大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言。Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的。当然,Spark也提供Java和Python的API。
Java是一门热度很高的开发语言,也是一个高龄语言。Java本身很牛逼,但它最牛逼的地方是——成就了JVM。
基于JVM的语言非常多,常用的除了Java还有Scala、Groovy、Kotlin、Clojure。能编译成字节码的语言,都能在JVM上运行。
Scala
Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。
Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的 Java 类库。
与JAVA的区别
我们学习的是大数据,重点不在于Scala用的有多么溜,够用就行。作为一个从Java上手的码农,我感觉Java是一个古板先生,语言和语法都规规矩矩,显得有点儿臃肿。Scala像一个翩翩少年,没那么多束缚,语法天马行空,用行话说就是“有很甜的语法糖”,一个API可以做很多事。用惯了Scala的数据集操作,简直就不想再用Java的那一套,什么都要自己写,太麻烦了。当然,想招聘一个精通Scala的人,这个难度比招一个精通Java的人要大得多,毕竟用的人少。
IDEA安装Scala插件
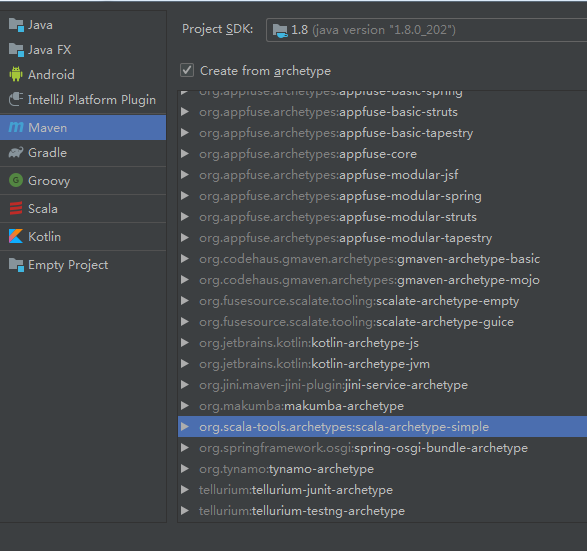
创建Scala Maven项目
建好项目把App、AppTest、MySpec三个类删掉。修改pom文件里scala的版本号。
<properties> <scala.version>2.12.0</scala.version> </properties>
引入spark-core依赖。
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.1.2</version> </dependency>
编写Scala代码
环境配好之后,可以写代码了。创建一个Scala的Object,它可以运行main方法。
package com.xy import org.apache.spark.{SparkConf, SparkContext} object Test { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Test").setMaster("local") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") val rdd = sc.parallelize(Array(1,2,3,2,1,4,5,2)) val kv = rdd.map(x=>(x,1)).reduceByKey(_+_) kv.foreach(println) } }
从(1,2,3,2,1,4,5,2)这个数据集里计算每个数字出现的次数,运行结果如下。
(4,1) (1,2) (3,1) (5,1) (2,3) Process finished with exit code 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号