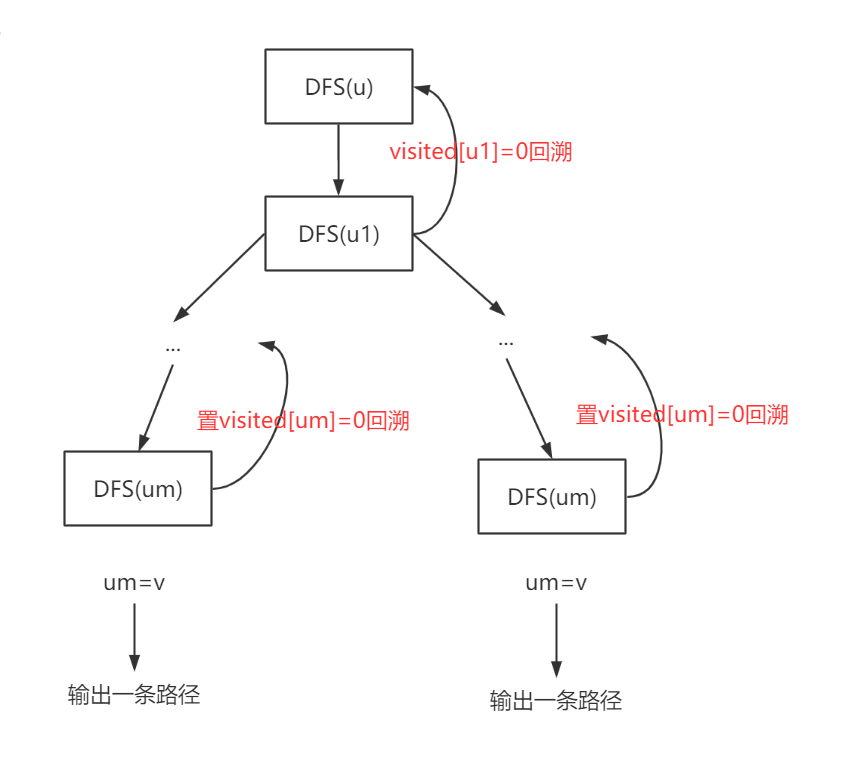
注意:每找到一条路径就需要回复环境,使下一次寻找是顶点仍可用。
- 代码实现:
void FindAllPath(AGraph *G,int u,int v,int path[],int d)
{ //d表示path中的路径长度,初始为-1
int w,i; ArcNode *p;
d++; path[d]=u; //路径长度d增1,顶点u加入到路径中
visited[u]=1; //置已访问标记
if (u==v && d>=1) //找到一条路径则输出
{ for (i=0;i<=d;i++)
printf("%2d",path[i]);
printf("\n");
}
p=G->adjlist[u].firstarc; //p指向顶点u的第一个相邻点
while (p!=NULL)
{ w=p->adjvex; //w为顶点u的相邻顶点
if (visited[w]==0) //若w顶点未访问,递归访问它
FindAllPath(G,w,v,path,d);
p=p->nextarc; //p指向顶点u的下一个相邻点
}
visited[u]=0;
}
如何找最短路径
在上述的内容中,我们查找路径运用的是DFS算法,并能够查找到多条路径,那么,怎么查找两个顶点之间的最短路径呢?在查找最短路径的问题方面,我们采用的是BFS算法。
利用广度优先算法的思想:离初始点越近的点越先遍历,因此,我们将路径进行分层,根据最短路径来分解层数,一层层向外寻找最短路径。
- 代码实现
void ShortPath(AdjGraph *G,int u,int v)
{ //输出从顶点u到顶点v的最短逆路径
ArcNode *p; int w,i;
QUERE qu[MAXV]; //定义非循环队列
int front=-1, rear=-1; //队列的头、尾指针
int visited[MAXV];
for (i=0;i<G->n;i++) //访问标记置初值0
visited[i]=0;
rear++; //顶点u进队
qu[rear].data=u;
qu[rear].parent=-1;
visited[u]=1;
while (front!=rear) //队不空循环
{ front++; //出队顶点w
w=qu[front].data;
if (w==v)
{ i=front;
while (qu[i].parent!=-1)
{ printf("%2d ",qu[i].data);
i=qu[i].parent;
}
printf("%2d\n",qu[i].data);
break;
}
p=G->adjlist[w].firstarc; //找w的第一个邻接点
while (p!=NULL)
{ if (visited[p->adjvex]==0)
{ visited[p->adjvex]=1;
rear++; //将w的未访问过的邻接点进队
qu[rear].data=p->adjvex;
qu[rear].parent=front;
}
p=p->nextarc; //找w的下一个邻接点
}
}
}
1.1.3最小生成树相关算法及应用
生成树的概念
