KDNuggets-博客中文翻译-二十九-
KDNuggets 博客中文翻译(二十九)
原文:KDNuggets
Python 向量数据库和向量索引:LLM 应用的架构设计
原文:
www.kdnuggets.com/2023/08/python-vector-databases-vector-indexes-architecting-llm-apps.html

图片由 Christina Morillo 提供
由于使用其硬件创建的生成 AI 应用,Nvidia 体验到了显著的增长。另一项软件创新——向量数据库——也在乘上生成 AI 的浪潮。
我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
开发者们正在使用 Python 和向量数据库构建 AI 驱动的应用程序。通过将数据编码为向量,他们可以利用向量空间的数学属性,实现对非常大数据集的快速相似性搜索。
让我们从基础开始吧!
向量数据库基础
向量数据库将数据存储为坐标空间中的数值向量。这使得可以通过如余弦相似度等操作计算向量之间的相似性。
最近的向量代表最相似的数据点。与标量数据库不同,向量数据库被优化用于相似性搜索,而不是复杂的查询或事务。
检索相似向量只需几毫秒,而非几分钟,即使在数十亿数据点中也是如此。
向量数据库构建索引,以通过接近度高效地查询向量。这有点类似于文本搜索引擎如何为快速全文搜索对文档进行索引。
向量搜索相较于传统数据库的好处
对于开发者来说,向量数据库提供:
-
快速相似性搜索 - 毫秒级找到相似向量
-
动态数据支持 - 持续用新数据更新向量
-
可扩展性 - 在多台机器上扩展向量搜索
-
灵活的架构 - 向量可以存储在本地、云对象存储或托管数据库中
-
高维度 - 每个向量索引数千维度
-
API - 如果你选择托管的向量数据库,它通常附带干净的查询 API 和与现有数据科学工具包或平台的集成。
向量搜索(向量数据库的关键功能)支持的流行用例示例如下:
-
视觉搜索 - 查找相似的产品图片
-
推荐 - 建议内容
-
聊天机器人 - 匹配查询意图
-
搜索 - 从文本向量中提取相关文档
向量搜索开始获得关注的用例有:
-
异常检测 - 识别异常向量
-
药物发现 - 按属性向量关联分子
什么是 Python 向量数据库?
一个包含支持向量数据库完整生命周期的 Python 库的向量数据库就是一个 Python 向量数据库。 数据库本身不需要用 Python 构建。
这些 Python 向量数据库库应该支持什么?
对向量数据库的调用可以分为两类 - 数据相关和管理相关。 好消息是它们遵循与传统数据库类似的模式。
数据相关功能库应支持的内容

标准管理相关功能库应支持的内容
现在让我们进入一个稍微复杂的概念,即在这些数据库之上构建 LLM 应用
架构 LLM 应用
在深入了解由向量搜索驱动的 LLM 应用架构之前,让我们从工作流的角度理解涉及的内容。
一个典型的工作流包括:
-
数据的丰富或清洗。这是一个轻量的数据转换步骤,有助于数据质量和一致的内容格式化。这也是需要对数据进行丰富的地方。
-
通过模型将数据编码为向量。这些模型包含一些变换器(例如句子变换器)
-
将向量插入向量数据库或向量索引(稍后会解释)
-
通过 Python API 暴露搜索
-
文档协调工作流
-
在应用程序和用户界面中测试和可视化结果(例如聊天用户界面)
现在让我们看看如何使用不同的架构组件来启用这个工作流的不同部分。
对于 1),你可能需要开始从其他源系统(包括关系型数据库或内容管理系统)获取元数据。
预训练模型几乎总是优选用于上面的步骤 2)。 OpenAI 模型是通过托管服务提供的最受欢迎的模型。 出于隐私和安全原因,你也可以托管本地模型。
对于 3),如果需要进行大规模相似性搜索(例如数据集超过十亿条记录),你需要一个向量数据库或向量索引。从企业的角度来看,通常在进行“搜索”之前会有更多背景信息。
关于 4)上面的内容,好消息是,暴露的搜索通常遵循类似的模式。类似于以下代码:
来自 [Pinecone]( https://docs.pinecone.io/docs/metadata-filtering#:~:text=eq"%3A ["comedy"%2C "documentary"]}}- ,Inserting%20metadata%20into%20an%20index,-Metadata%20can%20be)。
index = pinecone.Index("example-index")
index.upsert([
("A", [0.1, 0.1, 0.1, 0.1], {"genre": "comedy", "year": 2020}),
)
index.query(
vector=[0.1, 0.1, 0.1, 0.1],
filter={
"genre": {"$eq": "documentary"},
"year": 2019
},
top_k=1,
)
这里有一句有趣的话:
filter={
"genre": {"$eq": "documentary"},
"year": 2019
},
它真的将结果筛选到接近“类型”和“年份”的向量。你还可以按概念或主题筛选向量。
现在的挑战是在企业环境中,它包括其他业务过滤器。重要的是解决来自数据源(如表结构和元数据)的数据建模缺失的问题。需要改进文本的准确性,减少与结构化数据相矛盾的错误表达。在这种情况下,需要一种“数据管道”策略,企业“内容匹配”变得重要。
对于 5) 除了常见的扩展挑战外,变化中的语料库也有其挑战。新文档可能需要重新编码和重新索引整个语料库,以保持向量的相关性。
对于 6) 这是一个全新的领域,除了测试相似度水平外,还需要一种人工干预的方法,以确保搜索质量在各个范围内的一致性。
自动搜索评分和不同类型的上下文评分不是一个容易完成的任务。
Python 向量索引:为你现有数据库提供一种更简单的向量搜索替代方案。
向量数据库 是一个复杂的系统,能够实现如上例所示的上下文搜索,并具备所有额外的数据库功能(创建、插入、更新、删除、管理等)。
向量数据库的例子包括 Weaviate 和 Pinecone。这两个都提供了 Python API。
有时,更简单的设置已经足够。作为一种更轻量的替代方案,你可以使用已经在用的存储,并基于此添加一个 向量索引。这个向量索引用于检索带有上下文的搜索查询,例如用于你的生成性 AI。
在向量索引设置中,你需要:
-
你通常的数据存储(例如 PostgreSQL 或带文件的磁盘目录)提供了你需要的基本操作:创建、插入、更新、删除。
-
你的向量索引,能够在你的数据上实现快速的基于上下文的搜索。
实现向量索引的独立 Python 库包括 FAISS、Pathway LLM、Annoy。
好消息是,向量数据库和向量索引的 LLM 应用流程是相同的。主要区别在于,除了使用 Python 向量索引库外,你还需要继续使用现有的数据库进行“普通”数据操作和数据管理。例如,如果你使用 PostgreSQL,可能会用到 Psycopg;如果你将数据存储在文件中,可以使用标准的 Python “fs” 模块。
向量索引的支持者关注以下优点:
-
数据隐私:保持原始数据安全且不受干扰,减少数据暴露风险。
-
成本效率:减少与额外存储、计算能力和许可相关的成本。
-
可扩展性:通过减少管理的组件数量来简化扩展。
什么时候使用向量数据库与向量索引?
当以下一个或多个条件成立时,向量数据库是有用的:
-
你对大规模处理向量数据有特殊需求。
-
你正在为向量创建一个独立的定制应用程序。
-
你不期望在其他类型的应用程序中使用存储的数据。
向量索引在以下一个或多个条件成立时是有用的:
-
你不想信任新技术来进行数据存储。
-
你现有的存储可以从 Python 中轻松访问。
-
你的相似性搜索只是其他更大企业 BI 和数据库需求中的一种能力。
-
你需要将向量附加到现有的标量记录中。
-
你需要一种统一的方法来处理数据工程团队的管道。
-
你需要在数据上使用索引和图结构,以帮助你的LLM 应用程序或任务。
-
你需要来自其他来源的增强输出或增强上下文。
-
你想从语料库中创建规则,以应用于你的事务数据。
企业向量搜索的未来
向量搜索为开发者解锁了颠覆性的能力。随着模型和技术的进步,预计向量数据库或向量索引将成为应用程序堆栈的核心部分。
我希望这个概述为你探索 Python 中的向量数据库和向量索引提供一个坚实的起点。如果你对最近开发的向量索引感兴趣,请查看这个开源项目。
Anup Surendran 是一位产品和产品营销副总裁,专注于将 AI 产品推向市场。他曾与两家成功退出(被 SAP 和 Kroll 收购)的初创公司合作,并喜欢教授其他人如何利用 AI 产品提高组织的生产力。
更多相关主题
Python 与 R - 谁在数据科学、机器学习领域真正领先?
原文:
www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html
 评论我最近对 KDnuggets 调查结果的分析(Python 超越 R,成为数据科学和机器学习平台的领导者)引起了广泛关注,并生成了大量评论、讨论,以及来自两种语言支持者的不可避免的批评。
评论我最近对 KDnuggets 调查结果的分析(Python 超越 R,成为数据科学和机器学习平台的领导者)引起了广泛关注,并生成了大量评论、讨论,以及来自两种语言支持者的不可避免的批评。
一些人抱怨调查不具备科学性,投票者代表的是自我选择的样本。这显然是正确的。但 KDnuggets 自 2001 年以来一直进行调查,并且每月覆盖了数十万的访问者。根据我们的经验,KDnuggets 的调查一直是数据挖掘和数据科学趋势和发展的良好指标。我们跟踪了 R 与 Python 的辩论好几年,因此与其他网站不同,我们可以将最新的调查结果与几年前的结果进行比较。
让我们检查一下数据科学家对 Python 和 R 的受欢迎程度的其他衡量标准。
首先,我们分析了 Google Trends(这一点在我们调查结果发布后也被 DSC 进行了分析)。
Python 是一个更受欢迎的编程语言,它在 2017 年 IEEE Spectrum 第 1 语言 排名中名列前茅(感谢 Martin Skarzynski @marskar 提供的链接),因此直接比较 Python 和 R 的搜索量是不公平的,但我们可以比较 Google Trends 上的搜索词“Python 数据科学”与“R 数据科学”。
这是自 2012 年 1 月以来的图表。注意,如果选择包含完整月份的范围,并且从 2012 年开始,那么你会获得平滑的月度趋势,而不是更为混乱的每周趋势。

图 1: [Google Trends]( https://trends.google.com/trends/explore?date=2012-01-01 2017-08-31&q=Python data science ,R%20data%20science),2012 年 1 月 - 2017 年 8 月,“Python 数据科学”与“R 数据科学”。
我们注意到,在 2014 年和 2015 年,随着数据科学的普及,R 略微领先,但“Python 数据科学”搜索在 2016 年底超过了“R 数据科学”,并且自 2017 年 1 月以来明显领先。
注意:无论数据科学如何大写(“Data Science”或“data science”),统计数据都是相同的,但 Google 自动完成建议在 Python 和 R 中都使用“data science”。
不过,最近机器学习变得非常流行 - 请参见我在 机器学习超越大数据? 的帖子(2017 年 5 月),所以我们来看看 Google Trends 上的 Python 与 R 在“机器学习”方面的对比。
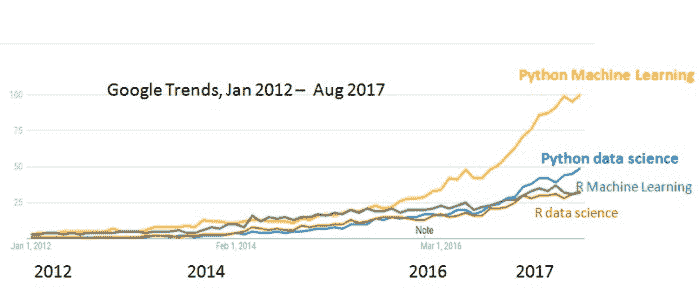
图 2:[Google 趋势]( https://trends.google.com/trends/explore?date=2012-01-01 2017-08-31&q=Python data science ,R%20data%20science,Python%20Machine%20Learning,R%20Machine%20Learning),2012 年 1 月 - 2017 年 8 月,“Python 机器学习”、“R 机器学习”、“Python 数据科学”和“R 数据科学”。
我们看到“Python 机器学习”远远领先于“Python 数据科学”,两者都显著领先于“R 数据科学”和“R 机器学习”。
2017 年 8 月的相对搜索量是
-
Python 机器学习:100
-
Python 数据科学:49
-
R 数据科学:33
-
R 机器学习:32
(注意:虽然 Google 自动完成建议搜索词“Python 数据科学”,并且以小写“data science”,它还建议了以大写的“Python 机器学习”。这里可能有一些深层次的含义……)
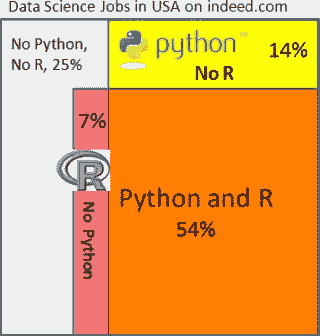
图 3:Snapshot of indeed.com 数据科学家职位广告在美国,同时包含 Python 和/或 R,2017 年 9 月接下来,我们来看 indeed.com 上的职位广告。以下所有数字均为截至 2017 年 9 月 11 日在美国的职位。
-
搜索 "数据科学家" 发现 3,558 个职位
-
搜索 "数据科学家" Python 发现 2,407 个职位(占所有职位的 68%)
-
搜索 "数据科学家" R 发现 2,179 个职位(占所有职位的 61%)。
-
搜索 "数据科学家" Python R 发现 1,906 个职位(占所有职位的 54%)
-
搜索 "数据科学家" -Python -R 发现 892 个职位(占所有职位的 25%)
我们在右侧的维恩图中展示了这种关系。
Indeed 职位趋势也显示,了解 Python 和了解 R 的数据科学家的需求直到最近才接近,并且这些职位占所有数据科学家职位的很大一部分。
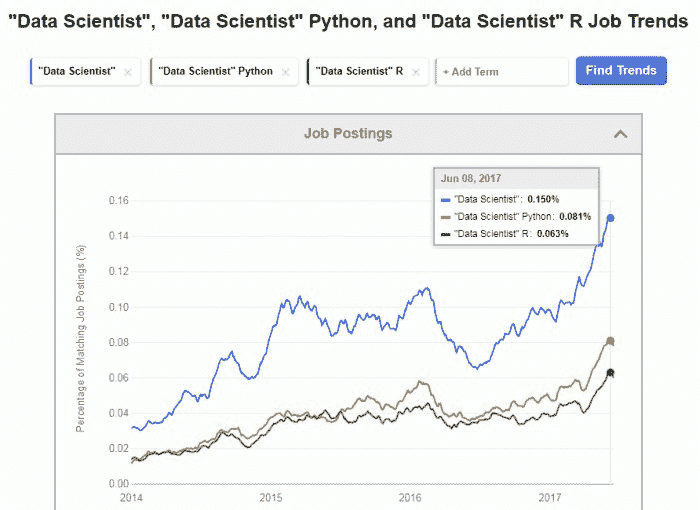
图 4:Indeed “数据科学家”、“数据科学家” Python 和 “数据科学家” R 职位趋势,2014-2017
这些职位广告数量表明,当前雇主认为大多数数据科学家能够根据需要使用 Python 和 R,但目前 Python 稍有优势。
Google 趋势结果表明,Python 的优势将会增长,而与 Python 相关的数据科学和机器学习职位的增长速度将快于与 R 相关的职位。
注意:使用 indeed.com 时,你需要仔细指定搜索字符串,搜索 [数据科学家 Python] 会包含很多职位,这些职位可能包含“数据”或“科学家”,但不一定两者都有。
最后,在我原始帖子 Python 超越 R 在数据科学中 上的许多评论中,我想强调两个观察点:
-
Stanislav Seltser 指出,在 github 上排名前 15 的语言中,
octoverse.github.com中,Python 排名第 3,而 R 不在列表中。 -
Stanislav 还提到 Kaggle 2016 年总结,其中指出
过去几年,R 是 Kaggle 上的首选语言,但 2016 年 Python 在编写的 kernels 数量上脱颖而出,成为明显的赢家。
![Kaggle Python 与 R Kernels 2016]()
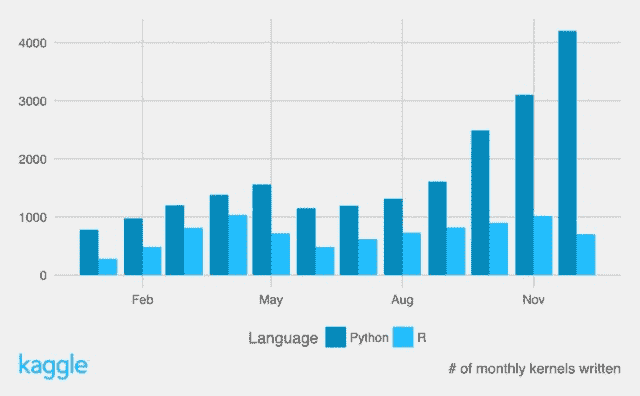
相关:
-
Python 超越 R,成为数据科学和机器学习平台的领导者
-
Python 超越 R?
-
Python 与 R 在人工智能、机器学习和数据科学中的对比
更多相关话题
初学者和 Udacity 深度学习纳米学位的 PyTorch 备忘单
原文:
www.kdnuggets.com/2019/08/pytorch-cheat-sheet-beginners.html
评论
由 Uniqtech 提供
使用一致的自上而下的方法入门 Pytorch 的备忘单。这份备忘单应该比官方文档更容易消化,并且应作为一个过渡工具,帮助学生和初学者尽快开始阅读文档。本文正在不断改进,频繁更新,并将保持在建设中,直到显著改善。您的反馈非常感谢 hi@uniqtech.co,错误和拼写错误将会被及时纠正。
大新闻:我们在 Medium 机器学习和数据科学主页上发表了文章。请点击 ← 并评论以表示支持。下面的备忘单主要是叙述性的。详细备忘单的 PDF JPEG 版本将很快发布,并将发布在本文中。更新于 2019 年 6 月 18 日,为了使本备忘单/教程更具连贯性,我们将插入来自获奖 Kaggle 内核的代码片段,以说明重要的 PyTorch 概念 — 使用 PyTorch 进行的疟疾检测,一个图像分类计算机视觉 Kaggle 内核 [见 Source 3 下] 作者 devilsknight 和 vishnu aka qwertypsv。

uniqtech 提供的初学者 PyTorch 备忘单
Pytorch 用自己的话定义
Pytorch 是“一个开源深度学习平台,提供从研究原型到生产部署的无缝路径。”
根据 Facebook 研究 [Source 1],PyTorch 是一个提供两个高级特性的 Python 包:
具有强大 GPU 加速的张量计算(如 NumPy)
基于带状自动微分系统构建的深度神经网络
你可以在需要时重用你最喜欢的 Python 包,如 NumPy、SciPy 和 Cython,以扩展 PyTorch。
Soumith Chintala,Facebook 研究工程师和 PyTorch 的创造者,提供了一些关于 PyTorch 的有趣事实:自动微分曾经是用 Python 编写的,但大多数(代码)已改为 C++(以适应生产)。他认为有趣的 PyTorch 1.0 特性包括混合前端、生产模型解析、使用 Jit 编译器使模型适合生产等。来源:Chintala 在 Udacity 学习中的访谈。
主要特点
组件 | 描述 [Source 2]
torch:一个类似于 NumPy 的张量库,具有强大的 GPU 支持
torch.autograd: 一个基于带状的自动微分库,支持 torch 中所有可微分的张量操作
torch.jit:一个编译堆栈(TorchScript),用于从 PyTorch 代码创建可序列化和可优化的模型。
torch.nn:一个深度集成自动求导的神经网络库,设计为最大灵活性。
torch.multiprocessing:Python 多进程,但具有跨进程共享 torch 张量的神奇内存功能。适用于数据加载和 Hogwild 训练。
torch.utils:DataLoader 和其他实用函数,方便使用。
主要特性:混合前端、分布式训练、Python 优先、工具和库。
这些功能通过 功能页面 上的并排代码示例得到了优雅的展示!

Pytorch 文档中的功能页面展示了优雅的代码示例以说明每个功能。还需注意 Python 3 的点积简写,如“@”。
混合前端允许在即时模式和(计算)图模式之间切换。Tensorflow 曾经仅支持图模式,这被认为是快速和高效的,但很难修改、原型设计和研究。由于 Tensorflow 现在也提供即时模式(不再需要session run),这个差距正在缩小。
分布式训练:支持 GPU、CPU 和两者之间的轻松切换。(Tensorflow 还支持 TPU,即 Tensor 处理单元。)
Python 优先:为 Python 开发者打造。轻松创建神经网络,在 Pytorch 中运行深度学习。工具和库包括强大的计算机视觉库(卷积神经网络和预训练模型)、自然语言处理等。
Pytorch 还包括像 torch.tensor 实例化和计算、模型、验证、评分、自动计算梯度的 Pytorch 特性(使用 autograd,它也会为你执行所有的反向传播)、迁移学习准备好的预加载模型和数据集(阅读我们关于迁移学习的超短有效文章),还有使用 CUDA 的 GPU。
何时使用 Pytorch
AWS、Google 和 GCP 的 GPU 支持 Pytorch 作为一流公民。
Pytorch 为 1.0 版本新增了生产和云合作伙伴支持,包括 AWS、Google Cloud Platform 和 Microsoft Azure。现在你可以在任何深度学习任务中使用 Pytorch,包括计算机视觉和自然语言处理,甚至是在生产环境中。
因为它易于使用且具有 Python 风格,高级数据科学家 Stefan Otte 说:“如果你想要有趣的体验,使用 pytorch”。
Pytorch 也得到了 Facebook AI 研究的支持,因此如果你想在 Facebook 从事数据和机器学习工作,你应该了解 Pytorch。如果你擅长 Python 并且想成为开源贡献者,Pytorch 也是一个不错的选择。
迁移学习
迁移学习使用模型来预测未曾训练的数据集的类型。它可以显著提高训练时间和准确性。它还可以帮助处理可用训练数据有限的情况。Pytorch 有一个专门页面,介绍了预训练模型及其在行业标准基准数据集上的性能。请在我们的 Pytorch 迁移学习文章中阅读更多内容。
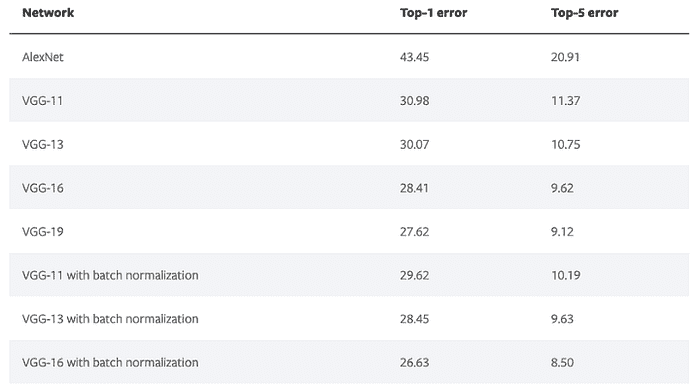
# pretrained models are at torchvision > models
model = torchvision.models.resnet152(pretrained=False)
阅读 Pytorch 文档中所有可用模型。请注意,模型的 top-1-error 和 top-5-error,即模型的性能也可以查看。
数据科学,学术研究 | 使用 Jupyter Notebook 进行演示
由于 Python 拥有庞大的开发者社区,因此在学生和研究人员中更容易找到转向数据科学和学术研究的 Python 人才,甚至使用 Pytorch 编写生产代码。这消除了学习另一种语言的需求。许多数据分析师和科学家已经熟悉 Jupyter Notebook,Pytorch 在其上运行得非常完美。请在我们的部署 Pytorch 模型到 Amazon Web Service SageMaker 中阅读更多内容。
Pytorch 是一个深度学习框架
Pytorch 是一个深度学习框架,就像 Tensorflow 一样,这意味着:对于传统的机器学习模型,目前请使用其他工具。Scikit-learn 是一个 Python 风格的深度学习框架,具有极易使用的 API。文档非常好,每页底部都有代码片段的示例。去看看。你知道吗,许多 Kaggle 用户包括大师们仍然使用 sklearn 的 train_test_split() 来拆分和 scaler 来预处理数据,sklearn 的 Gradient Boosting Tree 或支持向量机来基准测试性能,而顶级高性能的 XGBoost 却显著缺失。
Tensorflow.js 和 Tensorflow.lite 让 Tensorflow 在浏览器和移动设备上展翅飞翔。苹果刚刚在 2019 年 6 月宣布了 Swift 的 CreateML。移动支持在 Pytorch 中尚未原生实现。不要气馁。向下滚动以阅读关于 ONNX 的内容,它几乎被所有流行框架支持的交换格式。Pytorch 也有一个关于将模型移动到移动设备的教程,尽管这条路与 Tensorflow 相比仍有些绕行。
安装 Pytorch

对于安装技巧,首先使用官方的 Pytorch 文档。pytorch.org/get-started/locally/ 以上截图是可用安装的示例。
使用 Anaconda 安装 Pytorch 是一个在各种系统中包括 Windows 上的良好起点。我们能够在游戏电脑上使用 Anaconda 安装 Pytorch 并立即开始使用它的 CUDA GPU 功能。阅读我们的 Anaconda 速查表。
conda install numpy jupyter notebook
conda install pytorch torchvision -c pytorch
你好,Pytorch 的世界就像在启动 Google Colab 一样简单(没错,在 Google 的领地上),然后import torch,看看这个只读共享笔记本。现代托管数据科学笔记本如 Kaggle Kernel 和 Google Colab 都预先安装了 Pytorch。
看呐:无需服务器的深度学习!
更喜欢基于 Jupyter Notebook 的教程吗?从这篇文章底部找到 Udacity Intro to Pytorch 仓库开始入门。
更喜欢其他的安装方法?二进制文件,从源代码编译,和 Docker 镜像,请见来源 2。
来自来源 3 的代码片段
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
from torchvision import transforms, datasets, models
from torch.utils.data.sampler import SubsetRandomSampler
import os
print(os.listdir("../input/cell_images/cell_images/"))
导入torch是执行核心 Pytorch 任务所必需的。你还会看到导入 torch 神经网络模块nn、优化器optim和计算机视觉模块torchvision,数据转换管道transforms、datasets和现有的models。在这种情况下,Kaggle 团队还使用了一个SubsetRandomSampler,你将在后续片段中看到它如何被输送到数据转换和加载管道中。
数据转换
来自来源 3 的代码片段
注意,训练、测试和验证转换器是相似但不同的。为了增广数据,训练数据会被随机旋转、调整大小和裁剪,甚至垂直翻转(在这种情况下,一个翻转的疟疾细胞不会对分类结果产生负面影响)。因为测试和验证数据应该模拟真实世界数据,不引入任何随机噪音或翻转。就像它们一样,带有中心裁剪。注意大小必须保持一致。深度学习涉及大量的矩阵乘法。维度大小总是很重要的。在图像分类任务中,我们通常希望根据将要使用的预训练模型或现有数据集对图像进行归一化。
# Define your transforms for the training, validation, and testing sets
train_transforms = transforms.Compose([transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])test_transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])validation_transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
为什么要进行归一化?那些奇怪数字是什么?均值和标准差。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # Source 4
千万别忘记使用 ToTensor 将所有内容转换为 Pytorch 张量。
为什么?因为 Pytorch 需要它。阅读 Pytorch 的创作者 Chimtala 关于此的讨论串 [Source 5]。
输入图像首先被加载到范围[0, 1]中,然后这种归一化被应用到 RGB 图像中,如此描述.. torch vision — 专门用于计算机视觉的数据集、转换和模型
所有预训练模型都希望输入图像以相同方式进行归一化,即形状为(3 x H x W)的 3 通道 RGB 图像的小批量,其中 H 和 W 至少应为 224。
图像必须被加载到范围[0, 1]中,并且使用均值=[0.485, 0.456, 0.406]和标准差=[0.229, 0.224, 0.225]进行归一化
这种归一化的示例可在此 Imagenet 示例中找到[来源 4]
使用训练和测试加载器加载数据
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, num_workers=num_workers)
源 3 的代码片段
datasets.ImageFolder 和 torch.utils.data.DataLoader 一起工作,以根据 batch_size 和之前部分中的数据变换来分别加载训练、验证和测试数据。每个数据集都有自己的加载器。
img_dir='../input/cell_images/cell_images/'
train_data = datasets.ImageFolder(img_dir,transform=train_transforms)... # omitted
*# convert data to a normalized torch.FloatTensor*
... # omitted
*# obtain training indices that will be used for validation*
... # omitted
print(len(valid_idx), len(test_idx), len(train_idx))
*# define samplers for obtaining training and validation batches*
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
test_sampler = SubsetRandomSampler(test_idx)
*# prepare data loaders (combine dataset and sampler)*
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64,sampler=train_sampler, num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=32, sampler=valid_sampler, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(train_data, batch_size=20, sampler=test_sampler, num_workers=num_workers)
Pytorch 模型概述
使用 Sequential 是快速定义模型的一种简单方法。一个命名的有序字典包含了所有被封装在 nn.Sequential 中的层,然后将其存储在 model.classifier 变量中。这是一种快速定义模型基本结构的方法,但不一定是最 Pythonic 的。它帮助我们说明一个 Python 模型由全连接的线性层组成,形状由 (row, col) 元组指定。ReLU 激活层、20% 概率的 Dropout 和一个输出的 Softmax 或 LogSoftmax 函数。现在不用担心这些。你只需要知道 Softmax 通常是多分类任务深度学习模型的最后一层。著名的 ImageNet 数据集有 1000 多个类别,因此 Softmax 的输出至少有 1000 个以上的组件。
一个由全连接层组成的集合,间隔着 ReLU 激活层和一些 Dropout,最后是另一个全连接线性层,这个层连接到一个 Softmax 激活层,是一个典型的普通深度学习神经网络结构。
from collections import OrderedDictclassifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(2048, 1024)),
('relu', nn.ReLU()),
('dropout',nn.Dropout(0.2)),
('fc2', nn.Linear(1024, 512)),
('relu', nn.ReLU()),
('dropout',nn.Dropout(0.2)),
('fc3', nn.Linear(512, 256)),
('relu', nn.ReLU()),
('dropout',nn.Dropout(0.2)),
('fc4', nn.Linear(256, 102)),
('output', nn.LogSoftmax(dim=1))
]))model.classifier = classifier
在 Pytorch 中,查看模型结构非常简单,只需使用 print(model_name)。稍后会详细介绍。
源 3 的代码片段
如前所述,在 pytorch 部分的迁移学习中,我们可以使用如 resnet50 的预训练模型。将所有层的梯度关闭,除了最后新增的全连接层。
model = models.resnet50(pretrained=True)
for param in model.parameters():
param.requires_grad = False # turn all gradient off
model.fc = nn.Linear(2048, 2, bias=True)
#add new fully connected layer
fc_parameters = model.fc.parameters()
for param in fc_parameters:
param.requires_grad = True #turning last layer gradient to true
model
注意最后一层是 2048 x 2,因为我们只是分类两个类别:真或假,疟疾或非疟疾。
模型变量返回一个大型的 ResNet 模型结构,并包含我们自定义的最后一层。
Downloading: "https://download.pytorch.org/models/resnet50-19c8e357.pth" to /tmp/.torch/models/resnet50-19c8e357.pth
100%|██████████| 102502400/102502400 [00:01<00:00, 89692748.86it/s]
在下面的代码片段中,我们省略了很多细节,以便将模型架构适配到屏幕上。如果你访问源 3 的 kernel 链接,你会看到相当多的瓶颈和顺序层。
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
在这里,我们展示了最后的自定义层确实是 2048 x 2。注意,在平均池化和 relu 之前的层是 2048,因此是 2048 x 2。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
... #omitted
... #omitted
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=2048, out_features=2, bias=True)
)
Pytorch 训练循环
训练循环可能是 Pytorch 作为深度学习框架的最具特点的部分。在 Sklearn 中可以用 fit 来处理,在 Tensorflow 中可以用 transform。在 Pytorch 中,这部分要复杂得多。
model.train() 告诉你的模型你正在训练它。因此,像 dropout、batchnorm 等层在训练和测试过程中表现不同的情况下会知道发生了什么,并能相应地调整行为。
更多细节:它将模式设置为训练模式(见 源代码)。你可以调用 model.eval() 或 model.train(mode=False) 来表明你正在进行测试。期望 train 函数来训练模型是有些直观的,但实际上它并不会这么做。它只是设置模式。
model.eval() 会通知所有层你处于评估模式,这样,batchnorm 或 dropout 层将在评估模式而不是训练模式下工作。
torch.no_grad() 影响自动求导引擎并将其停用。它将减少内存使用并加快计算速度,但你将无法进行反向传播(在评估脚本中你不希望进行反向传播)。— albanD
代码片段训练循环源 3
use_cuda = torch.cuda.is_available()
if use_cuda:
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.fc.parameters(), lr=0.001 , momentum=0.9)
在开始训练之前,检查 CUDA 可用性,将准则设置为 CrossEntropyLoss(),将优化器设置为 Stochastic Gradient Descent。例如,注意学习率从非常小的 lr=0.001 开始。
注意,训练循环通常包括周期数、模型架构优化器和准则。损失值必须在每个循环开始时先归零!大循环遍历周期数。在每个周期中,我们将模型设置为训练模式 model.train(),如有必要,将模型和数据移到 CUDA,optimizer.zero_grad() 在开始之前将梯度归零,预测输出,使用准则计算损失,loss.backward 基于优化器计算权重变化,optimizer.step() 进行一次反向传播步骤以更新权重。在验证时,将模型切换到评估模式 model.eval()。如果验证损失有所减少,则保存模型,跟踪最低验证损失。
def train(n_epochs, model, optimizer, criterion, use_cuda, save_path):
*"""returns trained model"""*
*# initialize tracker for minimum validation loss*
valid_loss_min = np.Inf
for epoch in range(1, n_epochs+1):
*# initialize variables to monitor training and validation loss*
train_loss = 0.0
valid_loss = 0.0
*###################*
*# train the model #*
*###################*
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
*# move to GPU*
if use_cuda:
data, target = data.cuda(), target.cuda()
*# initialize weights to zero*
optimizer.zero_grad()
output = model(data)
*# calculate loss*
loss = criterion(output, target)
*# back prop*
loss.backward()
*# grad*
optimizer.step()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))
if batch_idx % 100 == 0:
print('Epoch %d, Batch %d loss: %.6f' %
(epoch, batch_idx + 1, train_loss))
*######################*
*# validate the model #*
*######################*
model.eval()
for batch_idx, (data, target) in enumerate(valid_loader):
*# move to GPU*
if use_cuda:
data, target = data.cuda(), target.cuda()
*## update the average validation loss*
output = model(data)
loss = criterion(output, target)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.data - valid_loss))
*# print training/validation statistics*
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch,
train_loss,
valid_loss
))
*## TODO: save the model if validation loss has decreased*
if valid_loss < valid_loss_min:
torch.save(model.state_dict(), save_path)
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
valid_loss_min = valid_loss
*# return trained model*
return model
开发工具
训练循环:
训练和前向传播
云端免费 GPU
感谢像 Google Colab 这样的新云技术。一旦你设置好笔记本,你可以在移动设备上继续训练和监控! 云端选择包括 Google Colab、Kaggle 和 AWS。本地选择包括你的个人笔记本电脑和游戏电脑。
我们之前将一台 MSI NVIDIA GTX 1060 重新用于《刺客信条:起源》 😄 如果你想了解更多,请告诉我们。
能够在本地 GPU 上进行训练是一个重大优势。我们能够快速进行参数调优组合的迭代而不会中断。Google Colab 有 12 小时的超时限制和 12GB 的配额限制。如果你是高级用户,务必避免不断下载数据集,而是将其存储在 Google Drive 中。删除 Google Drive 中的模型后,请务必清空回收站以实际删除它。
无论模型在哪里训练,如果训练损失接近零但验证损失没有减少(没有测试数据集),你可能要注意你的模型是否过拟合,可能在记忆训练数据。暂停并调整你的参数。即使你达到了 99% 的准确率,你的模型也可能不具备泛化能力,因此可能无法在其他地方使用。特别是对于 Udacity 的奖学金挑战和纳米学位的学生,这段信息尤其相关。对 99% 的准确率要保持高度怀疑,但可以先庆祝一下。
向前传播
Pytorch 向前传播实际上会计算 y = wx + b,在此之前我们只是写了占位符。
有用的 Pytorch 库和模块及其安装。
import torch
import torchvision
from torchvision import datasets, transforms, models
import torch.nn.functional as F
from collections import OrderedDict
from torch import nn
from torch import optim
Torchvision 模块非常强大。它包含图像处理和数据处理代码、卷积神经网络(CNN)以及其他预训练模型,如 ResNet 和 VGG。
转换
-
transforms.ToTensor()将数据数组转换为 Pytorch 张量。优点包括在 CUDA 和 GPU 训练中易于使用。 -
开发人员可以在 Pytorch 中 构建转换和转换管道。管道是指将多个转换串联在一起并顺序执行的一种方式。
Pytorch 卷积神经网络(CNN)
本节正在建设中… 请稍后再查看。
使用卷积神经网络完成计算机视觉、图像识别任务。转换和数据增强 API 非常重要,特别是在训练数据有限时。或者,也可以使用许多预加载的模型架构 —— 阅读我们的转移学习部分。
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
最大池化层会丢弃原始图像中包含的详细空间信息。
检查 Pytorch 模型
首先初始化模型。
vgg16 = models.vgg16(pretrained=True)
print(vgg16)
在 Pytorch 中,使用 print(model_name) 来打印模型及其架构。你可以轻松地了解模型的详细信息。
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
...
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
...
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
注意,每一层都有名称(编号,并且可以通过这个索引进行查询)。我们使用省略号来省略模型细节,以便 VGG 模型能够适应屏幕。
专业提示:检查模型架构是必须的。转移学习,简而言之,就是修改最后几个分类器层。在我们的转移学习文章中阅读更多。
专业提示:对于 Tensorflow,使用 keras model.summary() 来查看整个模型架构。它甚至会输出参数数量和维度。
高级特性
Pytorch 版本
对于 Udacity 项目,并非所有的纳米学位都已经迁移到 Pytorch 1.0。使用正确版本的 Pytorch 对相应的项目至关重要。你可能还需要在 Jupyter Notebook 中更改内核,以使用相应版本的 Python。Udacity 项目已经迁移到 Python3。并非所有现实世界中的项目都已迁移到 Python 3,但现在是时候从 Python 2 迁移过来了。
使用 CUDA
虽然我们决定将 CUDA 放在高级部分,但现实是 CUDA 非常易于使用。今天就使用它吧!通过 Anaconda、Pytorch 和 CUDA,我们将一台配备 NVIDIA 显卡的游戏电脑变成了家庭深度学习的强大机器。无需配置!它直接工作。这个框架在 Windows 机器上就能运行!(这是之前用于《刺客信条:起源》的 MSI NVIDIA GTX 1060 😄 如果你想了解更多,请告诉我们。)
gpu_is_avail = torch.cuda.is_available()if not gpu_is_avail:
print('CUDA is NOT available.')
else:
print('CUDA is available. ')device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
使用 CUDA 与 Pytorch 的一个常见错误是不将模型和数据同时移动到 CUDA 上。当需要时将它们都移回 CPU。一般来说,你的模型和数据应该始终位于同一个空间。
在生产环境中部署 Pytorch:将现有的 Pytorch 模型转换为生产就绪的部署有两种方法——追踪和脚本。追踪不支持具有代码控制流的复杂模型。脚本支持具有控制流的 Pytorch 代码,但仅支持有限数量的 Python 模块。
选择最佳的 Softmax 结果:在多类别分类中,通常使用激活函数 Softmax。Pytorch 有一个专门的函数来提取最顶级的结果——从 Softmax 输出中最可能的类别。torch.topk(input, k, dim)返回顶级概率。
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)
Returns the k largest elements of the given input tensor along a given dimension.
If dim is not given, the last dimension of the input is chosen.
If largest is False then the k smallest elements are returned.
在其他平台上使用 Pytorch 模型
import torch.onnx
import torchvision
dummy_input = torch.randn(1, 3, 224, 224)
model = torchvision.models.alexnet(pretrained=True)
torch.onnx.export(model, dummy_input, "alexnet.onnx")
“以标准 ONNX(开放神经网络交换)格式导出模型,以便直接访问 ONNX 兼容的平台、运行时、可视化工具等。” — Pytorch 1.0 文档
更多关于 Pytorch 迁移学习的内容
使用现有模型相当于冻结其某些层和参数,并且不对这些层和参数进行训练。通过将require_grad设置为 False 来关闭训练自动求导。
for param in model.parameters():
param.requires_grad = False
超参数调整
除了使用正确的优化器和调整学习率之外,你还可以使用学习率调度器动态调整学习率。
#define scheduler
scheduler = lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
模型和检查点保存
保存和加载模型检查点
专业提示:你知道可以在本地和 Google Drive 中保存和加载模型吗?这样你不必每次都从头开始。例如,如果你已经训练了 5 个周期,你可以保存权重,然后再训练另外 5 个周期。现在你总共训练了 10 个周期!非常方便。免费的 GPU 资源经常超时并被擦除。记住,增量训练是可能的。
你还可以保存一个检查点并在本地加载它。你可能会看到.pt和.pth扩展名。
# write and then use your custom load_checkpoint function
model = load_checkpoint('checkpoint_resnet50.pth')
print(model)# use pytorch torch.load and load_state_dict(state_dict)
checkpt = torch.load(‘checkpoint_resnet50.pth’)
model.load_state_dict(checkpt)#save locally, map the new class_to_idx, move to cpu
#note down model architecturecheckpoint['class_to_idx']
model.class_to_idx = image_datasets['train'].class_to_idx
model.cpu()
torch.save({'arch': 'resnet18',
'state_dict': model.state_dict(),
'class_to_idx': model.class_to_idx},
'classifier.pth')
来自源 3 的代码片段
model.load_state_dict(torch.load('malaria_detection.pt'))
请注意,你必须将任何检查点保存到 Google Colab 的 Google Drive 中,否则你的数据可能每 12 小时或更早被删除。虽然 GPU 访问是免费的,但 Google Colab 上的存储是临时的。
使用 Pytorch 进行预测
这里是我们不喜欢 Pytorch 的地方。使用 Pytorch 进行预测似乎有点拼凑。尽管编写自己的训练循环看似容易自定义,但比 Tensorflow 更难编写,权衡一下舒适度和自定义性是值得的。然而,预测过程很奇怪,有些函数看起来像是被拼凑在一起的。看看下面的代码片段以了解我们的意思:
来源 3 的代码片段:
def test(model, criterion, use_cuda):
... #omitted
*# convert output probabilities to predicted class*
pred = output.data.max(1, keepdim=True)[1]
*# compare predictions to true label*
correct += np.sum(np.squeeze(pred.eq(target.data.view_as(pred))).cpu().numpy())
total += data.size(0)
.... #omitteddef load_input_image(img_path):
image = Image.open(img_path)
prediction_transform = transforms.Compose([transforms.Resize(size=(224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
*# discard the transparent, alpha channel (that's the :3) and add the batch dimension*
image = prediction_transform(image)[:3,:,:].unsqueeze(0)
return imagedef predict_malaria(model, class_names, img_path):
*# load the image and return the predicted breed*
img = load_input_image(img_path)
model = model.cpu()
model.eval()
idx = torch.argmax(model(img))
return class_names[idx]
output.data.max,np.sum(np.squeeze()),cpu().numpy(),.unsqueeze(0),torch.argmax …… WTF?!这真的很让人沮丧。
重要的要点是:我们在这里处理的是转换为概率的 logits,还有需要转化为矩阵的张量和去除多余的括号。我们需要使用 max 或 argmax 来确定最可能的类别。我们需要将张量移回 CPU,因此使用 cpu(),并将张量转化为 ndarray 以便计算,使用 numpy()。
Pytorch 是一个深度学习框架,而深度学习常涉及矩阵运算,主要是调整维度,因此需要使用 squeeze 和 unsqueeze 来使维度匹配。
>>> import torch
>>> import numpy as np
>>> test = torch.tensor([[1,2,3]])
>>> np.squeeze(test)
tensor([1, 2, 3])
>>> torch.tensor([1]).unsqueeze(0)
tensor([[1]])
这部分备忘单将为你节省很多麻烦,不客气!np.squeeze() 去除了 [[1,2,3]] 中额外的 [] 和多余的维度,原本的形状是 (1, 3),现在变成了 (3,)。
而 unsqueeze 将 [1] 的形状 (1,) 变为 [[1]] 的形状 (1,1)。
深入阅读
-
来源 2: Pytorch Github 主页面
github.com/pytorch/pytorch#getting-started也提供了很好的备忘单。 -
极其棒的论坛,包括许多活跃的核心贡献者,补充了文档
discuss.pytorch.org/ -
来源 3: 使用 Pytorch 的疟疾检测 kaggle 内核
www.kaggle.com/devilsknight/malaria-detection-with-pytorch -
来源 4:
github.com/pytorch/examples/blob/97304e232807082c2e7b54c597615dc0ad8f6173/imagenet/main.py#L197-L198 -
来源 5: Pytorch 社区论坛 Pytorch 图像变换标准化
discuss.pytorch.org/t/whats-the-range-of-the-input-value-desired-to-use-pretrained-resnet152-and-vgg19/1683
Uniqtech: 我们经常编写像这样的适合初学者的 Cheat Sheets。关注我们的个人资料以及我们最受欢迎的数据科学训练营出版物。查看我们关于 Pytorch 中迁移学习、Amazon SageMaker 上的 Pytorch 和数据科学的 Anaconda Cheat Sheet 的单页文章。我们主要在 Medium 上活跃,这是一个我们喜爱并有强烈认同感的社区。Medium 对其作者很好,并拥有一个极好的读者社区。如果您想了解我们即将推出的数据科学训练营课程(2024 年秋季发布)、高质量文章的奖学金,或者想为我们写作、提供反馈,请通过 hi@uniqtech.co 发送电子邮件给我们。感谢 Medium 社区!
主要作者和贡献者 Sun.
原文. 经许可转载。
相关:
-
深度学习 Cheat Sheets
-
使用 PyTorch 框架进行 NLP 入门
-
3 个更多的 Google Colab 环境管理技巧
更多主题
Pytorch Lightning 与 PyTorch Ignite 与 Fast.ai
原文:
www.kdnuggets.com/2019/08/pytorch-lightning-vs-pytorch-ignite-vs-fast-ai.html
评论
由威廉·法尔孔,AI 研究员

显然,狮子、熊和老虎是朋友
我们的前三名课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
PyTorch-lightning 是一个最近发布的库,是一个类似 Keras 的 PyTorch 机器学习库。它将核心训练和验证逻辑留给你,并自动化其他部分。(顺便提一下,这里的 Keras 意味着没有样板代码,而不是过于简化)。
作为 Lightning 的核心作者,我曾多次被问及 Lightning 与 fast.ai、PyTorch ignite之间的核心差异。
在这里,我将尝试对这三种框架进行客观比较。这一比较基于在所有三个框架的教程和文档中客观发现的相似性和差异性。
动机
Fast.ai 最初是为了方便教学fast.ai 课程而创建的。最近,它还转变成了一个实现常见方法(如 GANs、RL 和迁移学习)的库。
PyTorch Ignite和Pytorch Lightning都是为了给予研究人员尽可能多的灵活性,要求他们定义训练循环和验证循环中的操作。
Lightning 有两个额外的、更雄心勃勃的目标:可重复性和普及最佳实践,只有 PyTorch 高级用户会实现(分布式训练、16 位精度等)。我将在后续章节中详细讨论这些目标。
因此,从基本层面上讲,目标用户是明确的:对于 fast.ai,目标用户是对深度学习感兴趣的人,而另外两个框架则专注于活跃的研究人员,无论是从事机器学习还是使用机器学习(例如:生物学家、神经科学家等)。
学习曲线
Lightning 和 Ignite 都具有非常简单的接口,因为大部分工作仍然由用户在纯 PyTorch 中完成。主要的工作发生在 Engine 和 Trainer 对象中。
然而,Fast.ai 确实需要在 PyTorch 之上学习另一个库。API 大部分时间并不直接操作纯 PyTorch 代码(也有一些地方会),但它需要像 DataBunches、 DataBlocs 等抽象。当“最佳”方法不明显时,这些 API 非常有用。
对于研究人员来说,关键在于不需要再学习另一个库,直接控制研究的关键部分,如数据处理,而不需要其他抽象来操作这些部分。
在这种情况下,fast.ai 库有更高的学习曲线,但如果你不一定知道“最佳”方法是什么,并且只是想把好的方法作为黑箱来使用,这一点是值得的。
Lightning vs Ignite
更像是共享
从上述内容可以明显看出,将 fast.ai 与这两个框架进行比较是不公平的,因为使用案例和用户群体不同(然而,我仍会在本文末尾的比较表中添加 fast.ai)。
Lightning 和 Ignite 之间的第一个主要区别是它们操作的接口。
在 Lightning 中,有一个标准接口(见 LightningModule),每个模型都必须遵循这 9 个必需的方法。
这种灵活的格式允许在训练和验证中获得最大的自由。这个接口应该被视为一个 系统,而不是一个模型。系统可能有多个模型(GANs、seq-2-seq 等),或者它可能是一个模型,比如这个简单的 MNIST 示例。
因此,研究人员可以自由尝试各种疯狂的东西,并且只需要担心这 9 个方法。
Ignite 需要非常类似的设置,但没有一个 标准 接口,每个模型都需要遵循。
请注意,run 函数可能会有不同的定义,即:可能有许多不同的事件添加到训练器中,或者它甚至可能被命名为其他名称,如 main, train, etc…
在一个复杂的系统中,比如训练可能以奇怪的方式进行(看着你们,GAN 和 RL),代码的运行情况可能不容易被直观理解。而在 Lightning 中,你可以查看 training_step 来弄清楚发生了什么。
可重复性

当你尝试重现工作时
如我所提到的,Lightning 是在第二个更雄心勃勃的广泛动机下创建的:可重复性。
如果你尝试阅读某人的论文实现,往往很难弄清楚发生了什么。我们早已不再只是设计不同的神经网络架构。
现代的 SOTA 模型实际上是系统,这些系统使用了多种模型或训练技术来实现特定的结果。
正如我之前所说,LightningModule 是一个系统,而不是一个模型。因此,如果你想知道所有那些复杂的技巧和超级复杂的训练发生在哪里,你可以查看 training_step 和 validation_step。
如果每个研究项目和论文都使用 LightningModule 模板进行实现,那么了解发生了什么将变得非常容易(但可能不容易理解,哈哈)。
在 AI 社区中进行这种标准化将允许一个生态系统蓬勃发展,该生态系统可以使用 LightningModule 接口来执行一些很酷的功能,比如自动化部署、审计系统中的偏差,甚至支持将权重哈希到区块链后端以重建用于关键预测的模型,这些模型可能需要进行审计。
开箱即用的功能
Ignite 和 Lightning 之间的另一个主要区别在于 Lightning 开箱即用的功能。开箱即用意味着你无需额外编写代码。
举例来说,让我们尝试在同一台机器上的多个 GPU 上训练一个模型。
Ignite (demo)**
Lightning (demo)**
好的,没有哪个是坏的……但如果我们想在多台机器上使用多个 GPU 呢?让我们在 200 个 GPU 上进行训练。
Ignite
…
好吧,这里没有内置支持……你需要扩展 这个示例 并添加一种提交脚本的简便方法。然后,你还需要处理加载/保存、确保不会覆盖权重/日志与所有进程等……你明白了。
Lightning
使用 Lightning,你只需设置节点数量并提交适当的作业。 这里有一个关于如何正确配置作业的详细教程。
开箱即用的功能是指那些你无需做任何事即可使用的功能。这意味着你可能现在不需要它们,但当你需要例如...累积梯度、梯度裁剪或 16 位训练时,你不会花费数天/数周的时间阅读教程来使其工作。
只需设置适当的 Lightning 标志,然后继续进行你的研究。
Lightning 预构建了这些功能,以便用户花更多时间进行研究,而不是进行工程开发。这对于非计算机科学/数据科学研究人员,如物理学家、生物学家等尤其有用,他们可能在编程方面不那么精通。
这些功能使 PyTorch 的特性变得普及,只有高级用户可能会花时间去实现。
这里有表格比较了所有三个框架在不同功能集上的特性。
如果我遗漏了任何重要内容,请留言,我会更新表格!
高性能计算
调试工具
可用性
结束语
在这里,我们对三个框架进行了多层次的深入比较。每个框架都有其自身的优点。
如果你刚刚学习或没有跟上所有最新的最佳实践,不需要超高级的训练技巧,并且有时间学习新的库,那么选择 fast.ai。
如果你需要最大的灵活性,可以选择 Ignite 或 Lightning。
如果你不需要超高级的功能,并且可以接受添加 Tensorboard 支持、累积梯度、分布式训练等,那么选择 Ignite。
如果你需要更高级的功能、分布式训练、最新的深度学习训练技巧,并且希望看到一个标准化的实现世界,那就使用 Lightning。
简介: 威廉·法尔肯 是 AI 研究员、初创公司创始人、CTO、Google Deepmind 学者以及 Facebook AI 的现任博士研究实习生。
原文。经许可转载。
相关内容:
-
初学者和 Udacity 深度学习纳米学位的 PyTorch 备忘单
-
使用 PyTorch 框架入门 NLP
-
XLNet 在多个 NLP 任务中超越 BERT
更多相关主题
PyTorch LSTM:文本生成教程
原文:
www.kdnuggets.com/2020/07/pytorch-lstm-text-generation-tutorial.html
评论
作者 Domas Bitvinskas,Closeheat
长短期记忆(LSTM)是一种流行的递归神经网络(RNN)架构。本教程讲解如何在 PyTorch 上使用 LSTM 生成文本;在这种情况下 - 一些相当无聊的笑话。
本教程需要:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
什么是 LSTM?
LSTM 是 RNN 的一种变体,广泛应用于深度学习。如果你在处理数据序列时,可以使用 LSTM。
以下是你可能熟悉的 LSTM 网络的最直接应用场景:
-
时间序列预测(例如,股票预测)
-
文本生成
-
视频分类
-
音乐生成
-
异常检测
RNN
在开始使用 LSTM 之前,你需要了解 RNN 的工作原理。
RNN 是处理序列数据的神经网络。它可以是视频、音频、文本、股市时间序列甚至单张图像被切割成序列的各部分。
与 RNN 相比,标准神经网络(卷积神经网络或普通神经网络)有一个主要缺点 - 它们不能利用之前的输入来指导后续的预测。没有某种形式的记忆,无法解决某些机器学习问题。
例如,当你有一些视频帧显示一个球的移动,并想预测球的方向时,你可能会遇到问题。标准神经网络看到的问题是:你在一张图像中看到一个球,在另一张图像中也看到一个球。它没有机制将这两张图像作为序列连接起来。标准神经网络不能将两个独立的球的图像与“球在移动”的概念联系起来。它只看到图像#1 中有一个球,图像#2 中也有一个球,但网络输出是分开的。
将其与 RNN 进行比较,RNN 记住最后的帧,并可以用来指导下一次预测。
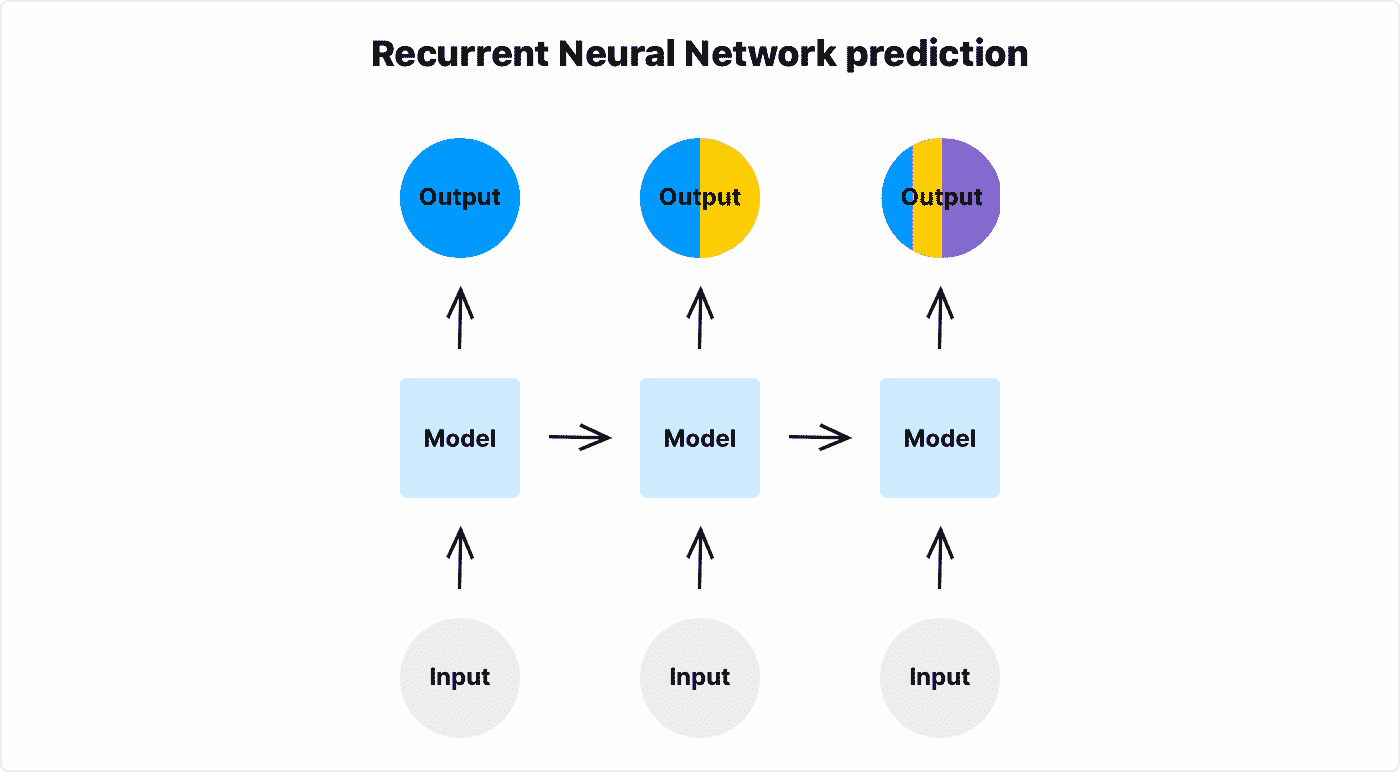
LSTM 与 RNN
典型的 RNN 无法记忆长序列。所谓的“梯度消失”效应发生在 RNN 单元网络的反向传播阶段。携带序列开始部分信息的单元梯度经过小数的矩阵乘法后在长序列中接近 0。换句话说,序列开始部分的信息对序列末端几乎没有影响。
你可以在递归神经网络示例中看到这一点。给定足够长的序列,序列第一个元素的信息对序列最后一个元素的输出没有影响。
LSTM 是一种 RNN 架构,可以记忆长序列 - 最多 100 个元素。LSTM 具有记忆门控机制,使长期记忆能够继续流入 LSTM 单元。
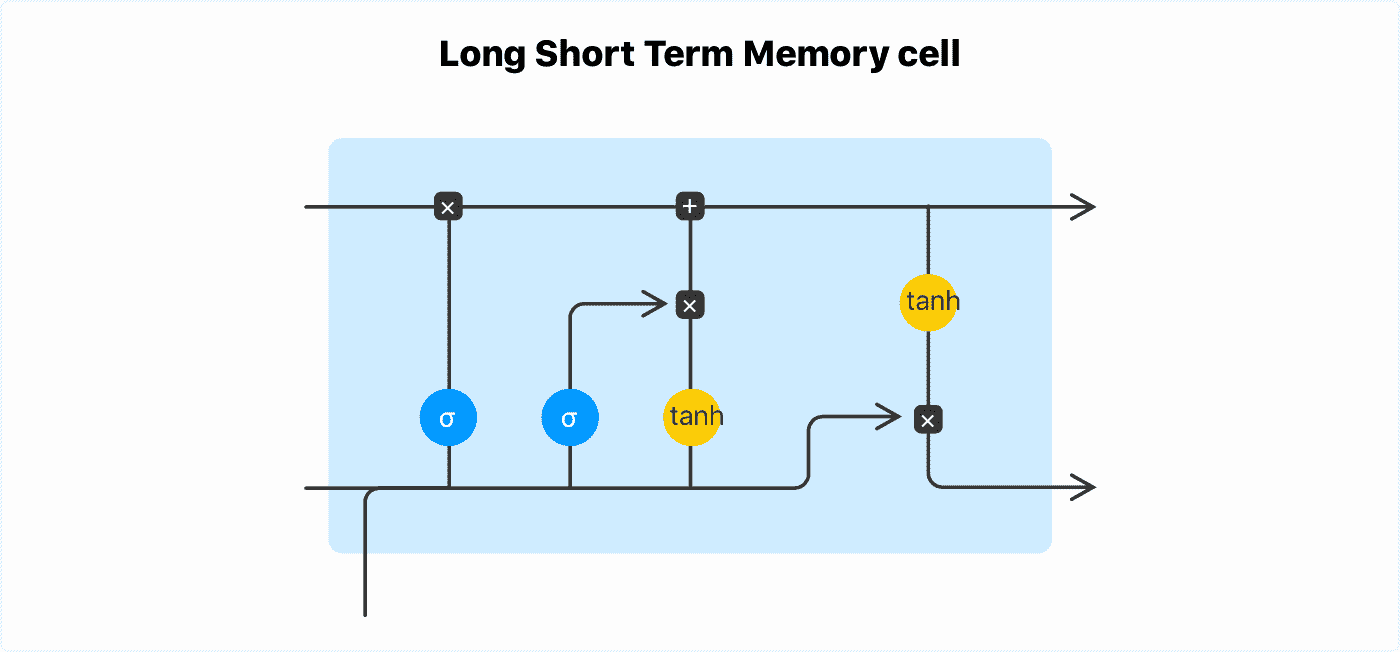
使用 PyTorch 进行文本生成
你将使用 PyTorch 中的 LSTM 网络训练一个笑话文本生成器,并遵循最佳实践。首先,创建一个新的文件夹来存储代码:
$ mkdir text-generation
模型
要创建一个 LSTM 模型,在text-generation文件夹中创建一个名为model.py的文件,内容如下:
import torch
from torch import nn
class Model(nn.Module):
def __init__(self, dataset):
super(Model, self).__init__()
self.lstm_size = 128
self.embedding_dim = 128
self.num_layers = 3
n_vocab = len(dataset.uniq_words)
self.embedding = nn.Embedding(
num_embeddings=n_vocab,
embedding_dim=self.embedding_dim,
)
self.lstm = nn.LSTM(
input_size=self.lstm_size,
hidden_size=self.lstm_size,
num_layers=self.num_layers,
dropout=0.2,
)
self.fc = nn.Linear(self.lstm_size, n_vocab)
def forward(self, x, prev_state):
embed = self.embedding(x)
output, state = self.lstm(embed, prev_state)
logits = self.fc(output)
return logits, state
def init_state(self, sequence_length):
return (torch.zeros(self.num_layers, sequence_length, self.lstm_size),
torch.zeros(self.num_layers, sequence_length, self.lstm_size))
这是一个标准的 PyTorch 模型。Embedding层将单词索引转换为单词向量。LSTM是网络的主要可学习部分 - PyTorch 实现中的LSTM单元内部实现了门控机制,可以学习长序列的数据。
如早前什么是 LSTM?部分所述 - RNN 和 LSTM 具有在训练周期之间传递的额外状态信息。forward函数具有一个prev_state参数。这个状态保持在模型外部,并手动传递。
它还具有init_state函数。在每个 epoch 开始时调用此函数,以初始化正确形状的状态。
数据集
在本教程中,我们使用 Reddit 清理笑话数据集来训练网络。下载 (139KB)数据集,并将其放入text-generation/data/文件夹中。
数据集包含 1623 个笑话,内容如下:
ID,Joke
1,What did the bartender say to the jumper cables? You better not try to start anything.
2,Don't you hate jokes about German sausage? They're the wurst!
3,Two artists had an art contest... It ended in a draw
…
要将数据加载到 PyTorch 中,请使用 PyTorch 的Dataset类。创建一个名为dataset.py的文件,内容如下:
import torch
import pandas as pd
from collections import Counter
class Dataset(torch.utils.data.Dataset):
def __init__(
self,
args,
):
self.args = args
self.words = self.load_words()
self.uniq_words = self.get_uniq_words()
self.index_to_word = {index: word for index, word in enumerate(self.uniq_words)}
self.word_to_index = {word: index for index, word in enumerate(self.uniq_words)}
self.words_indexes = [self.word_to_index[w] for w in self.words]
def load_words(self):
train_df = pd.read_csv('data/reddit-cleanjokes.csv')
text = train_df['Joke'].str.cat(sep=' ')
return text.split(' ')
def get_uniq_words(self):
word_counts = Counter(self.words)
return sorted(word_counts, key=word_counts.get, reverse=True)
def __len__(self):
return len(self.words_indexes) - self.args.sequence_length
def __getitem__(self, index):
return (
torch.tensor(self.words_indexes[index:index+self.args.sequence_length]),
torch.tensor(self.words_indexes[index+1:index+self.args.sequence_length+1]),
)
这个Dataset类继承自 PyTorch 的torch.utils.data.Dataset类,并定义了两个重要的方法__len__和__getitem__。详细了解 PyTorch 中Dataset类的工作原理,请参考数据加载教程。
load_words函数加载数据集。数据集中计算独特的词汇量,以定义网络的词汇表大小和嵌入大小。index_to_word和word_to_index将单词转换为数字索引,反之亦然。
这是过程的一部分是 分词。未来,torchtext 团队计划改进这一部分,但他们正在重新设计,新的 API 对于本教程来说过于不稳定。
训练
创建一个 train.py 文件并定义一个 train 函数。
import argparse
import torch
import numpy as np
from torch import nn, optim
from torch.utils.data import DataLoader
from model import Model
from dataset import Dataset
def train(dataset, model, args):
model.train()
dataloader = DataLoader(dataset, batch_size=args.batch_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(args.max_epochs):
state_h, state_c = model.init_state(args.sequence_length)
for batch, (x, y) in enumerate(dataloader):
optimizer.zero_grad()
y_pred, (state_h, state_c) = model(x, (state_h, state_c))
loss = criterion(y_pred.transpose(1, 2), y)
state_h = state_h.detach()
state_c = state_c.detach()
loss.backward()
optimizer.step()
print({ 'epoch': epoch, 'batch': batch, 'loss': loss.item() })
使用 PyTorch DataLoader 和 Dataset 抽象来加载笑话数据。
使用 CrossEntropyLoss 作为损失函数,并使用 Adam 作为默认参数的优化器。你可以稍后进行调整。
在他著名的 帖子 中,Andrew Karpathy 也建议最初保持这一部分的简单。
文本生成
将 predict 函数添加到 train.py 文件中:
def predict(dataset, model, text, next_words=100):
model.eval()
words = text.split(' ')
state_h, state_c = model.init_state(len(words))
for i in range(0, next_words):
x = torch.tensor([[dataset.word_to_index[w] for w in words[i:]]])
y_pred, (state_h, state_c) = model(x, (state_h, state_c))
last_word_logits = y_pred[0][-1]
p = torch.nn.functional.softmax(last_word_logits, dim=0).detach().numpy()
word_index = np.random.choice(len(last_word_logits), p=p)
words.append(dataset.index_to_word[word_index])
return words
执行预测
将以下代码添加到 train.py 文件中以执行已定义的函数:
parser = argparse.ArgumentParser()
parser.add_argument('--max-epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=256)
parser.add_argument('--sequence-length', type=int, default=4)
args = parser.parse_args()
dataset = Dataset(args)
model = Model(dataset)
train(dataset, model, args)
print(predict(dataset, model, text='Knock knock. Whos there?'))
使用以下命令运行 train.py 脚本:
$ python train.py
你可以看到损失随训练轮次变化。当训练结束时,模型在 Knock knock. Whos there? 之后预测接下来的 100 个词。默认情况下,它运行 10 个轮次,训练大约需要 15 分钟。
{'epoch': 9, 'batch': 91, 'loss': 5.953955173492432}
{'epoch': 9, 'batch': 92, 'loss': 6.1532487869262695}
{'epoch': 9, 'batch': 93, 'loss': 5.531163215637207}
['Knock', 'knock.', 'Whos', 'there?', '3)', 'moostard', 'bird', 'Book,',
'What', 'when', 'when', 'the', 'Autumn', 'He', 'What', 'did', 'the',
'psychologist?', 'And', 'look', 'any', 'jokes.', 'Do', 'by', "Valentine's",
'Because', 'I', 'papa', 'could', 'believe', 'had', 'a', 'call', 'decide',
'elephants', 'it', 'my', 'eyes?', 'Why', 'you', 'different', 'know', 'in',
'an', 'file', 'of', 'a', 'jungle?', 'Rock', '-', 'and', 'might', "It's",
'every', 'out', 'say', 'when', 'to', 'an', 'ghost', 'however:', 'the', 'sex,',
'in', 'his', 'hose', 'and', 'because', 'joke', 'the', 'month', '25', 'The',
'97', 'can', 'eggs.', 'was', 'dead', 'joke', "I'm", 'a', 'want', 'is', 'you',
'out', 'to', 'Sorry,', 'the', 'poet,', 'between', 'clean', 'Words', 'car',
'his', 'wife', 'would', '1000', 'and', 'Santa', 'oh', 'diving', 'machine?',
'He', 'was']
如果你跳过了这部分并想运行代码,这里有一个可以克隆的 Github 仓库。
下一步
恭喜!你已经编写了第一个 PyTorch LSTM 网络并生成了一些笑话。
接下来你可以做的事情来改进模型是:
-
通过去除非字母字符来清理数据。
-
通过添加更多的
Linear或LSTM层来增加模型的容量。 -
将数据集拆分为训练、测试和验证集。
-
添加检查点,以便你不必每次都训练模型才能运行预测。
简介: Domas Bitvinskas (@domasbitvinskas) 在 Closeheat 领导机器学习和增长实验。
原文。经许可转载。
相关:
-
PyTorch 深度学习:免费电子书
-
使用 TensorFlow 和 LSTM 循环神经网络生成烹饪食谱:逐步指南
-
你应该知道的 PyTorch 最重要的基础知识
更多相关主题
使用 torchlayers 轻松构建 PyTorch 模型
原文:
www.kdnuggets.com/2020/04/pytorch-models-torchlayers.html
评论
根据 在线搜索 和更重要的 PyTorch 采用率的持续增长 来看,PyTorch 继续受到广泛关注。PyTorch 被认为是强大而灵活的,这对研究人员来说是受欢迎的。然而,过去 PyTorch 因缺乏类似 TensorFlow 的 Keras 的简化高级 API 而受到批评。这个情况最近发生了变化。

torchlayers 旨在为 PyTorch 做到 Keras 对 TensorFlow 所做的事情。简洁地由项目开发者定义:
torchlayers 是一个基于 PyTorch 的库,提供
torch.nn层的自动形状和维度推断 + 当前 SOTA 架构中的附加构建块(例如 Efficient-Net)。上述操作无需用户干预(除了对 torchlayers.build 的单次调用),类似于 Keras 中的操作。
除了上述的形状和维度推断,torchlayers 还包括类似 Keras 的附加层,例如 [torchlayers.Reshape](https://szymonmaszke.github.io/torchlayers/packages/torchlayers.html?highlight=reshape#torchlayers.Reshape)(在保持批次维度的同时重塑输入张量),包含之前在 ImageNet 竞赛中看到的 SOTA 层(例如 [PolyNet](https://szymonmaszke.github.io/torchlayers/packages/torchlayers.convolution.html?highlight=polynet#torchlayers.convolution.Poly)),并提供一些有用的默认设置,例如卷积核大小(torchlayers 的默认值为 3)。
使用 pip 安装很简单:
pip install --user torchlayers
额外的安装信息(如 Docker 镜像和 GPU)可以在这里找到。完整的 torchlayers 文档 可以在这里找到。
torchlayers 的 GitHub 页面提供了一些示例来展示其功能。我喜欢这个 简单的图像和文本分类器! 示例,下面我复制了它的代码。这个示例展示了:
-
torch.nn和torchlayers层的混合使用 -
形状和维度推断(
Conv和Linear输入及BatchNorm) -
默认卷积核大小
-
Conv填充默认设置为 "same" -
使用 torchlayers 池化层(
GlobalMaxPool,类似于 Keras)
import torch
import torchlayers as tl
# torch.nn and torchlayers can be mixed easily
model = torch.nn.Sequential(
tl.Conv(64), # specify ONLY out_channels
torch.nn.ReLU(), # use torch.nn wherever you wish
tl.BatchNorm(), # BatchNormNd inferred from input
tl.Conv(128), # Default kernel_size equal to 3
tl.ReLU(),
tl.Conv(256, kernel_size=11), # "same" padding as default
tl.GlobalMaxPool(), # Known from Keras
tl.Linear(10), # Output for 10 classes
)
然后可以使用 [torchlayers.build](https://szymonmaszke.github.io/torchlayers/packages/torchlayers.html?highlight=build#torchlayers.build) 来构建一个定义的网络,同时指定输入形状(下面展示了图像和文本分类的输入形状,适用于上面定义的模型):
# Image...
mnist_model = tl.build(model, torch.randn(1, 3, 28, 28))
# ...or text
# [batch, embedding, timesteps], first dimension > 1 for BatchNorm1d to work
text_model = tl.build(model, torch.randn(2, 300, 1))
build 显然像在 Keras 中一样工作,将模型编译为 PyTorch 基本操作;它通过 post_build 函数(例如下面显示的权重初始化)提供一些附加功能,你可以在这里查看更多。
class _MyModuleImpl(torch.nn.Linear):
def post_build(self):
# You can do anything here really
torch.nn.init.eye_(self.weights)
torchlayers 提供了一些有助于使用 PyTorch 进行类似 Keras 的模型构建的功能,并填补了明显的空白。时间将证明该项目如何发展和长期受欢迎,但它无疑有一个有前途的开始。
相关:
-
OpenAI 正在采用 PyTorch... 他们并不孤单
-
PyTorch 1.2 的温和介绍
-
使用 TensorFlow 和 Keras 进行标记化和文本数据准备
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
PyTorch 多 GPU 指标库及新 PyTorch Lightning 发布中的更多内容
原文:
www.kdnuggets.com/2020/07/pytorch-multi-gpu-metrics-library-pytorch-lightning.html
评论
由 William Falcon,PyTorch Lightning 创始人
今天 [最近] 我们发布了 0.8.1,这是 PyTorch Lightning 的一个重要里程碑。随着用户的惊人增长和采用,我们继续构建工具以轻松进行 AI 研究。
这次重大发布使我们朝着即将到来的 v1.0.0 最终 API 更改的方向迈进!
PyTorch Lightning
PyTorch Lightning 是一个非常轻量的 PyTorch 结构——它更像是一个风格指南而不是一个框架。但一旦你结构化了你的代码,我们会为你提供免费的 GPU、TPU、16 位精度支持以及更多功能!

Lightning 只是结构化的 PyTorch

指标
此次发布在 Lightning 中新增了一个重大包——一个多 GPU 指标包!
关于 Lightning 中的指标包,有两个关键点。
-
它可以与普通 PyTorch 一起使用!
-
它通过 DDP 自动处理多 GPU。这意味着即使你在一个或 20 个 GPU 上计算准确性,我们也会为你自动处理。
指标包还包括与 sklearn 指标的映射,以桥接 numpy、sklearn 和 PyTorch 之间的差距,以及一个你可以用来实现自己指标的高级类。
**class** **RMSE**(TensorMetric):
**def** **forward**(self, x, y):
**return** torch**.**sqrt(torch**.**mean(torch**.**pow(x**-**y, 2.0)))
指标包目前实现了超过 18 种指标(包括功能性指标)。查看 我们的文档 获取完整列表!
overfit_batches
此次发布还清理了我们在 Lightning 中存在已久的非常酷的调试工具。overfit_batches 标志现在可以让你在数据的一个小子集上过拟合,以确保你的模型没有重大缺陷。
逻辑是,如果你甚至无法在 1 个批次的数据上过拟合,那么训练模型的其余部分没有意义。这可以帮助你确定是否正确实现了某些东西,或确保你的数学是正确的
Trainer(overfit_batches=1)
如果你在 Lightning 中这样做,你会得到以下结果:
更快的多 GPU 训练
此次发布的另一个关键部分是通过 DDP 对分布式训练的加速。变化来自允许 DDP 与 num_workers>0 一起在数据加载器中工作
Dataloader(dataset, num_workers=8)
今天,当你通过.spawn()启动 DDP 并尝试在数据加载器中使用 num_workers>0 时,你的程序可能会冻结并且无法开始训练(这在 Lightning 之外也是如此)。
对大多数人来说,解决方案是设置 num_workers=0,但这意味着你的训练将非常慢。为了启用 num_workers>0 和 DDP,我们现在在后台启动 DDP 而不使用 spawn。这消除了许多其他奇怪的限制,比如需要 pickle 一切,以及模型权重在训练完成后不可用的要求(因为权重是在具有不同内存的子进程中学习的)。
因此,我们的 DDP 实现比普通的快得多。当然,我们保留了两者以便灵活使用:
# very fast :)
Trainer(distributed_backend='ddp')# very slow
Trainer(distributed_backend='ddp_spawn')
发布的其他酷炫功能
- .test() 现在会自动加载最佳模型权重!
model = Model()
trainer = Trainer()
trainer.fit(model)# automatically loads the best weights!
trainer.test()
- 现在通过 conda 安装 Lightning
conda install pytorch-lightning -c conda-forge
- ModelCheckpoint 跟踪最佳权重的路径
ckpt_callback = ModelCheckpoint(...)
trainer = Trainer(model_checkpoint=ckpt_callback)
trainer.fit(model)best_weights = ckpt_callback.best_model_path
- 推理期间自动将数据移动到正确的设备
class LitModel(LightningModule): @auto_move_data
def forward(self, x):
return xmodel = LitModel()
x = torch.rand(2, 3)
model = model.cuda(2)# this works!
model(x)
- 还有许多速度改进,包括单 TPU 加速(我们也支持多 TPU)
Trainer(tpu_cores=8)
今天就试试 Lightning
如果你还没有!给 Lightning 一个机会 😃
这个视频讲解了如何将你的 PyTorch 代码重构为 Lightning。
简介:威廉·法尔孔 是一名 AI 研究员,也是 PyTorch Lightning 的创始人。他致力于理解大脑、构建 AI 并在规模上使用它。
原始内容。经授权转载。
相关内容:
-
Pytorch Lightning 与 PyTorch Ignite 与 Fast.ai
-
在 PyTorch 中训练 Lightning-fast 神经网络的 9 个技巧
-
Lit BERT:NLP 转移学习的 3 个步骤
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
PyTorch 张量基础
评论
现在我们知道了 张量是什么,并了解了 Numpy 的 ndarray 如何用来表示它们,接下来我们来看看它们在 PyTorch 中是如何表示的。
PyTorch 自 Facebook 在 2017 年初开源以来,在机器学习领域产生了令人印象深刻的影响。它可能没有 TensorFlow 那样广泛的采用——TensorFlow 最初发布的时间早了一年多,得到了 Google 的支持,并且在神经网络工具新潮流兴起时奠定了黄金标准——但 PyTorch 在研究界获得的关注确实非常真实。这种关注很大程度上来自于其与 Torch proper 的关系,以及其动态计算图。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
图片来源 尽管我最近对 PyTorch 的关注充满了兴奋,但这实际上并不是一个 PyTorch 教程;它更像是对 PyTorch 的 Tensor 类的介绍,该类与 Numpy 的 ndarray 类似。
张量(非常)基础
所以让我们来看看 PyTorch 的一些张量基础,从创建一个张量(使用 Tensor 类)开始:
import torch
# Create a Torch tensor
t = torch.Tensor([[1, 2, 3], [4, 5, 6]])
t
tensor([[ 1., 2., 3.],
[ 4., 5., 6.]])
你可以通过两种方式转置张量:
# Transpose
t.t()
# Transpose (via permute)
t.permute(-1,0)
两者都产生以下输出:
tensor([[ 1., 4.],
[ 2., 5.],
[ 3., 6.]])
请注意,这两种方法都不会改变原始张量。
使用视图重塑张量:
# Reshape via view
t.view(3,2)
tensor([[ 1., 2.],
[ 3., 4.],
[ 5., 6.]])
另一个例子:
# View again...
t.view(6,1)
tensor([[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.],
[ 6.]])
应该显而易见的是,Numpy 遵循的数学惯例也会延续到 PyTorch 张量中(具体来说,我指的是行和列的表示法)。
创建一个张量并用零填充它(你可以用 ones() 实现类似的功能):
# Create tensor of zeros
t = torch.zeros(3, 3)
t
tensor([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
创建一个从正态分布中抽取随机数的张量:
# Create tensor from normal distribution randoms
t = torch.randn(3, 3)
t
tensor([[ 1.0274, -1.3727, -0.2196],
[-0.7258, -2.1236, -0.8512],
[ 0.0392, 1.2392, 0.5460]])
张量对象的形状、维度和数据类型:
# Some tensor info
print('Tensor shape:', t.shape) # t.size() gives the same
print('Number of dimensions:', t.dim())
print('Tensor type:', t.type()) # there are other types
Tensor shape: torch.Size([3, 3])
Number of dimensions: 2
Tensor type: torch.FloatTensor
除了数学概念之外,ndarray 和 Tensor 实现之间还存在许多编程和实例化上的相似之处,这一点也应该显而易见。
你可以像切片ndarrays一样切片 PyTorch 张量,这对使用其他 Python 结构的人来说应该很熟悉:
# Slicing
t = torch.Tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Every row, only the last column
print(t[:, -1])
# First 2 rows, all columns
print(t[:2, :])
# Lower right most corner
print(t[-1:, -1:])
tensor([ 3., 6., 9.])
tensor([[ 1., 2., 3.],
[ 4., 5., 6.]])
tensor([[ 9.]])
PyTorch Tensor 与 Numpy ndarray 之间的转换
你可以轻松地从ndarray创建张量,反之亦然。这些操作很快,因为这两种结构的数据会共享相同的内存空间,所以不涉及复制。这显然是一种高效的方法。
# Numpy ndarray <--> PyTorch tensor
import numpy as np
# ndarray to tensor
a = np.random.randn(3, 5)
t = torch.from_numpy(a)
print(a)
print(t)
print(type(a))
print(type(t))
[[-0.52192738 -1.11579634 1.26925835 0.10449378 -1.02894372]
[-0.78707263 -0.05350072 -0.65815075 0.18810677 -0.52795765]
[-0.41677548 0.82031861 -2.46699201 0.60320375 -1.69778546]]
tensor([[-0.5219, -1.1158, 1.2693, 0.1045, -1.0289],
[-0.7871, -0.0535, -0.6582, 0.1881, -0.5280],
[-0.4168, 0.8203, -2.4670, 0.6032, -1.6978]], dtype=torch.float64)
<class 'numpy.ndarray'>
<class 'torch.Tensor'>
# tensor to ndarray
t = torch.randn(3, 5)
a = t.numpy()
print(t)
print(a)
print(type(t))
print(type(a))
tensor([[-0.1746, -2.4118, 0.4688, -0.0517, -0.2706],
[-0.8402, -0.3289, 0.4170, 1.9131, -0.8601],
[-0.6688, -0.2069, -0.8106, 0.8582, -0.0450]])
[[-0.17455131 -2.4117854 0.4688457 -0.05168453 -0.2706456 ]
[-0.8402392 -0.3289494 0.41703534 1.9130518 -0.86014426]
[-0.6688193 -0.20693372 -0.8105542 0.8581988 -0.04502954]]
<class 'torch.Tensor'>
<class 'numpy.ndarray'>
基本张量操作
这里有几个张量操作,你可以与 Numpy 实现进行比较以增添乐趣。首先是叉积:
# Compute cross product
t1 = torch.randn(4, 3)
t2 = torch.randn(4, 3)
t1.cross(t2)
tensor([[ 2.6594, -0.5765, 1.4313],
[ 0.4710, -0.3725, 2.1783],
[-0.9134, 1.6253, 0.7398],
[-0.4959, -0.4198, 1.1338]])
接下来是矩阵乘积:
# Compute matrix product
t = (torch.Tensor([[2, 4], [5, 10]]).mm(torch.Tensor([[10], [20]])))
t
tensor([[ 100.],
[ 250.]])
最后是逐元素相乘:
# Elementwise multiplication
t = torch.Tensor([[1, 2], [3, 4]])
t.mul(t)
tensor([[ 1., 4.],
[ 9., 16.]])
关于 GPU 的一些话
PyTorch 张量具有内置的 GPU 支持。指定使用 GPU 内存和 CUDA 核心来存储和执行张量计算非常简单;cuda包可以帮助确定是否有可用的 GPU,而该包的cuda()方法将张量分配给 GPU。
# Is CUDA GPU available?
torch.cuda.is_available()
# How many CUDA devices?
torch.cuda.is_available()
# Move to GPU
t.cuda()
相关:
-
什么是张量?!?
-
PyTorch 入门第一部分:了解自动微分的工作原理
-
构建神经网络的简单入门指南
更多相关话题
PyTorch 提升生产力的技巧
原文:
www.kdnuggets.com/2023/08/pytorch-tips-boost-productivity.html

作者提供的图片
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
你是否曾经花了几个小时来调试一个机器学习模型,却无法找到准确率没有提高的原因?你是否觉得一切都应该完美无缺,但由于某种神秘原因,你却没有得到理想的结果?
不再如此。对于初学者来说,探索 PyTorch 可能会令人望而却步。在这篇文章中,你将探索经过验证的工作流程,这些工作流程肯定会提高你的结果并提升你模型的性能。
1. 对单个批次进行过拟合
是否曾经在一个大型数据集上训练模型几个小时,却发现损失没有下降,准确率也没有改善?那么,首先做一个合理性检查。
在大型数据集上训练和评估可能是耗时的,首先在小数据子集上调试模型更容易。一旦我们确定模型正常工作,就可以轻松地将训练扩展到完整数据集上。
不要在整个数据集上进行训练,总是对单个批次进行训练以进行合理性检查。
batch = next(iter(train_dataloader)) # Get a single batch
# For all epochs, keep training on the single batch.
for epoch in range(num_epochs):
inputs, targets = batch
predictions = model.train(inputs)
考虑上述代码片段。假设我们已经有了一个训练数据加载器和一个模型。与其遍历整个数据集,不如轻松获取数据集的第一个批次。然后我们可以对这个单独的批次进行训练,以检查模型是否能够学习这个小数据部分中的模式和变化。
如果损失减少到非常小的值,我们知道模型可能会过拟合这些数据,并且可以确定它在短时间内已经学到了东西。然后,我们可以通过简单地修改一行代码在完整数据集上进行训练,如下所示:
# For all epochs, iterate over all batches of data.
for epoch in range(num_epochs):
for batch in iter(dataloader):
inputs, targets = batch
predictions = model.train(inputs)
如果模型能够对单个批次进行过拟合,它应该能够学习完整数据集中的模式。这种过拟合批次的方法使调试变得更加容易。如果模型甚至不能对单个批次进行过拟合,我们可以确定问题出在模型实现上,而不是数据集上。
2. 数据标准化和洗牌
对于数据顺序不重要的数据集,打乱数据是有帮助的。例如,对于图像分类任务,如果模型在单个批次中接收到不同类别的图像,它会更好地拟合数据。以相同的顺序传递数据,我们冒着模型根据数据传递的顺序学习模式的风险,而不是学习数据内部的固有方差。 因此,传递打乱后的数据更为合适。为此,我们可以简单地使用 PyTorch 提供的 DataLoader 对象,并将 shuffle 设置为 True。
from torch.utils.data import DataLoader
dataset = # Loading Data
dataloder = DataLoader(dataset, shuffle=True)
此外,在使用机器学习模型时,规范化数据是非常重要的。尤其是在数据方差较大且某个特定参数的值高于数据集中其他所有属性时,这一点尤为关键。这可能导致某个参数主导其他所有参数,从而降低模型的准确性。我们希望所有输入参数都在相同范围内,最好是均值为 0,方差为 1.0。 为此,我们必须转换数据集。了解数据集的均值和方差后,我们可以简单地使用 torchvision.transforms.Normalize 函数。
import torchvision.transforms as transforms
image_transforms = transforms.Compose([
transforms.ToTensor(),
# Normalize the values in our data
transforms.Normalize(mean=(0.5,), std=(0.5))
])
我们可以在 transforms.Normalize 函数中传递每通道的均值和标准差,它会自动将数据转换为均值为 0 和标准差为 1。
3. 梯度裁剪
梯度爆炸是 RNN 和 LSTM 中的一个已知问题。然而,这个问题不仅限于这些架构。任何具有深层的模型都可能遭遇梯度爆炸。高梯度的反向传播可能导致发散,而不是损失的逐渐减少。
参考下面的代码片段。
for epoch in range(num_epochs):
for batch in iter(train_dataloader):
inputs, targets = batch
predictions = model(inputs)
optimizer.zero_grad() # Remove all previous gradients
loss = criterion(targets, predictions)
loss.backward() # Computes Gradients for model weights
# Clip the gradients of model weights to a specified max_norm value.
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Optimize the model weights AFTER CLIPPING
optimizer.step()
为了解决梯度爆炸问题,我们使用梯度裁剪技术,将梯度值裁剪到指定范围内。例如,如果我们使用 1 作为裁剪值或规范值,如上所述,所有梯度将被裁剪到 [-1, 1] 范围内。如果我们遇到 50 的梯度爆炸值,它将被裁剪到 1。因此,梯度裁剪解决了梯度爆炸问题,允许模型向收敛方向进行缓慢优化。
4. 切换训练 / 评估模式
这一行代码将显著提高你的模型测试准确性。几乎所有深度学习模型都会使用 dropout 和归一化层。这些层仅在稳定训练和确保模型不会因数据方差而过拟合或发散时才需要。像 BatchNorm 和 Dropout 这样的层在训练过程中提供模型参数的正则化。然而,一旦训练完成,这些层就不再需要。将模型切换到评估模式可以禁用仅在训练中需要的层,从而使模型的所有参数都用于预测。
为了更好地理解,请考虑以下代码片段。
for epoch in range(num_epochs):
# Using training Mode when iterating over training dataset
model.train()
for batch in iter(train_dataloader):
# Training Code and Loss Optimization
# Using Evaluation Mode when checking accuarcy on validation dataset
model.eval()
for batch in iter(val_dataloader):
# Only predictions and Loss Calculations. No backpropogation
# No Optimzer Step so we do can omit unrequired layers.
在评估时,我们不需要对模型参数进行任何优化。在验证步骤中我们不会计算任何梯度。为了更好的评估,我们可以省略 Dropout 和其他归一化层。例如,这将启用所有模型参数,而不是像 Dropout 层中那样仅启用部分权重。这将显著提高模型的准确性,因为你将能够使用完整的模型。
5. 使用 Module 和 ModuleList
PyTorch 模型通常继承自 torch.nn.Module 基类。根据文档:
以这种方式分配的子模块将被注册,并且当你调用 to(),等等时,它们的参数也会被转换。
模块基类允许在模型中注册每一层。然后我们可以使用 model.to() 以及类似的函数,如 model.train() 和 model.eval(),这些函数将应用到模型中的每一层。如果不这样做,将不会更改模型中每一层的设备或训练模式,你需要手动进行。模块基类一旦在模型对象上使用函数,将自动为你进行转换。
此外,一些模型包含类似的顺序层,可以使用 for 循环轻松初始化并放在列表中。这简化了代码。然而,这也会导致上述问题,因为简单的 Python 列表中的模块不会自动在模型中注册。我们应该使用 ModuleList 来包含模型中的类似顺序层。
import torch
import torch.nn as nn
# Inherit from the Module Base Class
class Model(nn.Module):
def __init__(self, input_size, output_size):
# Initialize the Module Parent Class
super().__init__()
self.dense_layers = nn.ModuleList()
# Add 5 Linear Layers and contain them within a Modulelist
for i in range(5):
self.dense_layers.append(
nn.Linear(input_size, 512)
)
self.output_layer = nn.Linear(512, output_size)
def forward(self, x):
# Simplifies Foward Propogation.
# Instead of repeating a single line for each layer, use a loop
for layer in range(len(self.dense_layers)):
x = layer(x)
return self.output_layer(x)
上述代码片段展示了创建模型及其子层的正确方法。使用 Module 和 ModuleList 可以避免在训练和评估模型时出现意外错误。
结论
上述方法是 PyTorch 机器学习框架的最佳实践。它们被广泛使用,并且得到了 PyTorch 文档的推荐。使用这些方法应该是机器学习代码流的主要方式,并且肯定会提高你的结果。
穆罕默德·阿赫姆 是一位从事计算机视觉和自然语言处理的深度学习工程师。他曾在 Vyro.AI 上工作,部署和优化了多个生成 AI 应用程序,这些应用程序在全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型感兴趣,并相信持续改进。
更多相关内容
PyViz:简化 Python 中的数据可视化过程
原文:
www.kdnuggets.com/2019/06/pyviz-data-visualisation-python.html
评论
由 Parul Pandey,数据科学爱好者
可视化的目的是洞察,而不是图片。
―本·施奈德曼
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
如果你处理数据,那么数据可视化是你日常工作中的一个重要部分。如果你使用 Python 进行分析,你一定会被众多的数据可视化库所压倒。一些库如 Matplotlib 用于初步的基本探索,但对于展示数据中的复杂关系却不太有用。有些库适用于大数据集,而另一些则主要关注 3D 渲染。实际上,没有一个单一的可视化库可以被称为最好的。一个库在某些功能上可能优于另一个,反之亦然。总之,选择很多,几乎不可能学习和尝试所有的库,或者让它们全部协同工作。那么我们该如何完成工作呢?PyViz 可能有答案。
Python 当前的可视化格局
现有的 Python 数据可视化系统似乎是一个令人困惑的网状结构。
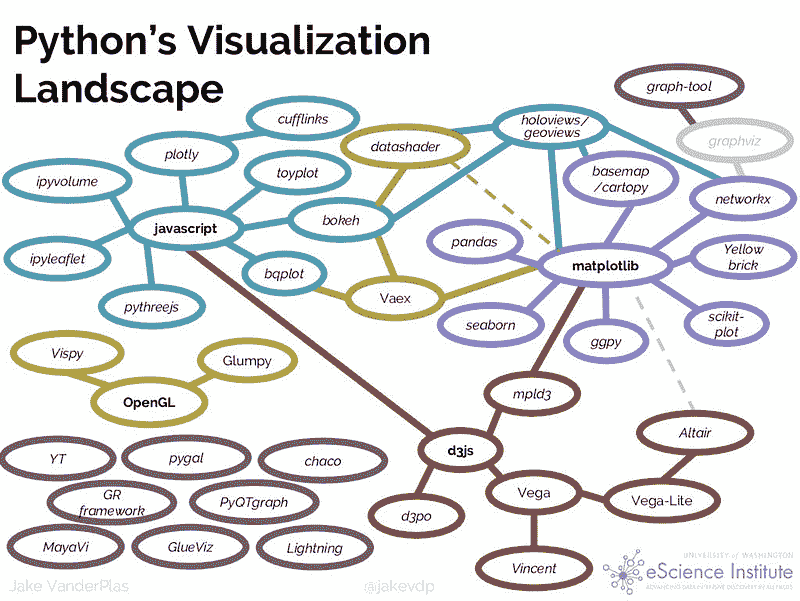
现在,从这些工具中选择最合适的一个有点棘手和令人困惑。PyViz 试图解决这一情况。它有助于简化在网页浏览器中处理小型和大型数据集(从几个点到数十亿个点)的过程,无论是进行探索性分析、制作简单的基于小部件的工具还是构建功能齐全的仪表板。
PyViz 生态系统
PyViz 是一个协调努力,使得 Python 中的数据可视化更易于使用、学习和更强大。PyViz 由一组开源 Python 包组成,可以在网页浏览器中轻松处理小型和大型数据集。无论是简单的 EDA 还是复杂的创建启用小部件的仪表板,PyViz 都是绝佳选择。
这是 PyViz 下的 Python 可视化格局。
PyViz 目标
Pyviz 的一些重要目标包括:
-
应重点关注任何规模的数据,而不是编码
-
完整功能和互动应直接在浏览器中提供(而非桌面端)
-
重点应更多放在 Python 用户上,而非网页程序员。
-
重点应更多放在 2D 可视化上,而非 3D。
-
利用 Python 用户已经熟悉的通用 SciPy/PyData 工具
库
组成 PyViz 的开源 库有:


-
HoloViews: 用于立即可视化数据的声明性对象,从方便的高级规格构建 Bokeh 绘图
-
GeoViews: 可视化的地理数据,可以与 HoloViews 对象混合和匹配
-
Bokeh: 在网页浏览器中进行互动绘图,运行 JavaScript 但由 Python 控制
-
Panel: 从许多不同的库中组装对象,创建布局或应用程序,无论是在 Jupyter notebook 还是独立的可服务仪表板中
-
Datashader: 快速将巨大的数据集栅格化为固定大小的图像
-
hvPlot: 快速从 Pandas、Xarray 或其他数据结构中返回互动 HoloViews 或 GeoViews 对象
-
Param: 声明用户相关参数,使得在笔记本上下文内外使用小部件变得简单
除此之外,PyViz 核心工具可以与以下库无缝配合。



此外,几乎所有其他绘图库中的对象都可以与 Panel 一起使用,包括对这里列出的所有内容的特定支持,以及任何可以生成 HTML、PNG 或 SVG 的内容。HoloViews 还支持 Plotly 进行 3D 可视化。
资源
PyViz 提供了示例、演示和培训材料,记录如何解决可视化问题。本教程提供了解决您自己可视化问题的起点。整个教程材料也托管在他们的 Github 代码库 中。
安装
请参阅 pyviz.org 以获取有关这些教程中使用的软件的完整安装说明。这里是这些说明的简化版本,假设您已经下载并安装了 Anaconda 或 Miniconda:
conda create -n pyviz-tutorial python=3.6
conda activate pyviz-tutorial
conda install -c pyviz/label/dev pyviz
pyviz examples
cd pyviz-examples
jupyter notebook
一旦所有内容都安装完成,以下单元格应打印出‘1.11.0a4’或更高版本:
import holoviews as hv
hv.__version__
'1.11.0a11'
hv.extension('bokeh', 'matplotlib')
#should see the HoloViews, Bokeh, and Matplotlib logos
#Import necessary libraries
import pandas
import datashader
import dask
import geoviews
import bokeh
如果完成没有错误,你的环境应该已经准备好了。
使用 PyViz 探索数据
在本节中,我们将探讨不同库如何在从数据中提取不同见解方面发挥作用,它们的结合可以真正帮助更好地分析数据。
数据集
所用数据集涉及每 10 万人中记录的 麻疹和百日咳病例数,涵盖了美国每个州随时间变化的数据。该数据集在 PyViz 教程中预装。
使用 Pandas 进行数据探索
在任何数据科学项目中,开始探索通常是从 pandas 开始。让我们导入并显示数据集的前几行。
import pandas as pd
diseases_data = pd.read_csv('../data/diseases.csv.gz')
diseases_data.head()

数字是好的,但图表能更好地展示数据中的模式。
使用 Matplotlib 进行数据探索
%matplotlib inline
diseases_data.plot();
这并没有传达太多信息。让我们使用 pandas 进行一些操作,以获得有意义的结果。
import numpy as np
diseases_by_year = diseases_data[["Year","measles"]].groupby("Year").aggregate(np.sum)
diseases_by_year.plot();
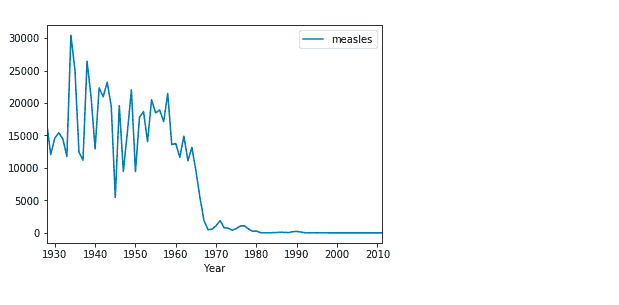
这就更有意义了。在这里,我们可以清楚地推断出大约在 1970 年发生了某些事情,导致麻疹的发生率几乎降为零。这是正确的,因为麻疹疫苗大约在 1963 年引入美国 [Wikipedia]
使用 HVPlot 和 Bokeh 进行数据探索
上面的图表传达了正确的信息,但没有提供交互性。这是因为它们是静态图,没有在网页浏览器中平移、悬停或缩放的功能。然而,我们可以通过简单导入 ** hvplot** 包来实现这种交互功能。
import hvplot.pandas
diseases_by_year.hvplot()
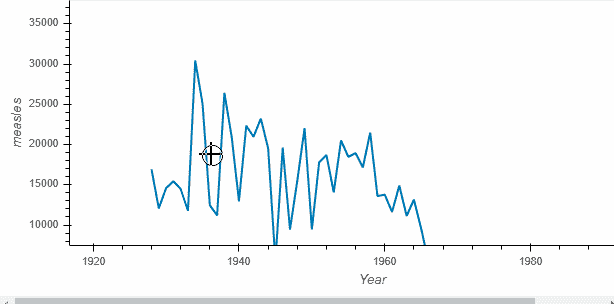
调用返回的对象称为 HoloViews 对象(这里是 Holoviews Curve),它 显示 为 Bokeh 图表。Holoviews 图表更丰富,方便在探索数据时捕捉你的理解。
让我们看看 HoloViews 还能做些什么:
在图表上捕捉重要点
1963 年在麻疹方面很重要,我们在图表上记录这一点怎么样。这还将帮助我们比较疫苗引入前后的麻疹病例数。
import holoviews as hv
vline = hv.VLine(1963).options(color='red')
vaccination_introduced = diseases_by_year.hvplot() * vline * \
hv.Text(1963, 27000, "Measles Vaccine Introduced", halign='left')
vaccination_introduced
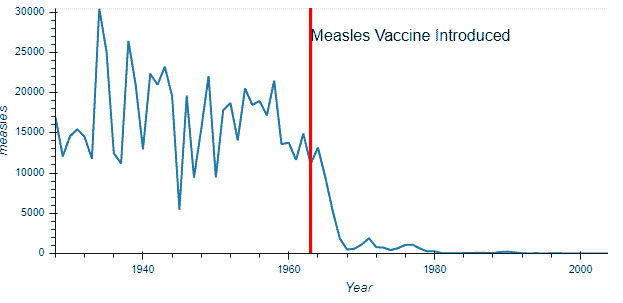
Holoviews 对象保存了原始数据,而不是其他绘图库。例如,可以以表格格式访问原始数据。
print(vaccination_introduced)
vaccination_introduced.Curve.I.data.head()
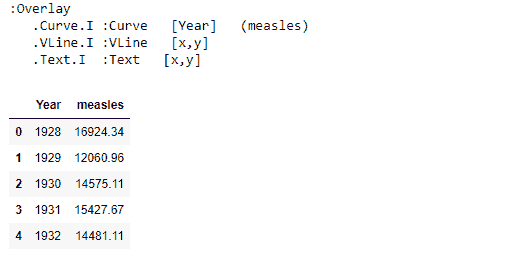
在这里,我们能够使用用于绘制图表的数据。此外,现在很容易以多种不同的方式拆分数据。
measles_agg = diseases_data.groupby(['Year', 'State'])['measles'].sum()
by_state = measles_agg.hvplot('Year', groupby='State', width=500, dynamic=False)
by_state * vline

