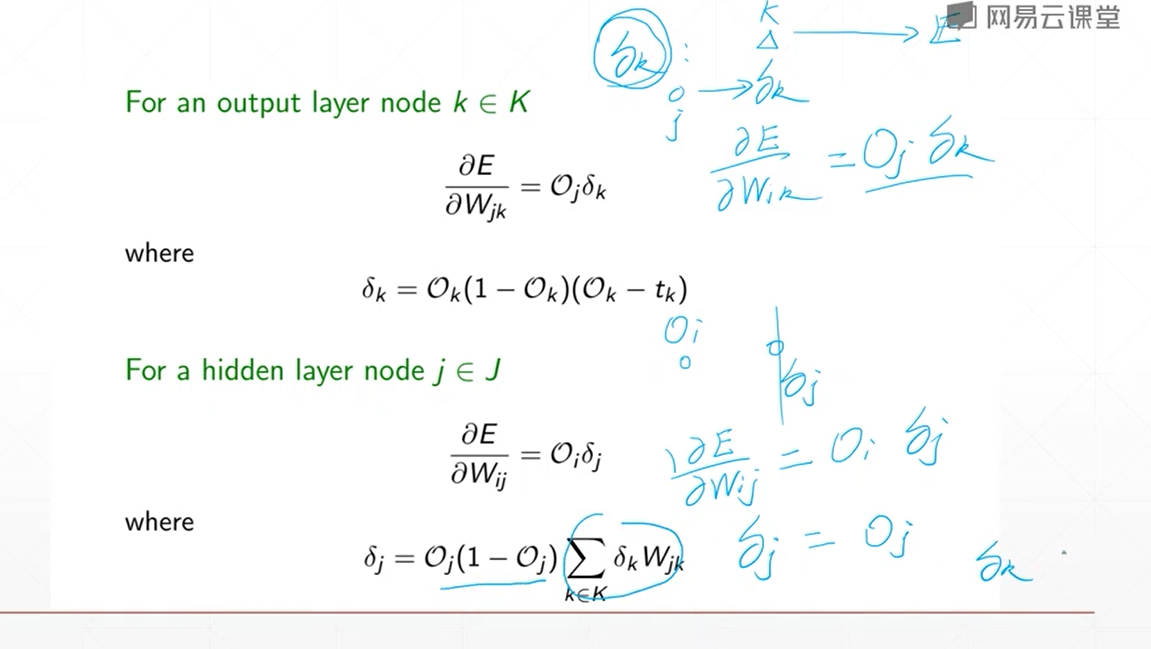
Tensorflow2学习--005(随机梯度下降)
随机梯度下降
Gradient梯度
导数
通用的概念 函数沿着某方向变化的速度
f(x+t) - f(x) / t 所以 一般来说 导数是 指向 f(x)变大的方向
偏微分
函数 沿着 x,y这些标准方向的 变化
梯度
一个向量,偏微分组成的向量
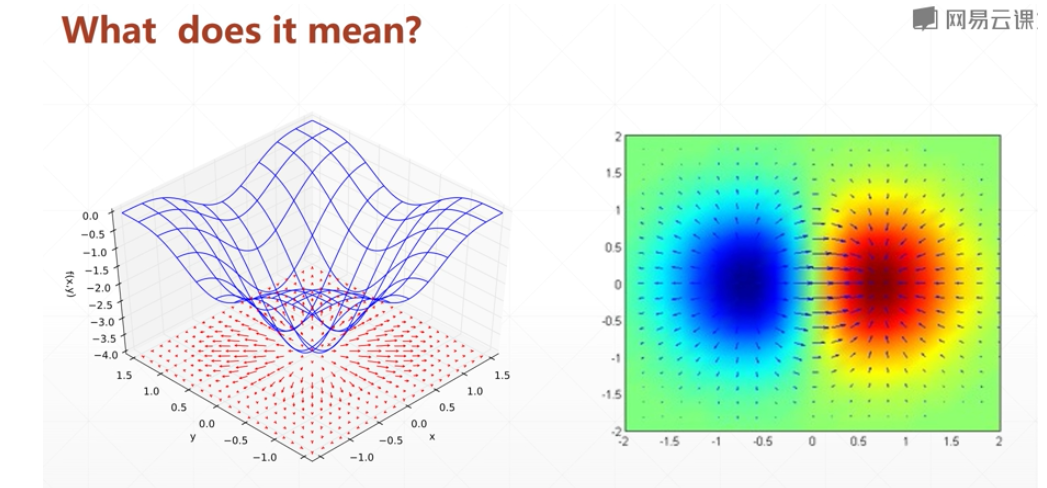
梯度是导数的最最大值,所以只要取相反的方向 就是下降的最大值
每个轴的方向上 都去相反的偏微分就可以


返还的是 每个变量的偏导数
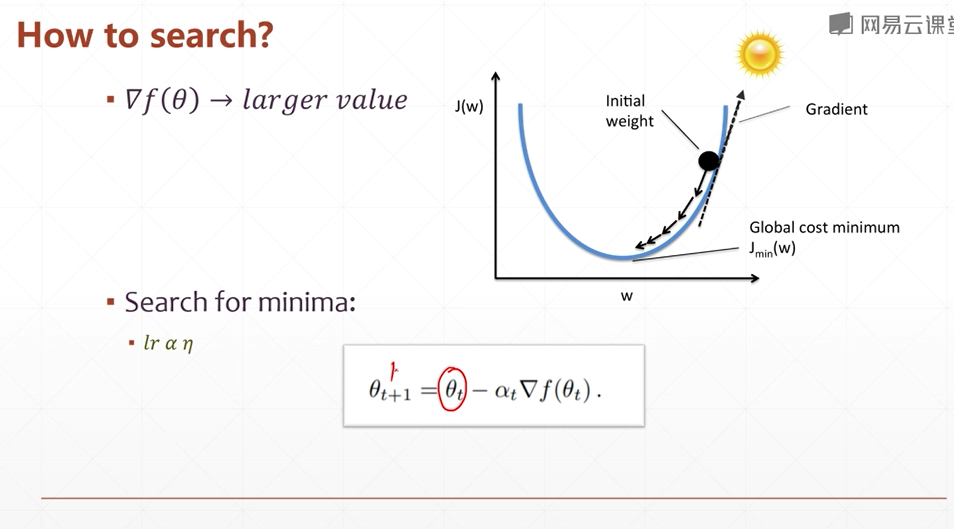
梯度求解:
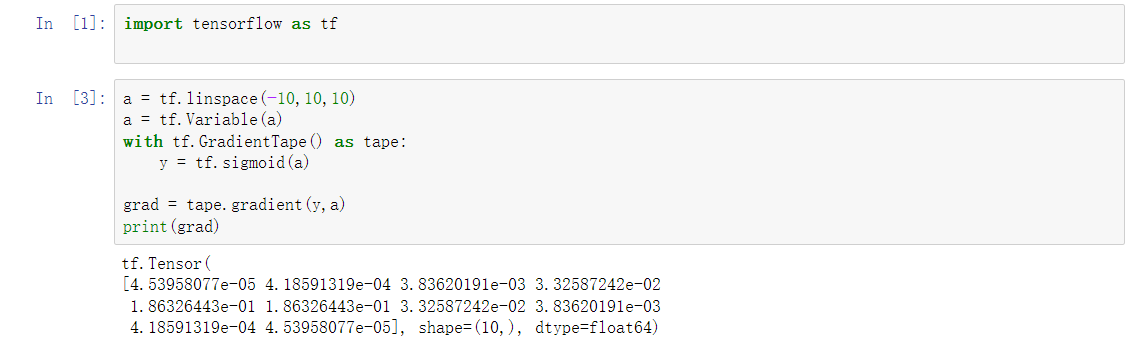
将 计算过程 包裹在 with tf.GradientTape() as tape中
[w_grad] = tape.gradient(loss,[w])
# 计算的是 loss 和 w的关系 在特定的 x下面,通过更新 w的值 减小loss
# 注意 进行 求导计算的 类型必须是tf.Variable类型
import tensorflow as tf
w = tf.reshape(tf.constant([1.,2.],dtype=tf.float32),[2,1])
print(w)
x = tf.reshape(tf.constant([1.,2.],dtype=tf.float32),[1,2])
w = tf.Variable(w)
x = tf.Variable(x)
print(x)
# x1w1 + x2w2 = y
with tf.GradientTape() as tape:
y = x @ w
print(y)
grad = tape.gradient(y,w)
print(grad)

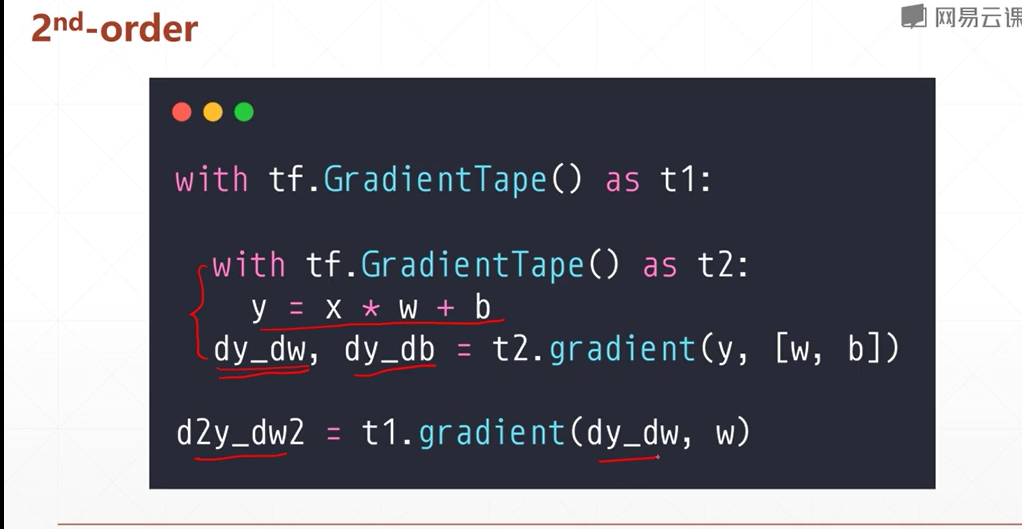
二阶梯度
激活函数和他的梯度
sigmoid
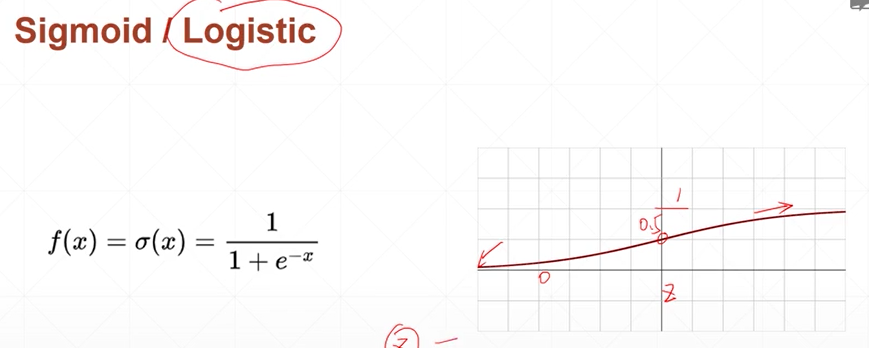

当sigmoid的值为 0.5时 导数最大, 当为0或者1时 为0
但是sigmoid 会出现梯度消失的情况 因为当sigmoid的值接近1或者0时 其导数接近0 参数将长时间不能更新
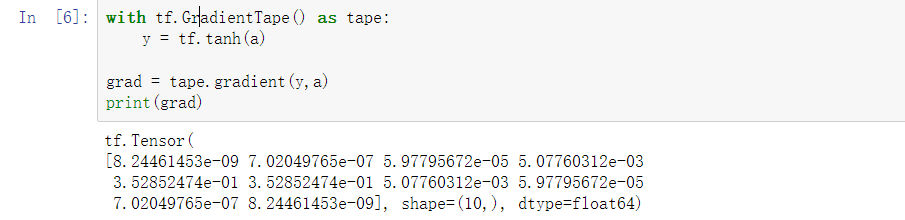
Tanh
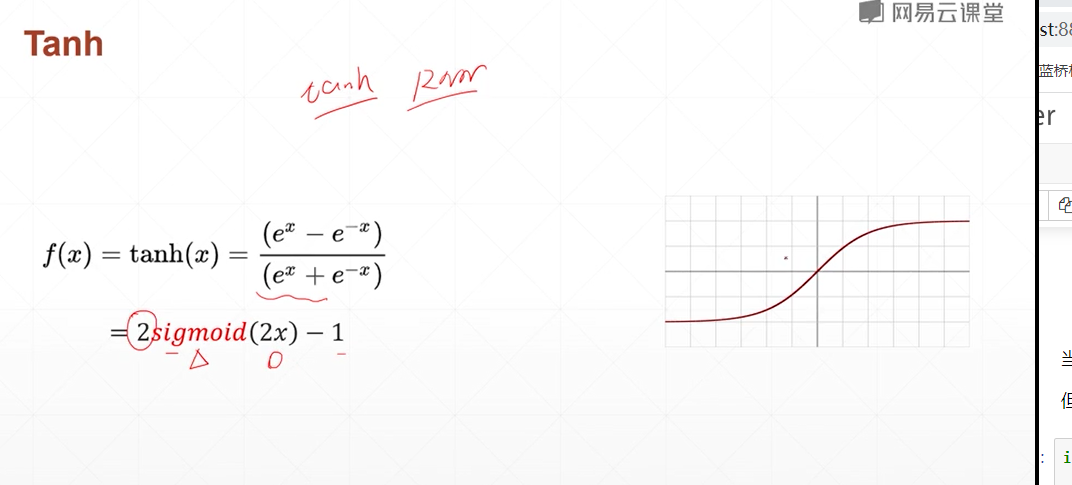
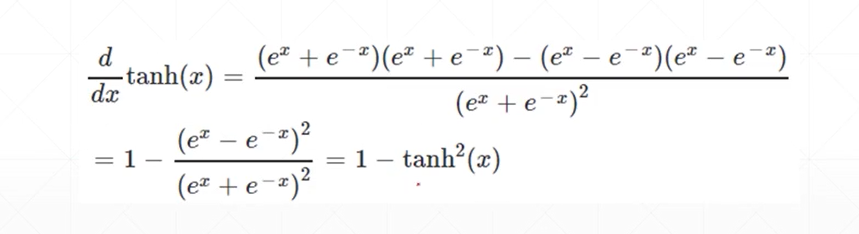
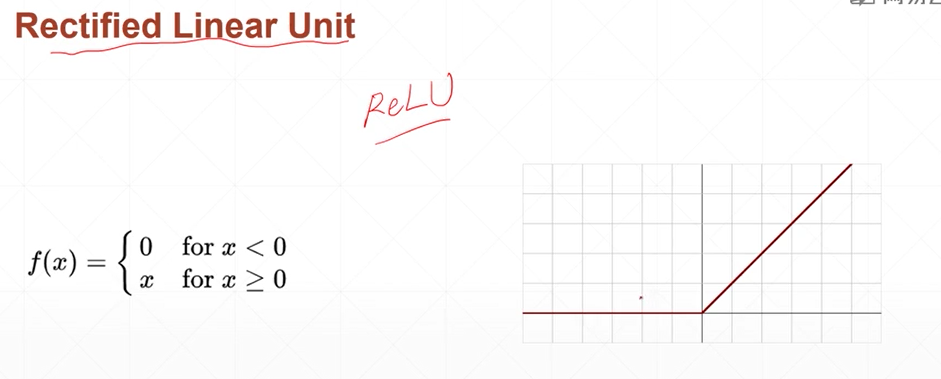
Relu
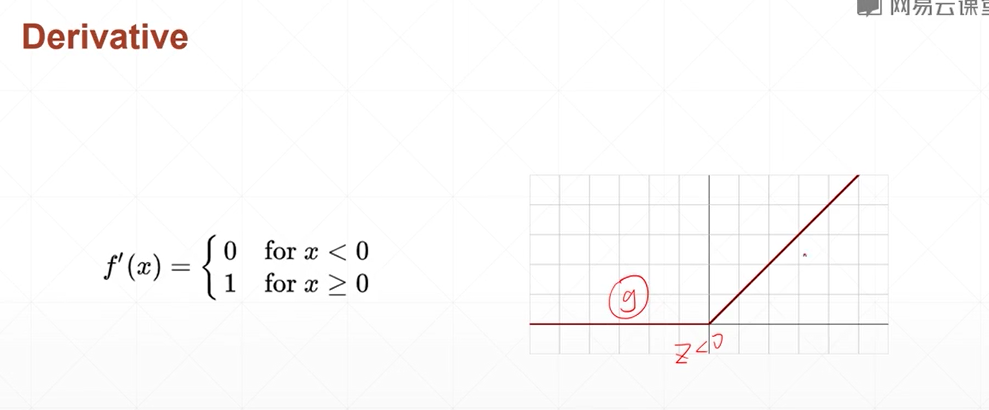

大于0的部分梯度 一直是1 所以不会梯度消失
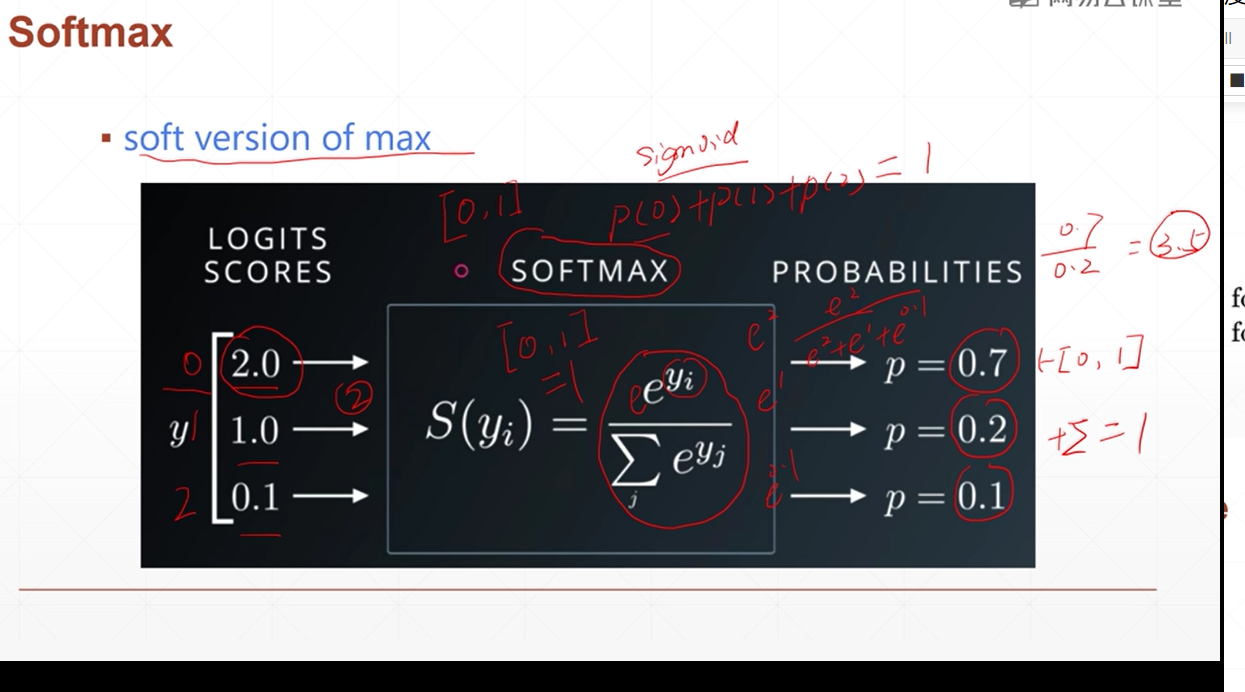
softmax
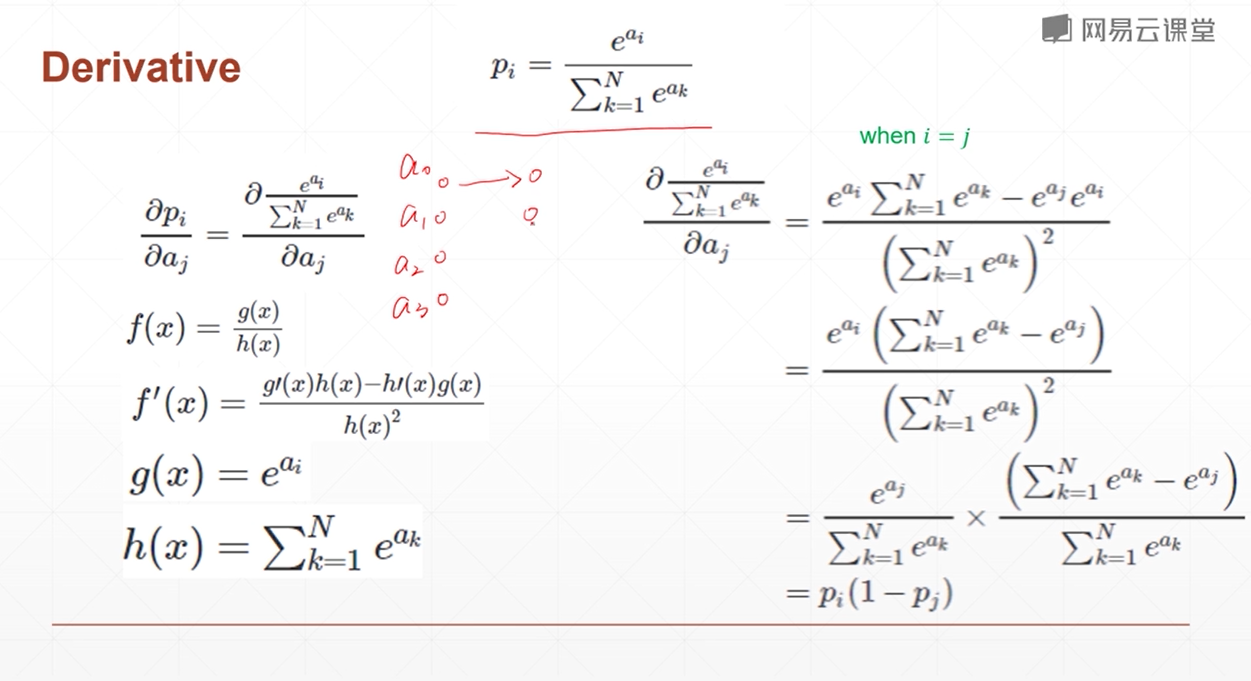

损失函数梯度推导
MSE
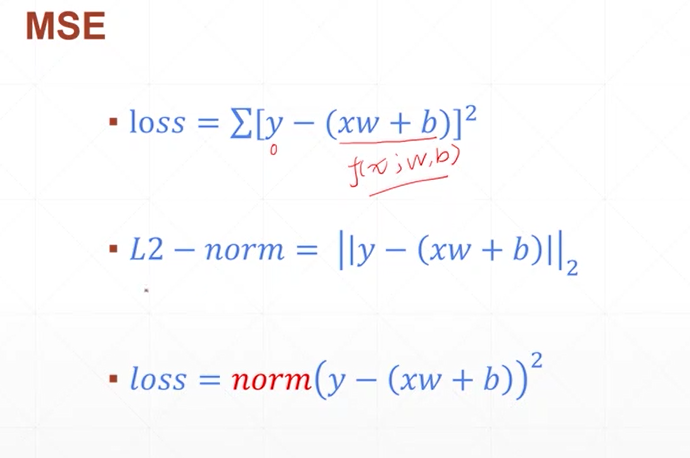

f(x)的梯度根据网络的不同 激活函数的不同而不同
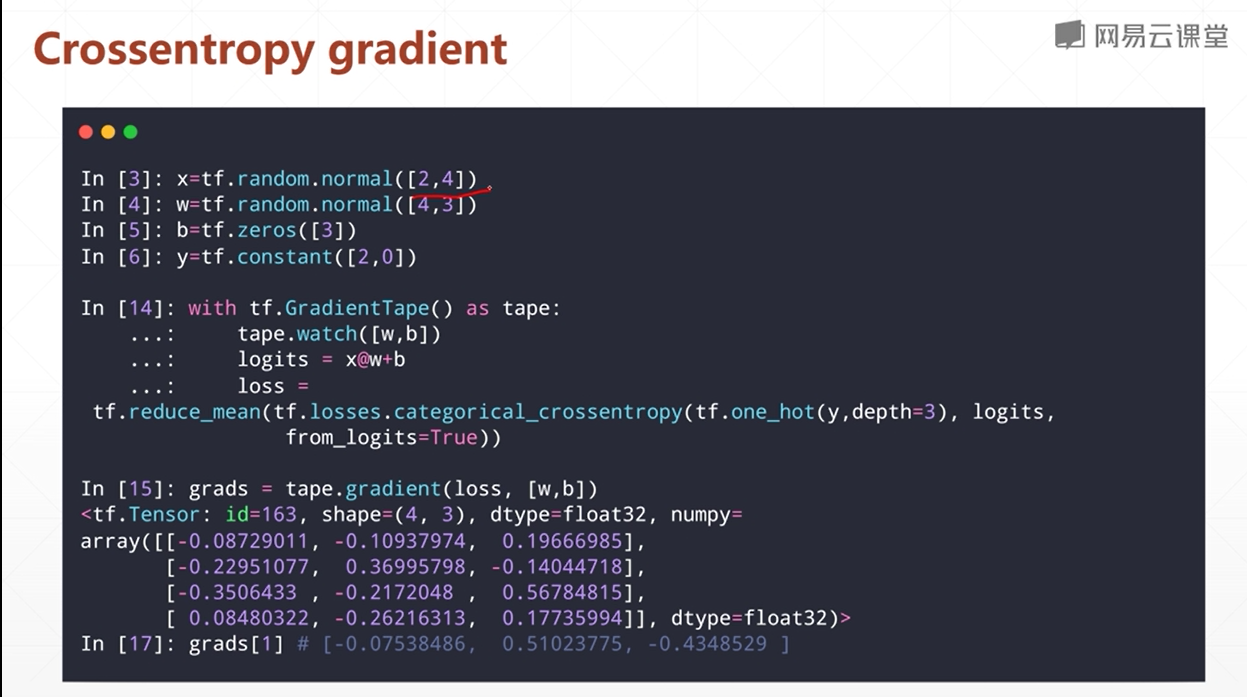
交叉熵
单层感知机梯度推导
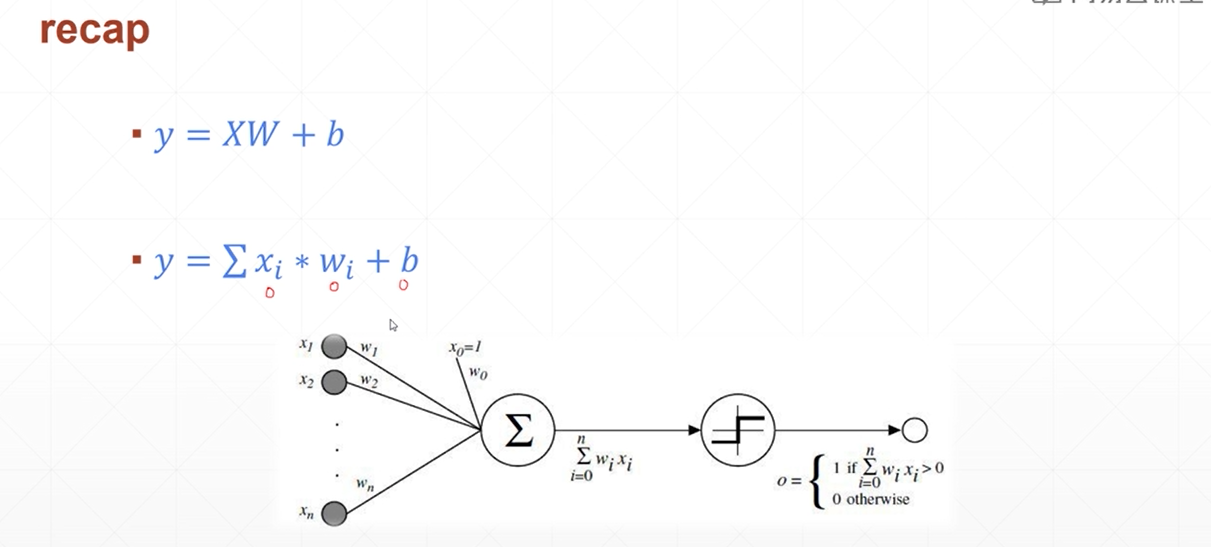