在一张连通图中,它的一个极小连通子图就是他的一棵生成树。一棵生成树含有图中所有的顶点和用于构成一棵完整树的(n-1)条边。由此也可以推出->生成树加上一条边即可构成一个环。
由不同的遍历方法得到的生成树可能是不同的,由同种方法生成的生成树也可能是不同的,即:一张连通图的生成树并不是唯一的。
最小生成树
对与一张带权连通图,可能会有多棵生成树,每棵树的所有边的权值之和也会不同,而其中权值和最小的生成树被称为该图的最小生成树。(可以类比于树中的哈夫曼树)
生成最小生成树的算法
- Prim算法
-
具体过程
(1)生成两个已选点集合U和未选点集合V-U,选取初始顶点v,初始化U={v},U-V集合中未其余未选中顶点,v到其他所有顶点的边记为侯选边;
(2)选取侯选边中权值最小的边输出,同时将该边对应的另一个顶点选入集合U中;
(3)继续考察V-U中的所有顶点到U中所有顶点的边,把他们记为侯选边,接着重复(2)(3)步骤
(4)直至所有顶点都被选完为止 -
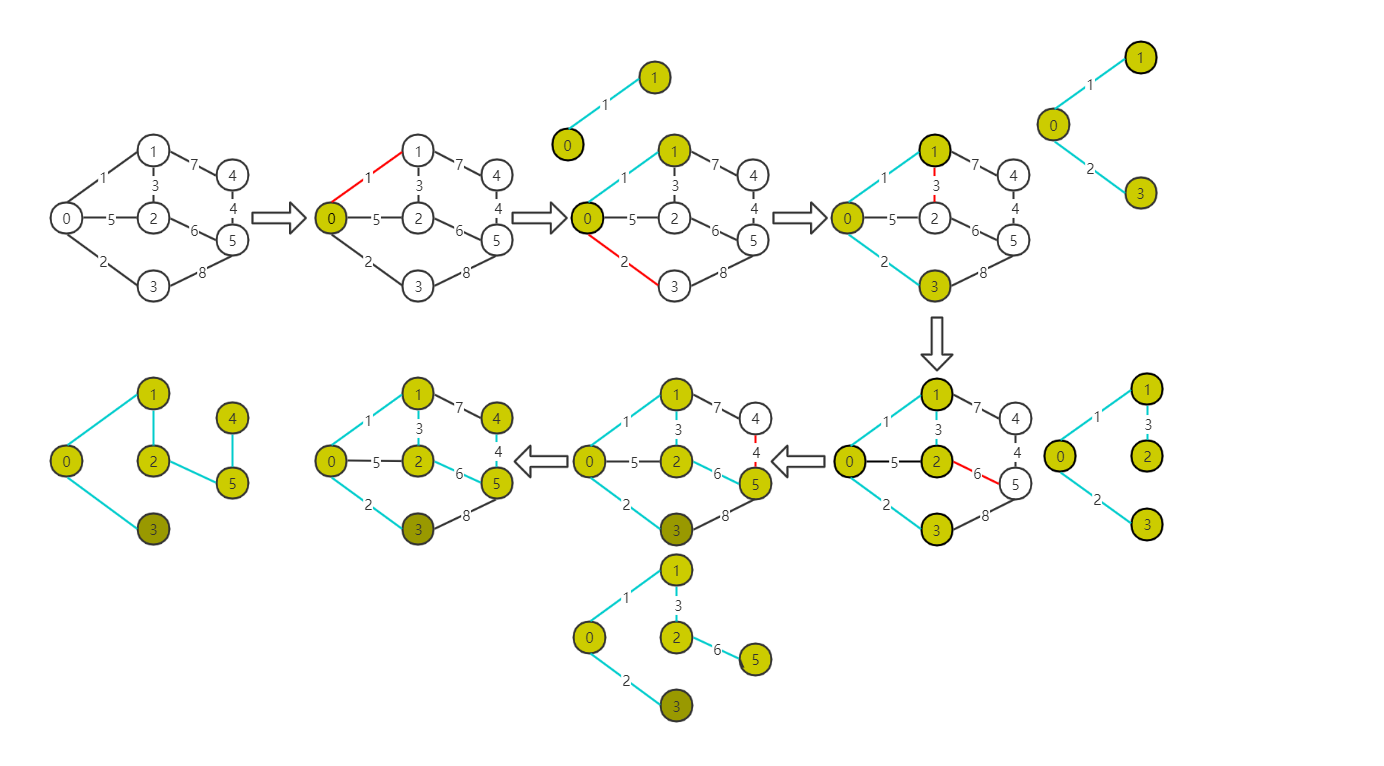
图示过程
![]()
-
算法思路:
依据上述过程,我们可以想到,算法的核心就是选取U和V-U两个顶点集合之间的最小边。因此我们分别定义clost[]数组用来储存顶点的最小边,lowcost[]数组用来储存权值,通过访问与已选择结点有边的未选择结点的边的权值,选出最小的那条所对应的顶点,加入到U集合中,依次递推。->所以,Prim算法其实有着贪心算法的影子,利用贪心算法进行局部最优的挑选,再进行局部调整,最后得到了全局最优解。 -
代码实现
-
#define INF 32767 //INF表示∞
void Prim(MatGraph g,int v)
{ int lowcost[MAXV];
int min;
int closest[MAXV], i, j, k;
for (i=0;i<g.n;i++) //给lowcost[]和closest[]置初值
{ lowcost[i]=g.edges[v][i];
closest[i]=v;
}
for (i=1;i<g.n;i++) //输出(n-1)条边
{ min=INF;
for (j=0;j<g.n;j++) //在(V-U)中找出离U最近的顶点k
if (lowcost[j]!=0 && lowcost[j]<min)
{ min=lowcost[j];
k=j; //k记录最近顶点编号
}
printf(" 边(%d,%d)权为:%d\n",closest[k],k,min);
lowcost[k]=0; //标记k已经加入U
for (j=0;j<g.n;j++) //修改数组lowcost和closest
if (lowcost[j]!=0 && g.edges[k][j]<lowcost[j])
{ lowcost[j]=g.edges[k][j];
closest[j]=k;
}
}
}
- Kruskal算法
-
具体过程
(1)共有n个顶点,将图中的所有顶点加入顶点集V中,令边集合TE为空集。
(2)将图中的所有边按照权值大小进行排序,之后由小到大依次选取
(3)判断所选边,若是所选边使树生成了回路,则舍弃,否则将边加入边集合TE,直至TE中包含了(n-1)条边为止。 -
