
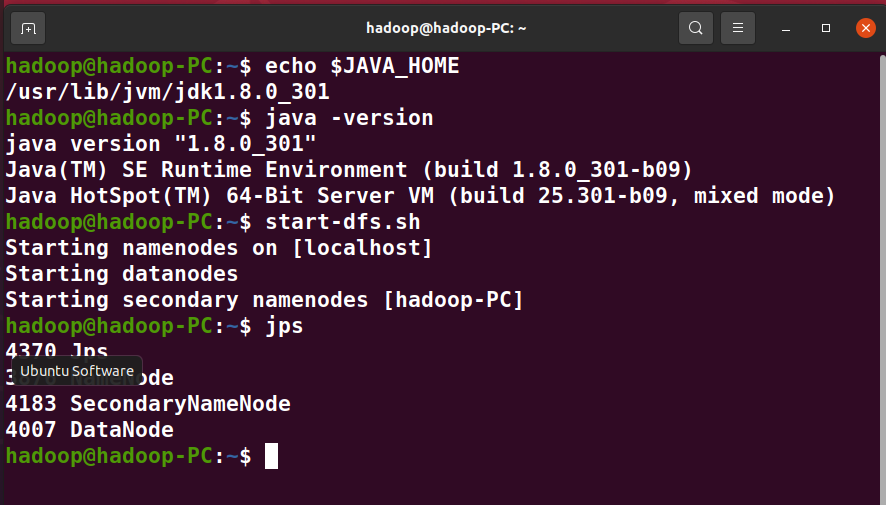
1、检查基础环境hadoop,jdk
启动hdfs查看进程
2、下载spark(省略,原来已下好Spark)
3、解压,文件夹重命名、权限(省略,原来已下好Spark)
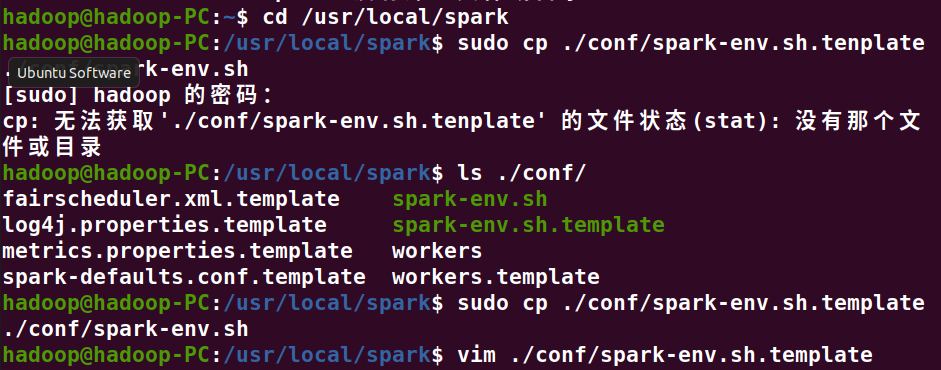
4、配置文件
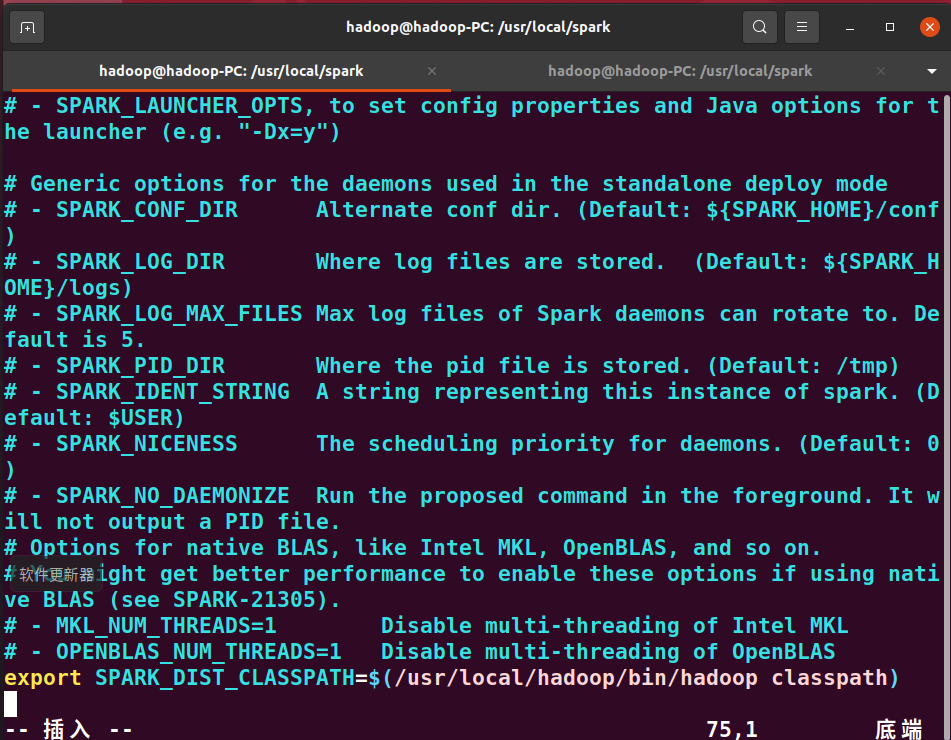