我们可以将图表并排放置,以便更好地进行比较,而不是使用下拉菜单。
by_state["Alabama"].relabel('Alabama') + by_state["Florida"].relabel('Florida')
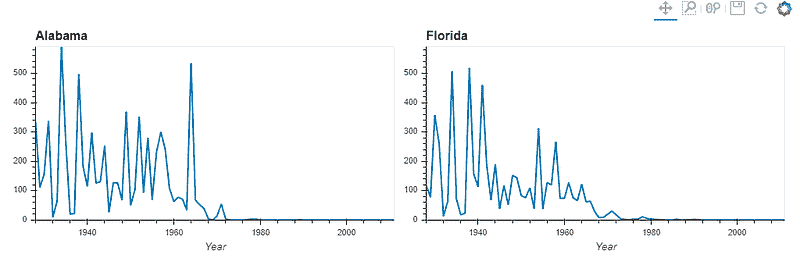
我们还可以改变图表的类型,比如改为柱状图。让我们比较 1980 年至 1985 年四个州的麻疹模式。
states = ['New York', 'Alabama', 'California', 'Florida']
measles_agg.loc[1980:1990, states].hvplot.bar('Year', by='State', rot=90)
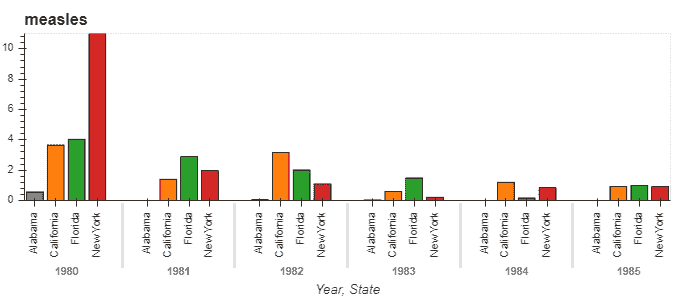
从以上示例可以明显看出,通过选择HoloViews+Bokeh图表,我们可以在浏览器中探索数据,具有完全的互动性和最小的代码。
使用 PyViz 可视化大型数据集
PyViz 还能够轻松处理非常大的数据集。对于这样的数据集,PyViz 套件的其他成员将发挥作用。
-
Colorcet用于感知上均匀的大数据色图
为了展示这些库在处理大量数据时的能力,让我们使用 NYC 出租车数据集,该数据集包含了高达 1000 万次出租车行程的数据。这些数据已在教程中提供。
#Importing the necessary libraries
import dask.dataframe as dd, geoviews as gv, cartopy.crs as crs
from colorcet import fire
from holoviews.operation.datashader import datashade
from geoviews.tile_sources import EsriImagery
Dask 是一个用于 Python 的灵活并行计算库。Dask DataFrame 是一个大型并行 DataFrame,由许多较小的 Pandas DataFrame 组成,按索引拆分。这些 Pandas DataFrame 可以存储在磁盘上,以便在单台机器上进行超出内存限制的计算,或在集群中的许多不同机器上进行计算。一个 Dask DataFrame 操作会触发许多操作在组成的 Pandas DataFrame 上。
Cartopy 是一个 Python 包,旨在进行地理空间数据处理,以生成地图和其他地理空间数据分析。
topts = dict(width=700, height=600, bgcolor='black', xaxis=None, yaxis=None, show_grid=False)
tiles = EsriImagery.clone(crs=crs.GOOGLE_MERCATOR).options(**topts)
dopts = dict(width=1000, height=600, x_sampling=0.5, y_sampling=0.5)
读取和绘制数据:
taxi = dd.read_parquet('../data/nyc_taxi_wide.parq').persist()
pts = hv.Points(taxi, ['pickup_x', 'pickup_y'])
trips = datashade(pts, cmap=fire, **dopts)
tiles * trips
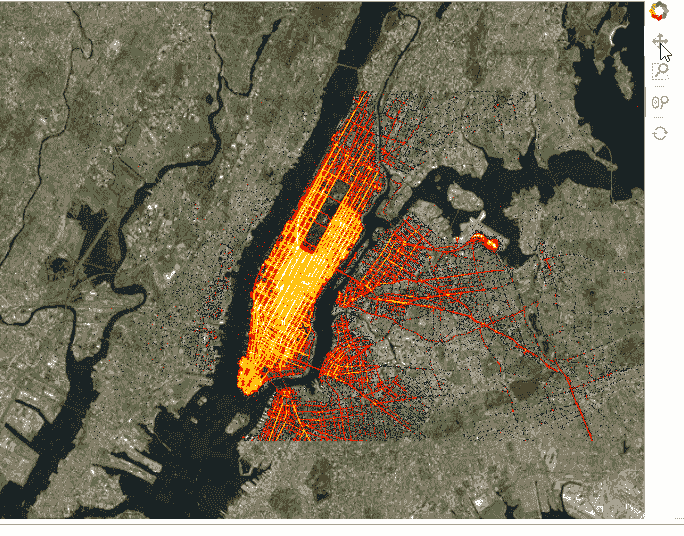
我们还可以添加小部件来控制选择。这可以在笔记本中完成,也可以通过标记可服务对象为.servable(),然后通过 Bokeh Server 运行.ipynb 文件,或者将代码提取到单独的.py 文件中并执行相同操作。
import param, panel as pn
from colorcet import palette
class NYCTaxi(param.Parameterized):
alpha = param.Magnitude(default=0.75, doc="Map tile opacity")
cmap = param.ObjectSelector('fire', objects=['fire','bgy','bgyw','bmy','gray','kbc'])
location = param.ObjectSelector(default='dropoff', objects=['dropoff', 'pickup'])
def make_view(self, **kwargs):
pts = hv.Points(taxi, [self.location+'_x', self.location+'_y'])
trips = datashade(pts, cmap=palette[self.cmap], **dopts)
return tiles.options(alpha=self.alpha) * trips
explorer = NYCTaxi(name="Taxi explorer")
pn.Row(explorer.param, explorer.make_view).servable()
出租车探索器
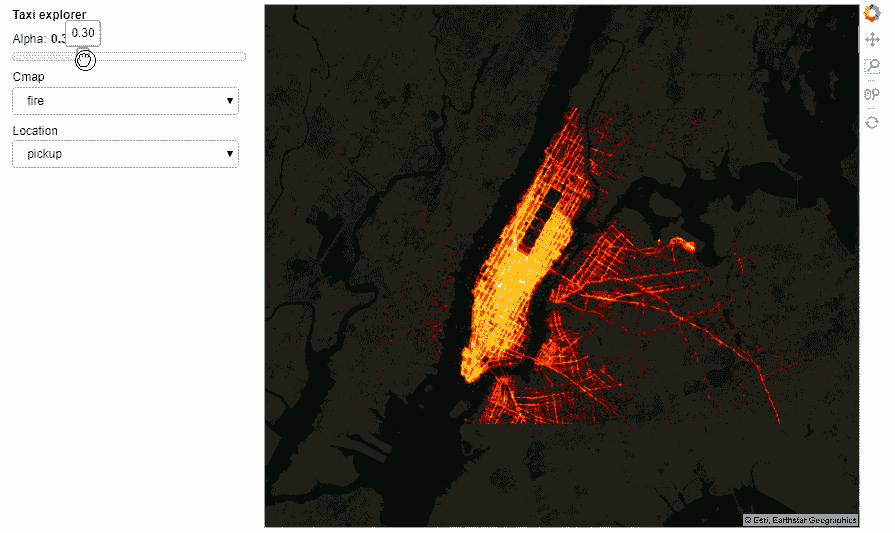
含有所有运行代码的 Notebook 可以从这里访问。然而,互动性在 GitHub 上无法呈现,但你仍然可以访问笔记本并在本地运行。
结论
PyViz 工具帮助我们即使用少量代码也能创建美观的可视化图表。PyViz 工具集合在一起构建高性能、可扩展、灵活且可部署的可视化、应用程序和仪表板,无需显式使用 JavaScript 或其他网页技术。本文只是对多功能 PyViz 生态系统的简单介绍。深入学习整个教程,以了解其复杂性及其在不同数据类型中的使用。
简介: Parul Pandey 是一位数据科学爱好者,常为数据科学出版物如 Towards Data Science 撰稿。
原文。经许可转载。
相关:
-
用代码在 Python 中进行 5 个快速而简单的数据可视化
-
Python 图形库
-
使用 Folium 在 Python 中可视化地理空间数据
更多相关话题
数据科学的定性研究方法?
原文:
www.kdnuggets.com/2017/05/qualitative-research-methods-data-science.html

虽然我接受过定性方法的培训,但我是一名量化专家,已经从事这个领域超过 30 年。然而,我在整个职业生涯中都是定性研究的用户。除非我们的数据科学领域与人类完全无关,否则这对于量化研究人员来说是非常相关的。我们所做的工作越接近市场研究——用户体验(UX)和客户关系管理(CRM)就是两个例子——它就变得越有用。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
定性研究提供背景和上下文,使得预测分析等量化分析对决策者更有用。消费者调查也是如此,并且这两种研究经常结合使用,定性阶段通常在调查前进行,有时在第三阶段进行。
定性研究如何有用?有很多方式,这里列举了一些例子。
首先,我们应该记住,两个人可能因为相同的原因购买相同的品牌(米勒轻啤味道好极了)。然而,他们也可能因为不同的原因购买相同的品牌(米勒轻啤味道好极了 与 米勒轻啤更不易饱腹),或者因为相同的原因购买不同的品牌(米勒轻啤味道好极了 与 百威轻啤味道好极了),或者因为不同的原因购买不同的品牌(米勒轻啤更不易饱腹 与 百威轻啤味道好极了)。消费者行为也可能因场合或时间的变化而有所不同,因为偏好和生活情况会因为结婚、生育、职位晋升、搬迁、健康问题等而发生变化。
了解人们在特定情况下做某些事情的原因可以帮助我们在构建和解释最终模型时。举例来说,在市场营销的情况下,这有助于我们理解如何与消费者沟通,而不仅仅是针对哪个消费者。还有许多其他方式定性研究可以帮助指导量化研究,但更详细的阐述需要比我这里所能提供的更多的空间。
任何研究都有其优缺点,定性研究也不例外。我的一个主要批评点是从业者的专业水平不可预测。坦率地说,一些从事定性研究的人是业余的。在某些情况下,缺乏培训或经验是罪魁祸首。其他人虽然作为研究者似乎不具备所需的能力,但在客户处理方面表现出色,因此获得了工作。
未经审视的假设是我的另一个痛点,定性研究者似乎比定量研究者更容易出现这种情况。另一个常被“量化派”提出的批评是分析师有时会根据自己的直觉而不是证据得出相当强的结论。将猜测当作事实是一种我们都容易犯的认知错误,但我在定性研究者中遇到这种情况更多。
当然,我们所有人都可能因为... 泛化的概括而指责泛化的概括!
我个人的观点是传统的:一般来说,定性研究应该仅作为探索工具使用,结论和影响应该比定量研究更为谨慎。然而,即使在这种限制下,它在帮助设计和解读定量研究以及发现定量方法无法揭示的洞察方面也可以是无价的。
虽然我不是定性研究专家,但我的许多联系人和商业伙伴是。其中之一是大卫·麦考汉,他是我们音频播客系列MR 现实的共同主持人。“MR”是市场研究的缩写,戴夫和我与特别嘉宾讨论了与市场研究相关的广泛话题。到目前为止,我们已经做了二十多个播客,这里是专门讨论定性研究的播客链接:
-
"符号学:定性研究中的问题儿童"(苏·贝尔,苏珊·贝尔研究)
-
"社交媒体:承诺、挑战与未来"(拉乌尔·库布勒教授,Ozyegin 大学)
-
"如何选择合适的在线定性方法?"(詹妮弗·戴尔,InsideHeads)
-
"行为经济学在客户洞察中的位置"(布里·威廉姆斯,People Patterns)
-
"民族志:从平凡中寻找意义"(戈登·米尔恩,Ipsos)
无需注册——只需点击链接。
认识我的人知道我喜欢书籍。以下是一些我发现特别有用的定性方法的热门书籍:
-
定性研究从头到尾(尹)
-
应用定性研究设计(罗勒和拉夫拉卡斯)
-
Qual-Online: 必备指南(Dale 和 Abbott)
-
内容分析:方法论简介(Krippendorff)
-
符号学基础(Chandler)
-
消费者研究中的人类学(Sunderland 和 Denny)
-
实用人类学(Ladner)
你喜欢的书商可能会让你看看书的内部内容,以便你自己判断这些书是否对你感兴趣。如果你想深入了解,还可以参考在线材料、专业协会和研讨会。
现实世界不像编写良好的计算机程序那样整洁,我建议你对定性研究保持开放的态度。如果没有它,我无法做我现在的工作。
我希望这些内容对你有趣且有帮助!
简历: Kevin Gray 是 Cannon Gray 的总裁,该公司是一家市场科学和分析咨询公司。
原创。经许可转载。
相关:
-
回归分析:入门
-
时间序列分析:入门
-
文本分析:入门
更多相关主题
招聘经理在数据科学家中寻找的素质
原文:
www.kdnuggets.com/2022/04/qualities-hiring-managers-looking-data-scientists.html

Cytonn Photography via Unsplash
作为一名数据科学家,你的首要目标是能够编写有效的代码,以实现组织的目标。
然而,许多其他特质对招聘经理在招聘新数据科学家时也很重要,这些特质有时被严重忽视。软技能对招聘经理来说与硬技能一样重要。我将介绍我认为最重要的那些。
1. 学习的意愿
许多招聘经理希望找到具备角色所需技能的人,同时也希望他们能够适应现有技能并发展新技能。
我们永远不会停止学习,特别是在一个高度技术化的领域中,新工具不断发布,旧工具不断改进。新算法不断被引入,因此如果你不愿意学习,对你的团队经理来说可能会非常令人沮丧。
冒名顶替综合症确实存在,并且影响到许多各个领域的人。它还可能成为你职业成功的障碍,因为你会不断怀疑自己的能力,因为你的主要目标是实现。专注于你当前拥有的技能,以及如何通过学习新技能来发展这些技能,是克服冒名顶替综合症的一种方法。
你将在面试中如何被测试?
许多招聘经理,不论你所在的领域,有时会问你这个问题:
“有没有过你觉得自己缺乏某种技能的时刻?发生了什么,你是如何解决这个问题的?”
这将帮助招聘经理了解你在特定项目或之前的角色中如何处理技能缺乏的情况;证明你是否愿意学习,或者你是否接受自己不知道技能并继续保持原状。
利用工作时间之外的空闲时间学习新技能或发展现有技能,是向招聘经理证明你愿意学习的另一种方式。作为数据科学家,你可以通过各种平台实现这一点,例如 Udemy、Coursera、edX 等。
2. 将代码与业务相关联

Mars via Unsplash
尽管编码是任何数据科学家的主要要求之一,但能够理解并将其应用于业务及其目标同样重要。
对任务和它如何与业务相关有全面的掌握,将使你编码得更好。这将向你的经理证明你理解什么是有利于业务的,而不仅仅是因为被要求完成任务。它可以区分你是否是团队和整个业务的积极成员。
通过这一点,作为数据科学家的你将比技术能力较弱的 CEO 或董事总经理拥有更好的技能和对当前问题的理解。你将能够利用你的硬技能,通过编码和商业头脑引导业务朝正确方向发展。
你将在面试中如何被测试?
在数据科学面试过程中,你将被要求经历一个技术阶段。招聘经理会要求你以对业务独特的方式处理技术测试。
例如,如果你申请的角色是具备机器学习模型专长的数据科学家,那么技术测试可能会涉及到业务中某一特定问题的不同建模解决方案。
这将向招聘经理证明你具备将编码技能应用于业务目标的能力。
3. 识别问题并提出解决方案
如上所述,你的团队中或在公司高层可能会有技术技能和理解能力较少的人。能够识别公司当前存在的问题或所选解决方案的问题,并提出自己的建议,将使你脱颖而出。
这向招聘经理证明你愿意帮助业务改进,当你获得工作时,它将向公司证明你是业务成功的宝贵资产。
说‘是’对每一个抛给你的任务很容易。但说‘我认为这不是正确的解决方案,试试 X 怎么样?’却更难。很多企业因未能采纳其他团队成员的建议和解决方案而失败。
提出你的建议并不会有害,最坏的情况就是你错了或者你的经理给你一个更好的理解,说明为什么业务不能使用那个特定的解决方案。最终,你仍然是在学习。
然而,如果你选择保留自己的想法,你是在对自己不利。雇主会认为你不是一个积极的员工,不愿意为业务的成功做出贡献。
你将在面试中如何被测试?
在面试阶段很难测试这种软技能,因为时间有限。然而,技术面试通常有多个阶段,因此你可以在每个阶段中随时被测试到这种技能。
招聘经理通常会问的问题是:
“是否有过你发现任务中的问题并提出自己的解决方案的情况?如果有,你是怎么做的?”
详细回答你的问题,因为招聘经理会知道你的回答是否肤浅。
4. 提问
大多数(如果不是全部)招聘经理都会问你是否有任何问题。问,问,问!如果你不问,你就得不到。
你申请这个职位是因为你想要这份工作。然而,你也需要确保这是适合你的角色。招聘经理会审查你,所以你也应该审查公司,看看公司的价值观和要求是否是你愿意投入的。
问题可能是:
-
我的典型一天会是什么样的?
-
公司是否提供培训?
-
公司在我在职期间是否提供自我发展的支持?
-
我能否更好地理解职位描述中的好处?
结论
数据科学家的招聘过程并不简单。它有不同的阶段,都需要大量的技术知识并考验你的软技能。
如果你想了解更多,请阅读:
-
数据科学面试指南 - 第一部分:结构
-
数据科学面试指南 - 第二部分:面试资源
尼莎·阿里亚 是一名数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何/能够促进人类生命的延续。作为一个热心的学习者,她希望拓宽技术知识和写作技能,同时帮助指导他人。
相关话题
量化与 LLMs:将模型浓缩到可管理的大小
原文:
www.kdnuggets.com/quantization-and-llms-condensing-models-to-manageable-sizes

LLM 的规模与复杂性
LLM 的惊人能力得益于其庞大的神经网络,这些网络由数十亿个参数组成。这些参数是通过在大量文本语料库上进行训练得到的,并经过微调以使模型尽可能准确和多才多艺。这种复杂性水平需要大量的计算能力来处理和存储。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持

附图条形图描绘了不同规模语言模型的参数数量。随着模型规模的增大,我们可以看到参数数量显著增加,从具有几百万参数的“小型”语言模型到具有数百亿参数的“大型”模型。
然而,具有 1750 亿个参数的 GPT-4 LLM 模型在参数规模上超越了其他模型。GPT-4 不仅使用了图表中最多的参数,还驱动了最具知名度的生成型 AI 模型——ChatGPT。图表中的这一庞大存在代表了同类的其他 LLMs,展示了驱动未来 AI 聊天机器人的需求以及支持如此先进 AI 系统所需的计算能力。
运行 LLMs 的成本与量化
部署和操作复杂的模型可能会很昂贵,因为它们需要使用高端 GPU、AI 加速器以及持续的能源消耗进行云计算。选择本地解决方案可以通过降低成本来节省大量资金,并提高硬件选择的灵活性和系统使用的自由度,但这需要付出维护成本和雇佣专业人员的代价。高成本使得小型企业在训练和运行先进 AI 方面面临挑战。这时,量化技术就显得非常重要。
什么是量化?
量化是一种技术,通过降低模型中每个参数的数值精度,从而减少其内存占用。这类似于将高分辨率图像压缩为较低分辨率,同时保留精髓和最重要的方面,但数据大小有所减少。这种方法使得在硬件条件较差的情况下,也能部署大型语言模型而不会造成显著的性能损失。
ChatGPT 的训练和部署使用了数千台 NVIDIA DGX 系统,数百万美元的硬件以及数万亿美元的基础设施费用。量化可以在性能不逊色(但硬件性能较低)的条件下,实现良好的概念验证甚至完全成熟的部署。
在接下来的部分中,我们将剖析量化的概念、方法及其在缩小大型语言模型对资源的高度依赖与日常技术使用的实际之间差距方面的意义。大型语言模型的变革力量可以在小规模应用中成为主流,为更广泛的受众提供巨大的好处。
量化基础
对大型语言模型进行量化是指减少模型中数值值的精度。在神经网络和深度学习模型的上下文中,包括大型语言模型,数值值通常表示为高精度的浮点数(例如 32 位或 16 位浮点格式)。有关浮点精度的更多信息。
量化通过将这些高精度浮点数转换为较低精度的表示形式,如 16 位或 8 位整数,从而提高模型在训练和推理时的内存效率和速度,尽管牺牲了一些精度。因此,模型的训练和推理需要较少的存储空间,消耗更少的内存,并且可以在支持低精度计算的硬件上更快地执行。
量化类型
为了增加主题的深度和复杂性,了解量化可以在模型开发和部署生命周期的不同阶段应用至关重要。每种方法都有其独特的优点和权衡,根据用例的具体要求和限制进行选择。
1. 静态量化
静态量化是一种在 AI 模型的训练阶段应用的技术,其中权重和激活被量化为较低的位精度,并应用于所有层。权重和激活提前量化并在整个过程中保持固定。静态量化非常适合于已知系统内存需求的模型部署计划。
-
静态量化的优点
-
简化部署规划,因为量化参数是固定的。
-
减少模型的大小,使其更适合边缘设备和实时应用。
-
-
静态量化的缺点
-
性能下降是可预测的;因此某些量化部分可能由于广泛的静态方法而遭受更大的损失。
-
对于静态量化适应性有限,适应不同输入模式的能力差,权重更新不够稳健。
-
2. 动态量化
动态量化涉及静态量化权重,但在模型推理期间激活会动态量化。权重会提前量化,而激活在数据通过网络时动态量化。这意味着模型的某些部分在不同的精度下执行量化,而不是默认固定量化。
-
动态量化的优点
-
平衡了模型压缩和运行效率,准确性没有显著下降。
-
对于激活精度比权重精度更为关键的模型特别有用。
-
-
动态量化的缺点
-
相较于静态方法,性能提升不可预测(但这不一定是坏事)。
-
动态计算意味着比其他方法需要更多的计算开销和更长的训练和推理时间,但仍比没有量化时更轻量。
-
3. 训练后量化(PTQ)
在这种技术中,量化被纳入到训练过程中。它涉及分析权重和激活的分布,然后将这些值映射到更低的位深。PTQ 被部署在资源受限的设备上,如边缘设备和手机。PTQ 可以是静态的也可以是动态的。
-
PTQ 的优点
-
可以直接应用于预训练模型,而无需重新训练。
-
减少模型大小,降低内存需求。
-
提升了推理速度,实现了部署期间和之后更快的计算。
-
-
PTQ 的缺点
-
由于权重的近似,可能会导致模型准确性下降。
-
需要仔细的校准和微调以减轻量化误差。
-
可能不适用于所有类型的模型,特别是那些对权重精度敏感的模型。
-
4. 量化感知训练(QAT)
在训练过程中,模型会了解在推理期间将应用的量化操作,并相应调整参数。这使得模型能够学会处理量化引起的误差。
-
QAT 的优点
-
相比 PTQ,QAT 倾向于保持模型准确性,因为模型训练时考虑了量化误差。
-
对于对精度敏感的模型更为稳健,即使在较低精度下也能更好地进行推理。
-
-
QAT 的缺点
-
需要重新训练模型,从而导致训练时间延长。
-
由于包含量化误差检查,因此计算开销较大。
-
5. 二进制三进制量化
这些方法将权重量化为两个值(二值)或三个值(三值),代表了量化的最极端形式。权重在训练过程中或之后被限制为二值量化的 +1 和 -1,或三值量化的 +1、0 和 -1。这将大幅减少可能的量化权重值数量,同时仍保持一定的动态性。
-
二值三值量化的优点
-
最大化模型压缩和推理速度,且内存需求最小。
-
快速推理和量化计算使得在性能不足的硬件上仍具备实用性。
-
-
二值三值量化的缺点
-
高压缩率和降低精度会显著降低准确性。
-
不适用于所有类型的任务或数据集,并且在处理复杂任务时表现不佳。
-
量化的好处与挑战

大型语言模型的量化带来了多种操作上的好处。主要是显著减少了这些模型的内存需求。我们对量化后的模型的目标是内存占用显著减少。更高的效率使得这些模型可以在内存能力较小的平台上部署,并且量化后的模型所需的处理能力减少,直接提高了推理速度和响应时间,从而提升了用户体验。
另一方面,量化也可能会引入一些模型精度的损失,因为它涉及到对真实数字的近似。挑战在于如何在不显著影响模型性能的情况下进行量化。可以通过在量化前后测试模型的精度和完成时间来评估效果、效率和准确性。
通过优化性能和资源消耗之间的平衡,量化不仅扩大了大语言模型的可及性,还促进了更可持续的计算实践。
原文。经许可转载。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写了有关深度学习不同方面的文章。
更多相关主题
量子计算如何对机器学习有用
原文:
www.kdnuggets.com/2019/04/quantum-computing-machine-learning.html
评论
作者:Roger Huang
如果你听说过量子计算,你可能会对将其应用于机器学习的可能性感到兴奋。如何利用这项新兴技术?我在 Springboard 工作,我们最近推出了一个包括职位保证的机器学习训练营。我们希望确保我们的毕业生接触到前沿的机器学习应用,因此我们将这篇文章作为我们研究量子计算与机器学习交集的一部分。
让我们先来探讨一下量子计算与经典计算的区别。 在经典计算中,数据存储在物理比特中,数据是二进制的且互为穷尽:比特要么处于 0 状态,要么处于 1 状态,不能同时处于两者状态。量子计算利用分子间小尺度物理相互作用的物理特性,使得量子比特(简称“qubit”)可以是经典 0 和 1 状态的线性组合——允许在一个 qubit 中存储比在普通比特中更多的数据。
量子计算确实会受到慢速的影响,因为量子分子彼此纠缠,并且直接物理观察它们所处的量子系统(即,从量子计算机中获取经典结果)会存在困难。但它可以更快地处理大量数据,并减少许多经典计算任务的空间/时间考虑——包括与机器学习相关的任务。
现在让我们看看量子计算在某些具体实例中如何提供帮助。
1- 量子退火器与量子隧穿中的损失函数最小化
首先要区分的是通用量子门计算机,它可以执行每个完整量子算法(前述链接中描述了大约 50 个算法)以及量子退火器,它们是适用于特定目的的量子计算机的简化版本。
你可能对量子退火器有所了解,比如来自D-Wave的设备。这篇文章深入解释了量子通用门计算机与退火器的区别。基本上,量子退火器是“简化版”的通用量子计算机,专注于找到超局部极小值,并比经典计算机更接近全局极小值。
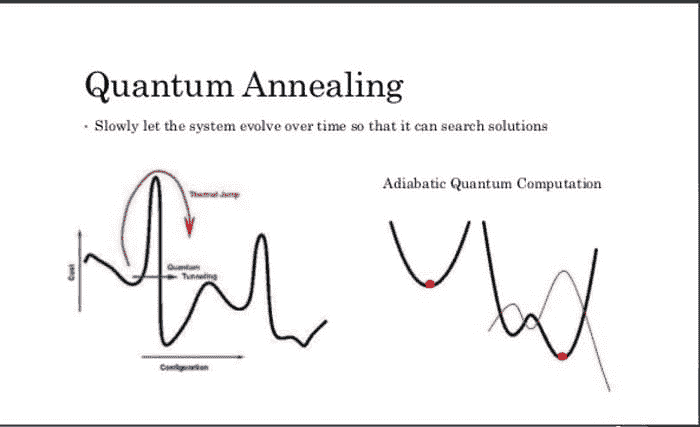
来源: www.slideshare.net/donotstalkme/quantum-computing-55840897
量子退火器通过一系列磁铁附着在一个网格上。磁铁相互影响,为了让系统整体节省能量,它们会翻转到一个协调的方向,从而最小化能量使用。在经典设置下,磁铁在找到更低的极小值之前会被困在低能量设置中,但由于量子特性如隧穿效应,它们可以跳过那些大的能量成本设置——这使得函数更容易从局部极小值下降到全局极小值或更接近全局极小值的局部极小值。
当涉及到成本函数时,这可以意味着梯度下降函数在次优设置下被困,还是在最优或接近最优的设置下,尤其是在复杂的非凸误差表面上。
如果你在急需“足够好”的答案的情况下,面对通常需要大量经典计算能力的复杂机器学习优化问题,它们可以是一个可靠的解决方案。通过利用量子隧穿效应,你可以更快地收敛于优化应用中的误差函数,比如投资组合分析(金融领域)。该技术已被用于分析美国电网,传感器每两秒钟收集大约 3PB 的数据,并几乎即时进行快速的损失函数计算。
2- 增强或替代 用于维度减少的支持向量机
机器学习面临的最大问题之一是处理高维空间中的计算。实际上,机器学习需要使用核技巧来有效地进行计算。量子计算机可以帮助简化这个问题:有量子解释的支持向量机核技巧可以帮助将计算减少到特定维度,并允许将高维数据集拆分成更易于管理的数据集。这篇 2016 年论文在进行维度减少时实现了量子计算机的指数级加速,超过了在经典计算机上运行的任何算法。
来源: 维基百科
随着可用量子比特数量的增加,这种实现变得越来越高效。
通过使用适用于量子门和量子计算的支持向量机实现,有可能以更高的速度和更低的计算成本对非常大且复杂的数据集进行分类,例如基于多个因素判断细胞是否为癌细胞,这比目前经典计算机所能实现的更为高效。
3- 小规模量子计算与强大经典计算的混合实现用于非常大数据集(例如:拓扑分析)
通过利用量子计算和经典计算的优势,你可以为涉及巨大数据集的问题创造新的解决方案。
如果你想例如分析数据的拓扑分布(通常这是一个非常困难的任务,即使对于较小的数据集),以便简化数据中的失真并实质性地权衡数据错误的风险,你可以使用量子计算,即使是在非常小的规模下,也能达到更优的效果,同时使用经典计算来完成其余分析。这是麻省理工学院、滑铁卢大学和南加州大学的学者们正在积极研究的方向。
通过在量子计算机上对数据集进行拓扑分析(当在经典计算机上进行此操作计算成本过高时),你可以快速获得数据集中的所有重要特征,评估其形状和方向,然后继续使用经典计算算法进行剩余工作,手中握有所需的特征和适当的算法方法。
来源:维基媒体
这种方法将使机器学习算法和方法在更大且不断增长的数据集中更有效地实现,结合了越来越强大的量子计算机和经典计算机。
希望这篇文章帮助你了解如何将量子算法和计算与机器学习结合起来。以下的EdX 课程将帮助你提供实际的两个领域结合的例子。Coursera 提供了有关量子计算概念的一系列课程,帮助你更加熟悉这一领域。如果你希望提高机器学习技能或进入一个全职从事机器学习的职业,并思考如上所述的问题,可以参考Springboard 的 AI/机器学习职业路径。
简介: Roger Huang 帮助公司在短短几周内实现收入倍增,并且现在正在帮助人们找到梦想中的工作。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT
更多相关话题
如何查询你的 Pandas 数据框
评论

图片由 Bruce Hong 拍摄,来源于 Unsplash [1]。
目录
-
介绍
-
多重条件
-
在多个特定列上合并
-
总结
-
参考
介绍
无论你是从数据工程师/数据分析师转行,还是想成为更高效的数据科学家,查询你的数据框可以证明是一种非常有用的方法,用于返回你想要的特定行。需要注意的是,pandas 有一个专门的查询函数,名为 query。不过,我将讨论其他模拟查询、筛选和合并数据的方法。我们将展示一些你可能向数据提出的常见场景或问题,而不是使用 SQL,我们将用 Python 来完成。在下面的段落中,我将概述一些用 Python 编程语言查询 pandas 数据框的简单方法。
多重条件
示例数据。作者截图 [2]。
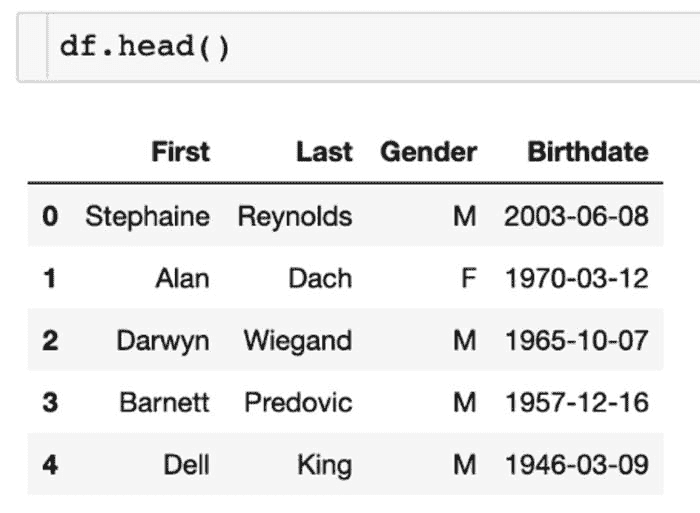
作为数据科学家或数据分析师,我们希望返回特定的行数据。一个这样的场景是你想在同一行代码中应用多个条件。为了展示我的示例,我创建了一些虚假的样本数据,包括名字和姓氏,以及相应的性别和出生日期。这些数据在截图中展示。
示例中的多个条件将本质上回答一个特定的问题,就像你使用 SQL 一样。问题是,我们的数据中有多少百分比是男性 OR 出生于 2010 年至 2021 年之间的人。
这是解决该问题的代码(有几种方法可以回答这个问题,但这是我具体的做法):
print(“Percent of data who are Males OR were born between 2010 and 2021:”,
100*round(df[(df[‘Gender’] == ‘M’) | (df[‘Birthdate’] >= ‘2010–01–01’) &
(df[‘Birthdate’] <= ‘2021–01–01’)][‘Gender’].count()/df.shape
[0],4), “%”)
为了更好地可视化这段代码,我还包括了上面的相同代码的截图,以及输出/结果。你也可以应用这些条件以返回实际行,而不是获取总行数的比例或百分比。

条件代码。作者截图 [3]。
这里是我们执行的命令顺序:
-
返回男性的
Gender -
包括 OR 函数
| -
返回
Birthdate> 2010 和 2021 的行 -
将所有条件结合起来,然后除以总行数
如你所见,这段代码与 SQL 中你会看到的内容类似。我个人认为在 pandas 中更容易,因为代码量可能更少,同时可以在一个易于查看的位置看到所有代码,而无需上下滚动(但这种格式只是我的偏好)。
在多个特定列上合并
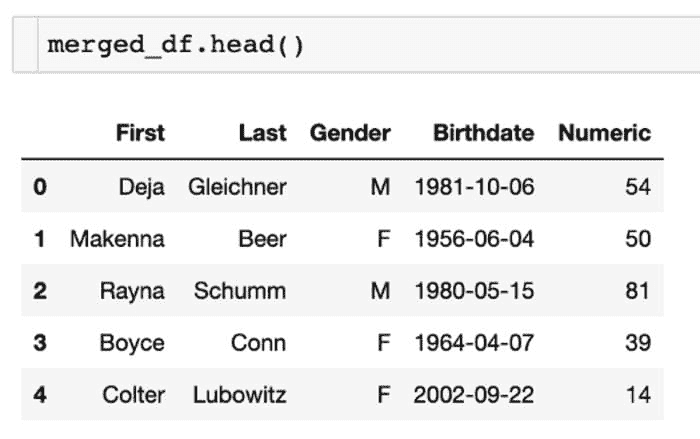
合并的数据框结果。截图由作者提供 [4]。
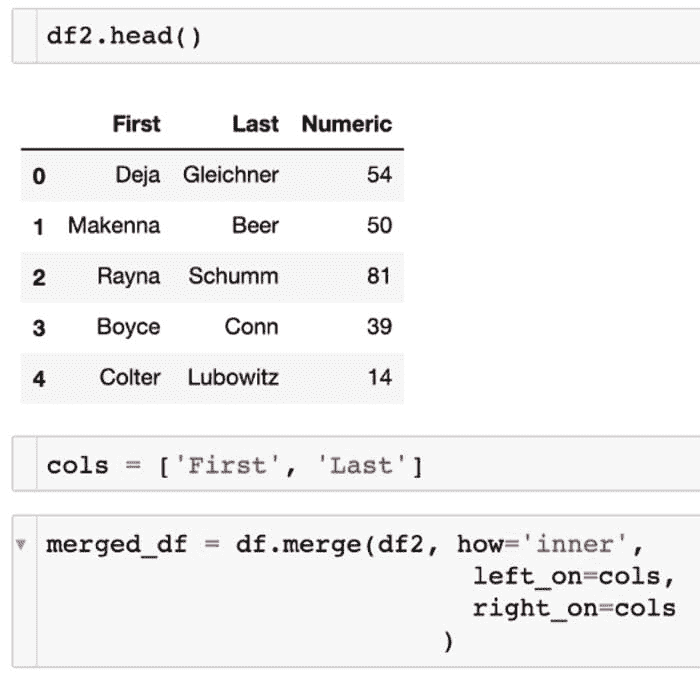
我们可能已经在其他教程中看到如何合并数据框,所以我想添加一种独特的方法,这种方法我还没有真正看到过,就是在多个特定列上合并。在这种情况下,我们希望连接两个数据框,其中两个字段在它们之间共享。如果有更多列,这种方法可能会更加有用。
我们有第一个数据框,即 df,然后我们在第二个数据框 df2 上合并列。以下是实现我们预期结果的代码:
merged_df = df.merge(df2, how=’inner’,
left_on=cols,
right_on=cols
)
为了更好地可视化这些合并和代码,我在下面展示了截图。你可以看到第二个数据框的样子,包含了First和Last名字,就像它们在第一个数据框中一样,但新增了一个Numeric列。然后,我们选择了要合并的特定列,同时返回了Gender、Birthdate和新的Numeric列。这些列是一个名为cols的列列表。
合并数据框。截图由作者提供 [5]。
如你所见,这种合并数据框的方式是一种简单的方法,可以实现与 SQL 查询相同的结果。
摘要
在本教程中,我们查看了在 SQL 中你会执行的两个常见问题或查询,而是用 Python 中的 pandas 数据框执行了它们。
总结一下,这里是我们处理的两种情况:
-
返回满足多个条件的行占总数据集的百分比
-
在多个特定列上合并以返回包含新列的最终数据框
我希望你觉得我的文章既有趣又有用。如果你对这些方法有不同的看法,请随时在下方评论。为什么?或者为什么不?这些内容当然可以进一步澄清,但我希望我能够阐明一些你可以用 pandas 和 Python 代替 SQL 的方法。感谢阅读!
请随时查看我的个人资料,Matt Przybyla,以及其他文章,也欢迎通过 LinkedIn 与我联系。
我与这些公司没有关联。
参考文献
[1] 图片由 Bruce Hong 提供,发布于 Unsplash, (2018)
[2] M. Przybyla, 示例数据截图, (2021)
[3] M. Przybyla, 条件代码截图, (2021)
[4] M. Przybyla,合并数据框结果截图,(2021)
[5] M. Przybyla,合并数据框截图,(2021)
简介: Matthew Przybyla 是 Favor Delivery 的高级数据科学家,同时也是一名自由技术写作人员,特别擅长数据科学领域。
原文。经许可转载。
相关:
-
数据科学家与机器学习工程师 – 他们的技能是什么?
-
Pandas 与 SQL:数据科学家何时使用每种工具
-
5 个 Python 数据处理技巧与代码片段
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 需求
更多相关话题
使用 SQL 查询你的 Pandas DataFrames
原文:
www.kdnuggets.com/2021/10/query-pandas-dataframes-sql.html

图片由 Jeffrey Czum 提供,来源于 Pexels(作者编辑)
Pandas —— 或更具体地说,它的主要数据容器,DataFrame —— 早已巩固了自己作为 Python 数据生态系统中的标准表格数据存储结构的地位。使用 Pandas DataFrame 具有访问、操控和对复合数据进行计算的特定规范,这些规范可以通过时间和坚持掌握,因为它遵循 Python 语法;如果你对 Python 非常熟悉,你已经在熟练掌握标准 Pandas API 的路上了。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
有很多用户对 Python 的掌握并不是很熟练,但由于 Python 在数据科学和数据分析以及相关领域和职业中的突出地位,他们还是选择了这门语言。许多转向 Python 的人可能已经对另一种重量级数据科学语言 SQL 感到熟悉。那么,为什么我们不能使用 SQL 这种专为表格数据访问而编写的语言来查询 Pandas DataFrames 中的数据呢?
进入 Fugue。Fugue 是一个在设计时考虑了逻辑与执行解耦的项目,主要目的是简化计算并行化。
Fugue 是一个抽象框架,它允许用户用原生 Python 或 Pandas 编写代码,然后将其移植到 Spark 和 Dask。
这项工作的核心组成部分是 FugueSQL。FugueSQL 不是纯 SQL;它描述其语法为“标准 SQL、json 和 python 之间的混合”。然而,你会发现,对于基本的查询操作,它的表现或多或少符合你的预期。具体来说,它被设计为“完全兼容标准 SQL SELECT 语句”。因此,对于数据处理的新手来说,它通常比在 Python 中查询 Pandas 更直接。
FugueSQL 的好处可以在并行代码中实现,结合 Fugue 项目的附加目标,或单独使用,在单台计算机上查询 DataFrames。本文将介绍如何立即在自己的工作中开始使用 FugueSQL,并提供相应的示例。
安装与准备
如果你想安装完整的 Fugue 库,以利用它所有的并行化功能,你可以这样安装:
pip install fugue
如果你只想要 FugueSQL API——这是本文示例所需的全部内容——可以这样安装:
pip install fugue[sql]
安装后,导入所需的库:
import pandas as pd
from fugue_sql import fsql
这样,只剩下创建一个可以在示例中查询的数据框。由于我需要这样做——并且我目前正在深入整理我的漫画书收藏——我们可以创建一个简单的玩具漫画书数据集。
简单的数据框将包含 4 列:某个漫画书标题的特定问题;漫画书出版商;专业且独立分配的漫画书评级(10 分制);该漫画书在其分配等级中的价值。
以下是实现上述目标的代码:
comics_df = pd.DataFrame({'book': ['Secret Wars 8',
'Tomb of Dracula 10',
'Amazing Spider-Man 252',
'New Mutants 98',
'Eternals 1',
'Amazing Spider-Man 300',
'Department of Truth 1'],
'publisher': ['Marvel', 'Marvel', 'Marvel', 'Marvel', 'Marvel', 'Marvel', 'Image'],
'grade': [9.6, 5.0, 7.5, 8.0, 9.2, 6.5, 9.8],
'value': [400, 2500, 300, 600, 400, 750, 175]})
print(comics_df)
book publisher grade value
0 Secret Wars 8 Marvel 9.6 400
1 Tomb of Dracula 10 Marvel 5.0 2500
2 Amazing Spider-Man 252 Marvel 7.5 300
3 New Mutants 98 Marvel 8.0 600
4 Eternals 1 Marvel 9.2 400
5 Amazing Spider-Man 300 Marvel 6.5 750
6 Department of Truth 1 Image 9.8 175
你不需要理解(或关心)有关漫画书收藏的更多信息来理解以下示例,所以我们开始吧。
示例 1:我的书中哪些评级超过 8.0?
标题已经说明了一切。我们将使用 FugueSQL 和标准的 SELECT 语句来查询我们的 Pandas DataFrame,以确定我的哪些漫画书在 10 分制中评分超过 8.0。
为此,我们首先需要定义 SQL 语句:
# which of my books are graded above 8.0?
query_1 = """
SELECT book, publisher, grade, value FROM comics_df
WHERE grade > 8.0
PRINT
"""
注意在我们的 SELECT 语句中使用 Pandas DataFrame 作为表名。
一旦查询定义完成,必须使用 Fugue 查询引擎执行它:
fsql(query_1).run()
这是我们返回的查询结果:
PandasDataFrame
book:str |publisher:str|grade:double|value:long
--------------------------------------------------------------+-------------+------------+----------
Secret Wars 8 |Marvel |9.6 |400
Eternals 1 |Marvel |9.2 |400
Department of Truth 1 |Image |9.8 |175
Total count: 3
在我们的数据框中,有 3 本书的评级超过 8.0:秘密战争 8;永恒族 1;和真相部 1。
如果你将这个结果与我们的原始数据框进行比较,你会发现我们的查询已被正确返回。成功了!非常酷,而且如果你熟悉 SQL 语法,这非常直接。
示例 2:我的书中哪些价值超过 500?
让我们看第二个示例,在这个示例中,我们将找出哪些书籍的价值超过 $500,考虑到它们的评级和本文发布时的市场情况。
再次,我们将首先定义 SQL 语句,然后使用 FugueSQL 引擎执行它。
# which of my books are valued above 500?
query_2 = """
SELECT book, publisher, grade, value FROM comics_df
WHERE value > 500
PRINT
"""
fsql(query_2).run()
结果如下:
PandasDataFrame
book:str |publisher:str|grade:double|value:long
--------------------------------------------------------------+-------------+------------+----------
Tomb of Dracula 10 |Marvel |5.0 |2500
New Mutants 98 |Marvel |8.0 |600
Amazing Spider-Man 300 |Marvel |6.5 |750
Total count: 3
在我们的数据框中,有 3 本书的价值超过 $500\。它们恰好是 3 个非常受欢迎角色的首次完整亮相,这导致了它们相对较高的价值:吸血鬼猎人布雷德;死侍;以及毒液,分别是。
示例 3:我的书中哪些是由 Image 出版的?
在我们的最后一个示例中,让我们看看这些漫画中哪些是由 Image Comics 出版的。
# which of my books are published by Image?
query_3 = """
SELECT book, publisher, grade, value FROM comics_df
WHERE publisher = 'Image'
PRINT
"""
fsql(query_3).run()
PandasDataFrame
book:str |publisher:str|grade:double|value:long
--------------------------------------------------------------+-------------+------------+----------
Department of Truth 1 |Image |9.8 |175
Total count: 1
只有这一本符合条件:《真相部》1,本书是一部精心创作的当代杰作,基于流行的阴谋论实际上改变现实的想法,是 Image 出版的唯一一本。
那么,返回的查询结果的数据类型是什么?让我们重新运行上述查询,将其存储到变量中,并检查其类型。
result = fsql(query_3).run()
print(type(result))
fugue.dataframe.dataframes.DataFrames
返回的结果是 Fugue dataframe 的形式。了解更多关于 Fugue dataframe 的信息,请点击 这里,以及如何进一步处理返回结果。
要获取更多示例,请 查看这个 FugueSQL 教程。
Matthew Mayo (@mattmayo13) 是 KDnuggets 的数据科学家和主编,KDnuggets 是重要的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
进一步了解此主题
数据科学能回答哪些问题?
原文:
www.kdnuggets.com/2016/01/questions-data-science-answer.html/2
多少/多少?
 当你需要找一个数字而不是类别时,应该使用回归算法家族。
当你需要找一个数字而不是类别时,应该使用回归算法家族。
-
下周二的气温会是多少?
-
我在葡萄牙的第四季度销售额会是多少?
-
30 分钟后,我的风电场将需求多少千瓦?
-
我下周会获得多少新关注者?
-
在一千个单位中,这款型号的轴承有多少能在使用 10,000 小时后存活?
通常,回归算法会给出一个实数值的答案;答案可能有很多小数位甚至是负数。对于一些问题,特别是以“多少…”开头的问题,负数可能需要重新解释为零,小数值需要重新解释为最接近的整数。
多类别分类作为回归
有时看起来像多值分类问题的问题实际上更适合回归。例如,“哪条新闻对这个读者最有趣?” 似乎在询问一个类别——从新闻故事列表中选一个。然而,你可以将其重新表述为 “这个列表中的每个故事对这个读者有多有趣?” 并给每篇文章一个数值评分。然后识别出得分最高的文章是件简单的事。这类问题通常表现为排名或比较。
-
“我的车队中哪辆车最需要维护?” 可以重新表述为 “我车队中的每辆车需要维护的程度如何?”
-
“我客户中哪 5%的人会在接下来的一年里转向竞争对手?” 可以重新表述为 “我每个客户在接下来的一年里转向竞争对手的可能性有多大?”
二分类作为回归
二分类问题也可以重新表述为回归问题可能不会令人惊讶。(事实上,在底层,一些算法将每个二分类问题重新表述为回归。)这在一个例子可能部分属于 A 和部分属于 B,或有可能两种情况都发生时尤其有用。当一个答案可能部分是肯定的和否定的,可能是打开的但也可能是关闭的,那么回归可以反映这一点。这类问题通常以“可能性有多大…”或“比例是多少…”开始。
-
这个用户点击我的广告的可能性有多大?
-
这个老丨虎丨机的多少次拉动会导致支付?
-
这个员工成为内部安全威胁的可能性有多大?
-
今天的航班中有多少会准时起飞?
如你所知,两类分类、多类分类、异常检测和回归等问题都密切相关。它们都属于同一个扩展家庭,即监督学习。它们有许多共同之处,通常可以将问题修改并在多个领域提出。它们的共同点是,它们是通过一组标记样本(称为训练)构建的,然后可以对未标记样本进行赋值或分类(称为评分)。
完全不同的数据科学问题属于无监督学习和强化学习的扩展算法家庭。
这些数据如何组织?
 有关数据如何组织的问题属于无监督学习。有多种技术尝试揭示数据的结构。其中一种是聚类,也称为分块、分组、捆绑或分段。它们试图将数据集分成直观的块。聚类与监督学习不同之处在于,没有数字或名称告诉你每个点属于哪个组、组的代表是什么,甚至没有指定应该有多少组。如果监督学习是从夜空中的星星中挑选行星,那么聚类就是发明星座。聚类试图将数据分成自然的“团块”,以便人类分析师可以更容易地解释和向他人解释。
有关数据如何组织的问题属于无监督学习。有多种技术尝试揭示数据的结构。其中一种是聚类,也称为分块、分组、捆绑或分段。它们试图将数据集分成直观的块。聚类与监督学习不同之处在于,没有数字或名称告诉你每个点属于哪个组、组的代表是什么,甚至没有指定应该有多少组。如果监督学习是从夜空中的星星中挑选行星,那么聚类就是发明星座。聚类试图将数据分成自然的“团块”,以便人类分析师可以更容易地解释和向他人解释。
聚类总是依赖于定义相似性或接近性的标准,称为距离度量。距离度量可以是任何可测量的量,如智商差异、共享的基因对数或直线距离。聚类问题都试图将数据划分为更均匀的组。
-
哪些购物者在农产品上的口味相似?
-
哪些观众喜欢相同类型的电影?
-
哪些打印机型号以相同的方式失败?
-
在一周中的哪些日子,这个电力变电站的电力需求类似?
-
如何将这些文档自然地划分为五个主题组?
另一类无监督学习算法称为降维技术。降维是简化数据的另一种方式,使其更易于沟通、更快地进行计算和更易于存储。
降维的核心在于创建一种描述数据点的简写方式。一个简单的例子是 GPA。大学生的学术能力通过数十门课程的数百次考试和数千次作业来衡量。每个作业都能反映出学生对课程内容的理解,但完整列出这些信息对任何招聘人员来说都过于繁杂。幸运的是,你可以通过将所有分数平均化来创建一个简写。你可以通过这种大规模简化来处理数据,因为在一项作业或课程中表现非常好的学生通常在其他方面也表现良好。通过使用 GPA 而不是完整的档案,虽然失去了一些细节,比如学生是否在数学上比英语更强,或在课后编程作业中得分是否比课堂小测验更高,但你获得的是简洁,这使得讨论和比较学生的能力变得容易得多。
与降维相关的问题通常是关于哪些因素倾向于一起变化。
-
在这台喷气发动机中,哪些传感器组的变化往往是互相关联的(或相反的)?
-
成功的 CEO 有哪些共同的领导实践?
-
美国的汽油价格变化中最常见的模式是什么?
-
在这组文档中,哪些词组倾向于一起出现?(它们涵盖了哪些主题?)
如果你的目标是总结、简化、浓缩或提炼一组数据,降维和聚类是你首选的工具。
我现在应该做什么?
第三类扩展的机器学习(ML)算法专注于采取行动。这些被称为强化学习(RL)算法。它们与监督学习和无监督学习算法略有不同。一个回归算法可能预测明天的高温为 98 度,但它不会决定如何应对。RL 算法会进一步选择行动,例如在天气仍然凉爽的时候预先冷却办公室的上层楼层。
RL 算法最初受到老鼠和人类大脑如何对惩罚和奖励做出反应的启发。它们选择行动,努力选择能够获得最大奖励的行动。你需要提供一组可能的行动,并在每次行动后得到反馈,了解该行动是好、一般还是巨大的错误。
通常,RL 算法非常适合那些需要在没有人工指导的情况下做出大量小决策的自动化系统。电梯、供暖、制冷和照明系统是很好的候选者。RL 最初是为了控制机器人而开发的,因此任何自行移动的设备,从检查无人机到吸尘器,都是适用的。RL 回答的问题总是关于应该采取什么行动,尽管通常由机器来执行这些行动。
-
我应该把这个广告放在网页的哪个位置,以便观众最有可能点击它?
-
我应该把温度调高、调低,还是保持现状?
-
我应该重新吸尘客厅还是继续保持在充电站?
-
我现在应该买多少股这只股票?
-
我应该在看到黄灯时继续保持当前速度、刹车还是加速?
强化学习(RL)通常比其他算法类型需要更多的努力,因为它与系统的其他部分紧密集成。好的一面是,大多数 RL 算法可以在没有数据的情况下开始工作。它们在进行过程中收集数据,通过试错学习。
本系列的第一篇文章介绍了进行优秀数据科学所需的基本要素。接下来的最后一篇文章将提供大量关于尖锐数据科学问题的具体示例,以及最适合每个问题的算法家族。敬请关注。
个人简介:Brandon Rohrer 是微软的高级数据科学家。
本文最初发布在 微软 TechNet 机器学习博客上。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
数据科学可以回答什么类型的问题
原文:
www.kdnuggets.com/2015/09/questions-data-science-can-answer.html/2
多分类作为回归
有时,看似多值分类的问题实际上更适合回归。例如,“哪个新闻故事对这位读者最有趣?”看起来像是要求一个类别——从新闻故事列表中选择一个项目。然而,你可以将其改述为“这个列表中的每个故事对这位读者有多有趣?”并为每篇文章打分。然后,识别得分最高的文章就很简单。这类问题通常以排名或比较的形式出现。
-
“我的车队中哪辆车最需要维修?”可以改述为“我车队中的每辆车需要维修的程度有多严重?”
-
“我的哪 5%客户将在明年离开我的业务去找竞争对手?”可以改述为“我的每个客户在明年离开我的业务去找竞争对手的可能性有多大?”
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
二分类作为回归
二分类问题也可以改述为回归问题,这可能并不令人惊讶。(事实上,一些算法在底层会将每个二分类问题改述为回归。)当一个示例可以同时属于 A 和 B 部分,或有可能朝两个方向发展时,这尤其有用。当一个答案可以部分是肯定的也可以是否定的,可能是开启的也可能是关闭的,那么回归可以反映这一点。这类问题通常以“可能性有多大……”或“比例是多少……”开始。
-
这个用户点击我的广告的可能性有多大?
-
拉动这个老丨虎丨机的多少比例会得到回报?
-
这个员工成为内部安全威胁的可能性有多大?
-
今天有多少航班会按时起飞?
正如你可能已经了解到的,二分类、多分类、异常检测和回归的家庭都是紧密相关的。它们都属于同一个扩展家庭,即监督学习。它们有很多共同点,问题经常可以在其中一种或多种方式中进行修改和提出。它们的共同点在于,它们是通过一组带标签的示例(一个称为训练的过程)构建的,之后可以将值或类别分配给未标记的示例(一个称为评分的过程)。
完全不同的数据科学问题属于无监督学习和强化学习的扩展算法家族。
这些数据是如何组织的?
关于数据如何组织的问题属于无监督学习。有多种技术尝试揭示数据的结构。这些技术中有一类执行聚类,也称为分块、分组、聚集或分段。它们试图将数据集分成直观的块。与监督学习不同的是,聚类没有一个数字或名称来告诉你每个点属于哪个组,组的代表是什么,甚至组的数量。若监督学习是从夜空中的星星中挑选行星,那么聚类就是发明星座。聚类试图将数据分成自然的“簇”,以便人类分析师更容易解读并向他人解释。
聚类始终依赖于一种被称为距离度量的相似度定义。距离度量可以是任何可测量的量,比如智商差异、共享基因对数或飞行距离。聚类问题都试图将数据分成更接近的组。
-
哪些购物者在农产品上的口味相似?
-
哪些观众喜欢相同类型的电影?
-
哪些打印机型号以相同的方式出现故障?
-
在一周中的哪些天,这个电力变电站的电力需求相似?
-
将这些文档自然地分成五个主题组的方式是什么?
另一类无监督学习算法被称为降维技术。降维是简化数据的另一种方式,使数据更易于沟通、计算更快、存储更方便。
从本质上讲,降维就是创建一种描述数据点的简写方式。一个简单的例子是 GPA。大学生的学术实力通过数十门课程、数百次考试和数千项作业来衡量。每项作业都反映了学生对课程材料的理解程度,但完整的列表对任何招聘人员来说都太庞大了。幸运的是,你可以通过将所有分数平均来创建一个简写。你可以通过这种大幅简化来解决问题,因为在某项作业或课程中表现非常好的学生通常在其他课程中也表现很好。使用 GPA 而不是完整的作品集虽然会失去丰富性,例如你无法知道学生在数学方面是否比英语强,或者她在家庭编程作业中的成绩是否优于课堂小测。但你获得的是简单性,这使得谈论和比较学生的能力变得更容易。
与降维相关的问题通常涉及那些一起变化的因素。
-
在这台喷气发动机中,哪些传感器组彼此之间(以及相互对立)变化?
-
成功的首席执行官有哪些共同的领导实践?
-
美国的汽油价格变化中最常见的模式是什么?
-
在这组文档中,哪些词汇组经常一起出现?(它们涵盖了哪些主题?)
如果你的目标是总结、简化、压缩或提炼一组数据,降维和聚类是你的首选工具。
我现在该怎么办?
机器学习算法的第三个扩展家族专注于采取行动。这些被称为强化学习(RL)算法。它们与监督学习和无监督学习算法略有不同。回归算法可能预测明天的高温将达到 98 度,但它不会决定如何处理这个结果。而 RL 算法则进一步采取行动,例如在白天气温仍然较低时预先为办公楼的上层制冷。
强化学习算法最初受到老鼠和人类大脑如何对惩罚和奖励做出反应的启发。它们选择行动,努力选择能够获得最大奖励的行动。你需要为它们提供一系列可能的行动,并且它们需要在每次行动后获得反馈,以了解该行动是好、一般还是严重错误。
通常,强化学习算法非常适合需要在没有人工指导的情况下做出大量小决策的自动化系统。电梯、供暖、制冷和照明系统是很好的候选者。强化学习最初是为了控制机器人而开发的,因此任何自动移动的设备,从检查无人机到吸尘器,都适用。强化学习解决的问题总是关于应该采取什么行动,尽管行动通常由机器执行。
-
我应该把这则广告放在网页的什么位置,以便观众最有可能点击?
-
我应该将温度调高、调低,还是保持不变?
-
我应该再次吸尘客厅,还是保持充电?
-
我现在应该买多少股这只股票?
-
对于那盏黄灯,我应该继续以相同的速度行驶、刹车,还是加速?
强化学习通常需要比其他算法类型更多的努力才能起效,因为它与系统的其他部分紧密集成。好处是,大多数强化学习算法可以在没有任何数据的情况下开始工作。它们在过程中收集数据,通过试错来学习。
本系列的下一篇也是最后一篇文章将提供许多具体的数据科学问题示例及适合每个问题的算法家族。敬请关注。
布兰登
关注我 Twitter 或在 LinkedIn 上联系我。
原文。
相关:
-
分析、数据挖掘、数据科学的应用
-
入门级分析专业人员的 10 个关键技巧
-
采访:Ali Vanderveld,Groupon 讨论数据科学如何改变全球电子商务市场
-
Reiner Kappenberger,HP Security Voltage 讨论如何保护数据传输中的安全
更多相关主题
初级数据科学家的两个问题
原文:
www.kdnuggets.com/2020/01/questions-junior-data-scientist.html
评论
由 Sowmya Vajjala 撰写,博客内容包括 NLP 研究和教学、R、Python 等。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
我认为,招聘数据科学家一般来说是一个困难的过程。有很多来自不同背景、学术学位水平和经验的人。不同公司对“数据科学家”的要求差异很大。此外,我们还看到越来越多的人在 LinkedIn 个人资料上添加了“数据科学家”的标签。评估一个有经验的数据科学家个人资料是否适合一个职位可能相对容易,但我们如何评估一个初级/入门级数据科学家个人资料?
在过去几个月中,我面试了几位应届毕业生/证书项目毕业生/实习候选人后,花了一些时间思考这个问题。我觉得在面试过程中有两个重要的问题需要提出。这篇文章就是关于这两个问题以及我提出这些问题的理由。
让我先给他们设置标题。
-
解决同一问题的不同方式
-
一般理解还是具体知识
解决同一问题的不同方式
让我举一个匿名的真实面试经验。我曾面试过一位学术背景非常优秀、作为学生已经完成了一系列令人印象深刻的项目的候选人。其中一个项目涉及使用强化学习解决自然语言处理领域的一个问题。这是一个 Kaggle 比赛(据我记得),候选人在其中名列前茅。我觉得他们解释自己做了什么的方式相当不错。
当时,我问:“如果被告知不能使用强化学习,你会怎么做?”候选人似乎对这个问题感到惊讶。经过一番思考,他们说:“深度学习。”我问:“深度学习中的什么?”他们说:“也许是 RNNs。”我说:“好的,假设决定我们不能使用深度学习。你能想到其他解决方案吗?”他们:(茫然的表情)。
在这种情况下,我们讨论的问题的一个流行算法(这在教科书中也可以找到)使用了正则表达式和简单的启发式方法!现在,有人可能会问,在这个时代问这个问题有什么意义?三个原因:
-
在行业项目中,通常构建一个快速的 MVP 或简单的解决方案、获取反馈并进行迭代是有意义的。因此,考虑几种不同的解决方案并评估哪个可以快速构建是有用的。
-
强化学习、深度学习或正则表达式只是解决问题的“方法”。它们不应成为问题本身的解决方案。
-
这也会告诉我候选人是否只是遵循了他们课程中强制项目的描述,还是实际上理解并考虑了解决问题的方式
所以,我的观点是:当我们刚开始时,避免停留在一个解决方案上,思考“还有其他解决方案吗?”。这也是我们在实际工作中常做的事情。我们在给定的约束下寻找最优解。虽然对刚开始的人来说,了解所有内容是困难的——这部分也涉及常识。当有人突然问你关于替代解决方案的问题时,你应该在面试中有一个答案。这在作为数据科学家成长的过程中将非常有用。
广泛的理解还是具体的知识
让我再举一个匿名的面试经验。一个刚毕业的候选人在简历上有一堆典型项目——垃圾邮件分类、MNIST 数据集数字识别、情感分析等。在其中一个项目中,候选人还声称自己在 Kaggle 排行榜上是前十名的表现者。虽然这很令人印象深刻,但这些与现实世界项目场景相差甚远。那么,我该怎么做呢?
我没有直接询问这些知名数据集和项目的具体细节,而是稍微修改了我的“问题描述”。我问了候选人解决问题的问题,例如:“假设我经营一个在线业务,经常收到客户抱怨的邮件。我只有三个客户支持部门:订单和账单、退货和退款、其他。我想要一个机器学习解决方案,将客户邮件分配到这三个部门中的一个。”——如果有人理解了他们做过的项目,他们应该将其映射到分类问题上,可能类似于垃圾邮件或情感分类。即使是入门级别,不看到这个关联对我来说也是一个警示信号。
对于这个问题,我有两个重点:
-
如果你展示的所有数据科学项目都是标准数据集和 Kaggle 竞赛,这完全没问题(几个月前,我曾质疑这是否有用,但我现在改变了看法)。不过,一个人需要知道如何将这些知识推广到新问题上。例如,如果你之前做过文本分类问题,你需要能够识别另一个文本分类问题,并了解解决它的一些步骤。
-
在这里,我的第二点与问题 1 类似。这告诉我候选人是否真正理解了他们所做的事情,还是只是跟随指令或在线教程。
总结来说,申请数据科学职位时,入门级候选人需要在项目方面考虑得更深入一点——寻找其他可能的解决方案,并寻找类似问题在实际应用中的例子。
当然,这些都是我的个人观点,并不一定适用于每一个数据科学面试!
原文。经许可转载。
简介:Sowmya Vajjala 是一位位于加拿大多伦多的 NLP 研究员,专注于使用机器学习方法处理和理解文本。此前,Sowmya 曾在爱荷华州立大学任教,并在多伦多担任数据科学家。
相关:
更多相关主题
寻找合适标注人才的快速指南
原文:
www.kdnuggets.com/2022/04/quick-guide-find-right-minds-annotation.html

数据报告矢量图由 storyset 创建 - www.freepik.com
共享职责一直是每个成功组织中最关键的组成部分,无论其性质或规模如何。在共享业务职责时,外包是一个可行的选择。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
鉴于此,将公司运营中的非核心方面委托给外包伙伴,可能会实现目标而不危及你的资金、资源或时间。
我们特别指的是你当前或即将进行的人工智能(AI)和机器学习(ML)项目,以及这些 AI 和 ML 系统在过程中将要消耗的训练数据。
坦白说,让你最宝贵和最昂贵的资源,例如数据科学家和 AI 模型规划师,去处理数据聚合和标注任务,而不是让他们专注于关键的 AI 和 ML 方面,这种做法是相当不明智的。
处理人工智能(AI)和机器学习(ML)集成的数据量过于庞大,无法在内部处理。最佳选择是寻找外包数据标注专家,他们可以利用其专业知识在规定的时间框架内开发高质量的训练数据。
数据注释和标注服务可以外包给专业公司,这些公司能提供高质量的服务。
下面我们来看看一些有用的技巧,以选择合适的外包合作伙伴来处理你下一个 AI 模型的标注工作。
1. 提供对优质劳动力的访问
自动化的概念在 AI 训练数据公司中创造了一个竞争激烈的领域,每个公司都声称自己是标注专家,而事实往往与声明相反。与一个新进入行业的公司合作,几乎都会导致 AI 训练数据的不足。
质量来自于具有多年行业经验的专业训练数据专家。这里的终极建议是找到行业中的领头羊,选择那些承诺为你的 AI 和 ML 项目提供最相关和高质量训练数据的公司。
手动的数据标记和注释方式由于其精确性和准确性,需要有良好的劳动力支持。事实上,注释过程消耗了大量的时间、精力和资源,以完成识别、汇总、过滤和标记与你的 AI 和 ML 项目相关的数据,这是一项艰巨的工作。
在整个过程中,质量始终是最重要的,找到一个具有良好行业经验和充足劳动力的外包注释和标记合作伙伴是最佳选择。
2. 拥有适应性生态系统
适应性——另一个成功商业活动的重要方面,在商业合作中较少见而更多被讨论。根据你不断变化的 AI 和 ML 系统及设计来满足训练数据需求对任何 AI 训练数据公司来说都是艰巨的任务。
你的 AI 训练数据需求可能会在类别、特征和数量上不断变化。能够满足你不断变化的 AI 训练数据需求的人实际上是合适的人选。
寻找外包的 AI 训练数据公司时,应该选择一个能随时调整以适应你不断变化的数据需求的公司。
目前的可行方法是找到能够在不失创新方向的情况下调整以适应你的需求的劳动力,并且不妥协数据交付质量。当你支付费用时,你有权在与数据训练公司合作期间保持你的选择。
3. 利用尖端技术
我们难道不应该感到欣喜若狂吗?我们生活在一个技术驱动的时代。生活中的每一个小事或大事都依赖于尖端技术——你的 AI 和机器学习项目也是如此。你正在使用的自动化系统实际上将在你获得丰富训练数据时发挥作用。技术在这一过程中扮演了重要角色。
在竞争激烈的领域保持对自动化的热情需要来自 AI 训练数据专家的优质数据交付。
数据丰富工具在提供显著提升数据注释能力的质量资源时表现优异。技术有可能通过增加工作流程输出来促进性能。
与一个利用尖端技术的数据训练公司合作,可以加快数据整合进你的 AI 和机器学习项目的速度。
4. 提供预算内的生产力
性能输出是评估一个培训数据提供商能力的关键指标之一。在寻找合格的数据公司时,一致性、沟通和完成的项目是三个重要的标准。
那些在向之前的客户提供优质数据交付方面保持一致,并因通过稳定沟通渠道建立有价值的参与而赢得声誉的公司,可能是作为培训数据合作伙伴的最佳选择。
可靠的培训数据提供商能够在需要时提供支持,并迅速回应您的查询。与一个值得信赖的培训数据提供商合作,可以使您的 AI 实施过程更加顺利,同时结合技术和短期标注期限——而且还能控制预算。
5. 具有不间断的沟通渠道
沟通是您业务增长的关键。保持数据标注团队与您的人工智能培训人员之间的沟通,可以确保 AI 数据集成计划和机器学习过程保持同步并按计划进行。
选择一个承诺提供不间断沟通渠道的培训数据提供商,将决定您 AI 和机器学习项目的未来方向。
在赶进度时,需要不断沟通和快速响应。确保您合作的数据标注公司通过不间断的沟通渠道为您提供全天候支持。
那些已经优化了其沟通渠道的数据标注公司,是与之合作以及时完成 AI 和 ML 项目的理想选择。
最终思考
所以,这就是在寻找外包数据标注合作伙伴时需要考虑的五个关键要素。希望阅读本指南能让您对找到合适的数据标注和注释专家有足够的思考。谨慎选择合作伙伴,因为与数据标注公司合作将决定您的 AI 实施计划的成功以及机器学习项目的未来。
Pramod Kumar 是一位热衷于人工智能和机器学习技术的读者和作家。Pramod 自豪于与 Cogito Tech LLC、Anolytics.ai 和一些其他顶级标注及数据标注公司作为自由撰稿人的合作。
更多相关话题
神经网络快速入门
原文:
www.kdnuggets.com/2016/11/quick-introduction-neural-networks.html/2
前馈神经网络可以由三种类型的节点组成:
-
输入节点 - 输入节点将来自外部世界的信息传递给网络,被统称为“输入层”。输入节点中不进行任何计算——它们只是将信息传递给隐藏节点。
-
隐藏节点 - 隐藏节点与外部世界没有直接连接(因此称为“隐藏”)。它们执行计算,并将信息从输入节点传递到输出节点。隐藏节点的集合形成了一个“隐藏层”。虽然前馈网络只有一个输入层和一个输出层,但它可以有零个或多个隐藏层。
-
输出节点 - 输出节点统称为“输出层”,负责计算并将信息从网络传递到外部世界。
在前馈网络中,信息仅朝一个方向移动——前进——从输入节点,通过隐藏节点(如有)到达输出节点。网络中没有循环或回路[3](这一前馈网络的特性不同于递归神经网络,其中节点之间的连接形成循环)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
下方给出了两个前馈网络的例子:
-
单层感知器 - 这是最简单的前馈神经网络[4],不包含任何隐藏层。您可以在[4],[5],[6],[7]中了解更多关于单层感知器的内容。
-
多层感知器 - 多层感知器具有一个或多个隐藏层。我们将仅讨论多层感知器,因为它们在实际应用中比单层感知器更有用。
多层感知器
多层感知器(MLP)包含一个或多个隐藏层(除了一个输入层和一个输出层)。虽然单层感知器只能学习线性函数,但多层感知器也可以学习非线性函数。
图 4 显示了一个具有单一隐藏层的多层感知器。注意,所有连接都有权重,但图中仅显示了三个权重(w0, w1, w2)。
输入层: 输入层有三个节点。偏置节点的值为 1。其他两个节点接受 X1 和 X2 作为外部输入(这些值取决于输入数据集的数值)。如上所述,输入层不进行计算,因此输入层的节点输出为 1、X1 和 X2,它们被送入隐藏层。
隐藏层: 隐藏层也有三个节点,偏置节点的输出为 1。隐藏层中其他两个节点的输出取决于输入层的输出(1、X1、X2)以及与连接(边)相关的权重。图 4 显示了一个隐藏节点(高亮显示)的输出计算。同样,其他隐藏节点的输出也可以计算。请记住,f 指的是激活函数。这些输出随后被送入输出层的节点。
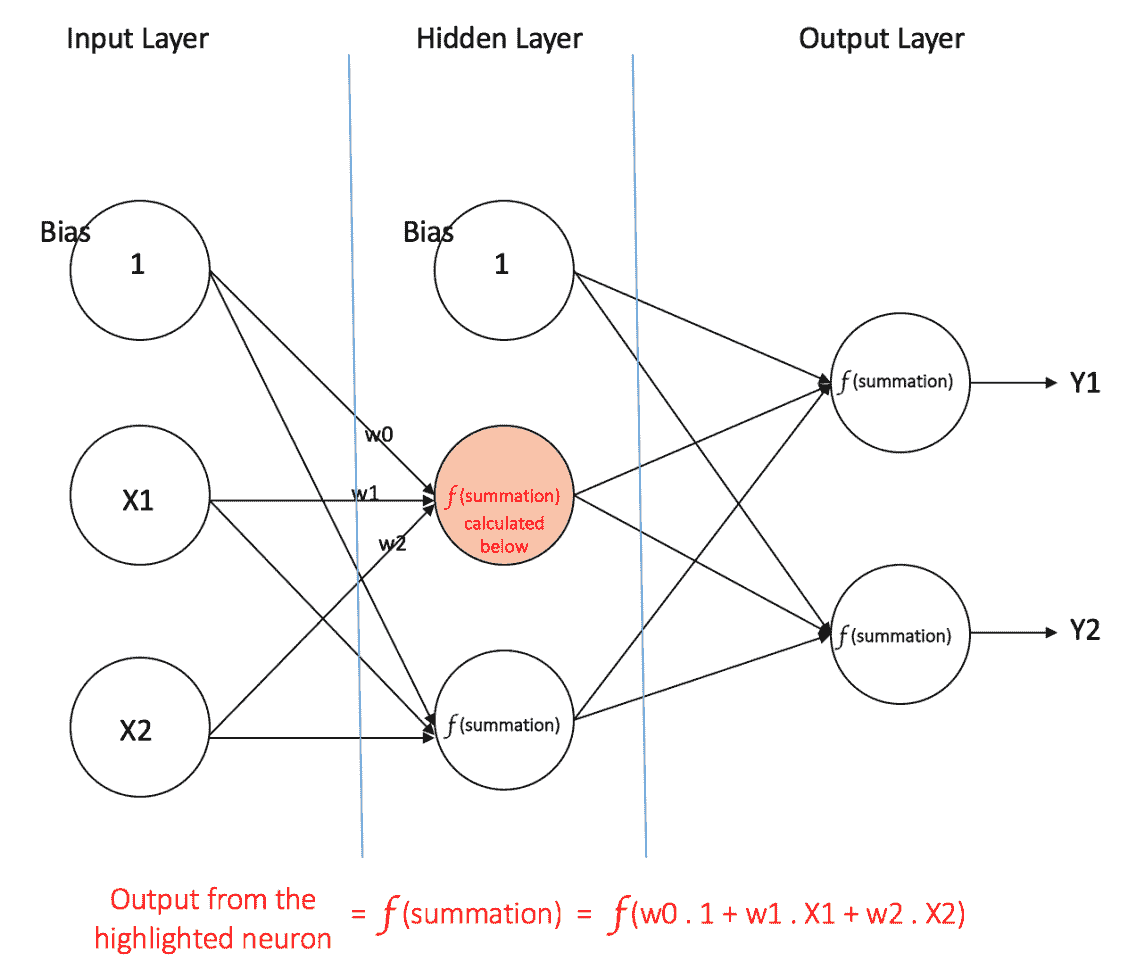
图 4:具有一个隐藏层的多层感知器
输出层: 输出层有两个节点,这些节点从隐藏层接受输入,并执行与高亮隐藏节点所示类似的计算。这些计算得到的值(Y1 和 Y2)作为多层感知器的输出。
给定一组特征X = (x1, x2, ...)和一个目标y,多层感知器可以学习特征与目标之间的关系,用于分类或回归。
让我们通过一个例子更好地理解多层感知器。假设我们有以下学生-成绩数据集:
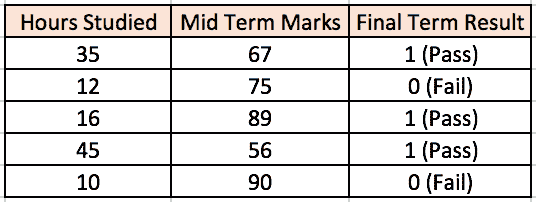
两个输入列显示了学生学习的小时数和学生在期中考试中获得的分数。期末结果列可以有两个值 1 或 0,表示学生是否通过了期末考试。例如,我们可以看到,如果学生学习了 35 小时并在期中考试中获得了 67 分,他/她最终通过了期末考试。
现在,假设我们想预测一个学习了 25 小时并在期中考试中得了 70 分的学生是否能通过期末考试。

这是一个二分类问题,其中多层感知器可以从给定的示例(训练数据)中学习,并在给定新的数据点时做出有根据的预测。我们将看到多层感知器如何学习这种关系。
训练我们的 MLP:反向传播算法
多层感知器学习的过程称为反向传播算法。我建议阅读Hemanth Kumar 在 Quora 上的回答(下文引用),它清楚地解释了反向传播。
反向误差传播,通常缩写为 BackProp,是训练人工神经网络(ANN)的几种方法之一。它是一种监督训练方案,这意味着它从标记的训练数据中学习(有监督者来指导其学习)。
简而言之,BackProp 就像是“从错误中学习”。监督者在 ANN 犯错时会进行纠正。
一个 ANN 由不同层中的节点组成:输入层、隐藏层和输出层。相邻层节点之间的连接有“权重”与之相关。学习的目标是为这些边分配正确的权重。给定一个输入向量,这些权重决定了输出向量。
在监督学习中,训练集是标记的。这意味着,对于一些给定的输入,我们知道期望的输出(标签)。
反向传播算法:
最初,所有边权重都是随机分配的。对于训练数据集中的每个输入,激活 ANN 并观察其输出。这个输出与我们已经知道的期望输出进行比较,并且误差被“传播”回上一层。记录这个误差并相应地“调整”权重。这个过程会重复进行,直到输出误差低于预定的阈值。
一旦上述算法终止,我们就拥有一个“学习过”的 ANN,我们认为它准备好处理“新”输入了。这个 ANN 被认为从多个示例(标记数据)和它的错误(误差传播)中学习了。
现在我们对反向传播的工作原理有了了解,让我们回到上面的学生分数数据集。
更多相关话题
-
深度神经网络不会引导我们走向 AGI
html)
-
A. W. Harley, "卷积神经网络的交互式节点-链接可视化," 见 ISVC, 页码 867-877, 2015 (链接)
原文。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
Voronoi 图概述
原文:
www.kdnuggets.com/2022/11/quick-overview-voronoi-diagrams.html

Vackground.com 来自 Unsplash
Voronoi 图。这是什么?它几乎存在于我们周围的自然界中。它们也被称为迪利克雷镶嵌或泰森多边形。尽管它们被称为如此复杂的名字,Voronoi 图实际上很简单,但具有显著的属性,并涉及到从计算机科学到艺术的不同领域。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
例如,在 1854 年伦敦霍乱流行期间,医生约翰·斯诺使用了 Voronoi 图,将每个多边形中的水泵位置用于识别特定的泵作为感染源,以统计死亡人数。有趣吧?那么这个图示是什么呢?
什么是 Voronoi 图?
Voronoi 图是一种在欧几里得平面上具有散布随机点(n)的图示。然后将平面划分成每个点周围的单元格,这些单元格包围了平面中离每个点最近的部分——形成一个覆盖平面的镶嵌多边形。
为了更好地视觉理解,可以查看下面的图像。每个随机点都被封闭在一个单元格中,该单元格在两个或多个点之间是等距的。
来源:MDPI
如上图所示,在(a)中,大多数点都集中在每个单元格的中心,但并非所有点都是如此。单元格的边界是基于到周围点的距离,而创建单元格的线条将点之间的空间完美地分隔开来。
如果向特定单元格中添加更多随机点,它们将更靠近该单元格内的原始点。
Voronoi 图在不同的情况下被看到和使用——其中许多来自自然界。我整理了一些自然发生的 Voronoi 图案的拼贴画,以帮助你更好地理解。
如果你对动物的形状和模式感兴趣,可以阅读这篇论文:整合哺乳动物模型中的形状和模式
来源:作者图像
Voronoi 划分是通过点的径向外扩展创建的,如下图所示。

来源:维基百科
背后的数学
点之间的距离可以通过以下方式测量:
欧几里得距离
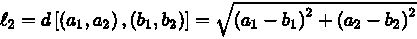
曼哈顿距离
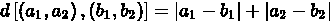
如果我们使用这两个度量标准上的 20 个点绘制 Voronoi 图,它们将会是这样的:
来源:维基百科
但这一切听起来很熟悉,对吗?通过数据点之间的距离来获取更多信息。听起来像是 k-最近邻算法——一种通过计算当前训练数据点之间的距离来对测试数据集进行预测的算法。
那么我们如何计算这个呢?
Delaunay 三角剖分
Delaunay 三角剖分有时也称为 Delone 三角剖分,是 Voronoi 图中细胞神经的三角剖分形式。简单来说,如果你将 Voronoi 图中的每个点与其邻近单元的点连接起来——你就得到了 Delaunay 三角剖分。
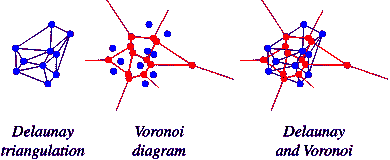
来源:数学世界
这是一个三角形集合,使用原始点集,基于一个条件:不允许有三角形位于其他三角形的外接圆内。
Lloyd 算法
Lloyd 算法,也称为 Voronoi 迭代,生成一个质心 Voronoi 划分。这意味着每个 Voronoi 单元的数据点也称为质心。该算法重复地将每个点移动到 Voronoi 单元的质心,然后根据其最接近的质心重新划分输入点。就像 k-means 聚类一样。
通过每次迭代,算法最终将通过创建更多类似 Voronoi 的单元来分隔点。
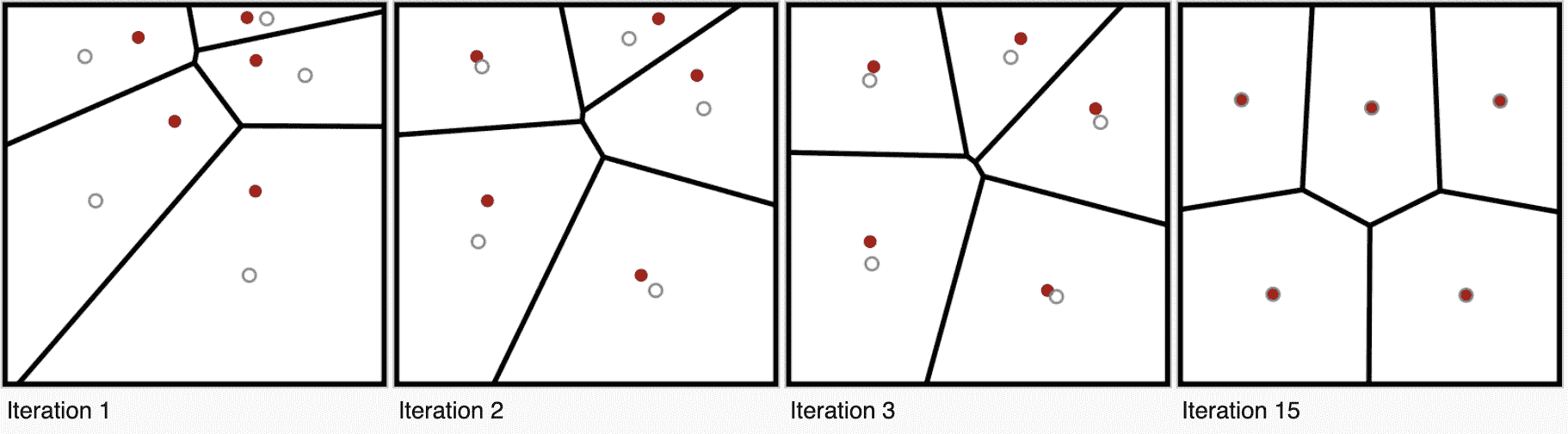
来源:维基百科
总结
我希望这对 Voronoi 图的快速概述和理解有所帮助。它在许多领域和不同情况下都被使用。我们能够介绍 Voronoi 图、其背后的数学、Delaunay 三角剖分和 Lloyd 算法。
希望这对你有帮助!
妮莎·阿里亚 是一名数据科学家和自由技术写作者。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何或可以促进人类寿命的不同方式。作为一个渴望学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
R 和 Hadoop 使机器学习对每个人都成为可能
原文:
www.kdnuggets.com/2014/11/r-hadoop-make-machine-learning-possible-everyone.html
评论作者:Joel Horwitz (H2O.ai),2014 年 11 月。
在统计学中,引导法可以指任何依赖于有放回随机抽样的测试或指标。简单来说,它提供了一种测量采样分布准确性的方法,这种方法通常用于构建假设测试。在商业领域,bootstrapping 指的是在没有外部帮助或资本的情况下启动业务。一般来说,bootstrapping 这个词指的是一个荒谬且不可能的行动,即“靠自己的靴带把自己拉过栅栏”。R 和 Hadoop 是非常自给自足的技术,它们在过去 20 年里几乎在所有行业和使用案例中依靠看似随机的贡献者,未接受任何直接投资。
R 海盗掠夺全球业务
R 首次出现于 1993 年,当时 Ross Ihaka 和 Robert Gentleman 在奥克兰大学发布了一个免费的软件包。从那时起,R 在美国的用户数量已超过 300 万人,根据去年发布的下载网站日志文件。
此外,R 超过了 SAS,拥有超过 7,000 个独特的包,你可以在 Crantastic 网站上查看。难怪它在许多行业和学术界得到了广泛应用。事实上,2014 年夏季,R 超过了 IBM SPSS,成为学术文章中使用最广泛的分析软件,依据是 Robert Muenchen。因此,R 现在成为了进行各种统计、经济学甚至机器学习的“黄金标准”。此外,根据我的经验,许多人(如果不是大多数的话)即使在使用其他更昂贵或流行的企业软件时,也会将 R 作为辅助工具来检查他们的工作。难怪 R 正迅速成为 21 世纪数据科学家的首选工具。
推动 R 增长的主要因素是社区通过许多博客和用户组提供对常见问题的解答,使核心软件更有用和相关。此外,根据 LinkedIn 的数据(见下图),显然存在未得到充分服务的职位市场。由于这种需求,R 现在在几乎所有主要大学中作为统计编程的事实标准语言提供,每天都有许多新的在线课程开始。Datacamp 就是一个例子,它建立了一个互动式的网络环境,提供丰富的课程,让非程序员可以轻松入门,无需触及命令行。
 企业也纷纷转向统计学,并接受数据扩展时出现的概率性问题,而传统的商业智能无法跟上。因此,许多人转向 Hadoop,以打开数据平台,解锁多年来一直远离业务分析师的企业数据管理世界。预先过滤、预先汇总的仪表板和 Excel 工作簿时代已经过去,这些仪表板和工作簿被随意地通过电子邮件发送给高管和决策者,几乎没有解释或“讲故事”来指导业务做出明智决策。
企业也纷纷转向统计学,并接受数据扩展时出现的概率性问题,而传统的商业智能无法跟上。因此,许多人转向 Hadoop,以打开数据平台,解锁多年来一直远离业务分析师的企业数据管理世界。预先过滤、预先汇总的仪表板和 Excel 工作簿时代已经过去,这些仪表板和工作簿被随意地通过电子邮件发送给高管和决策者,几乎没有解释或“讲故事”来指导业务做出明智决策。
Hadoop 增长
Apache Hadoop 出现几乎是在 R 于 2005 年首次登场后的 10 年,直到 2013 年,当超过一半的财富 50 强公司开始建立自己的集群时,它才被广泛采用。名字“ Hadoop”来源于著名的 Yahoo! 工程师 Doug Cutting 的一个玩具大象,他与 Mike Cafarella 一起最初开发了该技术以创建更好的搜索引擎。除了能够在相对便宜的硬件上处理大量数据外,它还使得可以在分布式文件系统(HDFS)上存储数据,而无需提前转换。与 R 类似,许多开源项目被创建出来以重新构想数据平台。从将数据导入 HDFS(sqoop、flume、kafka 等),到计算和流处理(Spark、YARN、MapReduce、Storm 等),再到数据查询(Hive、Pig、Stinger / Tez、Drill、Presto 等),到数据存储(Hbase、Cassandra、Redis、Voldermort 等),到调度器(Oozie、Cascading、Scalding 等),最后到机器学习(Mahout、MLlib、H2O 等),以及许多其他应用。
不幸的是,没有简单的方法可以像 R 一样通过一行代码查看所有这些技术并轻松安装。MapReduce 也不是一个普通开发者可以轻松掌握的语言。实际上,你可以通过 LinkedIn 清晰地看到像 R 一样,Hadoop 和 MapReduce 技能工人的短缺与职位数量之间的差距。正因为如此,Hadoop 并未像 R 那样全面普及,最近在纽约市举行的 Strata Hadoop World 会议上也有人谈论它的衰退。
真正的问题是什么?用一个答案来讲,就是数据
在过去几年中,数据科学领域的问题已经成为第一大问题,尤其是面对数据的广泛种类和体量。我不能不提及不断袭来的数据波浪对我们脆弱分析环境的冲击。事实上,预计到 2020 年,数据量将超过宇宙中的星星数量,根据 IDC。幸运的是,有一种全新的方法解决这个问题,直到现在我们一直在习惯性地想要将数据约束在查询工具中。
机器学习是新的 SQL
简而言之,“机器学习是一门科学学科,涉及构建和研究能够从数据中学习的算法。” 这是从单纯计数事物的标准方式到探索未知深层领域的量子跃迁的开始。
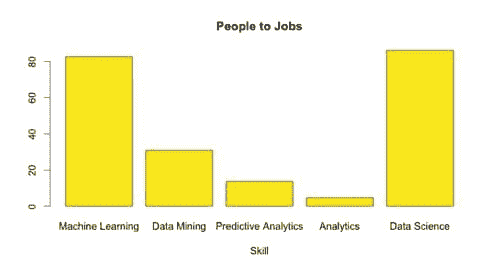
所以这里是故事的真正有趣部分。根据我的 LinkedIn 分析,机器学习和数据科学实际上非常符合市场对可用人员的整体需求(与 R 和 Hadoop 不同)。
我们需要另一个图表来真正了解数据科学与机器学习之间实际存在的职位数量。我对这个图表的解读是,今天数据科学家的工作相当于分析师或数据分析专业人员,而真正的机会在于不断增长的机器学习领域。
 机器学习是新兴领域
机器学习是新兴领域
数据科学最初被描述为编程或“黑客技能”、数学和统计学以及商业专业知识的交集,参考 Drew Conway 的 博客。事实证明,编程是一个过于笼统的术语,真正的含义是通过新算法应用数学于大规模数据,这些算法可以穿越这个复杂的网络。要在这片丛林中寻找答案,仅仅在树冠上飞过是无法揭示隐藏在树冠下的宝藏的。从涌现出的机器学习项目数量和市场接受概率信息的成熟度来看,显然这标志着我们在数据资产中寻找价值的竞赛进入了一个新时代。
“机器并不会使人类远离自然的伟大问题,而是让他更深刻地陷入其中。” - 安托万·德·圣-埃克苏佩里
Hadoop 2.0 已经来了,算是来了吧
很多人曾尝试声称 Hadoop 2.0 是通过 MR2、YARN 或高可用性 HDFS 功能实现的,但考虑到类似名称的 Web 2.0 将我们带入了 Facebook、Twitter、LinkedIn、Amazon 等网络应用的时代,这种说法是不准确的。根据现在 Strata 名声赫赫的 John Battelle 和 Tim O’Reilly 的定义,这种转变被简单地称为“Web 作为平台”,即软件应用程序建立在 Web 上,而非桌面上。Apache Spark 使得在 Hadoop 上开发应用程序变得更容易,H2O 使得 R 和 Hadoop 终于可以协同工作。对于我来说,在“大数据”行业工作一段时间后,我清楚地看到,软件开发人员和统计学家希望用他们的语言进行编程,而不是 MapReduce。现在是离开桌面,进入集群的激动人心的时刻,因为这里的限制被解除,机会无限。
作为一个开源项目,像 R 和 Apache Hadoop 一样,H2O 不仅要向社区展示持续的价值,还必须经受住最严格的行业用例考验。从 2012 年开始,H2O 首先专注于通过举办超过 120 次聚会来创建社区,将用户基础扩大到 7000 多人。H2O 是 R 用户从笔记本电脑转向大规模环境的桥梁,以训练超出笔记本内存的数据。这是我们处理数据问题的基本转变,并且为众多生产客户提供了可靠的结果,涵盖从零售到保险、健康再到高科技的各个领域。要了解更多关于如何开始的信息,请访问 www.h2o.ai 免费开始使用。
工作和技能分析说明
最近,许多人对统计软件的日益流行进行了研究,使用了如 间接方法 的学术研究引用、职位发布、书籍、网站流量、博客、调查(如 KDnuggets 年度 调查)、GitHub 活动等。然而,这些方法一般都侧重于技术人群。在我看来,LinkedIn 代表了商业世界,正是这些地方才是实际应用的关键。此外,如果你想要面对更广泛的受众,你可以使用 Google Adwords 执行相同的操作。逆向工程广告平台是一种获取市场规模信息的好方法。我在我的 个人博客 上写了一篇关于这个主题的完整博客。在接下来的说明中,我将讲解如何使用 LinkedIn 作为样本,并结合 R 来分析我上面的商业市场分析。
1. 数据收集
从 LinkedIn 获取数据有两种方式。一种是使用左侧图片中显示的广告,另一种是使用右侧下方显示的直接搜索功能。

在这种情况下,我选择了手动操作,并使用了搜索功能。对于每个产品类别,我搜索时会显示结果的计数,并将其作为需求的代理。 请见下文:
从这个例子中,我们可以看到“R 编程”有 1720 个结果。我还包括了“R 统计学”和其他相关的“R”术语。
2. 数据分析
作为一个新的 R 用户,我手动创建了每个数据框来保存数据,首先创建了个人和职位的各个向量:
name<-c(“R”,”Python”,"SAS","SPSS","Excel","RapidMiner","SQL") people <- c(230750,815555,128860,752205,15390756,3306,4648240) jobs <-c(5059,13519,2414,7429,123874,17,37571)
在我创建了一个简单的数据框后:
skills <- data.frame(c(name),c(people),c(jobs))
要获取比例,我简单地使用了 transform 函数:
skills <- transform(skills, ratio=people/job)
3. 数据可视化
R 配备了许多可视化包,其中最著名的是 ggplot2。在这种情况下,我使用了内置的条形图,因为它开箱即用更为简便。坦率地说,R 中生成的可视化可能在普通观众看来不够引人注目,但它确实促使你考虑你正在绘制的内容,从而生成更有信息量的可视化效果。
要获取条形图(使用 H2O 颜色):
barplot(skills$ratio,names.arg=name,col=“#fbe920”, main=“Ratio of People to Jobs”,xlab=“Skill”)
就这样!非常简单,我确信还有更优雅的分析方法,但对我来说,这样的分析方式能确保结果是合理的。
要获取完整的脚本,你可以下载来尝试或加入我的分析中。
相关:
-
数据科学技能与商业问题
-
使用 R 进行人口普查数据的可视化
-
STRATA + Hadoop World 2014 NYC 报告
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
相关主题更多
R 编程:谁、在哪里以及做什么
原文:
www.kdnuggets.com/2015/08/r-programming-who-where-what.html
comments
由 Ashwin Ramasamy(ContractIQ)。
R 编程的流行度逐年上升,在过去几年中位列前 10 名编程语言之一。数据科学作为一个学科正逐渐成为主流,主要受到互联网和软件技术公司迅速增长的推动。媒体、银行和其他传统领域正在逐渐认识到数据的力量,以提高效率和预测下一个重大趋势。尽管如此,还有一个抱怨是没有足够的人懂得软件和统计学。R 程序员数量不足。
除了轶事之外,我想检查数据以确认这些抱怨是否属实。无需多言,我向你呈现‘R 程序员的谁、哪里以及做什么’。在得出结论的过程中没有虐待数据。但我承认,我无法使用 R 来得出这些见解。Excel 做到了。
首先,全球只有大约 50,000 名 R 程序员。现在,谷歌的数据科学家年薪超过一百万的传言似乎是真的。对于那些还在从“我刚刚读到什么?”这种震惊中恢复过来的人来说,Glassdoor 提供了更易于理解的数字。他们说,数据科学家的年薪大约为 $118,000。
奇怪的是,当谈到 R 程序员的分布时,并没有前 3 个国家。只有美国,其次才是其他国家。美国拥有所有 R 程序员的 25% 以上。排名第二的是印度,拥有大约 4000 到 6000 名 R 程序员(美国的数量是其两倍或略多)。加拿大有超过 1000 名 R 程序员。
世界其他地方刚刚开始关注 R。是的,包括西欧在内的地区总共有大约 5000 名 R 程序员。整个亚洲、非洲、中东、南美洲和东欧在某些情况下拥有不到 500 名 R 程序员,大多数情况下仅有低双位数。也门有一名 R 程序员。他或她一定感到非常孤独。
就 R 程序员社区的年龄而言,经验似乎是制胜法宝。这是可以理解的,因为在尝试理解数据之前,需要了解和欣赏一个组织的运作。60% 的 R 程序员拥有超过 6 年的工作经验。事实上,拥有超过 10 年经验的人占 R 程序员的最大比例,为 30%。
那么,如果你是 R 程序员或正在招聘一个,你该怎么做:
-
现在是成为 R 程序员的好时机,无论你在世界的哪个地方。
-
你有 3 个选项来组建你的数据科学团队——美国、印度或加拿大。
-
如果你是一个初创企业正在招聘一批 R 程序员,很快你就得把你的平均年龄广告打到 20 多岁,因为 3 个里就有 1 个超过 30 岁。这既不是好事也不是坏事。你只需意识到你的初创企业正进入一个员工生活阶段多样化的阶段。此外,英国 3 个 R 程序员中就有 1 个是外国人。我相信,美国也不例外。
-
如果你负责美国企业的分析工作,如果你没有与大学合作建立人才库,你已经在失败了。供应有限,经济因素对你不利。
我查看了 R 程序员通常参与的行业和职能。如果您希望获得这样的见解和/或喜欢明亮的彩色信息图,您可以在 contractiq.com/ 找到它们。
简介: Ashwin Ramasamy 是 ContractIQ 的创始人,该平台和专家团队将您与全球一流的应用开发机构进行匹配。
相关内容:
-
如何成为数据科学家 – 简要回答
-
如何成为数据科学家并获得聘用
-
招聘量化分析师,优化你的招聘流程
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关主题
R 还是 Python?为什么不两个都用呢?
评论
忘掉R 与 Python 的争论吧。
在实际应用场景中,使用两者的情况是否有必要?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 部门
如果一个数据科学或分析团队由多个在两种语言方面都具备专业知识的成员组成呢?如果系统的设计利用了源自两种基础语言的库和包呢?如果某个特定的用例要求某个实现部分偏离了产品的其余部分所用的语言呢?
那么,如果你想使用一个 IDE 实现和管理这些不同的代码呢?
或者,如果你在不同的项目中使用 R 和 Python,并且只是想要一个单一的工作空间来编写所有代码呢?
进入prython,一个为 R 和 Python 编码设计的 IDE,甚至可以在同一个项目中使用。
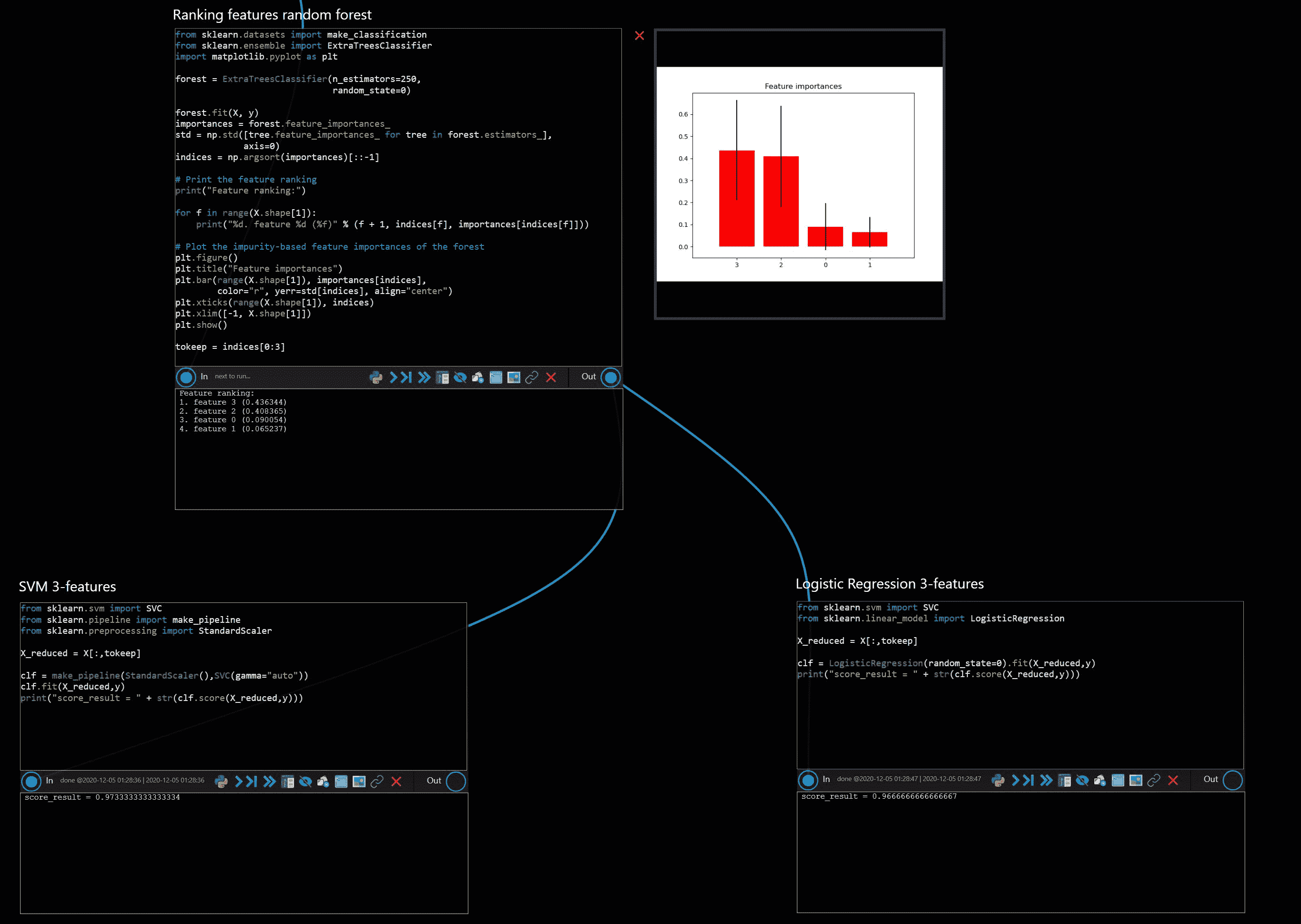
prython 是一个新颖的 IDE,它通过在画布中连接面板来支持 R 或 Python 编程(甚至可以在同一项目中同时使用)。它允许你组织代码,进行一键运行的实验,并在创建它们的面板旁边可视化你的图表+数据框。厌倦了记住哪些行需要注释掉以测试某些内容?还是仅仅想更好地组织代码?目前适用于 Windows,并与本地 R/Python 内核一起运行。
该项目的优点都与集成 Python 和 R 编程环境的简便性有关,包括用于输入和输出流管理的无代码功能、数据可视化、在项目流程的各个位置启动上下文控制台、混合数据框检查等。
主要缺点是 prython 目前仅支持 Windows 系统。
如果你是 Windows 用户,可以在这里下载 prython。
prython 基于面板的概念,这些面板可以在画布上相互连接,每个面板运行 Python 或 R 代码。面板具有输入和输出连接,这些相互连接可以根据需要配置和重新配置。面板可以独立运行,也可以与前后的面板一起运行。为什么要使用面板呢?
数据专业人员需要对他们的数据进行实验,构建大量的图表,并将代码分成不同的区域。他们很少想要一个从头到尾的线性脚本。这几乎不可避免地会导致非常混乱的脚本,不清晰的输出,混乱的图表,以及用户需要记住测试时需要注释掉什么。没有其他 IDE 适合这种需求。
根据其网站,使用 prython 的一些典型原因:
- 跟踪和描述实验及测试。与其记住在脚本中需要注释掉什么以测试 X 更改,你可以轻松地通过 prython 完成这一点
- 在一个画布上同时显示你的结果和图表
- 运行复杂的测试,能够通过一次点击在不同的模型上运行(例如:你想同时测试多个 scikit-learn 模型)
- 在画布上将你的代码分成不同区域。例如,一个区域用于输入加载,另一个区域用于模型训练,不同的区域用于图表/分析
- 在同一个项目中混合 Python 和 R 代码。
- 可视化数据框在脚本中如何变化和演变。prython 计算所有对数据框的更改(无论是在 R 还是 Python 中)跨面板显示,每当数据框被修改时,它都会作为表格显示在每个面板旁边
这个视频中有对 prython 的简要高级介绍:
项目的网站包含额外的视频教程以及充分的文档,帮助你快速上手并开始高效工作。
关于哪种语言是统治一切的唯一语言的争论已经结束,但这并不意味着其中一种是“赢家”。Python 和 R 是实现你的数据科学或数据分析目标的两个工具,而根据你所使用的工具来设定目标是适得其反的。因此,使用其中任何一种——或两者——并查看 prython 是否能通过其数据科学中心的 IDE 独特方法使你更高效。毕竟,工具的目的就是让你更高效。
相关:
-
R 中的简单直观集成学习
-
在 Python 中合并 Pandas 数据框
-
为数据科学家简单解释面向对象编程
更多相关内容
远程数据科学:如何从 Jupyter Notebooks 向 SQL Server 发送 R 和 Python 执行
原文:
www.kdnuggets.com/2018/07/r-python-execution-sql-server-jupyter.html
评论
简介
你知道吗?你可以在 SQL Server 中通过 Jupyter Notebooks 或任何 IDE 远程执行 R 和 Python 代码。SQL Server 中的机器学习服务消除了移动数据的需要。与其通过网络传输大量和敏感的数据或在 ML 训练中因样本 csv 文件而损失精度,不如让你的 R/Python 代码在数据库中执行。你可以在 Jupyter Notebooks、RStudio、PyCharm、VSCode、Visual Studio 等任何地方工作,然后将函数执行发送到 SQL Server,将智能带到你的数据所在之处。
本教程将展示如何将你的 Python 代码从 Jupyter Notebooks 发送到 SQL Server 执行。相同的原则也适用于 R 和任何其他 IDE。如果你更喜欢通过视频学习,本教程也在 YouTube 上发布,点击这里:

