RealPython-中文系列教程-十七-
RealPython 中文系列教程(十七)
原文:RealPython
使用 Python 和 Typer 构建命令行待办事项应用程序
当你正在学习一门新的编程语言或试图将你的技能提升到一个新的水平时,构建一个管理你的待办事项列表的应用程序可能是一个有趣的项目。在本教程中,您将使用 Python 和 Typer 为命令行构建一个功能性的待办事项应用程序,这是一个相对年轻的库,几乎可以立即创建强大的命令行界面(CLI)应用程序。
有了这样一个项目,您将应用广泛的核心编程技能,同时构建一个具有真实特性和需求的真实应用程序。
在本教程中,您将学习如何:
- 用 Python 中的类型器 CLI 构建一个功能性的待办应用程序
- 使用 Typer 将命令、参数和选项添加到你的待办事项应用中
- 用 Typer 的
CliRunner和 pytest 测试你的 Python 待办应用
此外,您将通过使用 Python 的json模块和使用 Python 的configparser模块管理配置文件来练习与处理 JSON 文件相关的技能。有了这些知识,您就可以马上开始创建 CLI 应用程序了。
您可以点击下面的链接并转到source_code_final/目录,下载该待办事项 CLI 应用程序的完整代码和所有附加资源:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
演示
在这个循序渐进的项目中,您将构建一个命令行界面(CLI) 应用程序来管理待办事项列表。您的应用程序将提供一个基于 Typer 的 CLI,这是一个用于创建 CLI 应用程序的现代化通用库。
在你开始之前,看看这个演示,看看你的待办事项应用程序在本教程结束后会是什么样子。演示的第一部分展示了如何获得使用该应用程序的帮助。它还展示了如何初始化和配置应用程序。视频的其余部分演示了如何与基本功能进行交互,例如添加、删除和列出待办事项:
https://player.vimeo.com/video/591043158
不错!该应用程序有一个用户友好的 CLI,允许您设置待办事项数据库。在那里,你可以使用适当的命令、参数和选项来添加、删除和完成待办事项。如果你遇到困难,你可以使用--help选项和适当的参数来寻求帮助。
你想开始这个待办事项应用程序项目吗?酷!在下一节中,您将计划如何构建项目的布局,以及您将使用什么工具来构建它。
项目概述
当你想启动一个新的应用程序时,你通常会首先考虑你希望这个应用程序如何工作。在本教程中,您将为命令行构建一个待办事项应用程序。您将把该应用程序称为rptodo。
您希望您的应用程序有一个用户友好的命令行界面,允许您的用户与应用程序交互并管理他们的待办事项列表。
首先,您希望 CLI 提供以下全局选项:
-v或--version显示当前版本并退出应用程序。--help显示整个应用程序的全局帮助信息。
您将在许多其他 CLI 应用程序中看到这些相同的选项。提供它们是一个好主意,因为大多数使用命令行的用户希望在每个应用程序中都找到它们。
关于管理待办事项列表,您的应用程序将提供初始化应用程序、添加和删除待办事项以及管理待办事项完成状态的命令:
| 命令 | 描述 |
|---|---|
init |
初始化应用程序的待办事项数据库 |
add DESCRIPTION |
向数据库中添加新的待办事项及其说明 |
list |
列出数据库中的所有待办事项 |
complete TODO_ID |
通过使用待办事项的 ID 将其设置为已完成来完成待办事项 |
remove TODO_ID |
使用待办事项的 ID 从数据库中删除待办事项 |
clear |
通过清除数据库来删除所有待办事项 |
这些命令提供了所有你需要的功能,将你的待办事项应用程序转化为一个最小可行产品(MVP) ,这样你就可以将它发布到 PyPI 或者你选择的平台,并开始从你的用户那里获得反馈。
要在待办事项应用程序中提供所有这些功能,您需要完成几项任务:
- 构建一个能够接受和处理命令、选项和参数的命令行界面
- 选择合适的数据类型来表示您的待办事项
- 实现一种方法来持久存储你的待办事项列表
- 定义一种方法来连接用户界面和待办数据
这些任务与所谓的模型-视图-控制器设计密切相关,这是一种架构模式。在这个模式中,模型处理数据,视图处理用户界面,控制器连接两端以使应用程序工作。
在您的应用程序和项目中使用这种模式的主要原因是提供关注点分离(SoC) ,使您代码的不同部分独立处理特定的概念。
您需要做出的下一个决定是关于您将用来处理您进一步定义的每个任务的工具和库。换句话说,你需要决定你的软件栈。在本教程中,您将使用以下堆栈:
您还将使用 Python 标准库中的 configparser 模块来处理配置文件中应用程序的初始设置。在配置文件中,您将在文件系统中存储待办事项数据库的路径。最后,您将使用 pytest 作为工具来测试您的 CLI 应用程序。
先决条件
要完成本教程并从中获得最大收益,您应该熟悉以下主题:
- 模型-视图-控制器模式
- Command-line interfaces (CLI)
- Python 类型提示,也称为类型注释
- 使用 pytest 进行单元测试
- Python 中的面向对象编程
- 配置文件用
configparser - JSON 文件与 Python 的
json - 文件系统路径操作同
pathlib
就是这样!如果你已经准备好动手创建你的待办事项应用,那么你可以开始设置你的工作环境和项目布局。
第一步:建立待办项目
要开始编写您的待办应用程序,您需要设置一个工作 Python 环境,其中包含您将在这个过程中使用的所有工具、库和依赖项。然后你需要给项目一个连贯的 Python 应用布局。这就是你在接下来的小节中要做的。
要下载您将在本节中创建的所有文件和项目结构,请单击下面的链接并转到source_code_step_1/目录:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
设置工作环境
在本节中,您将创建一个 Python 虚拟环境来处理您的待办项目。为每个独立的项目使用虚拟环境是 Python 编程中的最佳实践。它允许您隔离项目的依赖关系,而不会扰乱您的系统 Python 安装或破坏使用相同工具和库的不同版本的其他项目。
注意:这个项目是用 Python 3.9.5 构建和测试的,代码应该在大于等于 3.6 的 Python 版本上工作。
要创建 Python 虚拟环境,请转到您最喜欢的工作目录,并创建一个名为rptodo_project/的文件夹。然后启动终端或命令行,运行以下命令:
$ cd rptodo_project/
$ python -m venv ./venv
$ source venv/bin/activate
(venv) $
这里,首先使用cd进入rptodo_project/目录。该目录将是您项目的根目录。然后使用标准库中的 venv 创建一个 Python 虚拟环境。venv的参数是托管虚拟环境的目录的路径。一种常见的做法是根据您的喜好将该目录命名为venv、.venv或env。
第三个命令激活您刚刚创建的虚拟环境。您知道环境是活动的,因为您的提示会变成类似于(venv) $的内容。
注意:要在 Windows 上创建和激活虚拟环境,您将遵循类似的过程。
继续运行以下命令:
c:\> python -m venv venv
c:\> venv\Scripts\activate.bat
如果您在不同的平台上,那么您可能需要查看 Python 官方文档中关于创建虚拟环境的内容。
现在您已经有了一个工作的虚拟环境,您需要安装 Typer 来创建 CLI 应用程序和 pytest 来测试您的应用程序的代码。要安装 Typer 及其所有当前的可选依赖项,请运行以下命令:
(venv) $ python -m pip install typer==0.3.2 colorama==0.4.4 shellingham==1.4.0
该命令安装 Typer 及其所有推荐的依赖项,例如 Colorama ,它确保颜色在命令行窗口中正确工作。
要安装 pytest(稍后您将使用它来测试您的待办事项应用程序),请运行以下命令:
(venv) $ python -m pip install pytest==6.2.4
使用这最后一个命令,您成功地安装了开始开发您的待办事项应用程序所需的所有工具。您将使用的其余库和工具是 Python 标准库的一部分,因此您不必安装任何东西就可以使用它们。
定义项目布局
完成待办事项应用项目设置的最后一步是创建包、模块和构建应用布局的文件。该应用的核心包将位于rptodo_project/内的rptodo/目录中。
以下是对该包内容的描述:
| 文件 | 描述 |
|---|---|
__init__.py |
使rptodo/成为一个 Python 包 |
__main__.py |
提供一个入口点脚本,使用python -m rptodo命令从包中运行应用程序 |
cli.py |
为应用程序提供 Typer 命令行界面 |
config.py |
包含处理应用程序配置文件的代码 |
database.py |
包含处理应用程序的待办事项数据库的代码 |
rptodo.py |
提供将 CLI 与待办事项数据库连接起来的代码 |
您还需要一个包含一个__init__.py文件的tests/目录来将该目录转换成一个包,还需要一个test_rptodo.py文件来保存应用程序的单元测试。
继续使用以下结构创建项目布局:
rptodo_project/
│
├── rptodo/
│ ├── __init__.py
│ ├── __main__.py
│ ├── cli.py
│ ├── config.py
│ ├── database.py
│ └── rptodo.py
│
├── tests/
│ ├── __init__.py
│ └── test_rptodo.py
│
├── README.md
└── requirements.txt
README.md 文件将提供项目的描述以及安装和运行应用程序的说明。向您的项目添加一个描述性的详细的README.md文件是编程中的一个最佳实践,尤其是如果您计划将该项目作为开放源代码发布的话。
requirements.txt文件将为您的待办应用程序提供依赖项列表。继续填写以下内容:
typer==0.3.2
colorama==0.4.4
shellingham==1.4.0
pytest==6.2.4
现在,您的用户可以通过运行以下命令自动安装列出的依赖项:
(venv) $ python -m pip install -r requirements.txt
像这样提供一个requirements.txt可以确保您的用户将安装您用来构建项目的依赖项的精确版本,避免意外的问题和行为。
除了requirements.txt之外,此时您的项目的所有文件都应该是空的。在本教程中,您将使用必要的内容填充每个文件。在下一节中,您将使用 Python 和 Typer 编写应用程序的 CLI。
第二步:用 Python 和 Typer 设置待办事项 CLI 应用
至此,您应该有了待办事项应用程序的完整项目布局。您还应该有一个工作的 Python 虚拟环境,其中包含所有必需的工具和库。在这一步结束时,您将拥有一个功能型 CLI 应用程序。然后,您将能够在其最小功能的基础上进行构建。
您可以通过点击下面的链接并转到source_code_step_2/目录来下载您将在本节中添加的代码、单元测试和资源:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
启动代码编辑器,从rptodo/目录中打开__init__.py文件。然后向其中添加以下代码:
"""Top-level package for RP To-Do."""
# rptodo/__init__.py
__app_name__ = "rptodo"
__version__ = "0.1.0"
(
SUCCESS,
DIR_ERROR,
FILE_ERROR,
DB_READ_ERROR,
DB_WRITE_ERROR,
JSON_ERROR,
ID_ERROR,
) = range(7)
ERRORS = {
DIR_ERROR: "config directory error",
FILE_ERROR: "config file error",
DB_READ_ERROR: "database read error",
DB_WRITE_ERROR: "database write error",
ID_ERROR: "to-do id error",
}
这里,首先定义两个模块级名称来保存应用程序的名称和版本。然后定义一系列的返回和错误代码,并使用 range() 给它们分配整数。ERROR是一个字典,它将错误代码映射到人类可读的错误消息。您将使用这些消息告诉用户应用程序正在发生什么。
有了这些代码,就可以创建 Typer CLI 应用程序的框架了。这就是你在下一节要做的。
创建 Typer CLI 应用程序
在这一节中,您将创建一个支持--help、-v和--version选项的最小 Typer CLI 应用程序。为此,您将使用一个显式类型应用程序。这种类型的应用程序适用于包含多个命令和几个选项和参数的大型项目。
继续在文本编辑器中打开rptodo/cli.py,输入以下代码:
1"""This module provides the RP To-Do CLI."""
2# rptodo/cli.py
3
4from typing import Optional
5
6import typer
7
8from rptodo import __app_name__, __version__
9
10app = typer.Typer()
11
12def _version_callback(value: bool) -> None:
13 if value:
14 typer.echo(f"{__app_name__} v{__version__}")
15 raise typer.Exit()
16
17@app.callback()
18def main(
19 version: Optional[bool] = typer.Option(
20 None,
21 "--version",
22 "-v",
23 help="Show the application's version and exit.",
24 callback=_version_callback,
25 is_eager=True,
26 )
27) -> None:
28 return
Typer 广泛使用 Python 类型提示,因此在本教程中,您也将使用它们。这就是为什么你从 typing 导入 Optional 开始。接下来,你进口typer。最后,你从你的rptodo包中导入__app_name__和__version__。
下面是其余代码的工作方式:
-
第 10 行创建了一个显式类型应用程序
app。 -
第 12 到 15 行定义了
_version_callback()。这个函数采用一个名为value的布尔参数。如果value是True,那么该函数使用echo()打印应用程序的名称和版本。之后,它引发一个typer.Exit异常来干净地退出应用程序。 -
第 19 行定义了
version,其类型为Optional[bool]。这意味着它可以是bool或None类型。version参数默认为一个typer.Option对象,它允许您在 Typer 中创建命令行选项。 -
第 20 行将
None作为第一个参数传递给Option的初始化器。此参数是必需的,并提供选项的默认值。 -
第 21 行和第 22 行为
version选项设置命令行名称:-v和--version。 -
第 23 行为
version选项提供了一条help消息。 -
第 24 行将一个回调函数
_version_callback()附加到version选项上,这意味着运行该选项会自动调用该函数。 -
第 25 行将
is_eager参数设置为True。这个参数告诉 Typerversion命令行选项优先于当前应用程序中的其他命令。
有了这些代码,就可以创建应用程序的入口点脚本了。这就是你在下一节要做的。
创建一个入口点脚本
您几乎已经准备好第一次运行您的待办事项应用程序了。在此之前,您应该为应用程序创建一个入口点脚本。您可以用几种不同的方式创建这个脚本。在本教程中,您将使用rptodo包中的 __main__.py 模块来完成。在 Python 包中包含一个__main__.py模块使您能够使用命令python -m rptodo将包作为可执行程序运行。
回到代码编辑器,从rptodo/目录中打开__main__.py。然后添加以下代码:
"""RP To-Do entry point script."""
# rptodo/__main__.py
from rptodo import cli, __app_name__
def main():
cli.app(prog_name=__app_name__)
if __name__ == "__main__":
main()
在__main__.py中,你首先从rptodo导入cli和__app_name__。然后你定义main()。在这个函数中,您用cli.app()调用 Typer 应用程序,将应用程序的名称传递给prog_name参数。向prog_name提供一个值可以确保用户在命令行上运行--help选项时获得正确的应用程序名称。
有了这最后一项,您就可以第一次运行您的待办事项应用程序了。转到您的终端窗口,执行以下命令:
(venv) $ python -m rptodo -v
rptodo v0.1.0
(venv) $ python -m rptodo --help
Usage: rptodo [OPTIONS] COMMAND [ARGS]...
Options:
-v, --version Show the application's version and exit.
--install-completion Install completion for the current shell.
--show-completion Show completion for the current shell, to copy it
or customize the installation.
--help Show this message and exit.
第一个命令运行-v选项,显示应用程序的版本。第二个命令运行--help选项,为整个应用程序显示用户友好的帮助消息。Typer 会自动为您生成并显示此帮助消息。
使用 pytest 设置初始 CLI 测试
在本节中,您将运行的最后一个操作是为您的待办应用程序设置一个初始的测试套件。为此,您已经用一个名为test_rptodo.py的模块创建了tests包。正如您在前面所学的,您将使用 pytest 来编写和运行您的单元测试。
测试一个 Typer 应用程序很简单,因为这个库与 pytest 集成得很好。您可以使用一个名为 CliRunner 的 Typer 类来测试应用程序的 CLI。CliRunner允许您创建一个运行程序,用于测试您的应用程序的 CLI 如何响应实际命令。
回到代码编辑器,从tests/目录中打开test_rptodo.py。键入以下代码:
1# tests/test_rptodo.py
2
3from typer.testing import CliRunner
4
5from rptodo import __app_name__, __version__, cli
6
7runner = CliRunner()
8
9def test_version():
10 result = runner.invoke(cli.app, ["--version"])
11 assert result.exit_code == 0
12 assert f"{__app_name__} v{__version__}\n" in result.stdout
下面是这段代码的作用:
- 三号线从
typer.testing进口CliRunner。 - 第 5 行从你的
rptodo包中导入一些需要的对象。 - 第 7 行通过实例化
CliRunner创建一个 CLI 运行器。 - 第 9 行定义了测试应用程序版本的第一个单元测试。
- 第 10 行调用
runner上的.invoke()来运行带有--version选项的应用程序。您将这次调用的结果存储在result中。 - 第 11 行断言应用程序的退出代码 (
result.exit_code)等于0,以检查应用程序是否成功运行。 - 第 12 行断言应用程序的版本出现在标准输出中,可通过
result.stdout获得。
Typer 的CliRunner是 Click 的CliRunner 的子类。因此,它的.invoke()方法返回一个 Result 对象,该对象保存使用目标参数和选项运行 CLI 应用程序的结果。Result对象提供了几个有用的属性和特性,包括应用程序的退出代码和标准输出。更多细节请看一下类文档。
现在,您已经为 Typer CLI 应用程序设置了第一个单元测试,您可以使用 pytest 运行测试。回到命令行,从项目的根目录执行python -m pytest tests/:
========================= test session starts =========================
platform linux -- Python 3.9.5, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: .../rptodo
plugins: Faker-8.1.1, cov-2.12.0, celery-4.4.7
collected 1 item
tests/test_rptodo.py . [100%]
========================== 1 passed in 0.07s ==========================
就是这样!您第一次成功运行了您的测试套件!是的,到目前为止你只有一个测试。但是,您将在接下来的章节中添加更多的内容。如果你想挑战你的测试技巧,你也可以添加你自己的测试。
有了 to-do 应用程序的框架,现在您可以考虑设置 to-do 数据库以准备使用。这就是你在下一节要做的。
步骤 3:准备待办事项数据库以供使用
到目前为止,您已经为您的待办事项应用程序构建了一个 CLI,创建了一个入口点脚本,并且第一次运行了该应用程序。您还为应用程序设置并运行了一个最小的测试套件。下一步是定义应用程序如何初始化并连接到待办事项数据库。
您将使用一个 JSON 文件来存储关于您的待办事项的数据。JSON 是一种轻量级的数据交换格式,可读可写。Python 的标准库包括json,这是一个提供开箱即用的 JSON 文件格式支持的模块。这就是你要用来管理你的待办事项数据库。
您可以通过点击下面的链接并转到source_code_step_3/目录来下载本节的完整代码:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
在本节结束时,您已经编写了创建、连接和初始化待办事项数据库的代码,这样它就可以使用了。然而,第一步是定义应用程序如何在文件系统中找到待办事项数据库。
设置应用程序的配置
您可以使用不同的技术来定义应用程序如何连接以及如何在您的文件系统上打开文件。您可以动态地提供文件路径,创建一个环境变量来保存文件路径,创建一个用于存储文件路径的配置文件,等等。
注:配置文件,也称为配置文件,是程序员用来为给定程序或应用提供初始参数和设置的一种文件。
在本教程中,您将在个人目录中为待办事项应用程序提供一个配置文件来存储数据库的路径。为此,您将使用 pathlib 处理文件系统路径,使用configparser处理配置文件。这两个包都可以在 Python 标准库中找到。
现在回到你的代码编辑器,从rptodo/打开config.py。键入以下代码:
1"""This module provides the RP To-Do config functionality."""
2# rptodo/config.py
3
4import configparser
5from pathlib import Path
6
7import typer
8
9from rptodo import (
10 DB_WRITE_ERROR, DIR_ERROR, FILE_ERROR, SUCCESS, __app_name_
11)
12
13CONFIG_DIR_PATH = Path(typer.get_app_dir(__app_name__))
14CONFIG_FILE_PATH = CONFIG_DIR_PATH / "config.ini"
15
16def init_app(db_path: str) -> int:
17 """Initialize the application."""
18 config_code = _init_config_file()
19 if config_code != SUCCESS:
20 return config_code
21 database_code = _create_database(db_path)
22 if database_code != SUCCESS:
23 return database_code
24 return SUCCESS
25
26def _init_config_file() -> int:
27 try:
28 CONFIG_DIR_PATH.mkdir(exist_ok=True)
29 except OSError:
30 return DIR_ERROR
31 try:
32 CONFIG_FILE_PATH.touch(exist_ok=True)
33 except OSError:
34 return FILE_ERROR
35 return SUCCESS
36
37def _create_database(db_path: str) -> int:
38 config_parser = configparser.ConfigParser()
39 config_parser["General"] = {"database": db_path}
40 try:
41 with CONFIG_FILE_PATH.open("w") as file:
42 config_parser.write(file)
43 except OSError:
44 return DB_WRITE_ERROR
45 return SUCCESS
下面是这段代码的详细内容:
-
四号线进口
configparser。这个模块提供了ConfigParser类,允许你处理结构类似于 INI 文件的配置文件。 -
5 号线从
pathlib进口Path。这个类提供了一种跨平台的方式来处理系统路径。 -
7 号线进口
typer。 -
第 9 到 11 行从
rptodo导入一堆需要的对象。 -
第 13 行创建
CONFIG_DIR_PATH来保存 app 的目录路径。为了获得这个路径,您调用get_app_dir(),将应用程序的名称作为参数。此函数返回一个字符串,表示存储配置的目录的路径。 -
第 14 行定义
CONFIG_FILE_PATH来保存配置文件本身的路径。 -
第 16 行定义
init_app()。这个函数初始化应用程序的配置文件和数据库。 -
第 18 行调用第 26 到 35 行定义的
_init_config_file()助手函数。调用此函数使用Path.mkdir()创建配置目录。它还使用Path.touch()创建配置文件。最后,如果在创建目录和文件的过程中发生了错误,_init_config_file()会返回正确的错误代码。如果一切顺利,它将返回SUCCESS。 -
第 19 行检查在创建目录和配置文件的过程中是否出现错误,第 20 行相应地返回错误代码。
-
第 21 行调用
_create_database()助手函数,创建待办事项数据库。如果在创建数据库时发生了什么,这个函数将返回相应的错误代码。如果流程成功,它将返回SUCCESS。 -
第 22 行检查数据库创建过程中是否出现错误。如果是,那么第 23 行返回相应的错误代码。
-
如果一切运行正常,第 24 行返回
SUCCESS。
使用这段代码,您已经完成了设置应用程序的配置文件来存储 to-do 数据库的路径。您还添加了代码来将待办事项数据库创建为 JSON 文件。现在,您可以编写代码来初始化数据库并准备好使用它。这就是你在下一节要做的。
准备好待办事项数据库
要准备好待办事项数据库,您需要执行两个操作。首先,您需要一种从应用程序的配置文件中检索数据库文件路径的方法。其次,需要初始化数据库来保存 JSON 内容。
在您的代码编辑器中从rptodo/打开database.py,并编写以下代码:
1"""This module provides the RP To-Do database functionality."""
2# rptodo/database.py
3
4import configparser
5from pathlib import Path
6
7from rptodo import DB_WRITE_ERROR, SUCCESS
8
9DEFAULT_DB_FILE_PATH = Path.home().joinpath(
10 "." + Path.home().stem + "_todo.json"
11)
12
13def get_database_path(config_file: Path) -> Path:
14 """Return the current path to the to-do database."""
15 config_parser = configparser.ConfigParser()
16 config_parser.read(config_file)
17 return Path(config_parser["General"]["database"])
18
19def init_database(db_path: Path) -> int:
20 """Create the to-do database."""
21 try:
22 db_path.write_text("[]") # Empty to-do list
23 return SUCCESS
24 except OSError:
25 return DB_WRITE_ERROR
在这个文件中,第 4 行到第 7 行执行所需的导入。下面是代码的其余部分:
-
第 9 到 11 行定义
DEFAULT_DB_FILE_PATH来保存默认的数据库文件路径。如果用户没有提供自定义路径,应用程序将使用该路径。 -
第 13 到 17 行定义了
get_database_path()。该函数将应用程序配置文件的路径作为参数,使用ConfigParser.read()读取输入文件,并返回一个Path对象,表示文件系统上待办事项数据库的路径。ConfigParser实例将数据存储在一个字典中。"General"键代表存储所需信息的文件部分。"database"键检索数据库路径。 -
第 19 到 25 行定义
init_database()。这个函数获取一个数据库路径,并写入一个表示空列表的字符串。你在数据库路径上调用.write_text(),列表用一个空的待办列表初始化 JSON 数据库。如果流程运行成功,那么init_database()返回SUCCESS。否则,它返回适当的错误代码。
酷!现在,您有了从应用程序的配置文件中检索数据库文件路径的方法。您还可以用 JSON 格式的空待办事项列表来初始化数据库。是时候用 Typer 实现init命令了,这样用户就可以从 CLI 初始化他们的待办事项数据库。
执行init CLI 命令
将本节中编写的所有代码放在一起的最后一步是将init命令添加到应用程序的 CLI 中。该命令将采用可选的数据库文件路径。然后它会创建应用程序的配置文件和待办事项数据库。
继续将init()添加到您的cli.py文件中:
1"""This module provides the RP To-Do CLI."""
2# rptodo/cli.py
3
4from pathlib import Path 5from typing import Optional
6
7import typer
8
9from rptodo import ERRORS, __app_name__, __version__, config, database 10
11app = typer.Typer()
12
13@app.command() 14def init( 15 db_path: str = typer.Option(
16 str(database.DEFAULT_DB_FILE_PATH),
17 "--db-path",
18 "-db",
19 prompt="to-do database location?",
20 ),
21) -> None:
22 """Initialize the to-do database."""
23 app_init_error = config.init_app(db_path)
24 if app_init_error:
25 typer.secho(
26 f'Creating config file failed with "{ERRORS[app_init_error]}"',
27 fg=typer.colors.RED,
28 )
29 raise typer.Exit(1)
30 db_init_error = database.init_database(Path(db_path))
31 if db_init_error:
32 typer.secho(
33 f'Creating database failed with "{ERRORS[db_init_error]}"',
34 fg=typer.colors.RED,
35 )
36 raise typer.Exit(1)
37 else:
38 typer.secho(f"The to-do database is {db_path}", fg=typer.colors.GREEN)
39
40def _version_callback(value: bool) -> None:
41 # ...
下面是新代码的工作原理:
-
第 4 行和第 9 行更新所需的导入。
-
第 13 行和第 14 行使用
@app.command()装饰器将init()定义为一个键入命令。 -
第 15 到 20 行定义了一个 Typer
Option实例,并将其作为默认值赋给db_path。要为该选项提供一个值,您的用户需要使用--db-path或-db,后跟一个数据库路径。prompt参数显示一个询问数据库位置的提示。它还允许您通过按下Enter来接受默认路径。 -
第 23 行调用
init_app()创建应用程序的配置文件和待办事项数据库。 -
第 24 到 29 行检查对
init_app()的调用是否返回错误。如果是这样,第 25 到 28 行打印一条错误消息。第 29 行用一个typer.Exit异常和一个退出代码1退出应用程序,表示应用程序因出错而终止。 -
第 30 行调用
init_database()用一个空的待办事项列表初始化数据库。 -
第 31 到 38 行检查对
init_database()的调用是否返回错误。如果是,那么第 32 到 35 行显示一条错误消息,第 36 行退出应用程序。否则,第 38 行用绿色文本打印一条成功消息。
使用 typer.secho() 打印该代码中的信息。这个函数有一个前景参数fg,当将文本打印到屏幕上时,它允许你使用不同的颜色。Typer 在typer.colors中提供了几种内置颜色。在那里你会发现RED、BLUE、GREEN等等。你可以像这里一样用secho()使用这些颜色。
注意:本教程中代码示例中的行号是出于解释的目的。大多数情况下,它们不会与最终模块或脚本中的行号相匹配。
不错!有了所有这些代码,现在可以尝试一下init命令了。回到您的终端,运行以下命令:
(venv) $ python -m rptodo init
to-do database location? [/home/user/.user_todo.json]:
The to-do database is /home/user/.user_todo.json
该命令提示您输入数据库位置。可以按 Enter 接受方括号内的默认路径,也可以输入自定义路径后再按 Enter 。该应用程序创建了待办事项数据库,并告诉您从现在开始它将驻留在哪里。
或者,您可以通过使用带有-db或--db-path选项的init来直接提供一个定制的数据库路径,后跟所需的路径。在所有情况下,您的自定义路径都应该包括数据库文件名。
一旦你运行了上面的命令,看看你的主目录。您将拥有一个 JSON 文件,该文件以您在init中使用的文件名命名。在您的主文件夹中,您还会有一个包含一个config.ini文件的rptodo/目录。该文件的具体路径取决于您当前的操作系统。比如在 Ubuntu 上,文件会在/home/user/.config/rptodo/。
第四步:设置待办 App 后端
到目前为止,您已经找到了创建、初始化和连接 to-do 数据库的方法。现在您可以开始考虑您的数据模型了。换句话说,你需要考虑如何表示和存储关于你的待办事项的数据。您还需要定义应用程序将如何处理 CLI 和数据库之间的通信。
您可以通过点击下面的链接并转到source_code_step_4/目录来下载代码和您将在本节中使用的所有其他资源:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
定义一个单独的待办事项
首先,考虑定义一个待办事项所需的数据。在这个项目中,待办事项将由以下信息组成:
- 描述:如何描述这个待办事项?
- 优先级:这个待办事项比你的其他待办事项优先级高多少?
- 完成:这个待办事项完成了吗?
要存储这些信息,可以使用常规的 Python 字典:
todo = {
"Description": "Get some milk.",
"Priority": 2,
"Done": True,
}
"Description"键存储描述当前待办事项的字符串。"Priority"键可以有三个可能的值:1表示高优先级,2表示中优先级,3表示低优先级。当您完成待办事项时,"Done"键会按住True,否则会按住False。
与 CLI 通信
为了与 CLI 通信,您将使用两个包含所需信息的数据:
todo:保存当前待办事项信息的字典error:确认当前操作是否成功的返回或错误代码
为了存储这些数据,您将使用一个名为 tuple 的,并带有适当命名的字段。从rptodo打开rptodo.py模块,创建所需的命名元组:
1"""This module provides the RP To-Do model-controller."""
2# rptodo/rptodo.py
3
4from typing import Any, Dict, NamedTuple
5
6class CurrentTodo(NamedTuple):
7 todo: Dict[str, Any]
8 error: int
在rptodo.py中,首先从typing导入一些需要的对象。在第 6 行,您创建了一个名为CurrentTodo的 typing.NamedTuple的子类,它有两个字段todo和error。
子类化NamedTuple允许您为命名字段创建带有类型提示的命名元组。例如,上面的todo字段保存了一个字典,其中键的类型为str,值的类型为Any。error字段保存一个 int 值。
与数据库通信
现在,您需要另一个数据容器,它允许您向待办事项数据库发送数据和从中检索数据。在这种情况下,您将使用具有以下字段的另一个命名元组:
todo_list:你将从数据库中写入和读取的待办事项列表error:表示当前数据库操作相关的返回码的整数
最后,您将创建一个名为DatabaseHandler的类来读写 to-do 数据库中的数据。继续打开database.py。一旦你到了那里,输入以下代码:
1# rptodo/database.py
2
3import configparser
4import json 5from pathlib import Path
6from typing import Any, Dict, List, NamedTuple 7
8from rptodo import DB_READ_ERROR, DB_WRITE_ERROR, JSON_ERROR, SUCCESS 9
10# ...
11
12class DBResponse(NamedTuple): 13 todo_list: List[Dict[str, Any]]
14 error: int
15
16class DatabaseHandler: 17 def __init__(self, db_path: Path) -> None:
18 self._db_path = db_path
19
20 def read_todos(self) -> DBResponse:
21 try:
22 with self._db_path.open("r") as db:
23 try:
24 return DBResponse(json.load(db), SUCCESS)
25 except json.JSONDecodeError: # Catch wrong JSON format
26 return DBResponse([], JSON_ERROR)
27 except OSError: # Catch file IO problems
28 return DBResponse([], DB_READ_ERROR)
29
30 def write_todos(self, todo_list: List[Dict[str, Any]]) -> DBResponse:
31 try:
32 with self._db_path.open("w") as db:
33 json.dump(todo_list, db, indent=4)
34 return DBResponse(todo_list, SUCCESS)
35 except OSError: # Catch file IO problems
36 return DBResponse(todo_list, DB_WRITE_ERROR)
下面是这段代码的作用:
-
第 4、6 和 8 行添加了一些必需的导入。
-
第 12 到 14 行将
DBResponse定义为一个NamedTuple子类。todo_list字段是代表单个待办事项的字典列表,而error字段保存一个整数返回代码。 -
第 16 行定义了
DatabaseHandler,它允许你使用标准库中的json模块向待办数据库读写数据。 -
第 17 行和第 18 行定义了类初始化器,它接受一个表示文件系统上数据库路径的参数。
-
第 20 行定义
.read_todos()。这个方法从数据库中读取待办事项列表,反序列化它。 -
第 21 行开始一个
try…except语句来捕捉你打开数据库时发生的任何错误。如果出现错误,那么第 28 行返回一个带有空待办事项列表和一个DB_READ_ERROR的DBResponse实例。 -
第 22 行使用
with语句打开数据库进行读取。 -
第 23 行开始另一个
try…except语句,捕捉从待办数据库加载和反序列化 JSON 内容时发生的任何错误。 -
第 24 行返回一个
DBResponse实例,保存调用json.load()的结果,以待办数据库对象作为参数。这个结果由一个字典列表组成。每本词典都代表一项任务。DBResponse的error字段按住SUCCESS表示操作成功。 -
第 25 行在从数据库加载 JSON 内容时捕获任何
JSONDecodeError,第 26 行返回一个空列表和一个JSON_ERROR。 -
第 27 行在加载 JSON 文件时捕获任何文件 IO 问题,第 28 行返回一个带有空待办事项列表和
DB_READ_ERROR的DBResponse实例。 -
第 30 行定义了
.write_todos(),它获取待办字典列表并将其写入数据库。 -
第 31 行开始一个
try…except语句来捕捉你打开数据库时发生的任何错误。如果出现错误,那么第 36 行返回一个带有原始待办事项列表和一个DB_READ_ERROR的DBResponse实例。 -
第 32 行使用一个
with语句打开数据库进行写操作。 -
第 33 行将待办事项列表作为 JSON 负载转储到数据库中。
-
第 34 行返回一个保存待办事项列表和
SUCCESS代码的DBResponse实例。
哇!太多了!既然您已经完成了编码DatabaseHandler并设置了数据交换机制,那么您可以考虑如何将它们连接到应用程序的 CLI。
写控制器类,Todoer,
为了将DatabaseHandler逻辑与应用程序的 CLI 连接起来,您将编写一个名为Todoer的类。这个类的工作方式类似于模型-视图-控制器模式中的控制器。
现在回到rptodo.py并添加以下代码:
# rptodo/rptodo.py
from pathlib import Path from typing import Any, Dict, NamedTuple
from rptodo.database import DatabaseHandler
# ...
class Todoer:
def __init__(self, db_path: Path) -> None:
self._db_handler = DatabaseHandler(db_path)
这段代码包括一些导入和Todoer的定义。这个类使用了组合,所以它有一个DatabaseHandler组件来促进与待办事项数据库的直接通信。在接下来的部分中,您将向该类添加更多的代码。
在这一节中,你已经完成了许多设置,这些设置决定了你的待办事项应用程序的后端将如何工作。您已经决定了使用什么数据结构来存储待办事项数据。您还定义了将使用哪种数据库来保存待办事项信息,以及如何对其进行操作。
所有这些设置就绪后,您就可以开始通过允许用户填充他们的待办事项列表来为他们提供价值了。您还将实现一种在屏幕上显示待办事项的方法。
步骤 5:编写添加和列出待办功能的代码
在本节中,您将编写待办事项应用程序的一个主要特性。您将为您的用户提供一个命令,将新的待办事项添加到他们当前的列表中。您还可以允许用户在屏幕上以表格形式列出他们的待办事项。
在使用这些特性之前,您将为您的代码设置一个最小的测试套件。在写代码之前写一个测试套件会帮助你理解测试驱动开发(TDD) 是关于什么的。
要下载代码、单元测试和您将在本节中添加的所有附加资源,只需点击下面的链接并转到source_code_step_5/目录:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
为Todoer.add()定义单元测试
在本节中,您将使用 pytest 为Todoer.add()编写并运行一个最小的测试套件。这种方法会将新的待办事项添加到数据库中。测试套件就绪后,您将编写通过测试所需的代码,这是 TDD 背后的一个基本思想。
注意:如果您下载了本教程每一节的源代码和资源,那么您会发现本节和接下来的几节中有额外的单元测试。
看一看它们,试着理解它们的逻辑。运行它们以确保应用程序正常工作。扩展它们以添加新的测试用例。在这个过程中你会学到很多东西。
在为.add()编写测试之前,想想这个方法需要做什么:
- 获取待办事项描述和优先级
- 创建一个字典来保存待办信息
- 从数据库中读取待办事项列表
- 将新待办事项追加到当前待办事项列表中
- 将更新后的待办事项列表写回数据库
- 将新添加的待办事项连同返回码一起返回给调用者
代码测试中的一个常见实践是从给定方法或函数的主要功能开始。您将通过创建测试用例来检查.add()是否正确地向数据库添加了新的待办事项。
为了测试.add(),您必须创建一个Todoer实例,用一个合适的 JSON 文件作为目标数据库。为了提供该文件,您将使用 pytest 夹具。
回到代码编辑器,从tests/目录中打开test_rptodo.py。向其中添加以下代码:
# tests/test_rptodo.py
import json
import pytest from typer.testing import CliRunner
from rptodo import (
DB_READ_ERROR, SUCCESS, __app_name__,
__version__,
cli,
rptodo, )
# ...
@pytest.fixture def mock_json_file(tmp_path):
todo = [{"Description": "Get some milk.", "Priority": 2, "Done": False}]
db_file = tmp_path / "todo.json"
with db_file.open("w") as db:
json.dump(todo, db, indent=4)
return db_file
在这里,您首先更新您的导入来完成一些需求。fixturemock_json_file()创建并返回一个临时 JSON 文件db_file,其中有一个单项待办事项列表。在这个 fixture 中,您使用了 tmp_path ,这是一个pathlib.Path对象,pytest 使用它来提供一个用于测试目的的临时目录。
您已经有一个临时待办事项数据库可以使用。现在你需要一些数据来创建你的测试用例:
# tests/test_rptodo.py
# ...
test_data1 = {
"description": ["Clean", "the", "house"],
"priority": 1,
"todo": {
"Description": "Clean the house.",
"Priority": 1,
"Done": False,
},
}
test_data2 = {
"description": ["Wash the car"],
"priority": 2,
"todo": {
"Description": "Wash the car.",
"Priority": 2,
"Done": False,
},
}
这两个字典提供了测试Todoer.add()的数据。前两个键表示您将用作.add()的参数的数据,而第三个键保存方法的预期返回值。
现在是时候为.add()编写你的第一个测试函数了。使用 pytest,您可以使用参数化为单个测试函数提供多组参数和预期结果。这是一个非常好的特性。它使一个单一的测试函数表现得像运行不同测试用例的几个测试函数一样。
以下是在 pytest 中使用参数化创建测试函数的方法:
1# tests/test_rptodo.py
2# ...
3
4@pytest.mark.parametrize( 5 "description, priority, expected",
6 [
7 pytest.param( 8 test_data1["description"],
9 test_data1["priority"],
10 (test_data1["todo"], SUCCESS),
11 ),
12 pytest.param( 13 test_data2["description"],
14 test_data2["priority"],
15 (test_data2["todo"], SUCCESS),
16 ),
17 ],
18)
19def test_add(mock_json_file, description, priority, expected): 20 todoer = rptodo.Todoer(mock_json_file)
21 assert todoer.add(description, priority) == expected
22 read = todoer._db_handler.read_todos()
23 assert len(read.todo_list) == 2
@pytest.mark.parametrize()装饰器标记test_add()用于参数化。当 pytest 运行这个测试时,它调用test_add()两次。每个调用使用第 7 行到第 11 行以及第 12 行到第 16 行中的一个参数集。
第 5 行的字符串包含两个必需参数的描述性名称,以及一个描述性的返回值名称。注意test_add()有那些相同的参数。此外,test_add()的第一个参数与您刚刚定义的夹具同名。
在test_add()中,代码执行以下操作:
-
第 20 行用
mock_json_file作为参数创建了一个Todoer的实例。 -
第 21 行断言使用
description和priority作为参数对.add()的调用应该返回expected。 -
第 22 行从临时数据库中读取待办事项列表并存储在
read中。 -
第 23 行断言待办事项列表的长度为
2。为什么是2?因为mock_json_file()返回了一个带有待办事项的列表,现在你又添加了第二个。
酷!你有一个覆盖了.add()主要功能的测试。现在是时候再次运行您的测试套件了。回到你的命令行并运行python -m pytest tests/。您将得到类似如下的输出:
======================== test session starts ==========================
platform linux -- Python 3.8.5, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: .../rptodo
plugins: Faker-8.1.1, cov-2.12.0, celery-4.4.7
collected 3 items
tests/test_rptodo.py .FF [100%] ============================== FAILURES ===============================
# Output cropped
突出显示行中的字母 F 意味着您的两个测试用例失败了。测试失败是 TDD 的第一步。第二步是编写通过这些测试的代码。这就是你接下来要做的。
执行add CLI 命令
在本节中,您将在Todoer类中编写.add()代码。您还将在您的 Typer CLI 中编写add命令。有了这两段代码,您的用户将能够向他们的待办事项列表添加新项目。
待办应用每次运行都需要访问Todoer类,将 CLI 与数据库连接。为了满足这个需求,您将实现一个名为get_todoer()的函数。
回到你的代码编辑器,打开cli.py。键入以下代码:
1# rptodo/cli.py
2
3from pathlib import Path
4from typing import List, Optional 5
6import typer
7
8from rptodo import (
9 ERRORS, __app_name__, __version__, config, database, rptodo 10)
11
12app = typer.Typer()
13
14@app.command()
15def init(
16 # ...
17
18def get_todoer() -> rptodo.Todoer: 19 if config.CONFIG_FILE_PATH.exists():
20 db_path = database.get_database_path(config.CONFIG_FILE_PATH)
21 else:
22 typer.secho(
23 'Config file not found. Please, run "rptodo init"',
24 fg=typer.colors.RED,
25 )
26 raise typer.Exit(1)
27 if db_path.exists():
28 return rptodo.Todoer(db_path)
29 else:
30 typer.secho(
31 'Database not found. Please, run "rptodo init"',
32 fg=typer.colors.RED,
33 )
34 raise typer.Exit(1)
35
36def _version_callback(value: bool) -> None:
37 # ...
更新导入后,在第 18 行定义get_todoer()。第 19 行定义了一个条件,它检查应用程序的配置文件是否存在。为此,它使用了 Path.exists() 。
如果配置文件存在,那么第 20 行从中获得数据库的路径。如果文件不存在,则运行else子句。该子句将一条错误消息打印到屏幕上,并使用退出代码1退出应用程序,以发出错误信号。
第 27 行检查到数据库的路径是否存在。如果是这样,那么第 28 行创建一个Todoer的实例,并将路径作为参数。否则,从第 29 行开始的else子句打印一条错误消息并退出应用程序。
现在您已经有了一个具有有效数据库路径的Todoer实例,您可以编写.add()了。回到rptodo.py模块并更新Todoer:
1# rptodo/rptodo.py
2from pathlib import Path
3from typing import Any, Dict, List, NamedTuple 4
5from rptodo import DB_READ_ERROR 6from rptodo.database import DatabaseHandler
7
8# ...
9
10class Todoer:
11 def __init__(self, db_path: Path) -> None:
12 self._db_handler = DatabaseHandler(db_path)
13
14 def add(self, description: List[str], priority: int = 2) -> CurrentTodo: 15 """Add a new to-do to the database."""
16 description_text = " ".join(description)
17 if not description_text.endswith("."):
18 description_text += "."
19 todo = {
20 "Description": description_text,
21 "Priority": priority,
22 "Done": False,
23 }
24 read = self._db_handler.read_todos()
25 if read.error == DB_READ_ERROR:
26 return CurrentTodo(todo, read.error)
27 read.todo_list.append(todo)
28 write = self._db_handler.write_todos(read.todo_list)
29 return CurrentTodo(todo, write.error)
下面是.add()一行一行的工作方式:
-
第 14 行定义了
.add(),它以description和priority为自变量。描述是一个字符串列表。Typer 根据您在命令行输入的单词来创建这个列表,以描述当前的待办事项。在priority的情况下,它是一个表示待办事项优先级的整数值。默认值为2,表示中等优先级。 -
第 16 行使用
.join()将描述组件连接成一个字符串。 -
第 17 行和第 18 行如果用户没有添加句点(
"."),则在描述的末尾添加一个句点。 -
第 19 行到第 23 行根据用户的输入创建一个新的待办事项。
-
第 24 行通过调用数据库处理器上的
.read_todos()从数据库中读取待办事项列表。 -
第 25 行检查
.read_todos()是否返回一个DB_READ_ERROR。如果是,那么第 26 行返回一个命名的元组,CurrentTodo,包含当前的待办事项和错误代码。 -
第 27 行将新的待办事项添加到列表中。
-
第 28 行通过调用数据库处理程序上的
.write_todos()将更新后的待办事项列表写回数据库。 -
第 29 行返回一个
CurrentTodo的实例,带有当前的待办事项和一个适当的返回代码。
现在您可以再次运行您的测试套件来检查.add()是否正常工作。继续运行python -m pytest tests/。您将得到类似如下的输出:
========================= test session starts =========================
platform linux -- Python 3.9.5, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
plugins: Faker-8.1.1, cov-2.12.0, celery-4.4.7
rootdir: .../rptodo
collected 2 items
tests/test_rptodo.py ... [100%] ========================== 3 passed in 0.09s ==========================
三个绿点意味着你通过了三项测试。如果您从 GitHub 上的项目 repo 中下载了代码,那么您会得到一个包含更多成功测试的输出。
一旦你写完了.add(),你就可以去cli.py为你的应用程序的命令行界面写add命令:
1# rptodo/cli.py
2# ...
3
4def get_todoer() -> rptodo.Todoer:
5 # ...
6
7@app.command() 8def add( 9 description: List[str] = typer.Argument(...),
10 priority: int = typer.Option(2, "--priority", "-p", min=1, max=3),
11) -> None:
12 """Add a new to-do with a DESCRIPTION."""
13 todoer = get_todoer()
14 todo, error = todoer.add(description, priority)
15 if error:
16 typer.secho(
17 f'Adding to-do failed with "{ERRORS[error]}"', fg=typer.colors.RED
18 )
19 raise typer.Exit(1)
20 else:
21 typer.secho(
22 f"""to-do: "{todo['Description']}" was added """
23 f"""with priority: {priority}""",
24 fg=typer.colors.GREEN,
25 )
26
27def _version_callback(value: bool) -> None:
28 # ...
下面是对add命令功能的分析:
-
第 7 行和第 8 行使用
@app.command()Python decorator 将add()定义为 Typer 命令。 -
第 9 行将
description定义为add()的参数。此参数包含表示待办事项描述的字符串列表。为了建立论点,你可以使用typer.Argument。当您将一个省略号 (...)作为第一个参数传递给Argument的构造函数时,您是在告诉 Typer】是必需的。此参数是必需的这一事实意味着用户必须在命令行提供待办事项描述。 -
第 10 行将
priority定义为 Typer 选项,默认值为2。选项名为--priority和-p。正如您之前所决定的,priority只接受三个可能的值:1、2或3。为了保证这一条件,您将min设置为1并将max设置为3。这样,Typer 会自动验证用户的输入,并且只接受指定区间内的数字。 -
第 13 行得到一个要使用的
Todoer实例。 -
第 14 行在
todoer上调用.add(),并将结果解包到todo和error中。 -
第 15 行到第 25 行定义了一个条件语句,如果在向数据库添加新的待办事项时出现错误,则打印一条错误消息并退出应用程序。如果没有错误发生,那么第 20 行的
else子句在屏幕上显示一条成功消息。
现在,您可以回到您的终端,尝试一下您的add命令:
(venv) $ python -m rptodo add Get some milk -p 1
to-do: "Get some milk." was added with priority: 1
(venv) $ python -m rptodo add Clean the house --priority 3
to-do: "Clean the house." was added with priority: 3
(venv) $ python -m rptodo add Wash the car
to-do: "Wash the car." was added with priority: 2
(venv) $ python -m rptodo add Go for a walk -p 5
Usage: rptodo add [OPTIONS] DESCRIPTION...
Try 'rptodo add --help' for help.
Error: Invalid value for '--priority' / '-p': 5 is not in the valid range...
在第一个例子中,您执行带有描述"Get some milk"和优先级1的add命令。要设置优先级,您可以使用-p选项。按下 Enter 后,应用程序会添加待办事项并通知您添加成功。第二个例子非常相似。这次您使用--priority将待办事项优先级设置为3。
在第三个示例中,您提供了一个待办事项描述,但没有提供优先级。在这种情况下,应用程序使用默认的优先级值,即2。
在第四个例子中,您尝试添加一个优先级为5的新待办事项。由于这个优先级值超出了允许的范围,Typer 显示一个用法消息以及一个错误消息。请注意,Typer 会自动为您显示这些消息。您不需要添加额外的代码来实现这一点。
太好了!你的待办事项已经有了一些很酷的功能。现在你需要一种方法来列出你所有的待办事项,以了解你有多少工作要做。在下一节中,您将实现list命令来帮助您完成这项任务。
执行list命令
在本节中,您将把list命令添加到应用程序的 CLI 中。这个命令将允许你的用户列出他们当前所有的待办事项。在向 CLI 添加任何代码之前,您需要一种从数据库中检索整个待办事项列表的方法。为了完成这个任务,您将把.get_todo_list()添加到Todoer类中。
在代码编辑器或 IDE 中打开rptodo.py,添加以下代码:
# rptodo/rptodo.py
# ...
class Todoer:
# ...
def get_todo_list(self) -> List[Dict[str, Any]]: """Return the current to-do list."""
read = self._db_handler.read_todos()
return read.todo_list
在.get_todo_list()中,首先通过调用数据库处理程序上的.read_todos()从数据库中获得整个待办事项列表。对.read_todos()的调用返回一个命名的元组DBResponse,其中包含待办事项列表和一个返回代码。然而,您只需要待办事项列表,所以.get_todo_list()只返回.todo_list字段。
有了.get_todo_list(),您现在可以在应用程序的 CLI 中实现list命令。继续将list_all()添加到cli.py:
1# rptodo/cli.py
2# ...
3
4@app.command()
5def add(
6 # ...
7
8@app.command(name="list") 9def list_all() -> None: 10 """List all to-dos."""
11 todoer = get_todoer()
12 todo_list = todoer.get_todo_list()
13 if len(todo_list) == 0:
14 typer.secho(
15 "There are no tasks in the to-do list yet", fg=typer.colors.RED
16 )
17 raise typer.Exit()
18 typer.secho("\nto-do list:\n", fg=typer.colors.BLUE, bold=True)
19 columns = (
20 "ID. ",
21 "| Priority ",
22 "| Done ",
23 "| Description ",
24 )
25 headers = "".join(columns)
26 typer.secho(headers, fg=typer.colors.BLUE, bold=True)
27 typer.secho("-" * len(headers), fg=typer.colors.BLUE)
28 for id, todo in enumerate(todo_list, 1):
29 desc, priority, done = todo.values()
30 typer.secho(
31 f"{id}{(len(columns[0]) - len(str(id))) * ' '}"
32 f"| ({priority}){(len(columns[1]) - len(str(priority)) - 4) * ' '}"
33 f"| {done}{(len(columns[2]) - len(str(done)) - 2) * ' '}"
34 f"| {desc}",
35 fg=typer.colors.BLUE,
36 )
37 typer.secho("-" * len(headers) + "\n", fg=typer.colors.BLUE)
38
39def _version_callback(value: bool) -> None:
40 # ...
下面是list_all()的工作原理:
-
第 8 行和第 9 行使用
@app.command()装饰器将list_all()定义为一个类型命令。这个装饰器的name参数为命令设置了一个自定义名称,这里是list。注意list_all()没有任何参数或选项。它只是列出了用户从命令行运行list时的待办事项。 -
第 11 行获取您将使用的
Todoer实例。 -
第 12 行通过调用
todoer上的.get_todo_list()从数据库中获取待办事项列表。 -
第 13 到 17 行定义了一个条件语句来检查列表中是否至少有一个待办事项。如果没有,那么
if代码块将错误信息打印到屏幕上并退出应用程序。 -
第 18 行打印一个顶层标题来呈现待办事项列表。在这种情况下,
secho()接受一个名为bold的额外布尔参数,这使您能够以粗体格式显示文本。 -
第 19 到 27 行定义并打印所需的列,以表格格式显示待办事项列表。
-
第 28 行到第 36 行运行一个
for循环用适当的填充和分隔符将每个待办事项打印到自己的行上。 -
第 37 行打印一行破折号,最后一个换行符(
\n)可视地将待办事项列表与下一个命令行提示符分开。
如果您使用list命令运行应用程序,那么您会得到以下输出:
(venv) $ python -m rptodo list
to-do list:
ID. | Priority | Done | Description
----------------------------------------
1 | (1) | False | Get some milk.
2 | (3) | False | Clean the house.
3 | (2) | False | Wash the car.
----------------------------------------
这个输出在一个格式良好的表格中显示了当前所有的待办事项。这样,您的用户可以跟踪他们的任务列表的状态。请注意,输出应该在您的终端窗口中以蓝色字体显示。
步骤 6:编写待办事项完成功能的代码
您将添加到待办事项应用程序的下一个特性是一个 Typer 命令,它允许您的用户将一个给定的待办事项设置为完成。这样,您的用户可以跟踪他们的进度,并知道还有多少工作要做。
同样,您可以通过点击下面的链接并转到source_code_step_6/目录来下载本节的代码和所有资源,包括额外的单元测试:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
像往常一样,您将从在Todoer中编码所需的功能开始。在这种情况下,您需要一个方法,它接受一个待办事项 ID 并将相应的待办事项标记为完成。回到代码编辑器中的rptodo.py,添加以下代码:
1# rptodo/rptodo.py
2# ...
3from rptodo import DB_READ_ERROR, ID_ERROR 4from rptodo.database import DatabaseHandler
5
6# ...
7
8class Todoer:
9 # ...
10 def set_done(self, todo_id: int) -> CurrentTodo: 11 """Set a to-do as done."""
12 read = self._db_handler.read_todos()
13 if read.error:
14 return CurrentTodo({}, read.error)
15 try:
16 todo = read.todo_list[todo_id - 1]
17 except IndexError:
18 return CurrentTodo({}, ID_ERROR)
19 todo["Done"] = True
20 write = self._db_handler.write_todos(read.todo_list)
21 return CurrentTodo(todo, write.error)
您的新.set_done()方法完成了所需的工作。方法如下:
-
第 10 行定义
.set_done()。该方法采用一个名为todo_id的参数,它保存一个整数,表示您想要标记为完成的待办事项的 ID。当你使用list命令列出你的待办事项时,待办事项 ID 是与给定的待办事项相关联的数字。因为您使用 Python list 来存储待办事项,所以您可以将这个 ID 转换成从零开始的索引,并使用它从列表中检索所需的待办事项。 -
第 12 行通过调用数据库处理程序上的
.read_todos()来读取所有的待办事项。 -
第 13 行检查读取过程中是否出现错误。如果是,那么第 14 行返回一个命名的元组
CurrentTodo,带有一个空的待办事项和错误。 -
第 15 行开始一个
try…except语句来捕捉无效的待办事项 id,这些 id 转换成底层待办事项列表中的无效索引。如果发生了一个IndexError,那么第 18 行返回一个CurrentTodo实例,带有一个空的待办事项和相应的错误代码。 -
第 19 行将
True分配给目标待办字典中的"Done"键。这样,你就把待办事项设置为完成。 -
第 20 行通过调用数据库处理程序上的
.write_todos()将更新写回数据库。 -
第 21 行返回一个
CurrentTodo实例,带有目标待办事项和指示操作进行情况的返回代码。
当.set_done()就位后,你可以移动到cli.py并编写complete命令。下面是所需的代码:
1# rptodo/cli.py
2# ...
3
4@app.command(name="list")
5def list_all() -> None:
6 # ...
7
8@app.command(name="complete") 9def set_done(todo_id: int = typer.Argument(...)) -> None: 10 """Complete a to-do by setting it as done using its TODO_ID."""
11 todoer = get_todoer()
12 todo, error = todoer.set_done(todo_id)
13 if error:
14 typer.secho(
15 f'Completing to-do # "{todo_id}" failed with "{ERRORS[error]}"',
16 fg=typer.colors.RED,
17 )
18 raise typer.Exit(1)
19 else:
20 typer.secho(
21 f"""to-do # {todo_id} "{todo['Description']}" completed!""",
22 fg=typer.colors.GREEN,
23 )
24
25def _version_callback(value: bool) -> None:
26 # ...
看看这段代码是如何一行一行地工作的:
-
第 8 行和第 9 行用通常的
@app.command()装饰器将set_done()定义为一个类型命令。在这种情况下,您使用complete作为命令名。set_done()函数接受一个名为todo_id的参数,默认为typer.Argument的一个实例。该实例将作为必需的命令行参数。 -
第 11 行得到通常的
Todoer实例。 -
第 12 行通过调用
todoer上的.set_done()来设置特定todo_id的待办事项。 -
第 13 行检查过程中是否出现错误。如果是这样,那么第 14 到 18 行打印一个适当的错误消息,并使用退出代码
1退出应用程序。如果没有错误发生,那么第 20 到 23 行用绿色字体打印一条成功消息。
就是这样!现在你可以试试你的新complete命令了。回到终端窗口,运行以下命令:
(venv) $ python -m rptodo list
to-do list:
ID. | Priority | Done | Description
----------------------------------------
1 | (1) | False | Get some milk.
2 | (3) | False | Clean the house.
3 | (2) | False | Wash the car.
----------------------------------------
(venv) $ python -m rptodo complete 1
to-do # 1 "Get some milk." completed!
(venv) $ python -m rptodo list
to-do list:
ID. | Priority | Done | Description
----------------------------------------
1 | (1) | True | Get some milk.
2 | (3) | False | Clean the house.
3 | (2) | False | Wash the car.
----------------------------------------
首先,您列出所有的待办事项,以可视化对应于每个待办事项的 ID。然后使用complete将 ID 为1的待办事项设置为完成。当你再次列出待办事项时,你会看到第一个待办事项在完成栏中被标记为True。
关于complete命令和底层Todoer.set_done()方法需要注意的一个重要细节是,待办事项 ID 不是一个固定值。如果您从列表中删除一个或多个待办事项,那么一些剩余待办事项的 id 将会改变。说到删除待办事项,这就是你在接下来的部分要做的。
步骤 7:编写删除待办功能的代码
从列表中删除待办事项是你可以添加到待办事项应用程序中的另一个有用的功能。在本节中,您将使用 Python 向应用程序的 CLI 添加两个新的 Typer 命令。第一个命令将是remove。它将允许您的用户通过 ID 删除待办事项。第二个命令是clear,它将允许用户从数据库中删除所有当前的待办事项。
您可以通过点击下面的链接并转到source_code_step_7/目录来下载本节的代码、单元测试和其他资源:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
执行remove CLI 命令
要在应用程序的 CLI 中实现remove命令,首先需要在Todoer中编写底层的.remove()方法。该方法将提供使用待办事项 ID 从列表中删除单个待办事项的所有功能。请记住,您将待办事项 ID 设置为与特定待办事项相关联的整数。要显示待办事项 id,运行list命令。
以下是如何在Todoer中编写.remove()的方法:
1# rptodo/rptodo.py
2# ...
3
4class Todoer:
5 # ...
6 def remove(self, todo_id: int) -> CurrentTodo: 7 """Remove a to-do from the database using its id or index."""
8 read = self._db_handler.read_todos()
9 if read.error:
10 return CurrentTodo({}, read.error)
11 try:
12 todo = read.todo_list.pop(todo_id - 1)
13 except IndexError:
14 return CurrentTodo({}, ID_ERROR)
15 write = self._db_handler.write_todos(read.todo_list)
16 return CurrentTodo(todo, write.error)
这里,您的代码执行以下操作:
-
第 6 行定义
.remove()。此方法将待办事项 ID 作为参数,并从数据库中删除相应的待办事项。 -
第 8 行通过调用数据库处理程序上的
.read_todos()从数据库中读取待办事项列表。 -
第 9 行检查读取过程中是否出现错误。如果是,那么第 10 行返回一个命名的 tuple,
CurrentTodo,包含一个空的 to-do 和相应的错误代码。 -
第 11 行开始一个
try…except语句来捕捉任何来自用户输入的无效 id。 -
第 12 行从待办事项列表中删除索引
todo_id - 1处的待办事项。如果在这个操作过程中出现了一个IndexError,那么第 14 行返回一个CurrentTodo实例,带有一个空的待办事项和相应的错误代码。 -
第 15 行将更新后的待办事项列表写回数据库。
-
第 16 行返回一个
CurrentTodo元组,保存被移除的待办事项和一个指示操作成功的返回码。
现在你已经在Todoer中完成了.remove()的编码,你可以去cli.py并添加remove命令:
1# rptodo/cli.py
2# ...
3
4@app.command()
5def set_done(todo_id: int = typer.Argument(...)) -> None:
6 # ...
7
8@app.command() 9def remove( 10 todo_id: int = typer.Argument(...),
11 force: bool = typer.Option(
12 False,
13 "--force",
14 "-f",
15 help="Force deletion without confirmation.",
16 ),
17) -> None:
18 """Remove a to-do using its TODO_ID."""
19 todoer = get_todoer()
20
21 def _remove():
22 todo, error = todoer.remove(todo_id)
23 if error:
24 typer.secho(
25 f'Removing to-do # {todo_id} failed with "{ERRORS[error]}"',
26 fg=typer.colors.RED,
27 )
28 raise typer.Exit(1)
29 else:
30 typer.secho(
31 f"""to-do # {todo_id}: '{todo["Description"]}' was removed""",
32 fg=typer.colors.GREEN,
33 )
34
35 if force:
36 _remove()
37 else:
38 todo_list = todoer.get_todo_list()
39 try:
40 todo = todo_list[todo_id - 1]
41 except IndexError:
42 typer.secho("Invalid TODO_ID", fg=typer.colors.RED)
43 raise typer.Exit(1)
44 delete = typer.confirm(
45 f"Delete to-do # {todo_id}: {todo['Description']}?"
46 )
47 if delete:
48 _remove()
49 else:
50 typer.echo("Operation canceled")
51
52def _version_callback(value: bool) -> None:
53 # ...
哇!代码太多了。它是这样工作的:
-
第 8 行和第 9 行将
remove()定义为一个键入 CLI 命令。 -
第 10 行将
todo_id定义为int类型的参数。在这种情况下,todo_id是typer.Argument的必需实例。 -
第 11 行将
force定义为remove命令的一个选项。这是一个布尔选项,允许你在没有确认的情况下删除待办事项。该选项默认为False(第 12 行),其标志为--force和-f(第 13 行和第 14 行)。 -
第 15 行定义了
force选项的帮助信息。 -
第 19 行创建所需的
Todoer实例。 -
第 21 到 33 行定义了一个叫做
_remove()的内部函数。这是一个助手功能,允许您重用删除功能。该函数使用待办事项的 ID 删除待办事项。为此,它在todoer上调用.remove()。 -
第 35 行检查
force的值。一个True值意味着用户想要在没有确认的情况下删除待办事项。在这种情况下,第 36 行调用_remove()来运行删除操作。 -
第 37 行开始一个
else子句,如果force是False则运行该子句。 -
第 38 行从数据库中获取整个待办事项列表。
-
第 39 到 43 行定义了一个
try…except语句,从列表中检索所需的待办事项。如果发生了IndexError,那么第 42 行将打印一条错误消息,第 43 行将退出应用程序。 -
第 44 到 46 行调用 Typer 的
confirm()并将结果存储在delete中。该功能提供了另一种要求确认的方式。它允许您使用动态创建的确认提示,如第 45 行所示。 -
47 线检查
delete是否为True,如果是,48 线调用_remove()。否则,第 50 行告知操作被取消。
您可以通过在命令行上运行以下命令来尝试使用remove命令:
(venv) $ python -m rptodo list
to-do list:
ID. | Priority | Done | Description
----------------------------------------
1 | (1) | True | Get some milk.
2 | (3) | False | Clean the house.
3 | (2) | False | Wash the car.
----------------------------------------
(venv) $ python -m rptodo remove 1
Delete to-do # 1: Get some milk.? [y/N]:
Operation canceled
(venv) $ python -m rptodo remove 1
Delete to-do # 1: Get some milk.? [y/N]: y
to-do # 1: 'Get some milk.' was removed
(venv) $ python -m rptodo list
to-do list:
ID. | Priority | Done | Description
----------------------------------------
1 | (3) | False | Clean the house.
2 | (2) | False | Wash the car.
----------------------------------------
在这组命令中,首先用list命令列出当前所有的待办事项。然后你尝试用 ID 号1删除待办事项。这将向您显示是(y)或否(N)的确认提示。如果您按下 Enter ,则应用程序运行默认选项N,并取消移除操作。
注意:如果您使用的是高于 0.3.2 的 Typer 版本,那么上例中的确认提示可能会有所不同。
例如,在 macOS 上,确认提示没有默认答案:
$ # Typer version 0.4.0 on macOS
$ python -m rptodo remove 1
Delete to-do # 1: Get some milk.? [y/n]:
Error: invalid input
如果您的情况就是这样,那么您需要在命令行明确提供一个答案,然后按下 Enter 。
在第三个命令中,您显式地提供了一个y答案,因此应用程序删除了 ID 号为1的待办事项。如果你再次列出所有的待办事项,你会发现待办事项"Get some milk."已经不在列表中了。作为实验,继续尝试使用--force或-f选项,或者尝试删除列表中没有的待办事项。
执行clear CLI 命令
在本节中,您将实现clear命令。此命令将允许您的用户从数据库中删除所有待办事项。在clear命令下面是来自Todoer的.remove_all()方法,它提供后端功能。
回到rptodo.py,在Todoer的末尾加上.remove_all():
# rptodo/rptodo.py
# ...
class Todoer:
# ...
def remove_all(self) -> CurrentTodo: """Remove all to-dos from the database."""
write = self._db_handler.write_todos([])
return CurrentTodo({}, write.error)
在.remove_all()中,通过用一个空列表替换当前的待办事项列表,从数据库中删除所有的待办事项。为了一致性,该方法返回一个带有空字典和适当的返回或错误代码的CurrentTodo元组。
现在,您可以在应用程序的 CLI 中实现clear命令:
1# rptodo/cli.py
2# ...
3
4@app.command()
5def remove(
6 # ...
7
8@app.command(name="clear") 9def remove_all( 10 force: bool = typer.Option(
11 ...,
12 prompt="Delete all to-dos?",
13 help="Force deletion without confirmation.",
14 ),
15) -> None:
16 """Remove all to-dos."""
17 todoer = get_todoer()
18 if force:
19 error = todoer.remove_all().error
20 if error:
21 typer.secho(
22 f'Removing to-dos failed with "{ERRORS[error]}"',
23 fg=typer.colors.RED,
24 )
25 raise typer.Exit(1)
26 else:
27 typer.secho("All to-dos were removed", fg=typer.colors.GREEN)
28 else:
29 typer.echo("Operation canceled")
30
31def _version_callback(value: bool) -> None:
32 # ...
下面是这段代码的工作原理:
-
第 8 行和第 9 行使用带有
clear的@app.command()装饰器将remove_all()定义为一个类型命令。 -
第 10 到 14 行将
force定义为一个类型器Option。这是布尔类型的必需选项。prompt参数要求用户为force输入一个合适的值,可以是y或n。 -
第 13 行为
force选项提供帮助信息。 -
第 17 行得到通常的
Todoer实例。 -
第 18 行检查
force是否为True。如果是,那么if代码块使用.remove_all()从数据库中删除所有待办事项。如果在此过程中出错,应用程序会打印一条错误消息并退出(第 21 到 25 行)。否则,它会在第 27 行打印一条成功消息。 -
如果用户通过向
force提供一个假值,指示否,取消移除操作,则第 29 行运行。
要尝试这个新的clear命令,请在您的终端上运行以下命令:
(venv) $ python -m rptodo clear
Delete all to-dos? [y/N]:
Operation canceled
(venv) $ python -m rptodo clear
Delete all to-dos? [y/N]: y
All to-dos were removed
(venv) $ python -m rptodo list
There are no tasks in the to-do list yet
在第一个例子中,您运行clear。一旦你按下 Enter ,你会得到一个要求确认是(y)还是否(N)的提示。大写的N表示否是默认答案,所以如果你按下 Enter ,就有效取消了clear操作。
在第二个例子中,您再次运行clear。这一次,您显式地输入y作为提示的答案。这个答案使应用程序从数据库中删除整个待办事项列表。当您运行list命令时,您会收到一条消息,告知当前待办事项列表中没有任务。
就是这样!现在,您有了一个用 Python 和 Typer 构建的功能性 CLI 待办事项应用程序。您的应用程序提供了创建新待办事项、列出所有待办事项、管理待办事项完成情况以及根据需要删除待办事项的命令和选项。是不是很酷?
结论
构建用户友好的命令行界面(CLI) 应用程序是 Python 开发人员的一项基本技能。在 Python 生态系统中,您会发现一些创建这种应用程序的工具。诸如 argparse 、 Click 和 Typer 等库是 Python 中这些工具的很好的例子。这里,您使用 Python 和 Typer 构建了一个 CLI 应用程序来管理待办事项列表。
在本教程中,您学习了如何:
- 用 Python 和 Typer 构建一个待办应用
- 使用 Typer 将命令、参数和选项添加到您的待办事项应用程序中
- 使用 Python 中的 Typer 的
CliRunner和 pytest 来测试你的待办应用
您还练习了一些额外的技能,比如使用 Python 的json模块处理 JSON 文件,使用 Python 的configparser模块管理配置文件。现在,您已经准备好构建命令行应用程序了。
您可以通过点击下面的链接并转到source_code_final/目录来下载这个项目的全部代码和所有资源:
获取源代码: 点击此处获取源代码,您将使用使用 Python 和 Typer 为您的命令行构建一个待办事项应用程序。
接下来的步骤
在本教程中,您已经使用 Python 和 Typer 为命令行构建了一个功能性的待办事项应用程序。尽管应用程序只提供了最少的一组功能,但这是一个很好的起点,可以让您继续添加功能,并在这个过程中不断学习。这将帮助您将 Python 技能提升到一个新的水平。
以下是一些你可以用来继续扩展你的待办事项应用程序的想法:
-
添加对日期和截止日期的支持:您可以使用
datetime模块来完成这项工作。该功能将允许用户更好地控制他们的任务。 -
编写更多的单元测试:你可以使用 pytest 为你的代码编写更多的测试。这将增加代码覆盖率,并帮助您提高测试技能。你可能会在这个过程中发现一些错误。如果是这样的话,请在评论中发表吧。
这些只是一些想法。接受挑战,在这个项目的基础上建立一些很酷的东西!在这个过程中你会学到很多东西。**********
Python 中的变量
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的变量
在之前关于 Python 中的基本数据类型的教程中,您看到了如何创建各种 Python 数据类型的值。但到目前为止,显示的所有值都是文字值或常量值:
>>> print(5.3) 5.3如果您正在编写更复杂的代码,您的程序将需要随着程序执行而变化的数据。
下面是你将在本教程中学到的:你将学习如何用抽象术语对象来描述 Python 程序中的每一项数据,并且你将学习如何使用被称为变量的符号名称来操作对象。
免费 PDF 下载: Python 3 备忘单
参加测验:通过我们的交互式“Python 变量”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
变量赋值
把变量想象成一个特定对象的名字。在 Python 中,变量不需要像许多其他编程语言那样预先声明或定义。要创建一个变量,你只需要给它赋值,然后开始使用它。赋值用一个等号(
=)完成:
>>> n = 300
这被解读为“n被赋予值300。完成后,n可用于语句或表达式中,其值将被替换:
>>> print(n) 300正如在 REPL 会话中可以直接从解释器提示符显示文字值而不需要使用
print()一样,变量也是如此:
>>> n
300
稍后,如果您更改n的值并再次使用它,新值将被替换:
>>> n = 1000 >>> print(n) 1000 >>> n 1000Python 还允许链式赋值,这使得同时给几个变量赋值成为可能:
>>> a = b = c = 300
>>> print(a, b, c)
300 300 300
上面的链式赋值将300同时赋给变量a、b和c。
Python 中的变量类型
在许多编程语言中,变量是静态类型的。这意味着变量最初被声明为具有特定的数据类型,并且在它的生命周期中分配给它的任何值必须总是具有该类型。
Python 中的变量不受此限制。在 Python 中,变量可能被赋予一种类型的值,然后被重新赋予不同类型的值:
>>> var = 23.5 >>> print(var) 23.5 >>> var = "Now I'm a string" >>> print(var) Now I'm a string对象引用
当你给变量赋值时,实际上发生了什么?这在 Python 中是一个重要的问题,因为答案与您在许多其他编程语言中找到的答案有些不同。
Python 是一种高度面向对象的语言。事实上,Python 程序中的每一项数据都是特定类型或类的对象。(这一点将在这些教程中多次重申。)
考虑以下代码:
>>> print(300)
300
当出现语句print(300)时,解释器执行以下操作:
- 创建一个整数对象
- 给它赋值
300 - 将它显示到控制台
您可以看到一个整数对象是使用内置的type()函数创建的:
>>> type(300) <class 'int'>Python 变量是一个符号名,它是一个对象的引用或指针。一旦一个对象被赋值给一个变量,你就可以用这个名字来引用这个对象。但是数据本身仍然包含在对象中。
例如:
>>> n = 300
这种赋值创建了一个值为300的整数对象,并赋予变量n指向该对象。

以下代码验证n是否指向一个整数对象:
>>> print(n) 300 >>> type(n) <class 'int'>现在考虑以下语句:
>>> m = n
执行时会发生什么?Python 不会创建另一个对象。它只是创建一个新的符号名或引用,m,它指向与n所指向的对象相同的对象。

接下来,假设您这样做:
>>> m = 400现在 Python 用值
400创建了一个新的 integer 对象,m成为了对它的引用。
References to Separate Objects 最后,假设下面执行这条语句:
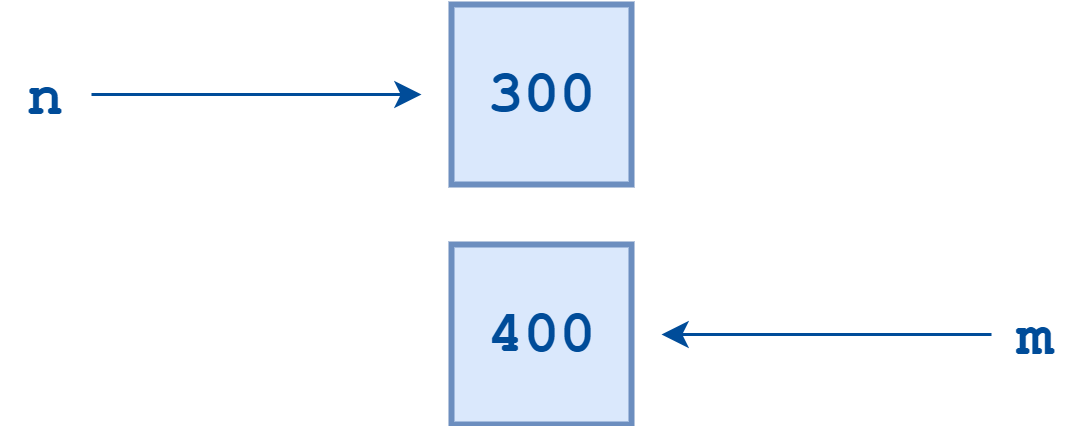
>>> n = "foo"
现在 Python 创建了一个值为"foo"的字符串对象,并让n引用它。
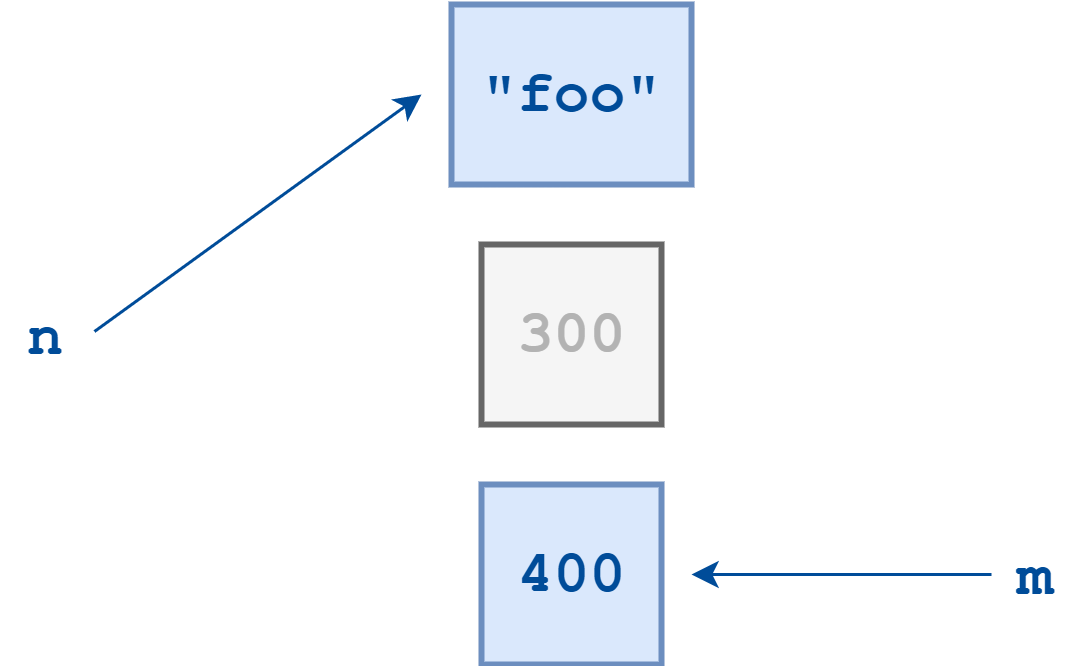
不再有对整数对象300的任何引用。它是孤立的,没有办法访问它。
本系列教程偶尔会提到对象的生存期。一个对象的生命从它被创建时就开始了,那时至少会创建一个对它的引用。在一个对象的生命周期中,可能会创建对它的额外引用,正如您在上面看到的,对它的引用也可能会被删除。可以说,只要至少有一个对一个对象的引用,该对象就一直存在。
当对一个对象的引用数降到零时,它就不再可访问了。到那时,它的生命周期就结束了。Python 最终会注意到它是不可访问的,并回收分配的内存,以便它可以用于其他用途。在计算机行话中,这个过程被称为垃圾收集。
物体身份
在 Python 中,创建的每个对象都被赋予一个唯一标识它的编号。保证没有两个对象在其生命周期重叠的任何期间具有相同的标识符。一旦一个对象的引用计数下降到零并且被垃圾回收,就像上面的300对象发生的那样,那么它的标识号就变得可用,并且可以再次使用。
内置 Python 函数id()返回对象的整数标识符。使用id()函数,您可以验证两个变量确实指向同一个对象:
>>> n = 300 >>> m = n >>> id(n) 60127840 >>> id(m) 60127840 >>> m = 400 >>> id(m) 60127872赋值
m = n后,m和n都指向同一个对象,通过id(m)和id(n)返回相同的数字来确认。一旦m被重新分配给400,m和n指向不同身份的不同对象。深入探讨:缓存小整数值
根据您现在对 Python 中变量赋值和对象引用的了解,以下内容可能不会让您感到惊讶:
`>>> m = 300 >>> n = 300 >>> id(m) 60062304 >>> id(n) 60062896`通过语句
m = 300,Python 创建了一个值为300的整数对象,并将m设置为对它的引用。类似地,n被赋值给一个值为300的整数对象,但不是同一个对象。因此,它们具有不同的身份,您可以从id()返回的值中验证这一点。但是考虑一下这个:
`>>> m = 30 >>> n = 30 >>> id(m) 1405569120 >>> id(n) 1405569120`这里,
m和n被分别分配给具有值30的整数对象。但是在这种情况下,id(m)和id(n)是一样的!出于优化的目的,解释器在启动时为范围
[-5, 256]内的整数创建对象,然后在程序执行期间重用它们。因此,当您将单独的变量赋给这个范围内的整数值时,它们实际上将引用同一个对象。变量名
到目前为止,您看到的例子都使用了简短的变量名,如
m和n。但是变量名可能更冗长。事实上,这通常是有益的,因为它使变量的目的乍一看更明显。正式来说,Python 中的变量名可以是任意长度,可以由大小写字母(
A-Z、a-z)、数字(0-9)和下划线字符(_)组成。另一个限制是,尽管变量名可以包含数字,但变量名的第一个字符不能是数字。注意:Python 3 的一个新增功能是完全的 Unicode 支持,它也允许在变量名中使用 Unicode 字符。您将在以后的教程中更深入地了解 Unicode。
例如,以下所有内容都是有效的变量名:
>>> name = "Bob"
>>> Age = 54
>>> has_W2 = True
>>> print(name, Age, has_W2)
Bob 54 True
但这个不是,因为变量名不能以数字开头:
>>> 1099_filed = False SyntaxError: invalid token请注意,case 是重要的。小写字母和大写字母不一样。使用下划线字符也很重要。下列各项定义了不同的变量:
>>> age = 1
>>> Age = 2
>>> aGe = 3
>>> AGE = 4
>>> a_g_e = 5
>>> _age = 6
>>> age_ = 7
>>> _AGE_ = 8
>>> print(age, Age, aGe, AGE, a_g_e, _age, age_, _AGE_)
1 2 3 4 5 6 7 8
没有什么可以阻止你在同一个程序中创建两个不同的变量,叫做age和Age,或者就此而言叫做agE。但这可能是不明智的。在你离开代码一段时间后,任何试图阅读你的代码的人,甚至你自己,肯定会感到困惑。
给一个变量取一个足够有描述性的名字来清楚地说明它的用途是值得的。例如,假设您正在统计大学毕业生的人数。你可以选择以下任何一个选项:
>>> numberofcollegegraduates = 2500 >>> NUMBEROFCOLLEGEGRADUATES = 2500 >>> numberOfCollegeGraduates = 2500 >>> NumberOfCollegeGraduates = 2500 >>> number_of_college_graduates = 2500 >>> print(numberofcollegegraduates, NUMBEROFCOLLEGEGRADUATES, ... numberOfCollegeGraduates, NumberOfCollegeGraduates, ... number_of_college_graduates) 2500 2500 2500 2500 2500他们都可能是比
n,或ncg,或类似的更好的选择。至少你可以从名字中知道变量的值应该代表什么。另一方面,它们不一定都同样清晰易读。与许多事情一样,这是个人喜好的问题,但大多数人会发现前两个例子,其中的字母都挤在一起,更难阅读,特别是所有大写字母的例子。构造多单词变量名最常用的方法是最后三个例子:
- 骆驼大小写:第二个及后续单词大写,使单词边界更容易看清。(大概,有人在某个时候突然想到,散布在变量名称中的大写字母有点像驼峰。)
- 示例:
numberOfCollegeGraduates- 帕斯卡大小写:与骆驼大小写相同,除了第一个字也是大写。
- 示例:
NumberOfCollegeGraduates- Snake Case: 单词之间用下划线隔开。
- 示例:
number_of_college_graduates程序员们以惊人的热情激烈地争论,哪一个更好。可以为他们所有人提出合理的论据。使用三个中最吸引你的一个。选择一个并坚持使用它。
稍后你会看到变量不是唯一可以命名的东西。您还可以命名函数、类、模块等等。适用于变量名的规则也适用于标识符,标识符是对程序对象命名的更一般的术语。
Python 代码的风格指南,也被称为 PEP 8 ,包含了命名约定,列出了不同对象类型名称的建议标准。PEP 8 包括以下建议:
- 函数和变量名应该使用大小写。
- 类名应该使用 Pascal 大小写。(PEP 8 将此称为“CapWords”约定。)
保留字(关键词)
对标识符名称还有一个限制。Python 语言保留了一小部分指定特殊语言功能的关键字。任何对象都不能与保留字同名。
在 Python 3.6 中,有 33 个保留关键字:
| Python
关键词 FalsedefifraiseNonedelimportreturnTrueelifintryandelseiswhileasexceptlambdawithassertfinallynonlocalyieldbreakfornotclassfromorcontinueglobalpass在 Python 解释器中输入
help("keywords")就可以随时看到这个列表。保留字区分大小写,必须严格按照所示使用。都是全小写,除了False、、、True。尝试创建与任何保留字同名的变量会导致错误:
>>> for = 3
SyntaxError: invalid syntax
结论
本教程涵盖了 Python 变量的基础知识,包括对象引用和标识,以及 Python 标识符的命名。
现在,您已经很好地理解了 Python 的一些数据类型,并且知道如何创建引用这些类型的对象的变量。
接下来,您将看到如何将数据对象组合成包含各种操作的表达式。
参加测验:通过我们的交互式“Python 变量”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Basic Data Types in PythonVariables in PythonOperators and Expressions in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的变量******
在 Docker 中运行 Python 版本:如何尝试最新的 Python 版本
总有新版本的 Python 在开发中。但是,自己编译 Python 来尝试新版本可能会很麻烦!在学习本教程的过程中,您将看到如何使用 Docker 运行不同的 Python 版本,包括如何在几分钟内让最新的 alpha 在您的计算机上运行。
在本教程中,您将学习:
- Python 有哪些版本
- 如何入门 Docker
- 如何在 Docker 容器中运行不同的 Python 版本
- 如何使用 Docker 容器作为 Python 环境
我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
了解 Python 版本和 Docker
从 Python 2 到 Python 3 的漫长旅程即将结束。尽管如此,重要的是,你要了解 Python 的不同版本,以及如何试用它们。一般来说,您应该了解三种不同的版本:
-
发布版本:通常,你会运行类似 Python 3.6 、 3.7 或 3.8 的版本。每一个版本都增加了新的特性,所以最好知道你运行的是哪个版本。例如, f 字符串是在 Python 3.6 中引入的,在旧版本的 Python 中不能工作。类似地,赋值表达式只在 Python 3.8 中可用。
-
开发版本:Python 社区正在持续开发新版本的 Python。在写这篇文章的时候, Python 3.9 正在开发中。为了预览和测试新功能,用户可以访问标有 alpha 、 beta 和 release candidate 的开发版本。
-
实现: Python 是一种有几种实现的语言。Python 的一个实现包含一个解释器和相应的库。CPython 是 Python 的参考实现,也是最常用的实现。然而,还有其他实现,如 PyPy 、 IronPython 、 Jython 、 MicroPython 和 CircuitPython 涵盖了特定的用例。
当你启动一个 REPL 时,你通常会看到你使用的是哪个版本的 Python。您也可以查看sys.implementation以了解更多信息:
>>> import sys >>> sys.implementation.name 'cpython' >>> sys.implementation.version sys.version_info(major=3, minor=9, micro=0, releaselevel='alpha', serial=1)可以看到这段代码运行的是 CPython 3.9 的第一个 alpha 版本。
传统上,你会使用像
pyenv和conda这样的工具来管理不同的 Python 版本。Docker 在大多数情况下可以代替这些,而且使用起来往往更简单。在本教程的其余部分,您将看到如何开始。使用 Docker
Docker 是一个运行预打包应用程序容器的平台。这是一个非常强大的系统,尤其适用于打包和部署应用程序和微服务。在本节中,您将看到使用 Docker 需要了解的基本概念。
安装对接器
Docker 可以在所有主流操作系统上使用:Windows、macOS 和 Linux。参见官方指南了解如何在您的系统上安装 Docker。除非有特殊需求,否则可以使用 Docker 引擎-社区版本。
运行容器
Docker 使用了图像和容器的概念。一个图像是一个独立的包,可以由 Docker 运行。一个容器是一个具有某种状态的运行图像。有几个包含预构建 Docker 映像的存储库。 Docker Hub 是您将在本教程中使用的默认存储库。对于第一个例子,运行
hello-world图像:$ docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:451ce787d12369c5df2a32c85e5a03d52cbcef6eb3586dd03075f3... Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. [ ... Full output clipped ... ]第一行显示 Docker 从 Docker Hub 下载了
hello-world。当它运行这个图像时,产生的容器产生一个"Hello from Docker!"消息,打印到您的终端。使用 Dockerfiles 构建您自己的图像
您可以使用 Dockerfiles 创建自己的图像,Dockerfiles 是一个描述 Docker 图像应该如何设置的纯文本文件。以下是 Dockerfile 文件的示例:
1FROM ubuntu 2RUN apt update && apt install -y cowsay 3CMD ["/usr/games/cowsay", "Dockerfiles are cool!"]Dockerfile 由一系列 Docker 命令组成。在上面的例子中,有三个步骤:
- 第 1 行基于名为
ubuntu的现有图像。您可以独立于运行 Docker 的系统来完成这项工作。- 第二行安装一个名为
cowsay的程序。- 第 3 行准备一个命令,当图像被执行时运行
cowsay。要使用这个 Dockerfile 文件,请将其保存在一个名为
Dockerfile的文本文件中,不要有任何文件扩展名。注意:您可以在任何平台上构建和运行 Linux 映像,所以像
ubuntu这样的映像非常适合构建应该可以跨平台使用的应用程序。相比之下,Windows 映像只能在 Windows 上运行,macOS 映像只能在 macOS 上运行。
接下来,从 docker 文件构建一个映像:
$ docker build -t cowsay .该命令在构建映像时会给出大量输出。
-t cowsay将用名称cowsay标记您的图像。您可以使用标签来跟踪您的图像。命令的最后一点指定当前目录作为映像的构建上下文。这个目录应该是包含Dockerfile的目录。现在,您可以运行自己的 Docker 映像:
$ docker run --rm cowsay _______________________ < Dockerfiles are cool! > ----------------------- \ ^__^ \ (oo)\_______ (__)\ )\/\ ||----w | || ||
--rm选项会在使用后清理你的容器。使用--rm来避免用陈旧的 Docker 容器填满你的系统是一个好习惯。注意: Docker 有几个命令来管理你的图像和容器。您可以分别使用
docker images和docker ps -a列出您的图像和容器。图像和容器都被分配了一个 12 个字符的 ID,您可以在这些清单中找到。要删除图像或容器,请使用具有正确 ID 的
docker rmi <image_id>或docker rm <container_id>。
docker命令行非常强大。使用docker --help和官方文件了解更多信息。在 Docker 容器中运行 Python
Docker 社区为所有新版本的 Python 发布并维护 Docker 文件,您可以用它来试验新的 Python 特性。此外,Python 核心开发人员维护着一个 Docker 镜像,包含所有当前可用的 Python 版本。在本节中,您将学习如何在 Docker 中运行不同的 Python 版本。
玩 REPL
当您从 Docker Hub 运行 Python 映像时,解释器已经设置好,因此您可以直接使用 REPL。要在 Python 容器中启动 REPL,请运行以下命令:
$ docker run -it --rm python:rc Python 3.8.0rc1 (default, Oct 2 2019, 23:30:03) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information.
该命令将从 Docker Hub 下载`python:rc`映像,启动一个容器,并在该容器中运行`python`。`-it`选项是交互式运行容器所必需的。标签`rc`是**候选发布版本**的简写,指向 Python 的最新开发版本。在这种情况下,它是 [Python 3.8](https://realpython.com/python38-new-features/#simpler-debugging-with-f-strings) 的最后一个候选版本:
>>>
```py
>>> import sys
>>> f"{sys.version_info[:] = }"
"sys.version_info[:] = (3, 8, 0, 'candidate', 1)"
第一次运行容器时,下载可能需要一些时间。以后的调用基本上是即时的。您可以像往常一样退出 REPL,例如,通过键入exit()。这也会退出容器。
注意:Docker Hub Python 图像保持了相当好的更新。随着新版本的成熟,它们的 alpha 和 beta 版本都可以在rc标签上获得。
然而,如果您想测试 Python 的绝对最新版本,那么核心开发人员的映像可能是一个更好的选择:
$ docker run -it --rm quay.io/python-devs/ci-image:master
稍后你会看到更多使用这张图片的例子。
对于更多的安装选项,您也可以查看完整的指南安装 Python 的预发布版本。
您可以在 Docker Hub 找到所有可用 Python 图像的列表。python:latest会一直给你 Python 最新的稳定版本,而python:rc会给你提供最新的开发版本。您还可以请求特定的版本,如python:3.6.3或python:3.8.0b4,Python 3.8 的第四个测试版本。你甚至可以使用像pypy:latest这样的标签来运行 PyPy 。
设置您的 Python 环境
Docker 容器是一个隔离的环境。所以通常不需要在容器内部添加一个虚拟环境。而是可以直接运行 pip 来安装必要的包。要修改容器以包含额外的包,可以使用 Dockerfile 文件。以下示例将 parse 和 realpython-reader 添加到 Python 3.7.5 容器中:
1FROM python:3.7.5-slim
2RUN python -m pip install \
3 parse \
4 realpython-reader
用名称Dockerfile保存该文件。第 1 行的-slim标签指向一个基于最小 Debian 安装的 Dockerfile 文件。这个标签给出了一个非常简洁的 Docker 映像,但是缺点是您可能需要自己安装更多的附加工具。
其他名称包括-alpine和-windowsservercore。你可以在 Docker Hub 上找到关于这些图像变体的更多信息。
注意:如果你想在 Docker 容器中使用虚拟环境,那么有一点需要注意。每个RUN命令都在一个单独的进程中运行,这意味着虚拟环境的典型激活在 docker 文件中不起作用。
相反,您应该通过设置VIRTUAL_ENV和 PATH 环境变量来手动激活虚拟环境:
FROM python:3.7.5-slim
# Set up and activate virtual environment
ENV VIRTUAL_ENV "/venv"
RUN python -m venv $VIRTUAL_ENV
ENV PATH "$VIRTUAL_ENV/bin:$PATH"
# Python commands run inside the virtual environment
RUN python -m pip install \
parse \
realpython-reader
更多信息请参见优雅地激活 Dockerfile 中的 virtualenv。
要构建并运行 docker 文件,请使用以下命令:
$ docker build -t rp .
[ ... Output clipped ... ]
$ docker run -it --rm rp
当您构建图像时,您用名称rp标记它。然后,当您运行映像,启动新的 REPL 会话时,将使用此名称。您可以确认parse已经安装在容器中:
>>> import parse >>> parse.__version__ '1.12.1'您还可以启动运行自定义命令的容器:
$ docker run --rm rp realpython The latest tutorials from Real Python (https://realpython.com/) 0 Run Python Versions in Docker: How to Try the Latest Python Release [ ... Full output clipped ... ]这不是启动 REPL,而是在
rp容器中运行realpython命令,该命令列出了在真实 Python 上发布的最新教程。有关realpython-reader包的更多信息,请查看如何将开源 Python 包发布到 PyPI 。使用 Docker 运行 Python 脚本
在这一节中,您将看到如何在 Docker 中运行脚本。首先,将以下示例脚本保存到计算机上名为
headlines.py的文件中:# headlines.py import parse from reader import feed tutorial = feed.get_article(0) headlines = [ r.named["header"] for r in parse.findall("\n## {header}\n", tutorial) ] print("\n".join(headlines))该脚本首先从真正的 Python 下载最新教程。然后它使用
parse找到教程中的所有标题,并将它们打印到控制台。在 Docker 容器中运行这样的脚本有两种一般方法:
- 在 Docker 容器中挂载一个本地目录作为卷。
- 将脚本复制到 Docker 容器中。
第一个选项在测试期间特别有用,因为当您对脚本进行更改时,您不需要重新构建 Docker 映像。要将您的目录挂载为一个卷,请使用
-v选项:$ docker run --rm -v /home/realpython/code:/app rp python /app/headlines.py Understanding Python Versions and Docker Using Docker Running Python in a Docker Container Conclusion Further Reading选项
-v /home/realpython/code:/app表示本地目录/home/realpython/code应该作为/app挂载到容器中。然后,您可以使用命令python /app/headlines.py运行脚本。如果您要将脚本部署到另一台机器上,您需要将脚本复制到容器中。您可以通过在 docker 文件中添加几个步骤来实现这一点:
FROM python:3.7.5-slim WORKDIR /usr/src/app RUN python -m pip install \ parse \ realpython-reader COPY headlines.py . CMD ["python", "headlines.py"]您可以在容器中设置一个工作目录来控制命令的运行位置。然后,您可以将
headlines.py复制到容器内的工作目录中,并将默认命令更改为使用python运行headlines.py。像往常一样重建您的映像,并运行容器:$ docker build -t rp . [ ... Output clipped ... ] $ docker run --rm rp Understanding Python Versions and Docker Using Docker Running Python in a Docker Container Conclusion Further Reading请注意,您的脚本是在运行容器时运行的,因为您在 docker 文件中指定了
CMD命令。有关构建自己的 Docker 文件的更多信息,请参见 Docker Hub 上的 Python 图像描述。
运行最新的 Alpha
到目前为止,您已经从 Docker Hub 中提取了图像,但是还有许多可用的图像存储库。例如,许多云提供商,如 AWS 、 GCP 和数字海洋提供专用的容器注册。
核心开发者的 Python 镜像可以在 Quay.io 获得。要使用非默认存储库中的图像,可以使用完全限定的名为。例如,您可以如下运行核心开发人员的映像:
$ docker run -it --rm quay.io/python-devs/ci-image:master默认情况下,这会在容器内部启动一个 shell 会话。从 shell 会话中,您可以显式运行 Python:
$ python3.9 -c "import sys; print(sys.version_info)" sys.version_info(major=3, minor=9, micro=0, releaselevel='alpha', serial=1)通过查看
/usr/local/bin内部,您可以看到 Python 的所有可用版本:$ ls /usr/local/bin/ 2to3 get-pythons.sh pydoc3.5 python3.7m 2to3-3.4 idle pydoc3.6 python3.7m-config 2to3-3.5 idle3.4 pydoc3.7 python3.8 2to3-3.6 idle3.5 pydoc3.8 python3.8-config 2to3-3.7 idle3.6 pydoc3.9 python3.9 2to3-3.8 idle3.7 python2.7 python3.9-config 2to3-3.9 idle3.8 python2.7-config pyvenv-3.4 codecov idle3.9 python3.4 pyvenv-3.5 coverage mypy python3.4m pyvenv-3.6 coverage-3.6 mypyc python3.4m-config pyvenv-3.7 coverage3 pip3.5 python3.5 smtpd.py dmypy pip3.6 python3.5m stubgen easy_install-3.5 pip3.7 python3.5m-config tox easy_install-3.6 pip3.8 python3.6 tox-quickstart easy_install-3.7 pip3.9 python3.6m virtualenv easy_install-3.8 pydoc python3.6m-config easy_install-3.9 pydoc3.4 python3.7如果您想在几个 Python 版本上测试您的代码,这张图片特别有用。Docker 镜像经常更新,包括 Python 的最新开发版本。如果您有兴趣了解 Python 的最新特性,甚至在它们正式发布之前,那么这张图片是一个很好的选择。
结论
在本教程中,您已经看到了使用 Docker 处理不同 Python 版本的快速介绍。这是测试和查看您的代码是否与新版本的 Python 兼容的好方法。将您的 Python 脚本打包到 Docker 容器中只需几分钟,因此您可以在最新的 alpha 发布后立即试用它!
现在你可以:
- 通过 Docker 启动 Python REPL
- 在 Docker 映像中设置 Python 环境
- 在 Docker 容器中运行脚本
当您在 Docker 中测试新的 Python 版本时,您为 Python 社区提供了无价的帮助。如果你有任何问题或意见,请在下面的评论区留下。
延伸阅读
有关 Docker 的更多信息,尤其是大型项目的工作流程,请查看 Docker 的运行——更健康、更快乐、更高效。
您还可以在以下教程中了解使用 Python 和 Docker 的其他示例:
- 如何用 Tweepy 用 Python 制作推特机器人
- 使用 Docker 简化离线 Python 部署
- 用 Docker Compose 和 Machine 开发 Django
- 通过 Docker 开发和部署 Cookiecutter-Django****
Python 虚拟环境:入门
原文:https://realpython.com/python-virtual-environments-a-primer/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: 使用 Python 虚拟环境
在本教程中,你将学习如何使用 Python 的
venv模块为你的 Python 项目创建和管理单独的虚拟环境。每个环境都可以使用不同版本的包依赖项和 Python。在您学会使用虚拟环境之后,您将知道如何帮助其他程序员复制您的开发设置,并且您将确保您的项目不会导致相互之间的依赖冲突。本教程结束时,你将知道如何:
- 创建和激活一个 Python 虚拟环境
- 解释为什么你想隔离外部依赖
- 当你创建一个虚拟环境时,想象 Python 做了什么
- 使用可选参数到
venv定制你的虚拟环境- 停用和移除虚拟环境
- 选择用于管理您的 Python 版本和虚拟环境的附加工具
虚拟环境是 Python 开发中常用且有效的技术。更好地理解它们是如何工作的,为什么需要它们,以及可以用它们做什么,将有助于您掌握 Python 编程工作流。
免费奖励: ,向您展示如何使用 Pip、PyPI、Virtualenv 和需求文件等工具避免常见的依赖管理问题。
在整个教程中,您可以为 Windows、Ubuntu Linux 或 macOS 选择代码示例。在相关代码块的右上角选择您的平台,以获得您需要的命令,如果您想了解如何在其他操作系统上使用 Python 虚拟环境,可以随意在选项之间切换。
参加测验:通过我们的交互式“Python 虚拟环境:入门”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
如何使用 Python 虚拟环境?