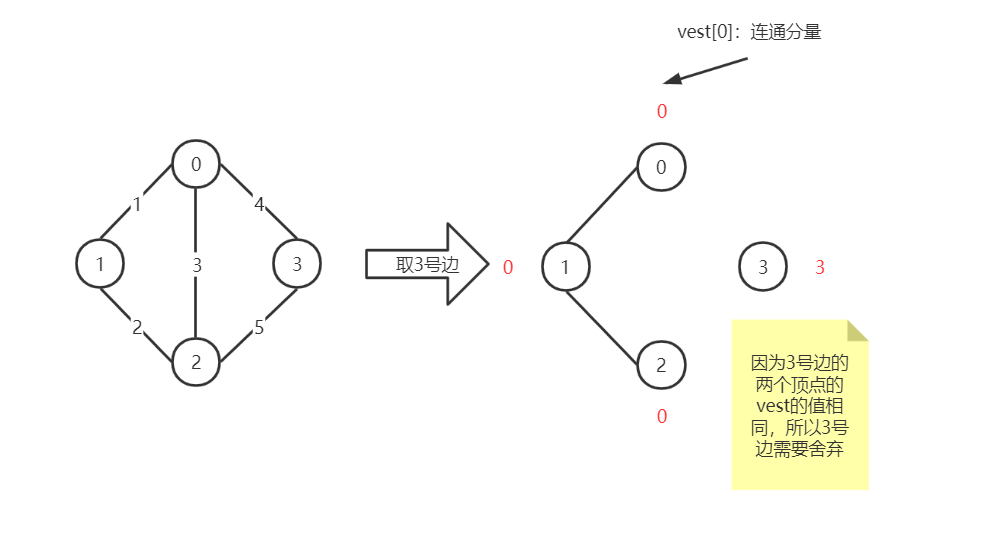
关于如何解决回路问题
为了解决选取边时可能出现的回路问题,我们这里采用连通分量编号或者顶点集合编号来进行处理,如图所示:
![]()
-
结构体定义和代码实现:
-
typedef struct
{ int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
} Edge;
void Kruskal(MatGraph g)
{ int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV];
Edge E[MaxSize]; //存放所有边
k=0; //E数组的下标从0开始计
for (i=0;i<g.n;i++) //由g产生的边集E
for (j=0;j<g.n;j++)
if (g.edges[i][j]!=0 && g.edges[i][j]!=INF)
{ E[k].u=i; E[k].v=j; E[k].w=g.edges[i][j];
k++;
}
InsertSort(E,g.e); //用直接插入排序对E数组按权值递增排序
for (i=0;i<g.n;i++) //初始化辅助数组
vset[i]=i;
k=1; //k表示当前构造生成树的第几条边,初值为1
j=0; //E中边的下标,初值为0
while (k<g.n) //生成的边数小于n时循环
{
u1=E[j].u;v1=E[j].v; //取一条边的头尾顶点
sn1=vset[u1];
sn2=vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1!=sn2) //两顶点属于不同的集合
{ printf(" (%d,%d):%d\n",u1,v1,E[j].w);
k++; //生成边数增1
for (i=0;i<g.n;i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
}
1.1.4最短路径相关算法及应用
路径的概念和最短路径
在上述内容中提到,边的权值通常来说可以代表路径的长度,收费额等等信息,在这里,对于一张带权有向图,我们把这张图上一条路径所经过的所有边的权值之和定义为该路径的路径长度或者陈称为带权路径长度。
而从起始点到终点的路径不可能只有一条,因此我们把所有路径中长度最短的那条路径称作最短路径。
单源路径的最短路径算法:Dijkstra算法
-
具体过程
(1)定义两个集合,分别为以求处最短路径的顶点集合S和未求出最短路径的集合U,初始时S中 只有一个出发点v,其初始最短路径为0,而U中的顶点j与v的距离为边上的权值(v与j有边,即v和j互为邻接点)或者为∞(v与j无边,即v与j不互为邻接点);
(2)在U中选择距离v最小的那个顶点u,并把该顶点加入到集合S中;
(3)以新加入的顶点u为新的中心点,对未选择顶点集合U中各顶点的最短路径长度进行修改,若此时从出发点v经过u到U中新的顶点i的路径长度比原先直接从v->i的路径长度短,则修改到顶点j的最短路径长度,并把j加入到S中;
