爬虫-scrapy框架的使用
Scrapy爬虫框架
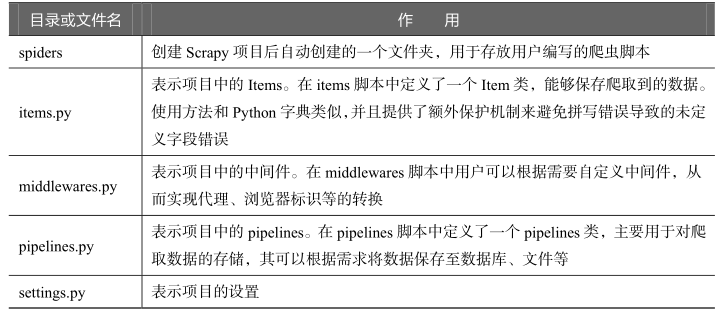
Scrapy是一个为了爬取网站数据 提前结构性数据而编写的应用程序框架
可以应用在数据挖掘 信息处理 存储历史信息等一系列程序
Scrapy爬虫框架的组成
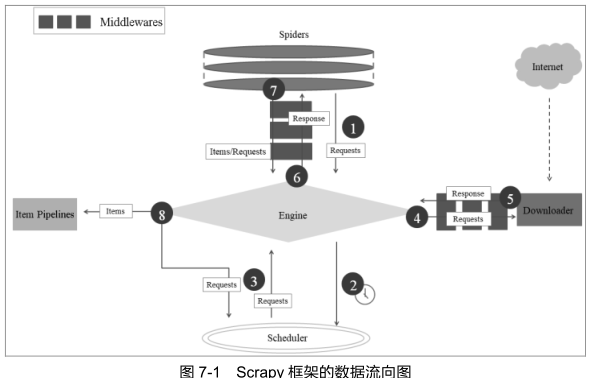
Engine 调度器(Scheduler) Downloader Spiders Item Pipelines 下载器中间件(Downloader Middlewares)
Spider中间件(Spider Middlewares)
引擎:
赋值数据在系统的各个组件内的流向 是整个爬虫的调度中心
调度器:
从引擎接收请求 并加入队列 当引擎需要时将请求交给引擎 比如URL会被放入调度器
调度器可以对URL自动去重
下载器:
获取网页内容 提供给引擎和Spiders
Spiders:
用户编写 用于分析响应 并提取表单和URL的一个类 每个Spider负责一个(一些)特定网站
下载器中间件:
引擎和下载器间的钩子 主要功能是处理 下载器传递给引擎的响应
Spider中间件:
Spiders和引擎间的钩子 处理输入 输出
Scrapy运行流程
1. 引擎打开一个网站 找到处理该网站的Spiders 向Spiders请求第一个要爬的URL
2. 将爬取请求转给调度器 调度器进行下一步
3. 引擎向调度器获取下一个爬取请求
4. 调度器返回下一个URL给引擎 引擎通过下载器中间件转给下载器
5. 网页下载完毕 下载器会生成一个网页响应 通过下载器中间件发给引擎
6. 引擎得到响应 通过Spider中间件 发给 Spiders处理
7.Sipders处理响应 并返回爬取的Item和跟进的请求给引擎
8. 引擎将爬取的Items 给 Item Pipelines 将请求返给调度器
9. 重复第二步至无更多URL请求 引擎关闭该网站
Scrapy常用的命令
startproject 创建项目
genspider 基于预定义末班 创建 Scrapy爬虫
settings 查看Scrapy设置
runspider 运行独立的爬虫python文件
shell 给指定的url启动Scarpy shell
fetch 使用下载器 下载给定的url
view 以爬虫看到的样子在浏览器打开给定的url
