

大数据第四次作业
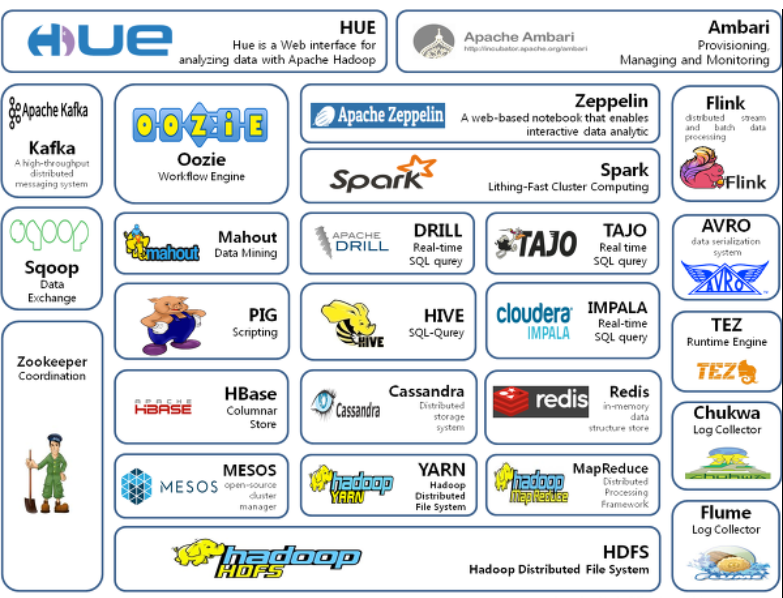
(Hadoop生态圈)
1.用图文简要描述Hadoop起源与发展阶段。
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。
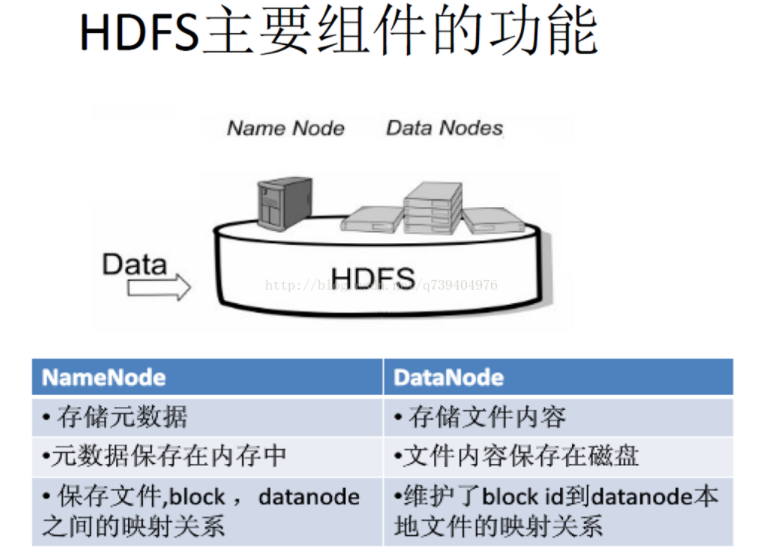
2.用图文简要描述名称节点、数据节点的主要功能及相互关系。
名称节点:作为中心服务器是整个文件系统的管理节点,维护着整个文件系统的文件目录树、文件/目录的元数据(Metadata)和每个文件对应的数据块列表,还接收用户的操作请求。
数据节点:是一个节点运行一个数据节点进程,提供真实文件数据的存储服务,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、复制和删除等操作。
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
HDFS整体架构:
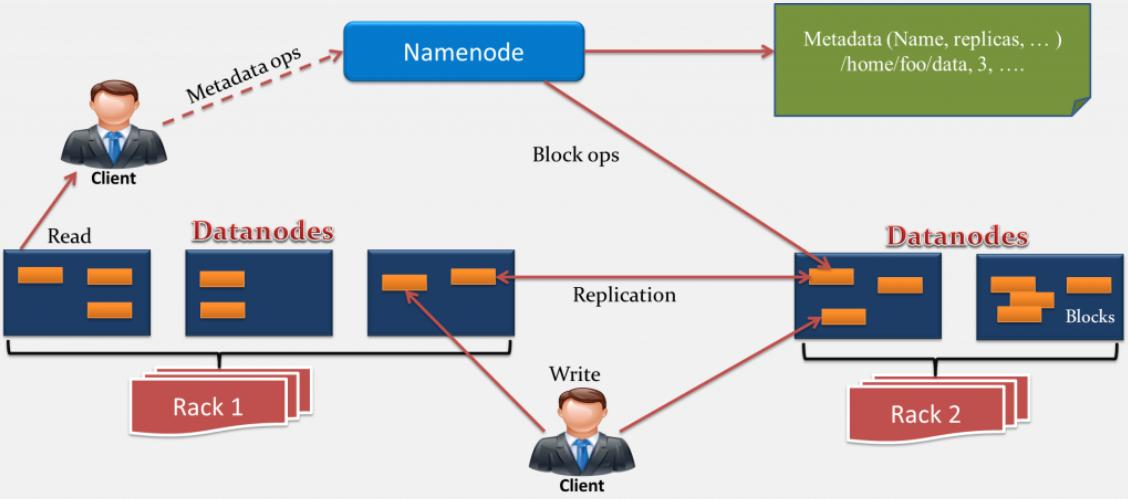
客户端读:
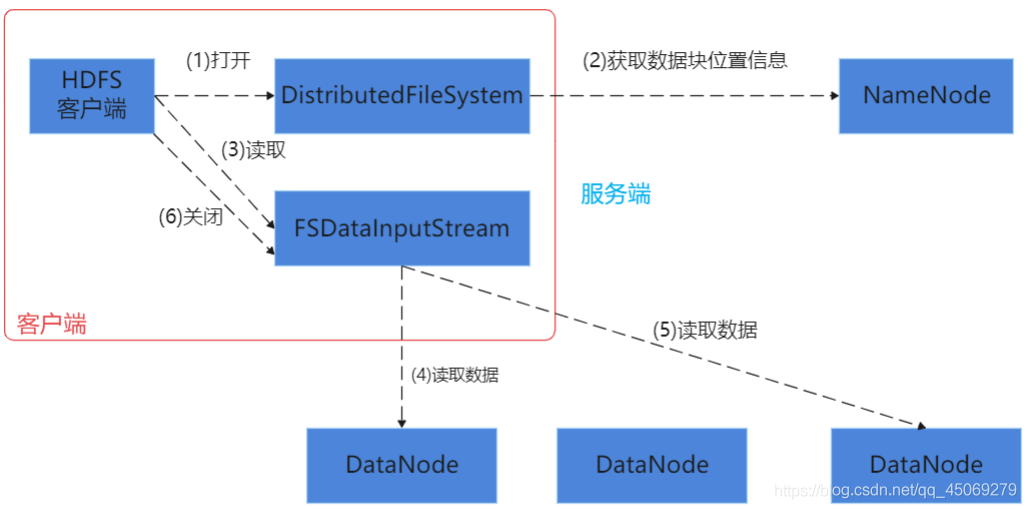
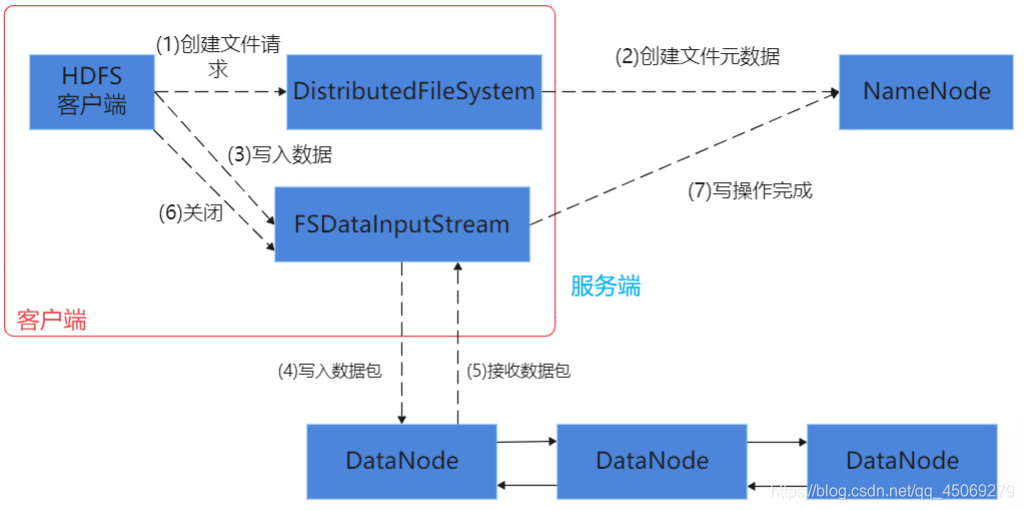
客户端写:
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
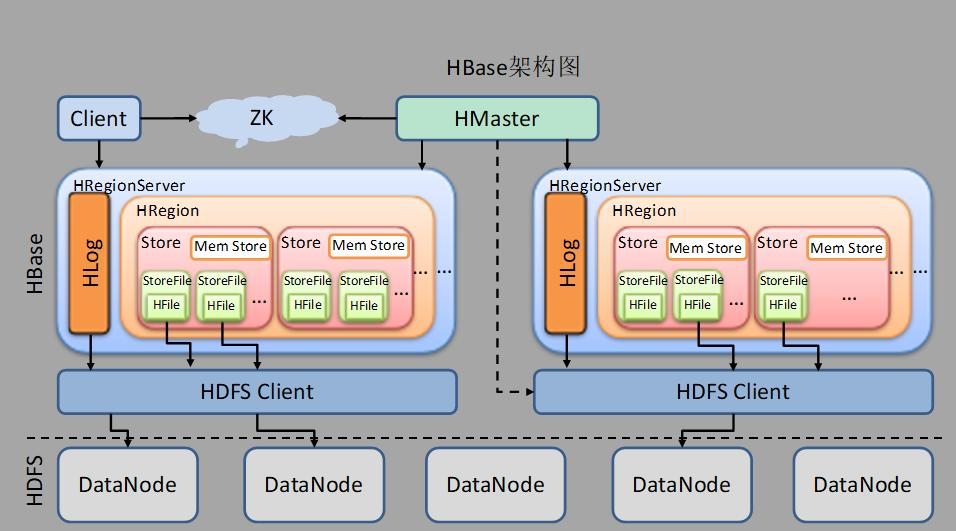
Master 功能:
1、为 RegionServer 分配 Region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 Region
4、HDFS 上的垃圾文件(HBase)回收
5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
RegionServer功能:
1、RegionServer 维护 Master 分配给它的 Region,处理对这些 Region 的 IO 请求
2、RegionServer 负责 Split 在运行过程中变得过大的 Region,负责 Compact 操作
ZooKeeper功能:
1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
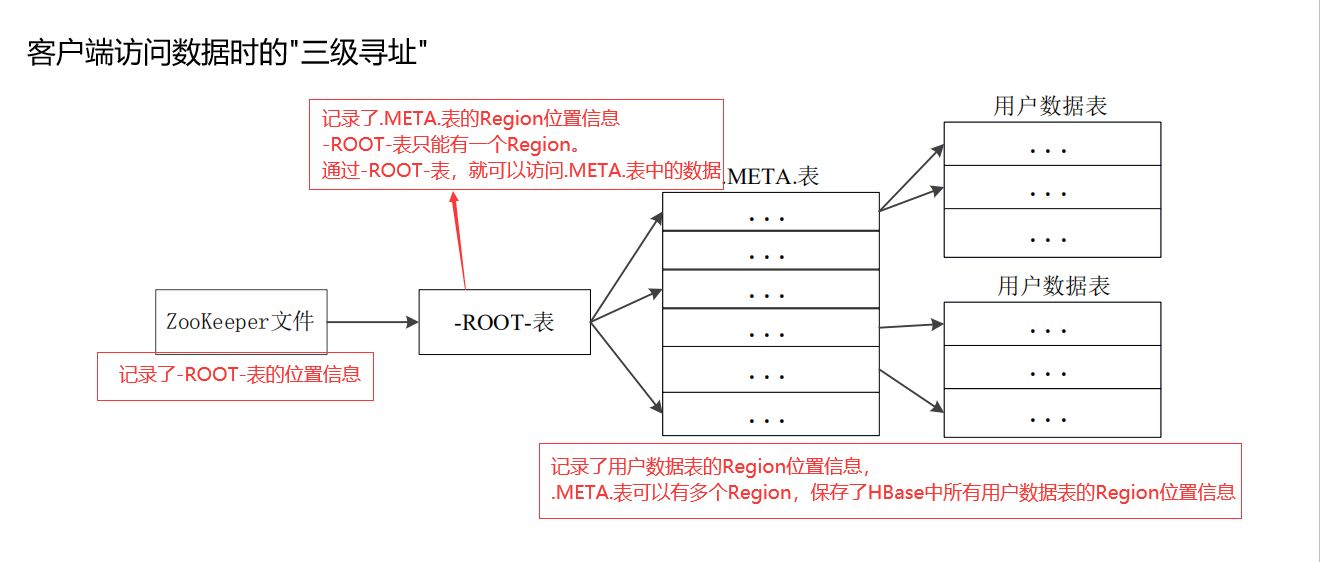
2、存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
Client请求流程:
Client 访问用户数据前需要首先访问 ZooKeeper,找到-ROOT-表的 Region 所在的位置,然 后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过 client 端会做 cache 缓存。
与HDFS关联:
HBase是一个内存数据库,而hdfs是一个存储空间;是物品和房子的关系。HBase 参考了 Google 公司的 Bigtable 建模,而 Bigtable 是基于 GFS 来完成数据的分布式存储的,因此,HBase 与 HDFS 有非常紧密的关系,它使用 HDFS 作为底层存储系统。
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。
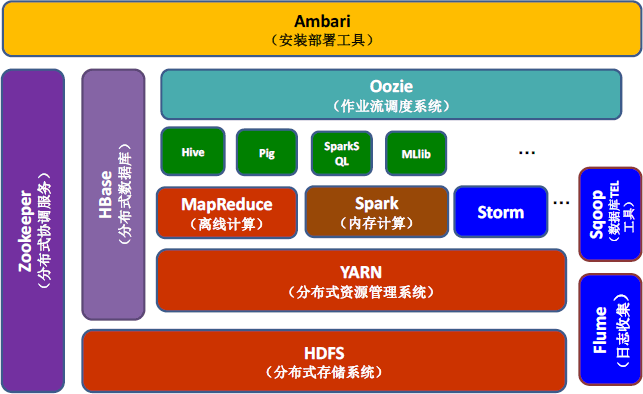
5.理解并描述Hbase表与Region与HDFS的关系。
hbase的客户端不同行为,导致了region的不同状态的变迁:
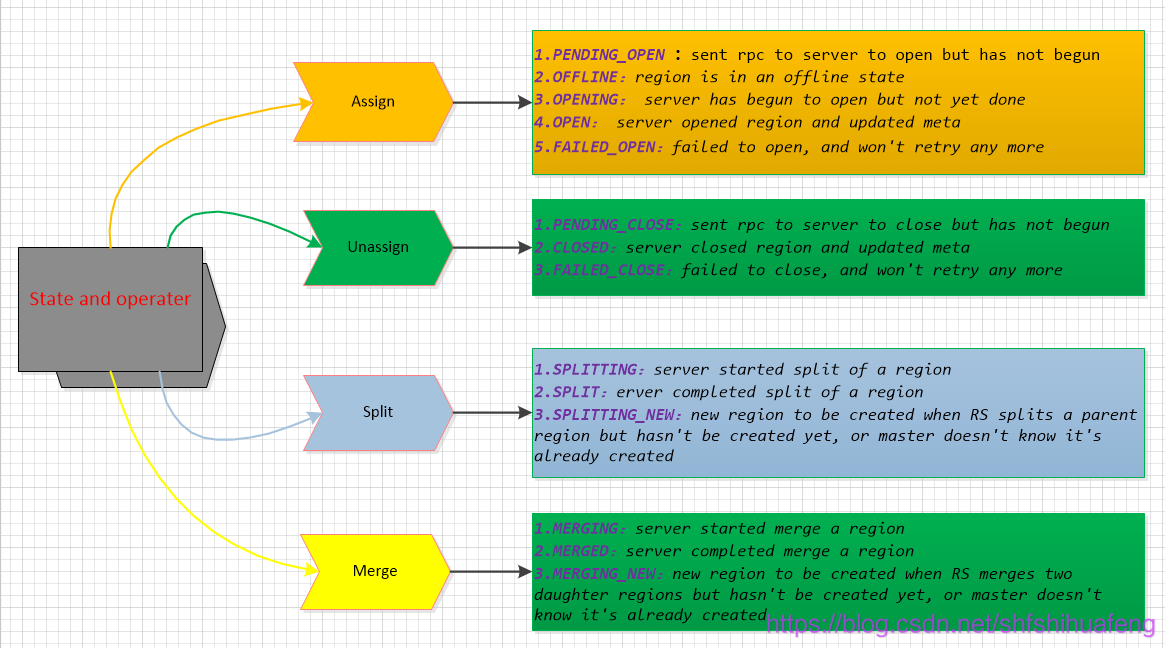
6.理解并描述Hbase的三级寻址。
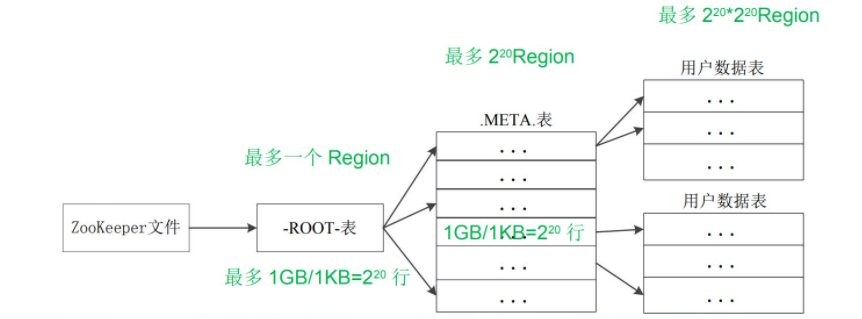
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
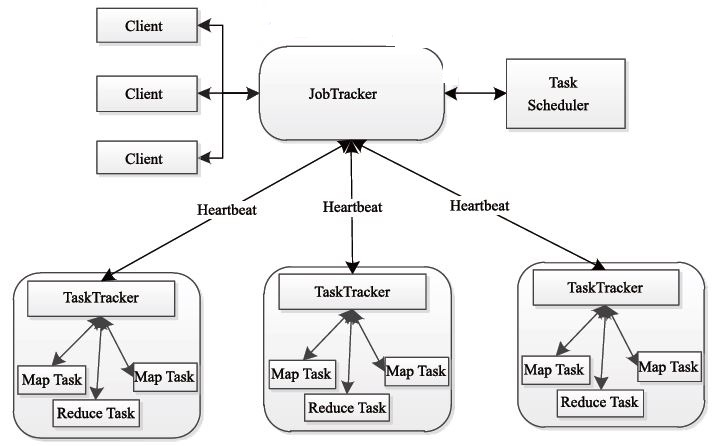