(4)重复(2)(3)步骤,直至U中顶点全部被选完。 -
设计思路
有了具体过程,我们就可以来思考算法的设计。根据上面的过程,我们可以知道,我们需要的两个重要的结果:路径长度和路径。因此,我们定义dist[]数组用于存放最短路径长度和path[]``数组用于存放最短路径。 在进行上述选取的过程中,path```数组用于保存当前路径中当前顶点的上一个顶点的信息。如图:
![]()
-
代码实现:(以v为出发点)

void Dijkstra(MatGraph g,int v)
{ int dist[MAXV],path[MAXV];
int s[MAXV];
int mindis,i,j,u;
for (i=0;i<g.n;i++)
{ dist[i]=g.edges[v][i]; //距离初始化
s[i]=0; //s[]置空
if (g.edges[v][i]<INF) //路径初始化
path[i]=v; //顶点v到i有边时
else
path[i]=-1; //顶点v到i没边时
}
s[v]=1;
for (i=0;i<g.n;i++) //循环n-1次
{ mindis=INF;
for (j=0;j<g.n;j++)
if (s[j]==0 && dist[j]<mindis)
{ u=j;
mindis=dist[j];
}
s[u]=1; //顶点u加入S中
for (j=0;j<g.n;j++) //修改不在s中的顶点的距离
if (s[j]==0)
if (g.edges[u][j]<INF && dist[u]+g.edges[u][j]<dist[j])
{ dist[j]=dist[u]+g.edges[u][j];
path[j]=u;
}
}
Dispath(dist,path,s,g.n,v); //输出最短路径
}
多源最短路径问题:Floyd算法
-
算法核心:通过迭代(即递推)来进行演算
若一张有向图采用邻接矩阵进行存储,这时我们设置一个二维数组A来存放顶点之间的有关信息,A[i][j]代表当前顶点i到顶点j的最短路径长度。 -
设计思路
- 利用二维数组A储存最短路径长度
- 利用二维数组path来存放最短路径 -
代码实现
void Floyd(MatGraph g) //求每对顶点之间的最短路径
{ int A[MAXVEX][MAXVEX]; //建立A数组
int path[MAXVEX][MAXVEX]; //建立path数组
int i, j, k;
for (i=0;i<g.n;i++)
for (j=0;j<g.n;j++)
{ A[i][j]=g.edges[i][j];
if (i!=j && g.edges[i][j]<INF)
path[i][j]=i; //i和j顶点之间有一条边时
else //i和j顶点之间没有一条边时
path[i][j]=-1;
}
for (k=0;k<g.n;k++) //求Ak[i][j]
{ for (i=0;i<g.n;i++)
for (j=0;j<g.n;j++)
if (A[i][j]>A[i][k]+A[k][j]) //找到更短路径
{ A[i][j]=A[i][k]+A[k][j]; //修改路径长度
path[i][j]=path[k][j]; //修改最短路径为经过顶点k