和sigmoid的导数有关

多输出感知机梯度推到
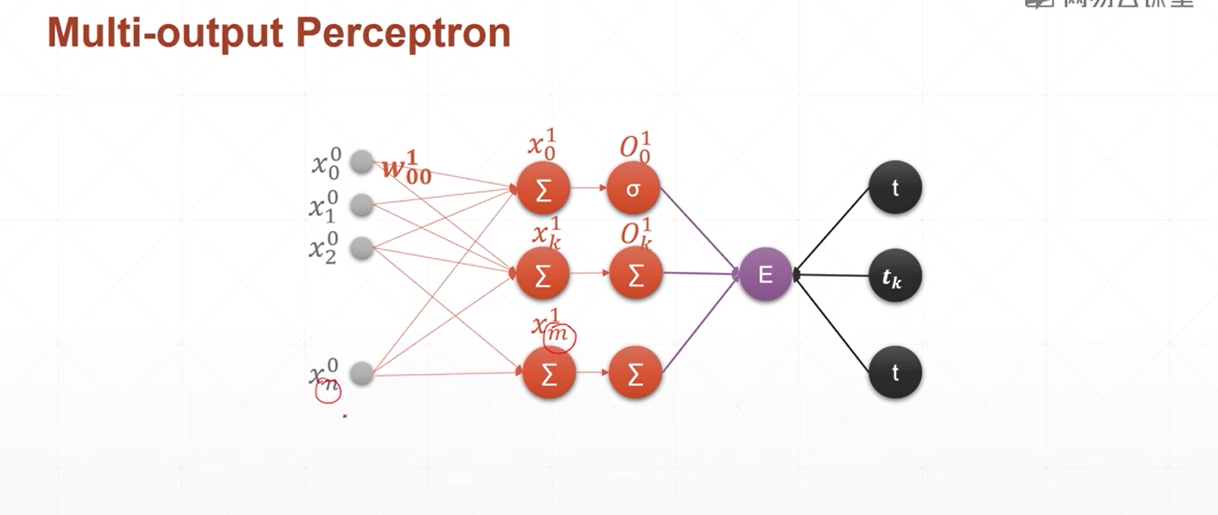
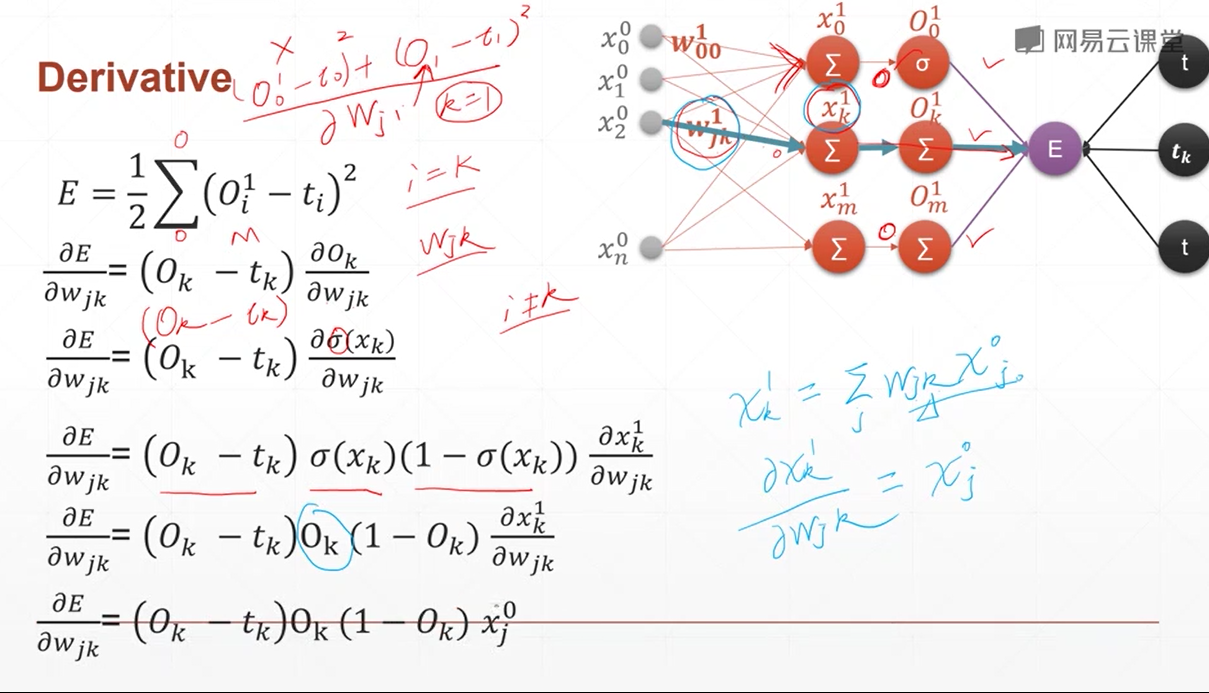
和单层感知机几乎一样,因为多输出感知机的w也紧紧影响一个输出
所以 只需要那一个输出节点 来对w进行反向传播
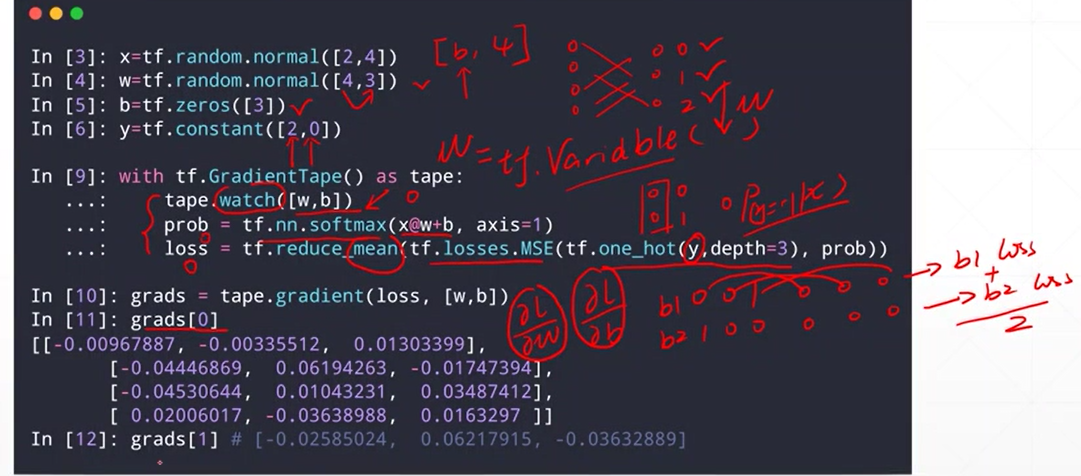
对于一个batch
在MSE中 通过了 reduce_mean() 来对一个batch中的多个loss进行了统一
所以 在反向传播的过程中 梯度是综合了 多张图片的 梯度
这个loss对于某w的梯度 不仅仅是一个x1 而是多个不同的x1的 综合考虑
链式法则
就是求导的那个链式法则
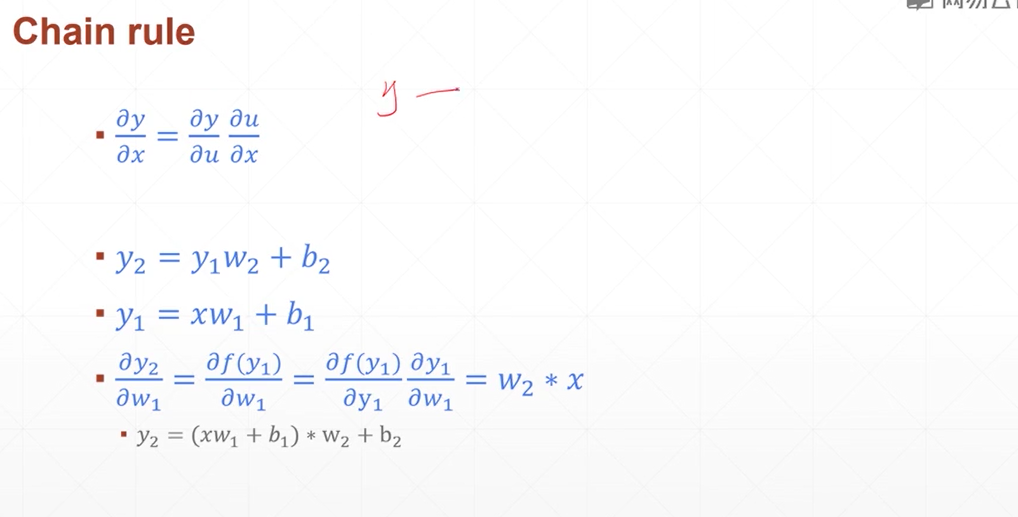
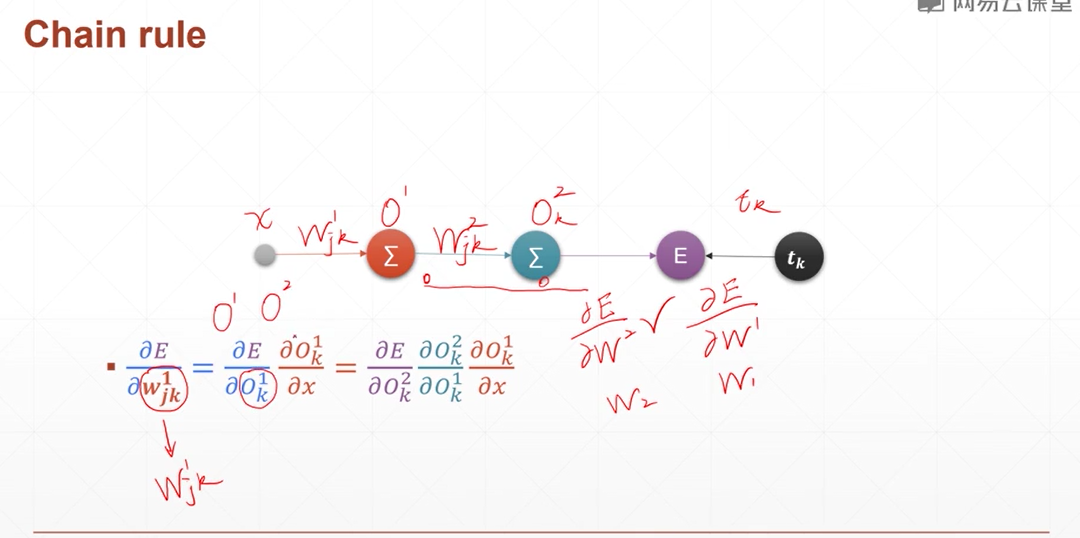
多层感知机的反向传播算法
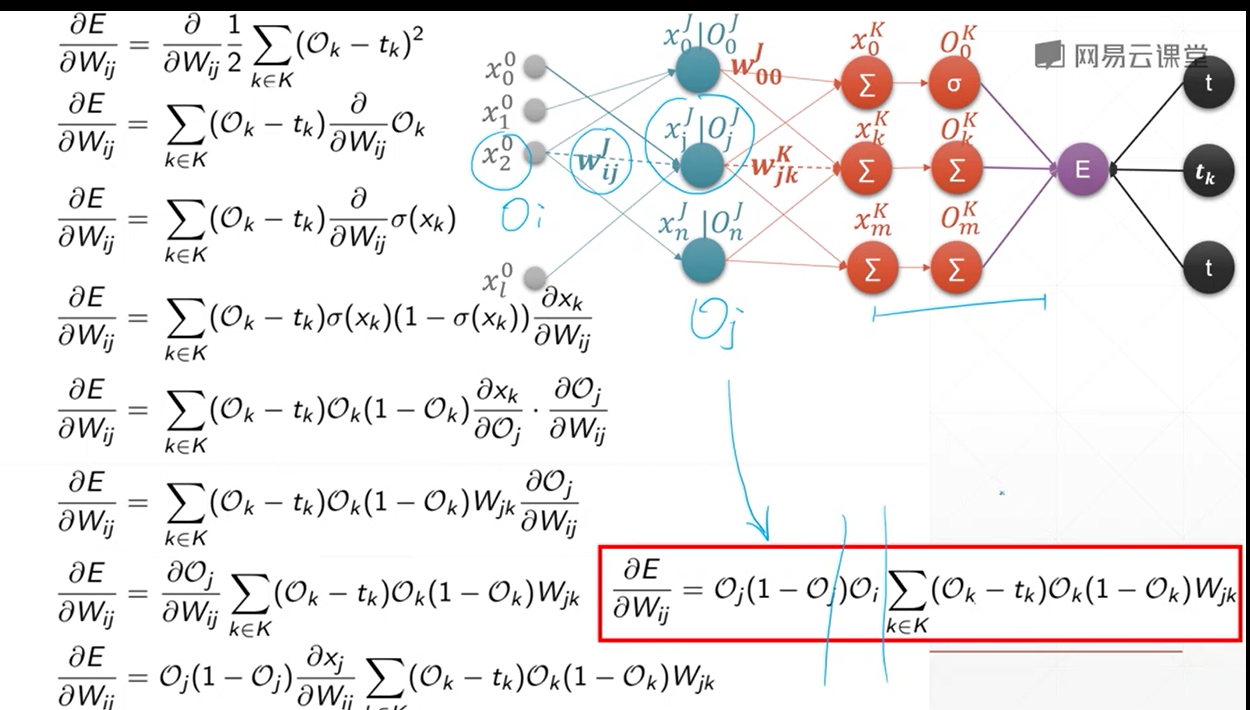
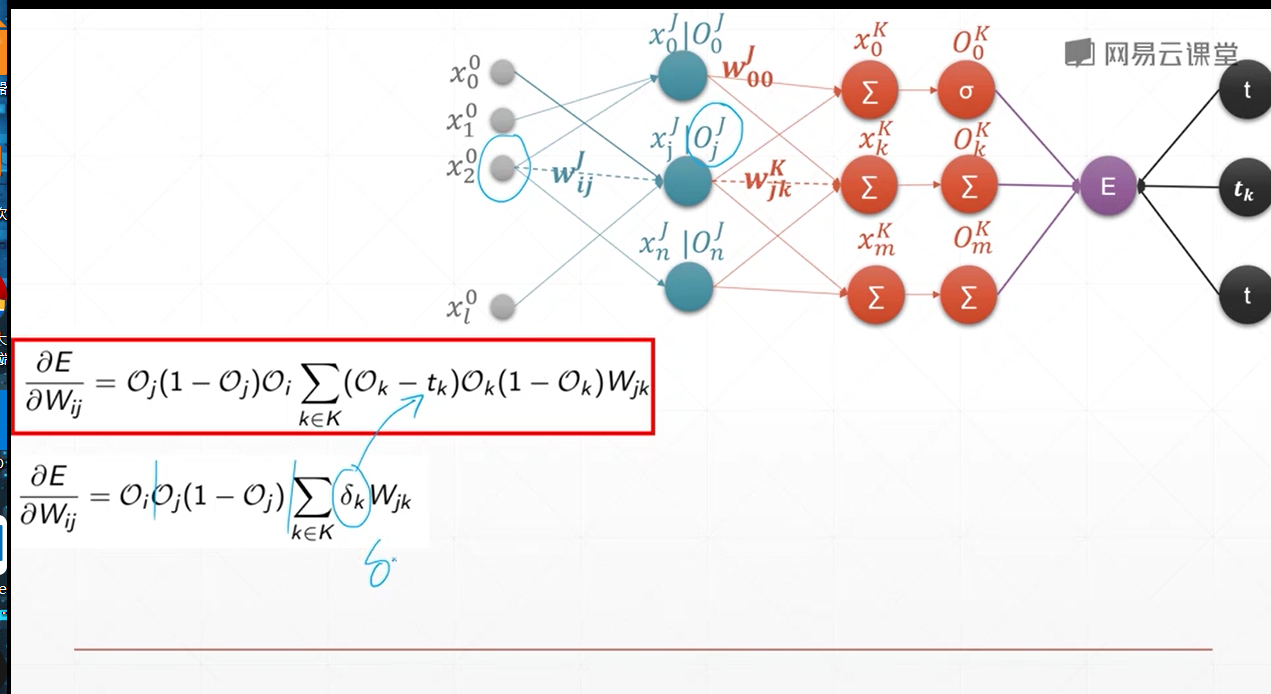
梯度下降实战
利用梯度下降算法 求得一个函数的极小值
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def z_func(x,y):
return (x**2+y-11)**2 + (x+y**2-7)**2
x = np.arange(-10,10,0.01)
y = np.arange(-10,10,0.01)
x,y = np.meshgrid(x,y)
z = z_func(x,y)
