

Redis实现之字符串
简单动态字符串
Redis中的字符串并不是传统的C语言字符串(即字符数组,以下简称C字符串),而是自己构建了一种简单动态字符串(simple dynamic string,SDS),并将SDS作为Redis的默认字符串表示。在Redis中,C字符串一般只用在无需对字符串值进行修改的地方,比如Redis的启动时的日志。Redis需要的字符串是一个可修改字符长度的字符串,就会用到SDS来表示一个字符串。比如下面这个例子:
127.0.0.1:6379> set msg "hello world" OK
这是一条很简单的命令,将"hello world"这个字符串与msg这个键建立映射关系。而"hello world"在Redis中的表示,就是一个SDS。说了那么久的SDS,那这个SDS到底长什么样呢?我们来看看
sds.h
struct sdshdr {
//记录buf数组中已使用字节的数量
//等于SDS所保存字符串的长度
int len;
//记录buf数组中尚未使用的字节数量
int free;
//字节数组,用于保存字符串
char buf[];
};
图1-1展示了一个SDS的示例:
- free属性的值为0,表示这个SDS没有任何剩余的可使用字节数
- len为5,表示这个SDS保存了一个长度为5的字符串
- buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而最后一个字节则保存空字符'\0',代表字符串结束

图1-1
看到这里,可能还有人不明白使用SDS的好处。没关系,我们接下来再看看另一个示例。我们看图1-2,这个SDS和图1-1的SDS不一样,虽然都保存字符串“Redis”。但图1-2中SDS的buf字符数组长度以及free所保存的值都与图1-1的SDS不一样
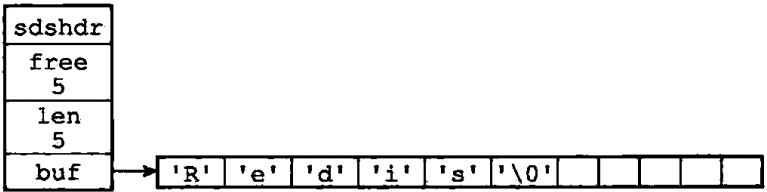
图1-2
我们都知道,Redis作为一款非关系型的内存数据库,他的值很容易变动。同时我们也知道,C语言中字符数组的长度是无法变动的。如果Redis中使用的字符串是C字符串,而不是SDS,当我们变动一个键所对应的字符串,如果新字符串的长度小于等于原先字符串的长度,那么我们只要替换字符数组上的内容,再把代表字符串结尾的提前(如果新旧字符串长度相等,则空字符串还留在原先的位置)。但如果新字符串的长度大于原先旧字符串的长度,那么很不幸,我们只能重新申请一个能容纳新字符串长度的数组,用于保存新字符串,这对Redis无疑是不利的
于是,Redis在为一个字符串创建一个SDS对象时,通常会申请比字符串长度更长的字节数组(buf),Redis将字符串保存进这个数组,同时在len这个变量保存字符串的长度,再用free这个变量保存buf尚未使用的字节数量。当客户端要求变动一个键所对应的字符串时,如果buf的长度大于新字符串的长度,那么就无需再声明一个新的数组来容纳新字符串了
我们再来看sdshdr这个结构体,这里面有free、len和buf这三个域。那么这个len会不会有些多余?因为free已经记录尚未使用的字节数量了,同时len我们也可以通过:strlen(buf)的方式来计算字符串长度,那么这个len真的是多余的吗?其实不是,如果有使用过Java、Python等这些高级语言的人都有经验,在这些高级语言中,我们可以轻而易举的调用一个函数来获取字符串的长度,而这些高级语言的字符串内部实现,同样也记录了字符串的长度,假设我们要计算一个字符串长度,每次都要调用strlen(buf),这个操作的时间复杂度为O(N),图1-3展示了C程序中计算字符串长度的过程
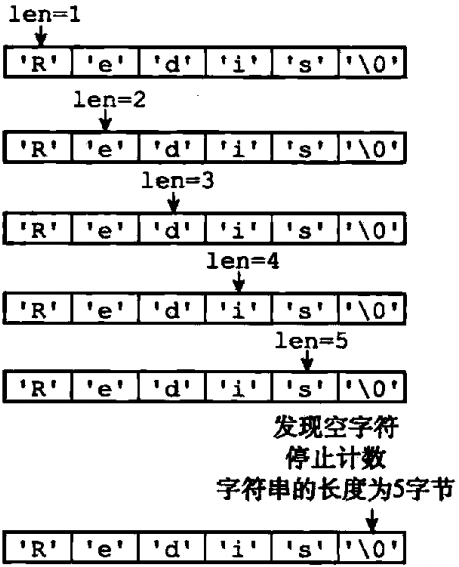
图1-3
从图1-3我们可以知道,当通过strlen(buf)计算一个C字符串的长度,游标会遍历到空字符处才停止,而大家在编程中,多多少少在一些业务场景会重复用到某个字符串长度。于是,SDS中,len域的作用就在于此,我们只需要计算一次字符串的长度,当需要用到时直接从len中取,这时的时间复杂度为O(1)
除了获取字符串长度的时间复杂度高之外,C字符串不记录自身长度带来的另一个问题是容易造成缓冲区溢出。C语言中的strcat函数可以拼接两个字符串,具体定义如下:
#include <string.h> char *strcat(char *dest, const char *src);
strcat函数可以将src字符串中的内容拼接到dest字符串之后,但因为C本身不记录字符串长度,默认认为dest已经分配了足够的内存空间。举个例子,假设程序中有紧邻的两个字符串S1和S2,其中S1保存了字符串“Redis”,而S2保存了字符串“MongoDB”,如图1-4所示

图1-4 在内存中紧邻的两个C字符串
如果程序员没有注意S1的长度,直接执行strcat(S1, "Cluster"),那么势必会覆盖到S2的内存,换言之S2所对应的字符数组的内容会被修改,如图1-5所示

如图1-5 S1的内容溢出到S2所在的位置上
与C字符串不同,SDS的空间分配策略完全杜绝了发生缓冲区溢出的可能性,当SDS API需要对SDS进行修改时,API会检查SDS的空间是否满足修改的要求,如果不满足的话,API会自动将SDS的空间扩展至执行所需的大小,然后才执行修改操作