}
}
}
1.1.5拓扑排序和关键路径
拓扑排序
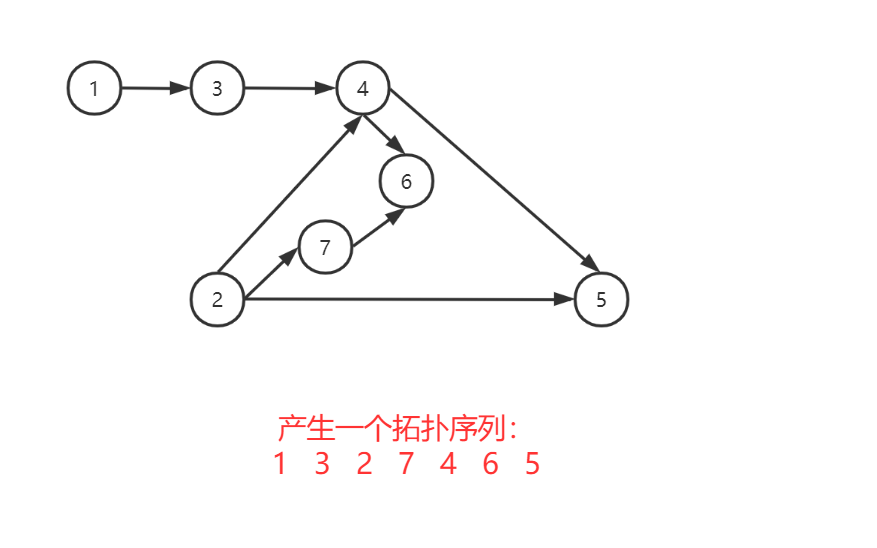
首先,在一个有向图中,若顶点序列v1->...->vn满足若i->j有一条路径则i必须排在j的前面,则称其为拓扑序列;而在一个有向图中找一个拓扑序列的过程,我们称为拓扑排序。
- 排序步骤
(1)在图中选择一个没有前驱(入度为0)的顶点作为起始点,输出起始点
(2)从图中删除此顶点同时删去该顶点的所有出边(即从该顶点出发的有向边)
(3)重复上述的(1)(2)步,直至图中没有顶点(不存在没有前驱的点)
![]()
- 结构体定义
typedef struct //表头结点类型
{ Vertex data; //顶点信息
int count; //存放顶点入度
ArcNode *firstarc; //指向第一条边
} VNode;
- 代码实现:
void TopSort(AdjGraph *G) //拓扑排序算法
{ int i,j;
int St[MAXV],top=-1; //栈St的指针为top
ArcNode *p;
for (i=0;i<G->n;i++) //入度置初值0
G->adjlist[i].count=0;
for (i=0;i<G->n;i++) //求所有顶点的入度
{ p=G->adjlist[i].firstarc;
while (p!=NULL)
{ G->adjlist[p->adjvex].count++;
p=p->nextarc;
}
}
for (i=0;i<G->n;i++) //将入度为0的顶点进栈
if (G->adjlist[i].count==0)
{ top++;
St[top]=i;
}
while (top>-1) //栈不空循环
{ i=St[top];top--; //出栈一个顶点i
printf("%d ",i); //输出该顶点
p=G->adjlist[i].firstarc; //找第一个邻接点
while (p!=NULL) //将顶点i的出边邻接点的入度减1
{ j=p->adjvex;
G->adjlist[j].count--;
if (G->adjlist[j].count==0) //将入度为0的邻接点进栈
{ top++;
St[top]=j;
}
p=p->nextarc; //找下一个邻接点
}
}
}
- 总结
1. 在我看来,拓扑排序更适合使用邻接表进行存储,因为邻接表特殊的存储方式,可以很明白的读出每个顶点的入度并进行统计。
2. 同时,由上述步骤代码可以知道,拓扑排序最后输出的序列用于无环图,若是有向有环图,则无法成功的进行拓扑排序->那么反之,我们可以利用拓扑排序进行对一张有向图的判断。利用拓扑排序对图进行排序,结束后可以遍历图中顶点,若是出现有顶点的入度不为0(存在前驱),那么就代表这张图是一个有向有环图。
关键路径
- AOE网
在学习关键路径之前,我们需要先了解AOE网。我们可以使用一张带权有向图来描述一个工程的预计进度。图中顶点代表事件,边代表了活动,边的权值代表完成该活动所需的时间。我们令入度为0的顶点表示这个工程的开始事件,出度为0的顶点代表工程结束事件。 - 关键路径