环境设置前提条件
- 在 SQL Server 上安装 ML 服务
为了让 R 或 Python 在 SQL 中执行,你首先需要安装和配置机器学习服务功能。请参阅此操作指南。
- 通过微软的 Python 客户端安装 RevoscalePy
为了从 Jupyter Notebooks 向 SQL 发送 Python 执行,你需要使用微软的 RevoscalePy 包。要获取 RevoscalePy,请下载并安装微软的 ML Services Python 客户端。文档页面 或 直接下载链接(适用于 Windows)。
下载完成后,以管理员身份打开 PowerShell 并导航到下载文件夹。使用此命令开始安装(可以自定义安装文件夹):
.\Install-PyForMLS.ps1 -InstallFolder "C:\Program Files\MicrosoftPythonClient"
请耐心等待,安装可能需要一些时间。安装完成后,导航到你安装的新路径。我们来创建一个空文件夹并打开 Jupyter Notebooks:
mkdir JupyterNotebooks; cd JupyterNotebooks; ..\Scripts\jupyter-notebook
创建一个新的使用 Python 3 解释器的笔记本:
为了测试一切是否设置正确,请在第一个单元格中导入 revoscalepy 并执行。如果没有错误消息,你可以继续进行。

数据库设置(仅本教程需要)
如果你不想复制所有代码,可以克隆 Github 上的这个 Jupyter Notebook。这个数据库设置是确保你拥有与本教程相同的数据的一次性步骤。你不需要执行这些设置步骤来使用自己的数据。
- 创建数据库
修改你的服务器连接字符串,并使用 pyodbc 创建一个新的数据库。
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "MLRemoteExec"
connection_string = "Driver=SQL Server;Server=localhost\
MSSQLSERVER2017;Database={0};Trusted_Connection=Yes;"
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE
[name] = '{0}') DROP DATABASE {0}".format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
- 从 SkLearn 导入 Iris 示例
Iris 是一个受欢迎的初学者数据科学教程数据集。它默认包含在 sklearn 包中。
from sklearn import datasets import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
- 使用 RecoscalePy APIs 创建表并加载 Iris 数据
(你也可以使用 pyodbc、sqlalchemy 或其他包来完成此操作)
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table
# You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=
connection_string.format(new_db_name), table="Iris")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
定义一个发送到 SQL Server 的函数
编写任何你想在 SQL 中执行的 Python 代码。在这个示例中,我们正在创建一个 Iris 数据集的散点矩阵,并只将 .png 的字节流返回到 Jupyter Notebooks 以在客户端渲染。
def send_this_func_to_sql()
from revoscalepy import RxSqlServerData, rx_data_step
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are
within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost\MSSQLSERVER2017;
Database=MLRemoteExec;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string,
sql_query = "select * from Iris")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.save fig(buf, format="png")
buf.seek(0)
return buf.getvalue()
将执行发送到 SQL
现在我们终于完成了设置,看看远程执行真的有多简单吧!首先,导入 revoscalepy。创建一个 sql_compute_context,然后使用 RxExec 无缝地将任何函数的执行发送到 SQL Server。没有原始数据需要从 SQL 传输到 Jupyter Notebook。所有计算都在数据库内完成,只有图像文件被返回以供显示。
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context =
RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql,
compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client.
#All data remained secure and was manipulated in my db.
display.Image(data=image)
尽管这个示例使用了 Iris 数据集很简单,但想象一下你现在解锁的额外规模、性能和安全能力。你可以使用任何最新的开源 R/Python 包,在 SQL Server 中处理大量数据,构建深度学习和人工智能应用程序。我们还提供微软 领先边缘、高性能的算法,分别在 RevoScaleR 和 RevoScalePy APIs 中。将这些与开源世界中的最新创新结合使用,可以为你的应用程序带来无与伦比的选择、性能和规模。
了解更多
查看 SQL 机器学习服务文档,了解如何轻松部署你的 R/Python 代码,使用 SQL 存储过程使其在 ETL 过程或任何应用程序中可访问。在你的数据库中训练和存储机器学习模型,将智能带到数据所在的位置。
基本的 R 和 Python 执行在 SQL Server 中:aka.ms/BasicMLServicesExecution
设置 SQL Server 中的机器学习服务:aka.ms/SetupMLServices
Github 上的端到端教程解决方案:microsoft.github.io/sql-ml-tutorials/
其他 YouTube 教程:
如何安装 SQL Server 机器学习服务: aka.ms/InstallMLServices 如何启用 SQL Server 机器学习服务: aka.ms/EnableMLServices SQL 中 R 和 Python 执行的基础: aka.ms/ExecuteMLServices
个人简介:Kyle Weller是微软 Azure 机器学习团队的项目经理。在几家初创公司担任软件开发人员后,他加入微软,并在 Office 和 Bing 从事可扩展数据仪表、平台和 API 解决方案的工作。他曾在 Cortana 数据与分析团队负责测量策略,研究用户行为模式,标准化 KPI,并为产品识别增长机会。他现在从事 Azure 机器学习产品的工作,专注于将智能带到数据存储的位置。这包括 SQL Server 的新机器学习服务,允许在 SQL 中执行 R + Python。
相关内容:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
R 与 Python(再论):一种人为因素的视角
原文:
www.kdnuggets.com/2022/01/r-python-human-factor-perspective.html

图像由作者根据 OpenClipart-Vectors 在 pixabay 的图像制作
我经常听到或看到类似的说法:“R 适合快速且粗糙的分析,但如果你想做严肃的工作,你应该使用 Python。” 我完全不同意这种说法,因为在 R 中编写高效、可靠、稳健、生产级别的代码是完全可能的——我做到了,所以其他人也可以做到。当比较两种语言时,你可以考虑它们的内在特性,比如语言结构、语法、函数和可用的库。但你也可以采用一种更为经验的方法,快速地在脑中回忆你遇到过的用这两种语言编写的所有代码示例。然后,我愿意承认,如果你将上述说法重新表述为“平均而言,Python 代码的质量高于平均 R 代码”,这可能有一些道理,这可以通过“人为因素”来解释。
免责声明:
这种观点显然不是基于严谨的科学方法,因为它不是基于客观数据的,因为这些数据并不存在(我认为也无法获得)。确实,我们无法获取所有曾经创建的 Python/R 代码(也不能获取去年创建的代码),也无法获取这类代码的代表性样本。我们也没有所有 Python/R 用户的教育背景和职业资料,也没有他们的代表性样本。即使我们拥有这些数据,定义一个平均的 Python/R 代码并评估其质量也将极其困难。所以这仅仅是基于我对情况的主观但诚实的评价。
阅读更多内容。
关于代码质量
虽然没有普遍适用的代码质量定义或测量标准,但普遍承认,好的代码应该是可读的(文档齐全,风格一致等)、模块化、可重用、可靠、可测试,并且能够完成预期的功能。它还应该高效地使用计算资源(内存、CPU)和时间资源,即运行速度要合理。
注意:
代码只是软件的一部分,还有代码实现的算法。无论你使用什么编程语言,即使你遵守上述代码质量要求,算法效率低的软件也不是好的软件。
典型的 R 用户画像
背景
大多数 R 用户来自科学背景。他们通常是自学的 R 程序员(Google 和 YouTube 是最重要的 R 教学资源!),即使他们接受过正式的 R 培训,这种培训也很可能相当有限,并且很可能是在统计学课程中(专业统计学家和数据科学家除外)。此外,他们可能没有接受过一般计算机科学培训和概念,因此不熟悉良好的编码实践。
使用情况
R 通常作为辅助工具来完成他们的主要工作——进行研究。因此,重要的是完成工作——分析数据,为博士论文、期刊或会议论文,或资助机构的项目报告制作表格和图表。因此,开发的代码是一次性的、临时的软件。文档或编码风格不是问题,频繁出现的是意大利面条风格的单一脚本而非模块化代码,更不用说硬编码的文件路径和其他参数,这破坏了代码复用的任何希望。代码通常由作者交互式运行,如果发生错误,会立即修复,因此当然没有适当的错误处理。如果代码今天在我的计算机和数据集上运行,那我就满意了,我完成了我的工作!但我们不应过于责怪他们——他们的工作是产生科学结果,而不是高效和高质量的计算机代码。可以肯定的是,一旦习惯了,编写高质量代码并不难,即使代码本意是一次性的,但其中的一些部分可能在其他场合被重复使用,但低质量的代码使得这个任务几乎不可能完成。考虑到所有这些,我们可以说,“普通” R 代码大多不符合高质量编码标准。
显著的例外再次是专业统计学家和数据科学家,对于他们来说,编写代码可以被视为他们主要任务的一部分——开发统计学和机器学习方法及工具,因此他们常常生产高质量的代码,并在 CRAN 和其他仓库中提供 R 包。
典型的 Python 用户画像
背景
大多数 Python 用户来自计算背景。Python 通常被用作大学介绍计算机科学概念的工具 (www.edx.org/learn/python)。即使他们没有计算机科学的学位,Python 用户可能也接受过一些正式的 Python 编程培训,因为这是一项工作要求。此外,即使他们最初没有学习计算机科学,他们也很可能接受过一般计算机科学的正式培训,除了 Python 编程之外,并且熟悉良好的编码实践。
使用情况
Python 通常由软件开发人员使用——这些人的主要任务是编写代码。代码的目的是多次运行,在不同的计算机(甚至可能是不同的操作系统)上运行,并处理许多不同的数据集。代码通常是稳健和可靠的,能够处理异常情况,并优雅地处理错误。还期望代码需要维护,可能由其他人进行(修复错误、适应、演变),因此文档、风格、可读性、重用等概念自然成为开发过程的一部分。考虑到这一点,我们可以认为“普通”Python 代码往往会符合高质量的编码标准。
结论
在这篇文章中,我尝试探讨有关 Python 是否比 R 更适合编写生产级代码的信念来源的假设。我认为这种信念并不来自于两种语言及其生态系统的固有特性。我猜这更可能来自于普通 R 用户可能对代码质量的关注程度低于 Python 用户,这可以通过他们的背景和编程在各自工作中的地位来解释。
当然,最终的结论是,认为 Python 在编写高质量代码方面优于 R 的信念是错误的!
Zivan Karaman 是一位自由的数据科学与软件工程顾问,热衷于利用数学、统计学和计算来将数据转化为可操作的见解,以帮助解决实际问题。特别钟爱 R 生态系统,早在 R 创建之前就已经使用(自 90 年代初期开始使用 R 的前身 S/S+)。 在 LinkedIn 上与他联系.
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
R、Python 双双成为顶级分析、数据科学软件 – KDnuggets 2016 软件调查结果
原文:
www.kdnuggets.com/2016/06/r-python-top-analytics-data-mining-data-science-software.html/2
完整结果及 3 年趋势
以下表格详细展示了调查结果,排除了深度学习工具,因为没有 3 年的结果。
% 单独使用是指仅使用该工具的投票者的百分比,仅对拥有 5%或以上投票的工具显示。例如,11.4%的 RapidMiner 用户只使用了 RapidMiner。
| 在过去 12 个月里,你为实际项目使用过哪些分析、Big Data、数据挖掘、数据科学软件? [2895 名投票者] |
|---|
| 说明:红色:免费/开源工具 绿色:商业工具
Fuchsia: Hadoop/Big Data 工具 |  % 用户在 2016 年
% 用户在 2016 年  % 用户在 2015 年
% 用户在 2015 年
 % 用户在 2014 年 |
% 用户在 2014 年 |
| R (1419) | |
|---|---|
| Python (1325) | |
| SQL (1029) | |
| Excel (972) | |
| RapidMiner (944),11.7% 单独使用 | |
| Hadoop (641) | |
| Spark (624) | |
| Tableau (536) | |
| KNIME (521) | |
| scikit-learn (497) | na |
| Java (487) | na |
| Anaconda (462) | na na |
| Hive (359) | na |
| MLlib (337) | |
| Weka (315) | |
| Microsoft SQL Server (314) | |
| Unix shell/awk/gawk (301) | |
| MATLAB (263) | |
| IBM SPSS Statistics (242) | |
| Dataiku (227),18.1% 单独使用 | na |
| SAS base (225) | |
| IBM SPSS Modeler (222) | |
| SQL on Hadoop 工具 (211) | na |
| C/C++ (210) | na |
| 其他免费分析/数据挖掘工具 (198) | |
| 其他编程和数据语言 (197) | |
| H2O (193) | |
| Scala (180) | na |
| SAS Enterprise Miner (162) | |
| Microsoft Power BI (161) | na |
| HBase (158) | na |
| QlikView (153) | |
| Microsoft Azure 机器学习 (147) | na |
| 其他基于 Hadoop/HDFS 的工具 (141) | |
| Apache Pig (132) | |
| IBM Watson (121) | na |
| Rattle (103) | |
| Salford SPM/CART/随机森林/MARS/TreeNet (100),单独占 63.0% | |
| Gnu Octave (89) | |
| Orange (89) | |
| Alteryx (87) | |
| RapidInsight/Veera (87),单独占 51.7% | |
| TIBCO Spotfire (80) | |
| Apache Mahout (74) | |
| 其他付费分析/数据挖掘/数据科学软件 (71) | |
| Dato (69) | |
| Pentaho (68) | |
| Perl (67) | |
| IBM Cognos (64) | |
| Splunk/ Hunk (63) | |
| JMP (58) | |
| C4.5/C5.0/See5 (58) | |
| Amazon Machine Learning (55) | na |
| Mathematica (53) | |
| Microsoft other ML/Data Science tools (46) | na na |
| Vowpal Wabbit (45) | na |
| Microstrategy (45) | na |
| SAP Analytics (42) | |
| Stata (39) | |
| Dell/StatSoft (36), 8.3 % alone | |
| XLMiner (35) | na na |
| SAP HANA (35) | na na |
| Julia (32) | |
| Oracle Adv. Analytics (31) | |
| BigML (25), 16.0 % alone | |
| Zementis (25) | |
| BayesiaLab (18) | |
| Alpine Data Labs (16),12.5 % 独立 | |
| DataRobot (15),6.7 % 独立 | na na |
| Datameer (13),7.7 % 独立 | |
| Lavastorm (12) | |
| F# (11) | |
| Clojure (11) | |
| Actian (10) | |
| WordStat (10) | |
| Ayasdi (9) | na |
| Skytree (8) | na |
| Lisp (7) | |
| Ontotext GraphDB (6) | na |
| SiSense (5) | |
| Birst (5) | na |
| FICO 模型构建器 (5) | |
| WPS 世界编程系统 (4) | |
| Angoss (3) | |
| Predixion 软件 (2) | |
评论中提到但未包含的其他工具包括
-
XLSTAT
-
BeyondCore
-
Timi 和 Anatella
-
SAS/STAT
-
Domino Data Lab
-
MapR
-
Neural Designer
-
Javascript
以下是过去调查的结果
-
R 领先 RapidMiner,Python 紧追,大数据工具增长,Spark 点燃,2015 年
-
KDnuggets 第 15 届年度分析、数据挖掘、数据科学软件调查:RapidMiner 继续领先,2014 年
-
KDnuggets 2013 年软件调查:RapidMiner 与 R 争夺第一
-
KDnuggets 2012 年调查:分析、数据挖掘、大数据软件使用情况
-
KDnuggets 2011 年调查:数据挖掘/分析工具使用情况
-
KDnuggets 2010 年调查:数据挖掘/分析工具使用情况
-
KDnuggets 2009 年调查:数据挖掘工具使用情况
-
KDnuggets 2008 年调查:数据挖掘软件使用情况
-
KDnuggets 2007 年调查:数据挖掘/分析软件工具
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
八个 R 用户在尝试学习 Python 时会感到沮丧的事情
原文:
www.kdnuggets.com/2016/11/r-user-frustrating-learning-python.html
评论
作者:安迪·尼科尔斯,芒果解决方案。
在与客户和其他 R 用户在如 LondonR 和 EARL 等活动中交流时,我注意到越来越多的人希望学习 Python 作为数据科学之旅的下一步。在芒果,我们的大多数顾问对使用任何一种语言都感到满意,但作为一个使用 R 已有 12 年的用户,我仅仅是尝试过 Python。然而,最近我发现自己不得不快速学习 Python,因此我想分享一些我的观察。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面

在你停止阅读之前,我应该说我完全知道有许多博客文章讨论了每种语言的高层次优缺点。对于这篇文章,我想深入探讨一下。一个 R 用户在尝试学习 Python 时真正体验到了什么?特别是那些来自统计背景的 R 用户会经历什么?
就个人而言,我找到了八个(虽然我想要 10 个,但 Python 实在太棒了),它们如下:
-
缺乏 Hadley。虽然有 Wes,但在功能上存在许多重复的包。开始时你导入统计包并找到均值函数,结果发现它已经被为 pandas 重写。后来你发现每个人对交叉验证的最佳实现方式都有自己的想法。这在开始时非常混乱。这让我想到:
-
绘图。我听说了很多关于 matplotlib 和 seaborn 的好评,但在我看来,ggplot2 无疑领先很多。我甚至可以说 ggplot2 的学习曲线更平缓。
-
集成开发环境(IDEs)。向 RStudio 致敬,它在 IDE 领域改变了 R 的世界。我记得在 RStudio 出现之前,R GUI、StatET 和 Tinn-R 是常态。事情的确有了很大改善。遗憾的是,Python 还没有完全达到这一点。作为一个 RStudio 用户,我选择了 Spyder。它还不错,但脚本编辑器需要改进。我与同事交流时发现 Jupyter Notebook 的集成似乎更好,但我不是很喜欢笔记本。
-
命名空间。我已经记不清多少次在 R 入门课程中告诉学员,掩蔽几乎不会困扰到用户(除非你在构建包,真的不会)。可以说,在 Python 中你必须小心。引入太多东西,你会覆盖自己的对象并引起混乱。这意味着你根据需要引入东西。为了更改工作目录等而必须显式导入 OS 实用程序是令人沮丧的。也就是说,Python 在这一领域的能力稍微优于 R。
-
面向对象。我渐渐喜欢上了 R 灵活的 S3 类,像这样的代码行:
py` > x <- 5 > class(x) <- "just_made_this_up" > x [1] 5 attr(,"class") [1] "just_made_this_up" ```py ````
在 Python 中,我总是不太确定一个对象有哪些方法以及何时应该使用函数式编程。你也真的需要了解类才能有效地使用 Python,而随意使用 R 的用户甚至可以在不知道 R 有类系统的情况下使用它。
-
对 R 的依赖。在我最近的项目中,我使用了 Python 中最好的统计能力。首先,我应该说它基本上都存在(除了某些奇怪原因的逐步 GLM)。然而,尽管我一直知道 Python 中的大多数统计建模功能都是从 R 移植过来的,但文档非常懒散,大部分只是指向 R 的文档。示例数据集甚至是一样的!说到文档。
-
帮助文档。我只能谈论这两种语言中更流行的包,但 R 的文档要丰富得多,并且通常包含更多的示例。
-
零基数组。我不能在没有提到这个的情况下写列表。我确实喜欢那些在其他语言中开发的自满编码者告诉我 R 是唯一一个从 1 开始索引的例外。然而,作为一个人,我从 1 开始计数,这对我来说总是更有意义。以 n-1 结束也是令人困惑的。对比一下:
py` # R x = seq(2,10, by = 2) x[1:3] # 选择前 3 个元素 [1] 2 4 6 py ```` py` # Python x = list(range(2,11, 2)) x[0:3] # 选择前 3 个元素 [2, 4, 6]py ````
我印象深刻的是 R 中广泛的统计能力已经被移植到 Python 中(例如,我没想到混合建模或生存分析的能力会像 R 中那样)。 然而,作为一个现有的 R 用户,实际上没有必要为了统计而转到 Python。 唯一的好处是如果你使用 Python 进行例如广泛的网页抓取,并且希望保持一致性。如果这是你的原因,那么让我把你指向 Chris Musselle 的博客文章“整合 Python 和 R 第二部分——从 Python 执行 R 及反之亦然”。 而且不要忘记你也可以直接使用rvest。
所以我的建议是,如果你打算学习 Python,不要以使用它来构建模型为目的来学习。 学习它是因为它是一种更灵活的全能编程语言,并且你有一些重的工作要做。 只需找一些在 R 中难做的事情,并尝试使用 Python 来完成。否则你会像我一样,写一篇抱怨的博客文章!
简介:安迪·尼科尔斯 是 Mango Solutions 的数据科学主管,同时也是一位全面的顾问和统计学家。
原文。 经许可转载。
相关:
-
R 与 Python 在数据科学中的较量:赢家是...
-
R 还是 Python?考虑同时学习两者
-
R 与 Python:逐对数据分析
更多相关内容
R 与 Python 在数据科学中的对决:胜者是…
由Martijn Theuwissen于 2015 年 5 月 26 日在数据科学工具、DataCamp、Python、Python 与 R、R上发表。
在DataCamp上,我们的学生经常询问他们是否应该使用 R 和/或 Python 来处理日常的数据分析任务。虽然我们主要提供交互式 R 教程,但我们总是回答,这一选择取决于他们面临的数据分析挑战的类型。
Python 和 R 都是流行的统计编程语言。虽然 R 的功能是为统计学家开发的(比如 R 强大的数据可视化能力!),Python 由于其易于理解的语法而受到赞誉。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇文章中,我们将突出 R 和 Python 之间的一些差异,以及它们在数据科学和统计世界中的各自角色。如果你喜欢视觉表现,务必查看相关的信息图表 “数据科学战争:R 与 Python”。
介绍 R
Ross Ihaka 和 Robert Gentleman在 1995 年创建了开源语言 R,作为 S 编程语言的实现。其目的是开发一种语言,专注于提供更好、更用户友好的数据分析、统计和图形模型的方法。最初,R 主要用于学术和研究,但最近企业界也开始发现 R。这使得 R 成为企业界增长最快的统计语言之一。
R 的主要优势之一是其庞大的社区,通过邮件列表、用户贡献的文档和非常活跃的 Stack Overflow 小组提供支持。还有CRAN,这是一个巨大的 R 包库,用户可以轻松贡献。 这些包是 R 函数和数据的集合,使得可以立即获得最新的技术和功能,而无需从头开始开发所有内容。
最后,如果你是一个有经验的程序员,你可能不会难以适应 R。然而,作为初学者,你可能会发现自己在陡峭的学习曲线中挣扎。幸运的是,现在有许多很好的学习资源可以咨询。
介绍 Python
Python 是由 Guido Van Rossem 于 1991 年创建的,强调生产力和代码可读性。那些希望深入数据分析或应用统计技术的程序员是 Python 在统计领域的主要用户之一。
当你在工程环境中工作时,你可能会更喜欢 Python。它是一种灵活的语言,非常适合做一些新颖的事情,而且由于其关注可读性和简洁性,学习曲线相对较低。
与 R 类似,Python 也有包。PyPi是 Python 包索引,包含用户可以贡献的库。就像 R 一样,Python 有一个很棒的社区,但由于它是通用语言,所以稍微分散。然而,Python 在数据科学中的应用正迅速在 Python 世界中占据主导地位:期望正在增长,更多创新的数据科学应用将在这里诞生。
R 与 Python:常用数字
在网上,你可以找到许多比较 R 和 Python 采用情况和受欢迎程度的数字。虽然这些数据通常很好地指示了这两种语言在计算机科学整体生态系统中的演变情况,但将它们并排比较是困难的。 主要原因是你会发现 R 只存在于数据科学环境中; 另一方面,作为一种通用语言,Python 广泛应用于许多领域,如 Web 开发。这通常会使排名结果倾向于 Python,而薪资受到一些负面影响。
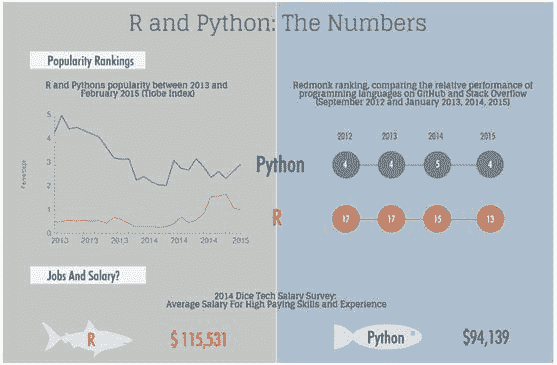 **何时以及如何使用 R?
**何时以及如何使用 R?
R 主要用于数据分析任务需要独立计算或在单独服务器上进行分析时。它非常适合探索性工作,并且由于大量的包和现成的测试,几乎适用于任何类型的数据分析,这些工具通常为你提供必要的工具,让你快速上手。R 甚至可以成为大数据解决方案的一部分。
在开始使用 R 时,一个好的第一步是安装令人惊叹的 RStudio IDE。完成后,我们建议你查看以下一些流行的包:
何时以及如何使用 Python?
当你的数据分析任务需要与网页应用集成,或统计代码需要整合到生产数据库中时,你可以使用 Python。作为一种完整的编程语言,它是实现生产使用算法的绝佳工具。
虽然 Python 数据分析包的初期阶段曾是一个问题,但这些年已经有了显著改善。确保安装 NumPy /SciPy(科学计算)和 pandas(数据处理),使 Python 可用于数据分析。同时查看一下 matplotlib 制作图形,以及 scikit-learn 进行机器学习。
与 R 不同,Python 并没有明确的“获胜”IDE。我们建议你查看一下 Spyder、IPython Notebook 和 Rodeo,看看哪个最适合你的需求。
R 和 Python:数据科学数字
如果你查看最近针对数据分析编程语言的调查,R 通常是明显的赢家。如果专注于 Python 和 R 的数据分析社区,类似的模式也会出现。
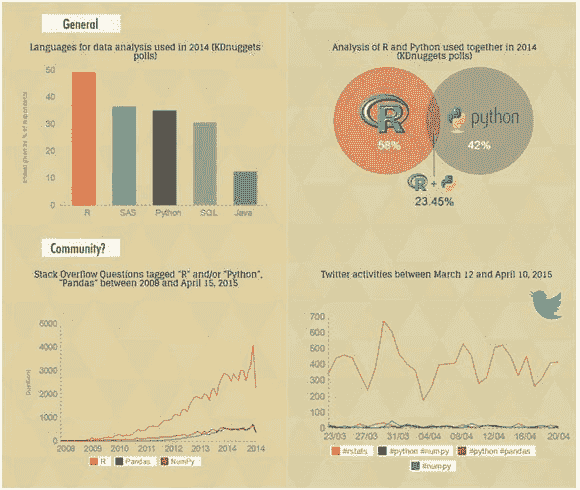
尽管上述数据如此,但有迹象表明更多人正在从 R 转向 Python。此外,还有一部分人群在适当的时候同时使用这两种语言。这正符合我们对学生的建议。
如果你计划开始数据科学的职业生涯,两种语言都很重要。就业趋势显示对这两种技能的需求增加,薪资远高于平均水平。
R:优缺点
优点:一张图胜过千言万语
可视化数据通常比单纯的原始数字更易于理解和有效。R 和可视化是完美的组合。一些必看的可视化包包括 ggplot2、ggvis、googleVis 和 rCharts。
优点:R 生态系统
R 拥有丰富的前沿包和活跃的社区。包可在 CRAN、BioConductor 和 Github 上获得。你可以在 Rdocumentation 上搜索所有 R 包。
优点:R 是数据科学的通用语言
R 是由统计学家为统计学家开发的。他们可以通过 R 代码和包传达思想和概念,你不一定需要计算机科学背景就能入门。此外,它在学术界之外的采纳率也在增加。
优缺点:R 较慢
R 的开发目的是为了让统计学家的工作更轻松,而不是为了让你的计算机更轻松。尽管 R 由于代码编写不佳可能被认为较慢,但有多个包可以提高 R 的性能:pqR、renjin 和 FastR、Riposte 等。
缺点:R 的学习曲线陡峭
R 的学习曲线并不简单,特别是如果你习惯于图形用户界面进行统计分析的话。如果不熟悉,寻找包也可能会非常耗时。
Python:优缺点
优点:IPython Notebook
IPython Notebook 使得使用 Python 和数据变得更容易。你可以轻松地与同事共享笔记本,而不需要他们安装任何东西。这大大减少了组织代码、输出和笔记文件的开销,让你有更多时间进行实际工作。
优点:通用语言
Python 是一种通用语言,易于学习且直观。这使得其学习曲线相对平缓,加快了编写程序的速度。简而言之,你需要更少的编码时间,有更多时间来玩耍!
此外,Python 测试框架是一个内置的、入门门槛低的测试框架,鼓励良好的测试覆盖率。这确保了你的代码是可重用和可靠的。
优点:多用途语言
Python 把背景各异的人们聚集在一起。作为一种通用、易于理解的语言,程序员都知道,统计学家也能轻松学习,你可以构建一个与工作流每个部分都集成的工具。
优缺点:可视化
可视化在选择数据分析软件时是一个重要标准。尽管 Python 有一些不错的可视化库,如 Seaborn、Bokeh 和 Pygal,但可能选择过多。此外,与 R 相比,可视化通常更复杂,结果也不总是那么令人满意。
缺点:Python 是一个挑战者
Python 是 R 的挑战者。它没有提供数百个必要的 R 包的替代品。虽然它在追赶,但是否会让人们放弃 R 仍然不明确。
最终赢家是..
由你决定!作为数据科学家,你的工作是选择最适合需求的语言。一些可以帮助你的问题:
1. 你想解决哪些问题?
-
学习一门语言的实际成本是多少?
-
在你的领域中,常用的工具有哪些?
-
还有其他可用的工具吗?这些工具与常用工具有何关系?
希望这对你有帮助!
关于 DataCamp
DataCamp 是一个在线互动教育平台,提供数据科学和 R 编程课程。每门课程围绕特定的数据科学主题构建,并结合视频讲解和浏览器内编码挑战,让你通过实践学习。你可以随时随地免费开始每门课程。
相关:
-
R 领先 RapidMiner,Python 迎头赶上,大数据工具增长,Spark 点燃
-
数据科学的语法:Python 与 R
-
顶级 KDnuggets 推文,4 月 2-5 日:数据科学生态系统:数据整理的实用工具和技巧
更多相关话题
-
数据科学、数据可视化及…的 38 个顶级 Python 库********
R 与 Python 数据可视化
原文:
www.kdnuggets.com/2019/03/r-vs-python-data-visualization.html
评论 ggplot2 vs seaborn
ggplot2 vs seaborn
R 和 Python 使我们能够生成复杂且吸引人的统计图形,以便获得见解和探索数据。两者都能处理数百万的数据点(可能取决于平台,甚至数十亿)。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
使用 Python 可视化数据
Seaborn 建立在 Matplotlib 之上,语法和结构相对简单。
首先,我们使用 import seaborn as sns; sns.set() 加载并设置 seaborn 主题默认值到 Python 会话中。由于两个库是一起使用的,Matplotlib 也必须加载。
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
-
sns.set_style()设置图表的背景主题。"ticks" 是最接近 R 中制作的图表的样式。 -
sns.set_context()将应用预定义的格式以适应可视化的用途或背景。font_scale=1用于设置图表中所有文本的字体大小比例。 -
plt.figure()是一个命令,用于控制 matpltlib 图形的不同方面(如前所述,seaborn 图形实际上是 Matplotlib 图形)。 -
sns.scatterplot()是用于传递参数以创建 seaborn 风格散点图的命令。
-
x="wt"将重量映射到 x 轴。 -
y="hp"将马力映射到 y 轴。 -
hue="cyl"将填充和着色散点。 -
palette=['red','green','blue']手动覆盖hue设置的颜色调色板,将其改为红色、绿色和蓝色。 -
data="mtcars"允许我们使用数据集中的数据。 -
style='cyl'为每个气缸类别分配形状。 -
legend='brief'将分配hue和size。
sizes=(800,1000)
控制图表上散点的最小和最大大小。
-
plt.title()为图表设置主标题。如果你是经验丰富的 Matplotlib 用户,或者之前使用过 plt.suptitle(),你会知道同时使用这两个函数时的困惑。 参数很明显。 -
plt.xlabel()将格式化 x 轴标签。我使用set_..访问类来包含美学属性。这有时可能会显得杂乱,但有许多方法可以格式化 seaborn/matplotlib 图形。这在图形创建后非常有用。图形已经用sns.scatterplot创建,因此我们需要以这种方式覆盖默认格式。 -
plt.ylabel()的工作方式与 x 轴完全相同,只是针对 y 轴。
#sns.set_style("darkgrid")
sns.set_style("ticks")
sns.set_context("talk")
#sns.set_context("notebook", font_scale=1)
plt.figure(figsize=(10,8)) #plt.figure(figsize=(width,height))
sns.scatterplot(x="wt", y="hp", hue='cyl', palette=['red','green','blue'],
data=mtcars, style='cyl', legend='brief', sizes=(800,1000)
)
plt.title('Motor Trend Car Road Tests of 1973-74 Models', fontsize=24, fontweight='bold')
plt.xlabel("Weigt (1000lbs)").set_fontsize('22')
plt.xlabel("Weigt (1000lbs)").set_fontweight("bold")
plt.ylabel("Gross Horsepower").set_fontsize('22')
plt.ylabel("Gross Horsepower").set_fontweight("bold");
 Seaborn:mtcars 散点图
Seaborn:mtcars 散点图
正如我们所见,该图形与 ggplot2 创建的图形非常相似。对于对这个图进行分面处理,Seaborn 是 Matplotlib 的一个更简单的替代方案。
在 Seaborn 中进行分面处理需要创建一个新图形。有多种方法可以实现,sns.relplot() 就是其中之一。
-
sns.set()将默认的 Seaborn 主题设置到 Python 环境中,也可以用于覆盖默认参数,如rc={'figure.figsize':(20,20)}。 -
sns.relplot()具有许多与上述讨论相同的参数,这里我们将讨论针对分面处理的新参数。
-
col="gear"指定了在 mtcars 数据集中用于分面化的列。 -
col_wrap=3指定了图形的排列方式。在这种情况下,图形将被放置在 3 列中。由于没有指定行数,所以它将位于一行中,但如果需要,可以指定行数。 -
aspect=0.6是控制图形大小的参数。我建议阅读相关文档,因为这个部分的解释可能会变得复杂。
g.fig.suptitle()为图形创建标题。
position=(0.5,1.05)是一个有趣的参数,因为它控制标题的位置。即使是小的变化也能显著改变标题的位置。
g.set_xlabels和g.set_ylabels将按之前讨论的方式工作。
sns.set(rc={'figure.figsize':(20,20)})
sns.set_style("ticks")
sns.set_context("talk")
g = sns.relplot(x="wt", y="hp", hue='cyl', palette=['red','green','blue'],
data=mtcars, col='gear', col_wrap=3,
height=6, aspect=0.6, style='cyl', sizes=(800,1000))
g.fig.suptitle('Motor Trend Car Road Tests of 1973-74 Models' ,position=(0.5,1.05), fontweight='bold', size=18)
g.set_xlabels("Weigt (1000lbs)",fontweight='bold', size=20)
g.set_ylabels("Gross Horsepower",fontweight='bold', size=20);
 Seaborn:mtcars 分面散点图
Seaborn:mtcars 分面散点图
在 R 中可视化数据
使用 ggplot2,我们可以通过向图形添加美学层来创建简单且可自定义的图形。对新用户来说,一个很棒的功能是,除了加载数据和指定几何形状外,美学层(大部分情况下)可以按照任何顺序添加。这是因为 ggplot2 建立在图形语法的原则之上。这些原则使我们能够创建引人注目且信息丰富的可视化。
以下 R 代码将加载 ggplot2 包(可能是 R 中最突出的可视化包),并为我们生成一个散点图。
-
ggplot(mtcars, aes(x=wt, y=hp))将加载 mtcars 数据集以供 ggplot2 使用,aes(x=wt, y=hp)将为我们的图形映射美学,其中 x 美学表示 x 轴的重量,y 美学表示 y 轴的马力。 -
geom_point(size=1,aes(color=cyl, shape=cyl, fill=cyl))将生成具有之前定义的美学属性和新的美学属性的散点图。color=cyl将根据气缸数为散点的轮廓赋予独特的颜色。shape=cyl将为散点赋予独特的形状,并与color一起工作。fill=cyl将填充散点的颜色,而不仅仅是轮廓。最好将color和fill一起使用(如果你仔细查看,会发现有一个细微的美学差异)。 -
theme_bw()提供了 ggplot2 中的一个预制主题,我们可以用来开始。然后可以使用正确的命令轻松调整。ggplot2 的语法简单易学,这使得调整变得容易。 -
theme()是允许你更改在第 3 点中设置的任何主题的默认设置的命令(你也可以用它来更改图表的其他美学属性)。-
axis.text=element_text(face='bold', size=7格式化了 y 轴和 x 轴的文本(轴上的数字)。face='bold'将加粗文本,而size="7"将其大小增加到指定的值。 -
axis.title=element_text(face='bold', size=10)与上述命令类似,但仅适用于轴标题。 -
axis.ticks=element_line(size=0.5)将使图表上的刻度线更加明显。 -
panel.background=element_rect(colour = NA)是我决定添加的一个美学措施,它去掉了包围图表的矩形边框。 -
plot.title=element_text(face='bold', size=11,hjust = 0.5))仅仅是加粗并更改主标题的大小。***hjust=0.5***将 使标题居中对齐。 -
scale_color_manual(breaks = c("4", "6", "8"), values=c("red", "green", "blue"))将覆盖默认的颜色方案,并将红色添加到 '4',绿色添加到 '6',蓝色添加到 '8'。这会手动覆盖散点的轮廓颜色。 -
scale_fill_manual(breaks = c("4", "6", "8"), values=c("red", "green", "blue"))将对散点的内部进行与上述相同的操作。 -
scale_y_continuous(breaks = seq(0,350,50))手动覆盖 y 轴上的数字,使其从零开始,到 350 结束,单位增量为 50。这将显示在主要刻度上。 -
scale_x_continuous(breaks = seq(1.5,5.5,0.5), minor_breaks=seq(1.5,5.5,1))对 x 轴做了与上述相同的操作,并手动覆盖了次要刻度,但这不会那么明显。 -
scale_shape_manual(values=c(21,4,22))将定义每个气缸类别的形状类型。
-
-
options(repr.plot.width=4, repr.plot.height=3)是一个方便的命令,当你想要调整图形的宽度和高度时特别有用。它在 Jupyter 中尤其实用。
library(ggplot2)
options(repr.plot.width=4, repr.plot.height=3)
p <- ggplot(mtcars, aes(x=wt, y=hp)) +
geom_point(size=1,aes(color=cyl, shape=cyl, fill=cyl)) +
labs(title='Motor Trend Car Road Tests of 1973-74 Models') +
xlab("Weigt (1000lbs)") +
ylab("Gross Horsepower") +
theme_bw() +
theme(axis.text=element_text(face='bold',
size=7),
axis.title=element_text(face='bold',
size=10),
axis.ticks=element_line(size=0.5),
panel.background=element_rect(colour = NA),
plot.title=element_text(face='bold', size=11,hjust = 0.5)) +
scale_color_manual(breaks = c("4", "6", "8"), values=c("red", "green", "blue"))+
scale_fill_manual(breaks = c("4", "6", "8"), values=c("red", "green", "blue"))+
scale_y_continuous(breaks = seq(0,350,50)) +
scale_x_continuous(breaks = seq(1.5,5.5,0.5), minor_breaks=seq(1.5,5.5,1)) +
scale_shape_manual(values=c(21,4,22))
p
ggplot: mtcars 散点图
ggplot2 的另一个优点是其 能够在一行代码中对数据进行分面,创建多个图表。
facet_grid(~gear)将按齿轮数量细分数据,并创建多个具有相同主题美学的相同图形。
options(repr.plot.width=7, repr.plot.height=4)
p + facet_grid(~gear)
ggplot: mtcars 分面散点图
结论
我认为主要的区别之一是,Seaborn 绘图的默认分辨率优于 ggplot2 图形,所需的语法也可能少得多(但这取决于具体情况)。Seaborn 使用编程方法,用户可以访问 Seaborn 和 Matplotlib 中的类来操作图形。ggplot2 使用分层方法,用户可以以任意顺序添加美学和格式来创建图形(尽管所需的代码量更多,我认为这种方法可能更简单)。大多数人不会注意到这一点,而这对某些人可能比其他人更为重要,Python 图形在保存为图像时占用的磁盘空间显著大于 R 生成的图形。在本文中的图形中,Seaborn/Matplotlib 图形占用的磁盘空间约为 ggplot2 图形的 6 倍。
尽管有些细微的差别,但使用 Seaborn 和 ggplot2 重新创建相同的图形是非常可能的。虽然工具不同,但仍然可以用它们创建相同的对象。
相关:
-
Python 图形画廊
-
五大最佳数据可视化库
-
数据可视化备忘单
评论
更多相关话题
RAG 与微调:哪个是提升您的 LLM 应用的最佳工具?
原文:
www.kdnuggets.com/rag-vs-finetuning-which-is-the-best-tool-to-boost-your-llm-application

图片由作者提供
前言
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT
随着对大型语言模型(LLMs)的兴趣激增,许多开发者和组织忙于构建利用其强大功能的应用程序。然而,当现成的预训练 LLM 的表现未达到预期时,如何提升 LLM 应用的性能成为一个问题。最终我们会问自己:我们应该使用检索增强生成(RAG)还是模型微调来改善结果?
在深入探讨之前,让我们解开这两种方法的神秘面纱:
RAG:这种方法将检索(或搜索)的力量整合到 LLM 文本生成中。它结合了一个检索系统,从大型语料库中提取相关文档片段,以及一个 LLM,利用这些片段中的信息生成回答。实质上,RAG 帮助模型“查找”外部信息以改善其回应。

图片由作者提供
微调:这是在较小的特定数据集上进一步训练预训练 LLM 的过程,以使其适应特定任务或提升其性能。通过微调,我们根据我们的数据调整模型的权重,使其更加符合我们应用的独特需求。

图片由作者提供
RAG 和微调都作为增强基于 LLM 的应用性能的强大工具,但它们关注优化过程中的不同方面,这在选择使用哪一种工具时至关重要。
以前,我通常会建议组织在深入微调之前先尝试 RAG。这是基于我认为这两种方法实现了类似的结果,但在复杂性、成本和质量上有所不同。我甚至用这样的图示来说明这一点:

图片由作者提供
在这个图中,复杂性、成本和质量等各种因素沿着一个维度表示。要点是?RAG 更简单且成本更低,但其质量可能无法匹配。我的建议通常是:从 RAG 开始,评估其性能,如果表现不佳,再转向微调。
然而,我的观点已经发生了变化。我认为将 RAG 和微调视为实现相同结果的两种技术,只不过一种比另一种更便宜、更简单,是一种过于简化的看法。它们在本质上是不同的——它们实际上是正交的,而不是共线的——并且服务于 LLM 应用的不同需求。
为了更清楚地说明这一点,可以考虑一个简单的现实世界类比:当被问到“我应该用刀子还是勺子来吃饭?”时,最合逻辑的反问是:“你在吃什么?”我问过朋友和家人这个问题,每个人都本能地用那个反问来回答,表明他们并不认为刀子和勺子是可以互换的,或者其中一个是另一个的劣等变体。
这到底是关于什么的?
在这篇博客文章中,我们将深入探讨在各个维度上区分 RAG 和微调的细微差别,这些维度在我看来对确定特定任务的最佳技术至关重要。此外,我们还会查看一些最受欢迎的 LLM 应用案例,并利用第一部分中建立的维度来识别哪种技术可能最适合哪个用例。在博客的最后部分,我们将识别在构建 LLM 应用时应考虑的额外方面。每一个方面可能都值得单独写一篇博客,因此在这篇文章中我们只能简要提及它们。
为什么你需要关心这些?
选择正确的技术来调整大型语言模型对 NLP 应用的成功有重大影响。选择错误的方法可能会导致:
-
在特定任务上的模型性能差,导致输出不准确。
-
如果技术未针对您的用例进行优化,模型训练和推理的计算成本会增加。
-
如果之后需要转向不同的技术,会增加额外的开发和迭代时间。
-
部署应用程序和将其展示给用户的延迟。
-
如果选择了过于复杂的适应方法,可能缺乏模型可解释性。
-
由于大小或计算限制,部署模型到生产环境中的困难。
RAG 和微调之间的细微差别涵盖了模型架构、数据需求、计算复杂性等方面。忽视这些细节可能会影响项目的时间线和预算。
本博客文章旨在通过清晰地阐述每种技术何时具有优势来防止浪费精力。通过这些见解,你可以从第一天开始就用正确的适配方法取得进展。详细的比较将使你能够做出最佳技术选择,实现业务和 AI 目标。本指南将帮助你选择合适的工具,为你的项目成功奠定基础。
那么,让我们深入探讨吧!
提升性能的关键考虑因素
在选择 RAG 还是微调之前,我们应该根据一些维度评估 LLM 项目的要求,并问自己几个问题。
我们的用例是否需要访问外部数据源?
在选择微调 LLM 还是使用 RAG 时,一个关键考虑因素是应用是否需要访问外部数据源。如果答案是肯定的,RAG 可能是更好的选择。
RAG 系统本质上设计用于通过在生成响应前从知识源中检索相关信息来增强 LLM 的能力。这使得这种技术非常适合需要查询数据库、文档或其他结构化/非结构化数据存储的应用。检索器和生成器组件可以被优化以利用这些外部资源。
相比之下,虽然可以通过微调 LLM 来学习一些外部知识,但这样做需要大量来自目标领域的标注数据集。这个数据集必须随着基础数据的变化而更新,这使得它在频繁变化的数据源中不切实际。微调过程也没有明确建模在查询外部知识时涉及的检索和推理步骤。
总结来说,如果我们的应用需要利用外部数据源,那么使用 RAG 系统通常比仅通过微调“嵌入”所需知识更有效且可扩展。
我们是否需要修改模型的行为、写作风格或领域特定知识?
另一个非常重要的方面是我们需要模型调整其行为、写作风格或为领域特定应用定制响应的程度。
微调在于能够将 LLM 的行为适应特定的细微差别、语调或术语。如果我们希望模型听起来更像医疗专业人士,采用诗意风格,或使用特定行业的术语,微调领域特定数据可以实现这些定制。影响模型行为的能力对于需要与特定风格或领域专业知识一致的应用至关重要。
RAG 虽然在融入外部知识方面非常强大,但主要关注于信息检索,并不会根据检索到的信息固有地调整其语言风格或领域特异性。它会从外部数据源中提取相关内容,但可能不会表现出微调模型所能提供的量身定制的细微差别或领域专业知识。
所以,如果我们的应用程序需要专业的写作风格或与特定领域的术语和惯例深度对齐,微调提供了更直接的途径来实现这种对齐。它提供了必要的深度和定制,以真正与特定受众或专业领域产生共鸣,确保生成的内容感觉真实且信息丰富。
快速回顾
在决定使用哪种方法来提升 LLM 应用性能时,这两个方面是迄今为止最重要的方面。有趣的是,在我看来,它们是正交的,可以独立使用(也可以结合使用)。
作者提供的图片
然而,在深入使用案例之前,我们应该考虑一些关键方面:
抑制幻觉的重要性有多大?
LLM 的一个缺点是它们容易产生幻觉——编造没有现实依据的事实或细节。这在准确性和真实性至关重要的应用中可能会非常成问题。
微调可以通过将模型固定在特定领域的训练数据中来帮助减少幻觉。然而,当面临不熟悉的输入时,模型仍可能会编造回应。需要在新数据上重新训练,以持续最小化虚假的编造。
相比之下,RAG 系统天生更不容易产生幻觉,因为它们将每个响应基于检索到的证据。检索器在生成器构造答案之前会从外部知识源中识别相关事实。这个检索步骤充当了事实检查机制,减少了模型的编造能力。生成器被限制在检索到的上下文支持的回应中合成答案。
因此,在抑制虚假和虚构内容至关重要的应用中,RAG 系统提供了内置的机制来最小化幻觉。响应生成之前的证据检索使 RAG 在确保事实准确和真实输出方面具有优势。
有多少标注的训练数据可用?
在 RAG 和微调之间做出决定时,一个关键因素是我们手头拥有的领域或任务特定的标注训练数据的量。
对 LLM 进行微调以适应特定任务或领域,严重依赖于可用标记数据的质量和数量。丰富的数据集可以帮助模型深入理解特定领域的细微差别、复杂性和独特模式,从而生成更准确和上下文相关的响应。然而,如果我们处理的是有限的数据集,微调带来的改进可能会很有限。在某些情况下,稀缺的数据集甚至可能导致过拟合,即模型在训练数据上表现良好,但在未见或现实世界输入中表现不佳。
相反,RAG 系统独立于训练数据,因为它们利用外部知识源来检索相关信息。即使我们没有一个广泛的标记数据集,RAG 系统仍能通过访问和整合其外部数据源的见解而表现出色。检索和生成的结合确保了系统在特定领域训练数据稀缺时仍保持知情。
从本质上讲,如果我们拥有捕捉领域复杂性的丰富标记数据,微调可以提供更量身定制和精细化的模型行为。但在这种数据有限的情况下,RAG 系统提供了一个稳健的替代方案,通过其检索能力确保应用保持数据驱动和上下文敏感。
数据的静态/动态特性如何?
选择 RAG 和微调之间的另一个基本方面是数据的动态特性。数据更新的频率如何?模型保持最新状态有多重要?
对特定数据集进行 LLM 微调意味着模型的知识在训练时成为该数据的静态快照。如果数据经常更新、变化或扩展,这可能很快使模型过时。为了在这种动态环境中保持 LLM 的最新状态,我们必须频繁地对其进行再训练,这一过程既耗时又资源密集。此外,每次迭代都需要仔细监控,以确保更新后的模型在不同场景下仍表现良好,并且没有产生新的偏见或理解上的缺口。
相比之下,RAG 系统在动态数据环境中固有的优势。它们的检索机制不断查询外部来源,确保用于生成响应的信息是最新的。随着外部知识库或数据库的更新,RAG 系统无缝地整合这些变化,保持其相关性,而无需频繁的模型再训练。
总结来说,如果我们面对的是快速变化的数据环境,RAG 提供了传统微调难以匹敌的灵活性。通过始终保持与最新数据的连接,RAG 确保生成的响应与当前信息状态保持一致,使其成为动态数据场景的理想选择。
我们的 LLM 应用需要多大的透明度/可解释性?
最后一个需要考虑的方面是我们需要多少关于模型决策过程的洞察。
虽然微调 LLM 非常强大,但它的操作类似于黑箱,使得其响应背后的推理变得更加不透明。随着模型从数据集中内化信息,识别每个响应的确切来源或推理变得困难。这可能使开发者或用户难以信任模型的输出,特别是在需要理解回答“为什么”的关键应用中。
另一方面,RAG 系统提供了一种通常在单纯的微调模型中找不到的透明度。由于 RAG 的两步特性——检索和生成——用户可以窥见这一过程。检索组件允许检查哪些外部文档或数据点被选为相关内容。这提供了可以评估的实质证据或参考,以理解响应构建的基础。在需要高度问责或验证生成内容准确性的应用中,追溯模型答案到特定数据源的能力是无价的。
本质上,如果透明度和解释模型响应基础的能力是优先考虑的,RAG 提供了明确的优势。通过将响应生成分解为不同阶段并允许对数据检索的深入了解,RAG 促进了对其输出的更大信任和理解。
总结
在考虑这些维度时,选择 RAG 和微调变得更为直观。如果我们需要依赖外部知识并重视透明度,RAG 是我们的首选。另一方面,如果我们处理的是稳定的标注数据并希望将模型更紧密地调整到特定需求,微调是更好的选择。

图片来源:作者
在接下来的部分,我们将看到如何根据这些标准评估流行的 LLM 使用案例。
使用案例
我们来看一些流行的使用案例以及上述框架如何帮助选择合适的方法:
总结(在专业领域和/或特定风格中)
1. 是否需要外部知识? 对于以往总结风格的任务,主要的数据来源是以往的总结。如果这些总结包含在一个静态数据集中,则无需持续检索外部数据。然而,如果有一个经常更新的动态总结数据库,并且目标是不断将风格与最新条目对齐,那么 RAG 可能会在这里发挥作用。
2. 需要模型适应吗? 这个用例的核心围绕适应专业领域或特定写作风格。微调特别擅长捕捉风格细节、语气变化和特定领域的词汇,使其成为这个维度的最佳选择。
3. 是否关键要最小化幻觉? 幻觉在大多数 LLM 应用中都是问题,包括总结。然而,在这个用例中,被总结的文本通常作为背景提供。这使得幻觉相较于其他用例的关注度较低。源文本限制了模型,减少了虚构。因此,虽然事实准确性总是重要的,但在有背景限制的情况下,抑制幻觉的优先级较低。
4. 有可用的训练数据吗? 如果有大量的标记或结构化的先前总结,模型可以从中学习,那么微调会变得非常有吸引力。另一方面,如果数据集有限,并且我们依赖外部数据库来进行风格对齐,RAG 可能会发挥作用,尽管它的主要优势不在于风格适应。
5. 数据有多动态? 如果先前总结的数据库是静态的或更新不频繁,微调模型的知识可能会保持较长时间的相关性。然而,如果总结频繁更新并且需要模型不断对齐最新的风格变化,RAG 可能具有优势,因为其动态数据检索能力。
6. 需要透明性/可解释性吗? 主要目标是风格对齐,因此对特定总结风格的“为什么”可能没有其他用例那样关键。不过,如果需要追溯并了解哪些先前总结影响了特定输出,RAG 提供了更多的透明性。尽管如此,这对这个用例来说可能是一个次要关注点。
推荐: 对于这个用例,微调 似乎是更合适的选择。主要目标是风格对齐,而微调在这一点上表现突出。假设有足够的先前总结可用于训练,微调 LLM 将允许深入适应所需风格,捕捉领域的细微差别和复杂性。然而,如果总结数据库极其动态且追溯影响有价值,可以考虑混合方法或倾向于 RAG。
组织知识的问答系统(即外部数据)
1. 需要外部知识? 依赖于组织知识库的问题/回答系统本质上需要访问外部数据,在这种情况下,是组织的内部数据库和文档存储。系统的有效性取决于它从这些来源中提取和检索相关信息以回答查询的能力。因此,RAG 在这个维度上更为适合,因为它设计用来通过从知识源中检索相关数据来增强大模型的能力。
2. 是否需要模型适配? 根据组织及其领域,可能需要模型符合特定的术语、语气或惯例。虽然 RAG 主要关注信息检索,微调可以帮助大模型调整其回答以适应公司的内部术语或其领域的细微差别。因此,根据具体要求,微调可能在这个维度上发挥作用。
3. 关键在于最小化虚假信息? 虚假信息在这个应用场景中是一个主要问题,因为大模型的知识截止日期。如果模型无法基于其训练的数据回答问题,它几乎肯定会回退到(部分或完全)编造一个看似合理但不正确的答案。
4. 是否有可用的训练数据? 如果组织有一个结构化且标记好的之前回答过的问题的数据集,这可以增强微调的方法。然而,并非所有内部数据库都被标记或结构化以用于训练。在数据没有被整齐标记或主要关注准确和相关答案的情况下,RAG 能够从外部数据源中提取数据而不需要大量标记数据集,这使其成为一个有吸引力的选择。
5. 数据的动态性如何? 组织内部的数据库和文档存储可能非常动态,具有频繁的更新、变化或添加。如果这种动态性是组织知识库的特征,RAG 提供了独特的优势。它不断查询外部来源,确保其答案基于最新的数据。微调则需要定期重新训练以跟上这些变化,这可能是不切实际的。
6. 需要透明度/可解释性? 对于内部应用,特别是在金融、医疗或法律等领域,理解答案背后的推理或来源可能至关重要。由于 RAG 提供了检索和生成的两步过程,它本质上提供了对哪些文档或数据点影响了特定答案的更清晰的洞察。这种可追溯性对于需要验证或进一步调查某些答案来源的内部利益相关者非常宝贵。
推荐: 对于这种使用场景,RAG 系统 似乎是更合适的选择。考虑到需要动态访问组织不断变化的内部数据库,以及可能需要在回答过程中的透明度,RAG 提供的功能与这些需求非常契合。然而,如果特别强调模型语言风格的定制或适应特定领域的细微差别,可以考虑引入微调元素。
客户支持自动化(即提供即时响应的自动聊天机器人或帮助台解决方案)
1. 是否需要外部知识? 客户支持通常需要访问外部数据,特别是在处理产品详情、账户特定信息或故障排除数据库时。虽然许多查询可以通过一般知识解决,但有些可能需要从公司数据库或产品常见问题中提取数据。在这里,RAG 从外部来源检索相关信息的能力将非常有益。然而,值得注意的是,许多客户支持互动也基于预定义的脚本或知识,这些可以通过微调模型有效处理。
2. 需要模型适应吗? 客户互动需要特定的语气、礼貌和清晰度,并且可能需要公司特定的术语。微调对于确保大型语言模型(LLM)适应公司的声音、品牌和特定术语尤其有用,从而确保一致且符合品牌的客户体验。
3. 是否关键于最小化虚假信息? 对于客户支持聊天机器人,避免虚假信息对保持用户信任至关重要。单靠微调会让模型在面对不熟悉的查询时容易产生虚假信息。相比之下,RAG 系统通过将回应基于检索到的证据来抑制虚假信息。这种对来源事实的依赖使得 RAG 聊天机器人能够最小化有害的虚假信息,并在准确性至关重要的地方提供可靠的信息。
4. 是否有培训数据? 如果公司有客户互动的历史记录,这些数据对微调来说非常宝贵。丰富的历史客户查询及其解决方案数据可以用来训练模型,以处理未来类似的互动。如果这样的数据有限,RAG 可以通过从外部来源(如产品文档)检索答案提供备用方案。
5. 数据动态性如何? 客户支持可能需要处理有关新产品、更新的政策或变化的服务条款的查询。在产品线、软件版本或公司政策经常更新的情况下,RAG 从最新文档或数据库动态提取信息的能力是有利的。另一方面,对于更静态的知识领域,微调可能就足够了。
6. 需要透明度/可解释性吗? 虽然在某些领域透明度是必需的,但在客户支持中,主要关注点是准确、快速和礼貌的回应。然而,对于内部监控、质量保证或处理客户争议,关于答案来源的可追溯性可能会有帮助。在这种情况下,RAG 的检索机制提供了额外的透明度层。
推荐: 对于客户支持自动化,混合方法可能是最优的。微调可以确保聊天机器人与公司的品牌、语调和一般知识一致,处理大多数典型的客户查询。RAG 可以作为补充系统,处理更动态或特定的询问,确保聊天机器人可以从最新的公司文档或数据库中获取信息,从而减少幻觉。通过整合这两种方法,公司可以提供全面、及时且品牌一致的客户支持体验。
图片作者
额外需要考虑的方面
如上所述,在决定使用 RAG 还是微调(或两者结合)时,还应考虑其他因素。我们无法深入探讨这些因素,因为它们都是多方面的,并且不像上述某些方面那样有明确的答案(例如,如果没有训练数据,微调根本不可行)。但这并不意味着我们应该忽视它们:
可扩展性
随着组织的成长和需求的变化,所讨论的方法的可扩展性如何?由于 RAG 系统具有模块化的特点,它们可能提供更直接的可扩展性,特别是当知识库增长时。另一方面,频繁地调整模型以适应扩展的数据集可能会计算上较为繁重。
延迟和实时要求
如果应用程序需要实时或近实时的响应,请考虑每种方法引入的延迟。RAG 系统涉及在生成响应之前检索数据,可能会比基于内化知识生成响应的微调 LLM 引入更多的延迟。
维护和支持
考虑长期情况。哪个系统更符合组织提供一致维护和支持的能力?RAG 可能需要维护数据库和检索机制,而微调则需要持续的再训练工作,特别是当数据或需求变化时。
鲁棒性和可靠性
每种方法对不同类型输入的鲁棒性如何?虽然 RAG 系统可以从外部知识来源中提取信息,可能处理各种问题,但经过良好微调的模型在某些领域可能提供更一致的表现。
伦理和隐私问题
从外部数据库存储和检索数据可能引发隐私问题,特别是当数据敏感时。另一方面,虽然微调的模型不查询实时数据库,但仍可能基于其训练数据生成输出,这也可能具有伦理问题。
与现有系统的集成
组织可能已经具备某些基础设施。RAG 或微调与现有系统的兼容性——无论是数据库、云基础设施还是用户界面——都可能影响选择。
用户体验
考虑最终用户及其需求。如果他们需要详细的、以参考为基础的回答,RAG 可能更为合适。如果他们重视速度和领域特定的专业知识,微调模型可能更适合。
成本
微调可能会变得昂贵,特别是对于非常大的模型。但在过去几个月中,得益于如 QLoRA 等参数高效技术,成本已显著降低。设置 RAG 可能需要大量的初始投资——包括集成、数据库访问,甚至许可费用——但还需考虑到对外部知识库的常规维护。
复杂性
微调可能会迅速变得复杂。虽然现在许多供应商提供一键微调,我们只需要提供训练数据,但跟踪模型版本并确保新模型在各方面表现良好是具有挑战性的。另一方面,RAG 也可能迅速变得复杂。需要设置多个组件,确保数据库保持新鲜,并确保各个部分——如检索和生成——完美契合。
结论
正如我们所探讨的,选择 RAG 和微调之间需要对 LLM 应用的独特需求和优先级进行细致评估。没有一刀切的解决方案;成功在于将优化方法与任务的具体要求对齐。通过评估关键标准——对外部数据的需求、适应模型行为、训练数据的可用性、数据动态、结果透明度等——组织可以对最佳前进路径做出明智的决策。在某些情况下,利用 RAG 和微调的混合方法可能是最佳选择。
关键在于避免假设某种方法是普遍优越的。像任何工具一样,它们的适用性取决于具体的任务。方法和目标的错位会阻碍进展,而正确的方法则会加速进展。当组织评估提升 LLM 应用的选项时,必须抵制过度简化的倾向,不应将 RAG 和微调视为可互换的工具,而是选择能够使模型发挥其能力并与用例需求对齐的工具。这些方法所解锁的可能性令人惊叹,但仅有可能性是不够的——执行才是关键。工具已经在这里——现在让我们开始使用它们。
原文。已获许可转载。
Heiko Hotz**** 是 NLP London 的创始人,该公司是一家人工智能咨询公司,帮助组织实施自然语言处理和对话 AI。Heiko 拥有超过 15 年的技术行业经验,是利用 AI 和机器学习解决复杂商业挑战的专家。
相关话题
随机森林算法是否需要归一化?
原文:
www.kdnuggets.com/2022/07/random-forest-algorithm-need-normalization.html

Irina Iriser 通过 Unsplash
我要从一些定义开始,以更好地理解这篇博客。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
随机森林是一个基于树的算法,由多个决策树组成,以改善决策。它被称为随机森林,因为它是一个使用袋装和特征随机性的树的森林。这些多棵树结合在一起进行预测。
归一化是一种在机器学习的数据准备阶段进行的技术。它是通过创建新值并展示数据,使其具有一般分布的过程。这是一种缩放技术,其中值被重新缩放到 0 和 1 之间——这也被称为 Min-Max 缩放。这是为了减少或完全去除冗余数据和数据错误。
我如何归一化我的数据?
你可以使用 sklearn 库通过导入 MinMaxScaler 来归一化你的数据
# data normalization with sklearn
from sklearn.preprocessing import MinMaxScaler
# fit scaler on your training data
norm = MinMaxScaler().fit(X_train)
# transform your training data
X_train_norm = norm.transform(X_train)
# transform testing database
X_test_norm = norm.transform(X_test)
如果你在谷歌上搜索标题中的问题,大多数人会说‘不需要’。原因如下...
为什么随机森林算法不需要归一化数据?
通过归一化来缩放数据的过程是为了确保某个特征不会优先于另一个特征。这种技术在基于距离的算法中尤其重要,例如 K 最近邻和 K-means,因为它们需要欧几里得距离。
然而,随机森林算法不是基于距离的模型——它是基于树的模型。随机森林中的每个节点不是比较特征值,而是简单地拆分一个需要绝对值的排序列表以进行分支。该算法基于数据分区来进行预测,因此不需要归一化。
例如,决策树在特征上拆分节点,而该特征不会被另一个特征影响,也不会影响另一个特征。这意味着所有剩余特征对拆分没有影响——所以我们可以说基于树的算法对特征的缩放不敏感。
基尼指数
随机森林算法通过基尼指数进一步理解特征的重要性,而不是缩放特征。基尼不纯度也被称为基尼 impurity,决定了决策树、随机森林或其他基于树的模型的分裂效果。
公式:
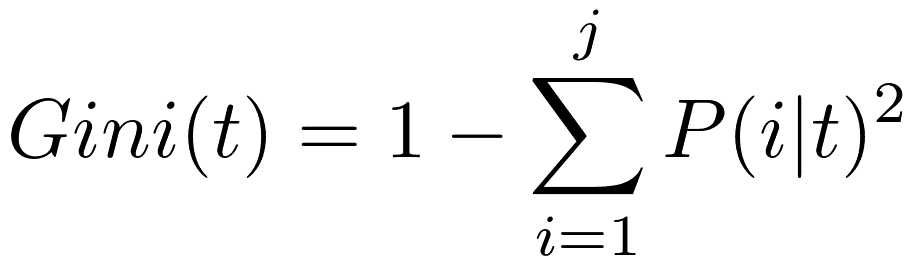
它计算了一个特定特征在随机选择时被错误分类的概率。基尼 impurity 的范围在 0 到 0.5 之间,其中最小值 0 是最佳值(分类是纯的),0.5 是我们能得到的最差值。
熵
熵是数据点中不纯或随机性的度量。在使用机器学习算法时,你的主要目标应是减少不确定性和随机性。

熵的范围从 0 到 1,其中最小值 0 是最佳值(纯度),1 是最差值(高水平的不纯)。
结论
当你的数据需要被缩放,且你选择的机器学习算法无法对数据的分布做出假设时,归一化是一个很好的技术。
基于树的模型并不依赖于特征间的距离关系。基尼指数和熵都用于计算信息增益,因此不需要归一化。
Nisha Arya 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程及理论知识,同时希望探索人工智能如何有利于人类寿命的延续。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
随机森林与决策树:关键区别
原文:
www.kdnuggets.com/2022/02/random-forest-decision-tree-key-differences.html

图片由 Todd Quackenbush 提供,来源于 Unsplash
算法对于执行任何动态计算机程序至关重要。算法的效率越高,执行速度越快。算法是基于我们已经知道的数学方法开发的。随机森林和决策树是用于分类和回归相关问题的算法。它们帮助处理大量数据,这些数据需要严格的算法来帮助做出更好的分析和决策。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
决策树
顾名思义,这种算法以树的结构构建模型,包括决策节点和叶节点。决策节点按两条或更多分支排序,而叶节点表示决策。决策树用于处理分类和连续数据。它是一个简单且有效的决策制定图。
如图所示,树是一种简单且方便的方式来可视化算法结果并理解决策的过程。决策树的主要优点在于它能够快速适应数据集。最终模型可以通过“树”图有序地查看和解释。相反,由于随机森林算法构建了许多独立的决策树并对这些预测取平均,因此它更不容易受到异常值的影响。
随机森林
此外,监督 机器学习算法 既适用于分类任务,也适用于回归任务。森林的超参数几乎与决策树相同。其决策树的集成方法是在随机划分的数据上生成的。整个集合是一个森林,其中每棵树都有一个不同的独立随机样本。
在随机森林算法的情况下,许多树可能使算法过于缓慢且在实时预测中效率低下。相比之下,结果是基于随机选择的观察值和构建在不同决策树上的特征生成的。
相反,由于随机森林仅使用少量预测变量来构建每棵决策树,最终的决策树往往会去相关,这意味着随机森林算法模型不太可能超越数据集。如前所述,决策树通常会覆盖训练数据——这意味着它们更容易匹配数据集中的“噪声”而不是实际的基础模型。

图片由 Arnaud Mesureur 提供,来源于 Unsplash
随机森林与决策树的区别
随机森林算法与决策树的关键区别在于,决策树是图形,用于通过分支方法展示决策的所有可能结果。相比之下,随机森林算法的输出是一组 决策树,这些决策树根据输出进行工作。
在现实世界中,机器学习工程师和数据科学家通常使用随机森林算法,因为它们非常准确,而且现代计算机和系统通常能够处理以前无法处理的大型数据集。
随机森林算法的缺点在于你无法可视化最终模型,如果处理能力不足或数据集非常庞大,它们可能需要很长时间来创建。
简单决策树的好处在于模型易于解释。当我们构建决策树时,我们知道使用哪个变量以及该变量的哪个值来拆分数据,从而快速预测结果。另一方面,随机森林算法模型更为复杂,因为它们是决策树的组合。在构建随机森林算法模型时,我们需要定义要生成多少棵树以及每个节点所需的变量数量。
一般来说,更多的树木会提高性能并使预测更稳定,但也会降低计算速度。对于回归问题,所有树木的平均值作为最终结果。随机森林算法回归模型有两个层次的均值:首先是树中目标单元的样本,然后是所有树。与线性回归不同,它使用现有观察来估计观察范围之外的值。
更准确的预测需要更多的树,这会导致模型变慢。如果有一种方法可以通过平均它们的解决方案来生成多个树,你可能会得到一个非常接近真实答案的结果。在这篇文章中,我们看到了随机森林算法与决策树之间的区别,决策树是一个使用分支方法的图结构,提供所有可能的结果。相比之下,随机森林算法将决策树从所有决策中合并,依赖于结果。决策树的主要优点是能够快速适应数据集,最终模型可以按顺序查看和解释。
让我们将各个事实对比,以便更好地理解每种模型的功能和优势。
| 决策树 | 随机森林 |
|---|---|
| 决策树是一个类似树的模型,展示了沿着决策路径的可能结果。 | 一种分类算法,由多个决策树结合以获得比单个树更准确的结果。 |
| 总是存在过拟合的可能性,这是由于方差的存在。 | 随机森林算法通过使用多个树来避免和防止过拟合。 |
| 结果不准确。 | 这提供准确且精确的结果。 |
| 决策树计算量低,从而减少了实现时间并且准确性较低。 | 这需要更多的计算。生成和分析过程耗时。 |
| 它容易可视化。唯一的任务是拟合决策树模型。 | 这具有复杂的可视化,因为它确定数据背后的模式。 |
数据处理
在决策树中,任何问题陈述的根本原因被表示为根节点。它包含一系列表示多个决策的决策节点。从决策节点出发,叶节点显示这些决策的影响。这些节点进一步分支以获得更好的信息,并将继续分支,直到所有节点具有相似的一致数据。
随机森林算法基于多个决策树的集体结果。有些可能无法提供正确的输出,但通过合并所有树,集体结果可以准确并用于进一步的阶段。
复杂性
根据回归和分类类型,决策树生成一系列决策,用于推断特定结果。虽然简单易懂,但拆分数据和预测输出的过程较快。另一方面,随机森林算法在每个节点直接增加模型复杂性的多个阶段中定义树和其他关键变量。
过拟合
在实施时,这两种算法都可能暴露于过拟合,导致在训练数据时出现瓶颈情况。对新数据模型的影响表明,当数据集未通过验证标准时,性能会受到负面影响。在这种情况下,决策树更容易过拟合。相反,随机森林算法通过多个树可以减少这种风险。
参考文献
随机森林算法和决策树的区别 是关键的,并且依赖于问题陈述。当涉及到多种特征数据类型并且需要容易解释时,会实现决策树。随机森林算法模型处理多个树,因此性能不会受到影响。它不需要缩放或归一化。请明智选择!
Saikumar Talari 是一位充满激情的内容创作者,目前在SkillsStreet工作。他是一名技术博客作者,喜欢撰写关于软件行业新兴技术的内容。在空闲时间,他喜欢踢足球。
更多相关主题
随机森林® — 一种强大的集成学习算法
原文:
www.kdnuggets.com/2020/01/random-forest-powerful-ensemble-learning-algorithm.html
评论
引言
在文章 决策树算法 — 解释中,我们学习了决策树及其如何通过从先前的数据(训练数据)中推断简单的决策规则来预测目标变量的类别或数值。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
但是,决策树的一个常见问题是,特别是当表格中有很多列时,它们会过拟合。 有时看起来像是树记住了训练数据集。如果没有对决策树设置限制,它将为训练数据集提供 100%准确性,因为在最坏的情况下,它将为每个观察值创建一个叶子。因此,这会影响对不属于训练集的样本进行预测时的准确性。
随机森林是解决过拟合问题的几种方法之一,现在让我们深入探讨这一强大的机器学习算法的工作原理和实现方式。在此之前,我建议你熟悉一下 决策树算法。
随机森林是一种集成学习算法,所以在讨论随机森林之前,让我们首先简单了解一下什么是集成学习算法。
集成学习算法
集成学习算法是 元算法 ,它们将多个机器学习算法结合成一个预测模型,以减少方差、偏差或改善预测。
算法可以是任何 机器学习 算法,如逻辑回归、决策树等。这些模型在作为集成方法的输入时,被称为”基础模型”。
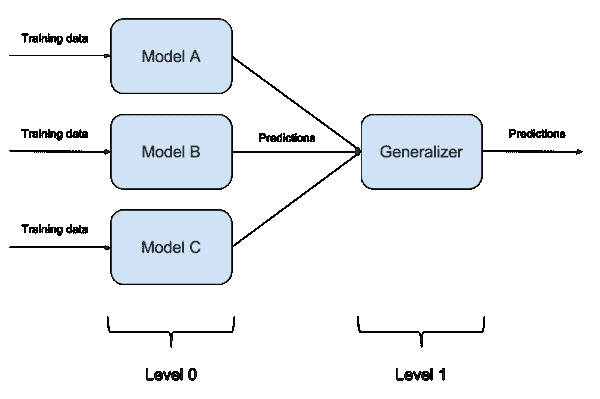
集成方法通常比单一模型产生更准确的解决方案。这在许多机器学习竞赛中已得到验证,获胜解决方案通常使用了集成方法。在著名的 Netflix 竞赛中,获胜者使用了集成方法来实现一个强大的协同过滤算法。另一个例子是 KDD 2009,获胜者也使用了集成方法。
集成算法或方法可以分为两组:
-
顺序集成方法——其中基学习器是顺序生成的(例如,AdaBoost)。
顺序方法的基本动机是利用基学习器之间的依赖性。通过对之前标记错误的例子加权,整体性能可以得到提升。
-
并行集成方法——其中基学习器是并行生成的(例如,随机森林)。
并行方法的基本动机是利用基学习器之间的独立性,因为通过平均可以显著减少误差。
大多数集成方法使用单一的基学习算法生成同质基学习器,即相同类型的学习器,导致同质集成。
也有一些方法使用异质学习器,即不同类型的学习器,导致异质集成。为了使集成方法比任何单一成员更准确,基学习器必须尽可能准确且尽可能多样化。
随机森林算法是什么?
随机森林是一种监督集成学习算法,既用于分类问题也用于回归问题。但实际上,它主要用于分类问题。正如我们知道的,森林由树木组成,树木越多,森林越强健。类似地,随机森林算法在数据样本上创建决策树,然后从每棵树中获得预测,并通过投票选出最佳解决方案。它是一种比单一决策树更好的集成方法,因为它通过平均结果来减少过拟合。
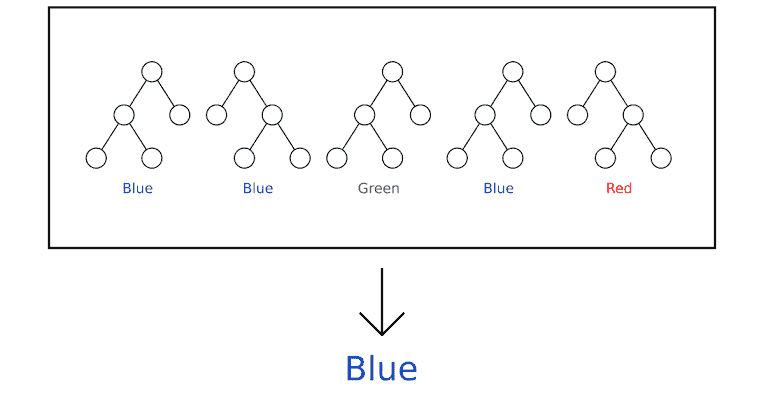
根据多数投票,最终结果是‘蓝色’。
随机森林的基本概念是一个简单但强大的理念——众智智慧。
“大量相对不相关的模型(树)作为一个委员会运作将优于任何单一的构成模型。”
模型之间的低相关性是关键。
随机森林能产生出色结果的原因是树木彼此保护,避免各自的错误。虽然某些树可能出错,但许多其他树会正确,因此作为一个整体,树木能够朝正确的方向发展。
为什么叫“随机”?
两个关键概念赋予了它“随机”这个名字:
-
在构建树时对训练数据集进行随机抽样。
-
在拆分节点时考虑的特征随机子集。
随机森林如何确保模型的多样性?
随机森林通过以下两种方法确保每棵树的行为与模型中任何其他树的行为不太相关:
-
Bagging 或 Bootstrap 聚合
-
随机特征选择
Bagging 或 Bootstrap 聚合
决策树对所训练的数据非常敏感,训练数据集的微小变化可能导致树结构的显著不同。随机森林利用这一点,通过允许每棵树从数据集中随机抽样(带有替换),从而生成不同的树。这一过程称为 Bagging。
注意,在 Bagging 中,我们并不是将训练数据子集分成较小的块,并在不同的块上训练每棵树。相反,如果我们有一个大小为N的样本,我们仍然给每棵树一个大小为N的训练集。但不是原始训练数据,而是带有替换的随机样本。
例如——如果我们的训练数据是[1,2,3,4,5,6],那么我们可能会给一棵树提供列表[1,2,2,3,6,6],而给另一棵树提供列表[2,3,4,4,5,6]。注意列表的长度是6,一些元素在我们提供给树的随机选择的训练数据中被重复(因为我们带有替换地抽样)。
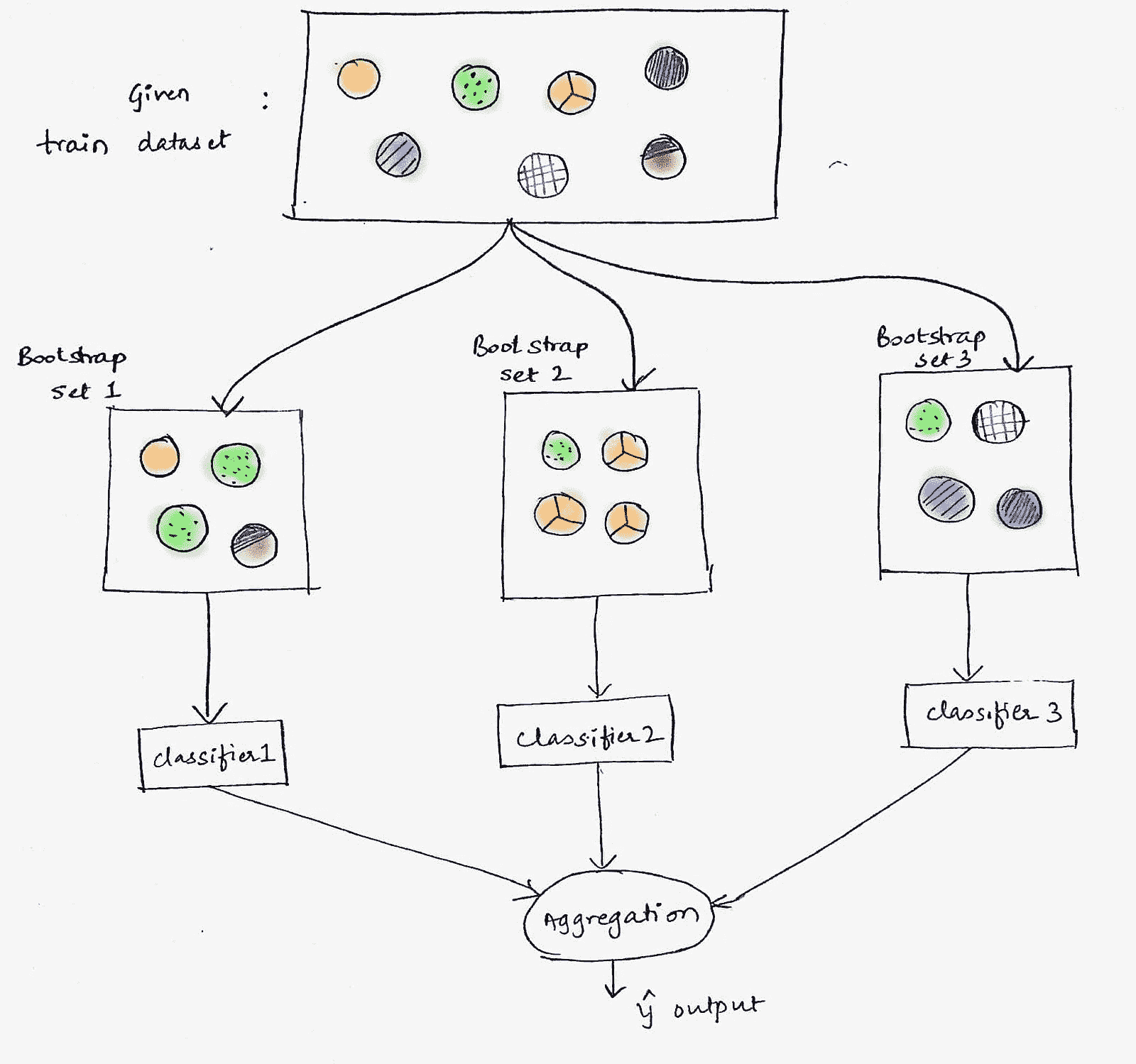
上图显示了如何从数据集中带有替换地抽取随机样本。
随机特征选择
在普通决策树中,当需要拆分节点时,我们考虑所有可能的特征,并选择在左节点与右节点之间产生最大分离的特征。相比之下,随机森林中的每棵树只能从特征的随机子集中选择。这迫使模型中的树之间有更多变化,并最终导致树之间的低相关性和更多的多样化。
因此,在随机森林中,我们得到的树是基于不同的数据集训练的,并且使用不同的特征来做决策。
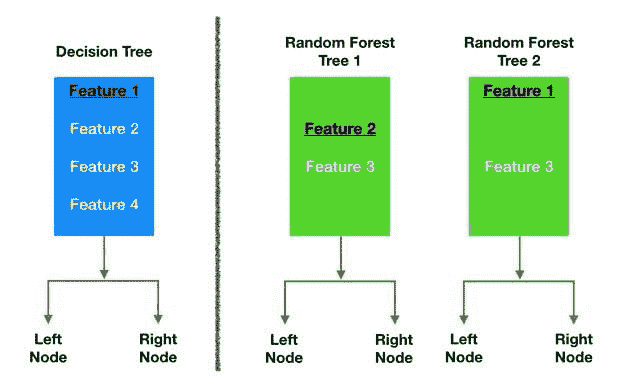
最终,无关的树创造了缓冲区,并从各自的错误中预测彼此。
随机森林创建伪代码:
-
从总共“m”个特征中随机选择“k”个特征,其中k << m
-
在“k”个特征中,使用最佳划分点计算节点“d”
-
使用最佳划分将节点拆分为子节点
-
重复 1到 3步,直到达到“l”个节点。
-
通过重复步骤 1 至 4 “n” 次来构建森林,从而创建“n” 棵树。
在 Scikit-learn 中构建随机森林分类器
在本节中,我们将使用随机森林算法从声音数据集中构建一个性别识别分类器。目的是根据声音和言语的声学属性识别声音为男性或女性。数据集包含 3,168 个录制的声音样本,来自男性和女性发言者。声音样本通过 R 中的声学分析进行预处理,使用了 seewave 和 tuneR 包,分析频率范围为 0Hz-280Hz。
数据集可以从 kaggle下载。
目标是创建一个决策树和随机森林分类器,并比较两个模型的准确性。以下是我们在模型构建过程中将执行的步骤:
1. 导入各种模块并加载数据集
2. 探索性数据分析(EDA)
3. 异常值处理
4. 特征工程
5. 数据准备
6. 模型构建
7. 模型优化
那么,让我们开始吧。
步骤-1: 导入各种模块并加载数据集
# Ignore the warnings
import warnings
warnings.filterwarnings('always')
warnings.filterwarnings('ignore')# data visualisation and manipulationimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
import seaborn as sns
import missingno as msno#configure
# sets matplotlib to inline and displays graphs below the corressponding cell.
%matplotlib inline
style.use('fivethirtyeight')
sns.set(style='whitegrid',color_codes=True)#import the necessary modelling algos.
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
#model selection
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score,precision_score
from sklearn.model_selection import GridSearchCV#preprocess.
from sklearn.preprocessing import MinMaxScaler,StandardScaler
现在加载数据集。
train=pd.read_csv("../RandomForest/voice.csv")df=train.copy()
步骤-2: 探索性数据分析(EDA)
df.head(10)
数据集
每个声音的以下声学属性被测量并包含在我们的数据中:
-
meanfreq: 平均频率(单位:kHz)
-
sd: 频率的标准差
-
median: 中位频率(单位:kHz)
-
Q25: 第一四分位数(单位:kHz)
-
Q75: 第三四分位数(单位:kHz)
-
IQR: 四分位数间距(单位:kHz)
-
skew: 偏度
-
kurt: 峰度
-
sp.ent: 频谱熵
-
sfm: 频谱平坦度
-
mode: 模态频率
-
centroid: 频率质心
-
peakf: 峰值频率(能量最高的频率)
-
meanfun: 在声学信号中测量的基频的平均值
-
minfun: 在声学信号中测量的基频的最小值
-
maxfun: 在声学信号中测量的基频的最大值
-
meandom: 在声学信号中测量的主频率的平均值
-
mindom: 在声学信号中测量的主频率的最小值
-
maxdom: 在声学信号中测量的主频率的最大值
-
dfrange: 在声学信号中测量的主频率范围
-
modindx: 调制指数,它是通过将相邻的基频测量的绝对差值累积后除以频率范围来计算的
-
label: 男性或女性
df.shape
请注意,我们有 3168 个声音样本,每个样本记录了 20 种不同的声学属性。最后,‘label’ 列是目标变量,我们需要预测的就是该人的性别。
现在我们下一步是处理缺失值。
*# check for null values.*
df.isnull().any()

我们的数据集中没有缺失值。
现在我将进行单变量分析。请注意,由于所有特征都是“数值型”的,因此最合理的绘制方式是“直方图”或“箱线图”。
此外,单变量分析对于离群值检测也很有用。因此,除了为每个列或特征绘制箱线图和直方图外,我还编写了一个小工具函数,可以告诉我们如果去除离群值后每个特征剩余的观测数。
为了检测离群值,我使用了标准的 1.5 四分位数范围(IQR)规则,该规则指出,任何低于“第一个四分位数 — 1.5 IQR”或高于“第三个四分位数 + 1.5 IQR”的观测值都是离群值。
def calc_limits(feature):
q1,q3=df[feature].quantile([0.25,0.75])
iqr=q3-q1
rang=1.5*iqr
return(q1-rang,q3+rang)
def plot(feature):
fig,axes=plt.subplots(1,2)
sns.boxplot(data=df,x=feature,ax=axes[0])
sns.distplot(a=df[feature],ax=axes[1],color='#ff4125')
fig.set_size_inches(15,5)
lower,upper = calc_limits(feature)
l=[df[feature] for i in df[feature] if i>lower and i<upper]
print("Number of data points remaining if outliers removed : ",len(l))
让我们绘制第一个特征,即 meanfreq。
plot('meanfreq')

从上述图表中得出的结论—
-
首先,请注意,值与描述方法数据框中观察到的情况一致。
-
请注意,根据 1.5 四分位数规则,我们有几个离群值(在箱线图中用“点”表示)。去除这些数据点或离群值后,我们剩下大约 3104 个值。
-
此外,从分布图来看,分布似乎有些负偏,因此我们可以进行归一化,使分布更对称。
-
最后,请注意,左尾分布在 Q1 以下的侧面有更多的离群值,而右尾在 Q3 以上的侧面则有更多的离群值。
通过绘制其他特征也可以得出类似的结论,我已经绘制了一些,你们可以检查所有的。
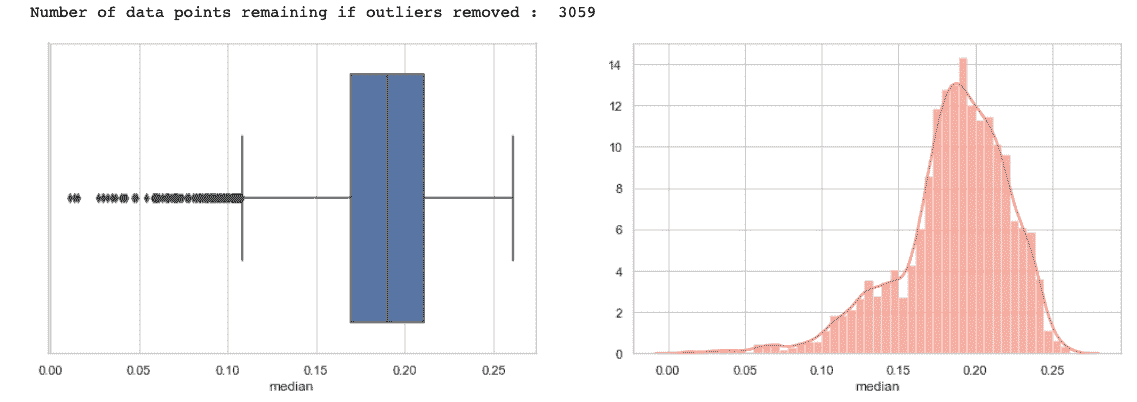
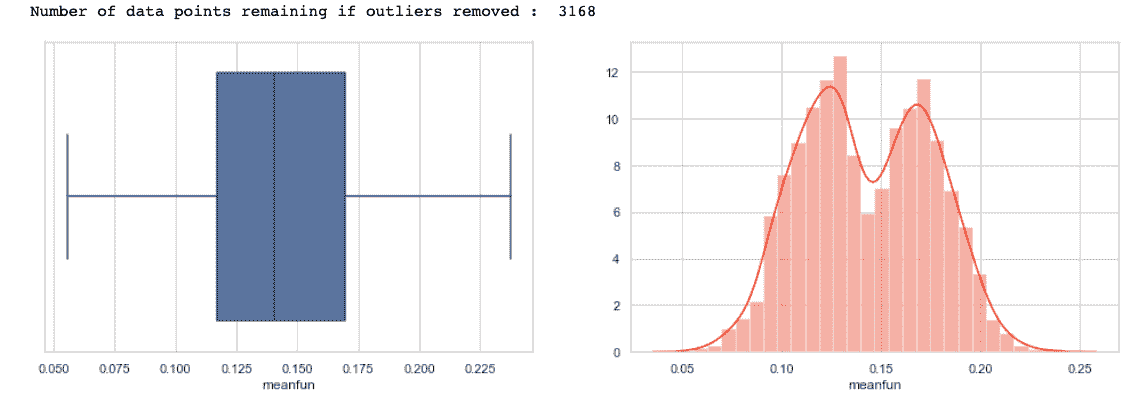
现在绘制和统计目标变量,以检查目标类别是否平衡。
sns.countplot(data=df,x='label')
df['label'].value_counts()
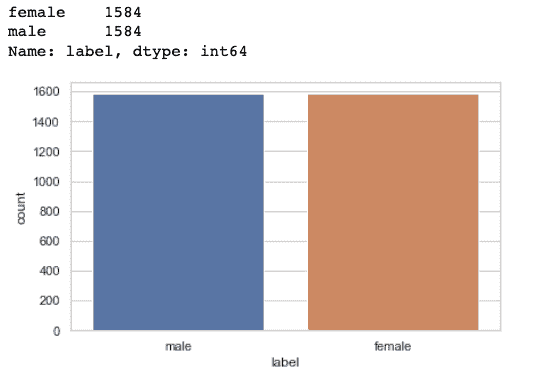
目标变量的绘图
我们的“男性”和“女性”类别的观测数量相等,因此这是一个平衡的数据集,我们不需要对此做任何处理。
现在我将进行双变量分析,以分析不同特征之间的相关性。为此,我绘制了一个“热图”,该图清晰地可视化了不同特征之间的相关性。
temp = []
for i in df.label:
if i == 'male':
temp.append(1)
else:
temp.append(0)
df['label'] = temp
#corelation matrix.
cor_mat= df[:].corr()
mask = np.array(cor_mat)
mask[np.tril_indices_from(mask)] = False
fig=plt.gcf()
fig.set_size_inches(23,9)
sns.heatmap(data=cor_mat,mask=mask,square=True,annot=True,cbar=True)

热图
从上述热图中得出的结论—
-
平均频率与标签的相关性适中。
-
IQR 和标签之间通常有很强的正相关关系。
-
频谱熵与标签的相关性也相当高,而 sfm 与标签的相关性适中。
-
偏度和峰度与标签的相关性不大。
-
meanfun 与标签的相关性非常负。
-
Centroid 和 median 具有根据公式预期的高正相关性。
-
此外,meanfreq 和 centroid 是根据公式完全相同的特征,它们的值也是一致的。因此,它们的相关性是完美的 1。在这种情况下,我们可以删除其中任何一列。
注意,质心通常与大多数其他特征有很高的相关性,因此我将删除质心列。
-
sd 与 sfm 高度正相关,sp.ent 与 sd 也是如此。
-
kurt 和 skew 也高度相关。
-
meanfreq 与中位数以及 Q25 高度相关。
-
IQR 与 sd 高度相关。
-
最后,自相关,即特征对自身的关系,等于 1,符合预期。
注意,我们可以丢弃一些高度相关的特征,因为它们会给模型带来冗余,但现在我们暂时保留所有特征。对于高度相关的特征,我们可以使用主成分分析(PCA)等降维技术来减少特征空间。
df.drop('centroid',axis=1,inplace=True)
步骤-3: 异常值处理
这里我们需要处理异常值。注意,我们在“单变量分析”部分发现了潜在的异常值。现在,要去除这些异常值,我们可以选择删除相应的数据点或用其他统计量(如中位数)进行填补(对异常值具有鲁棒性)。
目前,我将移除所有对“任何”特征都是异常值的观测值或数据点。这样做会大大减少数据集的大小。
*# removal of any data point which is an outlier for any fetaure.*
for col in df.columns:
lower,upper=calc_limits(col)
df = df[(df[col] >lower) & (df[col]<upper)]df.shape
注意,新形状为(1636,20),我们剩下 20 个特征。
步骤-4: 特征工程
在这里,我丢弃了一些根据我的分析证明不太有用或冗余的列。
temp_df=df.copy()temp_df.drop(['skew','kurt','mindom','maxdom'],axis=1,inplace=True) # only one of maxdom and dfrange.
temp_df.head(10)
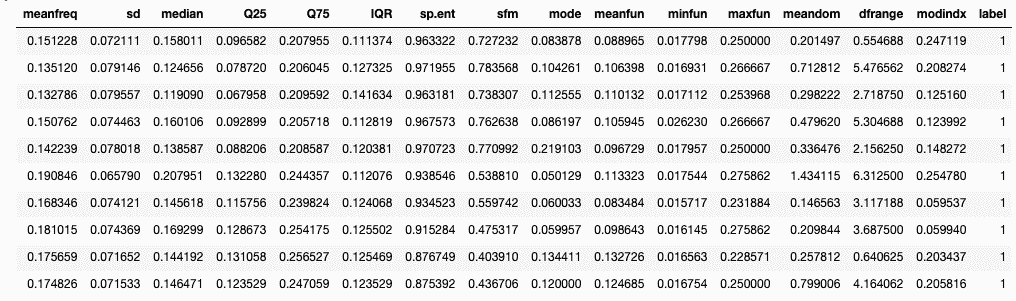
过滤后的数据集
现在让我们创建一些新特征。我在这里做了两件新事物。首先,我使‘meanfreq’,‘median’ 和 ‘mode’ 符合标准关系3Median = 2Mean + Mode。为此,我调整了‘median’列中的值,如下所示。你可以修改其他列中的值,比如‘meanfreq’列。
temp_df['meanfreq']=temp_df['meanfreq'].apply(lambda x:x*2)
temp_df['median']=temp_df['meanfreq']+temp_df['mode']
temp_df['median']=temp_df['median'].apply(lambda x:x/3)sns.boxplot(data=temp_df,y='median',x='label') # seeing the new 'median' against the 'label'
我添加的第二个新特征是一个新的特征,用于测量“偏度”。
为此,我使用了‘卡尔·皮尔森系数’,其计算公式为系数 = (均值 — 众数)/标准差
你还可以尝试一些其他系数,看看它们与目标(即“标签”列)相比如何。
temp_df['pear_skew']=temp_df['meanfreq']-temp_df['mode']
temp_df['pear_skew']=temp_df['pear_skew']/temp_df['sd']
temp_df.head(10)sns.boxplot(data=temp_df,y='pear_skew',x='label')
步骤-5: 数据准备
我们首先要做的是对所有特征进行标准化,基本上我们会执行特征缩放,以使所有值处于可比较的范围内。
scaler=StandardScaler()
scaled_df=scaler.fit_transform(temp_df.drop('label',axis=1))
X=scaled_df
Y=df['label'].as_matrix()
接下来,将数据拆分为训练集和测试集。
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.20,random_state=42)
步骤-6: 模型构建
现在我们将构建两个分类器,决策树和随机森林,并比较它们的准确率。
models=[RandomForestClassifier(), DecisionTreeClassifier()]model_names=['RandomForestClassifier','DecisionTree']acc=[]
d={}for model in range(len(models)):
clf=models[model]
clf.fit(x_train,y_train)
pred=clf.predict(x_test)
acc.append(accuracy_score(pred,y_test))
d={'Modelling Algo':model_names,'Accuracy':acc}
将准确率放入数据框中。
acc_frame=pd.DataFrame(d)
acc_frame
绘制准确率:
正如我们所见,仅仅使用我们模型的默认参数,随机森林分类器的表现优于决策树分类器(如预期)。
第 7 步:使用 GridSearchCV 进行参数调优
最后,让我们还使用 GridSearchCV 调整我们的随机森林分类器。
param_grid = {
'n_estimators': [200, 500],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth' : [4,5,6,7,8],
'criterion' :['gini', 'entropy']
}
CV_rfc = GridSearchCV(estimator=RandomForestClassifier(), param_grid=param_grid, scoring='accuracy', cv= 5)
CV_rfc.fit(x_train, y_train)
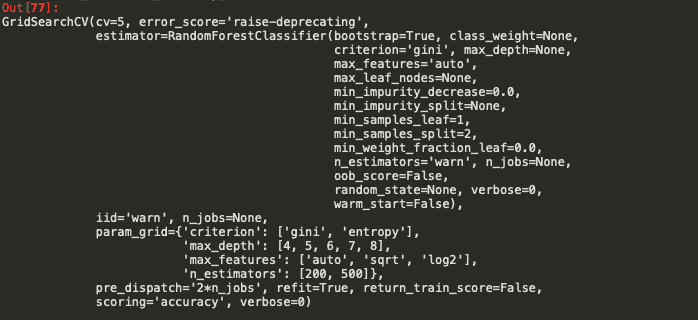
print("Best score : ",CV_rfc.best_score_)
print("Best Parameters : ",CV_rfc.best_params_)
print("Precision Score : ", precision_score(CV_rfc.predict(x_test),y_test))

经过超参数优化后,我们可以看到结果相当不错 😃
如果你愿意,你还可以检查每个特征的重要性。
df1 = pd.DataFrame.from_records(x_train)
tmp = pd.DataFrame({'Feature': df1.columns, 'Feature importance': clf_rf.feature_importances_})
tmp = tmp.sort_values(by='Feature importance',ascending=False)
plt.figure(figsize = (7,4))
plt.title('Features importance',fontsize=14)
s = sns.barplot(x='Feature',y='Feature importance',data=tmp)
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.show()