配置Spark的classPath,并加上最后一行代码
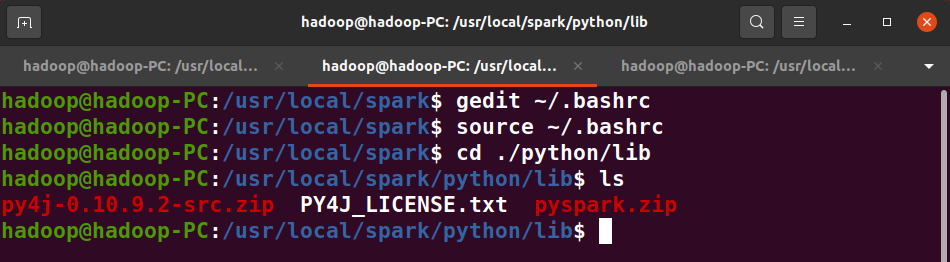
5、环境变量
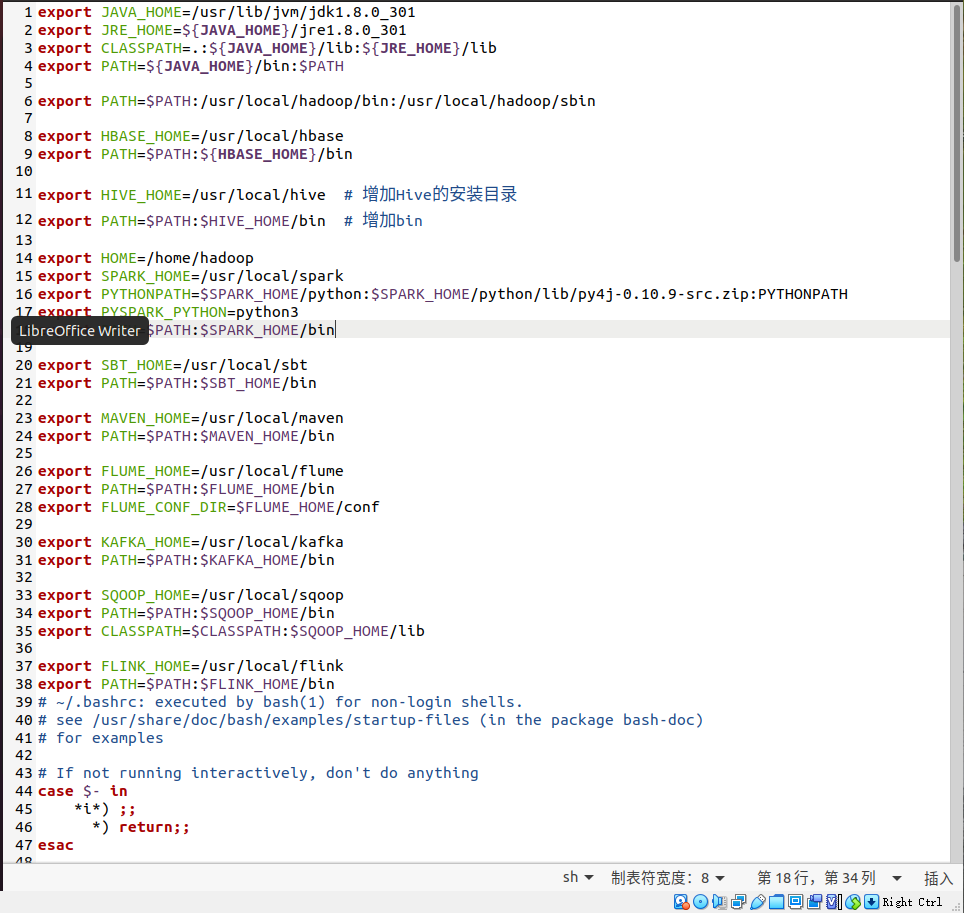
6、试运行Python代码
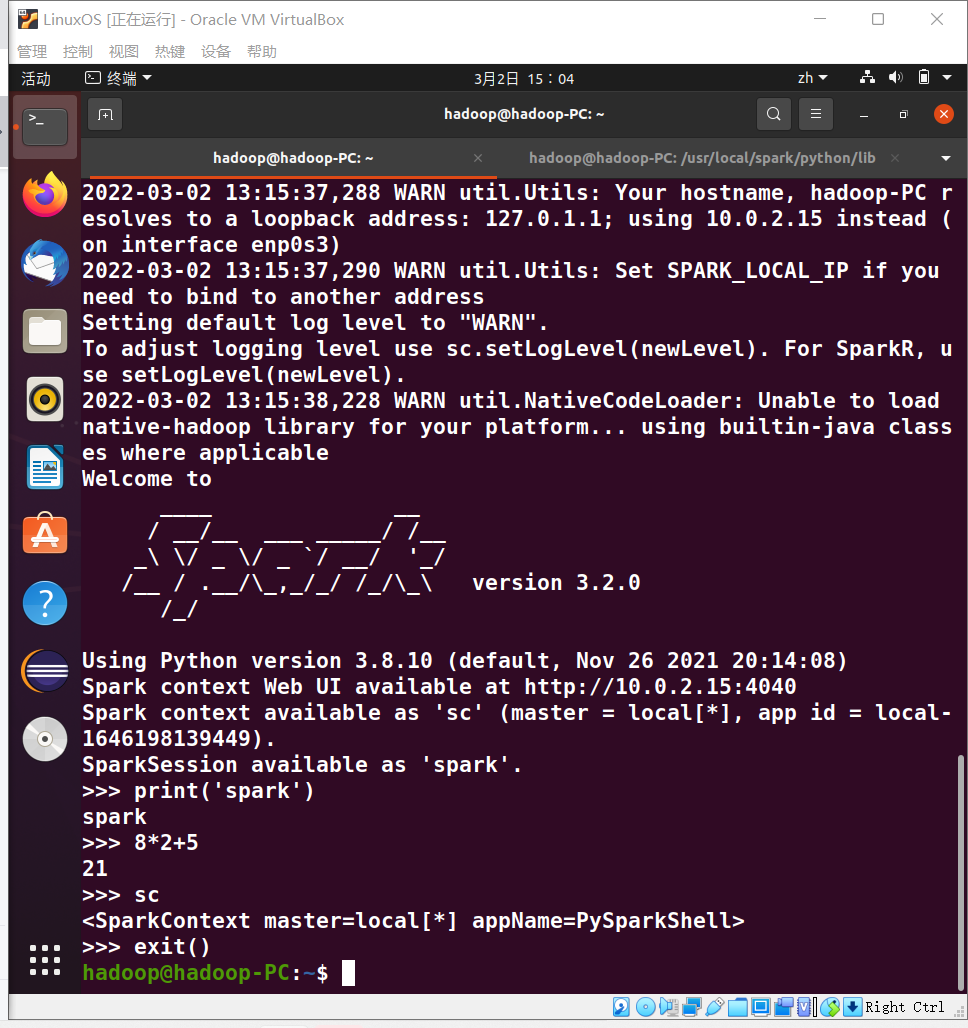
二、Python编程练习:英文文本的词频统计
1、准备文本文件