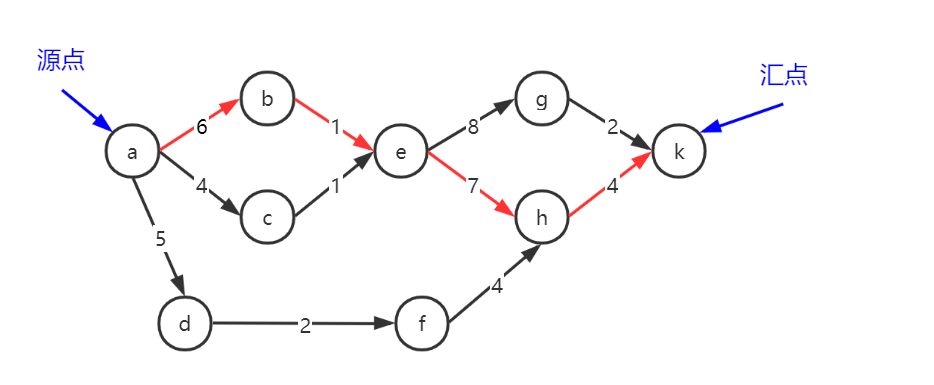
在AOE网中,从顶点到终点的最长路径,我们称之为关键路径,路径上的事件活动被称为关键活动。由于各个活动所需的时间不一定相同,所以一张带权有向图的关键路径可能不唯一。如图:
![]()
- 求解关键路径
可以看出,关键路径可以转变成查找图中最长路径问题,我们前面所学的Dijlstra算法用于求解最短路径,因此并不适用。我们求解关键路径的办法是求解AOE网中的关键活动。 - 求解过程
(1)事件的最早开始和最迟开始时间
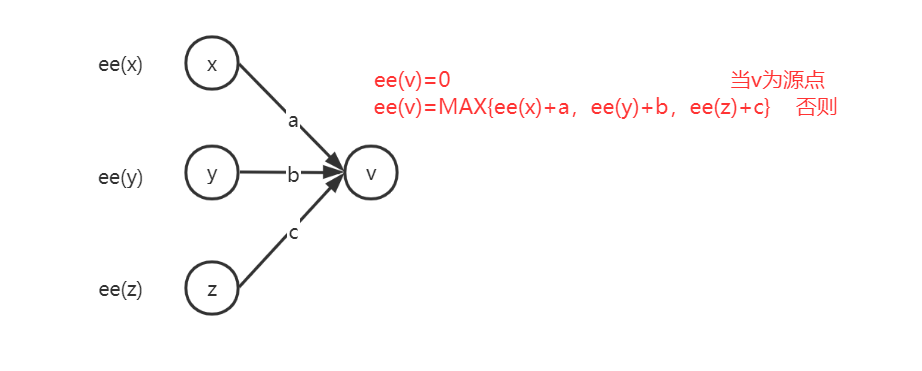
时间v的最早开始时间ee(v):若为源点时间,则最早开始时间为0;若为任意一点v,则为所有到v点的路径长度的最大值。如图:
![]()
事件v的最迟开始时间:定义在不影响整个工程进度的前提下事件v必须发生的时间称为事件v的最短开始时间le(v)。le(v)等于ee(y)与汇点的最长路径 长度之差
![]()
(2)活动的最早开始时间和最迟开始时间
![]()
(3)求关键活动
如上述,求得活动a的最早开始时间ee(a)和最迟开始时间le(a),此时可以求出d(a)=le(a)-ee(a),若d(a)=0的话,则称a为关键活动->即对于关键活动来说,不能存在富余的时间。如图:
![]()

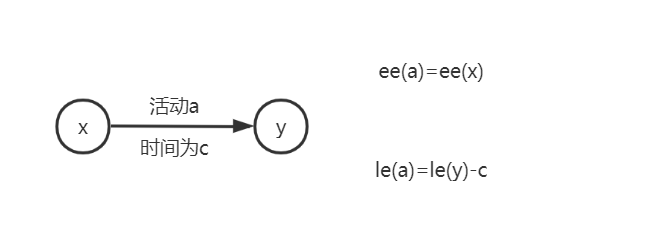

1.2谈谈你对图的认识及学习体会
在我看来,对比起前一章节的树的话,图在结构体的定义方面会稍加简单,在写pta的题的时候,感觉不用像树那样频繁的利用递归来解决问题。但是经过这段时间的学习,可以发现,我们已经开始接触和学习一些算法的知识了,在刚开始接触的时候,感觉算法有些不太好理解,尤其是在Floyd算法,感觉自己都不是特别懂这个算法的原理。在练习方面还需要多多加强。同时,和树差不多,图的题目也会和栈,队列等内容较多的结合,因此,我在做题,复习的时候也可以对前面的知识有较多的巩固。总之,学习不应该是单板块,我们在学习新知识的同时,也需要对曾经学过的知识进行进一步的巩固。
2.阅读代码,
2.1 题目及解题代码
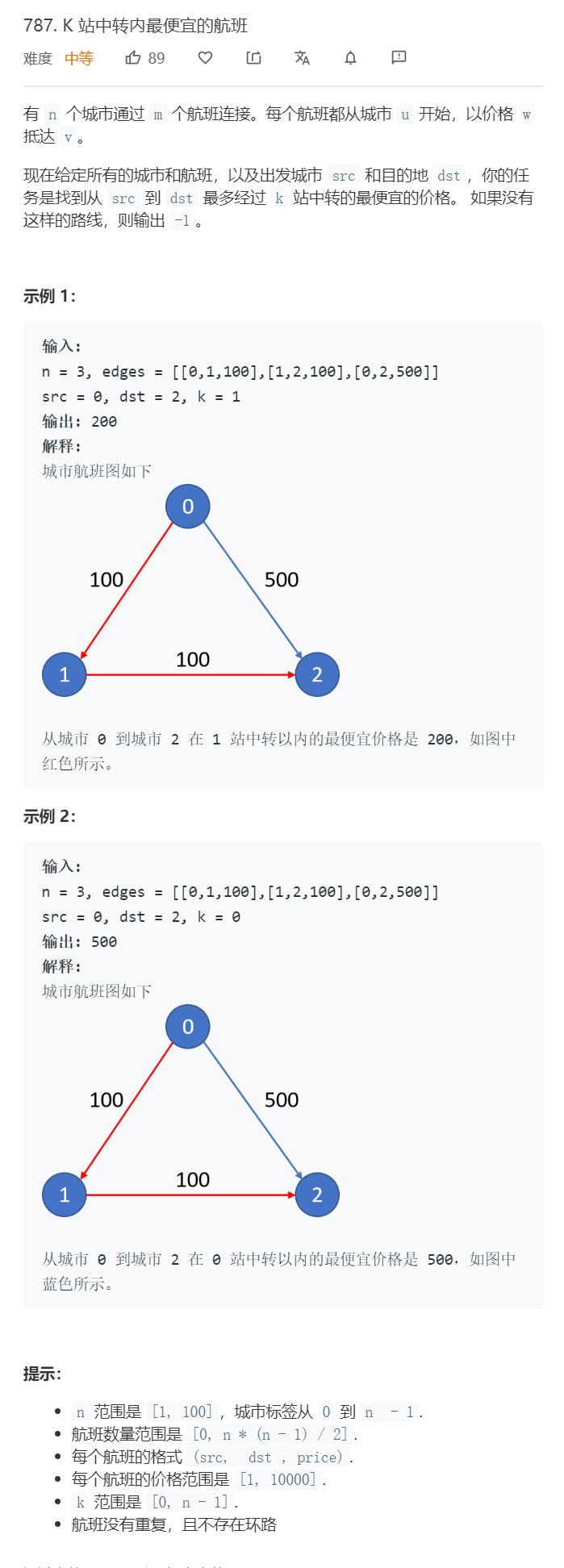

2.1.1 该题的设计思路
- 求取经过k个中转站所需的最小花费,实际上,题目就是已经给我们限定了路径距离,而我们要做的就是求取限定距离中,边权值和最小的路径的权值之和。所以,这道题其实可以认为是一道稍加变形的最短路径问题
- 关于最短路径的求解,本题采用的是Dijkstra 算法,在开始查找时,我们每次查找的其实都是最小花费的航线,因此,在查找的过程中,如果查找到某个城市时,它的k(即中转次数)已经过多,那么则不必继续搜索下去,否则,当查找到目标城市的时候,此时的花费就是最小花费。
2.1.2该题的伪代码
class Solution {
public int findCheapestPrice(int n, int[][] flights, int src, int dst, int K) {
定义优先队列PriorityQueue<int[]> pq = new PriorityQueue<int[]>((a, b) -> a[0] - b[0]);