结论
现在希望你已经掌握了随机森林的概念框架,并且这篇文章已经给了你开始在项目中使用随机森林所需的信心和理解。随机森林是一个强大的机器学习模型,但这不应妨碍我们了解它是如何工作的。我们对模型了解得越多,就越能有效地使用它,并解释它如何做出预测。
你可以在我的 Github 仓库 中找到源代码。
好了,这篇文章就是这些,希望你们喜欢阅读,如果这篇文章对你有帮助,我会很高兴。欢迎在评论区分享你的评论/想法/反馈。

谢谢阅读!!!
简介: Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等各个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原文。经许可转载。
随机森林® 是 Minitab 的注册商标。
相关内容:
-
支持向量机的友好介绍
-
比较决策树算法:随机森林与 XGBoost
-
从零开始构建人工神经网络:第一部分
更多相关主题
解释随机森林®(带 Python 实现)
评论
由学习机器
随机森林(+Python 实现)
1. 介绍
本文由学习机器撰写,这是一个新的开源项目,旨在创建一个互动路线图,包含 A 到 Z 的概念、方法、算法及其 Python 或 R 代码实现的解释,适合各种背景的人群。
查看我们的点击即用机器学习思维导图,包含算法解释和 Python 实现。
2. 随机森林
随机森林是一种灵活、易于使用的机器学习算法,即使在没有超参数调整的情况下,也能大多数时候产生很好的结果。它可以用于分类和回归任务。在这篇文章中,你将学习随机森林算法如何处理分类和回归问题。
要理解随机森林算法,你首先需要熟悉决策树。请阅读有关决策树的文章 这里**。
决策树常见的问题之一,特别是那些有许多列的决策树,是它们容易过拟合。有时看起来树只是记住了数据。这里是过拟合的决策树的典型例子,包括分类和连续数据:
I. 分类:
如果客户是男性,年龄在 15 到 25 岁之间,来自美国,喜欢冰淇淋,有一个德国朋友,讨厌鸟类,并且在 2012 年 8 月 25 日吃过煎饼,那么 - 他很可能会下载《精灵宝可梦 Go》。
II. 连续型:
随机森林避免了这个问题:它是由多个决策树组成的集合,而不仅仅是一个。而且,随机森林中的决策树数量越多,泛化效果越好。
更准确地说,随机森林的工作原理如下:
-
从总共有 m 个特征(列)的数据集中随机选择 k 个特征(列)(其中 k<<m)。然后,从这些 k 个特征中构建一个决策树。
-
重复 n 次,以便你从不同的随机 k 特征组合(或称为bootstrap sample)中构建n个决策树。
-
采用每一个构建好的 n 个决策树,并传递一个随机变量来预测结果。存储预测的结果(目标),从而你将得到来自n个决策树的总共n个结果。
-
计算每个预测目标的投票,并取众数(最频繁的目标变量)。换句话说,将高投票的预测目标视为随机森林算法的最终预测。
在回归问题中,对于一个新的记录,森林中的每棵树都预测 Y(输出)的一个值。最终值可以通过取森林中所有树预测值的平均值来计算。或者,在分类问题中,森林中的每棵树都预测新记录所属的类别。最后,新记录被分配到获得多数票的类别。
示例:
詹姆斯想决定在巴黎待一周期间应该去哪些地方。他去找一个在那儿住了一年的朋友,询问他过去去过哪些地方以及是否喜欢。基于他的经验,他会给詹姆斯一些建议。
这是一种典型的决策树算法方法。詹姆斯的朋友根据他一年的个人经验决定了詹姆斯应该去哪些地方。
后来,詹姆斯开始询问越来越多的朋友,以获取建议,他们推荐了自己去过的地方。然后詹姆斯选择了最常被推荐的地方,这就是典型的随机森林算法方法。
因此,随机森林是一种通过随机选择总共 m 个特征中的 k 个特征来构建 n 棵决策树的算法,并对预测结果取众数(如果是回归问题则取平均值)。
3. 优缺点
优点:
-
可用于分类和回归问题: 随机森林在处理分类和数值特征时表现良好。
-
减少过拟合: 通过对多个树进行平均,可以显著降低过拟合的风险。
-
仅当超过一半的基本分类器出错时才会做出错误预测: 随机森林非常稳定——即使数据集中引入了新的数据点,整体算法也不会受到太大影响,因为新数据可能会影响一棵树,但很难影响所有的树。
缺点:
-
观察到随机森林在某些噪声分类/回归任务的数据集上会过拟合。
-
比决策树算法更复杂且计算开销更大。
-
由于其复杂性,与其他可比算法相比,它们需要更多的训练时间。
4. 重要超参数
随机森林中的超参数要么用于提高模型的预测能力,要么使模型运行更快。下面描述了 sklearn 内置随机森林函数的超参数:
- 提高预测能力
-
n_estimators: 算法在进行最大投票或预测平均值之前构建的树的数量。一般来说,树的数量越多,性能越高,预测越稳定,但计算速度也会变慢。
-
max_features: 随机森林允许在单个树中尝试的最大特征数量。Sklearn 提供了几个选项,详细描述见其 文档。
-
min_sample_leaf: 确定拆分内部节点所需的最小叶子数。
- 提高模型速度
-
n_jobs: 告诉引擎可以使用多少处理器。如果其值为 1,则只能使用一个处理器。值为“-1”表示没有限制。
-
random_state: 使模型的输出可重复。当模型具有确定的 random_state 值并且使用相同的超参数和训练数据时,模型将始终产生相同的结果。
-
oob_score: (也称为 oob 采样) - 一种随机森林交叉验证方法。在这种采样中,大约三分之一的数据不用于训练模型,而是用于评估其性能。这些样本称为袋外样本。它与留一法交叉验证方法非常相似,但几乎没有额外的计算负担。
5. Python 实现
查看/下载位于 git 仓库中的随机森林模板 这里。
资源:
相关:
RANDOM FORESTS 和 RANDOMFORESTS 是 Minitab, LLC 注册的商标。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关话题
随机森林®,解析
在这篇文章中,我们将概述一种非常流行的集成方法——随机森林(®)。我们首先讨论这种集成学习算法的基本组件——决策树,然后介绍其底层算法和训练程序。我们还将讨论该工具的一些变体和优势,最后提供一些资源,帮助你入门这一强大的工具。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
决策树简述
决策树是一种机器学习算法,能够适应复杂的数据集,并执行分类和回归任务。树的核心思想是在训练集中寻找一对变量-值,并将其拆分,以生成“最佳”的两个子集。目标是基于最佳拆分标准创建分支和叶子,这一过程称为树的生长。具体来说,在每个分支或节点处,一个条件语句会根据特定变量的固定阈值对数据点进行分类,从而实现数据拆分。为了进行预测,每个新实例从根节点(树的顶部)开始,沿着分支移动,直到到达一个叶子节点,此时不再进行进一步的分支。
用于训练树的算法称为 CART(®)(分类与回归树)。正如我们之前提到的,算法寻找最佳的特征-值对来创建节点和分支。在每次拆分后,这一任务会递归进行,直到达到树的最大深度或找到一个优化的树。根据任务的不同,算法可能使用不同的度量标准(基尼不纯度、信息增益或均方误差)来衡量拆分的质量。需要提到的是,由于 CART 算法的贪婪特性,找到一个最优的树并不保证,通常情况下,一个合理的估计就足够了。
树有很高的过拟合训练数据的风险,并且如果在生长阶段没有适当约束和正则化,它们可能会变得计算复杂。这种过拟合意味着模型的低偏差、高方差权衡。因此,为了解决这个问题,我们使用集成学习,这种方法可以纠正过度学习的习惯,并希望得到更好、更强的结果。
什么是集成方法?
集成方法或集成学习算法通过汇总由不同预测因子集产生的多个输出以获得更好的结果。正式地说,基于一组“弱”学习者,我们试图为模型使用一个“强”学习者。因此,使用集成方法的目的是:通过多样化预测因子集来平均单个预测的结果,从而降低方差,得到一个强大的预测模型,减少对训练集的过拟合。
在我们的例子中,随机森林(强学习者)作为决策树(弱学习者)的集成来执行回归和分类等不同任务。
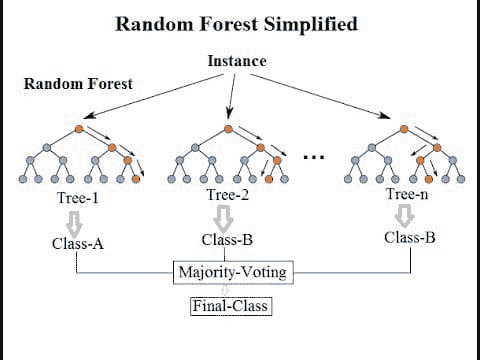
随机森林是如何训练的?
随机森林通过袋装方法进行训练。袋装或自助聚合方法包括随机抽取训练数据的子集,拟合模型到这些较小的数据集上,并汇总预测结果。由于我们进行有放回抽样,这种方法允许多个实例在训练阶段被重复使用。树袋装方法包括抽取训练集的子集,对每个子集拟合一棵决策树,并汇总它们的结果。
随机森林方法通过将袋装法应用于特征空间来引入更多的随机性和多样性。即,不是贪婪地寻找最佳预测因子来创建分支,而是随机抽取预测因子空间中的元素,从而增加更多多样性并降低树的方差,但代价是偏差相同或更高。这个过程也被称为“特征袋装”,正是这个强大的方法使得模型更加稳健。
现在我们来看看如何使用随机森林进行预测。记住,在决策树中,一个新实例从根节点走到最底层,直到在叶节点被分类。在随机森林算法中,每个新数据点经过相同的过程,但现在它访问集成中的所有不同树,这些树是使用训练数据和特征的随机样本生长起来的。根据手头的任务,聚合所用的函数会有所不同。对于分类问题,它使用个体树预测的模式或最频繁的类别(也称为多数投票),而对于回归任务,它使用每棵树的平均预测值。
尽管这是一种在机器学习中使用的强大且准确的方法,但你应该始终交叉验证你的模型,因为可能会出现过拟合。此外,尽管它非常稳健,但随机森林算法运行缓慢,因为在训练阶段必须生成许多树,正如我们所知,这是一个贪婪的过程。
变体
正如我们之前所述,随机森林使用训练数据和特征空间的采样子集,从而产生高多样性和随机性以及低方差。现在,我们可以更进一步,通过不仅寻找随机预测器,还考虑这些变量的随机阈值来引入更多的多样性。因此,它不是寻找特征和阈值的最佳配对用于分裂,而是使用这两者的随机样本来创建不同的分支和节点,从而进一步用偏差换取方差。这个集成方法也被称为极端随机树或额外树。这个模型也用更多的偏差换取较低的方差,但训练更快,因为它不像随机森林那样寻找最佳解。
附加属性
随机森林的另一个重要特性是它们在确定特征或变量重要性时非常有用。因为重要特征往往位于每棵树的顶部,而不重要的变量位于底部,可以通过测量这一点的平均深度来衡量其重要性。
更多信息
你可以在这个维基百科文章中找到更多关于随机森林的信息。约翰霍普金斯大学 Coursera 的实践机器学习课程提供了一个直观的方法,并且在 R 中有应用。对于 Python 实现,请跟随这段代码,它来自 Aurélien Géron 的书籍《动手机器学习:Scikit-Learn 和 TensorFlow》。
Random Forests™ 是 Leo Breiman 和 Adele Cutler 的商标,并被Salford Systems独家授权用于商业软件发布。CART(®) 是加利福尼亚统计软件公司的注册商标,并被Salford Systems独家授权。
相关内容
-
Python 中的随机森林
-
理解机器学习算法
-
与算法的亲密接触
更多相关话题
随机森林® 在 Python 中
这篇文章最初发表于 Yhat 博客。Yhat 是一家位于布鲁克林的公司,旨在使数据科学适用于开发人员、数据科学家和企业。Yhat 提供一个软件平台,用于将预测算法部署和管理为 REST API,同时消除与生产环境相关的痛苦工程障碍,如测试、版本控制、扩展和安全。
随机森林 是一种高度多用途的机器学习方法,应用广泛,从市场营销到医疗保健和保险。它可以用于建模市场营销的影响,如客户获取、留存和流失,或用于预测疾病风险和易感性。
随机森林可以进行回归和分类。它能处理大量特征,并且有助于估计在建模的基础数据中哪些变量是重要的。
这是一个关于使用 Python 的随机森林的帖子。
什么是随机森林?
随机森林是几乎任何预测问题的可靠选择(即使是非线性问题)。这是一种相对较新的机器学习策略(它起源于 90 年代的贝尔实验室),可以用于几乎任何用途。它属于一种称为集成方法的更大类的机器学习算法。
集成学习
集成学习涉及将多个模型组合在一起解决单一预测问题。它通过生成多个分类器/模型来工作,这些模型独立学习并进行预测。然后将这些预测组合成一个单一的(超级)预测,这个预测应该与任何一个分类器的预测一样好或更好。
随机森林是集成学习的一种,它依赖于决策树的集成。有关 Python 中集成学习的更多信息,请参见:Scikit-Learn 文档。
随机化决策树
所以我们知道随机森林是其他模型的聚合,但它聚合了哪些类型的模型呢?正如你可能从名字中猜到的那样,随机森林聚合了分类(或回归)树。决策树由一系列决策组成,这些决策可以用来对数据集中一个观察值进行分类。
随机 森林
用于生成随机森林的算法会自动创建一堆随机决策树。由于这些树是随机生成的,大多数树对你的分类/回归问题并没有什么有意义的帮助(可能有 99.9%的树)。

如果一个观测值的长度为 45,蓝色眼睛,2 条腿,它将被分类为 红色。
树木投票
那么,10000 个(可能)糟糕的模型有什么用呢?结果证明,它们真的不是很有帮助。但 有帮助的 是那些你同时生成的少数几个非常好的决策树。
当你做出预测时,新的观测值会被推入每棵决策树,并被分配一个预测值/标签。一旦森林中的每棵树都报告了其预测值/标签,预测结果将被汇总,并以所有树的模式投票作为最终预测。
简单来说,那 99.9% 的无关树做出的预测到处都是,并相互抵消。而少数几棵好的树的预测超越了这些噪音,得出了好的预测结果。

为什么你应该使用它?
很简单
随机森林是 Leatherman 的学习方法。你几乎可以对它进行任何操作,它都会做得很好。它特别擅长估计推断转换,因此不像 SVM 那样需要大量调优(即适合于时间紧迫的人)。
一个示例转换
随机森林能够在没有精心设计的数据转换的情况下进行学习。例如,考虑 f(x) = log(x) 函数。
好的,我们来写一些代码。我们将在 Yhat 自家的交互式环境 Rodeo 中编写 Python 代码。你可以在 这里 下载适用于 Mac、Windows 或 Linux 的 Rodeo。
首先,创建一些虚假数据并添加一点噪声。
import numpy as np
import pylab as pl
x = np.random.uniform(1, 100, 1000)
y = np.log(x) + np.random.normal(0, .3, 1000)
pl.scatter(x, y, s=1, label="log(x) with noise")
pl.plot(np.arange(1, 100), np.log(np.arange(1, 100)), c="b", label="log(x) true function")
pl.xlabel("x")
pl.ylabel("f(x) = log(x)")
pl.legend(loc="best")
pl.title("A Basic Log Function")
pl.show()
我们将在 Rodeo 中进行 Python 分析和可视化,Yhat 是一个开源的数据科学环境。想要跟随吗?你可以在 这里 下载适用于 Mac、Windows 或 Linux 的 Yhat Python IDE。
在 Rodeo 中跟随?这是你应该看到的内容。

让我们更详细地查看一下那个图表。

如果我们尝试建立一个基本的线性模型来预测y,使用x的话,我们最终会得到一条直线,这条直线大致上是将log(x)函数分开。相比之下,如果我们使用随机森林,它在近似log(x)曲线方面表现得更好,我们得到的结果看起来更像真实函数。

你可以说随机森林对log(x)函数进行了些许过拟合。无论如何,我认为这很好地说明了随机森林不受线性约束的限制。
用途
变量选择
随机森林最好的使用案例之一是特征选择。尝试许多决策树变体的副产品之一是你可以检查哪些变量在每棵树中表现最好/最差。
当某棵树使用一个变量而另一棵树不使用时,你可以比较因包括/排除该变量而丢失或获得的价值。好的随机森林实现会为你完成这项工作,所以你只需知道查看哪种方法或变量即可。
在接下来的例子中,我们试图找出哪些变量对于将酒分类为红酒或白酒最为重要。


分类
随机森林在分类方面也表现出色。它可以用于预测具有多个可能值的类别,并且可以校准以输出概率。然而,你需要注意的是过拟合。随机森林容易出现过拟合,尤其是在处理相对较小的数据集时。如果你的模型在测试集上的预测“过于准确”,你应该保持怀疑态度。
避免过拟合的一种方法是只在模型中使用真正相关的特征。虽然这并不总是简单明了,但使用特征选择技术(如前面提到的那种)可以使这变得容易得多。

回归
是的,它也做回归。
我发现与其他算法不同,随机森林在学习分类变量或分类变量与实际变量混合时表现非常好。具有高基数(可能值数量)的分类变量可能会很棘手,因此拥有类似的工具在你手头会非常有用。
一个简短的 Python 示例
Scikit-Learn 是入门随机森林的绝佳选择。scikit-learn API 在各种算法中非常一致,因此你可以非常容易地进行模型比较和切换。很多时候我从简单的模型开始,然后转向随机森林。
scikit-learn 中随机森林实现的最佳特性之一是n_jobs参数。这将根据你希望使用的核心数量自动并行化随机森林的拟合。这是一个很棒的演示,由 scikit-learn 贡献者 Olivier Grisel 介绍,他讲述了如何在 20 节点 EC2 集群上训练随机森林。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
跟上进度了吗?这是你应该看到的(大致)。我们使用的是随机选择的数据,因此你的确切值每次可能会有所不同。
| preds | sertosa | versicolor | virginica |
|---|---|---|---|
| actual | |||
| sertosa | 6 | 0 | 0 |
| versicolor | 0 | 16 | 1 |
| virginica | 0 | 0 | 12 |

最终思考
随机森林尽管非常先进,但使用起来却异常简单。与任何建模一样,要小心过拟合。如果你对在R中使用随机森林感兴趣,可以查看randomForest包。
原文。经许可转载。
RANDOM FORESTS 和 RANDOMFORESTS 是 Minitab, LLC 的注册商标。
相关:
-
随机森林:犯罪教程
-
深度学习何时优于 SVM 或随机森林?
-
伟大的算法教程汇总
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
如何在你的第一个 Kaggle 竞赛中排名前 10%
原文:
www.kdnuggets.com/2016/11/rank-ten-precent-first-kaggle-competition.html/4
Home Depot 搜索相关性
在这一部分,我将分享我在Home Depot 搜索相关性竞赛中的解决方案,以及我从竞赛后顶尖团队中学到的东西。
本次竞赛的任务是预测搜索词在 Home Depot 网站上的结果相关性。相关性是三名人工评估者的平均分,范围在 1~3 之间。因此这是一个回归任务。数据集包含搜索词、产品标题/描述以及品牌、尺寸和颜色等属性。评估指标是RMSE。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
这很像Crowdflower 搜索结果相关性。不同之处在于Cohen's Kappa在 Crowdflower 竞赛中被使用,这使得回归分数的最终截止点更加复杂。此外,Crowdflower 没有提供属性。
EDA
在我参加竞赛时,有几个相当好的 EDA,特别是这个。我了解到:
-
许多搜索词/产品出现了多次。
-
文本相似性是很好的特征。
-
许多产品没有属性特征。这会是一个问题吗?
-
产品 ID 似乎具有很强的预测能力。然而,训练集和测试集之间的产品 ID 重叠度不是很高。这会导致过拟合吗?
预处理
你可以在GitHub上找到我如何进行预处理和特征工程的详细信息。我这里只给出一个简要总结:
-
使用错别字词典来修正搜索词中的错别字。
-
统计属性。找出那些频繁出现且容易被利用的属性。
-
将训练集与测试集合并。这很重要,否则你将不得不进行两次特征变换。
特征
-
*属性特征
-
产品是否包含某个属性(品牌、尺寸、颜色、重量、室内/室外、能源之星认证等)
-
某个属性是否与搜索词匹配
-
-
元特征
-
每个文本字段的长度
-
产品是否包含属性字段
-
品牌(编码为整数)
-
产品 ID
-
-
匹配
-
搜索词是否出现在产品标题/描述/属性中
-
搜索词在产品标题/描述/属性中的出现次数和比例
-
*搜索词的第 i 个单词是否出现在产品标题/描述/属性中
-
-
搜索词与产品标题/描述/属性之间的文本相似度
-
潜在语义分析:通过对从 BOW/TF-IDF 向量化获得的矩阵进行SVD 分解,我们获得了不同搜索词/产品组的潜在表示。这使我们的模型能够区分不同组并为特征分配不同的权重,从而在一定程度上解决了数据依赖和产品缺乏某些特征的问题。
请注意,上面列出的带*的特征是我最后添加的一批特征。问题是,训练了这些特征的数据模型的表现比之前的模型差。起初我认为特征数量的增加会要求重新调整模型参数。然而,在浪费了大量 CPU 时间进行网格搜索后,我仍然无法超越旧模型。我认为这可能是上述特征相关性的问题。我实际上知道一个可能有效的解决方案,即通过堆叠将不同特征版本训练的模型进行组合。不幸的是,我没有足够的时间尝试它。事实上,大多数顶尖团队认为使用不同预处理和特征工程管道训练的模型的集成是成功的关键。
模型
起初我使用RandomForestRegressor来构建模型。然后我尝试了Xgboost,结果发现它比 Sklearn 快了两倍以上。从那时起,我每天做的基本上就是在工作站上运行网格搜索,同时在笔记本上处理特征。
本次比赛的数据集验证并不简单。数据不是独立同分布的,许多记录是相关的。我多次使用更好的特征/参数,结果 LB 分数却更差。正如许多成功的 Kaggle 选手所反复强调的那样,在这种情况下,你必须相信自己的 CV 分数。因此,我决定在交叉验证中使用 10 折而不是 5 折,并在接下来的尝试中忽略 LB 分数。
集成
我的最终模型是由 4 个基础模型组成的集成模型:
-
RandomForestRegressor -
ExtraTreesRegressor -
GradientBoostingRegressor -
XGBRegressor
堆叠模型也是一个XGBRegressor。
问题在于我所有的基础模型高度相关(最低相关系数为 0.9)。我考虑将线性回归、SVM 回归和XGBRegressor(使用线性提升器)纳入集成模型,但这些模型的 RMSE 分数比我最终使用的 4 个模型高出 0.02(这在排行榜上相当于数百个名次)。因此,我决定不再使用更多模型,尽管它们会带来更多的多样性。
好消息是,尽管基础模型高度相关,堆叠模型仍然大大提升了我的分数。更重要的是,自从开始使用堆叠模型后,我的 CV 分数和 LB 分数完全同步。
在比赛的最后两天,我还做了一件事:使用大约 20 个不同的随机种子生成集成模型,并将它们的加权平均作为最终提交。这实际上是一种袋装法(bagging)。理论上是有意义的,因为在堆叠中,我使用 80%的数据来训练每次迭代中的基础模型,而 100%的数据用于训练堆叠模型。因此它的效果不够干净。进行多次不同种子的运行可以确保每次使用不同的 80%数据,从而降低信息泄露的风险。然而,通过这种方式,我只取得了0.0004的提升,这可能仅仅是由于随机性造成的。
比赛结束后,我发现我最好的单一模型在私人排行榜上的分数是0.46378,而我最好的堆叠集成模型的分数是0.45849。这代表了 174 名和 98 名之间的差距。换句话说,特征工程和模型调优让我进入了前 10%,而堆叠模型让我进入了前 5%。
经验教训
从顶级团队分享的解决方案中有很多值得学习的地方:
-
产品标题中有一种模式。例如,产品是否附带某种配件将通过标题末尾的
With/Without XXX来指示。 -
使用外部数据。例如使用WordNet或Reddit 评论数据集来训练同义词和上位词。
-
一些基于字母而不是词语的特征。一开始我对此感到困惑。但如果考虑到这一点,就会有意义。例如,获得第三名的团队在计算文本相似性时考虑了匹配的字母数量。他们认为较长的词语更为具体,因此更有可能被人类赋予高相关性分数。他们还使用逐字比较 (
difflib.SequenceMatcher) 来测量视觉相似性,他们认为这对人类很重要。 -
对词语进行词性标注,找到头词并在计算各种距离度量时使用它们。
-
从产品标题/描述字段的 TF-IDF 中提取排名靠前的三元组,并计算搜索词出现在这些三元组中的比率。反之亦然。这就像从另一个角度计算潜在的索引。
-
一些新颖的距离度量方法,如Word Movers Distance。
-
除了 SVD,部分人使用了NMF。
-
生成配对多项式交互在排名靠前的特征之间。
-
对于交叉验证,构建训练集和测试集中产品 ID 不重叠的分割,以及 ID 重叠的分割。然后我们可以使用这些分割和相应的比率来估算公共/私人 LB 分割在本地交叉验证中的影响。
总结
要点
-
在竞赛早期开始进行集成是一个明智的选择。结果是,我在最后几天仍在处理特征。
-
建立一个能够自动训练模型和记录最佳参数的管道是优先事项。
-
特征最为重要! 我在这次竞赛中没有花足够的时间在特征上。
-
如果可能,花一些时间手动检查原始数据中的模式。
提出的问题
我在这次竞赛中遇到的几个问题具有很高的研究价值。
-
如何在相关数据下进行可靠的交叉验证。
-
如何量化多样性与准确性之间的权衡在集成学习中。
-
如何处理对模型性能有害的特征交互。以及如何确定新特征在这种情况下是否有效。
初学者建议
-
选择一个你感兴趣的竞赛。如果你对问题领域已有一些见解会更好。
-
无论是遵循我的方法还是别人的方法,开始探索、理解和建模数据。
-
从论坛和脚本中学习。查看其他人如何解释数据和构建特征。
-
查找之前比赛的获胜者访谈/博客文章。这些非常有帮助,特别是如果来自与你正在进行的比赛有相似之处的比赛。
-
在你达到相当好的分数(例如 10% ~ 20%)后,或者你觉得没有太多新特征的空间时(这通常是错误的),开始使用集成方法。
-
如果你认为自己有机会赢得奖项,试着组队合作!
-
不要在比赛结束前放弃。至少每天尝试一些新东西。
-
从比赛后的顶级团队分享中学习。反思你的方法。如果可能,花些时间验证你所学到的东西。
-
休息一下吧!
参考文献
 简介:Linghao Zhang 是复旦大学计算机科学大四学生和 Strikingly 的数据挖掘工程师。他的兴趣包括机器学习、数据挖掘、自然语言处理、知识图谱和大数据分析。
简介:Linghao Zhang 是复旦大学计算机科学大四学生和 Strikingly 的数据挖掘工程师。他的兴趣包括机器学习、数据挖掘、自然语言处理、知识图谱和大数据分析。
原文。经授权转载。
相关:
-
接近(几乎)任何机器学习问题
-
自动化数据科学与机器学习:与 Auto-sklearn 团队的访谈
-
数据科学基础:集成学习者简介
更多相关内容
增长最快的编程语言和计算框架
原文:
www.kdnuggets.com/2016/03/ranking-growth-programming-languages.html
评论
作者:Nathan Epstein
自 2010 年首次进行分析(将 Github 库数量与 Stack Overflow 帖子进行回归分析)以来,Redmonk 语言排名一直是排名编程语言受欢迎程度的重要工具。库数量和帖子数量相关的事实令人感到安慰,但并不能提供预测语言未来增长的指导。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
另一种方法是使用 Stack Overflow 开发者调查中的数据,涉及使用特定技术的开发者数量和希望使用这些技术的开发者数量(首次收集于 2015 年调查中)。
我们可以通过对现有用户与潜在用户进行回归分析来预测调查中各种技术的增长。
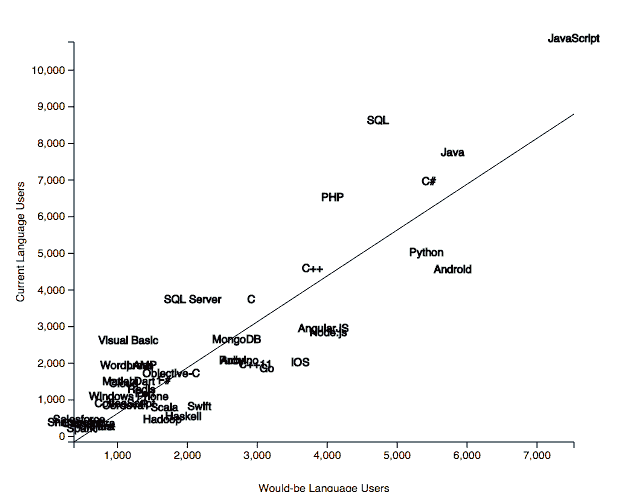
回归线有一个直观的解释。它是给定技术兴趣水平下预期的用户数量。因此,我们可以合理预期回归线下方的技术会增长,而回归线以上的技术会减少(如果我们假设兴趣驱动采纳的话)。
我们还可以根据“稳态”用户基础对各种技术进行排名,预测基于潜在用户数量(下文列为“排名加分”)。
在 2016 年 Stack Overflow 开发者调查结果发布之前,我们将无法验证预测的准确性。尽管如此,以下是 2015 年调查的结果和预测。
2015 年结果:
当前排名:
-
JavaScript
-
SQL
-
Java
-
C#
-
PHP
-
Python
-
C++
-
Android
-
SQL Server
-
C
排名加分:
-
JavaScript
-
Java
-
Android
-
C#
-
Python
-
SQL
-
PHP
-
Node.js
-
AngularJS
-
C++
最高增长:
-
Haskell
-
Hadoop
-
Swift
-
Rust
-
Scala
-
iOS
-
Go
-
C++11
-
Node.js
-
AngularJS
简介: Nathan Epstein 是一名数据科学家和软件工程师,现居纽约。他偶尔参与开源软件开发、公开演讲和学术研究。他在哥伦比亚大学和 Recurse Center 学习了应用数学和编程。
相关:
-
到 2018 年,企业将需要一百万名数据科学家
-
数据科学家必须掌握的一种语言
-
数据挖掘、数据科学和大数据的关键进展、主要趋势的研究领袖
更多相关主题
排名受欢迎的深度学习库用于数据科学
原文:
www.kdnuggets.com/2017/10/ranking-popular-deep-learning-libraries-data-science.html
作者:Rachel Allen 和 Michael Li,The Data Incubator。
在The Data Incubator我们以拥有最先进的数据科学课程而自豪。我们的课程很大程度上基于来自企业和政府合作伙伴的反馈,关于他们使用和学习的技术。除了这些反馈,我们还希望开发一个数据驱动的方法来确定我们应该在我们的数据科学企业培训和我们的免费奖学金中教授什么内容,面向希望进入数据科学行业的硕士和博士生。以下是结果。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
排名
以下是基于 Github 和 Stack Overflow 活动以及 Google 搜索结果的 23 个开源深度学习库的排名。这张表格显示了标准化分数,其中值为 1 表示高于平均水平一个标准差(平均值= 0 分)。例如,Caffe 在 Github 活动中高于平均水平一个标准差,而 deeplearning4j 接近平均水平。请参见下面的方法。

结果与讨论
排名基于三个组件的等权重:Github(stars 和 forks)、Stack Overflow(tags 和 questions)以及 Google 结果(总数和季度增长率)。这些数据是通过可用的 API 获取的。制定一个全面的深度学习工具包列表是棘手的 - 最终,我们抓取了五个我们认为具有代表性的列表(详情请见下面的方法)。计算每个指标的标准化分数可以让我们看到哪些包在每个类别中脱颖而出。完整排名在这里,而原始数据在这里。
TensorFlow 以最大规模的活跃社区主导领域
TensorFlow 在所有计算指标中至少比均值高出两个标准差。TensorFlow 的 Github fork 数量几乎是第二受欢迎框架 Caffe 的三倍,Stack Overflow 上的问题数量超过了 Caffe 的六倍。TensorFlow 于 2015 年由 Google Brain 团队首次开源,已经超越了 Theano (4) 和 Torch (8) 等更资深的库,成为我们列表中的顶尖位置。虽然 TensorFlow 是一个运行在 C++ 引擎上的 Python API,但我们列表中的几个库可以将 TensorFlow 用作后端,并提供它们自己的接口。这些库包括 Keras (2),它将 很快成为核心 TensorFlow 的一部分 和 Sonnet (6)。TensorFlow 的受欢迎程度可能是由于其通用的深度学习框架、灵活的接口、漂亮的计算图可视化以及 Google 的大量开发者和社区资源。
Caffe 尚未被 Caffe2 替代
Caffe 在我们的列表中稳居第三位,其 Github 活动比所有竞争对手(不包括 TensorFlow)都要多。Caffe 通常被认为比 TensorFlow 更专业,主要开发用于图像处理、物体识别和预训练卷积神经网络。Facebook 于 2017 年 4 月发布了 Caffe2 (11),它已经在深度学习库中排名前半。Caffe2 是 Caffe 的更轻量级、模块化和可扩展的版本,包含递归神经网络。Caffe 和 Caffe2 是独立的库,因此数据科学家可以继续使用原始的 Caffe。然而,像 Caffe Translator 这样的迁移工具提供了使用 Caffe2 驱动现有 Caffe 模型的方式。
Keras 是深度学习最受欢迎的前端
Keras (2) 是排名最高的非框架库。Keras 可以作为 TensorFlow (1)、Theano (4)、MXNet (7)、CNTK (9) 或 deeplearning4j (14) 的前端。Keras 在所有三项度量指标中表现优于平均水平。Keras 的受欢迎程度可能归因于其简洁性和易用性。Keras 允许快速原型设计,但牺牲了一些直接使用框架时的灵活性和控制力。数据科学家在数据集上尝试深度学习时,常常偏爱 Keras。Keras 的发展和受欢迎程度持续增长,R Studio 最近发布了 一个接口 供 Keras 在 R 中使用。
Theano 即使没有大规模的行业支持仍继续保持顶尖位置
在众多新的深度学习框架中,Theano(4)是我们排名中最古老的库。Theano 开创了计算图的使用,并且在深度学习和机器学习的研究社区中仍然很受欢迎。Theano 本质上是一个 Python 的数值计算库,但可以与像 Lasagne(15)这样的高级深度学习封装库一起使用。虽然谷歌支持 TensorFlow(1)和 Keras(2),Facebook 支持 PyTorch(5)和 Caffe2(11),MXNet(7)是 Amazon Web Services 的官方深度学习框架,而微软设计并维护 CNTK(9),Theano 依然在没有来自技术行业巨头的官方支持下保持受欢迎。
Sonnet 是增长最快的库
2017 年初,谷歌的 DeepMind 公开发布了 Sonnet(6)的代码,这是一个建立在 TensorFlow 之上的高级面向对象库。与上一季度相比,Google 搜索结果中 Sonnet 的页面数量增长了 272%,是我们排名中的所有库中增长最多的。尽管谷歌在 2014 年收购了这家英国人工智能公司,DeepMind 和 Google Brain 仍然保持着大致独立的团队。DeepMind 专注于人工通用智能,而 Sonnet 可以帮助用户在其特定的人工智能想法和研究基础上进行构建。
Python 是深度学习接口的语言
PyTorch(5),一个唯一接口在 Python 中的框架,是我们列表中增长第二快的库。与上季度相比,PyTorch 的 Google 搜索结果增加了 236%。在我们排名的 23 个开源深度学习框架和封装库中,只有三个没有 Python 接口:Dlib(10),MatConvNet(20),和 OpenNN(23)。C++和 R 接口仅在 23 个库中的七个和六个中提供。尽管数据科学社区在使用 Python 方面基本达成了共识,但深度学习库仍然有许多选择。
限制
像任何分析一样,在过程中做出了一些决策。所有源代码和数据都在我们的 Github 页面上。深度学习库的完整列表来自几个来源。
自然,使用时间较长的一些库将有更高的指标,因此排名也更高。唯一考虑到这一点的指标是 Google 搜索的季度增长率。
数据呈现出一些困难:
-
neural designer 和 Wolfram Mathematica 是专有的,已被移除
-
cntk 也称为微软认知工具包,但我们只使用了原始的 ctnk 名称。
-
neon 已更改为 nervana neon
-
paddle 已更改为 paddlepaddle
-
一些库显然是其他库的衍生品,如 Caffe 和 Caffe2。我们决定如果库有独特的 github 存储库,则单独对待这些库。
方法
所有源代码和数据都在我们的 Github 页面上。
我们首先生成了一个包含 23 个开源深度学习库的列表 从 每个 五个 不同 来源,然后收集了所有这些库的指标,以得出排名。Github 数据基于星标和分叉,Stack Overflow 数据基于标签和包含包名称的问题,Google 结果基于过去五年的 Google 搜索结果总数和过去三个月相较于前后三个月的结果季度增长率。
一些其他说明:
-
由于几个库的名称是常见词(如 caffe,chainer,lasagne),因此用来确定 Google 搜索结果数量的搜索词包括库名称和“深度学习”一词。
ing"。
-
任何不可用的 Stack Overflow 计数被转换为零计数。
-
计数标准化为均值 0 和标准差 1,然后平均得到 Github 和 Stack Overflow 评分,并结合搜索结果计算总体评分。
-
一些手动检查用于确认 Github 存储库位置。
所有数据均于 2017 年 9 月 14 日下载。
资源
源代码可在 The Data Incubator's GitHub 上获取。如果你有兴趣了解更多,请考虑
简介:Michael Li 曾在(Foursquare)担任数据科学家,在(D.E. Shaw,J.P. Morgan)担任量化分析师,以及在(NASA)担任火箭科学家。他在普林斯顿获得了赫兹奖学金博士学位,并作为马歇尔奖学金获得者在剑桥大学学习了数学三部分。在 Foursquare,Michael 发现他最喜欢的工作部分是教授和指导聪明的人关于数据科学的知识。他决定创建一个初创公司,让他专注于自己真正喜欢的事情。
更多相关主题
人工智能和机器学习可以做什么——以及不能做什么
原文:
www.kdnuggets.com/2017/08/rapidminer-ai-machine-learning-can-do.html
作者:Ingo Mierswa,RapidMiner。 赞助文章。
在我上一篇文章中,我写到了人工智能(AI)。上次我写人工智能时,重点在于技术方面:什么是人工智能系统的一部分,什么不是。然而,还有一个可能更重要的问题:我们在用人工智能做什么?
我工作的部分内容是帮助投资者在审查人工智能公司时进行尽职调查。我与他们讨论他们可能想投资的公司。在这个过程中,我观察到每个公司推介都充满了关于他们如何使用人工智能解决业务问题的内容。
我喜欢这一点,因为其中一些公司可能真的有创新之处,我相信每个创业者都应该有机会。然而,我的另一部分则把这看作是内置的人工智能“胡说八道检测器”。每当我听到某个创始人编造人工智能将如何帮助他们公司的故事时,我都会想要缩缩脖子。我听过很多创始人,他们对人工智能知之甚少,但知道这会帮助他们获得资金。我又算什么呢?
我见过人工智能(或至少是机器学习)对业务产生巨大影响的情况——也见过这种情况不成立的例子。那么,区别是什么呢?
在大多数组织在使用人工智能或机器学习失败的案例中,他们往往是在错误的背景下使用这些技术。如果你只有一个重要的决策需要做,机器学习模型的帮助并不大。分析工具仍然可以通过以易于理解的方式展示数据,使你更容易获取做出决策所需的数据。归根结底,这些单一的大决策往往非常战略性。构建一个机器学习模型或人工智能来帮助你做这个决策并不值得付出努力,往往也不会带来更好的结果。
这里就是机器学习和人工智能可以发挥作用的地方。机器学习和人工智能在你需要快速做出大量类似决策时能提供最大的价值。 一些好的例子包括:
-
在需求快速变化的市场中定义产品价格。
-
在商业平台上进行交叉销售的提案。
-
批准或拒绝信用申请。
-
识别高流失风险的客户并确定下一个最佳行动。
-
阻止欺诈性金融交易。
-
……等等
你可以看到,如果一个人拥有所有相关数据,他们可以做出这些决策——但没有 AI 或机器学习,他们无法做到这一点,因为他们需要每天做出数百万次这样的决策。想象一下,每天从 5000 万客户中筛选出高流失风险的客户。这对任何人来说都是不可能的,但对机器学习模型来说却完全没有问题。
所以,人工智能和机器学习的最大价值在于支持我们做出重大战略决策。机器学习在我们操作化模型并自动化数百万个决策时提供最大价值。
下图展示了决策的范围以及人类做出决策所需的时间。蓝色框表示分析可以提供帮助,但未能发挥全部价值的情况。橙色框表示 AI 和机器学习显示出真实价值的情况。有趣的观察是你能够自动化的决策越多,价值就越高(该范围的右上端)。
图 1:自动化决策的能力
这个现象的最佳描述之一来自于Andrew Ng,一位知名的 AI 领域研究人员。Andrew 描述了AI 能做什么,如下:
“如果一个普通人可以在不到一秒钟的时间内完成一个心理任务,我们现在或者不久的将来可能就可以用 AI 来自动化这个任务。”
我同意他对这种描述的看法,我喜欢他强调自动化和模型的操作化,因为这正是最大价值所在。我唯一不同意的是他选择的时间单位——选择分钟而不是秒钟更为安全。
如果你在寻找更多机器学习如何帮助你的业务的方法,可以查看我最近的网络研讨会如何通过数据科学和机器学习毁掉你的业务,在这个研讨会中,我讲述了如何将机器学习应用到你的业务中,并展示了如何从统计模型中得出完全错误的结论。
个人简介:Ingo Miersw,博士,RapidMiner 的创始人和总裁。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
更多相关主题
什么是人工智能、机器学习和深度学习?
原文:
www.kdnuggets.com/2017/07/rapidminer-ai-machine-learning-deep-learning.html
由 RapidMiner 提供。赞助帖子。
几乎每天我们都能在媒体上看到关于人工智能的新闻。以下是一些近期新闻标题的简短汇编:
-
这个机器人解释了为什么你不需要担心人工智能——没错,确实如此。一个会说话的机器人肯定能做到让那些反对者不再过度担忧…
-
人工智能如何学习变得有种族歧视——简单来说:它在模仿我们…
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
有趣的是,大多数这些文章都有一种怀疑甚至是负面的语气。这种情绪也受到比尔·盖茨、埃隆·马斯克甚至斯蒂芬·霍金的言论推动。恕我直言,我不会在公共场合谈论关于虫洞的废话,也许我们都应该多关注一下自己的专业领域。
这一切突显了两点:1. 人工智能和机器学习终于成为主流,2. 人们对这些技术了解惊人地少。
关于这些话题也存在大量炒作。我们都听说过“线性回归”。这并不令人惊讶,因为它是由勒让德和高斯 200 多年前发明的。尽管如此,这种炒作过度可能导致人们在使用这种方法时被带偏。这里是我最喜欢的一些推文交流,体现了这一点:
@katherinebailey 因为市场营销?每次有人把简单线性回归称为“人工智能”时,高斯都会在坟墓里翻身。
— RapidMiner (@RapidMiner) 2017 年 4 月 15 日
显然,这些术语周围存在很高的混淆。这篇文章应有助于你理解这些领域之间的差异以及它们之间的关系。让我们从下面的图片开始。它解释了三个术语:人工智能、机器学习和深度学习。

人工智能涵盖了任何使计算机表现得像人的东西。想想那个著名的(虽然有点过时的)图灵测试,用来确定是否如此。如果你在手机上跟 Siri 对话并得到答案,你已经很接近了。使用机器学习来更具适应性的自动交易系统也已经属于这一类别。
机器学习是人工智能的一个子集,处理从数据集中提取模式的问题。这意味着机器可以找到最佳行为的规则,还可以适应世界的变化。许多涉及的算法已经被知道了几十年甚至几个世纪。得益于计算机科学和并行计算的进步,它们现在可以扩展到庞大的数据量。
深度学习是使用复杂神经网络的机器学习算法的一种特定类别。从某种意义上说,它是一组相关技术,类似于“决策树”或“支持向量机”组。但由于并行计算的进步,它们最近得到了很多炒作,这就是为什么我在这里单独列出它们。正如你所看到的,深度学习是机器学习方法的一个子集。当有人解释深度学习与机器学习“截然不同”时,他们是错误的。如果你想要了解不含 BS 的深度学习视角,看看我之前做的这个网络研讨会。
但是,如果机器学习只是人工智能的一个子集,那么这个领域还有什么其他部分呢?以下是对这三个组中最重要的研究领域和方法的总结:
-
人工智能: 机器学习(当然!)、自然语言理解、语言合成、计算机视觉、机器人技术、传感器分析、优化与模拟等。
-
机器学习: 深度学习(再说一遍!)、支持向量机、决策树、贝叶斯学习、k 均值聚类、关联规则学习、回归等等。
-
深度学习: 人工神经网络、卷积神经网络、递归神经网络、长短期记忆网络、深度置信网络等等。
正如你所见,每个领域都有数十种技术,研究人员每周都会生成新的算法。虽然这些算法可能很复杂,但如上所述的概念差异却并不复杂。
我们希望这对你区分这些术语有所帮助。如果你对机器学习感兴趣,可以查看这篇关于 如何正确验证机器学习模型 的白皮书。
更多相关内容
K-最近邻——最懒的机器学习技术
原文:
www.kdnuggets.com/2017/09/rapidminer-k-nearest-neighbors-laziest-machine-learning-technique.html
由 Rapidminer 赞助的帖子。
K-最近邻(K-NN)是最简单的机器学习算法之一。像其他机器学习技术一样,它的灵感来源于人类推理。例如,当生活中发生重大事件时,你会记住这个经历,并将其作为未来决策的指南。
让我给你举一个掉落玻璃的场景。当玻璃正在下落时,你预测玻璃会在撞击地面时破碎。但你是怎么做到的呢?你之前从未见过这个玻璃破碎,对吧?
实际上,不是的。但你之前见过类似的玻璃掉落在地上。虽然情况可能并不完全相同,但你知道从 5 英尺高的地方掉落到混凝土地板上的玻璃通常会破碎,这使你对结果有很高的信心。
那么,掉落玻璃从较短的距离落在柔软的地毯上呢?你也经历过这种情况吗?我们可以看到,距离和地面表面都会对结果产生影响。
这就是 K-NN 算法使用的推理方式。当新的情况发生时,它会扫描所有过去的经历,并查找 k 个最接近的经历。这些经历(或称数据点)就是我们所谓的k 个最近邻。
如果你有一个分类任务,例如你想预测玻璃是否会破碎,你会根据所有 k 个邻居的多数投票来做出预测。如果 k=5,并且在你最相似的经历中有 3 次或更多次玻璃破碎,那么它会预测“是的,它会破碎”。
现在假设你想预测玻璃会破成多少片。在这种情况下,你想预测一个数字,我们称之为“回归”。你将 k 个邻居的玻璃碎片数量的平均值作为预测或评分。如果 k=5,碎片数量分别是 1(未破碎)、4、8、2 和 10,那么你的预测结果将是 5。
我们有蓝色和橙色的数据点。对于一个新的数据点(绿色),我们可以通过查看最近邻居的类别来确定最可能的类别。在这里,决定将是“蓝色”,因为这是大多数邻居的类别。
那么为什么这个算法被称为“懒惰”的呢?这是因为当你提供训练数据时,它不会进行任何训练。在训练时,它只是存储数据集,并不会在此时进行任何计算。它也不会尝试从数据中导出更紧凑的模型来进行评分。
理论
所有计算都发生在评分过程中,即当你将模型应用于未见过的数据点时。你需要确定在我们的训练集中哪些 k 个数据点最接近我们要预测的数据点。
假设我们的数据点如下所示:

我们有一个包含n行和m+1列的表格,其中前m列是我们用来预测剩余标签列(也称为“目标”)的属性。现在,假设所有属性值x都是数值型的,而标签值y是分类的,即我们有一个分类问题。
现在我们可以定义一个距离函数来计算数据点之间的距离。它应该为任何新点找到我们训练数据中最接近的数据点。如果数据是数值型的,欧几里得距离通常是一个不错的距离函数选择。如果我们的新数据点具有属性值s**1到s**m,我们可以通过以下公式计算点s到任何数据点x**j的距离d(s, xj:
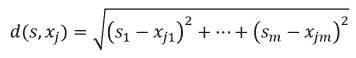
距离最近的 k 个数据点成为我们的 k 个邻居。对于分类任务,我们现在使用 k 个邻居中所有值y中最频繁的那个。对于回归任务,当y是数值型时,我们使用 k 个邻居中所有值y的平均值。
但如果我们的属性不是数值型的,且不包含数值和分类属性呢?那你可以使用其他能够处理这种数据类型的距离度量。这篇文章讨论了一些常见的选择。
顺便提一下,k=1 的 K-NN 模型是为什么计算训练错误完全没有意义的原因。你能看出为什么吗?
实际应用
K-NN 应该是你工具箱中的一个标准工具。它快速、易于理解,并且容易调整以适应不同类型的预测问题。
数据准备
使用 K-NN 时需要考虑一些问题。我们已经看到算法的关键部分是距离度量的定义,而欧几里得距离通常被使用。然而,这种距离度量将所有数据列视为相同。它在累加这些距离的平方之前,会减去每个维度的值。这意味着数据范围较大的列对距离的影响大于数据范围较小的列。
因此,你需要对数据集进行归一化,以使所有列的大致尺度相同。归一化有两种常见方法。首先,你可以将某列的所有值调整到 0 到 1 之间。或者你可以改变每列的值,使得该列在调整后具有均值为 0 和标准差为 1。我们称这种归一化方法为z-变换或标准分数。
提示:每当你知道机器学习算法在使用距离度量时,你应该对数据进行归一化。另一个著名的例子是 k-均值聚类。
调整参数
你需要调整的最重要参数是 k,即用于做出分类决策的邻居数量。最小值为 1,在这种情况下,你只查看每个预测的最近邻居以做出决策。理论上,你可以使用一个与训练集总量相同的 k 值。然而这样做没有意义,因为在这种情况下你总是会预测完整训练集的多数类别。
这里有一个好的方式来解释 k 的含义。小的 k 值表示“局部”模型,这些模型可以是非线性的,并且类别之间的决策边界会出现很多波动。如果 k 值增大,波动会减少,直到你几乎得到一个线性的决策边界。

我们看到左侧的一个二维数据集。通常,右上方是红色类,左下方是蓝色类。但在两个区域内部也有一些局部群体。k 值小会导致更为弯曲的决策边界。对于较大的 k 值,决策边界变得更平滑,这种情况下几乎是线性的。
合适的 k 值取决于你拥有的数据以及问题是否非线性。你应该尝试几个在 1 到训练数据集大小的约 10%之间的值,以查看是否有值得进一步优化 k 的有希望的区域。
你可能还需要考虑的第二个参数是你使用的距离函数类型。对于数值数据,欧氏距离是一个不错的选择。你也可以尝试一下曼哈顿距离,它有时也会被使用。对于文本分析,余弦距离也可以是一个值得尝试的好替代方案。
内存使用情况与运行时间
请注意,这个算法所做的只是存储完整的训练数据。因此,内存需求随着你提供的训练数据点数量线性增长。这个算法的更智能实现可能会选择以更紧凑的方式存储数据。但在最坏情况下,你仍然会面临大量的内存使用。
对于训练,运行时间已经是最好的。算法除了存储数据外没有进行任何计算,而存储是快速的。
然而,评分的运行时间可能会很长,这在机器学习领域是不常见的。所有计算都发生在模型应用期间。因此,评分运行时间与数据列数 m 和训练点数 n 线性增长。如果你需要快速评分而训练数据点数量又很大,那么 K-NN 不是一个好的选择。
RapidMiner 流程
想自己构建这个机器学习模型? 下载 RapidMiner并使用下面的过程*。
-
训练和应用 K-NN 模型: knn_training_scoring
-
优化 k 值: knn_optimize_parameter
下载 Zip 文件并提取其内容。结果将是一个.rmp 文件,可以通过“文件”->“导入过程”在 RapidMiner 中加载。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
相关主题更多信息
RAPIDS cuDF 在 Google Colab 上加速数据科学
原文:
www.kdnuggets.com/2023/01/rapids-cudf-accelerated-data-science-google-colab.html

图片由编辑提供
NVIDIA GPU 已成为加速计算密集型机器学习任务的最有效方式之一。现在,得益于 RAPIDS cuDF,GPU 还可以为你的数据分析工作提供加速。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
什么是 RAPIDS cuDF?
RAPIDS cuDF 是一个开源的、GPU 加速的数据框架库,它实现了熟悉的 pandas API 用于处理和分析数据。Python cuDF 接口基于 libcudf,即 CUDA/C++ 计算核心,能够加速从数据摄取和解析到连接、聚合等基本数据操作。在某些工作负载下,你会发现将 import pandas 切换到 import cudf 可以加速工作负载,并且数据处理速度提高 10 倍或更多。
例如,通过切换到 cuDF,一个简单的连接操作可以从 761 毫秒缩短到 27 毫秒:
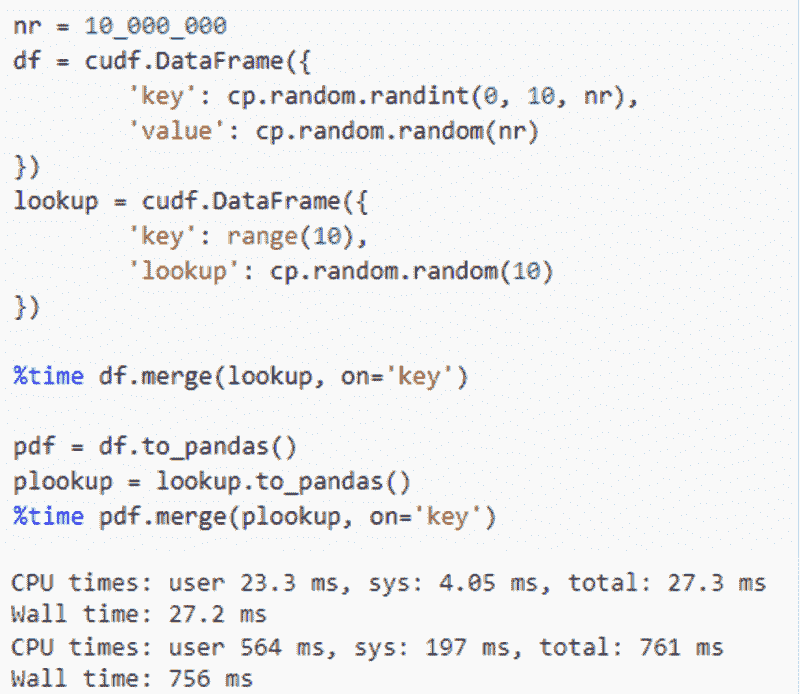
开始在 Colab 上使用 RAPIDS
现在在 Colab 上开始使用 RAPIDS 比以往任何时候都更加容易。借助 Colab 的 默认运行时更新到 Python 3.8 和新的 RAPIDS pip 包,你可以直接在浏览器中尝试 NVIDIA GPU 加速的数据科学。运行 RAPIDS 在 Colab 上只需两个快速步骤:
-
首先,选择一个使用 GPU 加速器的 Colab 运行时。导航到“运行时”菜单,选择“更改运行时类型”,然后从下拉菜单中选择“GPU”,并点击“保存”。你从 Colab 获得的 NVIDIA GPU 可能会因会话而异,包括新一代 GPU 和旧一代 GPU。使用 Colab 的“按需付费”层级,你现在可以选择通过 Colab Pro 升级运行时至“高级 GPU”,以便访问更强大的 NVIDIA A100 或 V100 Tensor Core GPU。 [查看 Google 的博客文章,了解更多关于 GPU 可用性的信息。]( https://blog.tensorflow.org/2022/09/colabs-pay-as-you-go-offers-more-access-to-powerful-nvidia-compute-for-machine-learning.html#:~:text=Paid Colab users can now ,or%20A100%20Tensor%20Core%20GPUs.)
-
第二步,在你的笔记本中安装 RAPIDS cuDF。使用新的 RAPIDS pip 包,这一步比以往任何时候都更简单。在代码块中执行以下命令,你将设置好运行 RAPIDS。安装完成后,确保重启你的运行时:
!pip install cudf-cu11 --extra-index-url=https://pypi.ngc.nvidia.com
!rm -rf /usr/local/lib/python3.8/dist-packages/cupy*
!pip install cupy-cuda11x
最后,检查 import cudf 是否在新的代码块中成功完成,然后你就可以开始了。如果遇到任何问题,请通过 在 RAPIDS Slack 中 联系我们,我们将帮助你解决问题。
在 Colab 上运行 10 分钟的 cuDF
现在你有了一个工作的 cuDF 安装和一个 GPU,你可以运行我们的教程笔记本,“10 分钟到 cuDF。” 这个笔记本受到了 Pandas 社区类似指南的启发,是我们完整笔记本“10 分钟到 cuDF 和 Dask-cuDF”的简化版。
在笔记本中运行时,你会发现数据框创建、数据过滤、转换、连接、聚合等示例。我们还包括了 Parquet、ORC 和 CSV 格式的文件读取和写入示例。随着你深入探索更复杂的数据处理,我们希望你将此作为 cuDF 文档的补充。
探索 RAPIDS 的其他部分
当你准备好深入了解时,RAPIDS 还包括 Dask-cuDF 用于大规模工作流, cuML 用于与 scikit-learn 兼容的加速机器学习,以及 cuGraph 用于图数据分析。按照以下代码块中所示的扩展安装列表更新你的 Colab 笔记本,你将准备好使用完整的工具包。
!pip install cudf-cu11 dask-cudf-cu11 cuml-cu11 cugraph-cu11 --extra-index-url=https://pypi.ngc.nvidia.com
!rm -rf /usr/local/lib/python3.8/dist-packages/cupy*
!pip install cupy-cuda11x
这里有一些额外的 RAPIDS 笔记本,你可以探索以了解更多关于 RAPIDS 的信息:
保罗·马勒 是位于科罗拉多州丹佛的 NVIDIA 高级数据科学家及机器学习技术产品经理。在 NVIDIA,保罗的工作重点是通过利用 GPU 技术的强大功能来构建加速数据科学工作流的工具。
原文。已获许可转载。
更多相关内容
使用 RAPIDS cuDF 在特征工程中利用 GPU
原文:
www.kdnuggets.com/2023/06/rapids-cudf-leverage-gpu-feature-engineering.html编辑备注:这是我们最近 NVIDIA + KDnuggets GPU 主题博客写作比赛的亚军。恭喜 Hasan 取得这一成就!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
特定方法成功解决问题的事实可能不会在不同规模上产生相同的结果。当距离改变时,鞋子也需要改变。
在机器学习中,数据及数据处理对模型的成功至关重要,而特征工程是其中的一部分。当数据量较小时,经典的 Pandas 库可以轻松处理 CPU 上的任何处理任务。然而,Pandas 在处理大数据时可能过于缓慢。提高数据处理和特征工程速度和效率的一个解决方案是 RAPIDS。
“RAPIDS 是一套开源软件库,用于在图形处理单元(GPU)上执行端到端的数据科学和分析管道。RAPIDS 加速了数据科学管道,以创建更高效的工作流程。[1]”

图片由brgfx提供,来源于 Freepik
RAPIDS 的一个工具,用于在特征工程和数据预处理中高效操作表格数据,是cuDF。RAPIDS cuDF 允许创建 GPU 数据框,并执行多个Pandas操作,如索引、分组、合并和字符串处理。正如 RAPIDS 网站定义的:
“cuDF 是一个 Python GPU DataFrame 库(基于 Apache Arrow 列式内存格式),用于加载、连接、聚合、过滤和以 DataFrame 风格的 API 处理表格数据,类似于 pandas。[2]”
本文尝试解释如何创建和操作数据框,并在 GPU 上使用cuDF应用特征工程,采用真实数据集。
我们的数据集属于 Kaggle 的 Optiver 实际波动预测。它包含与金融市场中实际交易执行相关的股票市场数据,包括订单簿快照和执行的交易[3]。
我们将在下一节中深入了解数据。然后,我们将整合 Google Colab 与 Kaggle 和 RAPIDS。在第三节中,我们将看到如何使用Pandas和cuDF对这个数据集进行特征工程。这将为我们提供两个库的比较性能评估。在最后一节中,我们将绘制并评估结果。
数据
我们将要使用的数据包括两个文件集[3]:
- book_[train/test].parquet:一个 Parquet 文件,按 stock_id 分区,提供市场中最具竞争力的买入和卖出订单的订单簿数据。此文件包含被动买入/卖出意图更新。
book_[train/test].parquet 中的特征列:
-
stock_id - 股票的 ID 代码。Parquet 在加载时将此列强制转换为分类数据类型。
-
time_id - 时间桶的 ID 代码。时间 ID 不一定是顺序的,但在所有股票中是一致的。
-
seconds_in_bucket - 从桶的开始时间起的秒数,总是从 0 开始。
-
bid_price[1/2] - 最具竞争力的买入价/第二具竞争力买入价的标准化价格。
-
ask_price[1/2] - 最具竞争力的卖出价/第二具竞争力卖出价的标准化价格。
-
bid_size[1/2] - 最具竞争力的买入价/第二具竞争力买入价的股份数量。
-
ask_size[1/2] - 最具竞争力的卖出价/第二具竞争力卖出价的股份数量。
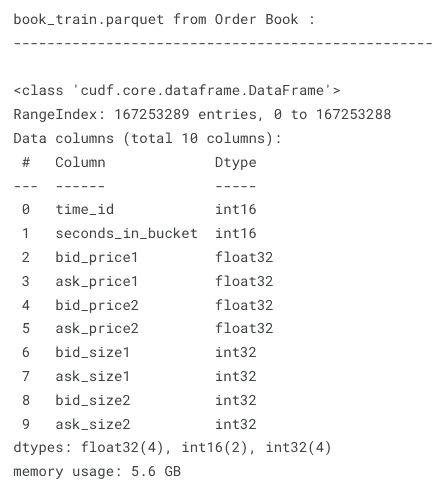
展示-1:book_[train/test].parquet 的描述(作者提供的图像)
此文件大小为 5.6 GB,包含超过 1.67 亿条记录。有 112 只股票和 3830 个 10 分钟的时间窗口(time_id)。每个时间窗口(桶)最多有 600 秒。由于每个时间窗口中的每只股票每秒钟可能会发生一个交易意图,因此上述数字的乘积可以解释为什么我们有数百万条记录。需要注意的是,并非每秒钟都会发生交易意图,这意味着某些时间窗口中的某些秒数是缺失的。
- trade_[train/test].parquet:一个 Parquet 文件,按 stock_id 分区,包含实际执行的交易数据。
trade_[train/test].parquet 中的特征列:
-
stock_id - 同上。
-
time_id - 同上。
-
seconds_in_bucket - 同上。请注意,由于交易和订单数据来自相同的时间窗口,并且交易数据通常更稀疏,因此此字段不一定从 0 开始。
-
price - 在一秒钟内执行交易的平均价格。价格已经过标准化,平均值按每笔交易中交易的股份数量加权。
-
size - 交易的总股数。
-
order_count - 交易订单的唯一数量。
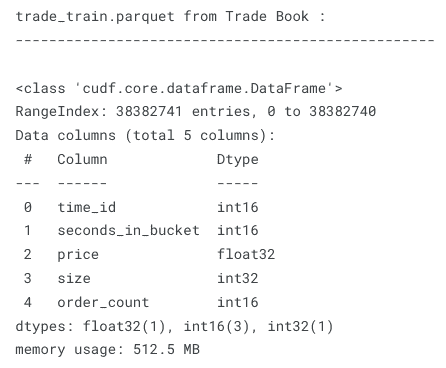
展示-2:trade_[train/test].parquet 文件描述(作者提供的图片)
trade_[train/test].parquet 文件远小于 book_[train/test].parquet。前者为 512.5 MB,有超过 3800 万条记录。由于实际交易不一定符合意图,交易数据更为稀疏,因此条目较少。
目标是预测在相同 stock_id/time_id 下的特征数据在接下来的 10 分钟窗口内的实际股票价格波动。该项目涉及大量特征工程,需在大数据集上进行。开发新特征还会增加数据量和计算复杂性。一种解决办法是使用 cuDF 替代 Pandas 库。
在这篇博客中,我们将探讨一些特征工程任务和数据框操作,同时尝试 Pandas 和 cuDF 以比较它们的性能。然而,我们不会使用所有数据,而只使用单只股票的记录以展示一个示例实现。可以查看 笔记本 来了解对整个数据进行的特征工程工作。
由于我们在 Google Colab 上执行代码,首先应配置我们的笔记本以集成 Kaggle 和 RAPIDS。
Google Colab 笔记本配置
配置 Colab 笔记本的步骤如下:
- 在 Kaggle 账户上创建一个 API 令牌,以便用 Kaggle 服务进行身份验证。
展示-3:在 Kaggle 账户上创建 API 令牌(作者提供的图片)
转到设置并点击“创建新令牌。” 会下载一个名为“kaggle.json”的文件,其中包含用户名和 API 密钥。
- 在 Google Colab 上启动一个新的笔记本并上传 kaggle.json 文件。
展示-4:在 Google Colab 中上传 kaggle.json 文件(作者提供的图片)
点击“上传到会话存储”图标,在 Google Colab 中上传 kaggle.json 文件。
-
点击页面顶部的“运行时”下拉菜单,然后选择“更改运行时类型”,确认实例类型为 GPU。
-
执行以下命令并检查输出,确保你分配到了 Tesla T4、P4 或 P100。
!nvidia-smi
- 获取 RAPIDS-Colab 安装文件并检查你的 GPU:
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git
!python rapidsai-csp-utils/colab/pip-install.py
确保你的 Colab 实例在该单元格的输出中兼容 RAPIDS。
展示-5:检查 Colab 实例是否兼容 RAPIDS(作者提供的图片)
- 检查 RAPIDS 库是否正确安装:
import cudf, cuml
cudf.__version__
如果设置没有错误,我们的 Google Colab 配置就绪。现在,我们可以上传 Kaggle 数据集。
导入和上传 Kaggle 数据集
我们需要在 Colab 实例中进行一些调整以从 Kaggle 导入数据集。
- 安装 Kaggle 库:
!pip install -q kaggle
- 创建一个名为“.kaggle”的目录:
!mkdir ~/.kaggle
- 将“kaggle.json”复制到这个新目录中:
!cp kaggle.json ~/.kaggle/
- 为此文件分配所需的权限:
!chmod 600 ~/.kaggle/kaggle.json
- 从 Kaggle 下载数据集:
!kaggle competitions download optiver-realized-volatility-prediction
- 为解压缩的数据创建一个目录:
!mkdir train
- 在新目录中解压数据:
!unzip optiver-realized-volatility-prediction.zip -d train
- 导入我们需要的所有其他库:
import glob
import numpy as np
import pandas as pd
from cudf import DataFrame
import matplotlib.pyplot as plt
from matplotlib import style
from collections import defaultdict
from IPython.display import display
import gc
import time
import warnings
%matplotlib inline
- 设置Pandas选项:
pd.set_option("display.max_colwidth", None)
pd.set_option("display.max_columns", None)
warnings.filterwarnings("ignore")
print("Threshold:", gc.get_threshold())
print("Count:", gc.get_count())
- 定义参数:
# Data directory that contains files
DIR = "/content/train/"
# Number of execution cycles
ROUNDS = 30
- 获取文件:
# Get order and trade books
order_files = glob.glob(DIR + "book_train.parquet" + "/*")
trade_files = glob.glob(DIR + "trade_train.parquet" + "/*")
print(order_files[:5])
print("\n")
print(trade_files[:5])
print("\n")
# Get stock_ids as a list
stock_ids = sorted([int(file.split('=')[1]) for file in order_files])
print(f"{len(stock_ids)} stocks: \n {stock_ids} \n")
现在,我们的笔记本已经准备好运行所有数据框任务并执行特征工程。
特征工程
本节将讨论在Pandas数据框和cuDF上进行的 13 种典型工程操作。我们将查看这些操作所需的时间和使用的内存。让我们首先加载数据。
1. 加载数据
def load_dataframe(files, dframe=0):
print("LOADING DATA FRAMES", "\n")
# Load the pandas dataframe
if dframe == 0:
print("Loading pandas dataframe..", "\n")
start = time.time()
df_pandas = pd.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"For pandas dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n")
return df_pandas, elapsed_time
# Load the cuDF dataframe
else:
print("Loading cuDF dataframe..", "\n")
start = time.time()
df_cudf = cudf.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"For cuDF dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n ")
return df_cudf, elapsed_time
当 dframe=0 时,数据将以Pandas数据框的形式加载,否则为cuDF。例如,
Pandas:
# Load pandas order dataframe and calculate time
df_pd_order, _ = load_dataframe(order_files, dframe=0)
display(df_pd_order.head())
这将返回订单簿(book_[train/test].parquet)的前五条记录:
展示-6:将数据加载为 Pandas 数据框(图片由作者提供)
cuDF:
# Load cuDF book dataframe and calculate time
df_cudf_order, _ = load_dataframe(order_files, dframe=1)
display(df_cudf_order.head())
输出:
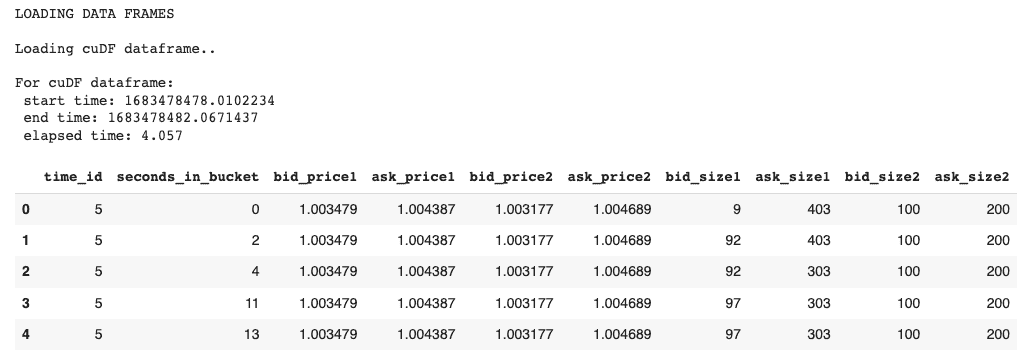
展示-7:将数据加载为 cuDF(图片由作者提供)
让我们从Pandas版本中获取订单簿数据的信息:
# Order dataframe info
display(df_pd_order.info())
输出:
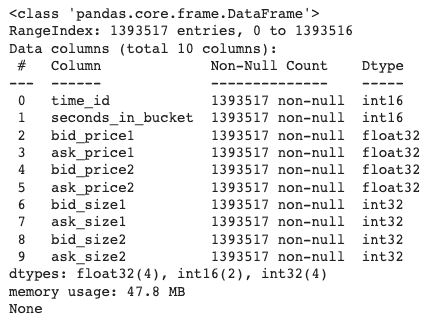
展示-8:有关第一个股票订单簿数据的信息(图片由作者提供)
上面的图片告诉我们,第一个股票大约有 140 万条记录,占用 47.8 MB 的内存空间。为了减少空间并提高速度,我们应该将数据类型转换为较小的格式,我们将在稍后完成。
以类似的方式,我们将订单簿数据加载到两个数据框库中,也就是交易簿(trade_[train/test].parquet)数据。数据及其信息如下所示:
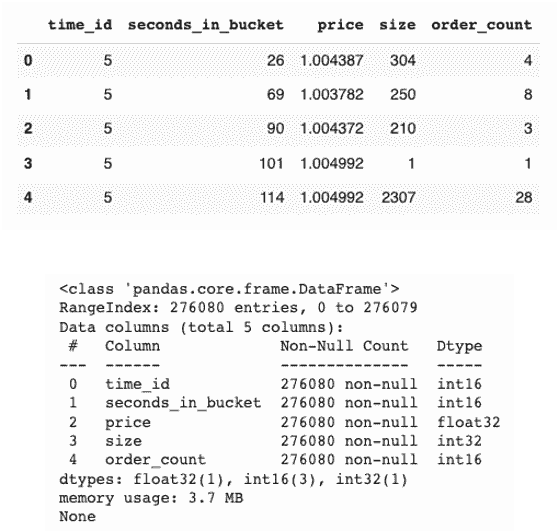
展示-9:第一个股票的交易簿数据及数据说明(图片由作者提供)
第一个股票的交易数据为 3.7 MB,记录超过 276 千条。
在订单簿和交易簿两个文件中,并非每个时间窗口都有 600 个秒点。换句话说,特定时间桶在 10 分钟间隔内可能只在某些秒钟有交易或出价。这使我们在两个文件中都面临着稀疏数据,其中一些秒钟缺失。我们应通过对缺失秒钟的所有列进行前向填充来解决此问题。虽然 Pandas 允许我们进行前向填充,但 cuDF 没有这个功能。因此,我们将在 Pandas 中进行前向填充,并从前向填充的 Pandas 数据框架重新创建 cuDF。对此我们感到遗憾,因为本博客的核心目标是展示 cuDF 如何胜过 Pandas。我曾多次查阅过此事,但据我所知,我无法找到 cuDF 中像 Pandas 中实现的方法。因此,我们可以按以下方式进行前向填充[4]:
# Forward fill data
def ffill(df, df_name="order"):
# Forward fill
df_pandas = df.set_index(['time_id', 'seconds_in_bucket'])
if df_name == "order":
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']), method='ffill')
df_pandas = df_pandas.reset_index()
else:
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']))
# Fill nan values with 0
df_pandas = df_pandas.fillna(0)
df_pandas = df_pandas.reset_index()
# Convert to a cudf dataframe
df_cudf = cudf.DataFrame.from_pandas(df_pandas)
return df_pandas, df_cudf
让我们以订单数据为例,看看它是如何处理的:
# Forward fill order dataframes
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
display(expanded_df_cudf_order.head())

展览-10:前向填充订单数据(作者提供的图片)
与展示 7 中的数据不同,展示 10 中的前向填充数据在时间桶“5”中有全部 600 秒,即从 0 到 599,全包括。我们在交易数据上也执行同样的操作。
2. 合并数据框架
我们有两个数据集,订单和交易,两者都已前向填充。这两个数据集在 Pandas 和 cuDF 框架中都有表现。接下来,我们将订单和交易数据集按 time_id 和 seconds_in_buckets 合并。
def merge_dataframes(df1, df2, dframe=0):
print("MERGING DATA FRAMES", "\n")
if dframe == 0:
df_type = "Pandas"
else:
df_type = "cuDF"
# Merge dataframes
print(f"Merging {df_type} dataframes..", "\n")
start = time.time()
df = df1.merge(df2, how="left", on=["time_id", "seconds_in_bucket"], sort=True)
end = time.time()
elapsed_time = round(end-start, 3)
print(f"For {df_type} dataframes: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n")
return df, elapsed_time
cuDF 将执行以下命令:
# Merge cuDF order and trade dataframes
df_cudf, cudf_merge_time = merge_dataframes(expanded_df_cudf_order, expanded_df_cudf_trade, dframe=1)
display(df_cudf.head())
expanded_df_cudf_trade 是前向填充的交易数据,与 expanded_df_pd_order 或 expanded_df_cudf_order 获取方式相同。合并操作将创建如下所示的组合数据框架:
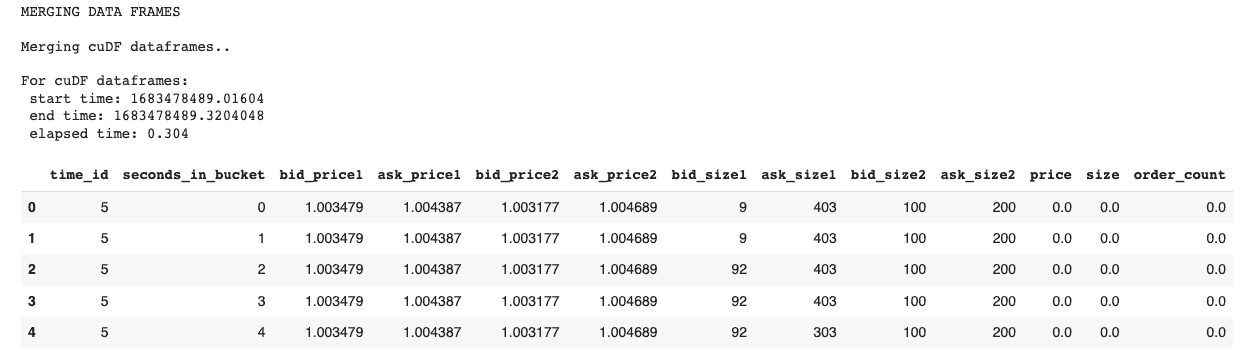
展览-11:合并数据框架(作者提供的图片)
两个数据集的所有列被合并为一个。合并操作也对 Pandas 数据框架重复执行。

图片由 pikisuperstar 在 Freepik 上提供
3. 改变数据类型
我们想要改变某些列的数据类型,以减少内存空间并提高计算速度。
# Make dtype changes
def change_dtype(df, dframe=0):
print("CHANGING DTYPES", "\n")
convert_dict = {"time_id": "int16",
"seconds_in_bucket": "int16",
"bid_size1": "int16",
"ask_size1": "int16",
"bid_size2": "int16",
"ask_size2": "int16",
"size": "int16",
"order_count": "int16"
}
df = df.astype(convert_dict)
return df, dframe
当我们执行以下命令时,
# Make dtype changes for cuDF data frame
df_cudf, _ = change_dtype(df_cudf)
display(df_cudf.info())
我们得到以下输出:

展览-12:改变数据类型(作者提供的图片)
如果没有进行数据类型转换,展示 12 中的数据将使用更多内存空间。它仍然有 78.9 MB,但在前向填充和合并操作之后,结果为 13 列和 230 万条记录。
我们为Pandas DF 和 cuDF 完成了每个特征工程任务。在这里,我们仅展示了一个cuDF的例子。
4. 获取唯一时间 ID
我们将在本节中使用 unique 方法提取 time_ids。
# Get unique values in time_id column and put them in a list
def get_unique_timeids(df, dframe=0):
global time_ids
print("GETTING UNIQUE VALUES", "\n")
# Get unique time_ids
if dframe == 0:
print(f"Getting sorted unique time_ids from Pandas dataframe..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().tolist())
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Unique time_ids from Pandas dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n")
else:
print(f"Getting sorted unique time_ids from cuDF dataframe..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().to_arrow().to_pylist())
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Unique time_ids from cuDF dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n")
print(f"{len(time_ids)} time buckets: \n {time_ids[:10]}...")
print("\n")
return df, time_ids
上述代码将从Pandas DF 和 cuDF 中获取唯一的 time_ids。
# Get time_ids from cuDF dataframe
time_ids = get_unique_timeids(df_cudf_order, dframe=1)
cuDF 的输出如下:
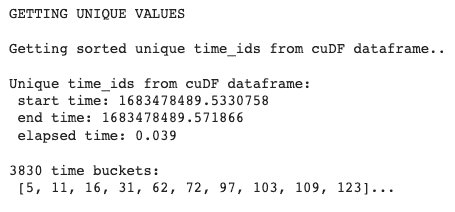
展示-13:获取唯一时间 ID(作者提供的图像)
5. 检查空值
然后,我们将检查数据框中的空值。
# Check df null values
def check_null_values(df, dframe=0):
print("CHECKING NULL VALUES", "\n")
print("Checking dataframe null values..", "\n")
display(df.isna().values.any())
display(df.isnull().sum())
return df, dframe
在cuDF中的检查空值示例:
# Check null values for cuDF dataframe
df_cudf, _ = check_null_values(df_cudf, dframe=0)
输出是:

展示-14:检查空值(作者提供的图像)
6. 添加列
我们想要创建更多的特征,因此添加了几列。
# Add columns
def add_column(df, dframe=0):
print("ADDING COLUMNS", "\n")
# Calculate WAPs
df['wap1'] = (df['bid_price1'] * df['ask_size1'] + df['ask_price1'] * df['bid_size1']) / (df['bid_size1'] + df['ask_size1'])
df['wap2'] = (df['bid_price2'] * df['ask_size2'] + df['ask_price2'] * df['bid_size2']) / (df['bid_size2'] + df['ask_size2'])
# Calculate order volumes
df['bid1_volume'] = df['bid_price1'] * df['bid_size1']
df['bid2_volume'] = df['bid_price2'] * df['bid_size2']
df['ask1_volume'] = df['ask_price1'] * df['ask_size1']
df['ask2_volume'] = df['ask_price2'] * df['ask_size2']
# Calculate volume imbalance
df['imbalance'] = np.absolute((df['ask_size1'] + df['ask_size2']) - (df['bid_size1'] + df['bid_size2']))
# Calculate trade volume imbalance
df['volume_imbalance'] = np.absolute((df['bid_price1'] * df['bid_size1']) - (df['ask_price1'] * df['ask_size1']))
return df, dframe
这将创建新的特征,如加权平均价格 (wap1 和 wap2)、订单量和成交量失衡。通过执行以下操作,总共会向数据框添加八列:
# Add a column in cuDF dataframe
df_cudf, _ = add_column(df_cudf)
display(df_cudf.head())
因此它将给我们:

展示-15:添加列和特征(作者提供的图像)
7. 删除列
我们决定通过删除 wap1 和 wap2 的列来去掉这两个特征:
# Drop columns
def drop_column(df, dframe=0):
print("DROPPING COLUMNS", "\n")
df.drop(columns=['wap1', 'wap2'], inplace=True)
return df, dframe
删除列的实现是:
# Add a column in cuDF dataframe
df_cudf, _ = drop_column(df_cudf)
display(df_cudf.head())
这使得我们得到的数据显示 wap1 和 wap2 列已被删除!
8. 按组计算统计数据
接下来,我们将通过时间 ID 计算一些特征的均值、中位数、最大值、最小值、标准差和总和。为此,我们将使用 groupby 和 agg 方法。
# Calculate statistics by selected features
def calc_agg_stats(df, dframe=0):
print("CALCULATING STATISTICS", "\n")
# Statistical calculations to be made
operations = ["mean", "median", "max", "min", "std", "sum"]
# Features for which statistical calculations will be made
features_list = ["bid1_volume", "bid2_volume", "ask1_volume", "ask2_volume"]
# Create a dictionary to store feature-calculation pairs
stats_dict = defaultdict(list)
for feature in features_list:
stats_dict[feature].extend(operations)
# Calculate aggregate statistics
df_stats = df.groupby('time_id', as_index=False, sort=True).agg(stats_dict)
return df, df_stats
我们创建了一个名为 features_list 的列表,以指定进行数学计算的特征。
# Calculate statistics by selected features in cuDF dataframe
_, df_cudf_stats = calc_agg_stats(df_cudf)
display(df_cudf_stats.head())
作为回报,我们得到以下输出:

展示-16:计算统计数据(作者提供的图像)
返回的表格是一个新的数据框。我们应将其与原始数据框 (df_cudf) 合并。我们将通过Pandas完成此操作:
# Merge data frame with stats
def merge_dataframes_2(df, dframe=0):
if dframe == 0:
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
else:
df = df.to_pandas()
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
df = cudf.DataFrame.from_pandas(df)
return df, dframe
# Merge cuDF data frames
df_cudf, _ = merge_dataframes_2(df_cudf, dframe=1)
display(df_cudf.head())
上述代码段将把 df_pd_stats 和 df_pd 放在一个数据框中,并将其保存为 df_cudf。
一如既往,我们对Pandas执行相同的任务。
下一步是计算两列之间的相关性:
# Calculate correlation between two selected features
def calc_corr(df, dframe=0):
correlation = df[["bid1_volume", "ask1_volume"]].corr()
print(f"Correlation between 'bid1_volume' and 'ask1_volume' is {correlation} \n")
return df, correlation
这段代码
# Calculate correlation in cuDF dataframe
_ = calc_corr(df_cudf)
将返回以下输出:
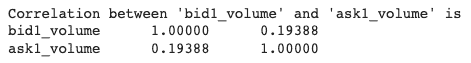
展示-17:计算两个特征之间的相关性(作者提供的图像)
9. 重命名列
为了消除任何混淆,我们应重命名两列。
# Rename columns
def rename_cols(df, dframe=0):
print("RENAMING COLUMNS", "\n")
df = df.rename(columns={"imbalance": "volume_imbalance", "volume_imbalance": "trade_volume_imbalance"})
return df, dframe
列的失衡和成交量失衡将分别重命名为成交量失衡和交易量失衡。
10. 对列进行分箱
我们还想进行另一项数据操作,即对 bid1_volume 进行分箱,并将分箱结果存储在新列中。
# Bin a selected column
def bin_col(df, dframe=0):
print("BINNING A COLUMN", "\n")
if dframe == 0:
df['bid1_volume_cut'] = pd.cut(df["bid1_volume"], bins=5, labels=["very high", "high", "average", "low", "very low"], ordered=True)
else:
df['bid1_volume_cut'] = cudf.cut(df["bid1_volume"], bins=5, labels=["very high", "high", "average", "low", "very low"], ordered=True)
return df, dframe
通过运行以下代码行
# Bin a selected column in cuDF dataframe
df_cudf, _ = bin_col(df_cudf, dframe=1)
display(df_cudf.head())
我们将得到一个数据框作为输出,下面展示了它的一部分:
展示-18:对列进行分箱(作者图片)
11. 显示数据框
特征工程步骤完成后,我们可以展示数据框。本节包含三个操作:显示数据框、获取有关数据框的信息以及描述数据框。
# Display data frame
def display_df(df, dframe=0):
print("DISPLAYING DATA FRAMES", "\n")
display(df.head())
print("\n")
return df, dframe
# Display dataframe info
def display_info(df, dframe=0):
print("DISPLAYING DATA FRAME INFO", "\n")
display(df.info())
print("\n")
return df, dframe
# Display dataframe info
def describe_df(df, dframe=0):
print("DESCRIBING DATA FRAMES", "\n")
display(df.describe())
print("\n")
return df, dframe
以下代码将完成这三个任务:
# Display cuDF dataframe and info
_, _ = display_df(df_cudf, dframe=1)
_, _ = display_info(df_cudf, dframe=1)
_, _ = describe_df(df_cudf, dframe=1)
我们已经完成了特征工程。
单次运行执行
总结一下,我们的特征工程工作集中在以下任务:
-
加载数据框
-
合并数据框
-
更改数据类型
-
获取唯一的
time_ids。 -
检查空值
-
添加列
-
删除列
-
计算统计信息
-
计算相关性
-
重命名列
-
对列进行分箱
-
显示数据框
-
显示数据信息
-
描述数据框
总共是 13 个任务,但我们在这里将“计算相关性”作为一个单独的实体。现在,我们希望在一次运行中按顺序执行这些任务,如下所示:
def run_and_report():
# Create a dictionary to store elapsed times
time_dict = defaultdict(list)
# List operations to be performed
labels = ["changing_dtype",
"getting_unique_timeids",
"checking_null_values",
"adding_column",
"dropping_column",
"calculating_agg_stats",
"merging_dataframes",
"renaming_columns",
"binning_col",
"calculating_corr",
"displaying_dfs",
"displaying_info",
"describing_dfs"]
# Load pandas order dataframe and calculate time
df_pd_order, pd_order_loading_time = load_dataframe(order_files, dframe=0)
print("-"*150, "\n")
# Load cuDF book dataframe and calculate time
df_cudf_order, cudf_order_loading_time = load_dataframe(order_files, dframe=1)
print("-"*150, "\n")
# Load pandas trade dataframe and calculate time
df_pd_trade, pd_trade_loading_time = load_dataframe(trade_files, dframe=0)
print("-"*150, "\n")
# Load cuDF trade dataframe and calculate time
df_cudf_trade, cudf_trade_loading_time = load_dataframe(trade_files, dframe=1)
print("-"*150, "\n")
# Get time_ids from Pandas data frame
_, time_ids = get_unique_timeids(df_pd_order, dframe=0)
print("-"*150, "\n")
# Get time_ids from cuDF dataframe
_, time_ids = get_unique_timeids(df_cudf_order, dframe=1)
print("-"*150, "\n")
# Store loading times
time_dict["loading_dfs"].extend([pd_order_loading_time, cudf_order_loading_time])
# Forward fill order dataframes
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
# Forward fill trade dataframes
expanded_df_pd_trade, expanded_df_cudf_trade = ffill(df_pd_trade, df_name="trade")
# Merge pandas order and trade dataframes
df_pd, pd_merge_time = merge_dataframes(expanded_df_pd_order, expanded_df_pd_trade, dframe=0)
print("-"*150, "\n")
# Merge pandas order and trade dataframes
df_cudf, cudf_merge_time = merge_dataframes(expanded_df_cudf_order, expanded_df_cudf_trade, dframe=1)
print("-"*150, "\n")
# Store merge times
time_dict["merging_dfs"].extend([pd_merge_time, cudf_merge_time])
# Apply functions
functions = [change_dtype,
get_unique_timeids,
check_null_values,
add_column,
drop_column,
calc_agg_stats,
merge_dataframes_2,
rename_cols,
bin_col,
calc_corr,
display_df,
display_info,
describe_df]
for label, function in enumerate(functions):
# Function for pandas
start_pd = time.time()
df_pd, x = function(df_pd, dframe=0)
end_pd = time.time()
elapsed_time_for_pd = round(end_pd-start_pd, 3)
print(f"For pandas dataframe: \n start time: {start_pd} \n end time: {end_pd} \n elapsed time: {elapsed_time_for_pd} \n")
# Function for cuDF
start_cudf = time.time()
df_cudf, x = function(df_cudf, dframe=1)
end_cudf = time.time()
elapsed_time_for_cudf = round(end_cudf-start_cudf, 3)
print(f"For cuDF dataframe: \n start time: {start_cudf} \n end time: {end_cudf} \n elapsed time: {elapsed_time_for_cudf} \n")
print("-"*150, "\n")
# Store elapsed times
time_dict[labels[label]].extend([elapsed_time_for_pd, elapsed_time_for_cudf])
# Delete the unsolicited time duration
del time_dict["merging_dataframes"]
labels.remove("merging_dataframes")
labels.insert(0, "merging_dfs")
labels.insert(0, "loading_dfs")
print(time_dict)
return time_dict, labels, df_pd, df_cudf
run_and_report 函数将以单个执行命令提供与之前相同的输出,但会生成完整报告。它将在 Pandas 和 cuDF 上执行 14 个任务,并记录两种数据框所需的时间。
time_dict, labels, df_pd, df_cudf = run_and_report()
我们可能需要运行多个周期,以更明显地看到两个数据库的相对性能。
最终评估
如果我们多次运行 run_and_report,例如在多轮中,我们可以更好地了解 Pandas 和 cuDF 之间性能的差异。因此,我们将轮次设置为 30。然后,我们记录每个操作、轮次和数据库的所有时间,并最终评估结果:
def calc_exec_times():
exec_times_by_round = {}
# Calculate execution times of operations in each round
for round_no in range(1, ROUNDS+1):
# cycle_no += 1
time_dict, labels, df_pd, df_cudf = run_and_report()
exec_times_by_round[round_no] = time_dict
print("exec_times_by_round: ", exec_times_by_round)
# Get durations by operation for each data frame
pd_summary, cudf_summary = get_statistics(exec_times_by_round, labels)
# Get durations by rounds for each data frame
round_total = get_total(exec_times_by_round)
print("\n"*3)
# Plot durations
plt.style.use('dark_background')
X_axis = np.arange(len(labels))
# Plot average duration of operation
plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis)
print("\n"*3)
# Plot total and difference in duration by operation
plot_diff_by_df(pd_summary, cudf_summary, labels)
print("\n"*3)
# Plot total and difference in duration by round
plot_total_by_df(round_total)
print("\n"*3)
calc_exec_times 函数执行了一些任务。它首先调用 get_statistics,以获取每个数据库在 30 轮中的“平均和总时间”。
def get_statistics(exec_times_by_round, labels):
# Separate and store duration statistics by data frame
pd_performance = defaultdict(list)
cudf_performance = defaultdict(list)
# Get and store durations for each operation by data frame
for label in labels:
for key, values in exec_times_by_round.items():
pd_performance[label].append(values[label][0])
cudf_performance[label].append(values[label][1])
print("pd_performance: ", pd_performance)
print("cudf_performance: ", cudf_performance)
# Compute average and total durations for each operation by data frame
pd_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in pd_performance.items()}
cudf_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in cudf_performance.items()}
print("pd_summary: ", pd_summary)
print("cudf_summary: ", cudf_summary)
return pd_summary, cudf_summary
接下来,它计算每个数据框架的“按轮次总时长”。
def get_total(exec_times_by_round):
def get_round_total(stat_list):
# Get total duration by round for each data frame
pd_round_total = round(sum([x[0] for x in stat_list]), 3)
cudf_round_total = round(sum([x[1] for x in stat_list]), 3)
return pd_round_total, cudf_round_total
# Collect total durations by round
for key, value in exec_times_by_round.items():
round_total = {key: get_round_total(list(value.values())) for key, value in exec_times_by_round.items()}
print("round_total", round_total)
return round_total
最后,它绘制了结果。这里,第一个图表显示了两个库的“按操作平均时间”。
def plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis):
# Figure size
fig = plt.subplots(figsize =(10, 4))
# Average duration by operation for each data frame
pd_avg = [value[1] for key, value in pd_summary.items()]
cudf_avg = [value[1] for key, value in cudf_summary.items()]
plt.bar(X_axis - 0.2, pd_avg, 0.4, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(X_axis + 0.2, cudf_avg, 0.4, color = '#C8C8FF', label = 'cuDF', align='center')
plt.xticks(X_axis, labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("Operations", fontsize=10)
plt.ylabel("Average Duration in Seconds", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Average Duration of Operation by Data Frame", fontsize=12)
plt.legend()
plt.show()
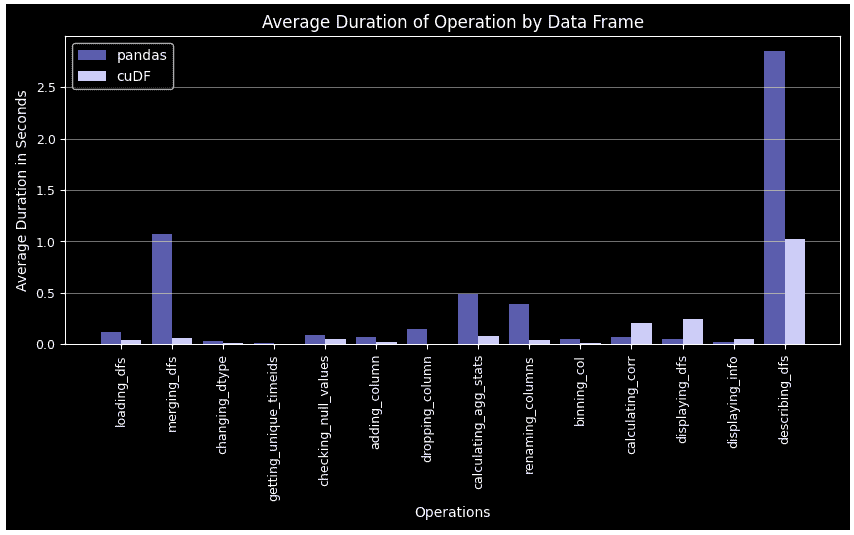
展示-19:Pandas 数据框和 cuDF 的操作平均时长(作者图片)
第二个图表显示了“按操作总时长”,即每个任务在 30 轮中的总时间。
def plot_diff_by_df(pd_summary, cudf_summary, labels):
# Figure size
fig = plt.subplots(figsize =(12, 6))
# Total duration by operation for each data frame
pd_total = [value[0] for key, value in pd_summary.items()]
cudf_total = [value[0] for key, value in cudf_summary.items()]
# Difference of total duration by operation for each data frame
diff = [x[0]-x[1] for x in zip(pd_total, cudf_total)]
# Set width of bar
barWidth = 0.25
# Set position of bar on X axis
br1 = np.arange(len(labels))
br2 = [x + barWidth for x in br1]
br3 = [x + barWidth for x in br2]
plt.bar(br1, pd_total, barWidth, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(br2, cudf_total, barWidth, color = '#C8C8FF', label = 'cuDF', align='center')
plt.bar(br3, diff, barWidth, color = '#AA1E1E', label = 'difference', align='center')
plt.xticks([r + barWidth for r in range(len(labels))], labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("Operations", fontsize=10)
plt.ylabel("Total Duration in Seconds", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Total Duration of Operation by Data Frame", fontsize=12)
plt.legend()
plt.show()
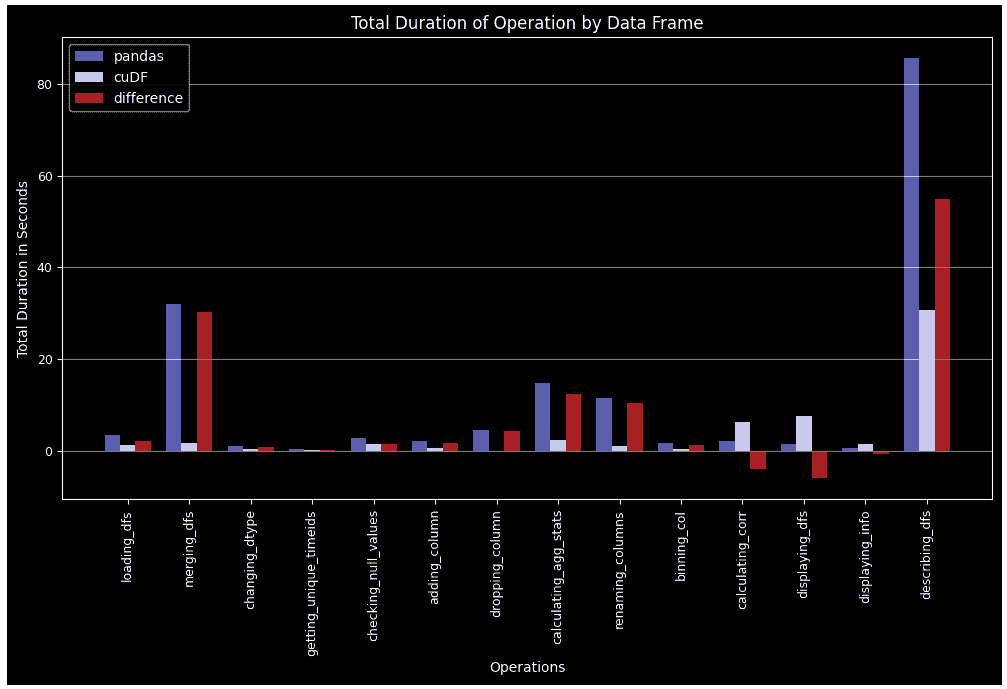
展示-20:Pandas 数据框和 cuDF 在 30 轮中的操作总时长(作者图片)
最终图表是“按轮次总时长”,显示了每轮中所有操作的总时间。
def plot_total_by_df(round_total):
# Figure size
fig = plt.subplots(figsize =(10, 6))
X_axis = np.arange(1, ROUNDS+1)
# Total duration by round for each data frame
pd_round_total = [value[0] for key, value in round_total.items()]
cudf_round_total = [value[1] for key, value in round_total.items()]
# Difference of total duration by round for each data frame
diff = [x[0]-x[1] for x in zip(pd_round_total, cudf_round_total)]
plt.plot(X_axis, pd_round_total, linestyle="-", linewidth=3, color = '#5A5AAF', label = "pandas")
plt.plot(X_axis, cudf_round_total, linestyle="-", linewidth=3, color = '#B0B05A', label = "cuDF")
plt.plot(X_axis, diff, linestyle="--", linewidth=3, color = '#AA1E1E', label = "difference")
plt.xticks(X_axis, fontsize=9)
plt.yticks(fontsize=9)
plt.xlabel("Rounds", fontsize=10)
plt.ylabel("Total Duration in Seconds", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Total Duration by Round", fontsize=12)
plt.legend()
plt.show()
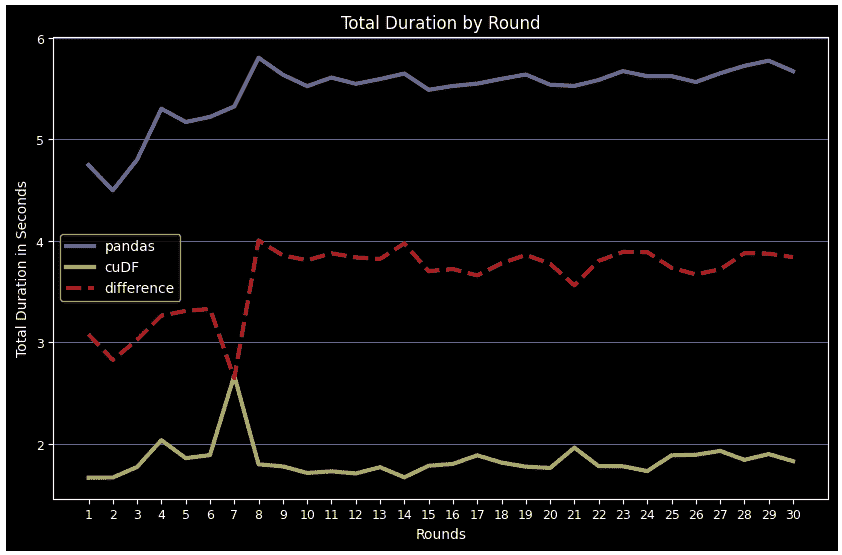
展示-21:Pandas 数据框和 cuDF 每轮所有操作的总时长(作者图片)
尽管我们没有涵盖数据集上每个特征工程任务,但它们与我们在这里展示的任务相同或类似。通过逐个解释 14 个操作,我们试图记录Pandas 数据框和cuDF的相对性能,并实现可重复性。
在所有情况下,除了相关性计算和数据框显示外,cuDF 都优于Pandas。这种性能优势在复杂任务如 groupby、merge、agg 和 describe 中尤为显著。另一个方面是,当更多轮次进行时,Pandas 数据框会变得疲惫,而cuDF则保持更稳定的模式。
请记住,我们只以一个股票作为例子进行回顾。如果我们处理所有 112 只股票,我们可以预期cuDF会表现得更好。如果股票的数量增加到数百只,cuDF的性能甚至可能更为显著。在大数据的情况下,执行并行任务是可能的,像Dask-cuDF这样的分布式框架,可以将并行计算扩展到cuDF GPU 数据框,是合适的工具。
参考文献
[1] RAPIDS 定义,www.heavy.ai/technical-glossary/rapids
[2] 10 分钟了解 cuDF 和 Dask-cuDF,docs.rapids.ai/api/cudf/stable/user_guide/10min/
[3] Optiver 实现的波动率预测,www.kaggle.com/competitions/optiver-realized-volatility-prediction/data
[4] 向前填充图书数据,www.kaggle.com/competitions/optiver-realized-volatility-prediction/discussion/251277
Hasan Serdar Altan 是数据科学家和 AWS 云架构师助理。
相关主题
RAPIDS cuDF 加速你的下一次数据科学工作流
原文:
www.kdnuggets.com/2023/04/rapids-cudf-speed-next-data-science-workflow.html