fig = plt.figure("my_plt")
ax = fig.gca(projection="3d")
ax.plot_surface(x,y,z)
# 第一个参数是水平线为轴 第二个是垂直线为轴 旋转
ax.view_init(30,30)
ax.set_xlabel("x")
ax.set_ylabel("y")
plt.show()
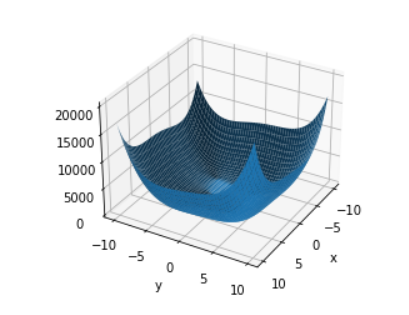
这只是一个示例,对于较大的一个非线性函数,蛮力法几乎求解不出来 画图只是为了看一下
# 利用梯度下降 求极小值
point = tf.constant([-4,0],dtype=tf.float32)
point = tf.Variable(point)
for step in range(200):
with tf.GradientTape() as tape:
z = z_func(point[0],point[1])
grad = tape.gradient(z,point)
print("grad:",grad)
print("point:",point)
print("z:",z)
print("\n")
# 对点进行梯度下降更新
point.assign_sub(grad*0.01)
梯度下降可以用来求loss的最小值 但是其实可以用其他的优化算法来实现
利用层实现神经网络
点击查看代码
import tensorflow as tf
import cv2 as cv
from tensorflow import keras
# 数据集使用 fashionMNIST 10分类数据集
# 数据集导入与预处理
(x,y),(x_test,y_test) = keras.datasets.fashion_mnist.load_data()