pq.offer(new int[]{0, 0, src});
while 队列不为空,do {
取队首int[] info = pq.poll();
变量赋值int cost = info[0], k = info[1], place = info[2];
if 中转的次数大于K,且原先路线的花费更低
停止搜索当前城市continue;
if 搜索到目标城市
返回此时的花费金额return cost;
for nei = 0 to n do
if graph数组对应的值>0
重新定义花费进行计算int newcost = cost + graph[place][nei];
if 从nei结点城市出发的航线花费更低
该结点入队也进行搜索
将newcost置入best容器中
end if
end for
end while
return -1;
}
}
- 时间复杂度:O(e+n㏒n)->e为航线的数量
- 空间复杂度:O(n)
2.1.3运行结果


2.1.4分析该题目解题优势及难点
- 优势
(1)首先采用了我们熟悉的Dijkstra算法,因此在阅读代码的时候对我们来说会使代码变得有迹可循,增加代码的可读性。
(2)同时运用了优先队列进行搜索,提高了代码的效率. - 难点
(1)因为题目限定了k,也就是说限定了最短路径中的顶点个数,因此,我们按照Dijkstra算法所求出来的路径可能并不是题目要求的最短路径,所以在中间我们需要对k进行判断,以防止k超出题目的限制
(2)![]() 题解中的这一点我在阅读代码的时候并没有考虑到,这个点使得我们再求取花费最小路径时搜索的范围扩大,不至于漏掉某些成本更低的道路。
题解中的这一点我在阅读代码的时候并没有考虑到,这个点使得我们再求取花费最小路径时搜索的范围扩大,不至于漏掉某些成本更低的道路。
 题解中的这一点我在阅读代码的时候并没有考虑到,这个点使得我们再求取花费最小路径时搜索的范围扩大,不至于漏掉某些成本更低的道路。
题解中的这一点我在阅读代码的时候并没有考虑到,这个点使得我们再求取花费最小路径时搜索的范围扩大,不至于漏掉某些成本更低的道路。2.2 题目及解题代码
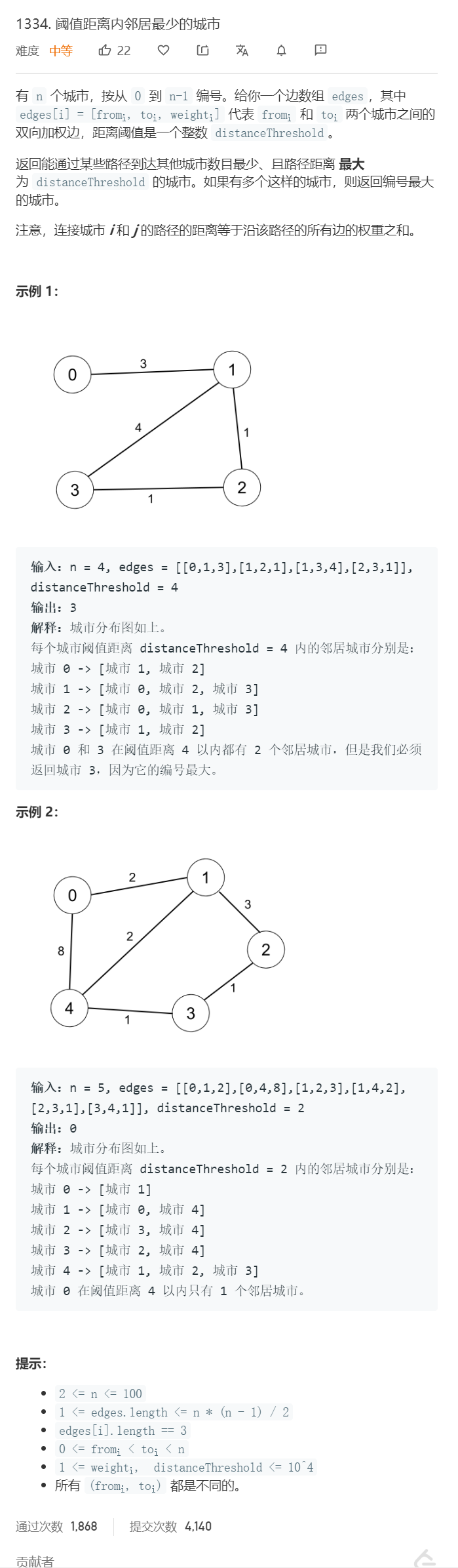

2.2.1 该题的设计思路
- 从题解的代码来看,因为我们需要算出每个城市在符合在阈值距离内的城市的个数,所以很明显的看出这份代码运用了Floyd算法。
- 通过邻接矩阵来对顶点之间的信息进行保存,D[i][j]用于保存顶点i到顶点j的距离,在遍历n个顶点的过程中,若通过某个顶点到达目标的距离更近,则更新顶点距离
2.2.2该题的伪代码
class Solution {
public:
int findTheCity(int n, vector <vector<int>> &edges, int distanceThreshold) {
定义矩阵D,并对其初始化为INT_MAX(无穷)
for循环初始化邻接矩阵D
end for
for k = 0 to n - 1 do
一次插入结点
for i = 0 to n - 1 do
for j = 0 to n - 1 do