图片来源:作者
多年来,数据科学应用呈指数级增长,得益于从各种来源收集的数据。在过去 10 年里,我们见证了数据科学、机器学习和深度学习的实施。尽管我们听到更多关于机器学习和深度学习的消息,但许多公司关注的是核心数据科学技术,因为这是他们赚钱和节省大量资金的地方。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
然而,研究表明 68% 的数据研究未被使用,90% 的数据未被结构化。这是因为公司未能关注数据分析处理阶段,因为这可能需要大量的时间、金钱和资源。
数据分析阶段包括数据聚合、数据探索和模型准备,占据数据科学家在数据管道中 40% 的时间。当前的 CPU 解决方案可能会使这一过程变得更长,从而拖慢模型开发。为了解决这个问题,有一个名为 RAPIDS 的 GPU 隔离解决方案。
什么是 RAPIDS?
RAPIDS 是一个 GPU 数据科学隔离平台,你可以在 GPU 上完成端到端的数据科学管道开发。如前所述,数据分析阶段占据了数据科学家 40% 的时间。然而,使用 RAPIDS 可以显著缩短你的数据分析时间。
从下图中,你可以看到在数据分析阶段使用 CPU 和 GPU 的工作流时间差异。

图片来源:Nvidia
从 CPU 转到 GPU 使你能够:
-
利用 NVIDIA CUDA 实现更快的工作流
-
缩短训练时间并实现更快的部署
-
在 GPU 上加速整个数据科学管道
-
通过一行代码更改加速熟悉的数据科学库
-
简化了在 NVIDIA GPU 上的数据科学工作
-
提高现有 Python 用户的生产力
-
用于内存中数据准备的 GPU 加速计算
-
针对大数据集的分析进行了优化
-
从大型数据集中提供实时洞察
在下面的图像中,你可以看到使用 CPU 和 GPU 的典型数据科学工作流之间的区别:
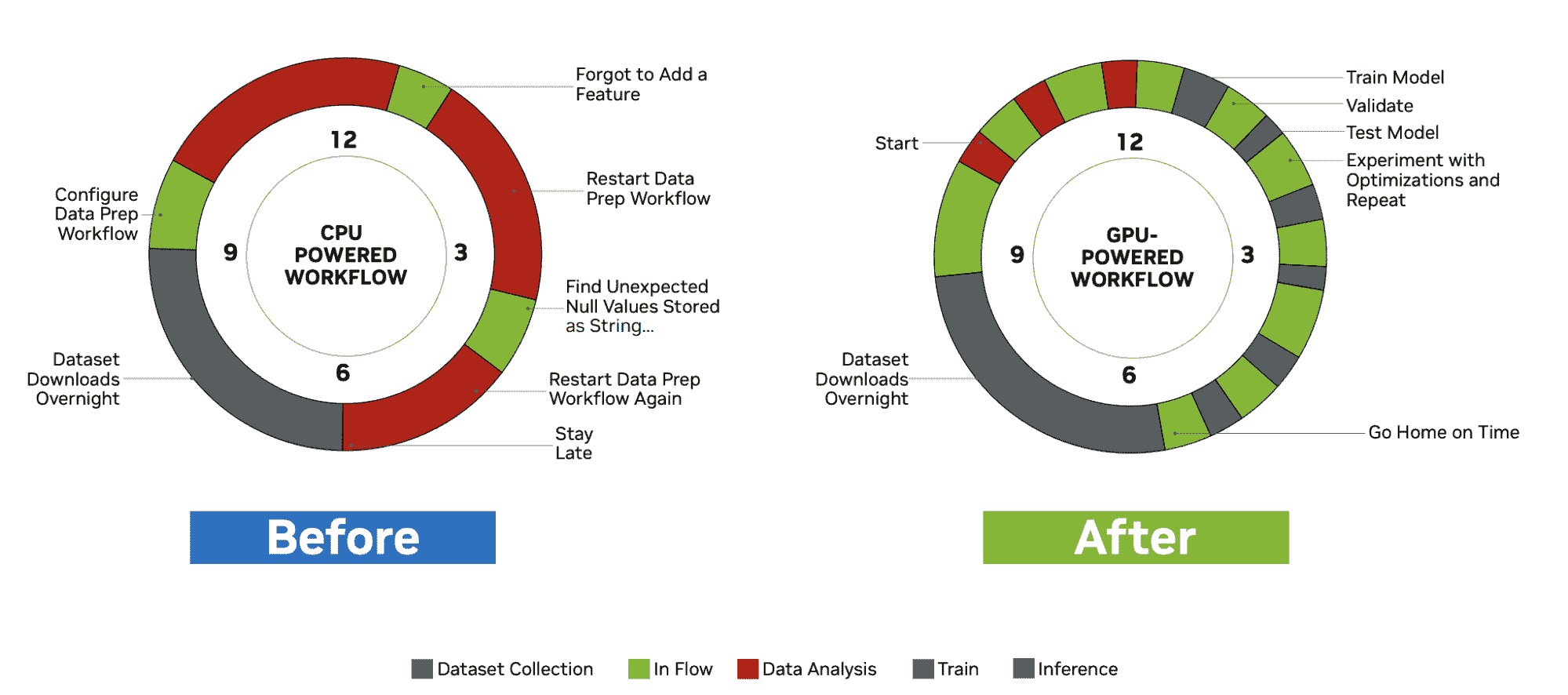
图片来源于 Nvidia
RAPIDS cuDF
RAPIDS cuDF 是一个 Python 中的 GPU 数据框架库,具有类似 Pandas 的 API,集成在 PyData 生态系统中。用户可以从文件、NumPy 数组和 Pandas 数据框架创建 GPU 数据框架,并利用 RAPIDS 的其他 GPU 加速库轻松创建机器学习管道。
cuDF 与 Pandas API 非常接近,但并不完全替代 Pandas。cuDF 和 Pandas 之间有一些相似之处和不同之处。例如,cuDF 支持类似于 Pandas 的数据结构和操作,如索引、筛选、连接、联接、分组等。要检查 cuDF 是否支持特定的 Pandas API,可以查看API 文档。
探索性数据分析
探索性数据分析是分析和总结数据集的过程,以便获得更多关于数据的见解和对模式的更好理解。你可以通过使用总结统计来量化数据,以了解分布情况,并能够检测异常值、异常情况和缺失数据。
探索性数据分析面临的挑战包括:
-
处理大型和复杂的数据集
-
理解多个变量之间的关系
-
执行计算密集型、运行时间长的查询
-
识别并用适当的方法填补缺失的数据点
-
处理维度灾难
-
,以及更多。
你可以自然地提高探索数据的时间,通过使用类似 Pandas 的操作,但运行速度显著更快。

时间序列数据处理
时间序列数据处理是指在固定时间间隔内收集的数据点,例如股票价格、天气数据和传感器读数。这有助于识别趋势、预测未来事件和检测异常。
时间序列数据面临的挑战包括:
-
数据来自多种来源,格式各异
-
数据质量可能受到众多现实世界事件的影响
-
缺失数据、异常值和虚假记录使得处理变得复杂
-
模式和关系可能随着时间变化
-
模型和预测迅速变得过时
-
高维度需要大量的计算能力和内存
-
,以及更多。
再次,cuDF 通过几乎相同的 pandas 端点支持复杂的数据操作。
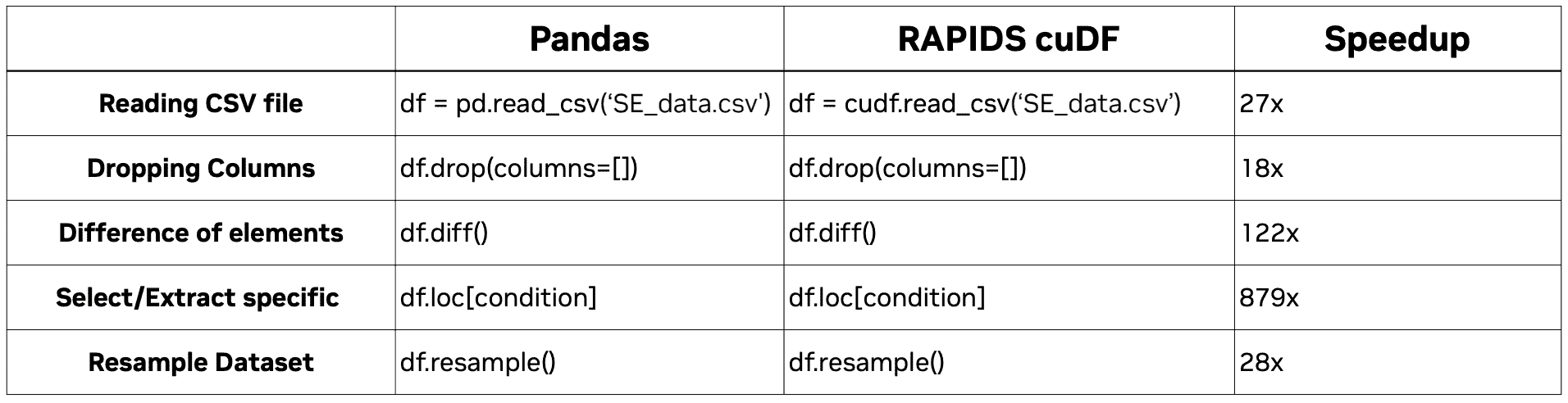
如你所见,Pandas 和 cuDF 在代码方面差异不大。然而,速度上有显著差异。
结论
每位数据科学家都希望减少数据科学流程中的几天或几周的时间浪费。为何不通过升级到 RAPIDS cuDF 来改变这段时间的浪费呢?
此外,RAPIDS cuDF 现在已在 Google Colab 上推出。请查看这里:RAPIDS cuDF Google Colab
如果你想了解更多关于 cuDF 和 Pandas 之间的差异,或想了解更多关于 cuDF 的信息以及如何将其用于你的下一次数据科学流程,请阅读:
Nisha Arya是一位数据科学家、自由技术作家及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何在提升人类生命长度方面发挥作用。作为一个热衷学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
树莓派 IoT 项目:乐趣与利润
原文:
www.kdnuggets.com/2018/09/raspberry-pi-iot-projects-fun-profit.html
评论
由 鲁本斯·津布雷斯,数据科学家
软件和硬件之间的边界令人着迷。我们数据科学家习惯于为商业目的开发机器学习算法,这些模型的输出通常以利润、成本节约甚至无形的成果(如客户满意度)来衡量。当然,我们可以使用 Power BI、Tableau 或云端的 Kibana、Quick Sight 或 Tago 等仪表盘来可视化我们的模型输出。但看到我们模型的结果在现实世界中展现出来,而不仅仅是屏幕上,这是一种相当有成就感的体验。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
我一直在金融和电信领域从事 IoT 工作。可以轻松地在仪表盘上生成关于特定系统故障的警报,例如 BTS(基站)的饱和,即电信信号通过的节点。现在想象一下,除了在仪表盘上的警报外,我们还会自动将电信数据流量重定向到另一个位置,以确保销售点(POS)始终保持连接。这将提高收单方的利润和商家的满意度。我们甚至可以在现实世界中调整机器的设置。
在 IoT 项目中,我们与硬件密切合作。设备如 POS、功率和水表、甘蔗磨、Libelium 套件(用于农业)、电梯、健康设备会发送可以进行分析的遥测数据,以开发预测维护模型,从而帮助企业降低成本、提高效率,同时优化物流。在这些情况下,可以使用 SIM 卡、Wi-Fi、蓝牙或无线信号(LoRa)实现连接。
IoT 解决方案的一部分是网关。它在设备(温度、湿度传感器)和云之间充当中介。在我之前的帖子中,我解释了如何将笔记本电脑转换为 IoT 设备,提供了如何将数据从设备发送到 AWS,并实现端到端解决方案的详细信息 (kdnuggets.com/2018/06/zimbres-iot-aws-machine-learning-dashboard.html)。
在这篇文章中,我将解释如何从命令行运行 IoT 项目,不使用图形界面,使用树莓派 3 的 Ubuntu Core。更简单的方法是使用 Raspbian,它为你的项目提供了图形界面。Raspbian 是一个基于 Debian 的计算机操作系统。然而,我决定尝试 Ubuntu Core,因为安全性应成为 IoT 中的主要关注点。Ubuntu Core 可以用于数字标牌、机器人、无人机和边缘网关。这是一个更具挑战性和安全性的决定。
下图显示了普通 Linux 系统和 Ubuntu Core 之间的区别:
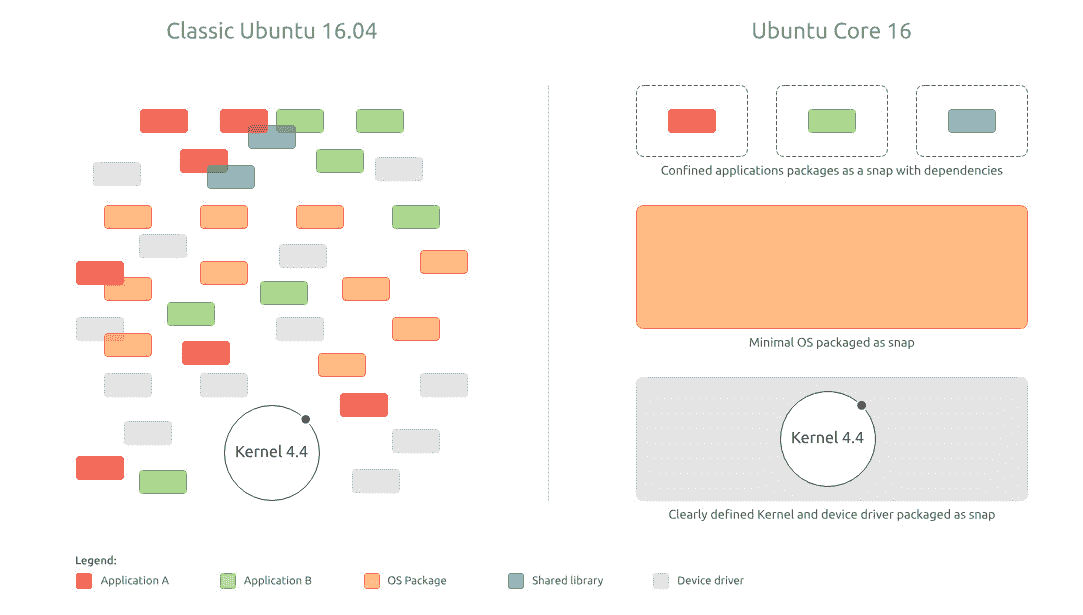
Ubuntu Core 是一个轻量级系统,核心在于安全。它由 snaps 组成,即“自包含、隔离和保护的代码片段”。即使使用 vim 命令 ESC :w !sudo tee %,也很难修改系统中的只读文件。
由于这是一个 ARM 系统,在其上安装机器学习库是相当不同的,因为有一些特定于此类型系统的包,并且许多依赖项没有包含,连“wget”也没有。所以,让我们开始吧。当你购买树莓派时,它没有能源源(右上角下面)和 SD 卡(右侧突出)。Model 3 B 具有 4 个 USB 接口和一个以太网接口。它还包含 HDMI、音频和摄像头接口。在这个项目中,我们不会使用鼠标,显示器、以太网电缆和键盘仅在系统的第一次运行中用于设置互联网连接。

首先要做的是在 SD 卡(micro)上安装操作系统。因此,从他们的网站下载 Ubuntu Core 镜像:cdimage.ubuntu.com/ubuntu-core/16/stable/current/ubuntu-core-16-pi3.img.xz
然后,下载 Etcher 以将映像刷入卡中:etcher.io/
现在,你需要生成私钥和公钥,这些密钥将上传到你的 Ubuntu One 账户( https://login.ubuntu.com/ )。
mkdir ~/.ssh
chmod 700 ~/.ssh
ssh-keygen -t rsa -b 4096
然后,复制密钥代码并粘贴到你的 Ubuntu One 账户中:
ssh-rsa ABCDEF1234512345 user@Dell
将卡插入树莓派,并打开电源开关。瞧,系统将启动:
初次运行时需要几秒钟,然后你将被引导到网络配置界面。配置 DHCP 以及你的 Wi-Fi 用户名和密码。然后 Ubuntu Core 会提供你应该用来 ssh 的地址。
以防万一,请确保端口 22(用于 ssh)已开启:
sudo ufw allow 22
现在,我们将把密钥复制到客户端计算机中的新目录 .ssh:
ssh-keygen -R 192.168.15.XXX
mkdir .ssh
cp id_rsa ~/.ssh/id_rsa
cp id_rsa.pub ~/.ssh/id_rsa.pub
cd .ssh
我们准备通过 ssh 连接到我们的 Raspberry。运行:
ssh -vvv user@192.168.15.XXX
Or
ssh -vvv 192.168.15.XXX -l user
-vvv 命令将为你提供关于 ssh 连接的详细信息。连接时,会弹出一个窗口要求输入密码。你已连接,登录信息将发生变化:
user@localhost:~$
此时,你可以断开显示器、键盘和以太网电缆,因为通信将通过 Wi-Fi 完成,整个项目将通过命令行进行。现在,让我们安装 snap classic,一个容器,我们将在其中安装机器学习库:
sudo snap install classic --edge --devmode
sudo classic
Creating classic environment
Parallel unsquashfs: Using 4 processors
11111 inodes (11975 blocks) to write
[===========================================================/] 11975/11975 100%
(classic)user@localhost:~$ sudo apt update
(classic)user@localhost:~$ sudo apt install snapcraft build-essential git
此时,你可以回到我之前的文章,测量 CPU 温度并发送到 Amazon AWS(kdnuggets.com/2018/06/zimbres-iot-aws-machine-learning-dashboard.html),或者我们可以继续:
export LC_ALL=C
source .bashrc
pip install setuptools
pip install AWSIoTPythonSDK
在 Ubuntu Core 中,生成和编辑笔记本并不简单。你不能打开 Jupyter、Spyder 或甚至 Notepad 创建新文件,因为没有图形界面。你必须使用命令 “touch” 创建文件:
touch AWS_Send_0.py
创建新文件后,你可以使用 “vim” 命令打开和编辑文件,并粘贴代码:
vi AWS_Send_0.py
输入“i”,然后 CTRL+SHIFT+V 代码,地址为: https://github.com/RubensZimbres/Repo-2018/blob/master/CPU Temperature - IoT Project/AWS_Send_test.py
之后,输入:
ESC :wq ENTER
这会保存文件。请记得将 rootCA.pem + *.crt + *private.pem.key + *.public.pem.key 复制到你的 Raspberry 上,以便正确访问 AWS IoT Core。
运行以下命令将 Raspberry CPU 温度发送到 AWS:
python AWS_Send_0.py -e a23312345.iot.us-east-1.amazonaws.com -r rootCA.pem -c 123412345-certificate.pem.crt -k 12345-private.pem.key -id arn:aws:iot:us-east-1:1123112345:thing/CPUDevice -t 'Topic'
你将通过 IoT Core 仪表板检查你的连接:
重要的是要注意,你是在 Ubuntu classic 环境下的 chroot 中运行 Python。因此,需要使用 “sudo python” 来访问 Raspberry 的 GPIO(通用输入/输出)。
更多相关主题
ReAct,推理与行动通过工具增强 LLMs!
原文:
www.kdnuggets.com/react-reasoning-and-acting-augments-llms-with-tools
介绍
缩写为推理与行动的这个论文介绍了一个新概念,它提高了 LLMs 的性能,并为我们提供了更多的解释性和可解释性。
人工智能通用智能(AGI)的目标可能是人类文明可以实现的最重要目标之一。想象一下创建能够推广到许多问题的人工智能。对于 AGI 的定义有很多种解释,我们什么时候可以说我们已经实现了它?
在过去几十年里,最有前途的 AGI 方法是强化学习路径,更具体地说,是 DeepMind 在解决困难任务方面取得的成就,如 AlphaGo、AlphaStar 以及许多突破……
然而,ReAct 的表现超越了模仿学习和强化学习方法,分别提高了 34%和 10%的绝对成功率,同时仅使用一个或两个上下文示例。
通过这种结果(当然,前提是没有数据泄漏,我们可以信任论文中提供的评估方法),我们不能再忽视 LLMs 推理的潜力,并将复杂任务分解为逻辑步骤。
论文背后的动机
本文从一个观点出发,即迄今为止,大型语言模型(LLMs)在语言理解方面表现令人印象深刻,它们已被用于生成 CoT(思维链)来解决一些问题,并且也被用于行动和计划生成。
尽管这两者一直被分开研究,但本文旨在以交替的方式结合推理和行动,以增强 LLM 的性能。
这一观点背后的原因是,如果你考虑一下你作为一个人如何执行某项任务。
第一步是你使用“内在语言”或以某种方式写下或与自己沟通,说明“我如何执行任务 X?要完成任务 X,我需要先做步骤 1,然后做步骤 2,依此类推”
更具体地说,如果你在厨房里做一道菜,你可以这样使用 ReAct:
“现在一切都切好了,我应该加热水锅”,以处理例外情况或根据情况调整计划(“我没有盐,所以我用酱油和胡椒代替”),并意识到何时需要外部信息(“我怎么准备面团?让我在互联网上搜索”)。
你还可以采取行动(翻开食谱书阅读食谱,打开冰箱,检查配料)来支持推理并回答问题(“我现在可以做什么菜?”)。
这种推理与行动的结合使得人类即使在之前未见的情况下或面对信息不确定性时,仍能学习并完成任务。
仅有推理的方法
先前的研究展示了 LLMs 进行推理的能力,例如,思维链提示(Chain of Thought Prompting)展示了模型能够提出解决算术、常识和符号推理问题的计划。
然而,这里的模型仍然是一个“静态黑箱”,因为它使用其内部语言表示来回答这些问题,而这种表示可能并不总是准确或最新的,这会导致事实幻觉(从自身想象中得出事实)或错误传播(思维链中的一个错误传播到错误答案)。
如果没有采取某种行动和更新其知识的能力,模型将受到限制。
仅行动方法
也有一些研究使用 LLMs 根据语言进行动作,这些研究通常会接收多模态输入(音频、文本和图像),将其转换为文本,使用模型生成领域内的动作,然后使用控制器执行这些动作。
如果没有规划一些步骤和推理该做什么的能力,模型将简单地输出错误的动作。
将两者结合成 ReAct
本文的提议是结合上述两种方法。ReAct 提示 LLMs 以交替的方式生成与任务相关的口头推理痕迹和行动,这允许模型进行动态推理,创建、维护和调整高层次的行动计划(推理以行动),同时也与外部环境(例如维基百科)互动,将额外的信息纳入推理(行动以推理)。
下面的图示展示了这一点:
Reason、Act 和 ReAct 之间的区别(照片摘自论文)
动作空间
因此,为了改进推理提示,他们设计了一个动作空间,即模型在回答问题时允许使用的三种动作。
这是通过维基百科 API 完成的,该 API 提供以下内容:
-
search[entity]:返回对应实体维基页面的前 5 个句子(如果存在),否则建议维基百科搜索引擎中的前 5 个相似实体
-
lookup[string],将返回包含字符串的页面中的下一句,模拟浏览器中的 Ctrl+F 功能
-
finish[answer],将用答案完成当前任务
这里不常见的一点是,信息检索工具比上述提到的工具强大得多。
这样做的目标是模拟人类行为以及人类如何与维基百科互动并推理以找到答案。
提示
除了提供的工具,我们还需要正确提示 LLM,以提供推理并适当地链式执行动作。
为此,他们使用了多种思路组合来分解问题,例如(“我需要搜索 x,找到 y,然后找到 z”),从维基百科观察中提取信息(“x 起始于 1844”, “该段落没有告诉 x”),进行常识推理(“x 不是 y,所以 z 必须是…”)或算术推理(“1844 < 1989”),指导搜索重组(“也许我可以搜索/查找 x”),并综合最终答案(“...所以答案是 x”)。
最终结果大致如下:

ReAct 如何工作并带来更好的结果(照片来自论文)
结果
选择用于评估的数据集如下:
HotPotQA:一个问答数据集,要求对一个或两个维基百科页面进行推理。
FEVER:一个事实验证基准,每个声明根据是否存在维基百科段落来验证该声明,标注为 SUPPORTS、REFUTES 或 NOT ENOUGH INFO。
ALFWorld:一个基于文本的游戏,包括 6 种任务类型,代理需要完成这些任务以实现高层次目标。
一个例子是“在桌灯下检查纸张”,通过文本行动(例如,去咖啡桌 1,拿纸 2,用桌灯 1)导航和与模拟的家庭进行互动。
WebShop:一个包含 118 万个真实世界产品和 1.2 万条人类指令的在线购物网站环境,具有更多的多样性和复杂性。
它要求一个代理根据用户指令购买产品。例如,“我在找一个带抽屉的床头柜。它应该有镍质饰面,价格低于 140 美元”,代理需要通过网络互动来实现这一点。
所以结果显示ReAct 总是优于 Act,这表明推理部分对于增强行动是极其重要的。
另一方面,ReAct 在 Fever 上的表现优于 CoT(60.9 对 56.3),而在 HotpotQA 上略逊于 CoT(27.4 对 29.4)。因此,对于 FEVER 数据集,通过获取更新的知识来采取行动显示出能够提供所需的提升,以做出正确的 SUPPORT 或 REFUTE 决策。
在比较 CoT 和 ReAct 在 HotpotQA 上的表现及其可比性时,发现了以下关键观察:
-
对 CoT 来说,幻觉是一个严重的问题,因此在没有更新知识的情况下,CoT 必须想象和产生幻觉,这是一个巨大的障碍。
-
虽然交替进行推理、行动和观察步骤可以提高ReAct的基础性和可信度,但这种结构约束也降低了其在制定推理步骤时的灵活性。ReAct 可能会迫使 LLM 执行动作,而有时仅仅进行 CoT 就足够了。
-
对于ReAct来说,通过搜索成功检索信息性知识至关重要。如果搜索检索到错误的信息,那么基于这些错误信息的推理也是错误的,所以获取正确的信息至关重要。

ReAct 和 CoT 在不同数据集上的结果(照片取自论文)
希望这篇文章帮助你理解这篇论文。你可以在这里查看它 arxiv.org/pdf/2210.03629.pdf
Mohamed Aziz Belaweid是 SoundCloud 的机器学习/数据工程师。他对研究和工程都很感兴趣。他喜欢阅读论文并实际将其创新实现。他曾从零开始训练语言模型到特定领域。从文本中提取信息,使用命名实体识别、多模态搜索系统、图像分类和检测。他还在模型部署、可复现性、扩展和推理等操作方面有工作经验。
原文。经许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
在转行至数据科学之前请阅读此文
原文:
www.kdnuggets.com/read-this-before-making-a-career-switch-to-data-science

作者提供的图片
你正在阅读这篇文章,因为你在考虑加入有志成为数据科学家的行列。谁能怪你呢?即便在哈佛商业评论给予其“最性感工作”称号十年后,数据科学依然是一个快速发展的领域。美国劳工统计局目前 预测 数据科学家的就业率将在 2022 年至 2032 年间增长 35%。相比之下,平均职位增长率仅为 5%。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
它还有其他优势:
-
收入丰厚(同样,BLS 发现 2022 年的中位薪资为 103k 美元)
-
生活质量高(比平均工作相关幸福度 更高 根据 Career Explorer 的数据)
-
尽管最近经历了一轮 裁员,但职位依然有保障——因为对这个角色的需求非常大。
因此,有很多理由想要进入这个领域。
来源: https://www.bls.gov/ooh/math/data-scientists.html
但是数据科学是一个非常广泛的领域,你需要掌握很多不同的职位名称和技能。本文将指导你了解可以选择的各种方向,以及进入数据科学所需的知识。
如何转行至数据科学职业
要成功转型为 数据科学职业,你需要遵循一个结构化的方法:
-
评估你的 数据科学技能 并识别技能差距。
-
在你较弱的领域获得实践经验。
-
扩展人脉。加入数据科学小组,参加聚会,参与论坛讨论。
让我们深入探讨。
评估你的起点
你已经知道了什么,它如何应用于数据科学?想一想:你拥有的任何编程知识、统计技能或数据分析经验。
接下来,识别你技能中的差距,特别是数据科学所必需的那些技能。SQL 是必不可少的,但 Python 或 R 编程、高级统计学、机器学习和数据可视化也极其有用。
一旦确定了这些差距,寻求相关的教育或培训以填补这些空白。这可以通过在线课程、大学项目、培训营或自学,重点是实践操作学习。
实践经验
你不应只是观看视频和阅读博客文章。实践经验在数据科学中至关重要。参与允许你在真实场景中应用新技能的项目,这可以是个人项目、对开源平台的贡献,或参加像 Kaggle 这样的数据竞赛。
如果你有一些基础技能,你可能想考虑寻求实习或自由职业以获得行业经验。
最重要的是,在一个作品集中记录你所有的项目和经验,突出你的问题解决过程、使用的技术和你工作的影响。
扩展人脉
进入数据科学领域往往取决于你认识谁,除了你知道什么。寻找导师,参加聚会、会议和研讨会以了解新趋势,并参与像 Stack Overflow、GitHub 或 Reddit 这样的在线数据科学社区。这些平台让你可以向他人学习,分享你的知识,并在数据科学社区中引起注意。
每个数据科学角色都需要……
如果你想从零开始成为数据科学家,将你需要发展的技能视为一棵树是有意义的。每个数据科学职位都有“主干”技能,然后每个专业都有继续分支的“枝干”技能。
每个数据科学家都需要的三项主要技能,无论他们走向哪个方向:
使用 SQL 进行数据处理/整理
数据科学基本上就是处理和组织大型数据集。为此,你需要知道 SQL。这是数据处理和整理的基本工具。

作者提供的图片
软技能
数据科学不是在真空中进行的。你需要与他人友好合作,这意味着要提升你的软技能。能够以清晰易懂的方式向非技术利益相关者传达复杂的数据发现与技术技能同样重要。这些包括有效沟通、解决问题和商业头脑。
解决问题有助于应对复杂的数据挑战,而商业头脑则确保数据驱动的解决方案与组织目标一致。
持续学习的态度
数据科学与五年前的情况不同。只需看看今天的 AI 与 2018 年的对比就知道了。新的工具、技术和理论不断涌现。这就是为什么你需要保持持续学习的心态,以便跟上最新的发展,适应该领域的新技术和方法。
你需要自我激励以学习和适应,并且要有主动获取新知识和技能的态度。
拆解
尽管如上所述有一些共同的技能,但每个角色都要求其特定的技能集。(记得吗?分支。)例如,统计分析、Python/R 编程技能和数据可视化都是更专业的数据科学职位所特有的技能。

图片由作者提供
让我们逐一拆解每个与数据科学相关的角色,以便你能了解需要什么。
商业/数据分析师
是的,这确实是一个数据科学角色!即使一些反对者不同意,我仍然相信,如果你打算进入数据科学职业道路,这个角色至少可以被视为一个垫脚石。
作为商业或数据分析师,你负责弥合数据洞察与商业战略之间的差距。这非常适合那些擅长理解商业需求并将其转化为数据驱动解决方案的人。
作为核心技能,你需要商业智能——这一点毫无意外——强大的分析能力,熟练掌握数据查询语言,主要是 SQL。在这个角色中,Python 和 R 是可选的,因为主要任务是处理数据。
这个角色有一个可视化组件,但根据你的工作,可能意味着在 Tableau 中创建仪表板或在 Excel 中绘制图表。
数据分析
这个角色专注于解释数据以提供可操作的洞察。如果你喜欢将数字转化为故事和商业策略,那么这份工作非常适合你。
你需要对统计分析和数据可视化有深入了解——虽然这些可以是 Tableau 仪表板和/或 Excel 图表。你还需要熟练使用 分析工具,如Excel、Tableau 和 SQL。Python/R 再次为可选,但请记住,它们在实施统计和自动化时确实能提供很大帮助。
机器学习
机器学习科学家开发预测模型和算法,以进行数据驱动的预测或决策。这些角色适合对 AI 和模型构建有强烈兴趣的人。
核心技能没有惊喜:你需要对算法有深刻理解,具备使用像 TensorFlow 和 PyTorch 这样的机器学习框架的经验,以及强大的编程技能。Python 和/或 R 不再是可选的,而是必备的。
数据工程
这个角色让你专注于数据管道的架构、管理和维护。适合那些喜欢管理和优化数据流及存储的技术挑战的人。
要进入这个职位,你需要在数据库管理、ETL 过程中的专业知识,以及对大数据技术(如 Hadoop 和 Spark)的熟练掌握。你还需要对数据管道自动化的熟练掌握,使用如 Airflow 等技术。
商业智能
在商业智能中,一切都是关于构建可视化的。这非常适合讲故事者和具有强烈商业感觉的人。
你需要熟练掌握如 Tableau 和 Qlik 等仪表板技术,因为这些是你用来构建可视化的工具。你还需要数据处理技能(即:SQL 技能),以帮助优化数据查询,使仪表板性能更快。
真实的情况
正如我在文章早些时候提到的,数据科学是一个快速发展的领域。新的工作和角色不断出现。回到我的树木类比,我喜欢将其视为在主数据科学树干上添加的新分支。现在有云工程师、SQL 专家、DevOps 角色等——所有这些仍然与数据科学轨道相关联。因此,这篇文章只是简要介绍了你可以在数据科学中发展的方向。
更重要的是,你还应该记住,数据科学带来的挑战也与那六位数的薪水挂钩。学习曲线非常陡峭,而且学习永远不会真正结束。新技术、新趋势和新工具都快速而猛烈地出现——如果你想保持你的工作,你必须跟上。
尽管如此,这仍然是一个很好的职业选择。掌握我提到的三个主要能力后,你将具备承担任何吸引你的数据科学角色的能力。
内特·罗斯迪 是一名数据科学家和产品战略专家。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过真实的面试问题为面试做准备。内特撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并覆盖所有 SQL 相关内容。
相关话题更多信息
在参加任何免费的数据科学课程之前请阅读此信息
原文:
www.kdnuggets.com/read-this-before-you-take-any-free-data-science-course

图片来源:作者
在今天的数字时代,迈克尔·哈克沃特的名言“如果你没有为产品付费,那么你就是产品”从未如此相关。虽然我们通常将其与 Facebook 等社交媒体平台联系在一起,但它同样适用于看似无害的免费资源,例如 YouTube 课程。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
当然,平台通过广告赚取收入,但你投入的时间、精力和动机呢?随着数据变得越来越有价值,仔细评估免费数据科学课程对你学习过程的潜在影响变得至关重要。
面对如此多的选择,确定哪些能真正提供价值可能令人不知所措。这就是为什么在投入任何免费资源之前,退一步考虑一些关键因素至关重要。这样,你将确保最大限度地利用你的学习体验,同时避免与免费课程相关的常见陷阱。
1. 深度和定制化不足
免费课程通常提供一刀切的课程内容,这可能与您的特定学习需求或技能水平不匹配。它们可能涵盖基本概念,但缺乏全面理解或解决复杂实际问题所需的深度。有些免费课程可能具备解决实际数据问题所需的所有必要成分,但缺乏结构,导致你不知从何开始。
2. 缺乏互动学习
单独学习编程语言可能是具有挑战性的,尤其是如果你来自非技术背景的话。数据科学是一个需要实践的方法的领域。免费课程通常提供有限的互动学习机会,例如实时编码会话、测验、项目或讲师反馈。这种被动学习体验可能会阻碍你有效应用概念,最终你可能会放弃学习。
3. 质量和信誉问题
互联网充斥着免费的课程,这使得辨别内容的质量和可信度变得具有挑战性。有些课程可能已经过时或由专家有限的人教授(假大师)。将时间投入到不提供准确或最新信息的课程中可能会适得其反。
这里列出了一些我认为高质量的免费课程:
-
用 Python 编程入门 由 HarvardX 提供
-
用 R 进行统计学习 由 StanfordOnline 提供
-
数据科学入门 由 Microsoft 提供
-
数据库与 SQL 由 freeCodeCamp 提供
-
机器学习 Zoomcamp 由 DataTalks.Club 提供
4. 动机与承诺
与付费课程不同,免费的资源没有外部的责任措施,如截止日期或成绩,这使得很容易失去动力而中途放弃课程。缺乏财务承诺意味着学生必须完全依赖内部驱动和自律来保持动力并坚持完成课程。大学就是一个很好的例子。学生在考虑退学时会经过反复思考,因为涉及到成本。大多数学生完成本科课程,因为他们已经申请了学生贷款,需要偿还。
5. 错失网络机会
网络建设是数据科学职业发展的重要部分。免费的课程通常缺乏付费课程中常见的社区支持,如同行互动、导师指导或校友网络,这些对于职业成长和机会至关重要。虽然有 Slack 和 Discord 群组,但它们通常是由社区驱动的,可能会处于不活跃状态。然而,在付费课程中,有专门的版主和社区经理负责促进学生之间的网络建设。
6. 缺乏职业服务
付费课程通常提供职业服务,如简历评审、认证、就业安置援助和面试准备。这些服务对于那些过渡到数据科学角色的人来说是必不可少的,但在免费课程中通常不可用。在整个招聘过程中获得指导并知道如何处理技术面试问题是至关重要的。
7. 认证与认可
虽然认证证书并非总是必要,但它们可以提升你的简历和信誉。免费的课程可能提供证书,但这些证书通常不如来自认证机构(如哈佛/斯坦福)或认可平台的证书那样有分量。雇主可能不会高度重视这些证书,这可能会影响你的就业前景。此外,认证考试评估工作中处理数据所需的关键技能,包括编码、数据管理、数据分析、报告和展示能力。
结论
尽管免费的数据科学课程可以作为初学或巩固技能的宝贵资源,但它们存在一定的局限性。重要的是要将这些局限性与个人目标、学习风格、经济状况和职业抱负相对照。为了确保全面有效的学习体验,你应该考虑用其他学习方式或投资付费培训班来补充这些免费资源。
最终,帮助你成为专业数据科学家的最关键因素是你的奉献精神和专注于实现目标。无论你花多少钱在课程上,如果缺乏所需的驱动力,你将学不到任何东西。因此,在你深入数据领域之前,请三思是否这是适合你的道路。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为面临心理健康问题的学生开发一个 AI 产品。
相关主题
阅读思维与人工智能:研究人员将脑电波转换为图像
原文:
www.kdnuggets.com/2023/03/reading-minds-ai-researchers-translate-brain-waves-images.html

图片由编辑提供
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
想象一下重新体验你的记忆或构建某人正在思考的图像。这听起来像是科幻电影中的情节,但随着计算机视觉和深度学习的最新进展,它正变成现实。尽管神经科学家仍在努力真正揭示人脑如何将我们眼睛所见转化为心理图像,但人工智能似乎在这方面越来越有能力。来自大阪大学前沿生物科学研究生院的两位研究人员提出了一种新方法,使用名为稳定扩散的 LDM,准确地重建了通过功能磁共振成像(fMRI)获得的人脑活动图像。虽然由Yu Takagi和Shinji Nishimotois撰写的论文“通过潜在扩散模型从人脑活动中高分辨率重建图像”尚未经过同行评审,但由于结果令人震惊的准确,它在互联网上引起了轰动。
这项技术有可能彻底改变心理学、神经科学,甚至刑事司法系统等领域。想象一下,一个嫌疑人被询问他在谋杀发生时在哪里,他回答说他在家。但重建的图像却显示他在犯罪现场。相当有趣,对吧?那么它到底是如何工作的呢?让我们深入研究这篇论文、其局限性以及未来的前景。
它是如何工作的?
研究人员使用了由明尼苏达大学提供的自然场景数据集 (NSD)。该数据集包含了四名受试者查看的 10,000 张不同图像的 fMRI 扫描数据。所有四名受试者查看的 982 张图像的子集被用作测试数据集。在这个过程中训练了两个不同的 AI 模型。一个用于将大脑活动与 fMRI 图像关联,而另一个则用于将其与受试者查看的图像的文字描述关联。这些模型结合起来,使 Stable Diffusion 能够将 fMRI 数据转化为相对准确的图像模仿,其准确率达到近 80%。

第一个模型能够有效地再现图像的布局和视角。但该模型在处理特定物体如钟楼时遇到了困难,并且生成了抽象且模糊的图像。研究人员并没有使用大型数据集来预测更多细节,而是使用了第二个 AI 模型,将图像标题中的关键词与 fMRI 扫描关联起来。例如,如果训练数据中有一张钟楼的照片,那么系统就会将大脑活动的模式与该物体关联起来。在测试阶段,如果被试者表现出类似的大脑模式,那么系统会将物体的关键词输入到 Stable Diffusion 的正常文本到图像生成器中,从而产生对真实图像的逼真模仿。

(最左侧)研究参与者看到的照片,(第二)仅使用大脑活动模式的布局和视角,(第三)仅使用文字信息的图像,(最右侧)结合文字信息和大脑活动模式来重新创建照片中的物体
在这篇论文中,研究人员还声称这是首次从神经科学的角度定量解释 LDM(Stable Diffusion)的每个组件。他们通过将特定组件映射到大脑的不同区域来实现这一点。尽管所提出的模型仍处于初期阶段,但人们对这篇论文的反应迅速,并将该模型称为下一个思维阅读器。
局限性和未来展望
尽管这个模型的准确性相当令人印象深刻,但它是在提供训练脑部扫描的人的脑部扫描上进行测试的。使用相同的数据进行训练和测试集可能会导致过拟合。然而,我们不应忽视这篇论文,因为这类出版物吸引了研究人员,我们开始看到相关论文的逐步改进。
考虑到计算机视觉领域的进步,这篇论文让我思考:我们是否很快能够重温我们的梦想? 这既令人兴奋又令人害怕。虽然相当引人入胜,但它引发了有关隐私侵犯的一些伦理问题。此外,要真正创造出梦境的主观体验还有很长的路要走。这个模型尚不适合日常使用,但我们离理解大脑的运作越来越近。这项技术还可能在医疗领域带来巨大的进展,特别是对于那些有沟通障碍的人。
结论
如果所提模型的改进成为现实,这可能是下一个突破的人工智能领域。但在广泛实施任何技术之前,必须权衡其利弊。希望你喜欢阅读这篇文章,我很想听听你对这篇惊人研究论文的看法。
Kanwal Mehreen 是一位有抱负的软件开发人员,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于趋势话题的文章分享技术知识,并热衷于改善女性在技术行业中的代表性。
更多相关话题
阅读论文如何帮助你成为更有效的数据科学家
原文:
www.kdnuggets.com/2021/02/reading-papers-effective-data-scientist.html
评论
由 Eugene Yan,亚马逊的应用科学家
“与其手动检查我们的数据,为什么不尝试 LinkedIn 的方法呢?这帮助他们实现了 95%的精确度和 80%的召回率。”
我们的前三名课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织在 IT 领域
我的队友分享了 LinkedIn 如何使用k-最近邻算法来识别不一致的标签(在职位名称中)。然后,LinkedIn 在一致的标签上训练了一个支持向量机(SVM),并使用这个 SVM 来更新不一致的标签。这帮助他们在职位标题分类器上达到了 95%的精确度。
这个建议在我们的讨论中最为有用。跟进这个建议让我们的产品分类器最终达到了 95%的准确率。我问她是如何提供这样关键的见解的。她回答道:“哦,我只是偶尔读读论文”,她具体说她每周尝试阅读 1-2 篇论文,通常是与团队正在研究的主题相关的。
通过阅读论文,我们能够了解其他人(例如,LinkedIn)发现哪些方法有效(以及哪些无效)。然后,我们可以调整他们的方法,而不必重新发明火箭。这帮助我们用更少的时间和精力交付有效的解决方案。
如果我比其他人看得更远,那是因为我站在巨人的肩膀上。
— 艾萨克·牛顿*
阅读论文也拓宽了我们的视野。虽然我们可能只关注数据科学的某些方面,但相关研究的进展往往是有帮助的。例如,词嵌入和图的理念在推荐系统中非常有用。同样,计算机视觉的思想 — 如迁移学习和数据增强 — 对自然语言处理(NLP)也很有帮助。
阅读论文也让我们保持最新。在过去十年间,NLP 领域取得了巨大的进展。然而,通过阅读最关键的 10 篇论文,我们可以迅速跟上最新进展。保持最新状态使我们在工作中更高效,从而减少时间和精力的投入。这样,我们将有更多时间来阅读和学习,从而形成良性循环。
如何选择要阅读的论文?
如果我们刚开始养成这个习惯,可以阅读任何感兴趣的内容——大多数论文都会教会我们一些东西。阅读我们感兴趣的话题也更容易养成习惯。
我们也可以根据实用性选择论文。例如,我们可能需要快速了解某个领域以完成一个项目。在开始一个项目之前,我几乎总是留出时间进行文献综述。花几天时间深入研究论文可以节省几周,甚至几个月的时间,避免走弯路和不必要的重复劳动。
推荐也是识别有用论文的便捷方法。一种窍门是关注我们欣赏的人在社交媒体上的动态,或订阅策划的通讯——我发现这些来源的信息噪声比率很高。
我阅读哪些论文?出于实际考虑,我主要阅读与工作相关的论文。这使我能立即应用所读内容,从而巩固学习。在工作之外,我对序列感兴趣,倾向于阅读关于NLP和强化学习的论文。我特别喜欢那些分享有效和无效方法的论文,比如通过消融研究。这包括关于Word2vec、BERT和T5的论文。
如何阅读论文?
谷歌搜索“如何阅读论文”会返回大量有用的结果。但如果你觉得这些信息太多,以下是一些我觉得有帮助的:
-
OMSCS 6460 如何阅读学术论文: 一位我喜欢的教授的建议
-
采访其他科学家分享他们的阅读方法
-
关于工程研究论文的一个方法
-
安慰我们并非唯一觉得困难的人
我的方法类似于三遍法。在下面的例子中,我将分享如何阅读几篇推荐系统论文,以了解新颖性、多样性、偶然性等指标。
在第一遍,我扫描摘要以了解论文是否包含我所需的内容。如果包含,我会浏览标题以识别问题陈述、方法和结果。在这个例子中,我特别寻找如何计算各种指标的公式。我会对列表上的所有论文进行第一次阅读(并且在完成列表之前避免开始第二遍)。在这个例子中,大约一半的论文进入了第二遍。
第一次阅读后,30 多篇论文减少到 14 篇——节省了不少精力。
在第二遍,我再次阅读每篇论文并突出相关部分。这有助于我在之后查阅论文时快速找到重要部分。然后,我为每篇论文做笔记。在这个例子中,笔记主要集中在指标(即方法、公式)上。如果是关于某个应用的文献综述(如推荐系统、产品分类、欺诈检测),笔记将重点关注方法、系统设计和结果。

来自三篇论文的示例笔记;与指标相关的笔记用红色框出。
对于大多数论文,第二遍已经足够。我已经捕捉了关键信息,并可以在未来需要时参考。尽管如此,如果我在进行文献综述时阅读论文,或者想要巩固我的知识,我有时会进行第三遍。
阅读只为大脑提供知识材料;思考才使我们所读的内容成为我们自己的。
— 约翰·洛克*
在第三遍,我将论文中的共通概念整合到自己的笔记中。不同的论文有各自测量新颖性、多样性、偶然性等的方式。我将它们汇总到一个笔记中,并比较其优缺点。在这个过程中,我经常发现笔记和知识的 gaps,必须重新查阅原论文。

关于偶然性和意外性指标的示例笔记。
最后,如果我认为对其他人有用,我会写下我所学到的,并在线发布。与从头开始相比,拥有笔记作为参考使得写作变得容易得多。这导致了如下作品:
亲自尝试一下
在深入下一个项目之前,花一两天时间浏览几篇相关论文。我相信这将为你节省中长期的时间和精力。不知道从哪里开始?以下是一些有用的资源供你参考:
-
带代码的论文: 机器学习研究及其实现代码
-
[applied-ml](https://github.com/eugeneyan/applied-ml): 组织如何构建和部署机器学习系统的论文 -
[ml-surveys](https://github.com/eugeneyan/ml-surveys): 总结近期机器学习进展的调研论文 -
Google Scholar 提醒: 当有新出版物符合你的查询时会收到更新
-
42 篇论文: AI 和计算机科学领域的热门论文
个人简介: Eugene Yan 在机器学习与产品的交叉领域工作,致力于构建实用的面向客户的机器学习系统。他目前是亚马逊的应用科学家。此前,他曾领导 Lazada 和 uCare.ai 的数据科学团队。他在 eugeneyan.com 上撰写和演讲关于数据科学、数据/机器学习系统和职业发展方面的内容,并在 @eugeneyan 上发推文。
原文。经允许转载。
相关资源:
-
5 篇必读的数据科学论文(及其使用方法)
-
2020 年十大计算机视觉论文
-
深度学习先驱 Geoff Hinton 论最新研究及 AI 未来
更多相关主题
实时图像分割使用 5 行代码
原文:
www.kdnuggets.com/2021/10/real-time-image-segmentation-5-lines-code.html
评论
作者 Ayoola Olafenwa,机器学习工程师
对实时图像分割应用的需求
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
图像分割是计算机视觉的一个方面,涉及将计算机视觉化的对象内容分割成不同类别以便更好地分析。图像分割在解决许多计算机视觉问题中,例如医疗图像分析、背景编辑、自动驾驶汽车视觉和卫星图像分析方面做出了重要贡献,使其成为计算机视觉中的一个宝贵领域。计算机视觉领域的一大挑战是保持实时应用中准确性和速度性能之间的平衡。在计算机视觉领域,有这样一个困境,即计算机视觉解决方案要么更准确但较慢,要么不那么准确但较快。
PixelLib 库是一个旨在通过少量 Python 代码实现图像和视频中对象分割的库。PixelLib 的早期版本使用 Tensorflow 深度学习作为其后端,利用 Mask R-CNN 执行实例分割。Mask R-CNN 是一个优秀的对象分割架构,但在实时应用中无法平衡准确性和速度性能。PixelLib 提供对 PyTorch 后端的支持,利用 PointRend 分割架构实现更快、更准确的图像和视频中对象的分割和提取。
PointRend 由 Alexander Kirillov et al 提供,用于替代 Mask R-CNN 执行对象实例分割。PointRend 是一种优秀的最先进神经网络,用于实现对象分割。它生成准确的分割掩码,并以高推理速度运行,满足对准确和实时计算机视觉应用的日益增长的需求。我将 PixelLib 与 Detectron2 的 PointRend Python 实现集成,Detectron2 仅支持 Linux 操作系统。我对原始的 Detectron2 PointRend 实现进行了修改,以支持 Windows 操作系统。PixelLib 支持的 PointRend 实现支持 Linux 和 Windows 操作系统。
注意: 本文基于使用 PyTorch 和 PointRend 进行实例分割。如果你想学习如何使用 Tensorflow 和 Mask R-CNN 进行实例分割,请阅读这篇 文章。

原始图像来源(左:MASK R-CNN,右:PointRend)

原始图像来源(左:MASK R-CNN,右:PointRend)
被标记为 PointRend 的图像显然比 Mask R-CNN 的分割结果更好。
下载与安装
下载 Python
PixelLib PyTorch 支持 Python 3.7 及以上版本。下载兼容的 Python 版本。
安装 PixelLib 及其依赖项
安装 PyTorch
PixelLib PyTorch 版本支持以下 PyTorch 版本(1.6.0,1.7.1,1.8.0 和 1.90)。不支持 PyTorch 1.7.0,且不使用任何低于 1.6.0 的 PyTorch 版本。安装兼容的 PyTorch 版本。
安装 Pycocotools
pip3 install pycocotools
安装 PixelLib
pip3 install pixellib
如果已安装,请使用以下命令升级到最新版本:
pip3 install pixellib -upgrade
图像分割
PixelLib 使用五行 Python 代码通过 PointRend 模型对图像和视频进行对象分割。下载 PointRend 模型。这是图像分割的代码。
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl")
ins.segmentImage("image.jpg", show_bboxes=True, output_image_name="output_image.jpg")
第 1-4 行: 引入了 PixelLib 包,同时也从模块 pixellib.torchbackend.instance 中引入了类 instanceSegmentation(从 PyTorch 支持中引入实例分割类)。我们创建了这个类的实例,并最终加载了我们下载的 PointRend 模型。
第 5 行: 我们调用了函数 segmentImage 来对图像中的对象进行分割,并向函数添加了以下参数:
-
Image_path: 这是待分割图像的路径。
-
Show_bbox: 这是一个可选参数,用于显示带有边界框的分割结果。
-
Output_image_name: 这是保存的分割图像的名称。
分割样本图像

ins.segmentImage("image.jpg", show_bboxes = True, output_image_name="output.jpg")
分割后的图像
The checkpoint state_dict contains keys that are not used by the model:
proposal_generator.anchor_generator.cell_anchors.{0, 1, 2, 3, 4}
如果你正在运行分割代码,上述日志可能会出现。这不是错误,代码将正常运行。
results, output = ins.segmentImage("image.jpg", show_bboxes=True, output_image_name="result.jpg")
print(results)
分割结果返回一个字典,字典中的值与图像中分割出的物体相关。打印的结果将如下格式:
{'boxes': array([[ 579, 462, 1105, 704],
[ 1, 486, 321, 734],
[ 321, 371, 423, 742],
[ 436, 369, 565, 788],
[ 191, 397, 270, 532],
[1138, 357, 1197, 482],
[ 877, 382, 969, 477],),
'class_ids': array([ 2, 2, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 2, 24, 24,2, 2,2, 0, 0, 0, 0, 0, 0], dtype=int64),
'class_names': ['car', 'car', 'person', 'person', 'person', 'person', 'person', 'car', 'person', 'person', 'person', 'person', 'car', 'backpack', 'backpack', 'car', 'car', 'car', 'person', 'person', 'person', 'person', 'person', 'person'],
'object_counts': Counter({'person': 15, 'car': 7, 'backpack': 2}),
'scores': array([100., 100., 100., 100., 99., 99., 98., 98., 97., 96., 95.,95., 95., 95., 94., 94., 93., 91., 90., 88., 82., 72.,69., 66.], dtype=float32),
'masks': array([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
'extracted_objects': []
检测阈值
PixelLib 使得可以确定物体分割的检测阈值。
ins.load_model("pointrend_resnet50.pkl", confidence = 0.3)
confidence: 这是在load_model函数中引入的新参数,设置为0.3,以30%为检测阈值。我设置的默认检测阈值为0.5,可以通过confidence参数进行调整。
速度记录
PixelLib 使得可以进行实时物体分割,并添加了调整推理速度以适应实时预测的功能。使用 4GB 容量的 Nvidia GPU 处理单张图像的默认推理速度约为0.26 秒。
速度调整
PixelLib 支持速度调整,有两种速度调整模式,分别是fast和rapid模式:
1. 快速模式
ins.load_model("pointrend_resnet50.pkl", detection_speed = "fast")
在load_model函数中,我们添加了参数detection_speed并将其值设置为fast。快速模式处理单张图像的时间为0.20 秒。
快速模式检测的完整代码
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl", detection_speed = "fast")
ins.segmentImage("image.jpg", show_bboxes=True, output_image_name="output_image.jpg")
2. 迅速模式
ins.load_model("pointrend_resnet50.pkl", detection_speed = "rapid")
在load_model函数中,我们添加了参数detection_speed并将其值设置为rapid。迅速模式处理单张图像的时间为0.15 秒。
快速模式检测的完整代码
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl", detection_speed = "rapid")
ins.segmentImage("image.jpg", show_bboxes=True, output_image_name="output_image.jpg")
PointRend 模型
有两种类型的 PointRend 模型用于物体分割,它们分别是resnet50 变体和resnet101 变体。在本文中使用的是resnet50 变体,因为它速度较快且准确性良好。resnet101 变体更准确,但比resnet50 变体慢。根据 官方报告上的信息,resnet50 变体在 COCO 上达到38.3 mAP,而resnet101 变体在 COCO 上达到40.1 mAP。
Resnet101 的速度记录: 分割的默认速度为0.5 秒,快速模式为0.3 秒,而迅速模式为0.25 秒。
Resnet101 变体的代码
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet101.pkl", network_backbone="resnet101")
ins.segmentImage("sample.jpg", show_bboxes = True, output_image_name="output.jpg")
使用 resnet101 模型进行推理的代码相同,只不过我们在load_model函数中加载了PointRend resnet101 模型。从这里下载 resnet101 模型。我们在load_model函数中添加了一个额外的参数network_backbone,并将其值设置为resnet101。
注意: 如果你想要实现高推理速度和良好的准确性,使用PointRend resnet50 变体,但如果你更关注准确性,使用PointRend resnet101 变体。所有这些推理报告均基于使用 4GB 容量的 Nvidia GPU。
图像分割中的自定义对象检测
使用的 PointRend 模型是一个预训练的 COCO 模型,支持 80 种对象类别。PixelLib 支持自定义对象检测,使得过滤检测结果和确保目标对象的分割成为可能。我们可以从支持的 80 个对象类别中选择,以匹配我们的目标。这是 80 个支持的对象类别:
person, bicycle, car, motorcycle, airplane,
bus, train, truck, boat, traffic_light, fire_hydrant, stop_sign,
parking_meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra,
giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard,
sports_ball, kite, baseball_bat, baseball_glove, skateboard, surfboard, tennis_racket,
bottle, wine_glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange,
broccoli, carrot, hot_dog, pizza, donut, cake, chair, couch, potted_plant, bed,
dining_table, toilet, tv, laptop, mouse, remote, keyboard, cell_phone, microwave,
oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy_bear, hair_dryer,
toothbrush.
目标类别分割的代码
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl")
target_classes = ins.select_target_classes(person = True)
ins.segmentImage("image.jpg", show_bboxes=True, segment_target_classes = target_classes, output_image_name="output_image.jpg")
调用了函数select_target_classes以选择需要分割的目标对象。函数segmentImage增加了一个新参数segment_target_classes,以从目标类别中选择并根据这些类别过滤检测结果。我们过滤检测结果,仅检测图像中的人。
图像中的对象提取
PixelLib 使得提取和分析图像中分割出的对象成为可能。
对象提取的代码
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl")
ins.segmentImage("image.jpg", show_bboxes=True, extract_segmented_objects=True,
save_extracted_objects=True, output_image_name="output_image.jpg" )
图像分割的代码相同,只是我们增加了额外的参数extract_segmented_objects和save_extracted_objects,分别用于提取分割对象和保存提取出的对象。每个分割出的对象将保存为segmented_object_index,例如segmented_object_1。对象将按提取顺序保存。
segmented_object_1.jpg
segmented_object_2.jpg
segmented_object_3.jpg
segmented_object_4.jpg
segmented_object_5.jpg
segmented_object_6.jpg

注意:图像中的所有对象都被提取了,我选择只显示其中的三个。
从边界框坐标中提取对象
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl")
ins.segmentImage("image.jpg", show_bboxes=True, extract_segmented_objects=True, extract_from_box = True,
save_extracted_objects=True, output_image_name="output_image.jpg" )
我们引入了一个新参数extract_from_box,用于从其边界框坐标中提取分割出的对象。每个提取出的对象将保存为object_extract_index,例如object_extract_1。对象将按提取顺序保存。

从边界框坐标提取
图像分割输出可视化
PixelLib 使得可以根据图像分辨率调节图像的可视化。
ins.segmentImage("sample.jpg", show_bboxes=True, output_image_name= "output.jpg")

可视化效果未能显示,因为文本大小和框厚度太细。我们可以调整文本大小、文本厚度和框厚度来调整可视化效果。
更好的可视化修改。
ins.segmentImage(“sample.jpg”, show_bboxes=True, text_size=5, text_thickness=4, box_thickness=10, output_image_name=”output.jpg”)
segmentImage 函数接受了新的参数,用于调整文本和边界框的厚度。
-
text_size: 默认文本大小为0.6,适用于分辨率适中的图像。对于高分辨率图像则显得过小。我将其增加到了 5。
-
text_thickness: 默认文本厚度为 1。我将其增加到 4,以匹配图像分辨率。
-
box_thickness: 默认框厚度为 2,我将其更改为 10,以匹配图像分辨率。
改进可视化的输出图像

注意: 根据图像的分辨率调整参数。我为分辨率为5760 x 3840的示例图像使用的值可能对分辨率较低的图像来说过大。如果您的图像分辨率非常高,可以将参数值增加到超过我在此示例代码中设置的值。text_thickness 和 box_thickness 参数值必须为整数,不能用浮点数表示。text_size 值可以用整数或浮点数表示。
我们在这篇文章中详细讨论了如何执行准确且快速的图像分割和对象提取。我们还描述了 PixelLib 的升级,通过 PointRend,使库能够满足计算机视觉中对精度和速度性能平衡的日益增长的需求。
注意: 阅读完整教程,其中包括如何使用 PixelLib 对一批图像、视频和实时摄像头视频进行对象分割。
简历:Ayoola Olafenwa 是一位自学编程的程序员、技术作家和深度学习从业者。Ayoola 开发了两个开源计算机视觉项目,被全球许多开发者使用,目前担任 DeepQuest AI 的机器学习工程师,负责在云端构建和部署机器学习应用。Ayoola 的专业领域是计算机视觉和机器学习。她有使用深度学习库如 PyTorch 和 Tensorflow 来构建和部署机器学习模型的经验,并在云计算平台如 Azure 上使用 Docker、Pulumi 和 Kubernetes 等 DevOp 工具进行生产部署。Ayoola 还在使用高效框架如 PyTorchMobile、TensorflowLite 和 ONNX Runtime 将机器学习模型部署到边缘设备如 Nvidia Jetson Nano 和 Raspberry PI 上。
相关:
-
使用 5 行代码提取图像和视频中的对象
-
使用 5 行代码更改任何图像的背景
-
使用 5 行代码更改任何视频的背景
更多相关话题
从敏捷数据科学团队获得真实世界的结果
原文:
www.kdnuggets.com/2017/02/real-world-results-agile-data-science-teams.html
评论
作者:John Akred,硅谷数据科学。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
数据科学是一个令人兴奋且不断变化的领域。好奇的头脑和热情的研究者常常被算法、模型和新技术所困扰。如果我们不小心,我们会忘记我们实际上是来做什么的:解决真实的问题。如果我们的工作只是理论,那又有什么意义呢?
为了保持相关性和实用性,数据科学家的日常活动必须
-
优先使用技术,以便产生最佳结果;
-
以消费者为中心设计技术和产品;并且
-
与合作伙伴和客户良好合作。
简而言之,数据科学应当产生真实的应用。这一现实是多方面的。一个重要的问题是如何管理数据团队以获得现实世界的结果。通过使用 敏捷数据科学方法,我们帮助数据团队快速而有方向地工作,并管理数据科学和应用开发固有的不确定性。
在这篇文章中,我将探讨管理敏捷数据科学的实际要素。
什么是敏捷数据科学团队,为什么我们需要它们?
数据科学结果是概率性的和不可预测的,这是一个事实。在项目开始时,它通常看起来从 A 到 B 有一条明显的路线。当你开始时,事情从来没有那么简单。敏捷团队摒弃了严格的计划,以创造性思维进入项目;他们接受不确定性而不是回避它。
当出现障碍时,这一点非常有用——传统的数据科学团队可能会在决定选项时陷入困境,而灵活的敏捷数据科学团队更有可能找到新的解决方案。不确定性和快速适应问题的需求不会让他们感到害怕,而是让他们感到兴奋。
与此同时,敏捷规划方法非常注重应用于客户的问题。否则,我们很容易陷入关于假设、模型和结果的严格规则中。在后一种情况下,我们最终会生产出有效的东西——验证我们的假设——但与我们为其生产的真实场景的实际应用关系不大。浪费时间对我们或我们的客户都不好。
关键概念
支撑我们在 SVDS 使用的敏捷方法的一些关键概念。它们共同为我们提供了项目目标、顶层调查策略以及日常行动计划。
-
任务——我们为什么要做这个项目?我们希望达到什么结果或结论?在项目结束时,我的客户需要什么?
-
调查主题——我如何收集和理解这些数据?我可以直接观察到什么?我可以实施什么来帮助我理解数据?
-
史诗——将调查主题拆分为一个或多个工作计划。
-
故事——构成史诗的工作单元。这些是可以在给定时间内完成的具体活动。
有一个方法是很棒的,但看到它如何用来解决实际问题会更有帮助。在 SVDS,我们使用这种方法创建了一个系统,通知乘客加州列车何时到达某个站点晚点,以及预计到达时间。让我们深入了解一下它是如何工作的。
一个加州列车的示例
我将简要概述我们在 Caltrain 的工作,但如果你想了解更多,可以查看我们的 项目页面。这个项目的目的,其 任务,是创建一个应用程序,告知用户加州列车何时晚点以及到达指定站点的时间。加州列车系统有自己的应用程序,但存在不准确的问题,并且没有告诉乘客列车是否晚点以及晚点了多久。没有人喜欢上班迟到,所以我们希望为他们创造一个解决方案。
下一步是定义 调查主题,这始于一个问题:“我如何知道列车是否晚点?”
史诗 部分包括回答调查主题中提出的大问题所需的所有小问题和任务。史诗包括诸如“在常规工作条件下为加州列车系统开发一个有效的模型”和“分类系统中的灾难性事件,这些事件阻止了常规工作模型的应用”之类的任务。
随着史诗被拆分为工作单元,故事 也随之产生。示例故事包括“我是否能准确且一致地使用 Twitter 查找列车晚点数据?”和“我是否能通过视频识别列车的方向?”
冲刺、站立会议和审查会议
给定工作拆解成史诗和故事,你如何管理其执行和规划?这通过冲刺、站会和回顾会议来实现。你会发现不同的敏捷从业者对这些会议有不同的看法,但基本原理都是相似的。
冲刺。故事在冲刺期间完成,冲刺是一个固定时间段来处理任务,通常为两周,目标是产生新的结果。冲刺开始于冲刺计划阶段,我们将与客户利益相关者一起决定启动或继续哪些史诗。数据科学家会将这些史诗分解为该冲刺的故事。
站会。在冲刺期间,每天团队都会召开站会。在这里,他们报告进展,说明接下来要做的事,并协调解决工作中的阻碍。站会,顾名思义,不用于长时间的讨论或解决问题。重点是快速传达信息,并安排进一步讨论。客户利益相关者可以选择参加这些站会。或者,我们每周单独安排一到两次更新。保持他们紧密参与进展非常重要。
回顾会议。冲刺过程中的最后一步是召开回顾会议,团队在会议中展示并评估结果。客户利益相关者也会参加此会议。我们展示工作,团队讨论这些工作。这些工作是否足够好?我们是否应该继续进行?它会有用吗,还是现在就应该放弃?我们通常将回顾会议(评估工作成果)与冲刺回顾会议(评估工作过程)结合起来。
这能防止团队花费大量时间在对客户没有实际帮助的事情上。如果工作未完成,你们会讨论如何推进。如果完成了,你们会讨论从中学到的经验。敏捷团队总是在从以往的工作中学习。
结论
敏捷数据科学团队以适应性、协作性和产生可用结果的方式工作。他们认同数据科学可以是创造性和创新性的。他们接受未知而不是做假设,并且不浪费时间在那些不起作用的事情上。
敏捷团队是数据科学的未来,这些富有创意的队友们共同协作,创造出有用的东西,并解决实际问题。未来充满变数,我们必须保持灵活才能成功。
编辑注:我们感谢 Amber McClincy 和 Edd Wilder-James 的贡献。
简介: 约翰·阿克雷德 是硅谷数据科学公司的首席技术官,拥有超过 20 年的先进分析解决方案和分析系统架构经验。他致力于帮助组织更加数据驱动,将其在分析和数据科学方面的深厚专业知识与商业头脑和动态工程领导力相结合。他是应用商业分析、机器学习、预测分析和操作数据挖掘领域的公认专家。
原文。经许可转载。
相关内容:
-
通过深度学习提升敏捷流程
-
为数据团队奠定基础
-
大数据分析的世界导航
了解更多相关内容
人工智能的实时翻译
무궁화 꽃이 피었습니다
这就是《鱿鱼游戏》中娃娃所说的。但你怎么知道呢!你有字幕在屏幕上。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
像《鱿鱼游戏》和《纸钞屋》这样的节目在 Netflix 排行榜上名列前茅,为观众提供了全新的戏剧和娱乐类型,探索不同语言的内容。在疫情期间,人们被锁在家中,这种特殊的方式让世界更加紧密地联系在一起。尽管这种亲近感已经在逐渐增长,但全球各地的各种发展使得“世界是一个大家庭”的概念比以往任何时候都更加真实。现代技术正在帮助我们以越来越无缝和实时的方式解读和翻译我们周围的世界。尽管当今世界充满了商业和经济活动,但随着贸易和商业活动跨越国界,国家之间的沟通也显著增加。在这种情况下,翻译是唯一允许跨通信的方法,也是将所有社会联系在一起的关键。因此,我们还没有完全实现,但语言的障碍比以往任何时候都小,而实时翻译的概念在人工智能的帮助下已不再是幻想。

什么是实时翻译?
实时翻译技术是一种技术驱动的解决方案,能够快速将材料从一种语言翻译成另一种语言。实时翻译是一项功能,可以即时将另一种语言翻译成用户选择的语言。任何人都可以使用这种技术来快速核实事实、获取快速翻译,并与说外语的人沟通。这提高了效率,并在企业层面提升了客户体验,使公司能够用数百种语言与客户连接,同时仍然利用现有的联络中心、服务台和员工。这项技术对全球组织来说是一个游戏规则改变者。它消除了对双语人员的需求,同时将公司与以前难以触及的客户、员工和合作伙伴连接起来。
实时翻译如何与人工智能协作?
随着时间的推移,实时翻译的方法经历了重大变化。旧版本的这项技术会将语音转换为文本,然后再翻译成目标语言。随着 AI 的使用,这一方法得到了进一步改进。当前的实时翻译技术基于人工智能和几种类型的机器学习,采用了能够区分噪声的高级模式匹配软件。它使用声音识别软件来匹配模式。为了准确理解所说内容并在词汇和句子的上下文中理解,使用了神经网络和深度学习程序。
这项技术正试图更快地翻译语音。该技术还访问了一个包含常见词汇、意义和其他数据的大型数据库,这些数据是通过对数百万份多语言文档的过去分析获得的。这些工具通过分析声音波形,聆听正在说的词语,并将与翻译相关的语音部分进行分类。它分析声音波形,以确定哪些语音部分与其翻译相关。然后,该技术将语音转换为其在目标语言中识别为常见的内容。

当前情况
近年来,实时翻译技术已经进步到完成翻译的预期时间现在少于 2 到 5 秒。由于许多翻译技术依赖于基于云的数据,语音和翻译之间存在差距。随着网络速度的提高,这一差距很可能会增加。阿里巴巴于 2020 年 10 月 21 日进行了全球首场实时翻译 214 种语言的电子商务直播。Facebook 在社交网络、Messenger 和 Instagram 上使用人工智能,每天进行超过 60 亿次翻译。
Google Translate 主导了在线翻译领域,提供将全球数百万种语言翻译的工具。用户可以使用 Google Translate 进行文本、文档和网页的跨语言翻译,这是 Google 开发的多语言神经机器翻译服务。截至 2021 年 12 月,它支持 109 种语言,并且截至 2016 年 4 月,它拥有超过 5 亿的累计用户,每天翻译超过 1000 亿个词。Google 还发布了包括实时语言翻译功能的无线耳机和 Pixel Buds。这一功能可以实时翻译两个讲不同语言的人的对话。此外,Google 最近表示,这一实时翻译功能将应用于所有支持 Google Assistant 的智能手机和耳机,使实时翻译对每个人都可用。
Google AI 还发布了 Translatotron 的第二个迭代版本,即 S2ST 模型,它可以在不使用多个中间子系统的情况下直接进行两种语言之间的语音翻译。Translatotron 于 2019 年发布,是由 Google AI 团队开发的端到端语音到语音翻译模型,该公司表示这是第一个将一种语言的语音直接转换为另一种语言的语音的端到端框架。

前进中的挑战
随着网络工具和机器学习的进步,预计大多数企业将采用实时语言翻译技术,这将帮助他们开发新的收入渠道。然而,为了满足需求,连接必须足够可靠,以加快翻译过程的速度。尽管近年来翻译领域取得了显著进展,但不要期望你的手机、智能音响、PC 或耳机能够很快打破所有语言障碍。同时,尽管有些翻译方法依赖于机器,但 AI 驱动的机器翻译方法不可能取代在高风险政治、法律、金融和健康相关对话中的昂贵且熟练的人类口译员、翻译员和多语言专家。另一个问题是,翻译在受控条件下或在有大量数据训练模型的情况下效果最好,而在当前的语言环境下可能并非如此。虽然实时语言翻译系统可以帮助打破语言障碍,但获得理解和信任需要一套更复杂的行为和对文化差异的尊重。
结论
随着世界向更精细的沟通形式发展,实时翻译将为更统一、高效和专业的翻译系统铺平道路,这一系统由技术引导,并依托于以往的翻译努力。这就是为什么,由于实时翻译技术将会持续存在,公司应该利用它来加速翻译过程。实时语言翻译很快将可在所有渠道和平台上使用,包括社交媒体和面对面交流。虽然人类翻译员的效能无可争议,但有了人工智能的团队,实时翻译技术将成为翻译的未来之路。
Neeraj Agarwal是Algoscale的创始人,这是一家数据咨询公司,涵盖数据工程、应用人工智能、数据科学和产品工程。他在这一领域拥有超过 9 年的经验,帮助了从初创公司到财富 100 强企业的各种组织摄取和存储大量原始数据,以便将其转化为可操作的见解,从而实现更好的决策和更快的商业价值。
重建我的 7 个 Python 项目
原文:
www.kdnuggets.com/2021/05/rebuilding-7-python-projects.html
评论
由Kaustubh Gupta,Python 开发者

照片由Fotis Fotopoulos提供,来源于Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
Python 是像我这样的编程爱好者最喜欢的语言。我对这门语言有浓厚的兴趣,并且使用了超过 2 年。今年我有很多闲暇时间来提升我的编程技能,并开发了许多围绕网页开发、安卓应用和数据科学的项目。在这篇文章中,我将解释每个项目的目的、我是如何制作的、与该项目相关的文章以及 GitHub 仓库链接。也许这能激发你脑海中的类似项目想法!让我们来探索这些项目吧。
1. PortfolioFy
作为开发者,我们创建了数以百计的仓库,但其中很少有真正成为我们在社交媒体/LinkedIn 上展示的最终项目。这项 GitHub 操作允许你生成一个自我更新的作品集,包含项目、黑客马拉松和最新博客。这个操作生成一个索引文件,并借助 GitHub 页面在提交到仓库后立即部署。这个项目的主要目的是帮助你展示你作为开发者的技能。
由此操作生成的示例预览!
最初,该项目仅支持一个非常基本的主题,但随着我不断收到社区的反馈,另一个主题被添加到项目中。现在,这个操作变得更加灵活,可以选择约束条件,例如是否添加博客、黑客马拉松,选择你想展示的 GitHub 统计数据类型,所有这些在较新版本中都变为可选项。
2. WhatsApp 群聊分析器
作为数据科学的追随者,我总是对发现数据中的趋势充满好奇。我总是尝试寻找可以轻松获取数据的现实世界场景,当我发现 WhatsApp 具有导出群聊的功能时,我忍不住要分析这些数据。我为我的大学小组做了这项工作,对此感到满意,但随后产生了一个想法:为什么不开发一个通用的网络应用程序,让任何人都可以上传他们的聊天文件并获取一些有趣的见解呢!这正是这个项目的目的。
展示网络应用使用情况的 GIF
它会处理导出的聊天记录文件(不包括媒体文件),对其进行清理,运行所有统计生成的自定义函数,并实时展示给用户!上传的文件在统计生成后会立即删除,以保护隐私。这个网络应用展示了总的表情符号计数、在群成员中的使用情况、每天成员的活动情况、总体活动情况及指定假期的活动情况,还有一些其他功能!这是一个优秀的数据清理和可视化项目,或者你可以基于这些数据开发一个预测模型,预测某人下一次的聊天内容。可能性无限!
3. 大学成绩门户
我目前在印度上大学(大三),正在攻读本科学位。我的大学以长 PDF 的形式发布学期考试成绩,这些 PDF 通常包含大量对学生不相关的信息。甚至科目名称也是以编码形式出现,很难计算获得的学分。此外,由于每年每个批次大约有 6000 名学生,手动预测候选人的排名几乎是不可能的。为了简化这个过程,我开发了一个解析脚本,可以读取这些长 PDF(有些接近 400 页!),将其存储为可读格式,应用所有的数据转换技术,以获得学分点、百分比以及在学院和大学级别的排名!

IPU 是我的大学的名字
假设每学期平均有 5000 条记录,我拥有 2017 年批次及以后的记录,每年有两个学期。因此,到目前为止我大概有 6 万条记录!该网站还提供了生成个人资料的功能,可以调取所有前一个学期的结果。这是我做过的最大的项目之一,整个过程花了大约 2 个月才完全满意。
4. 大学安卓应用
由于我成功地开发了网站,是时候将此功能扩展到其他平台,并发现如何用 Python 制作 Android 应用。这个过程得益于一个了不起的库——Kivy,以及 Kivymd 的材料设计。它能够向后端 API 发起请求,并以表格形式显示结果。掌握这个库花费了很多时间,但值得。

展示应用使用的 GIF
一旦我开发了这个应用,我对它产生了浓厚的兴趣,于是我在 Medium 上写了一个完整的系列文章,如果你有兴趣了解这个库,这里是第一部分:
5. Telegram 机器人!
我认为,我在这个结果项目上做得太多了,还制作了一个 Telegram 机器人!在开发机器人的第一个版本时,我犯了一个大错误,运行了一个无限循环来检查新消息,这个过程消耗了大量资源。当我第一次将其部署到 Heroku 时,第二天我收到邮件,说我当前的小时数已被消耗,那时我才意识到我犯了一个大错误。为了解决这个问题,我采用了 Telegram 的 webhook 概念,使得消息能够直接重定向到我的链接。
另一件我做的事是将机器人集成到 Flask 服务器中,这有助于防止机器人进入无限循环!现在每当有人发起结果请求时,它会将请求发送到休眠中的 Heroku 应用程序,并且通过这个请求,应用程序状态发生变化,结果也会被发送出去。
6. 歌词提取器
这个项目对我来说很特别,因为通过这个项目,我赢得了一个比赛!这个项目使用了 Brython,使你可以在前端网站上运行 Python 代码,而无需使用 Flask、Django 或其他服务器。我做了一个歌曲歌词提取器,它根据传递给网站的艺术家名字和专辑进行 API 调用。这个项目非常简单,我将其托管在 GitHub Pages 上,确保了更长的正常运行时间且没有持续成本!
作者提供的 GIF 示例
7. KivyML 应用
在发现 Kivy & Kivymd 库时,我发现我可以在安卓上部署机器学习模型。这是一种间接的方法,因为目前 python-to-android 不支持 sklearn。我不得不将模型作为 API 部署在 Heroku 上,然后通过 GET 请求获取预测结果,并将其显示在用户屏幕上。虽然这是一种初步的方法,还有许多其他东西可以在这里实现,但这就是我在构建这个项目时能想到的所有方法。
额外项目 - 我的个人网站!
这不是一个基于 Python 的项目,而是一个自动生成的 Wix 网站,我于 2019 年 7 月购买用于博客目的。尽管一旦我转向 Medium 平台进行博客写作后,我对这个网站的维护就减少了,而且由于年末我承诺升级所有可以展示的项目,我不得不对其进行调整,以便访客能够舒适地浏览。
作者网站的图片预览
KaustubhGupta (www.kaustubhgupta.xyz) - 了解所有关于技术和一般生活方式的内容
这个网站包含了我所有个人和非技术性的文章,我每年写这些文章的次数非常少。
结论
这就是我今年如何升级和管理我的 Python 项目。我还做了很多其他项目,但这些是我为这篇文章挑选的前 7 个。做一个项目是一个系统的过程,从构思、设计、编码,如果适用的话,还包括在互联网上部署。我希望我给读者们提供了一些激励,让你们能提出自己的想法,并向世界展示你们的技能。
至此,我们来到了这篇文章的结尾,也告别了 2020 年!祝所有读者圣诞快乐(我的生日也在这一天:圣诞节????),如果你喜欢我的文章或者从中受益,请确保在 Medium 上关注我,或者你可以通过 LinkedIn 联系我。再见!
简历: Kaustubh Gupta 是一位对数据科学和机器学习感兴趣的 Python 开发者,曾参与多个数据相关项目,对机器学习的实际应用充满兴趣。
原文。经许可转载。
相关:
-
如何在 2021 年组织你的数据科学项目
-
数据科学家的软件工程最佳实践
-
2020 年 10 个令人惊叹的机器学习项目
更多相关内容
接收器操作特性曲线揭秘(使用 Python)
原文:
www.kdnuggets.com/2018/07/receiver-operating-characteristic-curves-demystified-python.html
评论
由 Syed Sadat Nazrul 统计科学家
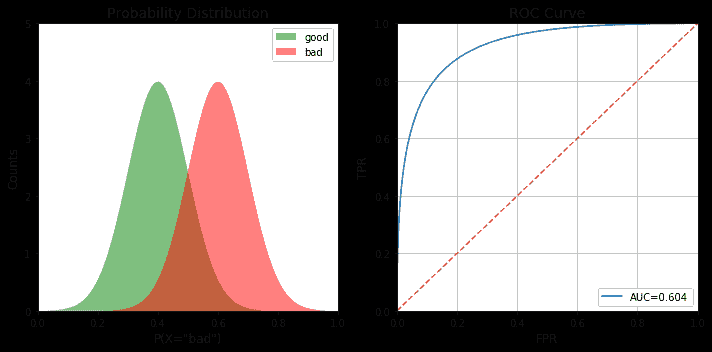
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在数据科学中,评估模型性能非常重要,而最常用的性能指标是分类得分。然而,当处理具有严重类别不平衡的欺诈数据集时,分类得分并没有太大意义。相反,接收器操作特性曲线(ROC 曲线)提供了一个更好的替代方案。ROC 是信号(真正率)与噪声(假正率)的图示。模型性能通过查看 ROC 曲线下的面积(或 AUC)来确定。最佳的 AUC 值是 1,而最差的是 0.5(45 度随机线)。任何低于 0.5 的值意味着我们可以简单地执行与模型推荐完全相反的操作,以将值恢复到 0.5 以上。
虽然 ROC 曲线很常见,但市面上并没有很多讲解如何计算或推导的教学资源。在这篇博客中,我将逐步揭示如何使用 Python 绘制 ROC 曲线。之后,我将解释基本 ROC 曲线的特点。
类别的概率分布
首先,假设我们的假设模型生成了一些用于预测每个记录类别的概率。与大多数二元欺诈模型一样,假设我们的类别是“好”和“坏”,模型生成了 P(X=‘坏’) 的概率。为了创建这个概率分布,我们绘制了一个高斯分布,每个类别具有不同的均值。有关高斯分布的更多信息,请阅读 这篇博客。
import numpy as np
import matplotlib.pyplot as plt
def pdf(x, std, mean):
cons = 1.0 / np.sqrt(2*np.pi*(std**2))
pdf_normal_dist = const*np.exp(-((x-mean)**2)/(2.0*(std**2)))
return pdf_normal_dist
x = np.linspace(0, 1, num=100)
good_pdf = pdf(x,0.1,0.4)
bad_pdf = pdf(x,0.1,0.6)
现在我们有了分布,让我们创建一个函数来绘制这些分布。
def plot_pdf(good_pdf, bad_pdf, ax):
ax.fill(x, good_pdf, "g", alpha=0.5)
ax.fill(x, bad_pdf,"r", alpha=0.5)
ax.set_xlim([0,1])
ax.set_ylim([0,5])
ax.set_title("Probability Distribution", fontsize=14)
ax.set_ylabel('Counts', fontsize=12)
ax.set_xlabel('P(X="bad")', fontsize=12)
ax.legend(["good","bad"])
现在让我们使用这个 plot_pdf 函数来生成图表:
fig, ax = plt.subplots(1,1, figsize=(10,5))
plot_pdf(good, bad, ax)

现在我们有了二元类别的概率分布,我们可以使用这个分布来推导 ROC 曲线。
导出 ROC 曲线
为了从概率分布中导出 ROC 曲线,我们需要计算真正正例率 (TPR) 和假正例率 (FPR)。以一个简单的例子为例,假设阈值为 P(X=‘坏’)=0.6。
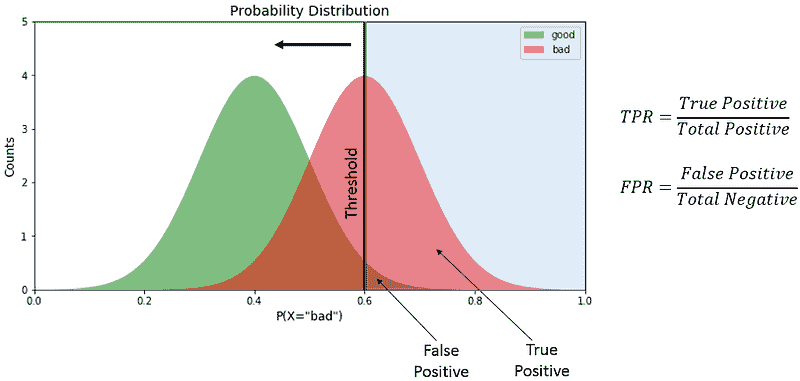
真正的正例是阈值右侧标记为“坏”的区域。假正例是阈值右侧标记为“好”的区域。总正例是“坏”曲线下方的总面积,而总负例是“好”曲线下方的总面积。我们按照图示的方法进行划分,以得出 TPR 和 FPR。我们通过不同的阈值得出 TPR 和 FPR 以获取 ROC 曲线。利用这些知识,我们创建了 ROC 绘图函数:
def plot_roc(good_pdf, bad_pdf, ax):
#Total
total_bad = np.sum(bad_pdf)
total_good = np.sum(good_pdf)
#Cumulative sum
cum_TP = 0
cum_FP = 0
#TPR and FPR list initialization
TPR_list=[]
FPR_list=[]
#Iteratre through all values of x
for i in range(len(x)):
#We are only interested in non-zero values of bad
if bad_pdf[i]>0:
cum_TP+=bad_pdf[len(x)-1-i]
cum_FP+=good_pdf[len(x)-1-i]
FPR=cum_FP/total_good
TPR=cum_TP/total_bad
TPR_list.append(TPR)
FPR_list.append(FPR)
#Calculating AUC, taking the 100 timesteps into account
auc=np.sum(TPR_list)/100
#Plotting final ROC curve
ax.plot(FPR_list, TPR_list)
ax.plot(x,x, "--")
ax.set_xlim([0,1])
ax.set_ylim([0,1])
ax.set_title("ROC Curve", fontsize=14)
ax.set_ylabel('TPR', fontsize=12)
ax.set_xlabel('FPR', fontsize=12)
ax.grid()
ax.legend(["AUC=%.3f"%auc])
现在让我们使用这个 plot_roc 函数来生成图表:
fig, ax = plt.subplots(1,1, figsize=(10,5))
plot_roc(good_pdf, bad_pdf, ax)
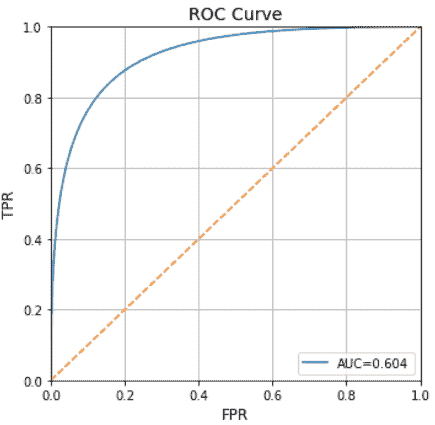
现在将概率分布图和 ROC 曲线并排绘制以进行视觉比较:
fig, ax = plt.subplots(1,2, figsize=(10,5))
plot_pdf(good_pdf, bad_pdf, ax[0])
plot_roc(good_pdf, bad_pdf, ax[1])
plt.tight_layout()
类别分离的影响
现在我们可以导出这两个图表了,让我们看看当类分离(即模型性能)改善时 ROC 曲线如何变化。我们通过改变概率分布中高斯分布的均值来实现这一点。
x = np.linspace(0, 1, num=100)
fig, ax = plt.subplots(3,2, figsize=(10,12))
means_tuples = [(0.5,0.5),(0.4,0.6),(0.3,0.7)]
i=0
for good_mean, bad_mean in means_tuples:
good_pdf = pdf(x,0.1,good_mean)
bad_pdf = pdf(x,0.1,bad_mean)
plot_pdf(good_pdf, bad_pdf, ax[i,0])
plot_roc(good_pdf, bad_pdf, ax[i,1])
i+=1
plt.tight_layout()
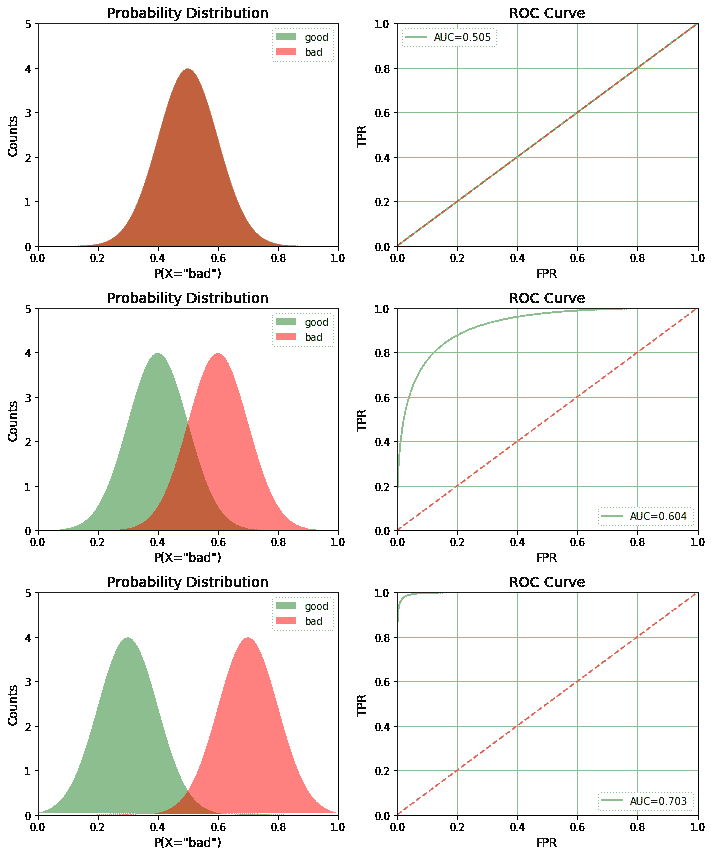
正如你所看到的,随着我们增加类之间的分离,AUC 也在增加。
超越 AUC 的视角
除了 AUC,ROC 曲线还可以帮助调试模型。通过查看 ROC 曲线的形状,我们可以评估模型的误分类情况。例如,如果曲线的左下角更接近随机线,这意味着模型在 X=0 时误分类。而如果曲线在右上角是随机的,这意味着错误发生在 X=1。另一个标志是如果曲线出现尖峰(而不是平滑的),这意味着模型不稳定。
附加信息
-
数据科学面试指南 - 数据科学是一个非常广泛且多样化的领域。因此,很难做到全能...
-
极端类别不平衡下的欺诈检测 - 数据科学中的一个热门领域是欺诈分析。这可能包括信用卡/借记卡欺诈、反洗钱...
个人简介:Syed Sadat Nazrul 白天使用机器学习抓捕网络和金融犯罪分子... 晚上写有趣的博客。
原文。经许可转载。
相关内容:
-
机器学习的学习曲线
-
选择合适的机器学习模型评估指标——第一部分
-
选择评估机器学习模型的正确指标 — 第二部分
更多相关话题
最近为了更好理解深度学习的进展
原文:
www.kdnuggets.com/2018/10/recent-advances-deep-learning.html
评论

我希望生活在一个建立在严谨、可靠、可验证的知识基础上的世界,而不是炼金术的世界。[...] 简单的实验和简单的定理是帮助理解复杂现象的基石。
对深度学习的更好理解的呼吁是 Ali Rahimi 在 2017 年 12 月 NIPS 上Test-of-Time Award presentation的核心。通过将深度学习与炼金术进行比较,Ali 的目标不是要抛弃整个领域,而是“开启对话”。这个目标确实已实现且人们仍在争论我们当前的深度学习实践是否应被视为炼金术、工程还是科学。
七个月后,机器学习社区再次聚集,这次是在斯德哥尔摩举行的国际机器学习会议(ICML)。会议吸引了超过 5000 名参与者和 629 篇论文,是关于基础机器学习研究的最重要事件之一。而深度学习理论已成为会议的最大主题之一。
这种重新引起的兴趣在第一天就显露出来,会议中最大的一个房间里充满了准备听取Sanjeev Arora 的深度学习理论理解讲座的机器学习从业者。在他的演讲中,普林斯顿大学计算机科学教授总结了当前深度学习理论研究的领域,将其分为四个分支:
-
非凸优化:我们如何理解与深度神经网络相关的高度非凸损失函数?为什么随机梯度下降算法甚至能够收敛?
-
过度参数化与泛化:在经典统计理论中,泛化依赖于参数的数量,但在深度学习中却不是这样。为什么?我们能否找到其他好的泛化衡量指标?
-
深度的作用:深度如何帮助神经网络收敛?深度与泛化之间有什么联系?
-
生成模型:为什么生成对抗网络(GANs)效果如此好?我们可以利用哪些理论属性来稳定它们或避免模式崩溃?
在这系列文章中,我们将基于最新的论文尝试在这四个领域建立直觉,特别关注 ICML 2018。
这篇文章将集中于深度网络中非凸优化的奥秘。
非凸优化
我敢打赌,你们很多人都尝试过从头开始训练一个深度网络,却因为无法使其表现良好而感到沮丧。我认为这不是你的错,而是梯度下降的问题。
Ali Rahimi 在 NIPS 的讲座中以挑衅的语气说道。随机梯度下降(SGD)确实是深度学习的基石。它应该能够找到一个高度非凸优化问题的解决方案,理解它何时有效或无效以及原因,是我们在深度学习的一般理论中必须解决的最根本的问题之一。更具体地说,非凸优化在深度神经网络中的研究可以分为两个问题:
-
损失函数的样子是什么?
-
为什么 SGD 会收敛?
损失函数的样子是什么?
如果我让你可视化一个全局最小值,很可能你脑海中第一个出现的表示方式会像这样:
这很正常。在二维世界中,围绕全局最小值找到一个严格凸的问题并不罕见(这意味着此点的 Hessian 矩阵的两个特征值都将严格为正)。但在拥有数十亿参数的世界中,例如深度学习中,围绕全局最小值的方向没有一个是平坦的几率是多少?或者等效地,Hessian 矩阵中不含单个零(或接近零)特征值的几率是多少?
Sanjeev Arora 在他的教程中提到的第一个评论是,损失函数上可以采取的可能方向的数量随着维度的增加而呈指数增长。

然后,直观上,全局最小值似乎不可能是一个点,而是一个连接的流形。这意味着如果你达到了全局最小值,你应该能够在一个平坦的路径上行走,其中所有的点也都是最小值。这一点已经在大型网络中被海德堡大学的一组团队在他们的论文 神经网络能量景观中的基本无障碍 [1]中通过实验验证。他们提出了一个更为普遍的论断,即任何两个全局最小值可以通过平坦路径连接。
已经知道这对于 MNIST 上的 CNN 或 PTB 上的 RNN [2] 是成立的,但这项工作将这一知识扩展到更大的网络(一些 DenseNets 和 ResNets),这些网络在更高级的数据集(CIFAR10 和 CIFAR100)上进行训练。为了找到这条路径,他们使用了来自分子统计力学的启发式方法,称为 AutoNEB。其思想是创建一个初始路径(例如线性路径)在两个最小值之间,并在该路径上放置支点。然后,迭代地修改支点的位置,以最小化每个支点的损失,并确保支点之间的距离保持大致相同(通过用弹簧建模支点之间的空间)。
如果他们没有理论上证明这一结果,他们给出了一些关于为什么存在这样的路径的直观解释:
如果我们扰动一个参数,比如通过添加一个小常数,但让其他参数自由适应这种变化以仍然最小化损失,可以认为通过某种调整,其他无数参数可以“弥补”对仅一个参数施加的变化
因此,这篇论文的结果可以帮助我们通过过参数化和高维空间的视角以不同的方式看待最小值。
更一般地,当考虑神经网络的损失函数时,你应该始终记住,在某一点上的可能方向数是巨大的。另一个后果是鞍点必须比局部最小值更加丰富:在给定(关键)点上,在数十亿个可能方向中,很可能会找到一个向下的方向(如果你不在全局最小值中)。这种直觉在一篇发表于 NIPS 2014 的论文中被严谨地形式化和实证证明: 高维非凸优化中的鞍点问题识别与攻击 [6]
为什么 SGD 会收敛(或不收敛)?
优化深度神经网络的第二个重要问题与 SGD 的收敛性质有关。虽然这个算法长期以来被视为梯度下降的更快但近似版本,但我们现在有证据表明 SGD 实际上收敛到更好、更通用的最小值 [3]。但我们能否形式化它并定量解释 SGD 逃离局部最小值或鞍点的能力?
SGD 修改了损失函数
论文 一种替代视角:SGD 何时逃离局部最小值? [4] 显示,执行 SGD 等同于对卷积(因此平滑的)损失函数进行常规梯度下降。从这一观点出发,在某些假设(作者证明在实践中通常是正确的)下,他们证明了 SGD 能够逃离局部最小值,并收敛到全局最小值附近的一个小区域。
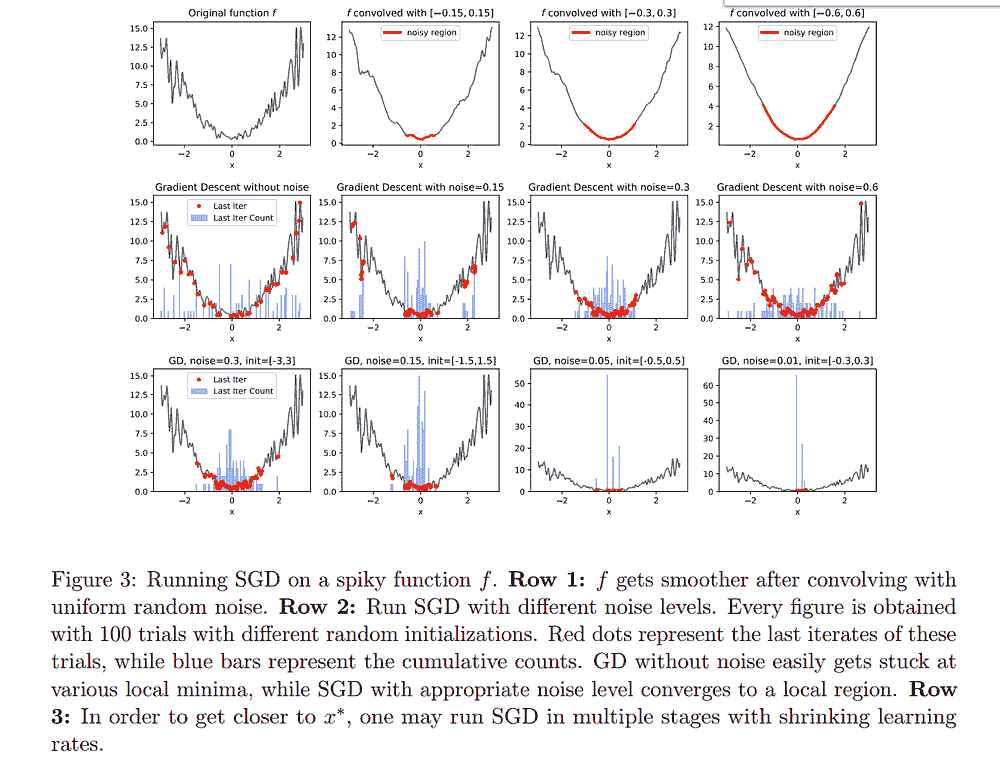
SGD 由随机微分方程支配
另一种真正改变了我对这一算法看法的方法是连续 SGD。这个想法是由 Yoshua Bengio 在他的讲座关于随机梯度下降、平坦性和泛化中提出的,该讲座在 ICML 非凸优化研讨会上进行。SGD 并不是在损失函数上移动一个点,而是移动一个点云,或者换句话说,一个分布。
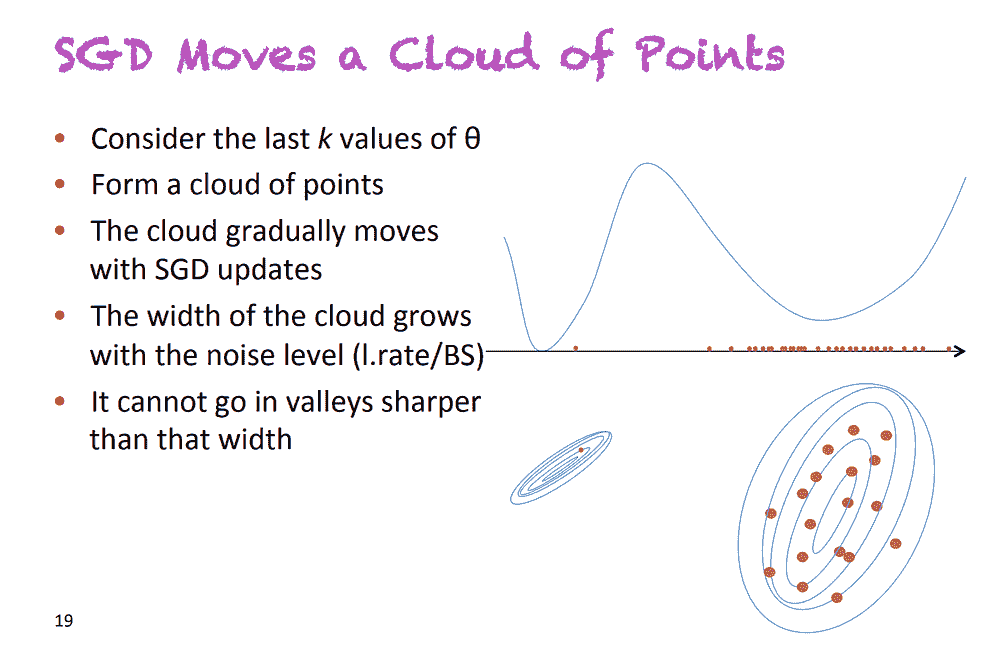
幻灯片摘自讲座关于随机梯度下降、平坦性和泛化,由 Y. Bengio 在 ICML 2018 上进行。他展示了看待 SGD 的一种替代方式,在这种方式中,你将点替换为分布(点云)
这个点云的大小(即相关分布的方差)与因子learning_rate / batch_size 成正比。Pratik Chaudhari 和 Stefano Soatto 在研讨会上展示的精彩论文随机梯度下降执行变分推断,收敛到深度网络的极限周期 [5]中给出了这个证明。这个公式相当直观:较低的批量大小意味着梯度噪声很大(因为是基于数据集的一个非常小的子集计算的),而较高的学习率意味着步伐噪声较大。
看到 SGD 作为随时间变化的分布的结果是,控制下降的方程现在是随机偏微分方程。更准确地说,在某些假设下,[5] 表明控制方程实际上是一个Fokker-Planck 方程。

幻灯片摘自讲座高维几何与深度网络的随机梯度下降动力学,由 P. Chaudhari 和 S. Soatto 在 ICML 2018 上进行。他们展示了如何将离散系统转化为由 Fokker-Planck 方程描述的连续系统
在统计物理中,这类方程描述了暴露于拖曳力(使分布漂移,即移动其均值)和随机力(使分布扩散,即增加其方差)的粒子的演化。在 SGD 中,拖曳力由真实梯度建模,而随机力对应于算法固有的噪声。正如上面的幻灯片所示,扩散项与温度项T=1/β=learning_rate/(2batch_size)*成正比,这再次显示了这个比率的重要性!
根据 Fokker-Planck 方程,分布的演化。它向左漂移并随时间扩散。来源:Wikipedia
利用这个框架,Chaudhari 和 Soatto 证明了我们的分布将单调收敛到某个稳态分布(从KL 散度的角度):