如果您只是需要启动并运行一个 Python 虚拟环境来继续您最喜欢的项目,那么这一部分是您的最佳选择。
本教程中的指令使用 Python 的
venv模块来创建虚拟环境。这个模块是 Python 标准库的一部分,也是自 Python 3.5 以来官方推荐的创建虚拟环境的方法。注意:还有其他很棒的第三方工具来创建虚拟环境,比如 conda 和 virtualenv ,你可以在本教程的后面了解更多。这些工具都可以帮助您设置 Python 虚拟环境。
对于基本用法,
venv是一个很好的选择,因为它已经打包在 Python 安装中。记住这一点,您就可以在本教程中创建您的第一个虚拟环境了。创建它
任何时候,当你在使用外部依赖项的 Python 项目上工作时,最好先创建一个虚拟环境,这些外部依赖项是你用
pip安装的:PS> python -m venv venv如果您正在 Windows 上使用 Python,并且还没有配置
PATH和PATHEXT变量,那么您可能需要提供 Python 可执行文件的完整路径:PS> C:\Users\Name\AppData\Local\Programs\Python\Python310\python -m venv venv上面显示的系统路径假设您使用 Python 下载页面提供的 Windows installer 安装了 Python 3.10。您系统上 Python 可执行文件的路径可能不同。使用 PowerShell,您可以使用
where.exe python命令找到路径。$ python3 -m venv venv许多 Linux 操作系统都附带了 Python 3 版本。如果
python3不起作用,那么您必须首先安装 Python ,并且您可能需要使用您安装的可执行版本的特定名称,例如 Python 3.10.x 的python3.10,如果您是这种情况,请记住将代码块中提到的python3替换为您的特定版本号。$ python3 -m venv venv旧版本的 macOS 系统安装了 Python 2.7.x,你应该永远不要用它来运行你的脚本。如果你在 macOS < 12.3 上工作,用
python而不是python3调用 Python 解释器,那么你可能会意外地启动过时的系统 Python 解释器。如果运行
python3不起作用,那么你必须首先安装一个现代版本的 Python 。激活它
太好了!现在,您的项目有了自己的虚拟环境。通常,在您开始使用它之前,您将首先通过执行安装附带的脚本来激活环境:
- 视窗
** Linux + macOS*PS> venv\Scripts\activate (venv) PS>$ source venv/bin/activate (venv) $在运行此命令之前,请确保您位于包含刚刚创建的虚拟环境的文件夹中。
注意:您也可以在不激活虚拟环境的情况下使用它。为此,您将在执行命令时向其 Python 解释器提供完整路径。然而,最常见的情况是,您希望在创建虚拟环境之后激活它,以节省重复输入长路径的努力。
一旦您可以在命令提示符中看到您的虚拟环境的名称,那么您就知道您的虚拟环境是活动的。您已经准备好安装您的外部软件包了!
将软件包安装到其中
创建并激活虚拟环境后,现在可以安装项目所需的任何外部依赖项:
- 视窗
** Linux + macOS*(venv) PS> python -m pip install <package-name>(venv) $ python -m pip install <package-name>这个命令是默认命令,您应该使用它来安装带有
pip的外部 Python 包。因为您首先创建并激活了虚拟环境,pip将在一个隔离的位置安装软件包。注意:因为您已经使用 Python 3 版本创建了您的虚拟环境,所以您不需要显式调用
python3或pip3。只要你的虚拟环境是活动的,python和pip链接到与python3和pip3相同的可执行文件。恭喜,您现在可以将软件包安装到您的虚拟环境中了。为了达到这一点,首先创建一个名为
venv的 Python 虚拟环境,然后在当前的 shell 会话中激活它。只要你不关闭你的终端,你将要安装的每一个 Python 包将会在这个隔离的环境中结束,而不是你的全局 Python 站点包。这意味着您现在可以在 Python 项目中工作,而不用担心依赖性冲突。
停用它
一旦您使用完这个虚拟环境,您就可以停用它:
- 视窗
** Linux + macOS*(venv) PS> deactivate PS>(venv) $ deactivate $执行
deactivate命令后,您的命令提示符恢复正常。这一变化意味着您已经退出了虚拟环境。如果您现在与 Python 或pip交互,您将与您的全局配置的 Python 环境交互。如果您想回到之前创建的虚拟环境,您需要再次运行该虚拟环境的激活脚本。
注意:在安装软件包之前,在命令提示符前面的括号中查找您的虚拟环境的名称。在上面的例子中,环境的名称是
venv。如果名称出现了,那么您知道您的虚拟环境是活动的,并且您可以安装您的外部依赖项。如果在命令提示符下没有看到这个名称,记得在安装任何包之前激活 Python 虚拟环境。
至此,您已经了解了使用 Python 虚拟环境的基本知识。如果这就是你所需要的,那么当你继续创作的时候,祝你快乐!
但是,如果你想知道刚刚到底发生了什么,为什么那么多教程一开始就要求你创建一个虚拟环境,真正的 Python 虚拟环境是什么,那就继续看下去吧!你要深入了!
为什么需要虚拟环境?
Python 社区中的几乎每个人都建议您在所有项目中使用虚拟环境。但是为什么呢?如果您想知道为什么首先需要建立一个 Python 虚拟环境,那么这是适合您的部分。
简单的回答是 Python 不擅长依赖管理。如果您不指定,那么
pip会将您安装的所有外部包放在 Python 基础安装中的一个名为site-packages/的文件夹中。从技术上讲,Python 附带了两个站点包文件夹:
purelib/应该只包含纯 Python 代码编写的模块。platlib/应该包含非纯 Python 编写的二进制文件,例如.dll、.so或.pydist文件。如果您正在使用 Fedora 或 RedHat Linux 发行版,您可以在不同的位置找到这些文件夹。
然而,大多数操作系统实现 Python 的 site-packages 设置,以便两个位置指向相同的路径,有效地创建单个 site-packages 文件夹。
您可以使用
sysconfig检查路径:***>>>
>>> import sysconfig >>> sysconfig.get_path("purelib") 'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\Lib\\site-packages' >>> sysconfig.get_path("platlib") 'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\Lib\\site-packages'
>>> import sysconfig
>>> sysconfig.get_path("purelib")
'/home/name/path/to/venv/lib/python3.10/site-packages'
>>> sysconfig.get_path("platlib")
'/home/name/path/to/venv/lib/python3.10/site-packages'
>>> import sysconfig >>> sysconfig.get_path("purelib") '/Users/name/path/to/venv/lib/python3.10/site-packages' >>> sysconfig.get_path("platlib") '/Users/name/path/to/venv/lib/python3.10/site-packages'最有可能的是,两个输出将向您显示相同的路径。如果两个输出相同,那么你的操作系统不会把
purelib模块放到与platlib模块不同的文件夹中。如果出现两个不同的路径,那么您的操作系统会进行区分。即使你的操作系统区分了这两者,依赖冲突仍然会出现,因为所有的
purelib模块将进入purelib模块的单一位置,同样的情况也会发生在platlib模块上。要使用虚拟环境,您不需要担心单个 site-packages 文件夹或两个独立文件夹的实现细节。事实上,你可能再也不需要去想它了。然而,如果你愿意,你可以记住,当有人提到 Python 的站点包目录时,他们可能在谈论两个不同的目录。*** ***如果所有的外部包都在同一个文件夹中,会出现几个问题。在本节中,您将了解更多关于它们的信息,以及虚拟环境可以缓解的其他问题。
避免系统污染
Linux 和 macOS 预装了 Python 的一个版本,操作系统使用该版本执行内部任务。
如果将包安装到操作系统的全局 Python 中,这些包将与系统相关的包混合在一起。这种混淆可能会对操作系统正常运行的关键任务产生意想不到的副作用。
此外,如果您更新操作系统,那么您安装的软件包可能会被覆盖并丢失。你不会希望这两种头痛发生的!
回避依赖冲突
您的一个项目可能需要不同版本的外部库。如果你只有一个地方可以安装软件包,那么你就不能使用同一个库的两个不同版本。这是推荐使用 Python 虚拟环境的最常见原因之一。
为了更好地理解为什么这如此重要,想象一下你正在为两个不同的客户构建 Django 网站。一个客户对他们现有的 web 应用程序很满意,这是你最初使用 Django 2.2.26 构建的,而那个客户拒绝将他们的项目更新到现代的 Django 版本。另一个客户想让你在他们的网站上包含异步功能,这个功能只能从 Django 4.0 开始使用。
如果您全局安装了 Django,那么您只能安装两个版本中的一个:
- 视窗
** Linux + macOS*PS> python -m pip install django==2.2.26 PS> python -m pip list Package Version ---------- ------- Django 2.2.26 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2 PS> python -m pip install django==4.0.3 PS> python -m pip list Package Version ---------- ------- asgiref 3.5.0 Django 4.0.3 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2 tzdata 2022.1$ python3 -m pip install django==2.2.26 $ python3 -m pip list Package Version ---------- ------- Django 2.2.26 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2 $ python3 -m pip install django==4.0.3 $ python3 -m pip list Package Version ---------- ------- asgiref 3.5.0 Django 4.0.3 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2如果您将同一个包的两个不同版本安装到您的全局 Python 环境中,第二个安装将覆盖第一个。出于同样的原因,为两个客户端提供一个虚拟环境也是行不通的。在一个 Python 环境中,不能有同一个包的两个不同版本。
看起来你将无法在这两个项目中的任何一个上工作!但是,如果您为每个客户的项目创建一个虚拟环境,那么您可以在每个项目中安装不同版本的 Django:
- 视窗
** Linux + macOS*PS> mkdir client-old PS> cd client-old PS> python -m venv venv --prompt="client-old" PS> venv\Scripts\activate (client-old) PS> python -m pip install django==2.2.26 (client-old) PS> python -m pip list Package Version ---------- ------- Django 2.2.26 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2 (client-old) PS> deactivate PS> cd .. PS> mkdir client-new PS> cd client-new PS> python -m venv venv --prompt="client-new" PS> venv\Scripts\activate (client-new) PS> python -m pip install django==4.0.3 (client-new) PS> python -m pip list Package Version ---------- ------- asgiref 3.5.0 Django 4.0.3 pip 22.0.4 setuptools 58.1.0 sqlparse 0.4.2 tzdata 2022.1 (client-new) PS> deactivate$ mkdir client-old $ cd client-old $ python3 -m venv venv --prompt="client-old" $ source venv/bin/activate (client-old) $ python -m pip install django==2.2.26 (client-old) $ python -m pip list Package Version ---------- ------- Django 2.2.26 pip 22.0.4 pytz 2022.1 setuptools 58.1.0 sqlparse 0.4.2 (client-old) $ deactivate $ cd .. $ mkdir client-new $ cd client-new $ python3 -m venv venv --prompt="client-new" $ source venv/bin/activate (client-new) $ python -m pip install django==4.0.3 (client-new) $ python -m pip list Package Version ---------- ------- asgiref 3.5.0 Django 4.0.3 pip 22.0.4 setuptools 58.1.0 sqlparse 0.4.2 (client-new) $ deactivate如果您现在激活这两个虚拟环境中的任何一个,那么您会注意到它仍然拥有自己特定的 Django 版本。这两个环境也有不同的依赖项,每个环境都只包含 Django 版本所必需的依赖项。
通过这种设置,您可以在处理一个项目时激活一个环境,而在处理另一个项目时激活另一个环境。现在,您可以同时让任意数量的客户满意!
最小化再现性问题
如果你所有的包都在一个地方,那么就很难找到与单个项目相关的依赖关系。
如果您使用 Python 已经有一段时间了,那么您的全局 Python 环境可能已经包含了各种第三方包。如果不是这样,那就拍拍自己的背吧!你可能最近安装了新版本的 Python,或者你已经知道如何处理虚拟环境来避免系统污染。
为了阐明在多个项目间共享 Python 环境时可能遇到的再现性问题,接下来我们将看一个例子。想象一下,在过去的一个月里,你从事两个独立的项目:
在不知道虚拟环境的情况下,您将所有必需的包安装到了您的全局 Python 环境中:
- 视窗
** Linux + macOS*PS> python -m pip install beautifulsoup4 requests PS> python -m pip install flask$ python3 -m pip install beautifulsoup4 requests $ python3 -m pip install flask你的 Flask 应用程序非常有用,所以其他开发人员也想开发它。他们需要重现你工作时的环境。您想要继续并固定您的依赖关系,以便您可以在线共享您的项目:
- 视窗
** Linux + macOS*PS> python -m pip freeze beautifulsoup4==4.10.0 certifi==2021.10.8 charset-normalizer==2.0.12 click==8.0.4 colorama==0.4.4 Flask==2.0.3 idna==3.3 itsdangerous==2.1.1 Jinja2==3.0.3 MarkupSafe==2.1.1 requests==2.27.1 soupsieve==2.3.1 urllib3==1.26.9 Werkzeug==2.0.3$ python3 -m pip freeze beautifulsoup4==4.10.0 certifi==2021.10.8 charset-normalizer==2.0.12 click==8.0.4 Flask==2.0.3 idna==3.3 itsdangerous==2.1.1 Jinja2==3.0.3 MarkupSafe==2.1.1 requests==2.27.1 soupsieve==2.3.1 urllib3==1.26.9 Werkzeug==2.0.3这些包中哪些与你的 Flask 应用相关,哪些是因为你的网络抓取项目而出现的?很难判断什么时候所有的外部依赖都存在于一个桶中。
对于像这样的单一环境,您必须手动检查依赖项,并知道哪些是您的项目所必需的,哪些不是。充其量,这种方法是乏味的,但更有可能的是,它容易出错。
如果您为您的每个项目使用一个单独的虚拟环境,那么从您的固定依赖项中读取项目需求会更简单。这意味着当你开发一个伟大的应用程序时,你可以分享你的成功,让其他人有可能与你合作!
躲避安装特权锁定
最后,您可能需要计算机上的管理员权限才能将包安装到主机 Python 的 site-packages 目录中。在公司的工作环境中,您很可能无法访问您正在使用的机器。
如果您使用虚拟环境,那么您可以在您的用户权限范围内创建一个新的安装位置,这允许您安装和使用外部软件包。
无论你是把在自己的机器上编程作为一种爱好,还是为客户开发网站,或者在公司环境中工作,从长远来看,使用虚拟环境将会为你省去很多麻烦。
什么是 Python 虚拟环境?
此时,您确信想要使用虚拟环境。很好,但是当您使用虚拟环境时,您在使用什么呢?如果您想了解什么是 Python 虚拟环境,那么这是适合您的部分。
简而言之,Python 虚拟环境是一个文件夹结构,它为您提供了运行轻量级且独立的 Python 环境所需的一切。
文件夹结构
当您使用
venv模块创建一个新的虚拟环境时,Python 会创建一个自包含的文件夹结构,并将 Python 可执行文件复制或符号链接到该文件夹结构中。你不需要深入研究这个文件夹结构来了解更多关于虚拟环境是由什么组成的。一会儿,你会小心翼翼地刮掉表层土,调查你发现的高层结构。
然而,如果你已经准备好铲子,并且你渴望挖掘,那么打开下面的可折叠部分:
欢迎,勇敢的人。您已经接受了挑战,更深入地探索虚拟环境的文件夹结构!在这个可折叠的部分,你会找到如何深入黑暗深渊的指导。
在命令行中,导航到包含虚拟环境的文件夹。深呼吸,振作精神,然后执行
tree命令,显示目录的所有内容:PS> tree venv /F$ tree venv你可能需要先安装
tree,比如用sudo apt install tree。$ tree venv
tree命令以一个非常长的树形结构显示你的venv目录的内容。注意:或者,你可以通过创建一个新的虚拟环境来磨练你的技能,在其中安装
rptree包,并使用它来显示文件夹的树形结构。你甚至可以走一个更大的弯路,然后自己构建目录树生成器!然而,当你最终显示出
venv/文件夹的所有内容时,你可能会对你的发现感到惊讶。许多开发人员在第一次看的时候都会有轻微的震惊。那里有很多 T2 的文件!如果这是你的第一次,你也有这种感觉,那么欢迎加入这个看了一眼就不知所措的群体。*** ***虚拟环境文件夹包含许多文件和文件夹,但您可能会注意到,使这种树形结构如此之长的大部分内容都在
site-packages/文件夹中。如果您减少其中的子文件夹和文件,最终会得到一个不太大的树形结构:venv\ │ ├── Include\ │ ├── Lib\ │ │ │ └── site-packages\ │ │ │ ├── _distutils_hack\ │ │ │ ├── pip\ │ │ │ ├── pip-22.0.4.dist-info\ │ │ │ ├── pkg_resources\ │ │ │ ├── setuptools\ │ │ │ ├── setuptools-58.1.0.dist-info\ │ │ │ └── distutils-precedence.pth │ │ ├── Scripts\ │ ├── Activate.ps1 │ ├── activate │ ├── activate.bat │ ├── deactivate.bat │ ├── pip.exe │ ├── pip3.10.exe │ ├── pip3.exe │ ├── python.exe │ └── pythonw.exe │ └── pyvenv.cfgvenv/ │ ├── bin/ │ ├── Activate.ps1 │ ├── activate │ ├── activate.csh │ ├── activate.fish │ ├── pip │ ├── pip3 │ ├── pip3.10 │ ├── python │ ├── python3 │ └── python3.10 │ ├── include/ │ ├── lib/ │ │ │ └── python3.10/ │ │ │ └── site-packages/ │ │ │ ├── _distutils_hack/ │ │ │ ├── pip/ │ │ │ ├── pip-22.0.4.dist-info/ │ │ │ ├── pkg_resources/ │ │ │ ├── setuptools/ │ │ │ ├── setuptools-58.1.0.dist-info/ │ │ │ └── distutils-precedence.pth │ ├── lib64/ │ │ │ └── python3.10/ │ │ │ └── site-packages/ │ │ │ ├── _distutils_hack/ │ │ │ ├── pip/ │ │ │ ├── pip-22.0.4.dist-info/ │ │ │ ├── pkg_resources/ │ │ │ ├── setuptools/ │ │ │ ├── setuptools-58.1.0.dist-info/ │ │ │ └── distutils-precedence.pth │ └── pyvenv.cfgvenv/ │ ├── bin/ │ ├── Activate.ps1 │ ├── activate │ ├── activate.csh │ ├── activate.fish │ ├── pip │ ├── pip3 │ ├── pip3.10 │ ├── python │ ├── python3 │ └── python3.10 │ ├── include/ │ ├── lib/ │ │ │ └── python3.10/ │ │ │ └── site-packages/ │ │ │ ├── _distutils_hack/ │ │ │ ├── pip/ │ │ │ ├── pip-22.0.4.dist-ino/ │ │ │ ├── pkg_resources/ │ │ │ ├── setuptools/ │ │ │ ├── setuptools-58.1.0.dist-info/ │ │ │ └── distutils-precedence.pth │ └── pyvenv.cfg这种简化的树结构让您可以更好地了解虚拟环境文件夹中的情况:
***
Include\是一个最初为空的文件夹,Python 使用它来包含 C 头文件,这些文件是你可能安装的依赖于 C 扩展的包。
Lib\包含site-packages\文件夹,这是创建你的虚拟环境的主要原因之一。此文件夹是您安装要在虚拟环境中使用的外部包的位置。默认情况下,您的虚拟环境预装了两个依赖项,pip和 setuptools。过一会儿你会学到更多关于它们的知识。
Scripts\包含你的虚拟环境的可执行文件。最值得注意的是 Python 解释器(python.exe)、pip可执行文件(pip.exe)和用于虚拟环境的激活脚本,它们有几种不同的风格,允许您使用不同的 shells。在本教程中,您已经使用了activate,它在大多数 shells 中处理 Windows 虚拟环境的激活。
pyvenv.cfg对于你的虚拟环境来说是一个至关重要的文件。它只包含几个键值对,Python 使用这些键值对来设置sys模块中的变量,这些变量决定当前 Python 会话将使用哪个 Python 解释器和哪个站点包目录。当您阅读虚拟环境如何工作时,您将了解到关于该文件中设置的更多信息。
bin/包含你的虚拟环境的可执行文件。最值得注意的是 Python 解释器(python)和pip可执行文件(pip,以及它们各自的符号链接(python3、python3.10、pip3、pip3.10)。该文件夹还包含虚拟环境的激活脚本。具体的激活脚本取决于您使用的 shell。例如,在本教程中,您运行了适用于 Bash 和 Zsh shells 的activate。
include/是一个最初为空的文件夹,Python 使用它来包含 C 头文件,这些文件是你可能安装的依赖于 C 扩展的包。
lib/包含嵌套在指定 Python 版本(python3.10/)的文件夹中的site-packages/目录。site-packages/是创建虚拟环境的主要原因之一。此文件夹是您安装要在虚拟环境中使用的外部包的位置。默认情况下,您的虚拟环境预装了两个依赖项,pip和 setuptools。过一会儿你会学到更多关于它们的知识。出于兼容性的考虑,许多 Linux 系统中的
lib64/是lib/的符号链接。一些 Linux 系统可能使用lib/和lib64/之间的区别来安装不同版本的库,这取决于它们的架构。
pyvenv.cfg对于你的虚拟环境来说是一个至关重要的文件。它只包含几个键值对,Python 使用这些键值对来设置sys模块中的变量,这些变量决定当前 Python 会话将使用哪个 Python 解释器和哪个站点包目录。当您阅读虚拟环境如何工作时,您将了解到关于该文件中设置的更多信息。
bin/包含你的虚拟环境的可执行文件。最值得注意的是 Python 解释器(python)和pip可执行文件(pip,以及它们各自的符号链接(python3、python3.10、pip3、pip3.10)。该文件夹还包含虚拟环境的激活脚本。具体的激活脚本取决于您使用的 shell。例如,在本教程中,您运行了适用于 Bash 和 Zsh shells 的activate。
include/是一个最初为空的文件夹,Python 使用它来包含 C 头文件,这些文件是你可能安装的依赖于 C 扩展的包。
lib/包含嵌套在指定 Python 版本(python3.10/)的文件夹中的site-packages/目录。site-packages/是创建虚拟环境的主要原因之一。此文件夹是您安装要在虚拟环境中使用的外部包的位置。默认情况下,您的虚拟环境预装了两个依赖项,pip和 setuptools。过一会儿你会学到更多关于它们的知识。
pyvenv.cfg对于你的虚拟环境来说是一个至关重要的文件。它只包含几个键值对,Python 使用这些键值对来设置sys模块中的变量,这些变量决定当前 Python 会话将使用哪个 Python 解释器和哪个站点包目录。当您阅读虚拟环境如何工作时,您将了解到关于该文件中设置的更多信息。从这个虚拟环境文件夹内容的鸟瞰图中,您可以进一步缩小以发现 Python 虚拟环境有三个基本部分:
- Python 二进制文件的副本或符号链接
- 一个
pyvenv.cfg文件- 一个站点包目录
在
site-packages/中安装的软件包是可选的,但是作为一个合理的缺省值。然而,如果这个目录是空的,你的虚拟环境仍然是一个有效的虚拟环境,并且有办法创建它而不安装任何依赖。在默认设置下,
venv将同时安装pip和 setuptools。使用pip是 Python 中安装包的推荐方式,setuptools 是对pip的依赖。因为安装其他包是 Python 虚拟环境中最常见的用例,所以您会想要访问pip。您可以使用
pip list仔细检查 Python 是否在您的虚拟环境中安装了pip和 setuptools:
- 视窗
** Linux + macOS*(venv) PS> python -m pip list Package Version ---------- ------- pip 22.0.4 setuptools 58.1.0(venv) $ python -m pip list Package Version ---------- ------- pip 22.0.4 setuptools 58.1.0您的版本号可能会有所不同,但是这个输出确认了当您使用默认设置创建虚拟环境时,Python 安装了这两个包。
注意:在这个输出下面,
pip可能还会显示一个警告,提示您没有使用最新版本的模块。先别担心这个。稍后,您将了解为什么会发生这种情况,以及如何在创建虚拟环境时自动更新pip。这两个已安装的包构成了新虚拟环境的大部分内容。然而,您会注意到在
site-packages/目录中还有几个其他的文件夹:
_distutils_hack/模块,以一种名副其实的方式确保当执行包安装时,Python 选择 setuptools 的本地._distutils子模块而不是标准库的distutils模块。
pkg_resources/模块帮助应用程序自动发现插件并允许 Python 包访问它们的资源文件。和setuptools一起分发的是。
pip和 setuptools 的{name}-{version}.dist-info/目录包含包分发信息,存在中记录已安装包的信息。最后,还有一个名为
distutils-precedence.pth的文件。该文件帮助设置distutils导入的路径优先级,并与_distutils_hack一起工作,以确保 Python 更喜欢与 setuptools 捆绑在一起的distutils版本,而不是内置版本。注意:为了完整起见,你正在学习这些额外的文件和文件夹。您不需要记住它们就能有效地在虚拟环境中工作。记住你的
site-packages/目录中的任何预装软件包都是标准工具,它们使得安装其他软件包更加用户友好。至此,如果您已经使用内置的
venv模块安装了 Python 虚拟环境,那么您已经看到了组成它的所有文件和文件夹。请记住,您的虚拟环境只是一个文件夹结构,这意味着您可以随时删除和重新创建它。但是为什么会有这种特定的文件夹结构,以及它使什么成为可能?
一个独立的 Python 安装
Python 虚拟环境旨在提供一个轻量级、隔离的 Python 环境,您可以快速创建该环境,然后在不再需要它时将其丢弃。您在上面看到的文件夹结构通过提供三个关键部分使之成为可能:
- Python 二进制文件的副本或符号链接
- 一个
pyvenv.cfg文件- 一个站点包目录
您希望实现一个隔离的环境,这样您安装的任何外部包都不会与全局站点包冲突。
venv所做的就是复制标准 Python 安装创建的文件夹结构。这个结构说明了 Python 二进制文件的副本或符号链接的位置,以及 Python 安装外部包的站点包目录。
注意:您的虚拟环境中的 Python 可执行文件是您的环境所基于的 Python 可执行文件的副本还是符号链接主要取决于您的操作系统。
Windows 和 Linux 可能创建符号链接而不是副本,而 macOS 总是创建副本。在创建虚拟环境时,您可以尝试用可选参数影响默认行为。然而,在大多数标准情况下,您不必担心这个问题。
除了 Python 二进制文件和 site-packages 目录之外,还会得到
pyvenv.cfg文件。这是一个小文件,只包含几个键值对。但是,这些设置对于虚拟环境的运行至关重要:home = C:\Users\Name\AppData\Local\Programs\Python\Python310 include-system-site-packages = false version = 3.10.3home = /usr/local/bin include-system-site-packages = false version = 3.10.3home = /Library/Frameworks/Python.framework/Versions/3.10/bin include-system-site-packages = false version = 3.10.3当阅读关于虚拟环境如何工作的时,您将在后面的章节中了解关于这个文件的更多信息。
假设您仔细检查了新创建的虚拟环境的文件夹结构。在这种情况下,您可能会注意到这个轻量级安装不包含任何可信的标准库模块。有人可能会说,没有标准库的 Python 就像一辆没有电池的玩具车!
然而,如果您从虚拟环境中启动 Python 解释器,那么您仍然可以访问标准库中的所有好东西:
>>> import urllib
>>> from pprint import pp
>>> pp(dir(urllib))
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__']
在上面的示例代码片段中,您已经成功地从漂亮打印模块中 urllib模块和pp()快捷方式导入了。然后你用dir()检查urllib模块。
这两个模块都是标准库的一部分,那么即使它们不在您的 Python 虚拟环境的文件夹结构中,您怎么能访问它们呢?
您可以访问 Python 的标准库模块,因为您的虚拟环境重用 Python 的内置模块和 Python 安装中的标准库模块,您可以从 Python 安装中创建您的虚拟环境。在后面的部分中,您将了解虚拟环境如何实现链接到 Python 标准库的 T2。
注意:因为您总是需要现有的 Python 安装来创建您的虚拟环境,venv选择重用现有的标准库模块,以避免将它们复制到您的新虚拟环境中的开销。这个有意的决定加速了虚拟环境的创建,并使它们更加轻量级,正如 PEP 405 的动机中所描述的。
除了标准的库模块,您还可以在创建环境时通过一个参数让您的虚拟环境访问基本安装的站点包:
- 视窗
** Linux + macOS*
PS C:\> python -m venv venv --system-site-packages
$ python3 -m venv venv --system-site-packages
如果在调用venv时加上--system-site-packages,Python 会将pyvenv.cfg到true中的值设置为include-system-site-packages。这个设置意味着您可以使用安装到您的基本 Python 中的任何外部包,就像您已经将它们安装到您的虚拟环境中一样。
这种连接只在一个方向起作用。即使您允许虚拟环境访问源 Python 的 site-packages 文件夹,您安装到虚拟环境中的任何新包都不会与那里的包混合在一起。Python 将尊重虚拟环境中安装的隔离特性,并将它们放入虚拟环境中单独的站点包目录中。
您知道 Python 虚拟环境只是一个带有设置文件的文件夹结构。它可能预装了pip,也可能没有,它可以访问源代码 Python 的 site-packages 目录,同时保持隔离。但是你可能想知道所有这些是如何工作的。
虚拟环境是如何工作的?
如果您知道什么是 Python 虚拟环境,但是想知道它如何设法创建它所提供的轻量级隔离,那么您就在正确的部分。在这里,您将了解到文件夹结构和pyvenv.cfg文件中的设置如何与 Python 交互,从而为安装外部依赖项提供一个可再现的隔离空间。
它复制结构和文件
当您使用venv创建虚拟环境时,该模块会在您的操作系统上重新创建标准 Python 安装的文件和文件夹结构。Python 还将 Python 可执行文件复制或符号链接到那个文件夹结构中,您已经用它调用了venv:
venv\
│
├── Include\
│
├── Lib\
│ │
│ └── site-packages\
│
├── Scripts\
│ ├── Activate.ps1
│ ├── activate
│ ├── activate.bat
│ ├── deactivate.bat
│ ├── pip.exe
│ ├── pip3.10.exe
│ ├── pip3.exe
│ ├── python.exe
│ └── pythonw.exe
│
└── pyvenv.cfg
venv/
│
├── bin/
│ ├── Activate.ps1
│ ├── activate
│ ├── activate.csh
│ ├── activate.fish
│ ├── pip
│ ├── pip3
│ ├── pip3.10
│ ├── python
│ ├── python3
│ └── python3.10
│
├── include/
│
├── lib/
│ │
│ └── python3.10/
│ │
│ └── site-packages/
│
├── lib64/
│ │
│ └── python3.10/
│ │
│ └── site-packages/
│
└── pyvenv.cfg
venv/
│
├── bin/
│ ├── Activate.ps1
│ ├── activate
│ ├── activate.csh
│ ├── activate.fish
│ ├── pip
│ ├── pip3
│ ├── pip3.10
│ ├── python
│ ├── python3
│ └── python3.10
│
├── include/
│
├── lib/
│ │
│ └── python3.10/
│ │
│ └── site-packages/
│
└── pyvenv.cfg
如果您在操作系统上找到系统范围的 Python 安装,并检查那里的文件夹结构,那么您将看到您的虚拟环境类似于该结构。
通过导航到在pyvenv.cfg中的home键下找到的路径,可以找到虚拟环境所基于的 Python 基础安装。
注意:在 Windows 上,你可能会注意到 Python 基础安装中的python.exe不在Scripts\中,而是在上一级文件夹中。在您的虚拟环境中,可执行文件被有意放置在Scripts\文件夹中。
这个对文件夹结构的小改变意味着你只需要添加一个目录到你的 shell PATH 变量来激活虚拟环境。
虽然您可能会在 Python 的基础安装中找到一些额外的文件和文件夹,但是您会注意到标准的文件夹结构与虚拟环境中的相同。创建这个文件夹结构是为了确保 Python 可以像预期的那样独立工作,而不需要应用很多额外的修改。
它采用前缀查找过程
有了标准的文件夹结构,虚拟环境中的 Python 解释器可以理解所有相关文件的位置。它只根据 venv规范对其前缀查找过程做了微小的修改。
Python 解释器首先寻找一个pyvenv.cfg文件,而不是寻找os模块来确定标准库的位置。如果解释器找到这个文件,并且它包含一个home键,那么解释器将使用这个键来设置两个变量的值:
sys.base_prefix将保存用于创建这个虚拟环境的 Python 可执行文件的路径,你可以在pyvenv.cfg中的home键下定义的路径中找到。sys.prefix会指向包含pyvenv.cfg的目录。
如果解释器没有找到一个pyvenv.cfg文件,那么它确定它没有在虚拟环境中运行,然后sys.base_prefix和sys.prefix将指向相同的路径。
您可以确认这是按照描述的方式工作的。在活动的虚拟环境中启动 Python 解释器,并检查两个变量:
***>>>
>>> import sys
>>> sys.prefix
'C:\\Users\\Name\\path\\to\\venv'
>>> sys.base_prefix
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310'
>>> import sys >>> sys.prefix '/home/name/path/to/venv' >>> sys.base_prefix '/usr/local'
>>> import sys
>>> sys.prefix
'/Users/name/path/to/venv'
>>> sys.base_prefix
'/Library/Frameworks/Python.framework/Versions/3.10'
您可以看到变量指向系统中的不同位置。
现在继续并停用虚拟环境,进入一个新的解释器会话,并重新运行相同的代码:
***>>>
>>> import sys
>>> sys.prefix
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310'
>>> sys.base_prefix
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310'
>>> import sys >>> sys.prefix '/usr/local' >>> sys.base_prefix '/usr/local'
>>> import sys
>>> sys.prefix
'/Library/Frameworks/Python.framework/Versions/3.10'
>>> sys.base_prefix
'/Library/Frameworks/Python.framework/Versions/3.10'
您应该看到sys.prefix和sys.base_prefix现在都指向相同的路径。****** *****如果这两个变量有不同的值,那么 Python 会适应它寻找模块的地方:
对
site和sysconfig标准库模块进行了修改,使得标准库和头文件相对于sys.base_prefix[…]找到,而站点包目录[…]仍然相对于sys.prefix[…]找到。(来源)
这一改变有效地允许虚拟环境中的 Python 解释器使用来自基本 Python 安装的标准库模块,同时指向其内部 site-packages 目录来安装和访问外部包。
它链接回你的标准库
Python 虚拟环境旨在成为一种轻量级方式,为您提供一个隔离的 Python 环境,您可以快速创建该环境,然后在不再需要它时将其删除。为了实现这一点,venv只复制最不必要的文件:
最简单形式的 Python 虚拟环境只包含 Python 二进制文件的副本或符号链接,以及一个
pyvenv.cfg文件和一个站点包目录。(来源)
虚拟环境中的 Python 可执行文件可以访问环境所基于的 Python 安装的标准库模块。Python 通过在pyvenv.cfg中的home设置中指向基本 Python 可执行文件的路径来实现这一点:
home = C:\Users\Name\AppData\Local\Programs\Python\Python310 include-system-site-packages = false
version = 3.10.3
home = /usr/local/bin include-system-site-packages = false
version = 3.10.3
home = /Library/Frameworks/Python.framework/Versions/3.10/bin include-system-site-packages = false
version = 3.10.3
如果您导航到pyvenv.cfg中高亮显示的行的路径值,并列出文件夹的内容,那么您会找到用于创建虚拟环境的基本 Python 可执行文件。从那里,您可以导航找到包含标准库模块的文件夹:
PS> ls C:\Users\Name\AppData\Local\Programs\Python\Python310
Directory: C:\Users\Name\AppData\Local\Programs\Python\Python310
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 12/19/2021 5:09 PM DLLs
d----- 12/19/2021 5:09 PM Doc
d----- 12/19/2021 5:09 PM include
d----- 12/19/2021 5:09 PM Lib
d----- 12/19/2021 5:09 PM libs
d----- 12/21/2021 2:04 PM Scripts
d----- 12/19/2021 5:09 PM tcl
d----- 12/19/2021 5:09 PM Tools
-a---- 12/7/2021 4:28 AM 32762 LICENSE.txt
-a---- 12/7/2021 4:29 AM 1225432 NEWS.txt
-a---- 12/7/2021 4:28 AM 98544 python.exe
-a---- 12/7/2021 4:28 AM 61680 python3.dll
-a---- 12/7/2021 4:28 AM 4471024 python310.dll
-a---- 12/7/2021 4:28 AM 97008 pythonw.exe
-a---- 12/7/2021 4:29 AM 97168 vcruntime140.dll
-a---- 12/7/2021 4:29 AM 37240 vcruntime140_1.dll
PS> ls C:\Users\Name\AppData\Local\Programs\Python\Python310\Lib
Directory: C:\Users\Name\AppData\Local\Programs\Python\Python310\Lib
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 12/19/2021 5:09 PM asyncio
d----- 12/19/2021 5:09 PM collections
# ...
-a---- 12/7/2021 4:27 AM 5302 __future__.py
-a---- 12/7/2021 4:27 AM 65 __phello__.foo.py
$ ls /usr/local/bin
2to3-3.10 pip3.10 python3.10
idle3.10 pydoc3.10 python3.10-config
$ ls /usr/local/lib/python3.10
$ ls
abc.py hmac.py shelve.py
aifc.py html shlex.py
_aix_support.py http shutil.py
antigravity.py idlelib signal.py
# ...
graphlib.py runpy.py zipimport.py
gzip.py sched.py zoneinfo
hashlib.py secrets.py
heapq.py selectors.py
$ ls /Library/Frameworks/Python.framework/Versions/3.10/bin
2to3 pip3.10 python3-intel64
2to3-3.10 pydoc3 python3.10
idle3 pydoc3.10 python3.10-config
idle3.10 python3 python3.10-intel64
pip3 python3-config
$ ls /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/
LICENSE.txt fnmatch.py rlcompleter.py
__future__.py fractions.py runpy.py
__phello__.foo.py ftplib.py sched.py
__pycache__ functools.py secrets.py
# ...
ensurepip quopri.py zipimport.py
enum.py random.py zoneinfo
filecmp.py re.py
fileinput.py reprlib.py
Python 被设置为通过将相关路径添加到sys.path来查找这些模块。在初始化过程中,Python 自动导入的site模块,为这个参数设置默认值。
您的 Python 会话在sys.path中可以访问的路径决定了 Python 可以从哪些位置导入模块。
如果激活虚拟环境并输入 Python 解释器,则可以确认基本 Python 安装的标准库文件夹的路径可用:
***>>>
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\python310.zip',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\DLLs',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib', 'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310',
'C:\\Users\\Name\\path\\to\\venv',
'C:\\Users\\Name\\path\\to\\venv\\lib\\site-packages']
>>> import sys >>> from pprint import pp >>> pp(sys.path) ['', '/usr/local/lib/python310.zip', '/usr/local/lib/python3.10', '/usr/local/lib/python3.10/lib-dynload', '/home/name/path/to/venv/lib/python3.10/site-packages']
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10', '/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload',
'/Users/name/path/to/venv/lib/python3.10/site-packages']
因为包含标准库模块的目录路径在sys.path中可用,所以当您在虚拟环境中使用 Python 时,您将能够导入它们中的任何一个。
它修改你的PYTHONPATH
为了确保您想要运行的脚本在您的虚拟环境中使用 Python 解释器,venv修改了您可以使用 sys.path 访问的 PYTHONPATH 环境变量。
如果在没有活动虚拟环境的情况下检查变量,您将看到默认 Python 安装的默认路径位置:
***>>>
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\python310.zip',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\DLLs',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310',
'C:\\Users\\Name\\AppData\\Roaming\\Python\\Python310\\site-packages', 'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib\\site-packages']
>>> import sys >>> from pprint import pp >>> pp(sys.path) ['', '/usr/local/lib/python310.zip', '/usr/local/lib/python3.10', '/usr/local/lib/python3.10/lib-dynload', '/usr/local/lib/python3.10/site-packages']
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages']
请注意突出显示的行,它们表示站点包目录的路径。该文件夹包含您要安装的外部模块,例如,使用pip安装的模块。如果没有激活的虚拟环境,该目录将嵌套在与 Python 可执行文件相同的文件夹结构中。
注意:Windows 上的Roaming文件夹包含一个额外的 site-packages 目录,该目录与使用带有pip的--user标志的安装相关。这个文件夹提供了小程度的虚拟化,但是它仍然在一个地方收集了所有的--user安装包。
但是,如果您在启动另一个解释器会话之前激活虚拟环境,并重新运行相同的命令,那么您将得到不同的输出:
***>>>
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\python310.zip',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\DLLs',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310',
'C:\\Users\\Name\\path\\to\\venv', 'C:\\Users\\Name\\path\\to\\venv\\lib\\site-packages']
>>> import sys >>> from pprint import pp >>> pp(sys.path) ['', '/usr/local/lib/python310.zip', '/usr/local/lib/python3.10', '/usr/local/lib/python3.10/lib-dynload', '/home/name/path/to/venv/lib/python3.10/site-packages']
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload',
'/Users/name/path/to/venv/lib/python3.10/site-packages']
Python 用虚拟环境中的路径替换了默认的站点包目录路径。这一变化意味着 Python 将加载虚拟环境中安装的任何外部包。相反,因为到您的基本 Python 的 site-packages 目录的路径不再在这个列表中,Python 不会从那里加载模块。
注意:在 Windows 系统上,Python 额外添加了你的虚拟环境的根文件夹路径到sys.path。
Python 路径设置的这一变化有效地在您的虚拟环境中创建了外部包的隔离。
可选地,通过在创建虚拟环境时传递一个参数,您可以获得对基本 Python 安装的系统站点包目录的只读访问权。
它在激活时改变你的 Shell PATH变量
为了方便起见,您通常会在工作之前激活您的虚拟环境,尽管您不必这样做。
要激活您的虚拟环境,您需要执行激活脚本:
- 视窗
** Linux + macOS*
PS> venv\Scripts\activate
(venv) PS>
$ source venv/bin/activate
(venv) $
您必须运行哪个激活脚本取决于您的操作系统和您使用的 shell。
如果您深入了解虚拟环境的文件夹结构,您会发现它附带了一些不同的激活脚本:
venv\
│
├── Include\
│
├── Lib\
│
├── Scripts\
│ ├── Activate.ps1 │ ├── activate │ ├── activate.bat │ ├── deactivate.bat
│ ├── pip.exe
│ ├── pip3.10.exe
│ ├── pip3.exe
│ ├── python.exe
│ └── pythonw.exe
│
└── pyvenv.cfg
venv/
│
├── bin/
│ ├── Activate.ps1 │ ├── activate │ ├── activate.csh │ ├── activate.fish │ ├── pip
│ ├── pip3
│ ├── pip3.10
│ ├── python
│ ├── python3
│ └── python3.10
│
├── include/
│
├── lib/
│
├── lib64/
│
└── pyvenv.cfg
venv/
│
├── bin/
│ ├── Activate.ps1 │ ├── activate │ ├── activate.csh │ ├── activate.fish │ ├── pip
│ ├── pip3
│ ├── pip3.10
│ ├── python
│ ├── python3
│ └── python3.10
│
├── include/
│
├── lib/
│
└── pyvenv.cfg
这些激活脚本都有相同的目的。然而,由于用户使用的操作系统和外壳各不相同,他们需要提供不同的实现方式。
注意:您可以在您最喜欢的代码编辑器中打开任何高亮显示的文件,以检查虚拟环境激活脚本的内容。请随意深入研究该文件,以便更深入地了解它的作用,或者继续阅读,以便快速了解它的要点。
激活脚本中会发生两个关键操作:
- 路径:它将
VIRTUAL_ENV变量设置为虚拟环境的根文件夹路径,并将 Python 可执行文件的相对位置添加到PATH中。 - 命令提示符:它将命令提示符更改为您在创建虚拟环境时传递的名称。它将这个名字放在括号中,例如
(venv)。
这些变化在您的 shell 中实现了虚拟环境的便利性:
- 路径:因为虚拟环境中所有可执行文件的路径现在都在
PATH的前面,所以当你输入pip或python时,你的 shell 将调用pip或 Python 的内部版本。 - 命令提示符:因为脚本改变了你的命令提示符,你会很快知道你的虚拟环境是否被激活。
这两个变化都是小的改动,纯粹是为了方便您而存在的。它们不是绝对必要的,但是它们让使用 Python 虚拟环境变得更加愉快。
您可以在虚拟环境激活前后检查您的PATH变量。如果您已经激活了您的虚拟环境,那么您将在PATH的开头看到包含您的内部可执行文件的文件夹的路径:
PS> $Env:Path
C:\Users\Name\path\to\venv\Scripts;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Users\Name\AppData\Local\Programs\Python\Python310\Scripts\;C:\Users\Name\AppData\Local\Programs\Python\Python310\;c:\users\name\.local\bin;c:\users\name\appdata\roaming\python\python310\scripts
$ echo $PATH
/home/name/path/to/venv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/name/.local/bin
$ echo $PATH
/Users/name/path/to/venv/bin:/Library/Frameworks/Python.framework/Versions/3.10/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Users/name/.local/bin
请记住,打印您的PATH变量的输出很可能看起来非常不同。重要的一点是,激活脚本已经在PATH变量的开头添加了虚拟环境的路径。
当您使用deactivate停用虚拟环境时,您的 shell 会撤销这些更改,并将PATH和您的命令提示符恢复到原来的状态。
注意:在 Windows 上,deactivate命令执行一个名为deactivate.bat的单独文件。在 UNIX 系统上,用于激活虚拟环境的同一脚本也提供了用于停用虚拟环境的代码逻辑。
试一试,检查一下变化。对您的PATH变量的这一小小的改变为您提供了在虚拟环境中运行可执行文件的便利,而无需提供完整的路径。
它从任何有绝对路径的地方运行
你不需要激活你的虚拟环境来使用它。您可以在不激活虚拟环境的情况下使用它,即使激活它是您经常看到的推荐的常见操作。
如果你只给你的 shell 提供一个可执行文件的名字,它会在记录在PATH中的位置寻找一个带有这个名字的可执行文件。然后,它会挑选并运行第一个符合该标准的。
激活脚本改变你的PATH变量,这样你的虚拟环境的二进制文件夹就是你的 shell 寻找可执行文件的第一个地方。这个改变允许你只输入pip或python来运行位于你的虚拟环境中的相应程序。
如果您没有激活您的虚拟环境,那么您可以转而在您的虚拟环境中传递 Python 可执行文件的绝对路径,以便从您的虚拟环境中运行任何脚本:
PS> C:\Users\Name\path\to\venv\Scripts\python.exe
$ /home/name/path/to/venv/bin/python
$ /Users/name/path/to/venv/bin/python
这个命令将在您的虚拟环境中启动 Python 解释器,就像您首先激活虚拟环境,然后用python调用它一样。
如何确认在不激活虚拟环境的情况下使用绝对路径会启动与激活虚拟环境并运行python时相同的解释器?
记下一些可能的检查方法,然后尝试下面的解决方案模块中提到的一些解决方案。
如本教程前面部分所述,您可以:
- 打印
sys.path并确认您的虚拟环境中的站点包目录已列出 - 确认
sys.prefix已经改变,现在指向虚拟环境文件夹结构中的一个文件夹 - 激活虚拟环境,然后检查
PATH外壳变量,找到您的虚拟环境的二进制可执行文件的路径
如果您不确定为什么这些方法中的任何一种能够确认这种工作方式,请点击本教程中相关部分的链接来刷新您的记忆。
或者,您可以通过启动解释器并运行import sys; sys.executable来确认您正在使用哪个 Python 可执行文件。这些命令将返回当前 Python 解释器的绝对路径。该路径是否通向您的虚拟环境文件夹结构?
您通常会在使用虚拟环境之前激活它,并在使用完毕后停用它。然而,在日常使用中,使用绝对路径是一种很有帮助的方法。
注意:绝对路径有助于在远程服务器上运行预定的脚本,或者在 Docker 容器中运行。具体来说,如果脚本需要外部依赖项,并且希望在 Python 虚拟环境中将其与服务器的其余部分隔离开来,那么您将希望使用绝对路径。
将虚拟环境的激活嵌入到脚本中是一项繁琐的工作,出错的几率比不出错的几率要高。相反,利用您在本教程中获得的知识,您可以在运行脚本时在虚拟环境中使用 Python 解释器的绝对路径。
例如,如果您在远程 Linux 服务器上设置了一个每小时一次的 CRON 作业,它使用您在虚拟环境中安装的外部aiohttp包异步检查站点连接,那么您可以使用这个方法:
0 * * * *
/home/name/Documents/connectivity-checker/venv/bin/python
-m rpchecker
-u google.com twitter.com
-a
您不需要激活您的虚拟环境来使用正确的 Python 解释器,它可以访问您在虚拟环境中安装的依赖项。相反,您只需将绝对路径传递给解释器的二进制文件。Python 会在初始化期间为您处理剩下的事情。
只要提供 Python 可执行文件的路径,就不需要激活虚拟环境来享受使用虚拟环境的好处。
如何定制虚拟环境?
如果您对什么是 Python 虚拟环境很有信心,并且想要为特定的用例定制它,那么您就在正确的地方。在本节中,您将了解在使用venv创建虚拟环境时可以传递的可选参数,以及这些定制如何帮助您精确地获得您需要的虚拟环境。
改变命令提示符
创建虚拟环境时,您可以通过传递除 venv 之外的名称来更改包含虚拟环境的文件夹名称。事实上,你经常会在不同的项目中看到不同的名字。其中一些是常用的:
venvenv.venv
您可以为您为虚拟环境创建的文件夹命名任何您想要的名称。
注意:命名你的虚拟环境文件夹venv只是一个惯例。坚持这个约定可以帮助你使用一个 .gitignore 文件可靠地将你的虚拟环境从版本控制中排除。
激活虚拟环境后,您选择的任何名称都会显示在您的命令提示符中:
- 视窗
** Linux + macOS*
PS> python -m venv your-fancy-name
PS> your-fancy-name\Scripts\activate
(your-fancy-name) PS>
$ python3 -m venv your-fancy-name
$ source your-fancy-name/bin/activate
(your-fancy-name) $
如果您为虚拟环境文件夹提供了一个备用名称,那么在运行激活脚本时也需要考虑这个名称,如上面的代码示例所示。
如果您希望方便地看到不同的命令提示符,但是您希望保持文件夹名称的描述性,以便您知道它包含一个虚拟环境,那么您可以将您想要的命令提示符名称传递给--prompt:
- 视窗
** Linux + macOS*
PS> python -m venv venv --prompt="dev-env"
PS> venv\Scripts\activate
(dev-env) PS>
$ python3 -m venv venv --prompt="dev-env"
$ source venv/bin/activate
(dev-env) $
使用可选的--prompt参数,您可以将虚拟环境活动时显示的命令提示符设置为描述性字符串,而无需更改虚拟环境文件夹的名称。
在上面的代码片段中,您可以看到您仍然在调用文件夹venv,这意味着您将能够使用熟悉的路径访问激活脚本。同时,激活后显示的命令提示符会是你传给--prompt的东西。
覆盖现有环境
您可能希望随时删除并重新创建一个虚拟环境。如果您经常这样做,那么您可能会很高兴知道,在 Python 创建新环境之前,您可以添加--clear参数来删除现有环境的内容。
在您尝试之前,了解一下运行命令创建一个新的虚拟环境而不使用会有所帮助,该参数不会覆盖同名的现有虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> venv\Scripts\pip.exe install requests
PS> venv\Scripts\pip.exe list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
PS> python -m venv venv PS> venv\Scripts\pip.exe list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
$ python3 -m venv venv
$ venv/bin/pip install requests
$ venv/bin/pip list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
$ python3 -m venv venv $ venv/bin/pip list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
在这个代码示例中,您首先创建了一个名为 venv 的虚拟环境,然后使用 environment-internal pip可执行文件将requests安装到虚拟环境的 site-packages 目录中。然后使用pip list来确认它已经安装,以及它的依赖项。
注意:您在没有激活虚拟环境的情况下运行了所有这些命令。相反,您使用内部pip可执行文件的完整路径来安装到您的虚拟环境中。或者,你可以激活虚拟环境。
在突出显示的行中,您试图使用相同的名称 venv 创建另一个虚拟环境。
您可能期望venv通知您在相同的路径上有一个现有的虚拟环境,但是它没有。您可能希望venv自动删除同名的现有虚拟环境,并用一个新的替换它,但是它也没有这样做。相反,当venv在你提供的路径上找到一个同名的现有虚拟环境时,它不会做任何事情——同样,它也不会向你传达这一点。
如果您在第二次运行虚拟环境创建命令后列出已安装的包,那么您会注意到requests及其依赖项仍然会出现。这可能不是你想要实现的。
您可以使用--clear显式地覆盖一个现有的虚拟环境,而不是导航到您的虚拟环境文件夹并首先删除它:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> venv\Scripts\pip.exe install requests
PS> venv\Scripts\pip.exe list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
PS> python -m venv venv --clear PS> venv\Scripts\pip.exe list
Package Version ---------- ------- pip 22.0.4 setuptools 58.1.0
$ python3 -m venv venv
$ venv/bin/pip install requests
$ venv/bin/pip list
Package Version
------------------ ---------
certifi 2021.10.8
charset-normalizer 2.0.12
idna 3.3
pip 22.0.4
requests 2.27.1
setuptools 58.1.0
urllib3 1.26.9
$ python3 -m venv venv --clear $ venv/bin/pip list
Package Version ---------- ------- pip 22.0.4 setuptools 58.1.0
使用与前面相同的示例,您在第二次运行 creation 命令时添加了可选的--clear参数。
然后,您确认 Python 自动丢弃了同名的现有虚拟环境,并创建了一个新的默认虚拟环境,而没有先前安装的包。
一次创建多个虚拟环境
如果一个虚拟环境不够,您可以通过向命令传递多个路径来一次创建多个独立的虚拟环境:
PS> python -m venv venv C:\Users\Name\Documents\virtualenvs\venv-copy
$ python3 -m venv venv /home/name/virtualenvs/venv-copy
$ python3 -m venv venv /Users/name/virtualenvs/venv-copy
运行此命令会在两个不同的位置创建两个独立的虚拟环境。这两个文件夹是独立的虚拟环境文件夹。因此,传递多个路径可以节省您多次键入创建命令的精力。
在上面的例子中,您可能会注意到第一个参数venv代表一个相对路径。相反,第二个参数使用绝对路径指向新的文件夹位置。在创建虚拟环境时,这两种方法都有效。你甚至可以混合搭配,就像你在这里做的那样。
注意:创建虚拟环境最常用的命令是python3 -m venv venv,它使用 shell 中当前位置的相对路径,并在该目录中创建新的文件夹venv。
你没必要这么做。相反,您可以提供一个指向系统任何地方的绝对路径。如果您的任何路径目录尚不存在,venv将为您创建它们。
您也不局限于同时创建两个虚拟环境。您可以传递任意数量的有效路径,用空白字符分隔。Python 将努力在每个位置建立一个虚拟环境,甚至在途中创建任何丢失的文件夹。
更新核心依赖关系
当您使用venv及其默认设置创建了一个 Python 虚拟环境,然后使用pip安装了一个外部包时,您很可能会遇到一条消息,告诉您您安装的pip已经过期:
- 视窗
** Linux + macOS*
WARNING: You are using pip version 21.2.4; however, version 22.0.4 is available.
You should consider upgrading via the
'C:\Users\Name\path\to\venv\Scripts\python.exe -m pip install --upgrade pip' command.
WARNING: You are using pip version 21.2.4; however, version 22.0.4 is available.
You should consider upgrading via the
'/path/to/venv/python -m pip install --upgrade pip' command.
创造新的东西却发现它已经过时了,这可能会令人沮丧。为什么会这样?
在创建默认配置为venv的虚拟环境时,您将收到的pip安装可能已经过时,因为venv使用 ensurepip 将pip引导到您的虚拟环境中。
ensurepip有意地不连接互联网,而是使用每一个新的 CPython 版本附带的pip轮子。因此,捆绑的pip比独立的pip项目有不同的更新周期。
一旦你使用pip安装了一个外部包,这个程序就会连接到 PyPI,并且还会识别pip本身是否过时。如果pip过时了,那么你会收到如上所示的警告。
虽然使用引导版本的pip在某些情况下会有所帮助,但是您可能希望使用最新的pip来避免旧版本中仍然存在的潜在安全问题或错误。对于现有的虚拟环境,您可以按照pip打印到您的终端上的指令,使用pip进行自我升级。
如果您想节省手动操作的工作量,您可以通过传递参数--upgrade-deps来指定您想要pip联系 PyPI 并在安装后立即更新它自己:
- 视窗
** Linux + macOS*
PS> python -m venv venv --upgrade-deps
PS> venv\Scripts\activate
(venv) PS> python -m pip install --upgrade pip
Requirement already satisfied: pip in c:\users\name\path\to\venv\lib\site-packages (22.0.4)
$ python3 -m venv venv --upgrade-deps
$ source venv/bin/activate
(venv) $ python -m pip install --upgrade pip
Requirement already satisfied: pip in ./venv/lib/python3.10/site-packages (22.0.4)
假设您在创建虚拟环境时使用可选的--upgrade-deps参数。在这种情况下,它会自动向 PyPI 轮询最新版本的pip和 setuptools,如果本地轮不是最新的,就安装它们。
讨厌的警告信息消失了,你可以放心使用最新版本的pip。
避免安装pip
您可能想知道为什么要花一些时间来设置 Python 虚拟环境,而它所做的只是创建一个文件夹结构。时间延迟的原因主要是pip的安装。pip它的依赖性很大,会将虚拟环境的大小从几千字节扩大到几兆字节!
在大多数用例中,您会希望在您的虚拟环境中安装pip,因为您可能会使用它来安装来自 PyPI 的外部包。然而,如果你出于某种原因不需要pip,那么你可以使用--without-pip来创建一个没有它的虚拟环境:
PS> python -m venv venv --without-pip
PS> Get-ChildItem venv | Measure-Object -Property length -Sum
Count : 1
Average :
Sum : 120
Maximum :
Minimum :
Property : Length
$ python3 -m venv venv --without-pip
$ du -hs venv
52K venv
$ python3 -m venv venv --without-pip
$ du -hs venv
28K venv
通过使用单独的 Python 可执行文件提供轻量级的隔离,您的虚拟环境仍然可以做任何符合虚拟环境条件的事情。
注意:即使你没有安装pip,运行pip install <package-name>可能仍然看起来可以工作。但是不要这样做,因为运行该命令不会得到您想要的结果。您将从系统的其他地方使用一个pip可执行文件,并且您的包将位于与该pip可执行文件相关联的任何 Python 安装的 site-packages 文件夹中。
要使用没有安装pip的虚拟环境,您可以手动将软件包安装到您的站点软件包目录中,或者将您的 ZIP 文件放在那里,然后使用 Python ZIP imports 导入它们。
包括系统站点包
在某些情况下,您可能希望保持对基本 Python 的 site-packages 目录的访问,而不是切断这种联系。例如,您可能已经在您的全局 Python 环境中设置了一个在安装期间编译的包,比如 Bokeh 。
Bokeh 恰好是您选择的数据探索库,您在所有项目中都使用它。您仍然希望将客户的项目保存在单独的环境中,但是将散景安装到每个环境中可能需要几分钟的时间。为了快速迭代,您需要访问现有的散景安装,而不需要为您创建的每个虚拟环境重新安装。
在创建虚拟环境时,通过添加--system-site-packages标志,可以访问所有已经安装到基本 Python 的站点包目录中的模块。
注意:如果您安装任何额外的外部包,那么 Python 会将它们放入您的虚拟环境的 site-packages 目录中。您只能读取系统站点包目录。
传递此参数时创建一个新的虚拟环境。您将会看到,除了您的本地站点包目录之外,到您的基本 Python 站点包目录的路径将会停留在sys.path中。
为了测试这一点,您可以使用--system-site-packages参数创建并激活一个新的虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv --system-site-packages
PS> venv\Scripts\activate
(venv) PS>
$ python3 -m venv venv --system-site-packages
$ source venv/bin/activate
(venv) $
您又一次创建了一个名为venv的新虚拟环境,但是这次您传递了--system-site-packages参数。添加这个可选参数会导致您的pyvenv.cfg文件中出现不同的设置:
home = C:\Users\Name\AppData\Local\Programs\Python\Python310
include-system-site-packages = true version = 3.10.3
home = /usr/local/bin
include-system-site-packages = true version = 3.10.3
home = /Library/Frameworks/Python.framework/Versions/3.10/bin
include-system-site-packages = true version = 3.10.3
现在,include-system-site-packages配置被设置为true,而不是显示默认值false。
这一变化意味着您将看到一个额外的sys.path条目,它允许您的虚拟环境中的 Python 解释器也能访问系统站点包目录。确保您的虚拟环境是活动的,然后启动 Python 解释器来检查路径变量:
***>>>
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\python310.zip',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\DLLs',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib',
'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310',
'C:\\Users\\Name\\path\\to\\venv',
'C:\\Users\\Name\\path\\to\\venv\\lib\\site-packages',
'C:\\Users\\Name\\AppData\\Roaming\\Python\\Python310\\site-packages', 'C:\\Users\\Name\\AppData\\Local\\Programs\\Python\\Python310\\lib\\site-packages']
>>> import sys >>> from pprint import pp >>> pp(sys.path) ['', '/usr/local/lib/python310.zip', '/usr/local/lib/python3.10', '/usr/local/lib/python3.10/lib-dynload', '/home/name/path/to/venv/lib/python3.10/site-packages', '/home/name/.local/lib/python3.10/site-packages', '/usr/local/lib/python3.10/site-packages']
>>> import sys
>>> from pprint import pp
>>> pp(sys.path)
['',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload',
'/Users/name/path/to/venv/lib/python3.10/site-packages',
'/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages']
突出显示的线条显示了当您使用--system-site-packages创建虚拟环境时,虚拟环境中存在的附加路径。它们指向 Python 基础安装的 site-packages 目录,并让虚拟环境中的解释器访问这些包。
复制或链接您的可执行文件
您收到的是 Python 二进制文件的副本还是符号链接取决于您使用的操作系统:
- Windows 可以创建符号链接或副本,但有些版本不支持符号链接。创建符号链接可能需要您拥有管理员权限。
- Linux 发行版可能会创建一个符号链接或者一个副本,并且通常选择符号链接而不是副本。
- macOS 总是会创建二进制文件的副本。
PEP 405 提到了创建符号链接的优点:
如果可能,最好使用符号链接,因为在升级到底层 Python 安装的情况下,在 venv 中复制的 Python 可执行文件可能会与安装的标准库不同步,需要手动升级。(来源)
虽然对可执行文件进行符号链接会有所帮助,这样即使您升级了基本 Python 安装,它们也会自动保持同步,但是这种方法增加的脆弱性可能会超过它的好处。比如你在 Windows 中双击python.exe,操作系统会急切的解析符号链接,忽略你的虚拟环境。
最有可能的是,您永远都不需要接触这些参数,但是如果您有一个很好的理由来尝试强制使用操作系统的默认符号链接或副本,那么您可以这样做:
--symlinks将尝试创建符号链接而不是副本。此选项对 macOS 构件没有任何影响。--copies将尝试创建您的 Python 二进制文件的副本,而不是将它们链接到基本 Python 安装的可执行文件。
创建虚拟环境时,您可以传递这些可选参数中的任何一个。
升级你的 Python 以匹配系统 Python
如果您已经使用副本而不是符号链接构建了您的虚拟环境,并且后来在您的操作系统上更新了您的基本 Python 版本,您可能会遇到与标准库模块不匹配的版本。
venv模块提供了一个解决方案。可选的--upgrade参数保持站点包目录不变,同时将二进制文件更新到系统上的新版本:
- 视窗
** Linux + macOS*
PS> python -m venv venv --upgrade
$ python3 -m venv venv --upgrade
如果您运行该命令,并且在最初创建虚拟环境后更新了 Python 版本,那么您将保留已安装的库,但是venv将更新pip和 Python 的可执行文件。
在本节中,您已经了解到可以对使用venv模块构建的虚拟环境进行大量定制。这些调整可以是纯粹的便利性更新,例如将命令提示符命名为与环境文件夹不同的名称,覆盖现有的环境,或者用一个命令创建多个环境。其他定制在您的虚拟环境中创建不同的功能,例如,跳过pip及其依赖项的安装,或者链接回基本 Python 的 site-packages 文件夹。
但是如果你想做更多的事情呢?在下一节中,您将探索内置venv模块的替代方案。
除了venv之外,还有哪些流行的选择?
venv模块是一种处理 Python 虚拟环境的好方法。它的一个主要优势是venv从 3.3 版本开始预装 Python。但这不是你唯一的选择。您可以使用其他工具在 Python 中创建和处理虚拟环境。
在本节中,您将了解两个流行的工具。它们有不同的作用域,但都通常用于与venv模块相同的目的:
- Virtualenv 是
venv的超集,并为其实现提供基础。这是一个强大的、可扩展的工具,用于创建隔离的 Python 环境。 - Conda 为 Python 和其他语言提供了包、依赖和环境管理。
它们相对于venv有一些优势,但是它们不随标准 Python 安装一起提供,所以你必须单独安装它们。
Virtualenv 项目
Virtualenv 是一款专门用于创建独立 Python 环境的工具。它一直是 Python 社区中最受欢迎的,并且先于内置的venv模块。
这个包是venv的超集,它允许你使用venv做所有你能做的事情,甚至更多。Virtualenv 允许您:
- 更快地创建虚拟环境
- 无需提供绝对路径即可发现已安装的 Python 版本
- 使用
pip升级工具 - 自己扩展工具的功能
当您处理 Python 项目时,这些额外的功能都会派上用场。您甚至可能希望将代码中的 virtualenv 蓝图与项目一起保存,以帮助再现。Virtualenv 有一个丰富的编程 API ,允许你描述虚拟环境,而无需创建它们。
在将virtualenv 安装到您的系统上之后,您可以创建并激活一个新的虚拟环境,类似于您使用venv的方式:
PS> virtualenv venv
created virtual environment CPython3.10.3.final.0-64 in 312ms
creator CPython3Windows(dest=C:\Users\Name\path\to\venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=C:\Users\Name\AppData\Local\pypa\virtualenv)
added seed packages: pip==22.0.4, setuptools==60.10.0, wheel==0.37.1
activators BashActivator,BatchActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
PS> Set-ExecutionPolicy Unrestricted -Scope Process
PS> venv\Scripts\activate
(venv) PS>
注意:为了避免在激活虚拟环境时遇到执行策略问题,您首先使用Set-ExecutionPolicy Unrestricted -Scope Process更改了当前 PowerShell 会话的执行策略。
$ virtualenv venv
created virtual environment CPython3.10.3.final.0-64 in 214ms
creator CPython3Posix(dest=/home/name/path/to/venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/name/.local/share/virtualenv)
added seed packages: pip==22.0.4, setuptools==60.10.0, wheel==0.37.1
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
$ source venv/bin/activate
(venv) $
$ virtualenv venv
created virtual environment CPython3.10.3.final.0-64 in 389ms
creator CPython3Posix(dest=/Users/name/path/to/venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/Users/name/Library/Application Support/virtualenv)
added seed packages: pip==22.0.4, setuptools==60.10.0, wheel==0.37.1
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
$ source venv/bin/activate
(venv) $
像使用venv一样,您可以传递一个相对或绝对路径,并命名您的虚拟环境。在使用 virtualenv 之前,您通常会使用提供的脚本之一激活它。
注意:您可能会注意到 virtualenv 创建隔离环境的速度比内置的venv模块快得多,这是可能的,因为工具缓存了特定于平台的应用数据,它可以快速读取这些数据。
与venv相比,virtualenv 有两个主要的用户优势:
- 速度: Virtualenv 创建环境的速度要快得多。
- 更新:由于 virtualenv 的嵌入式轮子,你将获得最新的
pip和设置工具,而不需要在你第一次设置虚拟环境时就连接到互联网。
如果您需要使用 Python 2.x 的遗留版本,那么 virtualenv 也可以提供帮助。它支持使用 Python 2 可执行文件构建 Python 虚拟环境,而使用venv是不可能的。
注意:如果你想尝试使用 virtualenv,但你没有安装它的权限,你可以使用 Python 的zipapp 模块来规避。遵循文档中关于通过 zipapp 安装 virtualenv 的说明。
如果您刚刚开始使用 Python 的虚拟环境,那么您可能希望继续使用内置的venv模块。然而,如果你已经使用了一段时间,并且遇到了该工具的局限性,那么开始使用 virtualenv 是个好主意。
Conda 包和环境管理器
Conda 为您提供了另一种包装和环境管理方法。虽然该工具主要与数据科学社区和 Anaconda Python 发行版相关联,但它的潜在用例超越了该社区,不仅仅是安装 Python 包:
任何语言的包、依赖和环境管理—Python、R、Ruby、Lua、Scala、Java、JavaScript、C/ C++、FORTRAN 等等。(来源)
虽然您也可以使用 conda 建立一个隔离的环境来安装 Python 包,但这只是该工具的一个特性:
pip 在和环境中安装 python 包;康达在康达环境中安装任何包。(来源)
正如你可能从这句话中了解到的,conda 实现这种隔离的方式不同于venv模块和 virtualenv 项目。
注意:关于 conda 包和环境管理器的完整讨论超出了本教程的范围。您将忽略其中的差异,并查看专门用于创建和使用 Python 虚拟环境的 conda。
Conda 是自己的项目,与pip无关。你可以使用 Miniconda 安装程序在你的系统上设置它,它带来了在你的系统上运行conda的最低要求。
在它的默认配置中,conda 从repo.anaconda.com而不是 PyPI 获得它的包。这个备选包索引由 Anaconda 项目维护,类似于 PyPI,但不完全相同。
因为 conda 并不局限于 Python 包,你会在 conda 的包索引中发现其他的,通常是数据科学相关的包,它们是用不同的语言编写的。相反,PyPI 上有一些 Python 包是不能用 conda 安装的,因为它们不在那个包库中。如果您的 conda 环境中需要这样一个包,那么您可以使用pip将它安装在那里。
如果您在数据科学领域工作,并且使用 Python 和其他数据科学项目,那么 conda 是跨平台和跨语言工作的绝佳选择。
安装 Anaconda 或 Miniconda 之后,您可以创建一个 conda 环境:
PS> conda create -n <venv-name>
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: C:\Users\Name\miniconda3\envs\<venv-name>
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate <venv-name>
#
# To deactivate an active environment, use
#
# $ conda deactivate
假设您的标准 PowerShell 会话在成功安装 Anaconda 后没有识别出conda命令。在这种情况下,您可以在您的程序中寻找 Anaconda PowerShell 提示符,并使用它来代替。
$ conda create -n <venv-name>
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /home/name/anaconda3/envs/<venv-name>
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate <venv-name>
#
# To deactivate an active environment, use
#
# $ conda deactivate
$ conda create -n <venv-name>
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /Users/name/opt/anaconda3/envs/<venv-name>
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate <venv-name>
#
# To deactivate an active environment, use
#
# $ conda deactivate
该命令在计算机的中心位置创建一个新的 conda 环境。
注意:因为所有的 conda 环境都位于同一个位置,所以所有的环境名称都需要是唯一的。因此,最好给它们起一个描述性的名字,而不是调用任何 conda 环境venv。
要在新的 conda 环境中工作,您需要激活它:
- 视窗
** Linux + macOS*
PS> conda activate <venv-name>
(<venv-name>) PS>
$ conda activate <venv-name>
(<venv-name>) $
激活环境后,您可以从 conda 的软件包存储库将软件包安装到该环境中:
- 视窗
** Linux + macOS*
(<venv-name>) PS> conda install numpy
(<venv-name>) $ conda install numpy
install命令将第三方软件包从 conda 的软件包库中安装到您的活动 conda 环境中。
当您在环境中完成工作后,您必须将其停用:
- 视窗
** Linux + macOS*
(<venv-name>) PS> conda deactivate
PS>
(<venv-name>) $ conda deactivate
$
您可能会注意到,总体思路类似于使用使用venv创建的 Python 虚拟环境。命令略有不同,但您将获得在隔离环境中工作的相同好处,您可以在必要时删除并重新创建。
如果您主要从事数据科学项目,并且已经使用过 Anaconda,那么您可能永远都不需要使用venv。在这种情况下,你可以阅读更多关于康达环境以及如何在你的机器上有效地使用它们。
如果您只有纯 Python 依赖,并且以前没有使用过 Anaconda,那么您最好直接使用更轻量级的venv模块,或者尝试一下 virtualenv。
您如何管理您的虚拟环境?
如果您已经吸收了前几节中的所有信息,但是您不确定如何处理已经开始聚集在您的系统上的大量环境文件夹,请继续阅读这里。
在本节中,您将学习如何将虚拟环境的基本信息提取到一个文件中,以便您可以随时在任何计算机上快速删除和重新创建虚拟环境文件夹。
您还将了解组织虚拟环境文件夹存放位置的两种不同方法,以及可以帮助您管理虚拟环境的一些流行的第三方工具。
决定在哪里创建环境文件夹
Python 虚拟环境只是一个文件夹结构。您可以将它放在系统的任何地方。但是,一致的结构会有所帮助,关于在何处创建虚拟环境文件夹,有两种主要观点:
- 在每个单独的项目文件夹内
- 在单个位置,例如在您主目录的子文件夹中
这两种方法各有优缺点,您的偏好最终取决于您的工作流程。
在项目-文件夹方法方法中,您在项目的根文件夹中创建一个新的虚拟环境,该虚拟环境将用于:
project_name/
│
├── venv/ │
└── src/
虚拟环境文件夹与您为该项目编写的任何代码并存。
这种结构的优点是,您将知道哪个虚拟环境属于哪个项目,并且一旦导航到项目文件夹,您就可以使用一个短的相对路径来激活您的虚拟环境。
在单文件夹方法中,您将所有虚拟环境保存在一个文件夹中,例如您主目录的子文件夹中:
C:\USERS\USERNAME\
│
├── .local\
│
├── Contacts\
│
├── Desktop\
│
├── Documents\
│ │
│ └── Projects\
│ │
│ ├── django-project\
│ │
│ ├── flask-project\
│ │
│ └── pandas-project\
│
├── Downloads\
│
├── Favorites\
│
├── Links\
│
├── Music\
│
├── OneDrive\
│
├── Pictures\
│
├── Searches\
│
├── venvs\ │ │ │ ├── django-venv\ │ │ │ ├── flask-venv\ │ │ │ └── pandas-venv\ │
└── Videos\
name/
│
├── Desktop/
│
├── Documents/
│ │
│ └── projects/
│ │
│ ├── django-project/
│ │
│ ├── flask-project/
│ │
│ └── pandas-project/
│
├── Downloads/
│
├── Music/
│
├── Pictures/
│
├── Public/
│
├── Templates/
│
├── venvs │ │ │ ├── django-venv/ │ │ │ ├── flask-venv/ │ │ │ └── pandas-venv/ │
└── Videos/
name/
│
├── Applications/
│
├── Desktop/
│
├── Documents/
│ │
│ └── projects/
│ │
│ ├── django-project/
│ │
│ ├── flask-project/
│ │
│ └── pandas-project/
│
├── Downloads/
│
├── Library/
│
├── Movies/
│
├── Music/
│
├── Pictures/
│
├── Public/
│
├── opt/
│
└── venvs
│ ├── django-venv/ │ ├── flask-venv/ │ └── pandas-venv/
如果您使用这种方法,跟踪您创建的虚拟环境可能会更容易。您可以在操作系统上的一个位置检查所有虚拟环境,并决定保留和删除哪些虚拟环境。
另一方面,当您已经导航到您的项目文件夹时,您将无法使用相对路径快速激活您的虚拟环境。相反,最好使用相应虚拟环境文件夹中激活脚本的绝对路径来激活它。
注意:您可以使用这两种方法中的任何一种,甚至可以混合使用。
你可以在系统的任何地方创建你的虚拟环境。请记住,清晰的结构会让你更容易知道在哪里可以找到文件夹。
第三种选择是将这个决定留给您的集成开发环境(IDE) 。这些程序中的许多都包括在您开始新项目时自动为您创建虚拟环境的选项。
要了解您最喜欢的 IDE 如何处理虚拟环境的更多信息,请查看它的在线文档。例如, VS Code 和 PyCharm 都有自己创建虚拟环境的方法。
将它们视为一次性物品
虚拟环境是可任意处理的文件夹结构,您应该能够在任何时候安全地删除和重新创建,而不会丢失有关代码项目的信息。
这意味着您通常不会将任何额外的代码或信息手动放入您的虚拟环境中。任何放入其中的东西都应该由您的包管理器来处理,通常是pip或conda。
你也不应该将你的虚拟环境提交给版本控制,也不应该将它与你的项目一起发布。
因为虚拟环境不是完全自给自足的 Python 安装,而是依赖于基本 Python 的标准库,所以您不会通过将虚拟环境与代码一起分发来创建可移植的应用程序。
注意:如果你想学习如何发布你的 Python 项目,那么你可以阅读关于发布一个开源包给 PyPI 或者使用 PyInstaller 发布 Python 应用的文章。
虚拟环境是轻量级的、一次性的、隔离的环境,可以在其中开发项目。
但是,您应该能够在不同的计算机上重新创建您的 Python 环境,以便您可以在那里运行您的程序或继续开发它。当您将虚拟环境视为可任意处置的,并且不将其提交给版本控制时,您如何实现这一点呢?
固定您的依赖关系
为了使您的虚拟环境可再现,您需要一种方法来描述它的内容。最常见的方法是在虚拟环境处于活动状态时创建一个 requirements.txt文件:
- 视窗
** Linux + macOS*
(venv) PS> python -m pip freeze > requirements.txt
(venv) $ python -m pip freeze > requirements.txt
这个命令将pip freeze的输出传输到一个名为requirements.txt的新文件中。如果您打开该文件,您会注意到它包含当前安装在您的虚拟环境中的外部依赖项的列表。
这个列表是pip知道要安装哪个包的哪个版本的诀窍。只要您保持这个requirements.txt文件是最新的,您就可以随时重新创建您正在工作的虚拟环境,甚至在删除了venv/文件夹或完全移动到不同的计算机之后:
- 视窗
** Linux + macOS*
(venv) PS> deactivate
PS> python -m venv new-venv
PS> new-venv\Scripts\activate
(new-venv) PS> python -m pip install -r requirements.txt
(venv) $ deactivate
$ python3 -m venv new-venv
$ source new-venv/bin/activate
(new-venv) $ python -m pip install -r requirements.txt
在上面的示例代码片段中,您创建了一个名为new-venv的新虚拟环境,激活了它,并安装了之前记录在requirements.txt文件中的所有外部依赖项。
如果您使用pip list来检查当前安装的依赖项,那么您将看到两个虚拟环境venv和new-venv现在包含相同的外部包。
注意:通过将您的requirements.txt文件提交到版本控制,您可以将您的项目代码与允许您的用户和合作者在他们的机器上重新创建相同的虚拟环境的方法一起发布。
请记住,虽然这是在 Python 中传递代码项目依赖信息的一种普遍方式,但它不是确定性的:
- Python 版本:这个需求文件不包括创建虚拟环境时使用哪个版本的 Python 作为基础 Python 解释器的信息。
- 子依赖关系:根据您创建需求文件的方式,它可能不包含关于依赖关系的子依赖关系的版本信息。这意味着如果在您创建您的需求文件之后,这个包被悄悄地更新了,那么有人可以得到一个不同版本的子包。
单靠requirements.txt无法轻松解决这些问题,但是许多第三方依赖管理工具试图解决它们以保证确定性的构建:
将虚拟环境工作流集成到其功能中的项目,除此之外,通常还会包括创建锁定文件的方法,以允许您的环境的确定性构建。
避免生产中的虚拟环境
您可能想知道在将项目部署到生产环境时,如何包含和激活您的虚拟环境。在大多数情况下,您不希望将虚拟环境文件夹包含在远程在线位置:
- GitHub: 不要把
venv/文件夹推送给 GitHub。 - CI/CD 管道:不要将您的虚拟环境文件夹包含在您的持续集成或持续交付管道中。
- 服务器部署:不要在您的部署服务器上设置虚拟环境,除非您自己管理该服务器并在其上运行多个独立的项目。
您仍然需要隔离的环境和代码项目的可再现性。您将通过固定您的依赖项来实现这一点,而不是包括您在本地使用的虚拟环境文件夹。
大多数远程托管提供商,包括 CI/CD 管道工具和平台即服务(PaaS)提供商,如 Heroku 或谷歌应用引擎(GAE) ,将自动为您创建这种隔离。
当您将代码项目推送到这些托管服务之一时,该服务通常会将服务器的虚拟部分分配给您的应用程序。这种虚拟化服务器在设计上是隔离的环境,这意味着默认情况下您的代码将在其独立的环境中运行。
在大多数托管解决方案中,您不需要处理创建隔离,但是您仍然需要提供关于在远程环境中安装什么的信息。为此,您将经常在您的requirements.txt文件中使用固定的依赖关系。
注意:如果您在自己托管的服务器上运行多个项目,那么您可能会从在该服务器上设置虚拟环境中受益。
在这种情况下,您可以像对待本地计算机一样对待服务器。即使这样,您也不会复制虚拟环境文件夹。相反,您将从您的固定依赖项在您的远程服务器上重新创建虚拟环境。
大多数托管平台提供商还会要求您创建特定于您正在使用的工具的设置文件。这个文件将包含没有记录在requirements.txt中的信息,但是平台需要为你的代码建立一个运行环境。你需要仔细阅读你打算使用的托管服务文档中的这些特定文件。
一个流行的选项是 Docker ,它将虚拟化提升到一个新的水平,并且仍然允许您自己创建许多设置。
使用第三方工具
Python 社区创建了许多附加工具,这些工具将虚拟环境作为其功能之一,并允许您以用户友好的方式管理多个虚拟环境。
因为许多工具出现在在线讨论和教程中,所以您可能想知道每个工具是关于什么的,以及它们如何帮助您管理虚拟环境。
虽然讨论每个项目超出了本教程的范围,但是您将大致了解存在哪些流行的项目,它们做什么,以及在哪里可以了解更多信息:
-
virtualenvwrapper是 virtualenv 项目的扩展,它使得创建、删除和管理虚拟环境变得更加简单。它将您的所有虚拟环境保存在一个地方,引入了用户友好的 CLI 命令来管理和切换虚拟环境,并且是可配置和可扩展的。
virtualenvwrapper-win是这个项目的一个 Windows 端口。 -
诗歌 是 Python 依赖管理和打包的工具。有了诗歌,你可以声明你的项目所依赖的包,类似于
requirements.txt但是具有确定性。然后,poems 会在一个自动生成的虚拟环境中安装这些依赖项,并帮助您管理虚拟环境。 -
Pipenv 旨在改进 Python 中的打包。它在后台使用
virtualenv为你的项目创建和管理虚拟环境。像诗歌一样, Pipenv 旨在改进依赖管理以允许确定性构建。这是一个相对较慢的高级工具,已经得到了 Python 打包权威(PyPA) 的支持。 -
pipx 允许你安装 Python 包,你习惯在隔离环境中作为独立的应用运行。它为每个工具创建了一个虚拟环境,并使其可以在全球范围内访问。除了帮助使用代码质量工具,如 black、isort、flake8、pylint 和 mypy,它对于安装替代的 Python 解释器也很有用,如 bpython、ptpython 或 ipython。
-
pipx-in-pipx 是一个您可以用来安装 pipx 的包装器,它通过允许您使用 pipx 本身来安装和管理 pipx,将
pip的递归缩写提升到了一个新的水平。 -
pyenv 与虚拟环境并没有内在联系,尽管它经常被提到与这个概念有关。您可以使用 pyenv 管理多个 Python 版本,这允许您在新版本和旧版本之间切换,这是您正在进行的项目所需要的。pyenv 还有一个名为 pyenv-win 的 Windows 端口。
-
pyenv-virtualenv 是 pyenv 的一个插件,结合了 pyenv 和 virtualenv,允许你在 UNIX 系统上为 pyenv 管理的 Python 版本创建虚拟环境。甚至还有一个混合 pyenv 和 virtualenvwrapper 的插件,叫做 pyenv-virtualenvwrapper 。
Python 社区构建了一整套第三方项目,可以帮助您以用户友好的方式管理 Python 虚拟环境。
请记住,这些项目旨在使您的过程更加方便,而不是在 Python 中处理虚拟环境所必需的。
结论
祝贺您完成了 Python 虚拟环境教程。在整个教程中,您已经对什么是虚拟环境、为什么需要虚拟环境、虚拟环境的内部功能以及如何在您的系统上管理虚拟环境有了全面的了解。
在本教程中,您学习了如何:
- 创建和激活一个 Python 虚拟环境
- 解释为什么你想隔离外部依赖
- 当你创建一个虚拟环境时,想象 Python 做了什么
- 使用可选参数到
venv定制你的虚拟环境 - 停用和移除虚拟环境
- 选择用于管理您的 Python 版本和虚拟环境的附加工具
下次教程告诉你创建和激活一个虚拟环境,你会更好地理解为什么这是一个好建议,以及 Python 在幕后为你做了什么。
参加测验:通过我们的交互式“Python 虚拟环境:入门”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: 使用 Python 虚拟环境*********************************************************************************************************************************************************
Python 与 C++:为工作选择合适的工具
你是一个比较 Python 和 C++的 C++开发者吗?你是不是看着 Python 想知道这一切大惊小怪的是什么?你想知道 Python 和你已经知道的概念相比怎么样吗?或者也许你打赌如果你把 C++和 Python 关在一个笼子里,让他们一决雌雄,谁会赢?那这篇文章就送给你了!
在本文中,您将了解到:
- 当你比较 Python 和 C++时的区别和相似之处
- 对于一个问题,Python 可能是更好的选择,反之亦然
- 学习 Python 时遇到问题时可以求助的资源
这篇文章针对的是正在学习 Python 的 C++开发者。它假定您对这两种语言都有基本的了解,并将使用 Python 3.6 及更高版本,以及 C++11 或更高版本中的概念。
让我们来看看 Python 和 C++的对比吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
比较语言:Python 与 C++
通常,您会发现赞美一种编程语言优于另一种编程语言的文章。通常情况下,他们会通过贬低一种语言来推广另一种语言。这不是那种类型的文章。
当你比较 Python 和 C++的时候,记住它们都是工具,并且它们都有不同的用途。想一想锤子和螺丝刀的比较。你可以用螺丝刀敲进钉子,你可以用锤子敲进螺丝,但这两种体验都不会那么有效。
在工作中使用正确的工具很重要。在本文中,您将了解 Python 和 C++的特性,这些特性使它们成为解决某些类型问题的正确选择。所以,不要把 Python vs C++中的“vs”理解为“反对”。更确切地说,把它当作一个比较。
编译 vs 虚拟机
让我们从比较 Python 和 C++的最大区别开始。在 C++中,你使用编译器将你的源代码转换成机器代码并生成可执行文件。可执行文件是一个单独的文件,可以作为独立程序运行:

这个过程为特定的处理器和操作系统输出实际的机器指令。在这幅图中,它是一个 Windows 程序。这意味着您必须为 Windows、Mac 和 Linux 分别重新编译您的程序:
您可能还需要修改 C++代码,以便在这些不同的系统上运行。
另一方面,Python 使用不同的过程。现在,记住你将看到的是该语言的标准实现 CPython 。除非你正在做一些特别的事情,否则这就是你正在运行的 Python。
每次执行程序时,Python 都会运行。它就像 C++编译器一样编译你的源代码。不同之处在于 Python 会编译成字节码,而不是本机代码。字节码是 Python 虚拟机的本机指令代码。为了加速程序的后续运行,Python 将字节码存储在.pyc文件中:

如果您使用的是 Python 2,那么您会在.py文件旁边找到这些文件。对于 Python 3,您可以在一个__pycache__目录中找到它们。
生成的字节码不会在您的处理器上自然运行。相反,它是由 Python 虚拟机运行的。这与 Java 虚拟机或。NET 公共运行时环境。代码的首次运行将导致编译步骤。然后,字节码将被解释为在您的特定硬件上运行:

只要程序没有改变,每次后续运行都将跳过编译步骤,并使用先前编译的字节码来解释:

解释代码比直接在硬件上运行本机代码要慢。那么为什么 Python 是这样工作的呢?嗯,解释虚拟机中的代码意味着只需要为特定处理器上的特定操作系统编译虚拟机。它运行的所有 Python 代码都可以在任何安装了 Python 的机器上运行。
注意: CPython 是用 C 编写的,所以它可以在大多数有 C 编译器的系统上运行。
这种跨平台支持的另一个特点是 Python 广泛的标准库可以在所有操作系统上工作。
例如,使用 pathlib 将为您管理路径分隔符,无论您使用的是 Windows、Mac 还是 Linux。这些库的开发人员花了很多时间使它具有可移植性,所以您不需要在 Python 程序中担心它!
在您继续之前,让我们开始跟踪 Python 与 C++的比较图表。当您介绍新的比较时,它们将以斜体添加:
| 特征 | 计算机编程语言 | C++ |
|---|---|---|
| 更快的执行速度 | x | |
| 跨平台执行 | x |
既然您已经看到了 Python 和 C++在运行时的差异,那么让我们深入研究一下这两种语言的语法细节。
语法差异
Python 和 C++在语法上有许多相似之处,但也有一些地方值得讨论:
- 空白
- 布尔表达式
- 变量和指针
- (听力或阅读)理解测试
让我们先从最有争议的一个开始:空白。
空白
大多数开发人员在比较 Python 和 C++时注意到的第一件事是“空白问题”Python 使用前导空格来标记范围。这意味着一个if块或其他类似结构的主体由缩进的级别来表示。C++用花括号({})表示同样的想法。
虽然 Python lexer 可以接受任何空格,只要你保持一致,但是pep 8(官方风格指南为每一级缩进指定了 4 个空格。大多数编辑器都可以配置为自动完成这项工作。
关于 Python 的空白规则,已经有大量的文章、文章和文章发表,所以让我们跳过这个问题,转到其他事情上来。
Python 使用行尾,而不是依靠像;这样的词法标记来结束每条语句。如果需要将一个语句扩展到一行,那么可以使用反斜杠(\)来表示。(请注意,如果您在一组括号内,则不需要继续字符。)
在空白问题上,双方都有人不满意。一些 Python 开发人员喜欢您不必键入大括号和分号。一些 C++开发人员讨厌对格式的依赖。学会适应这两者是你最好的选择。
既然您已经看到了空白问题,让我们继续讨论一个争议较少的问题:布尔表达式。
布尔表达式
与 C++相比,Python 中使用布尔表达式的方式略有不同。在 C++中,除了内置值之外,还可以使用数值来表示true或false。任何评估为0的值都被认为是false,而其他所有数值都是true。
Python 有一个类似的概念,但是将其扩展到包括其他情况。基本都挺像的。 Python 文档声明以下项目评估为False:
- 定义为 false 的常数:
NoneFalse
- 任何数字类型的零:
00.00jDecimal(0)Fraction(0, 1)
- 空序列和集合:
''()[]{}set()range(0)
其他所有项目都是True。这意味着空列表[]是False,而只包含零的列表[0]仍然是True。
大多数对象将评估为True,除非对象有返回False的__bool__()或返回 0 的__len__()。这允许您扩展您的自定义类来充当布尔表达式。
Python 与 C++相比,在布尔运算符方面也有一些细微的变化。首先,if和while语句不像在 C++中那样需要括号。然而,括号有助于提高可读性,所以请使用您的最佳判断。
大多数 C++布尔运算符在 Python 中都有类似的运算符:
| C++运算符 | Python 运算符 |
|---|---|
&& |
and |
|| |
or |
! |
not |
& |
& |
| |
| |
大部分操作符和 C++类似,但是如果你想温习一下,你可以阅读 Python 中的操作符和表达式。
变量和指针
当你用 C++写完之后第一次开始使用 Python 的时候,你可能不会太在意变量。它们似乎通常像在 C++中一样工作。然而,它们并不相同。在 C++中,你使用变量来引用值,而在 Python 中,你使用名称。
注意:在本节中,您将看到 Python 和 C++中的变量和名称,对于 C++您将使用变量,对于 Python 您将使用名称。在其他地方,它们都将被称为变量。
首先,让我们后退一点,更广泛地看看 Python 的对象模型。
在 Python 中,一切都是对象。数字被保存在物体中。模块保存在对象中。一个类的对象和这个类本身都是对象。函数也是对象:
>>> a_list_object = list() >>> a_list_object [] >>> a_class_object = list >>> a_class_object <class 'list'> >>> def sayHi(name): ... print(f'Hello, {name}') ... >>> a_function_object = sayHi >>> a_function_object <function sayHi at 0x7faa326ac048>调用
list()创建一个新的列表对象,您将它分配给a_list_object。使用类名list本身就在类对象上加了一个标签。您也可以在函数上放置新标签。这是一个强大的工具,像所有强大的工具一样,它可能是危险的。(我在看你,电锯先生。)注意:上面的代码显示运行在一个 REPL 中,代表“读取、评估、打印循环”这种交互式环境经常被用来试验 Python 和其他解释语言中的想法。
如果你在命令提示符下输入
python,它会弹出一个 REPL,你可以在这里开始输入代码并自己尝试!回到 Python 与 C++的讨论,注意这种行为与你在 C++中看到的不同。与 Python 不同,C++有分配给一个内存位置的变量,您必须指出该变量将使用多少内存:
int an_int; float a_big_array_of_floats[REALLY_BIG_NUMBER];在 Python 中,所有对象都是在内存中创建的,您可以给它们加上标签。标签本身没有类型,可以贴在任何类型的对象上:
>>> my_flexible_name = 1
>>> my_flexible_name
1
>>> my_flexible_name = 'This is a string'
>>> my_flexible_name
'This is a string'
>>> my_flexible_name = [3, 'more info', 3.26]
>>> my_flexible_name
[3, 'more info', 3.26]
>>> my_flexible_name = print
>>> my_flexible_name
<built-in function print>
您可以将my_flexible_name赋给任何类型的对象,Python 会随之滚动。
当你比较 Python 和 C++的时候,变量和名字的区别可能有点混乱,但是它带来了一些很好的好处。一个是在 Python 中你没有指针,你永远不需要考虑堆和栈的问题。在本文的稍后部分,您将深入了解内存管理。
理解
Python 有一个语言特性叫做 列表综合 。虽然在 C++中模拟列表理解是可能的,但这相当棘手。在 Python 中,它们是教给初级程序员的基本工具。
思考列表理解的一种方式是,它们就像列表、字典或集合的超级初始化器。给定一个 iterable 对象,您可以创建一个列表,并在创建时过滤或修改原始列表:
>>> [x**2 for x in range(5)] [0, 1, 4, 9, 16]这个脚本从 iterable
range(5)开始,创建一个包含 iterable 中每一项的方块的列表。可以向第一个 iterable 中的值添加条件:
>>> odd_squares = [x**2 for x in range(5) if x % 2]
>>> odd_squares
[1, 9]
本理解末尾的if x % 2将range(5)中使用的数字限定为奇数。
此时,你可能会有两种想法:
- 这是一个强大的语法技巧,将简化我的代码的某些部分。
- 你可以在 C++中做同样的事情。
虽然确实可以在 C++中创建奇数平方的vector,但这样做通常意味着代码要多一点:
std::vector<int> odd_squares; for (int ii = 0; ii < 10; ++ii) { if (ii % 2) { odd_squares.push_back(ii*ii); } }
对于来自 C 风格语言的开发人员来说,列表理解是他们能够编写更多 Pythonic 代码的第一个值得注意的方法之一。许多开发人员开始用 C++结构编写 Python:
odd_squares = []
for ii in range(5):
if (ii % 2):
odd_squares.append(ii)
这是完全有效的 Python。然而,它可能会运行得更慢,而且不像 list comprehension 那样清晰简洁。学会使用列表理解不仅会提高你的代码速度,还会让你的代码更有条理,更易读!
注:当你阅读 Python 的时候,你会经常看到单词Python被用来描述某事。这只是社区用来描述干净、优雅、看起来像是 Python 绝地武士写的代码的术语。
Python 的std::algorithms
C++标准库中内置了丰富的算法。Python 有一组类似的内置函数,涵盖了相同的领域。
其中第一个也是最强大的是 in操作符,它提供了一个可读性很强的测试来查看一个条目是否包含在列表、集合或字典中:
>>> x = [1, 3, 6, 193] >>> 6 in x True >>> 7 in x False >>> y = { 'Jim' : 'gray', 'Zoe' : 'blond', 'David' : 'brown' } >>> 'Jim' in y True >>> 'Fred' in y False >>> 'gray' in y False注意,
in操作符在字典上使用时,只测试键,而不是值。这由最终测试'gray' in y显示。
in可以与not结合使用,以获得可读性很强的语法:if name not in y: print(f"{name} not found")下一个 Python 内置操作符是
any。这是一个布尔函数,如果给定 iterable 的任何元素计算结果为True,则返回True。这看起来有点傻,直到你记起你的理解清单!结合这两者可以为许多情况产生强大、清晰的语法:
>>> my_big_list = [10, 23, 875]
>>> my_small_list = [1, 2, 8]
>>> any([x < 3 for x in my_big_list])
False
>>> any([x < 3 for x in my_small_list])
True
最后,你还有 all ,类似于any。如果——你猜对了 iterable 中的所有元素都是True,那么只返回True 。同样,将它与列表理解结合起来会产生一个强大的语言特性:
>>> list_a = [1, 2, 9] >>> list_b = [1, 3, 9] >>> all([x % 2 for x in list_a]) False >>> all([x % 2 for x in list_b]) True
any和all可以覆盖 C++开发人员期待std::find或std::find_if的大部分领域。注意:在上面的
any和all示例中,您可以删除括号([],而不会损失任何功能。(例如:all(x % 2 for x in list_a))这使用了生成器表达式,虽然很方便,但超出了本文的范围。在进入变量类型之前,让我们更新一下 Python 与 C++的比较图:
特征 计算机编程语言 C++ 更快的执行 x 跨平台执行 x 单一类型变量 x 多类型变量 x 理解 x 丰富的内置算法集 x x 好了,现在你可以看变量和参数类型了。我们走吧!
