

在字节跳动,一个更好的企业级SparkSQL Server这么做
SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。
前言
Spark 组件由于其较好的容错与故障恢复机制,在企业的长时作业中使用的非常广泛,而SparkSQL又是使用Spark组件中最为常用的一种方式。
相比直接使用编程式的方式操作Spark的RDD或者DataFrame的API,SparkSQL可直接输入SQL对数据进行ETL等工作的处理,极大提升了易用度。但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。
很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的易用性。除此之外,还可使用周边工具,如Livy,但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。
虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开发需求,具体的分析请查看:观点|SparkSQL在企业级数仓建设的优势
标准的JDBC接口
Java.sql包下定义了使用Java访问存储介质的所有接口,但是并没有具体的实现,也就是说JavaEE里面仅仅定义了使用Java访问存储介质的标准流程,具体的实现需要依靠周边的第三方服务实现。
例如,访问MySQL的mysql-connector-java启动包,即基于java.sql包下定义的接口,实现了如何去连接MySQL的流程,在代码中只需要通过如下的代码方式:
Class.forName("com.mysql.cj.jdbc.Driver");Connection connection= DriverManager.getConnection(DB_URL,USER,PASS);//操作connection.close();第一,初始化驱动、创建连接,第二,基于连接进行对数据的操作,例如增删改查。可以看到在Java定义的标准接口访问中,先创建一个connection完成存储介质,然后完成connection后续操作。
性能问题导致单次请求实时创建connection的性能较差。因此我们往往通过维护一个存有多个connection的连接池,将connection的创建与使用分开以提升性能,因而也衍生出很多数据库连接池,例如C3P0,DBCP等。
Hive 的JDBC实现
构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现上,与MySQL等关系型数据稍有不同。
首先,Hive Server2本身是提供了一系列RPC接口,具体的接口定义在org.apache.hive.service.rpc.thrift包下的TCLIService.Iface中,部分接口如下:
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws org.apache.thrift.TException;
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws org.apache.thrift.TException;
public TGetInfoResp GetInfo(TGetInfoReq req) throws org.apache.thrift.TException;
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws org.apache.thrift.TException;