version 打印版本
crawl 启动爬虫
check 协议检测
list 列出项目可用爬虫
edit 使用EDIROR环境变量或者设置中的编辑器编辑爬虫
parse 获取给定的URL并以爬虫处理它的方式解析它
bench 运行benchmark测试
主要使用的是 startproject genspider runspider 以及crawl list
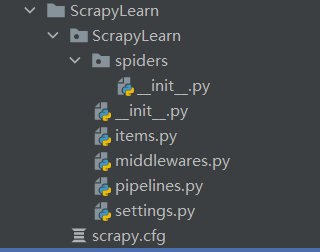
使用 Scrapy startproject 创建的项目结构
初步使用Scrapy爬取信息
使用 需要mysql Scrapy框架
0.使用Scrapy创建一个爬虫项目
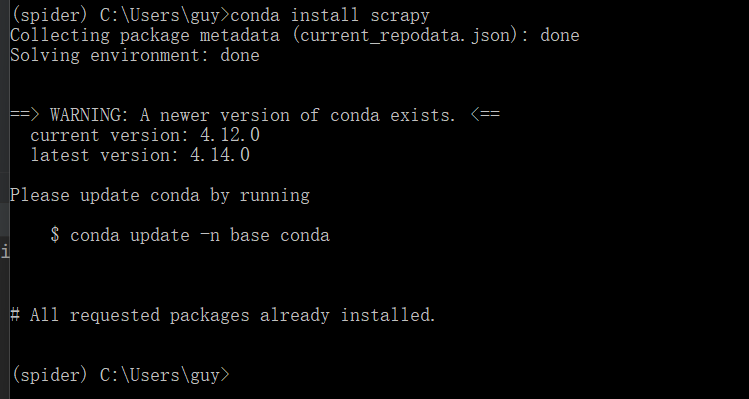
本文利用conda来来配置环境
在命令行使用 conda install scrapy即可安装本框架
安装完成后,使用命令 scrapy startproject projectName 创建爬虫项目
项目结构如下:
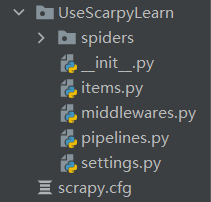
1. 配置piplines.py 和 items.py
items是本框架用于配置 爬取数据的数据类型
piplines用于数据的永久存储
items:
对于items的配置 仅需要在已经创建的类中创建字段即可
类似于 字典的结构
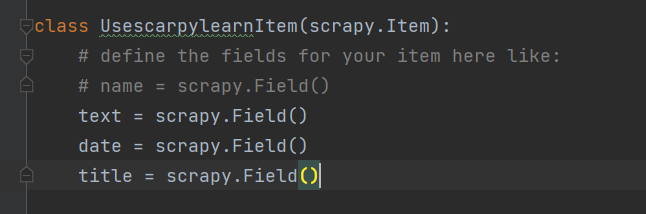
piplines:
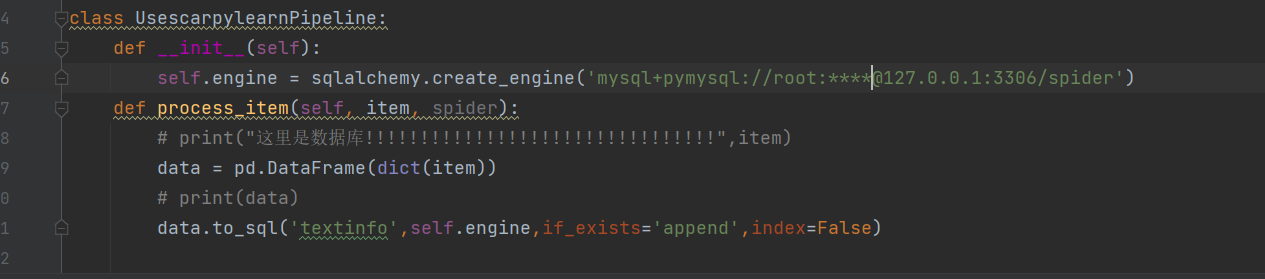
可以在此处连接数据库 每当爬虫内的函数 返还一个item,
即会调用process_item,所以可以在该函数内 对数据进行永久
化存储 item类型可以转为dict类型进而转为 dataFrame类型方便存储
2.创建项目内爬虫
使用cd到当前爬虫项目文件夹下 运行指令
scrapy genspider spiderName 域名
该命令会根据基本模板创建一个python(.py)文件用来写爬虫
本文件会被放入spiders文件夹内部
3.编写爬虫内容
在文件内编写爬虫内容
这里需要注意 在此处的函数返还值为yield生成器
框架会根据生成器返回实例的不同来运行不同的内容
关于为什么使用生成器: 由于直接retrun的数据量会非常大
