
Ollama的进一步了解;SAM3的API调用;流式输出理解;postman使用(接口测试);Supervisor进程管理工具部署SAM3至内网;ollama部署后API调用
1.Ollama与vLLM
Ollama主要应用场景是LLM大模型的部署,不包含图像处理模型,专注于本地化、轻量化部署 ,通过Docker容器技术简化模型运行流程,用户无需复杂配置即可快速启动模型。其设计目标是降低本地使用LLM的门槛,适合个人开发者或资源有限的环境。
vLLM : 侧重于高性能推理加速与服务端扩展 ,支持多机多卡分布式部署,通过优化GPU资源利用率和内存管理技术(如PagedAttention)提升高并发场景下的吞吐量。
| 项目 | Ollama | Dify |
|---|---|---|
| 本质 | 本地模型推理框架 | 大模型应用构建平台 |
| 作用 | 在本机/服务器加载并运行LLM模型 | 快速构建聊天助手、RAG、Agent、工作流等应用 |
| 需不需要 GPU | 推荐有 | 不强制(可接第三方 LLM) |
| 模型来源 | 本地模型文件 | 本地+云端模型,多供应商 |
| 开发友好度 | 偏底层(需要自己写业务逻辑) | 偏上层(无代码/低代码开发) |
| API | 提供本地推理 API | 提供应用 API 和工作流 API |
2.Ollama工作职责
GPU服务器
↓
⚙ Ollama(负责模型推理)
↓
🔗 REST / OpenAI API
↓
🚀 Dify(负责构建应用)
↓
👨💼用户(网页、App、企业系统)
3.SAM3的部署概况
Ollama由于的局限性,只能部署LLM模型架构。目前的需求是在线推理服务,于是采用python的FastAPI调用SAM3。
流式 = 数据一边生成、一边传输、一边展示,而不是等全部生成完成后一次性返回。
也可以理解为实时输出 / 边算边给结果。(如GPT)
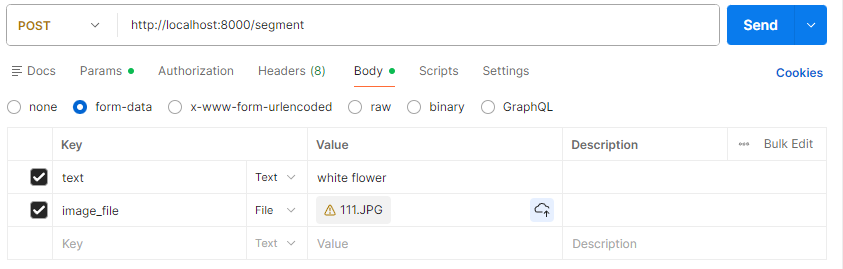
4.postman使用
VS Code中远程插件十分方便,能够转发内网端口,如下图,内网中8000端口被转发到本机的8000端口,方便调试。

postman初次尝试。
参数一般放在请求体中。
5.Supervisor部署SAM3至内网
为什么使用Supervisor、docker部署SAM3?
因为SAM3大模型没有被ollama管理部署,自行写了一个FastAPI调用大模型,如果直接在终端启动
终端关闭或服务器重启 → API 停掉
崩溃或异常退出 → 没有人自动重启
由于docker使用暂时还不熟练,暂时使用Supervisor。
Supervisor能够守护进程 supervisord 在后台运行、自动启动、自动重启、管理日志到指定文件、开发调试和生产运行互不干扰。
Supervisor主配置 [include] 决定子配置目录;目前GPU服务器目前指向/etc/supervisord.d/*.ini
配置文件sam3_api.ini示例
[program:sam3_api]
command=/home/user/miniconda3/envs/myenv/bin/python -m uvicorn only_text:app --host 0.0.0.0 --port 8000
directory=/home/user/my_model_project
autostart=true
autorestart=true
stderr_logfile=/var/log/sam3_api_err.log
stdout_logfile=/var/log/sam3_api_out.log
配置的加载、升级以及状态查询
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl status
更新了API代码或模型代码后,Supervisor不会自动重启服务,需要你手动执行操作才能让新代码生效。
sudo supervisorctl restart sam3_api
6.ollama部署后API调用
使用ollama,/api/generate
参考官方文档
https://docs.ollama.com/api/generate

 浙公网安备 33010602011771号
浙公网安备 33010602011771号