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws org.apache.thrift.TException;
public TGetSchemasResp GetSchemas(TGetSchemasReq req) throws org.apache.thrift.TException;
public TGetTablesResp GetTables(TGetTablesReq req) throws org.apache.thrift.TException;
public TGetTableTypesResp GetTableTypes(TGetTableTypesReq req) throws org.apache.thrift.TException;
public TGetColumnsResp GetColumns(TGetColumnsReq req) throws org.apache.thrift.TException;也就是说,Hive Server2的每一个请求都是独立的,并且是通过参数的方式将操作和认证信息传递。Hive 提供了一个JDBC的驱动实现,通过如下的依赖便可引入:
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>version/version></dependency>在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中缺乏的能力,例如实时的日志获取。但是使用该能力时,需要将对应的实现类转换为Hive的实现类,例如:
HiveStatement hiveStatement = (HiveStatement) connection.createStatement();List<String> logs = hiveStatement.getQueryLog();Log获取也需调用FetchResult接口,通过不同的参数来区分获取Log信息还是获取内容信息,因此,Hive JDBC封装的调用Hive Server2 RPC接口流程是:

如果该流程触发获取MetaData、获取Functions等操作,则会调用其他接口,其中身份信息即token,是用THandleIdentifier类进行封装。在OpenSession时,由Hive Server2生成并且返回,后续所有接口都会附带传递这个信息,此信息是一次Connection连接的唯一标志。
但是,Hive Server2在FetchResults方法中存在bug。由于Hive Server2没有很好处理hasMoreRows字段,导致Hive JDBC 客户端并未通过hasMoreRows字段去判断是否还有下一页,而是通过返回的List是否为空来判断。因此,相比Mysql Driver等驱动,Hive会多发起一次请求,直到返回List为空则停止获取下一页,对应的客户端的JDBC代码是:
ResultSet rs = hiveStatement.executeQuery(sql);while (rs.next()) { // }即Hive JDBC实现next方法是通过返回的List是否为空来退出while循环。
构建SparkSQL服务器
介绍了JDBC接口知识与Hive的JDBC知识后,如果要构建一个SparkSQL服务器,那么这个服务器需要有以下几个特点:
-
支持JDBC接口,即通过Java 的JDBC标准进行访问,可以较好与周边生态进行集成且降低使用门槛。
-
兼容Hive协议,如果要支持JDBC接口,那么需要提供SparkSQL的JDBC Driver。目前,大数据领域Hive Server2提供的Hive-JDBC-Driver已经被广泛使用,从迁移成本来说最好的方式就是保持Hive的使用方式不变,只需要换个端口就行,也就是可以通过Hive的JDBC Driver直接访问SparkSQL服务器。