静态与动态打字
当你比较 Python 和 C++时,另一个大话题是数据类型的使用。C++是静态类型的语言,而 Python 是动态类型的。让我们探索一下这意味着什么。
静态打字
C++是静态类型的,这意味着代码中使用的每个变量都必须有特定的数据类型,如
int、char、float等等。你只能把正确类型的值赋给一个变量,除非你遇到了一些困难。这对开发人员和编译器都有好处。开发人员的优势在于提前知道特定变量的类型,从而知道允许哪些操作。编译器可以使用类型信息来优化代码,使代码更小、更快,或者两者兼而有之。
然而,这种先进的知识是有代价的。传递给函数的参数必须与函数期望的类型相匹配,这会降低代码的灵活性和潜在的有用性。
鸭子打字
动态分型通常被称为鸭分型。这是一个奇怪的名字,一会儿你会读到更多关于它的内容!但首先,我们先举个例子。这个函数获取一个 file 对象并读取前十行:
def read_ten(file_like_object): for line_number in range(10): x = file_like_object.readline() print(f"{line_number} = {x.strip()}")要使用这个函数,您将创建一个 file 对象并将其传入:
with open("types.py") as f: read_ten(f)这显示了该函数的基本设计是如何工作的。虽然这个函数被描述为“从文件对象中读取前十行”,但是 Python 中并没有要求
file_like_object是文件。只要传入的对象支持.readline(),该对象可以是任何类型:class Duck(): def readline(self): return "quack" my_duck = Duck() read_ten(my_duck)用一个
Duck对象调用read_ten()会产生:0 = quack 1 = quack 2 = quack 3 = quack 4 = quack 5 = quack 6 = quack 7 = quack 8 = quack 9 = quack这就是鸭式打字的精髓。俗话说,“如果它长得像鸭子,游得像鸭子,叫得像鸭子,那么它大概就是鸭子。”
换句话说,如果对象有所需的方法,那么不管对象的类型如何,都可以传入它。Duck 或动态类型为您提供了巨大的灵活性,因为它允许在满足所需接口的地方使用任何类型。
但是,这里有一个问题。如果你传入一个不符合所需接口的对象会怎样?比如传一个数给
read_ten(),像这样:read_ten(3)?这将导致引发异常。除非您捕捉到异常,否则您的程序将会因一个回溯而崩溃:
Traceback (most recent call last): File "<stdin>", line 1, in <module> File "duck_test.py", line 4, in read_ten x = file_like_object.readline() AttributeError: 'int' object has no attribute 'readline'动态类型可能是一个非常强大的工具,但是正如您所看到的,在使用它时您必须小心。
注意: Python 和 C++都被认为是强类型语言。虽然 C++有更强的类型系统,但这方面的细节对于学习 Python 的人来说通常意义不大。
让我们转到受益于 Python 动态类型的一个特性:模板。
模板
Python 没有 C++那样的模板,但一般也不需要。在 Python 中,一切都是单个基本类型的子类。这就是允许你创建如上所述的鸭子类型函数的原因。
C++中的模板系统允许你创建在多种不同类型上操作的函数或算法。这是非常强大的,可以节省你大量的时间和精力。然而,它也可能是困惑和挫折的来源,因为模板中的编译器错误可能会让您感到困惑。
能够使用 duck typing 代替模板使得一些事情变得容易得多。但是这也会导致难以检测的问题。和所有复杂的决策一样,当你比较 Python 和 C++时,需要权衡利弊。
类型检查
最近在 Python 社区中有很多关于 Python 中静态类型检查的兴趣和讨论。像 mypy 这样的项目已经提高了在语言的特定位置添加运行前类型检查的可能性。这对于管理大型软件包或特定 API 之间的接口非常有用。
它有助于解决鸭子打字的一个缺点。对于使用函数的开发人员来说,如果他们能够完全理解每个参数需要是什么,那会很有帮助。这在大型项目团队中非常有用,因为许多开发人员需要通过 API 进行交流。
再一次,让我们看看你的 Python 和 C++对比图:
特征 计算机编程语言 C++ 更快的执行 x 跨平台执行 x 单一类型变量 x 多类型变量 x (听力或阅读)理解测试 x 丰富的内置算法集 x x 静态打字 x 动态打字 x 现在,您已经准备好了解面向对象编程的不同之处了。
面向对象编程
和 C++一样,Python 支持一个面向对象的编程模型。你在 C++中学到的许多相同的概念都被移植到 Python 中。您仍然需要对继承、复合和多重继承做出决定。
相似之处
在 Python 和 C++中,类之间的继承类似。一个新类可以从一个或多个基类继承方法和属性,就像你在 C++中看到的一样。然而,一些细节有些不同。
Python 中的基类不像 C++那样自动调用它们的构造函数。当你切换语言时,这可能会令人困惑。
多重继承在 Python 中也有效,它和在 C++中一样有很多怪癖和奇怪的规则。
类似地,您也可以使用组合来构建类,其中一种类型的对象包含其他类型。考虑到 Python 中的一切都是对象,这意味着类可以保存语言中的任何东西。
差异
然而,当你比较 Python 和 C++时,还是有一些不同的。前两者是有关联的。
第一个区别是 Python 没有类的访问修饰符的概念。类对象中的一切都是公共的。Python 社区已经开发了一个约定,任何以单下划线开头的类成员都被视为私有。语言并没有强制这样做,但是看起来效果很好。
Python 中每个类成员和方法都是公共的这一事实导致了第二个不同:Python 的封装支持比 C++弱得多。
如前所述,单下划线约定使得这在实际代码库中比在理论意义上更不成为问题。一般来说,任何违反这条规则并依赖于类内部工作的用户都是在自找麻烦。
运算符 ooverlord vs dunder 方法
在 C++中,可以添加运算符重载。这些允许您为某些数据类型定义特定语法操作符(如
==)的行为。通常,这是用来增加你的类的更自然的用法。对于==操作符,您可以确切地定义一个类的两个对象相等意味着什么。一些开发人员需要很长时间才能理解的一个区别是如何解决 Python 中缺少运算符重载的问题。Python 的对象可以在任何标准容器中工作,这很好,但是如果您想让
==操作符在新类的两个对象之间进行深度比较,该怎么办呢?在 C++中,你可以在你的类中创建一个operator==()来进行比较。Python 有一个类似的结构,在整个语言中使用得相当一致: dunder methods 。Dunder 方法之所以得名,是因为它们都以双下划线或“d-under”开头和结尾
Python 中许多操作对象的内置函数都是通过调用对象的 dunder 方法来处理的。对于上面的例子,您可以将
__eq__()添加到您的类中,进行您喜欢的任何奇特的比较:class MyFancyComparisonClass(): def __eq__(self, other): return True这将生成一个类,该类与其类的任何其他实例进行比较的方式相同。不是特别有用,但它证明了这一点。
Python 中使用了大量的 dunder 方法,内置函数广泛地利用了这些方法。例如,添加
__lt__()将允许 Python 比较两个对象的相对顺序。这意味着不仅<操作员可以工作,而且>、<=和>=也可以工作。更好的是,如果你的新类有几个对象在一个列表中,那么你可以在列表中使用
sorted(),它们将使用__lt__()排序。再一次,让我们看看你的 Python 和 C++对比图:
特征 计算机编程语言 C++ 更快的执行 x 跨平台执行 x 单一类型变量 x 多类型变量 x (听力或阅读)理解测试 x 丰富的内置算法集 x x 静态打字 x 动态打字 x 严格封装 x 既然您已经看到了跨两种语言的面向对象编码,那么让我们看看 Python 和 C++如何管理内存中的这些对象。
内存管理
当你比较 Python 和 C++时,最大的区别之一就是它们处理内存的方式。正如您在关于 C++和 Python 名称中的变量一节中看到的,Python 没有指针,也不容易让您直接操纵内存。虽然有时候你想拥有那种程度的控制,但大多数时候这是不必要的。
放弃对内存位置的直接控制会带来一些好处。您不需要担心内存所有权,也不需要确保内存在分配后被释放一次(且仅一次)。您也永远不必担心对象是分配在堆栈上还是堆上,这往往会让 C++开发新手感到困惑。
Python 为您管理所有这些问题。为了做到这一点,Python 中的所有东西都是从 Python 的
object派生的一个类。这允许 Python 解释器实现引用计数,作为跟踪哪些对象仍在使用,哪些对象可以被释放的手段。当然,这种便利是有代价的。为了释放分配给你的内存对象,Python 有时需要运行所谓的垃圾收集器,它会找到未使用的内存对象并释放它们。
注意: CPython 有一个复杂的内存管理方案,这意味着释放内存并不一定意味着内存被返回给操作系统。
Python 使用两种工具来释放内存:
- 引用计数收集器
- 世代收藏家
让我们分别看一下这些。
参考计数收集器
引用计数收集器是标准 Python 解释器的基础,并且总是在运行。它的工作原理是在程序运行时,记录给定的内存块(通常是 Python
object)有多少次被附加了一个名字。许多规则都描述了引用计数何时递增或递减,但有一个例子可以说明这一点:
1>>> x = 'A long string'
2>>> y = x
3>>> del x
4>>> del y
在上面的例子中,第 1 行创建了一个包含字符串"A long string"的新对象。然后将名称x放在这个对象上,将对象的引用计数增加到 1:
在第 2 行,它指定y来命名同一个对象,这将把引用计数增加到 2:
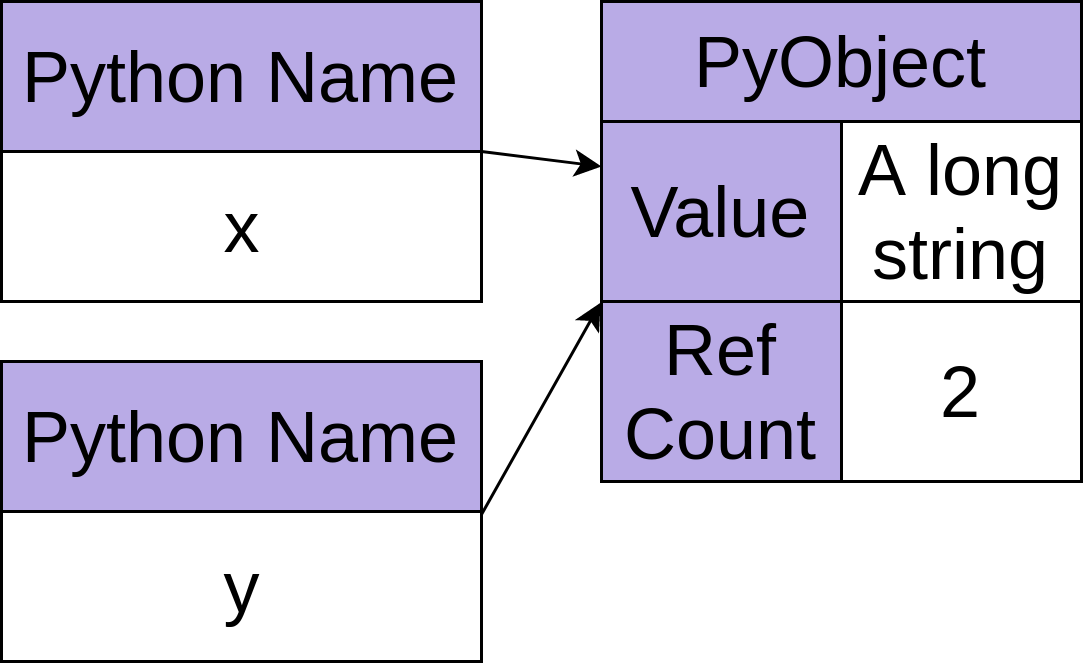
当您在第 3 行用x调用del时,您删除了对该对象的一个引用,将计数降回 1:

最后,当您删除对对象的最后一个引用y时,它的引用计数会降到零,并且可以被引用计数垃圾收集器释放。在这一点上,它可能会也可能不会被立即释放,但一般来说,这对开发人员来说并不重要:

虽然这将负责找到并释放许多需要释放的对象,但有一些情况它不会捕捉到。为此,您需要分代垃圾收集器。
分代垃圾收集器
引用计数方案中的一个大漏洞是你的程序可以构建一个引用循环,其中对象A有一个对对象B的引用,对象B有一个对对象A的引用。完全有可能遇到这种情况,并且代码中没有任何内容引用任何一个对象。在这种情况下,两个对象都不会达到引用计数 0。
分代垃圾收集器涉及一个复杂的算法,超出了本文的范围,但是它会找到一些孤立的引用循环,并为您释放它们。它偶尔运行,由文档中的描述的设置控制。其中一个参数是完全禁用这个垃圾收集器。
当你不想要垃圾收集时
当你比较 Python 和 C++的时候,就像你比较任何两个工具一样,每个优势都有一个权衡。Python 不需要显式的内存管理,但偶尔它会在垃圾收集上花费比预期更长的时间。对于 C++,情况正好相反:你的程序将有一致的响应时间,但是你需要在管理内存上花费更多的精力。
在许多程序中,偶尔的垃圾收集命中并不重要。如果你正在写一个只运行 10 秒钟的脚本,那么你不太可能注意到其中的区别。然而,有些情况需要一致的响应时间。实时系统就是一个很好的例子,在这种情况下,在固定的时间内对硬件做出响应对于系统的正常运行至关重要。
对实时性有严格要求的系统是 Python 不适合的语言选择。拥有一个严格控制的系统,其中你可以确定时间是 C++的一个很好的用途。当您决定项目的语言时,这些是需要考虑的问题类型。
是时候更新您的 Python 与 C++图表了:
| 特征 | 计算机编程语言 | C++ |
|---|---|---|
| 更快的执行 | x | |
| 跨平台执行 | x | |
| 单一类型变量 | x | |
| 多类型变量 | x | |
| (听力或阅读)理解测试 | x | |
| 丰富的内置算法集 | x | x |
| 静态打字 | x | |
| 动态打字 | x | |
| 严格封装 | x | |
| 直接内存控制 | x | |
| 垃圾收集 | x |
线程、多处理和异步 IO
C++和 Python 中的并发模型是相似的,但是它们有不同的结果和好处。这两种语言都支持线程、多处理和异步 IO 操作。让我们来看看每一个。
穿线
虽然 C++和 Python 都在语言中内置了线程,但结果可能会有明显的不同,这取决于您要解决的问题。通常,线程化用于解决性能问题。在 C++中,由于线程可以充分利用多处理器系统上的内核,因此线程可以为计算受限和 I/O 受限问题提供总体加速。
另一方面,Python 做了一个设计权衡,使用全局解释器锁,或者 GIL ,来简化它的线程实现。GIL 有很多好处,但缺点是一次只能运行一个线程,即使有多个内核。
如果您的问题是 I/O 受限的,比如一次获取几个网页,那么这个限制一点也不会困扰您。您将欣赏 Python 更简单的线程模型和用于线程间通信的内置方法。但是,如果您的问题是 CPU 受限的,那么 GIL 将会把您的性能限制在单个处理器上。幸运的是,Python 的多处理库有一个与其线程库相似的接口。
多重处理
标准库中内置了 Python 中的多处理支持。它有一个干净的界面,允许你旋转多个进程,并在它们之间共享信息。您可以创建一个进程池,并使用几种技术在它们之间分配工作。
虽然 Python 仍然使用类似的操作系统原语来创建新的流程,但许多底层的复杂性对开发人员来说是隐藏的。
C++依靠fork()来提供多处理支持。虽然这使您可以直接访问生成多个流程的所有控制和问题,但这也要复杂得多。
异步 IO
虽然 Python 和 C++都支持异步 IO 例程,但它们的处理方式不同。在 C++中,std::async方法很可能使用线程来实现其操作的异步 IO 特性。在 Python 中,异步 IO 代码只会在单线程上运行。
这里也有权衡。使用单独的线程允许 C++异步 IO 代码在计算受限的问题上执行得更快。在其异步 IO 实现中使用的 Python 任务更加轻量级,因此处理大量的 I/O 绑定问题会更快。
在本节中,Python 与 C++的对比图保持不变。两种语言都支持全面的并发选项,在速度和便利性之间有不同的权衡。
其他问题
如果您正在比较 Python 和 C++并考虑将 Python 添加到您的工具箱中,那么还有一些其他的事情需要考虑。虽然您当前的编辑器或 IDE 肯定适用于 Python,但您可能希望添加某些扩展或语言包。也值得看一看 PyCharm,因为它是 Python 特有的。
几个 C++项目都有 Python 绑定。像 Qt 、 WxWidgets 以及许多具有多语言绑定的消息传递 API。
如果你想在 C++ 中嵌入 Python,那么你可以使用 Python/C API 。
最后,有几种方法可以使用您的 C++技能来扩展 Python 和添加功能,或者从 Python 代码中调用您现有的 C++库。像 CTypes 、 Cython 、 CFFI 、 Boost 这样的工具。Python 和 Swig 可以帮助你将这些语言结合起来,发挥各自的优势。
总结:Python vs C++
您已经花了一些时间阅读和思考 Python 和 C++之间的区别。虽然 Python 具有更简单的语法和更少的尖锐边缘,但它并不是所有问题的完美解决方案。您已经了解了这两种语言的语法、内存管理、处理和其他几个方面。
让我们最后看一下 Python 和 C++的对比图:
| 特征 | 计算机编程语言 | C++ |
|---|---|---|
| 更快的执行 | x | |
| 跨平台执行 | x | |
| 单一类型变量 | x | |
| 多类型变量 | x | |
| (听力或阅读)理解测试 | x | |
| 丰富的内置算法集 | x | x |
| 静态打字 | x | |
| 动态打字 | x | |
| 严格封装 | x | |
| 直接存储控制 | x | |
| 碎片帐集 | x |
如果你比较 Python 和 C++,那么你可以从图表中看到,这不是一个比另一个好的例子。它们中的每一个都是为各种用例精心制作的工具。就像你不会用锤子来敲螺丝一样,在工作中使用正确的语言会让你的生活更轻松!
结论
恭喜你。您现在已经看到了 Python 和 C++的一些优点和缺点。您已经了解了每种语言的一些特征以及它们的相似之处。
您已经看到 C++在您需要时非常有用:
- 快速的执行速度(可能以开发速度为代价)
- 完全控制记忆
相反,当您需要时,Python 非常有用:
- 快速开发速度(可能以执行速度为代价)
- 托管内存
现在,您已经准备好在下一个项目中做出明智的语言选择了!*********
python vs . python istas 的 JavaScript
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python vs JavaScript for Python 开发者
如果你对 web 开发很认真,那么你需要在某个时候学习一下 JavaScript 。年复一年,无数的调查表明,JavaScript 是世界上最流行的编程语言之一,拥有庞大且不断增长的开发者群体。就像 Python 一样,现代 JavaScript 几乎可以在任何地方使用,包括前端,后端,桌面,移动,以及物联网 (IoT)。有时,在 Python 和 JavaScript 之间可能没有明显的选择。
如果您以前从未使用过 JavaScript,或者对其近年来的快速发展感到不知所措,那么本文将带您走上正确的道路。您应该已经知道 Python 的基础,以便从两种语言之间的比较中充分受益。
在这篇文章中,你将学习如何:
- 比较 Python 与 JavaScript
- 为工作选择正确的语言
- 用 JavaScript 编写一个 shell 脚本
- 在网页上生成动态内容
- 利用 JavaScript 生态系统
- 避免 JavaScript 中常见的陷阱
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
JavaScript 一览
如果你已经熟悉 JavaScript 的起源,或者只是想看看实际运行的代码,那么请随意跳到下一节。否则,请准备一堂简短的历史课,带您了解 JavaScript 的演变。
不是 Java!
许多人,尤其是一些 IT 招聘人员,认为 JavaScript 和 Java 是同一种语言。不过,很难责怪他们,因为发明这样一个听起来耳熟的名字是一种营销伎俩。
JavaScript 在更名为 LiveScript 之前最初被称为 Mocha ,最终在发布前不久更名为 JavaScript 。当时, Java 是一项很有前途的 web 技术,但是对于非技术型的网站管理员来说太难了。JavaScript 旨在作为一种有点类似但对初学者友好的语言,以补充 web 浏览器中的 Java 小程序。
趣闻:【Java 和 JavaScript 都是 1995 年发布的。Python 已经五岁了。
更令人困惑的是,由于缺乏许可权,微软开发了自己的语言版本,称为 JScript ,用于 Internet Explorer 3.0。今天,人们经常把 JavaScript 称为 JS 。
虽然 Java 和 JavaScript 在类似 C 的语法和标准库中有一些相似之处,但它们用于不同的目的。Java 从客户端发展成为一种更通用的语言。JavaScript 尽管简单,但足以验证 HTML 表单和添加小动画。
是 ECMAScript
JavaScript 是在网络早期由一家相对较小的公司开发的,名为 Netscape 。为了赢得与微软的市场竞争并缩小不同浏览器之间的差异,网景公司需要标准化他们的语言。在被国际万维网联盟(W3C) 拒绝后,他们向一个名为 ECMA (今天的 Ecma 国际)的欧洲标准化机构寻求帮助。
ECMA 为这种被称为 ECMAScript T1 的语言定义了一个正式规范,因为的 JavaScript T3 已经被的太阳微系统 T5 注册了商标。JavaScript 成了它最初启发的规范的实现之一。
注:换言之,JavaScript 符合 ECMAScript 规范。ECMAScript 家族的另一个著名成员是用于 Flash 平台的 ActionScript 。
虽然该规范的个别实现在某种程度上符合 ECMAScript,但它们也附带了额外的专有 API。这导致网页不能在不同的浏览器上正确显示,并且出现了像 jQuery 这样的库。
还有其他剧本吗?
直到今天,JavaScript 仍然是唯一一种被 web 浏览器原生支持的编程语言。这是网络的通用语。有人爱,有人不爱。
已经有很多尝试用其他技术取代 JavaScript,并且这种尝试还会继续下去,这些技术包括:
- 富互联网应用: Flash、Silverlight、JavaFX
- Transpilers: Haxe,Google Web Toolkit,pyjs
- JavaScript 方言: CoffeeScript,TypeScript
在 HTML5 出现之前,这些尝试不仅受到个人喜好的驱动,也受到网络浏览器的限制。在那个时代,你不能使用 JavaScript 来完成计算密集型任务,比如绘制矢量图形或处理音频。
另一方面,富互联网应用(RIA) 通过插件在浏览器中提供身临其境的桌面体验。它们非常适合游戏和处理媒体。不幸的是,他们中的大多数都是封闭的源代码。有些在某些平台上存在安全漏洞或性能问题。更糟糕的是,它们都严重限制了网络搜索引擎索引用这些插件构建的页面的能力。
大约在同一时间出现了 transpilers,它允许将其他语言自动翻译成 JavaScript。这使得前端开发的门槛大大降低,因为后端工程师突然可以在一个新的领域利用他们的技能。然而,缺点是开发时间较慢,对 web 标准的支持有限,以及对移植的 JavaScript 代码的调试繁琐。为了将它链接回原始代码,你需要一个源地图。
注:当编译器将高级编程语言编写的人类可读代码直接翻译成机器代码时,翻译程序将一种高级语言翻译成另一种。这就是为什么 transpilers 也被称为源到源编译器。不过,它们与为外国硬件平台生成机器码的交叉编译器不同。
要为浏览器编写 Python 代码,可以使用一个可用的 transpilers,比如 Transcrypt 或 pyjs 。后者是 Google Web Toolkit (GWT)的一个端口,这是一个非常流行的 Java-to-JavaScript transpiler。另一个选择是使用像 Brython 这样的工具,它运行纯 JavaScript 的 Python 解释器的精简版本。然而,这些好处可能会被糟糕的性能和缺乏兼容性所抵消。
Transpiling 允许大量新语言出现,旨在取代 JavaScript 并解决其缺点。其中一些语言与 JavaScript 的方言密切相关。也许第一个是大约十年前创作的 CoffeeScript 。最新的一个是谷歌的 Dart ,根据 GitHub 的数据,这是 2019 年发展最快的语言。随后出现了更多的语言,但是由于 JavaScript 最近的进步,它们中的大多数已经过时了。
一个明显的例外是微软的 TypeScript ,它在最近几年越来越受欢迎。这是一个完全兼容的 JavaScript 超集,增加了可选的静态类型检查。如果这听起来很熟悉,那是因为 Python 的类型提示受到了 TypeScript 的启发。

虽然现代 JavaScript 已经成熟并得到了积极的发展,但 transpiling 仍然是确保向后兼容旧浏览器的常用方法。即使您没有使用 TypeScript,这似乎是许多新项目的首选语言,您仍然需要将您的新 JavaScript 转换成该语言的旧版本。否则,您可能会遇到运行时错误。
一些 transpilers 还利用所谓的聚合填充来合成尖端的 web APIs,这些 API 在某些浏览器上可能是不可用的。
今天,JavaScript 可以被认为是网络的汇编语言。许多专业的前端工程师倾向于而不是手写。在这种情况下,它是通过传输从零开始生成的。
然而,即使是手写代码也经常以某种方式得到处理。例如,缩小删除空白并重命名变量以减少传输的数据量并混淆代码,从而更难进行逆向工程。这类似于将高级编程语言的源代码编译成本机代码。
除此之外,值得一提的是当代浏览器支持 WebAssembly 标准,这是一项相当新的技术。它为代码定义了一种二进制格式,可以在浏览器中以近乎本机的性能运行。它快速、可移植、安全,并允许交叉编译用 C++或 Rust 等语言编写的代码。例如,有了它,你可以把你最喜欢的视频游戏的几十年前的代码在浏览器中运行。
目前,WebAssembly 可以帮助您优化代码中计算关键部分的性能,但它也是有代价的。首先,你需要知道当前支持的编程语言之一。你必须熟悉底层的概念,比如内存管理,因为现在还没有垃圾收集器。与 JavaScript 代码的集成既困难又昂贵。此外,没有简单的方法从它调用 web APIs。
看来,经过这么多年,JavaScript 不会很快消失。
JavaScript 初学者工具包
在比较 Python 和 JavaScript 时,您会注意到的第一个相似之处是,两者的入门门槛都很低,这使得这两种语言对想要学习编码的初学者都非常有吸引力。对于 JavaScript,唯一的初始要求是拥有一个 web 浏览器。如果你正在读这篇文章,那么你已经知道了。这种可访问性有助于语言的流行。
地址栏
为了体验一下编写 JavaScript 代码的感觉,您现在可以停止阅读,在导航到地址栏之前,在地址栏中键入以下文本:

文字文字是javascript:alert('hello world'),但是不要随便复制粘贴!
前缀之后的部分是一段 JavaScript 代码。确认后,它会让您的浏览器显示一个对话框,其中包含hello world消息。每个浏览器呈现该对话框的方式略有不同。比如谷歌 Chrome 是这样显示的:

在大多数浏览器中,将这样的代码片段复制并粘贴到地址栏会失败,浏览器会过滤掉前缀javascript:,作为防止注入恶意代码的安全措施。
一些浏览器,如 Mozilla Firefox,则更进一步,完全阻止这种代码执行。在任何情况下,这都不是使用 JavaScript 的最方便的方式,因为您只能使用一行代码,并且只能使用一定数量的字符。有更好的方法。
网络开发工具
如果你是在台式机或笔记本电脑上查看这个页面,那么你可以利用 web 开发工具,它提供了跨竞争网络浏览器的可比体验。
注意:下面的例子使用的是谷歌浏览器版本80.0。其他浏览器的键盘快捷键可能会有所不同,但界面应该基本相同。
要切换这些工具,请参考您的浏览器文档或尝试以下常用键盘快捷键之一:
-
T2
F12 -
Ctrl+Shift+I -
Cmd+Option+I
例如,如果您使用的是 Apple Safari 或 Microsoft Edge,此功能可能会被默认停用。一旦 web developer 工具被激活,您将看到无数的选项卡和工具栏,其内容类似于以下内容:
总的来说,它是一个强大的开发环境,配备了 JavaScript 调试器、性能和内存分析器、网络流量管理器等等。甚至还有一个通过 USB 电缆连接的物理设备的远程调试器!
然而,目前只需关注控制台,你可以通过点击位于顶部的标签来访问它。或者,您可以在使用 web developer 工具的同时,随时按下 Esc 快速将其置于最前面。
控制台主要用于检查当前网页发出的日志消息,但是它也是一个很好的 JavaScript 学习助手。就像使用交互式 Python 解释器一样,你可以直接在控制台中键入 JavaScript 代码,让它在运行中执行:

它拥有你期望从典型的工具中得到的一切,甚至更多。特别是,控制台带有语法高亮、上下文自动完成、命令历史、类似于 GNU Readline 的行编辑,以及呈现交互元素的能力。它的呈现能力对于检查对象和表格数据、从堆栈跟踪跳转到源代码或查看 HTML 元素特别有用。
您可以使用预定义的console对象将自定义消息记录到控制台。JavaScript 的console.log()相当于 Python 的print() :
console.log('hello world');
这将使消息出现在 web developer 工具的 console 选项卡中。除此之外,console对象中还有一些有用的方法。
HTML 文档
到目前为止,JavaScript 代码最自然的位置是在它通常操作的 HTML 文档附近。稍后你会学到更多。您可以通过三种不同的方式从 HTML 引用 JavaScript:
| 方法 | 代码示例 |
|---|---|
| HTML 元素的属性 | `` |
HTML <script>标签 |
<script>alert('hello');</script> |
| 外存储器 | <script src="/path/to/file.js"></script> |
你想要多少就有多少。第一种和第二种方法将内嵌 JavaScript 直接嵌入到 HTML 文档中。虽然这很方便,但您应该尽量将命令式 JavaScript 与声明式 HTML 分开,以提高可读性。
更常见的是用 JavaScript 代码找到一个或多个引用外部文件的<script>标签。这些文件可以由本地或远程 web 服务器提供。
<script>标签可以出现在文档中的任何地方,只要它嵌套在<head>或<body>标签中:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Home Page</title>
<script src="https://server.com/library.js"></script>
<script src="local/assets/app.js"></script>
<script> function add(a, b) { return a + b; } </script>
</head>
<body>
<p>Lorem ipsum dolor sit amet (...)</p>
<script> console.log(add(2, 3)); </script>
</body>
</html>
重要的是网络浏览器如何处理 HTML 文档。从上到下阅读文档。每当发现一个<script>标签,它就会立即被执行,甚至在页面被完全加载之前。如果您的脚本试图找到尚未呈现的 HTML 元素,那么您会得到一个错误。
为了安全起见,请始终将<script>标签放在文档主体的底部:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Home Page</title>
</head>
<body>
<p>Lorem ipsum dolor sit amet (...)</p>
<script src="https://server.com/library.js"></script>
<script src="local/assets/app.js"></script>
<script> function add(a, b) { return a + b; } </script>
<script> console.log(add(2, 3)); </script>
</body>
</html>
这不仅可以防止你犯上述错误,还可以改善整体用户体验。通过向下移动这些标签,您允许用户在 JavaScript 文件开始下载之前看到完全呈现的页面。您还可以 defer 下载外部 JavaScript 文件,直到页面加载完毕:
<script src="https://server.com/library.js" defer></script>
如果你想了解更多关于混合 JavaScript 和 HTML 的知识,那么看看 W3Schools 的 JavaScript 教程。
Node.js
您不再需要 web 浏览器来执行 JavaScript 代码。有一个叫做 Node.js 的工具为服务器端 JavaScript 提供了一个运行时环境。
运行时环境由作为语言解释器或编译器的 JavaScript 引擎以及用于与外界交互的 API 组成。不同的 web 浏览器有几种可选的引擎:
| 网络浏览器 | JavaScript 引擎 |
|---|---|
| 苹果 Safari | JavaScriptCore |
| 微软 Edge | V8 |
| 微软 IE | 人体精神力量的中心 |
| Mozilla Firefox | 蜘蛛猴 |
| 谷歌浏览器 | V8 |
其中的每一项都由其供应商实施和维护。然而,对于最终用户来说,除了单个引擎的性能之外,没有明显的区别。Node.js 使用谷歌为其 Chrome 浏览器开发的相同 V8 引擎。
在 web 浏览器中运行 JavaScript 时,您通常希望能够响应鼠标点击,动态添加 HTML 元素,或者从网络摄像头获取图像。但是这在 Node.js 应用程序中没有意义,它运行在浏览器之外。
在为您的平台安装了 Node.js 之后,您就可以像使用 Python 解释器一样执行 JavaScript 代码了。要开始互动会话,请在您的终端上键入node:
$ node
> 2 + 2
4
这类似于您之前看到的 web 开发人员控制台。然而,一旦你试图引用与浏览器相关的东西,你就会得到一个错误:
> alert('hello world'); Thrown: ReferenceError: alert is not defined
这是因为您的运行时环境缺少另一个组件,即浏览器 API。同时,Node.js 提供了一组在后端应用程序中有用的 API,例如文件系统 API:
> const fs = require('fs'); > fs.existsSync('/path/to/file'); false
出于安全原因,你不会在浏览器中找到这些 API。想象一下,允许一些随机的网站控制你电脑上的文件!
如果标准库不能满足您的需求,那么您可以使用 Node.js 环境自带的节点包管理器 ( npm)安装第三方包。要浏览或搜索包,请进入npm 公共注册表,它类似于 Python 包索引 (PyPI)。
类似于python命令,您可以使用 Node.js 运行脚本:
$ echo "console.log('hello world');" > hello.js
$ node hello.js
hello world
通过提供一个包含 JavaScript 代码的文本文件的路径,您可以指示 Node.js 运行该文件,而不是启动一个新的交互式会话。
在类似 Unix 的系统上,您甚至可以在文件的第一行使用 shebang 注释来指定运行该文件的程序:
#!/usr/bin/env node
console.log('hello world');
注释必须是 Node.js 可执行文件的路径。然而,为了避免硬编码一个绝对路径,它可能在不同的安装中有所不同,最好让 env 工具计算出 Node.js 安装在机器上的什么位置。
然后,您必须使该文件成为可执行文件,然后才能像运行 Python 脚本一样运行它:
$ chmod +x hello.js
$ ./hello.js
hello world
用 Node.js 构建成熟的 web 应用程序的道路漫长而曲折,但用 Python 编写 Django 或 Flask 应用程序的道路也是如此。
外语
有时 JavaScript 的运行时环境可以是另一种编程语言。这是典型的脚本语言。比如 Python,在插件开发中被广泛使用。你会在崇高文本编辑器、 GIMP 和 Blender 中找到。
举个例子,您可以使用脚本 API 评估 Java 程序中的 JavaScript 代码:
package org.example; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; import javax.script.ScriptException; public class App { public static void main(String[] args) throws ScriptException { final ScriptEngineManager manager = new ScriptEngineManager(); final ScriptEngine engine = manager.getEngineByName("javascript"); System.out.println(engine.eval("2 + 2")); } }
这是一个 Java 扩展,尽管它可能在您特定的 Java 虚拟机中不可用。随后的几代 Java 捆绑了替代的脚本引擎,比如 Rhino 、 Nashorn 和 GraalVM 。
这为什么有用?
只要性能不太差,你可以重用现有 JavaScript 库的代码,而不是用另一种语言重写。也许用 JavaScript 解决一个问题,比如数学表达式求值,会比你的母语更方便。最后,在运行时使用脚本语言进行行为定制,比如数据过滤或验证,可能是编译语言的唯一出路。
JavaScript vs Python
在这一节中,您将从 Python 爱好者的角度比较 Python 和 JavaScript。前面会有一些新概念,但是您也会发现这两种语言之间的一些相似之处。
用例
Python 是一种通用、多范例、高级、跨平台、解释型编程语言,具有丰富的标准库和平易近人的语法。
因此,它被广泛用于各种学科,包括计算机科学教育、脚本和自动化、原型、软件测试、 web 开发、编程嵌入式设备和科学计算。尽管这是可行的,但你可能不会选择 Python 作为视频游戏或移动应用程序开发的主要技术。
另一方面,JavaScript 最初只是一种客户端脚本语言,让 HTML 文档更具交互性。它有意地简单,并且有一个唯一的焦点:向用户界面添加行为。尽管它的能力有所提高,但今天仍然如此。使用 Javascript,您不仅可以构建 web 应用程序,还可以构建桌面程序和移动应用程序。定制的运行时环境让您可以在服务器甚至物联网设备上执行 JavaScript。
哲学
Python 以牺牲表达能力为代价,强调代码的可读性和可维护性。毕竟,你甚至不能在不破坏代码的情况下对代码进行过多的格式化。你也不会像在 C++或 Perl 中那样找到深奥的运算符,因为大多数 Python 运算符都是英语单词。有些人开玩笑说 Python 是可执行的伪代码因为它的语法简单明了。
稍后你会发现,JavaScript 提供了更多的灵活性,但也带来了更多的麻烦。例如,在 JavaScript 中创建自定义数据类型没有唯一正确的方法。此外,即使新语法解决了问题,这种语言也需要保持与旧浏览器的向后兼容。
版本
直到最近,你还会在 Python 的官方网站上找到两个很不兼容的版本供下载。 Python 2.7 和 Python 3.x 之间的这种分歧让初学者感到困惑,也是减缓最新开发分支采用速度的主要因素。
2020 年 1 月,在拖延了多年的最后期限后,终于放弃了对 Python 2.7 的支持。然而,尽管一些政府机构发布了安全更新和警告,但仍有许多项目尚未迁移:
Brendan Eich 在 1995 年创造了 JavaScript,但是我们今天知道的 ECMAScript 在两年后被标准化了。从那时起,只有少数几个版本,与同一时期每年发布的多个新版本相比,这看起来停滞不前。
注意 ES3 和 ES5 之间的差距,它持续了整整十年!由于政治冲突和技术委员会的分歧, ES4 从未出现在 web 浏览器中,但它被 Macromedia(后来的 Adobe)用作 ActionScript 的基础。
2015 年,随着 ES6 的推出,JavaScript 迎来了第一次重大变革,ES6 也被称为 ES2015 或 ECMAScript Harmony 。它带来了许多新的语法结构,使语言更加成熟、安全,并且方便了程序员。这也标志着 ECMAScript 发布时间表的一个转折点,现在每年都会有一个新版本。
如此快的速度意味着你不能假设最新的语言版本已经被所有主要的网络浏览器所采用,因为它需要时间来推出更新。这就是为什么传输和多填充盛行的原因。今天,几乎所有现代网络浏览器都可以支持 ES5,这是 transpilers 的默认目标。
运行时间
要运行一个 Python 程序,你首先需要下载、安装,并可能为你的平台配置它的解释器。一些操作系统提供了开箱即用的解释器,但它可能不是您想要使用的版本。还有替代的 Python 实现,包括 CPython 、 PyPy 、 Jython 、 IronPython ,或者 Stackless Python 。您还可以从多个 Python 发行版中进行选择,比如 Anaconda ,它们带有预装的第三方包。
JavaScript 则不同。没有独立的程序可以下载。取而代之的是,每个主流的网络浏览器都附带了某种 JavaScript 引擎和 API,它们共同构成了运行时环境。在上一节中,您了解了 Node.js,它允许在浏览器之外运行 JavaScript 代码。您还知道在其他编程语言中嵌入 JavaScript 的可能性。
生态系统
一个语言生态系统包括它的运行时环境、框架、库、工具和方言,以及它的最佳实践和不成文的规则。您选择哪种组合将取决于您的特定用例。
在过去,编写 JavaScript 只需要一个好的代码编辑器。你可以下载一些库,比如 jQuery 、下划线. js 或者主干网. js ,或者依靠内容交付网络(CDN)为你的客户提供这些库。今天,你需要回答的问题的数量和你需要获得的工具甚至可以让你开始构建一个最简单的网站。
前端应用程序的构建过程与后端应用程序一样复杂,甚至更复杂。你的网络项目要经过林挺、传输、多填充、捆绑、缩小等等。见鬼,即使是 CSS 样式表也不再足够,需要由预处理器从扩展语言编译而来,如 Sass 或 Less 。
为了缓解这种情况,一些框架提供了一些实用工具,为您设置默认的项目结构、生成配置文件和下载依赖项。例如,如果您的计算机上已经有了最新的 Node.js,您可以用这个简短的命令创建一个新的 React 应用程序:
$ npx create-react-app todo
在撰写本文时,这个命令花了几分钟才完成,并在 1,815 个包中安装了巨大的 166 MB!相比之下,用 Python 开始一个 Django 项目,这是即时的:
$ django-admin startproject blog
现代 JavaScript 生态系统是巨大的,并且在不断发展,这使得我们不可能对其元素进行全面的概述。在学习 JavaScript 的过程中,你会遇到大量的外来工具。然而,其中一些概念听起来很熟悉。以下是将它们映射回 Python 的方法:
| 计算机编程语言 | Java Script 语言 | |
|---|---|---|
| 代码编辑器/ IDE | PyCharm , VS Code | 原子、 VS 代码、网络风暴 |
| 代码格式化程序 | black |
Prettier |
| 依赖性管理器 | Pipenv ,poetry |
bower(已弃用)npm,yarn |
| 文档工具 | T2Sphinx |
JSDoc,sphinx-js |
| 解释者 | bpython、ipython、python |
node |
| 图书馆 | requests ,dateutil |
axios,moment |
| 棉绒 | flake8、pyflakes、、pylint、 |
eslint,tslint |
| 包管理器 | pip ,twine |
bower(已弃用)npm,yarn |
| 包注册表 | 黑桃 | npm |
| 包装传送带 | pipx |
npx |
| 运行时管理器 | T2pyenv |
nvm |
| 脚手架工具 | cookiecutter |
cookiecutter,Yeoman |
| 测试框架 | doctest、nose、、pytest、 |
Jasmine、Jest、Mocha |
| Web 框架 | 姜戈,烧瓶,龙卷风 | 角、反应、视图。js |
这个列表并不详尽。此外,上面提到的一些工具有重叠的功能,所以很难在每个类别中进行比较。
有时候 Python 和 JavaScript 之间没有直接的相似之处。例如,虽然您可能习惯于为您的 Python 项目创建隔离的虚拟环境,但是 Node.js 通过将依赖项安装到本地文件夹中来解决这个问题。
相反,JavaScript 项目可能需要前端开发特有的额外工具。一个这样的工具是 Babel ,它根据被分组为预置的各种插件来传输你的代码。它可以处理实验性的 ECMAScript 特性以及 TypeScript,甚至 React 的 JSX 扩展语法。
另一类工具是模块捆绑器,它的作用是将多个独立的源文件合并成一个可以被网络浏览器轻松使用的文件。
在开发过程中,您希望将代码分解成可重用的、可测试的、自包含的模块。对于一个有经验的 Python 程序员来说,这是合理的。不幸的是,JavaScript 最初并不支持模块化。您仍然需要为此使用单独的工具,尽管这一需求正在发生变化。模块打包器的流行选择是 webpack 、package和 Browserify ,它们也可以处理静态资产。
然后你有构建自动化工具,比如咕噜和大口。它们与 Python 中的 Fabric 和 Ansible 有些相似,尽管它们在本地使用。这些工具自动化了枯燥的任务,如复制文件或运行 transpiler。
在一个有很多交互 UI 元素的大规模单页面应用(SPA)中,你可能需要一个专门的库比如 Redux 或者 MobX 进行状态管理。这些库不依赖于任何特定的前端框架,但是可以很快连接起来。
如您所见,学习 JavaScript 生态系统是一个漫长的旅程。
记忆模型
这两种语言都利用自动堆内存管理来消除人为错误并减少认知负荷。尽管如此,这并不能完全免除您遭受内存泄漏的风险,而且还会增加一些性能开销。
注意:当一块不再需要的内存被不必要地占用,并且没有办法释放它时,就会发生内存泄漏,因为你的代码不再能够访问它。JavaScript 中内存泄漏的一个常见来源是全局变量和持有对失效对象的强引用的闭包。
正统的 CPython 实现使用引用计数以及非确定性的垃圾收集 (GC)来处理引用周期。偶尔,当你冒险编写一个定制的 C 扩展模块时,你可能会被迫手动分配和回收内存。
在 JavaScript 中,内存管理的实际实现也留给您的特定引擎和版本,因为它不是语言规范的一部分。垃圾收集的基本策略通常是标记和清除算法,但是也存在各种优化技术。
例如,堆可以组织成几代,将短期对象和长期对象分开。垃圾收集可以并发运行,以卸载执行的主线程。采用增量方法有助于避免在清理内存时程序完全停止。
JavaScript 类型系统
您一定很想了解 JavaScript 语法,但是首先让我们快速看一下它的类型系统。它是定义任何编程语言的最重要的组件之一。
类型检查
Python 和 JavaScript 都是动态类型的,因为它们在运行时检查类型,当应用程序正在执行时,而不是在编译时。这很方便,因为您不必强制声明变量的类型,如int或str:
>>> data = 42 >>> data = 'This is a string'在这里,您为在计算机内存中具有不同表示的两种不同类型的实体重用相同的变量名。首先它是一个整数,然后它是一段文本。
注意:值得注意的是,一些静态类型语言,比如 Scala,也不需要显式的类型声明,只要可以从上下文中推断即可。
动态类型经常被误解为没有任何类型。这来自于这样一种语言,在这种语言中,变量就像一个只能容纳特定类型对象的盒子。在 Python 和 JavaScript 中,类型信息不是与变量联系在一起,而是与它所指向的对象联系在一起。这样的变量仅仅是一个别名,一个标签,或者一个指向内存中某个对象的指针。
缺少类型声明对于原型来说是很好的,但是在大型项目中,从维护的角度来看,这很快就会成为一个瓶颈。动态类型不太安全,因为在不经常使用的代码执行路径中检测不到错误的风险更高。
此外,对于人类和代码编辑者来说,这使得对代码的推理更加困难。Python 通过引入类型提示解决了这个问题,您可以用它来点缀变量:
data: str = 'This is a string'默认情况下,类型提示只提供信息值,因为 Python 解释器在运行时并不关心它们。然而,您可以向工具链添加一个单独的实用程序,比如一个静态类型检查器,以获得关于不匹配类型的早期警告。类型提示是完全可选的,这使得将动态类型代码与静态类型代码结合起来成为可能。这种方法被称为渐进打字。
渐进类型化的思想是从 TypeScript 借鉴来的,TypeScript 本质上是 JavaScript,其类型可以转换回普通的旧 JavaScript。
两种语言的另一个共同特征是使用 鸭类型 来测试类型兼容性。然而,Python 和 JavaScript 的一个显著不同之处是它们的类型检查机制的强度。
Python 通过拒绝对具有不兼容类型的对象采取行动,展示了强类型。例如,您可以使用加号(
+)运算符来添加数字,或者使用来连接字符串,但是您不能将这两者混合使用:
>>> '3' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
解释器不会隐式地将一种类型提升为另一种类型。你得自己决定,手工制作一个合适的类型铸件。如果你想要一个代数和,你应该这样做:
>>> int('3') + 2 5要将两个字符串连接在一起,您需要相应地转换第二个操作数:
>>> '3' + str(2)
>>> '32'
另一方面,JavaScript 使用弱类型,它根据一组规则自动强制类型。不幸的是,这些规则是不一致的,而且很难记住,因为它们依赖于操作符的优先级。
以前面的例子为例,当您使用加号(+)操作符时,JavaScript 会隐式地将数字转换为字符串:
> '3' + 2 '32'
只要这是你想要的行为,那就很好。否则,你会为试图找到一个逻辑错误的根本原因而焦虑不安。但是比这更可怕的是。让我们看看如果将操作符改为其他内容会发生什么:
> '3' - 2 1
现在是另一个操作数被转换成数字,所以最终结果不是字符串。如您所见,弱类型可能相当令人惊讶。
类型检查的力量不仅仅是黑白的。Python 位于这个范围的中间。例如,它会很高兴地将一个整数加到一个浮点数上,而在这种情况下, Swift 编程语言会产生一个错误。
注:强 vs 弱分型独立于静态 vs 动态分型。例如, C 编程语言同时是静态和弱类型的。
概括地说,JavaScript 是动态的,也是弱类型的,并且支持鸭类型。
JavaScript 类型
在 Python 中,一切都是一个对象,而 JavaScript 区分了原语和引用类型。它们在几个方面有所不同。
首先,只有几个预定义的基元类型需要关注,因为您不能自己创建。JavaScript 自带的大多数内置数据类型都是引用类型。
这些是 JavaScript 中唯一可用的原语类型:
booleannullnumberstringsymbol(从 ES6 开始)undefined
另一方面,这里有一些 JavaScript 现成的引用类型:
ArrayBooleanDateMapNumberObjectRegExpSetStringSymbol- (…)
还有一个提议在 ES11 中加入一个新的BigInt数字类型,一些浏览器已经支持了。除此之外,您可能定义的任何自定义数据类型都将是引用类型。
原语类型的变量存储在一个叫做栈的特殊内存区域,速度很快,但是大小有限,而且是短命的。相反,具有引用类型的对象是在堆上分配的,这仅受计算机上可用的物理内存量的限制。这类对象的生命周期要长得多,但访问速度稍慢。
基本类型是没有任何属性或方法可调用的空值。但是,一旦您尝试使用点符号访问一个对象,JavaScript 引擎就会立即将一个原始值包装在相应的包装器对象中:
> 'Lorem ipsum'.length 11
尽管 JavaScript 中的字符串文字是一种原始数据类型,但您可以检查它的.length属性。幕后发生的事情是,您的代码被替换为对String对象的构造函数的调用:
> new String('Lorem ipsum').length 11
构造函数是一种特殊的函数,它创建给定类型的新实例。可以看到,.length属性是由String对象定义的。这种包装机制被称为自动装箱,直接从 Java 编程语言复制而来。
原始类型和引用类型之间的另一个更明显的区别是它们是如何传递的。具体来说,每当您分配或传递一个基本类型的值时,您实际上在内存中创建了该值的一个副本。这里有一个例子:
> x = 42 > y = x > x++ // This is short for x += 1 > console.log(x, y) 43 42
赋值y = x在内存中创建新值。现在你有了由x和y引用的数字42的两个不同副本,所以增加一个不会影响另一个。
但是,当您传递对对象文字的引用时,两个变量都指向内存中的同一个实体:
> x = {name: 'Person1'} > y = x > x.name = 'Person2' > console.log(y) {name: 'Person2'}
Object是 JavaScript 中的引用类型。在这里,你有两个变量,x和y,引用一个Person对象的同一个实例。对其中一个变量的更改会反映在另一个变量中。
最后但不是最不重要的,原始类型是,这意味着一旦它们被初始化,你就不能改变它们的状态。每一次修改,比如增加一个数字或使文本大写,都会产生原始值的一个全新副本。虽然这有点浪费,但是有足够的理由使用不可变值,包括线程安全,更简单的设计,以及一致的状态管理。
注意:公平地说,这与 Python 处理传递对象的方式几乎相同,尽管它缺乏基本类型。可变类型如list和dict不创建副本,而不可变类型如int和str创建副本。
要在 JavaScript 中检查变量是基本类型还是引用类型,可以使用内置的typeof操作符:
> typeof 'Lorem ipsum' 'string' > typeof new String('Lorem ipsum') 'object'
对于引用类型,typeof操作符总是返回一个通用的"object"字符串。
注意:总是使用typeof操作符来检查变量是否为undefined。否则,你会发现自己有麻烦:
> typeof noSuchVariable === 'undefined' true > noSuchVariable === undefined ReferenceError: noSuchVariable is not defined
将一个不存在的变量与任何值进行比较都会抛出异常!
如果你想获得一个特定类型的更详细的信息,那么你有几个选择:
> today = new Date() > today.constructor.name 'Date' > today instanceof Date true > Date.prototype.isPrototypeOf(today) true
您可以尝试使用instanceof操作符检查一个对象的构造函数名,或者您可以使用.prototype属性测试它是否是从一个特定的父类型派生的。
类型层次
Python 和 JavaScript 是面向对象的编程语言。它们都允许您用封装了身份、状态和行为的对象来表达代码。虽然包括 Python 在内的大多数编程语言都使用基于类的继承,但 JavaScript 是少数不使用的语言之一。
注意:类是对象的模板。你可以考虑像饼干模具或对象工厂这样的类。
要在 JavaScript 中创建定制类型的层次结构,您需要熟悉原型继承。当您从更经典的继承模型进行转换时,这通常是最难理解的概念之一。如果你有 20 分钟的时间,那么你可以看一个很棒的关于原型的视频,它清楚地解释了这个概念。
注意:与 Python 相反,多重继承在 JavaScript 中是不可能的,因为任何给定的对象只能有一个原型。也就是说,你可以使用在 ES6 中引入的代理对象来减轻这个问题。
故事的主旨是 JavaScript 中没有类。嗯,从技术上来说,你可以使用 ES6 中引入的class关键字,但它纯粹是一个语法糖,让新来者更容易。原型仍然在幕后使用,因此有必要更仔细地观察它们,稍后您将有机会这样做。
功能类型
最后,函数是 JavaScript 和 Python 类型系统中有趣的一部分。在这两种语言中,它们通常被称为一等公民或一等对象,因为解释器不会将它们与其他数据类型区别对待。您可以将一个函数作为参数传递,从另一个函数返回,或者像普通值一样存储在变量中。
这是一个非常强大的特性,允许你定义高阶函数,并充分利用函数范式。对于函数是特殊实体的语言,你可以在设计模式的帮助下解决这个问题,比如策略模式。
就功能而言,JavaScript 甚至比 Python 更灵活。您可以定义一个匿名的函数表达式,其中充满了具有副作用的语句,而 Python 的 lambda 函数必须只包含一个表达式,不包含任何语句:
let countdown = 5; const id = setInterval(function() { if (countdown > 0) { console.log(`${countdown--}...`); } else if (countdown === 0) { console.log('Go!'); clearInterval(id); } }, 1000);
内置的 setInterval() 让你以毫秒为单位的时间间隔周期性地执行一个给定的函数,直到你用相应的 ID 调用clearInterval()为止。注意一个条件语句的使用和一个来自函数表达式外部范围的变量的突变。
JavaScript 语法
JavaScript 和 Python 都是高级脚本语言,在语法上有很多相似之处。尤其是他们的最新版本。也就是说,JavaScript 被设计成类似 Java,而 Python 是模仿 ABC 和 T2 的 Modula-3 语言。
代码块
Python 的标志之一是使用强制的缩进来表示代码块,这是非常不寻常的,并且不被新的 Python 转换者所接受。许多流行的编程语言,包括 JavaScript,都使用花括号或特殊的关键字来代替:
function fib(n) { if (n > 1) { return fib(n-2) + fib(n-1); } return 1; }
在 JavaScript 中,每一个由多行代码组成的代码块都需要一个开始{和一个结束},这给了你任意格式化代码的自由。你可以混合制表符和空格,不需要注意括号的位置。
不幸的是,这会导致混乱的代码和不同风格偏好的开发人员之间的宗派冲突。这使得代码审查很成问题。因此,您应该始终为您的团队建立编码标准,并一致地使用它们,最好是以自动化的方式。
注:你可以利用三元 if ( ?:)来简化上面的函数体,它有时被称为猫王运算符,因为它看起来像著名歌手的发型:
return (n > 1) ? fib(n-2) + fib(n-1) : 1;
这相当于 Python 中的一个条件表达式。
说到缩进,习惯上 JavaScript 代码的格式是每个缩进层次使用两个空格,而不是 Python 中推荐的四个空格。
语句
为了减少那些从 Java 或另一种 C 族编程语言转换过来的人的摩擦,JavaScript 用一个熟悉的分号 ( ;)终止语句。如果你曾经用这些语言中的一种编程过,那么你会知道在指令后面放一个分号变成了肌肉记忆:
alert('hello world');
不过,JavaScript 中不需要分号,因为解释器会猜测并自动为您插入一个。在大多数情况下,这是正确的,但有时可能会导致特殊的结果。
注意:你也可以在 Python 中使用分号!虽然它们不是很流行,但是它们有助于在一行中隔离多个语句:
import pdb; pdb.set_trace()
人们对是否明确使用分号有强烈的意见。虽然有一些重要的特例,但这在很大程度上只是一个惯例。
标识符
标识符,比如变量名或函数名,在 JavaScript 和 Python 中必须是字母数字的。换句话说,它们只能包含字母、数字和一些特殊字符。同时,它们不能以数字开头。虽然允许使用非拉丁字符,但通常应避免使用:
- 合法:
foo``foo42``_foo``$foo``fößar - 非法:
42foo
两种语言中的名字都区分大小写,所以像foo和Foo这样的变量是不同的。尽管如此,JavaScript 中的命名约定与 Python 中的略有不同:
| 计算机编程语言 | Java Script 语言 | |
|---|---|---|
| 类型 | ProjectMember |
ProjectMember |
| 变量、属性或函数 | first_name |
firstName |
一般来说,Python 建议对复合名称使用 lower _ case _ with _ underscores,也称为 snake_case ,这样各个单词就可以用下划线字符(_)隔开。该规则的唯一例外是类,其名称应该遵循大写单词或 Pascal 大小写风格。JavaScript 也对类型使用大写单词,但对其他类型使用 mixedCase,或小写字母。
评论
JavaScript 有单行和多行注释:
x++; // This is a single-line comment /*
This whole paragraph
is a comment and will
be ignored.
*/
您可以使用双斜线(//)在一行的任何地方开始注释,这类似于 Python 的散列符号(#)。虽然 Python 中没有多行注释,但是您可以通过在三重引号(''')中包含一段代码来创建一个多行字符串来模拟它们。或者,您可以将其包装在一个 if语句中,该语句永远不会计算为True:
if False:
...
例如,您可以使用这个技巧在调试期间临时禁用现有的代码块。
字符串文字
要在 JavaScript 中定义字符串文字,可以交替使用一对单引号(')或双引号("),就像在 Python 中一样。然而,在很长一段时间里,没有办法在 JavaScript 中定义多行字符串。只有 ES6 在 2015 年带来了模板文字,看起来像是从 Python 借来的 f 字符串和多行字符串的混合体:
var name = 'John Doe'; var message = `Hi ${name.split(' ')[0]},
We're writing to you regarding...
Kind regards,
Xyz
`;
模板以反勾号()开始,也称为重音符,而不是普通的引号。为了**插入**一个变量或者任何合法的表达式,你必须使用美元符号,后面跟着一对匹配的花括号:${...}`。这与 Python 的 f 字符串不同,后者不需要美元符号。
可变范围
当你在 JavaScript 中像在 Python 中一样定义变量时,你隐式地创建了一个全局变量。由于全局变量打破了封装,你应该很少需要它们!在 JavaScript 中声明变量的正确方式一直是通过var关键字:
x = 42; // This is a global variable. Did you really mean that? var y = 15; // This is global only when declared in a global context.
不幸的是,这并没有声明一个真正的局部变量,它有自己的问题,您将在下一节中发现。自 ES6 以来,有了一种更好的方法来分别用let和const关键字声明变量和常量:
> let name = 'John Doe'; > const PI = 3.14; > PI = 3.1415; TypeError: Assignment to constant variable.
与常量不同,JavaScript 中的变量不需要初始值。您可以稍后提供一个:
let name; name = 'John Doe';
当你去掉初始值时,你创建的是所谓的变量声明,而不是变量定义。这样的变量会自动接收一个特殊的值undefined,这是 JavaScript 中的原始类型之一。这在 Python 中是不同的,你总是定义除了变量注释之外的变量。但即使这样,这些变量在技术上也没有声明:
name: str
name = 'John Doe'
这样的注释不会影响变量的生命周期。如果你在赋值前引用了name,那么你会收到一个NameError异常。
开关语句
如果您一直在抱怨 Python 没有合适的 switch 语句,那么您会很高兴地得知 JavaScript 有:
// As with C, clauses will fall through unless you break out of them. switch (expression) { case 'kilo': value = bytes / 2**10; break; case 'mega': value = bytes / 2**20; break; case 'giga': value = bytes / 2**30; break; default: console.log(`Unknown unit: "${expression}"`); }
表达式可以计算任何类型,包括字符串,这在影响 JavaScript 的早期 Java 版本中并不总是如此。顺便说一下,你注意到上面代码片段中熟悉的取幂运算符 ( **)了吗?直到 2016 年的 ES7 才推出 JavaScript 版本。
枚举
在纯 JavaScript 中没有本地的枚举类型,但是您可以在 TypeScript 中使用enum类型,或者用类似下面的代码模拟一个类型:
const Sauce = Object.freeze({ BBQ: Symbol('bbq'), CHILI: Symbol('chili'), GARLIC: Symbol('garlic'), KETCHUP: Symbol('ketchup'), MUSTARD: Symbol('mustard') });
冻结对象可防止您添加或移除其属性。这与常量不同,常量可以是可变的!常数总是指向同一个对象,但是对象本身可能会改变它的值:
> const fruits = ['apple', 'banana']; > fruits.push('orange'); // ['apple', 'banana', 'orange'] > fruits = []; TypeError: Assignment to constant variable.
您可以向数组添加一个orange,它是可变的,但是您不能修改指向它的常量。
箭头功能
在 ES6 之前,你只能使用function关键字定义一个函数或者一个匿名的函数表达式:
function add(a, b) { return a + b; } let add = function(a, b) { return a + b; };
然而,为了减少样板代码并解决将函数绑定到对象的一个小问题,除了常规语法之外,现在还可以使用箭头函数:
let add = (a, b) => a + b;
注意,这里不再有关键字function,return 语句是隐式的。箭头符号(=>)将函数的参数与函数体分开。人们有时称它为胖箭头函数,因为它最初是从 CoffeeScript 借来的,coffee script 也有一个瘦箭头(->)对应函数。
箭头函数最适合小型匿名表达式,如 Python 中的 lambdas ,但如果需要,它们可以包含多个有副作用的语句:
let add = (a, b) => { const result = a + b; return result; }
当您想从 arrow 函数返回一个对象文字时,您需要用括号将它括起来,以避免代码块的模糊性:
let add = (a, b) => ({ result: a + b });
否则,函数体会对没有任何 return语句的代码块感到困惑,冒号会创建一个标记的语句,而不是一个键值对。
默认参数
从 ES6 开始,函数参数可以有默认值,就像 Python 中一样:
> function greet(name = 'John') { … console.log('Hello', name); … } > greet(); Hello John
然而,与 Python 不同的是,每次调用函数时都会解析默认值,而不是仅在定义函数时才解析。这使得安全使用可变类型以及动态引用运行时传递的其他参数成为可能:
> function foo(a, b=a+1, c=[]) { … c.push(a); … c.push(b); … console.log(c); … } > foo(1); [1, 2] > foo(5); [5, 6]
每次调用foo()时,它的默认参数都来自传递给函数的实际值。
可变函数
当您想在 Python 中声明一个参数数量可变的函数时,您可以利用特殊的*args语法。JavaScript 的等价物是用 spread ( ...)操作符定义的 rest 参数:
> function average(...numbers) { … if (numbers.length > 0) { … const sum = numbers.reduce((a, x) => a + x); … return sum / numbers.length; … } … return 0; … } > average(); 0 > average(1); 1 > average(1, 2); 1.5 > average(1, 2, 3); 2
扩展运算符也可用于组合可迭代序列。例如,您可以将一个数组的元素提取到另一个数组中:
const redFruits = ['apple', 'cherry']; const fruits = ['banana', ...redFruits];
根据您在目标列表中放置 spread 操作符的位置,您可以预先计划或追加元素,或者将它们插入到中间的某个位置。
析构分配
要将一个 iterable 解包为单个变量或常量,可以使用析构赋值:
> const fruits = ['apple', 'banana', 'orange']; > const [a, b, c] = fruits; > console.log(b); banana
同样,你可以析构甚至重命名对象属性:
const person = {name: 'John Doe', age: 42, married: true}; const {name: fullName, age} = person; console.log(`${fullName} is ${age} years old.`);
这有助于避免在一个作用域内定义的变量的名称冲突。
with报表
还有一种方法可以使用稍微古老的 with语句来深入到对象的属性:
const person = {name: 'John Doe', age: 42, married: true}; with (person) { console.log(`${name} is ${age} years old.`); }
它的工作原理类似于 Object Pascal 中的一个构造,其中一个局部作用域被给定对象的属性临时扩充。
注:Python vs JavaScript 中的with语句是假朋友。在 Python 中,使用一个with语句通过上下文管理器来管理资源。
由于这可能是晦涩的,with语句通常不被鼓励,甚至在严格模式中不可用。
可迭代程序、迭代器和生成器
自 ES6 以来,JavaScript 已经有了可迭代和迭代器协议以及生成器函数,它们看起来几乎与 Python 的可迭代、迭代器和生成器相同。要将常规函数转换成生成器函数,需要在关键字function后添加一个星号(*):
function* makeGenerator() {}
但是,你不能用箭头函数来生成生成器函数。
当你调用一个生成器函数时,它不会执行函数体。相反,它返回一个符合迭代器协议的挂起的生成器对象。为了推进您的生成器,您可以调用.next(),它类似于 Python 的内置next():
> const generator = makeGenerator(); > const {value, done} = generator.next(); > console.log(value); undefined > console.log(done); true
因此,您总是会得到一个具有两个属性的状态对象:后续值和一个指示生成器是否已耗尽的标志。当生成器中没有更多的值时,Python 抛出StopIteration异常。
要从生成器函数返回一些值,可以使用 yield 关键字或return关键字。生成器将继续输入值,直到不再有yield语句,或者直到您return过早地:
let shouldStopImmediately = false; function* randomNumberGenerator(maxTries=3) { let tries = 0; while (tries++ < maxTries) { if (shouldStopImmediately) { return 42; // The value is optional } yield Math.random(); } }
上面的生成器将不断产生随机数,直到它达到最大尝试次数,或者你设置一个标志使它提前终止。
Python 中的yield from表达式的等价物是yield*表达式,其中将迭代委托给另一个迭代器或可迭代对象:
> function* makeGenerator() { … yield 1; … yield* [2, 3, 4]; … yield 5; … } > const generator = makeGenerator() > generator.next(); {value: 1, done: false} > generator.next(); {value: 2, done: false} > generator.next(); {value: 3, done: false} > generator.next(); {value: 4, done: false} > generator.next(); {value: 5, done: false} > generator.next(); {value: undefined, done: true}
有趣的是,同时使用return和yield是合法的:
function* makeGenerator() { return yield 42; }
然而,由于语法限制,您必须使用括号才能在 Python 中达到相同的效果:
def make_generator():
return (yield 42)
为了解释发生了什么,您可以通过引入一个辅助常量来重写该示例:
function* makeGenerator() { const message = yield 42; return message; }
如果你知道 Python 中的协程,那么你会记得生成器对象既可以是生产者也可以是消费者。通过向.next()提供一个可选参数,可以将任意值发送到挂起的生成器中:
> function* makeGenerator() { … const message = yield 'ping'; … return message; … } > const generator = makeGenerator(); > generator.next(); {value: "ping", done: false} > generator.next('pong'); {value: "pong", done: true}
对.next()的第一次调用运行生成器,直到第一个yield表达式,恰好返回"ping"。第二个调用传递一个存储在常量中的"pong",并立即从生成器返回。
异步功能
上面探索的漂亮机制是异步编程和在 Python 中采用async和await关键字的基础。JavaScript 在 2017 年通过 ES8 引入了异步函数走了同样的路。
当生成器函数返回一种特殊的迭代器时,生成器对象,异步函数总是返回一个承诺,这是在 ES6 中首次引入的。承诺表示异步调用的未来结果,例如来自获取 API 的fetch()。
当您从异步函数返回任何值时,它会自动包装在一个 promise 对象中,该对象可以在另一个异步函数中等待:
async function greet(name) { return `Hello ${name}`; } async function main() { const promise = greet('John'); const greeting = await promise; console.log(greeting); // "Hello John" } main();
通常,您会await并一次性分配结果:
const greeting = await greet('John');
尽管您不能完全摆脱异步函数的承诺,但是它们显著地提高了代码的可读性。它开始看起来像同步代码,即使您的函数可以多次暂停和恢复。
与 Python 中异步代码的一个显著区别是,在 JavaScript 中,您不需要手动设置事件循环,它在后台隐式运行。JavaScript 天生就是异步的。
对象和构造函数
从本文前面的部分可以知道,JavaScript 没有类的概念。相反,它知道物体。您可以使用对象文字创建新对象,它们看起来像 Python 字典:
let person = { name: 'John Doe', age: 42, married: true };
它就像一个字典,您可以使用点语法或方括号来访问各个属性:
> person.age++; > person['age']; 43
对象属性不需要用引号括起来,除非它们包含空格,但这并不是一种常见的做法:
> let person = { … 'full name': 'John Doe' … }; > person['full name']; 'John Doe' > person.full name; SyntaxError: Unexpected identifier
就像字典和 Python 中的一些对象一样,JavaScript 中的对象有动态属性。这意味着您可以添加新属性或从对象中删除现有属性:
> let person = {name: 'John Doe'}; > person.age = 42; > console.log(person); {name: "John Doe", age: 42} > delete person.name; true > console.log(person); {age: 42}
从 ES6 开始,对象可以拥有带有计算名称的属性:
> let person = { … ['full' + 'Name']: 'John Doe' … }; > person.fullName; 'John Doe'
Python 字典和 JavaScript 对象允许包含函数作为它们的键和属性。有一些方法可以将这样的函数绑定到它们的所有者,这样它们的行为就像类方法一样。例如,您可以使用循环引用:
> let person = { … name: 'John Doe', … sayHi: function() { … console.log(`Hi, my name is ${person.name}.`); … } … }; > person.sayHi(); Hi, my name is John Doe.
sayHi()与它所属的对象紧密耦合,因为它通过名称引用了person变量。如果您要在某个时候重命名该变量,那么您必须遍历整个对象,并确保更新该变量名的所有出现。
一个稍微好一点的方法是利用暴露给函数的隐式this变量。根据调用函数的人的不同,this的值会有所不同:
> let jdoe = { … name: 'John Doe', … sayHi: function() { … console.log(`Hi, my name is ${this.name}.`); … } … }; > jdoe.sayHi(); Hi, my name is John Doe.
把一个硬编码的person替换成this后,类似于 Python 的self,变量名是什么就无所谓了,结果还是和以前一样。
注意:如果用箭头函数替换函数表达式,上面的例子就不起作用了,因为后者对this变量有不同的作用域规则。
这很好,但是一旦你决定引入更多同类的对象,你就必须重复每个对象的所有属性并重新定义所有函数。您更希望拥有的是一个用于Person对象的模板。
在 JavaScript 中创建自定义数据类型的规范方法是定义一个构造函数,这是一个普通的函数:
function Person() { console.log('Calling the constructor'); }
按照惯例,为了表示这样的函数有特殊的含义,您应该将大写单词后面的第一个字母大写,而不是通常的 mixedCase。
然而,在语法层面上,它只是一个可以正常调用的函数:
> Person(); Calling the constructor undefined
它的特别之处在于你如何称呼它:
> new Person(); Calling the constructor Person {}
当您在函数调用前添加new关键字时,它将隐式返回一个 JavaScript 对象的全新实例。这意味着你的构造函数不应该包含return语句。
解释器负责为新对象分配内存和搭建新对象,而构造器的作用是给对象一个初始状态。您可以使用前面提到的this关键字来引用正在构建的新实例:
function Person(name) { this.name = name; this.sayHi = function() { console.log(`Hi, my name is ${this.name}.`); } }
现在您可以创建多个不同的Person实体:
const jdoe = new Person('John Doe'); const jsmith = new Person('John Smith');
好吧,但是你仍然在复制所有Person类型实例的函数定义。构造函数只是一个将相同的值与单个对象挂钩的工厂。这是一种浪费,如果您在某个时候改变它,可能会导致不一致的行为。考虑一下这个:
> const jdoe = new Person('John Doe'); > const jsmith = new Person('John Smith'); > jsmith.sayHi = _ => console.log('What?'); > jdoe.sayHi(); Hi, my name is John Doe. > jsmith.sayHi(); What?
因为每个对象都有其属性的副本,包括函数,所以您必须小心地更新所有实例以保持一致的行为。否则,他们会做不同的事情,这通常不是你想要的。对象可能有不同的状态,但是它们的行为通常不会改变。
原型
根据经验,您应该将业务逻辑从关注数据的构造器转移到原型对象:
function Person(name) { this.name = name; } Person.prototype.sayHi = function() { console.log(`Hi, my name is ${this.name}.`); };
每个物体都有原型。您可以通过引用构造函数的.prototype属性来访问自定义数据类型的原型。它已经有了一些预定义的属性,比如.toString(),这些属性对于 JavaScript 中的所有对象都是通用的。您可以使用自定义方法和值添加更多属性。
当 JavaScript 寻找一个对象的属性时,它首先试图在该对象中找到它。一旦失败,它就转移到相应的原型。因此,原型中定义的属性在相应类型的所有实例中共享。
原型是链式的,所以属性查找会继续,直到链中不再有原型。这类似于通过继承的类型层次结构。
由于有了原型,您不仅可以在一个地方创建方法,还可以通过将它们附加到一个:
> Person.prototype.PI = 3.14; > new Person('John Doe').PI; 3.14 > new Person('John Smith').PI; 3.14
为了说明原型的强大功能,您可以尝试扩展现有对象的行为,甚至是内置的数据类型。让我们通过在 prototype 对象中指定一个新方法来为 JavaScript 中的string类型添加一个新方法:
String.prototype.toSnakeCase = function() { return this.replace(/\s+/g, '') .split(/(?<=[a-z])(?=[A-Z])/g) .map(x => x.toLowerCase()) .join('_'); };
它使用正则表达式将文本转换成 snake_case。突然之间,字符串变量、常量甚至字符串都可以从中受益:
> "loremIpsumDolorSit".toSnakeCase(); 'lorem_ipsum_dolor_sit'
然而,这是一把双刃剑。以类似的方式,有人可以在一个流行类型的原型中覆盖一个现有的方法,这将打破其他地方所做的假设。这样的猴子补丁在测试中可能有用,但在其他方面非常危险。
类别
从 ES6 开始,有了一种使用更熟悉的语法定义原型的替代方法:
class Person { constructor(name) { this.name = name; } sayHi() { console.log(`Hi, my name is ${this.name}.`); } }
尽管这看起来像是在定义一个类,但这只是在 JavaScript 中指定定制数据类型的一个方便的高级隐喻。在幕后,没有真正的类!出于这个原因,有些人甚至完全反对使用这种新语法。
您可以在您的类中拥有getter和setter,这类似于 Python 的类属性:
> class Square { … constructor(size) { … this.size = size; // Triggers the setter … } … set size(value) { … this._size = value; // Sets the private field … } … get area() { … return this._size**2; … } … } > const box = new Square(3); > console.log(box.area); 9 > box.size = 5; > console.log(box.area); 25
当您省略 setter 时,您创建了一个只读属性。然而,这是一种误导,因为您仍然可以像在 Python 中一样访问底层的private字段。
在 JavaScript 中封装内部实现的一种常见模式是立即调用函数表达式(life),看起来可能是这样的:
> const odometer = (function(initial) { … let mileage = initial; … return { … get: function() { return mileage; }, … put: function(miles) { mileage += miles; } … }; … })(33000); > odometer.put(65); > odometer.put(12); > odometer.get(); 33077
换句话说,它是一个调用自身的匿名函数。你也可以使用更新的箭头功能来创造生活:
const odometer = ((initial) => { let mileage = initial; return { get: _ => mileage, put: (miles) => mileage += miles }; })(33000);
这就是 JavaScript 在历史上如何模拟模块以避免全局名称空间中的名称冲突。如果没有 IIFE,它使用闭包和函数作用域只公开有限的面向公众的 API,那么一切都可以从调用代码中访问。
有时你想定义一个逻辑上属于你的类的工厂或实用函数。在 Python 中,你有@classmethod和@staticmethod装饰器,它们允许你将静态方法与类相关联。为了在 JavaScript 中达到同样的结果,您需要使用static方法修饰符:
class Color { static brown() { return new Color(244, 164, 96); } static mix(color1, color2) { return new Color(...color1.channels.map( (x, i) => (x + color2.channels[i]) / 2 )); } constructor(r, g, b) { this.channels = [r, g, b]; } } const color1 = Color.brown(); const color2 = new Color(128, 0, 128); const blended = Color.mix(color1, color2);
注意,目前没有定义静态类属性的方法,至少没有额外的 transpiler 插件。
当你从一个类extend到另一个类时,链接原型可以类似于类继承:
class Person { constructor(firstName, lastName) { this.firstName = firstName; this.lastName = lastName; } fullName() { return `${this.firstName} ${this.lastName}`; } } class Gentleman extends Person { signature() { return 'Mr. ' + super.fullName() } }
在 Python 中,你可以扩展不止一个类,但是在 JavaScript 中这是不可能的。要从父类中引用属性,您可以使用 super() ,它必须在构造函数中被调用来传递参数。
装修工
装饰器是 JavaScript 从 Python 复制的另一个特性。从技术上讲,它们仍然是 T2 的提案,可能会有变化,但是你可以使用 T4 的在线游乐场或当地的运输公司来测试它们。但是,需要注意的是,它们需要一些配置。根据所选择的插件及其选项,您会得到不同的语法和行为。
一些框架已经使用了装饰者的定制语法,这需要转换成普通的 JavaScript。如果您选择了 TC-39 提议,那么您将只能修饰类及其成员。JavaScript 中似乎不会有任何特殊的函数装饰语法。
JavaScript 怪癖
Brendan Eich 花了 10 天时间创建了后来成为 JavaScript 的原型。在一次商业会议上提交给利益相关者之后,这种语言被认为已经可以生产了,并且在很多年里没有经历太多的变化。
不幸的是,这使得这种语言因其古怪而声名狼藉。有些人甚至没有把 JavaScript 当成“真正的”编程语言,这让它成为了许多笑话和模因的牺牲品。
今天,这种语言比过去友好多了。然而,知道应该避免什么是值得的,因为许多遗留的 JavaScript 仍然在那里等着咬你。
伪数组
Python 的列表和元组被实现为传统意义上的数组,而 JavaScript 的Array类型与 Python 的字典有更多的共同点。那么什么是数组呢?
在计算机科学中,数组是一种占据连续内存块的数据结构,其元素是有序的,大小相同。这样,你可以用数字索引随机访问它们。
在 Python 中,列表是一个由典型的整数指针组成的数组,这些指针引用分散在不同内存区域的异构对象。
注意:对于 Python 中的低级数组,您可能有兴趣查看一下内置的 array 模块。
JavaScript 的数组是一个属性恰好是数字的对象。它们不一定紧挨着存放。然而,它们在迭代过程中保持正确的顺序。
在 JavaScript 中,当您从数组中删除一个元素时,会产生一个空白:
> const fruits = ['apple', 'banana', 'orange']; > delete fruits[1]; true > console.log(fruits); ['apple', empty, 'orange'] > fruits[1]; undefined
在移除其中一个元素后,数组的大小不会改变:
> console.log(fruits.length); 3
相反,即使数组短得多,也可以将新元素放在远处的索引处:
> fruits[10] = 'watermelon'; > console.log(fruits.length); 11 > console.log(fruits); ['apple', empty, 'orange', empty × 7, 'watermelon']
这在 Python 中是行不通的。
数组排序
Python 对于排序数据很聪明,因为它可以分辨出元素类型之间的区别。例如,当你对一列数字进行排序时,默认情况下,它会将它们按升序排列:
>>> sorted([53, 2020, 42, 1918, 7]) [7, 42, 53, 1918, 2020]然而,如果你想对一个字符串列表进行排序,那么它会神奇地知道如何比较这些元素,从而使它们按照字典顺序出现:
>>> sorted(['lorem', 'ipsum', 'dolor', 'sit', 'amet'])
['amet', 'dolor', 'ipsum', 'lorem', 'sit']
当你开始混合不同的类型时,事情就变得复杂了:
>>> sorted([42, 'not a number']) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'str' and 'int'到目前为止,您已经知道 Python 是一种强类型语言,不喜欢混合类型。另一方面,JavaScript 则相反。它会根据一些模糊的规则急切地转换不兼容类型的元素。
您可以使用
.sort()在 JavaScript 中进行排序:> ['lorem', 'ipsum', 'dolor', 'sit', 'amet'].sort(); ['amet', 'dolor', 'ipsum', 'lorem', 'sit']事实证明,对字符串进行排序的效果和预期的一样。让我们看看它是如何处理数字的:
> [53, 2020, 42, 1918, 7].sort(); [1918, 2020, 42, 53, 7]这里发生的事情是,数组元素被隐式转换为字符串,并按字典顺序排序。为了防止这种情况,您必须提供您的自定义排序策略,作为要比较的两个元素的函数,例如:
> [53, 2020, 42, 1918, 7].sort((a, b) => a - b); [7, 42, 53, 1918, 2020]您的策略和排序方法之间的约定是,您的函数应该返回三个值之一:
- 当两个元素相等时,归零
- 需要交换元素时的正数
- 元素顺序正确时的负数
这是其他语言中常见的模式,也是 Python 中排序的老方法。
自动插入分号
此时,您知道 JavaScript 中的分号是可选的,因为如果您自己不这样做,解释器会在每条指令的末尾自动插入分号。
在某些情况下,这可能会导致令人惊讶的结果:
function makePerson(name) { return ({ fullName: name, createdAt: new Date() }) }在这个例子中,您可能希望 JavaScript 引擎在函数的最后插入一个缺少的分号,就在对象文字的右括号后面。但是,当您调用该函数时,会发生以下情况:
> const jdoe = makePerson('John Doe'); > console.log(jdoe); undefined您的函数通过返回一个
undefined改变了预期的动作,因为插入了两个分号,而不是一个:function makePerson(name) { return; ({ fullName: name, createdAt: new Date() }); }如您所见,依赖分号是可选的这一事实会在您的代码中引入一些错误风险。另一方面,如果你开始到处放分号,那也没用。
要修复这个示例,您需要更改代码格式,以便返回值与
return语句在同一行开始:function makePerson(name) { return { fullName: name, createdAt: new Date() }; }在某些情况下,您不能依赖自动分号插入,而需要显式插入。例如,当您用括号开始一个新行时,不能省略分号:
const total = 2 + 3 (4 + 5).toString()由于缺少分号,这将产生一个运行时错误,使两行合并成一行:
const total = 2 + 3(4 + 5).toString();数值不能像函数一样被调用。
混乱的循环
JavaScript 中的循环尤其令人困惑,因为它们数量太多,而且看起来很像,而 Python 只有两个。JavaScript 中循环的主要类型是从 Java 移植而来的
for循环:const fruits = ['apple', 'banana', 'orange']; for (let i = 0; i < fruits.length; i++) { console.log(fruits[i]); }它有三个部分,都是可选的:
- 初始化:
let i = 0- 条件:
i < fruits.length- 清理:
i++第一部分在循环开始前只执行一次,它通常为计数器设置初始值。然后,在每次迭代之后,清理部分运行以更新计数器。紧接着,评估条件以确定循环是否应该继续。这大致相当于在 Python 中迭代索引列表:
fruits = ['apple', 'banana', 'orange'] for i in range(len(fruits)): print(fruits[i])注意 Python 为您做了多少工作。另一方面,暴露循环内部给了你很大的灵活性。这种类型的循环通常是确定性的,因为你知道它会从头开始迭代多少次。
在 JavaScript 中,您可以通过省略一个或多个部分来使传统的
for循环不确定,甚至使无限:for (;;) { // An infinite loop }然而,进行这种迭代的一种更惯用的方法是使用
while循环,这与 Python 中的循环非常相似:while (true) { const age = prompt('How old are you?'); if (age >= 18) { break; } }除此之外,JavaScript 还有一个
do...while循环,它保证至少运行一次,因为它在它的主体之后检查条件。您可以按以下方式重写此示例:let age; do { age = prompt('How old are you?'); } while (age < 18);除了使用
break关键字中途停止迭代之外,您还可以像在 Python 中一样使用continue关键字跳到下一次迭代:for (let i = 0; i < 10; i++) { if (i % 2 === 0) { continue; } console.log(i); }但是,您不能在循环中使用
else子句。您可能会尝试 JavaScript 中的
for...in循环,认为它会像 Pythonfor循环一样迭代值。虽然看起来很像,名字也差不多,但实际上表现却大相径庭!JavaScript 中的
for...in循环遍历给定对象的属性,包括原型链中的属性:> const object = {name: 'John Doe', age: 42}; > for (const attribute in object) { … console.log(`${attribute} = ${object[attribute]}`); … } name = John Doe age = 42如果您想排除附加到原型的属性,您可以调用
hasOwnProperty()。它将测试给定的属性是否属于一个对象实例。当您用一个数组填充
for...in循环时,它将遍历数组的数字索引。如您所知,JavaScript 中的数组只是美化了的字典:> const fruits = ['apple', 'banana', 'orange']; … for (const fruit in fruits) { … console.log(fruit); … } 0 1 2另一方面,数组公开了
.forEach(),它可以代替一个循环:const fruits = ['apple', 'banana', 'orange']; fruits.forEach(fruit => console.log(fruit));这是一个高阶函数,它接受一个回调,该回调将为数组中的每个元素运行。这种模式适合更大的范围,因为 JavaScript 通常采用函数式方法进行迭代。
注意:要测试一个对象中是否定义了一个属性,使用
in操作符:> 'toString' in [1, 2, 3]; true > '__str__' in [1, 2, 3]; false最后,当 ES6 规范引入 iterable 和 iterator 协议时,它允许实现一个期待已久的循环来迭代序列。然而,由于
for...in这个名字已经被使用,他们必须想出一个不同的名字。
for...of循环是 Python 中for循环的最近亲。使用它,您可以迭代任何可迭代的对象,包括字符串和数组:const fruits = ['apple', 'banana', 'orange']; for (const fruit of fruits) { console.log(fruit); }这可能是 Python 程序员在 JavaScript 中迭代的最直观的方式。
没有
new的构造函数让我们回到之前定义的
Person类型:function Person(name) { this.name = name; this.sayHi = function() { console.log(`Hi, my name is ${this.name}.`); } }如果您忘记正确调用前面有
new关键字的构造函数,那么它会无声地失败,留给您一个undefined变量:> let bob = Person('Bob'); > console.log(bob); undefined有一个小技巧可以保护你不犯这种错误。当你省略
new关键字时,将不会有任何对象被绑定,所以构造函数内部的this变量将指向全局对象,比如 web 浏览器中的window对象。您可以检测到这一点,并委托给有效的构造函数调用:> function Person(name) { … if (this === window) { … return new Person(name); … } … this.name = name; … this.sayHi = function() { … console.log(`Hi, my name is ${this.name}.`); … } … } > let person = Person('John Doe'); > console.log(person); Person {name: 'John Doe', sayHi: ƒ}这是您可能希望在构造函数中包含
return语句的唯一原因。注意:三重等号(
===)是有意的,与 JavaScript 中的弱类型有关。下面你会了解到更多。默认全局范围
除非您已经在全局范围内,否则当您没有在变量声明之前使用以下关键字之一时,变量会自动变成全局变量:
varletconst很容易陷入这个陷阱,尤其是当你来自 Python 的时候。例如,函数中定义的这样一个变量在函数外部将变得可见:
> function call() { … global = 42; … let local = 3.14 … } > call(); > console.log(global); 42 > console.log(local); ReferenceError: local is not defined有趣的是,在 Python 中决定你是声明局部变量还是全局变量的规则比这复杂得多。Python 中还有变量作用域的其他种类。
功能范围
这种怪癖只存在于遗留代码中,遗留代码使用
var关键字进行变量声明。你已经知道当一个变量被这样声明时,它就不是全局变量了。但是它也不会有局部范围。无论变量在函数中定义得有多深,它的作用域都是整个函数:
> function call() { … if (true) { … for (let i = 0; i < 10; i++) { … var notGlobalNorLocal = 42 + i; … } … } … notGlobalNorLocal--; … console.log(notGlobalNorLocal); … } > call(); 50在退出之前,变量在函数的顶层是可见的,并且仍然有效。然而,嵌套函数不会向外部作用域公开它们的变量:
> function call() { … function inner() { … var notGlobalNorLocal = 42; … } … inner(); … console.log(notGlobalNorLocal); … } > call(); ReferenceError: notGlobalNorLocal is not defined不过,情况正好相反。内部函数可以看到外部作用域中的变量,但是当您返回内部函数以备后用时,事情会变得更加有趣。这就产生了一个闭合。
吊装
这一条与前面的怪癖有关,同样适用于用臭名昭著的
var关键字声明的变量。让我们从一个小谜语开始:
var x = 42; function call() { console.log(x); // A = ??? var x = 24; console.log(x); // B = ??? } call(); console.log(x); // C = ???考虑一下结果会是什么:
- A =
42,B =24,C =42- A =
42,B =24,C =24- A =
24,B =24,C =42- A =
24,B =24,C =24SyntaxError: Identifier 'x' has already been declared当你在思考你的答案时,让我们仔细看看什么是吊装。简而言之,它是 JavaScript 中的一种隐式机制,将变量声明移动到函数的顶部,但仅限于那些使用
var关键字的变量声明。请记住,它移动的是声明,而不是定义。在一些编程语言中,比如 C,所有的变量都必须在函数的开头声明。其他语言,比如 Pascal,甚至更进一步,专门为变量声明开辟了一个特殊的部分。JavaScript 试图模仿这一点。
好了,准备好了吗?正确答案是以上都不是!它将打印以下内容:
- A =
undefined- B =
24- C =
42为了阐明这些结果背后的原因,您可以手动执行 JavaScript 在这种情况下会执行的提升:
var x = 42; function call() { var x; console.log(x); // A = undefined x = 24; console.log(x); // B = 24 } call(); console.log(x); // C = 42全局变量暂时被局部变量屏蔽,因为名称查找是向外的。函数内部的
x声明上移。当一个变量被声明但没有初始化时,它就有了undefined值。变量不是唯一受提升影响的构造。通常,当您在 JavaScript 中定义一个函数时,您甚至可以在定义它之前调用它:
call(); // Prints "hello" function call() { console.log('hello'); }这在交互式 shell 中是行不通的,在交互式 shell 中,每段代码都会被立即评估。
现在,当你使用
var关键字声明一个变量,并给这个变量分配一个函数表达式时,它将被提升:call(); // TypeError: call is not a function var call = function() { console.log('hello'); };因此,您的变量将保持
undefined,直到您初始化它。虚幻函数签名
JavaScript 中不存在函数签名。无论您声明哪种形式参数,它们对函数调用都没有影响。
具体来说,您可以将任意数量的参数传递给一个不需要任何东西的函数,它们将被忽略:
> function currentYear() { … return new Date().getFullYear(); … } > currentYear(42, 'foobar'); 2020您也可以避免传递看似必需的参数:
> function truthy(expression) { … return !!expression; … } > truthy(); false形参作为一个文档,允许你通过名字引用实参。否则,他们是不需要的。在任何函数中,您都可以访问一个特殊的
arguments变量,它代表传递的实际参数:> function sum() { … return [...arguments].reduce((a, x) => a + x); … } > sum(1, 2, 3, 4); 10
arguments是一个类似数组的对象,它是可迭代的,有数字索引,但不幸的是它没有附带.forEach()。要将其包装在数组中,可以使用 spread 运算符。这曾经是在 ES6 的 rest 参数之前在 JavaScript 中定义可变函数的唯一方式。
隐式类型强制
JavaScript 是一种弱类型编程语言,这表现在它能够隐式转换不兼容的类型。
当您比较两个值时,这可能会导致误报:
if ('2' == 2) { // Evaluates to true一般来说,为了安全起见,您应该选择严格比较运算符(
===):> '2' === 2; false > '2' !== 2; true该运算符比较操作数的值和类型。
没有整数类型
Python 有几个数据类型来表示数字:
intfloatcomplex之前的 Python 一代也有
long类型,最终合并成了int。其他编程语言甚至更慷慨,让您对内存消耗、取值范围、浮点精度以及对符号的处理进行细粒度控制。
JavaScript 只有一种数值类型:
Number,它对应于 Python 的float数据类型。实际上,它是一个 64 位双精度数字,符合 IEEE 754 规范。对于早期的 web 开发来说,这很简单,也足够了,但是今天它可能会引起一些问题。注意:在 JavaScript 中获取浮点数的整数部分,可以使用内置的
parseInt()。首先,在大多数情况下,这是非常浪费的 T2。如果你要用 JavaScript 的
Number来表示一个 FHD 视频帧的像素,那么你必须分配大约 50 MB 的内存。在支持字节流的编程语言中,比如 Python,你需要的内存只是这个数量的一小部分。其次,由于浮点数在计算机内存中的表示方式,它们会遭遇舍入误差。因此,它们不适合需要高精度的应用,比如货币计算:
> 0.1 + 0.2; 0.30000000000000004它们代表非常大和非常小的数字是不安全的:
> const x = Number.MAX_SAFE_INTEGER + 1; > const y = Number.MAX_SAFE_INTEGER + 2; > x === y; true但这还不是最糟糕的。毕竟,计算机内存一天比一天便宜,而且有办法规避舍入误差。
当 Node.js 流行起来后,人们开始用它来编写后端应用程序。他们需要一种访问本地文件系统的方法。一些操作系统通过任意整数来识别文件。有时候,这些数字在 JavaScript 中没有精确的表示,所以你不能打开文件,或者你在不知道的情况下读了一些随机文件。
为了解决 JavaScript 中处理大数的问题,将会有另一种原语类型可以可靠地表示任意大小的整数。一些网络浏览器已经支持这个提议:
> const x = BigInt(Number.MAX_SAFE_INTEGER) + 1n; > const y = BigInt(Number.MAX_SAFE_INTEGER) + 2n; > x === y; false因为不能将新的
BigInt数据类型与常规数字混合,所以必须包装它们或者使用特殊的文字:> typeof 42; 'number' > typeof 42n; 'bigint' > typeof BigInt(42); 'bigint'除此之外,
BigInt数字将与两个有点相关的有符号和无符号整数的类型化数组兼容:
BigInt64ArrayBigUint64Array虽然常规的
BigInt可以存储任意大的数字,但这两个数组的元素仅限于 64 位。
nullvsundefinedT2】编程语言提供了表示缺少值的方法。比如 Python 有
None,Java 有null,Pascal 有nil。在 JavaScript 中,你不仅可以得到null,还可以得到undefined。在一个值已经太多的情况下,用多种方法来表示缺失的值似乎有些奇怪:
我称之为我的十亿美元错误。这是 1965 年零引用的发明。(……)这导致了数不清的错误、漏洞和系统崩溃,在过去的四十年里,这些可能造成了数十亿美元的痛苦和损失。
— 东尼·霍尔
null和undefined的区别相当微妙。已声明但未初始化的变量将隐式获得undefined的值。另一方面,null值不会自动分配:let x; // undefined let y = null;您可以随时手动将
undefined值赋给变量:let z = undefined;在 ES6 之前,
null和undefined之间的区别经常被用来实现默认函数参数。一个可能的实现是这样的:function fn(required, optional) { if (typeof optional === 'undefined') { optional = 'default'; } // ... }如果——不管出于什么原因——您想为可选参数保留一个空值,那么您不能显式地传递
undefined,因为它将再次被默认值覆盖。为了区分这两种情况,您应该传递一个
null值:fn(42); // optional = "default" fn(42, undefined); // optional = "default" fn(42, null); // optional = null除了必须处理
null和undefined之外,您有时可能会遇到ReferenceError异常:> foobar; ReferenceError: foobar is not defined这表明你试图引用一个在当前作用域中没有声明的变量,而
undefined意味着声明但未初始化,而null意味着声明并初始化但值为空。
this范围Python 中的方法必须声明一个特殊的
self参数,除非它们是静态的或类方法。参数保存对类的特定实例的引用。它的名字可以是任何东西,因为它总是作为第一个位置参数被传递。在 JavaScript 中,像在 Java 中一样,您可以利用一个特殊的
this关键字,它对应于当前实例。但是当前的实例意味着什么呢?这取决于你如何调用你的函数。回想一下对象文字的语法:
> let jdoe = { … name: 'John Doe', … whoami: function() { … console.log(this); … } … }; > jdoe.whoami(); {name: "John Doe", whoami: ƒ}在函数中使用
this可以让您引用拥有该函数的特定对象,而无需硬编码变量名。无论函数是就地定义为匿名表达式,还是像下面这样的常规函数,都没有关系:> function whoami() { … console.log(this); … } > let jdoe = {name: 'John Doe', whoami}; > jdoe.whoami(); {name: "John Doe", whoami: ƒ}重要的是调用函数的对象:
> jdoe.whoami(); {name: "John Doe", whoami: ƒ} > whoami(); Window {…}在第一行中,您通过
jdoe对象的属性调用whoami()。在这种情况下,this的值与jdoe变量的值相同。然而,当你直接调用同一个函数时,this反而变成了全局对象。注意:这条规则不适用于用
new关键字调用的构造函数。在这种情况下,函数的this引用将指向新创建的对象。您可以将 JavaScript 函数视为附加到全局对象的方法。在 web 浏览器中,
window是全局对象,所以实际上,上面的代码片段是它的缩写:> jdoe.whoami(); {name: "John Doe", whoami: ƒ} > window.whoami(); Window {…}你看到这里的模式了吗?
默认情况下,函数中
this的值取决于点运算符前面的对象。只要你控制你的函数被调用的方式,一切都会好的。只有当你自己不调用函数时,它才成为一个问题,这是回调的常见情况。让我们定义另一个对象文字来演示这一点:
const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { this.items.forEach(function(item) { console.log(`${item} is a ${this.type}`); }); } };
collection是具有共同类型的元素的集合。目前,.show()不能像预期的那样工作,因为它没有揭示元素类型:> collection.show(); apple is a undefined banana is a undefined orange is a undefined虽然
this.items正确的引用了水果的数组,但是回调函数好像收到了不同的this引用。这是因为回调与对象文字无关。就好像它是在别处定义的一样:function callback(item) { console.log(`${item} is a ${this.type}`); } const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { this.items.forEach(callback); } };解决这个问题最直接的方法是用自定义变量或常量替换回调中的
this:const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { const that = this; this.items.forEach(function(item) { console.log(`${item} is a ${that.type}`); }); } };您将
this的值保存在一个本地常量中,回调将引用该常量。因为回调被定义为内部函数,所以它可以从外部作用域访问变量和常量。这对于一个独立的功能来说是不可能的。现在结果是正确的:
> collection.show(); apple is a fruit banana is a fruit orange is a fruit这种模式非常常见,以至于
.forEach()接受一个可选参数来替换回调中的this:const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { this.items.forEach(function(item) { console.log(`${item} is a ${this.type}`); }, this); } }; collection.show();这比您之前看到的自定义 hack 更优雅,也更通用,因为它允许您传递一个常规函数。虽然并不是 JavaScript 中的每个内置方法都如此优雅,但是还有三种方法可以修补
this引用:
.apply().bind().call()这些是函数对象上可用的方法。使用
.apply()和.call(),您可以调用一个函数,同时向它注入任意上下文。它们的工作方式相同,但使用不同的语法传递参数:> function whoami(x, y) { … console.log(this, x, y); … } > let jdoe = {name: 'John Doe'}; > whoami.apply(jdoe, [1, 2]); {name: "John Doe"} 1 2 > whoami.call(jdoe, 1, 2); {name: "John Doe"} 1 2在这三者中,
.bind()是最强大的,因为它允许您永久地更改this的值,以供将来调用。它的工作方式略有不同,因为它返回一个绑定到给定上下文的新函数:> const newFunction = whoami.bind(jdoe); > newFunction(1, 2); {name: "John Doe"} 1 2 > newFunction(3, 4); {name: "John Doe"} 3 4这有助于解决未绑定回调的早期问题:
const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { this.items.forEach(callback.bind(this)); } };你刚刚在 JavaScript 中读到的关于
this的内容都不适用于 ES6 中的箭头函数。顺便说一句,这很好,因为它消除了许多歧义。在 arrow 函数中没有上下文绑定,也没有隐式的this引用可用。相反,this被视为一个普通的变量,受词法范围规则的约束。让我们用箭头函数重写前面的一个例子:
> const collection = { … items: ['apple', 'banana', 'orange'], … type: 'fruit', … show: () => { … this.items.forEach((item) => { … console.log(`${item} is a ${this.type}`); … }); … } … }; > collection.show(); TypeError: Cannot read property 'forEach' of undefined如果您将两个函数都换成它们的 arrow 对应物,那么您会得到一个异常,因为作用域中不再有
this变量了。您可以保留外部函数,以便回调可以获取它的this引用:const collection = { items: ['apple', 'banana', 'orange'], type: 'fruit', show: function() { this.items.forEach((item) => { console.log(`${item} is a ${this.type}`); }); } }; collection.show();如您所见,箭头函数并不能完全取代传统函数。
这一部分仅仅是冰山一角。要了解更多关于古怪的 JavaScript 行为,请看一下棘手的代码示例,它也可以作为可安装的 Node.js 模块获得。另一个伟大的智慧来源是道格拉斯·克洛克福特的书 JavaScript:好的部分 ,其中也有一节专门讲述坏的和糟糕的部分。
下一步是什么?
作为一名 Pythonista,你知道掌握一门编程语言及其生态系统只是你通往成功之路的开始。一路上有更多的抽象概念需要把握。
文档对象模型
如果你打算做任何类型的客户端开发,那么你就不能逃避熟悉 DOM。
注意:您以前可能使用过相同的 DOM 接口来处理 Python 中的 XML 文档。
为了允许在 JavaScript 中操作 HTML 文档,网络浏览器公开了一个叫做 DOM 的标准接口,它包括各种对象和方法。当页面加载时,您的脚本可以通过预定义的
document实例访问文档的内部表示:const body = document.body;它是一个全局变量,你可以在代码的任何地方使用。
每个文档都是一个元素树。为了遍历这个层次,您可以从根开始,使用以下属性向不同的方向移动:
- 上升:
.parentElement- 左:
.previousElementSibling- 右:
.nextElementSibling- 往下:
.children``.firstElementChild``.lastElementChild这些属性在 DOM 树中的所有元素上都可以方便地获得,这对于递归遍历来说是完美的:
const html = document.firstElementChild; const body = html.lastElementChild; const element = body.children[2].nextElementSibling;如果不指向树中的元素,大多数属性将是
null。唯一的例外是.children属性,它总是返回一个可以为空的类似数组的对象。通常,您不知道元素在哪里。对象和树中的其他元素一样,有几个方法用于元素查找**。您可以通过标签名、ID 属性、CSS 类名甚至使用复杂的 CSS 选择器来搜索元素。*
*您可以一次查找一个元素,也可以一次查找多个元素。例如,要根据 CSS 选择器匹配元素,可以调用以下两种方法之一:
.querySelector(selector).querySelectorAll(selector)第一个方法返回第一次出现的匹配元素或
null,而第二个方法总是返回一个包含所有匹配元素的类似数组的对象。在document对象上调用这些方法将导致整个文档被搜索。您可以通过对以前找到的元素调用相同的方法来限制搜索范围:const div = document.querySelector('div'); // The 1st div in the whole document div.querySelectorAll('p'); // All paragraphs inside that div一旦有了对 HTML 元素的引用,就可以用它做很多事情,比如:
- 向其附加数据
- 改变它的风格
- 改变其内容
- 改变它的位置
- 让它互动
- 完全移除它
您还可以创建新元素并将它们添加到 DOM 树中:
const parent = document.querySelector('.content'); const child = document.createElement('div'); parent.appendChild(child);使用 DOM 最具挑战性的部分是熟练构建精确的 CSS 选择器。你可以使用网上提供的众多互动操场中的一个来练习和学习。
JavaScript 框架
DOM 接口是一组用于创建交互式用户界面的基本构件。它完成了工作,但是随着客户端代码的增长,它变得越来越难以维护。业务逻辑和表示层开始相交,违反了关注点分离原则,同时代码重复堆积。
网络浏览器由于没有统一的界面而火上浇油。有时候,你试图使用的特性并不是在所有主流浏览器上都可用,或者以不同的方式实现。为了确保一致的行为,您需要包含一个合适的样板代码,它隐藏了实现细节。
为了解决这些问题,人们开始共享 JavaScript 库,这些库封装了常见的模式,使浏览器 API 不那么不协调。有史以来最受欢迎的库是 jQuery ,直到最近,它的受欢迎程度还让今天的前端框架相形见绌:
Search Interest in JavaScript Frameworks According to Google Trends 虽然这不是一个完全真实的苹果和橘子的比较,但是它显示了 jQuery 曾经有多受欢迎。在高峰期,它的点击率超过了所有其他主要框架和库的总和。尽管有点老和不时髦,它仍然在许多遗留项目中使用,有时甚至在最近的项目中使用。
注意:一个库包含了你可以调用的底层实用函数,而一个框架拥有对你的代码生命周期的完全控制权。框架也强加了特定的应用程序结构,并且与库相比是重量级的。
jQuery 有很好的文档和最小的 API,因为只需要记住一个函数,即通用的
$()。您可以使用该函数来创建和搜索元素、更改它们的样式、处理事件等等。就一致性和对新兴网络标准的支持而言,现代网络浏览器要好得多。事实上,以至于有些人选择在没有任何前端框架帮助的情况下用普通 JavaScript 开发客户端代码。
那么,为什么大多数人倾向于使用前端框架呢?