SDS的API里面有一个用于执行拼接操作的sdscat函数,它可以将一个C字符串拼接到给定的SDS所保存的字符串后面,但是在执行拼接操作之前,sdscat会检查给定的SDS的空间是否足够,如果不够的话,sdscat就会扩展SDS的空间,然后才执行拼接操作
例如,我们执行sdscat(s, " Cluster"),其中SDS值s如图1-6所示,那么sdscat检查后发现,目前s的空间并不足以拼接" Cluster",之后,sdscat就会扩展s空间,然后执行拼接" Cluster"操作,拼接完之后的SDS如图1-7所示
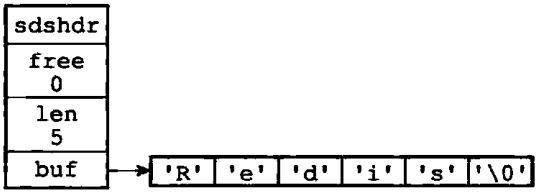
图1-6 sdscat执行之前的SDS

图1-7 sdscat执行之后的SDS
Redis作为内存数据库,经常被用于速度要求严苛,数据被频繁修改的场合,如果每次修改字符串长度都需要执行一次内存重分配的话,那么光是执行内存重分配的时间就会占去修改字符串所用时间的一大部分,如果这种修改频繁发生的话,可能还会对性能造成影响。为了避免C字符串的缺陷,SDS通过未使用空间解除字符串长度和底层数组长度之间的关联。在SDS中,buf数组的长度不一定是字符数量加一,数组里面可以包含未使用的字节,而这些字节的数量就由SDS的free属性记录。通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略
空间预分配
空间预分配用于优化SDS的字符串增长操作,我们都知道当SDS的API对一个SDS进行修改时,除了分配给本身所需的字节空间,还会再额外分配一些备用空间。那么,这个备用空间是多大呢?备用空间由以下公式决定:
- 如果对SDS进行修改后,SDS的长度(即len属性的值)小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS的free属性的值将于len属性的值相同。比如经过修改之后,SDS的len将变为13个字节,那么程序也会分配13个字节的备用空间,外加一个字节用于存储空字符串标识字符串结束,所以SDS的buf数组实际长度为13+13+1=27字节
- 如果对SDS进行修改之后,SDS的长度大于等于1MB,那么程序会多分配1MB的未使用时间。比如经修改后,SDS的len为30MB,那么程序会多分配1MB的未使用空间,SDS的buf数组的实际长度为30MB+10MB+1byte
惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作,当SDS的API需要缩短SDS保存的字符串时,程序其实并不立即使用内存重分配回收缩短后多出来的字节,而是将修改后尚未被使用的字节数存放在free中,用于以后使用
二进制安全
C字符串的必须必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符串将被误认到达字符串末尾,这限制了C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据
虽然数据库一般用于保存文本数据,但使用数据库来保存二进制数据的场景也不少见。因此,为了确保Redis可以适用于各种不同的场景,SDS的API都是二进制安全的,所有SDS API都会以处理二进制的方式来处理存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或假设,数据在写入时是什么样的,它被读取时就是什么样的
这也是我们将SDS的buf属性称为字节数组的原因,因为Redis不是用这个数组来保存字符,而是用它来保存一系列的二进制数据。且在SDS中,并非以一个空字符来判断是否到达字符数组的末尾,而是通过len属性的值,如图1-8
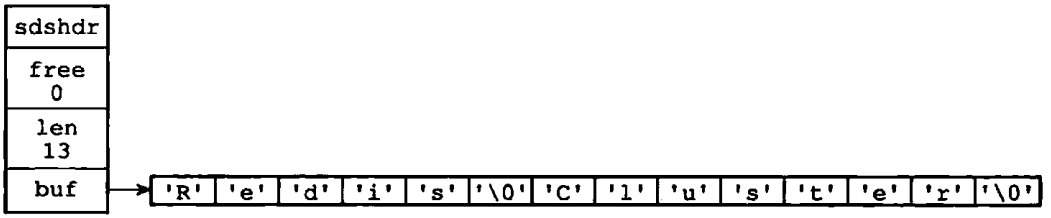
图1-8 保存了特殊数据格式的SDS
兼容部分C字符串函数
虽然SDS的API都是二进制安全的,但它们一样遵循C字符串以空字符结尾的惯例:这些API总会将SDS保存的数据的末尾设置为空字符,并且总会在为buf数组分配空间时多分配一个字节的空间来容纳空字符,这是为了让保存了文本数据的SDS可以重用一部分<string.h>库定义的函数。比如:strcasecmp是用于忽略大小写比较两个字符串的函数,使用它来对比SDS保存的字符串和另一个C字符串
strcasecmp(sds->buf, "hello world");
又或者,我们可以将sds中的buf所保存的内容,追加到另一个C字符串上。这样,就无需再去编写另外一套与<string.h>中功能类似的函数了
strcat(c_string, sds->buf);
现在,我们对C字符串和SDS的区别进行总结
| C字符串 | SDS |
| 获取字符串长度的时间复杂度为O(N) | 获取字符串长度的时间复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
上面的SDS结构是3.2以前较为早期的版本,3.2之后SDS有5种类型,分别用于存储不同长度的字符串:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];// buf[0]: z: 0101001