-
支持多租户,以及类似用户名+密码和Kerberos等常见的用户认证能力。
-
支持跨队列提交,同时支持在JDBC的参数里面配置Spark的相关作业参数,例如Driver Memory,Execute Number等。
这里还有一个问题需要考虑,即用户通过SparkSQL服务器提交的是一段SQL代码,而SparkSQL在执行时需要向Yarn提交Jar。那么,如何实现SQL到Jar提交转换?
一个最简单的方式是,用户每提交一个SQL就执行一次spark-submit命令,将结果保存再缓存,提供给客户端。还有更好方式,即提交一个常驻的Spark 作业,这个作业是一个常驻任务,作业会开启一个端口,用来接收用户的SQL进行执行,并且保存。
但是为了解决类似Spark Thrift Server的问题,作业需要和用户进行绑定,而不是随着Spark的组件启动进行绑定,即作业的提交以及接收哪个用户的请求,均来自于用户的行为触发。
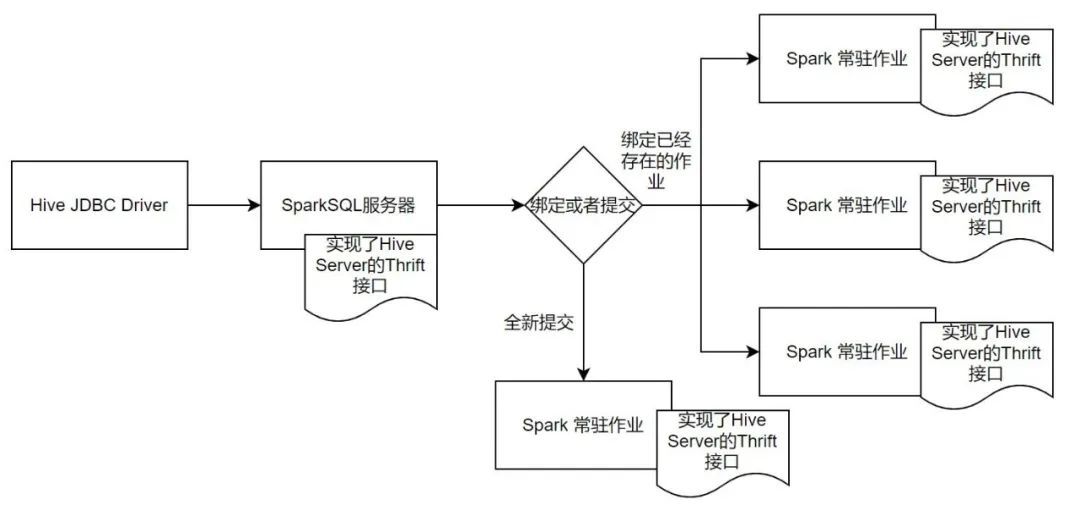
有了这样几个大的方向后,便可以开始开发SparkSQL服务器。首先需要实现TCLIService.Iface下的所有接口,下面用代码+注释的方式来讲述这些Thrift接口的含义,以及如果实现一个SparkSQL服务器,需要在这些接口做什么内容:
public class SparkSQLThriftServer implements TCLIService.Iface {
@Override
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws TException {
//Hive JDBC Driver在执行创建Connection的时候会调用此接口,在这里维护一个用户与Spark 作业的对应关系。
//来判断是需要复用一个已经存在的Spark作业,还是全新执行一次spark-submt。
//用户与是否需要spark-submit的关联关系均在这里实现。
//同时需要生成THandleIdentifier对象,并且和用户身份进行关联,后续其他方法调用均需要使用这个对象关联出用户的信息。
return null;
}
@Override
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws TException {
//客户端调用connection.close()方法后会进入到这里,在这里进行用户状态的清除,同时需要基于用户的情况判断是否需要停止用来执行该用户SQL的Spark 作业引擎。
return null;
}
@Override
public TGetInfoResp GetInfo(TGetInfoReq req) throws TException {
//获取服务器的元数据信息,例如使用BI工具,在命令会列出所连接的服务的版本号等信息,均由此方法提供。
return null;
}
@Override
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws TException {
//执行SQL任务,这里传递过来的是用户在客户端提交的SQL作业,接收到用户SQL后,将该SQL发送给常驻的Spark作业,这个常驻的作业在OpenSession的时候已经确定。
return null;
}
@Override
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws TException {
//获取数据库支持的类型信息,使用BI工具,例如beeline的时候会调用到这里。
return null;
}
@Override