MapReduce包括四个组成部分,分别为Client、JobTracker、TaskTracker和Task,下面我们具体介绍这四个组成部分。
1)Client client
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置參数 Configuration 打包成 JAR 文件存储在 HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和 ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。
2)JobTracker
JobTracke负责资源监控和作业调度。
JobTracker 监控全部TaskTracker 与job的健康状况。一旦发现失败,就将相应的任务转移到其它节点。同一时候。JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空暇时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块。用户能够依据自己的须要设计相应的调度器。
3)TaskTracker
TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的执行进度汇报给JobTracker,同一时候接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
TaskTracker 使用“slot”等量划分本节点上的资源量。
“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会执行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空暇slot 分配给Task 使用。slot 分为Map slot 和Reduce slot 两种。分别供Map Task 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置參数)限定Task 的并发度。
4)Task
Task 分为Map Task 和Reduce Task 两种。均由TaskTracker 启动。HDFS 以固定大小的block 为基本单位存储数据。而对于MapReduce 而言,其处理单位是split。
Map Task 执行步骤例如以下图 所看到的:由该图可知。Map Task 先将相应的split 迭代解析成一个个key/value 对,依次调用用户 自己定义的map() 函数进行处理。终于将暂时结果存放到本地磁盘上, 当中暂时数据被分成若干个partition。每一个partition 将被一个Reduce Task 处理。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号