
分布式计算技术之Stream流式计算
流式计算的概念
实时获取来自不同数据源的海量数据,进行实时分析处理,获得有价值的信息,一般用于处理数据密集型应用。流式计算属于持续性、低时延、事件驱动型的计算作业。
流式计算工作原理

1.提交流式计算作业,流式计算作业属于常驻计算服务,必须预先定义好计算逻辑,并提交到流计算系统中,在系统运行期间,流式计算作业的逻辑是不可更改的
2.加载流式数据进行流计算,流式计算系统中有多个流处理节点
3.持续输出计算结果
流式计算框架和平台
1.商业级:InfoSphere Streams,StreamBase
2.开源流计算框架:Apache Storm,S4, Spark,Flink
3.互联网公司自主研发:Facebook Puma,百度的Dstream等
Storm工作原理
架构图
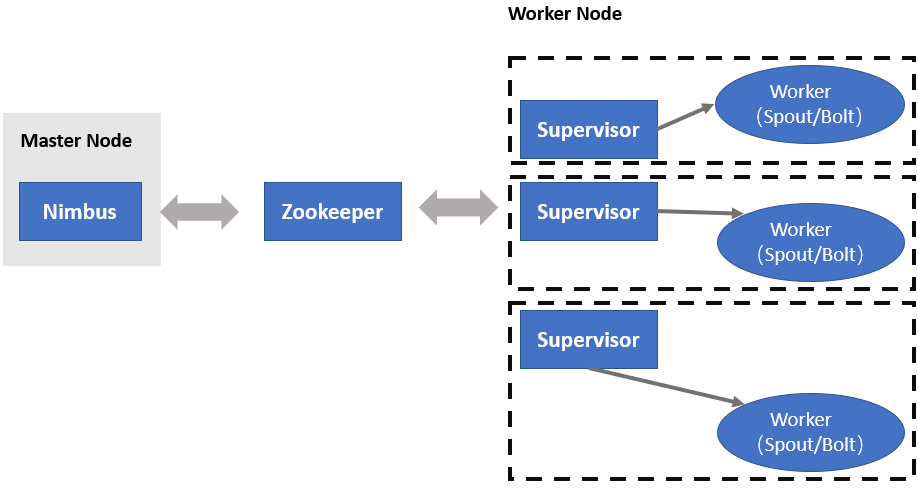
Nimbus守护进程:负责为集群分发代码,为工作节点分配任务并进行故障监控
Supervisor进程:负责监听分配给他所在机器上的工作,负责接收Nimbus分配的任务
Zookeeper:Nimbus和Supervisor进程之间的协调
Worker组件

Spout:用于接收源数据
Bolt:负责处理输入的数据流
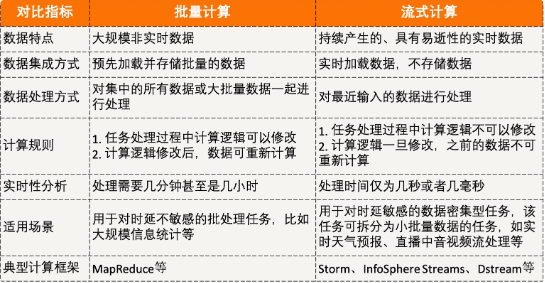
批量计算与流式计算对比
菜鸟程序员,博客只做记录,可能问题很多,有问题,还望不吝指出!转载请附上原文地址,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号