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
Redis会根据我们设置的字符串长度,选择不同的SDS结构体来存储,如果我们存储的字符串长度小于等于MaxUint8则用sdshdr8存储,如果我们的字符串长度大于MaxUint8且小于等于MaxUint16则用sdshdr16来存储。这5个结构体都使用了__attribute__ ((__packed__)),这个做法可以让编译器以紧凑的方式来分配内存,sdshdr16长度是5个字节,如果没有__attribute__ ((__packed__))属性,编译器会对结构体做内存对齐,那么sdshdr16占用的字节长度为6个字节。
除了sdshdr5,其他4个结构体都有len和alloc字段,这里len依旧代表buf存储的内容长度,而alloc则代表buf的总容量,如果我们要计算SDS剩余可存储字节,则用alloc-len,即为3.2前SDS的free字段。
flags的最低3位表示SDS的类型,如果flags的值为SDS_TYPE_5(即为:0),则代表这个SDS的类型为sdshdr5、如果flags的值为SDS_TYPE_8(即为:1),则代表这个这个SDS的类型为sdshdr8,以此类推,如果flags的值为SDS_TYPE_64(即为:4,4的二进制表示为200),则代表这个SDS类型为sdshdr64。这里会有人奇怪,为何每个SDS类型都需要一个flags来单独表示其SDS的类型,难道结构体本身不是已经代表其类型了吗?这是因为在Redis中很多时候传递SDS指针并不是以SDS对象的起始地址来传递的,而是以buf的起始地址来传递SDS对象。这里我们注意到每个SDS结构体的最后一个字段都是char buf[],这是一个没有指定长度的的字符数组,这是C语言中定义字符数组的一种特殊写法,称为柔性数组(flexible array member),只能定义在结构体的最后一个字段上。这个字段只起到标记的作用,表示在flags字段后面就是一个字符数组,或者说,它指明了紧跟在flags字段后面的这个字符数组在结构体中的偏移位置。而程序在为结构体分配的内存的时候,并不会为柔性数组计算需要占用的空间。如果计算sizeof(struct sdshdr16)的值,那么结果是5个字节,不会把buf字段的长度计算进去。当然,我们为一个SDS分配内存,并非要一板一眼只分配5个字节,那么这5个字节的内存空间,仅仅能存储sdshdr16除buf外的字段,如果我们申请一块16字节的内存分配给sdshdr16对象,那么除去5个字节分配给sdshdr16除buf外的字段,我们还有11个字节来存储字符串。如果我们拿到buf的起始地址,flags即为buf[-1],拿到flags后,我们便可以计算这个buf具体的SDS类型,继而可以获得len和alloc这两个字段,从而计算出这个数组要读取多少个字节才算结束,这个数组还可以容纳多少个字节的数据。
先前我们说Redis在创建SDS对象时,返回的并不是SDS对象本身,而是buf的起始地址,下面我们来看看Redis是如何创建SDS对象的:
sds sdsnewlen(const void *init, size_t initlen) {
//这个指针会指向SDS起始位置
void *sh;
//sds也是一个指针,这里会指向SDS中buf的起始位置
sds s;
//根据不同的长度返回对应的SDS类型
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
//如果判断要创建的SDS类型为5,且字符串为空串,则类型替换成SDS8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
//根据SDS类型获取内存占用大小,以便后续创建内存
int hdrlen = sdsHdrSize(type);
//fp用于指向SDS的flag地址
unsigned char *fp; /* flags pointer. */
//申请SDS大小+字符串长度+1的内存空间,这里+1是为了分配结束符号,C语言用\0表示字符串结束
sh = s_malloc(hdrlen+initlen+1);
//判断内存是否申请成功
if (sh == NULL) return NULL;
//判断是否处于init阶段
if (init==SDS_NOINIT)
init = NULL;
//如果不是init阶段则将申请来的内存清零
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
//将s指向SDS的buf起始地址
s = (char*)sh+hdrlen;
//s指向buf的起始地址,往前一个字节即指向SDS的flag地址
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
//这里使用了内联方法,声明一个对应SDS类型的变量sh
//#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