if i == j 或者i与k没有邻接或者k与j没有邻接 then
continue;
end if
选择最短的路径对D矩阵进行更新
end for
end for
end for
定义能到达其它城市最少的城市ret
int minNum = INT_MAX;
for i = 0 to n - 1 do
初始化 cnt = 0;
for j = 0 to n - 1 do
if i != j 且 距离在阈值范围内
cnt++;
end if
end for
if 当前顶点阈值内的城市数 <= minNum then
修正minNum = cnt;
记录此时的城市编号ret = i;
end if
end for
return ret;
}
};
时间复杂度:O(n^2)
空间复杂度:O(n^2)
2.2.3运行结果


2.2.4分析该题目解题优势及难点
- 优势
(1)巧妙的运用Floyd算法的动态规划对题目进行求解,提高代码的可读性和效率 - 难点
(1)在前期对数据的处理,怎么存储,运用什么算法,
(2)在确定了使用Floyd算法后,这个核心的操作怎么实现,尤其是哪三层循环怎么处理,我也是在看完了题解之后才知道每个顶点的插入必须放在第一层循环,这样做是为了归纳得到状态转移方程。
2.3 题目及解题代码


2.3.1 该题的设计思路
- 思路很清晰,和图着色运用的方法类似,即邻接点之间不能采用相同的花,那么本题在这里也是采用了邻接表的办法。
- 从第一个花园开始走,访问其所有的邻接点,如果其邻接点有花,将这种花从color{}中删去,删完之后从color{}中随机选取一种花进行种植,直至遍历完所有花园
2.3.2该题的伪代码
for循环建立邻接表
for i=0 to paths.size()-1 do
G[paths[i][0]-1].push_back(paths[i][1]-1);
G[paths[i][1]-1].push_back(paths[i][0]-1);
end for
初始化全部花园未种花answer(N,0);
for i=0 to N-1 do
每次循环都要初始化color
for j=0 to G[i].size()-1 do
从color中删除已经种过的花color.erase(answer[G[i][j]]);//把已染过色的去除
end for
对当前顶点种花answer[i]=*(color.begin());
end for
return answer;
}
};
时间复杂度:O(N)
空间复杂度:O(N),N均为花园的个数
2.3.3运行结果
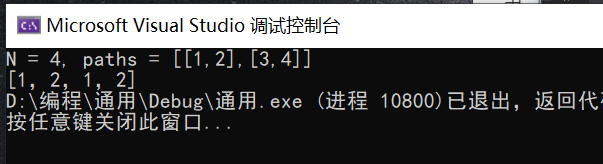
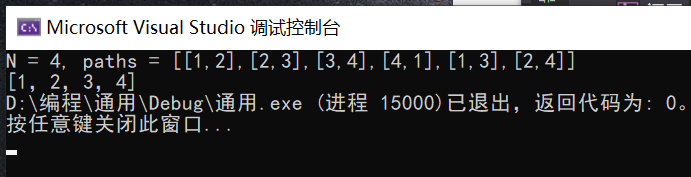
2.3.4分析该题目解题优势及难点
- 优势
(1)没有使用算法进行遍历顶点而是直接采用邻接表进行储存,便于访问邻接点的花的种类,使得代码无论是从代码量还是运行效率都有了大大的提高。 - 难点
(1)本题的难点在于color{}的定义,运用删除已有花的种类来巧妙的进行判断,这个点不易想到和 实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号