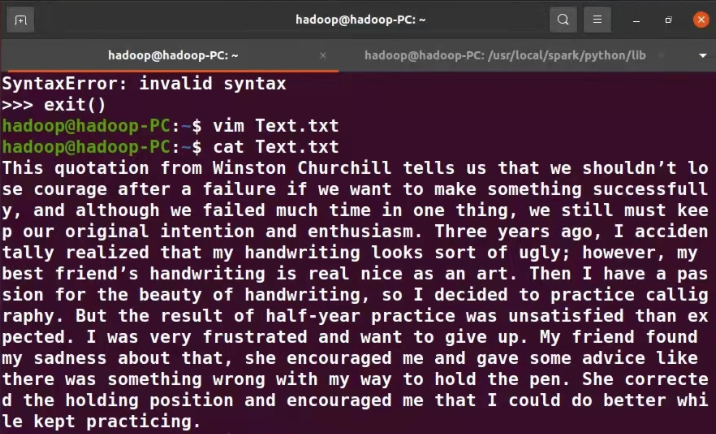
2、读文件
path='/usr/local/spark/sparkapps/Text.txt'
with open(path) as f:
text=f.read()
3、预处理:大小写,标点符号,停用词
4、分词
步骤三+步骤四
words = text.split()
5、统计每个单词出现的次数
for word in words:
wc[word]=wc.get(word,0)+1
