搜索笔记整理
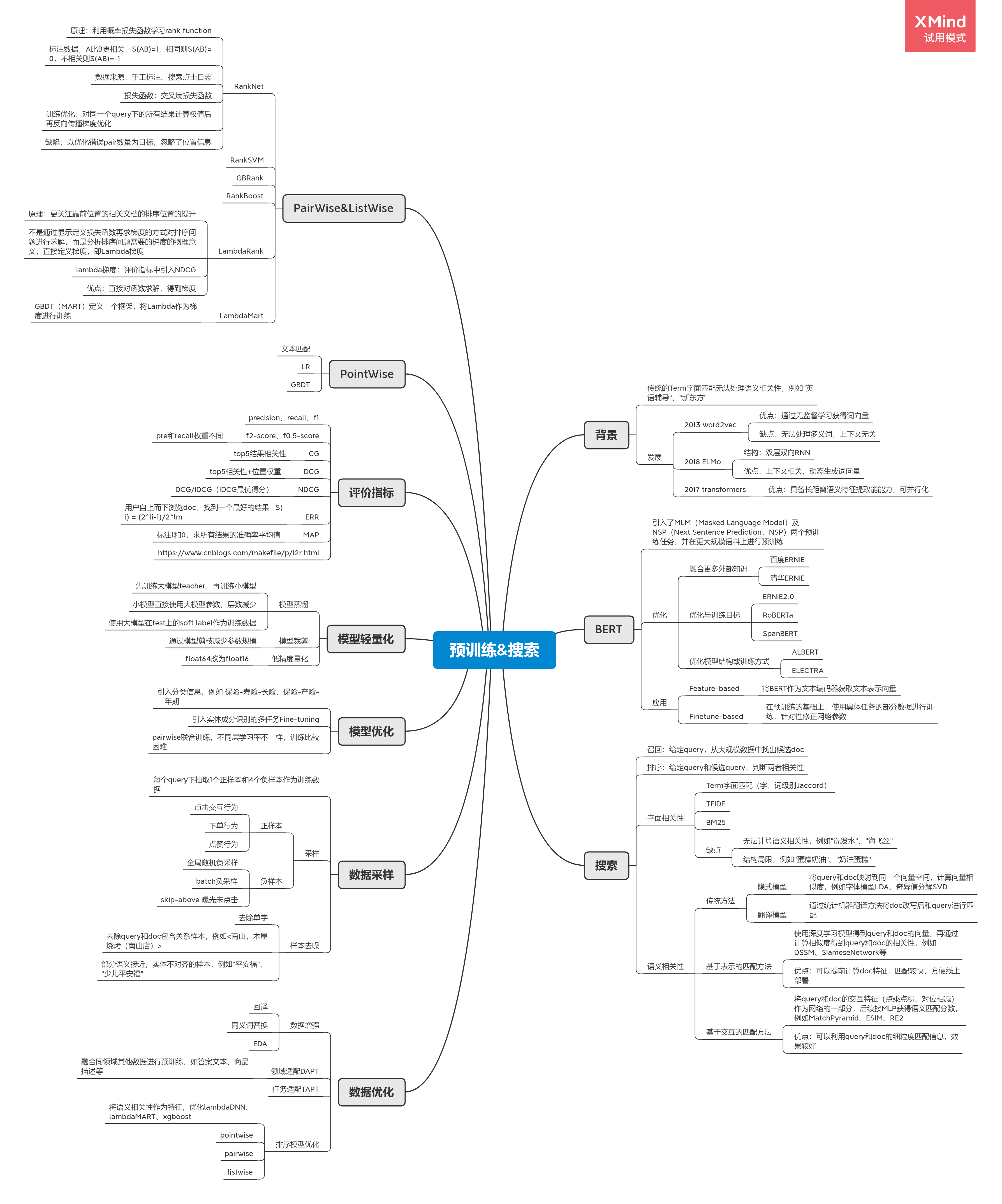
预训练&搜索
背景
传统的Term字面匹配无法处理语义相关性,例如“英语辅导”、“新东方”
发展
-
2013 word2vec
- 优点:通过无监督学习获得词向量
- 缺点:无法处理多义词,上下文无关
-
2018 ELMo
- 结构:双层双向RNN
- 优点:上下文相关,动态生成词向量
-
2017 transformers
- 优点:具备长距离语义特征提取能能力,可并行化
BERT
引入了MLM(Masked Language Model)及NSP(Next Sentence Prediction,NSP)两个预训练任务,并在更大规模语料上进行预训练
优化
-
融合更多外部知识
- 百度ERNIE
- 清华ERNIE
-
优化与训练目标
- ERNIE2.0
- RoBERTa
- SpanBERT
-
优化模型结构或训练方式
- ALBERT
- ELECTRA
应用
-
Feature-based
- 将BERT作为文本编码器获取文本表示向量
-
Finetune-based
- 在预训练的基础上,使用具体任务的部分数据进行训练,针对性修正网络参数
搜索
召回:给定query,从大规模数据中找出候选doc
排序:给定query和候选query,判断两者相关性
字面相关性
-
Term字面匹配(字、词级别Jaccord)
-
TFIDF
-
BM25
-
缺点
- 无法计算语义相关性,例如“洗发水”、“海飞丝”
- 结构局限,例如“蛋糕奶油”、“奶油蛋糕”
语义相关性
-
传统方法
-
隐式模型
- 将query和doc映射到同一个向量空间,计算向量相似度,例如字体模型LDA、奇异值分解SVD
-
翻译模型
- 通过统计机器翻译方法将doc改写后和query进行匹配
-
-
基于表示的匹配方法
- 使用深度学习模型得到query和doc的向量,再通过计算相似度得到query和doc的相关性,例如DSSM、SIameseNetwork等
- 优点:可以提前计算doc特征,匹配较快,方便线上部署
-
基于交互的匹配方法
- 将query和doc的交互特征(点乘点积、对位相减)作为网络的一部分,后续接MLP获得语义匹配分数,例如MatchPyramid、ESIM、RE2
- 优点:可以利用query和doc的细粒度匹配信息,效果较好
数据优化
数据增强
- 回译
- 同义词替换
- EDA
领域适配DAPT
- 融合同领域其他数据进行预训练,如答案文本、商品描述等
任务适配TAPT
排序模型优化
- 将语义相关性作为特征,优化lambdaDNN、lambdaMART、xgboost
- pointwise
- pairwise
- listwise