SDS_HDR_VAR(16,s);
//初始化len和alloc
sh->len = initlen;
sh->alloc = initlen;
//fp指针指向的内存赋值为对应的SDS类型
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
//如果initlen和init都不为空,则将init指向的内存拷贝initlen个字节到buf
if (initlen && init)
memcpy(s, init, initlen);
//分配一个结束符
s[initlen] = '\0';
//返回buf起始地址
return s;
}
除了创建SDS对象本身是返回buf的起始地址,在计算SDS字符串长度、计算buf容量、计算buf剩余容量……时,传入的也是buf的地址:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
static inline size_t sdslen(const sds s) {
//传入SDS的buf起始地址,往前一位即为flags
unsigned char flags = s[-1];
//SDS_TYPE_MASK的二进制表示为00000111,和flags注意与运算,得到的结果即为SDS的类型
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
/* sdsalloc() = sdsavail() + sdslen() */
static inline size_t sdsalloc(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->alloc;
case SDS_TYPE_16:
return SDS_HDR(16,s)->alloc;
case SDS_TYPE_32:
return SDS_HDR(32,s)->alloc;
case SDS_TYPE_64:
return SDS_HDR(64,s)->alloc;
}
return 0;
}
以上3个方法只是举例SDS在Redis中的传参方式,还有很多方法也是用buf地址作为参数传入,这里就不一一例举了。
这里在说明下为什么SDS不用内存对齐,首先我们要知道为什么要做内存对齐,一个32位的CPU在一个周期内只能读取32位的数据,而CPU每次读取数据的起始地址都是4的倍数,如果我们声明了一个struct A对象,a字段的地址是0~1,b字段的地址是1~4,那么CPU要读取b字段,需要先读0~3,再读3~4,CPU需要读取两次才能完整的读取b字段的数据,如果我们声明了一个struct B对象,字段a的地址是0~3,字段b的地址是3~7,那么CPU就可以在一个周期内完整地读取b字段的数据,由此可见,浪费一点内存空间,会使得CPU的性能更为高效。
struct __attribute__ ((__packed__)) A {
char a;
int b;
};
struct B {
char a;
int b;
};
既然内存对齐可以让CPU更加高效,那么Redis作为非关系型内存数据库又为何放弃内存对齐呢?这是因为SDS本身结构的特殊性让它只能是非内存对齐的。如果我们让SDS使用内存对齐,来看下各个SDS类型在64位机器下的内存占用:
#include <stdint.h>
#include <stdio.h>
struct sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
int main(int argc, char *argv[])
{
printf("sizeof sdshdr8:%d\n",sizeof(struct sdshdr8));
printf("sizeof sdshdr16:%d\n",sizeof(struct sdshdr16));
printf("sizeof sdshdr32:%d\n",sizeof(struct sdshdr32));
printf("sizeof sdshdr64:%d\n",sizeof(struct sdshdr64));
}
运行结果:
sizeof sdshdr8:3 sizeof sdshdr16:6 sizeof sdshdr32:12 sizeof sdshdr64:24
下面我们来看看各个SDS类型如果使用内存对齐的内存占用,len(1)、alloc(1)代表着两个字段占1个字节,同理len(2)、alloc(2)各占两个字节,pad为内存对齐做的字节填充。可以看到,不同的SDS类型所需要的字节填充都不一样,如果不放弃内存对齐,我们很难通过buf的偏移获取到flags进而推算出SDS的类型。
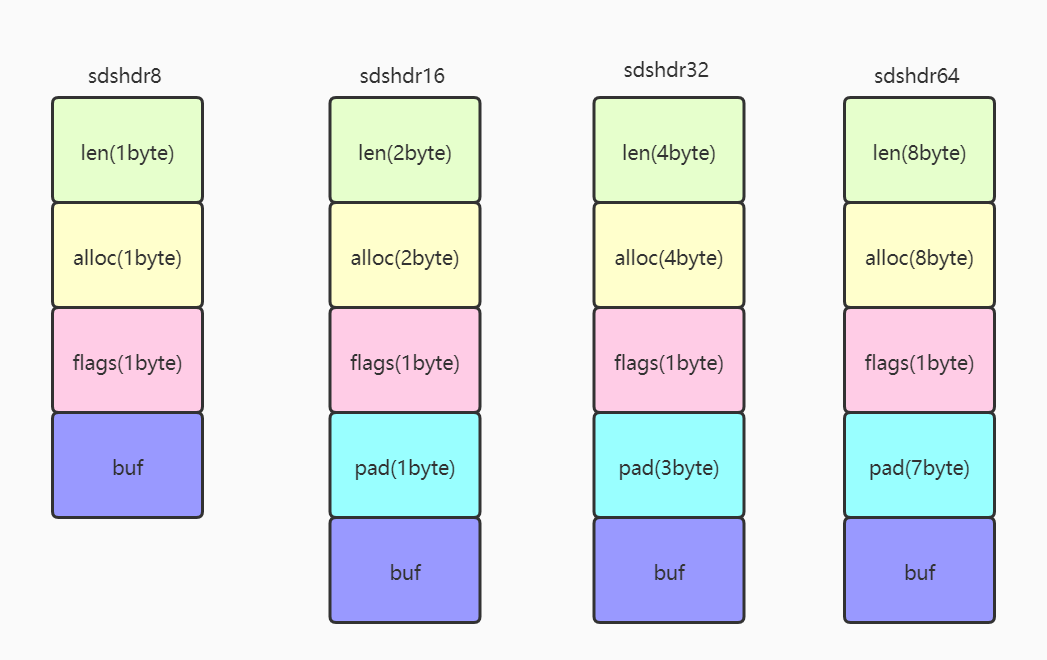
我们再来看SDS的编码,num、long1、long2都是字符串,用Redis的TYPE命令可以验证这一点,而这三种string类型,却是各有不同的实现,可以用OBJECT ENCODING来查看string类型的具体实现:
