第四次作业
大数据第四次作业
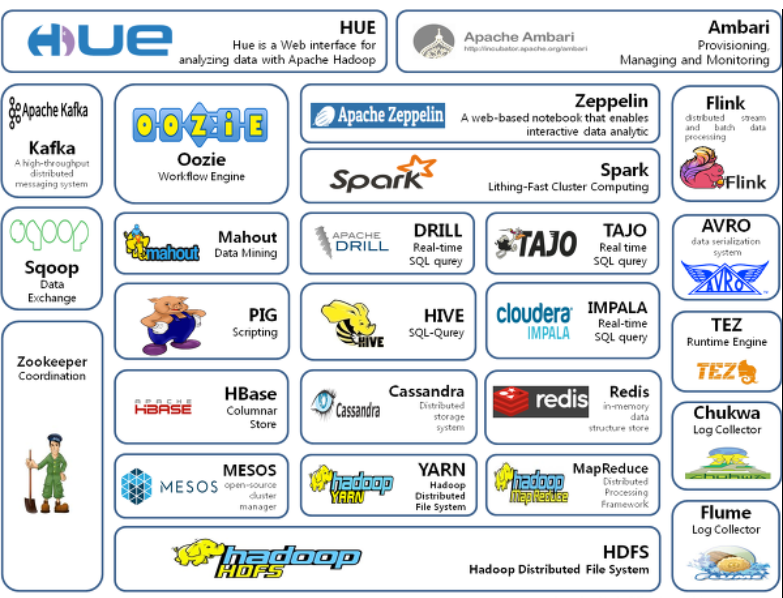
(Hadoop生态圈)
1.用图文简要描述Hadoop起源与发展阶段。
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。
2.用图文简要描述名称节点、数据节点的主要功能及相互关系。
名称节点:作为中心服务器是整个文件系统的管理节点,维护着整个文件系统的文件目录树、文件/目录的元数据(Metadata)和每个文件对应的数据块列表,还接收用户的操作请求。
数据节点:是一个节点运行一个数据节点进程,提供真实文件数据的存储服务,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、复制和删除等操作。
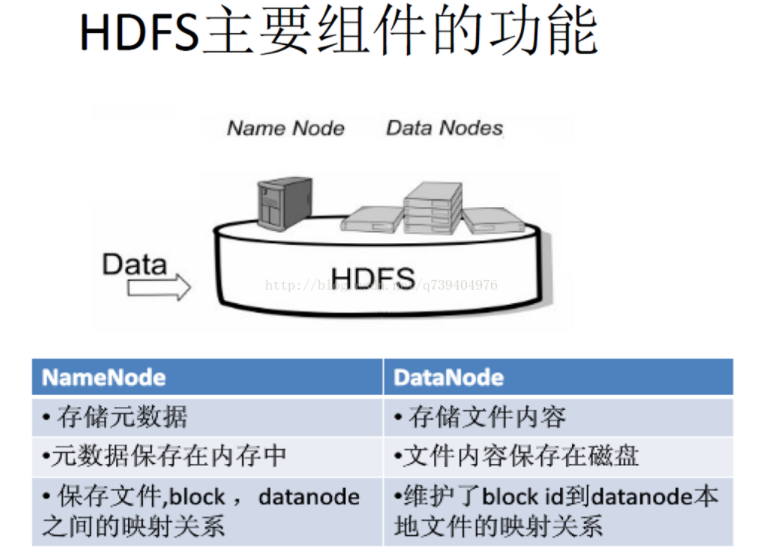
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
HDFS整体架构:
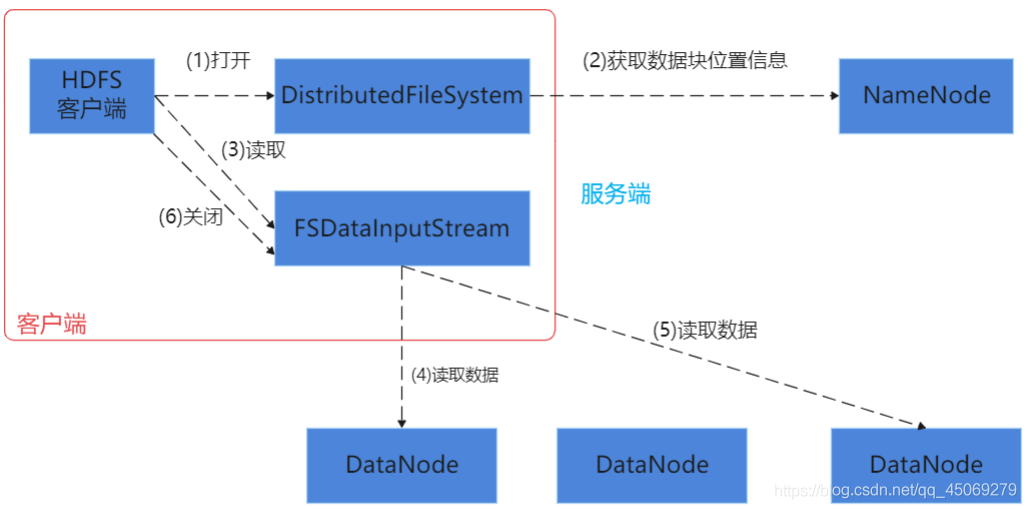
客户端读:
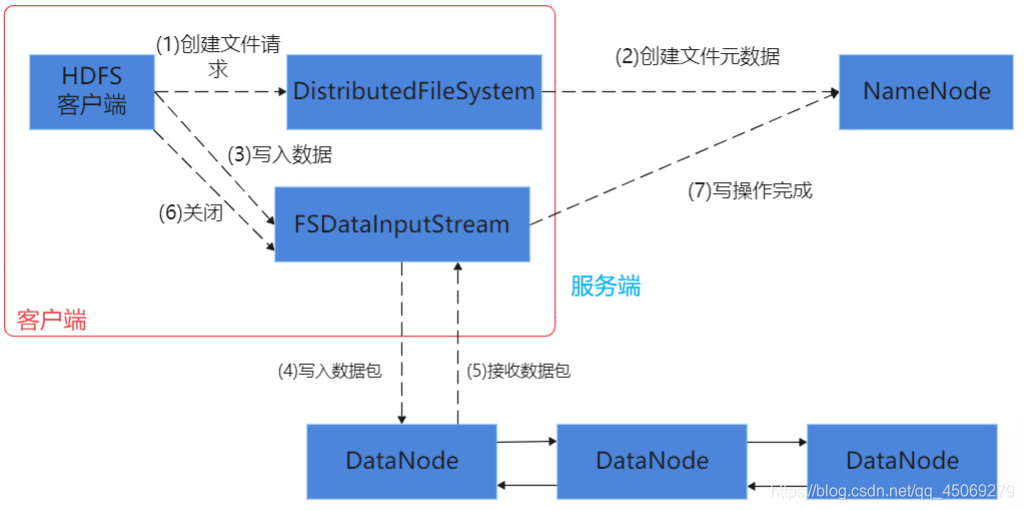
客户端写:
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
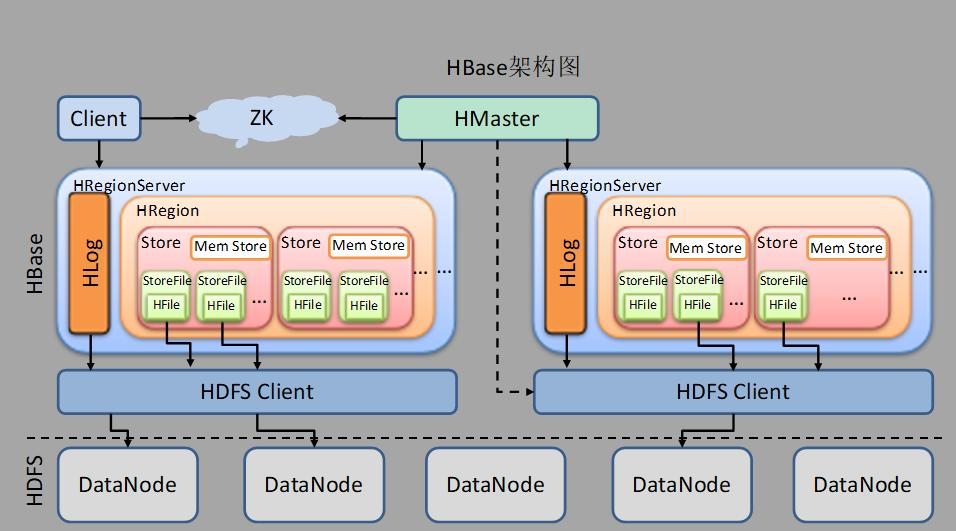
Master 功能:
1、为 RegionServer 分配 Region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 Region
4、HDFS 上的垃圾文件(HBase)回收
5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
RegionServer功能:
1、RegionServer 维护 Master 分配给它的 Region,处理对这些 Region 的 IO 请求
2、RegionServer 负责 Split 在运行过程中变得过大的 Region,负责 Compact 操作
ZooKeeper功能:
1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
2、存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
Client请求流程:
Client 访问用户数据前需要首先访问 ZooKeeper,找到-ROOT-表的 Region 所在的位置,然 后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过 client 端会做 cache 缓存。
与HDFS关联:
HBase是一个内存数据库,而hdfs是一个存储空间;是物品和房子的关系。HBase 参考了 Google 公司的 Bigtable 建模,而 Bigtable 是基于 GFS 来完成数据的分布式存储的,因此,HBase 与 HDFS 有非常紧密的关系,它使用 HDFS 作为底层存储系统。
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号