[5]中的主要定理之一,证明了分布对稳态的单调收敛(从 KL 散度的角度)。第二个方程表明,最小化 F 等同于最小化某个潜力ϕ,并最大化分布的熵(由温度 1/β控制的权衡)。
在上述定理中有几个有趣的点需要评论:
-
SGD 最小化的泛函可以重写为两个项的和(方程 11):一个潜力Φ的期望值和分布的熵。温度1/β控制这两个项之间的权衡。
-
潜力Φ仅取决于数据和网络的架构(而不是优化过程)。如果它等于损失函数,SGD 将收敛到全局最小值。然而,论文表明,这种情况很少发生,了解Φ离损失函数的距离将告诉你 SGD 收敛的可能性。
-
最终分布的熵取决于learning_rate/batch_size(温度)。直观上,熵与分布的大小相关,而高温通常意味着具有高方差的分布,这通常表示一个平坦的最小值。由于平坦的最小值通常被认为具有更好的泛化性,这与高学习率和低批量大小通常导致更好最小值的经验发现是一致的。
因此,将 SGD 视为一个随时间变化的分布使我们发现learning_rate/batch_size比每个超参数单独考虑在收敛性和泛化性方面更有意义。此外,这使得引入与收敛相关的网络潜力成为可能,这可以为架构搜索提供一个良好的度量。
结论
寻找深度学习理论的过程可以分为两部分:首先,通过玩具模型和实验建立对其如何以及为何有效的直觉,其次,将这些直觉表达为可以帮助解释我们当前结果并取得新成果的数学形式。
在这篇文章中,我们试图传达关于神经网络的高维损失函数和 SGD 的更多直觉,同时展示了为了拥有真正的深度神经网络优化数学理论,新的形式主义正在被构建。
然而,尽管非凸优化是深度学习的基石,其成功主要来自于其能够在层数和参数数量庞大的情况下仍能很好地泛化。这将是下一部分的内容。
参考文献
[1] Felix Draxler, Kambis Veschgini, Manfred Salmhofer, Fred Hamprecht. 神经网络能量景观中的实质性无障碍, ICML 2018.
[2] C. Daniel Freeman, Joan Bruna. 半矩形网络优化的拓扑与几何, arXiv:1611.01540, 2016.
[3] Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, Ping Tak Peter Tang. 关于深度学习的大批量训练:泛化差距与尖锐极小值, ICLR 2017
[4] Robert Kleinberg, Yuanzhi Li, Yang Yuan. 另一种观点:SGD 何时逃离局部最小值?, ICML 2018
[5] Pratik Chaudhari, Stefano Soatto. 随机梯度下降进行变分推断,收敛到深度网络的极限周期, ICLR 2018
[6] Yann Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, Yoshua Bengio. 识别并解决高维非凸优化中的鞍点问题, NIPS 2014
简介: Arthur Pesah 是 KTH 理论物理学的硕士研究生。机器学习爱好者,物理和数学爱好者,计算机极客。
原创。经许可转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
使用 Azure 机器学习服务构建推荐系统
原文:
www.kdnuggets.com/2019/05/recommender-systems-azure-machine-learning.html
评论
由 Heather Spetalnick,程序经理,ML 平台

推荐系统在零售、新闻和媒体等多个行业中都有应用。如果你曾经使用过流媒体服务或电子商务网站,并根据你之前观看或购买的内容收到过推荐,那么你就与推荐系统互动过。随着大量数据的可用性,许多企业将推荐系统作为关键的收入驱动因素。然而,找到合适的推荐算法对于数据科学家来说可能非常耗时。这就是微软提供一个GitHub 存储库的原因,该存储库包含了 Python 最佳实践示例,以方便使用Azure 机器学习服务来构建和评估推荐系统。
什么是推荐系统?
推荐系统主要有两种类型:协同过滤和基于内容的过滤。协同过滤(常用于电子商务场景)识别用户与他们评价的项目之间的互动,以推荐他们未见过的新项目。基于内容的过滤(常用于流媒体服务)识别关于用户档案或项目描述的特征,以推荐新内容。这些方法也可以结合起来用于混合方法。
推荐系统使客户在企业网站上停留更长时间,他们与更多的产品/内容互动,并且建议客户可能会购买或参与的产品或内容,就像商店销售助理可能会做的那样。下面,我们将向你展示这个存储库是什么,它是如何缓解数据科学家在构建和实施推荐系统时的痛点的。
缓解数据科学家的工作过程
推荐算法 GitHub 存储库提供了用于构建推荐系统的示例和最佳实践,这些示例以 Jupyter notebooks 的形式提供。示例详细说明了我们在五个关键任务上的经验:
reco utils 提供了几种工具,以支持加载不同算法预期格式的数据集、评估模型输出以及拆分训练/测试数据等常见任务。提供了几种最先进算法的实现,以便在组织或数据科学家的应用中进行自学和定制。
在下图中,你将找到仓库中可用的推荐算法列表。我们一直在增加更多推荐算法,所以请访问 GitHub 仓库以查看最新列表。
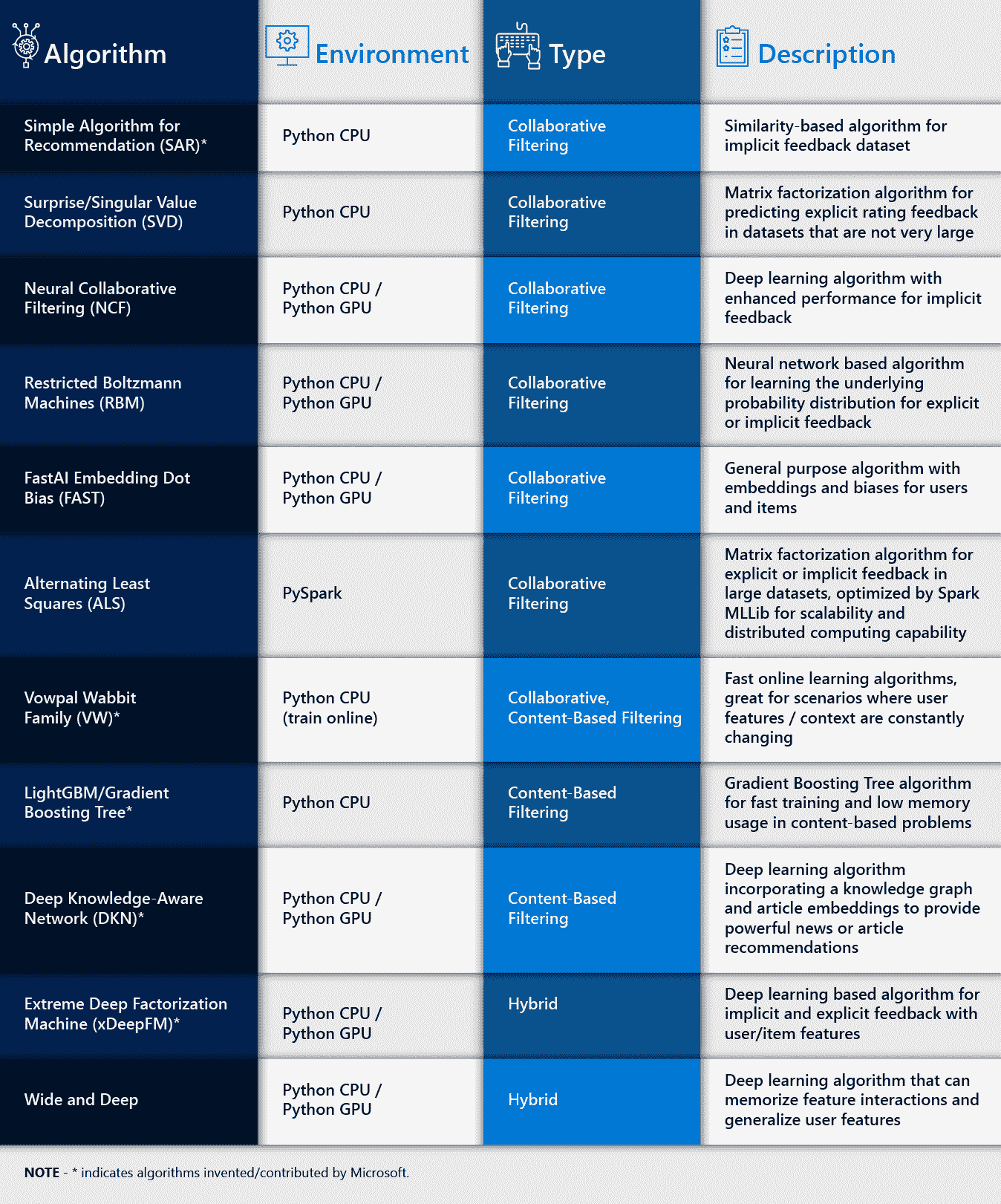
让我们更详细地了解推荐系统仓库如何解决数据科学家的痛点。
1. 评估不同推荐算法选项耗时
- 推荐系统 GitHub 仓库的一个主要优点是它提供了一组选项,并展示了哪些算法最适合解决特定类型的问题。它还提供了一个粗略的框架来切换不同的算法。如果模型性能准确度不够,需要更适合实时结果的算法,或者最初选择的算法不适合使用的数据类型,数据科学家可能需要切换到不同的算法。
2. 选择、理解和实现新的推荐系统模型可能成本高昂
- 从头开始选择合适的推荐算法并实现新的推荐系统模型可能成本高昂,因为这些模型需要大量的训练和测试时间以及计算能力。推荐的 GitHub 仓库简化了选择过程,通过节省数据科学家在测试许多不适合其项目/场景的算法上的时间,从而降低了成本。此外,结合Azure 的各种定价选项,减少了数据科学家在测试上的费用以及组织在部署上的成本。
实施更多最先进的算法可能看起来令人望而生畏
- 当被要求构建推荐系统时,数据科学家通常会转向更常见的算法,以减轻选择和测试更先进算法所需的时间和成本,即使这些更先进的算法可能更适合项目/数据集。推荐系统的 GitHub 代码库提供了一些知名和最先进的推荐算法,适合特定场景。它还提供了最佳实践,遵循这些实践会使实现更先进的算法变得更容易。
数据科学家对如何使用 Azure 机器学习服务来训练、测试、优化和部署推荐算法不熟悉
- 最后,推荐系统的 GitHub 代码库提供了如何在 Azure 和Azure 机器学习 (Azure ML) 服务上训练、测试、优化和部署推荐模型的最佳实践。实际上,有几个可用的笔记本演示了如何在 Azure ML 服务上运行代码库中的推荐算法。数据科学家还可以将任何已创建的笔记本提交到 Azure,几乎无需修改。
Azure ML 可以在各种笔记本中广泛用于 AI 模型开发相关任务,例如:
-
超参数调优
-
跟踪和监控指标以提升模型创建过程
-
在 DSVM 和 Azure ML 计算中进行规模扩展
-
将 Web 服务部署到 Azure Kubernetes 服务
-
提交管道
了解更多
了解更多关于Azure 机器学习服务的信息。
开始试用Azure 机器学习服务。
原文。经许可转载。
简介:Heather Spetalnick是微软在马萨诸塞州剑桥的项目经理,负责 Azure 机器学习的用户体验工作。
资源:
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT
更多相关内容
使用卷积自编码器重建指纹
原文:
www.kdnuggets.com/2020/03/recreating-fingerprints-using-convolutional-autoencoders.html
评论
生物识别技术 是身体测量和计算的技术术语。它指的是与人类特征相关的度量。生物识别认证(或现实认证)在计算机科学中用作身份识别和访问控制的一种形式。它也用于识别处于监控中的个人。
生物识别认证系统被分为两种类型:生理生物识别和行为生物识别。生理生物识别主要包括面部识别、指纹、手部几何、虹膜识别和 DNA。而行为生物识别包括击键、签名和语音识别。

指纹是用于个人身份识别的最可靠的特征,并且因其独特性和一致性被广泛应用于生物识别认证系统。指纹识别系统在需要高信任度验证或识别个人的许多场合中发挥着关键作用。
尽管自动指纹识别系统(AFIS)取得了巨大的进展,高效且准确的指纹匹配仍然是一个关键挑战。
指纹:如同你一样独特
想象一下你把智能手机放错了地方,开始感到恐慌,因为手机里有大量个人信息。你担心,因为你不希望捡到手机的人能够访问它。但随后你记得你已经设置了安全措施,以防这种情况发生。只有你自己才能解锁手机,它知道是你,因为你使用了指纹。
指纹 和脚趾印可以用于识别单个个体,因为它们对每个人都是独一无二的,并且不会随着时间而改变。令人惊讶的是,即使是同卵双胞胎的指纹也各不相同,你的手指之间也没有相同的指纹。指纹由脊线(即隆起的线条)和沟壑(即这些线条之间的凹陷)组成。正是这些脊线和沟壑的图案在每个人身上都是不同的。
脊线的图案是当你的手指触碰到一个表面时留下的印记。如果你留下了指纹,这些脊线会印在纸上,并可以用来匹配你可能在其他地方留下的指纹。
人类指纹细节丰富、几乎唯一、难以修改且在个体一生中保持耐用,使其成为长期标记人类身份的合适选择。
指纹特征
第一次接触指纹时,它们看起来复杂。你可能会想知道法医和执法人员如何利用它们。指纹可能看起来复杂,但实际上它们有一般的脊线图案,每个人的指纹都是独一无二的,这使得系统化分类成为可能。
指纹有三种基本脊线图案:“拱形”、“环形”和“涡纹/核心”。
拱形纹路
在这种图案类型中,脊线从一侧进入,从另一侧退出。相信全球 5%的人口在指纹中有拱形纹路。
环形纹路

这种图案类型的脊线从一侧进入,从同一侧退出。相信全球 60%–65%的人口在指纹中有环形纹路。
涡纹/核心

包含圆圈、多个环形或图案类型的混合。相信全球 30%–35%的人口在指纹中有涡纹。
指纹的独特性完全由局部脊线特征及其关系决定。指纹中的脊线和沟壑交替,沿局部恒定方向流动。最显著的局部脊线特征有:1) 脊线终点 和 2) 脊线分叉。脊线终点定义为脊线突然结束的点。脊线分叉定义为脊线分叉或分裂成支脊的点。这些特征统称为 细节点。

细节点
细节点集合被认为是指纹表示中最独特的特征,并广泛用于指纹匹配。曾认为细节点集合不包含足够的信息来重建提取细节点的原始指纹图像。然而,最近的研究表明,确实可以从细节点表示中重建指纹图像。
构建卷积自编码器
在概览指纹及其特征后,是时候利用我们新学会的技能来构建一个能够重建或再现指纹图像的神经网络了。
首先,我们将探索数据集,包括它包含哪些图像、如何读取图像、如何创建图像数组、探索指纹图像,最后对它们进行预处理,以便能够输入模型。
我使用了卷积自编码器来训练模型。接下来,我们将可视化训练和验证损失图,并最终预测测试集。
在这里,我假设你们对卷积神经网络和自编码器已经很熟悉了。不过,我还是会尝试用一句话来解释它们。
一个卷积神经网络(CNN)是一个具有一个或多个卷积层的神经网络,主要用于图像处理、分类和分割。
好的。什么是自编码器?
自编码器是一类神经网络,其输入与输出是相同的。它们通过将输入压缩到一个潜在空间表示中,然后从该表示中重建输出。了解更多请查看 这个。
那么卷积自编码器是什么?
卷积运算符允许对输入信号进行滤波,以提取其内容的一部分。传统形式的自编码器没有考虑到信号可以视为其他信号的总和这一事实。而卷积自编码器则使用卷积运算符来利用这一观察结果。它们学习将输入编码成一组简单的信号,然后尝试从这些信号中重建输入。更多信息请 查看这里。
一个 4x4x1 输入与一个 3x3x1 卷积滤波器的卷积操作。
结果是一个 2x2x1 的激活图。 来源
我使用的数据集是 FVC2002 指纹数据集。它由 4 种不同的传感器指纹组成,即低成本光学传感器、低成本电容传感器、光学传感器和合成生成器,每种传感器具有不同的图像尺寸。数据集中有 320 张图片,每种传感器 80 张图片。
加载所需的库:
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
from skimage.filters import threshold_otsu
import numpy as np
from glob import glob
import scipy.misc
from matplotlib.patches import Circle,Ellipse
from matplotlib.patches import Rectangle
import os
from PIL import Imageimport keras
from matplotlib import pyplot as plt
import numpy as np
import gzip
%matplotlib inline
from keras.layers import Input,Conv2D,MaxPooling2D,UpSampling2D
from keras.models import Model
from keras.optimizers import RMSprop
from keras.layers.normalization import BatchNormalization
加载数据集:
data = glob('./drive/My Drive/fingerprint/DB*/*')images = []
def readImages(data):
for i in range(len(data)):
img = scipy.misc.imread(data[i])
img = scipy.misc.imresize(img,(224,224))
images.append(img)
return imagesimages = readImages(data)
现在将这些图像转换为 float32 数组。
images_arr = np.asarray(images)
images_arr = images_arr.astype('float32')
images_arr.shape
一旦数据正确加载,你就可以开始分析它,以获取对数据集的一些直观理解。
数据探索:
print("Dataset (images) shape: {shape}".format(shape=images_arr.shape))##Dataset (images) shape: (320, 224, 224)
从上述输出中,你可以看到数据的形状为 320 x 224 x 224,因为有 320 个样本,每个样本是 224 x 224 维的矩阵。
查看数据集中前 5 张图片:
# Display the first 5 images in training data
for i in range(5):
plt.figure(figsize=[5, 5])
curr_img = np.reshape(images_arr[i], (224,224))
plt.imshow(curr_img, cmap='gray')
plt.show()





数据集
由于我们可以看到指纹并不是很清晰,因此观察卷积自编码器是否能够学习特征并正确重建这些图像将会很有趣。
数据集中的图像是灰度图像,像素值范围从 0 到 255,尺寸为 224 x 224,因此在将数据输入模型之前,预处理非常重要。我们将首先把每个 224 x 224 的图像转换为 224 x 224 x 1 的矩阵,这样我们就可以将其输入神经网络:
images_arr = images_arr.reshape(-1, 224,224, 1)
images_arr.shape##(320, 224, 224, 1)
接下来,我们需要确保检查 NumPy 数组的数据类型;它应该是float32格式,如果不是,你需要将其转换为这种格式,你还需要将像素值重新缩放到 0–1 的范围内。
images_arr.dtype
如果我们验证,应该得到dtype('float32')
接下来,用数据中图像的最大像素值来重新缩放数据:
np.max(images_arr)
images_arr = images_arr / np.max(images_arr)
让我们验证数据的最大值和最小值,重新缩放后应该是 0.0 和 1.0!
np.max(images_arr), np.min(images_arr)
如果我们验证,应该得到(1.0, 0.0)
为了使你的模型能够很好地泛化,你将数据分为两部分:训练集和验证集。你将在 80%的数据上训练模型,并在剩余训练数据的 20%上验证它。
这也有助于减少过拟合的可能性,因为你将在训练阶段未见过的数据上验证你的模型。
from sklearn.model_selection import train_test_split
train_X,valid_X,train_ground,valid_ground = train_test_split(images_arr,images_arr,test_size=0.2,random_state=13)
我们不需要训练和测试标签,这就是为什么我们将训练图像传递两次。我们的训练图像将同时作为输入和地面真实值,类似于分类任务中的标签。
现在我们可以定义网络并将数据输入网络。
卷积自编码器
图像的大小为 224 x 224 x 1 或 50,176 维的向量。我们将图像矩阵转换为数组,将其重新缩放到 0 和 1 之间,调整形状使其为 224 x 224 x 1,然后将其作为输入提供给网络。
此外,我们将使用 128 的批量大小,使用 256 或 512 的较大批量大小也是可取的,这完全取决于你训练模型的系统。这对确定学习参数和影响预测准确性有很大作用。我们将训练你的网络 300 个 epochs。
batch_size = 128
epochs = 300
x, y = 224, 224
input_img = Input(shape = (x, y, 1))
正如你可能已经知道的那样,自编码器分为两部分:编码器和解码器。
编码器
-
第一层将具有 32 个 3 x 3 的滤波器,随后是一个下采样(最大池化)层,
-
第二层将具有 64 个 3 x 3 的滤波器,随后是另一个下采样层,
-
编码器的最终层将具有 128 个 3 x 3 的滤波器。
解码器
-
第一层将具有 128 个 3 x 3 的滤波器,随后是一个上采样层,
-
第二层将具有 64 个 3 x 3 的滤波器,随后是另一个上采样层,
-
编码器的最终层将具有一个 3 x 3 的滤波器。
最大池化层每次使用时将输入下采样两倍,而上采样层每次使用时将输入上采样两倍。
注意:滤波器的数量、滤波器的大小、层的数量、训练模型的周期数,都是超参数,应该根据你自己的直觉来决定,你可以通过调整这些超参数来进行新的实验,并测量模型的性能。这就是你逐步学习深度学习艺术的方法!
def autoencoder(input_img):
#encoder
#input = 28 x 28 x 1 (wide and thin)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) #28 x 28 x 32
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) #14 x 14 x 32
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1) #14 x 14 x 64
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) #7 x 7 x 64
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2) #7 x 7 x 128 (small and thick)#decoder
conv4 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3) #7 x 7 x 128
up1 = UpSampling2D((2,2))(conv4) # 14 x 14 x 128
conv5 = Conv2D(64, (3, 3), activation='relu', padding='same')(up1) # 14 x 14 x 64
up2 = UpSampling2D((2,2))(conv5) # 28 x 28 x 64
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up2) # 28 x 28 x 1
return decodedautoencoder = Model(input_img, autoencoder(input_img))
注意,你还必须通过参数 loss 指定损失类型。在这种情况下,是均方误差,因为每个批次后的损失将通过逐像素均方误差计算预测输出批次和真实值之间的差距:
autoencoder.compile(loss='mean_squared_error', optimizer = RMSprop())
让我们通过使用 summary 函数来可视化你在上述步骤中创建的层;这将显示每一层中的参数(权重和偏差)数量,以及模型中的总参数。
终于到了用 Keras 的 fit()函数训练模型的时候了!模型训练了 300 个周期。
#Training
autoencoder_train = autoencoder.fit(train_X, train_ground, batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(valid_X, valid_ground))
最终!你在指纹数据集上训练了 300 个周期的模型,现在,让我们绘制训练和验证数据之间的损失图,以可视化模型性能。
loss = autoencoder_train.history['loss']
val_loss = autoencoder_train.history['val_loss']
epochs = range(300)
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
最后,你可以看到验证损失和训练损失都保持同步。这表明你的模型没有过拟合:验证损失在减少而不是增加,
因此,你可以说你的模型的泛化能力很好。
最后,是时候使用 Keras 的 predict()函数来重建测试图像,看看你的模型能多好地重建测试数据。
#Prediction
pred = autoencoder.predict(valid_X)#Reconstruction of Test Images
plt.figure(figsize=(20, 4))
print("Test Images")
for i in range(5):
plt.subplot(1, 5, i+1)
plt.imshow(valid_ground[i, ..., 0], cmap='gray')
plt.show()
plt.figure(figsize=(20, 4))
print("Reconstruction of Test Images")
for i in range(5):
plt.subplot(1, 5, i+1)
plt.imshow(pred[i, ..., 0], cmap='gray')
plt.show()
测试图像:

重建图像:
从上述图像中,你可以观察到你的模型在重建你用模型预测的测试图像时表现非常出色。至少在视觉上,测试图像和重建图像看起来几乎相似。
你还可以在我的 Github 中找到代码。
nageshsinghc4/Recreating-Fingerprints-using-Convolutional-Autoencoders
构建一个能够重建或再现指纹图像的神经网络。我使用的数据集…
结论
从未预见到,用于抓捕罪犯的指纹科学会被用于解锁手机和验证支付。当一个注册了的手指放在传感器上时,手机会立即解锁,但它拒绝识别旁边的手指,这就是指纹唯一性的实际体现。
好的,这就是本文的全部内容,希望大家阅读愉快,如果这篇文章对你有帮助,我将非常高兴。欢迎在评论区分享你的评论/想法/反馈。
感谢阅读!!!
简介:Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原始链接。转载已获许可。
相关:
-
神经网络 201:关于自编码器的一切
-
使用时间序列分析进行股票市场预测
-
使用机器学习进行系外行星猎寻
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关主题
使用迁移学习回收深度学习模型
原文:
www.kdnuggets.com/2015/08/recycling-deep-learning-representations-transfer-ml.html
评论
深度学习模型无疑是许多机器感知问题的最先进技术。使用具有多层隐藏层的神经网络和数百万个参数,深度学习算法利用了硬件能力和海量数据集的丰富性。相比之下,线性模型很快会饱和并且表现不佳。 但如果你没有大数据呢?

假设你有一个新颖的研究问题,例如根据照片识别癌症痣。进一步假设你生成了一个包含 10,000 张标记图像的数据集。虽然这看起来像是大数据,但与深度学习取得最大成功的权威数据集相比,这只是微不足道的。似乎一切都已经失去。幸运的是,还有希望。
考虑斯坦福大学教授李飞飞创建的著名 ImageNet 数据库。该数据集包含数百万张图像,每张图像属于 1000 个不同的层次化组织的物体类别中的一个。正如李博士在她的 TED 演讲中提到的,一个孩子在成长过程中会看到数百万张不同的图像。从直观上看,为了训练一个足够强大的模型,以便与人类物体识别能力竞争,可能需要一个类似规模的大型训练集。此外,在这种数据规模下占主导地位的方法,可能与在较小数据集上相同任务时的主导方法不同。李博士的洞察力迅速得到了回报。亚历克斯·克里日夫斯基、伊利亚·苏茨克维和杰弗里·辛顿轻松赢得了 2012 年 ImageNet 比赛,确立了卷积神经网络(CNN)在计算机视觉中的最先进地位。
![]()
扩展李博士的隐喻,虽然一个孩子在成长过程中会看到数百万张图像,但一旦长大,人类可以轻松学习识别一个新的物体类别,而无需从头学习如何看图像。现在考虑一个在 ImageNet 数据集上训练的 CNN。给定来自 1000 个 ImageNet 类别中的任何一个类别的图像,神经网络的最上层隐藏层构成了一个足够灵活的单一向量表示,可以用于将图像分类到这 1000 个类别中的每一个。合理的推测是,这种表示也可能对一个尚未见过的额外物体类别有用。
按照这种思路,计算机视觉研究人员现在通常使用预训练的卷积神经网络(CNN)为新任务生成表示,其中数据集可能不足以从头训练整个 CNN。另一种常见的策略是采用预训练的 ImageNet 网络,然后对整个网络进行微调以适应新任务。这通常通过端到端的反向传播和随机梯度下降来完成。我去年在与Oscar Beijbom的对话中首次了解了这种微调技术。Beijbom 是 UCSD 的视觉研究员,他成功地使用这一技术来区分各种类型的珊瑚图像。
去年 NIPs 会议上的一篇出色论文,由康奈尔大学的 Jason Yosinski 与 Jeff Clune、Yoshua Bengio 和 Hod Lipson 合作完成,针对这个问题进行了严谨的实证调查。作者重点关注 ImageNet 数据集以及闻名于 ImageNet 的 8 层 AlexNet 架构。他们指出,卷积神经网络的最底层长期以来已被知道类似于传统的计算机视觉特征,如边缘检测器和 Gabor 滤波器。此外,他们指出,最上层隐藏层在某种程度上专门化于其训练任务。因此,他们系统地探讨了以下问题:
-
从广泛有用到高度专业化特征的过渡发生在哪里?
-
微调整个网络与冻结转移层的相对性能如何?
为了研究这些问题,作者将注意力限制在 ImageNet 数据集上,但考虑了将数据划分为子集 A 和 B 的两种 50-50 分割。在第一组实验中,他们通过随机将每个图像类别分配到子集 A 或子集 B 来分割数据。在第二组实验中,作者考虑了更具对比性的分割,将自然图像分配到一个集合,而将人造物体图像分配到另一个集合。
作者研究了一个案例,其中网络在任务 A 上进行预训练,然后在任务 B 上进一步训练,保留前 k 层并随机初始化。他们还考虑了相同的实验,但在任务 B 上进行预训练,随机初始化顶部的 8-k 层,然后继续在任务 B 上训练。
在所有情况下,他们发现对预训练网络进行端到端的微调优于完全冻结转移的 k 层。有趣的是,他们还发现当预训练层被冻结时,特征的迁移能力在预训练层的数量上是非线性的。他们假设这归因于相邻层之间节点的复杂相互作用,这些作用难以重新学习。
- 如果要浪漫地说,这可能类似于对一个完全成长的成年人进行半球切除术,将右半脑替换为一块空白的儿童大脑。忽略这个例子的生物学荒谬性,可能直观地认为,新的右脑半球在填补左半球已经完全适应的预期角色时会遇到困难。

-
我参考了原始论文以获得实验的完整描述。本文未涉及的一个问题,但可能会激发未来的研究,是当新任务的样本数量远少于原任务时,这些结果是否仍然有效。在实践中,原任务和新任务之间标签样本数量的不平衡,通常是激励迁移学习的原因。一个初步的方法可能是重复这项工作,但将类别的分割比例改为 999 比 1,而不是 500 比 500。
-
通常,数据标注是昂贵的。对于许多任务而言,可能甚至是不可承受的。因此,经济和学术界都对如何利用现有标签在任务中表现良好而产生深刻理解充满兴趣。Yosinski 的工作在这方面迈出了重要的一步。
 扎卡里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部资助下,他对机器学习的理论基础和应用都很感兴趣。除了在 UCSD 的工作,他还曾在微软研究院实习。
扎卡里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部资助下,他对机器学习的理论基础和应用都很感兴趣。除了在 UCSD 的工作,他还曾在微软研究院实习。
相关:
-
深度学习与经验主义的胜利
-
别急:质疑深度学习的智商结果
-
模型可解释性的神话
-
(深度学习的深层缺陷)
-
数据科学中最常用、最混淆和滥用的术语
-
差分隐私:如何使隐私与数据挖掘兼容
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
了解更多相关内容
我如何将 100 多个 ETL 重新设计为 ELT 数据管道
原文:
www.kdnuggets.com/2021/11/redesigned-over-100-etl-elt-data-pipelines.html
评论
作者 Nicholas Leong,数据工程师,作家
作者提供的图片
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
大家:数据工程师做什么?
我:我们构建管道。
大家:你是说像水管工那样?
有点像,但不是水通过管道流动,而是数据通过我们的管道流动。
数据科学家构建模型,数据分析师将数据传达给利益相关者。那么,我们为什么需要数据工程师?
他们几乎不知道,没有数据工程师,模型甚至不会存在。不会有任何数据可以传递。数据工程师构建仓库和管道,使数据能够在组织内流动。我们连接这些点。
数据工程师是 2019 年增长最快的工作,年增长率为 50%,高于数据科学家32%的年增长率。
因此,我在这里为大家介绍一些数据工程师的日常任务。数据管道只是其中之一。
ETL/ELT 管道
ETL — 提取、转换、加载
ELT — 提取、加载、转换
这些是什么意思,它们之间有什么不同?
在数据管道的世界里,有一个源头和一个目的地。最简单的形式是,源头是数据工程师获取数据的地方,而目的地是他们希望将数据加载到的地方。
事实上,数据处理过程中往往需要进行一些处理。这可能是由于许多原因,包括但不限于—
-
数据存储类型的差异
-
数据的目的
-
数据治理/质量
数据工程师将数据处理标记为转换。这是他们施展魔法的地方,将各种数据转化为他们希望的形式。
在ETL 数据管道中,数据工程师在将数据加载到目标之前执行转换。如果表之间存在关系转换,这些转换发生在源数据库本身。在我的情况下,源是一个 Postgres 数据库。因此,我们在源中执行关系联接以获取所需的数据,然后将其加载到目标中。
在ELT 数据管道中,数据工程师将数据原始地加载到目标中。然后,他们在目标本身内执行任何关系转换。
在这篇文章中,我们将讨论我如何将组织中的 100 多个 ETL 管道转换为 ELT 管道,我们还将探讨我这样做的原因。
我是怎么做到的
最初,管道是使用 Linux cron 作业运行的。Cron 作业类似于传统的任务调度程序,它们通过 Linux 终端初始化。它们是调度程序的最基本方式,没有任何功能,例如 —
-
设置依赖关系
-
设置动态变量
-
构建连接
图片由作者提供
这是首先需要改变的,因为它造成了太多问题。我们需要扩展。为此,我们必须建立一个适当的工作流管理系统。
我们选择了Apache Airflow。我在这里详细写了关于它的所有内容。
数据工程 — Apache Airflow 基础 — 构建你的第一个管道
Airflow 最初是由Airbnb的团队开发的,并开放源代码。它还被像Twitter这样的大公司作为它们的管道管理系统使用。你可以阅读上面关于 Airflow 好处的所有内容。
在解决这个问题后,我们必须改变提取数据的方式。团队建议将我们的 ETL 管道重新设计为 ELT 管道。稍后会详细讲解我们这样做的原因。
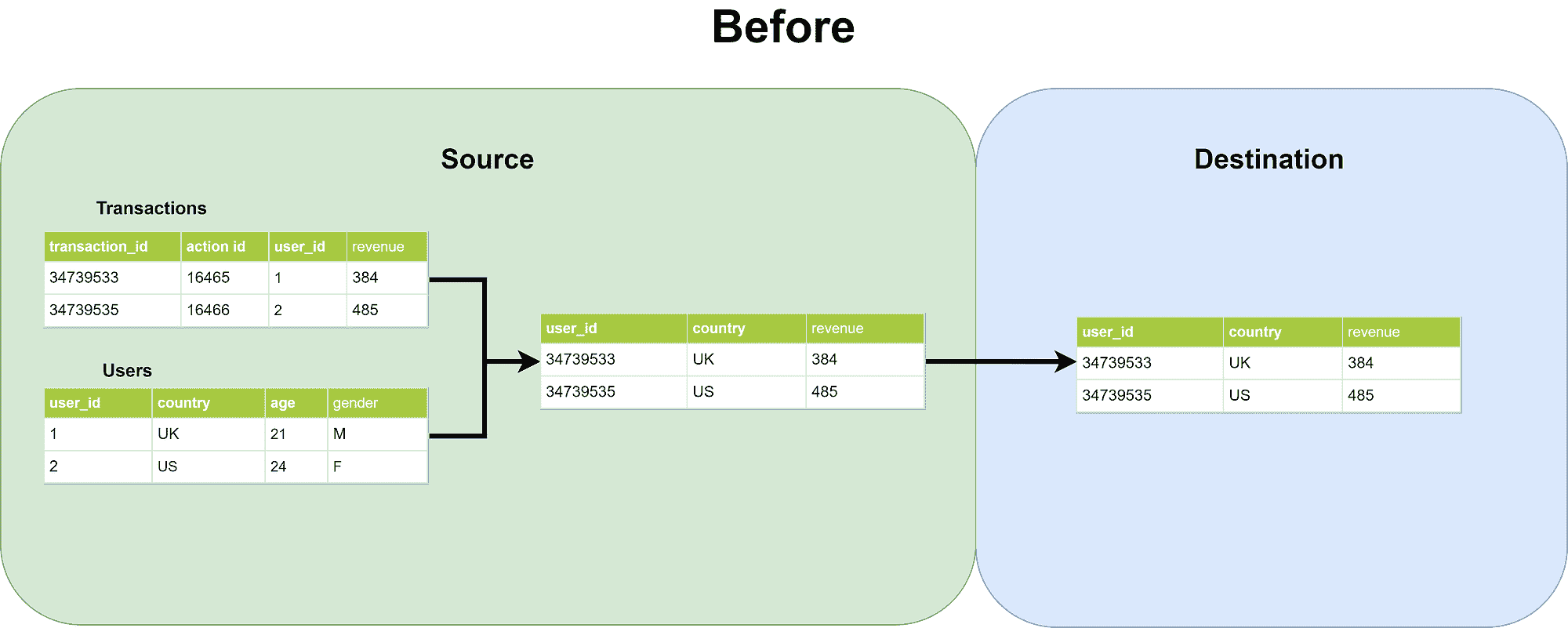
图片由作者提供
这是在重新设计之前的管道示例。我们处理的源是一个 Postgres 数据库。因此,为了以预期的形式获取数据,我们必须在源数据库中执行联接操作。
Select
a.user_id,
b.country,
a.revenue
from transactions a
left join users b on
a.user_id = b.user_id
这是在源数据库中运行的查询。当然,我简化了示例,实际的查询超过了 400 行 SQL。
查询结果被保存到 CSV 文件中,然后上传到目标,即Google Bigquery 数据库。在 Apache Airflow 中,它是这样的 —
这是一个 ETL 管道的简单示例。它按预期工作,但团队意识到将其重新设计为 ELT 管道的好处。稍后会详细介绍。
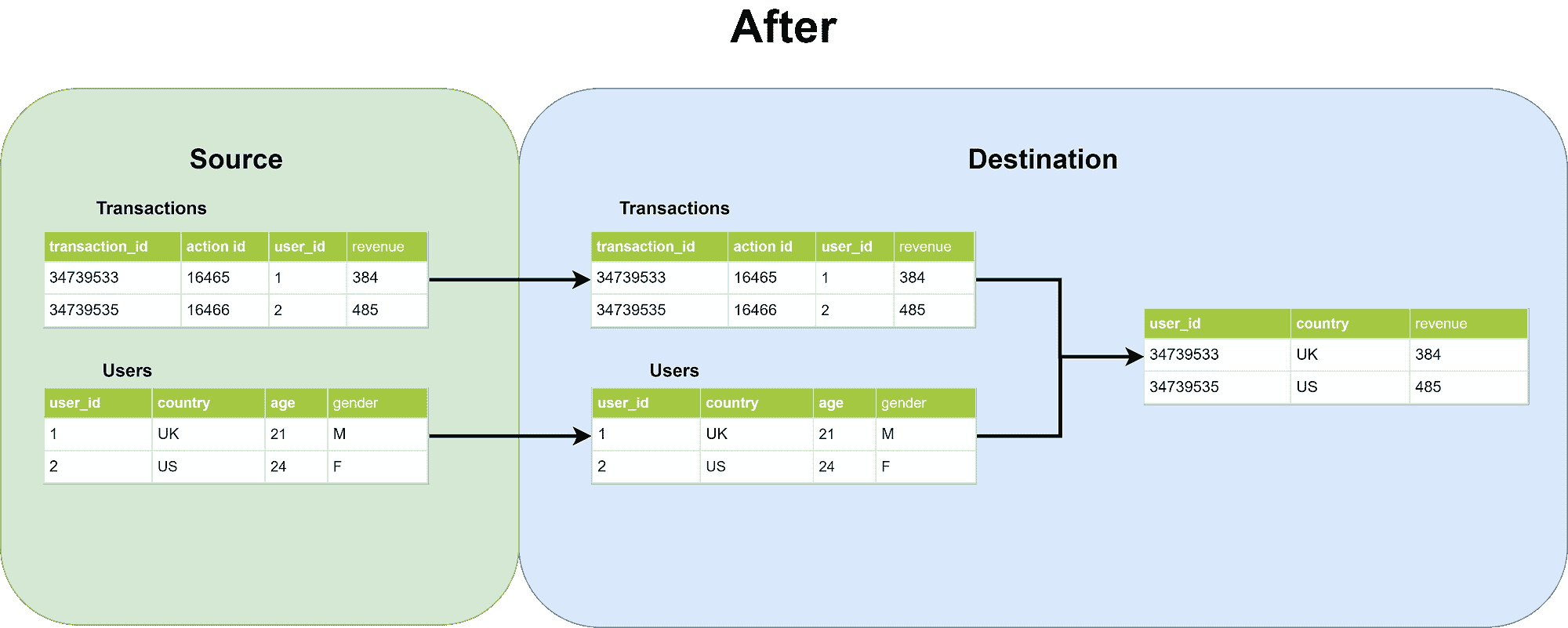
图片由作者提供
这是在重新设计之后的管道示例。观察一下表格是如何保持原样地带入目标的。在所有表格成功提取后,我们在目标中执行关系转换。
--transactions
Select
*
from transactions --
Select
*
from users
这是在源数据库中运行的查询。大多数提取使用的是‘Select *’语句没有任何联接。对于追加任务,我们包括where 条件以正确分隔数据。
同样,查询结果被保存到一个 CSV 文件中,然后上传到 Google BigQuery 数据库。我们随后为转换任务制作了一个单独的 dag,通过在 Apache Airflow 中设置依赖关系来实现。这是为了确保所有提取任务在运行转换任务之前都已完成。
我们使用Airflow Sensors设置依赖关系。你可以在这里了解它们。
数据工程 — 如何在 Apache Airflow 中设置数据管道之间的依赖关系
为什么我这么做
图片由 Markus Winkler 提供,来自 Unsplash
现在你了解了我是怎么做的,我们来讨论一下为什么——我们究竟为何将所有 ETL 重新编写为 ELT 管道?
成本
使用我们旧的数据管道花费了团队资源,特别是时间、精力和金钱。
为了理解成本方面的情况,你需要知道我们的源数据库(Postgres)是 2008 年设置的古老机器。它托管在本地,也运行着旧版本的 Postgres,这使事情变得更加复杂。
直到最近几年,组织才意识到对数据科学家和分析师来说需要一个集中的数据仓库。于是他们开始将旧的管道迁移到定时任务上。随着任务数量的增加,这消耗了机器上的资源。
之前的数据分析师编写的 SQL 联接也非常混乱。在某些数据管道中,一个查询中有超过20 个联接,而我们的数据管道接近 100 个。我们的任务通常在午夜开始运行,通常在下午 1 到 2 点结束,总共大约需要12 个小时以上,这绝对不可接受。
对于那些不知道的人来说,SQL 联接是最耗费资源的命令之一。随着联接数量的增加,它将使查询的运行时间呈指数级增长。

作者提供的图片
由于我们迁移到 Google Cloud,团队理解到 Google BigQuery 在计算 SQL 查询方面非常快速。你可以在这里阅读有关内容。
BigQuery 速度有多快?| Google Cloud 博客
因此,关键是只在源中运行简单的‘Select *’语句,并在 Google Cloud 上执行所有连接。
这使我们数据管道的 效率和速度 增加了两倍以上。
可扩展性

由 Quinten de Graaf 提供的照片,来自 Unsplash
随着业务的扩展,它们的工具和技术也在扩展。
通过迁移到 Google Cloud,我们可以轻松扩展我们的机器和管道,而无需过多担心。
Google Cloud 利用Cloud Monitoring,这是一个收集 Google Cloud 技术(如 Google Cloud Composer、Dataflow、Bigquery 等)的指标、事件和元数据的工具。你可以监控各种数据点,包括但不限于 —
-
虚拟机的成本
-
每个在 Google Bigquery 中运行的查询的成本
-
每个在 Google Bigquery 中运行的查询的大小
-
数据管道的持续时间
这使得监控对我们来说变得轻松。因此,通过在 Google Bigquery 上执行所有转换,我们能够准确监控我们的查询大小、持续时间和成本,随着扩展而进行调整。
即使我们增加我们的机器规模、数据仓库、数据管道等,我们也完全理解随之而来的成本和利益,并能完全控制是否需要开启或关闭。
这已经并将为我们省去很多麻烦。
结论

由 Fernando Brasil 提供的照片,来自 Unsplash
如果你读到这里,你肯定对数据非常感兴趣。
你应该这样做!
我们已经做了 ETLs 和 ELTs。谁知道我们将来会构建什么样的管道呢?
在这篇文章中,我们讨论了 —
-
什么是 ELT/ETL 数据管道?
-
我是如何将 ETL 重新设计为 ELT 管道的
-
我为什么这样做
一如既往,我以一句名言结尾。
数据是新的科学。大数据持有答案
— 佩特·盖尔辛格
订阅我的新闻通讯以保持联系。
你也可以通过 我的链接 支持我。你将能阅读我和其他优秀作家的无限故事!
我正在数据行业中创作更多故事、文章和指南。你可以期待更多类似的帖子。在此期间,随时查看我其他的 文章 来暂时满足你对数据的渴望。
感谢 阅读!如果你想与我联系,请随时通过 nickmydata@gmail.com 或我的 LinkedIn 个人资料 联系我。你还可以查看我以前文章的代码,位于我的 Github。*
简历:Nicholas Leong 是一名数据工程师,目前在一家在线分类广告技术公司工作。在他的多年经验中,Nicholas 完全设计了批处理和流处理管道,改进了数据仓库解决方案,并为组织执行了机器学习项目。在空闲时间,Nicholas 喜欢从事自己的项目以提高技能。他还撰写关于自己工作、项目和经验的文章,以与世界分享。访问我的网站查看我的工作!
原文。经许可转载。
相关:
-
Prefect:如何使用 Python 编写和调度你的第一个 ETL 管道
-
机器学习管道的设计模式
-
ETL 与 ELT:指南与市场分析
更多相关话题
RedPajama 项目:一个开源倡议,旨在普及 LLMs
原文:
www.kdnuggets.com/2023/06/redpajama-project-opensource-initiative-democratizing-llms.html

图片由作者提供(通过Stable Diffusion 2.1生成)
近年来,大型语言模型或 LLM 主导了世界。随着 ChatGPT 的推出,每个人都可以受益于文本生成模型。但是,许多强大的模型仅在商业上提供,留下了许多优秀的研究和定制工作。
当然,现在有很多项目尝试完全开源许多 LLMs。Pythia、Dolly、DLite等项目就是一些例子。但为什么要尝试使 LLMs 开源?这是社区的共识,促使所有这些项目填补封闭模型带来的限制。然而,开源模型是否比封闭模型差?当然不是。许多模型可以与商业模型竞争,并在许多领域展现出有前景的结果。
为了跟进这一运动,RedPajama 是一个开源项目,旨在普及 LLM。这个项目是什么,它如何能够使社区受益?让我们进一步探讨一下。
RedPajama
RedPajama是Ontocord.ai、ETH DS3Lab、Stanford CRFM和Hazy Research之间的合作项目,旨在开发可重复的开源 LLMs。RedPajama 项目包含三个里程碑,包括:
-
预训练数据
-
基础模型
-
指令调整数据和模型
在撰写本文时,RedPajama 项目已经开发了预训练数据和模型,包括基础版、指令版和聊天版。
RedPajama 预训练数据
在第一步中,RedPajama 尝试复制半开源模型的LLaMa数据集。这意味着 RedPajama 尝试构建具有 1.2 万亿标记的预训练数据,并将其完全开源以供社区使用。目前,可以在HuggingFace下载完整数据和样本数据。
RedPajama 数据集的数据来源总结如下表所示。
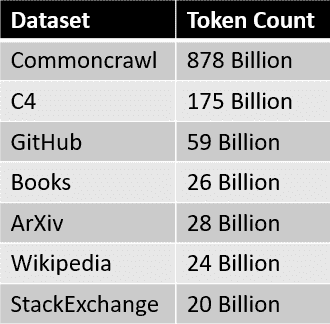
在每个数据片段经过仔细预处理和过滤后,标记的数量大致与 LLaMa 论文中报告的数量相符。
数据集创建后的下一步是开发基础模型。
RedPajama 模型
在 RedPajama 数据集创建后的几周内,第一个基于该数据集训练的模型发布了。基础模型有两个版本:一个是 30 亿参数,另一个是 70 亿参数。RedPajama 项目还发布了每个基础模型的两种变体:指令调优模型和对话模型。
每个模型的总结可以在下表中查看。

图片由作者提供(改编自 together.xyz)
你可以通过以下链接访问上述模型:
让我们试试 RedPajama 基础模型。例如,我们将使用来自HuggingFace的代码尝试 RedPajama 3B 基础模型。
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Mother Teresa is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)
a Catholic saint and is known for her work with the poor and dying in Calcutta, India.
Born in Skopje, Macedonia, in 1910, she was the youngest of thirteen children. Her parents died when she was only eight years old, and she was raised by her older brother, who was a priest.
In 1928, she entered the Order of the Sisters of Loreto in Ireland. She became a teacher and then a nun, and she devoted herself to caring for the poor and sick.
She was known for her work with the poor and dying in Calcutta, India.
3B 基础模型的结果很有希望,如果使用 7B 基础模型可能会更好。由于开发仍在进行中,项目未来可能会有更好的模型。
结论
生成性 AI 正在兴起,但遗憾的是许多优秀模型仍被锁定在公司的档案中。RedPajama 是领先的项目之一,试图复制半开放的 LLaMA 模型以民主化 LLMs。通过开发类似于 LLaMA 的数据集,RedPajama 成功创建了一个开源的 1.2 万亿标记数据集,许多开源项目已经使用了该数据集。
RedPajama 还发布了两种类型的模型;3B 和 7B 参数基础模型,每个基础模型包括指令调优和对话模型。
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
使用 SRU++ 降低 NLP 模型训练的高成本
原文:
www.kdnuggets.com/2021/03/reducing-high-cost-training-nlp-models-sru.html
评论
由 Tao Lei, PhD,ASAPP 研究负责人和科学家撰写
自然语言模型在 NLP 和相关领域取得了各种突破性成果 [1, 2, 3, 4]。与此同时,这些模型的规模大幅增加,参数量达到百万(甚至十亿),同时财务成本也显著上升。
训练大型模型的成本限制了研究社区的创新能力,因为一个研究项目通常需要大量实验。考虑在 Billion Word 基准上训练一个顶级语言模型 [5]。一个实验需要 384 GPU 天(6 天 * 64 V100 GPU,或者使用 AWS 按需实例花费高达 $36,000)。构建此类模型的高成本阻碍了它们在实际业务中的使用,并使 AI 和 NLP 技术的货币化变得更加困难。
我们的模型在使用 2.5 倍到 10 倍更少的训练时间和成本的情况下,获得了更好的困惑度和每字符比特数(bpc)。我们的结果重申了经验观察,即注意力机制并非我们所需的一切。
计算时间和成本的增加突显了发明计算效率高的模型的重要性,这些模型在减少或加速计算的情况下保持顶级建模能力。
Transformer 架构 被提出以加速 NLP 模型的训练。具体来说,它完全基于自注意力机制,避免使用递归。这一设计选择的理由,如原始工作中所述,是为了实现强大的并行化(通过充分利用 GPU 和 TPU 的计算能力)。此外,注意力机制是一个极其强大的组件,允许高效建模变长输入。这些优势使得 Transformer 成为一种表达能力强且高效的单元,从而成为 NLP 的主要架构。
在 Transformer 发展之后,出现了一些有趣的问题:
-
我们建模时是否只需要注意力机制?
-
如果递归不是计算瓶颈,我们能否找到更好的架构?
SRU++ 和相关工作
我们提出 SRU++ 作为上述问题的可能答案。SRU++ 的灵感来源于两方面的研究:
首先,以前的研究已经解决了 RNN 的并行化/速度问题,并提出了各种快速递归网络 [7,8,9,10]。例如,Quasi-RNN 和简单递归单元(SRU),都是高度并行的 RNN。这一进展消除了为了提高训练效率而避免使用递归的需求。
其次,近年来有几项研究通过结合递归和自注意力取得了优异的结果。例如,Merity(2019)展示了单头注意力 LSTM(SHA-LSTM)足以在字符级语言建模任务中取得有竞争力的结果,同时所需的训练时间显著减少。此外,RNN 被融入了 Transformer 架构中,导致在机器翻译和自然语言理解任务中取得了更好的结果 [8,12]。这些结果表明递归和注意力在序列建模中是互补的。
针对之前的研究,我们通过将自注意力纳入 SRU 架构来增强其建模能力。图 1c 展示了结果架构 SRU++ 的简单示意图。
图 1: SRU 和 SRU++ 网络的示意图。 (a) 原始 SRU 网络,(b) 使用投影技巧减少参数数量的 SRU 变体,Lei 等(2018)进行的实验,以及 (c) 本研究提出的 SRU++。数字表示中间输入/输出的隐藏尺寸。SRU 和 SRU++ 的更详细描述见我们的论文。
SRU++ 通过首先将输入投影到较小的维度来替代输入的线性映射(图 1a)。然后应用注意力操作,接着是残差连接。该维度被投影回 SRU 的逐元素递归操作所需的隐藏尺寸。此外,并不是每个 SRU++ 层都需要注意力。当 SRU++ 中禁用注意力时,网络会降级为使用维度减少的 SRU 变体,从而减少参数数量(图 1b)。
结果
1. SRU++ 是一种高效的神经网络架构
我们在多个语言建模基准上评估了 SRU++,如 Enwik8 数据集。与 Transformer 模型(如 Transformer-XL)相比,SRU++ 可以在只使用一部分资源的情况下实现类似的结果。图 2 比较了两者在直接可比训练设置下的训练效率。SRU++ 的效率比 Transformer-XL 高 8.7 倍,并且达到 BPC(每字符位数)1.17 的效率提高了 5.1 倍。
 图 2:Enwik8 数据集上的开发 BPC 与用于训练的 GPU 小时数的关系。SRU++ 和 Transformer-XL 模型均具有 41-42M 参数,并使用 fp32 精度和可比设置(例如学习率)进行训练。
图 2:Enwik8 数据集上的开发 BPC 与用于训练的 GPU 小时数的关系。SRU++ 和 Transformer-XL 模型均具有 41-42M 参数,并使用 fp32 精度和可比设置(例如学习率)进行训练。
| 模型 | 数据集 | 结果 | GPU 天数 |
|---|---|---|---|
| Longformer | Enwik8 | 0.99 | 104* |
| 全注意力网络 | Enwik8 | 0.98 | 64 |
| SRU++ | Enwik8 | 0.97 | 7* |
| SRU++ | Enwik8 | 0.96 | 15* |
| Transformer | Wiki-103 | 18.7 | 22* |
| 反馈 Transformer | Wiki-103 | 18.2 | 214 |
| SRU++ | Wiki-103 | 18.4 | 8* |
| SRU++ | Wiki-103 | 17.8 | 12* |
表 1:SRU++ 与各种 Transformer 模型之间报告的训练成本(以总 GPU 天数为度量)和测试结果的比较。(*)表示混合精度训练。数值越低越好。
表 1 进一步比较了 SRU++ 的训练成本与领先的基于 Transformer 的模型在 Enwik8 和 Wiki-103 数据集上的报告成本。我们的模型可以实现超过 10 倍的成本降低,同时在测试困惑度或 BPC 上仍然优于基线模型。
2. 由于递归,所需的注意力较少
类似于 Merity(2019)的观察,我们发现使用几层注意力足以获得最先进的结果。表 2 显示了仅在每 k 层 SRU++ 中启用注意力计算的分析。
| 带有注意力的层数 | 测试 BPC (42M 模型) | 测试 BPC (108M 模型) |
|---|---|---|
| 0 | 1.190 | – |
| 1 | 1.033 | 0.991 |
| 2 | 1.032 | 0.980 |
| 5 | 1.025 | 0.977 |
| 10 | 1.022 | 0.974 |
表 2:在 Enwik8 数据集上通过调整 SRU++ 模型中活跃注意力子层的数量来测试 BPC。我们测试了两个具有 42M 和 108M 参数的 10 层 SRU++ 模型。大多数收益是通过使用 1 或 2 个注意力子层获得的。数值越低越好。
结论
我们提出了一种带有可选内置自注意力的递归架构,达到了领先的模型能力和训练效率。我们展示了通过结合注意力和快速递归,可以得出高度表现力和高效的模型。我们的结果重新确认了观察到的经验事实,即注意力并不是我们所需的一切,还可以通过其他序列建模模块进行补充。
如需进一步阅读,ASAPP 还进行研究以降低模型推理的成本。请参阅我们发表的关于模型蒸馏和剪枝的工作。
简介:Tao Lei,博士 是 ASAPP 的研究负责人和科学家,领导着一个应用研究团队,专注于自然语言处理 (NLP) 和机器学习。在加入 ASAPP 之前,Lei 博士于 2017 年从 MIT 获得博士学位,导师为 Regina Barzilay 教授。Lei 博士的研究兴趣在于机器学习的算法视角及其在 NLP 中的应用。
原文。经授权转载。
相关:
-
Google 的模型搜索:一个利用神经网络构建神经网络的新开源框架
-
深度学习先驱 Geoff Hinton 论他的最新研究与 AI 的未来
-
2011:DanNet 引发深度 CNN 革命
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关主题
免费精通课程:成为大型语言模型专家
原文:
www.kdnuggets.com/ree-mastery-course-become-a-large-language-model-expert
作者提供的图片
在这篇博客文章中,我们将回顾一个著名的教育 GitHub 库,该库拥有 24K ⭐ 星标。这个库提供了一个结构来帮助你免费掌握大型语言模型(LLM)。我们将讨论课程结构、包含代码示例的 Jupyter 笔记本和涵盖最新 LLM 发展的文章。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
介绍
大型语言模型课程是一个全面的项目,旨在为学习者提供在快速发展的大型语言模型领域中脱颖而出的必要技能和知识。该课程包括三大核心部分,涵盖了基础和高级工具及概念。每个核心部分包含多个主题,这些主题配有 YouTube 教程、指南和免费在线资源。
这个 LLM 课程是一个有用的指南,通过集中提供免费的资源、教程、视频、笔记本和文章,提供了一种结构化的学习方式。即使你是完全的初学者,也可以从基础部分开始,学习算法、技术和各种工具,以解决简单的自然语言和机器学习问题。
课程结构
该课程分为三个主要部分,每部分关注 LLM(大型语言模型)专业的不同方面:
LLM 基础
这个基础部分涉及理解和使用 LLM 所需的基本知识。内容包括数学、Python 编程、神经网络基础和自然语言处理。对于那些希望进入机器学习领域或深化对其数学基础的理解的人来说,这部分是不可或缺的。提供的资源,包括 3Blue1Brown 的精彩视频系列和 Khan Academy 的全面课程,提供了适合不同学习风格的多种学习路径。
涵盖的主题:
-
机器学习的数学
-
机器学习中的 Python
-
神经网络
-
自然语言处理(NLP)
LLM 科学家
这个 LLM 科学家指南是为那些对开发前沿 LLM 感兴趣的个人设计的。它涵盖了 LLM 的架构,包括 Transformer 和 GPT 模型,并深入探讨了量化、注意力机制、微调和 RLHF 等高级主题。该指南详细解释了每个主题,并提供了教程和各种资源以巩固概念。整体概念是通过构建来学习。
涵盖的主题:
-
LLM 架构
-
构建指令数据集
-
预训练模型
-
监督微调
-
从人类反馈中进行强化学习
-
评估
-
量化
-
新趋势
LLM 工程师
本部分课程专注于 LLM 的实际应用。它将指导学习者创建基于 LLM 的应用程序并进行部署。涵盖的主题包括运行 LLM、构建用于检索增强生成的向量数据库、高级 RAG 技术、推理优化和部署策略。在本部分课程中,你将学习 LangChain 框架和 Pinecone,用于向量数据库,这些对集成和部署 LLM 解决方案至关重要。
涵盖的主题:
-
运行 LLM
-
构建向量存储
-
检索增强生成
-
高级 RAG
-
推理优化
-
部署 LLM
-
确保 LLM 的安全
笔记本和文章
构建、微调、推理和部署模型可能相当复杂,需要了解各种工具并仔细关注 GPU 内存和 RAM 使用情况。在这里,本课程提供了一整套笔记本和文章,可作为实施所讨论概念的有用参考。
关于笔记本和文章:
-
工具:涵盖了自动评估 LLM、合并模型、在 GGUF 格式中量化 LLM 以及可视化合并模型的工具。
-
微调: 提供了一个 Google Colab 笔记本,用于逐步指导微调模型,如 Llama 2,并使用先进的技术提升性能。
-
量化: 量化笔记本深入探讨了使用 4-bit GPTQ 和 GGUF 量化方法优化 LLM 的效率。
结论
无论你是希望了解基础知识的初学者,还是希望跟上最新研究和应用的资深从业者,LLM 课程都是深入了解 LLM 世界的绝佳资源。它提供了各种免费的资源、教程、视频、笔记本和文章,集中在一个地方。课程涵盖了 LLM 的所有方面,从理论基础到部署前沿 LLM,使其成为任何希望成为 LLM 专家的人的必修课程。此外,还包括笔记本和文章,以巩固每一部分讨论的概念。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一款 AI 产品,帮助那些饱受心理疾病困扰的学生。
更多相关话题
回归分析是否真的属于机器学习?
原文:
www.kdnuggets.com/2017/06/regression-analysis-really-machine-learning.html
评论
统计学与机器学习有何不同?
这是一个广泛的话题,已经被多次讨论。关于这个话题写的内容中,有很多是好的,也有很多是不好的。但我发现,统计学与机器学习的争论在那个层面上,往往过于关注整体,忽视了细节。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
例如,Aatash Shah 写道:
- 机器学习是一种能够从数据中学习的算法,而无需依赖基于规则的编程。
- 统计建模是对数据中变量之间关系的数学方程式形式的形式化。
Shah 的定义,我相信反映了许多方法,倾向于关注这些概念各自范围的不同端点,将机器学习视为实际活动,将统计学视为理论抽象(是的,我在这里将“统计建模”与“统计学”合并在一起……至少,暂时如此)。统计学与机器学习之间的关系实际上非常复杂,仅仅定义这两个概念对剖析这种联系并没有帮助。
对这个广泛的话题进行哲学性讨论很快会变成说教:
-
统计学是机器学习建立的基础吗?
-
机器学习是否是“传统”统计学的超集?
-
这两个概念是否有一个共同的第三个统一概念?
我相信这种高层次的方式是误导性的,并且最终是浪费时间。即使你有兴趣探讨这样的话题,研究更具体的问题可能会更有成效,并可能(希望?)导致更具体的结论。此外,更准确的框架是统计学与机器学习模型的比较。
所以,在这个背景下……回归分析实际上是一种机器学习形式吗?
Gregory Piatetsky-Shapiro,KDnuggets 的主席,在我询问他对这个更具体话题的看法时,分享了以下内容,驳斥了回归过于“简单”而不能被视为机器学习的观点:
一些机器学习研究者可能认为“传统”的线性回归过于简单,无法被视为“机器学习”,而仅仅是“统计学”,但我认为机器学习与统计学之间的界限是人为的。C4.5 决策树算法也不复杂,但它可能被认为是机器学习。
更高级的算法来源于线性回归,例如岭回归、最小角回归和 LASSO,这些算法可能被许多机器学习研究者使用,为了正确理解它们,你需要理解基础的线性回归。
是的,线性回归应该成为任何机器学习研究者工具箱的一部分。
我询问了Diego Kuonen 教授,CStat PStat CSci -- 瑞士 Statoo Consulting 首席执行官及首席行政官,瑞士日内瓦大学数据科学教授 -- 他很友好地提供了以下见解:
每个监督分析模型(来自统计学、数据科学和/或机器学习)都对输出的分布(或其某些方面)如何依赖于模型输入做出了假设。如果不做任何假设,就没有合理的基础来对观察到的数据进行推广。
因此,只基于有效模型(即假设经过验证的模型)得出结论是有意义的。换句话说,任何结论的可靠性取决于其所基于的模型。
如果你愿意,这种方法采用了较少分歧、更多统一的方式,将统计模型和机器学习模型都视为实现终极目标的工具:理解数据。Diego 似乎更关注工具的使用方式,而不是工具本身,确保工具的使用得当,构建有效的模型,并且结果是对数据的理解加深。讨论统计与机器学习的具体关系毫无意义,如果最终的归纳基于无效模型,不管采用什么方法构建模型。
就我个人而言,我多年来一直在思考这些问题。从我首次接触线性回归,以及在较小程度上接触决策树——从数据挖掘的书籍和课程的角度——我最初对这些简单的概念竟然可以被认为是“机器学习”感到非常惊讶。尤其是考虑到在那时我已经对统计学中的回归非常熟悉,而在这些早期的学习过程中没有人提到过“机器学习”这个术语。我想这可能是我所处的位置上的其他人,在教育和/或职业生涯的类似阶段也会有类似的反应。
简单来说,正如我曾经详细考虑过的数据挖掘与机器学习的关系——这也可能成为一种徒劳的行为——我喜欢将数据挖掘视为一个过程,而机器学习则是促进这一过程的工具。结合现代统计学定义(通过 Kuonen 提供的定义)是“从数据中学习的科学(或从数据中找出意义),以及测量、控制和传达不确定性”,我乐于接受将数据挖掘快速而粗略地定义为“高速度的大规模统计分析”。
类似地,机器学习的一个简化定义是由三部分组成:1)数据,2)模型或估计器,以及 3)要最小化的成本或损失。机器学习的整个存在理由是优化损失函数的过程,这个过程处理人类可以手动解决的类似统计问题,并大大增加了可以处理的数据的数量和/或性质。
那么,回到最初的问题(再一次),线性回归——回归分析中最简单的形式——是否符合这些要求?
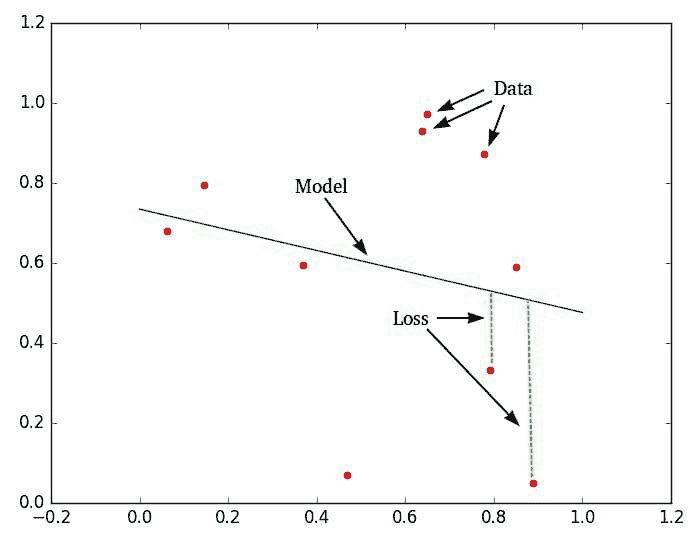
似乎确实如此!
当然,这并不能完全解决问题。如果我有一组 10 个数据点,绘制其中的 9 个数据点,将第 10 个数据点保留用于“测试”,然后通过手动解决方程并绘制结果,这算不算机器学习?如果这不算——显然不算——那么过渡到机器学习的界限在哪里?100 个数据点?足够多的实例属性?仅仅是使用计算机?我更倾向于将“传统”统计学和机器学习视为一个光谱的两个极端,并且这两者之间的过渡区域永远是模糊和无法定义的。
顺便提一下,与上述内容相反,迈克·约曼斯已经写道关于机器学习,我们应该“[t]将其简单地视为一个统计学分支,旨在处理大数据世界”,这一观点得到了库奥农的一些认可。库奥农还指出,虽然可以争论“数据挖掘是大规模和高速的统计学”(达里尔·普雷吉本,1999),但他指出它们的方法存在差异,你可以在这里阅读更多。
我将把最后的话留给凯文·格雷,Cannon Gray 的总裁,他在我联系他以征求意见时,恰到好处地总结了这个话题,怀疑这整个讨论是否真的必要。
我的观点是我不知道,但我想知道这是否重要。我对地区、爱国主义等事物不擅长。如果感觉不错(足够好),就做吧!😃
我想特别感谢迪亚哥·库奥农教授,感谢他在写作过程中提供的意见和反馈。
相关:
-
线性回归、最小二乘法与矩阵乘法:简明技术概述
-
回归分析:入门
-
大数据、圣经密码与邦费罗尼
更多相关话题
逻辑回归中的正则化:更好的拟合和更好的泛化?
原文:
www.kdnuggets.com/2016/06/regularization-logistic-regression.html
正则化不会提高模型用于学习参数(特征权重)的数据集上的性能。然而,它可以提高泛化性能,即在新的、未见过的数据上的表现,这正是我们想要的。
从直观上讲,我们可以把正则化看作是对复杂度的惩罚。增加正则化强度会惩罚“较大”的权重系数——我们的目标是防止模型捕捉到“特异性”、“噪声”或“在不存在模式的地方假设模式”。
再次强调,我们不希望模型记住训练数据集,我们希望模型对新的、未见过的数据有良好的泛化能力。
更具体来说,我们可以把正则化看作是增加(或提高)偏差的过程,如果我们的模型存在(高)方差(即,它过拟合了训练数据)。另一方面,过多的偏差会导致欠拟合(高偏差的一个特征指标是模型在训练和测试数据集上的表现都很“差”)。我们知道,在未正则化的模型中,我们的目标是最小化成本函数,即,我们想找到与全局成本最小值对应的特征权重(记住,逻辑回归的成本函数是凸的)。

现在,如果我们对成本函数进行正则化(例如,通过 L2 正则化),我们在成本函数(J)中增加一个额外的项,该项随着参数权重(w)值的增加而增加;请记住,我们添加的正则化还引入了一个新的超参数 lambda,用于控制正则化强度。

因此,我们的新问题是最小化成本函数,给定这个附加的约束。

从直观上讲,我们可以把图中坐标中心的“球体”看作是我们的“预算”。现在,我们的目标仍然是相同的:我们想要最小化成本函数。然而,我们现在受到正则化项的约束;我们希望在保持在我们的“预算”(即球体)内的同时尽可能接近全局最小值。
个人简介: 塞巴斯蒂安·拉施卡 是一位‘数据科学家’和机器学习爱好者,对 Python 和开源有着极大的热情。著作有《Python 机器学习》。密歇根州立大学。
原始文档。经许可转载。
相关:
-
深度学习何时优于 SVM 或随机森林?
-
分类作为学习机器的发展
-
为什么从头实现机器学习算法?
更多相关内容
机器学习中的正则化
原文:
www.kdnuggets.com/2018/01/regularization-machine-learning.html
评论
由 Prashant Gupta 提供
训练机器学习模型的一个主要方面是避免过拟合。如果模型过拟合,其准确性会很低。这发生在你的模型过于努力地捕捉训练数据集中的噪声时。噪声指的是那些不真正代表数据真实属性的数据点,而是随机的偶然性。学习这些数据点会使模型更加灵活,但也有过拟合的风险。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
平衡偏差和方差的概念,有助于理解过拟合现象。
避免过拟合的方法之一是使用交叉验证,这有助于估计测试集上的误差,并决定哪些参数最适合你的模型。
本文将重点介绍一种技术,帮助避免过拟合并提高模型的可解释性。
正则化
这是一种回归形式,约束/正则化或缩小系数估计值到接近零。换句话说,这种技术旨在避免学习更复杂或灵活的模型,以防止过拟合的风险。
线性回归的简单关系看起来是这样的。这里 Y 代表学到的关系,β 代表不同变量或预测器(X)的系数估计值。
Y ≈ β0 + β1X1 + β2X2 + … + βpXp
拟合过程涉及一个损失函数,称为残差平方和或 RSS。系数的选择是为了最小化这个损失函数。
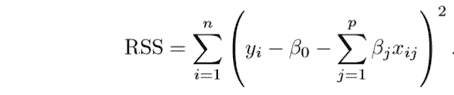
现在,这将根据你的训练数据调整系数。如果训练数据中存在噪声,那么估计的系数对未来数据的泛化能力就会差。这就是正则化发挥作用的地方,它将这些学习到的估计值缩小或正则化到接近零。
岭回归
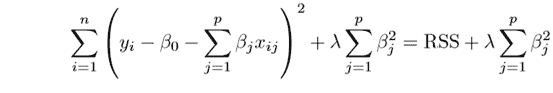
上图显示了岭回归,其中RSS 通过添加收缩量进行修改。现在,通过最小化此函数来估计系数。这里,λ是调整参数,它决定了我们希望对模型的灵活性施加多大惩罚。模型灵活性的增加由其系数的增加表示,如果我们希望最小化上述函数,则这些系数需要很小。这就是岭回归技术如何防止系数过高的原因。同时,请注意,我们收缩了每个变量与响应的估计关联,除了截距β0。这个截距是当 xi1 = xi2 = …= xip = 0 时响应的均值的度量。
当λ = 0 时,惩罚项没有效果,岭回归所产生的估计值将等于最小二乘估计。然而,随着λ→∞,收缩惩罚的影响逐渐增大,岭回归系数估计将趋近于零。如上所示,选择一个合适的λ值是关键。交叉验证对于这个目的非常有用。该方法产生的系数估计也被称为 L2 范数。
标准最小二乘法产生的系数是尺度不变的,即如果我们将每个输入乘以 c,则相应的系数将按 1/c 的因子进行缩放。因此,无论预测变量如何缩放,预测变量与系数的乘积(X[j]β[j])保持不变。然而,岭回归的情况则不同,因此,在进行岭回归之前,我们需要对预测变量进行标准化或将预测变量调整到相同的尺度。用于此操作的公式如下所示。
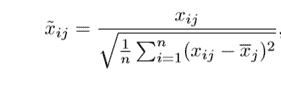
套索回归
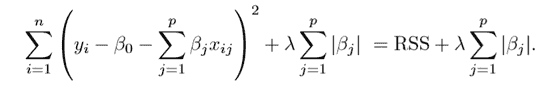
套索回归是另一种变体,其中上述函数被最小化。显然,这种变体与岭回归的区别在于对高系数的惩罚。它使用|βj|(绝对值)而不是β的平方作为惩罚。在统计学中,这被称为 L1 范数。
让我们从不同的角度来看待上述方法。岭回归可以看作是求解一个方程,其中系数的平方和小于或等于 s。而套索回归可以看作是一个方程,其中系数的绝对值之和小于或等于 s。这里,s 是对于每个收缩因子λ值存在的常量。这些方程也被称为约束函数。
考虑给定问题中有 2 个参数。 然后根据上述公式,岭回归表示为β1² + β2² ≤ s。这意味着岭回归系数在所有位于β1² + β2² ≤ s 的圆内的点上具有最小的 RSS(损失函数)。
同样,对于套索回归,方程变为 |β1|+|β2|≤ s。这意味着套索回归系数在所有位于由 |β1|+|β2|≤ s 给出的菱形内部的点上具有最小的 RSS(损失函数)。
下图描述了这些方程。
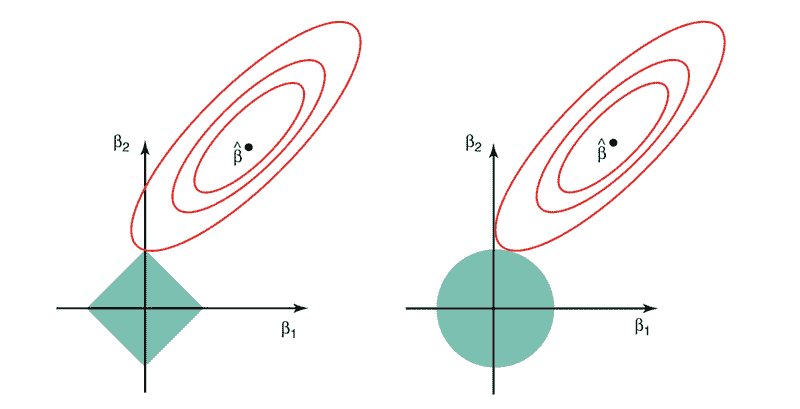
上图展示了套索回归(左)和岭回归(右)的约束函数(绿色区域),以及 RSS 的轮廓(红色椭圆)。椭圆上的点共享 RSS 的值。对于非常大的 s 值,绿色区域将包含椭圆的中心,使得两种回归技术的系数估计等于最小二乘估计。然而,上图中的情况并非如此。在这种情况下,套索回归和岭回归的系数估计由椭圆与约束区域接触的第一个点给出。由于岭回归具有没有尖锐点的圆形约束,因此这种交点通常不会发生在轴上,因此岭回归系数估计将完全非零。
然而,套索回归的约束在每个轴上都有角,因此椭圆通常会在轴上与约束区域相交。当这种情况发生时,其中一个系数将等于零。 在高维空间(参数远多于 2 的情况)中,许多系数估计可能会同时等于零。
这揭示了岭回归显而易见的缺点,即模型的可解释性。 它会将对最不重要预测变量的系数收缩到非常接近零,但永远不会将其完全变为零。换句话说,最终模型将包括所有预测变量。然而,在套索回归的情况下,L1 惩罚的效果是,当调节参数 λ 足够大时,迫使一些系数估计恰好为零。因此,套索方法还执行变量选择,并且被认为能够产生稀疏模型。
正则化的目标是什么?
标准最小二乘模型通常具有一定的方差,即该模型对于与其训练数据不同的数据集泛化效果较差。正则化显著减少了模型的方差,而不会显著增加其偏差。因此,正则化技术中使用的调节参数 λ 控制对偏差和方差的影响。随着 λ 值的增加,它会减少系数的值,从而减少方差。在某一点之前,λ 的增加是有益的,因为它仅减少方差(从而避免过拟合),而不会丢失数据中的任何重要属性。 但在某个值之后,模型开始丢失重要属性,导致模型偏差,从而出现欠拟合。因此,λ 的值应仔细选择。
这些都是你开始学习正则化所需的基础知识。这是一种有用的技术,可以帮助提高回归模型的准确性。一个实现这些算法的流行库是 Scikit-Learn。它拥有一个出色的 API,可以让你的模型在 仅用几行 Python 代码 的情况下运行起来。
如果你有任何问题,请留下评论,我会尽力回答。
你也可以通过 Twitter、直接发邮件给我 或 在 LinkedIn 上找我。我很期待你的消息。
这就是所有内容了,祝大家有美好的一天 😃
致谢
本文内容的灵感来源于《统计学习简介》一书,由 Gareth James、Daniela Witten、Trevor Hastie 和 Robert Tibshirani 合著。
简介: Prashant Gupta 是一名机器学习工程师、安卓开发者、技术爱好者。
原文。已获许可转载。
相关
相关内容
强化学习:商业用例,第一部分
原文:
www.kdnuggets.com/2018/08/reinforcement-learning-business-use-case-part-1.html
评论
作者:Aishwarya Srinivasan,深度学习研究员

强化学习的热潮始于 DeepMind 推出的 AlphaGo,这是一款专为围棋设计的人工智能系统。从那时起,各家公司投入了大量的时间、精力和研究,今天强化学习已经成为深度学习中的热门话题。尽管如此,大多数企业在寻找强化学习的应用场景或将其纳入业务逻辑方面仍面临困难。这并不令人惊讶。到目前为止,它仅在无风险、可观察且易于模拟的环境中进行研究,这意味着像金融、健康、保险和技术咨询等行业不愿意冒着自己资金的风险来探索其应用。此外,强化学习中的“风险因素”对系统施加了很大的压力。Coursera 的联合主席兼创始人 Andrew Ng 曾表示:“强化学习是一种对数据需求甚至超过监督学习的机器学习类型。获得足够的数据用于强化学习算法非常困难。还有更多工作需要完成,以将其转化为业务和实践。”
以这种略显悲观的观点为出发点,让我们利用本博客的第一部分深入探讨强化学习的技术方面。在第二部分中,我们将探讨一些可能的商业应用。从根本上说,RL 是一个复杂的算法,用于将观察到的实体和度量映射到一组动作,同时优化长期或短期奖励。RL 代理与环境互动,尝试学习策略,这些策略是获取奖励的决策或动作序列。实际上,RL 在驱动与代理的互动时,会考虑即时奖励和延迟奖励。
强化学习模型由一个代理组成,该代理推断出一个动作,然后对环境进行操作以实现改变,动作的意义通过奖励函数来反映。这个奖励是为代理优化的,反馈会传递给代理,以便其评估下一步最佳行动。系统通过回顾在类似情况下采取的最佳行动,从之前的动作中学习。
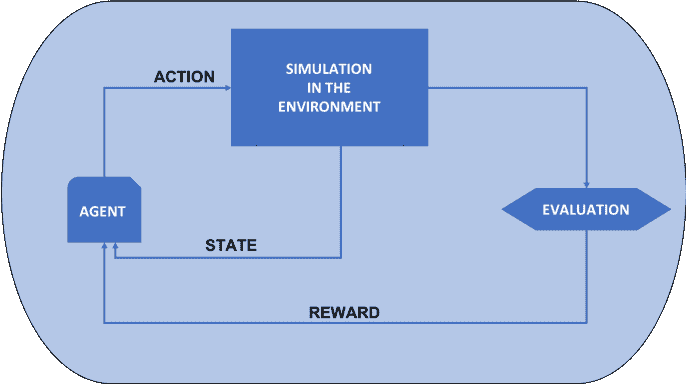
图 1:强化学习模型
从数学角度来看,我们可以将强化学习视为一个状态模型,特别是一个完全可观察的 马尔可夫决策过程(MDP)。要理解 MDP 背后的概率理论,我们需要了解马尔可夫属性:
“在给定当前状态的情况下,未来与过去无关”
马尔可夫属性用于不同结果的概率不依赖于过去状态的情况,因此只需要当前状态。一些人用“无记忆”来描述这种属性。在需要以前状态来决定结果的情况下,马尔可夫决策过程将不起作用。
模型的环境是一个随机有限状态机,代理发出的行动作为输入,环境向代理发出的奖励/反馈作为输出。整体奖励函数包括即时奖励和延迟奖励。即时奖励是行动对状态环境的定量影响。延迟奖励是行动对未来环境状态的影响。延迟奖励通过‘折扣因子 (γ)’ 参数进行计算,0 < γ <1。折扣因子的较高值使系统倾向于远见奖励,而较低值使系统倾向于即时奖励。X(t) 是时间 ‘t’ 的环境状态表示。A(t) 是代理在时间 ‘t’ 采取的行动。
状态转移函数:在环境中,由代理发出的行动导致从一个状态转移到另一个状态。
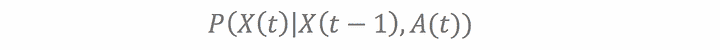
代理也被建模为一个随机有限状态机,其中环境发出的奖励是输入,而环境中为下一时间步发出的行动是输出。S(t) 是代理在时间 ‘t’ 收到环境反馈后的当前状态,反馈来自时间 ‘t-1’ 的环境应用,A(t) 表示使用模型学习通过整体奖励优化建立的策略。
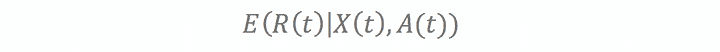
状态转移函数:在代理中,由环境发出的奖励导致从一个状态转移到另一个状态。
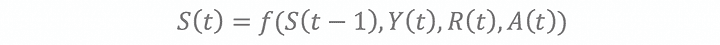
策略函数:从代理到环境的策略/输出函数,根据奖励函数的优化给出行动。
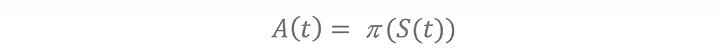
代理的目标是找到策略 P(pi),以最大化带有折扣因子的整体期望奖励。
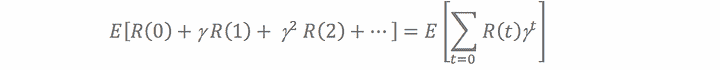
使用 MDP 训练的代理尝试从当前状态获得最多的预期奖励总和。因此,需要获得最优值函数。贝尔曼方程用于值函数,分解为当前奖励和下一状态值的折扣值。
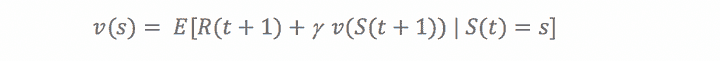
我希望你现在已经了解了强化学习的技术方面!!
在本系列文章的下一部分,我们将查看作为金融行业业务案例的实际应用,即股票交易。
继续深入学习!
简历:Aishwarya Srinivasan: 数据科学硕士 - 哥伦比亚大学 || IBM - 数据科学精英 || 数据科学领域的独角兽 || Scikit-Learn 贡献者 || 深度学习研究员
原文。经许可转载。
相关内容:
-
你需要了解的 5 件强化学习的事情
-
解释强化学习:主动 vs 被动
-
什么时候不应该使用强化学习?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
更多相关话题
强化学习:商业用例,第二部分
原文:
www.kdnuggets.com/2018/08/reinforcement-learning-business-use-case-part-2.html
评论
由 Aishwarya Srinivasan,深度学习研究员

在我 上一篇文章中,我专注于强化学习的计算和数学视角的理解,以及在商业用例中使用该算法时面临的挑战。
在这篇文章中,我将探讨强化学习在交易中的应用。金融行业一直在探索人工智能和机器学习在其用例中的应用,但经济风险导致了其犹豫。传统的算法交易近年来有所发展,现在高计算系统自动化了任务,但交易员仍然制定管理买卖选择的政策。一个基于估值和增长指标条件的股票购买算法模型可能定义一个“买入”或“卖出”信号,这些信号会被交易员定义的某些特定规则触发。
例如,一种算法方法可能是每当 S&P 指数收盘价高于过去 30 天的最高点时就买入,或者每当收盘价低于过去 30 天的最低点时就平仓。这些规则可能是趋势跟随型、逆势型,或者基于自然中的模式。不同的技术分析师不可避免地会以不同的方式定义模式和确认条件。为了使这种方法具有系统性,交易员必须指定精确的数学条件,以明确地定义是否形成了头肩形态,以及定义该模式确认的精确条件。
在当前金融市场的先进机器学习领域,我们可以关注 2017 年 10 月 EquBot 推出的基于 AI 的交易型基金(ETFs)。EquBot 自动化这些 ETF,以从数千家美国公司的市场信息、超过一百万个市场信号、季度新闻文章和社交媒体帖子中汇总数据。一个 ETF 可能会选择 30 到 70 家市场升值机会较大的公司,并且它会随着每笔交易不断学习。另一家知名市场参与者 Horizons 推出了类似的主动 AI 全球 ETF,该 ETF 由 Horizons 开发,使用了包括交易员政策制定在内的监督机器学习。通过监督学习方法,人类交易员帮助选择阈值,考虑延迟,估算费用等。
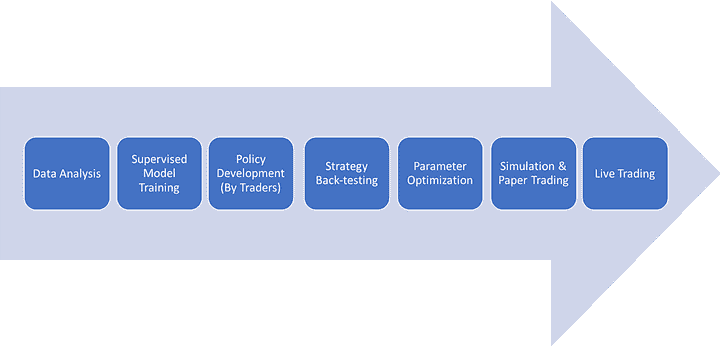
图 1:使用监督学习的交易流程
当然,如果要完全自动化,一个由 AI 驱动的交易模型必须做的不仅仅是预测价格。它需要一个基于规则的策略,该策略以股票价格作为输入,然后决定是买入、卖出还是持有。
在 2018 年 6 月,摩根士丹利任命了迈克尔·凯恩斯,一位来自宾夕法尼亚大学的计算机科学家,以扩大人工智能的应用。在接受彭博社采访时,凯恩斯博士指出,“虽然标准机器学习模型可以对价格进行预测,但它们并未指定最佳行动时间、交易的最佳规模或其对市场的影响。”他补充道,“通过强化学习,你可以学习做出预测,这些预测考虑了你的行为对市场状态的影响。”
强化学习允许端到端的优化,并最大化奖励。关键在于,RL 智能体自身调整参数以找到最佳结果。例如,我们可以设想在出现超过 30%的回撤时,给予大负奖励,这迫使智能体考虑不同的策略。我们还可以构建模拟,以改善在关键情况下的反应。例如,我们可以在强化学习环境中模拟延迟,以对智能体生成负奖励。这个负奖励反过来促使智能体学习处理延迟的方法。类似的策略使智能体能够随着时间的推移进行自动调优,不断增强其能力和适应性。
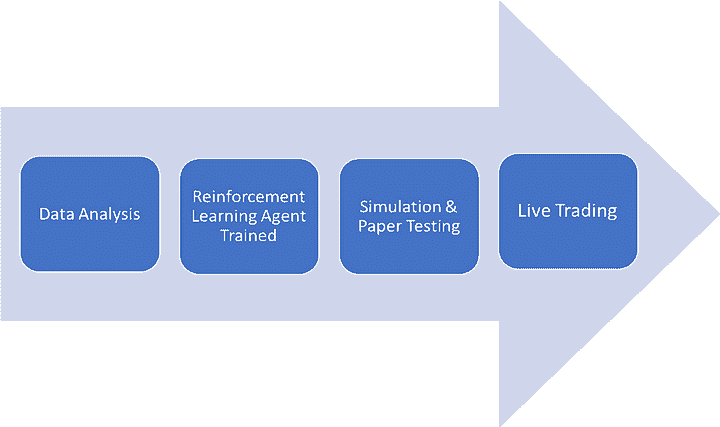
图 2:使用强化学习模型的交易流程
在 IBM,我们在DSX 平台上构建了一个复杂的系统,利用强化学习的力量进行金融交易。该模型通过使用随机行动对历史股票价格数据进行训练,我们根据每次交易的盈亏来计算奖励函数。
‘IBM 数据科学体验是一个企业数据科学平台,为团队提供最广泛的开源和数据科学工具,适用于任何技能水平,具有在多云环境中构建和部署的灵活性,以及更快地将数据科学结果付诸实践的能力。’
以下图表将强化学习方法与金融交易的用例结合起来。
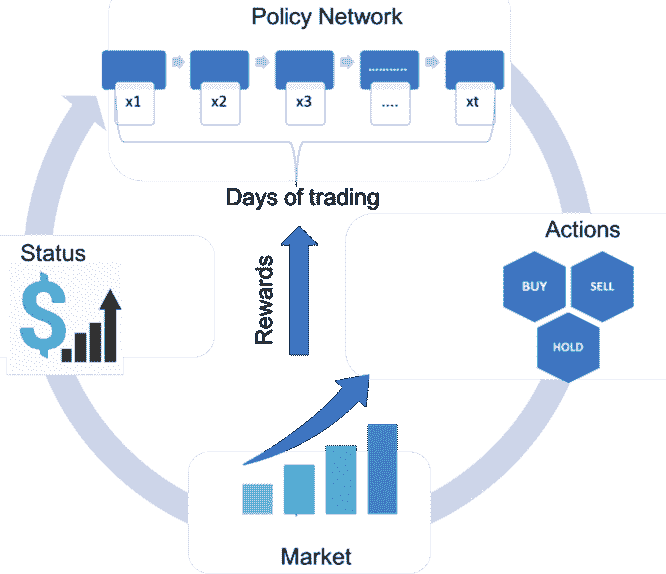
图 3:强化学习交易模型
我们使用 alpha 指标(投资的主动回报)来衡量强化交易模型的表现,并评估投资与代表市场整体走势的市场指数的表现。最后,我们将模型与简单的 买入并持有策略 和 ARIMA-GARCH 进行对比。我们发现,该模型根据市场走势进行了更加精细的调整,甚至能够捕捉到 头肩形态,这些非平凡的趋势可以预示市场的反转。
强化学习可能并不适用于每一个商业案例,但它在捕捉金融交易的细微之处方面的能力确实展示了其复杂性、强大和更大的潜力。
请继续关注,我们将测试强化学习在更多商业用例中的表现!
个人简介:Aishwarya Srinivasan:哥伦比亚大学数据科学硕士 || IBM 数据科学精英 || 数据科学领域的独角兽 || Scikit-Learn 贡献者 || 深度学习研究员
原始文章。经许可转载。
相关内容:
-
关于强化学习你需要知道的 5 件事
-
解释强化学习:主动与被动
-
强化学习不应使用的情况?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关话题
强化学习入门
原文:
www.kdnuggets.com/2022/05/reinforcement-learning-newbies.html
作者提供的图片
什么是强化学习(RL)
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT 工作
强化学习(RL)是一种机器学习模型,代理通过试错法学习以实现目标。这是一种以目标为导向的算法,当代理执行正确的动作时会获得奖励。这些奖励帮助代理在复杂的环境中导航以实现最终目标。就像幼儿通过试错法学习走路一样,机器也能在没有人工干预的情况下学习执行复杂任务。
RL 与其他机器学习算法有很大不同。它从环境中学习,并比人类表现更好。而监督学习和无监督学习模型依赖于从人类那里收集的现有数据,受限于人类智能。例如,Deepmind 的AlphaGo自行学习了各种策略以击败围棋世界冠军。
强化学习如何工作?
以一个马里奥游戏为例。在游戏开始时,代理(马里奥)处于状态零,基于其状态,代理将采取一个动作。在这种情况下,马里奥将向前移动。现在代理处于新状态(新帧)。代理会因为向前移动而获得奖励。代理将继续移动,直到完成关卡或在过程中死亡。RL 的主要目标是通过最小化步骤来最大化奖励的收集。
RL 的应用是什么?
目前,机器学习应用仅限于单一任务,并依赖于现有数据。但未来一切将发生变化,我们将把 RL 与计算机视觉、机器翻译以及各种模型结合起来,以实现超人类的表现,例如:
-
自动驾驶汽车:旅行变得更安全和快速
-
行业自动化:仓库管理
-
交易和金融:股票价格预测
-
自然语言处理(NLP):文本摘要、问答和机器翻译
-
医疗保健:有效的疾病检测和治疗
-
工程:优化大规模生产。
-
推荐系统:提供更好的新闻、电影和产品推荐。
-
游戏:制作更好的游戏关卡以优化玩家的参与度。
-
营销与广告:识别个人并根据需求通过广告进行精准投放。
-
机器人技术:执行复杂和重复的任务。
强化学习的关键组件
在我们开始构建自己的系统之前,有很多关于强化学习的知识需要学习。在这一部分,我们将学习强化学习的关键组件以及每个组件如何相互作用。
-
代理:可以是游戏角色、机器人或汽车。代理是一个执行动作的算法。在现实生活中,代理是人类。
-
动作(A):是代理可以执行的所有可能移动的集合。例如,马里奥可以跳跃、向左移动、向右移动和蹲下。
-
折扣因子:未来的奖励会被折扣,所以它的价值低于即时行动,以便对代理施加短期享乐主义。
-
环境:这是一个与代理交互的世界。在马里奥游戏中,环境就是地图。它将当前状态和代理的动作作为输入,并返回奖励和下一个状态。
-
状态(S):就像一个帧。当代理采取一个动作时,状态从当前帧改变到马里奥游戏中的下一帧。当前状态和下一个状态由环境提供。
-
奖励(R):是基于之前动作给予代理的反馈或奖励。如果代理完成了任务,奖励可能是正面的;如果失败,奖励可能是负面的。奖励也可以是即时的或延迟的。
-
策略(?):是代理为了基于状态和动作获得最高奖励而采取的策略。简单来说,它定义了代理如何根据当前状态采取行动。
-
价值(V):是带有折扣的预期长期回报。
-
轨迹:是状态和由这些状态影响的动作的序列。
-
回合:代理的一个完整周期,从开始到结束。例如,马里奥从开始处开始,当当前阶段完成时,第一个回合结束。当马里奥死亡时,回合也结束。
-
利用:采取最佳行动以最大化奖励收集。
-
探索:采取随机行动以探索环境,而不考虑奖励。
学习资源
这只是一个开始,如果你想深入了解强化学习,可以从学习基础知识开始。观看 YouTube 教程或完成一个课程。之后,开始进行一个项目或参加竞赛。我通过参与 Kaggle 竞赛学习了所有关于 RL 的知识,如果在过程中遇到困难,我会阅读博客或各种教程来扩展我的知识。
教程
课程
竞赛
书籍
博客
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为遭受心理疾病困扰的学生构建一个 AI 产品。
更多相关话题
强化学习:教计算机做出最佳决策
原文:
www.kdnuggets.com/2023/07/reinforcement-learning-teaching-computers-make-optimal-decisions.html
什么是强化学习?
强化学习是机器学习的一个分支,它涉及智能体通过经验学习如何与复杂环境互动。
从在复杂棋盘游戏(如象棋和围棋)中超越人类表现的 AI 智能体,到自主导航,强化学习具有一系列有趣且多样的应用。
在强化学习领域的显著突破包括 DeepMind 的智能体AlphaGo Zero,它可以击败甚至人类围棋冠军,以及AlphaFold,它可以预测复杂的 3D 蛋白质结构。
本指南将介绍强化学习范式。我们将通过一个简单但有启发性的现实世界例子来理解强化学习框架。
强化学习框架
我们首先来定义强化学习框架的组成部分。
强化学习框架 | 图片由作者提供
在典型的强化学习框架中:
-
有一个智能体在学习如何与环境互动。
-
智能体可以测量其状态,采取行动,并偶尔获得奖励。
这种设置的实际例子:智能体可以与对手对弈(比如,一场象棋比赛)或尝试在复杂环境中导航。
作为一个超级简化的例子,考虑一个在迷宫中的鼠标。这里,智能体不是与对手对战,而是试图找出通向出口的路径。如果有多个路径通向出口,我们可能会选择最短的路径。
迷宫中的鼠标 | 图片由作者提供
在这个例子中,鼠标是试图在迷宫中导航的智能体。这里的行动是鼠标在迷宫中的移动。当它成功找到出口时,它会获得一块奶酪作为奖励。
示例 | 图片由作者提供
行动序列发生在离散的时间步骤中(比如,t = 1, 2, 3,...)。在任何时间步骤t,鼠标只能测量其在迷宫中的当前状态。它还不知道整个迷宫的情况。
所以代理(小鼠)在时间步t测量其环境状态  ,采取一个有效的行动
,采取一个有效的行动  并移动到状态
并移动到状态  。
。
状态 | 作者提供的图像
强化学习有什么不同?
注意观察小鼠(代理)如何通过试错法找出迷宫的出口。如果小鼠碰到迷宫的墙壁,它必须尝试找到回去的路,并绘制一条不同的路线到达出口。
如果这是一个监督学习环境,那么在每次移动后,代理会知道该行动是否正确,并是否会导致奖励。监督学习就像是从教师那里学习。
当教师事先告诉你时,批评者总是在表演结束后告诉你—你的表现有多好或多坏。因此,强化学习也被称为在批评者存在下的学习。
终端状态和回合
当小鼠到达出口时,它达到了终端状态。这意味着它不能再进一步探索。
从初始状态到终端状态的一系列行动称为一个回合。对于任何学习问题,我们需要多个回合让代理学习导航。在这里,为了让我们的代理(小鼠)学习到达出口的行动序列,并随之获得奶酪,我们需要很多回合。
密集奖励和稀疏奖励
每当代理采取正确的行动或一系列正确的行动时,它就会获得一个奖励。在这种情况下,小鼠因绘制有效路径—穿越迷宫(环境)—到达出口而获得奶酪作为奖励。
在这个例子中,小鼠只有在最后—即到达出口时—才会得到一块奶酪。这是一个稀疏且延迟的奖励示例。
如果奖励更频繁,那么我们将拥有一个密集的奖励系统。
回顾过去,我们需要弄清楚(这并不简单)是哪一个行动或一系列行动使代理获得了奖励;这通常被称为信用分配问题。
策略、价值函数和优化问题
环境通常不是确定性的,而是概率性的,策略也是如此。给定一个状态 ,代理会采取一个行动并以一定的概率转移到另一个状态  。
。
策略有助于定义从可能状态集合到行动的映射。它有助于回答诸如以下问题:
-
应采取什么行动以最大化期望奖励?
-
或者更好地说:给定一个状态,代理能采取的最佳行动是什么,以最大化期望奖励?
因此,你可以把代理看作是执行策略 π:

另一个相关且有帮助的概念是价值函数。价值函数定义为:

这表示在给定策略π的情况下处于某状态的价值。这个量表示如果代理从某状态开始并随后执行策略π,那么未来的期望奖励。
总结一下:强化学习的目标是优化策略,以最大化期望的未来奖励。因此,我们可以将其视为一个优化问题,求解π。
折扣因子
注意到我们有了一个新的量ɣ。它代表什么?ɣ被称为折扣因子,一个介于 0 和 1 之间的量。意味着未来的奖励会被折扣(即:现在的价值大于未来)。
探索与利用的权衡
回到老鼠在迷宫中的食物循环示例:如果老鼠能够找到通向出口 A 的路线,并获得一小块奶酪,它可以不断重复这一过程并收集奶酪。但如果迷宫还有另一个出口 B,那里有一块更大的奶酪(更大的奖励)呢?
只要老鼠继续利用当前策略而不探索新策略,它就无法获得出口 B 处更大奶酪的更大奖励。
探索与利用 | 图片作者
但探索新策略和未来奖励的不确定性更大。那么我们如何在利用和探索之间取得平衡呢?这种在利用当前策略和探索具有潜在更好奖励的新策略之间的权衡被称为探索与利用的权衡。
一种可能的方法是ε-贪婪搜索。给定所有可能的行动,ε-贪婪搜索以概率ε探索可能的行动之一,同时以概率 1 - ε利用当前策略。
总结和下一步
让我们总结一下我们到目前为止学到的内容。我们学习了强化学习框架的组成部分:
-
代理与环境互动,测量其当前状态,采取行动,并获得作为正向强化的奖励。该框架是概率性的。
-
然后我们讨论了价值函数和策略,以及优化问题如何通常归结为找到最大化期望未来奖励的最优策略。
你现在已经学到了足够的知识来导航强化学习领域。接下来该怎么做?我们在本指南中没有讨论强化学习算法,你可以探索一些基本算法:
-
如果我们对环境了解一切(并且可以完全建模),我们可以使用基于模型的算法,如 策略迭代和价值迭代。
-
然而,在大多数情况下,我们可能无法完全建模环境。在这种情况下,你可以查看无模型算法,如 Q-learning,它优化状态-动作对。
如果你想进一步了解强化学习,YouTube 上的 David Silver 强化学习讲座 和 Hugging Face 深度强化学习课程 是一些不错的资源。
Bala Priya C 是一位来自印度的开发者和技术作者。她喜欢在数学、编程、数据科学和内容创作的交集上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、操作指南、评论文章等与开发者社区分享她的知识。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
数据科学中的远程工作:优缺点
原文:
www.kdnuggets.com/remote-work-in-data-science-pros-and-cons