127.0.0.1:6379> SET num 1 OK 127.0.0.1:6379> SET long1 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa OK 127.0.0.1:6379> SET long2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa OK 127.0.0.1:6379> TYPE long1 string 127.0.0.1:6379> TYPE long2 string 127.0.0.1:6379> TYPE num string 127.0.0.1:6379> OBJECT ENCODING num "int" 127.0.0.1:6379> STRLEN long1 (integer) 44 127.0.0.1:6379> OBJECT ENCODING long1 "embstr" 127.0.0.1:6379> STRLEN long2 (integer) 45 127.0.0.1:6379> OBJECT ENCODING long2 "raw"
从上面OBJECT ENCODING打印的实际编码可以看到,Redis会根据我们设置的值的类型和长度做不同的实现编码,当我们设置一个值的时候,Redis会尝试将这个值转成数字,如果可以转成功,就采用int类型的编码,如果无法转成数字,Redis继而判断这个值的长度是否小于等于44,如果小于等于44的话,Redis则采用embstr编码,否则采用raw编码。那么int、embstr和raw这三种编码各有什么不同呢?这里我们先来看一个结构体——redisObject:
#define LRU_BITS 24
// redisObject对象 : string , list ,set ,hash ,zset ...
typedef struct redisObject {
unsigned type:4; // 4 bit, sting , hash
unsigned encoding:4; // 4 bit
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time).
* 24 bit
* */
int refcount; // 4 byte
void *ptr; // 8 byte 总空间: 4 bit + 4 bit + 24 bit + 4 byte + 8 byte = 16 byte
} robj;
在Redis中每个键值对都是以redisObject来表示的,除了可以用来表示string,还可以表示list、set、zset、hash。
type表示对象的类型:
/* A redis object, that is a type able to hold a string / list / set */ /* The actual Redis Object */ #define OBJ_STRING 0 /* String object. */ #define OBJ_LIST 1 /* List object. */ #define OBJ_SET 2 /* Set object. */ #define OBJ_ZSET 3 /* Sorted set object. */ #define OBJ_HASH 4 /* Hash object. */
encoding表示对象的实际编码:
/* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
lru记录的是该对象上次被访问的时间当内存不足时,redis会优先释放最久没有被访问的数据。(当内存回收算法是volatile-lru或allkeys-lru时)
记录当前对象被引用的次数,通过引用次数判断对象内存是否可回收,当refcount为0时,表示当前对象处于可回收的状态。使用OBJECT refcount {key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。
ptr指向真实的数据对象。
下面我们来了解下为什么设置字符串时,非数字的字符串长度小于等于44是embstr编码,大于44则是raw编码。首先我们要来计算下redisObject的内存占用,type和encoding都是unsigned类型,理应各占用1个字节,但这里用到了位域的概念:type:4、encoding:4,这两个字段各占用4位,所以这两个字段总共占用1个字节,同理lru占用24位,占用了3个字节,所以前3个字段type、encoding、lru总共占据了4个字节,refcount是int类型占据4个字节,而ptr占用了8个字节,所以redisObject需要的内存占用为16个字节。
虽然redisObject的内存占用仅需要16个字节,但我们可以给redisObject多分配一些内存空间,比如64字节,那么redisObject所存储的数据对象就可以紧邻在ptr之后了。事实上,当我们创建一个字符串,如果字符串的长度足够短,Redis也是这么来做的,假设我们已经申请了一块64字节的内存空间,扣去redisObject本身需要的16个字节,还剩余48个字节,那么Redis又是如何来分配这48个字节呢?