所以使用yield来一次次的返回数据
点击查看代码
# 首先 框架会调用这个函数 因为返回的是一个 request实例 所以 会将地址请求后 传入 回调函数
def parse(self, response):
page_num = response.xpath("//div[@class = 'fpage']/div/a[last()]/text()").extract()
# 新闻简介页面
urls = ['http://www.tipdm.com/tipdm/tddt/index_{}.html'.format(i) for i in range(2,int(page_num[0])+1)]
# print("!!!!!!!!!!!!!urls:",urls)
for url in urls:
# 会将url 传入 callback内
# 利用生成器一次次的执行 避免一次性return 数据过多
# 会先进行请求 将请求结果传入 回调函数 而不是将网址传入回调函数
yield scrapy.http.Request(url,callback=self.parse_url,dont_filter=True)
response会传入开始网站
爬虫由此处开始
框架会对parse的返回的生成器实例化的值进行判断
如果是 一个Request类型的生成器 则迭代后 返回一个
Request的实例,框架会接收实例内的url,进行请求,获得网页,并且将网页传入
到该实例的回调函数中.
点击查看代码
def parse_url(self,response):
# 内部新闻页面
urls = response.xpath("//div[@class = 'item clearfix']/div/h1/a/@href").extract()
for text in urls:
textUrl = 'http://www.tipdm.com' + text
yield scrapy.http.Request(textUrl,callback=self.parse_text,dont_filter=True)
第一次调取parse的返回的网页被传入到回调函数中 及 paser_url 中去
paser_url会接收到parse传入的网页,本函数依旧返回一个迭代器,框架依旧根据