使用框架有好处也有坏处,但是最大的好处似乎是它们允许你在更高的抽象层次上操作。不用考虑文档元素,您可以构建自包含且可重用的组件,这将提高您作为程序员的生产力。
这与框架提供的声明性状态管理相结合,允许您处理高度交互的客户端 JavaScript 应用程序的复杂性。如果你坚持在足够长的时间内不使用 JavaScript 框架,那么你通常会在不知不觉中构建自己的框架。
至于选择哪个流行的框架,那就看你的目标了。为了保持相关性,您应该先花时间学习纯 JavaScript,因为前端框架来来去去是出了名的快。
如果你想找一份前端开发人员甚至全栈工程师的工作,那么你应该看看职位描述。他们可能会希望有人在这些框架中有经验:
在撰写本文时,这些可以说是最流行的 JavaScript 框架。
结论
在本教程中,您了解了 JavaScript 的起源,它的替代品,以及该语言的发展方向。您通过仔细观察 Python 和 JavaScript 在语法、运行时环境、相关工具和术语方面的异同,对它们进行了比较。最后,你学会了如何在 JavaScript 中避免致命的错误。
您现在能够:
- 比较 Python 与 JavaScript
- 为工作选择正确的语言
- 用 JavaScript 编写一个 shell 脚本
- 在网页上生成动态内容
- 利用 JavaScript 生态系统
- 避免 JavaScript 中常见的陷阱
尝试将 Node.js 用于您的下一个脚本项目,或者在 web 浏览器中构建一个交互式客户端应用程序。当您将刚刚学到的知识与现有的 Python 知识结合起来时,前途无量。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python vs JavaScript for Python 开发者***********
Walrus 运算符:Python 3.8 赋值表达式
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 赋值表达式和使用海象运算符
Python 的每个新版本都为该语言添加了新的特性。对于 Python 3.8,最大的变化是增加了赋值表达式。具体来说,
:=操作符为在表达式中间分配变量提供了一种新的语法。这位操作员俗称海象操作员。本教程是对 walrus 操作符的深入介绍。您将了解语法更新的一些动机,并探索赋值表达式有用的一些例子。
在本教程中,您将学习如何:
- 识别海象运算符并理解其含义
- 了解海象运营商的用例
- 使用 walrus 运算符避免重复代码
- 在使用 walrus 运算符的代码和使用其他赋值方法的代码之间转换
- 理解使用 walrus 操作符时对向后兼容性的影响
- 在赋值表达式中使用合适的样式
请注意,本教程中的所有 walrus 操作符示例都需要使用 Python 3.8 或更高版本。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
海象运营商基础知识
让我们从程序员用来指代这种新语法的一些不同术语开始。您已经在本教程中看到了一些。
:=运算符的正式名称是赋值表达式运算符。在早期的讨论中,它被称为海象操作符,因为:=语法类似于侧卧的海象的眼睛和长牙。您可能还会看到被称为冒号等于运算符的:=运算符。用于赋值表达式的另一个术语是命名表达式。你好,海象!
为了获得关于赋值表达式的第一印象,请启动您的 REPL,使用下面的代码:

1>>> walrus = False
2>>> walrus
3False
4
5>>> (walrus := True)
6True
7>>> walrus
8True
第 1 行显示了传统的赋值语句,其中值False被赋值给walrus。接下来,在第 5 行,使用赋值表达式将值True赋给walrus。在第 1 行和第 5 行之后,您可以通过使用变量名walrus来引用赋值。
您可能想知道为什么在第 5 行使用括号,稍后在本教程中您将了解为什么需要括号。
注意:Python 中的一个语句是一个代码单位。一个表达式是一个可以被赋值的特殊语句。
例如,1 + 2是一个计算值为3的表达式,而number = 1 + 2是一个不计算值的赋值语句。虽然运行语句number = 1 + 2不会计算出3,但是会将值3分配给number。
在 Python 中,你经常会看到简单语句像 return语句import语句,还有复合语句像 if语句和函数定义。这些都是陈述,不是表达。
前面看到的使用walrus变量的两种类型的赋值之间有一个微妙但重要的区别。赋值表达式返回值,而传统的赋值不返回值。当 REPL 在第 1 行的walrus = False后不打印任何值,而在第 5 行的赋值表达式后打印出True时,您可以看到这一点。
在这个例子中,您可以看到关于 walrus 操作符的另一个重要方面。虽然看起来很新,但是:=操作符做了而不是没有它就不可能做的任何事情。它只是使某些构造更加方便,有时可以更清楚地传达代码的意图。
注意:你至少需要 Python 3.8 来试用本教程中的例子。如果你还没有安装 Python 3.8,并且你有可用的 Docker ,开始使用 Python 3.8 的一个快速方法是运行官方 Docker 镜像中的:
$ docker container run -it --rm python:3.8-slim
这将下载并运行 Python 3.8 的最新稳定版本。有关更多信息,请参见 Docker 中的运行 Python 版本:如何尝试最新的 Python 版本。
现在您对:=操作符是什么以及它能做什么有了一个基本的概念。它是赋值表达式中使用的操作符,可以返回被赋值的值,不像传统的赋值语句。要更深入地真正了解 walrus 操作符,请继续阅读,看看哪些地方应该使用,哪些地方不应该使用。
实施
像 Python 中的大多数新特性一样,赋值表达式是通过 Python 增强提案 (PEP)引入的。 PEP 572 描述了引入 walrus 操作符的动机、语法细节,以及可以使用:=操作符改进代码的例子。
这个 PEP 最初是由克里斯·安吉利科在 2018 年 2 月写的。经过一番激烈的讨论,PEP 572 于 2018 年 7 月被的吉多·范·罗苏姆接受。从那时起,圭多宣布他将辞去BDFL终身仁慈独裁者的角色。从 2019 年初开始,Python 已经由选举产生的指导委员会管理。
walrus 操作符是由 Emily Morehouse 实现的,并在 Python 3.8 的第一个 T2 alpha 版本中可用。
动机
在许多语言中,包括 C 语言及其派生语言,赋值语句的作用相当于表达式。这可能是非常强大的,也是令人困惑的错误的来源。例如,下面的代码是有效的 C,但没有按预期执行:
int x = 3, y = 8; if (x = y) { printf("x and y are equal (x = %d, y = %d)", x, y); }
在这里,if (x = y)将计算为 true,代码片段将打印出x and y are equal (x = 8, y = 8)。这是你期待的结果吗?你试图比较x和y。x的值是怎么从3变成8的?
问题是您使用了赋值操作符(=)而不是相等比较操作符(==)。在 C 语言中,x = y是一个计算结果为y的表达式。在本例中,x = y被评估为8,这在if语句的上下文中被视为真值。
看看 Python 中相应的例子。这段代码引出了 SyntaxError :
x, y = 3, 8
if x = y:
print(f"x and y are equal ({x = }, {y = })")
与 C 示例不同,这段 Python 代码给出了一个显式错误,而不是 bug。
Python 中赋值语句和赋值表达式之间的区别对于避免这类难以发现的错误非常有用。PEP 572 认为Python 更适合赋值语句和表达式有不同的语法,而不是把现有的赋值语句变成表达式。
支撑 walrus 操作符的一个设计原则是,使用=操作符的赋值语句和使用:=操作符的赋值表达式在不同的代码上下文中都是有效的。例如,您不能用 walrus 运算符进行简单的赋值:
>>> walrus := True File "<stdin>", line 1 walrus := True ^ SyntaxError: invalid syntax在许多情况下,您可以在赋值表达式两边添加括号(
()),使其成为有效的 Python:
>>> (walrus := True) # Valid, but regular statements are preferred
True
在这样的圆括号中不允许写带有=的传统赋值语句。这有助于您捕捉潜在的错误。
在本教程的后面,你将了解更多关于不允许使用 walrus 操作符的情况,但首先你将了解你可能想要使用它们的情况。
海象运营商用例
在本节中,您将看到 walrus 操作符可以简化代码的几个例子。所有这些例子的一个普遍主题是,你将避免不同类型的重复:
- 重复的函数调用会让你的代码比必要的要慢。
- 重复的语句会让你的代码难以维护。
- 重复调用穷举迭代器会使你的代码过于复杂。
您将看到海象操作员如何在这些情况下提供帮助。
调试
可以说,walrus 操作符的最佳用例之一是调试复杂表达式。假设您想要找出地球表面上两个位置之间的距离。一种方法是使用哈弗辛公式:

ϕ 代表纬度 λ 代表每个位置的经度。为了演示这个公式,你可以计算出奥斯陆 (59.9 N 10.8 E)和温哥华 (49.3 N 123.1 W)之间的距离如下:
>>> from math import asin, cos, radians, sin, sqrt >>> # Approximate radius of Earth in kilometers >>> rad = 6371 >>> # Locations of Oslo and Vancouver >>> ϕ1, λ1 = radians(59.9), radians(10.8) >>> ϕ2, λ2 = radians(49.3), radians(-123.1) >>> # Distance between Oslo and Vancouver >>> 2 * rad * asin( ... sqrt( ... sin((ϕ2 - ϕ1) / 2) ** 2 ... + cos(ϕ1) * cos(ϕ2) * sin((λ2 - λ1) / 2) ** 2 ... ) ... ) ... 7181.7841229421165正如你所看到的,从奥斯陆到温哥华的距离不到 7200 公里。
注意: Python 源代码通常使用 UTF-8 Unicode 编写。这允许您在代码中使用类似于
ϕ和λ的希腊字母,这在翻译数学公式时可能很有用。Wikipedia 展示了在您的系统上使用 Unicode 的一些替代方法。虽然支持 UTF-8(例如,在字符串中),Python 的变量名使用更受限制的字符集。例如,你不能在给你的变量命名时使用表情符号。那是一个好的限制!
现在,假设您需要仔细检查您的实现,并想看看哈弗辛项对最终结果有多大贡献。您可以从您的主代码中复制并粘贴该术语,以单独评估它。但是,您也可以使用
:=操作符为您感兴趣的子表达式命名:
>>> 2 * rad * asin(
... sqrt(
... (ϕ_hav := sin((ϕ2 - ϕ1) / 2) ** 2) ... + cos(ϕ1) * cos(ϕ2) * sin((λ2 - λ1) / 2) ** 2
... )
... )
...
7181.7841229421165
>>> ϕ_hav
0.008532325425222883
这里使用 walrus 操作符的好处是,您可以计算完整表达式的值,同时跟踪ϕ_hav的值。这允许您确认在调试时没有引入任何错误。
列表和词典
列表是 Python 中强大的数据结构,通常表示一系列相关的属性。类似地,字典在 Python 中广泛使用,对于结构化信息非常有用。
有时,在建立这些数据结构时,您最终会多次执行相同的操作。作为第一个例子,计算一列数字的一些基本的描述性统计数据,并将它们存储在字典中:
>>> numbers = [2, 8, 0, 1, 1, 9, 7, 7] >>> description = { ... "length": len(numbers), ... "sum": sum(numbers), ... "mean": sum(numbers) / len(numbers), ... } >>> description {'length': 8, 'sum': 35, 'mean': 4.375}注意,
numbers列表的总和和长度都被计算了两次。在这个简单的例子中,结果并不太糟糕,但是如果列表更大或者计算更复杂,您可能需要优化代码。为此,您可以首先将函数调用移出字典定义:
>>> numbers = [2, 8, 0, 1, 1, 9, 7, 7]
>>> num_length = len(numbers)
>>> num_sum = sum(numbers)
>>> description = {
... "length": num_length,
... "sum": num_sum,
... "mean": num_sum / num_length,
... }
>>> description
{'length': 8, 'sum': 35, 'mean': 4.375}
变量num_length和num_sum仅用于优化字典内的计算。通过使用 walrus 操作符,这个角色可以变得更加清晰:
>>> numbers = [2, 8, 0, 1, 1, 9, 7, 7] >>> description = { ... "length": (num_length := len(numbers)), ... "sum": (num_sum := sum(numbers)), ... "mean": num_sum / num_length, ... } >>> description {'length': 8, 'sum': 35, 'mean': 4.375}
num_length和num_sum现在被定义在description的定义内。对于阅读这段代码的人来说,这是一个明确的暗示,这些变量只是用来优化这些计算,以后不会再使用。注意:
num_length和num_sum变量的范围在有 walrus 操作符的例子和没有 walrus 操作符的例子中是相同的。这意味着在这两个例子中,变量都是在定义了description之后才可用的。尽管这两个例子在功能上非常相似,但是使用赋值表达式的一个好处是,
:=操作符传达了这些变量的意图作为一次性优化。在下一个例子中,您将使用
wc实用程序的基本实现来计算文本文件中的行、单词和字符:1# wc.py 2 3import pathlib 4import sys 5 6for filename in sys.argv[1:]: 7 path = pathlib.Path(filename) 8 counts = ( 9 path.read_text().count("\n"), # Number of lines 10 len(path.read_text().split()), # Number of words 11 len(path.read_text()), # Number of characters 12 ) 13 print(*counts, path)这个脚本可以读取一个或几个文本文件,并报告每个文件包含多少行、单词和字符。下面是代码中发生的事情的分类:
- 第 6 行遍历用户提供的每个文件名。
sys.argv是一个列表,包含命令行中给出的每个参数,以脚本名开始。关于sys.argv的更多信息,可以查看 Python 命令行参数。- 第 7 行将每个文件名字符串翻译成一个对象。在一个
Path对象中存储一个文件名可以让你方便地阅读下一行的文本文件。- 第 8 行到第 12 行构建一个计数元组来表示一个文本文件中的行数、单词数和字符数。
- Line 9 读取一个文本文件,通过计算新行来计算行数。
- 第 10 行读取一个文本文件,通过分割空白来计算字数。
- 第 11 行读取一个文本文件,通过查找字符串的长度来计算字符数。
- 第 13 行将所有三个计数连同文件名一起打印到控制台。
*counts语法解包counts元组。在这种情况下,print()语句相当于print(counts[0], counts[1], counts[2], path)。要查看
wc.py的运行,您可以使用脚本本身,如下所示:$ python wc.py wc.py 13 34 316 wc.py换句话说,
wc.py文件由 13 行、34 个单词和 316 个字符组成。如果您仔细观察这个实现,您会注意到它远非最佳。特别是,对
path.read_text()的调用重复了三次。这意味着每个文本文件被读取三次。您可以使用 walrus 运算符来避免重复:# wc.py import pathlib import sys for filename in sys.argv[1:]: path = pathlib.Path(filename) counts = [ (text := path.read_text()).count("\n"), # Number of lines len(text.split()), # Number of words len(text), # Number of characters ] print(*counts, path)文件的内容被分配给
text,在接下来的两次计算中被重用。该程序的功能仍然相同:$ python wc.py wc.py 13 36 302 wc.py与前面的例子一样,另一种方法是在定义
counts之前定义text:# wc.py import pathlib import sys for filename in sys.argv[1:]: path = pathlib.Path(filename) text = path.read_text() counts = [ text.count("\n"), # Number of lines len(text.split()), # Number of words len(text), # Number of characters ] print(*counts, path)虽然这比前一个实现多了一行,但它可能提供了可读性和效率之间的最佳平衡。赋值表达式操作符并不总是可读性最好的解决方案,即使它使你的代码更加简洁。
列出理解
列表理解对于构建和过滤列表非常有用。它们清楚地陈述了代码的意图,并且通常运行得相当快。
有一个列表理解用例,其中 walrus 操作符特别有用。假设您想要对列表中的元素应用一些计算量很大的函数
slow(),并对结果值进行过滤。您可以像下面这样做:numbers = [7, 6, 1, 4, 1, 8, 0, 6] results = [slow(num) for num in numbers if slow(num) > 0]在这里,您过滤了
numbers列表,留下了应用slow()的正面结果。这段代码的问题是这个昂贵的函数被调用了两次。对于这种情况,一个非常常见的解决方案是重写您的代码,使用一个显式的
for循环:results = [] for num in numbers: value = slow(num) if value > 0: results.append(value)这个只会调用
slow()一次。不幸的是,代码现在变得更加冗长,代码的意图也更加难以理解。列表理解清楚地表明您正在创建一个新列表,而这更多地隐藏在显式的for循环中,因为几行代码将列表创建和.append()的使用分开。此外,列表理解比重复调用.append()运行得更快。你可以通过使用一个
filter()表达式或者一种双列表理解来编写一些其他的解决方案:# Using filter results = filter(lambda value: value > 0, (slow(num) for num in numbers)) # Using a double list comprehension results = [value for num in numbers for value in [slow(num)] if value > 0]好消息是每个号码只能调用一次
slow()。坏消息是代码的可读性在两个表达式中都受到了影响。弄清楚在双列表理解中实际发生了什么需要相当多的挠头。本质上,第二个
for语句仅用于给slow(num)的返回值命名为value。幸运的是,这听起来像是可以用赋值表达式来执行的事情!您可以使用 walrus 运算符重写列表理解,如下所示:
results = [value for num in numbers if (value := slow(num)) > 0]请注意,
value := slow(num)两边的括号是必需的。这个版本是有效的、可读的,并且很好地传达了代码的意图。注意:你需要在列表理解的
if子句上添加赋值表达式。如果您试图用对slow()的另一个调用来定义value,那么它将不起作用:
>>> results = [(value := slow(num)) for num in numbers if value > 0]
NameError: name 'value' is not defined
这将引发一个NameError,因为在理解开始时,在表达式之前评估了if子句。
让我们看一个稍微复杂一点的实际例子。说要用 真蟒提要找真蟒播客最后几集的标题。
您可以使用 Real Python Feed 阅读器下载关于最新 Real Python 出版物的信息。为了找到播客的剧集标题,你将使用第三方解析包。首先将两者安装到您的虚拟环境中:
(venv) $ python -m pip install realpython-reader parse
您现在可以阅读由 Real Python 发布的最新标题:
>>> from reader import feed >>> feed.get_titles() ['The Walrus Operator: Python 3.8 Assignment Expressions', 'The Real Python Podcast – Episode #63: Create Web Applications Using Anvil', 'Context Managers and Python's with Statement', ...]播客标题以
"The Real Python Podcast"开头,所以您可以在这里创建一个模式,Parse 可以使用它来识别它们:
>>> import parse
>>> pattern = parse.compile(
... "The Real Python Podcast – Episode #{num:d}: {name}"
... )
预先编译模式可以加快以后的比较,尤其是当您想要反复匹配相同的模式时。您可以使用pattern.parse()或pattern.search()来检查字符串是否匹配您的模式:
>>> pattern.parse( ... "The Real Python Podcast – Episode #63: " ... "Create Web Applications Using Anvil" ... ) ... <Result () {'num': 63, 'name': 'Create Web Applications Using Anvil'}>注意,Parse 能够挑选出播客的集号和集名。因为您使用了
:d格式说明符,所以剧集编号被转换为整数数据类型。让我们回到手头的任务上来。为了列出所有最近的播客标题,您需要检查每个字符串是否匹配您的模式,然后解析出剧集标题。第一次尝试可能是这样的:
>>> import parse
>>> from reader import feed
>>> pattern = parse.compile(
... "The Real Python Podcast – Episode #{num:d}: {name}"
... )
>>> podcasts = [ ... pattern.parse(title)["name"]
... for title in feed.get_titles() ... if pattern.parse(title)
... ]
>>> podcasts[:3]
['Create Web Applications Using Only Python With Anvil',
'Selecting the Ideal Data Structure & Unravelling Python\'s "pass" and "with"',
'Scaling Data Science and Machine Learning Infrastructure Like Netflix']
尽管它可以工作,但您可能会注意到之前看到的相同问题。您对每个标题进行了两次解析,因为您过滤掉了与您的模式匹配的标题,然后使用相同的模式来挑选剧集标题。
就像你之前做的那样,你可以通过使用一个显式的for循环或者一个双列表理解来重写列表理解,从而避免双重工作。然而,使用 walrus 操作符更加简单:
>>> podcasts = [ ... podcast["name"] ... for title in feed.get_titles() ... if (podcast := pattern.parse(title)) ... ]赋值表达式可以很好地简化这类列表理解。它们帮助您保持代码的可读性,同时避免两次执行潜在的昂贵操作。
注意:真正的 Python 播客有自己独立的 RSS 提要,如果你只想了解播客的信息,你应该使用它。你可以用下面的代码得到所有的剧集标题:
from reader import feed podcasts = feed.get_titles("https://realpython.com/podcasts/rpp/feed")请参见真正的 Python 播客,了解使用您的播客播放器收听该播客的选项。
在本节中,您已经关注了使用 walrus 操作符重写列表理解的例子。如果你发现你需要在一个字典理解,一个集合理解,或者一个生成器表达式中重复一个操作,同样的原则也适用。
以下示例使用生成器表达式来计算长度超过
50个字符的剧集标题的平均长度:
>>> import statistics
>>> statistics.mean(
... title_length
... for title in podcasts
... if (title_length := len(title)) > 50
... )
65.425
生成器表达式使用赋值表达式来避免两次计算每个剧集标题的长度。
While 循环
Python 有两种不同的循环构造: for循环和 while循环。当您需要迭代一个已知的元素序列时,通常会使用for循环。另一方面,当你事先不知道需要循环多少次时,就使用while循环。
在while循环中,你需要定义并检查循环顶部的结束条件。当您需要在执行检查之前做一些设置时,这有时会导致一些笨拙的代码。下面是一个选择题测验程序的片段,它要求用户从几个有效答案中选择一个来回答问题:
question = "Will you use the walrus operator?"
valid_answers = {"yes", "Yes", "y", "Y", "no", "No", "n", "N"}
user_answer = input(f"\n{question} ") while user_answer not in valid_answers:
print(f"Please answer one of {', '.join(valid_answers)}")
user_answer = input(f"\n{question} ")
这是可行的,但不幸的是重复了相同的input()行。在检查它是否有效之前,需要从用户那里获得至少一个答案。然后在while循环中再次调用input()来请求第二个答案,以防最初的user_answer无效。
如果你想让你的代码更容易维护,用一个while True循环重写这种逻辑是很常见的。不是让检查成为主while语句的一部分,而是稍后在循环中与显式break一起执行检查:
while True:
user_answer = input(f"\n{question} ")
if user_answer in valid_answers:
break
print(f"Please answer one of {', '.join(valid_answers)}")
这具有避免重复的优点。然而,实际的支票现在更难发现了。
赋值表达式通常可以用来简化这类循环。在本例中,您现在可以将支票与while放在一起,这样更有意义:
while (user_answer := input(f"\n{question} ")) not in valid_answers:
print(f"Please answer one of {', '.join(valid_answers)}")
while语句有点密集,但代码现在更清楚地传达了意图,没有重复的行或看似无限的循环。
您可以展开下面的框来查看多项选择测验程序的完整代码,并自己尝试几个关于 walrus 操作员的问题。
此脚本运行一个多项选择测验。您将按顺序回答每个问题,但每次回答的顺序都会改变:
# walrus_quiz.py
import random
import string
QUESTIONS = {
"What is the name of PEP 572?": [
"Assignment Expressions",
"Named Expressions",
"The Walrus Operator",
"The Colon Equals Operator",
],
"Which one of these is an invalid use of the walrus operator?": [
"[y**2 for x in range(10) if y := f(x) > 0]",
"print(y := f(x))",
"(y := f(x))",
"any((y := f(x)) for x in range(10))",
],
}
num_correct = 0
for question, answers in QUESTIONS.items():
correct = answers[0]
random.shuffle(answers)
coded_answers = dict(zip(string.ascii_lowercase, answers))
valid_answers = sorted(coded_answers.keys())
for code, answer in coded_answers.items():
print(f" {code}) {answer}")
while (user_answer := input(f"\n{question} ")) not in valid_answers: print(f"Please answer one of {', '.join(valid_answers)}")
if coded_answers[user_answer] == correct:
print(f"Correct, the answer is {user_answer!r}\n")
num_correct += 1
else:
print(f"No, the answer is {correct!r}\n")
print(f"You got {num_correct} correct out of {len(QUESTIONS)} questions")
请注意,第一个答案被认为是正确的。您可以自己在测验中添加更多问题。欢迎在教程下面的评论区与社区分享您的问题!
您通常可以通过使用赋值表达式来简化while循环。最初的 PEP 向展示了来自标准库的一个例子,它表达了同样的观点。
证人和反例
在迄今为止看到的例子中,:=赋值表达式操作符与旧代码中的=赋值操作符做的工作基本相同。您已经看到了如何简化代码,现在您将了解一种不同类型的用例,这种新的操作符使之成为可能。
在本节中,您将学习如何在调用 any() 时找到见证人,使用一个巧妙的技巧,不使用 walrus 操作符是不可能的。在这个上下文中,见证是满足检查并导致any()返回True的元素。
通过应用类似的逻辑,你还将学习如何在使用 all() 时找到反例。在这个上下文中,反例是不满足检查并导致all()返回False的元素。
为了处理一些数据,请定义以下城市名称列表:
>>> cities = ["Vancouver", "Oslo", "Houston", "Warsaw", "Graz", "Holguín"]您可以使用
any()和all()来回答关于您的数据的问题:
>>> # Does ANY city name start with "H"?
>>> any(city.startswith("H") for city in cities)
True
>>> # Does ANY city name have at least 10 characters?
>>> any(len(city) >= 10 for city in cities)
False
>>> # Do ALL city names contain "a" or "o"?
>>> all(set(city) & set("ao") for city in cities)
True
>>> # Do ALL city names start with "H"?
>>> all(city.startswith("H") for city in cities)
False
在每一种情况下,any()和all()给你简单的True或False答案。如果你也有兴趣看一个城市名称的例子或反例呢?看看是什么导致了你的True或False结果会很好:
-
有没有以
"H"开头的城市名?是的,因为
"Houston"是从"H"开始的。 -
所有的城市名称都是以
"H"开头吗?不会,因为
"Oslo"不是以"H"开头的。
换句话说,你想要一个证人或反例来证明答案。
在早期版本的 Python 中,捕捉一个any()表达式的见证并不直观。如果你在一个列表上调用any(),然后意识到你还需要一个见证,你通常需要重写你的代码:
>>> witnesses = [city for city in cities if city.startswith("H")] >>> if witnesses: ... print(f"{witnesses[0]} starts with H") ... else: ... print("No city name starts with H") ... Houston starts with H在这里,首先捕获所有以
"H"开头的城市名称。然后,如果至少有一个这样的城市名,就打印出以"H"开头的第一个城市名。注意,这里你实际上没有使用any(),即使你在列表理解中做了类似的操作。通过使用
:=运算符,您可以在any()表达式中直接找到见证:
>>> if any((witness := city).startswith("H") for city in cities):
... print(f"{witness} starts with H")
... else:
... print("No city name starts with H")
...
Houston starts with H
您可以在any()表达式中捕获一个见证。这个工作原理有点微妙,依赖于any()和all()使用短路评估:他们只检查必要的项目来确定结果。
注意:如果你想检查是否所有的城市名称都以字母"H"开头,那么你可以通过用all()替换any()并更新print()函数来报告第一个没有通过检查的项目来寻找反例。
通过将.startswith("H")封装在一个函数中,您可以更清楚地看到发生了什么,该函数还打印出正在检查的项目:
>>> def starts_with_h(name): ... print(f"Checking {name}: {name.startswith('H')}") ... return name.startswith("H") ... >>> any(starts_with_h(city) for city in cities) Checking Vancouver: False Checking Oslo: False Checking Houston: True True注意
any()实际上并没有检查cities中的所有项目。它只检查项目,直到找到满足条件的项目。组合:=操作符和any()通过迭代地将每个被检查的条目分配给witness来工作。然而,只有最后一个这样的项目存在,并显示哪个项目是最后由any()检查的。即使当
any()返回False时,也会发现一个见证:
>>> any(len(witness := city) >= 10 for city in cities)
False
>>> witness
'Holguín'
然而,在这种情况下,witness没有给出任何见解。'Holguín'不包含十个或更多字符。见证只显示最后评估的项目。
Walrus 运算符语法
在 Python 中赋值不是表达式的一个主要原因是赋值操作符(=)和相等比较操作符(==)的视觉相似性可能会导致错误。在引入赋值表达式时,我们花了很多心思来避免 walrus 操作符的类似错误。正如前面提到的,一个重要的特点是:=操作符永远不允许直接替代=操作符,反之亦然。
正如您在本教程开始时看到的,您不能使用普通的赋值表达式来赋值:
>>> walrus := True File "<stdin>", line 1 walrus := True ^ SyntaxError: invalid syntax使用赋值表达式只赋值在语法上是合法的,但前提是要添加括号:
>>> (walrus := True)
True
尽管这是可能的,但是,这确实是一个最好的例子,说明您应该远离 walrus 操作符,而使用传统的赋值语句。
PEP 572 显示了其他几个例子,其中:=操作符要么是非法的,要么是不被鼓励的。下面的例子都举了一个SyntaxError:
>>> lat = lon := 0 SyntaxError: invalid syntax >>> angle(phi = lat := 59.9) SyntaxError: invalid syntax >>> def distance(phi = lat := 0, lam = lon := 0): SyntaxError: invalid syntax在所有这些情况下,使用
=会更好。接下来的例子类似,都是法律代码。然而,在以下任何情况下,walrus 操作符都不会改进您的代码:
>>> lat = (lon := 0) # Discouraged
>>> angle(phi = (lat := 59.9)) # Discouraged
>>> def distance(phi = (lat := 0), lam = (lon := 0)): # Discouraged
... pass
...
这些例子都没有让你的代码更易读。相反,您应该使用传统的赋值语句单独完成额外的赋值。有关推理的更多细节,请参见 PEP 572 。
在一个用例中,:=字符序列已经是有效的 Python。在 f 字符串中,冒号(:)用于将值与它们的格式规范分开。例如:
>>> x = 3 >>> f"{x:=8}" ' 3'本例中的
:=看起来确实像一个 walrus 操作符,但是效果完全不同。为了解释 f 弦内部的x:=8,表达式被分解为三个部分:x、:和=8。这里,
x是数值,:作为分隔符,=8是格式规范。根据 Python 的格式规范迷你语言,在这个上下文中=指定了一个对齐选项。在这种情况下,该值在宽度为8的字段中用空格填充。要在 f 字符串中使用赋值表达式,需要添加括号:
>>> x = 3
>>> f"{(x := 8)}"
'8'
>>> x
8
这将按预期更新x的值。然而,你最好使用 f 弦之外的传统赋值。
让我们看看赋值表达式非法的其他一些情况:
-
属性和项目分配:您只能分配给简单的名称,不能分配给带点或索引的名称:
>>> (mapping["hearts"] := "♥") SyntaxError: cannot use assignment expressions with subscript >>> (number.answer := 42) SyntaxError: cannot use assignment expressions with attribute`这将失败,并显示一条描述性错误消息。没有简单的解决方法。
>>> lat, lon := 59.9, 10.8 SyntaxError: invalid syntax`如果您在整个表达式周围添加括号,它将被解释为一个包含三个元素
lat、59.9和10.8的三元组。 -
增广赋值:你不能像
+=一样使用 walrus 操作符结合增广赋值操作符。这就引出了一个SyntaxError:>>> count +:= 1 SyntaxError: invalid syntax`最简单的解决方法是显式地进行增强。例如,你可以做
(count := count + 1)。 PEP 577 最初描述了如何给 Python 添加增强赋值表达式,但是这个提议被撤回了。>>> number = 3 >>> if square := number ** 2 > 5: ... print(square) ... True`square绑定到整个表达式number ** 2 > 5。换句话说,square得到的是值True,而不是number ** 2的值,这正是我们的意图。在这种情况下,可以用括号分隔表达式:>>> number = 3 >>> if (square := number ** 2) > 5: ... print(square) ... 9`括号使得
if语句更加清晰,并且实际上是正确的。还有最后一个问题。当使用 walrus 操作符分配元组时,您总是需要在元组周围使用括号。比较以下分配:
>>> walrus = 3.7, False >>> walrus (3.7, False) >>> (walrus := 3.8, True) (3.8, True) >>> walrus 3.8 >>> (walrus := (3.8, True)) (3.8, True) >>> walrus (3.8, True)`注意,在第二个例子中,
walrus采用值3.8,而不是整个元组3.8, True。这是因为:=操作符比逗号绑定得更紧密。这可能看起来有点烦人。然而,如果:=操作符的约束没有逗号紧,那么在带有多个参数的函数调用中就不可能使用 walrus 操作符。 -
针对海象操作符的风格建议与用于赋值的
=操作符基本相同。首先,在代码中总是在:=操作符周围添加空格。第二,必要时在表达式两边使用括号,但避免添加不需要的额外括号。
赋值表达式的一般设计是在它们有用的时候使它们易于使用,但是在它们可能使你的代码混乱的时候避免过度使用它们。
海象运营商的陷阱
walrus 运算符是一种新语法,仅在 Python 3.8 及更高版本中可用。这意味着您编写的任何使用:=语法的代码都只能在最新版本的 Python 上运行。
如果需要支持旧版本的 Python,就不能发布使用赋值表达式的代码。有一些项目,像 walrus ,可以自动将 walrus 操作符翻译成与旧版本 Python 兼容的代码。这允许您在编写代码时利用赋值表达式,并且仍然分发与更多 Python 版本兼容的代码。
海象运营商的经验表明:=不会彻底改变 Python。相反,在有用的地方使用赋值表达式可以帮助您对代码进行一些小的改进,这对您的整体工作有好处。
很多时候你可以使用 walrus 操作符,但是这并不一定能提高代码的可读性和效率。在这种情况下,您最好以更传统的方式编写代码。
结论
现在您已经知道了新的 walrus 操作符是如何工作的,以及如何在自己的代码中使用它。通过使用:=语法,您可以避免代码中不同类型的重复,并使您的代码更有效、更易于阅读和维护。同时,你不应该到处使用赋值表达式。它们只会在某些用例中帮助你。
在本教程中,您学习了如何:
- 识别海象运算符并理解其含义
- 了解海象运营商的用例
- 使用 walrus 运算符避免重复代码
- 在使用 walrus 运算符的代码和使用其他赋值方法的代码之间转换
- 理解使用 walrus 操作符时对向后兼容性的影响
- 在赋值表达式中使用合适的样式
要了解更多关于赋值表达式的细节,请参见 PEP 572 。您还可以查看 PyCon 2019 演讲 PEP 572:海象运营商,其中达斯汀·英格拉姆概述了海象运营商以及围绕新 PEP 的讨论。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 赋值表达式和使用海象运算符*****
使用 Flask 的 Python Web 应用程序——第一部分
原文:https://realpython.com/python-web-applications-with-flask-part-i/
请注意:这是来自 Real Python 的 Michael Herman 和来自 De Deo Designs 的 Python 开发者 Sean Vieira 的合作作品。
本系列文章:
- 第一部分:应用设置← 当前文章T3】
- 第二部分:设置用户账户、模板、静态文件
- 第三部分:测试(单元和集成)、调试和错误处理
更新时间:2013 年 11 月 17 日
最近,由于一场精彩的演出,我重新向自己介绍了 Flask ,这是“Python 的微框架”。这是一个伟大的小框架;不幸的是,像辛纳特拉(它的灵感来源)一样,从小的“独立”应用程序过渡到大的应用程序是很困难的。有很多样板文件(包括我自己的烧瓶样板文件)可以帮助你更容易地完成过渡。然而,使用样板文件并不能帮助我们理解样板文件约定的“为什么”。
在查看了现有的教程后,我想,“一定有更好的方法”——然后我看到了米格尔·格林伯格的大型教程。为他的文章构建一个应用而不是样板文件给我留下了深刻的印象。因此,在本系列教程中,我们将构建一个我们自己的中型应用程序,并附带生成一个样板文件。希望当我们完成时,我们会对 Flask 提供的东西以及我们可以围绕它构建的东西有更好的理解。
我们在建造什么
本系列将关注名为烧瓶追踪的网络分析解决方案的开发。本系列的目标是拥有一个工作应用程序,使用户能够:
- 向应用程序注册。
- 将网站添加到他们的帐户。
- 在他们的网站上安装跟踪代码,以便在事件发生时跟踪各种事件。
- 查看关于其网站事件活动的报告。
最终,我们的目标(除了拥有符合上述餐巾纸规范的工作应用程序之外)是:
开始
本系列假设您已经对 Python 和 Flask 有所了解。你应该已经熟悉了 Python 的教程中的一切,熟悉了命令行(或者,至少,熟悉了 pip ),你也应该读过 Flask 的快速入门和教程。如果你想要更多的练习,更进一步,阅读我的烧瓶入门教程这里。也就是说,如果你是 Python 和 Flask 的新手,你应该仍然能够跟上。
我们今天的目标是实现应用程序的核心——跟踪对站点的访问。我们将允许多个网站,但我们不会担心用户或访问控制。
基本原则
在我们深入研究之前,我想谈一谈指导我们开发的一些原则——我们不会太深入地研究这些最佳实践的“为什么”,但是在可能的情况下,我们会提供一些文章的链接,解释这些实践为我们提供了什么。请将本系列中的所有观点视为强观点,弱观点。
Python 的禅宗
如果你还不知道,Python 有一个“开发哲学”,叫做 Python 的禅(也称为 PEP 20) 。要阅读它,只需打开 python 解释器并键入:
>>> import this然后你会看到:
蒂姆·彼得斯的《Python 之禅》
漂亮总比难看好。
显性比隐性好。
简单比复杂好。
复杂总比复杂好。
扁平的比嵌套的好。
疏比密好。
可读性很重要。
特例不足以特殊到打破规则。
虽然实用性战胜了纯粹性。
错误永远不会无声无息地过去。
除非明确沉默。
面对暧昧,拒绝猜测的诱惑。
应该有一种——最好只有一种——显而易见的方法来做这件事。
尽管这种方式一开始可能并不明显,除非你是荷兰人。
现在总比没有好。
虽然永远也不会比现在的对好。
如果实现很难解释,这是一个坏主意。
如果实现很容易解释,这可能是一个好主意。
名称空间是一个非常棒的想法——让我们多做一些吧!
这些是工作的依据。阅读丹尼尔·格林菲尔德关于理查德·琼斯的 19 篇 Pythonic 论文的笔记以获得更详细的解释。
首字母缩略词爆炸
我们还将使我们的开发实践符合以下原则:
- 虽然我们可以构建许多工具来使我们的生活变得更容易,但我们将把自己局限于构建使我们的应用程序工作所必需的工具,记住在许多情况下 YAGNI(你不会需要它)。
- 也就是说,当我们遇到我们在应用程序中重复的代码模式时,我们将重构我们的代码以保持其干燥。
- 我们从 YAGNI 穿越到 DRY 的触发器将是三振出局,你重构原则。在三个地方使用一个模式将使它有资格被提取。两种用途仍归 YAGNI 所有。(在大型项目中,许多人建议修改这条规则——当您需要重用它时,重构它。)
关于存储库结构的说明
在这个系列中,你可以在 Github 的
flask-tracking库中找到这些练习的完整代码。本教程的每个部分在资源库中都有一个分支和一个版本。该部分的代码在 part-1 分支中。如果您选择签出存储库,那么只需运行:$ git checkout part-N其中
N是该代码对应的文章编号(因此对于这篇文章使用git checkout part-1)。开始项目
前面的问题解决后,让我们开始创建一个新文件夹来保存我们的项目并激活一个虚拟环境(如果您不确定如何设置虚拟环境,请花一点时间查看 Flask 快速入门中的指南):
$ mkdir flask-tracking $ cd flask-tracking $ virtualenv --no-site-packages venv $ source venv/bin/activate依赖性
就像《爱丽丝梦游仙境》一样,我们希望我们的依赖关系“恰到好处”。太多的依赖,我们将无法在离开代码库一个月后不花一周时间审查文档的情况下继续工作。依赖太少,我们将花费时间开发除了我们的应用程序以外的一切。为了确保我们保持依赖关系“恰到好处”,我们将使用以下(不完美的)规则——每个依赖关系必须很好地解决至少一个困难的问题。我们将从对三个库的依赖开始——Flask 本身用于管理请求/响应周期, Flask-WTF 用于 CSRF 保护和数据验证,最后 Flask-SQLAlchemy 用于数据库连接池和对象/关系映射器。这是我们的 requirements.txt 文件:
Flask==0.10.1 Flask-SQLAlchemy==1.0 Flask-WTF==0.9.3现在我们可以运行
pip install -r requirements.txt将我们的需求安装到我们的虚拟环境中。超越小
大多数 Flask 应用程序开始都很小,然后随着项目范围的扩大而重构。对于我们这些没有编写并重构过小型 Flask 应用程序的人来说,我们在
part-0分支中有一个跟踪应用程序的单模块版本(总共 145 行*)。如果你已经在 Flask 中编写了一个单模块应用程序,请随意跳到下一节。对于那些留下来的人,请
git checkout part-0或者从库的发布部分下载第 0 部分。应用程序中应该有一个单独的模块tracking.py,整体结构应该如下所示:├── flask-tracking.db ├── requirements.txt ├── templates │ ├── data_list.html │ ├── helpers │ │ ├── forms.html │ │ └── tables.html │ ├── index.html │ ├── layout.html │ └── validation_error.html └── tracking.py如果你打开它,你看到的第一件事是:
_cwd = dirname(abspath(__file__)) SECRET_KEY = 'flask-session-insecure-secret-key' SQLALCHEMY_DATABASE_URI = 'sqlite:///' + join(_cwd, 'flask-tracking.db') SQLALCHEMY_ECHO = True WTF_CSRF_SECRET_KEY = 'this-is-not-random-but-it-should-be' app = Flask(__name__) app.config.from_object(__name__) db = SQLAlchemy(app)我们设置了一些基本的配置设置——
SECRET_KEY用于签署 Flask 的会话,SQLALCHEMY_DATABASE_URI是我们数据库的路径(我们现在使用的是SQLite),WTF_CSRF_SECRET_KEY用于签署 WTForms 的 CSRF 令牌。我们初始化一个新的 Flask 应用程序,告诉它用当前模块中所有的ALL_CAPS符号来配置自己(用我们的app.config.from_object调用)。然后,我们用应用程序初始化 Flask-SQLAlchemy 扩展。从那里开始,这是一个非常简单的方法——我们建立我们的模型:
class Site(db.Model): __tablename__ = 'tracking_site' id = db.Column(db.Integer, primary_key=True) base_url = db.Column(db.String) visits = db.relationship('Visit', backref='tracking_site', lazy='select') def __repr__(self): return '<Site %r>' % (self.base_url) def __str__(self): return self.base_url class Visit(db.Model): # ... snip ...和表单:
class SiteForm(Form): base_url = fields.StringField() class VisitForm(Form): # ... snip ...以及利用这些模型和形式的路线:
@app.route("/") def index(): site_form = SiteForm() visit_form = VisitForm() return render_template("index.html", site_form=site_form, visit_form=visit_form) @app.route("/site", methods=("POST", )) def add_site(): form = SiteForm() if form.validate_on_submit(): site = Site() form.populate_obj(site) db.session.add(site) db.session.commit() flash("Added site") return redirect(url_for("index")) return render_template("validation_error.html", form=form)还有几个帮助器函数可以将 SQLAlchemy 查询对象转换为模板的数据列表,然后在模块底部,我们设置了一个
main块来创建我们的表(如果它们不存在),并在调试模式下运行应用程序:if __name__ == "__main__": app.debug = True db.create_all() app.run()如果你运行
python tracking.py,然后在你的浏览器中导航到 localhost:5000 ,你会看到一个极其简单的应用程序。它是功能性的(你可以创建网站和添加访问),但它没有用户和访问控制——每个人都可以看到一切。
然而,正如你所看到的,
tracking.py已经是一个功能的混合体——控制器、模型、助手和命令行设置都被塞进了一个文件中。将它分解成独立的功能区域会使它更容易维护。此外,重新打包这个应用程序将使我们更清楚地知道在哪里添加我们想要的所有其他特性(用户、访问控制等)。).当你完成了第 0 部分的代码,运行git checkout part-1进入下一部分。一个存放所有东西的地方
让我们首先为我们的应用程序创建一个包(我们将使用 Flask 文档中描述的结构的修改形式,用于包和蓝图):
flask-tracking/ # Our working root flask_tracking/ # The application package __init__.py requirements.txt # Meta data needed by our application README.md # and developers请记住,我们今天的目标只是跟踪网站的访问,我们将避免为我们的跟踪代码创建一个子包…然而(记住,YAGNI,直到你需要它)。让我们继续添加单独的
models、forms和views模块来分别保存我们的领域模型、数据转换层和视图代码。让我们也创建一个templates子目录来保存我们将用来渲染站点的资源。最后,我们将添加一个配置文件和一个脚本来运行应用程序。现在我们应该有一个如下所示的目录结构:flask-tracking/ flask_tracking/ templates/ # Holds Jinja templates __init__.py # General application setup forms.py # User data to domain data mappers and validators models.py # Domain models views.py # well ... controllers, really. config.py # Configuration, just like it says on the cover README.md requirements.txt run.py # `python run.py` to bring the application up locally.领域模型
我们的领域模型很简单——一个站点有一个根 URL,一次访问有关于访问者的元数据(浏览器、IP 地址、URL 等)。).我们包含了
__repr__方法,在命令行上给我们更好的细节(<Visit for site ID 1: / - 2013-11-09 14:10:11>比<package.module.Visit object at 0x12345>更有用)。Site包含了一个__str__方法来控制我们在下拉菜单中显示站点列表时显示的内容。from flask.ext.sqlalchemy import SQLAlchemy db = SQLAlchemy() class Site(db.Model): __tablename__ = 'tracking_site' id = db.Column(db.Integer, primary_key=True) base_url = db.Column(db.String) visits = db.relationship('Visit', backref='tracking_site', lazy='select') def __repr__(self): return '<Site {:d} {}>'.format(self.id, self.base_url) def __str__(self): return self.base_url class Visit(db.Model): __tablename__ = 'tracking_visit' id = db.Column(db.Integer, primary_key=True) browser = db.Column(db.String) date = db.Column(db.DateTime) event = db.Column(db.String) url = db.Column(db.String) ip_address = db.Column(db.String) site_id = db.Column(db.Integer, db.ForeignKey('tracking_site.id')) def __repr__(self): r = '<Visit for site ID {:d}: {} - {:%Y-%m-%d %H:%M:%S}>' return r.format(self.site_id, self.url, self.date)注意,我们还没有用任何应用程序初始化我们的
flask.ext.sqlalchemy对象,所以这些模型没有绑定到这个特定的应用程序(这种灵活性带来了一些小代价,我们很快就会遇到)。数据转换层
我们的
forms代码是标准的 WTForms,只有一个例外。如果你看一下VisitForm:from .models import Site # ... snip ... class VisitForm(Form): browser = fields.StringField() date = fields.DateField() event = fields.StringField() url = fields.StringField() ip_address = fields.StringField("IP Address") site = QuerySelectField(query_factory=lambda: Site.query.all())你会注意到,我们需要将
Site.query.all包装在lambda中,而不是原样传递。由于在构建VisitForm时,我们的db没有绑定到应用程序,所以我们不能访问Site.query。创建一个只有在VisitForm被实例化时才调用Site.query的函数(例如,在我们的视图中我们调用form = VisitForm())确保了我们只有在可以访问 Flask 应用程序实例时才能访问Site.query。视图
我们的视图是应用程序中最复杂的部分(看看我们导入了多少依赖项):
from flask import Blueprint, flash, Markup, redirect, render_template, url_for from .forms import SiteForm, VisitForm from .models import db, query_to_list, Site, Visit我们从创建蓝图开始(我们也可以
from flask_tracking import app使用应用程序,但是我更喜欢在我的应用程序超出单个文件时切换到蓝图)tracking = Blueprint("tracking", __name__)然后,我们使用普通的 decorator 语法将我们的视图映射到 routes 我添加了关于一些功能的注释,在这些功能中,我们正在做的事情可能不是非常清楚(或者我们正在重复我们自己,并且我们以后会想要重构):
@tracking.route("/") def index(): site_form = SiteForm() visit_form = VisitForm() return render_template("index.html", site_form=site_form, visit_form=visit_form) @tracking.route("/site", methods=("POST", )) def add_site(): # The create a form, validate the form, # map the form to a model, save the model, # and redirect pattern will be pretty common # throughout the application. This is an area # that is ripe for improvement and refactoring. form = SiteForm() if form.validate_on_submit(): site = Site() form.populate_obj(site) db.session.add(site) db.session.commit() flash("Added site") return redirect(url_for(".index")) return render_template("validation_error.html", form=form) @tracking.route("/site/<int:site_id>") def view_site_visits(site_id=None): site = Site.query.get_or_404(site_id) query = Visit.query.filter(Visit.site_id == site_id) data = query_to_list(query) title = "visits for {}".format(site.base_url) return render_template("data_list.html", data=data, title=title) @tracking.route("/visit", methods=("POST", )) @tracking.route("/site/<int:site_id>/visit", methods=("POST",)) def add_visit(site_id=None): if site_id is None: # This is only used by the visit_form on the index page. form = VisitForm() else: site = Site.query.get_or_404(site_id) # WTForms does not coerce obj or keyword arguments # (otherwise, we could just pass in `site=site_id`) # CSRF is disabled in this case because we will *want* # users to be able to hit the /site/:id endpoint from other sites. form = VisitForm(csrf_enabled=False, site=site) if form.validate_on_submit(): visit = Visit() form.populate_obj(visit) visit.site_id = form.site.data.id db.session.add(visit) db.session.commit() flash("Added visit for site {}".format(form.site.data.base_url)) return redirect(url_for(".index")) return render_template("validation_error.html", form=form) @tracking.route("/sites") def view_sites(): query = Site.query.filter(Site.id >= 0) data = query_to_list(query) # The header row should not be linked results = [next(data)] for row in data: row = [_make_link(cell) if i == 0 else cell for i, cell in enumerate(row)] results.append(row) return render_template("data_list.html", data=results, title="Sites") _LINK = Markup('<a href="{url}">{name}</a>') def _make_link(site_id): url = url_for(".view_site_visits", site_id=site_id) return _LINK.format(url=url, name=site_id)这给了我们一个应用程序,让我们在主页上添加一个站点或一次访问,查看站点列表,并查看每个站点的访问。我们实际上还没有在应用程序中注册蓝图,所以…
应用程序设置
…向前到
__init__.py:from flask import Flask from .models import db from .views import tracking app = Flask(__name__) app.config.from_object('config') # Add the `constants` variable to all Jinja templates. @app.context_processor def provide_constants(): return {"constants": {"TUTORIAL_PART": 1}} db.init_app(app) app.register_blueprint(tracking)我们创建一个应用程序,配置它,在应用程序上注册我们的 Flask-SQLAlchemy 实例,最后注册我们的蓝图。现在弗拉斯克知道如何处理我们的路线。
配置和命令行运行程序
我们的配置更上一层楼,启用 Flask 的会话并设置我们的 SQLite 数据库:
# config.py from os.path import abspath, dirname, join _cwd = dirname(abspath(__file__)) SECRET_KEY = 'flask-session-insecure-secret-key' SQLALCHEMY_DATABASE_URI = 'sqlite:///' + join(_cwd, 'flask-tracking.db') SQLALCHEMY_ECHO = True如果数据库表不存在,我们的应用程序运行器会创建数据库表,并在调试模式下运行应用程序:
# run.py #!/usr/bin/env python from flask_tracking import app, db if __name__ == "__main__": app.debug = True # Because we did not initialize Flask-SQLAlchemy with an application # it will use `current_app` instead. Since we are not in an application # context right now, we will instead pass in the configured application # into our `create_all` call. db.create_all(app=app) app.run()参见 Flask-SQLAlchemy 的 上下文介绍 如果你想更好地理解为什么我们需要将
app传递给db.create_all调用。一切都各就各位
现在我们应该能够运行
python run.py并看到我们的应用程序启动。去 localhost:5000 创建一个网站进行测试。然后,要验证其他人是否可以添加对该网站的访问,请尝试运行:$ curl --data 'event=BashVisit&browser=cURL&url=/&ip_address=1.2.3.4&date=2013-11-09' localhost:5000/site/1/visit从命令行。当您返回应用程序时,单击“站点”,然后为您的站点单击“1”。页面上应显示一次访问:
总结
这个帖子到此为止。我们现在有一个工作应用程序,可以添加网站和访问记录。我们仍然需要添加用户帐户、易于使用的客户端跟踪 API 和报告。
在第二部分中,我们将添加用户,访问控制,并使用户能够从他们自己的网站添加访问。我们将探索编写模板、保持模型和表单同步以及处理静态文件的更多最佳实践。
在第三部分中,我们将探索为我们的应用程序编写测试,记录和调试错误。
在第四部分中,我们将进行一些测试驱动的开发,使我们的应用程序能够接受付款并显示简单的报告。
在第五部分中,我们将编写一个 RESTful JSON API 供其他人使用。
在第六部分中,我们将介绍使用 Fabric 和基本 A/B 特性测试的自动化部署(在 Heroku 上)。
最后,在第七部分中,我们将介绍如何用文档、代码覆盖率和质量度量工具来保护您的应用程序。
感谢阅读,下次继续收听!*****
使用 Flask 的 Python Web 应用程序–第二部分
原文:https://realpython.com/python-web-applications-with-flask-part-ii/
请注意:这是来自 Real Python 的 Michael Herman 和来自 De Deo Designs 的 Python 开发者 Sean Vieira 的合作作品。
本系列文章:
- 第一部分:应用程序设置
- 第二部分:设置用户账号、模板、静态文件← 本期文章
- 第三部分:测试(单元和集成)、调试和错误处理
欢迎回到烧瓶跟踪开发系列!对于那些刚刚加入我们的人来说,我们正在实现一个符合这个餐巾纸规范的网络分析应用。对于所有在家的人来说,你可以查看今天的代码:
$ git checkout v0.2或者,你可以从 Github 的发布页面下载。那些刚刚加入我们的人可能也希望读一读关于存储库结构的注释。
家务管理
快速回顾一下,在我们的上一篇文章中,我们设置了一个基本的应用程序,它可以通过简单的 web 界面或 HTTP 添加站点并记录访问。
今天,我们将添加用户,访问控制,并使用户能够使用跟踪信标从他们自己的网站添加访问。我们还将深入探讨编写模板、保持模型和表单同步以及处理静态文件的一些最佳实践。
从单包装到多包装
上次我们离开应用程序时,目录结构看起来像这样:
flask-tracking/ flask_tracking/ templates/ # Holds Jinja templates __init__.py # General application setup forms.py # User data to domain data mappers and validators models.py # Domain models views.py # well ... controllers, really. config.py # Configuration, just like it says on the cover README.md requirements.txt run.py # `python run.py` to bring the application up locally.为了清楚起见,让我们将现有的
forms、models和views移到一个tracking子包中,并为我们的User特定功能创建另一个子包,我们称之为users:flask_tracking/ templates/ tracking/ # This is the code from Part 1 __init__.py # Create this file - it should be empty. forms.py models.py views.py users/ # Where we are working today __init__.py __init__.py # This is also code from Part 1这意味着我们需要将
flask_tracking/__init__.py的进口从from .views import tracking改为from .tracking.views import tracking。然后是
tracking.models中的数据库设置。我们将把它移到父包(flask_tracking)中,因为数据库管理器将在包之间共享。让我们称那个模块为data:# flask_tracking/data.py from flask.ext.sqlalchemy import SQLAlchemy db = SQLAlchemy() def query_to_list(query, include_field_names=True): """Turns a SQLAlchemy query into a list of data values.""" column_names = [] for i, obj in enumerate(query.all()): if i == 0: column_names = [c.name for c in obj.__table__.columns] if include_field_names: yield column_names yield obj_to_list(obj, column_names) def obj_to_list(sa_obj, field_order): """Takes a SQLAlchemy object - returns a list of all its data""" return [getattr(sa_obj, field_name, None) for field_name in field_order]然后我们可以更新
tracking.models来使用from flask_tracking.data import db和tracking.views来使用from flask_tracking.data import db, query_to_list,我们现在应该有一个工作的多包应用程序。用户
既然我们已经将我们的应用程序分成了相关功能的独立包,让我们开始处理
users包。用户需要能够注册一个帐户,管理他们的帐户,登录和退出。可能会有更多与用户相关的功能(尤其是围绕权限),但为了清楚起见,我们将坚持这些基本功能。寻求帮助
我们有一个规则来处理依赖——我们添加的每一个依赖都必须很好地解决至少一个难题。维护用户会话有几个有趣的边缘情况,这使它成为依赖关系的绝佳候选。幸运的是,对于这个用例,有一个现成的工具- Flask-Login 。然而,有一件事 Flask-Login 根本不处理——认证。我们可以使用任何我们想要的身份验证方案——从“只需提供用户名”到像 Persona 这样的分布式身份验证方案。让我们保持简单,使用用户名和密码。这意味着我们需要存储一个用户的密码,我们希望对其进行哈希运算。由于正确地散列密码是一个困难的问题,我们将采用另一个依赖项来确保我们的密码被安全地散列。(我们选择 pbdkdf2 是因为在撰写本文时它被认为是安全的,并且包含在 Python 3.3 中——我们只在运行 Python 2 时需要它。)
让我们继续添加:
Flask-Login==0.2.7 backports.pbkdf2==0.1到我们的
requirements.txt文件,然后(确保我们的虚拟环境被激活)我们可以再次运行pip install -r requirements.txt来安装它们。(编译 pbkdf2 的 C 加速时可能会出现一些错误——可以忽略它们)。我们稍后将把它与我们的应用程序集成在一起——首先我们需要设置我们的用户,这样 Flask-Login 就可以使用了。型号
我们将在
users.models中建立我们的UserSQLAlchemy 类。我们将只存储用户名、电子邮件地址和密码:from random import SystemRandom from backports.pbkdf2 import pbkdf2_hmac, compare_digest from flask.ext.login import UserMixin from sqlalchemy.ext.hybrid import hybrid_property from flask_tracking.data import db class User(UserMixin, db.Model): __tablename__ = 'users_user' id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(50)) email = db.Column(db.String(120), unique=True) _password = db.Column(db.LargeBinary(120)) _salt = db.Column(db.String(120)) sites = db.relationship('Site', backref='owner', lazy='dynamic') @hybrid_property def password(self): return self._password # In order to ensure that passwords are always stored # hashed and salted in our database we use a descriptor # here which will automatically hash our password # when we provide it (i. e. user.password = "12345") @password.setter def password(self, value): # When a user is first created, give them a salt if self._salt is None: self._salt = bytes(SystemRandom().getrandbits(128)) self._password = self._hash_password(value) def is_valid_password(self, password): """Ensure that the provided password is valid. We are using this instead of a ``sqlalchemy.types.TypeDecorator`` (which would let us write ``User.password == password`` and have the incoming ``password`` be automatically hashed in a SQLAlchemy query) because ``compare_digest`` properly compares **all*** the characters of the hash even when they do not match in order to avoid timing oracle side-channel attacks.""" new_hash = self._hash_password(password) return compare_digest(new_hash, self._password) def _hash_password(self, password): pwd = password.encode("utf-8") salt = bytes(self._salt) buff = pbkdf2_hmac("sha512", pwd, salt, iterations=100000) return bytes(buff) def __repr__(self): return "<User #{:d}>".format(self.id)唷——这段代码几乎有一半是密码!更糟糕的是,当你读到这篇文章时,我们的
_hash_password实现很可能被认为是不完美的(这是加密技术不断变化的本质),但它确实涵盖了所有基本的最佳实践:
- 始终使用每个用户独特的盐。
- 使用带有可调工作单元的键拉伸算法。
- 使用常数时间算法比较哈希。
在与密码无关的注释中,我们在
Users 和Sites (sites = db.relationship('Site', backref='owner', lazy='dynamic'))之间建立了一对多关系,这样我们就可以让用户管理多个站点。此外,我们正在子类化 Flask-Login 的
UserMixin类。Flask-Login 要求User类实现某些方法 (get_id、is_authenticated等)。)以便它能完成它的工作。UserMixin提供了这些方法的缺省版本,对于我们的目的来说非常好。积分瓶-登录
现在我们有了一个
User,我们可以与 Flask-Login 集成。为了避免循环导入,我们将在名为auth的顶级模块中设置扩展:# flask_tracking/auth.py from flask.ext.login import LoginManager from flask_tracking.users.models import User login_manager = LoginManager() login_manager.login_view = "users.login" # We have not created the users.login view yet # but that is the name that we will use for our # login view, so we will set it now. @login_manager.user_loader def load_user(user_id): return User.query.get(user_id)
@login_manager.user_loader向 Flask-Login 注册我们的load_user函数,以便当用户登录 Flask-Login 后返回时,可以从存储在 Flask 的session中的 user_id 加载用户。最后,我们将
login_manager导入到flask_tracking/__init__.py中,并向我们的应用程序对象注册它:from .auth import login_manager # ... login_manager.init_app(app)视图
接下来,让我们为用户设置视图和控制器功能,以启用注册/登录/注销功能。首先,我们将设置我们的表单:
# flask_tracking/users/forms.py from flask.ext.wtf import Form from sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound from wtforms import fields from wtforms.validators import Email, InputRequired, ValidationError from .models import User class LoginForm(Form): email = fields.StringField(validators=[InputRequired(), Email()]) password = fields.StringField(validators=[InputRequired()]) # WTForms supports "inline" validators # which are methods of our `Form` subclass # with names in the form `validate_[fieldname]`. # This validator will run after all the # other validators have passed. def validate_password(form, field): try: user = User.query.filter(User.email == form.email.data).one() except (MultipleResultsFound, NoResultFound): raise ValidationError("Invalid user") if user is None: raise ValidationError("Invalid user") if not user.is_valid_password(form.password.data): raise ValidationError("Invalid password") # Make the current user available # to calling code. form.user = user class RegistrationForm(Form): name = fields.StringField("Display Name") email = fields.StringField(validators=[InputRequired(), Email()]) password = fields.StringField(validators=[InputRequired()]) def validate_email(form, field): user = User.query.filter(User.email == field.data).first() if user is not None: raise ValidationError("A user with that email already exists")同样,大量的代码,这一次主要是验证用户输入。需要注意的一点是,对于我们的登录表单,当用户通过身份验证时,我们将表单上的
User实例公开为form.user(因此我们不必在两个地方进行相同的查询——尽管 SQLAlchemy 在这里会做正确的事情,并且只访问数据库一次)。最后,我们可以建立我们的观点:
# flask_tracking/users/views.py from flask import Blueprint, flash, redirect, render_template, request, url_for from flask.ext.login import login_required, login_user, logout_user from flask_tracking.data import db from .forms import LoginForm, RegistrationForm from .models import User users = Blueprint('users', __name__) @users.route('/login/', methods=('GET', 'POST')) def login(): form = LoginForm() if form.validate_on_submit(): # Let Flask-Login know that this user # has been authenticated and should be # associated with the current session. login_user(form.user) flash("Logged in successfully.") return redirect(request.args.get("next") or url_for("tracking.index")) return render_template('users/login.html', form=form) @users.route('/register/', methods=('GET', 'POST')) def register(): form = RegistrationForm() if form.validate_on_submit(): user = User() form.populate_obj(user) db.session.add(user) db.session.commit() login_user(user) return redirect(url_for('tracking.index')) return render_template('users/register.html', form=form) @users.route('/logout/') @login_required def logout(): # Tell Flask-Login to destroy the # session->User connection for this session. logout_user() return redirect(url_for('tracking.index'))并将它们导入并注册到我们的应用程序对象:
# flask_tracking/__init__.py from .users.views import users # ... app.register_blueprint(users)注意在我们的
login视图中对load_user的调用。Flask-Login要求我们调用这个函数来激活我们用户的会话(它将为我们管理)。最后要看的是我们的
users/login.html模板:{% extends "layout.html" %} {% import "helpers/forms.html" as forms %} {% block title %}Log into Flask Tracking!{% endblock %} {% block content %} {{super()}} <form action="{{ url_for('users.login', ext=request.args.get('next', '')) }}" method="POST"> {{ forms.render(form) }} <p><input type="Submit" value="Sign In"></p> </form> {% endblock content %}我们一会儿将讨论
layout.html和forms宏——需要注意的关键是,对于表单的action,我们显式地传入了next参数的值:url_for('users.login', next=request.args.get('next', ''))这确保了当用户将表单提交给
users.login时,next参数可用于我们的重定向代码:login_user(form.user) flash("Logged in successfully.") return redirect(request.args.get("next") or url_for("tracking.index"))这段代码中有一个微妙的安全漏洞,我们将在下一篇文章中修复它(但是如果您已经发现了它,它会指出来)。
战斗复制
但是等等!你看到我们刚刚重复第三次的模式了吗?(我们实际上至少重复了和两种模式,但是我们今天只打算删除其中一种模式的重复部分)。这部分的
register代码:user = User() form.populate_obj(user) db.session.add(user) db.session.commit()也在
tracking代码中重复多次。让我们使用一个自定义 mixin 来提取数据库会话行为,我们可以从 Flask-Kit 中借用这个自定义 mixin。打开flask_tracking/data并添加以下代码:class CRUDMixin(object): __table_args__ = {'extend_existing': True} id = db.Column(db.Integer, primary_key=True) @classmethod def create(cls, commit=True, **kwargs): instance = cls(**kwargs) return instance.save(commit=commit) @classmethod def get(cls, id): return cls.query.get(id) # We will also proxy Flask-SqlAlchemy's get_or_44 # for symmetry @classmethod def get_or_404(cls, id): return cls.query.get_or_404(id) def update(self, commit=True, **kwargs): for attr, value in kwargs.iteritems(): setattr(self, attr, value) return commit and self.save() or self def save(self, commit=True): db.session.add(self) if commit: db.session.commit() return self def delete(self, commit=True): db.session.delete(self) return commit and db.session.commit()
CRUDMixin为我们提供了一种更简单的方式来处理四种最常见的模型操作(创建、读取、更新和删除):def create(cls, commit=True, **kwargs): pass def get(cls, id): pass def update(self, commit=True, **kwargs): pass def delete(self, commit=True): pass现在,如果我们将我们的
User类更新为子类CRUDMixin:from flask_tracking.data import CRUDMixin, db class User(UserMixin, CRUDMixin, db.Model):然后我们可以使用更清晰的:
user = User.create(**form.data)征求我们的意见。这使得推理我们的代码在做什么变得更容易,也使得重构变得更容易(因为每段代码处理的关注点更少)。我们也可以更新我们的
tracking包的代码来使用相同的方法。模板
在第一部分中,为了节省时间,我们跳过了对模板的审查。现在让我们花几分钟时间来回顾一下我们用来呈现 HTML 的更有趣的部分。
稍后,我们可能会将这些都分解成一个 RESTful 接口。我们可以使用 JavaScript MVC 框架来处理前端,并向后端发出请求以获取必要的数据,而不是让 Python/Flask/Jinja 提供预先格式化的页面。然后,客户端将向服务器发送请求以创建/注册新站点,并负责在创建新站点和访问时更新视图。视图将负责 REST 接口。
也就是说,由于我们关注的是 Flask,我们现在将使用 Jinja 来提供页面。
布局
首先,看看
layout.html(为了节省空间,我将大部分代码从本文中去掉,但我提供了完整代码的链接):<title>{% block title %}{{ title }}{% endblock %}</title> <!-- ... snip ... --> <h1>{{ self.title() }}</h1>这个片段展示了我最喜欢的两个技巧——首先,我们有一个包含变量的块(
title),这样我们就可以从我们的render_template调用中设置这个值(这样我们就不需要仅仅为了更改标题而创建一个全新的模板)。第二,我们用特殊的self变量重用我们的头块的内容。这意味着,当我们设置title(在子模板中或者通过关键字参数设置为render_template)时,我们提供的文本将在浏览器的标题栏和h1标签中显示。表单管理
值得一看的模板结构的另一部分是我们的宏。对于那些来自 Django 背景的人来说,Jinja 的宏是 Django 的类固醇。例如,我们的
form.render宏使得向我们的一个模板添加表单变得非常容易:{% macro render(form) %} <dl> {% for field in form if field.type not in ["HiddenField", "CSRFTokenField"] %} <dt>{{ field.label }}</dt> <dd>{{ field }} {% if field.errors %} <ul class="errors"> {% for error in field.errors %} <li>{{error}}</li> {% endfor %} </ul> {% endif %}</dd> {% endfor %} </dl> {{ form.hidden_tag() }} {% endmacro %}使用它非常简单:
{% import "helpers/forms.html" as forms %} <!-- ... snip ... --> <form action="{{url_for('users.register')}}" method="POST"> {{ forms.render(form) }} <p><input type="Submit" value="Learn more about your visitors"></p> </form>我们可以使用
form.render为表单中的每个字段自动生成样本 HTML,而不是一遍又一遍地编写相同的表单 HTML。这样,我们所有的形式看起来和功能都是一样的,如果我们不得不改变它们,我们只需要在一个地方做一次。不要重复自己可以产生非常干净的代码。重构跟踪应用程序
现在我们已经正确地设置好了所有这些,让我们回过头来重构应用程序的主体:请求跟踪。
在第一部分中,我们构建了请求跟踪器的框架。网站被创建在索引页面上,任何人都可以查看所有可用的网站。只要最终用户自己发送所有信息,Flask-Tracking 就会愉快地存储这些信息。现在,我们有了用户,所以我们想过滤网站的列表。此外,如果我们的应用程序可以从访问者那里获取一些数据,而不是要求应用程序的最终用户自己获取所有数据,那就更好了。
过滤网站
让我们从网站列表开始:
# flask_tracking/tracking/views.py @tracking.route("/sites", methods=("GET", "POST")) @login_required def view_sites(): form = SiteForm() if form.validate_on_submit(): Site.create(owner=current_user, **form.data) flash("Added site") return redirect(url_for(".view_sites")) query = Site.query.filter(Site.user_id == current_user.id) data = query_to_list(query) results = [] try: # The header row should not be linked results = [next(data)] for row in data: row = [_make_link(cell) if i == 0 else cell for i, cell in enumerate(row)] results.append(row) except StopIteration: # This happens when a user has no sites registered yet # Since it is expected, we ignore it and carry on. pass return render_template("tracking/sites.html", sites=results, form=form) _LINK = Markup('<a href="{url}">{name}</a>') def _make_link(site_id): url = url_for(".view_site_visits", site_id=site_id) return _LINK.format(url=url, name=site_id)从顶部开始,
@login_required装饰器由Flask-Login提供。任何试图访问/sites/的未登录用户都将被重定向到登录页面。接下来,我们检查用户是否正在添加一个新站点(form.validate_on_submit检查request.method是否是 POST 并验证表单——如果任何一个先决条件失败,该方法返回False,否则返回True)。如果用户正在创建一个新的站点,我们创建一个新的站点(使用我们的CRUDMixin定义的方法,所以如果您自己对代码进行更改,您将希望确保Site和Visit都从CRUDMixin继承)并重定向回同一个页面。我们在保存新站点后重定向回我们自己,以防止页面刷新导致用户试图添加站点两次。(这称为 Post-Redirect-Get 模式)。如果你不确定我的意思,试着注释掉
return redirect(url_for(".view_sites")),然后提交“添加一个站点”表单,当页面重新加载时,按下F5刷新你的浏览器。恢复重定向后,尝试同样的练习。(当重定向被删除时,浏览器将询问您是否真的要再次提交表单数据——浏览器发出的最后一个请求是创建新站点的帖子。通过重定向,浏览器发出的最后一个请求是 GET 请求,该请求重新加载了view_sites页面。接下来,如果用户没有创建新的站点(或者如果提供的数据有错误),我们将查询我们的数据库,以查找当前登录用户创建的所有站点。然后我们稍微转换一下我们的列表,将数据库 ID 转换成每个非标题行的 HTML 链接。当您还不知道模板模式是否值得“宏化”时,使用“内联”模板有利于快速原型开发。在我们的例子中,这是带有动作链接的表格的唯一视图,所以我们使用内联模板技术来演示另一种方法。
值得注意的是,我们已经选择使用
sites_view来显示站点及其访问和注册站点。如何拆分应用程序完全取决于您。拥有一个view_sites和一个add_site视图,其中前者仅可用于获取请求,后者用于发布也是一种有效的技术。无论哪种技术对你来说更清晰,你都应该更喜欢——只要确保你始终如一。从访问者那里获取数据
与此同时,
add_visit现在有点复杂(尽管它主要是映射代码):from flask import request from .geodata import get_geodata # ... snip ... @tracking.route("/sites/<int:site_id>/visit", methods=("GET", "POST")) def add_visit(site_id=None): site = Site.get_or_404(site_id) browser = request.headers.get("User-Agent") url = request.values.get("url") or request.headers.get("Referer") event = request.values.get("event") ip_address = request.access_route[0] or request.remote_addr geodata = get_geodata(ip_address) location = "{}, {}".format(geodata.get("city"), geodata.get("zipcode")) # WTForms does not coerce obj or keyword arguments # (otherwise, we could just pass in `site=site_id`) # CSRF is disabled in this case because we will *want* # users to be able to hit the /sites/{id} endpoint from other sites. form = VisitForm(csrf_enabled=False, site=site, browser=browser, url=url, ip_address=ip_address, latitude=geodata.get("latitude"), longitude=geodata.get("longitude"), location=location, event=event) if form.validate(): Visit.create(**form.data) # No need to send anything back to the client # Just indicate success with the response code # (204 is "Your request succeeded; I have nothing else to say.") return '', 204 return jsonify(errors=form.errors), 400我们已经移除了用户通过表单从我们的网站手动添加访问的能力(因此我们也移除了
add_visit上的第二条路线)。我们现在对可以在服务器上导出的数据(浏览器、IP 地址)进行显式映射,然后构造我们的VisitForm,直接传入这些映射值。我们从access_route获取的 IP 地址以防我们在代理之后,此后remote_addr将包含最后一个代理的 IP 地址,这根本不是我们想要的。我们禁用 CSRF 保护,因为我们实际上希望用户能够从其他地方向该端点发出请求。最后,我们知道这个请求是针对哪个站点的,因为我们已经为 URL 设置了<int:site_id>参数。这并不是这个想法的完美实现。我们没有任何方法来验证该请求是来自我们的跟踪信标的合法请求。有人可以修改 JavaScript 代码或者从另一台服务器提交修改过的请求,我们会很乐意保存它。这很简单,也很容易实现。但是您可能不应该在生产环境中使用这些代码。
get_geodata(ip_address)查询http://freegeoip.net/这样我们可以大致了解请求来自哪里:from json import loads from re import compile, VERBOSE from urllib import urlopen FREE_GEOIP_URL = "http://freegeoip.net/json/{}" VALID_IP = compile(r""" \b (25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \b """, VERBOSE) def get_geodata(ip): """ Search for geolocation information using http://freegeoip.net/ """ if not VALID_IP.match(ip): raise ValueError('Invalid IPv4 format') url = FREE_GEOIP_URL.format(ip) data = {} try: response = urlopen(url).read() data = loads(response) except Exception: pass return data将此作为
geodata.py保存在tracking目录中。返回到视图,这个视图所做的就是从请求中复制信息并将其存储在数据库中。它用 HTTP 204(无内容)响应来响应请求。这告诉浏览器请求成功了,但是我们不需要花费额外的时间来生成终端用户看不到的内容。
查看访问
我们还为每个站点的访问视图添加了身份验证:
@tracking.route("/sites/<int:site_id>") @login_required def view_site_visits(site_id=None): site = Site.get_or_404(site_id) if not site.user_id == current_user.id: abort(401) query = Visit.query.filter(Visit.site_id == site_id) data = query_to_list(query) return render_template("tracking/site.html", visits=data, site=site)这里唯一真正的变化是,如果用户登录,但不拥有该网站,他们将看到一个授权错误页面,而不是能够查看该网站的访问。
提供追踪访客的方法
最后,我们希望为用户提供一段代码,他们可以将这段代码放在自己的网站上,自动记录访问次数:
{# flask_tracking/templates/tracking/site.html #} {% block content %} {{ super() }} <p>To track visits to this site, simple add the following snippet to the pages that you wish to track:</p> <code><pre> <script> (function() { var img = new Image(); img.src = "{{ url_for('tracking.add_visit', site_id=site.id, event='PageLoad', _external=true) }}"; })(); </script> <noscript> <img src="{{ url_for('tracking.add_visit', site_id=site.id, event='PageLoad', _external=true) }}" width="1" height="1" /> </noscript> </pre></code> <h2>Visits for {{ site.base_url }}</h2> <table> {{ tables.render(visits) }} </table> {% endblock content %}我们的代码片段非常简单——当页面加载时,我们创建一个新的图像,并将其来源设置为我们的跟踪 URL。浏览器将立即加载指定的图像(这将是什么都没有),我们将在我们的应用程序中记录一个跟踪点击。我们也有一个
<noscript>块给那些没有启用 JavaScript 的人。(如果我们真的想跟上时代,我们也可以更新我们的服务器端代码来检查Do Not Track头,只有当用户选择跟踪时才记录访问。)总结
这个帖子到此为止。我们现在有了用户帐户,并且开始有了易于使用的客户端跟踪 API。我们仍然需要最终确定我们的客户端 API,应用程序的风格和添加报告。
应用程序的代码可以在这里找到。
您的应用程序现在应该如下所示:
展望未来:
- 在第三部分中,我们将探索为我们的应用程序编写测试,记录和调试错误。
- 在第四部分中,我们将进行一些测试驱动的开发,使我们的应用程序能够接受付款并显示简单的报告。
- 在第五部分中,我们将编写一个 RESTful JSON API 供其他人使用。
- 在第六部分中,我们将介绍使用 Fabric 和基本 A/B 特性测试的自动化部署(在 Heroku 上)。
- 最后,在第七部分中,我们将介绍如何用文档、代码覆盖率和质量度量工具来保护您的应用程序。*****
使用 Flask 的 Python Web 应用程序–第三部分
原文:https://realpython.com/python-web-applications-with-flask-part-iii/
请注意:这是来自 Real Python 的 Michael Herman 和来自 De Deo Designs 的 Python 开发者 Sean Vieira 的合作作品。
本系列文章:
- 第一部分:应用程序设置
- 第二部分:设置用户账户、模板、静态文件
- 第三部分:测试(单元和集成)、调试和错误处理← 当前文章
欢迎回到烧瓶跟踪开发系列!对于那些刚刚加入我们的人来说,我们正在实现一个符合这个餐巾纸规范的网络分析应用。对于所有在家的人来说,你可以查看今天的代码:
$ git checkout v0.3或者你可以从 Github 的发布页面下载。那些刚刚加入我们的人可能也希望读一读关于存储库结构的注释。
在前面的部分中,我们在应用程序中添加了用户账户。本周我们将致力于实现一个测试框架,讨论一下为什么测试很重要,然后为我们的应用程序编写一些测试。之后,我们将讨论一下应用程序和日志中的调试错误。
为什么要测试
在我们实际编写任何测试之前,让我们来谈谈为什么测试是重要的。如果你还记得《T2》第一部中的 Python 之禅,你可能已经注意到“简单比复杂好”就在“复杂比复杂好”的正上方。简单是理想,复杂往往是现实。尤其是 Web 应用程序,有许多可移动的部分,可以很快地从简单变得复杂。
随着应用程序复杂性的增加,我们希望确保我们创建的各种活动部件能够继续以和谐的方式一起工作。我们不想改变一个实用函数的签名,它破坏了生产中一个看似不相关的特性。此外,我们希望确保我们的更改仍然保留正确的 T2 功能。一个总是返回同一个
datetime实例的方法每天有效和正确两次,但在其余时间都有效和不正确。测试是很好的调试辅助工具。编写一个产生我们所看到的无效行为的测试有助于我们从不同的角度来看待我们的代码。此外,一旦我们通过了测试,我们就确保了我们不会再次引入这个 bug(至少以那种特定的方式)。
测试也是文档的极好来源。因为它们必须处理预期的输入和输出,所以阅读测试套件将澄清被测代码预期要做什么。这将阐明我们编写的文档中不清楚的部分(或者在简单的情况下,甚至替换它)。
最后,测试可以是一个很好的探索工具——在我们写代码之前,勾画出我们希望 T1 如何与我们的代码交互,揭示更简单的 API,并帮助我们掩盖一个领域的内部复杂性。“测试驱动开发”是对这个过程的最终承诺。在 TDD 中,我们首先编写测试来覆盖代码的功能,然后才编写代码。
测试将使它显而易见:
- 当代码不工作时,
- 什么代码被破坏了,还有
- 我们当初为什么要写这段代码。
每次我们向应用程序添加功能、修复 bug 或更改代码时,我们都应该确保我们的代码被测试充分覆盖,并且在我们完成后测试全部通过。
做:
- 添加测试以涵盖代码的基本功能。
- 添加测试来覆盖你能想到的尽可能多的代码的角落/边缘情况。
- 添加测试来覆盖您回去后没有想到的角落/边缘情况,并修复它们。
- 提醒您的编码同行充分测试他们的代码。
- 关于没有通过测试的代码的 Bug。
不要:
- 不经测试提交代码。
- 提交没有通过或破坏测试的代码。
- 更改您的测试,以便您的代码通过测试而不修复问题。
既然我们已经知道了为什么测试如此重要,让我们开始为我们的应用程序编写一些测试。
设置
每个功能块都需要测试。为了简洁明了地做到这一点,每个包中都有一个
tests.py模块。这样我们就知道每个包的测试在哪里,如果我们需要把它从应用程序中分离出来,它们就包含在包中。我们将使用
Flask-Testing扩展,因为它有一堆有用的测试特性,我们无论如何都要设置它们。继续将Flask-Testing==0.4添加到requirements.txt的底部,然后运行pip install -r requirements.txt。烧瓶测试消除了几乎所有为单元测试设置烧瓶的样板文件。剩下的一小部分我们将放入新模块
test_base.py:# flask_testing/test_base.py from flask.ext.testing import TestCase from . import app, db class BaseTestCase(TestCase): """A base test case for flask-tracking.""" def create_app(self): app.config.from_object('config.TestConfiguration') return app def setUp(self): db.create_all() def tearDown(self): db.session.remove() db.drop_all()这个测试用例没有做任何引人注目的事情——它只是用我们的测试配置来配置应用程序,在每个测试开始时创建所有的表,在每个测试结束时删除所有的表。这样,每个测试用例都是从一个干净的石板开始的,我们可以花更多的时间编写测试,花更少的时间调试我们的测试用例。由于每个测试用例都将继承我们新的
BaseTestCase()类,我们将避免复制和粘贴这个配置到我们为应用程序创建的每个包中。我们做的另外一件事是模块化我们的配置。最初的
config.py模块只支持一种配置——我们可以更新它以适应不同环境之间的差异。提醒一下,这是《T2》第二部中config.py的样子:# config.py from os.path import abspath, dirname, join _cwd = dirname(abspath(__file__)) SECRET_KEY = 'flask-session-insecure-secret-key' SQLALCHEMY_DATABASE_URI = 'sqlite:///' + join(_cwd, 'flask-tracking.db') SQLALCHEMY_ECHO = True现在看起来几乎是一样的——我们只是创建了一个保存所有这些配置值的类:
from os.path import abspath, dirname, join _cwd = dirname(abspath(__file__)) class BaseConfiguration(object): DEBUG = False TESTING = False SECRET_KEY = 'flask-session-insecure-secret-key' HASH_ROUNDS = 100000 # ... etc. ...我们可以从中继承:
class TestConfiguration(BaseConfiguration): TESTING = True WTF_CSRF_ENABLED = False SQLALCHEMY_DATABASE_URI = 'sqlite:///:memory:' # + join(_cwd, 'testing.db') # Since we want our unit tests to run quickly # we turn this down - the hashing is still done # but the time-consuming part is left out. HASH_ROUNDS = 1通过这种方式,可以轻松共享所有环境通用的设置,并且我们可以轻松地在特定于环境的配置中覆盖我们需要的设置。(这个模式直接来源于 Flask 的优秀文档。)
我们使用内存中的 SQLite 数据库进行测试,以确保我们的测试尽可能快地执行。我们想要享受运行测试的乐趣,只有当它们在合理的时间内执行时,我们才能做到这一点。如果我们真的需要访问测试运行的结果,我们可以用计算出的到
tests.db的路径覆盖:memory:设置。(那是我们TestConfiguration里注释掉的+ join(_cwd, 'testing.db'))。我们还在配置中添加了一个
HASH_ROUNDS键,以控制用户密码在存储之前应该散列多少次。我们可以改变flask_tracking.users.models.User的_hash_password方法来使用这个键:from flask import current_app # ... snip ... def _hash_password(self, password): # ... snip ... rounds = current_app.config.get("HASH_ROUNDS", 100000) buff = pbkdf2_hmac("sha512", pwd, salt, iterations=rounds)这确保了我们的单元测试将快速运行——否则,每次我们需要创建或登录用户时,我们将不得不等待 100,000 轮 sha512 完成,然后才能继续我们的测试。
最后,我们需要在
flask_tracking/__init__.py中更新我们的app.from_object调用。之前,我们使用app.from_object('config')加载配置。现在我们在配置模块中有了两个配置,我们想把它改为app.from_object('config.BaseConfiguration')。现在我们准备测试我们的应用程序。
测试
我们将从
users包开始。从上次的我们知道
users包负责:
- 注册,
- 登录,以及
- 注销。
因此,我们需要编写测试,涵盖用户注册、用户登录和用户注销。让我们从一个简单的例子开始——一个现有用户试图登录:
# flask_tracking/users/tests.py from flask import url_for from flask_tracking.test_base import BaseTestCase from .models import User class UserViewsTests(BaseTestCase): def test_users_can_login(self): User.create(name='Joe', email='joe@joes.com', password='12345') response = self.client.post(url_for('users.login'), data={'email': 'joe@joes.com', 'password': '12345'}) self.assert_redirects(response, url_for('tracking.index'))因为每个测试用例都是从一个完全干净的数据库开始的,所以我们必须首先创建一个现有的用户。然后,我们可以提交与用户(Joe)尝试登录时提交的请求相同的请求。我们希望确保如果 Joe 成功登录,他将被重定向回主页。
我们可以使用 Python 内置的
unittest测试运行器来运行我们的测试。从项目的根目录运行以下命令:$ python -m unittest discover这会产生以下输出:
---------------------------------------------------------------------- Ran 1 test in 0.045s OK万岁!我们现在有一个通过测试!让我们测试一下我们与 Flask-Login 的集成是否正常。
current_user应该是乔,所以我们应该能做到以下几点:from flask.ext.login import current_user # And then inside of our test_users_can_login function: self.assertTrue(current_user.name == 'Joe') self.assertFalse(current_user.is_anonymous())但是,如果我们尝试这样做,我们会得到以下错误:
AttributeError: 'AnonymousUserMixin' object has no attribute 'name'
current_user需要在请求的上下文中被访问(它是一个线程本地对象,就像flask.request)。当self.client.post完成请求并且每个线程本地对象被拆除时。我们需要保留请求上下文,以便测试我们与 Flask-Login 的集成。幸运的是,Flask的 test_client 是一个上下文管理器,这意味着我们可以在 with语句中使用它,只要我们需要它,它就会保留上下文:
with self.client:
response = self.client.post(url_for('users.login'),
data={'email': 'joe@joes.com', 'password': '12345'})
self.assert_redirects(response, url_for('index'))
self.assertTrue(current_user.name == 'Joe')
self.assertFalse(current_user.is_anonymous())
现在,当我们再次运行测试时,我们通过了!
----------------------------------------------------------------------
Ran 1 test in 0.053s
让我们确保当 Joe 登录时,他可以注销:
def test_users_can_logout(self):
User.create(name="Joe", email="joe@joes.com", password="12345")
with self.client:
self.client.post(url_for("users.login"),
data={"email": "joe@joes.com",
"password": "12345"})
self.client.get(url_for("users.logout"))
self.assertTrue(current_user.is_anonymous())
我们再一次创建了 Joe(记住,数据库在每次测试结束时都会被重置)。然后我们让他登录(我们知道这是可行的,因为我们的第一个测试通过了)。最后,我们通过self.client.get(url_for("users.logout"))请求注销页面让他注销,并确保我们拥有的用户再次匿名。再次运行测试,享受两次通过测试的满足感。
我们还需要检查其他一些东西:
- 用户可以注册然后登录应用程序吗?
- 当用户注销时,他们会被重定向回索引页面吗?
这些测试可以在的flask-tracking库中找到,如果你想复习的话。由于它们与我们已经写过的内容相似,我们将在这里跳过它们。
模拟和集成测试
不过,我们的应用程序有一个部分与其他部分略有不同——我们在tracking包中的add_visit端点不仅与数据库和用户交互——它还与第三方服务 Free GeoIP 交互。由于这是一个潜在的破损源,我们将希望彻底测试它。由于免费的 GeoIP 是一个第三方服务(我们可能并不总是能够获得),它也给了我们一个很好的机会来谈论单元测试和集成测试之间的区别。
单元测试与集成测试
到目前为止,我们所写的一切都属于单元测试的范畴。一个单元测试是对我们的代码的最小可能功能块的测试——对一段不可分割的代码(通常是一个函数或方法)的测试。
集成测试,另一方面,测试我们的应用程序的边界——我们的应用程序是否与其他应用程序(很可能是我们编写的)正确交互?测试我们的应用程序是否正确调用 Free GeoIP 并与之交互是一个集成测试。这类测试非常重要,因为它们让我们知道我们所依赖的特性仍然按照我们期望的方式工作。(是的,当我们在生产环境中运行我们的应用程序时,如果 Free GeoIP 更改其合同(API)或完全关闭,这对我们没有帮助,但这正是日志记录的目的——我们稍后将对此进行介绍。)
然而,集成测试的问题是它们通常比单元测试慢一个数量级以上。大量的集成测试会使我们的测试套件变慢,以至于需要一分钟以上的时间来运行——一旦越过这个界限,我们的测试套件就开始成为障碍而不是助手。现在花时间运行我们的测试会打断我们的注意力,而不是简单地验证我们是否在正确的轨道上。此外,对于像 Free GeoIP 这样的分布式服务,这意味着如果我们离线或 Free GeoIP 宕机,我们实际上无法运行我们的测试套件。
这让我们陷入了两难的境地——一方面,集成测试非常重要,另一方面,运行集成测试可能会中断我们的工作流程。
解决方案很简单——我们可以为我们调用的服务创建一个基本的本地实现(在测试术语中称为模拟),并使用这个模拟运行我们的单元测试。我们可以将集成测试分离到一个单独的文件中,并在提交代码更改之前运行这些测试。这样,我们获得了好的单元测试的速度,并保留了集成测试提供的确定性。
嘲讽免费地理信息
如果你还记得《T4》第二部分的话,我们在tracking包中添加了一个geodata模块,实现了一个单一的功能get_geodata。我们在我们的tracking.add_visit视图中使用这个函数:
ip_address = request.access_route[0] or request.remote_addr
geodata = get_geodata(ip_address)
在我们的单元测试中,我们想要做的是确保当get_geodata按预期工作时,我们将在数据库中正确地记录访问。然而,我们不想调用免费的 GeoIP(否则,我们的测试将比我们的其他测试慢,并且我们将无法在离线时运行测试。)我们需要用另一个函数(一个 mock)替换get_geodata。
首先,让我们安装一个模仿库来简化这个过程。将 mock==1.0.1 添加到 requirements.txt,再次添加pip install -r requirements.txt。(如果您使用的是 Python 3.3 或更高版本,那么您已经将 mock 安装为 unittest.mock 。)
现在我们可以编写我们的单元测试了:
# flask_tracking/tracking/tests.py
from decimal import Decimal
from flask import url_for
from mock import Mock, patch
from werkzeug.datastructures import Headers
from flask_tracking.test_base import BaseTestCase
from flask_tracking.users.models import User
from .models import Site, Visit
from ..tracking import views
class TrackingViewsTests(BaseTestCase):
def test_visitors_location_is_derived_from_ip(self):
user = User.create(name='Joe', email='joe@joe.com', password='12345')
site = Site.create(user_id=user.id)
mock_geodata = Mock(name='get_geodata')
mock_geodata.return_value = {
'city': 'Los Angeles',
'zipcode': '90001',
'latitude': '34.05',
'longitude': '-118.25'
}
url = url_for('tracking.add_visit', site_id=site.id)
wsgi_environment = {'REMOTE_ADDR': '1.2.3.4'}
headers = Headers([('Referer', '/some/url')])
with patch.object(views, 'get_geodata', mock_geodata):
with self.client:
self.client.get(url, environ_overrides=wsgi_environment,
headers=headers)
visits = Visit.query.all()
mock_geodata.assert_called_once_with('1.2.3.4')
self.assertEqual(1, len(visits))
first_visit = visits[0]
self.assertEqual("/some/url", first_visit.url)
self.assertEqual('Los Angeles, 90001', first_visit.location)
self.assertEqual(34.05, first_visit.latitude)
self.assertEqual(-118.25, first_visit.longitude)
不要担心——测试这类集成的痛苦会因为这样一个事实而减轻,即应用程序中的集成通常比代码单元要少。让我们一节一节地浏览这段代码,并把它分成易于理解的几个部分。
设置测试数据和模拟
首先,我们设置一个用户和一个站点,因为每次测试开始时数据库都是空的:
def test_visitors_location_is_derived_from_ip(self):
user = User.create(name='Joe', email='joe@joe.com', password='12345')
site = Site.create(user_id=user.id)
然后,我们创建一个 mock 函数,并指定它应该在每次被调用时返回一个包含洛杉矶坐标的字典(我们可以简单地创建一个总是返回字典的简单函数,但是 mock 还提供了 patch.* 上下文管理器,这非常有用,所以我们将使用这个库):
mock_geodata = Mock(name='get_geodata')
mock_geodata.return_value = {
'city': 'Los Angeles',
'zipcode': '90001',
'latitude': '34.05',
'longitude': '-118.25'
}
最后,我们设置我们将要访问的 URL 和我们需要让tracking.add_visit工作的 WSGI 环境的部分(在本例中,它只是我们的假终端用户的访问者的 IP 地址和他们应该来自的 URL):
url = url_for('tracking.add_visit', site_id=site.id)
wsgi_environment = {'REMOTE_ADDR': '1.2.3.4'}
headers = Headers([('Referer', '/some/url')])
将模拟补丁插入我们的跟踪模块
我们显式地将flask_tracking.tracking.views模块导入到我们的tests模块中:
from ..tracking import views
现在我们修补模块的get_views名,指向我们的mock_geodata对象,而不是flask_tracking.tracking.geodata.get_geodata函数:
with patch.object(views, 'get_geodata', mock_geodata):
通过使用patch.object作为上下文管理器,我们确保在我们退出这个with块后flask_tracking.tracking.views.get_geodata将再次指向flask_tracking.tracking.geodata.get_geodata。我们也可以使用patch.object作为装饰:
mock_geodata = Mock(name='get_geodata')
# ... snip return setup ...
class TrackingViewsTests(BaseTestCase):
@patch.object(views, 'get_geodata', mock_geodata)
def test_visitors_location_is_derived_from_ip(self):
或者甚至是一个班级装饰者:
@patch.object(views, 'get_geodata', mock_geodata)
class TrackingViewsTests(BaseTestCase):
唯一的区别是补丁的范围。函数装饰版本确保只要我们在test_visitors_location_is_derived_from_ip内部,函数get_geodata就指向我们的模拟,而类装饰版本确保每个在TrackingViewsTests内部以test开头的函数都将看到get_geodata的模拟版本。
就我个人而言,我更喜欢尽可能限制我的模仿范围。这有助于确保我记住我的测试范围,并避免我在期望访问真实对象并必须对其进行修补时出现意外。
运行测试
设置好我们需要的一切后,我们现在可以提出我们的请求:
with self.client:
self.client.get(url, environ_overrides=wsgi_environment,
headers=headers)
我们通过自己创建的wsgi_environment字典(wsgi_environment = {'REMOTE_ADDR': '1.2.3.4'})向控制器提供查看者的 IP 地址。Flask 的测试客户端是 Werkzeug 的测试客户端的一个实例——它支持你可以传递给 EnvironmentBuilder 的所有参数。
断言一切正常
最后,我们从tracking_visit表中获取所有的访问:
visits = Visit.query.all()
并验证:
- 我们使用用户的 IP 地址来查找他的地理数据:
mock_geodata.assert_called_once_with('1.2.3.4')
- 该请求只引发了一次访问:
self.assertEqual(1, len(visits))
- 位置数据被正确保存:
first_visit = visits[0]
self.assertEqual("/some/url", first_visit.url)
self.assertEqual('Los Angeles, 90001', first_visit.location)
self.assertEqual(Decimal("34.05"), first_visit.latitude)
self.assertEqual(Decimal("-118.25"), first_visit.longitude)
当我们运行python -m unittest discover时,我们得到以下输出:
F.....
======================================================================
FAIL: test_visitors_location_is_derived_from_ip (flask_tracking.tracking.tests.TrackingViewsTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "~/dev/flask-tracking/flask_tracking/tracking/tests.py", line 41, in test_visitors_location_is_derived_from_ip
self.assertEqual('Los Angeles, 90001', first_visit.location)
AssertionError: 'Los Angeles, 90001' != None
----------------------------------------------------------------------
Ran 6 tests in 0.147s
FAILED (failures=1)
啊,失败了!显然,我们没有正确地映射位置,因为Visit的位置没有被持久存储在数据库中。检查我们的视图代码发现,当我们构造我们的VisitForm时,我们确实在设置location…但是我们实际上并没有为我们的VisitForm设置字段!还好我们在直播前就发现了。(这种重复的字段会产生问题,应该会给大家带来一些启示——当它出现时,我建议大家看一看 wtforms-alchemy 。)
一旦我们将location、latitude和longitude字段添加到我们的VisitForm中,我们应该能够运行我们的测试并得到:
.....
----------------------------------------------------------------------
Ran 5 tests in 0.150s
OK
这就完成了我们的第一次模拟测试。
调试
我们的单元测试非常有用——但是当我们试图测试一些东西,而测试代码并没有做我们期望它做的事情时,会发生什么呢?或者更糟糕的是,当用户打电话给我们,抱怨他遇到了一个错误?如果这是一个系统范围的问题,运行我们的单元测试可能会揭示这个问题…但是这只有在我们没有运行我们的测试就签入并部署代码的情况下才会发生(我们永远不会这样做,不是吗?)
假设我们总是在提交和部署之前运行测试,那么当生产中出现问题时,我们的单元测试就无法帮助我们。相反,我们将需要要求用户为我们提供一个完整的例子,以便我们可以在本地调试它。
假设我们对我们的登录表单进行了一点点重构-
# If you can see what's broken already, give yourself a prize
# and write a test to ensure it never happens again :-)
class LoginForm(Form):
email = fields.StringField(validators=[InputRequired(), Email()])
password = fields.StringField(validators=[InputRequired()])
def validate_login(form, field):
try:
user = User.query.filter(User.email == form.email.data).one()
except (MultipleResultsFound, NoResultFound):
raise ValidationError("Invalid user")
if user is None:
raise ValidationError("Invalid user")
if not user.is_valid_password(form.password.data):
raise ValidationError("Invalid password")
# Make the current user available
# to calling code.
form.user = user
-当我们将其推向生产时,我们的第一个用户向我们发送了一封电子邮件,告诉我们他输入了错误的密码,并且仍然登录到系统中。我们在现场验证了这一点。哇,耐莉,这是完全不能接受的!因此,我们迅速关闭登录页面,代之以一条消息,说我们正在进行维护,我们会尽快回来(SaaS 法则# 0——永远以你希望被对待的方式对待你的客户)。
从本地来看,我们看不出用户应该能够不用密码登录的任何理由。然而,我们还没有编写任何测试来测试错误输入的密码会被错误消息拒绝,所以我们不能 100%确定这不是我们代码中的错误。因此,让我们编写一个测试用例,看看会发生什么:
def test_invalid_password_is_rejected(self):
User.create(name="Joe", email="joe@joes.com", password="12345")
with self.client:
response = self.client.post(url_for("users.login"),
data={"email": "joe@joes.com",
"password": "*****"})
self.assertTrue(current_user.is_anonymous())
self.assert_200(response)
self.assertIn("Invalid password", response.data)
运行测试会导致失败:
.F....