图片来源:Ketut Subiyanto
在不久前,数据科学家被束缚在隔间内,限制在实体办公室空间。然而,时代在变化,远程工作革命正在重塑职业格局。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
如今,从自己舒适的家中(或你选择的任何地方)追求你对数据科学的热情比以往任何时候都容易(当然,至少要有稳定的互联网连接)。
然而,与任何职业决策一样,数据科学领域的远程工作也有其优缺点。下面,我们将探讨数据科学远程工作的优点和缺点,并为你提供做出明智选择所需的见解。
数据科学中远程工作的优点
在讨论远程工作可能面临的挑战或陷阱之前,让我们先列出这种方法对数据科学家最重要的好处。
灵活性和工作与生活平衡
远程工作让你摆脱了传统 9 到 5 工作时间的严格限制。你可以将工作时间调整到你最具生产力的时间段,而无需遵循固定的时间表。
这种新发现的灵活性意味着,无论你是夜猫子还是早起鸟,你都可以优化你的工作以与最佳生产力时间对齐和自然节奏。
另一个远程工作的直接好处是消除了每日通勤的时间——不再有令人厌倦的交通堵塞或拥挤的公共交通。通过重新利用以前用于通勤的时间,你可以将宝贵的时间用于更有意义的活动,如数据分析、自我提升,或只是享受悠闲的早餐。
远程工作还使你能够以适合自己的方式融合职业和个人生活。这种和谐的整合允许你参与重要的家庭时刻,安排个人约会而无需请假,并实现符合你独特需求和优先事项的工作与生活平衡。
进入全球就业市场
对于数据科学家来说,远程工作不仅打破了地理障碍,还开启了一个充满可能性和优势的世界,可以改变你的职业生涯。不再局限于通勤半径内的职位,你可以从全球范围内获取各种机会。
这个全球就业市场为你提供了与前沿公司、初创企业或成熟组织合作的机会,无论它们的实际位置在哪里。结果是?一个更广泛的职位范围,可以满足你独特的技能和兴趣。
进入全球就业市场也带来了高薪数据科学职位的潜力。全球公司往往认识到数据科学家的价值,并愿意提供有竞争力的薪水来吸引顶尖人才。你甚至可以利用这一机会为薪水更高的地区的组织工作。
提高生产力
远程工作让你可以自由选择理想的工作环境。你不再受限于标准化的办公室设置,而是可以选择最适合你的空间。
无论你是在舒适的家庭办公室、小咖啡馆的热闹氛围,还是公园的宁静中,你都可以设计一个促进舒适和生产力的工作空间。
此外,远程工作可以让你摆脱传统办公室中充斥的各种干扰,例如话多的同事和临时会议。这种新获得的专注力对数据科学家来说可能是一个改变游戏规则的因素,因为它使你能够沉浸于复杂的分析任务和问题解决中,而不受持续干扰。
成本节约
远程工作的一个最明显的成本节约好处是消除了交通和通勤费用。你不再需要为与汽油、公共交通费用或车辆维护相关的日常开支进行预算。
此外,远程工作还可能带来潜在的税收优惠。根据你的所在地和税法,你可能有资格获得与家庭办公室费用相关的扣除。
这些扣除项可以包括你的一部分租金或按揭费用、水电费,甚至是办公室设备和用品的购买。请咨询税务专业人士,了解远程工作者可以享受的税收优惠。
更深层次地说,远程工作还允许数据科学专业人士迁移到生活成本较低的地区,从而使他们每月可以节省更多的收入。
数据科学远程工作的缺点
现在我们已经讨论了远程工作对数据科学家的各种好处,公平起见,也应该提到这种工作方式可能带来的挑战和不足之处。
缺乏面对面互动
远程工作有时会导致缺乏面对面的互动,这是传统办公室环境的一个显著特点。
作为一名远程工作的数据科学家,你可能会发现自己缺少与同事、上司和同行的面对面交流。缺少随意的水冷器边谈话、即兴头脑风暴会议以及工作场所的简单友谊,可能会产生孤立感。
除了可能对心理健康的影响外,社交技能,尤其是在工作场所相关的社交技能,是在职业生涯中晋升的重要因素。
干扰和缺乏纪律
在家工作可能会带来许多潜在的干扰。家庭琐事、家庭成员、宠物以及个人责任都可能侵占你的工作时间。当工作和个人生活混杂在同一个物理空间时,创建一个清晰的界限可能会很困难。
此外,远程工作通常需要高度的自律和有效的时间管理。缺乏结构化的办公室环境可能导致拖延和时间管理问题。当没有上司或同事的监督时,你可能会觉得有诱惑推迟任务或难以优先处理工作。
当你需要维护多个数据科学领域的客户并成功达到每个客户设定的 KPI,尤其是与产品/服务营销相关的 KPI 时,这尤其困难。例如,如果你是为一家 SaaS 公司工作的承包数据科学家,你可能会听到有人要求你加快速度,以便他们能推出一个最小可行产品(MVP)。
沟通挑战
远程工作虽然提供了灵活性和独立性,但也可能给数据科学家带来独特的沟通挑战。
首先,跨时区协作可能是一个重大挑战。这包括与客户和团队成员的协作。由于时差较大,安排会议和协调任务可能会导致延误和中断。这需要仔细的计划和考虑,以确保有效的沟通和工作流程。
其次,远程工作很大程度上依赖于书面沟通,如电子邮件和即时消息。不幸的是,书面沟通总是存在信息被误解的风险,这有时会导致不必要的延迟或混乱。
有限的工作安全性
尽管远程工作的受欢迎程度不断上升,但许多公司仍然不愿意或无法远程招聘数据科学家。
这意味着你可能会很容易陷入自由职业或合同项目的职位,比如使用数据科学来帮助非营利组织找到合适的银行和合作伙伴,或者利用你在自动驾驶运输领域的专长来为城市提供智能交通网络的建议。不幸的是,这些职位通常工作安全性和稳定性较差。
当然,有远程数据科学工作和各种副业,但如果你没有太多经验,可能需要做出妥协。
准备好启动你的远程数据科学职业生涯了吗?
对于重视自主性、工作生活平衡和灵活性的数据显示,远程工作可能是一个绝佳的机会。然而,在承诺远程职业之前,重要的是要仔细权衡利弊。
记住,这里没有绝对的对错——只有适合你的选择。你的决定应基于个人情况、愿景和克服潜在挑战的承诺。
无论你选择哪条道路,未来的工作将继续演变,数据科学也不例外。也就是说,无论你是在热闹的办公室中合作,还是在家中的舒适环境中默默处理数据,你的专业知识将始终是宝贵且受欢迎的资产。
Nahla Davies是一名软件开发人员和技术写作者。在全职从事技术写作之前,她曾担任过许多引人注目的职位,包括在一家 Inc. 5000 的体验品牌公司担任首席程序员,该公司的客户包括三星、时代华纳、Netflix 和索尼。
了解更多主题
使用 Python 中的标准差移除离群值
原文:
www.kdnuggets.com/2017/02/removing-outliers-standard-deviation-python.html
编辑器提供的图像
标准差:快速回顾
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
标准差是方差的度量,即单个数据点距离均值的程度。
例如,考虑这两个数据集:
27 23 25 22 23 20 20 25 29 29
和
12 31 31 16 28 47 9 5 40 47
两者的均值都是 25。然而,第一个数据集的值更接近均值,而第二个数据集的值则更分散。
更准确地说,第一个数据集的标准差为 3.13,而第二个数据集的标准差为 14.67。
然而,要理解像 3.13 或 14.67 这样的数字并不容易。现在,我们只知道第二组数据的“分散程度”比第一组更高。
让我们将其应用于更实际的使用。
什么是正态分布?
当我们进行分析时,我们经常遇到值围绕均值波动并且在均值上下几乎有相等结果的数据模式,例如。
-
人员身高,
-
血压值
-
测试分数
这样的值遵循正态分布。
根据 维基百科关于正态分布的文章,大约 68%的从正态分布中抽取的值在均值的一个标准差σ内;大约 95%的值在两个标准差内;大约 99.7%的值在三个标准差内。
这一事实被称为 68-95-99.7(经验)规则,或 3-sigma 规则。
使用正态分布和标准差移除离群值
当我需要清理来自数百万个生成取暖设备数据的 IoT 设备的数据时,我成功应用了这一规则。每个数据点包含某一时刻的电力使用情况。
然而,有时候设备的准确性不是 100%,可能会给出非常高或非常低的值。
我们需要移除这些离群值,因为它们使我们图表上的刻度不切实际。挑战在于这些离群值的数量从未固定。有时我们会获得所有有效的值,有时这些错误读数会占据多达 10%的数据点。
我们的方法是通过消除任何高于(均值 + 2标准差)和低于(均值 - 2标准差)的点来去除异常值,然后再绘制频率图。
你不必非得使用 2,你可以稍微调整一下,以获得更适合你数据的异常值检测公式。
这里是一个使用 Python 编程 的示例。数据集是经典的正态分布,但正如你所见,有一些值如 10、20 会干扰我们的分析并破坏图表上的刻度。
如你所见,我们移除了异常值,如果我们绘制这个数据集,图表看起来会好很多。
[386, 479, 627, 523, 482, 483, 542, 699, 535, 617, 577, 471, 615, 583, 441, 562, 563,
527, 453, 530, 433, 541, 585, 704, 443, 569, 430, 637, 331, 511, 552, 496, 484, 566,
554, 472, 335, 440, 579, 341, 545, 615, 548, 604, 439, 556, 442, 461, 624, 611, 444,
578, 405, 487, 490, 496, 398, 512, 422, 455, 449, 432, 607, 679, 434, 597, 639, 565,
415, 486, 668, 414, 665, 557, 304, 404, 454, 689, 610, 483, 441, 657, 590, 492, 476,
437, 483, 529, 363, 711, 543]
如你所见,我们能够去除异常值。不过,我不建议对所有统计分析使用这种方法,异常值在统计学中有重要作用,它们存在是有原因的!
但在我们的案例中,异常值显然是由于数据错误,而数据是正态分布的,因此标准差是合理的。
普尼特·贾约迪亚 是一位来自尼泊尔加德满都的企业家和软件开发人员。多才多艺是他最大的优势,因为他曾参与过各种项目,从浏览器上的实时 3D 模拟和大数据分析到 Windows 应用程序开发。他还是 Programiz.com 的联合创始人,该网站是最大的 Python 和 R 教程网站之一。
更多相关内容
我已被分析机器人取代
原文:
www.kdnuggets.com/2015/05/replaced-by-analytics-robot.html
评论
作者:Bob Muenchen (r4stats)
就在几年前,纽约时报称我的工作“性感”。我以前的统计学家职位听起来既平淡又沉闷,但后来充满了令人兴奋的术语:我是一名数据科学家,从事预测分析,偶尔还涉及大数据。在一个职位描述中出现了三个热门术语!然而,近年来,使我的工作如此引人注目的强大技术让我开始思考这一领域的未来。自动生成复杂模型的计算机程序变得越来越普遍。Rob Hyndman 的R 包、SAS Institute 的Forecast Studio和 IBM 的SPSS Forecasting 提供了生成预测的能力,这些预测曾经需要多年训练才能开发出来。类似的工具现在也适用于其他类型的模型。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
无数其他职业已经因为新技术而消失。美国曾经有超过 70% 的人口从事农业工作,而今天不到 2% 的人是农民。事物总在变化,人们转向其他职业。KDnuggets 最近询问了读者,
“何时大多数专家级预测分析/数据科学任务——目前由人工数据科学家完成——会被自动化?”
51% 的受访者——其中大多数是数据科学家——估计这一情况将在 10 年内发生。然而,并非所有受访者都持如此悲观的观点;19% 的人表示这将永远不会发生。

我的脑袋被取代我脑袋的机器分析了!(摄影:Mike O’Neil)
如果你在 1980 年问我,自动化将会首先淘汰我工作的哪个部分,我可能会说:脑电波分析。这比我做的其他任何工作都涉及更多的步骤。我们测量大脑许多部位的电活动,频率达到每秒数千次。仅仅比较两个组的分析就需要几周的全职工作。令人惊讶的是,这是我工作的第一个被淘汰的部分。然而,我们的统计咨询团队支持许多不同的部门,因此当工作停止从脑电图实验室送来时,我并没有真正注意到。几年后,我接到了新实验室主任的电话,邀请我认识我的替代者:一个名为LORETA的“机器人”。
当我访问实验室时,我被装备上了通常的满是电极的“洗澡帽”。脑电图胶(基本上是 K-Y 凝胶)被挤入每个电极的孔中,以确保良好的接触,然后机器开始记录我的脑电波。我使用生物反馈生成 alpha 波,这使得一辆车在一个简单的视频游戏中绕着轨道行驶。当你进入非常放松、冥想的状态时,你的大脑会产生 alpha 波。在我完成后不久,LORETA 已经分析了我的脑电波。“她”在短短几分钟内完成了几周的分析工作。
所以我职业生涯的那部分早已结束,但当时我并没有真正注意到。我太忙于利用 LORETA 节省下来的时间来学习使用ImageJ进行图像分析、使用WordStat和SAS Text Miner进行文本挖掘,以及利用各种任务的无限可能性。
R 语言。我从未有过没有充满有趣新工作的时刻。
我的领域还有一个容易被忽视的方面。当我开始我的职业生涯时,90%的时间都花在与计算机“搏斗”上。它们非常难以操作。今天,有人可能会给你发送一个数据文件,你在收到后几秒钟内就能看到数据。在 1980 年,数据是通过磁带传输的,每个计算机制造商使用不同的磁带格式,且每种格式都有许多不兼容的变体。除非你拥有创建磁带的程序,否则可能需要几天的繁琐编程才能将数据提取出来。即便是让计算机运行程序,也需要错误频出的作业控制语言。从这个角度来看,更易用的计算技术已经消除了我工作中 90%的内容。那部分工作并不有趣,所以这是一个积极的变化。
新兴的数据科学领域是否会通过为每一个需要解决的问题开发 LORETA 而自我淘汰?我们是否会让我们的星际迷航级计算机和机器人为我们工作,而我们自己则悠闲自得地自我实现?也许有一天会,但我怀疑这会很快发生!
简介:罗伯特·A·缪恩琴,@BobMuenchen 是 R for SAS and SPSS Users 的作者,与约瑟夫·M·希尔比共同著作了 R for Stata Users。他还是 r4stats.com 的创始人,这是一个致力于分析分析软件趋势并帮助人们学习 R 语言的热门网站。Bob 是一个拥有 30 年经验的 ASA 认证专业统计师™,目前是田纳西大学 OIT 研究计算支持(前身为统计咨询中心)的经理。
相关内容:
-
数据科学家将在 2025 年被自动化取代并失业?
-
数据科学历史信息图:5 个领域
-
采访:加里·肖特,昆泰尔斯谈医疗保健的未来与大数据技能
-
采访:迈克尔·布罗迪谈行业经验、知识发现与未来趋势
更多相关话题
可重复性、再现性和数据科学
原文:
www.kdnuggets.com/2019/11/reproducibility-replicability-data-science.html
评论
由 Sydney Firmin,Alteryx。
可重复性和再现性是科学探究的基石。虽然在术语和定义上存在一些争论,但如果某项结果是可重复的,这意味着可以通过遵循一组特定步骤和一致的数据集来再现相同的结果。如果某项结果是可再现的,这意味着可以使用稍微不同的数据或过程找到相同的结论或结果。没有可重复性,过程和发现无法得到验证。没有可再现性,很难信任单一研究的发现。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
科学方法旨在通过标准化科学探究过程来鼓励可重复性和可再现性。通过遵循如何提问和探索问题的共享过程,我们可以确保得出结论的一致性和严谨性。这也使其他研究人员更容易收敛于我们的结果。数据科学生命周期也不例外。数据科学生命周期
尽管有这些及其他旨在鼓励稳健科学研究的过程,但在过去几十年里,整个科学研究领域一直面临重复危机。许多高影响力期刊上发表的研究论文,如自然和科学,在后续研究中无法重复。尽管一些研究者认为这一叙述危机略显危言耸听且适得其反,但你可能会将其视为研究中存在的问题,即人们发布了虚假的积极结果和无法验证的发现。
对不可重复研究的日益关注,部分归因于技术——我们联系更加紧密,科学发现的传播比以往任何时候都要广泛。技术还使我们能够识别和利用策略,使科学研究比以往任何时候都更具可重复性。
数据科学位于统计学和计算机科学的交汇点,旨在促进学术研究和行业中的可重复性和再现性。
为什么可重复性很重要
作为研究人员或数据科学家,你可能无法控制很多事情。你可能无法以最理想的方式收集数据,也无法确保你捕捉到你尝试测量的内容。你不能真正保证你的研究或项目会被再现。你唯一能保证的是你的工作是可重复的。
此外,鼓励和标准化工作中的可重复性范式可以提高效率和准确性。在科学研究和数据科学项目中,我们通常希望在已有的工作基础上进行改进——这些工作可能是我们自己完成的,也可能是其他研究者完成的。包括可重复的方法——或者更好的是,可重复的代码——可以防止重复劳动,使我们可以更多地关注新的、具有挑战性的问题。这也使得其他研究人员(包括未来的自己)更容易检查你的工作,确保你的过程是正确的且无错误。
使你的项目具有可重复性
可重复性在数据科学和科学研究中是一种最佳实践,在许多方面,它归结为拥有一种软件工程的思维方式。它是关于以一种可重复的方式(最好是由计算机完成)并且文档化良好的方式来设置所有的流程。以下是一些(希望对你有帮助的)提示,帮助你使工作具有可重复性。
首先,也是可能最简单的事情是为所有事情使用可重复的方法——不再用 Excel 随意编辑数据,然后可能在记事本中记录你所做的事情。利用可以保存、注释和共享的代码或软件,这样其他人可以运行你的工作流程并完成相同的任务。如果你发现你重复使用相同的过程(超过几次)或用于不同的项目,最好将你的代码或工作流程转换为函数或宏,以便共享和轻松重用。
记录你的过程也是至关重要的。在你的代码(或工作流程)中写下注释,以便其他人(或者你自己在六个月后)能迅速理解你当时的意图。代码和工作流程通常在简单且易于解释时最为优雅,但并不能保证查看你工作的人员会与你有相同的理解;不要冒这个险,花额外的时间来描述你正在做什么。
另一个最佳实践是保留每个版本的所有内容;无论是工作流程还是数据,以便你可以跟踪变化。能够回溯版本的数据和过程使你能够了解过程中的任何变化,并追踪潜在错误可能被引入的地方。你可以使用版本控制系统,如Git或DVC。除了是控制代码版本的好方法外,像 Git 这样的版本控制系统可以处理许多不同的软件文件和数据格式。对数据进行版本控制对于数据科学项目是个好主意,因为分析或模型直接受其训练的数据集的影响。
除了将所有材料保存在共享的中央位置,版本控制对协作工作至关重要,或帮助你的队友跟上你已完成的项目的进度。拥有一个位于共享位置而非你电脑上的版本控制库的额外好处无法过分强调——有趣的是,这是我在上周电脑被砖化后第二次尝试编写这篇文章。我现在强迫自己将所有工作都保存在云端。
可重复性的挑战(及可能的解决方案)
尽管利用代码或其他可重复的方法来使科学研究和数据科学项目更具可重复性有很大的潜力,但仍然存在使可重复性具有挑战性的障碍。
这些障碍之一是计算环境。当你分享脚本时,你不能保证接收脚本的人拥有与你相同的环境组件——例如,Python 或 R 的相同版本。这可能会导致你记录和编写的过程在不同的机器上产生不同的结果。
这个用例正是Docker容器、像AWS这样的云服务以及Python 虚拟环境创建的目的。通过共享一个支持你的过程的迷你环境,你在确保你的过程可重复性方面迈出了额外的一步。当你与合作者一起工作时(可以说,这对于复制性很重要),这种额外的步骤尤为重要。
为什么复制性很重要
复制性通常是科学研究的目标。我们求助于科学来获得共享的、经验性的事实和真理。当我们的发现可以被其他实验室用不同的数据或略微不同的过程支持或确认时,我们就知道我们发现了可能有意义或真实的东西。
复制性比可重复性更难以保证,但研究人员也有一些实践,比如 p-hacking,使得期待你的结果能被复制变得不切实际。

Significant: https://xkcd.com/882/
P-Hacking
P-hacking(也称为data dredging或数据钓鱼)是指科学家或不诚实的统计学家对数据集进行大量统计测试,直到发现一个“统计显著”的关系(通常定义为 p < 0.05)。
你可以在 FiveThirtyEight 发布的文章Science Isn’t Broken中阅读更多关于 p-hacking 的内容(并玩一个演示其工作原理的有趣互动应用)。这个CrashCourseStatistics 的视频也很棒。
通常,p-hacking 并非出于恶意。在学术研究中,有各种各样的激励措施驱使研究人员操控他们的数据,直到他们找到一个有趣的结果。尝试找到支持你假设的数据也是很自然的。作为科学家或分析师,你必须在如何处理分析的不同方面上做出大量决策——从去除(或保留)异常值,到选择哪些预测变量来包含、转换或删除。p-hacking 通常是特定研究者偏见的结果——你相信某种方法有效,所以你折磨你的数据,直到它承认你“知道”的真相。研究人员对他们的假设情有独钟,并且(有意识或无意识地)操控数据直到证明自己是对的,这种情况并不罕见。
设置你的项目以进行复制
虽然确保复制性比确保可重复性更困难,但作为数据科学家,你可以采用一些最佳实践,以便在更广泛的世界中使你的发现取得成功。
在数据科学项目中,你可以做的一个相对简单而具体的事情是确保你的模型不过拟合;通过使用保留数据集进行评估或利用交叉验证来验证这一点。过拟合是指你的模型捕捉到了训练数据集中随机的变异,而不是找到变量之间的“真实”关系。这种随机变异在样本训练数据之外不会存在,因此使用不同的数据集评估你的模型可以帮助你发现这一点。
另一个有助于重复性的因素是确保你使用的是足够大的数据集。关于数据集何时“足够大”没有严格的规定——这完全取决于你的用例和你使用的建模算法的类型。
除了对统计分析有深刻的理解和获得足够大的样本量外,我认为提高你的研究或项目有可能重复的最重要的措施是让更多的人参与到开发或审查你的项目中。
在研究中引入多样化的团队有助于降低偏见的风险,因为你将不同的观点融入到问题的设置和数据的评估中。在这个意义上,聘请不同类型的研究人员,例如在生命科学研究的问题定义阶段包括一名统计学家,可以确保考虑到不同的问题和视角,使得最终的研究更加严谨。
同样地,接受研究是一个迭代过程,并将失败作为可能结果来对待是至关重要的。
最重要的是,必须承认不确定性,以及成功的结果可能是发现你拥有的数据无法回答你提出的问题,或者你怀疑的事情并没有得到数据的支持。大多数科学实验以“失败”告终,在许多方面,如果你进行了稳健的分析,这种失败可以被视为一种成功。即使你确实发现了“显著”的关系或结果,也可能很难保证模型在未来或在不同人群的样本数据中表现如何。承认分析的局限性或可能的缺陷是很重要的。承认科学方法以及数据科学和统计学中的固有不确定性,将帮助你更现实和准确地传达你的发现。
数据科学中的可重复性和再现性
科学的一个原则是自我纠正。如果一项研究被发表或接受,但最终被证明是错误的,它将被后续的研究纠正,随着时间的推移,科学可以趋向于“真理”。虽然这在实践中可能有些问题,但好消息是互联网似乎正在提供帮助。我们比以往任何时候都更紧密地联系在一起——因此,科学有机会自我纠正并严格测试,自我纠正,并传播发现。
数据科学可以被视为一个独立的科学探究领域。我们作为数据科学家的工作应当具备与其他领域相同的严谨标准。作为数据科学家,我们有责任保持这些标准。数据科学在许多方面已经为这些领域的成功奠定了基础。我们的工作本质上是计算机驱动的(因此是可重复的),而且是跨学科的——这意味着我们应该与拥有不同技能和背景的人组成团队。
原文。经许可转载。
个人简介: 训练有素的地理学家和心中有数据的极客,Sydney Firmin 坚信,当数据和知识能够被清晰地传达和理解时,它们才最有价值。在她目前的角色中,作为 Alteryx 数据科学创新团队的数据显示科学家,她为广泛的用户开发数据科学工具。
相关:
更多相关话题
研究指南:用于机器学习模型的高级损失函数
原文:
www.kdnuggets.com/2019/11/research-guide-advanced-loss-functions-machine-learning-models.html
comments
除了良好的训练数据和正确的模型架构,损失函数是训练准确机器学习模型的最重要部分之一。在这篇文章中,我希望给开发者概述一些更高级的损失函数及其如何用来提高模型的准确性,或者解决全新的任务。
例如,语义分割模型在训练过程中通常使用简单的交叉类别熵损失函数,但如果我们想分割具有许多细节的对象,如头发,向模型中添加梯度损失函数可以显著改善结果。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
这只是一个例子——以下指南探讨了围绕各种高级损失函数进行的研究。
基于布雷格曼散度的鲁棒双温度逻辑回归损失
当数据非常嘈杂时,逻辑回归损失函数在训练过程中表现不佳。这种噪声可能是由异常值和标记错误的数据造成的。在这篇论文中,谷歌大脑的作者通过用其对应的“温和”版本替换对数和指数函数,旨在解决逻辑回归损失函数的不足。
机器学习(ML)算法所生产模型的质量直接取决于训练数据的质量……
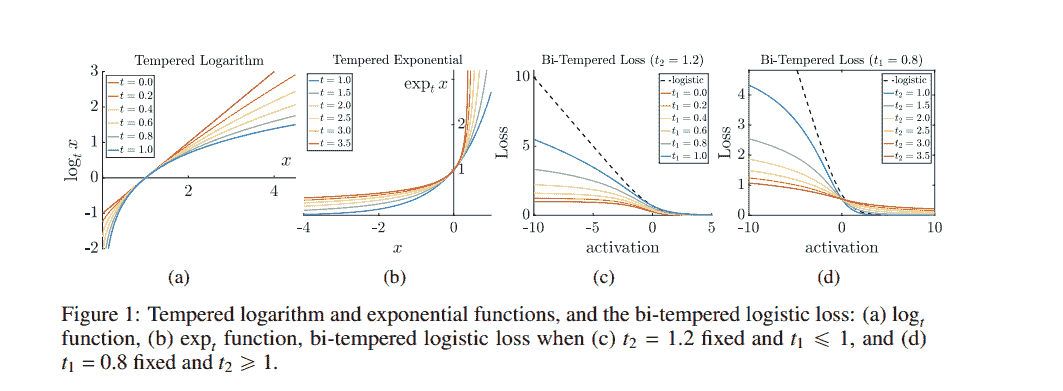
作者在指数函数中引入温度,并用高温的广义版本替换神经网络的 softmax 输出层。对数损失中使用的算法被低温对数替换。这两种温度经过调整,以创建非凸的损失函数。
最后一层神经网络被替换为逻辑损失的双温度推广。这使训练过程对噪声更具鲁棒性。本文提出的方法基于Bregman 散度。其性能可以在下图中可视化。
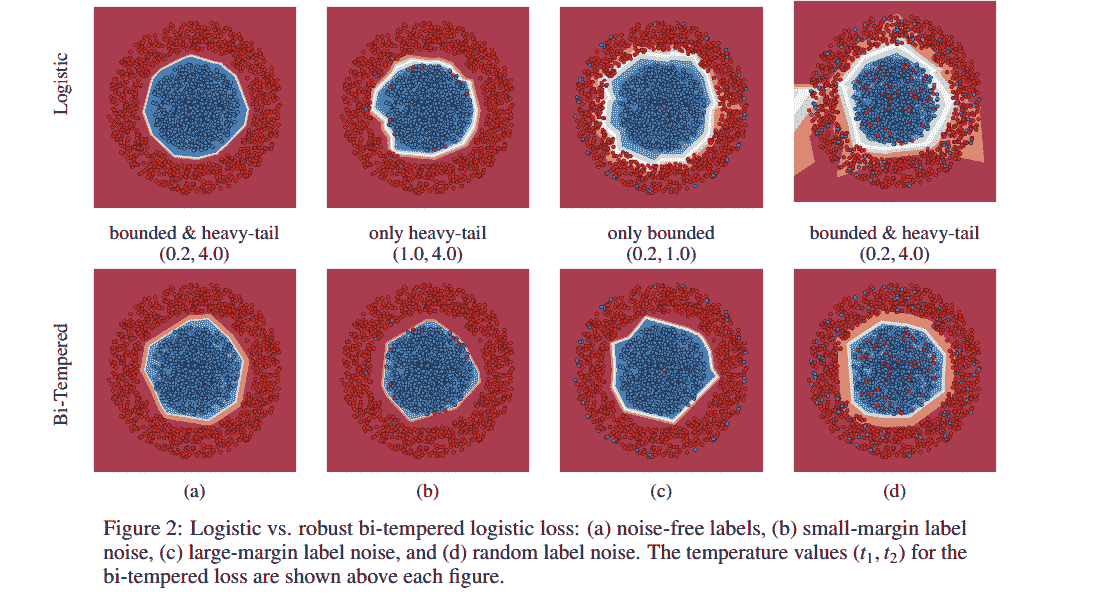
为了进行实验,作者向 MNIST 和 CIFAR-100 数据集添加了合成噪声。然后将其双温度损失函数获得的结果与普通逻辑损失函数进行了比较。双温度损失在 MNIST 上获得 98.56%的准确率,在 CIFAR-100 上为 62.5%。下图详细展示了性能。
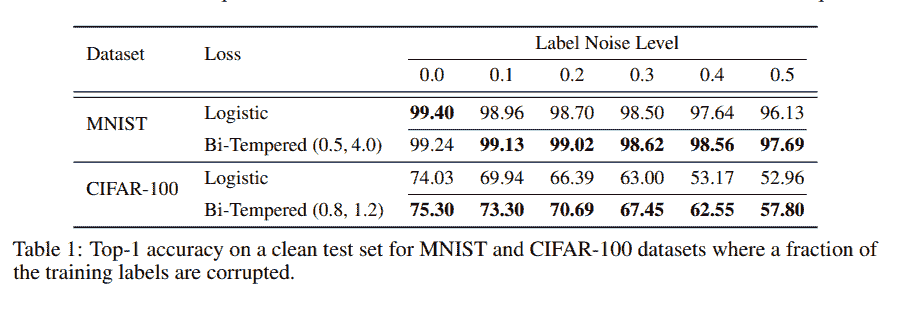
机器学习模型正越来越接近边缘设备。Fritz AI 来帮助这一过渡。探索我们的开发者工具套件,使设备学习看、听、感知和思考变得容易。
GANs 损失函数
判别器损失旨在最大化对真实图像和假图像的概率。最小最大损失在介绍 GAN 的论文中被使用。这是一种旨在减少最坏情况下可能损失的策略。它简单地最小化最大损失。这种损失也用于两人游戏,以减少一层的最大损失。
生成对抗网络(GAN)是生成模型的一个强大子类。尽管研究非常丰富...
在 GAN 的情况下,两位玩家是生成器和判别器。这涉及到生成器损失的最小化和判别器损失的最大化。判别器损失的修改形成了非饱和 GAN 损失,其目标是解决饱和问题。这涉及生成器最大化判别器概率的对数。这是针对生成的图像进行的。
最小二乘 GAN 损失是为应对二进制交叉熵损失的挑战而开发的,该损失导致生成的图像与真实图像非常不同。这个损失函数被用于判别器。由于这个原因,使用此损失函数的 GAN 能够生成比常规 GAN 更高质量的图像。下一图展示了两者的比较。
本报告总结了作者在 NIPS 2016 上关于生成对抗网络(GANs)展示的教程。...

Wasserstein 损失函数依赖于 GAN 架构的修改,其中鉴别器不进行实例分类。相反,鉴别器对每个实例输出一个数字。它试图使真实实例的数字大于虚假实例的数字。
在这个损失函数中,鉴别器试图最大化真实实例输出与虚假实例输出之间的差异。另一方面,生成器试图最大化鉴别器对其虚假实例的输出。
我们介绍了一种名为 WGAN 的新算法,作为传统 GAN 训练的替代方案。在这个新模型中,我们展示了...
这里是一张展示使用这种损失函数的 GANs 性能的图像。

焦点损失用于密集目标检测
本文通过重塑标准交叉熵标准提出了一种改进,使其对分类正确的样本分配的损失减小——焦点损失。该损失函数旨在解决类别不平衡问题。
焦点损失旨在对一组稀疏的困难样本进行训练,防止简单的负样本在训练中压倒检测器。在测试中,作者开发了 RetinaNet——一个简单的密集检测器。
Focal Loss for Dense Object Detection
迄今为止,最高精度的目标检测器基于 R-CNN 推广的两阶段方法,其中...
在这个损失函数中,交叉熵损失与随着正确类置信度增加而递减的缩放因子一起缩放。缩放因子会自动减少训练时简单样本的贡献,专注于困难样本。
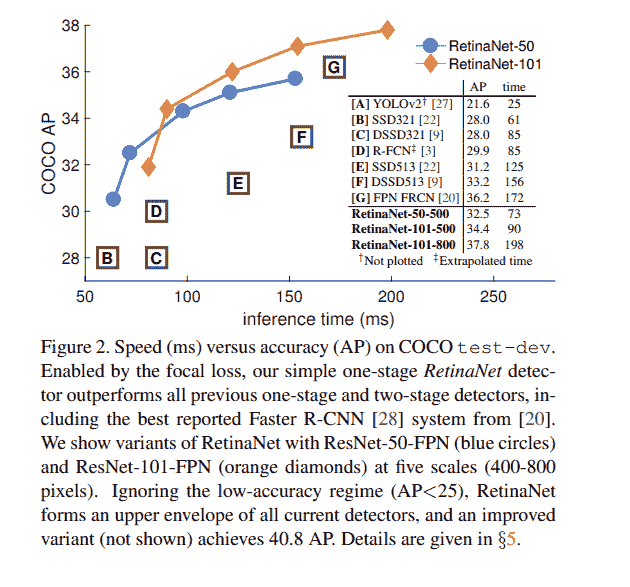
这里是通过焦点损失函数在 RetinaNet 上获得的结果。

针对单阶段目标检测的 Intersection over Union (IoU)-平衡损失函数
单阶段检测器采用的损失函数在定位上表现不佳。本文提出了一种基于 IoU 的损失函数,包括 IoU-平衡分类和 IoU-平衡定位损失。
IoU-balanced Loss Functions for Single-stage Object Detection
单阶段检测器效率高。然而,我们发现单阶段检测器采用的损失函数是...
IoU 平衡分类损失专注于高 IoU 的正面场景,可以增加分类与定位任务之间的相关性。该损失旨在减少低 IoU 示例的梯度,并增加高 IoU 示例的梯度。这提高了模型的定位准确性。
下面展示了该损失在 COCO 数据集上的表现。
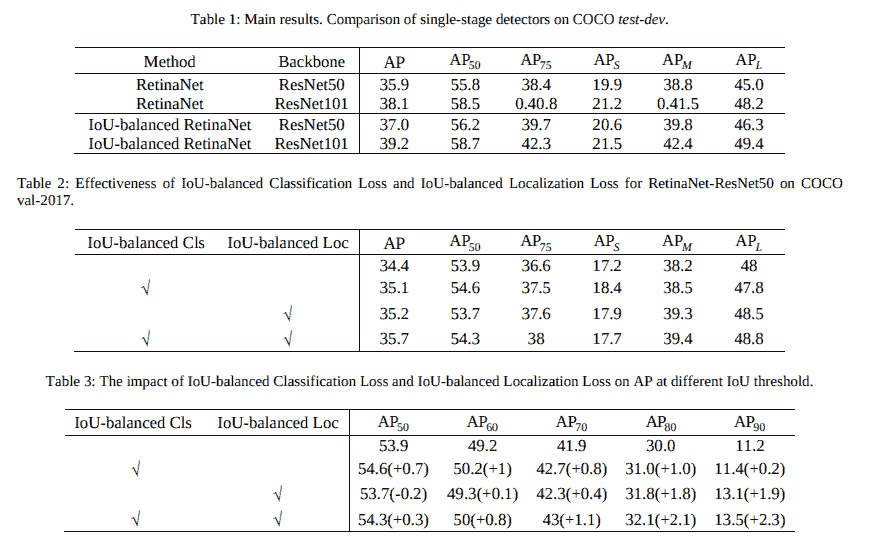
针对高度不平衡分割的边界损失
这篇论文提出了一种边界损失用于高度不平衡的分割。该损失形式为轮廓空间上的距离度量,而非区域。这是为了应对高度不平衡分割问题的区域损失挑战。该损失受到计算曲线演变梯度流的离散优化技术的启发。
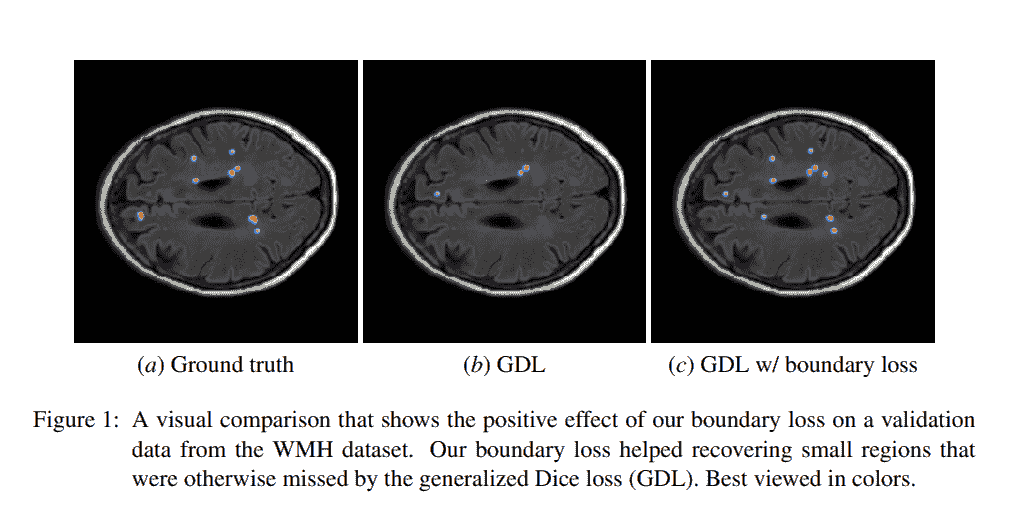
边界损失通过对区域之间的边界进行积分,而不是对区域进行不平衡积分。使用了计算边界变化的积分方法。作者将形状空间上的非对称 L2 距离表示为区域积分。这避免了涉及轮廓点的局部微分计算。最终得到了一个作为网络区域 softmax 概率输出之和的边界损失。该损失可以与区域损失轻松结合,并融入现有的深度网络架构中。
边界损失在缺血性中风病灶(ISLES)和白质高信号(WMH)基准数据集上进行了测试。
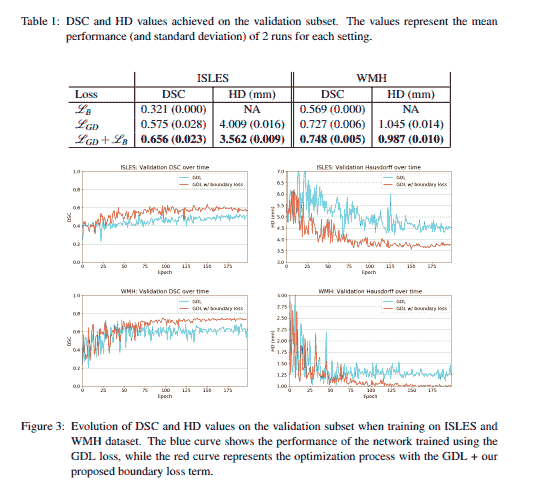
感知损失函数
该损失函数用于比较看起来相似的图像。主要用于训练前馈神经网络,用于图像转换任务。

我们考虑图像转换问题,其中输入图像被转换为输出图像。最近的方法...
感知损失函数通过将所有像素中间的平方误差相加并计算均值来工作。
在风格迁移中,感知损失使深度学习模型能够比其他损失函数更好地重建细节。在训练时,感知损失比逐像素损失函数更好地测量图像相似性。它们还使损失网络与转换网络之间的语义知识得以迁移。
结论
我们现在应该对一些最常见的——以及几种非常新的——高级损失函数有了了解。
上述提到并链接的论文/摘要也包含了其代码实现的链接。我们很高兴看到你在测试后得到的结果。
简介: 德里克·姆威提 是一名数据分析师、作家和导师。他致力于在每项任务中取得出色的结果,并且是 Lapid Leaders Africa 的导师。
原文。已获转载许可。
相关:
-
神经架构搜索研究指南
-
变压器研究指南
-
基于深度学习的视频帧插值研究指南
更多相关内容
深度学习视频帧插值研究指南
原文:
www.kdnuggets.com/2019/10/research-guide-video-frame-interpolation-deep-learning.html
评论
在本研究指南中,我们将深入探讨旨在合成现有视频中的视频帧的深度学习论文。这可能是在视频帧之间的插值,也可能是在视频帧之后的外推。
本指南的较大部分将涉及插值技术。插值在软件编辑工具以及生成视频动画中都很有用。它还可以用于生成清晰的视频帧,尤其是在视频模糊的部分。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
视频帧插值是一项非常常见的任务,特别是在电影和视频制作中。光流是解决这个问题的常见方法之一。光流估计是估算每个像素在一系列帧中的运动的过程。在本文中,我们将深入探讨使用深度学习技术的视频帧插值的先进方法。
自适应可分离卷积的视频帧插值(ICCV, 2017)
在本文中,作者提出了一种深度全卷积神经网络,输入两个帧,并估计所有像素的一维卷积核对。这种方法能够一次性估计卷积核并合成整个视频帧。这使得可以引入感知损失来训练神经网络,从而生成视觉上令人愉悦的帧。
标准的视频帧插值方法首先估计输入帧之间的光流,然后合成一个…
论文介绍了一种空间自适应可分离卷积技术,旨在插值生成两个视频帧之间的新帧。卷积基础的插值方法然后估计一对 2D 卷积核。这些卷积核被用来对两个视频帧进行卷积,以计算输出像素的颜色。
像素依赖的内核捕捉了插值所需的运动和重采样信息。通过将信息流导入四个子网络,估计了四组 1D 内核。每个子网络估计一个内核。使用了 3x3 卷积层的修正线性单元。

网络使用AdaMax优化器进行训练,学习率为 0.001,迷你批量大小为 16 个样本。训练视频来自于多个 YouTube 频道,如“Tom Scott”、“Casey Neistat”、“Linus Tech Tips”和“Austin Evans”。
通过随机裁剪进行数据增强,以确保网络不偏向某一类。卷积神经网络的实现使用了 Torch。以下是该模型与其他模型的比较。

自适应卷积的视频帧插值(CVPR 2017)
本文提出了一种将运动估计和像素合成结合成单一过程的视频帧插值方法。实现了一个深度全卷积神经网络,以为每个像素估计空间自适应卷积内核。
视频帧插值通常包括两个步骤:运动估计和像素合成。这种两步法...
对于插值帧中的一个像素,深度神经网络以该像素为中心的两个接收场补丁作为输入,估计卷积内核。该卷积内核用于与输入补丁进行卷积,以合成输出像素。给定两个视频帧,该模型旨在创建它们之间的临时帧。
该方法直接估计卷积内核,并使用该内核对两个帧进行卷积以插值像素颜色。像素合成通过卷积内核捕捉运动和重采样系数来实现。卷积作为像素插值使得像素合成可以在一步中完成,从而使这种方法更具鲁棒性。
卷积神经网络由若干卷积层和下卷积组成,作为最大池化层的替代。为了正则化,作者使用ReLUs作为激活函数,并进行批量归一化。下表展示了该网络的架构。
该模型使用 Torch 实现。以下是模型的性能:
视频处理技术,如插值,使许多计算机视觉应用成为可能——不仅在服务器和云端,还在移动设备上。了解更多关于 Fritz 如何教会你的移动设备“看”。
深度体素流的视频帧合成(ICCV 2017)
本文的作者提出了一种深度神经网络,通过从现有帧流动像素值来合成视频帧。该论文结合了生成卷积神经网络和光流的优点来解决这个问题。
我们解决了在现有视频中合成新视频帧的问题,无论是在现有帧之间…
本模型中使用的网络以无监督的方式进行训练。像素通过插值来自相邻帧的像素值来生成。该网络包括一个跨空间和时间的体素流层。通过在输入视频体积上进行三线性插值生成最终像素。该网络在UCF-101 数据集上进行训练,并在各种视频上进行测试。

他们提出的模型,深度体素流(DVF),是一个端到端的、完全可微的网络,用于视频帧合成。DVF 采用完全卷积的编码器-解码器架构,包含三个卷积层、三个反卷积层和一个瓶颈层。在该模型的训练过程中,提供两个帧作为输入,剩余的帧作为重建目标。该方法是自监督的,通过借用相邻帧的体素来学习重建帧。这使得结果更清晰、更真实。
作者使用峰值信噪比(PSN)和结构相似性指数(SSIM)来分析插值图像的质量。以下是他们取得的结果。
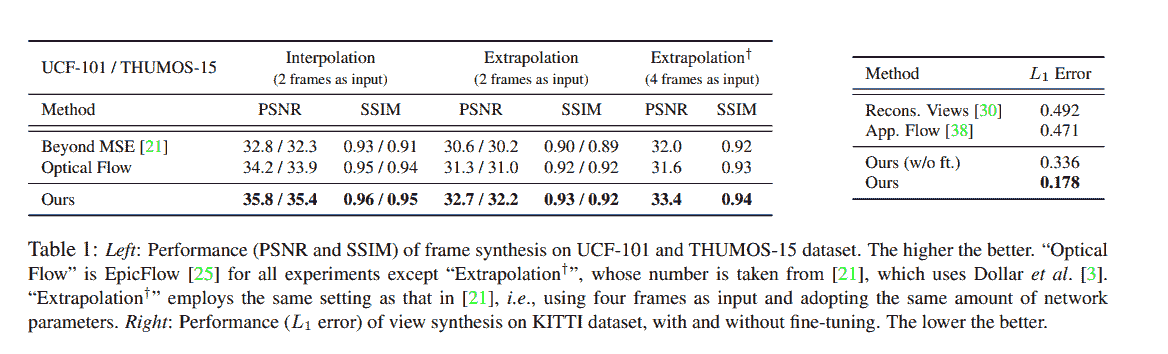
长期视频插值与双向预测网络(2017)
本文解决了在视频中生成两个非连续帧之间多个帧的挑战。作者提出了一种深度双向预测网络(BiPN),该网络从两个相反的方向预测中间帧。
本文考虑了长时间视频插值的挑战性任务。与大多数现有方法仅…
作者训练了一个卷积编码器-解码器网络,给定两个不连续的帧。该网络被训练以从两个相反的方向回归缺失的中间帧。网络由一个双向编码器-解码器组成,同时从起始帧预测未来-前向,并从结束帧预测过去-反向。
该模型在合成数据集“移动 2D 形状”和自然视频数据集 UCF101 上进行了评估。

BiPN 架构是一个编码器-解码器管道,具有双向编码器和单个解码器。双向编码器通过从起始帧和结束帧中编码信息来生成潜在帧表示。
解码器在接收特征表示作为输入后,预测了多个缺失的帧。前向和反向编码器由多个卷积层组成,每个卷积层都具有修正线性单元(ReLU)。
解码器由一系列上卷积层和 ReLU 组成。解码器输出一个特征图,其大小为 l ×h×w ×c 作为中间帧的目标预测,其中 l 是要预测的帧长度,h、w 和 c 分别是每帧的高度、宽度和通道数。
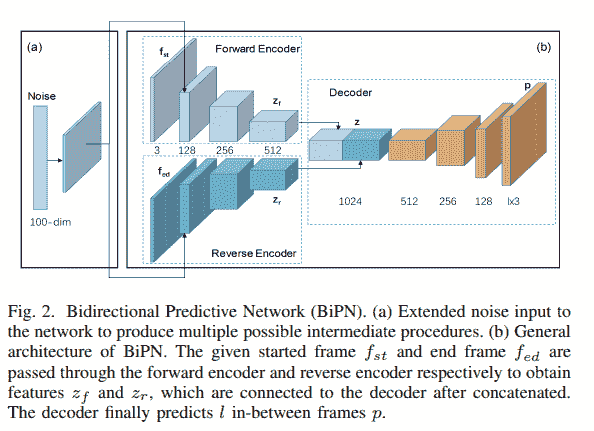
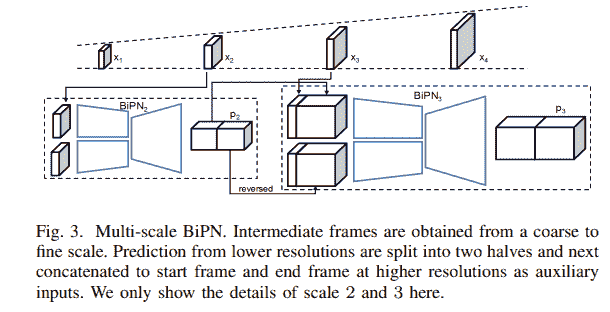
该模型使用 TensorFlow 实现,并部署在 Tesla K80 GPU上。该模型已经使用 UCF101 数据集进行了自然高分辨率视频的测试。

作者使用峰值信噪比(PSNR)和结构相似性指数(SSIM)来分析插值帧的质量。以下是他们取得的结果。
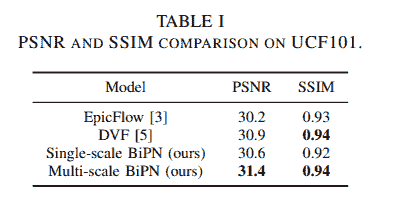
PhaseNet 用于视频帧插值(CVPR 2018)
PhaseNet 由一个神经网络解码器组成,该解码器估计中间帧的相位分解。该架构是一个结合了基于相位的方法与学习框架的神经网络。本文提出的网络旨在给定两个相邻图像作为输入时合成一个中间图像。

大多数视频帧插值方法需要准确的密集对应关系来合成中间帧…
PhaseNet 被设计为仅解码器网络,从而逐级提高其分辨率。在每个级别,都会结合相应的分解信息。除了最低级别外,所有其他级别在结构上都是相同的。每个级别还包含来自前一个级别的信息。
网络的输入是来自两个输入帧的可调金字塔分解的响应,包括每个像素在每个级别的相位和幅度值。这些值在通过网络之前会进行归一化处理。
每个分辨率级别都有一个 PhaseNet 块,该块以分解值作为输入。它还接受来自上一层的缩放特征图和缩放预测值。这些信息随后通过两个卷积层,每个卷积层后跟批归一化和 ReLU 非线性激活。
每个卷积生成 64 个特征图。每个 PhaseNet 块之后,预测中间帧分解值。这是通过将 PhaseNet 块的输出特征图通过一个 1 x 1 的卷积层来完成的。
这之后使用双曲正切函数来预测输出值。然后根据这些值计算中间图像的分解值。现在可以重建中间图像。

该网络的训练使用了来自DAVIS 视频数据集的帧三元组。
这里是为此模型获得的一些误差测量结果。
Super SloMo:高质量估计视频插值的多个中间帧(CVPR 2018)
这篇论文的作者提出了一种端到端卷积神经网络,用于可变长度的多帧视频插值。在这个模型中,运动拦截和遮挡推理被联合建模。
输入图像之间的双向光流是使用U-Net 架构计算的。然后在每个时间步长将这些光流线性组合,以逼近中间的双向光流。使用另一个 U-Net 对近似的光流进行精细化。
这个 U-Net 还预测了软可见性图。然后将两个输入图像进行扭曲和线性合成,形成每个中间帧。这种方法能够根据需要生成多个中间帧,因为学习到的网络参数是时间无关的。
给定两个连续帧,视频插值旨在生成中间帧,以形成空间上和…
在这个网络中,使用了流计算 CNN 来首先估计两个输入图像之间的双向光流。然后将其线性结合以近似所需的中间光流,以便对输入图像进行扭曲。
网络通过收集来自 YouTube 和手持摄像机的 240FPS 视频进行训练。训练后的模型在多个数据集上进行了评估,包括 Middlebury、UCF101、慢速流数据集 和 高帧率 MPI Sintel。无监督光流结果也在 KITTI 2012 光流基准 上进行了评估。

该架构中使用的 U-Net 是完全卷积的,由一个编码器和一个解码器组成。编码器和解码器在相同空间分辨率下有跳跃连接。编码器中有六个层次,由两个卷积层和 Leaky ReLU 层组成。
使用步幅为 2 的平均池化层在每个层次上减少空间维度,除了最后一个层次。解码器部分有五个层次。每个层次的开头是一个双线性上采样层,用于将空间维度增加 2 倍。接下来是两个卷积层和 Leaky ReLU 层。在前两个卷积层中使用 7 x 7 的卷积核,在第二个层次中使用 5 x 5 的卷积层。网络的其余部分使用 3 x 3 的卷积核。
以下是该模型在 UCF101 和 Adobe 数据集上的表现:
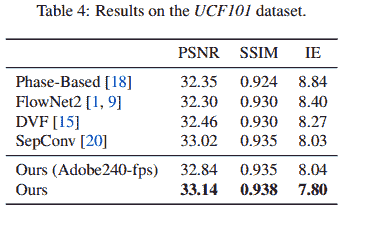
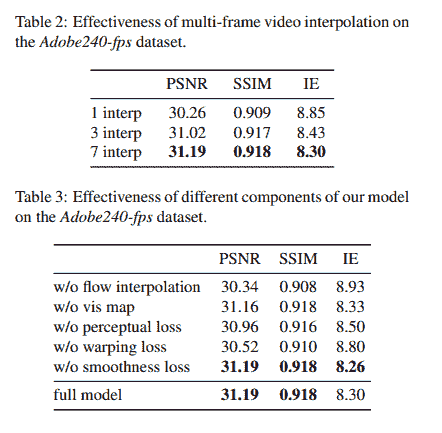
深度感知视频帧插值(CVPR 2019)
本文提出了一种视频帧插值方法,通过探索深度信息来检测遮挡。作者开发了一个深度感知流投影层,该层合成了比远处物体更靠近的即时流。
通过从邻近像素收集上下文信息来学习层次特征。然后通过基于光流和局部插值核扭曲输入帧、深度图和上下文特征来生成输出帧。
作者提出了一种深度感知视频帧插值(DAIN)模型,该模型有效利用光流、局部插值内核、深度图和上下文特征来生成高质量的视频帧。
视频帧插值旨在合成原始帧之间不存在的帧。虽然显著…
该模型使用 PWC-Net 作为流估计网络。流估计网络从预训练的 PWC-Net 初始化。对于深度估计网络,作者使用了 hourglass 架构。深度估计网络也从预训练版本初始化。上下文信息通过使用预训练的 ResNet来获取。
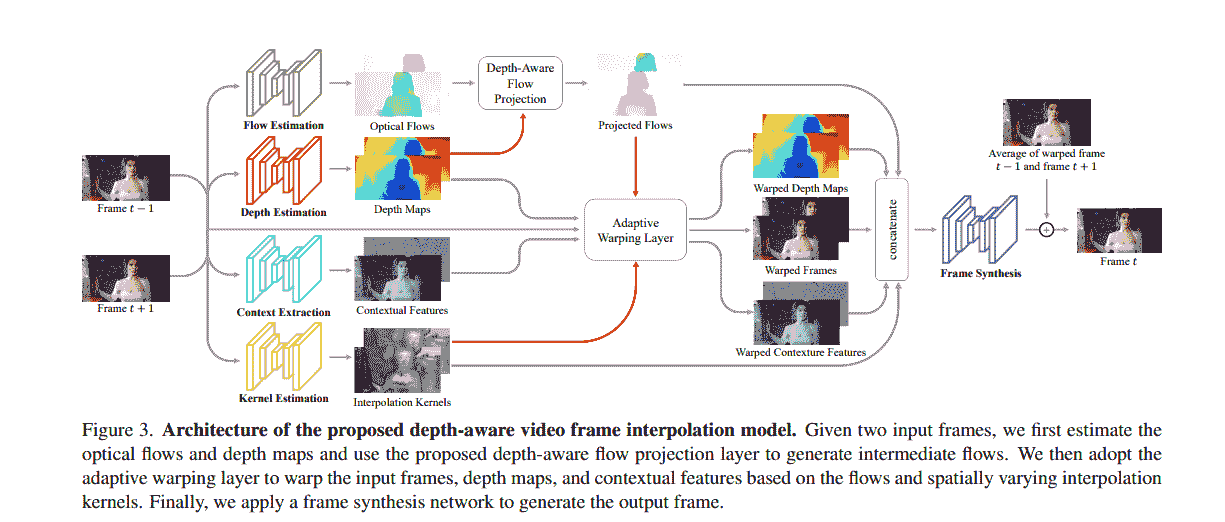
作者构建了一个上下文提取网络,该网络包含一个 7x7 卷积层和两个残差块,没有任何归一化层。然后通过将来自第一个卷积层和两个残差块的特征进行拼接,获得了分层特征。从头开始训练上下文提取网络确保其学习有效的上下文特征以进行视频帧插值。
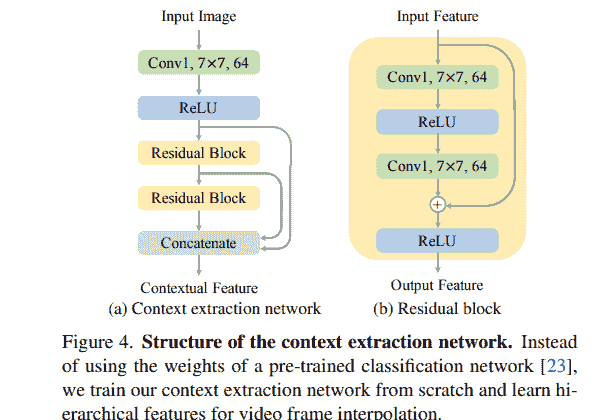
对于内核估计和自适应变形层,作者使用了 U-Net 架构来为每个像素估计 4 x 4 的局部内核。深度感知流投影层生成插值内核和中间流。自适应变形层被采用来变形输入帧、深度图和上下文特征。
最终帧输出是通过帧合成网络生成的。该网络以变形的输入帧、变形的深度图、上下文特征、投影流和插值内核作为输入。为了确保网络预测真实帧和混合帧之间的残差,两个变形帧被线性混合。
模型在 Vimeo90K 数据集上进行训练,优化策略采用 AdaMax。下方展示了获得的结果。
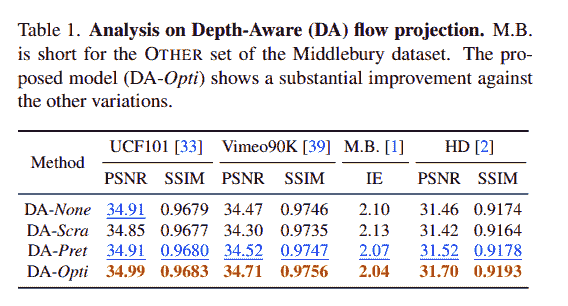
多尺度深度损失函数与生成对抗网络的帧插值(2019)
在这篇论文中,作者提出了一种用于帧插值的多尺度生成对抗网络(FIGAN)。通过多尺度残差估计模块最大化了该网络的效率,其中预测的流和合成的帧以粗到细的方式构建。
合成的中间视频帧的质量得到了提升,这是因为网络在不同级别上共同监督,并且使用了由对抗损失和两个内容损失组成的感知损失。该网络在 YouTube 上的 60fps 视频上进行了评估。

帧插值尝试从一个或多个连续的视频帧中合成帧。近年来,深度…
提议的模型由一个可训练的 CNN 架构组成,该架构直接从两个输入帧中估算一个插值帧。合成特征是通过构建一个金字塔结构并在不同尺度下估计两个帧之间的光流来获得的。合成精炼模块由一个 CNN 组成,它能够将合成图像与生成它的原始输入帧共同处理。

从该网络中获得的一些结果如下所示。

结论
我们现在应该了解了一些最常见的—以及几个非常新的—用于在各种背景下执行视频帧插值的技术。
上面提到并链接的论文/摘要还包含其代码实现的链接。我们很高兴看到你在测试它们后的结果。
个人简介: 德里克·穆伊提 是一名数据分析师、作家和导师。他致力于在每项任务中提供卓越的成果,并且是 Lapid Leaders Africa 的导师。
原文. 经许可转载。
相关:
-
神经架构搜索研究指南
-
2019 年深度学习语音合成指南
-
2019 年自动语音识别指南
更多相关话题
NLP 初学者的研究论文
原文:
www.kdnuggets.com/2022/11/research-papers-nlp-beginners.html

Sincerely Media 通过 Unsplash
如果你是数据世界的新手,并对 NLP(自然语言处理)有特别的兴趣,你可能在寻找资源以帮助你更好地理解。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
你可能已经遇到过许多不同的研究论文,并对选择哪一篇感到困惑。因为说实话,它们并不短,而且确实需要大量的脑力。因此,选择一篇对你掌握 NLP 有帮助的论文将是明智的。
我做了一些研究,并收集了一些在 NLP 领域高度推荐的研究论文,以供初学者和全面的 NLP 知识参考。
我会将其拆分为几个部分,以便你可以找到你想要的内容。
机器学习与 NLP
利用 EM 从标记和未标记文档中进行文本分类 作者:Kamal Nigam,1999 年
本论文讲述了如何通过将少量标记的训练文档与大量未标记的文档结合来提高文本分类器的准确性。
超越准确性:使用 CheckList 对 NLP 模型进行行为测试 作者:Marco Tulio Ribeiro 等,2020 年
在这篇论文中,你将更多地了解 CheckList,一种测试 NLP 模型的任务无关方法,因为不幸的是,一些目前最常用的方法高估了 NLP 模型的性能。
神经模型
自然语言处理(几乎)从零开始 作者:Ronan Collobert,2011 年
在这篇论文中,你将学习 NLP 的基础知识——正如标题所示,它几乎是从零开始的。主题包括命名实体识别、语义角色标注、网络、训练等。
理解 LSTM 网络 作者:Christopher Olah,2015 年
神经网络是 NLP 的重要组成部分,因此对其有良好的理解将对你长期受益。这篇论文重点关注广泛使用的 LSTM 网络。
单词/句子表示和嵌入
词汇和短语的分布式表示及其组合性 由 Tomas Mikolov 发表,2013 年
由 Mikolov 撰写,他引入了 Skip-gram 模型,用于从大量非结构化文本数据中学习高质量的单词向量表示——这篇论文将介绍原始 Skip-gram 模型的几个扩展。
句子和文档的分布式表示 由 Quoc Le 和 Tomas Mikolov 发表,2014 年
深入探讨了袋词模型的两个主要弱点,作者介绍了段落向量——这是一种无监督算法,用于从可变长度的文本片段(如句子)中学习固定长度的特征表示。
语言建模
语言模型是无监督的多任务学习者 由 Alec Radford 发表,2018 年
自然语言处理任务通常通过在特定任务的数据集上进行监督学习来解决。然而,多任务学习被测试作为一种有前途的框架,以提高 NLP 的整体性能。
递归神经网络的非凡有效性 由 Andrej Karpathy 发表,2015 年
这篇论文回溯了递归神经网络的起点,并探讨了它们为何如此有效和稳健,并附有代码示例以帮助你更好地理解。
注意力与 Transformer
BERT:深度双向 Transformer 的语言理解预训练 由 Jacob Devlin 等人 发表,2019 年
在学习机器学习时,你可能听说过 BERT——来自 Transformer 的双向编码表示。它被广泛使用,并以能够从未标记的文本中进行深度双向表示预训练而著称。在这篇论文中,你将进一步理解并学习如何基于 BERT 改进你的微调。
注意力机制才是关键 由 Ashish Vaswani 等人 发表,2017 年
这篇论文专注于 Transformer,完全关注注意力机制,这与通常基于复杂递归或卷积神经网络的模型不同。你将学习 Transformer 如何很好地泛化到其他任务,并可能是更好的选择。
HuggingFace 的 Transformers:最先进的自然语言处理 由 Thomas Wolf 等人 发表,2020 年
想了解更多关于已经成为自然语言处理主流架构的 Transformer 吗?在这篇论文中,你将深入了解它的架构以及它如何促进预训练模型的分发。
总结
正如我上面所说,我不想用这么多不同的研究论文让你感到困扰——因此我保持了最小化的水平。
如果你知道任何适合初学者的资源,请在评论中分享,以便他们可以看到。谢谢!
Nisha Arya 是一名数据科学家和自由技术作家。她特别关注提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何/能如何有助于人类寿命的延续。作为一个热衷于学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
成为数据工程师的 7 个资源
原文:
www.kdnuggets.com/2020/01/resources-become-data-engineer.html
评论
数据工程是数据科学从业者中增长最快、需求最旺盛的职业之一。随着我们每天使用越来越多的技术服务,生成的数据量不断增加,快速、高效、有效地收集、存储、查询、清理和处理数据库的能力变得越来越重要。
根据 Statista 的数据,到 2025 年,大数据市场的体量预计将从 2017 年的 26 泽字节增长到 175 泽字节。这代表了从 2017 年到 2025 年 573%的增长。 在 2017 年之前,大数据市场的体量在 2010 到 2016 年间增长了 800%。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的信息技术需求
对于初学者,Dataquest 可能是进入其他资格认证(特别是云认证)之前的一个良好起点。
1. 微软认证:Azure 数据工程师助理
级别:高级

Azure 数据工程师设计和实施数据管理、监控、安全和隐私,使用完整的 Azure 数据服务堆栈来满足业务需求。该认证是完成多个培训模块后的最终阶段。每个模块培训用户熟练使用 Azure 的产品套件,从而成功成为平台上的数据工程师。每个学习模块少于一天,具体时间取决于每个人的投入,通常不超过 10 小时。
2. Udacity 纳米学位项目:数据工程师
级别:初学者(具有先决条件)

Udacity 数据工程课程是全新的课程,旨在帮助弥补技能差距,满足公司对高级数据库知识及高效可扩展数据处理的需求。课程定于 2020 年 1 月 15 日开始,预计完成时间为 5 个月,每周需要投入 5 小时。
课程内容涉及 SQL、Spark、AWS 上的数据仓库、Apache Airflow 等领域。今天市场上有许多选择,可以在本地或云端创建数据库。
3. Google Cloud Platform 认证:专业数据工程师
级别:高级

在参加上述认证考试之前,您可能想参加他们推荐的 Qwiklabs 培训课程:Google Cloud Platform 上的数据工程。该培训课程也最适合对云计算有一定了解的人。认证和培训都是短期课程,教您使用 Hadoop、Google BigQuery 和在 GCP 上构建可扩展的机器学习应用程序。
4. Dataquest:数据工程师
级别:初学者

该课程从 Python 入门,接着学习 SQL,进一步深入到 PostgresSQL 和数据结构与算法的使用。课程内容覆盖广泛,主要围绕 Python 和 SQL。这是一个适合刚入门数据工程领域的课程,但由于课程结构,至少需要具备一些基础的 Python 知识。
5. 加州大学圣地亚哥分校:大数据专业化
级别:初学者

加州大学圣地亚哥分校在 Coursera 上的课程主要围绕使用 Hadoop 框架和 Spark,并在课程最后将这些大数据处理技术应用于机器学习实例。根据课程描述,不需要编程经验。该课程与 Splunk 合作制作。
此课程有特定的硬件和软件要求。
6. AWS 认证大数据 - 专业
级别:高级

AWS 作为服务和收入最多的云服务提供商,在数据工程领域也将是一个重要的参与者。
AWS 认证大数据 – 专业考试的新版本将于 2020 年 4 月推出,新的名称为 AWS 认证数据分析 – 专业。
因为这个认证面向高级用户,所以需要你有几年使用 AWS 的经验,并持有其他认证,比如 AWS 认证云从业者
7. 数据工程食谱 - 安德烈亚斯·克雷茨
级别:中级到高级

安德烈亚斯·克雷茨 创作了这本书,旨在分享他基于数据科学工作流的数据工程知识。他可能更因其播客 数据科学的水管工 而为人熟知,在播客中他讲解和教育我们数据工程的话题。
他在 LinkedIn 上非常活跃,正迅速成为那些希望成为或扩展知识领域的人的重要公众人物。
相关
-
数据科学与数据工程之间的细微差别
-
你需要的最后一本数据分析 SQL 指南
-
帮助准确确定分析工程项目范围的四个问题
更多相关话题
女性在 AI、数据科学和机器学习领域的资源
原文:
www.kdnuggets.com/2020/03/resources-women-ai-data-science-machine-learning.html
评论为了纪念 3 月 8 日的国际妇女节,我们提供了一些有用的资源,帮助更多女性进入并在这一领域取得成功。
-
AI 研究中的性别多样性通过对 arXiv 上 150 万篇论文的分析,本研究回顾了性别多样性在不同学科、国家和机构中的演变,以及有无女性合著者的 AI 论文之间的语义差异。
-
19 位激励人心的女性在 AI、大数据、数据科学、机器学习领域为了 2019 年国际妇女节,我们介绍了 19 位在 AI、大数据、数据科学和机器学习领域领先的激励女性。
-
女性在数据科学领域参与的增长我们在性别代表性变得更加平等之前还有很长的路要走,但整个领域显示出女性在这一角色中工作的希望趋势,或希望将来能如此。
-
女性在数据科学和机器学习领域的资源关于女性在数据科学和机器学习领域的资源的综合列表,包括有用的技术团体和寻找女性讲者的发布列表。
-
18 位激励人心的女性在 AI、大数据、数据科学、机器学习领域为了 2018 年国际妇女节,我们介绍了 18 位在 AI、分析、大数据、数据科学和机器学习领域领先的激励女性。
-
不再找借口——470 位杰出的分析女性如果你的网络中没有很多你可能考虑的杰出女性,我有一些列表可以帮助你入手。以下是找到更多信息和 470 位行业顶尖女性资料的链接。
-
作为女性在大数据领域留下印记的方法尽管大数据技术创新推动了巨大的增长和机会,但女性在这一领域的作用仍然很小。以下是考虑大数据职业的女性的 5 个思考。
更多相关话题
数据科学和机器学习领域女性的资源
原文:
www.kdnuggets.com/2018/06/resources-women-data-science-machine-learning.html
评论

多样性
当前关于多样性的对话阶段如下:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
本文的重点是分享针对数据科学领域女性和非二元性别人士的全面资源列表,以实现工作场所多样性的目标。
目标
大量研究表明女性是:
一些积极的消息是,研究表明女性的确实 能够推动平等的网络活动。
本指南旨在为女性和非二元性别的数据科学从业者提供资源,帮助她们在友好和支持的环境中实现以下目标:
-
建立社区
-
网络构建
-
发展技能,教育
-
共享知识
-
寻找工作
-
发展职业生涯
-
为自己和他人辩护
男性盟友
这个资源对寻求多元化其组织的男性盟友也很有价值,通过主动:
-
支持和推广女性
-
寻找女性讲者参加会议
-
招聘女性候选人
如果你邀请我在你的会议上演讲,请准备好接受这个答案。
我邀请其他男性也这样做。#多样性 #包容性 pic.twitter.com/gJlECWOAux
— Francesc @ #io18 (@francesc) 2018 年 4 月 12 日
参与指南
在加入任何组织或参加其活动之前,熟悉以下细节至关重要:
-
使命: 阅读组织的使命声明
-
行为规范: 阅读组织的 CoC
-
会员资格: 一些组织仅对女性和非二元性别者开放,其他组织对男性盟友开放。在加入之前,请了解并尊重他们的会员要求。
女性分析会议
数据科学中的女性(WiDS)
-
在斯坦福大学举办
-
全球直播,来自 50 多个国家的 10 万名以上参与者
-
每年 3 月举办一次会议
-
Twitter 标签:#WiDS2019
女性分析师
-
2018 年会议于 3 月 15 日在俄亥俄州哥伦布市举行
-
Twitter 标签:#WIA2018
女性机器人学 IV
- 2018 年会议于 6 月 29 日在宾夕法尼亚州 Pittsburgh 举行
统计与数据科学中的女性会议
-
由美国统计协会主办
-
2018 年会议于 10 月 18-20 日在俄亥俄州辛辛那提举行
女性机器学习研讨会(WiML)
-
2018 年会议于 12 月 3-4 日在加拿大蒙特利尔举行
-
与 NIPS 2018 同期举行
-
与 COLT、ICML 同期举行的其他活动 更多
女性科技会议
女性编程 CONNECT
-
2018 年会议于 4 月 28 日在加利福尼亚州旧金山举行
-
面向技术和软件工程领域的女性
写作/演讲/编码
- 2018 年会议于 8 月 1-4 日在纽约市举行
技术女性与盟友
- 2018 年会议于 9 月 12-14 日在纽约市举行
格蕾丝·霍珀庆典
-
世界上最大的女性技术人员聚会,超过 18K 名与会者
-
2018 年会议于 9 月 26-18 日在德克萨斯州休斯顿举行
-
2017 年的 Twitter 标签:#GHC17, #GHC2017
组织
以下是数据和技术领域的各种小组。你可以通过以下方式参与:
-
订阅他们的通讯
-
加入讨论:Slack 团队、LinkedIn 或 Facebook 群组、Twitter
-
加入本地分会或聚会小组
-
参加他们的讲座和研讨会(如有:黑客松、会议)
-
作为活动演讲者;举办研讨会
-
志愿奉献时间
如果没有本地分会,考虑启动一个并寻求他人帮助。
技术团体
多样性与包容性团体
| 组名 | 推特 |
|---|---|
| NumFOCUS DISC | @NumFOCUS |
| Project Include | @projectinclude |
| Power to Fly | @powertofly |
| 技术女性基金 | @womenintechfund |
| Women 2.0 | @women2 |
区域组
| 组织名称 | 推特 |
|---|---|
| 性别少数群体的 AI 俱乐部(伦敦) | @AIClubGenderMin |
| 女性学习编程(加拿大) | @learningcode |
需要申请才能加入的组织
| 组织名称 | 推特 |
|---|---|
| 数据探险家 | |
| 科技女性 | @techwomen |
收取会员费的组织
| 组织名称 | 推特 |
|---|---|
| Apres | @apresnyc |
| 科技女性 | @HireTechLadies |
| 国际技术女性组织 | @witi |
资源
多样性门票
一个 Travis 基金会的应用程序,帮助会议组织者通过提供票务和旅行补助来联系少数群体
极客女性主义
极客女性主义提供了各种资源,包括行为守则的模板
技术女孩
GIT 旨在通过创建专有的、创新的编程和战略全球合作伙伴关系,加速创新女性进入高科技行业和创办初创公司的成长。
全球女性基金
一个全球性的女性和女孩人权倡导者。他们利用我们强大的网络来寻找、资助并放大那些正在建立社会运动和挑战现状的女性的勇敢工作。
查找演讲者的已发布列表
这里是关于数据科学和人工智能领域女性的精选列表。下次有会议的征集提案(CFP)时,这是一个极好的参考。
-
- 你可以订阅这个推特列表,其中有 1400+名女性成员
-
-
这个列表由 @WiMLworkshop 维护
-
你可以选择加入并添加你的名字
-
-
服务于科学计算中代表性不足群体的组织,NumFOCUS
-
Meta Brown 的180+ 位杰出数据分析女性名单
-
Meta Brown 的285 位撰写数据分析书籍的女性
-
Onalytica 的科技女性顶级影响者名单 涵盖了 AI、金融科技、区块链、大数据、物联网、教育科技、市场科技
45%的演讲者是女性 ????????@NumFOCUS @wimlds #diversityawards #rstatsnyc
t.co/UNbqBESRa4— Reshama Shaikh (@reshamas) 2018 年 4 月 20 日
开源领域女性
女性在开源领域明显代表性不足。这里是一个受到Twitter 讨论启发的开源女性 Twitter 名单。
提升数据领域女性可见性的例子
这里有一些提高女性和非二元性别者在数据领域可见性的例子:
-
RLadies: 国际妇女节(IWD)推文流
-
统计学女性: Twitter 标签 #statswomen
-
David Robinson 的推文: 五位令人惊叹的 #rstats 数据科学家,如果你还没有关注的话
-
Amstat News: 庆祝统计学女性
-
KD Nuggets: 激励人心的数据领域女性
你不会被这位酷炫的 R-Lady 惊艳到吗?!
t.co/SQKK9oVU5Q#rladies #iwd2018 pic.twitter.com/KueF3yZb5E— IWD 2018 featured R-Ladies (@rladies_iwd2018) 2018 年 3 月 8 日
为了纪念女性历史月,我们正在庆祝几位在统计学和数据科学领域工作的 ASA 女性。这些杰出的女性之所以被选中,是因为她们激励和影响了她们领域中的其他女性。阅读她们的传记以了解她们为何选择统计学、谁影响了她们,以及她们取得的成就。
Slack 团队
-
R-Ladies: 发送邮件至
nyc@rladies.org以请求邀请 -
WiMLDS: 通过邮件
slack@wimlds.org申请邀请链接(仅限女性和非二元性别)
面向大学预科生
性别平等的障碍在教育早期就存在。以下是一些在大学之前影响年轻女性参与和留存的组织。
CoderDojo
一个全球性的免费志愿者主导的社区编程俱乐部网络,面向 7 至 17 岁的年轻人。在 Dojo 中,他们可以学习编程、建立网站、创建应用程序或游戏,并在非正式、富有创意和社交的环境中探索技术。
Girls Who Code
Girls Who Code 的使命是缩小科技领域的性别差距。
AI 4 All
核心模型是通过暑期营教育和支持下一代多样化的 AI 领导者,参与大学包括斯坦福大学、加州大学伯克利分校、普林斯顿大学、卡内基梅隆大学和波士顿大学的代表性不足的高中生。
支持组织
你可以通过以下方式支持这些组织:
-
订阅她们的通讯
-
在社交媒体上建立联系
-
熟悉她们的使命和项目
-
与他人分享她们的使命和项目
-
与这些组织建立关系
-
参与活动和网络交流
-
志愿服务
-
分享职位信息和实习机会
-
为她们的事业捐款
-
成为企业赞助商
数据科学资源
这个资源列表包括播客、会议列表、通讯、学习材料等。
参考资料
-
将女性排除在科技之外的危险,Maria Klawe,哈维穆德学院
-
不再找借口 – 470 位杰出的分析女性,Meta Brown
-
照片来源: 我们从全球最大女性技术大会上学到的东西
简介: Reshama Shaikh 是一位自由职业的数据科学家/统计学家及 MBA,具备 Python、R 和 SAS 的技能。她在制药行业担任生物统计学家超过 10 年。她还是 NYC Women in Machine Learning & Data Science 和 PyLadies 的聚会组织者。她在罗格斯大学获得统计学硕士学位,并在纽约大学斯特恩商学院获得 MBA 学位。
原文。经许可转载。
相关:
更多相关话题
1983-2010 年间的人工智能复兴
评论
序言
每个十年似乎都有其技术流行词:1980 年代有个人计算机;1990 年代有互联网和万维网;2000 年代有智能手机和社交媒体;而这个十年则是人工智能(AI)和机器学习。尽管如此,AI 领域已经有 67 年的历史,这是五篇系列文章中的第二篇,其中:
-
第一篇文章讨论了人工智能的起源以及 1950 年至 1982 年的首次炒作周期
-
本文讨论了人工智能的复兴及其在 1983-2010 年间的成就
-
第五篇文章讨论了 2018-2035 年可能对大脑、思想和机器的预示

人工智能的复兴
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT 工作
1950-82 年间,人工智能(AI)作为一个新领域诞生,进行了大量开创性的研究,产生了巨大的炒作,但当这种炒作没有实现时,AI 进入了休眠状态,研究资金也枯竭了[56]。在 1983 年至 2010 年期间,研究资金起伏不定,虽然“有些计算机科学家和软件工程师会避免使用‘人工智能’这一术语,以免被视为异想天开的人”[43],但 AI 研究依然持续升温。
在 1980 年代和 1990 年代,研究人员意识到许多 AI 解决方案可以通过使用数学和经济学中的技术如博弈论、随机建模、经典数值方法、运筹学和优化来改进。更好的数学描述被开发出来用于深度神经网络以及进化和遗传算法,这些在此期间得到了成熟。所有这些都导致了 AI 中新子领域和商业产品的诞生。
在本文中,我们首先简要讨论了监督学习、无监督学习和强化学习,以及在这一时期变得相当流行的浅层和深层神经网络。接下来,我们将讨论以下六个促使人工智能研究和发展加速的原因——硬件和网络连接变得更便宜和更快;并行和分布式计算变得实际可行,且大量数据(“大数据”)变得可用于训练人工智能系统。最后,我们将讨论一些在这一时期商业化的人工智能应用。
机器学习技术显著改进
监督机器学习
这些技术需要通过使用标记数据进行人工训练[58]。假设我们有几千张狗和猫的面部照片,我们希望将它们分成两组——一组包含狗,另一组包含猫。与其手动完成,不如由机器学习专家编写一个程序,程序中包括区分狗脸和猫脸的属性(例如,胡须长度、垂耳、角脸、圆眼)。在包含足够多的属性并检查程序的准确性后,将第一张图片提供给这个“黑箱”程序。如果其输出与“人类训练者”(可能是现场培训或提供了预标记图片)的输出不相同,程序会修改其内部代码,以确保其答案与训练者(或预标记图片)的答案相同。在经过几千张这样的图片并相应修改后,这个黑箱学会了区分狗脸和猫脸。到 2010 年,研究人员开发了许多可以在黑箱内部使用的算法,其中大多数在附录中提到,今天,一些常用这些技术的应用包括物体识别、说话人识别和语音转文本转换。

无监督学习算法
这些技术不需要任何预标记的数据,它们尝试从“未标记”的数据中确定隐藏的结构[59]。无监督学习的一个重要应用案例是计算相对于关键属性的隐藏概率分布并进行解释,例如,通过使用数据的属性来理解数据,然后将其分成“相似”的组。无监督学习中有几种技术,其中大多数在附录中提到。由于这些算法所处理的数据点是未标记的,它们的准确性通常很难定义。使用无监督学习的应用包括推荐系统(例如,如果某人购买了 x,那么此人是否会购买 y)、为营销目的创建群体(例如,按性别、消费习惯、教育程度、邮政编码进行聚类)和为改善疾病管理创建患者群体。由于 k-means 是最常用的技术之一,因此下面简要描述了它:
假设我们有很多数据点,每个数据点有 n 个属性(可以标记为 n 个坐标),我们想将它们划分为 k 个组。由于每个组有 n 个坐标,我们可以将这些数据点想象成在 n 维空间中。首先,算法将这些数据点任意划分为 k 个组。现在,对于每个组,算法计算其质心,这是一个虚拟点,每个坐标是该组中所有点相同坐标的平均值,即,这个虚拟点的第一个坐标是该组中所有点第一个坐标的平均值,第二个坐标是所有第二个坐标的平均值,以此类推。接下来,对于每个数据点,算法找到最接近该点的质心,并实现这些数据点的新 k 个组的划分。该算法再次找到这些组的质心,并重复这些步骤,直到它收敛或经过了指定次数的迭代。下图展示了 k=2 的二维空间示例:

另一种技术,层次聚类创建层次性组,在顶层会有‘超级组’,每个超级组包含子组,这些子组可能包含子子组,依此类推。k-means 聚类通常也用于创建层次性组。
强化学习
强化学习(RL)算法通过其行动的后果来学习,而不是通过人类教授或使用预标记的数据[60];这类似于巴甫洛夫的条件反射,当巴甫洛夫发现他的狗在他进入房间时会开始流口水,即使他没有带食物[61]。这些算法应遵守的规则事先给出,它们根据过去的经验和新选择来选择行动。因此,它们在模拟环境中通过试错学习。在每次“学习会话”结束时,RL 算法为自己提供一个“分数”,以表征其成功或失败的程度,随着时间的推移,算法尝试执行那些最大化该分数的行动。尽管 IBM 的深蓝没有使用强化学习作为例子,我们描述了一个潜在的用于下棋的 RL 算法:
作为输入,RL 算法提供了下棋的规则,例如,8*8 棋盘,棋子的初始位置,每个棋子在一步中可以做什么,玩家的王被将死时的分数为零,对方的王被将死时的分数为一,如果棋盘上只剩下两个王,则分数为 0.5。在这个实施方案中,RL 算法创建了两个相同的解决方案 A 和 B,它们开始相互下棋。在每局游戏结束后,RL 算法将适当的分数分配给 A 和 B,并且还保留了 A 和 B 所做的所有移动和反移动的完整历史,这些可以用于训练 A 和 B(各自)以更好地玩游戏。在第一轮中玩了几千局这样的游戏后,RL 算法使用“自生成”的标记数据(每局游戏的结果为 0、0.5 和 1 以及该游戏中所有的移动)并通过学习技术,确定了导致 A(以及类似地 B)获得较差分数的移动模式。因此,在下一轮中,它为 A 和 B 改进这些解决方案,并优化这些“差劲的移动”,从而在第二轮中改进它们,然后是第三轮,依此类推,直到一轮到另一轮的改进变得微不足道,此时 A 和 B 最终成为经过合理训练的解决方案。

1951 年,Minsky 和 Edmonds 建造了第一个神经网络机器 SNARC(随机神经类比强化计算机);它成功模拟了老鼠在迷宫中寻找食物的行为,当它在迷宫中移动时,一些突触连接的强度会增加,从而强化了基础行为,这似乎模拟了活体神经元的功能[5]。一般而言,强化学习算法在解决优化问题、游戏理论情境(例如,在玩掼蛋[62]或围棋[94])以及在商业规则明确的问题(例如,自动驾驶)中表现良好,因为它们可以通过与人类或彼此对抗进行自我学习。
混合学习
混合学习技术使用一种或多种监督学习、无监督学习和强化学习技术的组合。半监督学习在标记大数据集代价高或耗时的情况下特别有用,例如,在区分狗脸和猫脸时,如果数据库包含一些已标记的图像但大多数未标记的图像。它们的一些广泛用途包括分类、模式识别、异常检测和聚类/分组。

神经网络的复兴——浅层和深层
正如前一篇文章[56]中讨论的,一个单层感知器网络由一个输入层组成,连接到一个感知器的隐藏层,然后再连接到一个感知器的输出层[17]。通过连接传递的信号由该连接的“权重”重新校准,这个权重在“学习过程中”分配给连接。像人类神经元一样,如果所有的输入信号总和超过指定的潜在值,感知器就会“发射”,但与人类不同,在大多数此类网络中,信号只在一层与前面的层之间移动。术语“人工神经网络(ANNs)”由 Igor Aizenberg 及其同事于 2000 年创造,用于布尔阈值神经元,但也用于感知器和其他同类“神经元”[63]。下面给出了一个隐藏层和八个隐藏层网络的示例:

尽管多层感知器于 1965 年发明,并且在 1971 年提供了一个训练 8 层网络的算法[18, 19, 20],但“深度学习”这一术语由 Rina Dechter 在 1986 年引入[64]。就我们的目的而言,深度学习网络有超过一个隐藏层。
尽管多层感知器于 1965 年发明,并且在 1971 年提供了一个训练 8 层网络的算法,但“深度学习”这一术语由 Rina Dechter 在 1986 年引入
下面给出了在 1975 年到 2006 年期间开发的重要深度学习网络,并且今天仍然被频繁使用;它们的描述超出了本文的范围:
-
1979 年,Fukushima 提供了第一个“卷积神经网络”(CNN),他开发了 Neocognitron,并使用了分层的多层设计 [65]。CNN 广泛用于图像处理、语音到文本转换、文档处理以及基于结构的药物发现中的生物活性预测 [97]。
-
1983 年,Hopfield 推广了递归神经网络(RNN),这些网络最初由 Little 于 1974 年引入 [51,52,55]。RNN 类似于 Rosenblatt 的感知机网络,但由于允许连接既向输入层也向输出层延伸,因此不是前馈的,这使得 RNN 能够表现出时间行为。与前馈神经网络不同,RNN 使用其内部记忆处理任意序列的输入数据。RNN 此后被用于语音到文本转换、自然语言处理和心力衰竭早期检测 [98]。
-
1997 年,Hochreiter 和 Schmidhuber 开发了一种特定类型的深度学习递归神经网络,称为 LSTM(长短期记忆)[66]。LSTM 解决了训练 RNN 时出现的一些问题,非常适合与时间序列相关的预测。这些网络的应用包括机器人技术、时间序列预测、语音识别、语法学习、手写识别、蛋白质同源性检测以及医疗护理路径预测 [99]。
-
2006 年,Hinton、Osindero 和 Teh 发明了深度置信网络,并展示了在许多情况下,多层前馈神经网络可以通过将每一层视为无监督机器来逐层进行预训练,然后使用有监督的反向传播进行微调 [67]。这些网络的应用包括图像识别、手写识别以及识别肝癌和精神分裂症等疾病的发生 [100, 109]。
并行和分布式计算提高了 AI 能力
在 1983 到 2010 年间,硬件变得便宜了很多,速度提高了超过 50 万倍;然而,对于许多问题来说,一台计算机仍然不足以在合理的时间内执行许多机器学习算法。从理论上讲,1950-2000 年的计算机科学研究表明,通过同时使用许多计算机并以分布式方式处理,这些问题可以更快地解决。然而,以下与分布式计算相关的基本问题直到 2003 年才得到解决:(a)如何并行计算,(b)如何在计算机之间“公平”地分配数据并进行自动负载均衡,(c)如何处理计算机故障以及在计算机陷入无限循环时中断它们。2003 年,谷歌发布了 Google File Systems 论文,并在 2004 年发布了 MapReduce,这是一个用于在集群上处理和生成大数据集的并行分布式算法的框架及其相关实现[68]。由于 MapReduce 是谷歌专有的,2006 年,Cutting 和 Carafella(来自华盛顿大学,但在 Yahoo 工作)创建了一个开源的免费版本,称为 Hadoop[69]。此外,2012 年,Spark 及其弹性分布式数据集被发明,这相比于 MapReduce 和 Hadoop 实现降低了许多应用的延迟[70]。如今,基于 Hadoop-Spark 的基础设施可以处理 10 万台或更多计算机以及数亿千兆字节的存储。
大数据开始帮助人工智能系统
在 1998 年,John Mashey(在 Silicon Graphics)似乎首次创造了“Big Data”(大数据)这一术语,指的是数据生成和传输的巨大体量、多样性和速度[71]。由于大多数学习技术需要大量数据(尤其是标记数据),组织的存储库和万维网上存储的数据变得对人工智能至关重要。到 2000 年初,社交媒体网站如 Facebook、Twitter、Pinterest、Yelp 和 YouTube 以及博客和大量电子设备开始生成大数据,这为创建多个“开放数据库”提供了基础,这些数据库包含标记和未标记的数据(供研究人员实验使用)[72,73]。到 2010 年,人类已经创建了近一千万亿千兆字节(即一个 zettabyte)的数据,其中大多数是结构化的(例如,电子表格、关系数据库)或非结构化的(例如,文本、图像、音频和视频文件)[74]。

人工智能子领域的进展与商业应用
强化学习算法玩西洋双陆棋
在 1992 年,IBM 的 Gerald Tesauro 开发了 TD-Gammon,这是一个用来玩西洋双陆棋的强化学习程序;当时它的水平略低于顶尖的人类西洋双陆棋玩家[62]。
机器在国际象棋中战胜了人类
艾伦·图灵是 1953 年首次设计计算机象棋程序的人,尽管他是“通过翻阅算法的页面并在棋盘上执行指令来运行程序”[75]。1989 年,在卡内基梅隆大学开发的象棋程序 HiTech 和 Deep Thought 战胜了几位象棋大师[76]。1997 年,IBM 的 Deep Blue 成为第一个击败世界冠军加里·卡斯帕罗夫的计算机象棋系统。Deep Blue 的成功主要归功于其显著更好的工程设计和每秒处理 200 百万个棋步的能力[77]。
机器人技术
1994 年,Adler 及其斯坦福大学的同事们发明了一种立体定向放射外科手术机器人——Cyberknife,它能够手术切除肿瘤;它的准确性几乎与人类医生一样,在过去 20 年中,它已经治疗了超过 100,000 名患者[78]。1997 年,NASA 制造了 Sojourner,一种能够在火星表面执行半自主操作的小型机器人[79]。
更好的聊天机器人
1995 年,Wallce 创建了基于模式匹配的 A.L.I.C.E.,但没有推理能力[80]。随后,Jabberwacky(在 2008 年更名为 Cleverbot)被创造出来,具有网络搜索和游戏能力[81],但本质上仍然有限。这两款聊天机器人都使用了改进的自然语言处理算法来与人类交流。
改进的自然语言处理(NLP)
直到 1980 年代,大多数自然语言处理系统都基于复杂的手工编写规则。1980 年代末,研究人员开始使用机器学习算法进行语言处理。这是由于硬件的速度和成本的降低以及对乔姆斯基语言学理论的主导地位的削弱。于是,研究人员创建了统计模型,通过为适当的输入特征分配权重来做出概率决策,他们还开始使用监督学习和半监督学习技术以及部分标记的数据[82,83]。
语音和说话者识别
在 1990 年代末,SRI 研究人员使用深度神经网络进行说话者识别,并取得了显著的成功[84]。2009 年,Hinton 和 Deng 与多位来自多伦多大学、微软、谷歌和 IBM 的同事合作,展示了使用基于 LSTM 的深度网络在语音识别方面的显著进展[85,86]。
推荐系统
到 2010 年,几家公司(如 TiVo、Netflix、Facebook、Pandora)利用 AI 构建了推荐引擎,并开始将其用于营销和销售,从而提高了他们的收入和利润率[87]。
识别手写数字
1989 年,LeCun 及其同事首次展示了反向传播的实际应用;他们将卷积神经网络(CNN)与反向传播结合起来,以识别“手写”数字。这个系统最终被用于读取手写支票上的数字;到 1998 年及 2000 年代初,这些网络处理了美国约 10%到 20%的支票[88]。
在 1983 年至 2010 年期间,Hinton、Schmidhuber、Bengio、LeCun、Hochreiter 等人所做的杰出研究确保了深度学习的快速进展,并且一些网络也开始被用于商业应用。
结论
2000 年已过去,但艾伦·图灵关于人类创造 AI 计算机的预言仍未实现[3,4],而 Loebner 奖于 1990 年发起,旨在开发这样的计算机[89]。尽管如此,在 AI 方面取得了重大进展,特别是在深度神经网络方面,深度神经网络于 1965 年被发明,1971 年提出了训练它们的第一个算法[18,19,20];在 1983 年至 2010 年期间,Hinton、Schmidhuber、Bengio、LeCun、Hochreiter 等人所做的杰出研究确保了深度学习技术的快速进展[90,91,92,93],这些网络中的一些开始被用于商业应用。由于这些技术以及便宜的硬件和数据的可用性使其变得实际,研究和开发的步伐在 2005 年至 2010 年期间显著加快,这反过来又导致了 AI 解决方案的显著增长,这些解决方案在 2011 年至 2017 年期间开始与人类相抗衡;我们将在下一篇文章“AI 系统与人类竞争的领域”[151]中讨论这些解决方案。
本系列所有文章的参考文献可以在www.scryanalytics.com/bibliography找到。
简介: 阿洛克·阿加瓦尔博士,是Scry Analytics, Inc的首席执行官和首席数据科学家。他曾在 IBM 研究院约克镇工作,创立了 IBM 印度研究实验室,并且是 Evalueserve 的创始人和首席执行官,Evalueserve 在全球雇佣了 3000 多名员工。2014 年,他创办了 Scry Analytics。
原始。转载已获许可。
相关
何时重新训练机器学习模型?运行这 5 项检查来决定时间表。
原文:
www.kdnuggets.com/2021/07/retrain-machine-learning-model-5-checks-decide-schedule.html
评论
作者 Emeli Dral,Evidently AI 的首席技术官兼联合创始人 & Elena Samuylova,Evidently AI 的首席执行官兼联合创始人
世界和数据不是静态的。但大多数机器学习模型是静态的。一旦它们投入生产,它们随着时间变得不那么相关。数据分布在变化,行为模式也在改变,模型需要更新以跟上新的现实。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
通常的过程是在定义的时间间隔重新训练模型。这看起来相当简单:获取新数据、旧的训练流程,并再次拟合模型。
但是我们应该多久做一次呢?是每天、每周还是每月?还是每次获取一批新数据时?