迭代器返回的实例类型来进行选择,由于本迭代器返回的依旧是一个request类型的实例
所以框架会接收实例的url 并进行网页的请求,之后将内容传入到该迭代器的回调函数中
点击查看代码
def parse_text(self,response):
item = UsescarpylearnItem()
item['title'] = response.xpath("//div[@class='artTitle']/h1/text()").extract()
item['date'] = response.xpath("//div[@class = 'artInfo']/span[@class = 'date']/text()").extract()
texts = response.xpath("//div[@class='artCon']//p/text()").extract()
text = ''
for i in texts:
text = text + i+'\n'
# 字段信息接收的是一个列表
item['text'] = [text.strip()]
yield item
本处生成的是一个返回item类型的迭代器,框架在运行该迭代器后,发现类型是item,所以就将item传入到piplines内部进行处理.
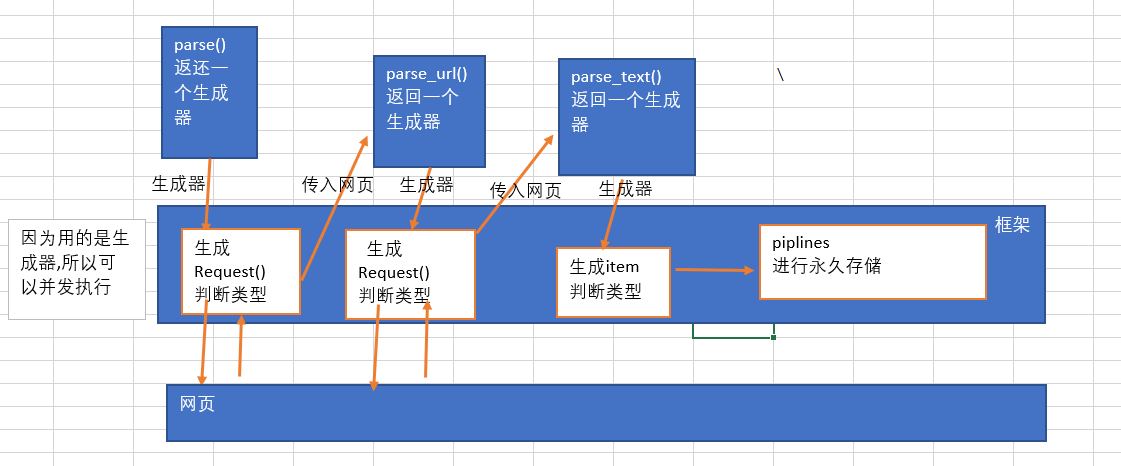
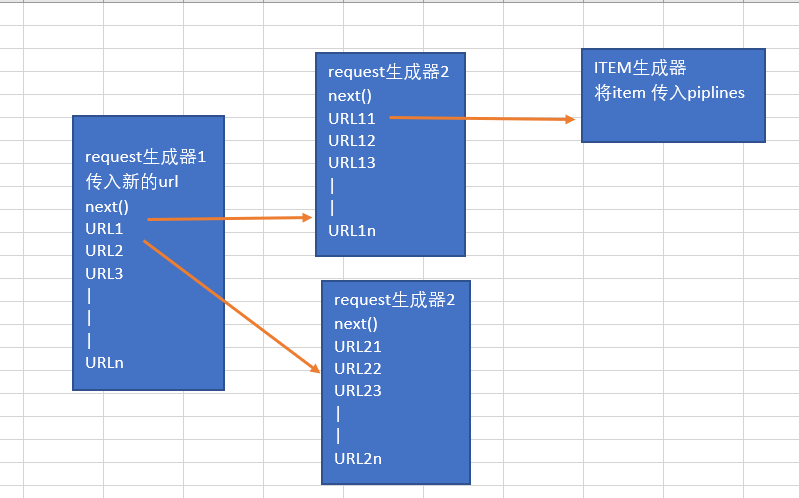
spiders的调用很像是 递归,但并不是.函数是由框架来进行调用的,而不是自己调用自己.
框架对parse函数进行实例化,创建生成器,然后根据生成器的内容,继续调用回调函数,如果回调
函数还是一个request生成器就继续调用回调函数,直到item,之后对item进行存储,然后next(生
成器)来获得新的内容
4. 配置settings
重要的一点是一定要配置 ITEM_PIPELINES 如果不进行配置则框架不会将item传入到piplines内部
进行永久的存储,而是会将内容简单的输出到命令行内部




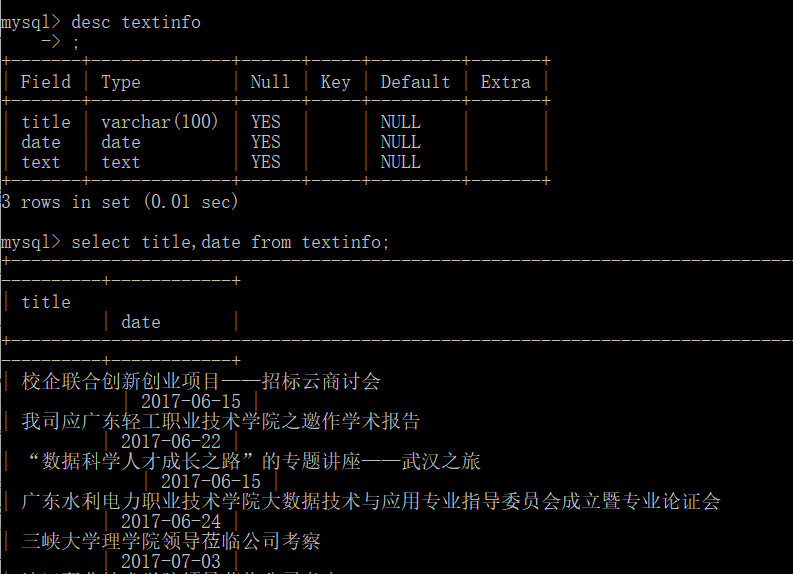
效果:
Scrapy内的spiders执行流程(我个人感觉容易迷的地方)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号