数据采样
每个query下抽取1个正样本和4个负样本作为训练数据
采样
-
正样本
- 点击交互行为
- 下单行为
- 点赞行为
-
负样本
- 全局随机负采样
- batch负采样
- skip-above 曝光未点击
样本去噪
- 去除单字
- 去除query和doc包含关系样本,例如<南山,木屋烧烤(南山店)>
- 部分语义接近,实体不对齐的样本,例如“平安福”、“少儿平安福”
模型优化
引入分类信息,例如 保险-寿险-长险、保险-产险-一年期
引入实体成分识别的多任务Fine-tuning
pairwise联合训练,不同层学习率不一样,训练比较困难
模型轻量化
模型蒸馏
- 先训练大模型teacher,再训练小模型
- 小模型直接使用大模型参数,层数减少
- 使用大模型在test上的soft label作为训练数据
模型裁剪
- 通过模型剪枝减少参数规模
低精度量化
- float64改为float16
评价指标
precision、recall、f1
f2-score、f0.5-score
- pre和recall权重不同
CG
- top5结果相关性
DCG
- top5相关性+位置权重
NDCG
- DCG/IDCG(IDCG最优得分)
ERR
- 用户自上而下浏览doc,找到一个最好的结果 S(i) = (2li-1)/2lm
MAP
- 标注1和0,求所有结果的准确率平均值
https://www.cnblogs.com/makefile/p/l2r.html
PointWise
文本匹配
LR
GBDT
PairWise&ListWise
RankNet
- 原理:利用概率损失函数学习rank function
- 标注数据,A比B更相关,S(AB)=1,相同则S(AB)=0,不相关则S(AB)=-1
- 数据来源:手工标注、搜索点击日志
- 损失函数:交叉熵损失函数
- 训练优化:对同一个query下的所有结果计算权值后再反向传播梯度优化
- 缺陷:以优化错误pair数量为目标,忽略了位置信息
RankSVM
GBRank
RankBoost
LambdaRank
- 原理:更关注靠前位置的相关文档的排序位置的提升
- 不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的梯度的物理意义,直接定义梯度,即Lambda梯度
- lambda梯度:评价指标中引入NDCG
- 优点:直接对函数求解,得到梯度
LambdaMart
- GBDT(MART)定义一个框架,将Lambda作为梯度进行训练
XMind - Trial Version
时间会记录下一切。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号