大数据学习(15)—— B+树和LSM
这一节介绍数据库存储引擎常用的两种数据结构。作为关系型数据库的代表,MySql的InnoDB使用B+树来存储索引。作为NoSQL的代表,HBase使用的LSM树,我们来看看两者有什么区别。
B+树
B+树是大学数据结构里的内容。要了解什么是B+树,先从简单的开始。
二叉排序树
简单的说,二叉排序树首先是一个二叉树,每个结点最多只有两个分支,每个结点存储一个数据。左子树的所有结点都比父结点小(或相等),右子树的所有结点都比父结点大(或相等)。两个括号里的“或相等”附加说明,只能存在一个。
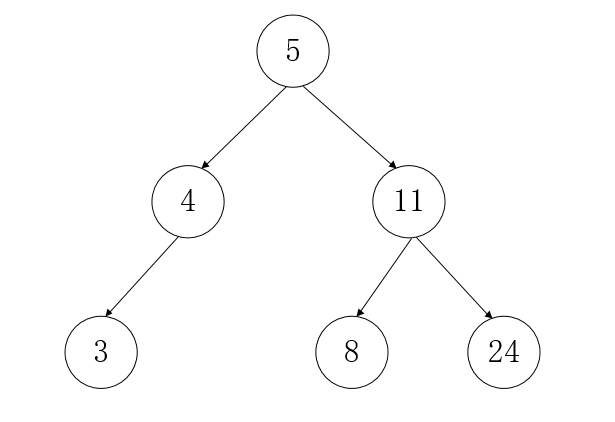
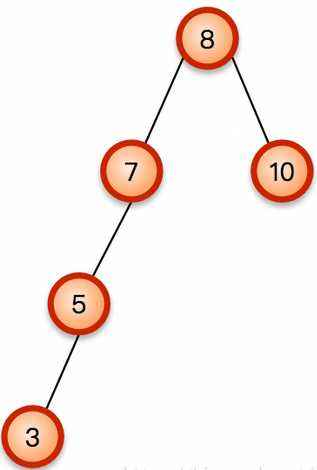
上面这两个图片都是二叉排序树。第一个树是平衡二叉树(任意结点左右子树高度差小于等于1,AVL),第二个树不平衡。不平衡会导致数据查询效率下降,因此要避免数据倾斜。
B树
二叉树的结点能保存数据,但是它存在缺点,如果数据量很大,它的深度会很大,查询效率低。比如:20层的满二叉树也只能存储100多万条数据。对于动辄数百万条记录的关系型数据库来说,要是查找一条记录如果要发生十几次IO,这个延时是不能接受的。
平衡树(B树,Balance Tree)是一种平衡多叉树,结点之间和结点内部也是有序的,每个结点有多个子结点,每个结点可以存储多个数据。二叉树因为瘦高,查询效率低。B树因为矮胖,降低了树的深度,查询效率快很多。具体定义自行百度。
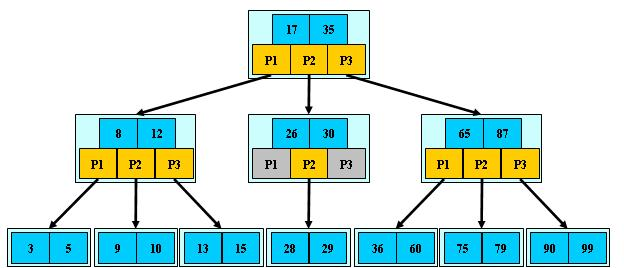
B+树
B+树是B树的一个变形,B+树的非叶子结点不存储数据,只作为索引。B+树的叶子结点内部,数据是有序排列的。
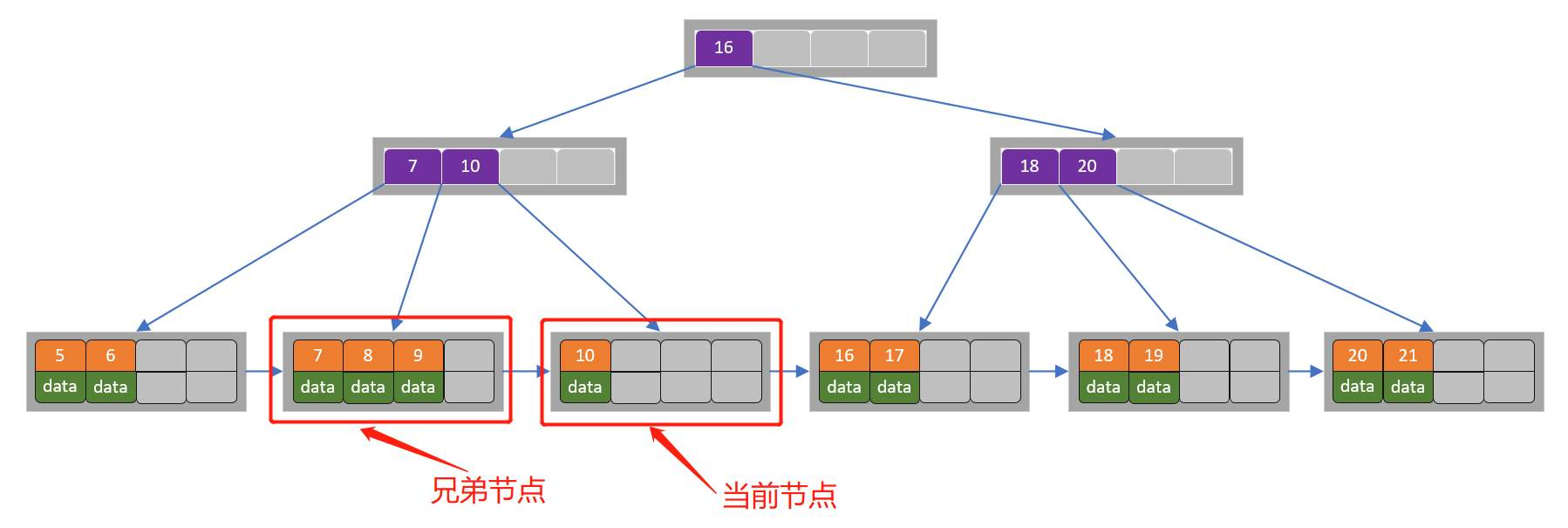
B+树的叶子结点兄弟之间有从左至右的指针,方便范围查询。
LSM
Log-Structured Merge-Tree,日志结构合并树,强调三点:一是这不是一个具体的数据结构只是一种做法,二是像写日志那样只追加,三是树会合并。
LSM为KV存储系统量身定做,只追加不修改不删除的特性很好地利用了机械硬盘顺序写入快、随机写入慢的特性。LSM首先是写内存,在内存中是一颗小树,内存要足够大,这比直接写磁盘也快了十万倍。内存写满了再落盘,追加到尾部,并且对大量的小文件做合并操作形成大树。为了将随机写转换为顺序写,LSM存储了大量的重复过时数据,这是空间换时间的做法。
上面这一点对于大量的写操作是非常高效的,但是读性能会略微受影响。读取数据的时候由于没有一颗完整有序的大树,所以要从最新的小树里查找数据,找不到的话就往前找。当然,这个缺陷可以使用布隆过滤器来优化。
我看了很多资料,都提到LSM是基于机械硬盘磁臂移动慢出现的,那么换成SSD还有这问题吗?老外对这个问题已经有研究了,看这里Separating Keys from Values in SSD-conscious Storage
当机械硬盘退出生产环境舞台的时候,LSM也许会迎来一波变革吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号