======================================================================
FAIL: test_invalid_password_is_rejected (app.users.tests.UserViewsTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "~/dev/flask-tracking/flask_tracking/users/tests.py", line 34, in test_invalid_password_is_rejected
self.assertTrue(current_user.is_anonymous())
AssertionError: False is not true
好吧,我们可以在本地复制它。我们有一个测试用例对我们大喊大叫,直到我们解决问题。很好。我们在路上了!
有几种方法可以调试这个问题:
- 我们可以将
print语句分散在整个应用程序中,直到找到错误的来源。 - 我们可以在代码中故意生成错误,并使用 Flask 的内置调试器查看现有环境。
- 我们可以使用调试器来单步调试代码。
我们将使用这三种技术。首先,让我们给我们的app.users.models.LoginForm#validate_login方法添加一个简单的print语句:
def validate_login(self, field):
print 'Validating login'
当我们再次运行测试时,我们根本看不到“验证登录”消息。这告诉我们我们的方法没有被调用。让我们在视图中添加一个故意的错误,并利用 Flask 的内部调试器来验证世界的状态。首先,我们将为调试创建一个新的配置:
# config.py
class DebugConfiguration(BaseConfiguration):
DEBUG = True
然后我们将更新flask_tracking.__init__以使用新的调试配置:
app.config.from_object('config.DebugConfiguration')
最后,我们将在我们的login_view方法中添加一个算术错误:
def login_view():
form = LoginForm(request.form)
1 / 0 # KABOOM!
现在,如果我们跑:
$ python run.py
导航到登录页面,我们会看到一个很好的追溯。点击回溯(1 / 0)最后一行右边的外壳图标,将得到一个交互式 REPL,我们可以用它来测试我们的功能:
>>> form.validate_login(field=None) # We don't use the field argument这导致:
Traceback (most recent call last): File "<debugger>", line 1, in <module> form.validate_login(None) File "~/dev/flask-tracking/flask_tracking/users/forms.py", line 15, in validate_login raise validators.ValidationError('Invalid user') ValidationError: Invalid user所以现在我们知道我们的验证函数起作用了——它只是没有被调用。让我们从登录视图中删除这个被零除的错误,代之以对 Python 调试器
pdb的调用。def login_view(): form = LoginForm(request.form) import pdb; pdb.set_trace()现在,当我们再次运行测试时,我们会得到一个调试器:
python -m unittest discover . .> ~/dev/flask-tracking/app/users/views.py(18)login_view() -> if form.validate_on_submit(): (Pdb)我们可以通过键入“s”表示“step”来进入
validate_on_submit方法,并用“n”表示“next”来跳过我们不感兴趣的调用(对 PDB 的完整介绍超出了本教程的范围——有关 PDB 的更多信息,请参见它的文档,或者在pdb中键入“h”):(Pdb) s --Call-- > ~/.virtualenvs/realpython/lib/python2.7/site-packages/flask_wtf/form.py(120)validate_on_submit() -> def validate_on_submit(self):我不会带你经历整个调试过程,但是不用说,问题出在我们的代码上。WTForms 允许形式为
validate_[fieldname]的内联验证器。我们的validate_login方法从未被调用,因为我们的表单中没有名为login的字段。让我们从控制器中移除set_trace调用,并将我们的flask_tracking.users.forms.LoginForm.validate_login方法重新命名为LoginForm.validate_password,这样 WTForms 就会将它作为我们的password字段的内联验证器。这确保了只有在 name 和 password 字段都被验证为包含用户提供的数据之后,才会调用它。现在,当我们再次运行我们的单元测试时,它们应该会通过。本地测试表明我们确实解决了这个问题。我们现在可以安全地部署和记录我们的维护消息。
错误处理
正如我们已经发现的,一个测试套件并不能保证我们的应用程序没有错误。用户仍有可能在生产中遇到错误。例如,如果我们简单地盲目访问我们的一个控制器中的
request.args['some_optional_key'],并且我们只使用请求中的可选键集来编写测试,最终用户将默认从 Flask 得到一个400 Bad Request响应。在这种情况下,我们希望向用户显示一条有用的错误消息。我们还希望避免向用户显示没有品牌或过期的页面,而没有太多的帮助去哪里,或者下一步做什么。我们可以向 Flask 注册错误处理程序来明确处理这类问题。让我们为最常见的错误注册一个——输入错误或不再存在的链接:
@app.errorhandler(404) def page_not_found(e): return render_template('404.html'), 404我们可能还希望显式处理其他类型的错误,例如 Flask 为丢失的键生成的 400 个错误请求错误,以及为未捕获的异常生成的 500 个内部服务器错误:
@app.errorhandler(400) def key_error(e): return render_template('400.html'), 400 @app.errorhandler(500) def internal_server_error(e): return render_template('generic.html'), 500除了我们可能不得不处理的 HTTP 错误之外,Flask 还允许我们在一个未捕获的异常出现时显示不同的错误页面。现在,让我们只为所有未捕获的异常注册一个通用的错误处理程序(但是稍后我们可能希望为我们无能为力的更常见的错误情况注册特定的错误处理程序):
@app.errorhandler(Exception) def unhandled_exception(e): return render_template('generic.html'), 500现在,所有最常见的错误都应该由我们的应用程序优雅地处理了。
然而,我们可以做得更好——让我们确保每个错误都有很好的样式,我们可以为每个可能的错误条件注册相同的错误处理程序:
# flask_tracking/errors.py from flask import current_app, Markup, render_template, request from werkzeug.exceptions import default_exceptions, HTTPException def error_handler(error): msg = "Request resulted in {}".format(error) current_app.logger.warning(msg, exc_info=error) if isinstance(error, HTTPException): description = error.get_description(request.environ) code = error.code name = error.name else: description = ("We encountered an error " "while trying to fulfill your request") code = 500 name = 'Internal Server Error' # Flask supports looking up multiple templates and rendering the first # one it finds. This will let us create specific error pages # for errors where we can provide the user some additional help. # (Like a 404, for example). templates_to_try = ['errors/{}.html'.format(code), 'errors/generic.html'] return render_template(templates_to_try, code=code, name=Markup(name), description=Markup(description), error=error) def init_app(app): for exception in default_exceptions: app.register_error_handler(exception, error_handler) app.register_error_handler(Exception, error_handler) # This can be used in __init__ with a # import .errors # errors.init_app(app)这确保了 Flask 知道如何处理的所有 HTTP 错误条件(4XX 和 5XX 级错误)都将
error_handler函数注册为它们的处理程序。再加上一个app.register_error_handler(Exception, error_handler),这将涵盖我们的应用程序可能抛出的几乎每一个错误。(有一些例外,比如SystemExit不会以这种方式被捕获,C 级 segfaults 或 OS 级事件显然不会以这种方式被捕获和处理,但是这些灾难性事件应该是不可抗力事件,而不是我们的应用程序需要半定期准备处理的事情)。记录日志
最后说一下日志。用户并不总是有足够的时间向我们提交一份完整的 bug 报告(更不用说,坏人会积极寻找利用我们的方法)。)我们需要一种方法来确保我们可以及时回顾过去,看看发生了什么,什么时候发生的。
幸运的是,Python 和 Flask 都有日志功能,所以我们也不需要重新发明轮子。在
app.logger的 Flask 对象上有一个标准的 Pythonlogging记录器。我们可以使用日志记录的第一个地方是在我们的错误处理程序中。我们不需要记录 404,因为如果设置正确,代理服务器会为我们做这件事,但是我们希望记录其他异常(400、500 和异常)的原因。让我们继续向这些处理程序添加一些更详细的日志记录。因为我们对所有的错误都使用相同的处理程序,所以这很简单:
def error_handler(error): error_name = error.__name__ if error else "Unknown-Error" app.logger.warning('Request resulted in {}'.format(error_name), exc_info=error) # ... etc. ...Python 关于日志模块的文档对各种可用的日志级别以及它们最适合的用途进行了很好的分类。
当我们无法访问
app(比如说,在我们的view模块内部)时,我们可以像使用app一样使用线程本地current_app。举个例子,让我们在登录和注销处理程序中添加一些日志记录:from flask import current_app @users.route('/logout/') def logout_view(): current_app.debug('Attempting to log out the current user') logout_user() current_app.debug('Successfully logged out the current user') return redirect(url_for('tracking.index'))这段代码很好地展示了我们在日志记录中可能遇到的一个问题——日志记录太多和太少一样糟糕。在这种情况下,我们的调试代码和应用程序代码一样多,很难再跟踪代码的流程。我们将继续删除这个特定的日志记录代码,因为除了我们在代理服务器的访问日志中看到的内容之外,它没有添加任何内容。
如果我们需要记录每个控制器的进入和退出,我们可以为
app.before_request和app.teardown_request添加处理程序。只是为了好玩,下面是我们如何记录对应用程序的每次访问:@app.before_request def log_entry(): context = { 'url': request.path, 'method': request.method, 'ip': request.environ.get("REMOTE_ADDR") } app.logger.debug("Handling %(method)s request from %(ip)s for %(url)s", context)如果我们在调试模式下运行我们的应用程序并访问我们的主页,那么我们将看到:
-------------------------------------------------------------------------------- DEBUG in __init__ [~/dev/flask-tracking/flask_tracking/__init__.py:68]: Handling GET request from 127.0.0.1 for / --------------------------------------------------------------------------------如上所述,在生产日志中,这类信息会复制我们的代理服务器(Apache with mod_wsgi,ngnix with uwsgi,等等)的日志。)将会生成。只有当我们为每个请求生成一个我们绝对需要跟踪的唯一值时,我们才应该这样做。
向我们的日志添加上下文和格式
然而,在我们的异常处理程序中有来自我们的
log_entry处理程序的上下文就更好了。让我们继续向记录器添加一个Filter实例,以便向所有感兴趣的记录器提供 url、方法、IP 地址和用户 id(这被称为“上下文日志记录”:# flask_tracking/logs.py import logging class ContextualFilter(logging.Filter): def filter(self, log_record): log_record.url = request.path log_record.method = request.method log_record.ip = request.environ.get("REMOTE_ADDR") log_record.user_id = -1 if current_user.is_anonymous() else current_user.get_id() return True这个过滤器实际上并不过滤我们的任何消息——相反,它提供了一些我们可以在日志中使用的附加信息。以下是我们如何使用此过滤器的示例:
# Create the filter and add it to the base application logger context_provider = ContextualFilter() app.logger.addFilter(context_provider) # Optionally, remove Flask's default debug handler # del app.logger.handlers[:] # Create a new handler for log messages that will send them to standard error handler = logging.StreamHandler() # Add a formatter that makes use of our new contextual information log_format = "%(asctime)s\t%(levelname)s\t%(user_id)s\t%(ip)s\t%(method)s\t%(url)s\t%(message)s" formatter = logging.Formatter(log_format) handler.setFormatter(formatter) # Finally, attach the handler to our logger app.logger.addHandler(handler)日志消息可能是这样的:
2013-10-12 09:22:52,764 DEBUG 1 127.0.0.1 GET / Some additional message需要注意的一点是,我们传递给
app.logger.[LOGLEVEL]的消息没有用上下文中的值来扩展。因此,如果我们保留我们的before_request日志调用,并将我们的 before request 日志调用更改为# Note the missing context argument app.logger.debug("Handling %(method)s request from %(ip)s for %(url)s")-格式字符串将原封不动地通过。但是既然我们的
Formatter中有它们,我们就可以把它们从我们的个人消息中去掉,只留下:@app.before_request def log_entry(): app.logger.debug("Handling request")这就是上下文日志记录的优势——我们可以在所有日志条目中包含重要信息,而不需要在每个日志调用的站点手动收集这些信息。
将原木导向不同的地方
我们将记录的大部分信息不会立即付诸行动。然而,我们想立即了解某些类型的错误。例如,一连串的 500 个错误可能意味着我们的应用程序出了问题。我们不能 24/7 粘在我们的日志上,所以我们需要将严重的错误发送给我们。
幸运的是,向我们的应用程序日志记录器添加新的处理程序很容易——因为每个处理程序都可以过滤日志条目,只过滤它感兴趣的条目,所以我们可以避免被日志淹没,但当某些东西严重损坏时,我们仍然会收到警报。
举例来说,让我们添加另一个处理程序,将错误和关键日志消息记录到一个特殊的文件中。这不会给我们想要的提醒,但是电子邮件或短信设置取决于您的主机(我们将在 Heroku 的后续文章中进行这样的设置)。为了激起你的兴趣,请看 Flask 的记录文档或中如何记录电子邮件的例子,这些食谱:
from logging import ERROR from logging.handlers import TimedRotatingFileHandler # Only set up a file handler if we know where to put the logs if app.config.get("ERROR_LOG_PATH"): # Create one file for each day. Delete logs over 7 days old. file_handler = TimedRotatingFileHandler(app.config["ERROR_LOG_PATH"], when="D", backupCount=7) # Use a multi-line format for this logger, for easier scanning file_formatter = logging.Formatter(''' Time: %(asctime)s Level: %(levelname)s Method: %(method)s Path: %(url)s IP: %(ip)s User ID: %(user_id)s Message: %(message)s ---------------------''') # Filter out all log messages that are lower than Error. file_handler.setLevel(ERROR) file_handler.addFormatter(file_formatter) app.logger.addHandler(file_handler)如果我们使用此设置,错误和关键日志消息将同时出现在控制台和配置中指定的文件中。
总结
我们在这篇文章中已经讨论了很多。
- 从单元测试开始,我们讨论了什么是测试以及为什么我们需要测试。
- 我们继续编写测试,包括有模拟和没有模拟。
- 我们简要介绍了本地调试错误的三种方法(
pdb。)- 我们讨论了错误处理,并确保我们的最终用户只能看到有风格的错误页面。
- 最后,我们讨论了日志设置。
在第四部分中,我们将进行一些测试驱动的开发,使我们的应用程序能够接受付款并显示简单的报告。
在第五部分中,我们将编写一个 RESTful JSON API 供其他人使用。
在第六部分中,我们将介绍使用 Fabric 和基本 A/B 特性测试的自动化部署(在 Heroku 上)。
最后,在第七部分中,我们将介绍如何用文档、代码覆盖率和质量度量工具来保护您的应用程序。
和往常一样,代码可以从库中获得。期待与您一起继续这一旅程。******
Python Web 应用程序:将脚本部署为 Flask 应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Flask 在 Web 上部署你的 Python 脚本
你写了一个令你自豪的 Python 脚本,现在你想向全世界炫耀它。但是怎么会是?大多数人不会知道如何处理你的
.py文件。将你的脚本转换成一个 Python web 应用是一个让你的代码对广大受众可用的好办法。在本教程中,您将学习如何从本地 Python 脚本到完全部署的 Flask web 应用程序,您可以与全世界共享该应用程序。
本教程结束时,你会知道:
- 什么是网络应用以及你如何在线托管它们
- 如何将 Python 脚本转换成 Flask web 应用
- 如何通过在 Python 代码中添加 HTML 来改善用户体验
- 如何将你的 Python web 应用部署到谷歌应用引擎
除了浏览一个示例项目之外,您还会在整个教程中找到大量的练习。他们会给你机会通过额外的练习巩固你所学的东西。您也可以通过单击下面的链接下载将用于构建 web 应用程序的源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
温习基础知识
在本节中,您将在本教程实践部分的不同主题中获得理论基础:
- 存在哪些类型的 Python 代码分发
- 为什么构建 web 应用程序是一个好的选择
- 什么是 web 应用程序
- 内容如何通过互联网传递
- 虚拟主机意味着什么
- 存在哪些托管提供商,使用哪一个
重温这些主题可以帮助你在为 Web 编写 Python 代码时更加自信。然而,如果你已经熟悉了它们,那么请随意跳过,安装 Google Cloud SDK,并开始构建你的 Python web 应用。
分发您的 Python 代码
把你的代码带给你的用户叫做分发。传统上,有三种不同的方法可以用来分发您的代码,以便其他人可以使用您的程序:
- Python 库
- 独立程序
- Python web 应用程序
您将仔细研究下面的每一种方法。
Python 库
如果你使用过 Python 广泛的包生态系统,那么你可能已经安装了带有
pip的 Python 包。作为一名程序员,您可能希望在 PyPI 上发布您的 Python 包,以允许其他用户通过使用pip安装它来访问和使用您的代码:$ python3 -m pip install <your-package-name>在您成功地将代码发布到 PyPI 之后,这个命令将在您的任何用户的计算机上安装您的包,包括它的依赖项,前提是他们有互联网连接。
如果您不想将代码发布为 PyPI 包,那么您仍然可以使用 Python 的内置
sdist命令来创建一个源发行版或一个 Python 轮来创建一个构建发行版来与您的用户共享。像这样分发代码可以使它接近您编写的原始脚本,并且只添加其他人运行它所必需的内容。然而,使用这种方法也意味着您的用户需要使用 Python 来运行您的代码。许多想要使用脚本功能的人不会安装 Python,或者不熟悉直接处理代码所需的过程。
向潜在用户展示代码的一种更加用户友好的方式是构建一个独立的程序。
独立程序
计算机程序有不同的形状和形式,将 Python 脚本转换成独立程序有多种选择。下面你会读到两种可能性:
- 打包您的代码
- 构建 GUI
像 PyInstaller 、 py2app 、 py2exe 或公文包这样的程序可以帮助打包你的代码。它们将 Python 脚本转换成可执行程序,可以在不同平台上使用,而不需要用户显式运行 Python 解释器。
注意:要了解更多关于打包代码的信息,请查看使用 PyInstaller 轻松分发 Python 应用程序的或收听真正的 Python 播客插曲打包 Python 应用程序的选项。
虽然打包代码可以解决依赖性问题,但是代码仍然只能在命令行上运行。大多数人习惯于使用提供图形用户界面(GUI)的程序。您可以通过为 Python 代码构建一个 GUI 来让更多的人访问您的代码。
注意:有不同的软件包可以帮助你构建 GUI,包括 Tkinter 、 wxPython 和 PySimpleGUI 。如果你想构建一个基于桌面的应用,那么看看 Python GUI 编程的学习路径。
虽然一个独立的 GUI 桌面程序可以让你的代码被更多的人访问,但是它仍然是人们入门的一个障碍。在运行你的程序之前,潜在用户需要完成几个步骤。他们需要找到适合其操作系统的正确版本,下载并成功安装。有些人可能在成功之前就放弃了。
许多开发人员转而构建可以在互联网浏览器上快速访问和运行的 web 应用程序,这是有道理的。
Python 网络应用
web 应用程序的优势在于它们是独立于平台的,任何能够访问互联网的人都可以运行。他们的代码在后端服务器上实现,程序在那里处理输入的请求,并通过所有浏览器都能理解的共享协议做出响应。
Python 支持许多大型 web 应用程序,并且是后端语言的常见选择。许多 Python 驱动的 web 应用程序从一开始就被规划为 web 应用程序,并且是使用 Python web 框架构建的,比如您将在本教程中使用的 Flask 。
然而,与上面描述的 web 优先的方法不同,您将从一个不同的角度出发。毕竟,你没有计划构建一个网络应用。您刚刚创建了一个有用的 Python 脚本,现在您想与全世界分享。为了让更多的用户能够访问它,您将把它重构为一个 web 应用程序,然后部署到互联网上。
是时候回顾一下什么是 web 应用程序,以及它与 Web 上的其他内容有何不同。
了解 Python Web 应用程序
从历史上看,网站有固定的内容,对于访问该页面的每个用户都是一样的。这些网页被称为静态网页,因为当你与它们互动时,它们的内容不会改变。当提供静态网页时,web 服务器通过发回该网页的内容来响应您的请求,而不管您是谁或您采取了什么其他操作。
您可以在第一个上线的 URL浏览静态网站的示例,以及它链接到的页面:
The history of the WWW 这种静态网站不被认为是应用程序,因为它们的内容不是由代码动态生成的。虽然静态网站曾经构成了整个互联网,但今天的大多数网站都是真正的网络应用程序,提供可以改变内容的动态网页(T2)。
例如,一个网络邮件应用程序允许你以多种方式与之交互。根据您的操作,它可以显示不同类型的信息,通常停留在一个页面中:
A single-page Webmail application Python 驱动的 web 应用使用 Python 代码来决定采取什么动作和显示什么内容。您的代码由托管您网站的 web 服务器运行,这意味着您的用户不需要安装任何东西。他们只需要一个浏览器和一个互联网连接就可以与你的代码进行交互。
让 Python 在网站上运行可能很复杂,但是有许多不同的 web 框架自动处理细节。如上所述,在本教程中,您将构建一个基本的 Flask 应用程序。
在接下来的部分中,您将从较高的层面了解在服务器上运行 Python 代码并向用户提供响应所需的主要过程。
查看 HTTP 请求-响应周期
通过互联网提供动态内容涉及许多不同的部分,它们都必须相互通信才能正常工作。以下是用户与 web 应用程序交互时发生的情况的概述:
发送:首先,你的用户在你的 web 应用上请求一个特定的网页。例如,他们可以通过在浏览器中键入 URL 来实现这一点。
接收:这个请求被托管你的网站的网络服务器接收。
匹配:您的 web 服务器现在使用一个程序将用户的请求匹配到您的 Python 脚本的特定部分。
运行:程序调用适当的 Python 代码。当您的代码运行时,它会写出一个网页作为响应。
传送:然后程序通过网络服务器将这个响应传送给你的用户。
查看:最后,用户可以查看 web 服务器的响应。例如,生成的网页可以在浏览器中显示。
这是内容如何通过互联网传送的一般过程。服务器上使用的编程语言以及用于建立连接的技术可能会有所不同。然而,用于跨 HTTP 请求和响应进行通信的概念保持不变,被称为 HTTP 请求-响应周期。
注意: Flask 将为您处理大部分这种复杂性,但它有助于在头脑中保持对这一过程的松散理解。
要让 Flask 在服务器端处理请求,您需要找到一个 Python 代码可以在线的地方。在线存储你的代码来运行一个网络应用程序叫做虚拟主机,有很多提供商提供付费和免费的虚拟主机服务。
选择托管提供商:谷歌应用引擎
选择虚拟主机提供商时,您需要确认它支持运行 Python 代码。它们中的许多都需要花钱,但本教程将坚持使用一个免费的选项,它是专业的、高度可扩展的,但设置起来仍然合理: Google App Engine 。
注意: Google App Engine 对每个应用强制执行每日配额。如果你的网络应用超过了这些限额,那么谷歌将开始向你收费。如果你是谷歌云的新客户,那么你可以在注册时获得一个免费促销积分。
还有许多其他的免费选项,比如 PythonAnywhere 、 Repl.it 或 Heroku ,你可以稍后再去探索。使用 Google App Engine 将为您学习如何将 Python 代码部署到 web 上提供一个良好的开端,因为它在抽象掉复杂性和允许您自定义设置之间取得了平衡。
谷歌应用引擎是谷歌云平台(GCP)的一部分,该平台由谷歌运营,代表着一个大型云提供商,另外还有微软 Azure 和亚马逊网络服务(AWS) 。
要开始使用 GCP,请为您的操作系统下载并安装 Google Cloud SDK 。除了本教程,你还可以参考谷歌应用引擎的文档。
注意:您将使用 Python 3 标准环境。谷歌应用引擎的标准环境支持 Python 3 运行时,并提供一个免费层。
Google Cloud SDK 安装还包括一个名为
gcloud的命令行程序,您稍后将使用它来部署您的 web 应用程序。安装完成后,您可以通过在控制台中键入以下命令来验证一切正常:$ gcloud --version您应该会在终端中收到一个文本输出,类似于下面的内容:
app-engine-python 1.9.91 bq 2.0.62 cloud-datastore-emulator 2.1.0 core 2020.11.13 gsutil 4.55您的版本号可能会不同,但是只要在您的计算机上成功找到了
gcloud程序,您的安装就成功了。有了这个概念的高级概述和 Google Cloud SDK 的安装,您就可以设置一个 Python 项目,稍后您将把它部署到互联网上。
构建一个基本的 Python Web 应用程序
Google App Engine 要求您使用 web 框架在 Python 3 环境中创建 web 应用程序。由于您试图使用最小的设置将您的本地 Python 代码放到互联网上,所以像 Flask 这样的微框架是一个不错的选择。Flask 的最小实现是如此之小,以至于您可能甚至没有注意到您正在使用一个 web 框架。
注意:如果你以前在 Python 2.7 环境下使用过 Google App Engine,那么你会注意到这个过程已经发生了显著的变化。
两个值得注意的变化是 webapp2 已经退役,你不再能够在
app.yaml文件中指定动态内容的 URL。这两个变化的原因是 Google App Engine 现在要求您使用 Python web 框架。您将要创建的应用程序将依赖于几个不同的文件,因此您需要做的第一件事是创建一个项目文件夹来保存所有这些文件。
设置您的项目
创建一个项目文件夹,并给它一个描述您的项目的名称。对于本练习项目,调用文件夹
hello-app。这个文件夹中需要三个文件:
main.py包含你的 Python 代码,包装在 Flask web 框架的最小实现中。requirements.txt列出了代码正常工作所需的所有依赖关系。app.yaml帮助谷歌应用引擎决定在其服务器上使用哪些设置。虽然三个文件听起来很多,但是您会看到这个项目在所有三个文件中使用了不到十行代码。这代表了您需要为任何可能启动的 Python 项目提供给 Google App Engine 的最小设置。剩下的就是你自己的 Python 代码了。您可以通过单击下面的链接下载将在本教程中使用的完整源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
接下来,您将查看每个文件的内容,从最复杂的文件
main.py开始。创建
main.py是 Flask 用来传递内容的文件。在文件的顶部,您在第 1 行导入了
Flask类,然后您在第 3 行创建了一个 Flask 应用程序的实例:1from flask import Flask 2 3app = Flask(__name__) 4 5@app.route("/") 6def index(): 7 return "Congratulations, it's a web app!"创建 Flask
app后,在第 5 行编写一个名为@app.route的 Python 装饰器,Flask 用它来连接函数中包含的代码的 URL 端点。@app.route的参数定义了 URL 的路径组件,在本例中是根路径("/")。第 6 行和第 7 行的代码组成了
index(),由装饰器包装。该函数定义了当用户请求已定义的 URL 端点时应该执行的操作。它的返回值决定了用户加载页面时会看到什么。注:
index()的命名只是约定俗成。它关系到一个网站的主页面通常怎么叫index.html。如果需要,您可以选择不同的函数名。换句话说,如果用户在他们的浏览器中输入你的 web 应用的基本 URL,那么 Flask 运行
index()并且用户看到返回的文本。在这种情况下,该文本只是一句话:Congratulations, it's a web app!您可以呈现更复杂的内容,也可以创建多个函数,以便用户可以访问应用程序中的不同 URL 端点来接收不同的响应。然而,对于这个初始实现,坚持使用这个简短且令人鼓舞的成功消息是很好的。
创建
requirements.txt下一个要看的文件是
requirements.txt。因为 Flask 是这个项目唯一的依赖项,所以您只需要指定:Flask==2.1.2如果您的应用程序有其他依赖项,那么您也需要将它们添加到您的
requirements.txt文件中。在服务器上设置项目时,Google App Engine 将使用
requirements.txt为项目安装必要的 Python 依赖项。这类似于在本地创建并激活一个新的虚拟环境之后你会做的事情。创建
app.yaml第三个文件
app.yaml,帮助 Google App Engine 为您的代码建立正确的服务器环境。这个文件只需要一行代码,它定义了 Python 运行时:runtime: python38上面显示的行阐明了 Python 代码的正确运行时是 Python 3.8。这足以让 Google App Engine 在其服务器上进行必要的设置。
注意:确保您想要使用的 Python 3 运行时环境在 Google App Engine 上可用。
您可以使用 Google App Engine 的
app.yaml文件进行额外的设置,例如向您的应用程序添加环境变量。您还可以使用它来定义应用程序静态内容的路径,如图像、CSS 或 JavaScript 文件。本教程不会深入这些额外的设置,但是如果你想添加这样的功能,你可以参考 Google App Engine 关于app.yaml配置文件的文档。这九行代码完成了这个应用程序的必要设置。您的项目现在可以部署了。
然而,在将代码投入生产之前对其进行测试是一个很好的做法,这样可以捕捉到潜在的错误。接下来,在将代码部署到互联网之前,您将检查本地的一切是否如预期的那样工作。
本地测试
Flask 附带了一个开发 web 服务器。您可以使用这个开发服务器来复查您的代码是否按预期工作。为了能够在本地运行 Flask development server,您需要完成两个步骤。一旦您部署了代码,Google App Engine 将在其服务器上执行相同的步骤:
- 建立一个虚拟环境。
- 安装
flask包。为了设置 Python 3 虚拟环境,在终端上导航到您的项目文件夹,并键入以下命令:
$ python3 -m venv venv这将使用您系统上安装的 Python 3 版本创建一个名为
venv的新虚拟环境。接下来,您需要通过获取激活脚本来激活虚拟环境:$ source venv/bin/activate执行该命令后,您的提示符将会改变,表明您现在正在虚拟环境中操作。成功设置并激活虚拟环境后,就可以安装 Flask 了:
$ python3 -m pip install -r requirements.txt这个命令从 PyPI 获取
requirements.txt中列出的所有包,并将它们安装到您的虚拟环境中。在这种情况下,唯一安装的包将是 Flask。等待安装完成,然后打开
main.py并在文件底部添加以下两行代码:if __name__ == "__main__": app.run(host="127.0.0.1", port=8080, debug=True)这两行告诉 Python 在从命令行执行脚本时启动 Flask 的开发服务器。只有在本地运行脚本时才会用到它。当您将代码部署到 Google App Engine 时,一个专业的 web 服务器进程,如 Gunicorn ,将会为应用程序提供服务。你不需要做任何改变来实现这一点。
现在,您可以启动 Flask 的开发服务器,并在浏览器中与 Python 应用程序进行交互。为此,您需要通过键入以下命令来运行启动 Flask 应用程序的 Python 脚本:
$ python3 main.pyFlask 启动开发服务器,您的终端将显示如下所示的输出:
* Serving Flask app "main" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://127.0.0.1:8080/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 315-059-987这个输出告诉您三条重要的信息:
WARNING: 这是 Flask 的开发服务器,也就是说你不想用它来为你的代码在生产中服务。谷歌应用引擎将为你处理。
Running on http://127.0.0.1:8080/: 这是你可以找到你的应用的网址。这是你的本地主机的网址,这意味着应用程序正在你自己的电脑上运行。在浏览器中导航到该 URL 以实时查看您的代码。
Press CTRL+C to quit: 同一行还告诉你,按键盘上的Ctrl+C可以退出开发服务器。按照说明,在
http://127.0.0.1:8080/打开一个浏览器标签。您应该看到一个页面,显示您的函数返回的文本:Congratulations, it's a web app!注意:URL
127.0.0.1也叫 localhost ,意思是指向自己的电脑。冒号(:)后面的数字8080称为端口号。该端口可以被认为是一个特定的频道,类似于广播电视或无线电频道。您已经在
main.py文件的app.run()中定义了这些值。在端口8080上运行应用程序意味着您可以监听这个端口号,并接收来自开发服务器的通信。端口8080通常用于本地测试,但是您也可以使用不同的号码。您可以使用 Flask 的开发服务器来检查您对 Python 应用程序代码所做的任何更改。服务器监听您在代码中所做的更改,并将自动重新加载以显示它们。如果您的应用程序在开发服务器上不能像您期望的那样呈现,那么它也不能在生产中工作。因此,在部署它之前,请确保它看起来不错。
还要记住,即使它在本地工作得很好,部署后也可能不一样。这是因为当您将代码部署到 Google App Engine 时,还涉及到其他因素。然而,对于一个基本的应用程序,比如你在本教程中构建的应用程序,如果它在本地运行良好,你可以确信它可以在生产中运行。
更改
index()的返回值,并确认您可以看到浏览器中反映的更改。玩弄它。当你把index()的返回值改为 HTML 代码,比如<h1>Hello</h1>,而不是使用纯文本字符串,会发生什么?在本地开发服务器上检查了您的设置和代码的功能之后,您就可以将它部署到 Google App Engine 了。
部署您的 Python Web 应用程序
终于到了让你的应用上线的时候了。但是首先,你的代码需要在谷歌的服务器上有一个位置,你需要确保它安全到达那里。在本节教程中,您将在云中和本地完成必要的部署设置。
在谷歌应用引擎上设置
一步一步地阅读下面的设置过程。您可以将您在浏览器中看到的内容与截图进行比较。示例截图中使用的项目名称是
hello-app。首先登录谷歌云平台。导航到仪表板视图,您会在窗口顶部看到一个工具栏。选择工具栏左侧的向下箭头按钮。这将弹出一个包含 Google 项目列表的模式:
该模式显示您的项目列表。如果您尚未创建任何项目,该列表可能为空。在该模式的右上角,找到新项目按钮并点击它:
点击新项目会将你重定向到一个新页面,在这里你可以为你的项目选择一个名字。这个名称将出现在您的应用程序的 URL 中,看起来类似于
http://your-application-name.nw.r.appspot.com。使用hello-app作为这个项目的名称,以与教程保持一致:
您可以在项目名称输入框下看到您的项目 ID。项目 ID 由您输入的名称和 Google App Engine 添加的数字组成。在本教程的例子中,您可以看到项目 ID 是
hello-app-295110。复制您的个人项目 ID,因为您将在以后的部署中需要它。注意:由于项目 ID 需要是唯一的,您的编号将与本教程中显示的不同。
你现在可以点击创建并等待项目在 Google App Engine 端建立。完成后,会弹出一个通知,告诉你一个新项目已经创建。它还为您提供了选择它的选项。点击选择项目继续操作:
点击选择项目会将你重定向到新的谷歌云平台项目的主页。看起来是这样的:
从这里,你想切换到谷歌应用引擎的仪表板。你可以点击左上角的汉堡菜单,向下滚动选择第一个列表中的应用引擎,然后选择下一个弹出列表顶部的仪表盘:
这将最终把您重定向到新项目的 Google App Engine 仪表板视图。由于该项目到目前为止是空的,因此该页面将类似于以下内容:
当您看到此页面时,意味着您已经完成了在 Google App Engine 上设置一个新项目。现在,您已经准备好返回到您计算机上的终端,并完成将您的应用程序部署到该项目所需的本地步骤。
为部署在本地设置
在成功地安装了谷歌云 SDK 之后,你就可以访问
gcloud命令行界面了。该程序附带了指导您部署 web 应用程序的有用说明。首先键入在 Google App Engine 网站上创建新项目时建议您使用的命令:
正如您在页面右下角看到的,Google App Engine 建议使用一个终端命令将您的代码部署到这个项目中。打开您的终端,导航到您的项目文件夹,然后运行建议的命令:
$ gcloud app deploy当您在没有任何预先设置的情况下执行此命令时,程序将响应一条错误消息:
ERROR: (gcloud.app.deploy) You do not currently have an active account selected. Please run: $ gcloud auth login to obtain new credentials. If you have already logged in with a different account: $ gcloud config set account ACCOUNT to select an already authenticated account to use.您收到此错误消息是因为您无法将任何代码部署到您的 Google App Engine 帐户,除非您向 Google 证明您是该帐户的所有者。您需要从本地计算机使用您的 Google App Engine 帐户进行身份验证。
gcloud命令行应用程序已经为您提供了您需要运行的命令。将它键入您的终端:$ gcloud auth login这将通过生成一个验证 URL 并在浏览器中打开它来启动身份验证过程。通过在浏览器窗口中选择您的 Google 帐户并授予 Google Cloud SDK 必要的权限来完成该过程。完成此操作后,您可以返回到您的终端,在这里您会看到一些关于认证过程的信息:
Your browser has been opened to visit: https://accounts.google.com/o/oauth2/auth?client_id=<yourid> You are now logged in as [<your@email.com>]. Your current project is [None]. You can change this setting by running: $ gcloud config set project PROJECT_ID如果您看到此消息,则身份验证成功。您还可以看到,命令行程序再次为您提供了关于下一步的有用信息。
它告诉您当前没有项目集,您可以通过运行
gcloud config set project PROJECT_ID来设置一个。现在您将需要您之前记录的项目 ID。注意:您可以随时通过访问 Google App Engine 网站,点击向下箭头,调出显示您所有 Google 项目的模式,从而获得您的项目 ID。项目标识列在项目名称的右侧,通常由项目名称和一个六位数组成。
在运行建议的命令时,确保用您自己的项目 ID 替换
hello-app-295110:$ gcloud config set project hello-app-295110您的终端将打印出一条简短的反馈消息,表明项目属性已经更新。在成功地验证和设置默认项目为您的项目 ID 之后,您已经完成了必要的设置步骤。
运行部署流程
现在,您已经准备好再次尝试初始部署命令:
$ gcloud app deploy
gcloud应用程序从您刚刚设置的默认配置中获取您的认证凭证和项目 ID 信息,并允许您继续。接下来,您需要选择一个区域来托管您的应用程序:You are creating an app for project [hello-app-295110]. WARNING: Creating an App Engine application for a project is irreversible and the region cannot be changed. More information about regions is at <https://cloud.google.com/appengine/docs/locations>. Please choose the region where you want your App Engine application located: [1] asia-east2 [2] asia-northeast1 [3] asia-northeast2 [4] asia-northeast3 [5] asia-south1 [6] asia-southeast2 [7] australia-southeast1 [8] europe-west [9] europe-west2 [10] europe-west3 [11] europe-west6 [12] northamerica-northeast1 [13] southamerica-east1 [14] us-central [15] us-east1 [16] us-east4 [17] us-west2 [18] us-west3 [19] us-west4 [20] cancel Please enter your numeric choice:输入左侧列出的数字之一,然后按下
Enter。注意:你选择哪个地区的这个 app 并不重要。但是,如果您正在构建一个流量很大的大型应用程序,那么您会希望将它部署到一个在物理上靠近大多数用户所在位置的服务器上。
输入一个数字后,CLI 将继续设置过程。在将您的代码部署到 Google App Engine 之前,它会向您展示部署的概况,并要求您进行最终确认:
Creating App Engine application in project [hello-app-295110] and region [europe-west]....done. Services to deploy: descriptor: [/Users/realpython/Documents/helloapp/app.yaml] source: [/Users/realpython/Documents/helloapp] target project: [hello-app-295110] target service: [default] target version: [20201109t112408] target url: [https://hello-app-295110.ew.r.appspot.com] Do you want to continue (Y/n)?在您通过键入
Y确认设置之后,您的部署将最终上路。当 Google App Engine 在其服务器上设置您的项目时,您的终端将向您显示更多信息和一个小的加载动画:Beginning deployment of service [default]... Created .gcloudignore file. See `gcloud topic gcloudignore` for details. ╔════════════════════════════════════════════════════════════╗ ╠═ Uploading 3 files to Google Cloud Storage ═╣ ╚════════════════════════════════════════════════════════════╝ File upload done. Updating service [default]...⠼由于这是首次部署您的 web 应用程序,因此可能需要几分钟才能完成。部署完成后,您将在控制台中看到另一个有用的输出。它看起来与下面的类似:
Deployed service [default] to [https://hello-app-295110.ew.r.appspot.com] You can stream logs from the command line by running: $ gcloud app logs tail -s default To view your application in the web browser run: $ gcloud app browse现在,您可以在浏览器中导航到提到的 URL,或者键入建议的命令
gcloud app browse来访问您的 live web 应用程序。您应该会看到与之前在本地主机上运行应用程序时看到的相同的简短文本响应:Congratulations, it's a web app!请注意,此网站有一个您可以与其他人共享的 URL,他们将能够访问它。您现在拥有了一个真实的 Python web 应用程序!
再次更改
index()的返回值,并使用gcloud app deploy命令第二次部署您的应用。确认您可以在浏览器中看到实时网站上反映的更改。至此,您已经完成了将本地 Python 代码发布到 web 上的必要步骤。然而,到目前为止你放在网上的唯一功能是打印出一串文本。
是时候加快步伐了!按照同样的过程,您将在下一节中带来更多有趣的在线功能。您将把本地温度转换器脚本的代码重构到 Flask web 应用程序中。
将脚本转换成网络应用程序
由于本教程是关于从您已有的代码创建和部署 Python web 应用程序,因此在此为您提供了温度转换器脚本的 Python 代码:
def fahrenheit_from(celsius): """Convert Celsius to Fahrenheit degrees.""" try: fahrenheit = float(celsius) * 9 / 5 + 32 fahrenheit = round(fahrenheit, 3) # Round to three decimal places return str(fahrenheit) except ValueError: return "invalid input" if __name__ == "__main__": celsius = input("Celsius: ") print("Fahrenheit:", fahrenheit_from(celsius))这是一个简短的脚本,允许用户将摄氏温度转换为等效的华氏温度。
将代码保存为 Python 脚本,并尝试一下。确保它按预期工作,并且您了解它的功能。请随意改进代码。
有了这个工作脚本,现在需要修改代码,将其集成到 Flask 应用程序中。这样做有两个要点需要考虑:
- 执行:web app 怎么知道什么时候运行代码?
- 用户输入:web app 将如何收集用户输入?
您已经学习了如何通过将代码添加到分配了路由的函数中来告诉 Flask 执行特定的代码。首先从解决这项任务开始。
添加代码作为功能
Flask 将不同的任务分成不同的函数,每个函数通过
@app.route装饰器被分配一条路径。当用户通过 URL 访问指定的路径时,相应函数中的代码就会被执行。首先将
fahrenheit_from()添加到main.py文件中,并用@app.route装饰器包装它:from flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Congratulations, it's a web app!" @app.route("/") def fahrenheit_from(celsius): """Convert Celsius to Fahrenheit degrees.""" try: fahrenheit = float(celsius) * 9 / 5 + 32 fahrenheit = round(fahrenheit, 3) # Round to three decimal places return str(fahrenheit) except ValueError: return "invalid input" if __name__ == "__main__": app.run(host="127.0.0.1", port=8080, debug=True)到目前为止,您只将 Python 脚本的代码复制到 Flask 应用程序的一个函数中,并添加了
@app.route装饰器。然而,这个设置已经有一个问题了。当您在开发服务器中运行代码时会发生什么?试试看。
目前,您的两个功能都由同一条路径触发(
"/")。当用户访问该路径时,Flask 选择第一个与之匹配的函数并执行该代码。在您的例子中,这意味着fahrenheit_from()永远不会被执行,因为index()匹配相同的路由并首先被调用。您的第二个功能将需要其自己的唯一路径才能访问。此外,您仍然需要允许您的用户为您的功能提供输入。
将值传递给代码
您可以通过告诉 Flask 将基本 URL 之后的 URL 的任何剩余部分视为一个值并将其传递给函数来解决这两个任务。这只需要在
fahrenheit_from()之前对@app.route装饰器的参数做一个小的改变:@app.route("/<celsius>") def fahrenheit_from(celsius): # -- snip --尖括号语法(
<>)告诉 Flask 捕捉基本 URL ("/")后面的任何文本,并将其传递给装饰器包装为变量celsius的函数。注意fahrenheit_from()需要celsius作为输入。注意:确保您捕获的 URL 路径组件与您传递给函数的参数同名。否则,Flask 会感到困惑,并通过向您显示一条错误消息来让您知道这一点。
回到您的 web 浏览器,使用 Flask 的开发服务器尝试新功能。现在,您可以使用不同的 URL 端点通过 web 应用程序访问这两项功能:
- 索引(
/): 如果你去基础网址,那么你会看到之前的鼓励短信。- 摄氏度(
/42): 如果你在正斜杠后添加一个数字,那么你会看到转换后的温度出现在你的浏览器中。更多地使用它,尝试输入不同的输入。即使您的脚本中的错误处理仍然有效,并在用户输入非数字输入时显示一条消息。您的 web 应用程序处理的功能与 Python 脚本在本地处理的功能相同,只是现在您可以将其部署到互联网上。
重构你的代码
Flask 是一个成熟的 web 框架,允许你把很多任务交给它的内部。例如,你可以让 Flask 负责类型检查你的函数的输入,如果不合适就返回一个错误消息。所有这些都可以通过
@app.route的参数中的简洁语法来完成。将以下内容添加到路径捕获器中:@app.route("/<int:celsius>")在变量名前添加
int:告诉 Flask 检查它从 URL 接收的输入是否可以转换成整数。如果可以,则将内容传递给fahrenheit_from()。如果不能,那么 Flask 会显示一个Not Found错误页面。注意:
Not Found错误意味着 Flask 试图将它从 URL 中截取的路径组件与它知道的任何函数进行匹配。然而,它目前知道的唯一模式是空的基本路径(
/)和后跟数字的基本路径,例如/42。由于像/hello这样的文本不匹配这些模式,它会告诉你在服务器上没有找到请求的 URL。在应用 Flask 的类型检查后,您现在可以安全地移除
fahrenheit_from()中的try…except块。Flask 只会将整数传递给函数:from flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Congratulations, it's a web app!" @app.route("/<int:celsius>") def fahrenheit_from(celsius): """Convert Celsius to Fahrenheit degrees.""" fahrenheit = float(celsius) * 9 / 5 + 32 fahrenheit = round(fahrenheit, 3) # Round to three decimal places return str(fahrenheit) if __name__ == "__main__": app.run(host="127.0.0.1", port=8080, debug=True)至此,您已经完成了将温度转换脚本转换为 web 应用程序的工作。确认本地一切正常,然后将您的应用再次部署到 Google App Engine。
重构
index()。它应该返回解释如何使用温度转换器 web 应用程序的文本。请记住,您可以在返回字符串中使用 HTML 标记。HTML 将在您的登录页面上正确呈现。在成功地将您的温度转换 web 应用程序部署到互联网后,您现在就有了一个链接,可以与其他人共享,并允许他们将摄氏温度转换为华氏温度。
然而,界面看起来仍然很基本,web 应用程序的功能更像是一个 API 而不是前端 web 应用程序。许多用户可能不知道如何在当前状态下与 Python web 应用程序进行交互。这向您展示了使用纯 Python 进行 web 开发的局限性。
如果你想创建更直观的界面,那么你至少需要开始使用一点 HTML。
在下一节中,您将继续迭代您的代码,并使用 HTML 创建一个输入框,它允许用户直接在页面上输入一个数字,而不是通过 URL。
改进您的网络应用程序的用户界面
在这一节中,您将学习如何向您的 web 应用程序添加 HTML
<form>input 元素,以允许用户以他们习惯于从其他在线应用程序使用的直接方式与之交互。为了改善 web 应用程序的用户界面和用户体验,您需要使用 Python 以外的语言,即前端语言,如 HTML、CSS 和 JavaScript。本教程尽可能避免深入讨论这些内容,而是专注于 Python 的使用。
然而,如果你想在你的网络应用中添加一个输入框,那么你需要使用一些 HTML。您将只实现绝对最小化,以使您的 web 应用程序看起来和感觉上更像用户熟悉的网站。您将使用 HTML
<form>元素来收集他们的输入。注:如果你想了解更多关于 HTML 的知识,那就去看看 Real Python 的面向 Python 开发者的 HTML 和 CSS或者 MDN 的HTML 简介。
更新您的 web 应用程序后,您将有一个文本字段,用户可以在其中输入以摄氏度为单位的温度。将会有一个转换按钮将用户提供的摄氏温度转换为华氏温度:
https://player.vimeo.com/video/492638932?background=1
转换后的结果将显示在下一行,并在用户点击转换时更新。
您还将更改应用程序的功能,以便表单和转换结果显示在同一页面上。您将重构代码,这样您只需要一个 URL 端点。
收集用户输入
首先在您的登录页面上创建一个
<form>元素。将以下几行 HTML 复制到index()的返回语句中,替换之前的文本消息:@app.route("/") def index(): return """<form action="" method="get"> <input type="text" name="celsius"> <input type="submit" value="Convert"> </form>"""当您在基本 URL 重新加载页面时,您会看到一个输入框和一个按钮。HTML 会正确呈现。恭喜,您刚刚创建了一个输入表单!
注意:请记住,这几行 HTML 代码本身并不构成一个有效的 HTML 页面。然而,现代浏览器被设计成可以填补空白并为你创建缺失的结构。
当你输入一个值然后点击转换会发生什么?虽然页面看起来一样,但您可能会注意到 URL 发生了变化。它现在显示一个查询参数,在基本 URL 后面有一个值。
例如,如果您在文本框中输入
42并点击按钮,那么您的 URL 将如下所示:http://127.0.0.1:8080/?celsius=42。这是好消息!该值被成功记录并作为查询参数添加到 HTTP GET 请求中。看到这个 URL 意味着您再次请求基本 URL,但是这一次您发送了一些额外的值。然而,这个额外的值目前没有任何作用。虽然表单已经设置好了,但是它还没有正确地连接到 Python web 应用程序的代码功能。
为了理解如何建立这种联系,您将阅读
<form>元素的每一部分,看看不同的部分是关于什么的。您将分别查看以下三个元素及其属性:
<form>元素- 输入箱
- 提交按钮
每一个都是独立的 HTML 元素。虽然本教程旨在将重点放在 Python 而不是 HTML 上,但是对这段 HTML 代码有一个基本的了解仍然是有帮助的。从最外层的 HTML 元素开始。
<form>元素元素创建了一个 HTML 表单。另外两个
<input>元素被包装在里面:<form action="" method="get"> <input type="text" name="celsius" /> <input type="submit" value="Convert" /> </form>
<form>元素还包含两个 HTML 属性,称为action和method:
action决定用户提交的数据将被发送到哪里。您在这里将值保留为空字符串,这使得您的浏览器将请求定向到调用它的同一个 URL。在您的情况下,这是空的基本 URL。
method定义了表单产生什么类型的 HTTP 请求。使用默认的"get"创建一个 HTTP GET 请求。这意味着用户提交的数据将在 URL 查询参数中可见。如果您提交敏感数据或与数据库通信,那么您需要使用 HTTP POST 请求。检查完
<form>元素及其属性后,下一步是仔细查看两个<input>元素中的第一个。输入框
第二个 HTML 元素是嵌套在
<form>元素中的<input>元素:<form action="" method="get"> <input type="text" name="celsius" /> <input type="submit" value="Convert" /> </form>第一个
<input>元素有两个 HTML 属性:
type定义了应该创建什么类型的<input>元素。有很多可供选择,比如复选框和下拉元素。在这种情况下,您希望用户输入一个数字作为文本,所以您将类型设置为"text"。
name定义用户输入的值将被称为什么。你可以把它想象成一个字典的键,其中的值是用户在文本框中输入的任何内容。您看到这个名称作为查询参数的键出现在 URL 中。稍后您将需要这个键来检索用户提交的值。HTML
<input>元素可以有不同的形状,其中一些需要不同的属性。当查看第二个<input>元素时,您会看到一个这样的例子,它创建了一个提交按钮,并且是组成代码片段的最后一个 HTML 元素。提交按钮
第二个
<input>元素创建了允许用户提交输入的按钮:<form action="" method="get"> <input type="text" name="celsius" /> <input type="submit" value="Convert" /> </form>这个元素还有两个 HTML 属性,分别命名为
type和value:
type定义了将创建什么样的输入元素。使用值"submit"创建一个按钮,允许您向前发送捆绑的表单数据。
value定义按钮应该显示什么文本。您可以随意更改它,看看按钮如何显示您更改的文本。通过对不同 HTML 元素及其属性的简短概述,您现在对添加到 Python 代码中的内容以及这些元素的用途有了更好的理解。
将表单提交连接到 Flask 代码所需的信息是第一个
<input>元素的name值celsius,您将使用它来访问函数中提交的值。接下来,您将学习如何更改 Python 代码来正确处理提交的表单输入。
接收用户输入
在您的
<form>元素的action属性中,您指定了 HTML 表单的数据应该被发送回它来自的同一个 URL。现在您需要包含在index()中获取值的功能。为此,您需要完成两个步骤:
导入 Flask 的
request对象:像许多 web 框架一样,Flask 将 HTTP 请求作为全局对象传递。为了能够使用这个全局request对象,您首先需要导入它。获取值:
request对象包含提交的值,并允许您通过 Python 字典语法访问它。您需要从全局对象中获取它,以便能够在函数中使用它。现在重写您的代码并添加这两个更改。您还需要将捕获的值添加到表单字符串的末尾,以显示在表单之后:
from flask import Flask from flask import request app = Flask(__name__) @app.route("/") def index(): celsius = request.args.get("celsius", "") return ( """<form action="" method="get"> <input type="text" name="celsius"> <input type="submit" value="Convert"> </form>""" + celsius ) @app.route("/<int:celsius>") def fahrenheit_from(celsius): """Convert Celsius to Fahrenheit degrees.""" fahrenheit = float(celsius) * 9 / 5 + 32 fahrenheit = round(fahrenheit, 3) # Round to three decimal places return str(fahrenheit) if __name__ == "__main__": app.run(host="127.0.0.1", port=8080, debug=True)
request.args字典包含通过 HTTP GET 请求提交的任何数据。如果您的基本 URL 最初被调用,没有表单提交,那么字典将是空的,您将返回一个空字符串作为默认值。如果页面通过提交表单被调用,那么字典将在celsius键下包含一个值,您可以成功地获取它并将其添加到返回的字符串中。旋转一下!现在,您可以输入一个数字,并看到它显示在表单按钮的正下方。如果你输入一个新的号码,那么旧的会被替换。您可以正确地发送和接收用户提交的数据。
在您继续将提交的值与您的温度转换器代码集成之前,您能想到这个实现有什么潜在的问题吗?
当你输入一个字符串而不是一个数字时会发生什么?试试看。
现在输入简短的 HTML 代码
<marquee>BUY USELESS THINGS!!!</marquee>并按下转换。目前,你的网络应用程序接受任何类型的输入,无论是一个数字,一个字符串,甚至是 HTML 或 JavaScript 代码。这是非常危险的,因为用户可能会通过输入特定类型的内容,无意或有意地破坏您的 web 应用程序。
大多数情况下,您应该允许 Flask 通过使用不同的项目设置来自动处理这些安全问题。但是,您现在就处于这种情况下,所以了解如何手动使您创建的表单输入安全是一个好主意。
转义用户输入
接受用户的输入并在没有首先调查你将要显示什么的情况下显示该输入是一个巨大的安全漏洞。即使没有恶意,您的用户也可能会做一些意想不到的事情,导致您的应用程序崩溃。
尝试通过添加一些 HTML 文本来破解未转义的输入表单。不要输入数字,复制下面一行 HTML 代码,将其粘贴到您的输入框中,然后单击 Convert :
<marquee><a href="https://www.realpython.com">CLICK ME</a></marquee>Flask 将文本直接插入到 HTML 代码中,这会导致文本输入被解释为 HTML 标记。因此,您的浏览器会忠实地呈现代码,就像处理任何其他 HTML 一样。你突然不得不处理一个时髦的教育垃圾链接,而不是以文本的形式显示输入,这个链接是从 90 年代穿越到现在的:
https://player.vimeo.com/video/492638327?background=1
虽然这个例子是无害的,并且不需要刷新页面,但是您可以想象当以这种方式添加其他类型的内容时,这会带来怎样的安全问题。你不想让你的用户编辑你的 web 应用程序中不应该被编辑的部分。
为了避免这种情况,您可以使用 Flask 内置的
escape(),它将特殊的 HTML 字符<、>和&转换成可以正确显示的等价表示。您首先需要将
escape导入到您的 Python 脚本中来使用这个功能。然后,当您提交表单时,您可以转换任何特殊的 HTML 字符,并使您的表单输入防 90 年代黑客攻击:from flask import Flask from flask import request, escape app = Flask(__name__) @app.route("/") def index(): celsius = str(escape(request.args.get("celsius", ""))) return ( """<form action="" method="get"> <input type="text" name="celsius"> <input type="submit" value="Convert"> </form>""" + celsius ) @app.route("/<int:celsius>") def fahrenheit_from(celsius): """Convert Celsius to Fahrenheit degrees.""" fahrenheit = float(celsius) * 9 / 5 + 32 fahrenheit = round(fahrenheit, 3) # Round to three decimal places return str(fahrenheit) if __name__ == "__main__": app.run(host="127.0.0.1", port=8080, debug=True)刷新您的开发服务器并尝试提交一些 HTML 代码。现在它将作为您输入的文本字符串显示给您。
注意:需要将转义序列转换回 Python
str。否则,Flask 也会贪婪地将函数返回的<form>元素转换成转义字符串。当构建更大的 web 应用程序时,你不必处理输入的转义,因为所有的 HTML 都将使用模板来处理。如果你想了解更多,那么看看烧瓶的例子。
在学习了如何收集用户输入以及如何对其进行转义之后,您终于准备好实现温度转换功能,并向用户显示他们输入的摄氏温度的华氏等效温度。
处理用户输入
因为这种方法只使用一个 URL 端点,所以您不能像前面那样依靠 Flask 通过 URL 路径组件捕获来检查用户输入。这意味着你需要从原始代码的初始
fahrenheit_from()重新引入你的try…except块。注意:因为你在
fahrenheit_from()中验证用户输入的类型,你不需要实现flask.escape(),它也不会是你最终代码的一部分。您可以安全地移除escape的导入,并将对request.args.get()的调用剥离回初始状态。这一次,
fahrenheit_from()将不会与一个@app.route装饰者相关联。继续删除那行代码。当访问特定的 URL 端点时,您将从index()显式调用fahrenheit_from(),而不是让 Flask 执行它。在从
fahrenheit_from()中删除装饰器并重新引入try…except块之后,接下来您将添加一个条件语句到index(),检查全局request对象是否包含一个celsius键。如果是,那么你要调用fahrenheit_from()来计算相应的华氏温度。如果没有,那么您将一个空字符串赋给fahrenheit变量。这样做允许您将
fahrenheit的值添加到 HTML 字符串的末尾。空字符串在您的页面上是不可见的,但是如果用户提交了一个值,它就会显示在表单下面。应用这些最终更改后,您完成了温度转换器烧瓶应用程序的代码:
1from flask import Flask 2from flask import request 3 4app = Flask(__name__) 5 6@app.route("/") 7def index(): 8 celsius = request.args.get("celsius", "") 9 if celsius: 10 fahrenheit = fahrenheit_from(celsius) 11 else: 12 fahrenheit = "" 13 return ( 14 """<form action="" method="get"> 15 Celsius temperature: <input type="text" name="celsius"> 16 <input type="submit" value="Convert to Fahrenheit"> 17 </form>""" 18 + "Fahrenheit: " 19 + fahrenheit 20 ) 21 22def fahrenheit_from(celsius): 23 """Convert Celsius to Fahrenheit degrees.""" 24 try: 25 fahrenheit = float(celsius) * 9 / 5 + 32 26 fahrenheit = round(fahrenheit, 3) # Round to three decimal places 27 return str(fahrenheit) 28 except ValueError: 29 return "invalid input" 30 31if __name__ == "__main__": 32 app.run(host="127.0.0.1", port=8080, debug=True)由于有相当多的变化,这里是一步一步的审查编辑行:
第 2 行:您不再使用
flask.escape(),因此您可以将其从 import 语句中删除。第 8、11 和 12 行:和以前一样,您通过 Flask 的全局
request对象获取用户提交的值。通过使用 dictionary 方法.get(),您可以确保如果没有找到键,将返回一个空字符串。如果页面最初被加载,而用户还没有提交表单,就会出现这种情况。这在第 11 行和第 12 行实现。第 19 行:通过返回末尾带有默认空字符串的表单,可以避免在表单提交之前显示任何内容。
第 9 行和第 10 行:在用户输入一个值并点击 Convert 之后,相同的页面再次被加载。这一次,
request.args.get("celsius", "")找到了celsius键并返回相关的值。这使得条件语句评估为True,并且用户提供的值被传递给fahrenheit_from()。第 24 到 29 行:
fahrenheit_from()检查用户是否提供了有效的输入。如果提供的值可以转换成一个float,那么该函数将应用温度转换代码并返回华氏温度。如果它不能被转换,那么就产生一个ValueError异常,函数返回字符串"invalid input"。第 19 行:这一次,当你将
fahrenheit变量连接到 HTML 字符串的末尾时,它指向fahrenheit_from()的返回值。这意味着转换后的温度或错误信息字符串将被添加到您的 HTML 中。第 15 行和第 18 行:为了使页面更容易使用,您还向这个相同的 HTML 字符串添加了描述性标签
Celsius temperature和Fahrenheit。即使您添加这些字符串的方式不代表有效的 HTML,您的页面也会正确呈现。这要感谢现代浏览器的强大功能。
请记住,如果你有兴趣更深入地研究 web 开发,那么你需要学习 HTML 。但是为了让您的 Python 脚本在线部署,这就足够了。
现在,您应该能够在浏览器中使用温度转换脚本了。您可以通过输入框提供摄氏温度,单击按钮,然后在同一网页上看到转换后的华氏温度结果。因为您使用的是默认的 HTTP GET 请求,所以您也可以看到提交的数据出现在 URL 中。
注意:事实上,您甚至可以绕开表单,通过提供一个适当的地址来为
celsius提供您自己的值,类似于您在没有 HTML 表单的情况下构建脚本时如何使用转换。例如,尝试直接在你的浏览器中输入 URL
localhost:8080/?celsius=42,你会看到结果温度转换出现在你的页面上。使用
gcloud app deploy命令将完成的应用程序再次部署到 Google App Engine。部署完成后,转到提供的 URL 或运行gcloud app browse来查看您的 Python web 应用程序在互联网上的实况。通过添加不同类型的输入来测试它。一旦你满意了,与世界分享你的链接。您的 temperature converter web 应用程序的 URL 仍然类似于
https://hello-app-295110.ew.r.appspot.com/。这不能反映你的应用程序的当前功能。重新查看部署说明,在 Google App Engine 上创建一个新项目,使用一个更合适的名称,并在那里部署您的应用。这将让你练习创建项目和将 Flask 应用程序部署到 Google App Engine。
至此,您已经成功地将 Python 脚本转换为 Python web 应用程序,并将其部署到 Google App Engine 进行在线托管。您可以使用相同的过程将更多的 Python 脚本转换成 web 应用程序。
创建你自己的诗歌生成器,允许用户使用网络表单创建短诗。您的 web 应用程序应该使用单个页面和单个表单来接受 GET 请求。您可以使用这个示例代码来开始,或者您可以编写自己的代码。
如果你想了解更多关于你可以用 Google App Engine 做什么的信息,那么你可以阅读关于使用静态文件的并添加一个 CSS 文件到你的 Python web 应用程序来改善它的整体外观。
在线托管您的代码可以让更多的人通过互联网访问它。继续把你最喜欢的脚本转换成 Flask 应用程序,并向全世界展示它们。
结论
您在本教程中涉及了很多内容!您从一个本地 Python 脚本开始,并将其转换为一个用户友好的、完全部署的 Flask 应用程序,现在托管在 Google App Engine 上。
在学习本教程的过程中,您学习了:
- 网络应用程序如何通过互联网提供数据
- 如何重构你的 Python 脚本,以便你可以在线托管
- 如何创建一个基本的烧瓶应用程序
- 如何手动转义用户输入
- 如何将你的代码部署到谷歌应用引擎
现在,您可以将您的本地 Python 脚本放到网上供全世界使用。如果您想下载在本教程中构建的应用程序的完整代码,可以单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
如果你想学习更多关于使用 Python 进行 web 开发的知识,那么你现在已经准备好尝试 Python web 框架,比如 Flask 和 Django 。继续努力吧!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Flask 在 Web 上部署你的 Python 脚本*********
Python 中 Web 抓取的实用介绍
原文:https://realpython.com/python-web-scraping-practical-introduction/
Web 抓取是从 Web 上收集和解析原始数据的过程,Python 社区已经开发出一些非常强大的 Web 抓取工具。
互联网可能是这个星球上最大的信息源。许多学科,如数据科学、商业智能和调查报告,可以从收集和分析网站数据中受益匪浅。
在本教程中,您将学习如何:
- 使用字符串方法和正则表达式解析网站数据
- 使用 HTML 解析器解析网站数据
- 与表单和其他网站组件交互
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“与 Web 交互”一章。
这本书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在整个教程中,你会偶尔看到对 IDLE 的引用。然而,从您选择的编辑器和环境运行示例代码应该没有问题。
源代码: 点击这里下载免费的源代码,你将使用它来收集和解析来自网络的数据。
从网站上抓取并解析文本
使用自动化过程从网站收集数据被称为网络搜集。一些网站明确禁止用户使用自动化工具抓取他们的数据,就像你将在本教程中创建的工具一样。网站这样做有两个可能的原因:
- 该网站有充分的理由保护其数据。例如,谷歌地图不会让你太快地请求太多结果。
- 向网站的服务器发出多次重复请求可能会耗尽带宽,降低其他用户访问网站的速度,并可能使服务器过载,从而导致网站完全停止响应。
在使用 Python 技能进行 web 抓取之前,您应该始终检查目标网站的可接受使用政策,以确定使用自动化工具访问网站是否违反了其使用条款。从法律上讲,违背网站意愿的网络抓取是一个灰色地带。
重要提示:请注意,在禁止抓取网页的网站上使用以下技术可能是非法的。
对于本教程,您将使用一个托管在 Real Python 服务器上的页面。您将访问的页面已经设置为与本教程一起使用。
既然你已经阅读了免责声明,你可以开始有趣的事情了。在下一节中,您将开始从单个 web 页面获取所有 HTML 代码。
打造你的第一台网络刮刀
你可以在 Python 的标准库中找到的一个有用的 web 抓取包是
urllib,它包含了处理 URL 的工具。特别是,urllib.request模块包含一个名为urlopen()的函数,您可以用它来打开程序中的 URL。在 IDLE 的交互窗口中,键入以下内容以导入
urlopen():



>>> from urllib.request import urlopen
您将打开的网页位于以下 URL:
>>> url = "http://olympus.realpython.org/profiles/aphrodite"要打开网页,请将
url传递给urlopen():
>>> page = urlopen(url)
urlopen()返回一个HTTPResponse对象:
>>> page <http.client.HTTPResponse object at 0x105fef820>要从页面中提取 HTML,首先使用
HTTPResponse对象的.read()方法,该方法返回一个字节序列。然后使用.decode()将字节解码成使用 UTF-8 的字符串:
>>> html_bytes = page.read()
>>> html = html_bytes.decode("utf-8")
现在你可以打印HTML 来查看网页的内容:
>>> print(html) <html> <head> <title>Profile: Aphrodite</title> </head> <body bgcolor="yellow"> <center> <br><br> <img src="/static/aphrodite.gif" /> <h2>Name: Aphrodite</h2> <br><br> Favorite animal: Dove <br><br> Favorite color: Red <br><br> Hometown: Mount Olympus </center> </body> </html>你看到的输出是网站的 HTML 代码,当你访问
http://olympus.realpython.org/profiles/aphrodite时,你的浏览器会显示出来:
使用
urllib,您可以像在浏览器中一样访问网站。但是,您没有可视化地呈现内容,而是将源代码作为文本获取。既然已经有了文本形式的 HTML,就可以用几种不同的方法从中提取信息。用字符串方法从 HTML 中提取文本
从网页的 HTML 中提取信息的一种方法是使用字符串方法。例如,您可以使用
.find()在 HTML 文本中搜索<title>标签,并提取网页的标题。首先,您将提取您在前一个示例中请求的 web 页面的标题。如果你知道标题的第一个字符的索引和结束标签
</title>的第一个字符的索引,那么你可以使用一个字符串切片来提取标题。因为
.find()返回一个子串第一次出现的索引,所以可以通过将字符串"<title>"传递给.find()来获得开始<title>标签的索引:
>>> title_index = html.find("<title>")
>>> title_index
14
但是,您并不需要<title>标签的索引。您需要标题本身的索引。要获得标题中第一个字母的索引,可以将字符串"<title>"的长度加到title_index中:
>>> start_index = title_index + len("<title>") >>> start_index 21现在通过将字符串
"</title>"传递给.find()来获取结束</title>标签的索引:
>>> end_index = html.find("</title>")
>>> end_index
39
最后,您可以通过切分html字符串来提取标题:
>>> title = html[start_index:end_index] >>> title 'Profile: Aphrodite'现实世界中的 HTML 可能比阿芙罗狄蒂个人资料页面上的 HTML 复杂得多,也不太容易预测。这里是另一个个人资料页面,你可以抓取一些更混乱的 HTML:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
尝试使用与上例相同的方法从这个新 URL 中提取标题:
>>> url = "http://olympus.realpython.org/profiles/poseidon" >>> page = urlopen(url) >>> html = page.read().decode("utf-8") >>> start_index = html.find("<title>") + len("<title>") >>> end_index = html.find("</title>") >>> title = html[start_index:end_index] >>> title '\n<head>\n<title >Profile: Poseidon'哎呦!标题中夹杂了一点 HTML。为什么会这样?
/profiles/poseidon页面的 HTML 看起来类似于/profiles/aphrodite页面,但是有一点小小的不同。开始的<title>标签在结束的尖括号(>)前有一个额外的空格,呈现为<title >。
html.find("<title>")返回-1,因为精确的子串"<title>"不存在。当-1加到len("<title>")上,即7时,start_index变量被赋值6。字符串
html的索引6处的字符是一个换行符(\n),正好在<head>标签的左尖括号(<)之前。这意味着html[start_index:end_index]返回所有从新行开始并在</title>标签之前结束的 HTML。这类问题会以无数种不可预测的方式出现。您需要一种更可靠的方法来从 HTML 中提取文本。
了解正则表达式
正则表达式——或者简称为正则表达式——是可以用来在字符串中搜索文本的模式。Python 通过标准库的
re模块支持正则表达式。注意:正则表达式不是 Python 特有的。它们是一个通用的编程概念,许多编程语言都支持它们。
要使用正则表达式,您需要做的第一件事是导入
re模块:
>>> import re
正则表达式使用称为元字符的特殊字符来表示不同的模式。例如,星号字符(*)代表零个或多个出现在星号前面的实例。
在下面的例子中,您使用.findall()来查找字符串中匹配给定正则表达式的任何文本:
>>> re.findall("ab*c", "ac") ['ac']
re.findall()的第一个参数是要匹配的正则表达式,第二个参数是要测试的字符串。在上面的例子中,您在字符串"ac"中搜索模式"ab*c"。正则表达式
"ab*c"匹配字符串中以"a"开头、以"c"结尾并且在两者之间有零个或多个"b"实例的任何部分。re.findall()返回所有匹配的列表。字符串"ac"匹配这个模式,所以它被返回到列表中。以下是应用于不同字符串的相同模式:
>>> re.findall("ab*c", "abcd")
['abc']
>>> re.findall("ab*c", "acc")
['ac']
>>> re.findall("ab*c", "abcac")
['abc', 'ac']
>>> re.findall("ab*c", "abdc")
[]
注意,如果没有找到匹配,那么.findall()返回一个空列表。
模式匹配区分大小写。如果您想匹配这个模式而不考虑大小写,那么您可以传递第三个参数,值为re.IGNORECASE:
>>> re.findall("ab*c", "ABC") [] >>> re.findall("ab*c", "ABC", re.IGNORECASE) ['ABC']您可以使用句点(
.)来代表正则表达式中的任何单个字符。例如,您可以找到包含由单个字符分隔的字母"a"和"c"的所有字符串,如下所示:
>>> re.findall("a.c", "abc")
['abc']
>>> re.findall("a.c", "abbc")
[]
>>> re.findall("a.c", "ac")
[]
>>> re.findall("a.c", "acc")
['acc']
正则表达式中的模式.*代表重复任意次的任意字符。例如,您可以使用"a.*c"来查找以"a"开始并以"c"结束的每个子串,而不管中间是哪个或哪些字母:
>>> re.findall("a.*c", "abc") ['abc'] >>> re.findall("a.*c", "abbc") ['abbc'] >>> re.findall("a.*c", "ac") ['ac'] >>> re.findall("a.*c", "acc") ['acc']通常,您使用
re.search()来搜索字符串中的特定模式。这个函数比re.findall()稍微复杂一些,因为它返回一个名为MatchObject的对象,该对象存储不同的数据组。这是因为在其他匹配中可能有匹配,而re.search()返回每一个可能的结果。
MatchObject的细节在这里无关紧要。现在,只需知道在MatchObject上调用.group()将返回第一个也是最具包容性的结果,这在大多数情况下正是您想要的:
>>> match_results = re.search("ab*c", "ABC", re.IGNORECASE)
>>> match_results.group()
'ABC'
在re模块中还有一个对解析文本有用的函数。 re.sub() ,是 substitute 的简称,允许你用新文本替换匹配正则表达式的字符串中的文本。它的表现有点像 .replace() 弦法。
传递给re.sub()的参数是正则表达式,后面是替换文本,后面是字符串。这里有一个例子:
>>> string = "Everything is <replaced> if it's in <tags>." >>> string = re.sub("<.*>", "ELEPHANTS", string) >>> string 'Everything is ELEPHANTS.'也许这并不是你所期望的。
re.sub()使用正则表达式"<.*>"查找并替换第一个<和最后一个>之间的所有内容,从<replaced>开始到<tags>结束。这是因为 Python 的正则表达式是贪婪的,这意味着当使用像*这样的字符时,它们试图找到最长的可能匹配。或者,您可以使用非贪婪匹配模式
*?,它的工作方式与*相同,只是它匹配可能的最短文本字符串:
>>> string = "Everything is <replaced> if it's in <tags>."
>>> string = re.sub("<.*?>", "ELEPHANTS", string)
>>> string
"Everything is ELEPHANTS if it's in ELEPHANTS."
这次,re.sub()找到了两个匹配项,<replaced>和<tags>,并用字符串"ELEPHANTS"替换这两个匹配项。
用正则表达式从 HTML 中提取文本
有了所有这些知识,现在试着从另一个个人资料页面解析出标题,其中包括这段相当粗心的 HTML 代码:
<TITLE >Profile: Dionysus</title / >
.find()方法在处理这里的不一致时会有困难,但是通过巧妙使用正则表达式,您可以快速有效地处理这段代码:
# regex_soup.py
import re
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
pattern = "<title.*?>.*?</title.*?>"
match_results = re.search(pattern, html, re.IGNORECASE)
title = match_results.group()
title = re.sub("<.*?>", "", title) # Remove HTML tags
print(title)
通过将字符串分成三部分来仔细查看pattern中的第一个正则表达式:
-
<title.*?>匹配html中的开始<TITLE >标签。模式的<title部分与<TITLE匹配,因为re.search()是用re.IGNORECASE调用的,而.*?>匹配<TITLE之后直到第一个>实例的任何文本。 -
.*?非贪婪地匹配开头<TITLE >后的所有文本,停在第一个匹配的</title.*?>。 -
</title.*?>与第一个模式的不同之处仅在于它使用了/字符,因此它匹配html中的结束</title / >标记。
第二个正则表达式,字符串"<.*?>",也使用非贪婪的.*?来匹配title字符串中的所有 HTML 标签。通过用""替换任何匹配,re.sub()删除所有标签,只返回文本。
注意:用 Python 或任何其他语言进行 Web 抓取可能会很乏味。没有两个网站是以相同的方式组织的,HTML 通常是混乱的。此外,网站会随着时间而变化。今天有效的网页抓取工具不能保证明年或者下周也有效。
如果使用正确,正则表达式是一个强大的工具。在这篇介绍中,您仅仅触及了皮毛。有关正则表达式以及如何使用它们的更多信息,请查看由两部分组成的系列文章正则表达式:Python 中的正则表达式。
检查你的理解能力
展开下面的方框,检查您的理解情况。
编写一个程序,从以下 URL 获取完整的 HTML:
>>> url = "http://olympus.realpython.org/profiles/dionysus"然后使用
.find()显示名称:和喜爱的颜色:之后的文本(不包括任何可能出现在同一行的前导空格或尾随 HTML 标签)。您可以展开下面的方框查看解决方案。
首先,从
urlib.request模块导入urlopen函数:from urllib.request import urlopen然后打开 URL 并使用由
urlopen()返回的HTTPResponse对象的.read()方法来读取页面的 HTML:url = "http://olympus.realpython.org/profiles/dionysus" html_page = urlopen(url) html_text = html_page.read().decode("utf-8")
.read()方法返回一个字节串,所以使用.decode()通过 UTF-8 编码对字节进行解码。现在您已经将 web 页面的 HTML 源代码作为一个字符串分配给了
html_text变量,您可以从 Dionysus 的概要文件中提取他的名字和最喜欢的颜色。狄俄尼索斯个人资料的 HTML 结构与您之前看到的阿芙罗狄蒂个人资料的结构相同。您可以通过在文本中找到字符串
"Name:"并提取该字符串第一次出现之后和下一个 HTML 标签之前的所有内容来获得名称。也就是说,您需要提取冒号(:)之后和第一个尖括号(<)之前的所有内容。你可以用同样的技巧提取喜欢的颜色。下面的
for循环为名称和喜爱的颜色提取文本:for string in ["Name: ", "Favorite Color:"]: string_start_idx = html_text.find(string) text_start_idx = string_start_idx + len(string) next_html_tag_offset = html_text[text_start_idx:].find("<") text_end_idx = text_start_idx + next_html_tag_offset raw_text = html_text[text_start_idx : text_end_idx] clean_text = raw_text.strip(" \r\n\t") print(clean_text)看起来在这个
for循环中进行了很多工作,但这只是一点点计算提取所需文本的正确索引的运算。继续并分解它:
您使用
html_text.find()来查找字符串的起始索引,可以是"Name:"或"Favorite Color:",然后将索引分配给string_start_idx。由于要提取的文本紧接在
"Name:"或"Favorite Color:"中的冒号之后开始,所以通过将字符串的长度加到start_string_idx中可以获得紧跟在冒号之后的字符的索引,然后将结果赋给text_start_idx。通过确定第一个尖括号(
<)相对于text_start_idx的索引,计算要提取的文本的结束索引,并将该值赋给next_html_tag_offset。然后将该值加到text_start_idx上,并将结果赋给text_end_idx。你通过从
text_start_idx到text_end_idx分割html_text来提取文本,并将这个字符串分配给raw_text。使用
.strip()删除raw_text开头和结尾的任何空白,并将结果赋给clean_text。在循环结束时,使用
print()显示提取的文本。最终输出如下所示:Dionysus Wine这个解决方案是解决这个问题的众多解决方案之一,所以如果你用不同的解决方案得到相同的输出,那么你做得很好!
当你准备好了,你可以进入下一部分。
在 Python 中使用 HTML 解析器进行 Web 抓取
虽然正则表达式通常非常适合模式匹配,但有时使用专门为解析 HTML 页面而设计的 HTML 解析器更容易。有许多 Python 工具是为此而编写的,但是 Beautiful Soup 库是一个很好的开始。
装美汤
要安装 Beautiful Soup,您可以在终端中运行以下命令:
$ python -m pip install beautifulsoup4使用这个命令,您可以将最新版本的 Beautiful Soup 安装到您的全局 Python 环境中。
创建一个
BeautifulSoup对象在新的编辑器窗口中键入以下程序:
# beauty_soup.py from bs4 import BeautifulSoup from urllib.request import urlopen url = "http://olympus.realpython.org/profiles/dionysus" page = urlopen(url) html = page.read().decode("utf-8") soup = BeautifulSoup(html, "html.parser")这个程序做三件事:
使用
urllib.request模块中的urlopen()打开网址http://olympus.realpython.org/profiles/dionysus以字符串形式从页面中读取 HTML,并将其赋给
html变量创建一个
BeautifulSoup对象,并将其分配给soup变量分配给
soup的BeautifulSoup对象是用两个参数创建的。第一个参数是要解析的 HTML,第二个参数是字符串"html.parser",它告诉对象在后台使用哪个解析器。"html.parser"代表 Python 内置的 HTML 解析器。使用一个
BeautifulSoup对象保存并运行上面的程序。当它完成运行时,您可以使用交互窗口中的
soup变量以各种方式解析html的内容。注意:如果你没有使用 IDLE,那么你可以用
-i标志运行你的程序进入交互模式。类似于python -i beauty_soup.py的东西将首先运行你的程序,然后让你进入一个 REPL,在那里你可以探索你的对象。例如,
BeautifulSoup对象有一个.get_text()方法,可以用来从文档中提取所有文本,并自动删除任何 HTML 标签。在 IDLE 的交互窗口中或编辑器中的代码末尾键入以下代码:
>>> print(soup.get_text())
Profile: Dionysus
Name: Dionysus
Hometown: Mount Olympus
Favorite animal: Leopard
Favorite Color: Wine
这个输出中有很多空行。这些是 HTML 文档文本中换行符的结果。如果需要,可以用.replace() string 方法删除它们。
通常,您只需要从 HTML 文档中获取特定的文本。首先使用 Beautiful Soup 提取文本,然后使用.find() string 方法,这有时比使用正则表达式更容易。
然而,其他时候 HTML 标签本身是指出您想要检索的数据的元素。例如,您可能想要检索页面上所有图像的 URL。这些链接包含在<img> HTML 标签的src属性中。
在这种情况下,您可以使用find_all()返回该特定标记的所有实例的列表:
>>> soup.find_all("img") [<img src="/static/dionysus.jpg"/>, <img src="/static/grapes.png"/>]这将返回 HTML 文档中所有
<img>标签的列表。列表中的对象看起来可能是代表标签的字符串,但它们实际上是 Beautiful Soup 提供的Tag对象的实例。Tag对象为处理它们所包含的信息提供了一个简单的接口。您可以先从列表中解包
Tag对象,对此进行一些探索:
>>> image1, image2 = soup.find_all("img")
每个Tag对象都有一个.name属性,该属性返回一个包含 HTML 标签类型的字符串:
>>> image1.name 'img'您可以通过将名称放在方括号中来访问
Tag对象的 HTML 属性,就像属性是字典中的键一样。例如,
<img src="/static/dionysus.jpg"/>标签只有一个属性src,其值为"/static/dionysus.jpg"。同样,像链接<a href="https://realpython.com" target="_blank">这样的 HTML 标签有两个属性,href和target。要获得 Dionysus profile 页面中图像的来源,可以使用上面提到的字典符号访问
src属性:
>>> image1["src"]
'/static/dionysus.jpg'
>>> image2["src"]
'/static/grapes.png'
HTML 文档中的某些标签可以通过Tag对象的属性来访问。例如,要获得文档中的<title>标签,可以使用.title属性:
>>> soup.title <title>Profile: Dionysus</title>如果您通过导航到个人资料页面来查看 Dionysus 个人资料的源代码,右键单击该页面,并选择查看页面源代码,那么您会注意到
<title>标签全部用大写字母和空格书写:
Beautiful Soup 通过删除开始标签中多余的空格和结束标签中多余的正斜杠(
/)自动为您清理标签。您还可以使用
Tag对象的.string属性来检索标题标签之间的字符串:
>>> soup.title.string
'Profile: Dionysus'
Beautiful Soup 的一个特性是能够搜索特定类型的标签,这些标签的属性与某些值相匹配。例如,如果您想要查找所有具有与值/static/dionysus.jpg相等的src属性的<img>标签,那么您可以向.find_all()提供以下附加参数:
>>> soup.find_all("img", src="/static/dionysus.jpg") [<img src="/static/dionysus.jpg"/>]这个例子有些武断,从这个例子中可能看不出这种技术的用处。如果你花一些时间浏览各种网站并查看它们的页面源代码,那么你会注意到许多网站都有极其复杂的 HTML 结构。
当使用 Python 从网站抓取数据时,您通常会对页面的特定部分感兴趣。通过花一些时间浏览 HTML 文档,您可以识别具有独特属性的标签,这些标签可用于提取您需要的数据。
然后,不用依赖复杂的正则表达式或使用
.find()来搜索整个文档,您可以直接访问您感兴趣的特定标签并提取您需要的数据。在某些情况下,你可能会发现漂亮的汤并没有提供你需要的功能。lxml 库开始有点棘手,但是它提供了比解析 HTML 文档更大的灵活性。一旦你习惯了使用美丽的汤,你可能会想要检查一下。
注意:在定位网页中的特定数据时,像美人汤这样的 HTML 解析器可以节省您大量的时间和精力。然而,有时 HTML 写得很差,没有条理,甚至像 Beautiful Soup 这样复杂的解析器也不能正确地解释 HTML 标签。
在这种情况下,您通常需要使用
.find()和正则表达式技术来解析出您需要的信息。Beautiful Soup 非常适合从网站的 HTML 中抓取数据,但是它没有提供任何处理 HTML 表单的方法。例如,如果你需要在一个网站上搜索一些查询,然后搜索结果,那么单靠美丽的汤不会让你走得很远。
检查你的理解能力
展开下面的方框,检查您的理解情况。
编写一个程序,从 URL
http://olympus.realpython.org/profiles的页面获取完整的 HTML。使用 Beautiful Soup,通过查找名为
a的 HTML 标记并检索每个标记的href属性所取的值,打印出页面上所有链接的列表。最终输出应该如下所示:
http://olympus.realpython.org/profiles/aphrodite http://olympus.realpython.org/profiles/poseidon http://olympus.realpython.org/profiles/dionysus确保在基本 URL 和相对 URL 之间只有一个斜杠(
/)。您可以展开下面的方框查看解决方案:
首先,从
urlib.request模块中导入urlopen函数,从bs4包中导入BeautifulSoup类:from urllib.request import urlopen from bs4 import BeautifulSoup在
/profiles页面上的每个链接 URL 是一个相对 URL ,所以用网站的基本 URL 创建一个base_url变量:base_url = "http://olympus.realpython.org"您可以通过连接
base_url和一个相对 URL 来构建一个完整的 URL。现在用
urlopen()打开/profiles页面,使用.read()获取 HTML 源代码:html_page = urlopen(base_url + "/profiles") html_text = html_page.read().decode("utf-8")下载并解码 HTML 源代码后,您可以创建一个新的
BeautifulSoup对象来解析 HTML:soup = BeautifulSoup(html_text, "html.parser")返回 HTML 源代码中所有链接的列表。您可以遍历这个列表,打印出网页上的所有链接:
for link in soup.find_all("a"): link_url = base_url + link["href"] print(link_url)您可以通过
"href"下标访问每个链接的相对 URL。将该值与base_url连接,创建完整的link_url。当你准备好了,你可以进入下一部分。
与 HTML 表单交互
到目前为止,您在本教程中使用的
urllib模块非常适合请求网页内容。但是,有时您需要与网页交互来获取您需要的内容。例如,您可能需要提交表单或单击按钮来显示隐藏的内容。注:本教程改编自 Python 基础知识:Python 实用入门 3 中“与 Web 交互”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
Python 标准库并没有提供一个内置的交互处理网页的方法,但是许多第三方包可以从 PyPI 获得。其中, MechanicalSoup 是一个流行且相对简单的软件包。
本质上,MechanicalSoup 安装了所谓的无头浏览器,这是一个没有图形用户界面的网络浏览器。该浏览器通过 Python 程序以编程方式控制。
安装机械汤
您可以在您的终端中安装带有
pip的机械汤:$ python -m pip install MechanicalSoup您需要关闭并重新启动您的空闲会话,以便 MechanicalSoup 在安装后加载并被识别。
创建一个
Browser对象在 IDLE 的交互窗口中键入以下内容:
>>> import mechanicalsoup
>>> browser = mechanicalsoup.Browser()
对象代表无头网络浏览器。您可以使用它们通过向它们的.get()方法传递一个 URL 来请求来自互联网的页面:
>>> url = "http://olympus.realpython.org/login" >>> page = browser.get(url)
page是一个Response对象,存储从浏览器请求 URL 的响应:
>>> page
<Response [200]>
数字200代表请求返回的状态码。状态代码200表示请求成功。如果 URL 不存在,不成功的请求可能会显示状态代码404,如果请求时出现服务器错误,则可能会显示状态代码500。
MechanicalSoup 使用 Beautiful Soup 来解析请求中的 HTML,page有一个代表BeautifulSoup对象的.soup属性:
>>> type(page.soup) <class 'bs4.BeautifulSoup'>您可以通过检查
.soup属性来查看 HTML:
>>> page.soup
<html>
<head>
<title>Log In</title>
</head>
<body bgcolor="yellow">
<center>
<br/><br/>
<h2>Please log in to access Mount Olympus:</h2>
<br/><br/>
<form action="/login" method="post" name="login">
Username: <input name="user" type="text"/><br/>
Password: <input name="pwd" type="password"/><br/><br/>
<input type="submit" value="Submit"/>
</form>
</center>
</body>
</html>
注意,这个页面上有一个<form>和用于用户名和密码的<input>元素。
提交带有机械汤的表格
在浏览器中打开上一个示例中的 /login 页面,在继续之前亲自查看一下:
尝试输入随机的用户名和密码组合。如果你猜错了,那么消息错误的用户名或密码!显示在页面底部。
但是,如果您提供了正确的登录凭证,那么您将被重定向到 /profiles 页面:
| 用户名 | 密码 |
|---|---|
zeus |
ThunderDude |
在下一个例子中,您将看到如何使用 Python 来使用 MechanicalSoup 填写和提交这个表单!
HTML 代码的重要部分是登录表单——也就是说,<form>标签中的所有内容。该页面上的<form>的name属性被设置为login。这个表单包含两个<input>元素,一个名为user,另一个名为pwd。第三个<input>元素是提交按钮。
既然您已经知道了登录表单的底层结构,以及登录所需的凭证,那么请看一个填写表单并提交表单的程序。
在新的编辑器窗口中,键入以下程序:
import mechanicalsoup
# 1
browser = mechanicalsoup.Browser()
url = "http://olympus.realpython.org/login"
login_page = browser.get(url)
login_html = login_page.soup
# 2
form = login_html.select("form")[0]
form.select("input")[0]["value"] = "zeus"
form.select("input")[1]["value"] = "ThunderDude"
# 3
profiles_page = browser.submit(form, login_page.url)
保存文件,按 F5 运行。要确认您已成功登录,请在交互式窗口中键入以下内容:
>>> profiles_page.url 'http://olympus.realpython.org/profiles'现在分解上面的例子:
您创建了一个
Browser实例,并使用它来请求 URLhttp://olympus.realpython.org/login。使用.soup属性将页面的 HTML 内容分配给login_html变量。
login_html.select("form")返回页面上所有<form>元素的列表。因为页面只有一个<form>元素,所以可以通过检索列表中索引0处的元素来访问表单。当一页上只有一个表格时,你也可以使用login_html.form。接下来的两行选择用户名和密码输入,并将它们的值分别设置为"zeus"和"ThunderDude"。你用
browser.submit()提交表格。注意,您向这个方法传递了两个参数,一个是form对象,另一个是通过login_page.url访问的login_page的 URL。在交互窗口中,您确认提交成功地重定向到了
/profiles页面。如果出了问题,那么profiles_page.url的值仍然是"http://olympus.realpython.org/login"。注意:黑客可以通过快速尝试许多不同的用户名和密码,直到他们找到一个有效的组合,使用类似上面的自动化程序来暴力破解登录。
除了这是高度非法的,几乎所有的网站这些天来锁定你,并报告你的 IP 地址,如果他们看到你做了太多失败的请求,所以不要尝试!
既然您已经设置了
profiles_page变量,那么是时候以编程方式获取/profiles页面上每个链接的 URL 了。为此,您再次使用
.select(),这次传递字符串"a"来选择页面上所有的<a>锚元素:
>>> links = profiles_page.soup.select("a")
现在您可以迭代每个链接并打印出href属性:
>>> for link in links: ... address = link["href"] ... text = link.text ... print(f"{text}: {address}") ... Aphrodite: /profiles/aphrodite Poseidon: /profiles/poseidon Dionysus: /profiles/dionysus每个
href属性中包含的 URL 都是相对 URL,如果您想稍后使用 MechanicalSoup 导航到它们,这些 URL 没有太大帮助。如果您碰巧知道完整的 URL,那么您可以分配构建完整 URL 所需的部分。在这种情况下,基本 URL 只是
http://olympus.realpython.org。然后,您可以将基本 URL 与在src属性中找到的相对 URL 连接起来:
>>> base_url = "http://olympus.realpython.org"
>>> for link in links:
... address = base_url + link["href"]
... text = link.text
... print(f"{text}: {address}")
...
Aphrodite: http://olympus.realpython.org/profiles/aphrodite
Poseidon: http://olympus.realpython.org/profiles/poseidon
Dionysus: http://olympus.realpython.org/profiles/dionysus
你可以只用.get()、.select()和.submit()做很多事情。也就是说,机械汤可以做得更多。要了解更多关于机械汤的信息,请查阅官方文件。
检查你的理解能力
展开下面的方框,检查您的理解情况
使用 MechanicalSoup 向位于 URL http://olympus.realpython.org/login的登录表单提供正确的用户名(zeus)和密码(ThunderDude)。
提交表单后,显示当前页面的标题,以确定您已经被重定向到 /profiles 页面。
你的程序应该打印文本<title>All Profiles</title>。
您可以展开下面的方框查看解决方案。
首先,导入mechanicalsoup包并创建一个Broswer对象:
import mechanicalsoup
browser = mechanicalsoup.Browser()
通过将 URL 传递给browser.get()将浏览器指向登录页面,并获取带有.soup属性的 HTML:
login_url = "http://olympus.realpython.org/login"
login_page = browser.get(login_url)
login_html = login_page.soup
login_html是一个BeautifulSoup实例。因为页面上只有一个表单,所以您可以通过login_html.form访问该表单。使用.select(),选择用户名和密码输入,并填入用户名"zeus"和密码"ThunderDude":
form = login_html.form
form.select("input")[0]["value"] = "zeus"
form.select("input")[1]["value"] = "ThunderDude"
现在表单已经填写完毕,您可以使用browser.submit()提交它:
profiles_page = browser.submit(form, login_page.url)
如果您用正确的用户名和密码填写了表单,那么profiles_page实际上应该指向/profiles页面。你可以通过打印分配给profiles_page:的页面标题来确认这一点
print(profiles_page.soup.title)
您应该会看到以下显示的文本:
<title>All Profiles</title>
如果您看到文本Log In或其他东西,那么表单提交失败。
当你准备好了,你可以进入下一部分。
与网站实时互动
有时,您希望能够从提供持续更新信息的网站获取实时数据。
在你学习 Python 编程之前的黑暗日子里,你不得不坐在浏览器前,每当你想检查更新的内容是否可用时,点击刷新按钮来重新加载页面。但是现在您可以使用 MechanicalSoup Browser对象的.get()方法来自动化这个过程。
打开您选择的浏览器并导航至 URL http://olympus.realpython.org/dice:
这个 /dice 页面模拟一个六面骰子的滚动,每次刷新浏览器都会更新结果。下面,您将编写一个程序,反复抓取页面以获得新的结果。
您需要做的第一件事是确定页面上的哪个元素包含掷骰子的结果。现在,右键单击页面上的任意位置并选择查看页面源即可。HTML 代码中间多一点的地方是一个类似下面的<h2>标签:
<h2 id="result">3</h2>
对于您来说,<h2>标签的文本可能不同,但是这是抓取结果所需的页面元素。
注意:对于这个例子,您可以很容易地检查出页面上只有一个带有id="result"的元素。尽管id属性应该是惟一的,但实际上您应该总是检查您感兴趣的元素是否被惟一标识。
现在开始编写一个简单的程序,打开 /dice 页面,抓取结果,并打印到控制台:
# mech_soup.py
import mechanicalsoup
browser = mechanicalsoup.Browser()
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
这个例子使用了BeautifulSoup对象的.select()方法来查找带有id=result的元素。传递给.select()的字符串"#result"使用 CSS ID 选择器 #来表示result是一个id值。
为了定期获得新的结果,您需要创建一个循环,在每一步加载页面。因此,上面代码中位于行browser = mechanicalsoup.Browser()之下的所有内容都需要放在循环体中。
对于本例,您希望以 10 秒的间隔掷出 4 次骰子。为此,代码的最后一行需要告诉 Python 暂停运行十秒钟。你可以用 Python 的 time模块中的 .sleep() 来做到这一点。.sleep()方法采用单个参数,表示以秒为单位的睡眠时间。
这里有一个例子来说明sleep()是如何工作的:
import time
print("I'm about to wait for five seconds...")
time.sleep(5)
print("Done waiting!")
当您运行这段代码时,您将会看到在第一个print()函数被执行 5 秒钟后才会显示"Done waiting!"消息。
对于掷骰子的例子,您需要将数字10传递给sleep()。以下是更新后的程序:
# mech_soup.py
import time
import mechanicalsoup
browser = mechanicalsoup.Browser()
for i in range(4):
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
time.sleep(10)
当您运行该程序时,您将立即看到打印到控制台的第一个结果。十秒钟后,显示第二个结果,然后是第三个,最后是第四个。打印第四个结果后会发生什么?
程序继续运行十秒钟,然后最终停止。那有点浪费时间!您可以通过使用一个 if语句来阻止它这样做,只对前三个请求运行time.sleep():
# mech_soup.py
import time
import mechanicalsoup
browser = mechanicalsoup.Browser()
for i in range(4):
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
# Wait 10 seconds if this isn't the last request
if i < 3:
time.sleep(10)
有了这样的技术,你可以从定期更新数据的网站上抓取数据。但是,您应该意识到,快速连续多次请求某个页面可能会被视为对网站的可疑甚至恶意使用。
重要提示:大多数网站都会发布使用条款文档。你经常可以在网站的页脚找到它的链接。
在试图从网站上抓取数据之前,请务必阅读本文档。如果您找不到使用条款,那么尝试联系网站所有者,询问他们是否有关于请求量的任何政策。
不遵守使用条款可能会导致您的 IP 被封锁,所以要小心!
过多的请求甚至有可能使服务器崩溃,所以可以想象许多网站都很关心对服务器的请求量!始终检查使用条款,并在向网站发送多个请求时保持尊重。
结论
虽然可以使用 Python 标准库中的工具解析来自 Web 的数据,但是 PyPI 上有许多工具可以帮助简化这个过程。
在本教程中,您学习了如何:
- 使用 Python 内置的
urllib模块请求网页 - 使用美汤解析 HTML
- 使用 MechanicalSoup 与 web 表单交互
- 反复从网站请求数据以检查更新
编写自动化的网络抓取程序很有趣,而且互联网上不缺乏可以带来各种令人兴奋的项目的内容。
请记住,不是每个人都希望你从他们的网络服务器上下载数据。在你开始抓取之前,一定要检查网站的使用条款,尊重你的网络请求时间,这样你就不会让服务器流量泛滥。
源代码: 点击这里下载免费的源代码,你将使用它来收集和解析来自网络的数据。
额外资源
有关使用 Python 进行 web 抓取的更多信息,请查看以下资源:
注意:如果你喜欢在这个例子中从 Python 基础知识:Python 3 实用介绍中所学到的东西,那么一定要看看本书的其余部分。********
什么是 Python 轮子,为什么要关心?
Python .whl文件,或者说轮子,是 Python 中很少被讨论的部分,但是它们对于 Python 包的安装过程是一个福音。如果你已经使用 pip 安装了一个 Python 包,那么很有可能是一个轮子使得安装更快更有效。
Wheels 是 Python 生态系统的一个组件,它有助于让包安装正常工作。它们允许更快的安装和更稳定的软件包分发过程。在本教程中,您将深入了解什么是轮子,它们有什么好处,以及它们是如何获得牵引力并使 Python 变得更加有趣的。
在本教程中,您将学习:
- 什么是车轮,它们与源分布相比如何
- 如何使用轮子来控制包装安装过程
- 如何为你自己的 Python 包创建和分发轮子
您将从用户和开发人员的角度看到使用流行的开源 Python 包的例子。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
设置
接下来,激活一个虚拟环境,并确保你已经安装了最新版本的pip、wheel和setuptools:
$ python -m venv env && source ./env/bin/activate
$ python -m pip install -U pip wheel setuptools
Successfully installed pip 20.1 setuptools-46.1.3 wheel-0.34.2
这就是你安装和制造轮子所需要的全部实验!