6、按词频大小排序
wclist=list(Text.items()) wclist.sort(key=lambda x:x[1],reverse=True)
7、结果写文件
print(wclist)
运行结果截图

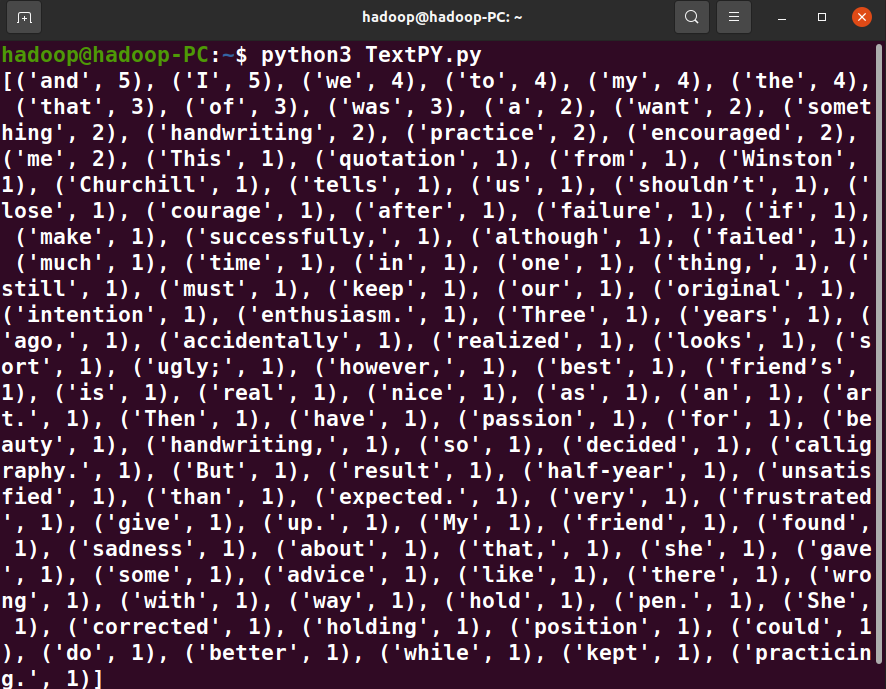
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号