print(x.shape,y.shape)
print(x_test.shape,y_test.shape)
# 数据的预处理 将图片的值归一化 并且将标签转为int类型
def preprocess(x,y):
x = tf.cast(x,dtype=tf.float32) / 255.
y = tf.cast(y,dtype=tf.int32)
return x,y
# 生成数据集 并且构造x和y的迭代器
db = tf.data.Dataset.from_tensor_slices((x,y))
# map函数 可以将迭代器的每个值进行放入函数
db = db.map(preprocess)
# 生成测试集
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.map(preprocess)
# 超参数定义 一组多少张图片
batchs = 64
# 将图片打乱,并且分组
db = db.shuffle(60000).batch(batchs)
db_test = db_test.shuffle(10000).batch(batchs)
# 从迭代器中 取出一组图片
sample = next(iter(db))
# sample[0]是图片 sample[1]是标签
print("sample:",sample[0].shape,sample[1])
# 建立网络 相比于运用张量 手动搭建网络 可以不需要 初始化 w,b
# 每个Dense相当于一个全连接层
layer1 = keras.layers.Dense(256,activation=tf.nn.relu)
layer2 = keras.layers.Dense(128,activation=tf.nn.relu)
layer3 = keras.layers.Dense(64,activation=tf.nn.relu)
layer4 = keras.layers.Dense(32,activation=tf.nn.relu)
layer5 = keras.layers.Dense(10)
# Sequential 相当于一个空的网络 将层按顺序放入 会自动的连接
model = keras.Sequential([layer1,layer2,layer3,layer4,layer5])
# 设置输入的类型的shape
model.build(input_shape=[None,28*28])
# summary()可以看到网络的总结
model.summary()
# model.trainable_variables 可以查看参数
for i in model.trainable_variables:
print(i.name,i.shape)
# 进行前向传播
# 优化器 可以帮助完成 w -= lr * grad
# 这种优化器 可以帮助我们对 w和b进行更新 不用手动更新
optimizer = tf.optimizers.Adam(lr = 1e-3)
# 循环30次
for epoch in range(30):
# 从迭代器内取数据
for step,(x,y) in enumerate(db):
# x [b,28*28]
# y [b]
x = tf.reshape(x,[-1,28*28])
with tf.GradientTape() as tape:
# 张量计算
# h1 = x @ w1 + b1
# h1 = tf.nn.relu(h1)
# h2 = h1 @ w2 + b2
# h2 = tf.nn.relu(h2)
# logits = h2 @ w3 + b3
# model(x) 带入训练数据
# 运用层 不需要张量计算 直接带入 会自动计算
logits = model(x)
# logits [b,10] 标签转换为one_hot类型
y_onehot = tf.one_hot(y,depth=10)
# sf_res = tf.nn.softmax(logits)
# loss = tf.reduce_mean(tf.losses.MSE(sf_res,y_onehot))
# 利用交叉熵 求loss
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot,logits,from_logits=True))
# 计算模型中参数的梯度
# grads = tape.gradient(loss,[w1,b1,w2,b2,w3,b3]) 对于利用keras建立的网络 不需要一个个传入参数算的梯度
# 运用层 可以直接获得全部的参数的梯度
grad = tape.gradient(loss,model.trainable_variables)
# 直接对所有的参数进行 梯度下降 优化器直接利用 梯度和变量w和b进行更新 不用手动更新
# 优化器 可以很方便的对参数进行优化 不用和张量一样 自己一个个的计算
optimizer.apply_gradients(zip(grad,model.trainable_variables))
if step % 100 == 0:
print(epoch,step,"loss:",loss)
# test:
total_num = 0