Python 打包变得更好:Python Wheels 简介
在您学习如何将一个项目打包到一个轮子之前,了解从用户的角度看使用一个轮子是什么样子会有所帮助。这听起来可能有点落后,但是学习轮子如何工作的一个好方法是从安装一个不是轮子的东西开始。
您可以像平常一样,通过在您的环境中安装一个 Python 包来开始这个实验。在这种情况下,安装 uWSGI 版本 2.0.x:
1$ python -m pip install 'uwsgi==2.0.*'
2Collecting uwsgi==2.0.*
3 Downloading uwsgi-2.0.18.tar.gz (801 kB) 4 |████████████████████████████████| 801 kB 1.1 MB/s
5Building wheels for collected packages: uwsgi
6 Building wheel for uwsgi (setup.py) ... done
7 Created wheel for uwsgi ... uWSGI-2.0.18-cp38-cp38-macosx_10_15_x86_64.whl
8 Stored in directory: /private/var/folders/jc/8_hqsz0x1tdbp05 ...
9Successfully built uwsgi
10Installing collected packages: uwsgi
11Successfully installed uwsgi-2.0.18
要完全安装 uWSGI,pip需要经过几个不同的步骤:
- 在第 3 行的上,它下载了一个名为
uwsgi-2.0.18.tar.gz的 TAR 文件(tarball),这个文件已经用 gzip 压缩过了。 - 在的第 6 行,它获取 tarball 并通过调用
setup.py构建一个.whl文件。 - 在线 7 上,它标记车轮
uWSGI-2.0.18-cp38-cp38-macosx_10_15_x86_64.whl。 - 在第 10 行上,它在构建完车轮后安装实际的包。
pip取回的tar.gz tarball 是一个源分布,或sdist,而不是一个轮子。在某些方面,sdist是轮子的反义词。
注意:如果您看到 uWSGI 安装出错,您可能需要安装 Python 开发头文件。
一个源代码分发包含源代码。这不仅包括 Python 代码,还包括与软件包捆绑在一起的任何扩展模块的源代码(通常用 C 或 C++ )。对于源代码发行版,扩展模块是在用户端编译的,而不是在开发人员端。
源代码发行版还包含一个名为 <package-name>.egg-info 的目录中的元数据包。这些元数据有助于构建和安装软件包,但是用户实际上不需要做任何事情。
从开发人员的角度来看,源代码发行版是在运行以下命令时创建的:
$ python setup.py sdist
现在尝试安装一个不同的包, chardet :
1$ python -m pip install 'chardet==3.*'
2Collecting chardet
3 Downloading chardet-3.0.4-py2.py3-none-any.whl (133 kB) 4 |████████████████████████████████| 133 kB 1.5 MB/s
5Installing collected packages: chardet
6Successfully installed chardet-3.0.4
您可以看到与 uWSGI 安装明显不同的输出。
安装 chardet 直接从 PyPI 下载一个.whl文件。轮子名称chardet-3.0.4-py2.py3-none-any.whl遵循一个特定的命名约定,您将在后面看到。从用户的角度来看,更重要的是,当pip在 PyPI 上找到一个兼容的轮子时,没有构建阶段。
从开发人员的角度来看,轮子是运行以下命令的结果:
$ python setup.py bdist_wheel
为什么 uWSGI 给你一个源码分发而 chardet 提供一个轮子?通过查看 PyPI 上每个项目的页面,并导航到下载文件区域,你就能明白其中的原因。本节将向您展示pip在 PyPI 索引服务器上实际看到的内容:
- uw SGIT3】由于与项目复杂性相关的原因,只提供了一个源分布 (
uwsgi-2.0.18.tar.gz)。 - chardet 提供了一个轮子和一个源分布,但是如果与你的系统兼容的话
pip会更喜欢轮子。稍后您将看到如何确定这种兼容性。
用于轮子安装的兼容性检查的另一个例子是 psycopg2 ,它为 Windows 提供了一系列轮子,但不为 Linux 或 macOS 客户端提供任何轮子。这意味着pip install psycopg2可以根据您的具体设置获取一个轮或一个源分布。
为了避免这些类型的兼容性问题,一些包提供了多个轮子,每个轮子都适合特定的 Python 实现和底层操作系统。
到目前为止,你已经看到了轮子和sdist之间的一些明显区别,但是更重要的是这些区别对安装过程的影响。
轮子让东西跑得更快
在上面,您看到了获取预建轮子的安装和下载sdist的安装的比较。Wheels 使得 Python 包的端到端安装更快,原因有二:
- 在其他条件相同的情况下,轮子通常比源分布的尺寸小,这意味着它们可以在网络中更快地移动。
- 从 wheels 直接安装避免了在源代码发行版之外构建包的中间步骤。
几乎可以保证,chardet 的安装只需要 uWSGI 所需时间的一小部分。然而,这可能是一个不公平的比较,因为 chardet 是一个非常小和不复杂的包。使用不同的命令,您可以创建一个更直接的比较,来演示轮子产生了多大的差异。
您可以通过传递--no-binary选项使pip忽略其向车轮的倾斜:
$ time python -m pip install \
--no-cache-dir \
--force-reinstall \
--no-binary=:all: \ cryptography
该命令对 cryptography 包的安装进行计时,告诉pip即使有合适的轮子也要使用源分布。包含:all:使得规则适用于cryptography及其所有依赖项。
在我的机器上,从开始到结束大约需要32 秒。不仅安装要花很长时间,而且构建cryptography还需要有 OpenSSL 开发头文件,并且 Python 可以使用。
注意:在--no-binary中,你很可能会看到一个关于cryptography安装所需的头文件丢失的错误,这是使用源代码发行版令人沮丧的原因之一。如果是这样的话,cryptography文档的安装部分会建议你为一个特定的操作系统需要哪些库和头文件。
现在你可以重新安装cryptography,但是这次要确保pip使用 PyPI 的轮子。因为pip更喜欢一个轮子,这类似于没有任何参数地调用pip install。但是在这种情况下,您可以通过要求一个带有--only-binary的轮子来明确意图:
$ time python -m pip install \
--no-cache-dir \
--force-reinstall \
--only-binary=cryptography \ cryptography
这个选项只需要 4 秒多一点,或者说只需要对cryptography及其依赖项使用源代码发行版的八分之一的时间。
什么是巨蟒轮?
Python .whl文件本质上是一个 ZIP ( .zip)档案,带有一个特制的文件名,告诉安装人员 wheel 将支持哪些 Python 版本和平台。
一个轮子是一种型的建成分布型的。在这种情况下,build意味着这个轮子以一种现成的格式出现,允许你跳过源代码发行版所需要的构建阶段。
注意:值得一提的是,尽管使用了术语构建,但是一个轮子并不包含.pyc文件,或者编译的 Python 字节码。
车轮文件名被分成由连字符分隔的多个部分:
{dist}-{version}(-{build})?-{python}-{abi}-{platform}.whl
{brackets}中的每一部分都是一个标签,或者是轮子名称的一个组成部分,承载着轮子包含的内容以及轮子在哪里可以工作或者不可以工作的一些含义。
下面是一个使用 cryptography 滚轮的示例:
cryptography-2.9.2-cp35-abi3-macosx_10_9_x86_64.whl
cryptography分配多个车轮。每个轮子都是一个平台轮子,这意味着它只支持 Python 版本、Python ABIs、操作系统和机器架构的特定组合。您可以将命名约定分成几个部分:
-
cryptography是包名。 -
2.9.2是cryptography的打包版本。版本是符合 PEP 440 的字符串,例如2.9.2、3.4或3.9.0.a3。 -
cp35是 Python 标签,表示轮子需要的 Python 实现和版本。cp代表 CPython ,Python 的参考实现,35代表 Python 3.5 。例如,这个轮子与 Jython 不兼容。 -
abi3是 ABI 的标记。ABI 代表应用二进制接口。你真的不需要担心它需要什么,但是abi3是 Python C API 二进制兼容性的一个独立版本。 -
macosx_10_9_x86_64是站台标签,恰好相当拗口。在这种情况下,它可以进一步分解为子部分:macosx就是 macOS 操作系统。10_9是 macOS developer tools SDK 版本,用于编译 Python,进而构建这个轮子。x86_64是对 x86-64 指令集架构的引用。
最后一个组件在技术上不是标签,而是标准的.whl文件扩展名。综合起来看,上述部件表示该cryptography轮设计用于的目标机器。
现在让我们来看一个不同的例子。以下是您在上述 chardet 案例中看到的内容:
chardet-3.0.4-py2.py3-none-any.whl
你可以把它分解成标签:
chardet是包名。3.0.4是 chardet 的包版本。py2.py3是 Python 标签,意思是轮子支持任何 Python 实现的 Python 2 和 3。none是 ABI 的标记,意思是 ABI 不是一个因素。any是站台。这个轮子几乎可以在任何平台上工作。
车轮名称的py2.py3-none-any.whl段很常见。这是一个万向轮,它将与 Python 2 或 3 一起安装在任何带有 ABI 的平台上。如果轮子以none-any.whl结束,那么它很可能是一个不关心特定 Python ABI 或 CPU 架构的纯 Python 包。
另一个例子是jinja2模板引擎。如果你导航到 Jinja 3.x alpha 版本的下载页面,那么你会看到下面的轮子:
Jinja2-3.0.0a1-py3-none-any.whl
注意这里缺少了py2。这是一个纯 Python 项目,可以在任何 Python 3.x 版本上工作,但它不是万向轮,因为它不支持 Python 2。相反,它被称为纯蟒蛇轮。
注:2020 年,多个项目也在放弃对 Python 2 的支持,Python 2 于 2020 年 1 月 1 日达到寿命终止(EOL)。Jinja 版于 2020 年 2 月放弃 Python 2 支持。
以下是为一些流行的开源包分发的.whl名称的几个例子:
| 车轮 | 事实真相 |
|---|---|
PyYAML-5.3.1-cp38-cp38-win_amd64.whl |
PyYAML 用于采用 AMD64 (x86-64)架构的 Windows 上的 CPython 3.8 |
numpy-1.18.4-cp38-cp38-win32.whl |
用于 Windows 32 位上的 CPython 3.8 的 NumPy |
scipy-1.4.1-cp36-cp36m-macosx_10_6_intel.whl |
SciPy 用于 macOS 10.6 SDK 上的 CPython 3.6,带有胖二进制(多指令集) |
既然你对什么是轮子有了透彻的了解,是时候谈谈它们有什么好处了。
Python 车轮的优势
这里有一个来自 Python 打包权威 (PyPA)的轮子的证明:
并不是所有的开发人员都有合适的工具或经验来构建用这些编译语言编写的组件,所以 Python 创建了 wheel,这是一种旨在将库与编译后的工件一起发布的包格式。事实上,Python 的包安装程序
pip总是更喜欢轮子,因为安装总是更快,所以即使是纯 Python 的包也能更好地使用轮子。(来源)
更全面的描述是,wheels 在几个方面对 Python 包的用户和维护者都有好处:
-
对于纯 Python 包和扩展模块,轮子的安装速度都比源代码发行版快。
-
轮子比源分布更小。比如
six轮大约是对应源分布的三分之一大小。当您考虑到单个包的pip install实际上可能会引发一系列依赖项的下载时,这种差异就变得更加重要了。 -
车轮切
setup.py执行出方程式。从源代码安装运行无论包含在那个项目的setup.py中。正如 PEP 427 所指出的,这相当于任意代码执行。轮子完全避免了这一点。 -
不需要编译器来安装包含已编译扩展模块的轮子。扩展模块包含在针对特定平台和 Python 版本的 wheel 中。
-
pip自动生成.pyc文件在轮子中匹配正确的 Python 解释器。 -
轮子提供了一致性,它将安装包所涉及的许多变量排除在方程式之外。
您可以使用 PyPI 上项目的下载文件选项卡来查看不同的可用发行版。例如,熊猫分发各种各样的轮子。
告诉pip下载什么
可以对pip进行细粒度控制,并告诉它喜欢或避免哪种格式。您可以使用--only-binary和--no-binary选项来完成此操作。您已经在安装cryptography包的前一节中看到了它们,但是有必要仔细看看它们做了什么:
$ pushd "$(mktemp -d)"
$ python -m pip download --only-binary :all: --dest . --no-cache six
Collecting six
Downloading six-1.14.0-py2.py3-none-any.whl (10 kB)
Saved ./six-1.14.0-py2.py3-none-any.whl
Successfully downloaded six
在本例中,您使用pushd "$(mktemp -d)"切换到一个临时目录来存储下载内容。你使用pip download而不是pip install,这样你就可以检查最终的轮子,但是你可以用install代替download,同时保持相同的选项集。
你下载的 six 模块有几个标志:
--only-binary :all:告诉pip约束自己使用轮子并忽略源分布。如果没有这个选项,pip将只会偏好轮子,但在某些情况下会退回到源分布。--dest .告诉pip将six下载到当前目录。--no-cache告诉pip不要在本地下载缓存中查找。您使用这个选项只是为了演示从 PyPI 的实时下载,因为您很可能在某个地方有一个six缓存。
我前面提到过,wheel 文件本质上是一个.zip档案。你可以从字面上理解这句话,也可以这样看待轮子。例如,如果您想查看一个轮子的内容,您可以使用unzip:
$ unzip -l six*.whl
Archive: six-1.14.0-py2.py3-none-any.whl
Length Date Time Name
--------- ---------- ----- ----
34074 01-15-2020 18:10 six.py
1066 01-15-2020 18:10 six-1.14.0.dist-info/LICENSE
1795 01-15-2020 18:10 six-1.14.0.dist-info/METADATA
110 01-15-2020 18:10 six-1.14.0.dist-info/WHEEL
4 01-15-2020 18:10 six-1.14.0.dist-info/top_level.txt
435 01-15-2020 18:10 six-1.14.0.dist-info/RECORD
--------- -------
37484 6 files
six是一个特例:它实际上是一个单独的 Python 模块,而不是一个完整的包。Wheel 文件也可能非常复杂,稍后您会看到这一点。
与--only-binary相反,您可以使用--no-binary来做相反的事情:
$ python -m pip download --no-binary :all: --dest . --no-cache six
Collecting six
Downloading six-1.14.0.tar.gz (33 kB)
Saved ./six-1.14.0.tar.gz
Successfully downloaded six
$ popd
本例中唯一的变化是切换到--no-binary :all:。这告诉pip忽略轮子,即使它们可用,而是下载一个源发行版。
--no-binary什么时候可能有用?这里有几个案例:
-
对应的轮子坏了。这是对轮子的讽刺。它们的设计是为了减少东西损坏的频率,但在某些情况下,轮子可能会配置错误。在这种情况下,为自己下载并构建源代码发行版可能是一个可行的替代方案。
您也可以使用上述带有pip install的标志。此外,:all:不仅会将--only-binary规则应用到您正在安装的包,还会应用到它的所有依赖项,您可以向--only-binary和--no-binary传递应用该规则的特定包的列表。
下面举几个安装网址库 yarl 的例子。包含 Cython 代码,依赖 multidict ,包含纯 C 代码。对于yarl及其依赖项,有几个严格使用或严格忽略轮子的选项:
$ # Install `yarl` and use only wheels for yarl and all dependencies
$ python -m pip install --only-binary :all: yarl
$ # Install `yarl` and use wheels only for the `multidict` dependency
$ python -m pip install --only-binary multidict yarl
$ # Install `yarl` and don't use wheels for yarl or any dependencies
$ python -m pip install --no-binary :all: yarl
$ # Install `yarl` and don't use wheels for the `multidict` dependency
$ python -m pip install --no-binary multidict yarl
在本节中,您了解了如何微调pip install将使用的发布类型。虽然常规的pip install应该没有选项,但了解这些选项对于特殊情况是有帮助的。
manylinux车轮标签
Linux 有许多变体和风格,比如 Debian、CentOS、Fedora 和 Pacman。其中的每一个都可能在共享库(如libncurses)和核心 C 库(如glibc)中略有不同。
如果你正在写一个 C/C++扩展,那么这可能会产生一个问题。用 C 编写并在 Ubuntu Linux 上编译的源文件不能保证在 CentOS 机器或 Arch Linux 发行版上是可执行的。你需要为每一个 Linux 变种建立一个单独的轮子吗?
幸运的是,答案是否定的,这要归功于一组特别设计的标签,称为 manylinux 平台标签家族。目前有三种变体:
-
manylinux1是人教版 513 中规定的原始格式。 -
manylinux2010是 PEP 571 中指定的更新,升级到 CentOS 6 作为 Docker 镜像所基于的底层操作系统。理由是 CentOS 5.11,即manylinux1中允许的库列表的来源,于 2017 年 3 月达到 EOL,并停止接收安全补丁和错误修复。 -
manylinux2014是 PEP 599 中指定的升级到 CentOS 7 的更新,因为 CentOS 6 计划于 2020 年 11 月达到 EOL。
你可以在熊猫项目中找到一个manylinux分布的例子。这里是从 PyPI 下载的可用熊猫列表中的两个(从许多中选出来的):
pandas-1.0.3-cp37-cp37m-manylinux1_x86_64.whl
pandas-1.0.3-cp37-cp37m-manylinux1_i686.whl
在这种情况下,pandas 为 CPython 3.7 构建了manylinux1轮子,支持 x86-64 和 i686 架构。
在它的核心,manylinux是一个 Docker 镜像,构建于 CentOS 操作系统的某个版本之上。它捆绑了一个编译器套件、多个版本的 Python 和pip,以及一组允许的共享库。
注意:术语允许表示一个低级的库,默认情况下会出现在几乎所有的 Linux 系统上。这个想法是,依赖关系应该存在于基本操作系统上,而不需要额外安装。
截至 2020 年中期,manylinux1仍然是主要的manylinux标签。其中一个原因可能只是习惯。另一个原因可能是客户端(用户)对manylinux2010及以上版本的支持仅限于的更新版本或pip:
| 标签 | 要求 |
|---|---|
manylinux1 |
8.1.0 或更高版本 |
manylinux2010 |
pip 19.0 或更高版本 |
manylinux2014 |
pip 19.3 或更高版本 |
换句话说,如果你是一个构建manylinux2010轮子的包开发者,那么使用你的包的人将需要pip19.0(2019 年 1 月发布)或更高版本来让pip从 PyPI 找到并安装manylinux2010轮子。
幸运的是,虚拟环境已经变得越来越普遍,这意味着开发人员可以在不接触系统pip的情况下更新虚拟环境的pip。然而,情况并非总是如此,一些 Linux 发行版仍然附带了过时版本的pip。
也就是说,如果你正在 Linux 主机上安装 Python 包,那么如果包的维护者不怕麻烦地创建了manylinux轮子,你应该感到幸运。这将几乎保证软件包的安装没有任何麻烦,不管您的具体 Linux 变体或版本如何。
注意:注意 PyPI 轮在 Alpine Linux (或者 BusyBox )上不工作。这是因为 Alpine 使用 musl 代替了标准 glibc 。musl libc图书馆标榜自己是“一个新的libc,努力做到快速、简单、轻量级、免费和正确。”不幸的是,说到轮子,glibc就不是了。
平台车轮的安全注意事项
从用户安全的角度来看,wheels 的一个值得考虑的特性是,wheels可能会受到版本腐烂的影响,因为它们捆绑了一个二进制依赖项,而不允许系统包管理器更新该依赖项。
例如,如果一个轮子包含了 libfortran 共享库,那么该轮子的发行版将使用它们所捆绑的libfortran版本,即使你用一个包管理器如apt、yum或brew来升级你自己机器的libfortran版本。
如果您在一个具有高度安全防范措施的环境中进行开发,某些平台轮子的这个特性是需要注意的。
召集所有开发者:打造你的车轮
本教程的标题是“你为什么要关心?”作为一名开发人员,如果您计划向社区分发 Python 包,那么您应该非常关心为您的项目分发 wheels,因为它们使最终用户的安装过程更干净,更简单。
你可以用兼容的轮子支持的目标平台越多,你就会越少看到标题为“在 XYZ 平台上安装失败”的问题为 Python 包分发轮子客观上降低了包的用户在安装过程中遇到问题的可能性。
在本地构建一个轮子你需要做的第一件事就是安装wheel。确保setuptools也是最新的也无妨:
$ python -m pip install -U wheel setuptools
接下来的几节将带您在各种不同的场景中构建轮子。
不同类型的车轮
正如本教程中所提到的,轮子有几种不同的变体,轮子的类型反映在其文件名中:
-
一个万向轮包含
py2.py3-none-any.whl。它在任何操作系统和平台上都支持 Python 2 和 Python 3。在巨蟒轮网站上列出的大多数轮子都是万向轮。 -
一个纯蟒轮包含
py3-none-any.whl或py2.none-any.whl。它支持 Python 3 或 Python 2,但不支持两者。它在其他方面与万向轮相同,但它将贴上py2或py3的标签,而不是py2.py3的标签。 -
一个平台轮支持特定的 Python 版本和平台。它包含指示特定 Python 版本、ABI、操作系统或架构的段。
轮子类型之间的差异取决于它们支持的 Python 版本以及它们是否针对特定的平台。以下是车轮变化之间差异的简明摘要:
| 车轮类型 | 支持 Python 2 和 3 | 支持所有 ABI、操作系统和平台 |
|---|---|---|
| 普遍的 | -好的 | -好的 |
| 纯 Python 语言 | -好的 | |
| 平台 |
正如您接下来将看到的,您可以通过相对较少的设置来构建万向轮和纯 Python 轮,但是平台轮可能需要一些额外的步骤。
打造纯 Python 车轮
您可以使用setuptools 为任何项目构建一个纯 Python 轮子或通用轮子,只需一个命令:
$ python setup.py sdist bdist_wheel
这将创建一个源分布(sdist)和一个轮(bdist_wheel)。默认情况下,两者都将放在当前目录下的dist/中。为了自己看,你可以为 HTTPie 构建一个轮子,这是一个用 Python 编写的命令行 HTTP 客户端,旁边还有一个sdist。
下面是为 HTTPie 包构建两种类型的发行版的结果:
$ git clone -q git@github.com:jakubroztocil/httpie.git
$ cd httpie
$ python setup.py -q sdist bdist_wheel $ ls -1 dist/
httpie-2.2.0.dev0-py3-none-any.whl
httpie-2.2.0.dev0.tar.gz
这就够了。您克隆项目,移动到它的根目录,然后调用python setup.py sdist bdist_wheel。你可以看到dist/包含了一个轮子和一个源分布。
默认情况下,得到的分布放在dist/中,但是您可以用-d / --dist-dir选项来改变它。您可以将它们放在临时目录中,而不是用于构建隔离:
$ tempdir="$(mktemp -d)" # Create a temporary directory
$ file "$tempdir"
/var/folders/jc/8_kd8uusys7ak09_lpmn30rw0000gk/T/tmp.GIXy7XKV: directory
$ python setup.py sdist -d "$tempdir"
$ python setup.py bdist_wheel --dist-dir "$tempdir"
$ ls -1 "$tempdir"
httpie-2.2.0.dev0-py3-none-any.whl
httpie-2.2.0.dev0.tar.gz
您可以将sdist和bdist_wheel步骤合并成一个,因为setup.py可以接受多个子命令:
$ python setup.py sdist -d "$tempdir" bdist_wheel -d "$tempdir"
如此处所示,您需要将选项如-d传递给每个子命令。
指定万向轮
万向轮是支持 Python 2 和 3 的纯 Python 项目的轮子。有多种方法可以告诉setuptools和distutils一个轮子应该是通用的。
选项 1 是在您项目的 setup.cfg 文件中指定选项:
[bdist_wheel] universal = 1
选项 2 是在命令行传递恰当命名的--universal标志:
$ python setup.py bdist_wheel --universal
选项 3 是使用它的options参数告诉setup()它自己关于标志的信息:
# setup.py
from setuptools import setup
setup(
# ....
options={"bdist_wheel": {"universal": True}}
# ....
)
虽然这三个选项中的任何一个都可以,但前两个是最常用的。你可以在 chardet 设置配置中看到这样的例子。之后,您可以使用前面所示的bdist_wheel命令:
$ python setup.py sdist bdist_wheel
无论您选择哪一个选项,最终的控制盘都是相同的。这种选择很大程度上取决于开发人员的偏好以及哪种工作流最适合您。
构建平台轮(macOS 和 Windows)
二进制发行版 是包含编译扩展的构建发行版的子集。扩展是你的 Python 包的非 Python 依赖或组件。
通常,这意味着你的包包含一个扩展模块或者依赖于一个用静态类型语言编写的库,比如 C,C++,Fortran,甚至是 Rust 或者 Go。平台轮的存在主要是针对单个平台,因为它们包含或依赖于扩展模块。
说了这么多,是时候造一个平台轮了!
根据您现有的开发环境,您可能需要完成一两个额外的先决步骤来构建平台轮子。下面的步骤将帮助您建立 C 和 C++扩展模块,这是目前最常见的类型。
在 macOS 上,您需要通过 xcode 获得命令行开发工具:
$ xcode-select --install
在 Windows 上,你需要安装微软 Visual C++ :
- 在浏览器中打开 Visual Studio 下载页面。
- 选择Visual Studio 工具→Visual Studio 构建工具→下载。
- 运行产生的
.exe安装程序。 - 在安装程序中,选择 C++构建工具→安装。
- 重启你的机器。
在 Linux 上,你需要一个 gcc 或者g++ / c++这样的编译器。
做好准备后,您就可以为 UltraJSON ( ujson)构建一个平台轮了,这是一个用纯 C 编写的 JSON 编码器和解码器,使用 Python 3 绑定。使用ujson是一个很好的玩具示例,因为它涵盖了几个基础:
- 它包含一个扩展模块,
ujson。 - 它依赖于要编译的 Python 开发头文件(
#include <Python.h>),但并不复杂。ujson就是为了做一件事,并且做好这件事,就是读写 JSON!
您可以从 GitHub 克隆这个项目,导航到它的目录,然后编译它:
$ git clone -q --branch 2.0.3 git@github.com:ultrajson/ultrajson.git
$ cd ultrajson
$ python setup.py bdist_wheel
您应该会看到大量的输出。这里有一个在 macOS 上的精简版本,其中使用了 Clang 编译器驱动程序:
clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g ...
...
creating 'dist/ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl'
adding 'ujson.cpython-38-darwin.so'
以clang开头的代码行显示了对编译器的实际调用,包括一组编译标志。根据操作系统的不同,你可能还会看到像MSVC (Windows)或gcc (Linux)这样的工具。
如果在执行完上面的代码后遇到了一个fatal error,不用担心。你可以展开下面的方框,学习如何处理这个问题。
对ujson的这个setup.py bdist_wheel调用需要 Python 开发头文件,因为ujson.c拉入了<Python.h>。如果您没有将它们放在可搜索的位置,那么您可能会看到如下错误:
fatal error: 'Python.h' file not found
#include <Python.h>
要编译扩展模块,您需要将开发头文件保存在编译器可以找到它们的地方。
如果您使用的是 Python 3 的最新版本和虚拟环境工具,比如venv,那么 Python 开发头很可能会默认包含在编译和链接中。
否则,您可能会看到一个错误,指示找不到头文件:
fatal error: 'Python.h' file not found
#include <Python.h>
在这种情况下,您可以通过设置CFLAGS来告诉setup.py在其他地方寻找头文件。要找到头文件本身,可以使用python3-config:
$ python3-config --include
-I/Users/<username>/.pyenv/versions/3.8.2/include/python3.8
这告诉您 Python 开发头文件位于所示的目录中,您现在可以将它与python setup.py bdist_wheel一起使用:
$ CFLAGS="$(python3-config --include)" python setup.py bdist_wheel
更一般地说,您可以传递您需要的任何路径:
$ CFLAGS='-I/path/to/include' python setup.py bdist_wheel
在 Linux 上,您可能还需要单独安装头文件:
$ apt-get install -y python3-dev # Debian, Ubuntu
$ yum install -y python3-devel # CentOS, Fedora, RHEL
如果你检查 UltraJSON 的 setup.py ,那么你会看到它定制了一些编译器标志比如-D_GNU_SOURCE。通过setup.py控制编译过程的复杂性超出了本教程的范围,但是您应该知道,对编译和链接如何发生进行细粒度的控制是可能的。
如果你查看dist,那么你应该会看到创建的轮子:
$ ls dist/
ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl
请注意,该名称可能因平台而异。例如,您会在 64 位 Windows 上看到win_amd64.whl。
您可以查看 wheel 文件,发现它包含编译后的扩展名:
$ unzip -l dist/ujson-*.whl
...
Length Date Time Name
--------- ---------- ----- ----
105812 05-10-2020 19:47 ujson.cpython-38-darwin.so
...
这个例子显示了 macOS 的输出,ujson.cpython-38-darwin.so,这是一个共享对象(.so)文件,也称为动态库。
Linux:构建manylinux轮子
作为一名软件包开发人员,您很少想为一个单一的 Linux 变种构建轮子。Linux wheels 需要一套专门的约定和工具,以便它们可以跨不同的 Linux 环境工作。
与 macOS 和 Windows 的 wheels 不同,在一个 Linux 版本上构建的 wheels 不能保证在另一个 Linux 版本上工作,即使是具有相同机器架构的版本。事实上,如果您在现成的 Linux 容器上构建一个轮子,那么如果您试图上传它,PyPI 甚至不会接受这个轮子!
如果您希望您的包可以在一系列 Linux 客户机上使用,那么您需要一个manylinux轮子。manylinux轮是一种特殊类型的平台轮,被大多数 Linux 变体所接受。它必须在一个特定的环境中构建,并且需要一个名为auditwheel的工具来重命名车轮文件,以表明它是一个manylinux车轮。
注意:即使你是从开发者的角度而不是从用户的角度来阅读本教程,在继续本节之前,请确保你已经阅读了关于和manylinux滚轮标签的章节。
建立一个manylinux轮子可以让你瞄准更广泛的用户平台。 PEP 513 指定了 CentOS 的一个特定(和古老)版本,并提供了一系列 Python 版本。在 CentOS 和 Ubuntu 或任何其他发行版之间的选择没有任何特殊的区别。要点是构建环境由一个普通的 Linux 操作系统和一组有限的外部共享库组成,这些库对于不同的 Linux 变体是通用的。
谢天谢地,你不必亲自去做。PyPA 提供了一组 Docker 图像,只需点击几下鼠标就能提供这个环境:
- 选项 1 是从您的开发机器上运行
docker,并使用 Docker 卷挂载您的项目,以便它可以在容器文件系统中被访问。 - 选项 2 是使用一个 CI/CD 解决方案,比如 CircleCI、GitHub Actions、Azure DevOps 或 Travis-CI,它们将提取你的项目并在一个动作(比如 push 或 tag)上运行构建。
为不同的manylinux口味提供了 Docker 图像:
manylinux标签 |
体系结构 | Docker 图像 |
|---|---|---|
manylinux1 |
x86-64 | quay.io/pypa/manylinux1_x86_64 |
manylinux1 |
i686 | quay.io/pypa/manylinux1_i686 |
manylinux2010 |
x86-64 | quay.io/pypa/manylinux2010_x86_64 |
manylinux2010 |
i686 | quay.io/pypa/manylinux2010_i686 |
manylinux2014 |
x86-64 | quay.io/pypa/manylinux2014_x86_64 |
manylinux2014 |
i686 | quay.io/pypa/manylinux2014_i686 |
manylinux2014 |
aarh64 足球俱乐部 | quay . io/pypa/manylinox 2014 _ aach 64 |
manylinux2014 |
ppc64le | quay . io/pypa/manylinox 2014 _ ppc64 le |
manylinux2014 |
s390x | quay.io/pypa/manylinux2014_s390x |
为了开始,PyPA 还提供了一个示例库, python-manylinux-demo ,这是一个结合 Travis-CI 构建manylinux轮子的演示项目。
虽然构建轮子作为远程托管 CI 解决方案的一部分很常见,但是您也可以在本地构建manylinux轮子。为此,你需要安装 Docker 。Docker 桌面可用于 macOS、Windows 和 Linux。
首先,克隆演示项目:
$ git clone -q git@github.com:pypa/python-manylinux-demo.git
$ cd python-manylinux-demo
接下来,分别为manylinux1 Docker 映像和平台定义几个 shell 变量:
$ DOCKER_IMAGE='quay.io/pypa/manylinux1_x86_64'
$ PLAT='manylinux1_x86_64'
DOCKER_IMAGE变量是 PyPA 为建造manylinux车轮维护的图像,托管在 Quay.io 。平台(PLAT)是提供给auditwheel的必要信息,让它知道应用什么平台标签。
现在,您可以提取 Docker 图像并在容器中运行 wheel-builder 脚本:
$ docker pull "$DOCKER_IMAGE"
$ docker container run -t --rm \
-e PLAT=$PLAT \
-v "$(pwd)":/io \
"$DOCKER_IMAGE" /io/travis/build-wheels.sh
这告诉 Docker 在manylinux1_x86_64 Docker 容器中运行build-wheels.sh shell 脚本,将PLAT作为容器中可用的环境变量传递。由于您使用了-v(或--volume)来绑定挂载一个卷,容器中生成的轮子现在可以在您的主机上的wheelhouse目录中访问:
$ ls -1 wheelhouse
python_manylinux_demo-1.0-cp27-cp27m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp27-cp27mu-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp35-cp35m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp36-cp36m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp37-cp37m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp38-cp38-manylinux1_x86_64.whl
在几个简短的命令中,您就有了一组用于 CPython 2.7 到 3.8 的manylinux1轮子。一种常见的做法也是迭代不同的架构。例如,您可以对quay.io/pypa/manylinux1_i686 Docker 图像重复这个过程。这将建立针对 32 位(i686)架构的manylinux1轮子。
如果你想更深入地研究制造轮子,那么下一步最好是向最好的人学习。从 Python Wheels 页面开始,选择一个项目,导航到它的源代码(在 GitHub、GitLab 或 Bitbucket 之类的地方),亲自看看它是如何构建轮子的。
Python Wheels 页面上的许多项目都是纯 Python 项目,并分发通用轮子。如果您正在寻找更复杂的情况,那么请留意使用扩展模块的包。这里有两个例子可以吊起你的胃口:
如果你对建造manylinux车轮感兴趣,这两个项目都是著名的项目,提供了很好的学习范例。
捆绑共享库
另一个挑战是为依赖外部共享库的包构建轮子。manylinux图像包含一组预先筛选的库,如libpthread.so.0和libc.so.6。但是如果你依赖于列表之外的东西,比如 ATLAS 或者 GFortran 呢?
在这种情况下,有几种解决方案可供选择:
auditwheel将外部库捆绑成一个已经构建好的轮子。delocate在 macOS 上也是如此。
便利地,auditwheel出现在manylinux Docker 图像上。使用auditwheel和delocate只需要一个命令。只需告诉他们有关车轮文件的信息,剩下的工作由他们来完成:
$ auditwheel repair <path-to-wheel.whl> # For manylinux
$ delocate-wheel <path-to-wheel.whl> # For macOS
这将通过项目的setup.py检测所需的外部库,并将它们捆绑到轮子中,就像它们是项目的一部分一样。
利用auditwheel和delocate的项目的一个例子是 pycld3 ,它为紧凑语言检测器 v3 (CLD3)提供 Python 绑定。
pycld3包依赖于 libprotobuf ,不是一般安装的库。如果你偷看一个 pycld3 macOS 轮的内部,那么你会看到libprotobuf.22.dylib包含在那里。这是一个动态链接的共享库,它被捆绑到轮子中:
$ unzip -l pycld3-0.20-cp38-cp38-macosx_10_15_x86_64.whl
...
51 04-10-2020 11:46 cld3/__init__.py
939984 04-10-2020 07:50 cld3/_cld3.cpython-38-darwin.so
2375836 04-10-2020 07:50 cld3/.dylibs/libprotobuf.22.dylib --------- -------
3339279 8 files
车轮预装了libprotobuf。一个.dylib类似于一个 Unix .so文件或者 Windows .dll文件,但是我承认我不知道除此之外的本质区别。
auditwheel和delocate知道包括libprotobuf是因为 setup.py通过libraries的论证告诉他们:
setup(
# ...
libraries=["protobuf"],
# ...
)
这意味着auditwheel和delocate为用户省去了安装protobuf的麻烦,只要他们从一个平台和 Python 组合中安装,这个平台和 Python 组合有一个匹配的轮子。
如果你正在发布一个像这样有外部依赖的包,那么你可以帮你的用户一个忙,使用auditwheel或者delocate来省去他们自己安装依赖的额外步骤。
在持续集成中构建车轮
在本地机器上构建轮子的另一种方法是在项目的 CI 管道中自动构建轮子。
有无数的 CI 解决方案与主要的代码托管服务相集成。其中有 Appveyor 、 Azure DevOps 、 BitBucket Pipelines 、 Circle CI 、 GitLab 、 GitHub Actions 、 Jenkins 和 Travis CI 等等。
本教程的目的不是判断哪种 CI 服务最适合构建车轮,并且考虑到 CI 支持的发展速度,任何列出哪些 CI 服务支持哪些容器的列表都会很快过时。然而,这一节可以帮助你开始。
如果你正在开发一个纯 Python 包,那么bdist_wheel步骤是一个幸福的单行程序:你在哪个容器操作系统和平台上构建轮子基本上无关紧要。事实上,所有主要的 CI 服务都应该通过在项目中的一个特殊的 YAML 文件中定义步骤,使您能够以一种简洁的方式做到这一点。
例如,下面是您可以在 GitHub 操作中使用的语法:
1name: Python wheels 2on: 3 release: 4 types: 5 - created 6jobs: 7 wheels: 8 runs-on: ubuntu-latest 9 steps: 10 - uses: actions/checkout@v2 11 - name: Set up Python 3.x 12 uses: actions/setup-python@v2 13 with: 14 python-version: '3.x' 15 - name: Install dependencies 16 run: python -m pip install --upgrade setuptools wheel 17 - name: Build wheels 18 run: python setup.py bdist_wheel 19 - uses: actions/upload-artifact@v2 20 with: 21 name: dist 22 path: dist
在此配置文件中,您使用以下步骤构建一个轮子:
- 在第 8 行中,您指定作业应该在 Ubuntu 机器上运行。
- 在第 10 行中,您使用
checkout动作来设置您的项目存储库。 - 在第 14 行中,您告诉 CI 运行程序使用 Python 3 的最新稳定版本。
- 在第 21 行中,您请求生成的轮子作为工件可用,一旦作业完成,您可以从 UI 下载。
然而,如果您有一个复杂的项目(可能是一个带有 C 扩展或 Cython 代码的项目),并且您正在努力创建一个 CI/CD 管道来自动构建轮子,那么可能会涉及到额外的步骤。这里有几个项目,你可以通过例子来学习:
许多项目推出自己的配置项配置。然而,已经出现了一些解决方案来减少在配置文件中指定的构建轮子的代码量。您可以直接在 CI 服务器上使用 cibuildwheel 工具来减少构建多个平台轮子所需的代码和配置行。还有 multibuild ,它提供了一组 shell 脚本来帮助在 Travis CI 和 AppVeyor 上构建轮子。
确保你的车轮旋转正确
构建结构正确的车轮可能是一项精细的操作。例如,如果你的 Python 包使用了一个 src布局,而你忘记了在setup.py 中正确地指定它,那么产生的轮子可能在错误的位置包含了一个目录。
在bdist_wheel之后可以使用的一个检查是 check-wheel-contents 工具。它会查找常见问题,例如包目录结构异常或存在重复文件:
$ check-wheel-contents dist/*.whl
dist/ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl: OK
在这种情况下,check-wheel-contents表示使用ujson滚轮的一切都检查完毕。如果没有,stdout将会显示一个可能问题的概要,就像flake8中的过磅信息一样。
另一种确认你建造的轮子是否有合适的材料的方法是使用 TestPyPI 。首先,您可以在那里上传软件包:
$ python -m twine upload \
--repository-url https://test.pypi.org/legacy/ \
dist/*
然后,您可以下载相同的包进行测试,就像它是真实的一样:
$ python -m pip install \
--index-url https://test.pypi.org/simple/ \
<pkg-name>
这允许你通过上传然后下载你自己的项目来测试你的轮子。
上传 Python 轮子到 PyPI
现在是上传你的 Python 包的时候了。由于默认情况下sdist和轮子都放在dist/目录中,所以您可以使用 twine 工具来上传它们,这是一个用于将包发布到 PyPI 的实用程序:
$ python -m pip install -U twine
$ python -m twine upload dist/*
由于默认情况下sdist和bdist_wheel都输出到dist/,您可以放心地告诉twine使用 shell 通配符(dist/*)上传dist/下的所有内容。
结论
理解轮子在 Python 生态系统中扮演的关键角色可以让 Python 包的用户和开发者的生活更加轻松。此外,提高您在轮子方面的 Python 素养将有助于您更好地理解当您安装一个包时会发生什么,以及在越来越少的情况下,操作何时出错。
在本教程中,您学习了:
- 什么是车轮,它们与源分布相比如何
- 如何使用轮子来控制包装安装过程
- 万向、纯蟒、平台车轮有什么区别
- 如何为你自己的 Python 包创建和分发轮子
现在,您已经从用户和开发人员的角度对轮子有了很好的理解。您已经准备好打造自己的车轮,让项目的安装过程变得快速、方便和稳定。
请参阅下一节的附加阅读材料,深入了解快速扩张的车轮生态系统。
资源
Python Wheels 页面致力于跟踪 PyPI 上下载最多的 360 个包中对 Wheels 的支持。在本教程中,采用率是相当可观的,360 个中有 331 个,大约 91%。
有许多 Python 增强提案(pep)帮助规范和发展了 wheel 格式:
- PEP 425 -已构建发行版的兼容性标签
- PEP 427 -车轮二进制包格式 1.0
- PEP 491 -车轮二进制包格式 1.9
- PEP 513 -一个用于可移植 Linux 构建发行版的平台标签
- PEP 571-
manylinux2010平台标签 - PEP 599-
manylinux2014平台标签
以下是本教程中提到的各种车轮包装工具的列表:
- T2
pypa/wheel - T2
pypa/auditwheel - T2
pypa/manylinux pypa/python-manylinux-demo- T2
jwodder/check-wheel-contents - T2
matthew-brett/delocate - T2
matthew-brett/multibuild - T2
joerick/cibuildwheel
Python 文档中有几篇文章介绍了 wheels 和源代码发行版:
最后,这里有一些来自 PyPA 的更有用的链接:
- 打包您的项目
- Python 打包概述**********
python“while”循环(无限迭代)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 掌握 While Loops
迭代意味着一遍又一遍地执行同一个代码块,可能是多次。实现迭代的编程结构被称为循环。
在编程中,有两种类型的迭代,不定迭代和确定迭代:
-
使用无限迭代,循环执行的次数没有事先明确指定。相反,只要满足某些条件,就重复执行指定的块。
-
使用确定迭代,指定块将被执行的次数在循环开始时被明确指定。
在本教程中,您将:
- 了解
while循环,这是用于无限迭代的 Python 控制结构 - 了解如何提前脱离循环或循环迭代
- 探索无限循环
完成后,你应该很好地掌握了如何在 Python 中使用无限迭代。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
参加测验:通过我们的交互式“Python”while“Loops”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
while循环
让我们看看 Python 的while语句是如何用来构造循环的。我们将从简单开始,然后不断修饰。
基本while循环的格式如下所示:
while <expr>:
<statement(s)>
<statement(s)>表示要重复执行的块,通常称为循环体。这用缩进来表示,就像在一个语句中一样。
记住:Python 中所有的控制结构都是用缩进来定义块的。参见前面教程中关于分组语句的讨论进行回顾。
控制表达式<expr>通常包含一个或多个变量,这些变量在开始循环之前被初始化,然后在循环体的某个地方被修改。
当遇到while循环时,首先在布尔上下文中评估<expr>。如果为真,则执行循环体。然后再次检查<expr>,如果仍然为真,则再次执行主体。这一直持续到<expr>变为假,此时程序执行继续到循环体之外的第一条语句。
考虑这个循环:
1>>> n = 5 2>>> while n > 0: 3... n -= 1 4... print(n) 5... 64 73 82 91 100以下是本例中发生的情况:
n最初是5。第 2 行的while语句头中的表达式是n > 0,这是真的,所以循环体执行。在第 3 行的循环体内,n从1递减到4,然后打印出来。当循环体结束时,程序执行返回到循环顶部的第 2 行,并再次计算表达式。还是真的,所以主体再执行一次,打印出
3。这一直持续到
n变成0为止。此时,当表达式被测试时,它是假的,并且循环终止。执行将在循环体后面的第一条语句处继续,但在本例中没有这样的语句。注意,在发生任何事情之前,首先测试的是
while循环的控制表达式。如果一开始就为 false,循环体将永远不会被执行:
>>> n = 0
>>> while n > 0:
... n -= 1
... print(n)
...
在上面的例子中,当遇到循环时,n就是0。控制表达式n > 0已经为假,所以循环体永远不会执行。
这里是另一个while循环,涉及一个列表,而不是一个数字比较:
>>> a = ['foo', 'bar', 'baz'] >>> while a: ... print(a.pop(-1)) ... baz bar foo当在布尔上下文中评估一个列表时,如果列表中有元素,则为 true,如果列表为空,则为 falsy。在这个例子中,
a只要包含元素,就是真的。一旦用.pop()方法移除了所有的条目并且列表为空,a为假,循环终止。Python 的
break和continue语句到目前为止,在您看到的每个例子中,
while循环的整个主体都在每次迭代中执行。Python 提供了两个关键字,可以提前终止循环迭代:
Python
break语句立即终止整个循环。程序执行到循环体后面的第一条语句。Python
continue语句立即终止当前循环迭代。执行跳转到循环的顶部,重新计算控制表达式以确定循环是再次执行还是终止。下图展示了
break和continue之间的区别:
break and continue 这里有一个名为
break.py的脚本文件,它演示了break语句:1n = 5 2while n > 0: 3 n -= 1 4 if n == 2: 5 break 6 print(n) 7print('Loop ended.')从命令行解释器运行
break.py会产生以下输出:C:\Users\john\Documents>python break.py 4 3 Loop ended.当
n变为2时,执行break语句。循环完全终止,程序执行跳转到第 7 行的print()语句。注:如果你的编程背景是在 C 、 C++ 、 Java ,或者 JavaScript ,那么你可能会疑惑 Python 的 do-while 循环在哪里。坏消息是 Python 没有 do-while 结构。但是好消息是,您可以使用一个带有
break语句的while循环来模拟。下一个脚本
continue.py,除了用continue语句代替了break之外,其他都是一样的:1n = 5 2while n > 0: 3 n -= 1 4 if n == 2: 5 continue 6 print(n) 7print('Loop ended.')
continue.py的输出如下所示:C:\Users\john\Documents>python continue.py 4 3 1 0 Loop ended.这一次,当
n为2时,continue语句导致迭代终止。因此,2不会被打印。执行返回到循环的顶部,重新计算条件,并且仍然为真。循环继续,当n变成0时终止,如前所述。
else条款Python 允许在一个
while循环的末尾有一个可选的else子句。这是 Python 独有的特性,在大多数其他编程语言中没有。语法如下所示:while <expr>: <statement(s)> else: <additional_statement(s)>
else子句中指定的<additional_statement(s)>将在while循环终止时执行。
现在,你可能会想,“这有什么用?”您可以通过将这些语句直接放在
while循环之后,而不使用else来完成同样的事情:while <expr>: <statement(s)> <additional_statement(s)>有什么区别?
在后一种情况下,如果没有
else子句,<additional_statement(s)>将在while循环终止后执行,无论如何。当
<additional_statement(s)>被放在else子句中时,只有当循环“因穷尽”而终止时,它们才会被执行——也就是说,如果循环迭代,直到控制条件变为假。如果循环被一个break语句退出,那么else子句将不会被执行。考虑下面的例子:

>>> n = 5
>>> while n > 0:
... n -= 1
... print(n)
... else: ... print('Loop done.') ...
4
3
2
1
0
Loop done.
在这种情况下,循环重复,直到条件用尽:n变成0,所以n > 0变成假。因为循环过了它的自然寿命,可以这么说,所以执行了else子句。现在观察这里的区别:
>>> n = 5 >>> while n > 0: ... n -= 1 ... print(n) ... if n == 2: ... break ... else: ... print('Loop done.') ... 4 3 2这个循环因
break而提前终止,所以else子句没有被执行。看起来似乎单词
else的含义不太适合while循环,也不太适合if陈述。Python 的创造者吉多·范·罗苏姆曾说过,如果让他重来一次,他会把while循环的else子句从语言中删除。以下解释之一可能有助于使其更加直观:
把循环的头(
while n > 0)想象成一个被反复执行的if语句(if n > 0),当条件变为假时,else子句最终被执行。把
else想象成nobreak,因为如果没有break,后面的块就会被执行。如果你觉得这两种解释都没有帮助,那就忽略它们吧。
while循环中的else子句什么时候有用?一种常见的情况是,您正在搜索特定项目的列表。如果找到了该项,您可以使用break退出循环,并且else子句可以包含在没有找到该项时要执行的代码:
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> s = 'corge'
>>> i = 0
>>> while i < len(a):
... if a[i] == s:
... # Processing for item found
... break
... i += 1
... else:
... # Processing for item not found
... print(s, 'not found in list.')
...
corge not found in list.
注意:上面显示的代码有助于说明这个概念,但是你实际上不太可能以这种方式搜索一个列表。
首先,列表通常用确定的迭代来处理,而不是一个while循环。明确迭代将在本系列的下一篇教程中介绍。
其次,Python 提供了在列表中搜索条目的内置方法。您可以使用in运算符:
>>> if s in a: ... print(s, 'found in list.') ... else: ... print(s, 'not found in list.') ... corge not found in list.
list.index()方法也可以。如果在列表中找不到条目,这个方法会引发一个ValueError异常,所以您需要理解异常处理才能使用它。在 Python 中,使用try语句来处理异常。下面给出一个例子:
>>> try:
... print(a.index('corge'))
... except ValueError:
... print(s, 'not found in list.')
...
corge not found in list.
在本系列的后面,您将了解异常处理。
带有while循环的else子句有点奇怪,并不常见。但是,如果您发现有一种情况,您觉得它增加了代码的清晰度,请不要回避它!
无限循环
假设你写了一个理论上永远不会结束的while循环。听起来很奇怪,对吧?
考虑这个例子:
>>> while True: ... print('foo') ... foo foo foo . . . foo foo foo KeyboardInterrupt Traceback (most recent call last): File "<pyshell#2>", line 2, in <module> print('foo')该代码被
Ctrl+C终止,从键盘产生一个中断。否则,事情会没完没了地继续下去。在所示的输出中,许多foo输出行已被删除并替换为垂直省略号。显然,
True永远不会是假的,否则我们都有大麻烦了。因此,while True:启动了一个无限循环,理论上将永远运行下去。也许这听起来不像是您想要做的事情,但是这种模式实际上很常见。例如,您可能为一个服务编写代码,该服务启动并永远运行,接受服务请求。“永远”在这个上下文中的意思是直到你关闭它,或者直到宇宙的热寂,无论哪个先出现。
更通俗地说,记住循环可以用
break语句来打破。基于循环体内识别的条件终止循环可能更简单,而不是基于在顶部评估的条件。这是上面显示的循环的另一个变体,它使用
.pop()从列表中连续删除项目,直到它为空:
>>> a = ['foo', 'bar', 'baz']
>>> while True:
... if not a:
... break
... print(a.pop(-1))
...
baz
bar
foo
当a变为空时,not a变为真,break语句退出循环。
您也可以在一个循环中指定多个break语句:
while True:
if <expr1>: # One condition for loop termination
break
...
if <expr2>: # Another termination condition
break
...
if <expr3>: # Yet another
break
在这种情况下,结束循环有多种原因,从几个不同的位置开始break通常更干净,而不是试图在循环头中指定所有的终止条件。
无限循环非常有用。请记住,您必须确保循环在某个点被打破,这样它才不会真正变成无限的。
嵌套的while循环
一般来说,Python 控制结构可以相互嵌套。例如,if / elif / else条件语句可以嵌套:
if age < 18:
if gender == 'M':
print('son')
else:
print('daughter')
elif age >= 18 and age < 65:
if gender == 'M':
print('father')
else:
print('mother')
else:
if gender == 'M':
print('grandfather')
else:
print('grandmother')
类似地,一个while循环可以包含在另一个while循环中,如下所示:
>>> a = ['foo', 'bar'] >>> while len(a): ... print(a.pop(0)) ... b = ['baz', 'qux'] ... while len(b): ... print('>', b.pop(0)) ... foo > baz > qux bar > baz > qux嵌套循环中的
break或continue语句适用于最近的封闭循环:while <expr1>: statement statement while <expr2>: statement statement break # Applies to while <expr2>: loop break # Applies to while <expr1>: loop此外,
while循环可以嵌套在if/elif/else语句中,反之亦然:if <expr>: statement while <expr>: statement statement else: while <expr>: statement statement statementwhile <expr>: if <expr>: statement elif <expr>: statement else: statement if <expr>: statement事实上,所有 Python 控制结构可以根据您的需要任意混合。这是理所应当的。想象一下,如果有意想不到的限制,比如“一个
while循环不能包含在一个if语句中”或者“while循环最多只能嵌套四层”,那会有多令人沮丧你很难把它们都记住。看似任意的数字或逻辑限制被认为是糟糕的编程语言设计的标志。幸运的是,在 Python 中你不会发现很多。
单行
while循环与
if语句一样,while循环可以在一行中指定。如果组成循环体的块中有多个语句,可以用分号(;)分隔:
>>> n = 5
>>> while n > 0: n -= 1; print(n)
4
3
2
1
0
不过这只适用于简单的语句。你不能将两个复合语句合并成一行。因此,您可以像上面一样在一行中指定一个while循环,并在一行中编写一个if语句:
>>> if True: print('foo') foo但是你不能这样做:
>>> while n > 0: n -= 1; if True: print('foo')
SyntaxError: invalid syntax
记住 PEP 8 不鼓励在一行中有多个语句。所以你可能不应该经常这样做。
结论
在本教程中,您学习了使用 Python while循环的无限迭代。您现在能够:
- 构建基本和复杂的
while循环 - 用
break和continue中断循环执行 - 使用带有
while循环的else子句 - 处理无限循环
现在,您应该已经很好地掌握了如何重复执行一段代码。
参加测验:通过我们的交互式“Python”while“Loops”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
本系列的下一篇教程将介绍带有for循环的确定迭代——循环执行,其中明确指定了重复的次数。
« Conditional Statements in PythonPython "while" LoopsPython "for" Loops »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 掌握 While Loops******
在 Windows 上为机器学习设置 Python
原文:https://realpython.com/python-windows-machine-learning-setup/
在过去的几年里,Python 已经被大量用于数值和科学应用。然而,为了以高效的方式执行数值计算,Python 依赖于外部库,有时是用其他语言实现的,比如部分使用 Fortran 语言实现的 NumPy 库。
由于这些依赖性,有时为数值计算建立一个环境并链接所有必要的库并不容易。在涉及使用 Python 进行机器学习的研讨会上,人们很难让事情运转起来,这是很常见的,尤其是当他们使用的操作系统缺乏包管理系统时,例如 Windows。
在本文中,您将:
- 浏览在 Windows 操作系统上为数值计算设置 Python 环境的细节
- 介绍 Anaconda,这是一个 Python 发行版,旨在避免这些设置问题
- 了解如何在 Windows 机器上安装发行版并使用它的工具来管理包和环境
- 使用已安装的 Python 堆栈来构建神经网络,并对其进行训练以解决经典的分类问题
免费奖励: 点击此处获取 Conda 备忘单,其中包含管理您的 Python 环境和包的便捷使用示例。
介绍蟒蛇和康达
从 2011 年开始,Python 包含了 pip ,一个用来安装和管理用 Python 编写的软件包的包管理系统。然而,对于数值计算,有几个依赖关系不是用 Python 写的,所以最初发布的 pip 不能自己解决问题。
为了解决这个问题,Continuum Analytics 发布了专注于科学应用的 Python 发行版 Anaconda ,以及 Anaconda 发行版使用的软件包和环境管理系统 Conda 。值得注意的是, pip 的最新版本可以使用轮子处理外部依赖,但是,通过使用 Anaconda,您将能够更顺利地安装数据科学的关键库。(你可以在这里阅读更多关于这个讨论[。)]( http://jakevdp.github.io/blog/2016/08/25/conda-myths-and-misconceptions/#Myth-#6:-Now-that-pip-uses-wheels ,-conda-is-no-longer-necessary)
尽管 Conda 与 Anaconda Python 发行版紧密耦合,但两者是具有不同目标的不同项目:
-
Anaconda 是该软件在 PyData 生态系统中的完整发行版,包括 Python 本身以及几个第三方开源项目的二进制文件。除了 Anaconda 之外,还有 Miniconda ,这是一个最小的 Python 发行版,基本上包括 conda 及其依赖项,因此您可以从头开始只安装您需要的包
-
Conda 是一个包、依赖和环境管理系统,可以在没有 Anaconda 或 Miniconda 发行版的情况下安装。它运行在 Windows、macOS 和 Linux 上,是为 Python 程序创建的,但它可以为任何语言打包和分发软件。主要目的是通过下载软件的预编译版本,以一种简单的方式解决外部依赖性问题。
从这个意义上说,它更像是通用软件包管理器的跨平台版本,如 APT 或 YUM ,它以一种语言无关的方式帮助找到并安装软件包。此外,Conda 是一个环境管理器,所以如果您需要一个需要不同版本 Python 的包,通过使用 Conda,可以用完全不同的 Python 版本建立一个单独的环境,在您的默认环境中保持您通常的 Python 版本。
有很多关于为 Python 生态系统创建另一个包管理系统的讨论。值得一提的是,Conda 的创造者将 Python 标准打包推到了极限,只有在明确这是唯一合理的前进方式时,才创建第二个工具。
奇怪的是,就连吉多·范·罗苏姆在 2012 年 PyData meetup 的开幕演讲中也说,当谈到打包时,“与更大的 Python 社区相比,你的需求听起来真的很不寻常,所以你最好建立自己的需求。”(大家可以看一段这个讨论的视频。)关于这次讨论的更多信息可以在这里和这里找到。
Anaconda 和 Miniconda 已经成为最流行的 Python 发行版,广泛用于各种公司和研究实验室的数据科学和机器学习。它们是免费的开源项目,目前在库中包含 1400 多个包。在下一节中,我们将介绍如何在 Windows 机器上安装 Miniconda Python 发行版。
安装 Miniconda Python 发行版
在本节中,您将逐步了解如何在 Windows 上设置 data science Python 环境。与完整的 Anaconda 发行版不同,您将使用 Miniconda 来建立一个只包含 conda 及其依赖项的最小环境,并使用它来安装必要的包。
注意:要在 Windows 上设置通用 Python 编程环境,请查看 Real Python 的设置指南。
Miniconda 和 Anaconda 的安装过程非常相似。基本的区别在于,Anaconda 提供了一个包含许多预安装包的环境,其中许多包从未被使用过。(可以在这里查看列表。)Miniconda 是极简的、干净的,它允许您轻松地安装 Anaconda 的任何包。
在本文中,重点将是使用命令行界面(CLI)来设置包和环境。然而,如果你愿意,也可以使用 Conda 来安装 Anaconda Navigator ,一个图形用户界面(GUI)。
Miniconda 可以使用安装程序进行安装这里。您会注意到有 Windows、macOS 和 Linux 以及 32 位或 64 位操作系统的安装程序。您应该根据您的 Windows 安装考虑合适的架构,并下载 Python 3.x 版本(在撰写本文时,是 3.7)。
没有理由再在一个新项目中使用 Python 2,如果您正在进行的某个项目确实需要 Python 2,由于某些库尚未更新,即使您安装了 Miniconda Python 3.x 发行版,也可以使用 Conda 建立 Python 2 环境,您将在下一节看到这一点。
下载完成后,您只需运行安装程序并遵循安装步骤:
- 点击欢迎屏幕上的下一个:
- 点击我同意同意许可条款:
[
- 选择安装类型,点击下一步。使用 Anaconda 或 Miniconda 的另一个优点是可以使用本地帐户安装发行版。(没有必要拥有管理员帐户。)如果是这种情况,选择就我。否则,如果您有管理员帐户,您可以选择所有用户:
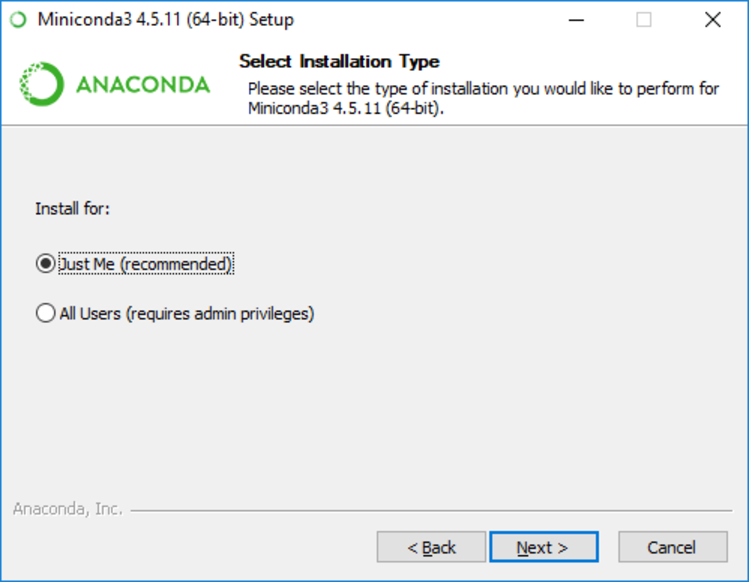
- 选择安装位置,点击下一步的。如果你选择只为自己安装,默认位置将是你的用户的个人文件夹下的文件夹 Miniconda3 。重要的是不要在 Miniconda 路径中的文件夹名称中使用空格,因为许多 Python 包在文件夹名称中使用空格时会出现问题:

- 在高级安装选项中,建议使用默认选项,即不要将 Anaconda 添加到 PATH 环境变量中,并将 Anaconda 注册为默认 Python。点击安装开始安装:
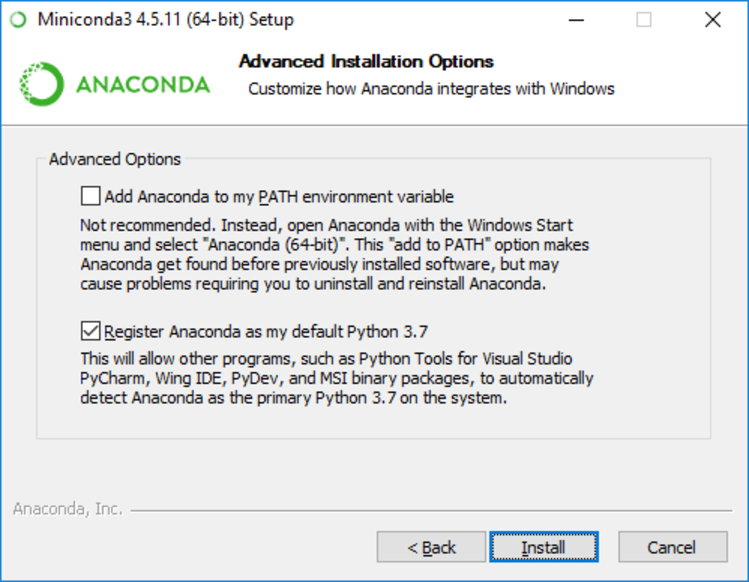
- 安装程序正在复制文件,请稍候:
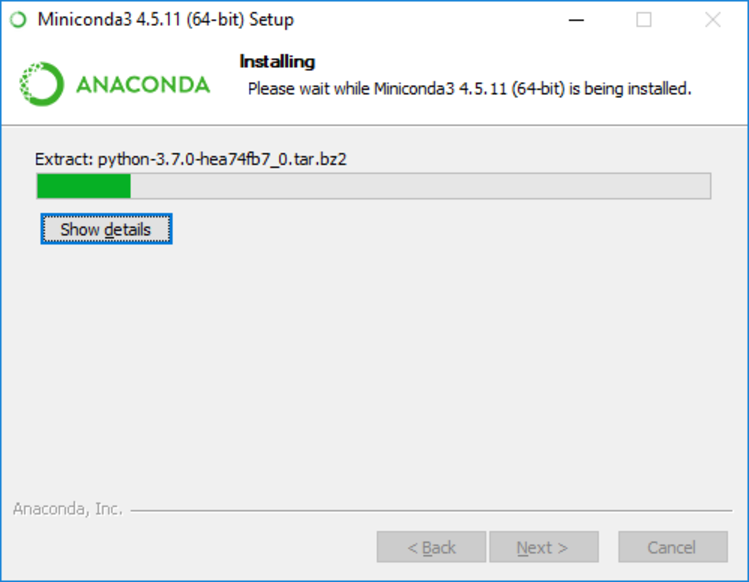
- 安装完成后,点击下一个的:
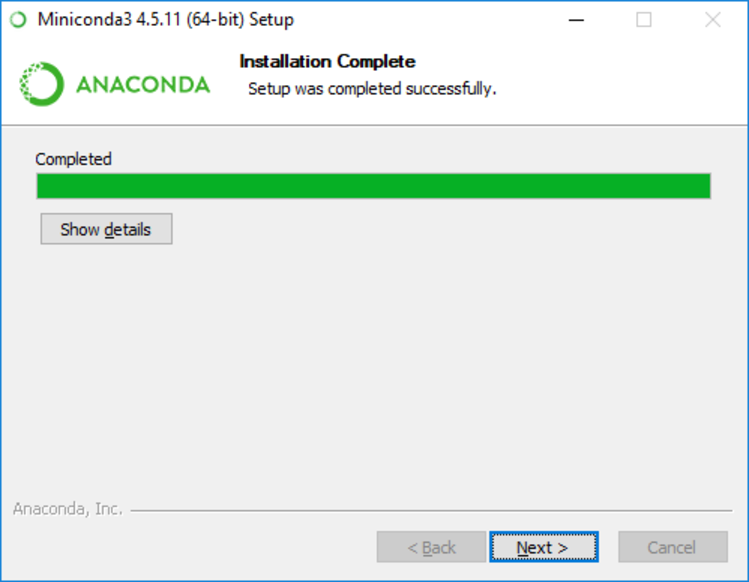
- 点击完成完成安装并关闭安装程序:

因为 Anaconda 没有包含在 PATH 环境变量中,所以它的命令在 Windows 默认命令提示符下不起作用。要使用该发行版,您应该启动它自己的命令提示符,这可以通过点击开始按钮和 Anaconda3 (64 位)下的 Anaconda 提示符来完成:

当提示符打开时,您可以通过运行conda --version来检查 Conda 是否可用:
(base) C:\Users\IEUser>conda --version
conda 4.5.11
要获得关于安装的更多信息,您可以运行conda info:
(base) C:\Users\IEUser>conda info
active environment : base
active env location : C:\Users\IEUser\Miniconda3
shell level : 1
user config file : C:\Users\IEUser\.condarc
populated config files : C:\Users\IEUser\.condarc
conda version : 4.5.11
conda-build version : not installed
python version : 3.7.0.final.0
base environment : C:\Users\IEUser\Miniconda3 (writable)
channel URLs : https://repo.anaconda.com/pkgs/main/win-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/free/win-64
https://repo.anaconda.com/pkgs/free/noarch
https://repo.anaconda.com/pkgs/r/win-64
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/pro/win-64
https://repo.anaconda.com/pkgs/pro/noarch
https://repo.anaconda.com/pkgs/msys2/win-64
https://repo.anaconda.com/pkgs/msys2/noarch
package cache : C:\Users\IEUser\Miniconda3\pkgs
C:\Users\IEUser\AppData\Local\conda\conda\pkgs
envs directories : C:\Users\IEUser\Miniconda3\envs
C:\Users\IEUser\AppData\Local\conda\conda\envs
C:\Users\IEUser\.conda\envs
platform : win-64
user-agent : conda/4.5.11 requests/2.19.1 CPython/3.7.0 Windows/10 Windows/10.0.17134
administrator : False
netrc file : None
offline mode : False
现在您已经安装了 Miniconda,让我们看看 conda 环境是如何工作的。
了解康达环境
当您从头开始开发项目时,建议您使用所需库的最新版本。然而,当使用其他人的项目时,比如运行来自 Kaggle 或 Github 的示例时,由于兼容性问题,您可能需要安装特定版本的包,甚至另一个版本的 Python。
当您尝试运行一个很久以前开发的应用程序时,也可能会出现这个问题,该应用程序使用了一个特定的库版本,但由于更新,该版本不再适用于您的应用程序。
虚拟环境是这类问题的解决方案。通过使用它们,可以创建多个环境,每个环境都有不同版本的包。一个典型的 Python 设置包括 Virtualenv ,这是一个创建隔离的 Python 虚拟环境的工具,在 Python 社区中广泛使用。
Conda 包括自己的环境管理器,并提供了一些优于 Virtualenv 的优势,特别是在数值应用程序方面,例如管理非 Python 依赖项的能力和管理不同版本 Python 的能力,这是 Virtualenv 所不具备的。除此之外,Conda 环境完全兼容默认的 Python 包,可以使用pip安装。
Miniconda 安装提供了 conda 和一个根环境,其中安装了一个 Python 版本和一些基本包。除了这个根环境之外,还可以设置其他环境,包括不同版本的 Python 和包。
使用 Anaconda 提示符,可以通过运行conda env list来检查可用的 conda 环境:
(base) C:\Users\IEUser>conda env list
# conda environments:
#
base * C:\Users\IEUser\Miniconda3
这个基础环境是根环境,由 Miniconda 安装程序创建。可以通过运行conda create --name otherenv来创建另一个名为otherenv的环境:
(base) C:\Users\IEUser>conda create --name otherenv
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\otherenv
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate otherenv
#
# To deactivate an active environment, use
#
# $ conda deactivate
正如环境创建过程完成后所通知的,可以通过运行conda activate otherenv来激活otherenv环境。您会注意到,通过提示符开头括号中的指示,环境已经发生了变化:
(base) C:\Users\IEUser>conda activate otherenv
(otherenv) C:\Users\IEUser>
您可以在这个环境中通过运行python来打开 Python 解释器:
(otherenv) C:\Users\IEUser>python
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
该环境包括 Python 3.7.0,与 root base 环境中包含的版本相同。要退出 Python 解释器,只需运行quit():
>>> quit()
(otherenv) C:\Users\IEUser>
要停用otherenv环境并返回到根基础环境,您应该运行deactivate:
(otherenv) C:\Users\IEUser>deactivate
(base) C:\Users\IEUser>
如前所述,Conda 允许您使用不同版本的 Python 轻松创建环境,这对于 Virtualenv 来说并不简单。要在一个环境中包含不同的 Python 版本,您必须在运行conda create时使用python=<version>来指定它。例如,要用 Python 2.7 创建一个名为py2的环境,您必须运行conda create --name py2 python=2.7:
(base) C:\Users\IEUser>conda create --name py2 python=2.7
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\py2
added / updated specs:
- python=2.7
The following NEW packages will be INSTALLED:
certifi: 2018.8.24-py27_1
pip: 10.0.1-py27_0
python: 2.7.15-he216670_0
setuptools: 40.2.0-py27_0
vc: 9-h7299396_1
vs2008_runtime: 9.00.30729.1-hfaea7d5_1
wheel: 0.31.1-py27_0
wincertstore: 0.2-py27hf04cefb_0
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate py2
#
# To deactivate an active environment, use
#
# $ conda deactivate
(base) C:\Users\IEUser>
如conda create的输出所示,这次安装了一些新的包,因为新环境使用 Python 2。您可以通过激活新环境并运行 Python 解释器来检查新环境是否确实使用了 Python 2:
(base) C:\Users\IEUser>conda activate py2
(py2) C:\Users\IEUser>python
Python 2.7.15 |Anaconda, Inc.| (default, May 1 2018, 18:37:09) [MSC v.1500 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
现在,如果您运行conda env list,除了根基础环境之外,您应该看到创建的两个环境:
(py2) C:\Users\IEUser>conda env list
# conda environments:
#
base C:\Users\IEUser\Miniconda3
otherenv C:\Users\IEUser\Miniconda3\envs\otherenv
py2 * C:\Users\IEUser\Miniconda3\envs\py2
(py2) C:\Users\IEUser>
在列表中,星号表示已激活的环境。可以通过运行conda remove --name <environment name> --all删除环境。由于无法移除已激活的环境,您应该首先停用py2环境,以移除它:
(py2) C:\Users\IEUser>deactivate
(base) C:\Users\IEUser>conda remove --name py2 --all
Remove all packages in environment C:\Users\IEUser\Miniconda3\envs\py2:
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\py2
The following packages will be REMOVED:
certifi: 2018.8.24-py27_1
pip: 10.0.1-py27_0
python: 2.7.15-he216670_0
setuptools: 40.2.0-py27_0
vc: 9-h7299396_1
vs2008_runtime: 9.00.30729.1-hfaea7d5_1
wheel: 0.31.1-py27_0
wincertstore: 0.2-py27hf04cefb_0
Proceed ([y]/n)? y
(base) C:\Users\IEUser>
现在您已经介绍了使用 Conda 管理环境的基础知识,让我们看看如何在环境中管理包。
使用 Conda 了解基本包管理
在每个环境中,可以使用 Conda 软件包管理器安装软件包。默认情况下,Miniconda 安装程序创建的根基础环境包括一些不属于 Python 标准库的包。
默认安装包括使用 Conda 所需的最小软件包。要检查环境中已安装软件包的列表,您只需确保它已被激活并运行conda list。在根环境中,默认情况下会安装以下软件包:
(base) C:\Users\IEUser>conda list
# packages in environment at C:\Users\IEUser\Miniconda3:
#
# Name Version Build Channel
asn1crypto 0.24.0 py37_0
ca-certificates 2018.03.07 0
certifi 2018.8.24 py37_1
cffi 1.11.5 py37h74b6da3_1
chardet 3.0.4 py37_1
conda 4.5.11 py37_0
conda-env 2.6.0 1
console_shortcut 0.1.1 3
cryptography 2.3.1 py37h74b6da3_0
idna 2.7 py37_0
menuinst 1.4.14 py37hfa6e2cd_0
openssl 1.0.2p hfa6e2cd_0
pip 10.0.1 py37_0
pycosat 0.6.3 py37hfa6e2cd_0
pycparser 2.18 py37_1
pyopenssl 18.0.0 py37_0
pysocks 1.6.8 py37_0
python 3.7.0 hea74fb7_0
pywin32 223 py37hfa6e2cd_1
requests 2.19.1 py37_0
ruamel_yaml 0.15.46 py37hfa6e2cd_0
setuptools 40.2.0 py37_0
six 1.11.0 py37_1
urllib3 1.23 py37_0
vc 14 h0510ff6_3
vs2015_runtime 14.0.25123 3
wheel 0.31.1 py37_0
win_inet_pton 1.0.1 py37_1
wincertstore 0.2 py37_0
yaml 0.1.7 hc54c509_2
(base) C:\Users\IEUser>
要管理这些包,您还应该使用 Conda。接下来,让我们看看如何使用 Conda 搜索、安装、更新和删除软件包。
搜索和安装包
软件包由 Conda 从名为通道的库安装,一些默认通道由安装程序配置。要搜索特定的包,可以运行conda search <package name>。例如,这是你如何搜索keras包(一个机器学习库):
(base) C:\Users\IEUser>conda search keras
Loading channels: done
# Name Version Build Channel
keras 2.0.8 py35h15001cb_0 pkgs/main
keras 2.0.8 py36h65e7a35_0 pkgs/main
keras 2.1.2 py35_0 pkgs/main
keras 2.1.2 py36_0 pkgs/main
keras 2.1.3 py35_0 pkgs/main
keras 2.1.3 py36_0 pkgs/main
... (more)
根据前面的输出,包有不同的版本,每个版本有不同的 builds,比如 Python 3.5 和 3.6。
之前的搜索只显示名为keras的包的精确匹配。要执行更广泛的搜索,包括名称中包含keras的所有包,您应该使用通配符*。例如,当您运行conda search *keras*时,您会得到以下结果:
(base) C:\Users\IEUser>conda search *keras*
Loading channels: done
# Name Version Build Channel
keras 2.0.8 py35h15001cb_0 pkgs/main
keras 2.0.8 py36h65e7a35_0 pkgs/main
keras 2.1.2 py35_0 pkgs/main
keras 2.1.2 py36_0 pkgs/main
keras 2.1.3 py35_0 pkgs/main
keras 2.1.3 py36_0 pkgs/main
... (more)
keras-applications 1.0.2 py35_0 pkgs/main
keras-applications 1.0.2 py36_0 pkgs/main
keras-applications 1.0.4 py35_0 pkgs/main
... (more)
keras-base 2.2.0 py35_0 pkgs/main
keras-base 2.2.0 py36_0 pkgs/main
... (more)
正如前面的输出所示,默认通道中还有一些其他与 keras 相关的包。
要安装一个包,你应该运行conda install <package name>。默认情况下,最新版本的软件包将安装在活动环境中。所以,让我们在您已经创建的环境otherenv中安装软件包keras:
(base) C:\Users\IEUser>conda activate otherenv
(otherenv) C:\Users\IEUser>conda install keras
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\otherenv
added / updated specs:
- keras
The following NEW packages will be INSTALLED:
_tflow_1100_select: 0.0.3-mkl
absl-py: 0.4.1-py36_0
astor: 0.7.1-py36_0
blas: 1.0-mkl
certifi: 2018.8.24-py36_1
gast: 0.2.0-py36_0
grpcio: 1.12.1-py36h1a1b453_0
h5py: 2.8.0-py36h3bdd7fb_2
hdf5: 1.10.2-hac2f561_1
icc_rt: 2017.0.4-h97af966_0
intel-openmp: 2018.0.3-0
keras: 2.2.2-0
keras-applications: 1.0.4-py36_1
keras-base: 2.2.2-py36_0
keras-preprocessing: 1.0.2-py36_1
libmklml: 2018.0.3-1
libprotobuf: 3.6.0-h1a1b453_0
markdown: 2.6.11-py36_0
mkl: 2019.0-117
mkl_fft: 1.0.4-py36h1e22a9b_1
mkl_random: 1.0.1-py36h77b88f5_1
numpy: 1.15.1-py36ha559c80_0
numpy-base: 1.15.1-py36h8128ebf_0
pip: 10.0.1-py36_0
protobuf: 3.6.0-py36he025d50_0
python: 3.6.6-hea74fb7_0
pyyaml: 3.13-py36hfa6e2cd_0
scipy: 1.1.0-py36h4f6bf74_1
setuptools: 40.2.0-py36_0
six: 1.11.0-py36_1
tensorboard: 1.10.0-py36he025d50_0
tensorflow: 1.10.0-mkl_py36hb361250_0
tensorflow-base: 1.10.0-mkl_py36h81393da_0
termcolor: 1.1.0-py36_1
vc: 14-h0510ff6_3
vs2013_runtime: 12.0.21005-1
vs2015_runtime: 14.0.25123-3
werkzeug: 0.14.1-py36_0
wheel: 0.31.1-py36_0
wincertstore: 0.2-py36h7fe50ca_0
yaml: 0.1.7-hc54c509_2
zlib: 1.2.11-h8395fce_2
Proceed ([y]/n)?
Conda 在安装包时管理包的必要依赖项。由于包keras有很多依赖项,当你安装它时,Conda 设法安装这个大的包列表。
值得注意的是,由于keras包的最新版本使用 Python 3.6,而otherenv环境是使用 Python 3.7 创建的,所以python包 3.6.6 版作为一个依赖项被包含进来。确认安装后,可以检查一下otherenv环境的 Python 版本是否降级到了 3.6.6 版本。
有时,您不希望包被降级,最好是用必要的 Python 版本创建一个新环境。要在不安装软件包的情况下检查软件包所需的新软件包、更新和降级列表,您应该使用参数--dry-run。例如,要检查安装包keras将会改变的包,您应该运行以下命令:
(otherenv) C:\Users\IEUser>conda install keras --dry-run
然而,如果有必要,可以通过安装特定版本的包python来更改 Conda 环境的默认 Python。为了演示这一点,让我们创建一个名为envpython的新环境:
(otherenv) C:\Users\IEUser>conda create --name envpython
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\envpython
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate envpython
#
# To deactivate an active environment, use
#
# $ conda deactivate
如您之前所见,由于根基础环境使用 Python 3.7,因此创建了包含相同版本 Python 的envpython:
(base) C:\Users\IEUser>conda activate envpython
(envpython) C:\Users\IEUser>python
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> quit()
(envpython) C:\Users\IEUser>
要安装软件包的特定版本,可以运行conda install <package name>=<version>。例如,这是您在envpython环境中安装 Python 3.6 的方式:
(envpython) C:\Users\IEUser>conda install python=3.6
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\envpython
added / updated specs:
- python=3.6
The following NEW packages will be INSTALLED:
certifi: 2018.8.24-py36_1
pip: 10.0.1-py36_0
python: 3.6.6-hea74fb7_0
setuptools: 40.2.0-py36_0
vc: 14-h0510ff6_3
vs2015_runtime: 14.0.25123-3
wheel: 0.31.1-py36_0
wincertstore: 0.2-py36h7fe50ca_0
Proceed ([y]/n)?
如果您需要在一个环境中安装多个包,可以只运行conda install一次,传递包的名称。为了说明这一点,让我们安装numpy、scipy和matplotlib,在 root base 环境中进行数值计算的基本包:
(envpython) C:\Users\IEUser>deactivate
(base) C:\Users\IEUser>conda install numpy scipy matplotlib
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3
added / updated specs:
- matplotlib
- numpy
- scipy
The following packages will be downloaded:
package | build
---------------------------|-----------------
libpng-1.6.34 | h79bbb47_0 1.3 MB
mkl_random-1.0.1 | py37h77b88f5_1 267 KB
intel-openmp-2019.0 | 117 1.7 MB
qt-5.9.6 | vc14h62aca36_0 92.5 MB
matplotlib-2.2.3 | py37hd159220_0 6.5 MB
tornado-5.1 | py37hfa6e2cd_0 668 KB
pyqt-5.9.2 | py37ha878b3d_0 4.6 MB
pytz-2018.5 | py37_0 232 KB
scipy-1.1.0 | py37h4f6bf74_1 13.5 MB
jpeg-9b | hb83a4c4_2 313 KB
python-dateutil-2.7.3 | py37_0 260 KB
numpy-base-1.15.1 | py37h8128ebf_0 3.9 MB
numpy-1.15.1 | py37ha559c80_0 37 KB
mkl_fft-1.0.4 | py37h1e22a9b_1 120 KB
kiwisolver-1.0.1 | py37h6538335_0 61 KB
pyparsing-2.2.0 | py37_1 96 KB
cycler-0.10.0 | py37_0 13 KB
freetype-2.9.1 | ha9979f8_1 470 KB
icu-58.2 | ha66f8fd_1 21.9 MB
sqlite-3.24.0 | h7602738_0 899 KB
sip-4.19.12 | py37h6538335_0 283 KB
------------------------------------------------------------
Total: 149.5 MB
The following NEW packages will be INSTALLED:
blas: 1.0-mkl
cycler: 0.10.0-py37_0
freetype: 2.9.1-ha9979f8_1
icc_rt: 2017.0.4-h97af966_0
icu: 58.2-ha66f8fd_1
intel-openmp: 2019.0-117
jpeg: 9b-hb83a4c4_2
kiwisolver: 1.0.1-py37h6538335_0
libpng: 1.6.34-h79bbb47_0
matplotlib: 2.2.3-py37hd159220_0
mkl: 2019.0-117
mkl_fft: 1.0.4-py37h1e22a9b_1
mkl_random: 1.0.1-py37h77b88f5_1
numpy: 1.15.1-py37ha559c80_0
numpy-base: 1.15.1-py37h8128ebf_0
pyparsing: 2.2.0-py37_1
pyqt: 5.9.2-py37ha878b3d_0
python-dateutil: 2.7.3-py37_0
pytz: 2018.5-py37_0
qt: 5.9.6-vc14h62aca36_0
scipy: 1.1.0-py37h4f6bf74_1
sip: 4.19.12-py37h6538335_0
sqlite: 3.24.0-h7602738_0
tornado: 5.1-py37hfa6e2cd_0
zlib: 1.2.11-h8395fce_2
Proceed ([y]/n)?
既然你已经介绍了如何搜索和安装软件包,让我们看看如何使用 Conda 更新和删除它们。
更新和删除软件包
有时候,当新的包发布时,你需要更新它们。为此,您可以运行conda update <package name>。如果您希望更新一个环境中的所有包,您应该激活该环境并运行conda update --all。
要删除一个包,可以运行conda remove <package name>。例如,这是从根基础环境中删除numpy的方法:
(base) C:\Users\IEUser>conda remove numpy
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3
removed specs:
- numpy
The following packages will be REMOVED:
matplotlib: 2.2.3-py37hd159220_0
mkl_fft: 1.0.4-py37h1e22a9b_1
mkl_random: 1.0.1-py37h77b88f5_1
numpy: 1.15.1-py37ha559c80_0
scipy: 1.1.0-py37h4f6bf74_1
Proceed ([y]/n)?
值得注意的是,当您删除一个包时,所有依赖于它的包也会被删除。
使用频道
有时,您在安装程序配置的默认频道上找不到您想要安装的软件包。例如,这是你如何安装 pytorch ,另一个机器学习包:
(base) C:\Users\IEUser>conda search pytorch
Loading channels: done
PackagesNotFoundError: The following packages are not available from current channels:
- pytorch
Current channels:
- https://repo.anaconda.com/pkgs/main/win-64
- https://repo.anaconda.com/pkgs/main/noarch
- https://repo.anaconda.com/pkgs/free/win-64
- https://repo.anaconda.com/pkgs/free/noarch
- https://repo.anaconda.com/pkgs/r/win-64
- https://repo.anaconda.com/pkgs/r/noarch
- https://repo.anaconda.com/pkgs/pro/win-64
- https://repo.anaconda.com/pkgs/pro/noarch
- https://repo.anaconda.com/pkgs/msys2/win-64
- https://repo.anaconda.com/pkgs/msys2/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
在这种情况下,您可以在这里搜索包。如果你搜索pytorch,你会得到以下结果:
频道pytorch有一个名为pytorch的包,版本为0.4.1。要从一个特定的频道安装一个包,你可以使用带有conda install的-c <channel>参数:
(base) C:\Users\IEUser>conda install -c pytorch pytorch
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3
added / updated specs:
- pytorch
The following packages will be downloaded:
package | build
---------------------------|-----------------
pytorch-0.4.1 |py37_cuda90_cudnn7he774522_1 590.4 MB pytorch
The following NEW packages will be INSTALLED:
pytorch: 0.4.1-py37_cuda90_cudnn7he774522_1 pytorch
Proceed ([y]/n)?
或者,您可以添加通道,以便 Conda 使用它来搜索要安装的软件包。要列出当前使用的通道,您可以运行conda config --get channels:
(base) C:\Users\IEUser>conda config --get channels
--add channels 'defaults' # lowest priority
(base) C:\Users\IEUser>
Miniconda 安装程序仅包含defaults通道。当包含更多的通道时,有必要设置它们的优先级,以确定从哪个通道安装软件包,以防它可从多个通道获得。
要将优先级最低的频道添加到列表中,您应该运行conda config --append channels <channel name>。要将优先级最高的通道添加到列表中,您应该运行conda config --prepend channels <channel name>。建议添加低优先级的新通道,以便优先使用默认通道。因此,或者,您可以安装pytorch,添加pytorch通道并运行conda install pytorch:
(base) C:\Users\IEUser>conda config --append channels pytorch
(base) C:\Users\IEUser>conda config --get channels
--add channels 'pytorch' # lowest priority
--add channels 'defaults' # highest priority
(base) C:\Users\IEUser>conda install pytorch
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3
added / updated specs:
- pytorch
The following packages will be downloaded:
package | build
---------------------------|-----------------
pytorch-0.4.1 |py37_cuda90_cudnn7he774522_1 590.4 MB pytorch
The following NEW packages will be INSTALLED:
pytorch: 0.4.1-py37_cuda90_cudnn7he774522_1 pytorch
Proceed ([y]/n)?
并非所有套餐都可以在康达频道上买到。然而,这不是问题,因为您也可以使用pip在 Conda 环境中安装包。让我们看看如何做到这一点。
在康达环境中使用pip
有时候,你可能需要纯 Python 包,一般来说,这些包在 Conda 的频道上是没有的。比如你搜索unipath,一个用 Python 处理文件路径的包,Conda 就找不到。
conda create --name newproject
接下来,要安装pip,您应该激活环境并安装 Conda 包pip:
(base) C:\Users\IEUser>conda activate newproject
(newproject) C:\Users\IEUser>conda install pip
Solving environment: done
## Package Plan ##
environment location: C:\Users\IEUser\Miniconda3\envs\newproject
added / updated specs:
- pip
The following NEW packages will be INSTALLED:
certifi: 2018.8.24-py37_1
pip: 10.0.1-py37_0
python: 3.7.0-hea74fb7_0
setuptools: 40.2.0-py37_0
vc: 14-h0510ff6_3
vs2015_runtime: 14.0.25123-3
wheel: 0.31.1-py37_0
wincertstore: 0.2-py37_0
Proceed ([y]/n)?
最后,使用pip安装包unipath:
(newproject) C:\Users\IEUser>pip install unipath
Collecting unipath
Installing collected packages: unipath
Successfully installed unipath-1.1
You are using pip version 10.0.1, however version 18.0 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
(newproject) C:\Users\IEUser>
安装后,您可以使用conda list列出已安装的软件包,并使用 pip 检查Unipath是否已安装:
(newproject) C:\Users\IEUser>conda list
# packages in environment at C:\Users\IEUser\Miniconda3\envs\newproject:
#
# Name Version Build Channel
certifi 2018.8.24 py37_1
pip 10.0.1 py37_0
python 3.7.0 hea74fb7_0
setuptools 40.2.0 py37_0
Unipath 1.1 <pip>
vc 14 h0510ff6_3
vs2015_runtime 14.0.25123 3
wheel 0.31.1 py37_0
wincertstore 0.2 py37_0
(newproject) C:\Users\IEUser>
也可以使用pip从版本控制系统(VCS)安装软件包。例如,让我们安装supervisor,版本 4.0.0dev0,可以在 Git 库中获得。由于 Git 没有安装在newproject环境中,您应该首先安装它:
(newproject) C:\Users\IEUser> conda install git
然后,安装supervisor,使用pip从 Git 存储库安装它:
(newproject) pip install -e git://github.com/Supervisor/supervisor@abef0a2be35f4aae4a4edeceadb7a213b729ef8d#egg=supervisor
安装完成后,您可以看到supervisor列在已安装包列表中:
(newproject) C:\Users\IEUser>conda list
#
# Name Version Build Channel
certifi 2018.8.24 py37_1
git 2.18.0 h6bb4b03_0
meld3 1.0.2 <pip>
pip 10.0.1 py37_0
python 3.7.0 hea74fb7_0
setuptools 40.2.0 py37_0
supervisor 4.0.0.dev0 <pip>
... (more)
现在,您已经了解了使用 Conda 环境和管理软件包的基本知识,让我们创建一个简单的机器学习示例,使用神经网络解决一个经典问题。
一个简单的机器学习例子
在本节中,您将使用 Conda 设置环境,并训练神经网络像 XOR 门一样工作。
异或门实现数字逻辑异或运算,广泛应用于数字系统中。它采用两个数字输入,可以等于代表数字假值的0或代表数字真值的1,如果输入不同,则输出1 ( 真),如果输入相等,则输出0 ( 假)。下表(在数字系统术语中称为真值表)总结了 XOR 门的操作:
| 输入 A | 输入 B | 输出:A XOR B |
|---|---|---|
| Zero | Zero | Zero |
| Zero | one | one |
| one | Zero | one |
| one | one | Zero |
XOR 运算可以被解释为一个分类问题,假设它采用两个输入,并且应该根据输入是彼此相等还是彼此不同将它们分类到由0或1表示的两个类别中的一个。
它通常用作训练神经网络的第一个例子,因为它简单,同时需要非线性分类器,例如神经网络。神经网络将仅使用来自真值表的数据,而不知道它来自哪里,来“学习”由 XOR 门执行的操作。
为了实现神经网络,让我们创建一个新的 Conda 环境,命名为nnxor:
(base) C:\Users\IEUser>conda create --name nnxor
然后,让我们激活它并安装软件包keras:
(base) C:\Users\IEUser>conda activate nnxor
(nnxor) C:\Users\IEUser>conda install keras
keras 是在著名的机器学习库之上制作易于实现的神经网络的高级 API,比如 TensorFlow 。
您将训练以下神经网络充当 XOR 门:

网络接受两个输入,A 和 B和 T3,并将它们输入到两个神经元,用大圆圈表示。然后,它获取这两个神经元的输出,并将它们馈送到输出神经元,该输出神经元应该根据 XOR 真值表提供分类。
简而言之,训练过程包括调整权重值 w_1 直到 w_6 ,使得输出与 XOR 真值表一致。为此,将一次输入一个输入示例,将根据权重的当前值计算输出,通过将输出与真值表给出的期望输出进行比较,将逐步调整权重的值。
为了组织这个项目,您将在 Windows 用户文件夹(C:\Users\IEUser)中创建一个名为nnxor的文件夹,并使用一个名为nnxor.py的文件来存储实现神经网络的 Python 程序:

在nnxor.py文件中,您将定义网络,执行训练,并测试它:
import numpy as np
np.random.seed(444)
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.optimizers import SGD
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y = np.array([[0], [1], [1], [0]])
model = Sequential()
model.add(Dense(2, input_dim=2))
model.add(Activation('sigmoid'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
sgd = SGD(lr=0.1)
model.compile(loss='mean_squared_error', optimizer=sgd)
model.fit(X, y, batch_size=1, epochs=5000)
if __name__ == '__main__':
print(model.predict(X))
首先,您导入numpy,初始化一个随机种子,以便您可以在再次运行程序时重现相同的结果,并导入您将用来构建神经网络的keras对象。
然后,定义一个X数组,包含 XOR 运算的 4 个可能的 A-B 输入集,以及一个y数组,包含在X中定义的每个输入集的输出。
接下来的五行定义了神经网络。Sequential()模型是keras提供的用于定义神经网络的模型之一,其中网络的层是以顺序的方式定义的。然后定义第一层神经元,由两个神经元组成,由两个输入供电,将它们的激活函数定义为序列中的 sigmoid 函数。最后,您定义由一个具有相同激活函数的神经元组成的输出层。
下面两行定义了网络训练的细节。为了调整网络的权重,您将使用学习速率等于0.1的随机梯度下降 (SGD),并且您将使用均方误差作为要最小化的损失函数。
最后,通过运行fit()方法来执行训练,使用X和y作为训练样本,并在每个训练样本被输入网络后更新权重(batch_size=1)。epochs的数字代表整个训练集将被用来训练神经网络的次数。
在这种情况下,您使用包含 4 个输入输出示例的训练集重复训练 5000 次。默认情况下,每次使用训练集时,都会打乱训练示例。
在最后一行,训练过程完成后,打印 4 个可能的输入示例的预测值。
通过运行此脚本,您将看到随着新的训练示例输入到网络中,训练过程的演变和性能的提高:
(nnxor) C:\Users\IEUser>cd nnxor
(nnxor) C:\Users\IEUser\nnxor>python nnxor.py
Using TensorFlow backend.
Epoch 1/5000
2018-09-16 09:49:05.987096: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2018-09-16 09:49:05.993128: I tensorflow/core/common_runtime/process_util.cc:69] Creating new thread pool with default inter op setting: 2\. Tune using inter_op_parallelism_threads for best performance.
4/4 [==============================] - 0s 39ms/step - loss: 0.2565
Epoch 2/5000
4/4 [==============================] - 0s 0us/step - loss: 0.2566
Epoch 3/5000
4/4 [==============================] - 0s 0us/step - loss: 0.2566
Epoch 4/5000
4/4 [==============================] - 0s 0us/step - loss: 0.2566
Epoch 5/5000
4/4 [==============================] - 0s 0us/step - loss: 0.2566
Epoch 6/5000
4/4 [==============================] - 0s 0us/step - loss: 0.2566
训练完成后,您可以检查网络对可能输入值的预测:
Epoch 4997/5000
4/4 [==============================] - 0s 0us/step - loss: 0.0034
Epoch 4998/5000
4/4 [==============================] - 0s 0us/step - loss: 0.0034
Epoch 4999/5000
4/4 [==============================] - 0s 0us/step - loss: 0.0034
Epoch 5000/5000
4/4 [==============================] - 0s 0us/step - loss: 0.0034
[[0.0587215 ]
[0.9468337 ]
[0.9323144 ]
[0.05158457]]
正如您定义的X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]),预期输出值是0、1、1和0,这与网络的预测输出一致,假设您应该对它们进行舍入以获得二进制值。
何去何从
数据科学和机器学习应用正在最多样化的领域出现,吸引了更多的人。然而,为数值计算建立一个环境可能是一项复杂的任务,经常会发现用户在数据科学研讨会上遇到困难,尤其是在使用 Windows 时。
在本文中,您已经了解了使用 Anaconda Python 发行版在 Windows 机器上设置 Python 数值计算环境的基础。
免费奖励: 点击此处获取 Conda 备忘单,其中包含管理您的 Python 环境和包的便捷使用示例。
现在您已经有了一个工作环境,是时候开始使用一些应用程序了。Python 是数据科学和机器学习中使用最多的语言之一,Anaconda 是最受欢迎的发行版之一,用于各种公司和研究实验室。它提供了几个软件包来安装 Python 所依赖的用于数据获取、争论、处理和可视化的库。
幸运的是,在 Real Python 上有很多关于这些库的教程,包括以下内容:
- NumPy 教程
- 使用 Matplotlib 进行 Python 绘图(指南)
- Python 直方图绘制:NumPy,Matplotlib,Pandas & Seaborn
- 纯 Python vs NumPy vs TensorFlow 性能对比
- 蟒蛇熊猫:诡计&你可能不知道的特点
- 快速、灵活、简单、直观:如何加快你的熊猫项目
- 用 NumPy 和 Pandas 清理 Pythonic 数据
此外,如果您想更深入地了解 Anaconda 和 conda,请查看以下链接:
上下文管理器和 Python 的 with 语句
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 上下文管理器和 Python 的 with 语句
Python 中的with语句对于正确管理程序中的外部资源是一个非常有用的工具。它允许您利用现有的上下文管理器来自动处理安装和拆卸阶段,无论您何时处理外部资源或需要这些阶段的操作。
此外,上下文管理协议允许你创建自己的上下文管理器,这样你就可以定制处理系统资源的方式。那么,with语句有什么用呢?
在本教程中,您将学习:
- Python
with语句是做什么的以及如何使用 - 什么是上下文管理协议
- 如何实现自己的上下文管理器
有了这些知识,你就可以编写更有表现力的代码,避免程序中的资源泄露和 T2。with语句通过抽象它们的功能并允许它们被分解和重用,帮助您实现一些常见的资源管理模式。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
用 Python 管理资源
你在编程中会遇到的一个常见问题是如何正确管理外部资源,比如文件、锁,以及网络连接。有时,一个程序会永远保留那些资源,即使你不再需要它们。这种问题被称为内存泄漏,因为每次创建和打开给定资源的新实例而不关闭现有实例时,可用内存都会减少。
合理管理资源通常是一个棘手的问题。它需要一个安装阶段和一个拆卸阶段。后一个阶段需要你执行一些清理动作,比如关闭一个文件,释放一个锁,或者关闭一个网络连接。如果您忘记执行这些清理操作,那么您的应用程序将保持资源活动。这可能会危及宝贵的系统资源,如内存和网络带宽。
例如,当开发人员使用数据库时,一个常见的问题是程序不断创建新的连接而不释放或重用它们。在这种情况下,数据库后端可以停止接受新的连接。这可能需要管理员登录并手动终止这些过时的连接,以使数据库再次可用。
另一个常见的问题出现在开发人员处理文件的时候。将文本写入文件通常是一个缓冲操作。这意味着在文件上调用.write()不会立即导致将文本写入物理文件,而是写入临时缓冲区。有时,当缓冲区未满,开发人员忘记调用.close()时,部分数据可能会永远丢失。
另一种可能是你的应用程序遇到错误或异常,导致控制流绕过负责释放手头资源的代码。下面是一个使用 open() 将一些文本写入文件的例子:
file = open("hello.txt", "w")
file.write("Hello, World!")
file.close()
如果在调用.write()的过程中出现异常,这个实现不能保证文件会被关闭。在这种情况下,代码永远不会调用.close(),因此您的程序可能会泄漏一个文件描述符。
在 Python 中,可以使用两种通用方法来处理资源管理。您可以将代码包装在:
- 一个
try…finally构念 - 一个
with构造
第一种方法非常通用,允许您提供安装和拆卸代码来管理任何类型的资源。但是,有点啰嗦。此外,如果您忘记了任何清理操作怎么办?
