nodejs学习之文件上传
最近要做个图片上传的需求,因为服务端春节请假回家还没来,所以就我自己先折腾了一下,大概做出来个效果,后台就用了nodejs,刚开始做的时候想网上找一下资料,发现大部分资料都是用node-formidable插件实现上传的。但是自己又想手动实现一下,所以就开始折腾了。写此博文也就是做个记录。
先大概整理一下整个思路,自己想要实现的效果是能够在页面上无刷新上传一个图片并且显示(后来做着做着就变成所有文件的上传了,不过都一个样)。
在前端部分,想要无刷新首先想到的是ajax,但是ajax无法上传文件,所以还是老老实实用form上传,如果用form的话又要保证页面无刷新,那就使用iframe来实现了。所以前端需要两个页面,一个用户操作页面index.html为主页面,还有一个是专门用来上传的页面upload.html,html如下:
index.html: <body> 您上传的东西为:<br><br> <div class="data"> (无) </div> <br> <button class="choose">上传东西</button> <iframe src="upl" frameborder="0" id="upl"></iframe> </body> upload.html: <body> <form action="/upload" method=post enctype="multipart/form-data" accept-charset="utf-8"> <input type="file" id="data" name="data" /> <input type="submit" value="上传" id="sub"/> </form> </body>
index.html页面点击上传按钮,js将会触发iframe里的upload页面里的input file的click事件,所以进行文件选择,选择好后再触发upload页面里的submit的click事件,文件便开始上传,文件上传成功后,后台将会返回一段html代码,里面就包含着文件链接。index.html页面获取到文件链接,如果是图片则显示图片,如果是其他则显示下载链接。index.html的js代码如下:
window.onload = function(){ var frame = $("#upl")[0]; var cd; frameInit() frame.onload = function(){ frameInit() if($(cd).find("#path").length>0){ var path = $(cd).find("#path")[0].innerHTML; if(/png|gif|jpg/g.test(path)){ $(".data").html("<img src='"+path+"'><br>") }else { $(".data").html("<a href='"+path+"' target='_blank'>"+path+"</a><br>") } frame.src = "upl"; } } $(".choose").click(function(){ $(cd).find("#data").click(); }); function frameInit(){ cd = frame.contentDocument.body; var img = $(cd).find("#data")[0] if(img){ img.onchange = function(){ $(cd).find("#sub").click(); } } } }
通过iframe的onload事件来获取后台返回的链接。以上代码比较简单,就不具体解释了。
接下来是后台的实现:
首先先是要建个http server,然后,因为有两个页面,再加上还有文件下载之类的,所以先弄个最简单的路由:
var http = require('http'); var fs = require('fs'); http.createServer(function(req , res){ var imaps = req.url.split("/"); var maps = []; imaps.forEach(function(m){ if(m){maps.push(m)} }); switch (maps[0]||"index"){ case "index": var str = fs.readFileSync("./index.html"); res.writeHead(200, { 'Content-Type': 'text/html' }); res.end(str , "utf-8"); break; case "upl": var str = fs.readFileSync("./upload.html"); res.writeHead(200, { 'Content-Type': 'text/html' }); res.end(str , "utf-8"); break; case "upload": break; default : var path = maps.join("/"); var value = ""; var filename = maps[maps.length-1]; var checkReg = /^.+.(gif|png|jpg|css|js)+$/; if(maps[0]=="databox"){ checkReg = /.*/ } if(checkReg.test(filename)){ try{ value = fs.readFileSync(path) }catch(e){} } if(value){ res.end(value); }else { res.writeHead(404); res.end(''); } break; } }).listen(9010);
上面代码也很简单,路由index指向index.html,upl指向upload.html,而其他如果是非指向databox里的链接则只允许访问图片、css、js文件,如果是指向databox的链接则允许访问一切,databox是用来存储上传文件的文件夹。上面代码中upload路由就是文件上传的提交地址,所以文件上传后,对文件的处理就是这里。
对post过来的数据的处理,常用的办法就是:
var chunks = []; var size = 0; req.on('data' , function(chunk){ chunks.push(chunk); size+=chunk.length; }); req.on("end",function(){ var buffer = Buffer.concat(chunks , size); });