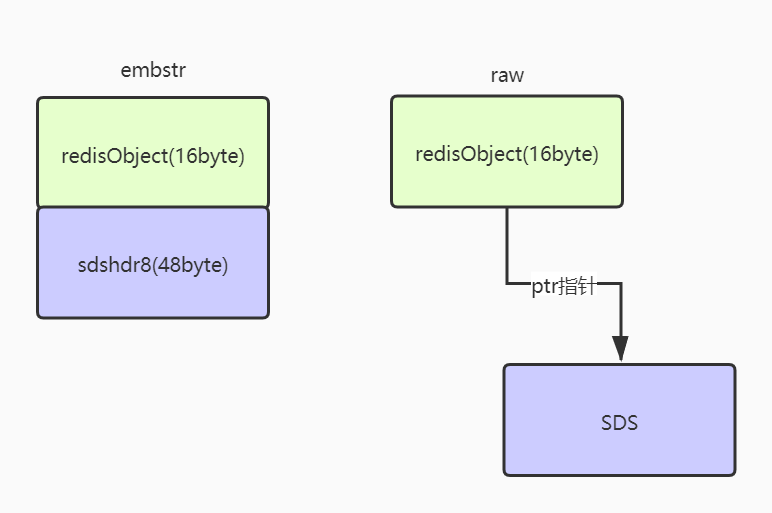
首先,既然我们要存储的是字符串,那么紧随在ptr之后的对象应该是SDS对象,但SDS又有多种类型,那么Redis会使用哪一种呢?如果我们使用sdshdr64对象,那么这48个字节我们将占去17个字节,仅剩31个字节存储我们字符串,而用uint64来存储这31个字节数组当前的占用和总容量又有点大小采用,于是我们把目光放到sdshdr32上,而sdshdr32的内存占用是9,除去内存占用,可供存储字符的长度也就39,而用uint32来存储39个字节数组的占用和总容量依旧大材小用,以此类推,我们最终把目光锁定在sdshdr8上,sdshdr8只需占用3个字节,剩余还有45个字节可供我们存储,而MaxUint8为255,也足够计算buf的长度和总容量。那么会有人奇怪,既然有45个字节供我们使用,那为什么上面的案例44个字节的编码是embstr,45个字节的编码是raw呢?别忘了,在C语言中每个字符串的末尾都以'\0'来结尾,Redis为了兼容C语言的字符串函数库,也使用了这一规则,所以我们只能使用小于等于44个字节的空间。
因此,embstr和raw两种编码在内存的布局如下,embstr的SDS对象紧邻着redisObject,处于一块连续内存,而raw的redisObject和SDS对象不处于同一块内存内存。
SDS API
| 函数 | 作用 | 时间复杂度 |
| sdsnew | 创建一个包含给定C字符串的SDS | O(N) ,N 为给定C字符串的长度 |
| sdsempty | 创建一个不包含任何内容的空SDS | O(1) |
| sdsfree | 释放给定的SDS | O(1) |
| sdslen | 返回SDS的已使用空间字节数 | 这个值可以通过读取SDS的len属性来直接获得,复杂度为O(1) |
| sdsavail | 返回SDS的未使用空间字节数 | 这个值可以通过读取SDS的free属性来直接获得,复杂度为 O(1) |
| sdsdup | 创建一个给定SDS的副本(copy) | O(N),N为给定SDS的长度 |
| sdsclear | 清空SDS保存的字符串内容 | 因为惰性空间释放策略,复杂度为O(1) |
| sdscat | 将给定C字符串拼接到SDS字符串的末尾 | O(N),N为被拼接C字符串的长度 |
| sdscatsds | 将给定SDS字符串拼接到另一个SDS字符串的末尾 | O(N),N为被拼接SDS字符串的长度 |
| sdscpy | 将给定的C字符串复制到SDS里面,覆盖SDS原有的字符串 | O(N),N为被复制C字符串的长度 |
| sdsgrowzero | 用空字符将SDS扩展至给定长度 | O(N),N为扩展新增的字节数 |
| sdsrange | 保留SDS给定区间内的数据,不在区间内的数据会被覆盖或清除 | O(N),N为被保留数据的字节数 |
| sdstrim | 接受一个SDS和一个C字符串作为参数,从SDS左右两端分别移除所有在C字符串中出现过的字符 | O(M*N),M为SDS的长度,N为给定C字符串的长度 |
| sdscmp | 对比两个SDS字符串是否相同 | O(N),N为两个SDS中较短的那个SDS的长度 |
使用场景
假设我们要把用户数据存到Redis上,最常见的做法,就是将用户数据的每个序列化成一个JSON字符串,以键值对的形式SET到Redis上:
127.0.0.1:6379> SET user::1 "{\"id\":1,\"age\":16,\"name\":\"Amy\"}"
OK
但这样的做法会产生一个问题,假设我仅单单要把年龄修改成17,势必要先把整个JSON字符串反序列化成一个User对象,在修改age字段后再序列化回JSON字符串存回Redis,这其中多了没必要的id和name的带宽占用和反序列化开销。
如果MSET命令则简单很多,我们可以以MSET user::{id}::{field}的形式存储用户数据,这样当我们要修改用户年龄,不需要像之前那样将整个用户数据反序列化出来。
127.0.0.1:6379> MSET user::1::name Amy user::2::name Tom OK 127.0.0.1:6379> MSET user::1::age 16 user::2::age 19 OK 127.0.0.1:6379> MSET user::1::age 17 OK
当我们有需要获取用户的全量数据,也可以用MGET批量获取:
127.0.0.1:6379> MGET user::1::name user::1::age 1) "Amy" 2) "17"
可能不少同学在工作中会遇到这样的业务场景:计算连续3天登陆,或者最近3天内有登陆的用户。按照一般的做法,在用户登陆的时候,我们判断当天是不是用户第一次登陆,是的话则记录一个登陆时间,如果不是就不需要记录,然后我们收集3天内有登陆时间的用户,将每一天有登陆的用户数据划分成一个集合,然后做交集或者去重操作,来计算连续3天登陆,或者3天内有登陆的用户。但存储这批登陆数据,对登陆数据进行判断、计算,无疑是非常麻烦的,而Redis提供了一种bitmap的数据结构可以简化我们的工作。
我们先来了解下bitmap,bitmap可以理解为是以位(bit)作为单位的数组。我们知道一个字节(byte)是8个位(bit),一个位(bit)只有0或者1两种表示。如果我们有个字符串变量a="abc",我可以通过执行a[1]='e',将a变量索引1位置上'b'替换成'e',a变量的值为"aec"。同理,如果我们有一个“位数组”,我们也可以通过索引来修改数组上的内容,比如b=01010000,这既是一个字节,也是一个位数组,我们可以通过b[6]=1来修改索引位置对应的内容,修改完毕后b=01010010。Redis的bitmap就是一个以位作为单位的数组,它允许我们提供一个索引,以及索引位置上的内容,对索引对应的位进行修改:
#设置索引3、7、10位置上的内容为1,设置完毕后会返回原先位置上的内容,初始为0 127.0.0.1:6379> SETBIT bitmap 3 1 (integer) 0 127.0.0.1:6379> SETBIT bitmap 7 1 (integer) 0 127.0.0.1:6379> SETBIT bitmap 10 1 (integer) 0 #获取索引3、10、7位置上的内容 127.0.0.1:6379> GETBIT bitmap 3 (integer) 1 127.0.0.1:6379> GETBIT bitmap 10 (integer) 1 127.0.0.1:6379> GETBIT bitmap 7 (integer) 1 #获取索引6、15位置上的内容,由于从未设置过这两个索引,所以返回内容为初始值0 127.0.0.1:6379> GETBIT bitmap 6 (integer) 0 127.0.0.1:6379> GETBIT bitmap 15 (integer) 0 #统计bitmap上有多少个bit值不为0 127.0.0.1:6379> BITCOUNT bitmap (integer) 3 #将索引19位置上的内容设置为0,返回位置上原先的值,即我们设置的1 127.0.0.1:6379> SETBIT bitmap 10 0 (integer) 1 #再次统计多少个bit值不为0,目前只有3、7索引上的值不为0 127.0.0.1:6379> BITCOUNT bitmap (integer) 2
那么这个bitmap又和我们先前说到的统计留存数据有什么关系呢?我们可以为系统中的用户分配一个id,这个id将会作为bitmap的索引,当一个用户登陆时,我们只需要计算拿到用户登陆的年月日,以登陆时间的年月日作为key,用户id作为索引,将bitmap索引位置上的值设置为1即可。
#2021-05-25号登陆的用户有:3、9、7、15、20、30 127.0.0.1:6379> SETBIT login-20210525 3 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210525 9 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210525 7 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210525 15 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210525 20 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210525 30 1 (integer) 0 #2021-05-26登陆的用户有:3、9、20 127.0.0.1:6379> SETBIT login-20210526 3 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210526 9 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210526 20 1 (integer) 0 #2021-05-27登陆的用户有:20、9、3、7、8 127.0.0.1:6379> SETBIT login-20210527 20 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210527 9 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210527 3 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210527 7 1 (integer) 0 127.0.0.1:6379> SETBIT login-20210527 8 1 (integer) 0 #可以通过BITOP AND destkey key [key ...]对多个bitmap的key做AND运算,并将结果存到destkey中,从而计算出连续3天登陆的用户 127.0.0.1:6379> BITOP AND login-and-20210525-20210507 login-20210525 login-20210526 login-20210527 (integer) 4 #统计连续3天登陆的用户数,连续3天有登陆的用户3、9、20 127.0.0.1:6379> BITCOUNT login-and-20210525-20210507 (integer) 3 127.0.0.1:6379> GETBIT login-and-20210525-20210507 3 (integer) 1 127.0.0.1:6379> GETBIT login-and-20210525-20210507 9 (integer) 1 127.0.0.1:6379> GETBIT login-and-20210525-20210507 20 (integer) 1 #如果要结算3天内有登陆的用户,只需要对25~27号的用户做一个或(|)运算 127.0.0.1:6379> BITOP OR login-or-20210525-20210507 login-20210525 login-20210526 login-20210527 (integer) 4 127.0.0.1:6379> BITCOUNT login-or-20210525-20210507 (integer) 7
BITOP除了支持AND和OR操作,还支持NOT、XOR,大家可以根据业务来选择操作。
我们不禁要思考,bitmap的底层实现究竟是什么呢?这里我们用TYPE key和OBJECT ENCODING key来看看:
127.0.0.1:6379> TYPE login-20210525 string 127.0.0.1:6379> OBJECT ENCODING login-20210525 "raw"
