
一、Hadoop生态的各个组件及其功能:
Hadoop生态以HDFS和MapReduce为核心,拥有Hive、HBase、Zookeeper、Sqoop、Pig、Mahout、Flume、YARN、Ambari等功能组件
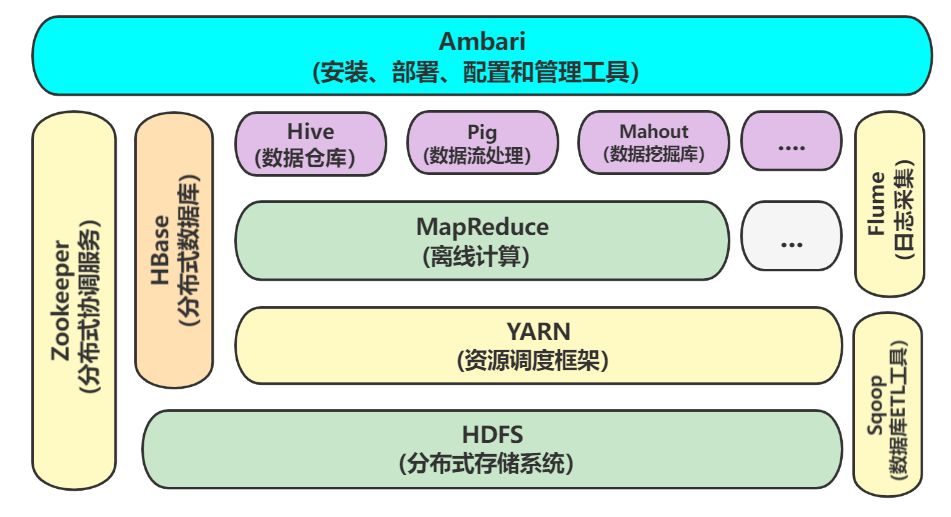
1.HDFS
分布式文件系统HDFS是Hadoop两大核心组成部分之一。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,有着高容错性的特点,并且兼容廉价的硬件设备。可以低成本的实现大流量和大数据的读写。HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。而数据节点负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
2. MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。MapReduce是一个基于集群的高性能并行计算平台,允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。MapReduce是一个并行计算与运行软件框架,提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理。MapReduce是一个并行程序设计模型与方法,它提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
3. hive
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4.hbase
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5.zookeeper
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6.sqoop
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7.pig
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
8.mahout
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9.flume
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
二、对比Hadoop与Spark的优缺点
Spark基于RDD,数据并不存放在RDD中,只是通过RDD进行转换,通过装饰者设计模式,数据之间形成血缘关系和类型转换。Spark用scala语言编写,相比java语言编写的Hadoop程序更加简洁。相比Hadoop中对于数据计算只提供了Map和Reduce两个操作,Spark提供了丰富的算子,可以通过RDD转换算子和RDD行动算子,实现很多复杂算法操作,这些在复杂的算法在Hadoop中需要自己编写,而在Spark中直接通过scala语言封装好了,直接用就可以。Hadoop中对于数据的计算,一个Job只有一个Map和Reduce阶段,对于复杂的计算,需要使用多次MR,这样涉及到落盘和磁盘IO,效率不高;而在Spark中,一个Job可以包含多个RDD的转换算子,在调度时可以生成多个Stage,实现更复杂的功能。Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用,而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作。Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能。在性能上:由处理速度衡量的Spark性能比Hadoop更优;在成本上:Spark和Hadoop都可以作为开源Apache项目免费获得,Hadoop需要更多的磁盘内存,而Spark需要更多的内存,这意味着设置Spark集群可能会更加昂贵;在安全性上:Spark和Hadoop都可以支持Kerberos身份验证,但Hadoop对HDFS具有更加细化的安全控制。
三、如何实现Hadoop与Spark的统一部署
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号