那个buffer就是post过来的所有数据了,当我们console.log(buffer.toString()),我们就可以看到post过来的数据的格式:
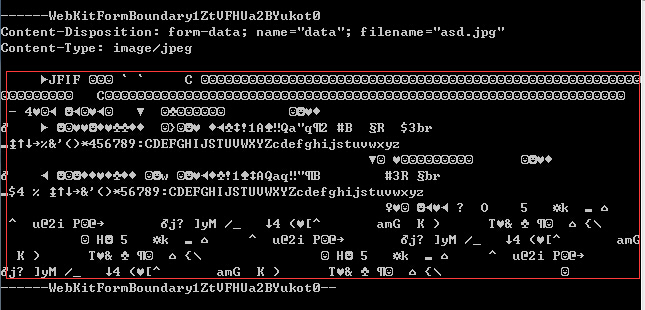
其中,红色方框里的乱码其实就是文件数据了,前面的是文件信息报头。如果想获得里面的数据,就得先把非文件数据过滤掉,根据控制台输出的信息可知过滤的方法很简单,根据\r\n来分割就可以了,数据开头四个\r\n之后就是文件数据,而结尾的话则是去掉\r\n--WebKitFormblabla--\r\n,也是根据\r\n来过滤。所以把上面那段代码补全后就是如下:
var chunks = []; var size = 0; req.on('data' , function(chunk){ chunks.push(chunk); size+=chunk.length; }); req.on("end",function(){ var buffer = Buffer.concat(chunks , size); if(!size){ res.writeHead(404); res.end(''); return; } var rems = []; //根据\r\n分离数据和报头 for(var i=0;i<buffer.length;i++){ var v = buffer[i]; var v2 = buffer[i+1]; if(v==13 && v2==10){ rems.push(i); } } //图片信息 var picmsg_1 = buffer.slice(rems[0]+2,rems[1]).toString(); var filename = picmsg_1.match(/filename=".*"/g)[0].split('"')[1]; //图片数据 var nbuf = buffer.slice(rems[3]+2,rems[rems.length-2]); var path = './databox/'+filename; fs.writeFileSync(path , nbuf); console.log("保存"+filename+"成功"); res.writeHead(200, { 'Content-Type': 'text/html;charset=utf-8'}); res.end('<div id="path">'+path+'</div>'); });
对数据的过滤直接通过分析buffer,刚开始自己写的时候是把buffer转成string来分析,但是问题出现了,当过滤完后,把数据写入文件前需要把string再转成buffer写进去,结果写出来的文件都是错误的。改各种编码转buffer都不行,折腾了N久,最后的终于找到对应的方案,就是在buffer转string的时候写成buffer.toString("binary"),然后再过滤完后再处理成buffer的时候写成new Buffer(str , 'binary')才行,但是查了一下文件,貌似buffer中binary的编码被弃用了,或者说不建议使用。所以自己就想不转string,直接分析buffer。通过查ascii表很容易通过一个for循环把\r\n找出来了。于是问题就解决了。
运行效果良好:
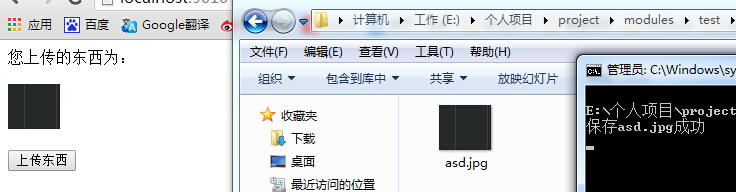
这看似把上传文件的功能实现了,但是仔细一想,好像还有问题,因为自己此时是想实现个文件上传了,而不是单单的图片上传,所以如果我上传的数据几百M,那么一次性把buffer全部读出来再处理,不要说处理速度慢,就单单这文件数据就能把内存耗的差不多了。所以这种把数据全部接收过来再处理的方法貌似不行,最好就是数据一边接收一边处理,不让所有数据全部挤在内存上。所以,我就使用了stream。
整个处理代码改成了,本来是在数据接收完成上进行处理改成在接收数据的时候进行处理:
var imgsays = []; var num = 0; var isStart = false; var ws; var filename; var path; req.on('data' , function(chunk){ var start = 0; var end = chunk.length; var rems = []; for(var i=0;i<chunk.length;i++){ if(chunk[i]==13 && chunk[i+1]==10){ num++; rems.push(i); if(num==4){ start = i+2; isStart = true; var str = (new Buffer(imgsays)).toString(); filename = str.match(/filename=".*"/g)[0].split('"')[1]; path = './databox/'+filename; ws = fs.createWriteStream(path); }else if(i==chunk.length-2){ //说明到了数据尾部的\r\n end = rems[rems.length-2]; break; } } if(num<4){ imgsays.push(chunk[i]) } } if(isStart){ ws.write(chunk.slice(start , end)); } }); req.on("end",function(){ ws.end(); console.log("保存"+filename+"成功"); res.writeHead(200, { 'Content-Type': 'text/html;charset=utf-8'}); res.end('<div id="path">'+path+'</div>'); });
原理差不多,对每次接收的buffer段进行判断,当经过四个\r\n后分析文件报头获取文件类型,创建一个写入流,并且开始写入,同时加上对是否到了数据尾部判断,数据尾部会跟着一个\r\n,如果到了尾部,则过滤掉尾部的信息。
如此一来,上传的文件就不会因为太大而把内存撑爆了。
附上github地址:https://github.com/whxaxes/node-test/tree/master/server/upload 有兴趣的可以down下来
本人前端小菜,若有不当之处请指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号