total_correct = 0
for x,y in db_test:
x = tf.reshape(x,[-1,28*28])
logits = model(x)
prob = tf.nn.softmax(logits,axis=1)
pred = tf.cast(tf.argmax(prob,axis=1),dtype=tf.int32)
correct = tf.reduce_sum(tf.cast(tf.equal(pred,y),dtype=tf.int32))
total_correct += int(correct)
total_num += 64
print("correct:",total_correct/total_num)
TensorBoard可视化
是一个tensorflow的一个工具 可以将各种统计数据 显示在网页上 并画出 统计图
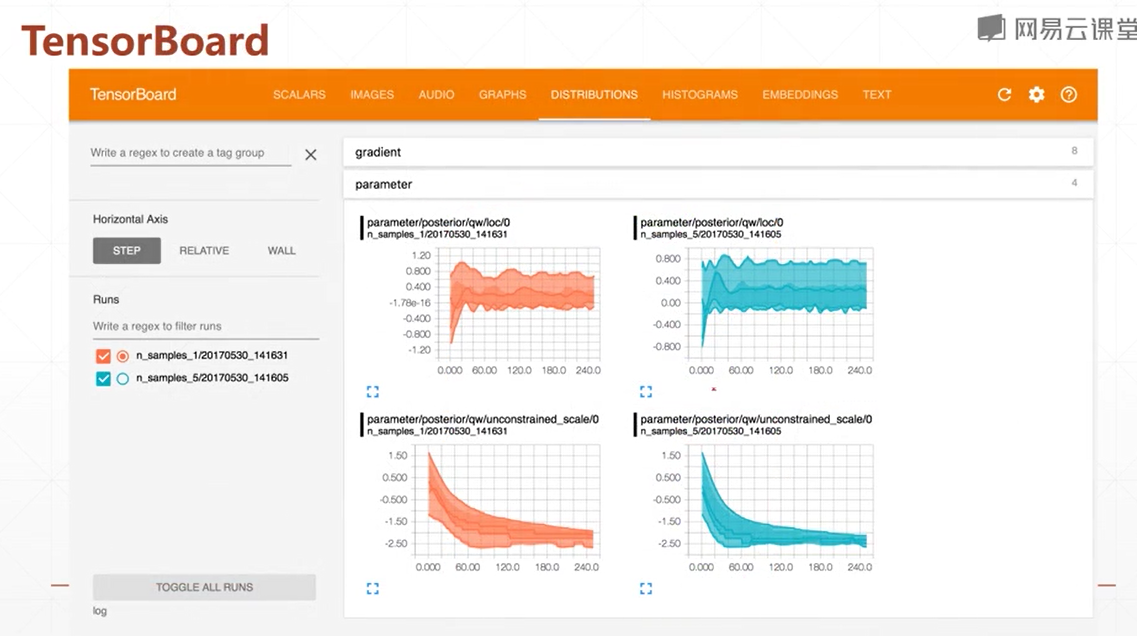
使用步骤
1. 开启监听 logdir指定监听的日志目录

2.创建日志
在程序内 建立一个日志路径 表示将数据放入哪里
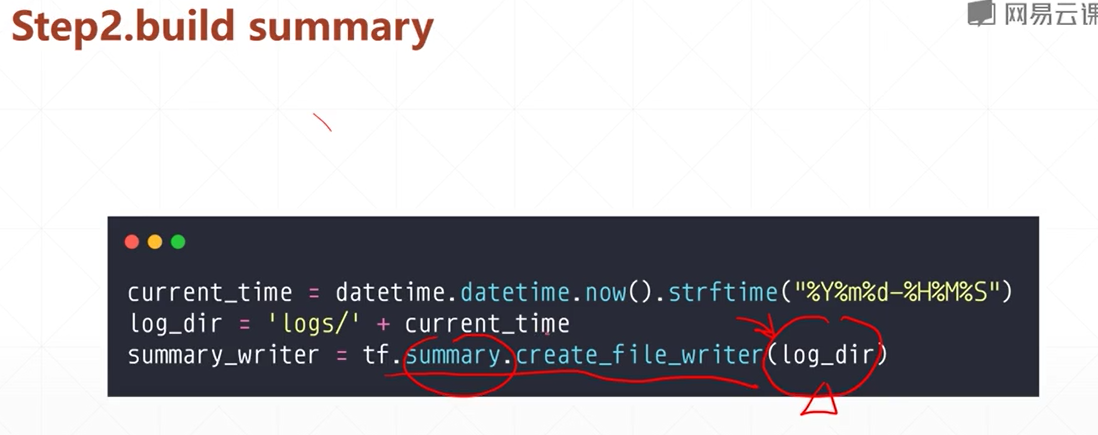
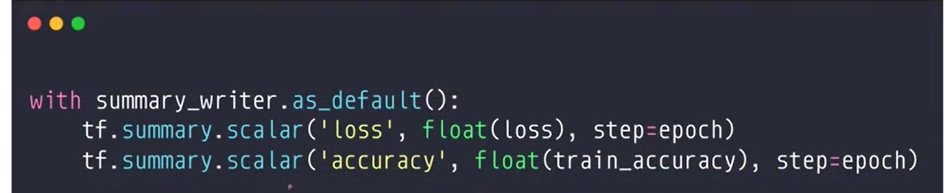
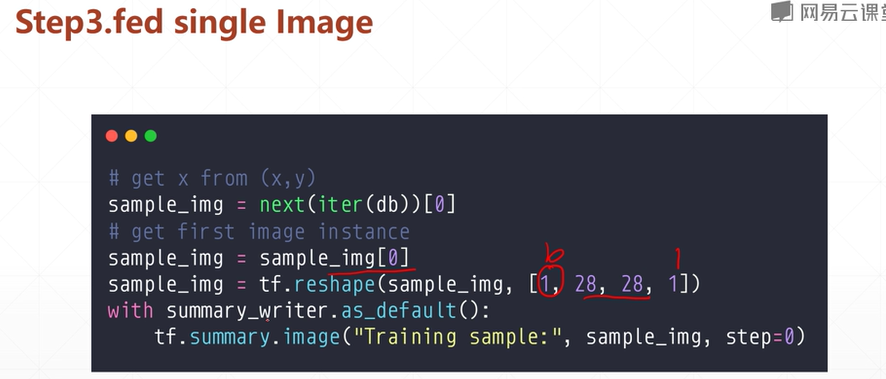
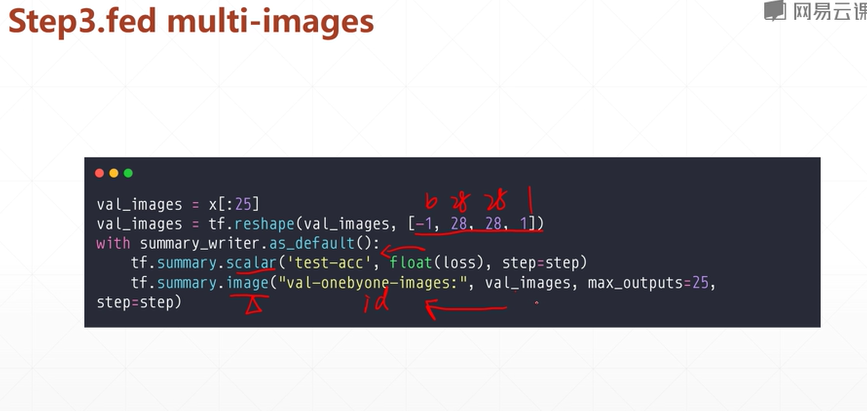
3.填入数据
第二步创建了一个日志 这一步将数据写入日志 对日志进行更新 这样第一步的监听也会同步的更新显示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号