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws TException {
//获取Catalog,使用BI工具,例如beeline的时候会调用到这里。
return null;
}
@Override
public TFetchResultsResp FetchResults(TFetchResultsReq req) throws TException {
//返回查询结果,基于THandleIdentifier对象查询到用户的SQL执行的情况,将请求转发至常驻的Spark 实例,获取结果。
//参数中通过TFetchResultsReq的getFetchType来区分是获取日志数据还是查询结果数据,getFetchType == 1为获取Log,为0是查询数据查询结果。
return null;
}
}
我们采用复用当前生态的方式,来实现兼容Hive JDBC Driver的服务器。有了上面的Thrift接口实现后,则需要启动一个Thrift服务,例如:
TThreadPoolServer.Args thriftArgs = new TThreadPoolServer.Args(serverTransport)
.processorFactory(new TProcessorFactory(this))
.transportFactory(new TSaslServerTransport.Factory())
.protocolFactory(new TBinaryProtocol.Factory())
.inputProtocolFactory(
new TBinaryProtocol.Factory(
true,
true,
10000,
10000
)
)
.requestTimeout(1000L)
.requestTimeoutUnit(TimeUnit.MILLISECONDS)
.beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executorService);
thriftArgs
.executorService(
new ThreadPoolExecutor(
config.getMinWorkerThreads(),
config.getMaxWorkerThreads(),
config.getKeepAliveTime(),
TimeUnit.SECONDS, new SynchronousQueue<>()));
TThreadPoolServer server = new TThreadPoolServer(thriftArgs);
server.serve();
至此便开发了一个支持Hive JDBC Driver访问的服务器,并且在这个服务器的方法中,实现了对Spark 作业的管理。后续,还需要开发预设Spark Jar,Jar同样实现了如上接口,只是该作业的实现是实际执行用户的SQL。
经过前面的流程,已经完成一个可以工作SparkSQL服务器开发,拥有接收用户请求,执行SQL,并且返回结果的能力。但如何做的更加细致?例如,如何实现跨队列的提交、如何实现用户细粒度的资源管理、如何维护多个Spark 作业的连接池,我们接下来会讲到。
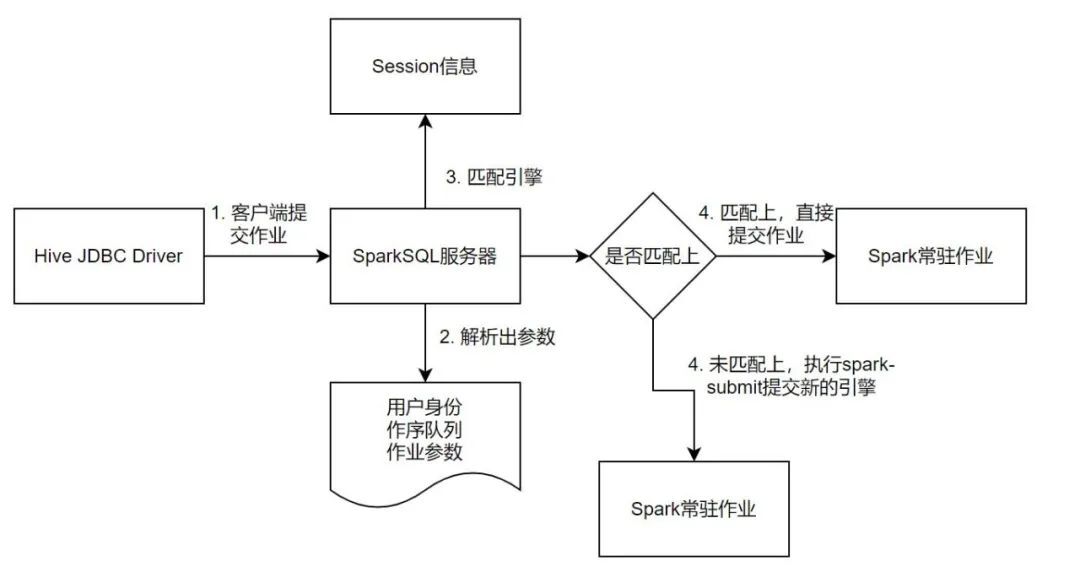
由于对于Spark作业在Yarn上的提交,运行,停止均由SparkSQL服务器管理,对用户是不可见的,用户只需要编写标准的JDBC代码即可,因此可以基于用户的参数信息来匹配合适的引擎去执行,同时还可以限制一个Spark 常驻作业的任务个数,实现更加灵活的SparkSQL作业的管理,同时也可以实现类似C3P0连接池的思想,维护一个用户信息到Spark常驻作业的关联池。