可以看到,bitmap在Redis的底层实现也是一个SDS,我们也可以用string的命令来操作bitmap,只是没什么意义:
#20210525这天的bitmap的字节长度为4,当天最大的用户索引为30,Redis会分配4个字节,即32个bit来存储这些索引小于等于30的用户登陆记录 127.0.0.1:6379> STRLEN login-20210525 (integer) 4 #如果用GET key命令来查询登陆数据,则会看到一堆难以理解的字符串 127.0.0.1:6379> GET login-20210525 "\x11A\b\x02"
如果我们需要获取存储在Redis上面的所有key值,可以用keys *命令来获取,但这个命令只适用于key数量较少的情况,如果Redis存储了上百万上千万的key,那么执行keys *势必会阻塞其他用户命令的执行。这时候我们可以用SCAN命令渐进式遍历key:SCAN cursor [MATCH pattern] [COUNT count]
SCAN参数提供了三个参数,第一个是cursor整数值(hash桶的索引值),Redis本身就是一个hash map,第二个是key的正则模式,第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第一次遍历时,cursor值为0,然后将返回结果中第一个整数值作为下一次遍历的cursor。一直遍历到返回的cursor值为0时结束。
我们用下面这段脚本在Redis上创建一些key,用来测试SCAN命令,下面的脚本将会创建20个<foo{i},bar{i}>和100个<hello{j},world{j}>的键值对:
import redis
r = redis.StrictRedis(host="127.0.0.1", port=6379, password="123456", db=0)
for i in range(20):
r.set("foo" + str(i), "bar" + str(i))
for i in range(100):
r.set("hello" + str(i), "world" + str(i))
r.close()
通过SCAN命令我们可以获取Redis上部分的key值,执行SCAN命令会返回游标,初始游标从0开始,之后返回8和116,如果我们还需要获取第三次key值,游标就从116开始,上面说过COUNT是一次遍历的key的数量,但Redis不一定完全按照这个值来返回,可能多于或者少于,比如在我们第二次获取时,Redis返回11个key。
127.0.0.1:6379> SCAN 0 COUNT 10
1) "8"
2) 1) "hello81"
2) "foo2"
3) "hello34"
4) "hello77"
5) "hello49"
6) "foo10"
7) "hello13"
8) "hello82"
9) "hello61"
10) "hello4"
127.0.0.1:6379> SCAN 8 COUNT 10
1) "116"
2) 1) "hello50"
2) "hello2"
3) "foo19"
4) "foo17"
5) "hello72"
6) "hello65"
7) "hello83"
8) "hello66"
9) "hello27"
10) "hello7"
11) "hello41"
如果我们不想获取所有key值,而是想根据某个规则来匹配,则需要搭配上MATCH关键字,这里相比于上面我们可以更清楚的看到COUNT只是一个参考值,Redis并不一定完全按照我们给定的值返回固定数量的key,甚至可能会返回空,比如第三次获取时,返回的游标是98,但没有返回任何key,不断根据给定的游标查找key,最后返回的游标为0,代表查找结束。
127.0.0.1:6379> SCAN 0 MATCH foo* COUNT 10 1) "8" 2) 1) "foo2" 2) "foo10" 127.0.0.1:6379> SCAN 8 MATCH foo* COUNT 10 1) "116" 2) 1) "foo19" 2) "foo17" 127.0.0.1:6379> SCAN 116 MATCH foo* COUNT 10 1) "98" 2) (empty array) 127.0.0.1:6379> SCAN 98 MATCH foo* COUNT 10 1) "10" 2) 1) "foo3" 127.0.0.1:6379> SCAN 10 MATCH foo* COUNT 10 1) "102" 2) 1) "foo12" 2) "foo0" 127.0.0.1:6379> SCAN 102 MATCH foo* COUNT 10 1) "65" 2) 1) "foo5" 127.0.0.1:6379> SCAN 65 MATCH foo* COUNT 10 1) "69" 2) 1) "foo16" 2) "foo18" 127.0.0.1:6379> SCAN 69 MATCH foo* COUNT 10 1) "13" 2) (empty array) 127.0.0.1:6379> SCAN 13 MATCH foo* COUNT 10 1) "3" 2) 1) "foo9" 2) "foo1" 3) "foo11" 127.0.0.1:6379> SCAN 3 MATCH foo* COUNT 10 1) "91" 2) 1) "foo14" 2) "foo4" 3) "foo13" 127.0.0.1:6379> SCAN 91 MATCH foo* COUNT 10 1) "47" 2) 1) "foo15" 127.0.0.1:6379> SCAN 47 MATCH foo* COUNT 10 1) "0" 2) 1) "foo8" 2) "foo6" 3) "foo7"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号