第二种方法提供了一种简单的方式来提供和重用安装和拆卸代码。在这种情况下,您将受到限制,即with语句仅适用于上下文管理器。在接下来的两节中,您将学习如何在代码中使用这两种方法。
try……finally接近
处理文件可能是编程中资源管理最常见的例子。在 Python 中,可以使用一个try … finally语句来正确地处理打开和关闭文件:
# Safely open the file
file = open("hello.txt", "w")
try:
file.write("Hello, World!")
finally:
# Make sure to close the file after using it
file.close()
在这个例子中,您需要安全地打开文件hello.txt,这可以通过在try … except语句中包装对open()的调用来实现。稍后,当你试图写file时,finally子句将保证file被正确关闭,即使在try子句中调用.write()的过程中出现异常。当您在 Python 中管理外部资源时,可以使用这种模式来处理安装和拆卸逻辑。
上例中的try块可能会引发异常,比如AttributeError或NameError。您可以像这样在except子句中处理这些异常:
# Safely open the file
file = open("hello.txt", "w")
try:
file.write("Hello, World!")
except Exception as e:
print(f"An error occurred while writing to the file: {e}")
finally:
# Make sure to close the file after using it
file.close()
在本例中,您捕获了在写入文件时可能发生的任何潜在异常。在现实生活中,您应该使用特定的异常类型而不是通用的 Exception 来防止未知错误无声无息地传递。
with语句接近
Python with语句创建了一个运行时上下文,允许你在上下文管理器的控制下运行一组语句。 PEP 343 增加了with语句,以便能够分解出try … finally语句的标准用例。
与传统的try … finally结构相比,with语句可以让你的代码更加清晰、安全和可重用。标准库中的很多类都支持with语句。一个经典的例子是 open() ,它允许你使用with来处理文件对象。
要编写一个with语句,需要使用以下通用语法:
with expression as target_var:
do_something(target_var)
上下文管理器对象是在with之后评估expression的结果。换句话说,expression必须返回一个实现上下文管理协议的对象。该协议包括两种特殊方法:
.__enter__()被with语句调用进入运行时上下文。.__exit__()在执行离开with代码块时被调用。
as说明符是可选的。如果您提供一个带有as的target_var,那么在上下文管理器对象上调用.__enter__()的返回值将被绑定到该变量。
注意:一些上下文管理器从.__enter__()返回None,因为它们没有有用的对象返回给调用者。在这些情况下,指定一个target_var没有意义。
下面是 Python 遇到with语句时该语句的处理方式:
- 调用
expression来获取上下文管理器。 - 存储上下文管理器的
.__enter__()和.__exit__()方法以备后用。 - 在上下文管理器上调用
.__enter__(),并将其返回值绑定到target_var(如果提供的话)。 - 执行
with代码块。 - 当
with代码块完成时,调用上下文管理器上的.__exit__()。
在这种情况下,.__enter__(),通常提供设置代码。with语句是一个复合语句,它启动一个代码块,类似于条件语句或 for循环。在这个代码块中,可以运行几条语句。通常,如果适用的话,您可以使用with代码块来操作target_var。
一旦with代码块完成,.__exit__()就会被调用。这个方法通常提供拆卸逻辑或清理代码,比如在打开的文件对象上调用.close()。这就是为什么with语句如此有用。它使得正确获取和释放资源变得轻而易举。
下面是如何使用with语句打开hello.txt文件进行写入的方法:
with open("hello.txt", mode="w") as file:
file.write("Hello, World!")
当您运行这个with语句时,open()返回一个 io.TextIOBase 对象。这个对象也是一个上下文管理器,所以with语句调用.__enter__(),并将其返回值赋给file。然后,您可以在with代码块中操作该文件。当块结束时,.__exit__()会自动被调用并为您关闭文件,即使在with块中出现异常。
这个with构造比它的try … finally替代要短,但是也不那么通用,正如你已经看到的。您只能对支持上下文管理协议的对象使用with语句,而try … finally允许您对任意对象执行清理操作,而无需支持上下文管理协议。
在 Python 3.1 和更高版本中,with语句支持多个上下文管理器。您可以提供任意数量的上下文管理器,用逗号分隔:
with A() as a, B() as b:
pass
这类似于嵌套的with语句,但是没有嵌套。当您需要一次打开两个文件(第一个用于读取,第二个用于写入)时,这可能很有用:
with open("input.txt") as in_file, open("output.txt", "w") as out_file:
# Read content from input.txt
# Transform the content
# Write the transformed content to output.txt
pass
在这个例子中,您可以添加代码来读取和转换input.txt的内容。然后你在同一个代码块里把最终结果写到output.txt里。
然而,在一个with中使用多个上下文管理器有一个缺点。如果您使用这个特性,那么您可能会突破您的行长度限制。要解决这个问题,您需要使用反斜杠(\)来延续行,因此您可能会得到一个难看的最终结果。
with语句可以使处理系统资源的代码更具可读性、可重用性和简洁,更不用说更安全了。它有助于避免 bug 和泄漏,因为它让你在使用资源后几乎不可能忘记清理、关闭和释放资源。
使用with允许您抽象出大部分资源处理逻辑。不需要每次都写一个带有安装和拆卸代码的明确的try … finally语句,with会为您处理这些并避免重复。
使用 Python with语句
只要 Python 开发人员将with语句整合到他们的编码实践中,该工具已经被证明有几个有价值的用例。Python 标准库中越来越多的对象现在提供了对上下文管理协议的支持,因此您可以在with语句中使用它们。
在本节中,您将编写一些示例,展示如何在标准库中和第三方库中的几个类中使用with语句。
使用文件
到目前为止,您已经使用了open()来提供上下文管理器,并在with结构中操作文件。通常推荐使用with语句打开文件,因为它确保打开的文件描述符在执行流离开with代码块后自动关闭。
正如您之前看到的,使用with打开文件的最常见方式是通过内置的open():
with open("hello.txt", mode="w") as file:
file.write("Hello, World!")
在这种情况下,由于上下文管理器在离开with代码块后关闭文件,一个常见的错误可能如下:
>>> file = open("hello.txt", mode="w") >>> with file: ... file.write("Hello, World!") ... 13 >>> with file: ... file.write("Welcome to Real Python!") ... Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: I/O operation on closed file.第一个
with成功将"Hello, World!"写入hello.txt。注意,.write()返回写入文件的字节数,13。然而,当你试图运行第二个with时,你会得到一个ValueError,因为你的file已经关闭。使用
with语句打开和管理文件的另一种方法是使用pathlib.Path.open():
>>> import pathlib
>>> file_path = pathlib.Path("hello.txt")
>>> with file_path.open("w") as file:
... file.write("Hello, World!")
...
13
Path 是一个表示你电脑中物理文件的具体路径的类。在指向物理文件的Path对象上调用.open()会像open()一样打开它。因此,Path.open()的工作方式类似于open(),但是文件路径是由您调用方法的Path对象自动提供的。
由于 pathlib 提供了一种优雅、简单且Python 化的方式来操作文件系统路径,您应该考虑在您的with语句中使用Path.open()作为 Python 中的最佳实践。
最后,每当你加载一个外部文件时,你的程序应该检查可能的问题,比如一个丢失的文件,读写访问,等等。以下是您在处理文件时应该考虑使用的一般模式:
import pathlib
import logging
file_path = pathlib.Path("hello.txt")
try:
with file_path.open(mode="w") as file:
file.write("Hello, World!")
except OSError as error:
logging.error("Writing to file %s failed due to: %s", file_path, error)
在这个例子中,您将with语句包装在一个 try … except语句中。如果在执行with的过程中出现了 OSError ,那么您可以使用 logging 用一条用户友好的描述性消息来记录错误。
遍历目录
os 模块提供了一个名为 scandir() 的函数,该函数返回给定目录中条目对应的 os.DirEntry 对象的迭代器。这个函数是专门设计来在遍历目录结构时提供最佳性能的。
以给定目录的路径作为参数调用scandir()会返回一个支持上下文管理协议的迭代器:
>>> import os >>> with os.scandir(".") as entries: ... for entry in entries: ... print(entry.name, "->", entry.stat().st_size, "bytes") ... Documents -> 4096 bytes Videos -> 12288 bytes Desktop -> 4096 bytes DevSpace -> 4096 bytes .profile -> 807 bytes Templates -> 4096 bytes Pictures -> 12288 bytes Public -> 4096 bytes Downloads -> 4096 bytes在本例中,您编写了一个将
os.scandir()作为上下文管理器供应商的with语句。然后你遍历所选目录中的条目("."),然后在屏幕上打印出它们的名称和大小。在这种情况下,.__exit__()调用scandir.close()关闭迭代器,释放获取的资源。请注意,如果在您的机器上运行此命令,您将得到不同的输出,这取决于您当前目录的内容。执行高精度计算
与内置的浮点数不同,
decimal模块提供了一种调整精度的方法,以便在涉及Decimal数字的给定计算中使用。精度默认为28位,但是您可以更改它以满足您的问题要求。使用decimal的localcontext()进行自定义精度计算的快速方法是:
>>> from decimal import Decimal, localcontext
>>> with localcontext() as ctx:
... ctx.prec = 42
... Decimal("1") / Decimal("42")
...
Decimal('0.0238095238095238095238095238095238095238095')
>>> Decimal("1") / Decimal("42")
Decimal('0.02380952380952380952380952381')
这里,localcontext()提供了一个上下文管理器,它创建一个本地十进制上下文,并允许您使用自定义精度执行计算。在with代码块中,您需要将.prec设置为您想要使用的新精度,即上面示例中的42位置。当with代码块结束时,精度被重置回默认值,28位。
处理多线程程序中的锁
在 Python 标准库中有效使用with语句的另一个好例子是 threading.Lock 。这个类提供了一个原语锁,以防止多个线程在一个多线程应用程序中同时修改一个共享资源。
您可以在一个with语句中使用一个Lock对象作为上下文管理器来自动获取和释放一个给定的锁。例如,假设您需要保护一个银行账户的余额:
import threading
balance_lock = threading.Lock()
# Use the try ... finally pattern
balance_lock.acquire()
try:
# Update the account balance here ...
finally:
balance_lock.release()
# Use the with pattern
with balance_lock:
# Update the account balance here ...
第二个例子中的with语句在执行流进入和离开语句时自动获取和释放一个锁。这样,您可以专注于代码中真正重要的东西,而忘记那些重复的操作。
在这个例子中,with语句中的锁创建了一个被称为临界区的受保护区域,它防止对账户余额的并发访问。
使用 pytest 测试异常
到目前为止,您已经使用 Python 标准库中可用的上下文管理器编写了几个示例。然而,一些第三方库包括支持上下文管理协议的对象。
假设你正在用 pytest 测试你的代码。您的一些函数和代码块在某些情况下会引发异常,您希望测试这些情况。为此,您可以使用 pytest.raises() 。此函数允许您断言代码块或函数调用会引发给定的异常。
因为pytest.raises()提供了一个上下文管理器,所以您可以像这样在with语句中使用它:
>>> import pytest >>> 1 / 0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero >>> with pytest.raises(ZeroDivisionError): ... 1 / 0 ... >>> favorites = {"fruit": "apple", "pet": "dog"} >>> favorites["car"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'car' >>> with pytest.raises(KeyError): ... favorites["car"] ...在第一个例子中,您使用
pytest.raises()来捕捉表达式1 / 0引发的ZeroDivisionError。第二个示例使用函数来捕获当您访问给定字典中不存在的键时引发的KeyError。如果您的函数或代码块没有引发预期的异常,那么
pytest.raises()会引发一个失败异常:
>>> import pytest
>>> with pytest.raises(ZeroDivisionError):
... 4 / 2
...
2.0
Traceback (most recent call last):
...
Failed: DID NOT RAISE <class 'ZeroDivisionError'>
pytest.raises()的另一个很酷的特性是,您可以指定一个目标变量来检查引发的异常。例如,如果您想要验证错误消息,那么您可以这样做:
>>> with pytest.raises(ZeroDivisionError) as exc: ... 1 / 0 ... >>> assert str(exc.value) == "division by zero"您可以使用所有这些
pytest.raises()特性来捕获您从函数和代码块中引发的异常。这是一个很酷很有用的工具,您可以将它整合到您当前的测试策略中。总结
with陈述的优点为了总结到目前为止您所学到的内容,这里列出了在代码中使用 Python
with语句的一系列好处:
- 使资源管理比其等价的
try…finally语句更安全- 封装了上下文管理器中
try…finally语句的标准用法- 允许重用自动管理给定操作的设置和拆卸阶段的代码
- 帮助避免资源泄漏
一致地使用
with语句可以提高代码的总体质量,并通过防止资源泄漏问题使代码更加安全。使用
async with语句
with语句也有异步版本,async with。您可以使用它来编写依赖于异步代码的上下文管理器。在这种代码中很容易看到async with,因为许多 IO 操作都涉及安装和拆卸阶段。例如,假设您需要编写一个异步函数来检查给定的站点是否在线。为此,您可以像这样使用
aiohttp、asyncio和async with:1# site_checker_v0.py 2 3import aiohttp 4import asyncio 5 6async def check(url): 7 async with aiohttp.ClientSession() as session: 8 async with session.get(url) as response: 9 print(f"{url}: status -> {response.status}") 10 html = await response.text() 11 print(f"{url}: type -> {html[:17].strip()}") 12 13async def main(): 14 await asyncio.gather( 15 check("https://realpython.com"), 16 check("https://pycoders.com"), 17 ) 18 19asyncio.run(main())下面是这个脚本的作用:
- 第 3 行 导入
aiohttp,为asyncio和 Python 提供异步 HTTP 客户端和服务器。注意,aiohttp是一个第三方包,可以通过在命令行运行python -m pip install aiohttp来安装。- 第 4 行导入
asyncio,它允许你使用async和await语法编写并发代码。- 第 6 行使用
async关键字将check()定义为异步函数。在
check()中,您定义了两个嵌套的async with语句:
- 第 7 行定义了一个外部
async with,它实例化aiohttp.ClientSession()以获得一个上下文管理器。它将返回的对象存储在session中。- 第 8 行定义了一个内部
async with语句,使用url作为参数调用session上的.get()。这将创建第二个上下文管理器并返回一个response。- 第 9 行打印手头
url的响应状态码。- 10 号线在
response上运行对.text()的唤醒调用,并将结果存储在html中。- 第 11 行打印站点
url及其文件类型,doctype。- 第 13 行定义了脚本的
main()函数,也是一个协程。- 第 14 行从
asyncio调用gather()。该函数按顺序同时运行个可应用对象。在这个例子中,gather()用不同的 URL 运行check()的两个实例。- 19 线运行
main()使用asyncio.run()。该函数创建一个新的asyncio事件循环,并在操作结束时关闭它。如果您从命令行运行这个脚本,那么您将得到类似如下的输出:
$ python site_checker_v0.py https://realpython.com: status -> 200 https://pycoders.com: status -> 200 https://pycoders.com: type -> <!doctype html> https://realpython.com: type -> <!doctype html>酷!您的脚本正常工作,并且您确认两个站点当前都可用。您还可以从每个站点的主页检索有关文档类型的信息。
注意:由于并发任务调度和网络延迟的不确定性,您的输出可能会略有不同。特别是,各行可以以不同的顺序出现。
async with语句的工作方式类似于常规的with语句,但是它需要一个异步上下文管理器。换句话说,它需要一个能够在其进入和退出方法中暂停执行的上下文管理器。异步上下文管理器实现特殊的方法.__aenter__()和.__aexit__(),它们对应于常规上下文管理器中的.__enter__()和.__exit__()。
async with ctx_mgr构造隐式地在进入上下文时使用await ctx_mgr.__aenter__(),在退出上下文时使用await ctx_mgr.__aexit__()。这无缝地实现了async上下文管理器行为。创建自定义上下文管理器
您已经使用过标准库和第三方库中的上下文管理器。
open()、threading.Lock、decimal.localcontext()或其他人没有什么特别或神奇的。它们只是返回实现上下文管理协议的对象。您可以通过在基于类的上下文管理器中实现
.__enter__()和.__exit__()特殊方法来提供相同的功能。您还可以使用标准库中的contextlib.contextmanager装饰器和适当编码的生成器函数创建定制的基于函数的上下文管理器。一般来说,上下文管理器和
with语句并不局限于资源管理。它们允许您提供和重用常见的安装和拆卸代码。换句话说,使用上下文管理器,您可以执行任何一对需要在另一个操作或过程的之前和之后完成的操作,例如:
- 打开和关闭
- 锁定并释放
- 更改和重置
- 创建和删除
- 进入和退出
- 开始和停止
- 安装和拆卸
您可以提供代码来安全地管理上下文管理器中的任何一对操作。然后,您可以在整个代码的
with语句中重用该上下文管理器。这可以防止错误并减少重复的样板代码。它也让你的API更安全、更干净、更用户友好。在接下来的两节中,您将学习创建基于类和基于函数的上下文管理器的基础知识。
编码基于类的上下文管理器
要实现上下文管理协议并创建基于类的上下文管理器,您需要将
.__enter__()和__exit__()特殊方法添加到您的类中。下表总结了这些方法的工作原理、它们采用的参数以及可以放入其中的逻辑:
方法 描述 .__enter__(self)该方法处理设置逻辑,并在进入新的 with上下文时被调用。它的返回值被绑定到with目标变量。.__exit__(self, exc_type, exc_value, exc_tb)该方法处理拆卸逻辑,并在执行流离开 with上下文时被调用。如果发生异常,那么exc_type、exc_value和exc_tb分别保存异常类型、值和回溯信息。当
with语句执行时,它调用上下文管理器对象上的.__enter__(),表示您正在进入一个新的运行时上下文。如果您提供一个带有as说明符的目标变量,那么.__enter__()的返回值将被赋给该变量。当执行流离开上下文时,
.__exit__()被调用。如果with代码块中没有出现异常,那么.__exit__()的最后三个参数被设置为None。否则,它们保存与当前异常相关联的类型、值和回溯。如果
.__exit__()方法返回True,那么with块中发生的任何异常都会被吞掉,并在with之后的下一条语句处继续执行。如果.__exit__()返回False,那么异常被传播到上下文之外。当方法不显式返回任何内容时,这也是默认行为。您可以利用这个特性在上下文管理器中封装异常处理。编写一个基于类的上下文管理器示例
这里有一个基于类的上下文管理器示例,它实现了两种方法,
.__enter__()和.__exit__()。它还展示了 Python 如何在一个with构造中调用它们:
>>> class HelloContextManager:
... def __enter__(self):
... print("Entering the context...")
... return "Hello, World!"
... def __exit__(self, exc_type, exc_value, exc_tb):
... print("Leaving the context...")
... print(exc_type, exc_value, exc_tb, sep="\n")
...
>>> with HelloContextManager() as hello:
... print(hello)
...
Entering the context...
Hello, World!
Leaving the context...
None
None
None
HelloContextManager实现了.__enter__()和.__exit__()。在.__enter__()中,您首先打印一条消息,表示执行流正在进入一个新的上下文。然后你返回"Hello, World!"字符串。在.__exit__()中,您打印一条消息,表示执行流正在离开上下文。您还可以打印它的三个参数的内容。
当with语句运行时,Python 会创建一个新的HelloContextManager实例,并调用它的.__enter__()方法。你知道这一点是因为屏幕上印着Entering the context...。
注意:使用上下文管理器的一个常见错误是忘记调用传递给with语句的对象。
在这种情况下,语句无法获得所需的上下文管理器,您会得到这样一个AttributeError:
>>> with HelloContextManager as hello: ... print(hello) ... Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: __enter__异常消息没有说太多,在这种情况下,您可能会感到困惑。所以,一定要调用
with语句中的对象来提供相应的上下文管理器。然后 Python 运行
with代码块,将hello打印到屏幕上。注意,hello保存着.__enter__()的返回值。当执行流退出
with代码块时,Python 调用.__exit__()。你知道这一点是因为你把Leaving the context...印在了你的屏幕上。输出的最后一行确认了.__exit__()的三个参数被设置为None。注:当你不记得
.__exit__()的确切签名并且不需要访问它的参数时,一个常用的技巧是使用*args和**kwargs,就像在def __exit__(self, *args, **kwargs):中一样。现在,如果在执行
with块的过程中出现异常,会发生什么?继续编写下面的with语句:
>>> with HelloContextManager() as hello:
... print(hello)
... hello[100]
...
Entering the context...
Hello, World!
Leaving the context...
<class 'IndexError'>
string index out of range
<traceback object at 0x7f0cebcdd080>
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
IndexError: string index out of range
在这种情况下,您尝试在字符串 "Hello, World!"中检索索引100处的值。这引发了一个IndexError,并且.__exit__()的参数设置如下:
exc_type是例外类,IndexError。exc_value是例外的实例。exc_tb是追溯对象。
当您想要在上下文管理器中封装异常处理时,这种行为非常有用。
在上下文管理器中处理异常
作为在上下文管理器中封装异常处理的一个例子,假设您希望在使用HelloContextManager时IndexError是最常见的异常。您可能希望在上下文管理器中处理该异常,这样就不必在每个with代码块中重复异常处理代码。在这种情况下,您可以这样做:
# exc_handling.py
class HelloContextManager:
def __enter__(self):
print("Entering the context...")
return "Hello, World!"
def __exit__(self, exc_type, exc_value, exc_tb):
print("Leaving the context...")
if isinstance(exc_value, IndexError):
# Handle IndexError here...
print(f"An exception occurred in your with block: {exc_type}")
print(f"Exception message: {exc_value}")
return True
with HelloContextManager() as hello:
print(hello)
hello[100]
print("Continue normally from here...")
在.__exit__()中,你检查exc_value是否是IndexError的一个实例。如果是这样,那么您打印几条信息性消息,最后用True返回。返回一个真值使得在with代码块之后,可以吞下异常并继续正常执行。
在这个例子中,如果没有IndexError发生,那么该方法返回None并且异常传播出去。然而,如果你想更明确,那么你可以从if块外面返回False。
如果您从命令行运行exc_handling.py,那么您会得到以下输出:
$ python exc_handling.py
Entering the context...
Hello, World!
Leaving the context...
An exception occurred in your with block: <class 'IndexError'>
Exception message: string index out of range
Continue normally from here...
HelloContextManager现在能够处理发生在with代码块中的IndexError异常。因为当一个IndexError发生时你返回True,执行流程在下一行继续,就在退出with代码块之后。
打开文件进行写入:第一版
既然您已经知道了如何实现上下文管理协议,那么您可以通过编写一个实际的例子来了解这一点。下面是如何利用open()来创建一个打开文件进行写入的上下文管理器:
# writable.py
class WritableFile:
def __init__(self, file_path):
self.file_path = file_path
def __enter__(self):
self.file_obj = open(self.file_path, mode="w")
return self.file_obj
def __exit__(self, exc_type, exc_val, exc_tb):
if self.file_obj:
self.file_obj.close()
WritableFile实现了上下文管理协议,支持with语句,就像最初的open()一样,但是它总是使用"w"模式打开文件进行写入。以下是如何使用新的上下文管理器:
>>> from writable import WritableFile >>> with WritableFile("hello.txt") as file: ... file.write("Hello, World!") ...运行这段代码后,您的
hello.txt文件包含了"Hello, World!"字符串。作为一个练习,你可以写一个补充的上下文管理器来打开文件进行阅读,但是使用pathlib功能。去试试吧!重定向标准输出
当您编写自己的上下文管理器时,需要考虑一个微妙的细节,即有时您没有从
.__enter__()返回的有用对象,因此无法分配给with目标变量。在那些情况下,你可以显式返回None或者你可以只依赖 Python 的隐式返回值,也就是None。例如,假设您需要将标准输出
sys.stdout临时重定向到磁盘上的给定文件。为此,您可以创建一个上下文管理器,如下所示:# redirect.py import sys class RedirectedStdout: def __init__(self, new_output): self.new_output = new_output def __enter__(self): self.saved_output = sys.stdout sys.stdout = self.new_output def __exit__(self, exc_type, exc_val, exc_tb): sys.stdout = self.saved_output这个上下文管理器通过它的构造函数获取一个文件对象。在
.__enter__()中,您将标准输出sys.stdout重新分配给一个实例属性,以避免丢失对它的引用。然后重新分配标准输出,使其指向磁盘上的文件。在.__exit__()中,你只是将标准输出恢复到它的原始值。要使用
RedirectedStdout,您可以这样做:
>>> from redirect import RedirectedStdout
>>> with open("hello.txt", "w") as file:
... with RedirectedStdout(file):
... print("Hello, World!")
... print("Back to the standard output...")
...
Back to the standard output...
本例中的外层with语句提供了一个文件对象,您将使用它作为新的输出,hello.txt。内部的with临时将标准输出重定向到hello.txt,因此对print()的第一次调用直接写入该文件,而不是在屏幕上打印"Hello, World!"。注意,当你离开内部的with代码块时,标准输出会回到它的初始值。
RedirectedStdout是一个上下文管理器的简单例子,它没有从.__enter__()返回有用的值。然而,如果您只是重定向print()输出,您可以获得相同的功能,而不需要编写上下文管理器。你只需要像这样给print()提供一个file参数:
>>> with open("hello.txt", "w") as file: ... print("Hello, World!", file=file) ...在这个例子中,
print()将您的hello.txt文件作为一个参数。这使得print()直接写入你磁盘上的物理文件,而不是将"Hello, World!"打印到你的屏幕上。测量执行时间
就像其他类一样,上下文管理器可以封装一些内部的状态。下面的例子展示了如何创建一个有状态上下文管理器来测量给定代码块或函数的执行时间:
# timing.py from time import perf_counter class Timer: def __enter__(self): self.start = perf_counter() self.end = 0.0 return lambda: self.end - self.start def __exit__(self, *args): self.end = perf_counter()当你在一个
with语句中使用Timer时,就会调用.__enter__()。该方法使用time.perf_counter()获取with代码块开头的时间,并存储在.start中。它还初始化.end并返回计算时间增量的lambda函数。在这种情况下,.start保持初始状态或时间测量。注意:要深入了解如何为代码计时,请查看 Python 计时器函数:三种监控代码的方法。
一旦
with块结束,.__exit__()就会被调用。该方法获取块结束时的时间,并更新.end的值,以便lambda函数可以计算运行with代码块所需的时间。下面是如何在代码中使用这个上下文管理器:
>>> from time import sleep
>>> from timing import Timer
>>> with Timer() as timer:
... # Time-consuming code goes here...
... sleep(0.5)
...
>>> timer()
0.5005456680000862
使用Timer,你可以测量任何一段代码的执行时间。在这个例子中,timer保存了计算时间增量的lambda函数的一个实例,所以您需要调用timer()来获得最终结果。
创建基于功能的上下文管理器
Python 的生成器函数和 contextlib.contextmanager 装饰器提供了实现上下文管理协议的另一种便捷方式。如果您用@contextmanager修饰一个适当编码的生成器函数,那么您会得到一个基于函数的上下文管理器,它自动提供所需的方法.__enter__()和.__exit__()。这可以为您节省一些样板代码,让您的生活更加愉快。
使用@contextmanager和生成器函数创建上下文管理器的一般模式如下:
>>> from contextlib import contextmanager >>> @contextmanager ... def hello_context_manager(): ... print("Entering the context...") ... yield "Hello, World!" ... print("Leaving the context...") ... >>> with hello_context_manager() as hello: ... print(hello) ... Entering the context... Hello, World! Leaving the context...在本例中,您可以在
hello_context_manager()中识别两个可见部分。在yield语句之前,有 setup 部分。在那里,您可以放置获取托管资源的代码。当执行流进入上下文时,yield之前的一切都开始运行。在
yield语句之后,有一个 teardown 部分,您可以在其中释放资源并进行清理。yield之后的代码运行在with块的末尾。yield语句本身提供了将被分配给with目标变量的对象。这种实现和使用上下文管理协议的实现实际上是等效的。根据你觉得哪一个更有可读性,你可能会更喜欢其中一个。基于函数的实现的缺点是它需要理解高级 Python 主题,比如装饰器和生成器。
@contextmanager装饰器减少了创建上下文管理器所需的样板文件。不用用.__enter__()和.__exit__()方法写整个类,你只需要用一个yield实现一个生成器函数,它产生你想要.__enter__()返回的任何东西。打开文件进行写入:第二版
您可以使用
@contextmanager来重新实现您的WritableFile上下文管理器。下面是用这种技术重写后的样子:
>>> from contextlib import contextmanager
>>> @contextmanager
... def writable_file(file_path):
... file = open(file_path, mode="w")
... try:
... yield file
... finally:
... file.close()
...
>>> with writable_file("hello.txt") as file:
... file.write("Hello, World!")
...
在这种情况下,writable_file()是一个打开file进行写入的生成器函数。然后它暂时挂起自己的执行,让出资源,这样with可以将它绑定到它的目标变量。当执行流程离开with代码块时,函数继续执行并正确关闭file。
嘲笑时间
作为如何使用@contextmanager创建定制上下文管理器的最后一个例子,假设您正在测试一段使用时间测量的代码。代码使用 time.time() 来获得当前的时间测量值并做一些进一步的计算。由于时间度量不同,您决定模仿time.time(),这样您就可以测试您的代码。
这里有一个基于函数的上下文管理器可以帮你做到这一点:
>>> from contextlib import contextmanager >>> from time import time >>> @contextmanager ... def mock_time(): ... global time ... saved_time = time ... time = lambda: 42 ... yield ... time = saved_time ... >>> with mock_time(): ... print(f"Mocked time: {time()}") ... Mocked time: 42 >>> # Back to normal time >>> time() 1616075222.4410584在
mock_time()中,你使用一个global语句来表示你将要修改全局名time。然后,您将原始的time()函数对象保存在saved_time中,这样您可以在以后安全地恢复它。下一步是使用一个总是返回相同值42的lambda函数来猴子补丁time()。裸露的
yield语句指定这个上下文管理器没有有用的对象发送回with目标变量供以后使用。在yield之后,您将全局time重置为其原始内容。当执行进入
with块时,任何对time()的调用都返回42。一旦离开with代码块,对time()的调用将返回预期的当前时间。就是这样!现在您可以测试与时间相关的代码了。用上下文管理器编写好的 APIs】
上下文管理器非常灵活,如果您创造性地使用
with语句,那么您可以为您的类、模块和包定义方便的 API。例如,如果您想要管理的资源是某种报告生成器应用程序中的文本缩进级别该怎么办?在这种情况下,您可以编写如下代码:
with Indenter() as indent: indent.print("hi!") with indent: indent.print("hello") with indent: indent.print("bonjour") indent.print("hey")这读起来几乎像是一种用于缩进文本的领域特定语言(DSL) 。另外,请注意这段代码如何多次进入和离开同一个上下文管理器,以便在不同的缩进级别之间切换。运行此代码片段会产生以下输出,并打印出格式整齐的文本:
hi! hello bonjour hey如何实现上下文管理器来支持这一功能?这可能是一个很好的练习,让你了解上下文管理器是如何工作的。因此,在您检查下面的实现之前,您可能需要一些时间,尝试自己解决这个问题,作为一个学习练习。
准备好了吗?下面是如何使用上下文管理器类实现此功能:
class Indenter: def __init__(self): self.level = -1 def __enter__(self): self.level += 1 return self def __exit__(self, exc_type, exc_value, exc_tb): self.level -= 1 def print(self, text): print(" " * self.level + text)在这里,每当执行流进入上下文时,
.__enter__()将.level增加1。该方法还返回当前实例self。在.__exit__()中,你减少.level,这样每次退出上下文,打印的文本都后退一级。这个例子中的关键点是从
.__enter__()返回self允许您在几个嵌套的with语句中重用同一个上下文管理器。这将在每次进入和离开给定的上下文时改变文本的缩进级别。此时,对您来说,一个很好的练习是编写这个上下文管理器的基于函数的版本。来吧,试一试!
创建异步上下文管理器
要创建异步上下文管理器,您需要定义
.__aenter__()和.__aexit__()方法。下面的脚本是您之前看到的原始脚本site_checker_v0.py的重新实现,但是这次您提供了一个定制的异步上下文管理器来包装会话创建和关闭功能:# site_checker_v1.py import aiohttp import asyncio class AsyncSession: def __init__(self, url): self._url = url async def __aenter__(self): self.session = aiohttp.ClientSession() response = await self.session.get(self._url) return response async def __aexit__(self, exc_type, exc_value, exc_tb): await self.session.close() async def check(url): async with AsyncSession(url) as response: print(f"{url}: status -> {response.status}") html = await response.text() print(f"{url}: type -> {html[:17].strip()}") async def main(): await asyncio.gather( check("https://realpython.com"), check("https://pycoders.com"), ) asyncio.run(main())此脚本的工作方式与其先前的版本
site_checker_v0.py相似。主要区别在于,在本例中,您提取了原始外部async with语句的逻辑,并将其封装在AsyncSession中。在
.__aenter__()中,您创建一个aiohttp.ClientSession(),等待.get()响应,最后返回响应本身。在.__aexit__()中,您关闭会话,这对应于这个特定情况下的拆卸逻辑。注意.__aenter__()和.__aexit__()必须返回一个合适的对象。换句话说,您必须用async def来定义它们,这将返回一个根据定义可调用的协程对象。如果您从命令行运行该脚本,那么您会得到类似如下的输出:
$ python site_checker_v1.py https://realpython.com: status -> 200 https://pycoders.com: status -> 200 https://realpython.com: type -> <!doctype html> https://pycoders.com: type -> <!doctype html>太好了!您的脚本就像它的第一个版本一样工作。它同时向两个站点发送
GET请求,并处理相应的响应。最后,在编写异步上下文管理器时,通常的做法是实现四种特殊的方法:
.__aenter__().__aexit__().__enter__().__exit__()这使得您的上下文管理器可以与两种版本的
with一起使用。结论
Python
with语句是管理程序中外部资源的强大工具。然而,它的用例并不局限于资源管理。您可以使用with语句以及现有的和定制的上下文管理器来处理给定流程或操作的设置和拆除阶段。底层的上下文管理协议允许您创建定制的上下文管理器,并分解设置和拆卸逻辑,以便您可以在代码中重用它们。
在本教程中,您学习了:
- Python
with语句是做什么的以及如何使用- 什么是上下文管理协议
- 如何实现自己的上下文管理器
有了这些知识,你就能写出安全、简洁、有表现力的代码。您还可以避免程序中的资源泄漏。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 上下文管理器和 Python 的 with 语句********
Python 中 XML 解析器的路线图
如果你以前曾经尝试过用 Python 解析一个 XML 文档,那么你就会知道这样的任务有多困难。一方面,Python 的禅只承诺一个显而易见的方法来实现你的目标。与此同时,标准库遵循电池内置的格言,让您从不止一个而是几个 XML 解析器中进行选择。幸运的是,Python 社区通过创建更多的 XML 解析库解决了这个多余的问题。
玩笑归玩笑,在这个充满或大或小挑战的世界里,所有 XML 解析器都有自己的位置。熟悉可用的工具是值得的。
在本教程中,您将学习如何:
- 选择正确的 XML 解析模型
- 使用标准库中的 XML 解析器
- 使用主要的 XML 解析库
- 使用数据绑定以声明方式解析 XML 文档
- 使用安全的 XML 解析器消除安全漏洞
您可以将本教程作为路线图来引导您穿过 Python 中令人困惑的 XML 解析器世界。结束时,您将能够为给定的问题选择正确的 XML 解析器。为了从本教程中获得最大收益,您应该已经熟悉了 XML 及其构建模块,以及如何在 Python 中使用处理文件。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
选择正确的 XML 解析模型
事实证明,您可以使用一些与语言无关的策略来处理 XML 文档。每一种都展示了不同的内存和速度权衡,这可以部分地证明 Python 中可用的 XML 解析器的多样性。在接下来的部分,你会发现他们的不同和优势。
文档对象模型
历史上,解析 XML 的第一个也是最广泛的模型是 DOM,或最初由万维网联盟(W3C)定义的文档对象模型。你可能已经听说过 DOM,因为网络浏览器通过 JavaScript 公开了一个 DOM 接口,让你操作你网站的 HTML 代码。XML 和 HTML 都属于同一家族的标记语言,这使得用 DOM 解析 XML 成为可能。
DOM 可以说是最简单和最通用的模型。它定义了一些标准操作来遍历和修改对象层次结构中的文档元素。整个文档树的抽象表示存储在内存中,让您可以对单个元素进行随机访问。
虽然 DOM 树允许快速和全方位的导航,但首先构建它的抽象表示可能很耗时。此外,作为一个整体,XML 会被立刻解析,所以它必须足够小以适应可用的内存。这使得 DOM 只适合中等大小的配置文件,而不是几千兆字节的 XML 数据库。
当便利性比处理时间更重要,并且内存不是问题时,使用 DOM 解析器。一些典型的用例是当您需要解析一个相对较小的文档时,或者当您只需要偶尔进行解析时。
XML 的简单应用编程接口(SAX)
为了解决 DOM 的缺点,Java 社区通过合作开发出了一个库,这个库后来成为用其他语言解析 XML 的替代模型。没有正式的规范,只有邮件列表上的有机讨论。最终结果是一个基于事件的流 API ,它对单个元素而不是整个树进行顺序操作。
元素按照它们在文档中出现的顺序从上到下进行处理。解析器触发用户定义的回调来处理在文档中找到的特定 XML 节点。这种方法被称为“推”解析,因为元素是由解析器推送到函数中的。
SAX 还允许您丢弃不感兴趣的元素。这意味着它比 DOM 占用的内存少得多,并且可以处理任意大的文件,这对于单遍处理来说非常好,比如索引、转换成其他格式等等。
然而,查找或修改随机的树节点很麻烦,因为它通常需要多次遍历文档并跟踪被访问的节点。SAX 也不方便处理深度嵌套的元素。最后,SAX 模型只允许只读解析。
简而言之,SAX 在空间和时间上很便宜,但是在大多数情况下比 DOM 更难使用。它非常适合解析非常大的文档或实时解析输入的 XML 数据。
XML 流应用编程接口(StAX)
虽然在 Python 中不太流行,但这第三种解析 XML 的方法是建立在 SAX 之上的。它扩展了流的概念,但是使用了一个“拉”解析模型,这给了你更多的控制。您可以将 StAX 想象成一个迭代器,通过 XML 文档推进一个光标对象,其中自定义处理程序按需调用解析器,而不是相反。
注意:可以组合多个 XML 解析模型。例如,可以使用 SAX 或 StAX 在文档中快速找到感兴趣的数据,然后在内存中构建该特定分支的 DOM 表示。
使用 StAX 可以让您更好地控制解析过程,并允许更方便的状态管理。流中的事件只有在被请求时才被使用,启用了惰性评估。除此之外,它的性能应该与 SAX 相当,这取决于解析器的实现。
了解 Python 标准库中的 XML 解析器
在这一节中,您将了解 Python 的内置 XML 解析器,几乎每个 Python 发行版中都提供了这些解析器。您将把这些解析器与一个示例可伸缩矢量图形(SVG) 图像进行比较,这是一种基于 XML 的格式。通过用不同的解析器处理同一个文档,您将能够选择最适合您的解析器。
您将要保存在本地文件中以供参考的示例图像描绘了一个笑脸。它由以下 XML 内容组成:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd" [ <!ENTITY custom_entity "Hello"> ]> <svg xmlns="http://www.w3.org/2000/svg" xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape" viewBox="-105 -100 210 270" width="210" height="270"> <inkscape:custom x="42" inkscape:z="555">Some value</inkscape:custom> <defs> <linearGradient id="skin" x1="0" x2="0" y1="0" y2="1"> <stop offset="0%" stop-color="yellow" stop-opacity="1.0"/> <stop offset="75%" stop-color="gold" stop-opacity="1.0"/> <stop offset="100%" stop-color="orange" stop-opacity="1"/> </linearGradient> </defs> <g id="smiley" inkscape:groupmode="layer" inkscape:label="Smiley"> <!-- Head --> <circle cx="0" cy="0" r="50" fill="url(#skin)" stroke="orange" stroke-width="2"/> <!-- Eyes --> <ellipse cx="-20" cy="-10" rx="6" ry="8" fill="black" stroke="none"/> <ellipse cx="20" cy="-10" rx="6" ry="8" fill="black" stroke="none"/> <!-- Mouth --> <path d="M-20 20 A25 25 0 0 0 20 20" fill="white" stroke="black" stroke-width="3"/> </g> <text x="-40" y="75">&custom_entity; <svg>!</text> <script> <![CDATA[ console.log("CDATA disables XML parsing: <svg>") const smiley = document.getElementById("smiley") const eyes = document.querySelectorAll("ellipse") const setRadius = r => e => eyes.forEach(x => x.setAttribute("ry", r)) smiley.addEventListener("mouseenter", setRadius(2)) smiley.addEventListener("mouseleave", setRadius(8)) ]]> </script> </svg>它以一个 XML 声明开始,接着是一个文档类型定义(DTD) 和
<svg>根元素。DTD 是可选的,但是如果您决定使用 XML 验证器,它可以帮助验证您的文档结构。根元素为编辑器特定的元素和属性指定了默认名称空间xmlns以及前缀名称空间xmlns:inkscape。该文件还包含:
- 嵌套元素
- 属性
- 评论
- 字符数据(
CDATA)- 预定义和自定义实体
继续,将 XML 保存在名为 smiley.svg 的文件中,并使用现代 web 浏览器打开它,浏览器将运行最后出现的 JavaScript 片段:
该代码向图像添加了一个交互式组件。当你将鼠标悬停在笑脸上时,它会眨眼睛。如果你想使用方便的图形用户界面(GUI)来编辑笑脸,那么你可以使用矢量图形编辑器来打开文件,比如 Adobe Illustrator 或 T2 Inkscape。
注意:与 JSON 或 YAML 不同,XML 的一些特性可能会被黑客利用。Python 中的
xml包中可用的标准 XML 解析器是不安全的,容易受到一系列攻击。为了安全地解析来自不可信来源的 XML 文档,最好使用安全的替代方法。更多细节可以跳转到本教程的最后一节。值得注意的是,Python 的标准库定义了抽象接口来解析 XML 文档,同时让您提供具体的解析器实现。实际上,您很少这样做,因为 Python 为 Expat 库捆绑了一个绑定,Expat 库是一个广泛使用的用 c 编写的开源 XML 解析器。标准库中的所有以下 Python 模块默认使用 Expat。
不幸的是,虽然 Expat 解析器可以告诉您文档是否格式良好,但它不能根据XML 模式定义(XSD)或文档类型定义(DTD)来验证文档的结构。为此,您必须使用稍后讨论的第三方库之一。
xml.dom.minidom:最小 DOM 实现考虑到使用 DOM 解析 XML 文档可以说是最简单的,所以在 Python 标准库中找到 DOM 解析器也就不足为奇了。然而,令人惊讶的是,实际上有两个 DOM 解析器。
xml.dom包包含了两个模块来处理 Python 中的 DOM:
xml.dom.minidomxml.dom.pulldom第一个是 DOM 接口的精简实现,它符合 W3C 规范的一个相对较旧的版本。它提供了由 DOM API 定义的常见对象,如
Document、Element和Attr。正如您将会发现的那样,这个模块没有得到很好的记录,并且用处非常有限。第二个模块有一个稍微容易让人误解的名字,因为它定义了一个流拉解析器,它可以或者生成文档树中当前节点的 DOM 表示。稍后您将找到关于
pulldom解析器的更多信息。
minidom中有两个函数可以让您解析来自各种数据源的 XML 数据。一个接受文件名或文件对象的,而另一个期望一个 Python 字符串:

>>> from xml.dom.minidom import parse, parseString
>>> # Parse XML from a filename
>>> document = parse("smiley.svg")
>>> # Parse XML from a file object
>>> with open("smiley.svg") as file:
... document = parse(file)
...
>>> # Parse XML from a Python string
>>> document = parseString("""\
... <svg viewBox="-105 -100 210 270">
... <!-- More content goes here... -->
... </svg>
... """)
三重引号字符串有助于嵌入多行字符串文字,而无需在每行末尾使用延续字符(\)。在任何情况下,您都会得到一个Document实例,它展示了熟悉的 DOM 接口,允许您遍历树。
除此之外,您将能够访问 XML 声明、DTD 和根元素:
>>> document = parse("smiley.svg") >>> # XML Declaration >>> document.version, document.encoding, document.standalone ('1.0', 'UTF-8', False) >>> # Document Type Definition (DTD) >>> dtd = document.doctype >>> dtd.entities["custom_entity"].childNodes [<DOM Text node "'Hello'">] >>> # Document Root >>> document.documentElement <DOM Element: svg at 0x7fc78c62d790>如您所见,尽管 Python 中的默认 XML 解析器不能验证文档,但它仍然允许您检查 DTD
.doctype(如果它存在的话)。注意,XML 声明和 DTD 是可选的。如果 XML 声明或给定的 XML 属性缺失,那么对应的 Python 属性将是None。要通过 ID 查找元素,必须使用
Document实例,而不是特定的父元素Element。示例 SVG 图像有两个带有id属性的节点,但是您找不到它们中的任何一个:
>>> document.getElementById("skin") is None
True
>>> document.getElementById("smiley") is None
True
对于只使用过 HTML 和 JavaScript,但以前没有使用过 XML 的人来说,这可能会令人惊讶。虽然 HTML 为某些元素和属性定义了语义,比如<body>或id,但是 XML 并没有为其构建块赋予任何意义。您需要使用 DTD 或者通过调用 Python 中的.setIdAttribute()来显式地将属性标记为 ID,例如:
| 定义样式 | 履行 |
|---|---|
| 文档类型定义(Document Type Definition 的缩写) | <!ATTLIST linearGradient id ID #IMPLIED> |
| 计算机编程语言 | linearGradient.setIdAttribute("id") |
但是,如果您的文档有默认的名称空间,使用 DTD 不足以解决问题,示例 SVG 图像就是这种情况。为了解决这个问题,您可以递归地访问 Python 中的所有元素,检查它们是否具有id属性,并一次性地将其指定为它们的 ID:
>>> from xml.dom.minidom import parse, Node >>> def set_id_attribute(parent, attribute_name="id"): ... if parent.nodeType == Node.ELEMENT_NODE: ... if parent.hasAttribute(attribute_name): ... parent.setIdAttribute(attribute_name) ... for child in parent.childNodes: ... set_id_attribute(child, attribute_name) ... >>> document = parse("smiley.svg") >>> set_id_attribute(document)您的自定义函数
set_id_attribute()接受一个父元素和 identity 属性的可选名称,默认为"id"。当在 SVG 文档中调用该函数时,所有具有id属性的子元素都可以通过 DOM API 访问:
>>> document.getElementById("skin")
<DOM Element: linearGradient at 0x7f82247703a0>
>>> document.getElementById("smiley")
<DOM Element: g at 0x7f8224770940>
现在,您将获得对应于id属性值的预期 XML 元素。
使用 ID 最多可以找到一个唯一的元素,但是您也可以通过它们的标记名找到一组相似的元素。与.getElementById()方法不同,您可以在文档或特定父元素上调用.getElementsByTagName()来缩小搜索范围:
>>> document.getElementsByTagName("ellipse") [ <DOM Element: ellipse at 0x7fa2c944f430>, <DOM Element: ellipse at 0x7fa2c944f4c0> ] >>> root = document.documentElement >>> root.getElementsByTagName("ellipse") [ <DOM Element: ellipse at 0x7fa2c944f430>, <DOM Element: ellipse at 0x7fa2c944f4c0> ]注意,
.getElementsByTagName()总是返回元素的列表,而不是单个元素或None。当您在两种方法之间切换时忘记它是一个常见的错误来源。不幸的是,像
<inkscape:custom>这样以名称空间标识符作为前缀的元素将不会被包含在内。必须使用.getElementsByTagNameNS()来搜索它们,它需要不同的参数:
>>> document.getElementsByTagNameNS(
... "http://www.inkscape.org/namespaces/inkscape",
... "custom"
... )
...
[<DOM Element: inkscape:custom at 0x7f97e3f2a3a0>]
>>> document.getElementsByTagNameNS("*", "custom")
[<DOM Element: inkscape:custom at 0x7f97e3f2a3a0>]
第一个参数必须是 XML 名称空间,通常采用域名的形式,而第二个参数是标记名。请注意,名称空间前缀是不相关的!要搜索所有名称空间,可以提供一个通配符(*)。
注意:要找到 XML 文档中声明的名称空间,可以检查根元素的属性。理论上,它们可以在任何元素上声明,但是顶级元素通常是你可以找到它们的地方。
一旦你找到你感兴趣的元素,你就可以用它来遍历树。然而,minidom的另一个不和谐之处是它如何处理元素之间的空白字符:
>>> element = document.getElementById("smiley") >>> element.parentNode <DOM Element: svg at 0x7fc78c62d790> >>> element.firstChild <DOM Text node "'\n '"> >>> element.lastChild <DOM Text node "'\n '"> >>> element.nextSibling <DOM Text node "'\n '"> >>> element.previousSibling <DOM Text node "'\n '">换行符和前导缩进被捕获为单独的树元素,这是规范所要求的。一些解析器允许您忽略这些,但 Python 不允许。但是,您可以手动折叠此类节点中的空白:
>>> def remove_whitespace(node):
... if node.nodeType == Node.TEXT_NODE:
... if node.nodeValue.strip() == "":
... node.nodeValue = ""
... for child in node.childNodes:
... remove_whitespace(child)
...
>>> document = parse("smiley.svg")
>>> set_id_attribute(document)
>>> remove_whitespace(document)
>>> document.normalize()
注意,你还必须将 .normalize() 文档中相邻的文本节点组合起来。否则,您可能会得到一堆只有空格的冗余 XML 元素。同样,递归是访问树元素的唯一方式,因为不能用循环遍历文档及其元素。最后,这应该会给您带来预期的结果:
>>> element = document.getElementById("smiley") >>> element.parentNode <DOM Element: svg at 0x7fc78c62d790> >>> element.firstChild <DOM Comment node "' Head '"> >>> element.lastChild <DOM Element: path at 0x7f8beea0f670> >>> element.nextSibling <DOM Element: text at 0x7f8beea0f700> >>> element.previousSibling <DOM Element: defs at 0x7f8beea0f160> >>> element.childNodes [ <DOM Comment node "' Head '">, <DOM Element: circle at 0x7f8beea0f4c0>, <DOM Comment node "' Eyes '">, <DOM Element: ellipse at 0x7fa2c944f430>, <DOM Element: ellipse at 0x7fa2c944f4c0>, <DOM Comment node "' Mouth '">, <DOM Element: path at 0x7f8beea0f670> ]元素公开了一些有用的方法和属性,让您可以查询它们的详细信息:
>>> element = document.getElementsByTagNameNS("*", "custom")[0]
>>> element.prefix
'inkscape'
>>> element.tagName
'inkscape:custom'
>>> element.attributes
<xml.dom.minidom.NamedNodeMap object at 0x7f6c9d83ba80>
>>> dict(element.attributes.items())
{'x': '42', 'inkscape:z': '555'}
>>> element.hasChildNodes()
True
>>> element.hasAttributes()
True
>>> element.hasAttribute("x")
True
>>> element.getAttribute("x")
'42'
>>> element.getAttributeNode("x")
<xml.dom.minidom.Attr object at 0x7f82244a05f0>
>>> element.getAttribute("missing-attribute")
''
例如,您可以检查元素的名称空间、标记名或属性。如果您要求一个缺失的属性,那么您将得到一个空字符串('')。
处理命名空间属性没什么不同。您只需要记住在属性名前面加上相应的前缀或提供域名:
>>> element.hasAttribute("z") False >>> element.hasAttribute("inkscape:z") True >>> element.hasAttributeNS( ... "http://www.inkscape.org/namespaces/inkscape", ... "z" ... ) ... True >>> element.hasAttributeNS("*", "z") False奇怪的是,通配符(
*)在这里并不像以前在.getElementsByTagNameNS()方法中那样起作用。因为本教程只是关于 XML 解析,所以您需要查看
minidom文档中修改 DOM 树的方法。它们大多遵循 W3C 规范。如您所见,
minidom模块并不十分方便。它的主要优势来自于作为标准库的一部分,这意味着您不必在项目中安装任何外部依赖项来使用 DOM。
xml.sax:Python 的 SAX 接口要开始使用 Python 中的 SAX,您可以像以前一样使用相同的
parse()和parseString()便利函数,但是要从xml.sax包中获取。您还必须提供至少一个必需的参数,它必须是一个内容处理程序实例。本着 Java 的精神,您可以通过对特定的基类进行子类化来提供一个:from xml.sax import parse from xml.sax.handler import ContentHandler class SVGHandler(ContentHandler): pass parse("smiley.svg", SVGHandler())在解析文档时,内容处理程序接收与文档中的元素相对应的事件流。运行这段代码不会做任何有用的事情,因为您的处理程序类是空的。为了让它工作,你需要从超类中重载一个或多个回调方法。
启动您最喜欢的编辑器,键入以下代码,并将其保存在名为
svg_handler.py的文件中:# svg_handler.py from xml.sax.handler import ContentHandler class SVGHandler(ContentHandler): def startElement(self, name, attrs): print(f"BEGIN: <{name}>, {attrs.keys()}") def endElement(self, name): print(f"END: </{name}>") def characters(self, content): if content.strip() != "": print("CONTENT:", repr(content))这个修改后的内容处理程序在标准输出中打印出一些事件。SAX 解析器将为您调用这三个方法,以响应找到开始标记、结束标记以及它们之间的一些文本。当您打开 Python 解释器的交互式会话时,导入您的内容处理程序并进行测试。它应该产生以下输出:
>>> from xml.sax import parse
>>> from svg_handler import SVGHandler
>>> parse("smiley.svg", SVGHandler())
BEGIN: <svg>, ['xmlns', 'xmlns:inkscape', 'viewBox', 'width', 'height']
BEGIN: <inkscape:custom>, ['x', 'inkscape:z']
CONTENT: 'Some value'
END: </inkscape:custom>
BEGIN: <defs>, []
BEGIN: <linearGradient>, ['id', 'x1', 'x2', 'y1', 'y2']
BEGIN: <stop>, ['offset', 'stop-color', 'stop-opacity']
END: </stop>
⋮
这本质上是观察者设计模式,它允许您将 XML 逐步转换成另一种分层格式。假设您想将 SVG 文件转换成简化的 JSON 表示。首先,您希望将内容处理程序对象存储在一个单独的变量中,以便以后从中提取信息:
>>> from xml.sax import parse >>> from svg_handler import SVGHandler >>> handler = SVGHandler() >>> parse("smiley.svg", handler)因为 SAX 解析器发出事件时没有提供任何关于它所找到的元素的上下文,所以您需要跟踪您在树中的位置。因此,将当前元素推入并弹出到一个堆栈是有意义的,您可以通过一个常规的 Python 列表来模拟这个堆栈。您还可以定义一个助手属性
.current_element,它将返回放置在堆栈顶部的最后一个元素:# svg_handler.py # ... class SVGHandler(ContentHandler): def __init__(self): super().__init__() self.element_stack = [] @property def current_element(self): return self.element_stack[-1] # ...当 SAX 解析器找到一个新元素时,您可以立即捕获它的标记名和属性,同时为子元素和值创建占位符,这两者都是可选的。现在,您可以将每个元素存储为一个
dict对象。用新的实现替换您现有的.startElement()方法:# svg_handler.py # ... class SVGHandler(ContentHandler): # ... def startElement(self, name, attrs): self.element_stack.append({ "name": name, "attributes": dict(attrs), "children": [], "value": "" })SAX 解析器将属性作为映射提供给你,你可以通过调用
dict()函数将其转换成普通的 Python 字典。元素值通常分布在多个片段上,您可以使用加号运算符(+)或相应的增强赋值语句将这些片段连接起来:# svg_handler.py # ... class SVGHandler(ContentHandler): # ... def characters(self, content): self.current_element["value"] += content以这种方式聚合文本将确保多行内容出现在当前元素中。例如,样本 SVG 文件中的
<script>标记包含六行 JavaScript 代码,它们分别触发对characters()回调的调用。最后,一旦解析器发现了结束标记,就可以从堆栈中弹出当前元素,并将其附加到父元素的子元素中。如果只剩下一个元素,那么它将是你的文档的根,你以后应该保留它。除此之外,您可能希望通过删除具有空值的键来清除当前元素:
# svg_handler.py # ... class SVGHandler(ContentHandler): # ... def endElement(self, name): clean(self.current_element) if len(self.element_stack) > 1: child = self.element_stack.pop() self.current_element["children"].append(child) def clean(element): element["value"] = element["value"].strip() for key in ("attributes", "children", "value"): if not element[key]: del element[key]注意
clean()是在类体外部定义的函数。清理必须在最后完成,因为没有办法预先知道可能有多少文本片段要连接。您可以展开下面的可折叠部分,查看完整的内容处理程序代码。# svg_handler.py from xml.sax.handler import ContentHandler class SVGHandler(ContentHandler): def __init__(self): super().__init__() self.element_stack = [] @property def current_element(self): return self.element_stack[-1] def startElement(self, name, attrs): self.element_stack.append({ "name": name, "attributes": dict(attrs), "children": [], "value": "" }) def endElement(self, name): clean(self.current_element) if len(self.element_stack) > 1: child = self.element_stack.pop() self.current_element["children"].append(child) def characters(self, content): self.current_element["value"] += content def clean(element): element["value"] = element["value"].strip() for key in ("attributes", "children", "value"): if not element[key]: del element[key]现在,是时候通过解析 XML、从内容处理程序中提取根元素并将其转储到 JSON 字符串来测试一切了:
>>> from xml.sax import parse
>>> from svg_handler import SVGHandler
>>> handler = SVGHandler()
>>> parse("smiley.svg", handler)
>>> root = handler.current_element
>>> import json
>>> print(json.dumps(root, indent=4))
{
"name": "svg",
"attributes": {
"xmlns": "http://www.w3.org/2000/svg",
"xmlns:inkscape": "http://www.inkscape.org/namespaces/inkscape",
"viewBox": "-105 -100 210 270",
"width": "210",
"height": "270"
},
"children": [
{
"name": "inkscape:custom",
"attributes": {
"x": "42",
"inkscape:z": "555"
},
"value": "Some value"
},
⋮
值得注意的是,这个实现并没有比 DOM 增加多少内存,因为它像以前一样构建了整个文档的抽象表示。不同之处在于,您制作了一个定制的字典表示,而不是标准的 DOM 树。但是,您可以想象在接收 SAX 事件时直接写入文件或数据库,而不是内存。这将有效地解除你的计算机内存限制。
如果您想解析 XML 名称空间,那么您需要用一些样板代码自己创建和配置 SAX 解析器,并实现稍微不同的回调:
# svg_handler.py
from xml.sax.handler import ContentHandler
class SVGHandler(ContentHandler):
def startPrefixMapping(self, prefix, uri):
print(f"startPrefixMapping: {prefix=}, {uri=}")
def endPrefixMapping(self, prefix):
print(f"endPrefixMapping: {prefix=}")
def startElementNS(self, name, qname, attrs):
print(f"startElementNS: {name=}")
def endElementNS(self, name, qname):
print(f"endElementNS: {name=}")
这些回调接收关于元素名称空间的附加参数。要让 SAX 解析器真正触发这些回调而不是一些早期的回调,必须显式启用 XML 名称空间支持:
>>> from xml.sax import make_parser >>> from xml.sax.handler import feature_namespaces >>> from svg_handler import SVGHandler >>> parser = make_parser() >>> parser.setFeature(feature_namespaces, True) >>> parser.setContentHandler(SVGHandler()) >>> parser.parse("smiley.svg") startPrefixMapping: prefix=None, uri='http://www.w3.org/2000/svg' startPrefixMapping: prefix='inkscape', uri='http://www.inkscape.org/namespaces/inkscape' startElementNS: name=('http://www.w3.org/2000/svg', 'svg') ⋮ endElementNS: name=('http://www.w3.org/2000/svg', 'svg') endPrefixMapping: prefix='inkscape' endPrefixMapping: prefix=None设置这个特性会将元素
name变成一个由名称空间的域名和标记名组成的元组。
xml.sax包提供了一个体面的基于事件的 XML 解析器接口,它模仿了原始的 Java API。与 DOM 相比,它有些局限,但应该足以实现一个基本的 XML 流推送解析器,而不需要借助第三方库。考虑到这一点,Python 中提供了一个不太冗长的 pull 解析器,您将在接下来探索它。
xml.dom.pulldom:流拉解析器Python 标准库中的解析器经常一起工作。例如,
xml.dom.pulldom模块包装了来自xml.sax的解析器,以利用缓冲并分块读取文档。同时,它使用来自xml.dom.minidom的默认 DOM 实现来表示文档元素。但是,这些元素一次处理一个,没有任何关系,直到您明确要求它。注意:在
xml.dom.pulldom中默认启用 XML 名称空间支持。虽然 SAX 模型遵循观察者模式,但是您可以将 StAX 视为迭代器设计模式,它允许您在事件的平面流上循环。同样,您可以调用从模块导入的熟悉的
parse()或parseString()函数来解析 SVG 图像:
>>> from xml.dom.pulldom import parse
>>> event_stream = parse("smiley.svg")
>>> for event, node in event_stream:
... print(event, node)
...
START_DOCUMENT <xml.dom.minidom.Document object at 0x7f74f9283e80>
START_ELEMENT <DOM Element: svg at 0x7f74fde18040>
CHARACTERS <DOM Text node "'\n'">
⋮
END_ELEMENT <DOM Element: script at 0x7f74f92b3c10>
CHARACTERS <DOM Text node "'\n'">
END_ELEMENT <DOM Element: svg at 0x7f74fde18040>
解析文档只需要几行代码。xml.sax和xml.dom.pulldom最显著的区别是缺少回调,因为你驱动整个过程。在构建代码时,你有更多的自由,如果你不想使用类,你就不需要使用它们。
注意,从流中提取的 XML 节点具有在xml.dom.minidom中定义的类型。但是如果你检查他们的父母、兄弟姐妹和孩子,你会发现他们对彼此一无所知:
>>> from xml.dom.pulldom import parse, START_ELEMENT >>> event_stream = parse("smiley.svg") >>> for event, node in event_stream: ... if event == START_ELEMENT: ... print(node.parentNode, node.previousSibling, node.childNodes) <xml.dom.minidom.Document object at 0x7f90864f6e80> None [] None None [] None None [] None None [] ⋮相关属性为空。无论如何,拉解析器可以帮助以混合方式快速查找某个父元素,并只为以它为根的分支构建一个 DOM 树:
from xml.dom.pulldom import parse, START_ELEMENT def process_group(parent): left_eye, right_eye = parent.getElementsByTagName("ellipse") # ... event_stream = parse("smiley.svg") for event, node in event_stream: if event == START_ELEMENT: if node.tagName == "g": event_stream.expandNode(node) process_group(node)通过在事件流上调用
.expandNode(),您实际上是向前移动迭代器并递归解析 XML 节点,直到找到父元素的匹配结束标记。结果节点将有正确初始化属性的子节点。此外,您将能够对它们使用 DOM 方法。pull 解析器结合了两者的优点,为 DOM 和 SAX 提供了一个有趣的替代品。它使用起来高效、灵活、简单,导致代码更紧凑、可读性更好。您还可以使用它更容易地同时处理多个 XML 文件。也就是说,到目前为止提到的 XML 解析器没有一个可以与 Python 标准库中最后一个解析器的优雅、简单和完整性相媲美。
xml.etree.ElementTree:一个轻量级的 Pythonic 替代品到目前为止,您已经了解的 XML 解析器完成了这项工作。然而,它们不太符合 Python 的哲学,这不是偶然的。虽然 DOM 遵循 W3C 规范,而 SAX 是在 Java API 的基础上建模的,但这两者都不太像 Pythonic。
更糟糕的是,DOM 和 SAX 解析器都感觉过时了,因为它们在 CPython 解释器中的一些代码已经二十多年没有改变了!在我写这篇文章的时候,它们的实现还没有完成,并且有丢失的打字存根,这破坏了代码编辑器中的代码完成。
同时,Python 2.5 带来了解析和编写 XML 文档的新视角——元素树 API。它是一个轻量级的、高效的、优雅的、功能丰富的接口,甚至一些第三方库都是基于它构建的。要入门,必须导入
xml.etree.ElementTree模块,有点拗口。因此,习惯上是这样定义别名的:import xml.etree.ElementTree as ET在稍微旧一点的代码中,您可能会看到导入了
cElementTree模块。这是一个比用 c 编写的相同接口快几倍的实现。今天,只要有可能,常规模块就使用快速实现,所以您不再需要费心了。您可以通过采用不同的解析策略来使用 ElementTree API:
非增量 增量(阻塞) 增量(非阻塞) ET.parse()✔️ ET.fromstring()✔️ ET.iterparse()✔️ ET.XMLPullParser✔️ 非增量策略以类似 DOM 的方式将整个文档加载到内存中。模块中有两个适当命名的函数,用于解析包含 XML 内容的文件或 Python 字符串:
>>> import xml.etree.ElementTree as ET
>>> # Parse XML from a filename
>>> ET.parse("smiley.svg")
<xml.etree.ElementTree.ElementTree object at 0x7fa4c980a6a0>
>>> # Parse XML from a file object
>>> with open("smiley.svg") as file:
... ET.parse(file)
...
<xml.etree.ElementTree.ElementTree object at 0x7fa4c96df340>
>>> # Parse XML from a Python string
>>> ET.fromstring("""\
... <svg viewBox="-105 -100 210 270">
... <!-- More content goes here... -->
... </svg>
... """)
<Element 'svg' at 0x7fa4c987a1d0>
用parse()解析文件对象或文件名会返回一个 ET.ElementTree 类的实例,它代表整个元素层次结构。另一方面,用fromstring()解析字符串将返回特定的根 ET.Element 。
或者,您可以使用流拉解析器递增地读取 XML 文档,这将产生一系列事件和元素:
>>> for event, element in ET.iterparse("smiley.svg"): ... print(event, element.tag) ... end {http://www.inkscape.org/namespaces/inkscape}custom end {http://www.w3.org/2000/svg}stop end {http://www.w3.org/2000/svg}stop end {http://www.w3.org/2000/svg}stop end {http://www.w3.org/2000/svg}linearGradient ⋮默认情况下,
iterparse()只发出与结束 XML 标记相关联的end事件。但是,您也可以订阅其他活动。你可以用字符串常量找到它们,比如"comment":
>>> import xml.etree.ElementTree as ET
>>> for event, element in ET.iterparse("smiley.svg", ["comment"]):
... print(element.text.strip())
...
Head
Eyes
Mouth
以下是所有可用事件类型的列表:
start: 元素的开始end: 一个元素结束comment: 评论元素pi: 加工指令,如 XSLstart-ns: 命名空间的开始end-ns: 一个名称空间的结束
iterparse()的缺点是它使用阻塞调用来读取下一个数据块,这可能不适合在单个执行线程上运行的异步代码。为了缓解这种情况,您可以查看一下 XMLPullParser ,这稍微有点冗长:
import xml.etree.ElementTree as ET
async def receive_data(url):
"""Download chunks of bytes from the URL asynchronously."""
yield b"<svg "
yield b"viewBox=\"-105 -100 210 270\""
yield b"></svg>"
async def parse(url, events=None):
parser = ET.XMLPullParser(events)
async for chunk in receive_data(url):
parser.feed(chunk)
for event, element in parser.read_events():
yield event, element
这个假设的例子向解析器提供几秒钟后到达的 XML 块。一旦有了足够的内容,就可以迭代解析器缓冲的一系列事件和元素。这种非阻塞的增量解析策略允许在下载多个 XML 文档的同时对它们进行真正的并行解析。
树中的元素是可变的、可迭代的和可索引的序列。它们的长度对应于其直接子代的数量:
>>> import xml.etree.ElementTree as ET >>> tree = ET.parse("smiley.svg") >>> root = tree.getroot() >>> # The length of an element equals the number of its children. >>> len(root) 5 >>> # The square brackets let you access a child by an index. >>> root[1] <Element '{http://www.w3.org/2000/svg}defs' at 0x7fe05d2e8860> >>> root[2] <Element '{http://www.w3.org/2000/svg}g' at 0x7fa4c9848400> >>> # Elements are mutable. For example, you can swap their children. >>> root[2], root[1] = root[1], root[2] >>> # You can iterate over an element's children. >>> for child in root: ... print(child.tag) ... {http://www.inkscape.org/namespaces/inkscape}custom {http://www.w3.org/2000/svg}g {http://www.w3.org/2000/svg}defs {http://www.w3.org/2000/svg}text {http://www.w3.org/2000/svg}script标记名可能以一对花括号(
{})中的可选名称空间为前缀。定义时,默认的 XML 名称空间也会出现在那里。注意突出显示的行中的交换赋值是如何使<g>元素出现在<defs>之前的。这显示了序列的可变性质。这里还有一些值得一提的元素属性和方法:
>>> element = root[0]
>>> element.tag
'{http://www.inkscape.org/namespaces/inkscape}custom'
>>> element.text
'Some value'
>>> element.attrib
{'x': '42', '{http://www.inkscape.org/namespaces/inkscape}z': '555'}
>>> element.get("x")
'42'
这个 API 的好处之一是它如何使用 Python 的原生数据类型。上面,它为元素的属性使用了 Python 字典。在前面的模块中,它们被包装在不太方便的适配器中。与 DOM 不同的是,ElementTree API 不公开任何方向遍历树的方法或属性,但是有一些更好的替代方法。
正如您之前看到的,Element类的实例实现了序列协议,允许您通过一个循环迭代它们的直接子类:
>>> for child in root: ... print(child.tag) ... {http://www.inkscape.org/namespaces/inkscape}custom {http://www.w3.org/2000/svg}defs {http://www.w3.org/2000/svg}g {http://www.w3.org/2000/svg}text {http://www.w3.org/2000/svg}script您将获得根的直接子元素的序列。然而,要深入嵌套的后代,您必须调用祖先元素上的
.iter()方法:
>>> for descendant in root.iter():
... print(descendant.tag)
...
{http://www.w3.org/2000/svg}svg
{http://www.inkscape.org/namespaces/inkscape}custom
{http://www.w3.org/2000/svg}defs
{http://www.w3.org/2000/svg}linearGradient
{http://www.w3.org/2000/svg}stop
{http://www.w3.org/2000/svg}stop
{http://www.w3.org/2000/svg}stop
{http://www.w3.org/2000/svg}g
{http://www.w3.org/2000/svg}circle
{http://www.w3.org/2000/svg}ellipse
{http://www.w3.org/2000/svg}ellipse
{http://www.w3.org/2000/svg}path
{http://www.w3.org/2000/svg}text
{http://www.w3.org/2000/svg}script
根元素只有五个子元素,但总共有十三个后代。还可以通过使用可选的tag参数仅过滤特定的标签名称来缩小后代的范围:
>>> tag_name = "{http://www.w3.org/2000/svg}ellipse" >>> for descendant in root.iter(tag_name): ... print(descendant) ... <Element '{http://www.w3.org/2000/svg}ellipse' at 0x7f430baa03b0> <Element '{http://www.w3.org/2000/svg}ellipse' at 0x7f430baa0450>这一次,你只得到两个
<ellipse>元素。记得在标签名中包含 XML 名称空间,比如{http://www.w3.org/2000/svg}——只要它已经被定义了。否则,如果您只提供标记名而没有正确的名称空间,那么您可能会得到比最初预期的更少或更多的后代元素。使用
.iterfind()处理名称空间更方便,它接受前缀到域名的可选映射。要指示默认名称空间,您可以将键留空或分配一个任意前缀,这个前缀必须在后面的标记名中使用:
>>> namespaces = {
... "": "http://www.w3.org/2000/svg",
... "custom": "http://www.w3.org/2000/svg"
... }
>>> for descendant in root.iterfind("g", namespaces):
... print(descendant)
...
<Element '{http://www.w3.org/2000/svg}g' at 0x7f430baa0270>
>>> for descendant in root.iterfind("custom:g", namespaces):
... print(descendant)
...
<Element '{http://www.w3.org/2000/svg}g' at 0x7f430baa0270>
名称空间映射允许您用不同的前缀引用同一个元素。令人惊讶的是,如果您像以前一样尝试查找那些嵌套的<ellipse>元素,那么.iterfind()不会返回任何内容,因为它需要一个 XPath 表达式,而不是一个简单的标记名:
>>> for descendant in root.iterfind("ellipse", namespaces): ... print(descendant) ... >>> for descendant in root.iterfind("g/ellipse", namespaces): ... print(descendant) ... <Element '{http://www.w3.org/2000/svg}ellipse' at 0x7f430baa03b0> <Element '{http://www.w3.org/2000/svg}ellipse' at 0x7f430baa0450>巧合的是,字符串
"g"恰好是相对于当前root元素的有效路径,这也是函数之前返回非空结果的原因。但是,要找到嵌套在 XML 层次结构中更深一层的省略号,您需要一个更详细的路径表达式。ElementTree 对 XPath 小型语言有有限的语法支持,可以用来查询 XML 中的元素,类似于 HTML 中的 CSS 选择器。还有其他方法接受这样的表达式:
>>> namespaces = {"": "http://www.w3.org/2000/svg"}
>>> root.iterfind("defs", namespaces)
<generator object prepare_child.<locals>.select at 0x7f430ba6d190>
>>> root.findall("defs", namespaces)
[<Element '{http://www.w3.org/2000/svg}defs' at 0x7f430ba09e00>]
>>> root.find("defs", namespaces)
<Element '{http://www.w3.org/2000/svg}defs' at 0x7f430ba09e00>
当.iterfind()产生匹配元素时,.findall()返回一个列表,.find()只返回第一个匹配元素。类似地,您可以使用.findtext()提取元素的开始和结束标记之间的文本,或者使用.itertext()获取整个文档的内部文本:
>>> namespaces = {"i": "http://www.inkscape.org/namespaces/inkscape"} >>> root.findtext("i:custom", namespaces=namespaces) 'Some value' >>> for text in root.itertext(): ... if text.strip() != "": ... print(text.strip()) ... Some value Hello <svg>! console.log("CDATA disables XML parsing: <svg>") ⋮首先查找嵌入在特定 XML 元素中的文本,然后查找整个文档中的所有文本。按文本搜索是 ElementTree API 的一个强大功能。可以使用其他内置的解析器来复制它,但是代价是增加了代码的复杂性,降低了便利性。
ElementTree API 可能是其中最直观的一个。它是 Pythonic 式的、高效的、健壮的、通用的。除非您有特定的理由使用 DOM 或 SAX,否则这应该是您的默认选择。
探索第三方 XML 解析器库
有时候,接触标准库中的 XML 解析器可能感觉像是拿起一把大锤敲碎一颗坚果。在其他时候,情况正好相反,您希望解析器能做更多的事情。例如,您可能希望根据模式或使用高级 XPath 表达式来验证 XML。在这些情况下,最好检查一下在 PyPI 上可用的外部库。
下面,您将找到一系列复杂程度不同的外部库。
untangle:将 XML 转换成 Python 对象如果您正在寻找一个可以将 XML 文档转换成 Python 对象的一行程序,那么不用再找了。虽然已经有几年没有更新了,但是
untangle库可能很快就会成为您最喜欢的用 Python 解析 XML 的方式。只需要记住一个函数,它接受 URL、文件名、文件对象或 XML 字符串:
>>> import untangle
>>> # Parse XML from a URL
>>> untangle.parse("http://localhost:8000/smiley.svg")
Element(name = None, attributes = None, cdata = )
>>> # Parse XML from a filename
>>> untangle.parse("smiley.svg")
Element(name = None, attributes = None, cdata = )
>>> # Parse XML from a file object
>>> with open("smiley.svg") as file:
... untangle.parse(file)
...
Element(name = None, attributes = None, cdata = )
>>> # Parse XML from a Python string
>>> untangle.parse("""\
... <svg viewBox="-105 -100 210 270">
... <!-- More content goes here... -->
... </svg>
... """)
Element(name = None, attributes = None, cdata = )
在每种情况下,它都返回一个Element类的实例。您可以使用点操作符访问其子节点,使用方括号语法通过索引获取 XML 属性或其中一个子节点。例如,要获取文档的根元素,您可以像访问对象的属性一样访问它。要获取元素的一个 XML 属性,可以将其名称作为字典键传递:
>>> import untangle >>> document = untangle.parse("smiley.svg") >>> document.svg Element(name = svg, attributes = {'xmlns': ...}, ...) >>> document.svg["viewBox"] '-105 -100 210 270'不需要记住函数或方法的名字。相反,每个被解析的对象都是唯一的,所以您真的需要知道底层 XML 文档的结构才能用
untangle遍历它。要找出根元素的名称,在文档上调用
dir():
>>> dir(document)
['svg']
这显示了元素的直接子元素的名称。注意,untangle为其解析的文档重新定义了dir()的含义。通常,您调用这个内置函数来检查一个类或一个 Python 模块。默认实现将返回属性名列表,而不是 XML 文档的子元素。
如果有多个子元素具有给定的标记名,那么您可以用一个循环迭代它们,或者通过索引引用一个子元素:
>>> dir(document.svg) ['defs', 'g', 'inkscape_custom', 'script', 'text'] >>> dir(document.svg.defs.linearGradient) ['stop', 'stop', 'stop'] >>> for stop in document.svg.defs.linearGradient.stop: ... print(stop) ... Element <stop> with attributes {'offset': ...}, ... Element <stop> with attributes {'offset': ...}, ... Element <stop> with attributes {'offset': ...}, ... >>> document.svg.defs.linearGradient.stop[1] Element(name = stop, attributes = {'offset': ...}, ...)您可能已经注意到了,
<inkscape:custom>元素被重命名为inkscape_custom。不幸的是,这个库不能很好地处理 XML 名称空间,所以如果这是你需要依赖的东西,那么你必须去别处看看。由于点符号,XML 文档中的元素名必须是有效的 Python 标识符。如果不是,那么
untangle将自动重写它们的名字,用下划线替换被禁止的字符:
>>> dir(untangle.parse("<com:company.web-app></com:company.web-app>"))
['com_company_web_app']
子标签名称不是您可以访问的唯一对象属性。元素有一些预定义的对象属性,可以通过调用vars()来显示:
>>> element = document.svg.text >>> list(vars(element).keys()) ['_name', '_attributes', 'children', 'is_root', 'cdata'] >>> element._name 'text' >>> element._attributes {'x': '-40', 'y': '75'} >>> element.children [] >>> element.is_root False >>> element.cdata 'Hello <svg>!'在幕后,
untangle使用内置的 SAX 解析器,但是因为这个库是用纯 Python 实现的,并且创建了许多重量级对象,所以它的性能相当差。虽然它旨在读取微小的文档,但是您仍然可以将它与另一种方法结合起来读取数千兆字节的 XML 文件。以下是方法。如果你去维基百科档案馆,你可以下载他们的一个压缩 XML 文件。顶部的一个应该包含文章摘要的快照:
<feed> <doc> <title>Wikipedia: Anarchism</title> <url>https://en.wikipedia.org/wiki/Anarchism</url> <abstract>Anarchism is a political philosophy...</abstract> <links> <sublink linktype="nav"> <anchor>Etymology, terminology and definition</anchor> <link>https://en.wikipedia.org/wiki/Anarchism#Etymology...</link> </sublink> <sublink linktype="nav"> <anchor>History</anchor> <link>https://en.wikipedia.org/wiki/Anarchism#History</link> </sublink> ⋮ </links> </doc> ⋮ </feed>下载后大小超过 6 GB,非常适合这个练习。这个想法是扫描文件,找到连续的开始和结束标签
<doc>,然后为了方便起见,使用untangle解析它们之间的 XML 片段。内置的
mmap模块可以让您创建文件内容的虚拟视图,即使它不适合可用内存。这给人一种使用支持搜索和常规切片语法的巨大字节串的印象。如果您对如何将这个逻辑封装在一个 Python 类中并利用一个生成器进行惰性评估感兴趣,那么请展开下面的可折叠部分。下面是
XMLTagStream类的完整代码:import mmap import untangle class XMLTagStream: def __init__(self, path, tag_name, encoding="utf-8"): self.file = open(path) self.stream = mmap.mmap( self.file.fileno(), 0, access=mmap.ACCESS_READ ) self.tag_name = tag_name self.encoding = encoding self.start_tag = f"<{tag_name}>".encode(encoding) self.end_tag = f"</{tag_name}>".encode(encoding) def __enter__(self): return self def __exit__(self, *args, **kwargs): self.stream.close() self.file.close() def __iter__(self): end = 0 while (begin := self.stream.find(self.start_tag, end)) != -1: end = self.stream.find(self.end_tag, begin) yield self.parse(self.stream[begin: end + len(self.end_tag)]) def parse(self, chunk): document = untangle.parse(chunk.decode(self.encoding)) return getattr(document, self.tag_name)这是一个定制的上下文管理器,它使用被定义为内嵌生成器函数的迭代器协议。生成的生成器对象在 XML 文档中循环,就好像它是一长串字符一样。
注意,
while循环利用了相当新的 Python 语法,即 walrus 操作符(:=) ,来简化代码。您可以在赋值表达式中使用该操作符,表达式可以被求值并赋值给变量。无需深入细节,下面介绍如何使用这个定制类快速浏览一个大型 XML 文件,同时使用
untangle更彻底地检查特定元素:
>>> with XMLTagStream("abstract.xml", "doc") as stream:
... for doc in stream:
... print(doc.title.cdata.center(50, "="))
... for sublink in doc.links.sublink:
... print("-", sublink.anchor.cdata)
... if "q" == input("Press [q] to exit or any key to continue..."):
... break
...
===============Wikipedia: Anarchism===============
- Etymology, terminology and definition
- History
- Pre-modern era
⋮
Press [q] to exit or any key to continue...
================Wikipedia: Autism=================
- Characteristics
- Social development
- Communication
⋮
Press [q] to exit or any key to continue...
首先,您打开一个文件进行读取,并指出您想要查找的标记名。然后,迭代这些元素,得到 XML 文档的解析片段。这几乎就像透过一个在无限长的纸上移动的小窗口看一样。这是一个相对肤浅的例子,忽略了一些细节,但是它应该让您对如何使用这种混合解析策略有一个大致的了解。
xmltodict:将 XML 转换成 Python 字典
如果你喜欢 JSON,但不是 XML 的粉丝,那么看看 xmltodict ,它试图在两种数据格式之间架起一座桥梁。顾名思义,该库可以解析 XML 文档并将其表示为 Python 字典,这也恰好是 Python 中 JSON 文档的目标数据类型。这使得 XML 和 JSON T4 之间的转换成为可能。
注意:字典是由键-值对组成的,而 XML 文档本来就是层次化的,这可能会导致转换过程中的一些信息丢失。最重要的是,XML 有属性、注释、处理指令和其他定义元数据的方式,这些都是字典中没有的。
与迄今为止的其他 XML 解析器不同,这个解析器期望以二进制模式打开一个 Python 字符串或类似文件的对象进行读取:
>>> import xmltodict >>> xmltodict.parse("""\ ... <svg viewBox="-105 -100 210 270"> ... <!-- More content goes here... --> ... </svg> ... """) OrderedDict([('svg', OrderedDict([('@viewBox', '-105 -100 210 270')]))]) >>> with open("smiley.svg", "rb") as file: ... xmltodict.parse(file) ... OrderedDict([('svg', ...)])默认情况下,库返回一个
OrderedDict集合的实例来保留元素顺序。然而,从 Python 3.6 开始,普通字典也保持插入顺序。如果您想使用常规词典,那么将dict作为dict_constructor参数传递给parse()函数:
>>> import xmltodict
>>> with open("smiley.svg", "rb") as file:
... xmltodict.parse(file, dict_constructor=dict)
...
{'svg': ...}
现在,parse()返回一个普通的旧字典,带有熟悉的文本表示。
为了避免 XML 元素和它们的属性之间的名称冲突,库自动为后者加上前缀@字符。您也可以通过适当地设置xml_attribs标志来完全忽略属性:
>>> import xmltodict >>> # Rename attributes by default >>> with open("smiley.svg", "rb") as file: ... document = xmltodict.parse(file) ... print([x for x in document["svg"] if x.startswith("@")]) ... ['@xmlns', '@xmlns:inkscape', '@viewBox', '@width', '@height'] >>> # Ignore attributes when requested >>> with open("smiley.svg", "rb") as file: ... document = xmltodict.parse(file, xml_attribs=False) ... print([x for x in document["svg"] if x.startswith("@")]) ... []默认情况下,另一条被忽略的信息是 XML 名称空间声明。这些被视为常规属性,而相应的前缀成为标记名的一部分。但是,如果需要,您可以扩展、重命名或跳过一些命名空间:
>>> import xmltodict
>>> # Ignore namespaces by default
>>> with open("smiley.svg", "rb") as file:
... document = xmltodict.parse(file)
... print(document.keys())
...
odict_keys(['svg'])
>>> # Process namespaces when requested
>>> with open("smiley.svg", "rb") as file:
... document = xmltodict.parse(file, process_namespaces=True)
... print(document.keys())
...
odict_keys(['http://www.w3.org/2000/svg:svg'])
>>> # Rename and skip some namespaces
>>> namespaces = {
... "http://www.w3.org/2000/svg": "svg",
... "http://www.inkscape.org/namespaces/inkscape": None,
... }
>>> with open("smiley.svg", "rb") as file:
... document = xmltodict.parse(
... file, process_namespaces=True, namespaces=namespaces
... )
... print(document.keys())
... print("custom" in document["svg:svg"])
... print("inkscape:custom" in document["svg:svg"])
...
odict_keys(['svg:svg'])
True
False
在上面的第一个例子中,标记名不包括 XML 名称空间前缀。在第二个例子中,它们是因为您请求处理它们。最后,在第三个示例中,您将默认名称空间折叠为svg,同时用None取消 Inkscape 的名称空间。
Python 字典的默认字符串表示可能不够清晰。为了改善它的表现,你可以美化它或者将其转换成另一种格式,如 JSON 或 YAML :
>>> import xmltodict >>> with open("smiley.svg", "rb") as file: ... document = xmltodict.parse(file, dict_constructor=dict) ... >>> from pprint import pprint as pp >>> pp(document) {'svg': {'@height': '270', '@viewBox': '-105 -100 210 270', '@width': '210', '@xmlns': 'http://www.w3.org/2000/svg', '@xmlns:inkscape': 'http://www.inkscape.org/namespaces/inkscape', 'defs': {'linearGradient': {'@id': 'skin', ⋮ >>> import json >>> print(json.dumps(document, indent=4, sort_keys=True)) { "svg": { "@height": "270", "@viewBox": "-105 -100 210 270", "@width": "210", "@xmlns": "http://www.w3.org/2000/svg", "@xmlns:inkscape": "http://www.inkscape.org/namespaces/inkscape", "defs": { "linearGradient": { ⋮ >>> import yaml # Install first with 'pip install PyYAML' >>> print(yaml.dump(document)) svg: '@height': '270' '@viewBox': -105 -100 210 270 '@width': '210' '@xmlns': http://www.w3.org/2000/svg '@xmlns:inkscape': http://www.inkscape.org/namespaces/inkscape defs: linearGradient: ⋮
xmltodict库允许反过来转换文档——也就是说,从 Python 字典转换回 XML 字符串:
>>> import xmltodict
>>> with open("smiley.svg", "rb") as file:
... document = xmltodict.parse(file, dict_constructor=dict)
...
>>> xmltodict.unparse(document)
'<?xml version="1.0" encoding="utf-8"?>\n<svg...'
如果需要的话,在将数据从 JSON 或 YAML 转换成 XML 时,该字典作为一种中间格式可能会派上用场。
在xmltodict库中还有很多特性,比如流媒体,所以你可以自由探索它们。然而,这个图书馆也有点过时了。此外,如果您真的在寻找高级 XML 解析特性,那么它是您应该考虑的下一个库。
lxml:使用类固醇元素树
如果你想把最好的性能、最广泛的功能和最熟悉的界面都打包在一个包里,那么就安装 lxml ,忘掉其余的库。它是 C 库 libxml2 和 libxslt 的 Python 绑定,支持多种标准,包括 XPath、XML Schema 和 xslt。
该库与 Python 的 ElementTree API 兼容,您在本教程的前面已经了解过。这意味着您可以通过只替换一条 import 语句来重用现有代码:
import lxml.etree as ET
这将给你带来巨大的性能提升。最重要的是,lxml库提供了一组广泛的特性,并提供了使用它们的不同方式。例如,它让您根据几种模式语言来验证您的 XML 文档,其中之一是 XML 模式定义:
>>> import lxml.etree as ET >>> xml_schema = ET.XMLSchema( ... ET.fromstring("""\ ... <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> ... <xsd:element name="parent"/> ... <xsd:complexType name="SomeType"> ... <xsd:sequence> ... <xsd:element name="child" type="xsd:string"/> ... </xsd:sequence> ... </xsd:complexType> ... </xsd:schema>""")) >>> valid = ET.fromstring("<parent><child></child></parent>") >>> invalid = ET.fromstring("<child><parent></parent></child>") >>> xml_schema.validate(valid) True >>> xml_schema.validate(invalid) FalsePython 标准库中的 XML 解析器都没有验证文档的能力。同时,
lxml允许您定义一个XMLSchema对象并通过它运行文档,同时保持与 ElementTree API 的大部分兼容性。除了 ElementTree API 之外,
lxml还支持另一种接口 lxml.objectify ,这将在后面的数据绑定部分中介绍。
BeautifulSoup:处理格式错误的 XML在这个比较中,您通常不会使用最后一个库来解析 XML,因为您最常遇到的是 web 抓取 HTML 文档。也就是说,它也能够解析 XML。 BeautifulSoup 带有一个可插拔架构,可以让你选择底层解析器。前面描述的
lxml实际上是官方文档推荐的,也是目前该库唯一支持的 XML 解析器。根据您想要解析的文档类型、期望的效率和特性可用性,您可以选择以下解析器之一:
文件类型 分析器名称 Python 库 速度 超文本标记语言 "html.parser"- 温和的 超文本标记语言 "html5lib"T2 html5lib慢的 超文本标记语言 "lxml"lxml快的 可扩展标记语言 "lxml-xml"或"xml"lxml快的 除了速度,各个解析器之间还有明显的差异。例如,当涉及到畸形元素时,它们中的一些比另一些更宽容,而另一些则更好地模拟了 web 浏览器。
趣闻:库名指的是标签汤,描述语法或结构不正确的 HTML 代码。
假设您已经将
lxml和beautifulsoup4库安装到活动的虚拟环境中,那么您可以立即开始解析 XML 文档。你只需要导入BeautifulSoup:from bs4 import BeautifulSoup # Parse XML from a file object with open("smiley.svg") as file: soup = BeautifulSoup(file, features="lxml-xml") # Parse XML from a Python string soup = BeautifulSoup("""\ <svg viewBox="-105 -100 210 270"> <!-- More content goes here... --> </svg> """, features="lxml-xml")如果您不小心指定了一个不同的解析器,比如说
lxml,那么这个库会为您将缺少的 HTML 标签,比如<body>添加到解析后的文档中。在这种情况下,这可能不是您想要的,所以在指定解析器名称时要小心。BeautifulSoup 是一个强大的解析 XML 文档的工具,因为它可以处理无效内容,并且有一个丰富的 API 来提取信息。看看它是如何处理不正确的嵌套标签、禁用字符和放置不当的文本的:
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("""\
... <parent>
... <child>Forbidden < character </parent>
... </child>
... ignored
... """, features="lxml-xml")
>>> print(soup.prettify())
<?xml version="1.0" encoding="utf-8"?>
<parent>
<child>
Forbidden
</child>
</parent>
另一个不同的解析器会引发一个异常,并在检测到文档有问题时立即放弃。在这里,它不仅忽略了问题,而且还找到了修复其中一些问题的明智方法。这些元素现在已经正确嵌套,并且没有无效内容。
用 BeautifulSoup 定位元素的方法太多了,这里无法一一介绍。通常,您会在 soup 元素上调用.find()或.findall()的变体:
>>> from bs4 import BeautifulSoup >>> with open("smiley.svg") as file: ... soup = BeautifulSoup(file, features="lxml-xml") ... >>> soup.find_all("ellipse", limit=1) [<ellipse cx="-20" cy="-10" fill="black" rx="6" ry="8" stroke="none"/>] >>> soup.find(x=42) <inkscape:custom inkscape:z="555" x="42">Some value</inkscape:custom> >>> soup.find("stop", {"stop-color": "gold"}) <stop offset="75%" stop-color="gold" stop-opacity="1.0"/> >>> soup.find(text=lambda x: "value" in x).parent <inkscape:custom inkscape:z="555" x="42">Some value</inkscape:custom>
limit参数类似于 MySQL 中的LIMIT子句,它让您决定最多希望接收多少个结果。它将返回指定数量或更少的结果。这不是巧合。您可以将这些搜索方法看作是一种简单的查询语言,带有强大的过滤器。搜索界面非常灵活,但超出了本教程的范围。你可以查看库的文档以了解更多细节,或者阅读另一篇关于 Python 中的 web 抓取的教程,该教程涉及 BeautifulSoup。
将 XML 数据绑定到 Python 对象
假设您想通过一个低延迟的 WebSocket 连接使用一个实时数据馈送,并以 XML 格式交换消息。出于本演示的目的,您将使用 web 浏览器向 Python 服务器广播您的鼠标和键盘事件。您将构建一个定制协议,并使用数据绑定将 XML 转换成本地 Python 对象。
数据绑定背后的想法是声明性地定义一个数据模型*,同时让程序弄清楚如何在运行时从 XML 中提取有价值的信息。如果你曾经和 Django models 一起工作过,那么这个概念应该听起来很熟悉。
首先,从设计数据模型开始。它将由两种类型的事件组成:
KeyboardEventMouseEvent每一个都可以代表一些特殊的子类型,比如键盘的按键或释放键以及鼠标的单击或右键。下面是响应按住
Shift+2组合键时生成的示例 XML 消息:<KeyboardEvent> <Type>keydown</Type> <Timestamp>253459.17999999982</Timestamp> <Key> <Code>Digit2</Code> <Unicode>@</Unicode> </Key> <Modifiers> <Alt>false</Alt> <Ctrl>false</Ctrl> <Shift>true</Shift> <Meta>false</Meta> </Modifiers> </KeyboardEvent>该消息包含特定的键盘事件类型、时间戳、键码及其 Unicode ,以及修改键,如
Alt、Ctrl或Shift。元键通常是Win或Cmd键,这取决于你的键盘布局。类似地,鼠标事件可能如下所示:
<MouseEvent> <Type>mousemove</Type> <Timestamp>52489.07000000145</Timestamp> <Cursor> <Delta x="-4" y="8"/> <Window x="171" y="480"/> <Screen x="586" y="690"/> </Cursor> <Buttons bitField="0"/> <Modifiers> <Alt>false</Alt> <Ctrl>true</Ctrl> <Shift>false</Shift> <Meta>false</Meta> </Modifiers> </MouseEvent>然而,代替键的是鼠标光标位置和一个对事件中按下的鼠标按钮进行编码的位域。零位域表示没有按钮被按下。
一旦客户端建立连接,它将开始向服务器发送大量消息。该协议不会包含任何握手、心跳、正常关机、主题订阅或控制消息。通过注册事件处理程序并在不到 50 行代码中创建一个
WebSocket对象,您可以用 JavaScript 对此进行编码。然而,实现客户机并不是本练习的重点。因为你不需要理解它,只需展开下面可折叠的部分来显示嵌入了 JavaScript 的 HTML 代码,并将其保存在一个名为随便你喜欢的文件中。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Real-Time Data Feed</title> </head> <body> <script> const ws = new WebSocket("ws://localhost:8000") ws.onopen = event => { ["keydown", "keyup"].forEach(name => window.addEventListener(name, event => ws.send(`\ <KeyboardEvent> <Type>${event.type}</Type> <Timestamp>${event.timeStamp}</Timestamp> <Key> <Code>${event.code}</Code> <Unicode>${event.key}</Unicode> </Key> <Modifiers> <Alt>${event.altKey}</Alt> <Ctrl>${event.ctrlKey}</Ctrl> <Shift>${event.shiftKey}</Shift> <Meta>${event.metaKey}</Meta> </Modifiers> </KeyboardEvent>`)) ); ["mousedown", "mouseup", "mousemove"].forEach(name => window.addEventListener(name, event => ws.send(`\ <MouseEvent> <Type>${event.type}</Type> <Timestamp>${event.timeStamp}</Timestamp> <Cursor> <Delta x="${event.movementX}" y="${event.movementY}"/> <Window x="${event.clientX}" y="${event.clientY}"/> <Screen x="${event.screenX}" y="${event.screenY}"/> </Cursor> <Buttons bitField="${event.buttons}"/> <Modifiers> <Alt>${event.altKey}</Alt> <Ctrl>${event.ctrlKey}</Ctrl> <Shift>${event.shiftKey}</Shift> <Meta>${event.metaKey}</Meta> </Modifiers> </MouseEvent>`)) ) } </script> </body> </html>客户端连接到侦听端口 8000 的本地服务器。一旦你将 HTML 代码保存在一个文件中,你就可以用你最喜欢的浏览器打开它。但是在此之前,您需要实现服务器。
Python 没有 WebSocket 支持,但是您可以将
websockets库安装到您的活动虚拟环境中。稍后您还将需要lxml,因此这是一个一次性安装两个依赖项的好时机:$ python -m pip install websockets lxml最后,您可以搭建一个最小的异步 web 服务器:
# server.py import asyncio import websockets async def handle_connection(websocket, path): async for message in websocket: print(message) if __name__ == "__main__": future = websockets.serve(handle_connection, "localhost", 8000) asyncio.get_event_loop().run_until_complete(future) asyncio.get_event_loop().run_forever()当您启动服务器并在 web 浏览器中打开保存的 HTML 文件时,您应该看到 XML 消息出现在标准输出中,以响应您的鼠标移动和按键。可以在多个标签页甚至多个浏览器同时打开客户端!