SparkSQL服务器的HA
Hive Server2在启动的时候会将自己的服务器信息写入Zookeeper中,结构体如下所示:
[zk: localhost:2181(CONNECTED) 1] ls /hiveserver2\[serverUri=127.0.01:10000;version=3.1.2;sequence=0000000000]当连接HA模式下的服务器的时候,Hive JDBC Driver的URL需要切换成zookeeper的地址,Hive JDBC Driver会从多个地址中随机选择一个,作为该Connection的地址,在整个Connection中均会使用该地址。
因此对于我们实现的SparkSQL服务器,只需要在服务器启动的时候,保持与Hive一致的数据格式,将自己的服务器的地址信息写入到Zookeeper中即可,便可通过标准的zk地址进行访问,例如:
./bin/beeline -u "jdbc:hive2://127.0.01/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=自定义的节点;auth=LDAP" -n 用户名 -p密码由于服务器的选择基于Connection级别的,也就是在Connection被生成新的之前,整个服务器的地址是不会发生变化的,在发生错误的时候服务端可以进行重试,进行地址的切换,因此HA的力度是在Connection级别而非请求级别。
对接生态工具
完成以上开发之后,即可实现在大部分的场景下,使用标准的Hive驱动只需要切换一个端口号。特别提到Hue工具,由于和Hive的集成并未使用标准的JDBC接口,而是直接分开调用的Hive Server2的Thrift接口,也就是Hue自行维护来如何访问Thrift的接口的顺序问题。
可以发现在这样的情况会有一个问题就是对于Hue来说,并没有Connection的概念,正常的SparkSQL在JDBC的交互方式下处理流程是:
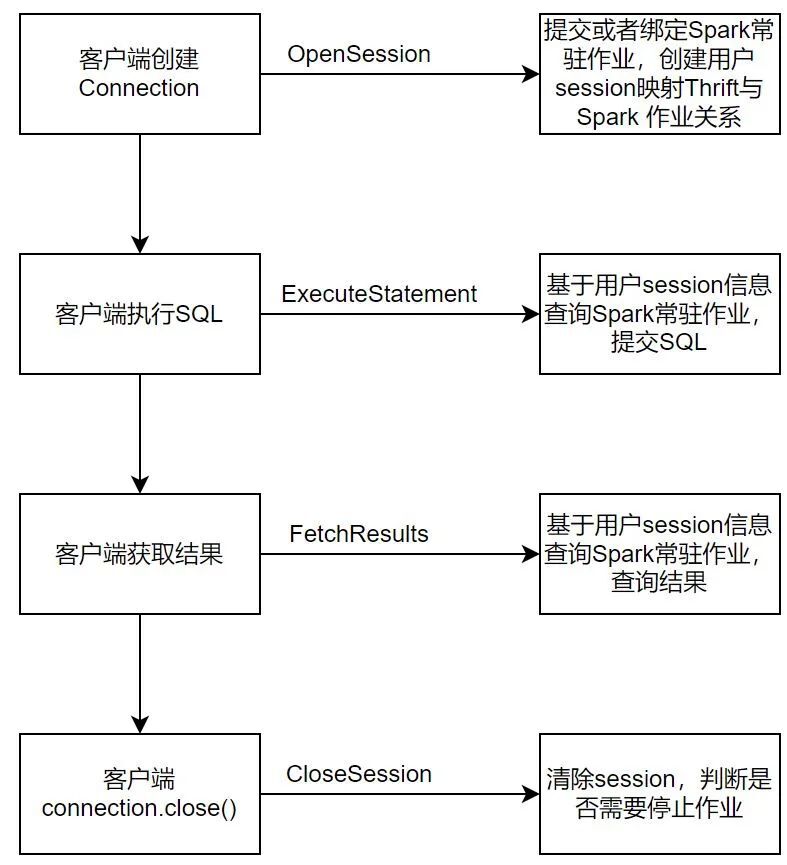
由于Hue没有Connection概念,因此Hue的请求并不会先到OpenSession,而是直接发起ExecuteStatement。由于没有上下文信息,正常流程下ExecuteStatement处接收到Hue的请求会发现该请求为非法,所以OpenSession不能作为连接的起点,而是需要在每一个Thrift接口处实现OpenSession的能力,以此作为上下文初始化。
尾声
SparkSQL在企业中的使用比重越来越大,而有一个更好用的SQL服务器,则会大大提升使用效率和降低使用门槛。目前,SparkSQL在服务器这方面的能力显然不如Hive Server2提供的更加标准,所以各个企业均可基于自身情况,选择是否需要开发一个合适于自身的SparkSQL服务器。
本文所提到的相关能力已通过火山引擎EMR产品向外部企业开放。结合字节跳动内部以及外部客户的需求情况,火山引擎EMR产品的Ksana for SparkSQL提供一个生产可用的SparkSQL服务器,并且在Spark 性能方面也做了较大的优化,本文主要围绕技术实现的角度来阐述如何实现一个SparkSQL服务,后续会有更多文章讲述其他相关的优化。
产品介绍
火山引擎 E-MapReduce
支持构建开源Hadoop生态的企业级大数据分析系统,完全兼容开源,提供 Hadoop、Spark、Hive、Flink集成和管理,帮助用户轻松完成企业大数据平台的构建,降低运维门槛,快速形成大数据分析能力。
更多技术交流、求职机会、试用福利,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群

 浙公网安备 33010602011771号
浙公网安备 33010602011771号