用 XPath 表达式定义模型
现在,您的消息以纯字符串格式到达。使用这种格式的信息不太方便。幸运的是,您可以使用
lxml.objectify模块,通过一行代码将它们转换成复合 Python 对象:# server.py import asyncio import websockets import lxml.objectify async def handle_connection(websocket, path): async for message in websocket: try: xml = lxml.objectify.fromstring(message) except SyntaxError: print("Malformed XML message:", repr(message)) else: if xml.tag == "KeyboardEvent": if xml.Type == "keyup": print("Key:", xml.Key.Unicode) elif xml.tag == "MouseEvent": screen = xml.Cursor.Screen print("Mouse:", screen.get("x"), screen.get("y")) else: print("Unrecognized event type") # ...只要 XML 解析成功,就可以检查根元素的常见属性,比如标记名、属性、内部文本等等。您将能够使用点运算符导航到元素树的深处。在大多数情况下,库会识别合适的 Python 数据类型,并为您转换值。
保存这些更改并重新启动服务器后,您需要在 web 浏览器中重新加载页面,以建立新的 WebSocket 连接。下面是修改后的程序的输出示例:
$ python server.py Mouse: 820 121 Mouse: 820 122 Mouse: 820 123 Mouse: 820 124 Mouse: 820 125 Key: a Mouse: 820 125 Mouse: 820 125 Key: a Key: A Key: Shift Mouse: 821 125 Mouse: 821 125 Mouse: 820 123 ⋮有时,XML 可能包含不是有效 Python 标识符的标记名,或者您可能希望调整消息结构以适应您的数据模型。在这种情况下,一个有趣的选择是用声明如何使用 XPath 表达式查找信息的描述符定义定制的模型类。这是开始类似 Django 模型或 Pydantic 模式定义的部分。
您将使用一个定制的
XPath描述符和一个附带的Model类,为您的数据模型提供可重用的属性。描述符要求在收到的消息中使用 XPath 表达式进行元素查找。底层实现有点高级,所以可以随意从下面的可折叠部分复制代码。import lxml.objectify class XPath: def __init__(self, expression, /, default=None, multiple=False): self.expression = expression self.default = default self.multiple = multiple def __set_name__(self, owner, name): self.attribute_name = name self.annotation = owner.__annotations__.get(name) def __get__(self, instance, owner): value = self.extract(instance.xml) instance.__dict__[self.attribute_name] = value return value def extract(self, xml): elements = xml.xpath(self.expression) if elements: if self.multiple: if self.annotation: return [self.annotation(x) for x in elements] else: return elements else: first = elements[0] if self.annotation: return self.annotation(first) else: return first else: return self.default class Model: """Abstract base class for your models.""" def __init__(self, data): if isinstance(data, str): self.xml = lxml.objectify.fromstring(data) elif isinstance(data, lxml.objectify.ObjectifiedElement): self.xml = data else: raise TypeError("Unsupported data type:", type(data))假设您的模块中已经有了期望的
XPath描述符和Model抽象基类,您可以使用它们来定义KeyboardEvent和MouseEvent消息类型以及可重用的构建块以避免重复。有无数种方法可以做到这一点,但这里有一个例子:# ... class Event(Model): """Base class for event messages with common elements.""" type_: str = XPath("./Type") timestamp: float = XPath("./Timestamp") class Modifiers(Model): alt: bool = XPath("./Alt") ctrl: bool = XPath("./Ctrl") shift: bool = XPath("./Shift") meta: bool = XPath("./Meta") class KeyboardEvent(Event): key: str = XPath("./Key/Code") modifiers: Modifiers = XPath("./Modifiers") class MouseEvent(Event): x: int = XPath("./Cursor/Screen/@x") y: int = XPath("./Cursor/Screen/@y") modifiers: Modifiers = XPath("./Modifiers")
XPath描述符允许惰性评估,因此 XML 消息的元素只有在被请求时才被查找。更具体地说,只有当您访问事件对象的属性时,才会查找它们。此外,结果被缓存,以避免多次运行相同的 XPath 查询。描述符还考虑到了类型注释,并将反序列化的数据自动转换为正确的 Python 类型。使用这些事件对象与之前由
lxml.objectify自动生成的没有太大区别:if xml.tag == "KeyboardEvent": event = KeyboardEvent(xml) if event.type_ == "keyup": print("Key:", event.key) elif xml.tag == "MouseEvent": event = MouseEvent(xml) print("Mouse:", event.x, event.y) else: print("Unrecognized event type")还有一个创建特定事件类型的新对象的额外步骤。但是除此之外,在独立于 XML 协议构建模型方面,它给了您更多的灵活性。此外,可以基于接收到的消息中的属性派生出新的模型属性,并在此基础上添加更多的方法。
从 XML 模式生成模型
实现模型类是一项乏味且容易出错的任务。然而,只要您的模型反映了 XML 消息,您就可以利用一个自动化的工具来基于 XML Schema 为您生成必要的代码。这种代码的缺点是通常比手写的可读性差。
最古老的第三方模块之一是 PyXB ,它模仿了 Java 流行的 JAXB 库。不幸的是,它最后一次发布是在几年前,目标是遗留的 Python 版本。您可以研究一种类似但仍被积极维护的
generateDS替代方案,它从 XML 模式生成数据结构。假设您有这个描述您的
KeyboardEvent消息的models.xsd模式文件:<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="KeyboardEvent" type="KeyboardEventType"/> <xsd:complexType name="KeyboardEventType"> <xsd:sequence> <xsd:element type="xsd:string" name="Type"/> <xsd:element type="xsd:float" name="Timestamp"/> <xsd:element type="KeyType" name="Key"/> <xsd:element type="ModifiersType" name="Modifiers"/> </xsd:sequence> </xsd:complexType> <xsd:complexType name="KeyType"> <xsd:sequence> <xsd:element type="xsd:string" name="Code"/> <xsd:element type="xsd:string" name="Unicode"/> </xsd:sequence> </xsd:complexType> <xsd:complexType name="ModifiersType"> <xsd:sequence> <xsd:element type="xsd:string" name="Alt"/> <xsd:element type="xsd:string" name="Ctrl"/> <xsd:element type="xsd:string" name="Shift"/> <xsd:element type="xsd:string" name="Meta"/> </xsd:sequence> </xsd:complexType> </xsd:schema>模式告诉 XML 解析器预期的元素、它们的顺序以及它们在树中的级别。它还限制了 XML 属性的允许值。这些声明和实际的 XML 文档之间的任何差异都会使它无效,并使解析器拒绝该文档。
此外,一些工具可以利用这些信息生成一段代码,对您隐藏 XML 解析的细节。安装完库之后,您应该能够在您的活动虚拟环境中运行
generateDS命令:$ generateDS -o models.py models.xsd它将在与生成的 Python 源代码相同的目录中创建一个名为
models.py的新文件。然后,您可以导入该模块并使用它来解析传入的消息:
>>> from models import parseString
>>> event = parseString("""\
... <KeyboardEvent>
... <Type>keydown</Type>
... <Timestamp>253459.17999999982</Timestamp>
... <Key>
... <Code>Digit2</Code>
... <Unicode>@</Unicode>
... </Key>
... <Modifiers>
... <Alt>false</Alt>
... <Ctrl>false</Ctrl>
... <Shift>true</Shift>
... <Meta>false</Meta>
... </Modifiers>
... </KeyboardEvent>""", silence=True)
>>> event.Type, event.Key.Code
('keydown', 'Digit2')
它看起来类似于前面显示的lxml.objectify示例。不同之处在于,使用数据绑定强制符合模式,而lxml.objectify动态地产生对象,不管它们在语义上是否正确。
用安全解析器化解 XML 炸弹
Python 标准库中的 XML 解析器容易受到大量安全威胁的攻击,这些威胁最多会导致拒绝服务(DoS) 或数据丢失。公平地说,那不是他们的错。他们只是遵循 XML 标准的规范,这比大多数人知道的更复杂和强大。
注意:请注意,您应该明智地使用您将要看到的信息。您不希望最终成为攻击者,将自己暴露在法律后果之下,或者面临终身禁止使用某个特定服务。
最常见的攻击之一是 XML 炸弹,也被称为亿笑攻击。攻击利用 DTD 中的实体扩展来炸毁内存,尽可能长时间占用 CPU。要阻止未受保护的 web 服务器接收新流量,您只需几行 XML 代码:
import xml.etree.ElementTree as ET
ET.fromstring("""\
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "lol">
<!ELEMENT lolz (#PCDATA)>
<!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>""")
一个天真的解析器将试图通过检查 DTD 来解析放置在文档根中的定制实体&lol9;。但是,该实体本身多次引用另一个实体,后者又引用另一个实体,依此类推。当您运行上面的脚本时,您会注意到内存和处理单元有些令人不安的地方:
https://player.vimeo.com/video/563603395?background=1
看看当其中一个 CPU 以 100%的容量工作时,主内存和交换分区是如何在几秒钟内耗尽的。当系统内存变满时,记录会突然停止,然后在 Python 进程被终止后恢复。
另一种被称为 XXE 的流行攻击利用通用外部实体读取本地文件并发出网络请求。然而,从 Python 3.7.1 开始,这个特性被默认禁用,以增加安全性。如果您信任您的数据,那么您可以告诉 SAX 解析器处理外部实体:
>>> from xml.sax import make_parser >>> from xml.sax.handler import feature_external_ges >>> parser = make_parser() >>> parser.setFeature(feature_external_ges, True)这个解析器将能够读取你的计算机上的本地文件。它可能会在类似 Unix 的操作系统上提取用户名,例如:
>>> from xml.dom.minidom import parseString
>>> xml = """\
... <?xml version="1.0" encoding="UTF-8"?>
... <!DOCTYPE root [
... <!ENTITY usernames SYSTEM "/etc/passwd">
... ]>
... <root>&usernames;</root>"""
>>> document = parseString(xml, parser)
>>> print(document.documentElement.toxml())
<root>root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
⋮
realpython:x:1001:1001:Real Python,,,:/home/realpython:/bin/bash
</root>
将数据通过网络发送到远程服务器是完全可行的!
现在,你如何保护自己免受这种攻击呢?Python 官方文档明确警告您使用内置 XML 解析器的风险,并建议在关键任务应用程序中切换到外部包。虽然没有随 Python 一起发布, defusedxml 是标准库中所有解析器的替代者。
该库施加了严格的限制,并禁用了许多危险的 XML 特性。它应该可以阻止大多数众所周知的攻击,包括刚才描述的两种攻击。要使用它,从 PyPI 获取库并相应地替换您的导入语句:
>>> import defusedxml.ElementTree as ET >>> ET.parse("bomb.xml") Traceback (most recent call last): ... raise EntitiesForbidden(name, value, base, sysid, pubid, notation_name) defusedxml.common.EntitiesForbidden: EntitiesForbidden(name='lol', system_id=None, public_id=None)就是这样!被禁止的功能不会再通过了。
结论
XML 数据格式是一种成熟的、功能惊人的标准,至今仍在使用,尤其是在企业环境中。选择正确的 XML 解析器对于在性能、安全性、合规性和便利性之间找到最佳平衡点至关重要。
本教程为您提供了一个详细的路线图,帮助您在 Python 中的 XML 解析器迷宫中导航。你知道在哪里走捷径,如何避免死胡同,节省你很多时间。
在本教程中,您学习了如何:
- 选择正确的 XML 解析模型
- 使用标准库中的 XML 解析器
- 使用主要的 XML 解析库
- 使用数据绑定以声明方式解析 XML 文档
- 使用安全的 XML 解析器消除安全漏洞
现在,您已经理解了解析 XML 文档的不同策略以及它们的优缺点。有了这些知识,您就能够为您的特定用例选择最合适的 XML 解析器,甚至可以组合多个解析器来更快地读取几千兆字节的 XML 文件。************
YAML:Python 中缺失的电池
Python 经常被宣传为一种包含电池的语言,因为它几乎具备了你对编程语言的所有期望。这种说法基本上是正确的,因为标准库和外部模块涵盖了广泛的编程需求。然而,Python 缺乏对通常用于配置和序列化的 YAML 数据格式的内置支持,尽管这两种语言之间有明显的相似之处。
在本教程中,您将学习如何使用可用的第三方库在 Python 中使用 YAML,重点是 PyYAML 。如果你刚到 YAML 或者有一段时间没有使用它,那么在深入研究这个主题之前,你将有机会参加一个快速速成班。
在本教程中,您将学习如何:
- 用 Python 读和写 YAML 文档
- 序列化 Python 的内置的和自定义的数据类型到 YAML
- 安全读取来自不可信来源的 YAML 文件
- 控制在较低层次解析 YAML 文档
稍后,您将了解 YAML 的高级、潜在危险功能以及如何保护自己免受其害。为了在底层解析 YAML,您将在 HTML 中构建一个语法高亮工具和一个交互式预览。最后,您将利用自定义 YAML 标记来扩展数据格式的语法。
为了充分利用本教程,您应该熟悉 Python 中的面向对象编程,并且知道如何创建一个类。如果您已经准备好了,那么您可以通过下面的链接获得您将在本教程中编写的示例的源代码:
获取源代码: 点击此处获取源代码,您将使用在 Python 中使用 YAML。
在 YAML 参加速成班
在这一节中,您将了解关于 YAML 的基本事实,包括它的用法、语法以及一些独特而强大的功能。如果你以前和 YAML 一起工作过,那么你可以跳到下一节继续阅读,这一节涵盖了在 Python 中使用 YAML。
历史背景
YAML,与 camel 押韵,是一个递归首字母缩略词,代表 YAML 不是标记语言,因为它是而不是标记语言!有趣的是,YAML 规范的最初草案将该语言定义为另一种标记语言,但是后来采用了当前的 backronym 来更准确地描述该语言的用途。
一种真正的标记语言,比如 Markdown 或 HTML,可以让你用混合在内容中的格式或处理指令来注释文本。因此,标记语言主要关注文本文档,而 YAML 是一种 数据序列化格式 ,它与许多编程语言固有的常见数据类型集成得很好。在 YAML 没有固有的文本,只有数据来代表。
YAML 原本是为了简化可扩展标记语言(XML) ,但实际上,它与 JavaScript 对象符号(JSON) 有很多共同之处。事实上,它是 JSON 的超集。
尽管 XML 最初被设计成一种为文档创建标记语言的元语言,但人们很快就将其作为标准的数据序列化格式。尖括号类似 HTML 的语法让 XML 看起来很熟悉。突然间,每个人都想使用 XML 作为他们的配置、持久性或消息格式。
作为这个领域的第一个孩子,XML 统治了这个领域很多年。它成为了一种成熟可靠的数据交换格式,并帮助形成了一些新概念,比如构建交互式网络应用。毕竟, AJAX 中的字母 X ,一种无需重新加载页面就能从服务器获取数据的技术,代表的正是 XML。
具有讽刺意味的是,正是 AJAX 最终导致了 XML 受欢迎程度的下降。当数据通过网络发送时,冗长、复杂和冗余的 XML 语法浪费了大量带宽。用 JavaScript 解析 XML 文档既慢又乏味,因为 XML 的固定文档对象模型(DOM) 与应用程序的数据模型不匹配。社区最终承认他们在工作中使用了错误的工具。
那就是 JSON 进入画面的时候。它是在考虑数据序列化的基础上从头开始构建的。Web 浏览器可以毫不费力地解析它,因为 JSON 是他们已经支持的 JavaScript 的子集。JSON 的极简语法不仅吸引了开发人员,而且比 XML 更容易移植到其他平台。直到今天,JSON 仍然是互联网上最瘦、最快、最通用的文本数据交换格式。
YAML 与 JSON 在同一年出现,纯属巧合,它在语法和语义层面上几乎是 JSON 的完整超集。从 YAML 1.2 开始,该格式正式成为 JSON 的严格超集,这意味着每一个有效的 JSON 文档也恰好是 YAML 文档。
然而,实际上,这两种格式看起来不同,因为 YAML 规范通过在 JSON 之上添加更多的语法糖和特性,更加强调人类可读性。因此,YAML 更适用于手工编辑的配置文件,而不是作为一个传输层。
与 XML 和 JSON 的比较
如果你熟悉 XML 或 JSON ,那么你可能想知道 YAML 带来了什么。这三种都是主要的数据交换格式,它们共享一些重叠的特性。例如,它们都是基于文本的,或多或少具有可读性。同时,它们在许多方面有所不同,这一点你接下来会发现。
注意:还有其他不太流行的文本数据格式,比如 TOML ,Python 中的新构建系统就是基于这种格式。目前,只有像poems这样的外部打包和依赖管理工具可以读取 TOML,但是 Python 3.11 很快就会在标准库中有一个 TOML 解析器。
常见的二进制数据序列化格式包括谷歌的协议缓冲区和阿帕奇的 Avro 。
现在来看一个样本文档,它用所有三种数据格式表示,但是表示的是同一个人。您可以单击以展开可折叠部分,并显示以这些格式序列化的数据:
<?xml version="1.0" encoding="UTF-8" ?> <person firstName="John" lastName="Doe"> <dateOfBirth>1969-12-31</dateOfBirth> <married>true</married> <spouse> <person firstName="Jane" lastName="Doe"> <dateOfBirth/> <!- This is a comment --> </person> </spouse> </person>{ "person": { "dateOfBirth": "1969-12-31", "firstName": "John", "lastName": "Doe", "married": true, "spouse": { "dateOfBirth": null, "firstName": "Jane", "lastName": "Doe" } } }%YAML 1.2 --- person: dateOfBirth: 1969-12-31 firstName: John lastName: Doe married: true spouse: dateOfBirth: null # This is a comment firstName: Jane lastName: Doe乍一看,XML 似乎具有最令人生畏的语法,这增加了许多噪音。JSON 在简单性方面极大地改善了这种情况,但是它仍然将信息隐藏在强制分隔符之下。另一方面,YAML 使用 Python 风格的块缩进来定义结构,使它看起来干净和简单。缺点是,在通过网络传输消息时,不能通过折叠空白来减小大小。
注意: JSON 是唯一不支持注释的数据格式。它们被从规范中删除是为了简化解析器,防止人们滥用它们来定制处理指令。
这里有一个对 XML、JSON 和 YAML 的主观比较,让您了解它们作为当今的数据交换格式是如何相互比较的:
可扩展标记语言 JSON 亚姆 采用和支持 ⭐⭐⭐⭐ ⭐⭐⭐⭐ ⭐⭐ 可读性 ⭐⭐ ⭐⭐⭐ ⭐⭐⭐⭐ 读写速度 ⭐⭐ ⭐⭐⭐⭐ ⭐ 文件大小 ⭐ ⭐⭐⭐ ⭐⭐ 当你查看 [Google Trends]( https://trends.google.com/trends/explore?date=all&q=XML ,JSON,YAML) 来追踪对这三个搜索短语的兴趣时,你会得出结论,JSON 是当前的赢家。然而,XML 紧随其后,YAML 吸引了最不感兴趣的 T2。此外,自从 Google 开始收集数据以来,XML 的受欢迎程度似乎一直在稳步下降。
注意:在这三种格式中,XML 和 JSON 是 Python 开箱即用支持的唯一格式,而如果您希望使用 YAML,那么您必须找到并安装相应的第三方库。然而,Python 并不是唯一一种比 YAML 更好地支持 XML 和 JSON 的语言。您可能会在各种编程语言中发现这种趋势。
YAML 可以说是最容易看的,因为可读性一直是它的核心原则之一,但是 JSON 也不错。有些人甚至会发现 JSON 不那么杂乱和嘈杂,因为它的语法非常简洁,并且与 Python 列表和字典非常相似。XML 是最冗长的,因为它需要将每一条信息包装在一对开始和结束标记中。
在 Python 中,处理这些数据格式时的性能会有所不同,并且对您选择的实现非常敏感。纯 Python 实现总会输给编译过的 C 库。除此之外,使用不同的 XML 处理模型——(DOM、 SAX 或 StAX )也会影响性能。
除了实现之外,YAML 的通用、自由和复杂的语法使它成为迄今为止解析和序列化最慢的。另一方面,你会发现 JSON,它的语法可以放在一张名片上。相比之下,YAML 自己的语法文档声称创建一个完全兼容的解析器几乎是不可能的。
趣闻:yaml.org官方网站被写成有效的 YAML 文件。
说到文档大小,JSON 再次成为明显的赢家。虽然多余的引号、逗号和花括号占用了宝贵的空间,但是您可以删除各个元素之间的所有空白。您可以对 XML 文档做同样的事情,但是它不会克服开始和结束标记的开销。YAML 位于中间,拥有相对中等的面积。
从历史上看,XML 在广泛的技术中得到了最好的支持。JSON 是在互联网上传输数据的无与伦比的全方位交换格式。那么,谁在使用 YAML,为什么?
YAML 的实际用途
如前所述,YAML 最受称赞的地方是它的可读性,这使得它非常适合以人类可读的格式存储各种配置数据。它在开发工程师中变得特别受欢迎,他们围绕它开发了自动化工具。这些工具的几个例子包括:
- Ansible : 使用 YAML 来描述远程基础设施的期望状态,管理配置,并协调 IT 流程
- Docker Compose : 使用 YAML 来描述组成您的 Docker 化应用程序的微服务
- Kubernetes : 使用 YAML 来定义计算机集群中的各种对象以进行编排和管理
除此之外,一些通用工具、库和服务为您提供了通过 YAML 配置它们的选项,您可能会发现这比其他数据格式更方便。例如,像 CircleCI 和 GitHub 这样的平台经常求助于 YAML 来定义持续集成、部署和交付(CI/CD) 管道。 OpenAPI 规范允许基于RESTful API的 YAML 描述生成代码存根。
注意:Python 的日志框架的文档提到了 YAML,尽管该语言本身并不支持 YAML。
完成本教程后,也许你会决定在未来的项目中采用 YAML!
YAML 语法
YAML 从你以前可能听说过的其他数据格式和语言中汲取了很多灵感。也许 YAML 语法中最引人注目和熟悉的元素是它的块缩进,它类似于 Python 代码。每行的前导空格定义了块的范围,不需要任何特殊字符或标记来表示它的开始或结束位置:
grandparent: parent: child: name: Bobby sibling: name: Molly这个示例文档定义了一个以
grandparent为根元素的家庭树,它的直接子元素是parent元素,在树的最底层有两个带有name属性的子元素。在 Python 中,您可以将每个元素想象成一个开始语句,后跟一个冒号(:)。注意:YAML 规范禁止使用制表符进行缩进,并认为它们的使用是一种语法错误。这与 Python 的 PEP 8 推荐的更喜欢空格而不是制表符不谋而合。
同时,YAML 允许你利用从 JSON 借鉴来的另一种内联块语法。您可以用以下方式重写同一文档:
grandparent: parent: child: {name: Bobby} sibling: {'name': "Molly"}请注意如何在一个文档中混合缩进块和内联块。此外,如果您愿意,可以自由地将属性及其值用单引号(
')或双引号(")括起来。这样做可以启用特殊字符序列的两种插值方法之一,否则会用另一个反斜杠(\)为您转义。下面,您将在 YAML 旁边找到 Python 的等价物:
亚姆 计算机编程语言 描述 Don''t\nDon''t\\n不加引号的字符串被逐字解析,这样像 \n这样的转义序列就变成了\\n。'Don''t\n'Don't\\n单引号字符串只内插双撇号( ''),而不内插\n这样的传统转义序列。"Don''t\n"Don''t\n双引号( ")字符串插入转义序列,如\n、\r或\t,这在 C 编程语言中是已知的,但不是双撇号('')。如果这看起来令人困惑,不要担心。无论如何,在 YAML 的大部分情况下,您都希望指定不带引号的字符串文字。一个值得注意的例外是声明一个字符串,解析器可能会将其误解为错误的数据类型。例如,不带任何引号的
True可能会被视为一个 Python 布尔值。YAML 的三种基本数据结构(T0)与 T2 的 Perl(T3)基本相同,Perl 曾是一种流行的脚本语言。它们是:
- 标量:像数字、字符串或布尔这样的简单值
- 数组:标量或其他集合的序列
- 散列:关联数组,也称为由键值对组成的映射、字典、对象或记录
您可以定义一个 YAML 标量,类似于对应的 Python 文字。这里有几个例子:
数据类型 亚姆 空 null,~布尔代数学体系的 true、false、 ( 前 YAML 1.2: 、no、on、off)整数 10、0b10、0x10、0o10、 ( 前 YAML 1.2: 、010)浮点型 3.14、12.5e-9、.inf、.nan线 Lorem ipsum日期和时间 2022-01-16、23:59、2022-01-16 23:59:59您可以用小写(
null)、大写(NULL)或大写(Null)在 YAML 中编写保留字,以便将它们解析为所需的数据类型。此类单词的任何其他大小写变体都将被视为纯文本。null常量或其代字号(~)别名允许您显式声明缺少值,但是您也可以将该值留空以获得相同的效果。注:YAML 的这种隐式打字看似方便,实则如同玩火,在边缘情况下会造成严重问题。结果,YAML 1.2 规范放弃了对一些内置文字的支持,比如
yes和no。YAML 中的序列就像 Python 列表或 JSON 数组一样。它们在内嵌块模式中使用标准的方括号语法(
[])或者在块缩进时在每行的开头使用前导破折号(-):fruits: [apple, banana, orange] veggies: - tomato - cucumber - onion mushrooms: - champignon - truffle您可以将列表项保持在与其属性名相同的缩进级别,或者添加更多的缩进,如果这样可以提高可读性的话。
最后,YAML 有类似于 Python 字典或 JavaScript 对象的散列。它们由键组成,也称为属性或属性名称,后跟一个冒号(
:)和一个值。在本节中,您已经看到了一些 YAML 散列的例子,但是这里有一个更复杂的例子:person: firstName: John lastName: Doe dateOfBirth: 1969-12-31 married: true spouse: firstName: Jane lastName: Smith children: - firstName: Bobby dateOfBirth: 1995-01-17 - firstName: Molly dateOfBirth: 2001-05-14你刚刚定义了一个人,约翰·多伊,他娶了简·史密斯,有两个孩子,鲍比和莫莉。注意孩子列表是如何包含匿名对象的,不像,例如,在名为
"spouse"的属性下定义的配偶。当匿名或未命名对象作为列表项出现时,您可以通过它们的属性来识别它们,这些属性与一个短划线(-)对齐。注意:YAML 的属性名非常灵活,因为它们可以包含空白字符,并且可以跨越多行。此外,您不仅限于使用字符串。与 JSON 不同,但与 Python 字典类似,YAML 散列允许您使用几乎任何数据类型作为键!
当然,这里你只是触及了皮毛,因为 YAML 还有很多更先进的功能。现在您将了解其中的一些。
独特的功能
在这一部分,你将了解 YAML 一些最独特的特色,包括:
- 数据类型
- 标签
- 锚和别名
- 合并属性
- 流动和块状样式
- 多文档流
虽然 XML 都是关于文本的,JSON 继承了 JavaScript 的少数数据类型,但 YAML 的定义特性是与现代编程语言的类型系统紧密集成。例如,您可以使用 YAML 来序列化和反序列化 Python 中内置的数据类型,如日期和时间:
亚姆 计算机编程语言 2022-01-16 23:59:59datetime.datetime(2022, 1, 16, 23, 59, 59)2022-01-16datetime.date(2022, 1, 16)23:59:598639959:593599YAML 理解各种日期和时间格式,包括 ISO 8601 标准,并且可以在任意时区工作。时间戳(如 23:59:59)被反序列化为自午夜以来经过的秒数。
为了解决潜在的歧义,您可以通过使用以双感叹号(
!!)开头的 YAML 标签,将值转换为特定的数据类型。有一些独立于语言的标签,但是不同的解析器可能会提供只与你的编程语言相关的附加扩展。例如,您稍后将使用的库允许您将值转换为本机 Python 类型,甚至序列化您的自定义类:text: !!str 2022-01-16 numbers: !!set ? 5 ? 8 ? 13 image: !!binary R0lGODdhCAAIAPAAAAIGAfr4+SwAA AAACAAIAAACDIyPeWCsClxDMsZ3CgA7 pair: !!python/tuple - black - white center_at: !!python/complex 3.14+2.72j person: !!python/object:package_name.module_name.ClassName age: 42 first_name: John last_name: Doe在日期对象旁边使用了
!!str标记,这使得 YAML 把它当作一个普通的字符串。问号(?)表示 YAML 的映射键。它们通常是不必要的,但可以帮助您从另一个集合中定义一个复合键或包含保留字符的键。在这种情况下,您想要定义空白键来创建一个集合数据结构,这相当于一个没有键的映射。而且,你可以使用
!!binary标签来嵌入 Base64 编码的二进制文件比如图像或者其他资源,这些文件在 Python 中将成为bytes的实例。以!!python/为前缀的标签由 PyYAML 提供。上面的 YAML 文档将被翻译成下面的 Python 字典:
{ "text": "2022-01-16", "numbers": {8, 13, 5}, "image": b"GIF87a\x08\x00\x08\x00\xf0\x00…", "pair": ("black", "white"), "center_at": (3.14+2.72j), "person": <package_name.module_name.ClassName object at 0x7f08bf528fd0> }请注意,在 YAML 标记的帮助下,解析器如何将属性值转换成各种 Python 数据类型,包括字符串、集合、字节对象、元组、复数,甚至自定义类实例。
YAML 的其他强大特性是锚和别名,它允许你定义一个元素一次,然后在同一个文档中多次引用它。潜在的使用案例包括:
- 重复使用发货地址进行开票
- 膳食计划中的轮换膳食
- 参考培训计划中的练习
要声明一个锚,你可以把它看作一个命名的变量,你可以使用符号(
&) ,而稍后要取消引用这个锚,你可以使用星号(*) 符号:recursive: &cycle [*cycle] exercises: - muscles: &push-up - pectoral - triceps - biceps - muscles: &squat - glutes - quadriceps - hamstrings - muscles: &plank - abs - core - shoulders schedule: monday: - *push-up - *squat tuesday: - *plank wednesday: - *push-up - *plank在这里,您已经根据之前定义的练习创建了一个锻炼计划,并在各种日常活动中重复进行。另外,
recursive属性展示了一个循环引用的例子。这个属性是一个序列,它的唯一元素是序列本身。换句话说,recursive[0]与recursive相同。注意:与普通的 XML 和 JSON 不同,它们只能用单个根元素来表示树状层次,YAML 也使得用递归循环来描述有向图结构成为可能。不过,在定制扩展或方言的帮助下,XML 和 JSON 中的交叉引用是可能的。
您还可以通过组合两个或更多对象来合并 (
<<)或覆盖在其他地方定义的属性:shape: &shape color: blue square: &square a: 5 rectangle: << : *shape << : *square b: 3 color: green
rectangle对象继承了shape和square的属性,同时添加了一个新属性b,并更改了color的值。YAML 的标量支持流样式或块样式,这给了你对多行字符串中换行符处理的不同级别的控制。流标量可以在其属性名所在的同一行开始,也可以跨多行:
text: Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet在这种情况下,每一行的前导和尾随空格将总是被折叠成一个空格,将段落变成行。这有点像 HTML 或 Markdown,会产生下面这段文本:
Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet如果你想知道, Lorem ipsum 是写作和网页设计中用来填充可用空间的常见占位符文本。它没有任何意义,因为它故意是无意义的,而且是用不恰当的拉丁文写的,让你专注于形式而不是内容。
与流标量相反,块标量允许改变如何处理换行符、尾随换行符或缩进。例如,位于属性名之后的竖线(
|)指示符按字面意思保留了换行符,这对于在您的 YAML 文件中嵌入 shell 脚本非常方便:script: | #!/usr/bin/env python def main(): print("Hello world") if __name__ == "__main__": main()上面的 YAML 文档定义了一个名为
script的属性,它包含一个由几行代码组成的简短 Python 脚本。如果没有管道指示符,YAML 解析器会将下面几行视为嵌套元素,而不是整体。Ansible 是一个利用 YAML 这一特点的著名例子。如果您只想折叠由段落中第一行确定缩进的行,则使用大于号(
>)指示符:text: > Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet这将产生以下输出:
Lorem ipsum dolor sit amet Lorem ipsum dolor sit amet最后,您可以将多个 YAML 文档存储在一个文件中,用三重破折号(
---)分隔。您可以选择使用三点符号(...)来标记每个文档的结尾。Python YAML 入门
正如您在简介中了解到的,在 Python 中使用 YAML 需要一些额外的步骤,因为该语言不支持这种现成的数据格式。您将需要一个第三方库来将 Python 对象序列化为 YAML,反之亦然。
除此之外,您可能会发现将这些带有 pip 的命令行工具安装到您的虚拟环境中有助于调试:
这些都是 Python 工具,但是还有 yq 的一个广泛使用的 Go 实现,它有一个稍微不同的命令行接口。如果您不能或不想安装这些程序,您可以随时使用在线工具,例如:
请注意,您只需要在下面的小节中用到其中的一些工具,而在本教程的其余部分,您将会接触到纯 Python 中的 YAML。
将 YAML 文档序列化为 JSON
即使 Python 没有提供专用的 YAML 解析器或序列化器,您也可以借助内置的
json模块在一定程度上避开这个问题。毕竟,您已经知道 YAML 是 JSON 的超集,所以您可以将数据转储为 Python 中的常规 JSON 格式,并期望外部 YAML 解析器接受它。首先,制作一个示例 Python 脚本,以便在标准输出上打印出 JSON:
# print_json.py import datetime import json person = { "firstName": "John", "dateOfBirth": datetime.date(1969, 12, 31), "married": False, "spouse": None, "children": ["Bobby", "Molly"], } print(json.dumps(person, indent=4, default=str))您创建了一个字典,然后对它调用
json.dumps()来转储一个字符串。参数default指定当 Python 不能将对象序列化为 JSON 时要调用的函数,本例中的出生日期就是这种情况。内置的str()函数将把一个datetime.date对象转换成一个 ISO 8601 字符串。现在,运行您的脚本,并通过 Unix 管道(
|)将其输出提供给前面提到的命令行 YAML 解析器之一,比如yq或shyaml:$ python print_json.py | yq -y . firstName: John dateOfBirth: '1969-12-31' married: false spouse: null children: - Bobby - Molly $ python print_json.py | shyaml get-value firstName: John dateOfBirth: '1969-12-31' married: false spouse: null children: - Bobby - Molly不错!两种解析器都以更规范的 YAML 格式格式化数据,而没有抱怨。然而,因为
yq是 JSON 的jq的一个薄薄的包装,所以您必须请求它使用-y选项和一个尾随点作为过滤表达式来进行代码转换。另外,请注意yq和shyaml之间产生的缩进略有不同。注意:要使用
yq,你必须先在你的操作系统中安装jq,如果它还没有的话。好吧,这感觉像是作弊,而且只有一种方式,因为你不能使用
json模块将 YAML 文件读回 Python。谢天谢地,有办法做到这一点。安装 PyYAML 库
Python 目前最流行的第三方 YAML 库是 PyYAML ,它一直是从 PyPI 下载的顶级包之一。它的界面看起来有点类似于内置的 JSON 模块,它得到了积极的维护,它得到了 YAML 官方网站的支持,该网站将它与一些不太受欢迎的竞争者列在一起。
要将 PyYAML 安装到您的活动虚拟环境中,请在您的终端中键入以下命令:
(venv) $ python -m pip install pyyaml该库是自包含的,不需要任何进一步的依赖,因为它是用纯 Python 编写的。然而,大多数发行版为 LibYAML 库捆绑了一个编译好的 C 绑定,这使得 PyYAML 运行得更快。要确认 PyYAML 安装是否附带了 C 绑定,请打开交互式 Python 解释器并运行以下代码片段:
>>> import yaml
>>> yaml.__with_libyaml__
True
尽管 PyYAML 是您已经安装的库的名称,但是您将导入 Python 代码中的yaml包。另外,请注意,您需要明确请求 PyYAML 利用明显更快的共享 C 库,否则它将退回到默认的纯 Python。请继续阅读,了解如何改变这种默认行为。
尽管 PyYAML 很受欢迎,但它也有一些缺点。例如,如果您需要使用 YAML 1.2 中引入的特性,比如完全 JSON 兼容性或更安全的文字,那么您最好使用从更早的 PyYAML 版本派生而来的 ruamel.yaml 库。另外,它可以进行往返解析,以在需要时保留注释和原始格式。
另一方面,如果类型安全是您主要关心的问题,或者您想要根据模式来验证 YAML 文档,那么看看 StrictYAML ,它通过忽略其最危险的特性来有意限制 YAML 规范。请记住,它不会像其他两个库一样运行得那么快。
现在,在本教程的剩余部分,您将继续使用 PyYAML,因为它是大多数 Python 项目的标准选择。请注意,前面列出的工具——YAML int、yq 和 shy AML——在表面下使用 PyYAML!
阅读并编写您的第一份 YAML 文档
假设您想要读取并解析一封假想的电子邮件,该邮件已经序列化为 YAML 格式,并存储在 Python 中的一个字符串变量中:
>>> email_message = """\ ... message: ... date: 2022-01-16 12:46:17Z ... from: john.doe@domain.com ... to: ... - bobby@domain.com ... - molly@domain.com ... cc: ... - jane.doe@domain.com ... subject: Friendly reminder ... content: | ... Dear XYZ, ... ... Lorem ipsum dolor sit amet... ... attachments: ... image1.gif: !!binary ... R0lGODdhCAAIAPAAAAIGAfr4+SwAA ... AAACAAIAAACDIyPeWCsClxDMsZ3CgA7 ... """将这样一段 YAML 反序列化为 Python 字典的最快方法是通过
yaml.safe_load()函数:
>>> import yaml
>>> yaml.safe_load(email_message)
{
'message': {
'date': datetime.datetime(2022, 1, 16, 12, 46, 17, tzinfo=(...)),
'from': 'john.doe@domain.com',
'to': ['bobby@domain.com', 'molly@domain.com'],
'cc': ['jane.doe@domain.com'],
'subject': 'Friendly reminder',
'content': 'Dear XYZ,\n\nLorem ipsum dolor sit amet...\n',
'attachments': {
'image1.gif': b'GIF87a\x08\x00\x08\x00\xf0\x00\x00\x02...'
}
}
}
调用safe_load()是目前推荐的处理来自不可信来源的内容的方式,这些内容可能包含恶意代码。YAML 有一个富有表现力的语法,充满了方便的特性,不幸的是,这为大量的漏洞打开了大门。稍后你会学到更多关于利用 YAML的弱点。
注意:在 PyYAML 库 6.0 版本之前,解析 YAML 文档的默认方式一直是yaml.load()函数,默认使用不安全的解析器。在最新的版本中,您仍然可以使用这个函数,但是它要求您显式地指定一个特定的 loader 类作为第二个参数。
引入这个额外的参数是一个突破性的变化,导致了许多维护依赖 PyYAML 的软件的人的抱怨。关于这种向后不兼容,在该库的 GitHub 库上仍然有一个固定的问题。
在撰写本教程时,官方的 PyYAML 文档以及捆绑的文档字符串还没有更新以反映当前的代码库,它们包含不再工作的示例。
safe_load()函数是几个速记函数中的一个,这些函数封装了各种 YAML 加载器类的使用。在这种情况下,单个函数调用会转化为以下更显式但等效的代码片段:
>>> from yaml import load, SafeLoader >>> load(email_message, SafeLoader) { 'message': { 'date': datetime.datetime(2022, 1, 16, 12, 46, 17, tzinfo=(...)), 'from': 'john.doe@domain.com', 'to': ['bobby@domain.com', 'molly@domain.com'], 'cc': ['jane.doe@domain.com'], 'subject': 'Friendly reminder', 'content': 'Dear XYZ,\n\nLorem ipsum dolor sit amet...\n', 'attachments': { 'image1.gif': b'GIF87a\x08\x00\x08\x00\xf0\x00\x00\x02...' } } }使用速记函数时要记住的一点是,它们硬编码了纯 Python 实现。如果你想使用更快的 C 实现,那么你必须自己写一点点样板代码:
>>> try:
... from yaml import CSafeLoader as SafeLoader
... except ImportError:
... from yaml import SafeLoader
>>> SafeLoader
<class 'yaml.cyaml.CSafeLoader'>
首先,您尝试导入一个以字母 C 为前缀的 loader 类来表示 C 库绑定的使用。如果失败,那么导入一个用 Python 实现的相应类。不幸的是,这使您的代码看起来更加冗长,并阻止您使用上面提到的快捷函数。
注意:如果你的 YAML 包含多个文档,那么load()或者它的包装器会抛出一个异常。
您之前已经通过滥用内置的json模块将一个 Python 对象序列化到 YAML,但是结果不是 YAML 的规范形式。现在,您将利用已安装的第三方 PyYAML 库来解决这个问题。有一个对应的yaml.safe_dump()函数,它接受一个 Python 对象并将其转换成一个字符串。您可以将yaml.safe_load()的输出提供给它,以便逆转解析过程:
>>> yaml.safe_dump(yaml.safe_load(email_message)) "message:\n attachments:\n image1.gif: !!binary |\n (...) >>> print(yaml.safe_dump(yaml.safe_load(email_message))) message: attachments: image1.gif: !!binary | R0lGODdhCAAIAPAAAAIGAfr4+SwAAAAACAAIAAACDIyPeWCsClxDMsZ3CgA7 cc: - jane.doe@domain.com content: 'Dear XYZ, Lorem ipsum dolor sit amet... ' date: 2022-01-16 12:46:17+00:00 from: john.doe@domain.com subject: Friendly reminder to: - bobby@domain.com - molly@domain.com结果是一个字符串对象,您的电子邮件再次序列化到 YAML。然而,这与你最初开始时的 YAML 不太一样。如您所见,
safe_dump()为您排序了字典键,引用了多行字符串,并使用了略有不同的缩进。你可以通过几个关键字参数改变其中的一些内容,并对格式进行更多的调整,这将在下一节的中探讨。用 Python 加载 YAML 文档
加载 YAML 归结为读取一段文本并根据数据格式的语法对其进行解析。由于可供选择的函数和类过多,PyYAML 可能会使这种情况变得混乱。另外,该库的文档并没有清楚地解释它们的区别和有效的用例。为了避免您调试底层代码,您将在本节中找到关于使用 PyYAML 加载文档的最重要的事实。
选择加载器类别
如果您想要最好的解析性能,那么您需要手动导入合适的 loader 类,并将其传递给通用的
yaml.load()函数,如前所示。但是你应该选择哪一个呢?要找到答案,请看一下您可以使用的装载机的高层次概述。简短的描述应该让您对可用的选项有一个大致的了解:
加载程序类 功能 描述 BaseLoader- 不解析或支持任何标签,只构造基本的 Python 对象( str、list、dict)Loader- 保持向后兼容性,其他方面与 UnsafeLoader相同UnsafeLoaderunsafe_load()支持所有标准、库和自定义标签,并且可以构造任意的 Python 对象 SafeLoadersafe_load()只支持像 !!str这样的标准 YAML 标签,不构造类实例FullLoaderfull_load()应该可以安全地装载几乎整个 YAML 您最有可能使用的三个加载器都有相应的速记函数,您可以调用这些函数,而不是将加载器类传递给通用的
yaml.load()函数。记住,这些都是用 Python 写的,所以为了提高性能,你需要导入一个合适的以字母 C 为前缀的加载器类,比如CSafeLoader,并调用yaml.load()。有关各个加载器类支持的特性的更详细的分类,请查看下表:
加载程序类 锚,别名 YAML 标签 PyYAML 标记 辅助类型 自定义类型 代码执行 UnsafeLoader(Loader)✔️ ✔️ ✔️ ✔️ ✔️ ✔️ FullLoader✔️ ✔️ ✔️ ✔️ 错误 错误 SafeLoader✔️ ✔️ 错误 ✔️ 错误 错误 BaseLoader✔️ 忽视 忽视 忽视 忽视 忽视
UnsafeLoader支持所有可用功能,允许任意代码执行。除了代码执行和反序列化定制 Python 类的能力(这会导致解析错误)之外,FullLoader是类似的。SafeLoaderpy YAML 提供的特定于 Python 的标签也有错误,比如!!python/tuple。另一方面,BaseLoader通过忽略大多数特性来保持不可知论。比较装载机的特性
下面,您将获得上述特性的快速演示。首先,导入
yaml模块并检查一个锚和别名示例:
>>> import yaml
>>> yaml.safe_load("""
... Shipping Address: &shipping |
... 1111 College Ave
... Palo Alto
... CA 94306
... USA
... Invoice Address: *shipping
... """)
{
'Shipping Address': '1111 College Ave\nPalo Alto\nCA 94306\nUSA\n',
'Invoice Address': '1111 College Ave\nPalo Alto\nCA 94306\nUSA\n'
}
您在发货地址附近定义了一个锚点&shipping,然后在别名*shipping的帮助下为发票重新使用同一个地址。因此,您只需指定一次地址。此功能适用于所有类型的装载机。
下一个例子展示了一个标准的 YAML 标签的作用:
>>> yaml.safe_load(""" ... number: 3.14 ... string: !!str 3.14 ... """) {'number': 3.14, 'string': '3.14'} >>> from yaml import BaseLoader >>> yaml.load(""" ... number: 3.14 ... string: !!str 3.14 ... """, BaseLoader) {'number': '3.14', 'string': '3.14'}默认情况下,像
3.14这样的数字文字被视为浮点数,但是您可以使用!!str标签请求将类型转换为字符串。几乎所有装载机都遵守标准的 YAML 标签。唯一的例外是BaseLoader类,它用字符串表示标量,不管你是否标记它们。为了利用库提供的 PyYAML 标签,可以使用
FullLoader或UnsafeLoader,因为它们是唯一可以处理特定于 Python 的标签的加载器:
>>> yaml.full_load("""
... list: [1, 2]
... tuple: !!python/tuple [1, 2]
... """)
{'list': [1, 2], 'tuple': (1, 2)}
上面例子中的!!python/tuple标签将一个内联列表转换成一个 Python 元组。前往 PyYAML 文档以获得支持标签的完整列表,但是一定要交叉检查 GitHub 上的源代码,因为文档可能不是最新的。
大多数加载器都善于将标量反序列化为辅助类型,比基本的字符串、列表或字典更加具体:
>>> yaml.safe_load(""" ... married: false ... spouse: null ... date_of_birth: 1980-01-01 ... age: 42 ... kilograms: 80.7 ... """) { 'married': False, 'spouse': None, 'date_of_birth': datetime.date(1980, 1, 1), 'age': 42, 'kilograms': 80.7 }在这里,您有一个混合的类型,包括一个
bool、一个None、一个datetime.date实例、一个int和一个float。同样,BaseLoader是唯一一个始终将所有标量视为字符串的加载器类。假设您想从 YAML 反序列化一个自定义类,在您的 Python 代码中调用一个函数,或者甚至在解析 YAML 时执行一个 shell 命令。在这种情况下,您唯一的选择是
UnsafeLoader,它接受一些特殊的库标签。其他加载程序要么抛出异常,要么忽略这些标签。现在您将了解更多关于 PyYAML 标记的内容。探索装载机的不安全特性
PyYAML 允许您通过接入接口来序列化和反序列化任何可选择的 Python 对象。请记住,这允许任意代码执行,您很快就会发现这一点。然而,如果您不在乎损害您的应用程序的安全性,那么这个功能会非常方便。
该库提供了几个由
UnsafeLoader识别的 YAML 标签来完成对象创建:
!!python/object!!python/object/new!!python/object/apply它们后面都必须跟一个要实例化的类的完全限定名,包括包和模块名。第一个标记期望一个键-值对的映射,要么是流样式,要么是块样式。这里有一个例子:
# Flow style: !!python/object:models.Person {first_name: John, last_name: Doe} # Block style: !!python/object:models.Person first_name: John last_name: Doe其他两个标签更复杂,因为每个标签都有两种风格。然而,这两个标签几乎是相同的,因为
!!python/object/new将处理委托给了!!python/object/apply。唯一的区别是,!!python/object/new在指定的类上调用特殊方法.__new__(),而不调用.__init__(),而!!python/object/apply调用类本身,这是您在大多数情况下想要的。该语法的一种风格允许通过一列位置参数来设置对象的初始状态,如下所示:
# Flow style: !!python/object/apply:models.Person [John, Doe] # Block style: !!python/object/apply:models.Person - John - Doe这两种风格都通过调用
Person类中的.__init__()方法来实现类似的效果,这两个方法将两个值作为位置参数传递。或者,您可以使用稍微冗长一点的语法,允许您混合位置和关键字参数,以及一些为了简洁而忽略的更高级的技巧:!!python/object/apply:models.Person args: [John] kwds: {last_name: Doe}这仍然会调用你的类上的
.__init__(),但是其中一个参数会作为关键字参数传递。在任何情况下,您都可以手动定义Person类,或者利用 Python 中的数据类:# models.py from dataclasses import dataclass @dataclass class Person: first_name: str last_name: str这种简洁的语法将使 Python 生成类初始化器以及其他一些您必须自己编码的方法。
注意,您可以对任何可调用对象使用
!!python/object/apply,包括常规函数,并指定要传递的参数。这允许您执行一个内置函数、一个定制函数,甚至是一个模块级函数,PyYAML 会很乐意为您导入这些函数。那是一个巨大的安全漏洞!想象一下使用os或subprocess模块运行一个 shell 命令来检索您的私有 SSH 密钥(如果您已经定义了一个):
>>> import yaml
>>> yaml.unsafe_load("""
... !!python/object/apply:subprocess.getoutput
... - cat ~/.ssh/id_rsa
... """)
'-----BEGIN RSA PRIVATE KEY-----\njC7PbMIIEow...
创建对象时,通过网络用窃取的数据发出 HTTP 请求并不困难。不良行为者可能会利用这些信息,使用您的身份访问敏感资源。
有时,这些标记会绕过正常的对象创建路径,这通常是对象序列化机制的典型特征。假设您想从 YAML 加载一个用户对象,并使其成为以下类的实例:
# models.py
class User:
def __init__(self, name):
self.name = name
您将User类放在一个名为models.py的单独的源文件中,以保持有序。用户对象只有一个属性—名称。通过只使用一个属性并显式实现初始化器,您将能够观察 PyYAML 调用各个方法的方式。
当你决定在 YAML 使用!!python/object标签时,那么库调用.__new__()而没有任何参数,并且从不调用.__init__()。相反,它直接操纵新创建对象的.__dict__属性,这可能会产生一些不良影响:
>>> import yaml >>> user = yaml.unsafe_load(""" ... !!python/object:models.User ... no_such_attribute: 42 ... """) >>> user <models.User object at 0x7fe8adb12050> >>> user.no_such_attribute 42 >>> user.name Traceback (most recent call last): ... AttributeError: 'User' object has no attribute 'name'虽然您无疑已经创建了一个新的
User实例,但是它没有正确初始化,因为缺少了.name属性。然而,它确实有一个意想不到的.no_such_attribute,这在类体中是无处可寻的。您可以通过在您的类中添加一个
__slots__声明来解决这个问题,一旦对象存在于内存中,它将禁止动态添加或删除属性:# models.py class User: __slots__ = ["name"] def __init__(self, name): self.name = name现在,你的用户对象根本不会有
.__dict__属性。因为没有固有的.__dict__,所以对于空白对象上的每个键-值对,这个库只能调用setattr()。这确保了只有__slots__中列出的属性会通过。这些都很好,但是如果
User类接受了密码参数会怎么样呢?为了减少数据泄漏,您肯定不希望以明文形式序列化密码。那么序列化有状态属性怎么样呢,比如文件描述符或者数据库连接?好吧,如果恢复对象的状态需要运行一些代码,那么您可以在您的类中使用特殊的.__setstate__()方法定制序列化过程:# models.py import codecs class User: __slots__ = ["name"] def __init__(self, name): self.name = name def __setstate__(self, state): self.name = codecs.decode(state["name"], "rot13")您使用原始的 ROT-13 密码对持久化的用户名进行解码,该密码将字符在字母表中旋转十三个位置。但是,对于严格的加密,您必须超越标准库。请注意,如果您想安全地存储密码,也可以使用内置
hashlib模块中的哈希算法。这里有一种从 YAML 加载编码状态的方法:
>>> user = yaml.unsafe_load("""
... !!python/object:models.User
... name: Wbua Qbr
... """)
>>> user.name
'John Doe'
只要你已经定义了.__setstate__()方法,它总是优先的,并且给你设置对象状态的控制权。这就是为什么您能够从上面的编码文本中恢复原来的名称'John Doe'。
在继续之前,值得注意的是 PyYAML 提供了两个更不安全的标签:
!!python/name!!python/module
第一种方法允许您在代码中加载对 Python 对象的引用,如类、函数或变量。第二个标记允许引用给定的 Python 模块。在下一节中,您将看到 PyYAML 允许您从中加载文档的不同数据源。
从字符串、文件或流中加载文档
一旦选择了 loader 类或使用了其中一个速记函数,就不再局限于只解析字符串了。PyYAML 公开的safe_load()和其他函数接受单个参数,这是字符或字节的通用流。这种流最常见的例子是字符串和 Python bytes对象:
>>> import yaml >>> yaml.safe_load("name: Иван") {'name': 'Иван'} >>> yaml.safe_load(b"name: \xd0\x98\xd0\xb2\xd0\xb0\xd0\xbd") {'name': 'Иван'}根据 YAML 1.2 规范,为了与 JSON 兼容,解析器应该支持用 UTF-8 、 UTF-16 或 UTF-32 编码的 Unicode 。但是,因为 PyYAML 库只支持 YAML 1.1,所以您唯一的选择是 UTF-8 和 UTF-16:
>>> yaml.safe_load("name: Иван".encode("utf-8"))
{'name': 'Иван'}
>>> yaml.safe_load("name: Иван".encode("utf-16"))
{'name': 'Иван'}
>>> yaml.safe_load("name: Иван".encode("utf-32"))
Traceback (most recent call last):
...
yaml.reader.ReaderError: unacceptable character #x0000:
special characters are not allowed
in "<byte string>", position 1
如果你尝试从 UTF-32 编码的文本中加载 YAML,你会得到一个错误。然而,这在实践中几乎不成问题,因为 UTF-32 不是一种常见的编码。在任何情况下,您都可以在加载 YAML 之前,使用 Python 的 str.encode()和str.decode() 方法自己进行适当的代码转换。或者,您可以尝试前面提到的其他 YAML 解析库。
你也可以直接从文件中读取 YAML 的内容。继续操作,创建一个包含示例 YAML 内容的文件,并使用 PyYAML 将其加载到 Python 中:
>>> with open("sample.yaml", mode="wb") as file: ... file.write(b"name: \xd0\x98\xd0\xb2\xd0\xb0\xd0\xbd") ... 14 >>> with open("sample.yaml", mode="rt", encoding="utf-8") as file: ... print(yaml.safe_load(file)) ... {'name': 'Иван'} >>> with open("sample.yaml", mode="rb") as file: ... print(yaml.safe_load(file)) ... {'name': 'Иван'}您在当前工作目录下创建一个名为
sample.yaml的本地文件,并编写 14 个字节来表示一个示例 YAML 文档。接下来,您打开该文件进行读取,并使用safe_load()获取相应的字典。该文件可以以文本或二进制模式打开。事实上,您可以传递任何类似文件的字符流或字节流,比如内存中的 io。StringIO 文本缓冲区或二进制 io。字节流:
>>> import io
>>> yaml.safe_load(io.StringIO("name: Иван"))
{'name': 'Иван'}
>>> yaml.safe_load(io.BytesIO(b"name: \xd0\x98\xd0\xb2\xd0\xb0\xd0\xbd"))
{'name': 'Иван'}
如您所见,PyYAML 中的加载函数非常通用。比较一下json模块,它根据输入参数的类型提供不同的函数。然而,PyYAML 捆绑了另一组函数,可以帮助您从一个流中读取多个文档。现在您将了解这些功能。
加载多个文档
PyYAML 中的所有四个加载函数都有它们的 iterable 对应物,可以从单个流中读取多个 YAML 文档。他们仍然只需要一个参数,但是他们没有立即将它解析成 Python 对象,而是用一个可以迭代的生成器迭代器将它包装起来:
>>> import yaml >>> stream = """\ ... --- ... 3.14 ... --- ... name: John Doe ... age: 53 ... --- ... - apple ... - banana ... - orange ... """ >>> for document in yaml.safe_load_all(stream): ... print(document) ... 3.14 {'name': 'John Doe', 'age': 53} ['apple', 'banana', 'orange']单个文档必须以三连破折号(
---)开头,也可以选择以三个点(...)结尾。在本节中,您了解了 PyYAML 中用于加载文档的高级函数。不幸的是,他们试图急切地一口气读完整个流,这并不总是可行的。以这种方式读取大文件会花费太长时间,甚至由于有限的内存而失败。如果您想以类似于 XML 中 SAX 接口的流式方式处理 YAML,那么您必须使用 PyYAML 提供的低级 API 。
将 Python 对象转储到 YAML 文档中
如果您以前在 Python 中使用过 JSON,那么将 Python 对象序列化或“转储”到 YAML 看起来会比加载它们更熟悉。PyYAML 库有一个有点类似于内置
json模块的接口。它还提供了比加载器更少的转储器类和包装器函数可供选择,因此您不必处理那么多选项。选择转储器类别
PyYAML 中全面的 YAML 序列化函数是
yaml.dump(),它以一个可选的 dumper 类作为参数。如果在函数调用过程中没有指定,那么它会使用特性最丰富的yaml.Dumper。其他选择如下:
转储器类别 功能 描述 BaseDumperdump(Dumper=BaseDumper)不支持任何标签,只对子类化有用 SafeDumpersafe_dump()只产生像 !!str这样的标准 YAML 标签,并且不能表示类实例,这使得它与其他 YAML 解析器更加兼容Dumperdump()支持所有标准、库和自定义标签,可以序列化任意 Python 对象,因此它可能会生成其他 YAML 解析器无法加载的文档 实际上,你真正的选择是在
Dumper和SafeDumper之间,因为BaseDumper只是作为子类扩展的基类。通常,在大多数情况下,您会希望坚持使用默认的yaml.Dumper,除非您需要生成没有 Python 特有的怪癖的可移植 YAML。同样,记住导入相应的以字母 C 为前缀的转储器类,以获得最佳的序列化性能,并且记住 Python 和 C 实现之间可能会有细微的差别:
>>> import yaml
>>> print(yaml.dump(3.14, Dumper=yaml.Dumper))
3.14
...
>>> print(yaml.dump(3.14, Dumper=yaml.CDumper))
3.14
例如,pure Python dumper 在 YAML 文档的末尾添加了可选的点,而 LibYAML 库的一个类似的包装器类没有这样做。但是,这些只是表面上的差异,对序列化或反序列化的数据没有实际影响。
转储到字符串、文件或流
在 Python 中序列化 JSON 需要您根据您希望内容被转储到哪里来选择是调用json.dump()还是json.dumps()。另一方面,PyYAML 提供了一个二合一的转储函数,根据您对它的调用方式,它的行为会有所不同:
>>> data = {"name": "John"} >>> import yaml >>> yaml.dump(data) 'name: John\n' >>> import io >>> stream = io.StringIO() >>> print(yaml.dump(data, stream)) None >>> stream.getvalue() 'name: John\n'当用单个参数调用时,该函数返回一个表示序列化对象的字符串。但是,您可以选择传递第二个参数来指定要写入的目标流。它可以是一个文件或任何类似文件的对象。当您传递这个可选参数时,函数返回
None,您需要根据需要从流中提取数据。如果你想把你的 YAML 转储到一个文件中,那么一定要在写模式下打开这个文件。此外,当文件以二进制模式打开时,必须通过可选的关键字参数将字符编码指定给
yaml.dump()函数:
>>> with open("/path/to/file.yaml", mode="wt", encoding="utf-8") as file:
... yaml.dump(data, file)
>>> with open("/path/to/file.yaml", mode="wb") as file:
... yaml.dump(data, file, encoding="utf-8")
当你在文本模式下打开一个文件时,显式地设置字符编码总是一个好习惯。否则,Python 将采用您平台的默认编码,这可能会降低可移植性。字符编码在二进制模式下没有意义,二进制模式处理的是已经编码的字节。不过,您应该通过yaml.dump()函数设置编码,该函数接受更多可选参数,您很快就会了解到。
转储多个文档
PyYAML 中的两个 YAML 转储函数dump()和safe_dump()无法知道您是想要序列化多个单独的文档还是包含一个元素序列的单个文档:
>>> import yaml >>> print(yaml.dump([ ... {"title": "Document #1"}, ... {"title": "Document #2"}, ... {"title": "Document #3"}, ... ])) - title: 'Document #1' - title: 'Document #2' - title: 'Document #3'他们总是假设后者,转储一个带有元素列表的 YAML 文档。要转储多个文档,请使用
dump_all()或safe_dump_all():
>>> print(yaml.dump_all([
... {"title": "Document #1"},
... {"title": "Document #2"},
... {"title": "Document #3"},
... ]))
title: 'Document #1'
---
title: 'Document #2'
---
title: 'Document #3'
现在,您得到一个包含多个 YAML 文档的字符串,用三重破折号(---)分隔。
请注意,dump_all()是唯一使用的函数,因为所有其他函数,包括dump()和safe_dump(),都将处理委托给它。所以,不管你调用哪个函数,它们都有相同的形参列表。
用可选参数调整格式
PyYAML 中的转储函数接受一些位置参数和一些可选的关键字参数,这使您可以控制输出的格式。唯一需要的参数是 Python 对象或要序列化的对象序列,在所有转储函数中作为第一个参数传递。您将仔细查看本节中的可用参数。
委托给yaml.dump_all()的三个包装器有下面的函数签名,揭示了它们的位置参数:
def dump(data, stream=None, Dumper=Dumper, **kwargs): ...
def safe_dump(data, stream=None, **kwargs): ...
def safe_dump_all(documents, stream=None, **kwargs): ...
第一个函数需要一到三个位置参数,因为其中两个有可选值。另一方面,上面列出的第二个和第三个函数只需要两个位置参数,因为它们都使用预定义的SafeDumper。要找到可用的关键字参数,您必须查看yaml.dump_all()函数的签名。
您可以在所有四个转储函数中使用相同的关键字参数。它们都是可选的,因为它们的默认值等于None或False,除了sort_keys参数,其默认值为True。总共有六个布尔标志,您可以打开和关闭它们来更改生成的 YAML 的外观:
| 布尔标志 | 意义 |
|---|---|
allow_unicode |
不要对 Unicode 进行转义,也不要使用双引号。 |
canonical |
以标准形式输出 YAML。 |
default_flow_style |
更喜欢流动风格而不是块状风格。 |
explicit_end |
以三点(...)结束每个文档。 |
explicit_start |
每个文档以三连破折号(---)开始。 |
sort_keys |
按关键字对字典的输出进行排序。 |
其他数据类型也有几个参数可以给你更多的自由:
| 参数 | 类型 | 意义 |
|---|---|---|
indent |
int |
块缩进级别,必须大于 1 小于 10 |
width |
int |
线宽,必须大于缩进的两倍 |
default_style |
str |
标量报价样式,必须是下列之一:None、"'"或'"' |
encoding |
str |
字符编码,设置时产生bytes而不是str |
line_break |
str |
换行符,必须是下列字符之一:'\r'、'\n'或'\r\n' |
tags |
dict |
由标记句柄组成的附加标记指令 |
version |
tuple |
主要和次要 YAML 版本,如(1, 2)为版本 1.2 |
大部分都是不言自明的。然而,tags参数必须是一个字典,它将定制的标签句柄映射到 YAML 解析器识别的有效的 URI 前缀:
{"!model!": "tag:yaml.org,2002:python/object:models."}
指定这样的映射会将相关的标记指令添加到转储的文档中。标签句柄总是以感叹号开始和结束。它们是完整标记名的简写符号。例如,在 YAML 文档中使用相同标签的所有等效方式如下:
%TAG !model! tag:yaml.org,2002:python/object:models. --- - !model!Person first_name: John last_name: Doe - !!python/object:models.Person first_name: John last_name: Doe - !<tag:yaml.org,2002:python/object:models.Person> first_name: John last_name: Doe
通过在 YAML 文档上面使用一个%TAG指令,您声明了一个名为!model!的定制标记句柄,它被扩展成下面的前缀。双感叹号(!!)是默认名称空间的内置快捷方式,对应于前缀tag:yaml.org,2002:。
您可以通过更改关键字参数的值并重新运行您的代码来查看结果,从而试验可用的关键字参数。然而,这听起来像是一个乏味的任务。本教程的辅助材料附带了一个交互式应用程序,可让您在 web 浏览器中测试参数及其值的不同组合:
https://player.vimeo.com/video/673144581?background=1
这是一个动态网页,使用 JavaScript 通过网络与用 FastAPI 编写的最小 HTTP 服务器通信。服务器需要一个 JSON 对象,除了关键字参数tags之外,其他参数都包含在内,并对下面的测试对象调用yaml.dump():
{
"person": {
"name_latin": "Ivan",
"name": "Иван",
"age": 42,
}
}
上面的示例对象是一个包含整数和字符串字段的字典,其中包含 Unicode 字符。要运行服务器,您必须首先在您的虚拟环境中安装 FastAPI 库和一个 ASGI web 服务器,比如uvicon,您之前已经在那里安装了 PyYAML:
(venv) $ python -m pip install fastapi uvicorn
(venv) $ uvicorn server:app
要运行服务器,必须提供模块名,后跟一个冒号和该模块中 ASGI 兼容的可调用程序的名称。实现这样一个服务器和一个客户机的细节远远超出了本教程的范围,但是您可以随意下载示例材料来自己学习:
获取源代码: 点击此处获取源代码,您将使用在 Python 中使用 YAML。
接下来,您将了解更多关于使用 PyYAML 转储自定义类的内容。
转储自定义数据类型
正如您已经知道的,此时,您可以使用 PyYAML 提供的特定于 Python 的标记之一来序列化和反序列化您的自定义数据类型的对象,比如类。您还知道,这些标记只被不安全的加载程序和转储程序识别,这明确地允许潜在危险的代码执行。该库将拒绝序列化特定于 Python 的类型,如复数,除非您选择不安全的转储器类:
>>> import yaml >>> yaml.safe_dump(complex(3, 2)) Traceback (most recent call last): ... yaml.representer.RepresenterError: ('cannot represent an object', (3+2j)) >>> yaml.dump(complex(3, 2)) "!!python/complex '3.0+2.0j'\n"在第一种情况下,安全转储器不知道如何在 YAML 表示您的复数。另一方面,调用
yaml.dump()在幕后隐式使用不安全的Dump类,这利用了!!python/complex标签。当您尝试转储自定义类时,情况类似:
>>> class Person:
... def __init__(self, first_name, last_name):
... self.first_name = first_name
... self.last_name = last_name
...
>>> yaml.safe_dump(Person("John", "Doe"))
Traceback (most recent call last):
...
yaml.representer.RepresenterError: ('cannot represent an object',
<__main__.Person object at 0x7f55a671e8f0>)
>>> yaml.dump(Person("John", "Doe"))
!!python/object:__main__.Person
first_name: John
last_name: Doe
你唯一的选择就是不安全的yaml.dump()。然而,可以将您的类标记为可安全解析的,这样即使是安全的加载程序也能够在以后处理它们。为此,您必须对您的类进行一些更改:
>>> class Person(yaml.YAMLObject): ... yaml_tag = "!Person" ... yaml_loader = yaml.SafeLoader ... def __init__(self, first_name, last_name): ... self.first_name = first_name ... self.last_name = last_name首先,让类从
yaml.YAMLObject继承。然后指定两个类属性。一个属性将代表与您的类相关联的自定义 YAML 标记,而第二个属性将是要使用的加载器类。现在,当你把一个Person对象转储到 YAML 时,你将能够用yaml.safe_load()把它装载回来:
>>> print(jdoe := yaml.dump(Person("John", "Doe")))
!Person
first_name: John
last_name: Doe
>>> yaml.safe_load(jdoe)
<__main__.Person object at 0x7f6fb7ba9ab0>
Walrus 操作符(:= ) 允许您定义一个变量,并在一个步骤中将其用作print()函数的参数。将类标记为安全是一个很好的妥协,允许您通过忽略安全性并允许它们进入来对一些类进行例外处理。当然,在尝试加载关联的 YAML 之前,您必须绝对确定它们没有任何可疑之处。
底层解析 YAML 文档
到目前为止,您使用的类和一些包装函数构成了一个高级 PyYAML 接口,它隐藏了使用 YAML 文档的实现细节。这涵盖了大多数用例,并允许您将注意力集中在数据上,而不是数据的表示上。但是,有时您可能希望对解析和序列化过程有更多的控制。
在那些罕见的情况下,该库通过几个低级函数向您公开其内部工作方式。有四种方法可以阅读 YAML 流:
| 阅读功能 | 返回值 | 懒? |
|---|---|---|
yaml.scan() |
代币 | ✔️ |
yaml.parse() |
事件 | ✔️ |
yaml.compose() |
结节 | |
yaml.compose_all() |
节点 | ✔️ |
所有这些函数都接受一个流和一个可选的 loader 类,默认为yaml.Loader。除此之外,它们中的大多数返回一个生成器对象,让你以一种流的方式处理 YAML,这在这一点上是不可能的。稍后您将了解令牌、事件和节点之间的区别。
还有一些对应的函数可以将 YAML 写到流中:
| 书写功能 | 投入 | 例子 |
|---|---|---|
yaml.emit() |
事件 | yaml.emit(yaml.parse(data)) |
yaml.serialize() |
结节 | yaml.serialize(yaml.compose(data)) |
yaml.serialize_all() |
节点 | yaml.serialize_all(yaml.compose_all(data)) |
请注意,无论您选择什么功能,您都可能比以前有更多的工作要做。例如,处理 YAML 标签或将字符串值解释为正确的原生数据类型现在就在您的法庭上。但是,根据您的使用情况,其中一些步骤可能是不必要的。
在本节中,您将在 PyYAML 中实现这些低级函数的三个实际例子。请记住,您可以通过下面的链接下载它们的源代码:
获取源代码: 点击此处获取源代码,您将使用在 Python 中使用 YAML。
标记一个 YAML 文档
通过扫描 YAML 文档获得一串令牌,您将获得最细粒度的控制。每个标记都有独特的含义,并告诉您它在哪里开始,在哪里结束,包括确切的行号和列号,以及从文档开始的偏移量:
>>> import yaml >>> for token in yaml.scan("Lorem ipsum", yaml.SafeLoader): ... print(token) ... print(token.start_mark) ... print(token.end_mark) ... StreamStartToken(encoding=None) in "<unicode string>", line 1, column 1: Lorem ipsum ^ in "<unicode string>", line 1, column 1: Lorem ipsum ^ ScalarToken(plain=True, style=None, value='Lorem ipsum') in "<unicode string>", line 1, column 1: Lorem ipsum ^ in "<unicode string>", line 1, column 12: Lorem ipsum ^ StreamEndToken() in "<unicode string>", line 1, column 12: Lorem ipsum ^ in "<unicode string>", line 1, column 12: Lorem ipsum ^令牌的
.start_mark和.end_mark属性包含所有相关信息。例如,如果你想为你最喜欢的代码编辑器实现一个 YAML 语法荧光笔插件,这是完美的。事实上,您为什么不继续构建一个用于彩色打印 YAML 内容的基本命令行工具呢?首先,您需要缩小标记类型的范围,因为您只对着色标量值、映射键和 YAML 标记感兴趣。创建一个名为
colorize.py的新文件,并将以下函数放入其中:1# colorize.py 2 3import yaml 4 5def tokenize(text, loader=yaml.SafeLoader): 6 last_token = yaml.ValueToken(None, None) 7 for token in yaml.scan(text, loader): 8 start = token.start_mark.index 9 end = token.end_mark.index 10 if isinstance(token, yaml.TagToken): 11 yield start, end, token 12 elif isinstance(token, yaml.ScalarToken): 13 yield start, end, last_token 14 elif isinstance(token, (yaml.KeyToken, yaml.ValueToken)): 15 last_token = token它是 PyYAML 的
yaml.scan()函数的一个瘦包装器,该函数生成包含起始索引、结束索引和一个令牌实例的元组。以下是更详细的分类:
- 第 6 行定义了一个变量来保存最后一个令牌实例。只有标量和标记令牌包含值,所以您必须记住它们的上下文,以便以后选择正确的颜色。当文档只包含一个标量而没有任何上下文时,使用初始值。
- 第 7 行在扫描的代币上循环。
- 第 8 行和第 9 行从所有标记上可用的索引标记中提取标记在文本中的位置。令牌的位置由
start和end界定。- 第 10 到 13 行检查当前的令牌类型,并产生索引和一个令牌实例。如果令牌是一个标签,那么它就会被放弃。如果令牌是标量,那么就会产生
last_token,因为标量可以出现在不同的上下文中,您需要知道当前的上下文是什么才能选择适当的颜色。- 第 14 行和第 15 行如果当前令牌是映射键或值,则更新上下文。其他标记类型被忽略,因为它们没有有意义的可视化表示。
当您将函数导入到交互式 Python 解释器会话中时,您应该能够开始迭代带有相关索引的标记子集:
>>> from colorize import tokenize
>>> for token in tokenize("key: !!str value"):
... print(token)
...
(0, 3, KeyToken())
(5, 10, TagToken(value=('!!', 'str')))
(11, 16, ValueToken())
整洁!您可以利用这些元组,使用第三方库或 ANSI 转义序列来注释原始文本中的标记,只要您的终端支持它们。以下是一些带有转义序列的颜色示例:
| 颜色 | 字体粗细 | 换码顺序 |
|---|---|---|
| 蓝色 | 大胆的 | ESC[34;1m |
| 蓝绿色 | 规则的 | ESC[36m |
| 红色 | 规则的 | ESC[31m |
例如,键可能变成蓝色,值可能变成青色,YAML 标签可能变成红色。记住你不能在迭代的时候修改元素序列,因为那样会改变它们的索引。然而,您可以做的是从另一端开始迭代。这样,插入转义序列不会影响文本的其余部分。
现在返回代码编辑器,向 Python 源文件添加另一个函数:
# colorize.py
import yaml
def colorize(text):
colors = {
yaml.KeyToken: lambda x: f"\033[34;1m{x}\033[0m",
yaml.ValueToken: lambda x: f"\033[36m{x}\033[0m",
yaml.TagToken: lambda x: f"\033[31m{x}\033[0m",
}
for start, end, token in reversed(list(tokenize(text))):
color = colors.get(type(token), lambda text: text)
text = text[:start] + color(text[start:end]) + text[end:]
return text
# ...
这个新函数在 reverse 中遍历一个标记化的文本,并在由start和end指示的地方插入转义码序列。请注意,这不是最有效的方法,因为由于切片和连接,您最终会制作大量文本副本。
拼图的最后一块是从标准输入中取出 YAML,并将其呈现到标准输出流中:
# colorize.py
import sys import yaml
# ...
if __name__ == "__main__":
print(colorize("".join(sys.stdin.readlines())))
从 Python 的标准库中导入sys模块,并将sys.stdin引用传递给刚刚创建的colorize()函数。现在,您可以在终端中运行您的脚本,并享受彩色编码的 YAML 代币:
https://player.vimeo.com/video/673193047?background=1
请注意,cat命令在 Windows 上不可用。如果那是你的操作系统,那么使用它的 type 对应物,并确保通过终端应用程序运行命令,而不是通过命令提示符(cmd.exe ) 或 Windows PowerShell 来默认启用 ANSI 转义码支持。
展开下面的可折叠部分,查看脚本的完整源代码:
# colorize.py
import sys
import yaml
def colorize(text):
colors = {
yaml.KeyToken: lambda x: f"\033[34;1m{x}\033[0m",
yaml.ValueToken: lambda x: f"\033[36m{x}\033[0m",
yaml.TagToken: lambda x: f"\033[31m{x}\033[0m",
}
for start, end, token in reversed(list(tokenize(text))):
color = colors.get(type(token), lambda text: text)
text = text[:start] + color(text[start:end]) + text[end:]
return text
def tokenize(text, loader=yaml.SafeLoader):
last_token = yaml.ValueToken(None, None)
for token in yaml.scan(text, loader):
start = token.start_mark.index
end = token.end_mark.index
if isinstance(token, yaml.TagToken):
yield start, end, token
elif isinstance(token, yaml.ScalarToken):
yield start, end, last_token
elif isinstance(token, (yaml.KeyToken, yaml.ValueToken)):
last_token = token
if __name__ == "__main__":
print(colorize("".join(sys.stdin.readlines())))
标记化对于实现语法高亮器非常有用,它必须能够引用源 YAML 文件中的符号。但是,对于其他不关心输入数据的确切布局的应用程序来说,这可能有点太低级了。接下来,您将了解处理 YAML 的另一种方法,这也涉及到流。
解析事件流
PyYAML 提供的另一个底层接口是一个事件驱动的流 API,它的工作方式类似于 XML 中的 SAX。它将 YAML 转化为由单个元素触发的事件的平面序列。事件被延迟评估,而不需要将整个文档加载到内存中。你可以把它想象成透过一扇移动的窗户偷窥。
这有助于绕过试图读取大文件时可能面临的内存限制。它还可以大大加快在噪音海洋中搜索特定信息的速度。除此之外,流式传输还可以为您的数据逐步构建另一种表示方式。在本节中,您将创建一个 HTML 构建器,以一种粗略的方式可视化 YAML。
当您使用 PyYAML 解析文档时,该库会产生一系列事件:
>>> import yaml >>> for event in yaml.parse("[42, {pi: 3.14, e: 2.72}]", yaml.SafeLoader): ... print(event) ... StreamStartEvent() DocumentStartEvent() SequenceStartEvent(anchor=None, tag=None, implicit=True) ScalarEvent(anchor=None, tag=None, implicit=(True, False), value='42') MappingStartEvent(anchor=None, tag=None, implicit=True) ScalarEvent(anchor=None, tag=None, implicit=(True, False), value='pi') ScalarEvent(anchor=None, tag=None, implicit=(True, False), value='3.14') ScalarEvent(anchor=None, tag=None, implicit=(True, False), value='e') ScalarEvent(anchor=None, tag=None, implicit=(True, False), value='2.72') MappingEndEvent() SequenceEndEvent() DocumentEndEvent() StreamEndEvent()如您所见,有各种类型的事件对应于 YAML 文档中的不同元素。其中一些事件公开了额外的属性,您可以检查这些属性以了解更多关于当前元素的信息。
您可以想象这些事件如何自然地转化为 HTML 等分层标记语言中的开始和结束标记。例如,您可以用下面的标记片段表示上面的结构:
<ul> <li>42</li> <li> <dl> <dt>pi</dt> <dd>3.14</dd> <dt>e</dt> <dd>2.72</dd> </dl> </li> </ul>单个列表项被包装在
<li>和</li>标签之间,而键值映射利用了描述列表(<dl>) ,它包含交替的术语(<dt>) 和定义(<dd>) 。这是一个棘手的部分,因为它需要在给定的嵌套层次上计算后续的 YAML 事件,以确定一个事件是否应该成为 HTML 中的一个术语或定义。最终,您希望设计一个
HTMLBuilder类来帮助您以一种懒惰的方式解析来自流的多个 YAML 文档。假设您已经定义了这样一个类,那么您可以在一个名为yaml2html.py的文件中创建下面的帮助函数:# yaml2html.py import yaml # ... def yaml2html(stream, loader=yaml.SafeLoader): builder = HTMLBuilder() for event in yaml.parse(stream, loader): builder.process(event) if isinstance(event, yaml.DocumentEndEvent): yield builder.html builder = HTMLBuilder()代码在一系列解析器事件上循环,并将它们交给您的类,该类通过增量构建其表示将 YAML 转换为 HTML。一旦该函数检测到流中 YAML 文档的结尾,它就会产生一个 HTML 片段,并创建一个新的空构建器来重新开始。这避免了在处理可能无限长的 YAML 文档流的过程中发生阻塞,这些文档可能通过网络到达:
>>> from yaml2html import yaml2html
>>> for document in yaml2html("""
... ---
... title: "Document #1"
... ---
... title: "Document #2"
... ---
... title: "Document #3"
... """):
... print(document)
...
<dl><dt>title</dt><dd>Document #1</dd></dl>
<dl><dt>title</dt><dd>Document #2</dd></dl>
<dl><dt>title</dt><dd>Document #3</dd></dl>
上面的例子演示了一个由三个 YAML 文档组成的流,helper 函数将这些文档转换成单独的 HTML 片段。现在您已经理解了预期的行为,是时候实现HTMLBuilder类了。
构建器类中的初始化器方法将定义两个私有字段来跟踪当前的上下文和到目前为止构建的 HTML 内容:
# yaml2html.py
import yaml
class HTMLBuilder:
def __init__(self):
self._context = []
self._html = []
@property
def html(self):
return "".join(self._html)
# ...
上下文是一个作为 Python 列表实现的栈,它存储了到目前为止处理的给定级别上的键值对的数量。堆栈还可以包含指示SequenceStartEvent和SequenceEndEvent之间状态的列表标记。另一个字段是 HTML 标签及其内容的列表,由一个公共类属性连接。
有几个 YAML 事件你会想要处理:
1# yaml2html.py
2
3import yaml
4
5from yaml import (
6 ScalarEvent,
7 SequenceStartEvent,
8 SequenceEndEvent,
9 MappingStartEvent,
10 MappingEndEvent,
11)
12
13OPEN_TAG_EVENTS = (ScalarEvent, SequenceStartEvent, MappingStartEvent)
14CLOSE_TAG_EVENTS = (ScalarEvent, SequenceEndEvent, MappingEndEvent)
15
16class HTMLBuilder:
17 # ...
18
19 def process(self, event):
20
21 if isinstance(event, OPEN_TAG_EVENTS):
22 self._handle_tag()
23
24 if isinstance(event, ScalarEvent):
25 self._html.append(event.value)
26 elif isinstance(event, SequenceStartEvent):
27 self._html.append("<ul>")
28 self._context.append(list)
29 elif isinstance(event, SequenceEndEvent):
30 self._html.append("</ul>")
31 self._context.pop()
32 elif isinstance(event, MappingStartEvent):
33 self._html.append("<dl>")
34 self._context.append(0)
35 elif isinstance(event, MappingEndEvent):
36 self._html.append("</dl>")
37 self._context.pop()
38
39 if isinstance(event, CLOSE_TAG_EVENTS):
40 self._handle_tag(close=True)
41# ...
通过检查堆栈上是否有任何打开的标记等待某个操作来开始处理一个事件。您将该检查委托给另一个助手方法._handle_tag(),稍后您将添加该方法。然后,添加对应于当前事件的 HTML 标记,并再次更新上下文。
下面是上面片段的快速逐行摘要:
- 第 5 行到第 11 行从 PyYAML 导入所需的事件类型。
- 第 13 行和第 14 行指定了对应于 HTML 开始和结束标签的事件类型。
- 第 24 行到第 37 行附加相应的 HTML 标签,并根据需要更新堆栈。
- 第 21、22、39 和 40 行打开或关闭堆栈上的挂起标签,并可选地更新被处理的键值对的数量。
缺少的部分是在必要时负责打开和关闭匹配标记的 helper 方法:
# yaml2html.py
import yaml
# ...
class HTMLBuilder:
# ...
def _handle_tag(self, close=False):
if len(self._context) > 0:
if self._context[-1] is list:
self._html.append("</li>" if close else "<li>")
else:
if self._context[-1] % 2 == 0:
self._html.append("</dt>" if close else "<dt>")
else:
self._html.append("</dd>" if close else "<dd>")
if close:
self._context[-1] += 1
# ...
如果堆栈上已经有东西了,那么你就检查最后一个被放进去的东西。如果是列表,则打开或关闭列表项。否则,根据键-值映射的数量的奇偶性,是时候打开或关闭描述列表中的术语或定义了。
您可以通过在底部添加 if __name__习语来将您的 Python 模块转换成可执行脚本:
# yaml2html.py
import sys
# ...
if __name__ == "__main__":
print("".join(yaml2html("".join(sys.stdin.readlines()))))
当您将 HTML 输出通过管道传输到基于文本的网络浏览器(如 T2 的 Lynx 或 T4 的 html2text 转换器)时,它可以让您在终端上预览 YAML 的视觉表现:
$ echo '[42, {pi: 3.14, e: 2.72}]' | python yaml2html.py | html2text
* 42
* pi
3.14
e
2.72
命令应该可以在所有主要的操作系统上运行。它在终端中打印一段文本,您可以使用竖线字符(|)将这段文本连接到另一个命令管道。在这种情况下,您用您的yaml2html.py脚本处理一个简短的 YAML 文档,然后将生成的 HTML 转换成简化的文本形式,您可以在终端中预览,而无需启动一个成熟的 web 浏览器。
单击下面的可折叠部分以显示完整的源代码:
# yaml2html.py
import sys
import yaml
from yaml import (
ScalarEvent,
SequenceStartEvent,
SequenceEndEvent,
MappingStartEvent,
MappingEndEvent,
)
OPEN_TAG_EVENTS = (ScalarEvent, SequenceStartEvent, MappingStartEvent)
CLOSE_TAG_EVENTS = (ScalarEvent, SequenceEndEvent, MappingEndEvent)
class HTMLBuilder:
def __init__(self):
self._context = []
self._html = []
@property
def html(self):
return "".join(self._html)
def process(self, event):
if isinstance(event, OPEN_TAG_EVENTS):
self._handle_tag()
if isinstance(event, ScalarEvent):
self._html.append(event.value)
elif isinstance(event, SequenceStartEvent):
self._html.append("<ul>")
self._context.append(list)
elif isinstance(event, SequenceEndEvent):
self._html.append("</ul>")
self._context.pop()
elif isinstance(event, MappingStartEvent):
self._html.append("<dl>")
self._context.append(0)
elif isinstance(event, MappingEndEvent):
self._html.append("</dl>")
self._context.pop()
if isinstance(event, CLOSE_TAG_EVENTS):
self._handle_tag(close=True)
def _handle_tag(self, close=False):
if len(self._context) > 0:
if self._context[-1] is list:
self._html.append("</li>" if close else "<li>")
else:
if self._context[-1] % 2 == 0:
self._html.append("</dt>" if close else "<dt>")
else:
self._html.append("</dd>" if close else "<dd>")
if close:
self._context[-1] += 1
def yaml2html(stream, loader=yaml.SafeLoader):
builder = HTMLBuilder()
for event in yaml.parse(stream, loader):
builder.process(event)
if isinstance(event, yaml.DocumentEndEvent):
yield builder.html
builder = HTMLBuilder()
if __name__ == "__main__":
print("".join(yaml2html("".join(sys.stdin.readlines()))))
干得好!你现在可以在你的网页浏览器中看到 YAML 了。然而,呈现是静态的。用一点点互动来增加趣味不是很好吗?接下来,您将使用不同的方法来解析 YAML,这将允许!
构建节点树
有时候,你确实需要将整个文档保存在内存中,以便向前看,并根据接下来的内容做出明智的决定。PyYAML 可以构建 YAML 元素层次结构的对象表示,类似于 XML 中的 DOM。通过调用yaml.compose(),您将获得一个元素树的根节点:
>>> import yaml >>> root = yaml.compose("[42, {pi: 3.14, e: 2.72}]", yaml.SafeLoader) >>> root SequenceNode( tag='tag:yaml.org,2002:seq', value=[ ScalarNode(tag='tag:yaml.org,2002:int', value='42'), MappingNode( tag='tag:yaml.org,2002:map', value=[ ( ScalarNode(tag='tag:yaml.org,2002:str', value='pi'), ScalarNode(tag='tag:yaml.org,2002:float', value='3.14') ), ( ScalarNode(tag='tag:yaml.org,2002:str', value='e'), ScalarNode(tag='tag:yaml.org,2002:float', value='2.72') ) ] ) ] )根可通过方括号语法进行遍历。您可以使用 node 的
.value属性和下标访问树中的任何后代元素:
>>> key, value = root.value[1].value[0]
>>> key
ScalarNode(tag='tag:yaml.org,2002:str', value='pi')
>>> value
ScalarNode(tag='tag:yaml.org,2002:float', value='3.14')
因为只有三种节点(ScalarNode、SequenceNode和MappingNode),所以可以用递归函数自动遍历它们:
# tree.py
import yaml
def visit(node):
if isinstance(node, yaml.ScalarNode):
return node.value
elif isinstance(node, yaml.SequenceNode):
return [visit(child) for child in node.value]
elif isinstance(node, yaml.MappingNode):
return {visit(key): visit(value) for key, value in node.value}
将这个函数放在名为tree.py的 Python 脚本中,因为您将开发代码。该函数采用单个节点,并根据其类型返回其值或进入相关的子树。注意,映射键也必须被访问,因为它们在 YAML 中可以是非标量值。
然后,在交互式 Python 解释器会话中导入您的函数,并针对您之前创建的根元素进行测试:
>>> from tree import visit >>> visit(root) ['42', {'pi': '3.14', 'e': '2.72'}]结果得到一个 Python 列表,但是其中包含的单个标量值都是字符串。PyYAML 检测与标量值相关联的数据类型,并将其存储在节点的
.tag属性中,但是您必须自己进行类型转换。这些类型使用 YAML 全局标签进行编码,比如"tag:yaml.org,2002:float",所以您可以提取第二个冒号(:之后的最后一位。通过调用新的
cast()函数包装标量的返回值来修改函数:# tree.py import base64 import datetime import yaml def visit(node): if isinstance(node, yaml.ScalarNode): return cast(node.value, node.tag) elif isinstance(node, yaml.SequenceNode): return [visit(child) for child in node.value] elif isinstance(node, yaml.MappingNode): return {visit(key): visit(value) for key, value in node.value} def cast(value, tag): match tag.split(":")[-1]: case "null": return None case "bool": return bool(value) case "int": return int(value) case "float": return float(value) case "timestamp": return datetime.datetime.fromisoformat(value) case "binary": return base64.decodebytes(value.encode("utf-8")) case _: return str(value)您可以利用 Python 3.10 中引入的新的
match和case关键字以及结构模式匹配语法,或者您可以使用普通的旧if语句重写这个示例。底线是,当您在交互式解释器会话中重新加载模块时,您现在应该获得原生 Python 类型的值:
>>> import importlib, tree
>>> importlib.reload(tree)
<module 'tree' from '/home/realpython/tree.py'>
>>> visit(root)
[42, {'pi': 3.14, 'e': 2.72}]
>>> visit(yaml.compose("when: 2022-01-16 23:59:59"))
{'when': datetime.datetime(2022, 1, 16, 23, 59, 59)}
您已经准备好生成 HTML 字符串,而不是 Python 对象。将visit()中的返回值替换为对更多助手函数的调用:
# tree.py
import base64
import datetime
import yaml
def visit(node):
if isinstance(node, yaml.ScalarNode):
return cast(node.value, node.tag)
elif isinstance(node, yaml.SequenceNode):
return html_list(node) elif isinstance(node, yaml.MappingNode):
return html_map(node)
# ...
def html_list(node):
items = "".join(f"<li>{visit(child)}</li>" for child in node.value)
return f'<ul class="sequence">{items}</ul>'
def html_map(node):
pairs = "".join(
f'<li><span class="key">{visit(key)}:</span> {visit(value)}</li>'
if isinstance(value, yaml.ScalarNode) else (
"<li>"
"<details>"
f'<summary class="key">{visit(key)}</summary> {visit(value)}'
"</details>"
"</li>"
)
for key, value in node.value
)
return f"<ul>{pairs}</ul>"
两个助手函数都接受一个节点实例并返回一段 HTML 字符串。html_list()函数期望用生成器表达式迭代SequenceNode,而html_map()迭代MappingNode的键和值。这就是提前了解整个树结构的好处。如果映射值是一个ScalarNode,那么用一个<span>元素替换它。其他节点类型被包装在一个可折叠的 <details> 标签中。
因为您将生成 HTML 输出,所以您可以通过只返回普通字符串来简化类型转换函数。同时,您可以为 Base64 编码的数据返回一个 HTML <img>元素,并显示该元素,而不是显示原始字节。除此之外,常规标量可以包装在一个<span>或一个适当样式的<div>元素中,这取决于它们是包含单行内容还是多行内容:
# tree.py
import yaml
# ...
def cast(value, tag):
match tag.split(":")[-1]:
case "binary":
return f'<img src="data:image/png;base64, {value}" />'
case _:
if "\n" in value:
return f'<div class="multiline">{value}</div>'
else:
return f"<span>{value}</span>"
HTML <img>元素的src属性识别编码数据。请注意,您不再需要base64或datetime导入,所以继续操作并从文件顶部删除它们。
和往常一样,您希望通过从标准输入中读取内容来使您的脚本可运行。您还可以在一个新的html_tree()函数中用一些样板文件包装生成的 HTML 主体:
# tree.py
import sys import yaml
def html_tree(stream, loader=yaml.SafeLoader):
body = visit(yaml.compose(stream, loader))
return (
"<!DOCTYPE html>"
"<html>"
"<head>"
" <meta charset=\"utf-8\">"
" <title>YAML Tree Preview</title>"
" <link href=\"https://fonts.googleapis.com/css2"
"?family=Roboto+Condensed&display=swap\" rel=\"stylesheet\">"
" <style>"
" * { font-family: 'Roboto Condensed', sans-serif; }"
" ul { list-style: none; }"
" ul.sequence { list-style: '- '; }"
" .key { font-weight: bold; }"
" .multiline { white-space: pre; }"
" </style>"
"</head>"
f"<body>{body}</body></html>"
)
# ...
if __name__ == "__main__":
print(html_tree("".join(sys.stdin.readlines())))
这个 HTML 使用了一个嵌入的谷歌字体,看起来更舒服。内联 CSS 样式从常规无序列表中移除项目符号,因为您使用项目符号进行键值映射。但是,显式标记为序列的列表在每个项目前使用破折号。映射键以粗体显示,多行字符串保留空白。
当您针对一些测试数据运行脚本时,它会输出一段 HTML 代码,您可以将这段代码重定向到一个本地文件,您可以使用默认的 web 浏览器打开该文件:
C:\> type data.yaml | python tree.py > index.html
C:\> start index.html
$ cat data.yaml | python tree.py > index.html
$ xdg-open index.html
$ cat data.yaml | python tree.py > index.html
$ open index.html
在 web 浏览器中预览时,生成的页面将允许您交互式地展开和折叠各个键-值对:
https://player.vimeo.com/video/691778178?background=1
请注意 web 浏览器如何呈现描绘笑脸的 Base64 编码图像。您将在下面的可折叠部分找到最终代码:
# tree.py
import sys
import yaml
def html_tree(stream, loader=yaml.SafeLoader):
body = visit(yaml.compose(stream, loader))
return (
"<!DOCTYPE html>"
"<html>"
"<head>"
" <meta charset=\"utf-8\">"
" <title>YAML Tree Preview</title>"
" <link href=\"https://fonts.googleapis.com/css2"
"?family=Roboto+Condensed&display=swap\" rel=\"stylesheet\">"
" <style>"
" * { font-family: 'Roboto Condensed', sans-serif; }"
" ul { list-style: none; }"
" ul.sequence { list-style: '- '; }"
" .key { font-weight: bold; }"
" .multiline { white-space: pre; }"
" </style>"
"</head>"
f"<body>{body}</body></html>"
)
def visit(node):
if isinstance(node, yaml.ScalarNode):
return cast(node.value, node.tag)
elif isinstance(node, yaml.SequenceNode):
return html_list(node)
elif isinstance(node, yaml.MappingNode):
return html_map(node)
def cast(value, tag):
match tag.split(":")[-1]:
case "binary":
return f'<img src="data:image/png;base64, {value}" />'
case _:
if "\n" in value:
return f'<div class="multiline">{value}</div>'
else:
return f"<span>{value}</span>"
def html_list(node):
items = "".join(f"<li>{visit(child)}</li>" for child in node.value)
return f'<ul class="sequence">{items}</ul>'
def html_map(node):
pairs = "".join(
f'<li><span class="key">{visit(key)}:</span> {visit(value)}</li>'
if isinstance(value, yaml.ScalarNode) else (
"<li>"
"<details>"
f'<summary class="key">{visit(key)}</summary> {visit(value)}'
"</details>"
"</li>"
)
for key, value in node.value
)
return f"<ul>{pairs}</ul>"
if __name__ == "__main__":
print(html_tree("".join(sys.stdin.readlines())))
好了,这就是使用 PyYAML 库在底层解析 YAML 文档的全部内容。相应的yaml.emit()和yaml.serialize()函数以相反的方式工作,分别获取一系列事件或根节点,并将它们转换成 YAML 表示。但是你很少需要使用它们。
结论
您现在知道在哪里可以找到 Python 中读写 YAML 文档所缺少的电池了。您已经创建了一个 YAML 语法荧光笔和一个 HTML 格式的交互式 YAML 预览。在这个过程中,您了解了这种流行的数据格式中强大而危险的特性,以及如何在 Python 中利用它们。
在本教程中,您学习了如何:
- 用 Python 读和写 YAML 文档
- 序列化 Python 的内置的和自定义的数据类型到 YAML
- 安全读取来自不可信来源的 YAML 文件
- 控制解析下级的 YAML 文档
要获得本教程中示例的源代码,请访问下面的链接:
获取源代码: 点击此处获取源代码,您将使用在 Python 中使用 YAML。*************
Python YouTube 频道的终极列表
我们在网上找不到一个好的、最新的 Python 开发者或 Python 编程 YouTube 频道列表。
如今,在 YouTube 上学习 Python 是一个可行的选择,我们对这种新媒体能为编程教育做些什么感到兴奋。
YouTube 上有一些非常好的关注 Python 开发的频道,但是我们找不到一个既全面又最新的列表。所以我们用最好最 Pythonic 化的 YouTubers 创建了我们自己的。
我们最初是根据通过阅读论坛帖子和直接在 YouTube 上搜索 Python 频道收集的信息来编写这个列表的。我们将根据您的反馈继续添加列表。我们计划不断更新这个列表,所以如果你认为有什么遗漏或者你想看到自己的 YouTube Python 教程被添加,请随时在页面末尾留下评论或者发推文给我们。
要将一个渠道纳入我们的列表,它必须:
- 关注 Python 教程
- 不是全新的(超过 2000 名用户)
- 保持活跃(新视频即将推出)或拥有有趣的旧内容存档,值得观看
享受 Python 的好处吧!📹🐍
阿尔斯威加特T2】
"大量甜蜜的计算机相关教程和一些其他可怕的视频!"
- 网址:automatetheboringstuff.com
- 推特: @AlSweigart
- 订阅: YouTube
阿纳康达公司
“Anaconda 拥有超过 450 万用户,是世界上最受欢迎的 Python 数据科学平台。Anaconda,Inc .继续领导开放源码项目,如 Anaconda、NumPy 和 SciPy,它们构成了现代数据科学的基础。Anaconda 的旗舰产品 Anaconda Enterprise 允许组织保护、管理、扩展和扩展 Anaconda,以提供可操作的见解,推动企业和行业向前发展。”
除了他们公司开发的视频,包括有趣的乐高动画短片和 T2 短片,Anaconda 的 YouTube 频道包含了 AnacondaCon 的所有视频,这是一个充满激情的社区,聚集了所有使用 Anaconda 发行版的数据科学家、IT 专业人员、分析师、开发人员和商业领袖。
- 网址:anaconda.com
- Twitter: @anacondainc
- 订阅: YouTube
克里斯蒂安·汤普森
“关于我的一点点,关于 Python 初学者编程的很多内容。我是一名使用 Python 作为教学语言的初高中教师。我坚信任何人都可以(也应该)学习计算机编程,Python 是学习编程的完美语言。”
- 网址:christianthompson.com
- 推特: @tokyoedtech
- 订阅: YouTube
聪明的程序员
“你可以在这里找到很棒的编程课程!此外,期待将你的编码技能提升到下一个水平的编程技巧和诀窍。”
- 网址:cleverprogrammer.com
- 推特: @cleverqazi
- 订阅: YouTube
CodingEntrepreneurs
《为企业家编程》是一个面向非技术创业者的编程系列。学习 Django、Python、API、接受支付、Stripe、jQuery、Twitter Bootstrap 等等。”
- 网址:www.codingforentrepreneurs.com
- 推特: @joincfe
- 订阅: YouTube
科里斯查费T2】
“这个频道专注于为软件开发人员、程序员和工程师创建教程和演练。我们涵盖了所有不同技能水平的主题,所以无论你是初学者还是有多年经验的人,这个频道都会有适合你的东西。”
- 网址:coreyms.com
- 推特: @CoreyMSchafer
- 订阅: YouTube ⋅ Patreon
克里斯·霍克斯
"我们将学习编程、网页设计、响应式网页设计、Reactjs、Django、Python、网页抓取、游戏、表单应用等等!"
- 推特: @realchrishawkes
- 订阅: YouTube
CS 道场
“大家好!我叫 YK,我在这里制作的视频大多是关于编程和计算机科学的。”
数据学院(凯文·马卡姆)
“您正试图在数据科学领域开创自己的事业,我想帮助您实现这一目标!我的深入教程将帮助您使用 Python 和 r 等开源工具掌握关键的数据科学主题。”
- 网址: www.dataschool.io
- 推特: @justmarkham
- 订阅: YouTube ⋅ Patreon
大卫·比兹利
"大卫·比兹利的会议、用户组和培训讲座的档案."
- 网址:www.dabeaz.com
- 推特: @dabeaz
- 订阅: YouTube
深谋远虑
“超过 15 年来,Enthought 以科学和工程为核心构建了人工智能解决方案。我们通过让公司及其员工利用人工智能和机器学习的优势来加速数字化转型。”
此外,Enthought 因早期开发、维护和持续支持 SciPy 而闻名,也是 SciPy US 和 EuroSciPy 会议的主要赞助商。除了公司开发的内容,该频道还提供了 SciPy US 和 EuroScipy(2016 年之前)会议、讲座和教程的所有视频记录,这些视频记录专门关注通过数学、科学和工程领域的开源 Python 软件推进科学计算。
- 网址:enthought.com
- 推特:@ entthought
- 订阅: YouTube
迈坚(谈蟒)
"关于编程的视频、演示和讲座——尤其是 Python 和 web 主题."
- 网址: talkpython.fm
- 推特: @mkennedy
- 订阅: YouTube
pretty printedT2】
“我是安东尼。我制作编程视频。”
- 网址:prettyprinted.com
- 推特: @pretty_printed
- 订阅: YouTube
PyCon 会议录音
这些都是 YouTube 上的 PyCon 演讲和会议记录。没有一个单一的渠道将这些结合起来。相反,你可以在一个单独的“PyCon 20…”频道上观看每年的视频。或者,您可以使用 PyVideo.org 的来观看会议录像。
- 网址:www.pycon.org
- 推特: @PyCon
- 订阅:YouTubePyVideo.org⋅
PyData
“PyData 为数据分析工具的国际用户和开发人员提供了一个交流思想和相互学习的论坛。全球 PyData 网络促进对数据管理、处理、分析和可视化的最佳实践、新方法和新兴技术的讨论。PyData 社区使用许多语言来研究数据科学,包括(但不限于)Python、Julia 和 r。
- 网址:pydata.org
- 推特: @PyData
- 订阅: YouTube
真正的巨蟒
“Python 教程和 Pythonistas 培训视频,超越了基础知识。在这个频道上,你每周都会看到新的 Python 视频和截屏。它们很小,而且很中肯,所以你可以把它们融入你的一天,并顺便学习新的 Python 技能。”
- 网址:realpython.com⋅dbader.org
- 推特:@ real python⋅@ dbader _ org
- 订阅: YouTube ⋅ 播客
鲁文·勒纳T2】
“我是鲁文·勒纳,我为世界各地的公司教授 Python 和数据科学。在这个 YouTube 频道上,我发布了一些视频,可以帮助你学习 Python 编程。”
- 网址:lerner.co.il
- Twitter:@ reuvenmler
- 订阅: YouTube
森德克斯
“Python 编程教程,不仅仅是基础知识。了解机器学习、金融、数据分析、机器人、网页开发、游戏开发等等。”
- 网址:pythonprogramming.net
- 推特:@ send ex
- 订阅: YouTube ⋅ Patreon
苏格拉底
“苏格拉底制作高质量的数学和科学教育视频。每周都有新视频!我们是加州理工的毕业生,相信你应该得到更好的视频。和我们在一起,你会学到更多!”
- 网址:www.socratica.com
- Twitter:@ socratica
- 订阅: YouTube ⋅ Patreon
新波斯顿(Bucky Roberts)
"大量甜蜜的计算机相关教程和一些其他可怕的视频!"
- 网址:thenewboston.com
- 推特: @bucky_roberts
- 订阅: YouTube ⋅ Patreon
小型 Python 会议
以下频道提供了世界各地举行的许多小型本地 Python 会议的教程、讲座和会议录音。
虽然就其本身而言,这些频道中的大多数都不满足 2000 订户的要求,但我们在这里将它们列为荣誉奖,因为它们代表了世界各地不同的 Python 社区。
请注意,这些会议的一些(可能更早)视频(以及其他非 Python 内容)可以在第二天的视频和工程师那里获得。SG 通道。或者,PyVideo.org 的可以作为一个一站式商店,在那里你可以找到大多数(但不是全部)这些会议录音。
- 欧洲巨蟒
- EuroSciPy
- 猕猴桃果
- PyCascades
- PyCon 阿根廷(Ar)
- PyCon 澳大利亚(AU)
- 加拿大 PyCon】
- PyCon 捷克语(CZ)
- 芬兰 PyCon】
- PyCon 德国(德)
- 香港 PyCon(HG)
- 爱尔兰派康(IE)
- 意大利派康(Nove)
- PyCon 日本(JP)
- 朝鲜半岛(KR)
- 马来西亚 PyCon(MY)
- PyCon phillipins(PH)
- 波兰皮孔
- 新加坡 PyCon(SG)
- PyCon 斯洛伐克(SK)
- PyCon 乌克兰(非盟)
- PyCon 英国(英国)
- PyGotham 2017
- PyOhio
如果你认为这个列表中缺少了什么,或者如果你想看到你自己的 Python YouTube 频道被添加,那么请在下面留下评论,或者发推文给我们。***

 浙公网安备 33010602011771号
浙公网安备 33010602011771号