太多时候,答案基于直觉或便利性。有人选择一个合理的时间间隔并安排定期的重新训练工作。
相反,我们可以采取更数据驱动的方法。为了更精确地规划模型维护,我们可以提前进行一些检查。
根据模型的重要性,您可能需要经历所有这些步骤或仅部分步骤。
检查 #1. 模型是否已经足够好?
在制定重新训练计划之前,检查是否完成了训练是有帮助的!也许,模型还没有达到最佳性能?
实现这一点的简单方法是查看经典的学习曲线。
如何进行?我们可以固定测试集,用于评估模型性能。然后,通过在不同部分的训练数据上训练模型,运行一系列实验。
我们可以使用随机分割方法并通过更改训练大小来进行迭代。这样,我们可以专注于数据量如何影响性能。
我们可以从中学到两件事:1)我们需要多少数据才能达到最佳性能 2)模型是否能用现有的训练数据达到这个平稳状态。
有时候我们会发现模型并不需要我们拥有的所有数据。 例如,我们有多年的销售数据,但使用仅仅一年的训练数据就能达到相同的质量。
我们可以丢弃额外的数据,使模型更加轻量化。
在其他情况下,我们可能会看到模型质量持续提升。模型渴望更多的数据!还有更多步骤需要完成,以将模型调整到最佳状态。
与其考虑模型重新训练以保持其质量,我们应该计划持续改进。只要我们获得足够的新数据,就可以利用它来获得更好的性能。
第一个测试还提供了数据中信号的规模和“密度”的感觉。我们需要 10、100 还是 1000 个观察值来看到对模型性能的有意义的影响?我们需要一天还是一个月来收集这数量的新数据?
这是一个有用的信息!
检查 #2. 事物变化的速度有多快?
当我们创建机器学习模型时,我们假设现实世界的过程是有一定稳定性的。否则,从过去学习就没有多大意义了!
我们也知道事物在变化。当处理一个动态过程时,我们也可以假设这些新模式的积累有一定的速度。
然后我们可以尝试计算一下!
让我们拿到我们的模型,看看如果我们模拟它在过去的应用,它能“持续”多久。
我们可以使用一些较旧的数据来训练模型,然后将其“应用”到后来的时期。就像我们对待保留集一样,但这里我们只是简单地取几个连续的数据。
我们可以从一个单点估计开始,看看性能下降得有多快。
如果我们有足够的历史数据,我们可以多次重复这个检查,然后对结果进行平均。只需留意潜在的异常值和稀有事件!
有时候我们会发现一个“旧”模型的表现和新模型一样好。 一些人喜欢经常重新训练模型以保持其“新鲜”,但这并不总是有理的。
不要修复那些没有坏的东西!
如果不需要频繁的重新训练,你可以选择一个更轻量的服务架构。你也可以减少与任何变化相关的技术错误风险。组织开销也是如此,尤其是当新模型需要审批过程时。
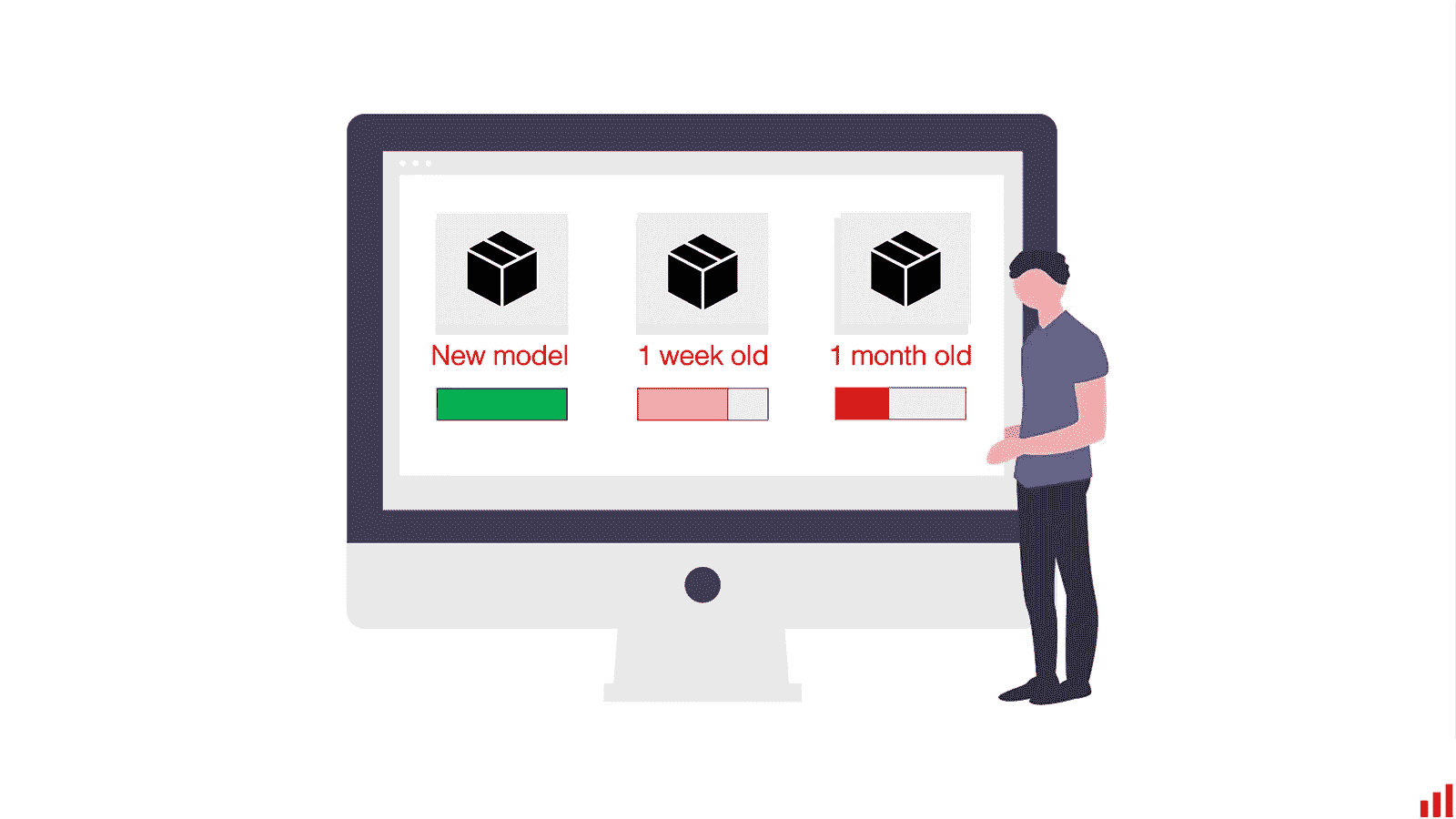
在其他情况下,你可能会发现模型衰老得非常快! 提前了解这一点是好的,以便设置适当的监控并准备基础设施。
你可能会决定重新考虑你的训练方法,以使模型更加稳定。例如,改变特征工程或模型架构,使其在测试集上的表现稍微逊色,但长期来看更稳定。在其他情况下,你可能会使用较短的训练周期来训练模型,但进行频繁的校准或考虑主动学习。
我们还可能面临重新训练模型能力的限制。
这引出了下一个检查。
检查 #3。我们何时获取新数据?
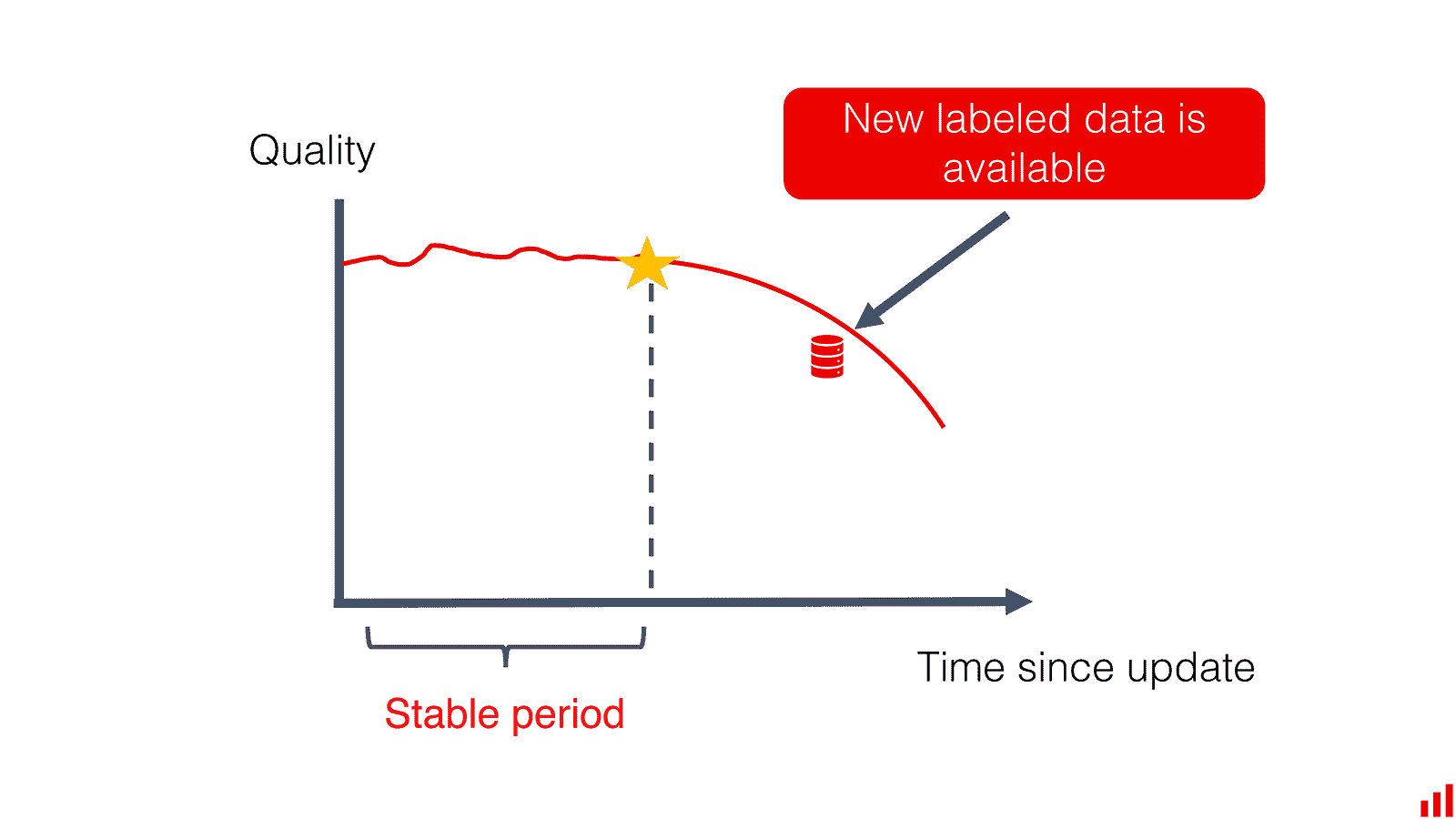
在这里,我们关注的是业务流程而非数据。
有时,我们几乎可以立即获得实际反馈。例如,你推荐一篇文章阅读,你很快就知道用户是否点击了链接。
在其他情况下,你可以用来重新训练模型的新数据有延迟。
如果你有较长的预测时间范围,你必须等待以了解你的预测是否正确。对于其他任务,你需要一个单独的标记过程。有时,限制来自数据的移动或生成方式。例如,手动数据输入每月进行一次。

我们可能会发现自己处于两种情况之一。
在某些情况下,模型在新数据到达之前就已经退化。 这成为一种限制。
如果我们没有及时获取数据以重新训练模型,我们可能需要再次重新考虑方法。例如,创建一个具有不同重新训练时间的模型集成,或将机器学习与规则或人工参与结合起来。作为最后的手段,我们还可以调整我们的性能期望,并准备应对模型质量下降。
在其他情况下,新数据在模型退化之前开始积累。 在这种情况下,我们可以选择。
我们当然可以在数据到达后的任何时间点启动重新训练。如果我们想要更精确,有一种方法可以做到这一点。
继续阅读!
检查 #4。我们需要多少数据才能看到改进?
假设新数据每天到达,但模型仅在 30 天后退化。那么最佳的行动是什么?我们应该每天、每周还是每月重新训练一次?
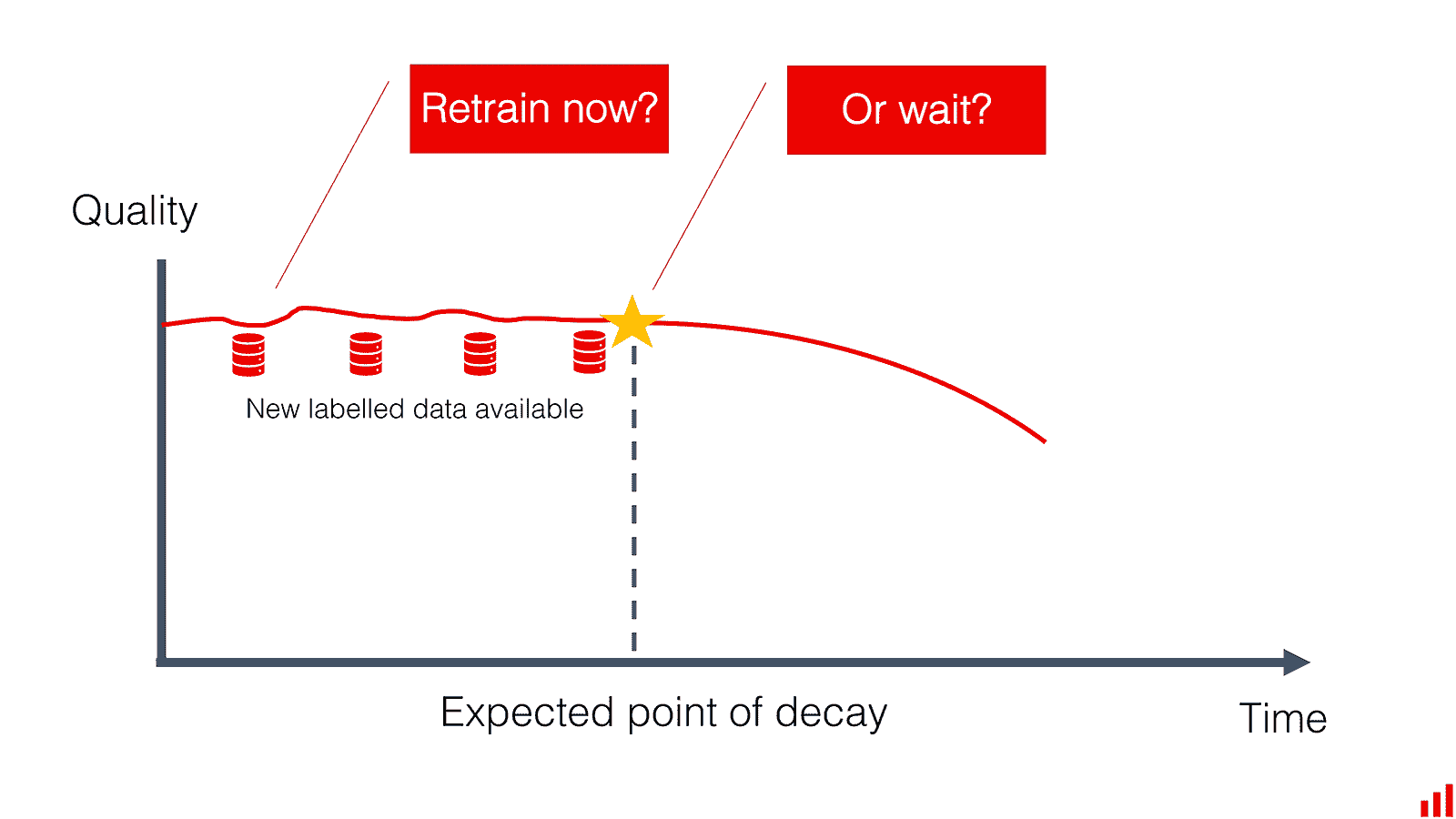
我们可以通过检查新的数据桶是否带来了我们想要的改进来做出更精确的判断。
问题是,有时添加一小组新数据点不会改变任何东西。有一个最小的数据量要求,它对性能有明显的影响。
我们可以评估这一点。
为此,我们选择一个已知退化期间的测试集。我们知道何时性能下降:然后可以检查在新数据上重新训练是否能改善性能。
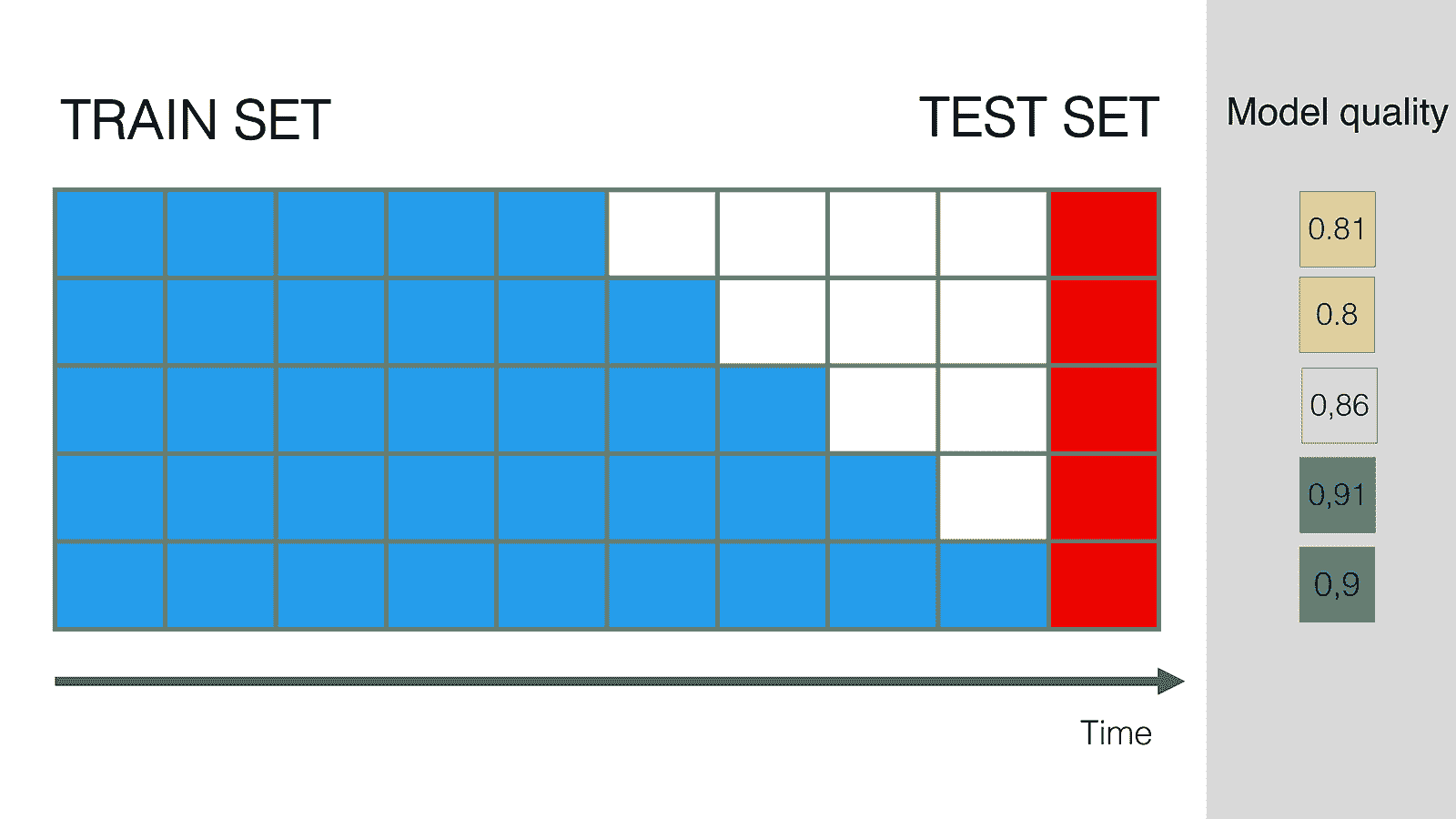
我们可以在数据到达时逐步添加数据。然后,观察它对测试性能的影响。
经常发生的情况是,我们需要等待一段时间才能收集到“有用”的数据——例如,至少一周的数据以捕捉相关的季节性模式。
结果是,我们实际选择的重新训练窗口可能比看起来要狭窄!一方面,它受到数据提供速度的限制;另一方面,则受到收集足够数据以使重新训练产生效果的需求限制。
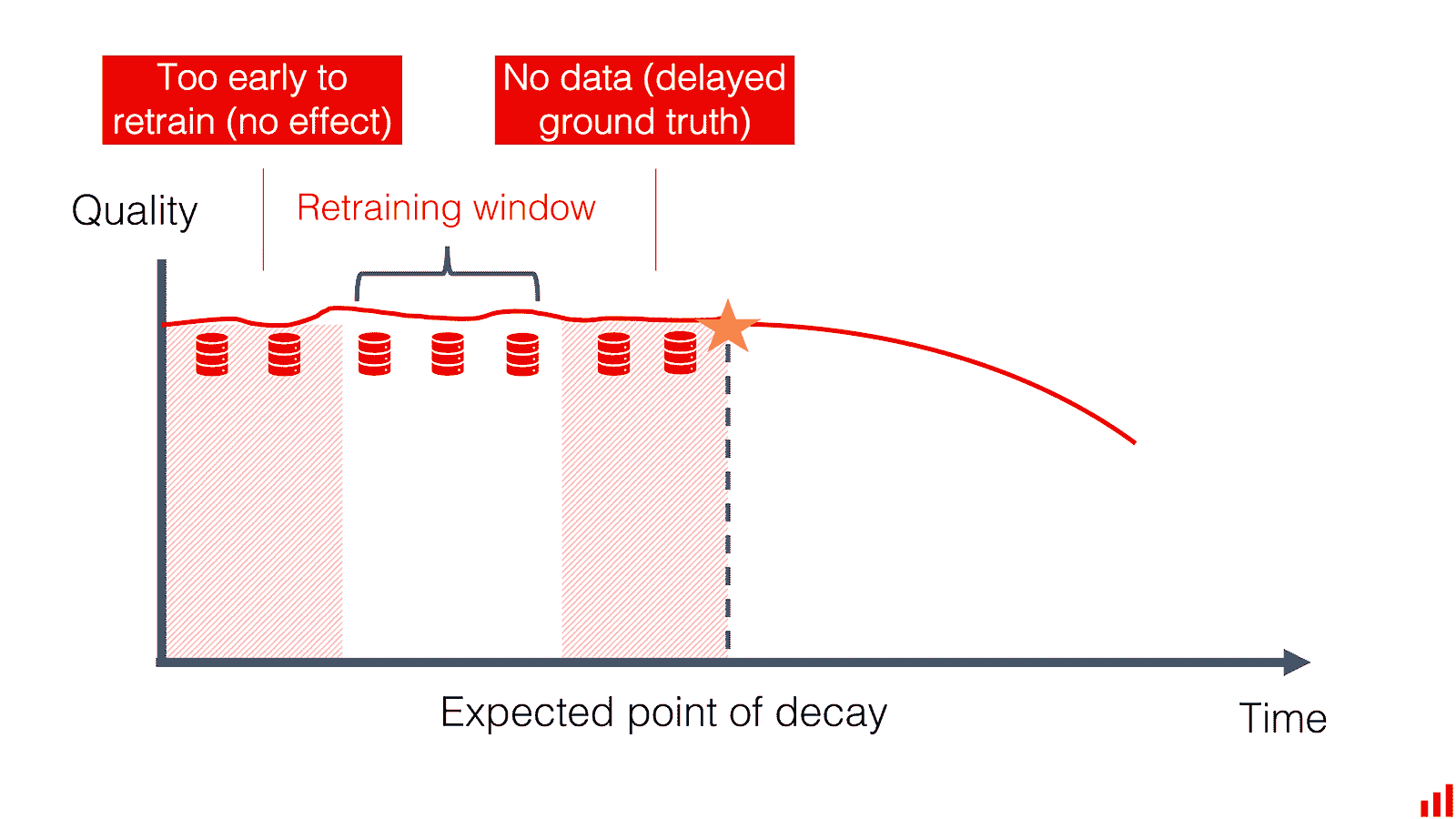
在这个时间框架内,你可以根据实际情况和使用案例选择适合的周期。
检查 #5。我们应该保留旧数据吗?
还有一个经常出现的问题。我们应该如何重新训练模型?是否应该添加一些新数据并丢弃一些旧数据?是否应该持续增加训练集?
这是我们可以运行的一个额外检查。
我们可以在选择的间隔进行模型重新训练,然后检查如果开始丢弃旧数据会发生什么变化。
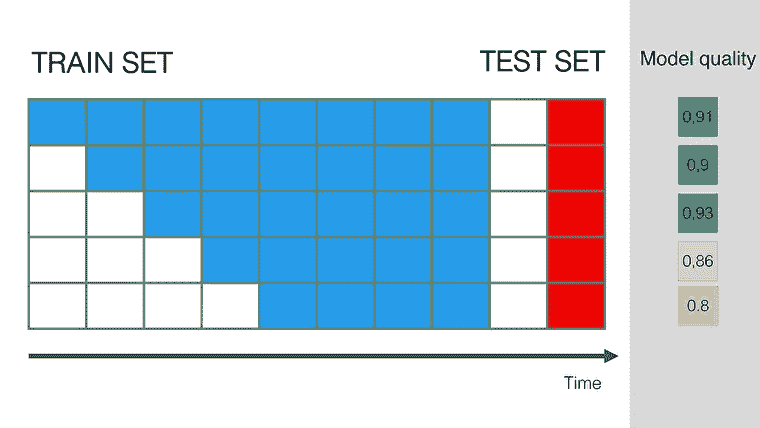
我们常常会看到,省略旧数据没有任何影响。那么,保持训练过程更轻量化可能是合理的。
更重要的是,有时这会使模型变得更好!保留旧的无关数据可能会导致性能下降,尤其是当你有一个动态使用案例时。这是值得事先了解的。
当然,我们也可能会发现暂时保留所有数据是有意义的。你可以稍后重复检查。
下一步是什么?
通过这些检查,你可以为模型维护做好准备。你可以设置你的重新训练管道,以便在选择的间隔准备好更新。
不过,我们不能仅仅依靠我们的计划。我们还需要进行现实检查。这意味着在模型上线后监控它们。
为了获得可见性,我们可以建立一个 监控仪表板 或安排定期检查以计算实际模型性能(如果我们有实际数据),或者监控输入数据的统计分布漂移和异常值。

即使是稳定的模型也可能面临 数据和概念漂移 或某些罕见事件。在这种情况下,我们可能需要比计划更早进行干预。
另一方面,如果情况看起来稳定,我们可以跳过比计划时间更长的更新。
规划定期重新训练并结合持续监控通常是使模型达到承诺性能的最佳策略!
链接
你可以在 这里 找到这篇文章的扩展版本。
机器学习监控检查清单
Emeli Dral 是 Evidently AI 的联合创始人兼首席技术官,她在公司开发用于分析和监控机器学习模型的工具。她曾共同创办过一家工业 AI 初创公司,并担任 Yandex Data Factory 的首席数据科学家。她还是 Coursera 机器学习和数据分析课程的共同作者,该课程拥有超过 100,000 名学生。
Elena Samuylova 是 Evidently AI 的联合创始人兼首席执行官。她曾共同创办过一家工业 AI 初创公司,并在 Yandex Data Factory 负责业务发展。自 2014 年以来,她与从制造业到零售业的公司合作,提供基于 ML 的解决方案。2018 年,Elena 被 Product Management Festival 评选为欧洲 50 位产品女性之一。
相关:
-
从机器学习错误中学习
-
机器学习模型监控检查清单:7 个跟踪项
-
MLOps:模型监控 101
更多相关话题
-
[Pandas 中 7 个关键数据质量检查]https://www.kdnuggets.com/7-essential-data-quality-checks-with-pandas)
检索增强生成:信息检索与文本生成的结合
原文:
www.kdnuggets.com/retrieval-augmented-generation-where-information-retrieval-meets-text-generation

图片由作者创建
RAG 介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在不断发展的语言模型世界中,有一种特别值得注意的稳固方法是检索增强生成(RAG),这是一种将信息检索(IR)元素融入文本生成语言模型框架中的过程,以生成类似人类的文本,其目标是比仅由默认语言模型生成的文本更有用和准确。我们将在这篇文章中介绍 RAG 的基本概念,并计划在后续文章中构建一些 RAG 系统。
RAG 概述
我们使用庞大而通用的数据集创建语言模型,这些数据集并没有针对你个人或定制的数据进行调整。为了应对这一现实,RAG 可以将你的特定数据与语言模型的现有“知识”结合起来。为了实现这一点,必须对你的数据进行索引,使其可搜索。当执行由你的数据组成的搜索时,从索引数据中提取相关和重要的信息,可以在查询语言模型时使用,以返回由模型生成的相关和有用的响应。任何对构建聊天机器人、现代信息检索系统或其他类型个人助理感兴趣的 AI 工程师、数据科学家或开发者,了解 RAG 和如何利用自己的数据至关重要。
简而言之,RAG 是一种新颖的技术,通过输入检索功能丰富语言模型,提升了语言模型,将 IR 机制融入生成过程,这些机制可以个性化(增强)模型用于生成目的的固有“知识”。
总结一下,RAG 包括以下高级步骤:
-
从你的定制数据源中检索信息
-
将这些数据作为额外背景添加到你的提示中
-
让 LLM 基于增强的提示生成响应
RAG 相较于模型微调提供了这些优势:
-
RAG 不进行训练,因此没有微调成本或时间
-
定制数据的更新取决于你自己的维护,因此模型可以有效保持最新。
-
在过程中(或之后)可以引用具体的定制数据文档,因此系统更加可验证和可信。
更深入的了解
经过更详细的检查,我们可以说 RAG 系统将经历 5 个操作阶段。
1. 加载:收集原始文本数据——来自文本文件、PDF、网页、数据库等——是许多步骤中的第一步,将文本数据放入处理管道中,使其成为过程中的必要步骤。没有数据加载,RAG 就无法正常工作。
2. 索引:现在你拥有的数据必须进行结构化和维护,以便于检索、搜索和查询。语言模型将利用从内容中创建的向量嵌入提供数据的数值表示,并使用特定的元数据以确保成功的搜索结果。
3. 存储:在创建之后,索引必须与元数据一起保存,确保这一过程不需要定期重复,从而使 RAG 系统的扩展更为轻松。
4. 查询:有了这个索引后,可以使用索引器和语言模型遍历内容,根据各种查询处理数据集。
5. 评估:评估性能与其他可能的生成步骤相比是有用的,无论是在改变现有流程还是在测试这类系统的固有延迟和准确性时。
图片由作者创建
简短示例
参考以下简单的 RAG 实现。假设这是一个用于处理关于虚构在线商店的客户咨询的系统。
1. 加载:内容将来自产品文档、用户评论和客户反馈,存储在多种格式中,如留言板、数据库和 API。
2. 索引:你将为产品文档和用户评论等生成向量嵌入,同时索引分配给每个数据点的元数据,例如产品类别或客户评级。
3. 存储:开发出的索引将保存在向量存储中,这是一个专门用于存储和优化检索向量的数据库,嵌入就是以这种形式存储的。
4. 查询:当客户查询到达时,将根据问题文本在向量存储数据库中进行查找,然后使用语言模型生成响应,利用这些前体数据的来源作为上下文。
5. 评估:系统性能将通过将其与其他选项(如传统语言模型检索)进行比较来评估,衡量指标包括回答正确性、响应延迟和整体用户满意度,以确保 RAG 系统可以进行调整和优化,以提供更优异的结果。
这个示例演练应该让你对 RAG 背后的方法论及其在传达信息检索能力方面的应用有一定了解。
结论
引入检索增强生成(RAG),即结合文本生成和信息检索以提高语言模型输出的准确性和上下文一致性,是本文的主题。该方法允许将存储在索引来源中的数据提取并增强,融入到语言模型生成的输出中。这种 RAG 系统可以比仅仅微调语言模型提供更好的价值。
我们 RAG 之旅的下一步将是学习行业工具,以便实现我们自己的 RAG 系统。我们将首先专注于利用来自 LlamaIndex 的工具,如数据连接器、引擎和应用连接器,以简化 RAG 的集成和扩展。但我们将把这留到下一篇文章。
在即将到来的项目中,我们将构建复杂的 RAG 系统,并考察 RAG 技术的潜在用途和改进。希望在人工智能领域揭示许多新的可能性,并利用这些多样的数据源构建更智能和具备上下文的系统。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的执行编辑,以及机器学习大师的特约编辑,马修致力于让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的人工智能。他的使命是使数据科学社区的知识普及化。马修从 6 岁开始编程。
更多相关主题
重新定义数据可视化:掌握 Pandas 中的时间基础重采样
原文:
www.kdnuggets.com/revamping-data-visualization-mastering-timebased-resampling-in-pandas

图片来源于 Freepik
这篇综合文章将讨论使用 Pandas 库进行时间基础的数据可视化。正如你所知,时间序列数据是一座宝贵的洞察宝藏,通过熟练的数据重采样技巧,你可以将原始时间数据转化为视觉上引人注目的叙事。不论你是数据爱好者、科学家、分析师,还是对揭示时间基础数据中的隐藏故事充满好奇,这篇文章将为你提供重塑数据可视化技能的知识和工具。所以,让我们开始讨论 Pandas 重采样技巧,将数据转化为信息丰富且引人入胜的时间作品。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
为什么需要数据重采样?
在处理基于时间的数据可视化时,数据重采样至关重要且非常有用。它允许你控制数据的粒度,从而提取有意义的见解并创建视觉上引人注目的表示,以更好地理解数据。在下面的图片中,你可以观察到,你可以根据需求对时间序列数据进行上采样或下采样。
图片来源于 SQLRelease
基本上,数据重采样的两个主要目的如下:
-
细粒度调整: 收集大数据可以让你更改数据点的收集或汇总时间间隔。你可以只获取重要信息,而不是噪声。这可以帮助你去除噪声数据,使数据更易于进行可视化。
-
对齐: 这还帮助对齐来自多个来源的数据,这些数据具有不同的时间间隔,确保在创建可视化或进行分析时的一致性。
例如,
假设你从股票交易所获取了某公司每日股价数据,并且你希望在分析中可视化长期趋势,而不包含噪声数据点。因此,你可以通过计算每个月的平均收盘价,将这些日数据重采样为月频率,结果是可视化的数据量减少,你的分析可以提供更好的洞察。
import pandas as pd
# Sample daily stock price data
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'StockPrice': [100 + i + 10 * (i % 7) for i in range(365)]
}
df = pd.DataFrame(data)
# Resample to monthly frequency
monthly_data = df.resample('M', on='Date').mean()
print(monthly_data.head())
在上述示例中,你可以观察到我们将日数据重采样为月间隔,并计算了每个月的平均收盘价,这使你获得了更平滑、噪声更少的股票价格数据表示,便于识别长期趋势和模式以作出决策。
选择正确的重采样频率
在处理时间序列数据时,重采样的主要参数是频率,你必须正确选择,以获得有洞察力和实用的可视化。基本上,数据的细粒度(即数据的详细程度)与数据的清晰度(即数据模式的显现程度)之间存在权衡。
例如,
想象一下你有一年的每分钟记录的温度数据。如果你需要可视化年度温度趋势,使用分钟级数据会导致图表过于密集和混乱。另一方面,如果将数据聚合到每年平均值,你可能会丧失有价值的信息。
# Sample minute-level temperature data
data = {
'Timestamp': pd.date_range(start='2023-01-01', periods=525600, freq='T'),
'Temperature': [20 + 10 * (i % 1440) / 1440 for i in range(525600)]
}
df = pd.DataFrame(data)
# Resample to different frequencies
daily_avg = df.resample('D', on='Timestamp').mean()
monthly_avg = df.resample('M', on='Timestamp').mean()
yearly_avg = df.resample('Y', on='Timestamp').mean()
print(daily_avg.head())
print(monthly_avg.head())
print(yearly_avg.head())
在这个例子中,我们将分钟级温度数据重采样为每日、每月和每年的平均值。根据你的分析或可视化目标,你可以选择最符合你目的的详细级别。每日平均值揭示了每日温度模式,而每年平均值提供了年度趋势的高层次概览。
通过选择最佳的重采样频率,你可以平衡数据细节的数量与可视化的清晰度,确保你的观众能够轻松辨别你想传达的模式和洞察。
聚合方法和技术
在处理基于时间的数据时,了解各种聚合方法和技术至关重要。这些方法使你能够有效地总结和分析数据,揭示时间信息的不同方面。标准聚合方法包括计算总和和均值或应用自定义函数。
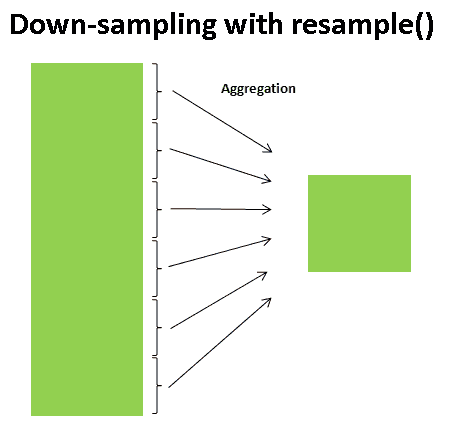
图片来源于 TowardsDataScience
例如,
假设你有一个包含零售店一年内每日销售数据的数据集。你想分析年度收入趋势。为此,你可以使用聚合方法计算每个月和每年的总销售额。
# Sample daily sales data
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'Sales': [1000 + i * 10 + 5 * (i % 30) for i in range(365)]
}
df = pd.DataFrame(data)
# Calculate monthly and yearly sales with the aggregation method
monthly_totals = df.resample('M', on='Date').sum()
yearly_totals = df.resample('Y', on='Date').sum()
print(monthly_totals.head())
print(yearly_totals.head())
在这个例子中,我们使用 sum() 聚合方法将每日销售数据重采样为每月和每年的总数。通过这样做,你可以在不同的粒度层次上分析销售趋势。每月总额提供了季节性变化的见解,而年度总额则提供了年度表现的高层次概览。
根据你的具体分析需求,你还可以使用其他聚合方法,如计算均值和中位数,或根据数据集分布应用自定义函数,这对于问题来说是有意义的。这些方法使你能够通过以符合你的分析或可视化目标的方式总结数据,从而从基于时间的数据中提取有价值的洞察。
处理缺失数据
处理缺失数据是处理时间序列时的一个关键方面,确保即使在处理数据中的空白时,你的可视化和分析仍然准确和有用。
例如,
想象一下你正在处理一个历史温度数据集,但由于设备故障或数据收集错误,一些天的温度读数缺失。你必须处理这些缺失值,以创建有意义的可视化并保持数据的完整性。
# Sample temperature data with missing values
data = {
'Date': pd.date_range(start='2023-01-01', periods=365, freq='D'),
'Temperature': [25 + np.random.randn() * 5 if np.random.rand() > 0.2 else np.nan for _ in range(365)]
}
df = pd.DataFrame(data)
# Forward-fill missing values (fill with the previous day's temperature)
df['Temperature'].fillna(method='ffill', inplace=True)
# Visualize the temperature data
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(df['Date'], df['Temperature'], label='Temperature', color='blue')
plt.title('Daily Temperature Over Time')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.grid(True)
plt.show()
输出:
图片由作者提供
在上面的例子中,你可以看到首先,我们模拟了缺失的温度值(约占数据的 20%),然后使用前向填充(ffill)方法来填补这些空白,这意味着缺失的值被替换为前一天的温度。
因此,处理缺失数据可以确保你的可视化准确地代表时间序列中的潜在趋势和模式,防止空白扭曲你的洞察或误导你的受众。根据数据的性质和研究问题,可以采用各种策略,如插值或向后填充。
可视化趋势和模式
在 pandas 中的数据重采样使你能够可视化顺序或基于时间的数据中的趋势和模式,这进一步帮助你收集洞察并有效地向他人传达结果。因此,你可以找到清晰且信息丰富的数据可视化,突出显示不同的组成部分,包括趋势、季节性和不规则模式(可能是数据中的噪声)。
例如,
假设你有一个包含过去几年每天网站流量数据的数据集。你的目标是可视化未来几年的总体流量趋势,识别任何季节性模式,并发现流量中的不规则峰值或下降。
# Sample daily website traffic data
data = {
'Date': pd.date_range(start='2019-01-01', periods=1095, freq='D'),
'Visitors': [500 + 10 * ((i % 365) - 180) + 50 * (i % 30) for i in range(1095)]
}
df = pd.DataFrame(data)
# Create a line plot to visualize the trend
plt.figure(figsize=(12, 6))
plt.plot(df['Date'], df['Visitors'], label='Daily Visitors', color='blue')
plt.title('Website Traffic Over Time')
plt.xlabel('Date')
plt.ylabel('Visitors')
plt.grid(True)
# Add seasonal decomposition plot
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df['Visitors'], model='additive', freq=365)
result.plot()
plt.show()
输出:
图片由作者提供
在上面的示例中,我们首先创建了一张折线图来可视化网站流量随时间的趋势。这张图描述了数据集的总体增长以及任何不规则的模式。此外,为了将数据分解为不同的组成部分,我们使用了 statsmodels 库中的季节性分解技术,包括趋势、季节性和残差组成部分。
通过这种方式,你可以有效地向利益相关者传达网站的流量趋势、季节性和异常情况,这增强了你从基于时间的数据中提取重要洞察并将其转化为数据驱动决策的能力。
总结
Colab Notebook 链接: colab.research.google.com/drive/19oM7NMdzRgQrEDfRsGhMavSvcHx79VDK#scrollTo=nHg3oSjPfS-Y
在这篇文章中,我们讨论了 Python 中的数据的基于时间的重采样。因此,为了总结我们的讨论,让我们回顾一下文章中涵盖的重要点:
-
基于时间的重采样是一种强大的技术,用于转换和总结时间序列数据,以便获得更好的决策洞察。
-
精确选择重采样频率对平衡数据可视化中的粒度和清晰度至关重要。
-
聚合方法如求和、均值和自定义函数有助于揭示基于时间的数据的不同方面。
-
有效的可视化技术有助于识别趋势、季节性和不规则模式,促进发现的清晰沟通。
-
现实世界中的金融、天气预报和社交媒体分析用例展示了基于时间的重采样的广泛影响。
Aryan Garg 是一名 B.Tech. 电气工程专业的学生,目前正处于本科的最后一年。他对 Web 开发和机器学习领域充满兴趣。他已经追求了这个兴趣,并渴望在这些方向上继续工作。
Aryan Garg**** 是一名 B.Tech. 电气工程专业的学生,目前正处于本科的最后一年。他对 Web 开发和机器学习领域充满兴趣。他已经追求了这个兴趣,并渴望在这些方向上继续工作。
更多相关主题
计算机嗡嗡声:重新审视萨顿的 AI 苦涩教训
原文:
www.kdnuggets.com/2020/11/revisiting-sutton-bitter-lesson-ai.html
回顾理查德·萨顿的 AI 苦涩教训
不久前,在一个与我们今天所居住的世界相差无几的世界里,达特茅斯学院的一个雄心勃勃的项目旨在弥合人类与机器智能之间的差距。那是 1956 年,尽管Dartmouth Summer Research Project并不是第一个考虑思考机器潜力的项目,但它为这一概念命名,并开创了一群有影响力的研究者。在约翰·麦卡锡、马文·明斯基、克劳德·香农和内森尼尔·罗切斯特编写的提案中,作者提出了今天看来颇具天真的雄心:
“我们将尝试找到让机器使用语言、形成抽象和概念、解决目前仅限于人类的问题,并自我改进的方法。如果一组精心挑选的科学家在夏季共同研究这些问题,我们认为可以在一个或多个这些问题上取得显著进展。” – 1955 年达特茅斯夏季人工智能研究项目提案
人工智能的起点
在这段时间里,AI 研究经历了一系列热情的起伏。1956 年流行的方法包括细胞自动机、控制论和信息理论。多年来,专家系统、形式推理、连接主义等方法都曾闪耀过一时。
当前 AI 的复兴是由最新形式的连接主义传承——深度学习驱动的。尽管一些新想法在该领域产生了重大影响(例如注意力机制、残差连接和批量归一化),但关于如何构建和训练深度神经网络的许多思想早在 80 年代和 90 年代就已经提出。然而,今天 AI 或 AI 相关技术的角色显然不是以前那些“AI 春天”中的研究者所预见的。例如,很少有人能预测到广告技术和算法新闻推送的普及及其社会影响,我相信许多人对现今社会缺乏机器人感到失望。

约翰·麦卡锡,达特茅斯提案的共同作者以及“人工智能”一词的创造者。图片* CC BY SA flickr 用户 null0。*
一个归因于约翰·麦卡锡的引用抱怨那些在现实世界中找到实际应用的 AI 技术通常会变得不那么令人印象深刻,并在过程中失去“AI”标签。然而,我们今天看到的并非如此,也许我们可以把这归咎于风险投资和政府资助机构,他们激励了相反的情况。伦敦风险投资公司 MMC 的一项调查发现,2019 年多达 40%的自称为 AI 初创公司的企业实际上并未将 AI 作为其业务的核心组成部分。
深度学习与人工智能研究的区别
深度学习时代与之前的人工智能研究高峰之间的区别似乎取决于我们在摩尔定律的 S 型曲线上的位置。许多人将“ImageNet 时刻”视为当前 AI/ML 复兴的开始,当时一个名为AlexNet的模型以显著的优势赢得了 2012 年 ImageNet 大规模视觉识别竞赛(ILSVRC)。AlexNet 架构与 20 多年前开发的LeNet-5相差不大。
AlexNet 比 LeNet 略大,有 5 层卷积层,而 LeNet 有 3 层,总共有 8 层,而 LeNet 有 7 层(尽管这 7 层包括 2 层池化层)。因此,重大突破来自于实现神经网络原语(卷积和矩阵乘法)以利用图形处理单元(GPU)上的并行执行,以及由 Fei-Fei Li 及其斯坦福实验室开发的ImageNet 数据集的规模和质量。
硬件加速中的苦涩教训
硬件加速是今天深度学习从业者理所当然的事情。这是像PyTorch、TensorFlow和JAX等流行深度学习库的一部分。不断增长的深度学习社区和对 AI/ML 数据产品的商业需求促进了一个协同反馈循环,这推动了良好的硬件支持。随着基于 FPGA、ASIC,甚至光子或量子芯片的新硬件加速器的出现,主要库中的软件支持必定会紧随其后。
ML 硬件加速器和更广泛计算资源对 AI 研究的影响在 Richard Sutton 的一篇简短而(不)著名的文章 “The Bitter Lesson.” 中被简洁地描述。在文章中,Sutton 这个实际上(共同)撰写了 这本书 的人,关于 强化学习,似乎声称 AI 研究者所做的所有勤奋努力和巧妙的黑客行为在宏观层面上几乎没有多少意义。 Sutton 认为 AI 进展的主要驱动力是计算资源的日益丰富,应用于我们已经拥有的简单学习和搜索算法,并且几乎没有硬编码的人类知识。具体来说,Sutton 主张基于尽可能通用的方法的 AI,如无约束的搜索和学习。
许多研究人员对 Sutton 的教训有相反反应也不足为奇。毕竟,这些人中的许多人已经将自己的生活献给了开发巧妙的技巧和理论基础,以推动 AI 的进步。许多 AI 研究者不仅对如何最好地陈述最先进的度量感兴趣,而且对一般智能的本质以及更抽象的,人类在宇宙中的角色有着更深入的探索。 Sutton 的声明似乎支持了这样一个令人不满意的结论:从理论神经科学、数学、认知心理学等领域寻找洞见对于推动 AI 进展是无用的。

甜腻的怀疑者对苦涩教训
对 Sutton 文章的值得注意的批评包括机器人专家 Rodney Brooks 的 “A Better Lesson,” 、来自牛津计算机科学教授 Shimon Whiteson 的 推文序列 以及 Shopify 数据科学家 Katherine Bailey 的 博客文章。 Bailey 认为,尽管 Sutton 对现代 AI 领域中用作度量的有限范围任务的观点可能是正确的,但这种短视完全错过了要点。 AI 研究的最终目的是以有用的方式理解智能,而不是为每个狭隘的基于度量的任务从零开始训练一个新模型,这会在过程中产生巨大的财务和能源成本。 Bailey 认为现代机器学习从业者常常 误把度量当作目标;研究者们并不是为了自身而构建超人类的国际象棋引擎或围棋选手,而是因为这些任务在关键方面似乎体现了人类智能的某些方面。
Brooks 和 Whiteson 认为,Sutton 使用的所有被认为没有人类先验的示例实际上都是大量人类聪明才智的结晶。例如,想象一下没有卷积层的平移不变性的现代 ResNets 可能达到的表现是很困难的。我们还可以识别出当前网络的具体短板,例如缺乏旋转不变性或色彩恒常性,这只是众多例子中的两个。架构和训练细节也往往大量依赖于人类直觉和智慧。即使神经架构搜索(NAS)自动化 有时能找到比人工设计的更优的架构,NAS 算法可用的组件空间也远远小于所有可能操作的空间,而这种缩小有用范围的过程无疑是人类设计师的职责。

Whiteson 认为,复杂性不仅没有消除,而且还需要人类智慧来构建机器学习系统。
对于这段痛苦教训的尖锐批评者与 对深度学习普遍持怀疑态度 的研究人员之间有很大的重叠。尽管计算预算膨胀和对 能源 消耗 的环境担忧不断增加,深度学习仍然因其规模而令人印象深刻。而且,没有任何保证深度学习不会在未来的某个时刻,可能是很快,就遇到瓶颈。
边际收益何时不再能证明额外开支的合理性?深度学习的进展之所以令人惊讶,是因为模型本身可能几乎不可解;模型的表现是一个拥有数百万到数十亿个参数的复杂系统的涌现产物。预测或分析它们最终可能具备的能力是困难的。
也许我们应该从经典的传统人工智能(GOFAI)参考书中吸取教训: “人工智能:一种现代的方法” 由 Stuart Russell 和 Peter Norvig 合著。 在最后一章的结尾处,我们发现了这样一个警告,我们首选的人工智能方法,在我们这里是深度学习,可能就像:
“…试图通过爬树到达月球;人们可以报告稳定的进展,一直到树顶。“ -AIMA, Russel 和 Norvig
作者们正在改述 1992 年由休伯特·德雷福斯所著《计算机不能做什么》一书中的一个类比,该类比经常回到月球旅行的树栖策略。虽然许多原始的智人可能曾尝试这种方法,但实际上达到月球需要从树上下来,开始建立太空计划的基础。
结果证明了一切
尽管这些批评很有吸引力,但它们可能被视为有些酸葡萄的心态。尽管学术界对“更多计算能力”的智力上令人不满的呼声感到厌烦,但大型私人研究机构的研究人员依然因将工程工作主要应用于直接扩展的项目而成为头条新闻。
OpenAI 可能因这种方法而最为臭名昭著。
OpenAI 的关键人员,该公司去年从非营利组织转型为有限合伙企业结构,一直不吝啬他们对大量计算能力的偏爱。创始人 Greg Brockman 和 Ilya Sutskever坚定地属于Richard Sutton 的“苦涩教训”阵营,许多技术人员也如此。这导致了令人印象深刻的基础设施工程壮举,以支持 OpenAI 为实现里程碑而进行的大规模训练。
OpenAI Five 能够击败(人类)Dota 2 世界冠军 Team OG,而这仅仅是让这些代理进行了 45,0000 个模拟年,或大约每天 250 年的游戏时间,才能学会如何玩游戏。这相当于在 10 个月内达到 800 petaflop/s-days。假设世界领先的效率为每瓦 17 Gigaflop/s,这相当于1.1 吉瓦时:相当于一个普通美国家庭 92 年的用电量。
OpenAI 的另一个高调且资源密集的项目是他们的Dactyl 灵巧度项目,使用了 Shadow 机器人手。该项目最终实现了足够的灵巧操作来解决一个魔方(尽管使用了确定性求解器来选择移动)。魔方项目建立在大约13,000 年模拟经验的基础上。DeepMind 的类似项目,如 AlphaStar(384 TPUs 训练 12 个智能体的 44 天,经历了数千年的模拟游戏)或AlphaGo 谱系(AlphaGo Zero: ~1800 petaflop/s 天)也需要大量计算资源。
但它们并不总是达成一致
在 The Bitter Lesson 中注意到的趋势中,有一个显著的例外可以在 AlphaGo 系列的游戏代理中看到,这些代理实际上在达到更好性能时需要的计算量更少。 AlphaGo 谱系确实是一个奇特的案例,无法完全融入 bitter lesson 框架中。是的,该项目开始时使用了大量的 HPC 训练,AlphaGo 在 176 个 GPU 上运行,并在测试时消耗了 40,000 瓦特。但从 AlphaGo 到 MuZero 的每次迭代,在训练和游戏中都使用了更少的能量和计算。
实际上,当 AlphaGo Zero 对战StockFish时,这一深度学习前沿棋类引擎使用的搜索资源要比 StockFish 少得多且更具专用性。虽然 AlphaGo Zero 确实使用了蒙特卡罗树搜索,但它由深度神经网络价值函数引导。Stockfish 采用的 alpha-beta 剪枝搜索更为通用,而 Stockfish 在每轮中评估的棋盘位置大约是 AlphaGo Zero 的 400 倍。
应该让 Bitter Lesson 超越更多专用方法吗?
你会记得,Sutton 提到的无约束搜索是通用方法的一个主要例子。如果我们将 Bitter Lesson 照字面理解,它应该超越执行缩小搜索的更专用方法。相反,我们在 AlphaGo 谱系中看到的是,每一次迭代(AlphaGo,AlphaGo Zero,AlphaZero 和 MuZero)比前一个更具通用能力,但却使用了更专用的学习和搜索。MuZero 用一个学习得到的深度模型来替代所有Alpha前身使用的真实游戏模拟器,用于游戏状态表示、游戏动态和预测。
设计学到的游戏模型代表了比原始 AlphaGo 更多的人类开发,而 MuZero 在通用学习能力方面有所扩展,通过在 57 个 Atari 游戏基准测试中达到 SOTA 性能,以及之前的Alpha模型所学的国际象棋、将棋和围棋。MuZero 每个搜索节点的计算量比 AlphaZero 少 20%,而且在硬件改进的部分帮助下,训练过程中所需的 TPU 数量减少了 4 到 5 倍。
Deepmind 的 AlphaGo 系列机器游戏玩家是深度强化学习进展的一个特别优雅的例子。如果 AlphaGo 团队能够在减少计算需求的同时持续提升能力和通用学习能力,这难道不直接与苦涩教训相矛盾吗?
如果是这样,这对追求通用智能有何启示?许多人认为 RL 是构建人工通用智能的一个很好的候选者,因为它与人类和动物在回应奖励时的学习方式相似。然而,也有其他智能模式被一些人视为 AGI 前驱者的候选者。
语言模型:规模的苏丹
Sutton 的文章重新获得关注的一个原因(它最近甚至被重新发布为 KDnuggets 上的热门文章)是因为引人注目的OpenAI 的 GPT-3 语言模型和 API 的发布。GPT-3 是一个拥有 1750 亿个参数的变换器,超越了由微软的 Turing-NLG保持的语言模型规模的前纪录,超过了 10 倍。GPT-3 也是“太危险而无法发布”的 GPT-2 的 100 倍以上。
GPT-3 的发布是 OpenAI API Beta 宣布的核心部分。基本上,API 让实验者可以访问 GPT-3 模型(但不能调整参数)并控制几个可以用于控制推理的超参数。可以理解的是,幸运获得 API 访问权限的 beta 测试者们对 GPT-3 热情高涨,且结果 令人印象深刻。实验者们构建了基于文本的游戏、用户界面生成器、虚假博客以及大量其他创意用途的巨大模型。GPT-3 显著优于 GPT-2,唯一的重大区别就是规模。
趋势向更大规模的语言模型发展早于大型 GPT 的出现,并且不仅限于 OpenAI 的研究。但自从首次引入“Attention is all You Need.”以来,这一趋势确实得到了快速发展。变换器模型的参数数量已稳步增加到数十亿,如果在一年左右展示一个万亿参数的变换器,我也不会感到惊讶。变换器似乎特别适合通过规模来提升,并且变换器架构不仅限于处理文本的自然语言处理。变换器已经被应用于强化学习、预测化学反应、生成音乐以及生成图像。要了解变换器模型中使用的注意力机制的视觉解释,请阅读这篇文章。
以当前的模型增长速度,几年来有人将训练出一个参数数量与人脑总突触(~100 万亿)相当的模型。科幻小说中充斥着机器通过积累足够的规模和复杂性达到意识和通用智能的例子。这是我们可以期待的变换器发展的最终结果吗?
AI 未来的答案在极端之间
大型变换器的性能确实令人印象深刻,并且由于规模的持续进步似乎符合苦涩的教训。然而,将所有其他 AI 努力排在规模之后仍显得不够优雅和令人满意,同时对能源资源的需求也带来了自身的问题。云端训练让许多大实验室的研究人员远离训练低效的实际感受。但任何在小型办公室或公寓中进行深度学习实验的人,都时刻被工作站后方不断排出的热空气提醒着这一点。

[肖像]( https://en.wikipedia.org/wiki/File:Richard_Sutton ,_October_27,_2016.jpg)* 的理查德·萨顿经CC BY 史蒂夫·朱尔维特森。
训练一个大型 NLP 变换器,进行超参数和架构搜索所产生的碳排放量,往往会比所有其他活动的个人总碳排放量还要大,一个小型研究团队的情况就是如此。
我们知道,智力可以在大约 20 瓦(加上另外约 80 瓦的支持机械)上持续运行。如果你对此有疑问,你应该验证你耳朵之间的存在证明。相比之下,训练 OpenAI Five 所需的能量大于人类玩家的终生卡路里需求,假设 90 年的寿命。
一位细心的观察者会指出,人脑的 20 瓦功耗并不能代表整个学习算法。相反,架构和操作规则是经过 40 亿年黑箱优化过程——进化——的结果。考虑到所有祖先的总能耗,可能使得人类与机器游戏玩家的比较更加有利。即便如此,模型架构和训练算法的集体进步远非纯粹的随机搜索。与动物智力的进化相比,人类推动的机器智能进步显得要快得多。
那么痛苦教训是对还是错?
明显的答案,对于绝对主义者来说可能不尽如人意,它存在于极端之间。注意力机制、卷积层、乘法递归连接,以及许多大模型中常见的机制,都是人类智慧的产物。换句话说,这些是人类认为可能使学习效果更好的先验,它们对于我们迄今看到的规模改进至关重要。完全忽视这些发明而只依赖于摩尔定律和痛苦教训,至少和只依赖于手工编码的专家知识一样短视。
配置错误的优化过程可以运行到宇宙的热寂而始终无法解决问题。牢记这个教训对获得规模效益至关重要。
原文。经许可转载。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
使用 PandasGUI 彻底改变数据分析
原文:
www.kdnuggets.com/2023/06/revolutionizing-data-analysis-pandasgui.html
在当今数据驱动的世界中,有效的数据分析对企业至关重要,而 Pandas,一个用于处理和清洗数据的 Python 库,已成为一个宝贵的资产。尽管对于初学者或那些喜欢更直观的学习方法的人来说并不容易快速掌握,但 PandasGUI 提供了一个令人惊叹的解决方案:一个具有图形用户界面的库,简化了数据操作和可视化能力。本文将介绍如何安装它,并展示其卓越的功能,这些功能可以提升数据分析能力。
由Mateusz Butkiewicz拍摄,图片来源于Unsplash
开始使用 PandasGUI
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
要开始使用 PandasGUI,第一步是下载其软件包。你可以通过在命令行中运行以下命令来完成:
pip install pandasgui
现在你可以使用以下命令加载和导入它:
import pandas as pd
import pandasgui
如果你使用的是除了 Windows 以外的其他操作系统,你可能会遇到由于缺少环境变量 APPDATA 而导致的一些问题。如果你使用的是 Mac OS 或 Linux 并尝试导入 PandasGUI,你将遇到类似的错误:

解决这个问题的一个简单方法是将环境变量的值设置为空字符串。这样,你可以绕过任何错误,并让代码继续运行——这是一个高效的解决方案,可以迅速缓解当前的问题。
import os
os.environ['APPDATA'] = ""
现在你可以没有错误地导入它。你可能会收到一个警告信息,这没关系。这个警告的原因是 Mac OS 中缺少某些推荐接口的实现,因此系统给出了这个警告。

最后一步是加载数据集以演示该库的功能。你可以加载你选择的结构化数据集,也可以使用 PandasGUI 提供的数据集。在本文中,我们将使用 PandasGUI 库附带的 Titanic 数据集。
from pandasgui.datasets import titanic
现在,我们准备启动 PandasGUI。只需调用如下代码中的 show() 函数:
pandasgui.show(titanic)
一旦执行这些命令,将会打开一个新窗口,显示你上传的数据框。
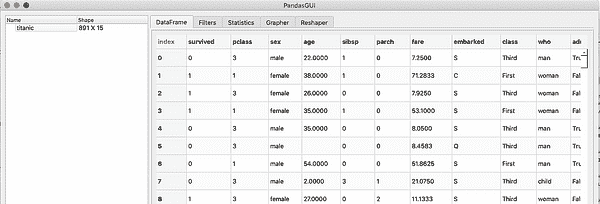
PandasGUI 显示的 Titanic 数据框
PandasGUI 功能
界面相当直观。它包括以下组件。我将在后面的子部分中介绍它们。
-
查看和排序数据框
-
重新调整数据框
-
数据框过滤
-
摘要统计
-
交互式绘图
查看和排序数据框
PandasGPU 的第一个功能是查看和排序数据框,支持升序和降序。这是数据探索的重要步骤,可以像下面的图像中所示那样轻松完成:
查看和排序数据框
重新调整数据框
PandasGUI 提供了两种方法来重新调整数据框,即 pivot 和 melt。Pivot 通过将值从一列移动到几列来转换数据框。当你试图围绕特定列进行数据重构时,可以使用此功能。通过指定索引和用于 pivot 操作的列,你可以更轻松地重新调整数据框。
另一方面,melt 方法使你能够对数据框进行反透视,将多个列合并为一个列,同时保持其他列作为变量。此功能特别适合从宽格式转到长格式或标准化数据集时使用。
在下面的 gif 中,我们将使用 pivot 方法来重新调整 Titanic 数据框:
使用 pivot 重新调整数据框
数据框过滤
在许多情况下,你可能希望根据某些条件过滤数据集,以便进一步了解数据或从数据集中提取特定切片。要使用 PandasGUI 对数据应用过滤器,首先你需要进入过滤器部分并编写每个过滤器,然后应用它。假设我们想要仅获取以下乘客:
-
男性
-
属于 Pclass 3
-
幸存于海难
-
年龄在 30 到 40 之间
因此,我们将对数据集应用以下四个过滤器:
-
性别 == ‘male’
-
Pclass == ‘3’
-
幸存 == 1
-
30 < 年龄 < 40
在下面的 gif 中是对 Titanic 数据集应用这四个过滤器的逐步指南:
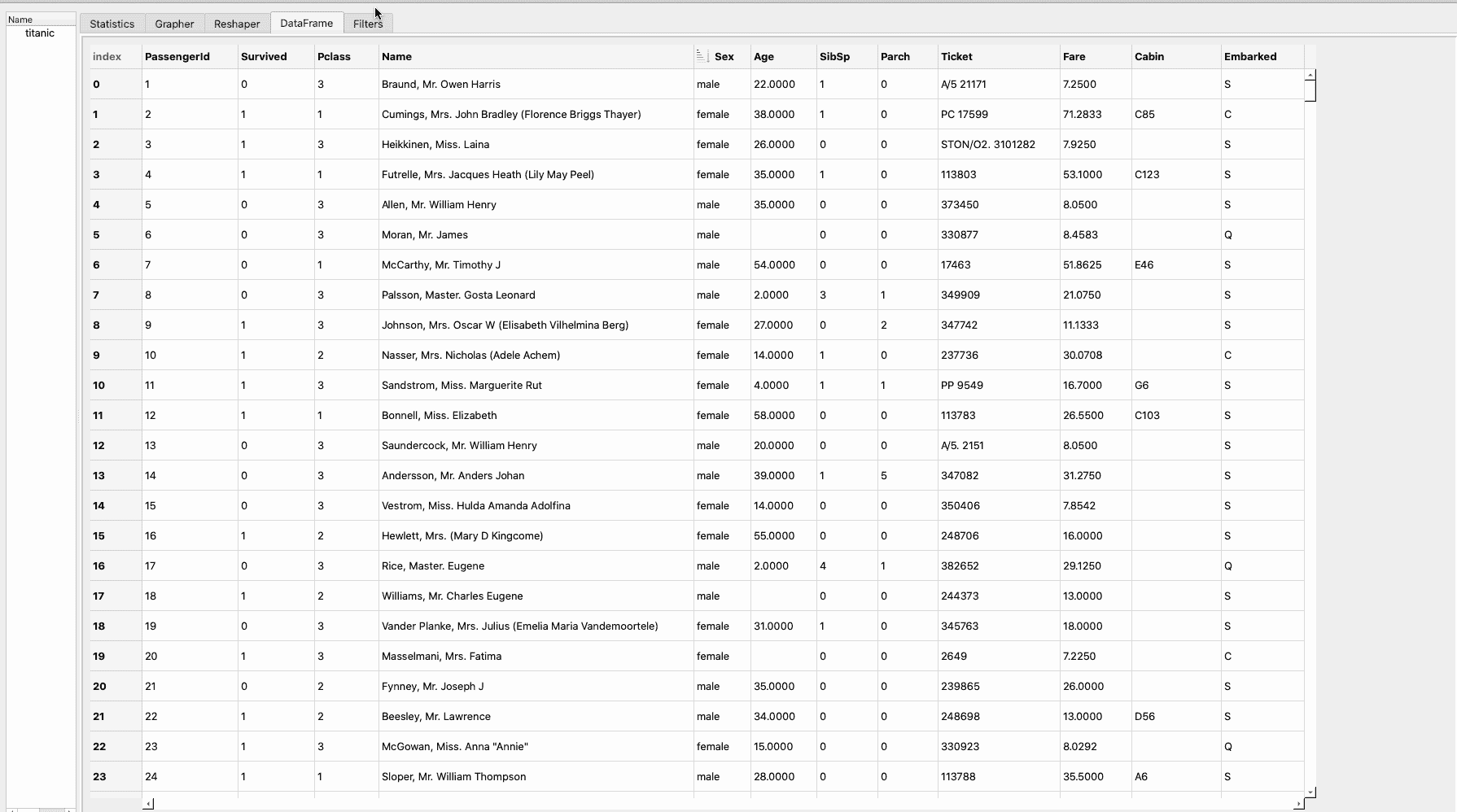
摘要统计
你还可以使用 PandasGUI 提供 DataFrame 的详细统计概览。这将包括每列的均值、标准差、最小值和最大值。
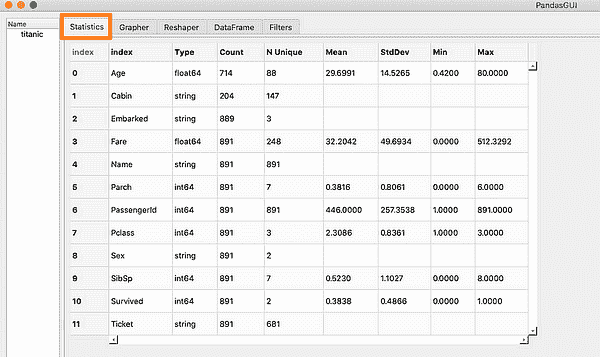
互动绘图
最后,PandasGUI 为数据集提供了强大的互动绘图选项,包括:
-
直方图
-
散点图
-
折线图
-
条形图
-
箱形图
-
小提琴图
-
3D 散点图
-
热图
-
等高线图
-
饼图
-
SpLOM 图
-
词云

在下面的 gif 中,我们将为数据集创建三个互动图:饼图、条形图和词云。
本文重点介绍了 PandasGUI 的功能,这是一种强大的库,为广泛使用的 Pandas 库增加了图形用户界面。我们首先演示了它的安装,加载了一个示例数据集,并探索了如过滤、排序和统计分析等功能。
参考文献
Youssef Rafaat 是计算机视觉研究员和数据科学家。他的研究专注于为医疗保健应用开发实时计算机视觉算法。他还在营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关内容
机器学习数学:开启数据科学和人工智能的大门
原文:
www.kdnuggets.com/2018/07/rhan-math-machine-learning-ebook-course.html
,作者理查德·韩。赞助帖子。
从自动驾驶汽车和推荐系统到语音和面部识别,机器学习是未来的发展方向。你是否希望学习机器学习背后的数学,以进入数据科学和人工智能的激动人心的领域?目前并没有很多资源提供简单详细的示例,并一步步引导你学习这些主题。
这本电子书不仅解释了涉及的数学内容和令人困惑的符号,还直接向你介绍了机器学习的基础主题。这本书将以一种顺畅自然的方式帮助你入门机器学习,为更高级的主题做准备,并打破机器学习复杂、困难和令人生畏的观点。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关主题
机器学习的数学
原文:
www.kdnuggets.com/2019/01/rhan-math-machine-learning-ebook.html
赞助帖子。
机器学习的数学,作者理查德·韩。

从自动驾驶汽车和推荐系统到语音和面部识别,机器学习是未来的发展方向。你是否想学习机器学习背后的数学,以进入数据科学和人工智能的激动人心的领域?目前并没有许多资源提供简单详细的例子,并且一步一步地讲解这些主题。
这本电子书 不仅解释了涉及的数学类型和混淆的符号,还直接介绍了机器学习中的基础主题。这本书将帮助你以顺畅自然的方式入门机器学习,为更高级的主题做好准备,打破机器学习复杂、困难和令人畏惧的观念。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
为你的数据集选择合适的聚类算法
原文:
www.kdnuggets.com/2019/10/right-clustering-algorithm.html
数据聚类是安排正确且全面数据模型的关键步骤。为了进行分析,信息的量应该根据共性进行分类。主要问题是,哪种共性参数提供了最佳结果——以及“最佳”的定义到底意味着什么。
这篇文章对于初学数据科学的人员或希望回顾相关主题的专家将非常有用。它包含了最广泛使用的聚类算法,以及对这些算法的深刻评析。根据每种方法的特点,提供了关于其应用的建议。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
四种基本算法及其选择方法
根据聚类模型的不同,区分出四类常见的算法。总共有不少于 100 种算法,但它们的受欢迎程度相对适中,以及它们的应用领域。
基于连接性的聚类
基于计算整个数据集对象之间距离的聚类称为基于连接性的聚类,或称为层次聚类。根据算法的“方向”,它可以联合或相反地分割信息数组——凝聚型和分裂型的名称正源于这种变化。最受欢迎且合理的类型是凝聚型,你从输入数据点的数量开始,然后将这些点逐渐联合成越来越大的聚类,直到达到限制。
基于连接性的聚类最显著的例子是植物的分类。数据集的“树”从特定物种开始,到达几个植物界,每个界由更小的聚类(门、纲、目等)组成。
应用基于连接性的算法后,你会得到一个数据树状图,它展示了信息的结构,而不是其在簇中的明确分离。这种特性可能既有利也有害:算法的复杂性可能过高,或者对几乎没有层次结构的数据集来说根本不适用。它还表现出较差的性能:由于迭代次数过多,完整处理将花费不合理的时间。此外,使用层次算法无法获得精确的结构。
与此同时,从计数器中获取的输入数据包括数据点的数量,这对最终结果影响不大,或预设的距离度量,该度量也是粗略和近似的。
基于质心的聚类
基于质心的聚类,凭我的经验,由于其相对简单性,是最常见的模型。该模型旨在将数据集中的每个对象分类到特定簇中。簇的数量(k)是随机选择的,这可能是该方法的最大“弱点”。这种 k-means 算法在机器学习中尤其受欢迎,因为它与 k-最近邻 (kNN) 方法类似。
计算过程包含多个步骤。首先,选择输入数据,即数据集应被划分的粗略簇数。簇的中心应尽可能远离彼此,这将提高结果的准确性。
其次,算法计算数据集中每个对象与每个簇之间的距离。最小坐标(如果我们谈论的是图形表示)决定了对象被移动到哪个簇中。
之后,根据所有对象坐标的均值重新计算簇的中心。算法的第一步会重复,但使用重新计算的新簇中心。这样的迭代会继续,直到达到某些条件。例如,算法可能在簇中心没有移动或从上一次迭代中移动不大时结束。
尽管 k-means 在数学和编码上都很简单,但它仍有一些缺点,使我无法在所有可能的地方使用它。这些缺点包括:
-
每个簇的边缘不精确,因为优先级设置在簇的中心,而不是其边界;
-
无法创建一个可以被分类到多个聚类中且分类程度相同的数据集结构;
-
需要猜测最佳的k数量,或需要进行初步计算以指定该度量。
期望最大化聚类
期望最大化算法则允许避免这些复杂性,同时提供更高的准确度。简单来说,它计算每个数据点与我们指定的所有聚类的关系概率。用于这种聚类模型的主要“工具”是高斯混合模型(GMM)——即数据点一般遵循高斯分布的假设。
k-means 算法基本上是 EM 原理的简化版本。它们都需要手动输入聚类数量,这也是这些方法的主要复杂之处。除此之外,计算原理(无论是 GMM 还是 k-means)都很简单:聚类的近似范围随着每次新的迭代逐渐确定。
与基于质心的模型不同,EM 算法允许点被分类到两个或多个聚类中——它只是为每个事件提供可能性,从而进行进一步分析。更重要的是,与 k-means 中聚类以圆形视觉呈现不同,EM 算法中每个聚类的边界组成不同尺寸的椭球。然而,该算法对于数据点不遵循高斯分布的数据集将无效。这是该方法的主要缺点:它更适用于理论问题,而不是实际测量或观察。
基于密度的聚类
最终,基于密度的聚类,也就是数据科学家心中的非官方最爱,登场了。这个名称包含了模型的主要点——将数据集划分为聚类,计数器输入ε参数,即“邻域”距离。如果对象位于ε半径的圆(球体)内,则它与该聚类相关。
步步进行,DBSCAN(基于密度的空间聚类算法)算法检查每个对象,将其状态更改为“已查看”,将其分类为聚类或噪声,直到整个数据集处理完毕。DBSCAN 确定的聚类可以具有任意形状,因此非常准确。此外,该算法无需计算聚类的数量——它会自动确定。
尽管如此,即便是像 DBSCAN 这样的杰作也有一个缺点。如果数据集包含变密度的簇,该方法效果较差。如果对象的分布过于接近,而且 ε 参数难以估计,这也可能不是你的选择。
总结
总而言之,不存在所谓的错误选择的算法——有些算法只是更适合特定的数据集结构。为了总能选择最佳(即更合适)的算法,你需要深入了解它们的优缺点及其特点。
某些算法可能从一开始就会被排除,例如,如果它们与数据集规格不符。为了避免奇怪的工作,你可以花一点时间记住信息,而不是选择试错的路径并从自己的错误中学习。
我们希望你总是能够首先选择最佳算法。继续保持出色的工作!
乔什·汤普森 是 数据科学硕士 的首席编辑。他负责撰写案例研究、操作指南和关于 AI、ML、大数据以及数据专家辛勤工作的博客文章。在闲暇时间,他喜欢游泳和摩托车骑行。
更多相关内容
如何提出可以用数据回答的正确问题
原文:
www.kdnuggets.com/2021/03/right-questions-answered-using-data.html
评论

照片由 You X Ventures 提供,来自 Unsplash。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据科学是一个跨学科领域,它使用科学方法、过程和算法从数据中提取知识和洞见。数据科学领域有几个子领域,如数据挖掘、数据转换、数据可视化、机器学习、深度学习等。在本文中,我们将重点讨论如何提出可以通过数据回答的有意义的问题。任何数据分析的质量都取决于你提出正确问题的能力。以下提示将帮助你提出可以用数据解决的正确问题。
-
探索你的数据:在对数据进行任何分析之前,重要的是仔细探索可用的数据。这将帮助你了解数据的范围、质量、类型(有序或分类;静态或动态)、数据中的模式以及特征之间的关系。
-
确定使用数据解决的问题类型:根据你的数据集,待解决的问题可能属于以下类别之一:描述性分析、预测性分析或规范性分析。这三类数据科学任务将在下面的案例研究部分详细讨论。
-
了解你作为数据科学家的局限性:数据科学家可能对感兴趣的系统缺乏领域知识。例如,根据你工作的组织,你可能需要与工程师(工业数据集)、医生(医疗数据集)等团队合作,以确定在模型中使用的预测特征和目标特征。例如,一个工业仓库系统可能有传感器实时生成数据以跟踪仓库操作。在这种情况下,作为数据科学家,你可能对该系统没有技术知识。因此,你需要与工程师和技术人员合作,让他们指导你决定哪些特征是重要的,哪些是预测变量和目标变量。因此,团队合作对于整合项目的不同方面至关重要。根据我在一个工业数据科学项目中的个人经验,我们的团队必须与系统工程师、电气工程师、机械工程师、现场工程师和技术人员合作了 3 个月,仅仅是为了理解如何用可用数据框定正确的问题。这样的多学科问题解决方法在现实世界的数据科学项目中是至关重要的。
我们现在将探讨数据科学项目的不同案例研究以及从数据中需要解答的问题。
描述性数据分析
在描述性分析中,你会关注于研究数据集中特征之间的关系。数据可视化在这里发挥着至关重要的作用。你需要决定适合当前项目的数据可视化类型。可能是散点图、条形图、折线图、密度图、热图等。以下是一些数据可视化项目的示例。
简单条形图:这里的项目是展示 7 个工业化国家的电动车市场份额。
图 1. 2016 年选定国家的电动车市场份额。图片由 Benjamin O. Tayo 提供。
生成图 1 所用的数据集和代码可以在这里找到:2016 年电动车全球市场份额。
带有分类变量的条形图:这里的项目是展示来自 3 家公司(Best Buy(BBY)、Walgreens(WGN)和 Walmart(WMT))的营销邮件。
图 2. 2018 年来自 Best Buy(BBY)、Walgreens(WGN)和 Walmart(WMT)的广告邮件数量。图片由 Benjamin O. Tayo 提供。
用于生成图 2 的数据集和代码可以在这里找到:个人营销电子邮件的条形图
比较条形图:这里的项目是比较按技能划分的全球科技职位数量。

图 3. 2020 年全球按技能划分的工作数量。图片来源:Benjamin O. Tayo。
热图绘制:这里的问题是研究和量化数据集中特征之间的相关性。
图 4. 显示数据集中各特征之间相关系数的协方差矩阵图。图片来源:Benjamin O. Tayo。
天气数据图:这里的问题是显示 2005 年至 2014 年的记录温度。
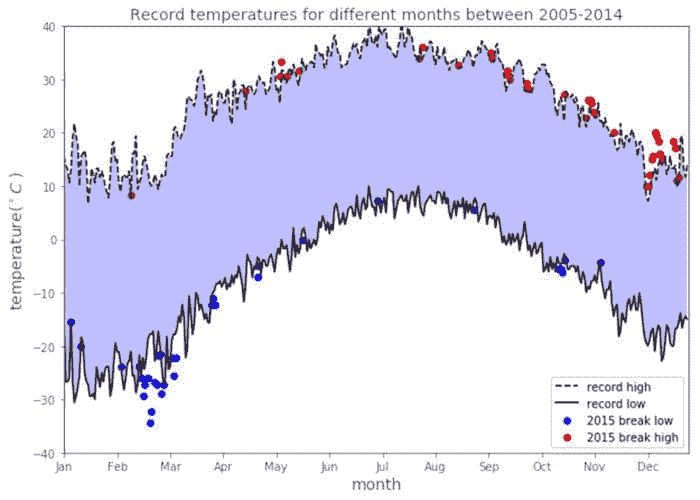
图 5. 2005 年至 2014 年不同月份的记录温度。图片来源:Benjamin O. Tayo。
预测数据分析
在预测分析中,目标是使用可用数据构建一个模型,然后用这个模型对未见数据进行预测。这里要构建的模型类型将取决于目标变量的类型。如果目标变量是连续的,可以使用线性回归;如果目标变量是离散的,可以使用分类。规范数据分析的框架在下面的图 6 中说明。

图 6. 机器学习项目工作流程示意图。图片来源:Benjamin O. Tayo
预测分析的工作流程通常包括 4 个主要阶段:问题定义、数据分析、模型构建和应用。
A. 问题定义
这是你决定要解决什么类型的问题,例如:将电子邮件分类为垃圾邮件或非垃圾邮件的模型、将肿瘤细胞分类为恶性或良性的模型、通过将电话路由到不同类别来改善客户体验的模型,以便由具有正确专业知识的人员接听电话、预测贷款是否会逾期(违约)的模型、基于不同特征或预测因子的房屋价格预测模型等。
B. 数据分析
这是你分析用于构建模型的数据的地方。它包括特征的数据可视化、处理缺失数据、处理分类数据、编码类标签、特征的标准化和规范化、特征工程、降维、数据划分为训练集、验证集和测试集等。
C. 模型构建
在这里,你需要选择你希望使用的模型,例如线性回归、逻辑回归、KNN、SVM、k-means、蒙特卡洛模拟、时间序列分析等。数据集必须被划分为训练集、验证集和测试集。使用超参数调优来微调模型,以防止过拟合。通过交叉验证来确保模型在验证集上的表现良好。经过微调后的模型会被应用于测试数据集。模型在测试数据集上的表现大致等于当模型用于对未见数据进行预测时的预期表现。
D. 应用
在这个阶段,最终的机器学习模型投入生产,以开始改善客户体验或提高生产力,或决定银行是否应批准借款人信用等。模型在生产环境中进行评估,以评估其性能。这可以通过将机器学习解决方案的性能与基线或对照解决方案进行比较,使用如 A/B 测试等方法来完成。在从实验模型到实际生产线表现的过程中遇到的任何错误都需要被分析。这些错误可以反馈到原始模型中,用于微调模型以提高其预测能力。
预测数据分析项目的一个例子可以在这里找到:机器学习过程教程。
处方数据分析
有时,可用的数据可能仅作为样本数据,用于生成更多的数据。生成的数据可以用于处方分析,推荐行动方案。一个例子是贷款状态预测问题:使用蒙特卡洛模拟预测贷款状态。
总之,我们讨论了一些使用可用数据提出正确问题的技巧。对数据进行的任何分析的质量都取决于你提出正确问题的能力。因此,在使用数据进行任何类型的分析之前,提出正确的问题是很重要的。
相关:
更多相关话题
ChatOps/LMOps 的崛起
作者提供的图片
我们越来越多地使用消息应用程序。无论是 WhatsApp 还是 Telegram - 它们已经成为我们生活的一部分。随着这些消息应用程序的兴起,聊天机器人也在上升。我们看到越来越多的企业和消费者从它们的能力中受益。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
什么是 ChatOps?
ChatOps 代表聊天操作。它是利用聊天机器人、聊天客户端或其他实时通信工具来促进软件开发和操作任务。这是对这些操作任务的自动化处理,有些 ChatOps 甚至能够控制公司整个基础设施。
一系列开发和操作工具被放入一个流程中,以提供协作平台。这使团队能够更有效地沟通,并更好地管理他们的工作流程。流行的协作平台示例包括 Slack 和 Microsoft Team。
ChatOps 的主要目标是将对话从典型的消息应用程序(如电子邮件)转移到业务聊天工具,使应用程序能够承担这些任务,减轻员工的工作负担。
ChatOps 工具
部署 ChatOps 环境的三大主要分类工具包括:
-
通知系统
-
聊天机器人 - 例如,Hubot
-
聊天室集成工具 - 例如,Slack
许多人最常接触的 ChatOps 形式是聊天机器人。它们是人工智能系统,通过消息、文本和语音实现用户互动。
ChatOps 的开创者是 GitHub,作为一种通过聊天机器人自动化大多数与操作相关的任务的方法。
ChatOps 和聊天机器人的区别
ChatOps 主要关注公司如何简化操作并增加团队之间的协作。它有助于指导基于对话的协作工具,如聊天机器人。
ChatOps 的目标是帮助促进工作流程中的步骤,以及快速解决问题所需的行动。聊天机器人允许用户简单对话,并将其引导到所需的确切内容。
聊天机器人并不是 ChatOps 的必需品。它们是用来帮助创建从 ChatOps 洞察中获得的自动化流程的工具。
什么是 LMOps?
所以现在你可能在想我为什么把 LMOps 放在标题里,对吧?通过数据和统计测试,聊天机器人能够预测一系列单词的概率。它们建立在语言模型上。因此有了 LMOps(语言模型操作)。
LMOps 旨在利用基础研究和技术来构建 AI 产品,并特别在大型语言模型(LLMs)和生成 AI 模型上实现 AI 能力。
微软研究院开源了LMOps,提供了一系列工具来帮助改善作为生成 AI 模型输入的文本提示。
研究表明,随着语言模型(LMs)变得越来越大,它们自然会变得更能在上下文中学习。
如果你想了解更多关于 LLM 的信息,可以查看这个博客:大型语言模型的顶级免费课程。你还可以看看:顶级开源大型语言模型。
最近一个流行的 LLMs 示例是 ChatGPT AI 聊天机器人。我们都知道它变得多么受欢迎。每个人都在谈论它。这是 ChatOps 的崛起吗?
ChatOps 中的自然语言处理
自然语言处理(NLP) 是计算机/软件/应用程序通过语音和文本检测和理解人类语言的能力,就像我们人类一样。
NLP 帮助你的聊天机器人和其他聊天工具分析和理解自然语言,并与客户进行沟通。
但你需要明白,NLP 在每个 ChatOps 中可能并不重要——这取决于你用它来做什么。如果你使用 ChatOps 来帮助处理客户互动、参与、呼叫中心等——你将需要 NLP。它使 ChatOps 工具能够尽可能准确地回答尽可能多的问题。
然而,使用 NLP 和 LLMs,你将能够构建更好、更准确的 ChatOps 工具。
ChatOps 正在帮助公司自动化任务,并在内部和外部进行更好的沟通。随着 LLMs 的最新进展,它们有很大的可能性会驱动下一代聊天机器人。
ChatOps 的好处
自动化
自动化你的任务是节省时间的好方法。如果你的文档和资源被保存在一个存储库中,它们可以被集中到一个通讯平台中。然后,ChatOps 工具可以执行重复的任务和操作,并专注于更具协作性的工作。
上下文协作
必须浏览大量文件和文档以找到你所需的内容,对于许多公司来说,这可能是一个大麻烦和时间消耗。你的公司越大,文档就越多。
与其将资源分散到多个渠道,并需要翻阅这些渠道以获取上下文信息,不如使用 ChatOps 在几秒钟内轻松获取最新的上下文信息。
生产力和员工参与度
不同团队之间的协作使员工变得更高效和投入。科技公司实时访问上下文数据,从而节省了工作流程中的时间。
通过 ChatOps 实现自动化任务,这减少了大量繁琐的工作,使员工能够更加投入,并专注于其他任务。
总结
我们已经迎来了 ChatGPT 的发布,并了解了 GoogleBard。人们争相尝试这些聊天机器人,许多人和公司从中受益。话虽如此,由于聊天机器人源自 ChatOps,我们很可能会看到更多关于 ChatOps 的发展。
尼莎·阿雅 是一名数据科学家、自由技术写作人员以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。她还希望探索人工智能如何能够促进人类寿命的延续。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
GPU 数据库的崛起
评论
作者:Ami Gal,CEO SQream。
你可能没有意识到,但今年我们设计和使用计算资源的方式发生了重要的变革。这个变化是什么呢?许多企业和云服务提供商开始从传统的中央处理单元(CPU)处理转向使用图形处理单元(GPU)。GPU 数据库是这一趋势中的最新发展,它们有潜力彻底改变数据库的运作方式。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT

这就是它们如何改变游戏规则及其最佳应用领域:
GPU 数据库的好处
在对大量数据执行重复操作时,GPU 数据库提供了显著的改进。这是因为 GPU 每张卡上通常有成千上万的核心和高带宽内存。
GPU 提供了许多独特的好处;
-
更快速的创新。GPU 仍然遵循阿姆达尔定律,效率提升通常是 CPU 的两倍,且发布周期更快。
-
相比于 CPU,GPU 在处理相同工作负载时通常快 10 倍至 100 倍。
-
GPU 比 CPU 小得多(比 CPU 小 6.5 倍至 20 倍)。仅 16 台 GPU 加速服务器就能达到 1000 台 CPU 集群的性能。
-
实时可视化和处理数据的能力。由于数据本身就在强大的图形渲染引擎上,因此结果以闪电般的速度显示出来!
-
数据摄取速率非常快
-
接近实时的数据探索——实时数据探索和快速摄取速率通常意味着数据科学家和机器学习算法从使用 GPU 中受益良多。
GPU 数据库的亮点
就在一两年前,数据库领域的许多人还将 GPU 数据库视为一种时尚,可能只适用于内存数据库旁的小众领域。他们认为传统数据库仍然是最佳选择。
然而,一些创新公司并没有这样看待它。GPU 数据库的使用迅速扩展,安装遍及所有垂直行业——包括金融、电信,甚至是 notoriously 缓慢发展的政府部门。为什么?简单来说,GPU 数据库在用于分析时表现出色,投资却仅为其一小部分。
GPU 数据库是对 Hadoop 的完美补充,因为 Hadoop 从未设计用于关系数据分析。可以通过美国邮政服务的例子来理解这一优势,该服务现在使用一排 GPU 服务器。美国邮政服务覆盖了 1.54 亿个地址,分布在 20 万个投递路线中,并分析每个投递员的位置信息。因此,可以想象他们有一个大型数据库。
有了这些数据,他们可以估计交付时间,向监督者提供实时通知,并优化临时路线。得益于他们的 GPU 数据库,他们可以在加载网页的时间内处理这些复杂的查询。这非常令人印象深刻。
GPU 数据库为广告技术、金融、电信、零售、安全/IT,甚至能源行业提供了巨大的机会。它们在国防情报领域也得到了广泛应用。
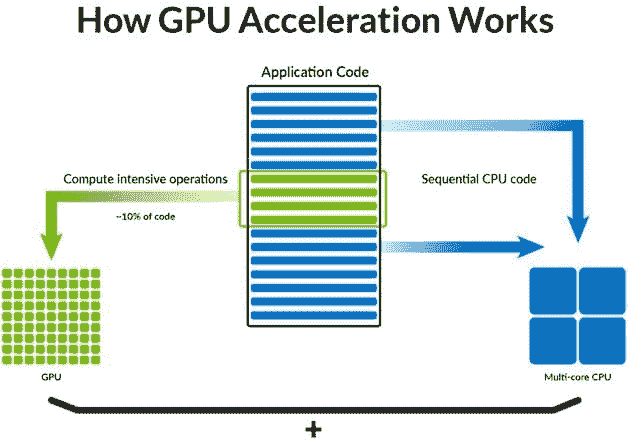
谁从 GPU 数据库中受益?
尽管所有业务部门从更快的查询、更快的数据摄取和降低的 IT 成本中获益似乎微不足道,但实际上是数据科学家从 GPU 数据库中获益最大。
超快的数据摄取和查询意味着数据科学工作的典型周期从几天减少到几小时。其他工作负载可能从几小时减少到几分钟甚至几秒钟。缩短这些业务关键数据科学和机器学习工作负载的周期,将数据科学家从普通的“二级”数据库用户提升为 GPU 数据库的主要受益者。
GPU 数据库项目如何实施?
- 大多数 GPU 数据库在云环境中运行,环境范围从 IBM Bluemix 到 Amazon AWS。不过,也可以在本地数据库和混合设置中运行。一旦数据库设置完成,使用包括在内的行业标准驱动程序通过标准 SQL 查询数据:
-
JDBC, ODBC
-
Python, Jupyter, sklearn…
-
R 和其他机器学习库
之后,扩展通常就像在系统中添加另一块 GPU 一样简单。由于每个 GPU 具有如此强大的计算能力,添加新服务器的情况较少。实际上,使用某些 GPU 数据库,最多可以在标准的 2U 服务器中存储和查询高达 100TB 的原始数据。
大多数 GPU 数据库的整个设置过程通常非常简单,几乎不需要数据建模,也不需要新的或昂贵的开发和使用技能。大多数 GPU 数据库也通常与您的生态系统兼容。它们与您现有的数据源、数据采集工具,甚至您的 BI、报告、分析和可视化工具配合良好。
最后思考
鉴于数据量现在每两年翻一番,预计到年底,存储系统将存储约 17.6 万亿字节的数据。然而,大数据的价值在于其分析速度。快速分析能让你的数据以你尚未想象的方式为你的组织增加价值。
如果你的业务依赖于传统数据库,你应该考虑适合你的 GPU 数据库。毕竟,对系统的需求只会持续增加。
简介: 艾米·加尔 是 SQream 的首席执行官兼联合创始人。
相关:
-
深度学习 – 过去、现在和未来
-
机器学习中的并行性:GPUs、CUDA 和实际应用
-
数据分析的 4 种类型
主题更多
机器学习工程师的崛起
原文:
www.kdnuggets.com/2020/11/rise-machine-learning-engineer.html
评论
作者 Edward Bullen,Telstra 数据工程和数据科学负责人。

初期 — 数据科学家
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在 2010 年代初期,大数据的炒作真正起飞。随着对高级分析和分析非结构化数据的期望增加,“数据科学家”这一角色出现在 Gartner 炒作周期的上升阶段(见下图)。
与此同时,实施 Gartner 图表中提到的各种重要新数据平台(例如 Map Reduce 和其他分布式系统及数据库平台即服务)的挑战开始显现,这些挑战也开始出现在 Gartner 炒作周期的下滑阶段。这些平台并没有神奇地为数据科学家提供所需的数据,而且显然需要大量的设计和工程工作来将这些数据平台与数据科学家的需求对齐。此外,围绕 NoSQL 数据库的巨大炒作和期望也在发展,但这主要集中在 Web 规模应用和敏捷开发的需求上,而不是数据分析的需求上。
大多数人已经达到的阶段 — 一半的路程
数据与分析之间的脱节导致了幻灭、挫败感,并且无法完成许多数据科学和分析项目,因为数据部分缺失。
到 2015 年,大数据已经被从炒作周期中移除(参见 www.datasciencecentral.com/profiles/blogs/big-data-falls-off-the-hype-cycle),分析和数据科学的世界将希望寄托在新的数据平台技术上,如Apache Spark和数据湖。

数据工程师的登场
因此,数据工程师的角色应运而生,对这一职位的需求猛增——到 2020 年,根据www.itjobswatch.co.uk/,英国所有 IT 职位中有 1.5%与数据工程相关——为了对比,所有 IT 职位中有 1.2%是为网页开发而招聘的:
有趣的是,同时在 2015 年,对机器学习的期望和希望被认为达到了顶峰。机器学习提供了一种利用所有这些数据的方法。
需要解决的新问题——我们如何将其投入生产?
赫斯·罗宾逊的煎饼机。
随着数据工程师角色的成熟,这些专家开始解决数据科学家所有的数据来源和处理问题,一个新的问题出现了——如何将所有这些机器学习模型部署到生产中(即,让它们运行实际的业务部分),现在数据科学家已经获得了他们所需的数据?
到 2019 年,对机器学习的关注提升到了一个新的水平,并进入了一个完全不同的 Gartner Hype-Cycle,其中考虑了多种类型的机器学习和人工智能技术及应用场景:twitter.com/kdnuggets/status/1234871536391245824
进入机器学习工程师的角色
要让机器学习解决方案对其部署的业务、研究机构或非政府组织具有价值,它需要:
-
与实时数据源集成
-
保持可靠、稳健和准确
-
实际上能够被其他人使用——可能是许多其他人和应用。
从根本上说,机器学习或“人工智能”解决方案只是一种应用算法或数学于数据的软件产品。
为了实现一个集成的、稳健且可扩展的软件产品,将需要软件源代码控制和自动化测试框架,用于将更改和更新合并到发布版本中。这使得团队成员能够在一个超越数据科学家在 Jupyter(IPython)笔记本中演示的概念的软件产品上进行协作。
此外,这需要一个能够应对硬件和网络故障并且能够扩展以满足需求的架构作为支持。
最终,由于领域的性质,应用将会高度依赖数据,这方面的要求比典型的网络应用或事务系统更为复杂。很可能会有许多大规模数据聚合需求和复杂的数据特征工程方面的要求,或许还会结合高吞吐量的数据流环境。
为了实现这一点,必须跨越多个学科——数据架构和工程、数据科学和统计以及DevOps 或软件工程——机器学习工程师的角色由此诞生:
机器学习工程师不仅仅是构建,他们还需要设计。
机器学习工程师具备多个领域的混合知识,是设计过程中的关键部分,而不仅仅是实现部分。
数据科学和建模阶段的微小妥协通常会在数据层面带来巨大的效率提升。同时,了解数据科学家采用的编码方法的背景将有助于将其转化为生产代码的部署。相反,将代码部署平台和数据处理平台的约束以数据科学家能够理解的语言反馈给数据科学家,可以使这些因素融入到分析和建模方法中。
通过这种方式,机器学习工程师的引入打破了跨学科的壁垒,最终将数据工程师提供的数据和数据科学家分析的数据转化为有价值的机器学习应用。
原文。经许可转载。
相关:
更多相关主题
用户生成的数据标记的兴起
原文:
www.kdnuggets.com/2019/12/rise-user-generated-data-labeling.html
评论
作者 Nandhini TS,Xtract.io
猎豹使用监督学习技术来捕捉猎物。你可能会说这是一个奇怪的、随机的陈述。但想想看,猎豹通过实践、观察、经验和计算,发展出了一种非常精细的狩猎方法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
就像训练数据集以创建一个出色的 AI 模型一样。它们会被不断训练和教导,直到能够独立操作。神奇的猎豹物种也经历了类似的过程,直到它能够预测各种猎物的逃跑策略,并调整其速度以实现快速转弯——而不仅仅依靠灵活性和速度。认知是通过大量训练获得的,这一过程的核心是数据标记。
这是一个重要的前提,它帮助你的机器学习算法根据标记的输入进行“学习”。现在,有几种方法可以做到这一点——自主管理的人力劳动、外包给个人/公司、第三方管理的标记服务提供商等等。
不过,假设你的项目庞大且需要持续进行数据标记——无论你在移动中、睡觉还是吃饭时。这时候你需要免费完成这些任务。当然,它可以外包,但如果你考虑成本、覆盖概率和准确性,我相信你会欣赏用户生成的数据标记。
我有 6 个有趣的例子来帮助你理解这个,我们直接深入吧!
1. Netflix 标注了缩略图,你知道吗?
数据科学在像 Netflix 这样的平台上的一个简单应用当然是他们的推荐引擎如何处理隐式数据。假设用户“A”在 4 天内连续观看了一个节目,比如“处女的秘密”(所有季节),隐式数据就是你喜欢这个节目,因为你显然牺牲了大量的睡眠来观看它。行为数据与成千上万其他数据点结合,是 Netflix 机器学习算法实际运作的基础。
Netflix 产品创新副总裁 Todd Yellin 表示,他们考虑的数据是 “我们从这些资料中看到的数据类型 – 人们观看什么,他们之后观看了什么,他们之前观看了什么,他们一年前观看了什么,他们最近观看了什么,以及一天中的时间”。
所以,如果你看过《贞爱不忍》,Netflix 的机器学习算法很可能会考虑观看过这个节目之后人们观看了什么,分析社区偏好的趋势,看看他们是否喜欢强势女性主角,或是欣赏喜剧、腐败警察、神秘谋杀等。
现在,Netflix 基于类似的兴趣对节目和电影进行分类和推荐,并且在此基础上更进一步(以提高点击率),采用了一种称为缩略图个性化的概念。这些基本上是 Netflix 从电影或节目的视频帧中标注的图像。

图片来源**: Becominghuman.ai
那么,用户生成的数据标注在哪里呢?正是 Netflix 收集不同的缩略图,并根据用户的过去行为、对特定类型的偏好、过滤器和光线、最喜欢的明星等进行标注。这种推荐对每个用户都是独特的,它基于数千个类似的兴趣,这些兴趣帮助提高了点击率。Netflix 如何巧妙地收集用户数据并有效利用这些数据来改善体验真是太棒了。
赞美 Netflix!
2. 现在是玩游戏的时候了,听说过 Quickdraw 吗?
Quickdraw 是由 Google 提供的最大涂鸦数据集,包含 5000 万幅绘画,涵盖 345 个类别。这是一个你画画而神经网络试图猜测的游戏。但图像的构思对每个人来说都是非常主观的,这也是神经网络可能并不总是准确的原因。
关键在这里。为了使预测准确,模型在你与其互动时会不断学习。
为了帮助你更好地理解:我被要求画一个月亮。虽然对自己的绘画技能感到尴尬,我还是会展示我画的图来帮助你理解这个概念!

好吧,图像明显显示神经网络没有识别出它(我不是毕加索,对吧?)无论如何,游戏只有在用户感到自己战胜了神经网络时才会变得有趣,因为神经网络能够识别他们如何构思和表现被要求绘制的内容。这正是这个概念的成功之处。但由于有数百万种不同的可能性以及像我这样适合玩画图游戏(在空气中绘画)的人所具备的技能,这个模型利用了用户生成的数据。
现在,我那幅可怜的月亮图被作为标记为“moon”的训练数据集用来帮助提高准确性。这里是神经网络识别为月亮的图像以及它如何学会识别它的情况。

3. Grammarly 需要你的帮助来确认你是否正确
所有作家都熟悉 Grammarly。它是一个帮助你保持写作免于语法错误的工具,包括拼写、标点符号等等。Grammarly 不仅关注语法错误,它还帮助你识别剽窃、词汇选择不当、俚语、语气检测等。Grammarly 使用一个复杂的人工智能系统,幕后有一支计算语言学家和深度学习工程师的团队。算法通过分析研究语料库(这些是用于研究和开发的大量标记文本集合)来学习写作规则并提出建议。
所以,我们都知道任何 AI 模型的基础是持续学习。就像人类通过丰富他们的知识变得更聪明一样,机器也是如此!但是,机器基于规则工作。如果存在否定,它们会报告错误。同样,Grammarly 通过你的帮助(用户)变得更聪明。让我以你刚刚读到的上一行作为例子。我看到“is”的红色下划线,认为我犯了一个错误(见下文)。
但,从逻辑和语法上讲,使用“are”可能是正确的。不过,超越语法,写作需要连贯,最重要的是你的句子需要读起来顺畅。在这个例子中,我使用了“is”因为这个过程仍在进行,因此使用现在进行时。然而,Grammarly 有其他的想法。所以,作为用户,我帮助 Grammarly 对其进行标记,以更好地适应上下文,并忽略了将其修改得更聪明的建议。
4. Google 套件中的一些产品,它们是最好的,对吧?
a. Gmail 如何帮助你自动完成
Google 的 Smart Compose 显然依靠人工智能。其确切功能是通过使用 词袋语言模型 与递归神经网络。它基本上利用主题行和之前的电子邮件进行学习,并将这些内容编码为词嵌入,并转换为向量。这里有一个示例,Grammarly 正在检测语气!

b. Google 地图变得更聪明
假设一个非英语使用者使用 Google 地图(语音)来跟踪位置,而应用程序返回了不正确的信息。当你迅速按下返回按钮时,模型学习到发生了错误,这就成了学习。原因是我们知道发音和口音因地区而异。这些数据集将帮助机器学习模型准确地执行语音转文本转换。
c. 最不喜欢的图像验证码
我们都经历过无数次 Google 要求你确认图像集的过程,以区分人类和机器人。由于这种验证码被机器人绕过的情况越来越多,现在这些验证码变得有些复杂。为了提高图像分类的准确性,用户参与的数据被用作机器学习模型的训练数据集,以便随着时间的推移提高其准确性。
5. Instagram 可以自动检测并删除辱骂性评论
自然语言处理(NLP)帮助机器像人类一样理解语言。对于 Instagram 来说,仅含中性词的句子仍可能具有攻击性,而充满脏话的句子可能是一首流行歌曲。这很复杂。但是,对于使用 DeepText 自动识别和删除攻击性评论的 Instagram 来说,这就不那么复杂了。
在 一项调查 中,由 Ditch the Label 进行,超过 10,000 名年龄在 12 到 25 岁之间的英国青少年中,42% 报告称 Instagram 是他们遭受欺凌最多的平台。
DeepText 由人类训练,以识别和标记在不同上下文中什么是攻击性的,什么不是攻击性的,从而理解攻击性语言。但是,仍然存在将某些内容错误分类为攻击性的风险。
Kevin Systrom(Instagram 的首席执行官)表示,“机器学习的整体理念是,它在理解这些细微差别方面远胜于过去的任何算法,或任何单一的人类。”
“我认为我们需要做的是弄清楚如何进入那些灰色区域,并评估这个算法的表现是否随着时间的推移真正改善了情况。因为,如果它引发问题而且没有效果,我们将废弃它并从头开始尝试新的方案。”
正是这种风险因素,Instagram 最近推出了一个选项,如果用户确定要发布评论,会使用 AI 驱动的技术进行提醒,实际测试鼓励用户后退。
要让一个 AI 模型如此智能(分类哪些是攻击性的,哪些不是),它确实需要基于用户贡献的持续训练,不是吗?
6. Smartbasket - Bigbasket 迄今为止最智能的推出
印度的在线杂货店 Bigbasket 利用基于 AI 的技术来改善客户体验。
Bigbasket 的分析负责人 Subramanai 在 一次采访 中表示,“鉴于这种背景,我们的 AI 旅程到目前为止主要集中在机器学习上。我们现在正处于更深入地探索 AI 和相关技术(如物联网、计算机视觉和高级分析)以促进业务增长的阶段。”
AI 在 Bigbasket 的多个案例中都有应用,例如他们如何分析当前流量数据并将其与交付承诺进行映射。另一个是 Smartbasket——这是非常有趣的。Smartbasket 的引入旨在为客户创建个性化的购物篮。
“通常,客户的最终订单中有 90%已经包含在 Smartbasket 中。我们的数据表明,这些客户现在花费的时间只有他们通常的一半,” 数据分析负责人表示。
他们的机器学习算法也在变得更智能,其中客户将 40%的推荐产品添加到购物车中。
因此,如果我们深入探讨推荐引擎和 Smartbasket 概念,从客户收集的数据——行为分析、偏好、购买历史、对同一产品的社区行为以及其他数千条信息,都会作为训练数据输入推荐引擎。点击量随着模式的智能化而提升,这一过程基于每次用户对推荐类型的反馈。
推荐系统有三种类型——协同过滤、基于内容和混合推荐。像 Bigbasket 和 Netflix 这样的公司利用混合推荐,即考虑独特的用户行为以及类似用户的模式。总而言之,在这里,用户在使推荐引擎更智能方面发挥了巨大的作用!
结论
大型用户基础公司利用其客户帮助标注数据,这种做法在上下文中非常契合,以至于我们作为用户,甚至没有意识到这一点。尽管如此,对于像 Bigbasket 和 Netflix 这样的在线商店和媒体服务的推荐引擎,用户在标注数据和使模型更智能方面的贡献并不明显,因为过程中的额外分析工作非常繁琐。
但对于像 Quick draw 这样的系统,标注则相对简单。如果神经网络失败,数据会立即作为学习输入。这些情况对于处理海量实时信息的大型公司来说很常见。但对于其他 AI 项目来说,数据标注仍然重要,你可以使用市场上好用的数据注释工具,如 Xtract.io、Cloudfactory 和 figure eight。
个人简介: Nandhini TS 是 Xtract.io 的产品营销助理——一家数据解决方案公司。她喜欢写关于数据在成功业务操作中的力量和影响的文章。在闲暇时间,她专注于发展副业和狂看恐龙纪录片。
相关内容:
-
数据标注如何促进 AI 模型
-
机器学习数据准备 101:为什么重要以及如何进行
-
数据科学项目准备的奇妙四步
更多相关话题
超越 Pandas 性能的 Rising Library
原文:
www.kdnuggets.com/2020/12/rising-library-beating-pandas-performance.html
评论
由 Ezz El Din Abdullah,数据平台工程师

我们的前 3 个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织 IT
pandas 最初在 2008 年发布,使用 Python, Cython 和 C 编写。今天,我们将比较这个著名库与 pypolars 的性能,后者是一个使用 Rust 编写的新兴 DataFrame 库。我们在排序和连接 2500 万记录的数据以及连接两个 CSV 文件时进行了比较。
下载 Reddit 用户名数据
首先从 Kaggle 下载一个包含约 2600 万个 Reddit 用户名的 CSV 文件:www.kaggle.com/colinmorris/reddit-usernames
接下来,让我们创建另一个 CSV 文件,你可以使用你喜欢的文本编辑器或通过命令行创建它:
$ cat >> fake_users.csv
author,n
x,5
z,7
y,6
排序
现在,让我们比较这两种排序算法:
pandas
$ python sort_with_pandas.py
Time: 34.35690135599998
pypolars
$ python sort_with_pypolars.py
Time: 23.965840922999973
约 24 秒,意味着 pypolars 在这里比 pandas 快 1.4 倍
级联
现在我们将查看在连接两个数据框并将它们堆叠成一个数据框时每种工具的表现
pandas
pandas 用时 18 秒
$ python concat_with_pandas.py
Time: 18.12720185799992
pypolars
在这里 pypolars 快 1.2 倍
$ python concat_with_pypolars.py
Time: 15.001723207000055
连接
下载 COVID 跟踪数据
从 COVID Tracking Project 下载数据,使用这个命令:
$ curl -LO https://covidtracking.com/data/download/all-states-history.csv
将获得你所需的最新冠状病毒传播数据,这些数据存储在 all-states-history.csv 文件中
下载州数据
这是一个 CSV 文件,指示了每个州的缩写,因为我们需要将其与之前只列出了州列缩写的 CSV 进行连接。我们通过这个命令获取数据:
$ curl -LO https://gist.githubusercontent.com/afomi/8824ddb02a68cf15151a804d4d0dc3b7/raw/5f1cfabf2e65c5661a9ed12af27953ae4032b136/states.csv
这将输出 states.csv 文件,该文件包含两列:State 和 Abbreviation
pandas
让我们使用 csvcut 来筛选出这个结果文件 joined_pd.csv:
$ csvcut -c date,state,State joined_pd.csv | head | csvlook
| date | state | State |
| ---------- | ----- | ----------- |
| 2020-11-16 | AK | ALASKA |
| 2020-11-16 | AL | ALABAMA |
| 2020-11-16 | AR | ARKANSAS |
| 2020-11-16 | AS | |
| 2020-11-16 | AZ | ARIZONA |
| 2020-11-16 | CA | CALIFORNIA |
| 2020-11-16 | CO | COLORADO |
| 2020-11-16 | CT | CONNECTICUT |
| 2020-11-16 | DC | |
看起来连接正常,且是左连接。如果你对 AS 和 DC 的相关State 值为何为空感到好奇,那是因为在states.csv文件中不存在这些缩写。如果你查看Abbreviation列,你会发现 AS 和 DC 的值都为空。
这里没有 AS 缩写:
$ grep AS states.csv
ALASKA,AK
ARKANSAS,AR
KANSAS,KS
MASSACHUSETTS,MA
NEBRASKA,NE
TEXAS,TX
WASHINGTON,WA
这里 DC 的值为空:
$ grep DC states.csv
附言:如果你不清楚csvcut的用途,我们有一些关于 csvkit 的教程(csvkit 是一个命令行工具,包含 csvcut 及其他用于清理、处理和分析 CSV 的实用命令行工具)。
pypolars
$ python join_with_pypolars.py
Time: 0.41163978699978543
现在让我们看看合并的数据框是怎样的:
$ csvcut -c date,state,State joined_pl.csv | head | csvlook
| date | state | State |
| ---------- | ----- | ----------- |
| 2020-11-16 | AK | ALASKA |
| 2020-11-16 | AL | ALABAMA |
| 2020-11-16 | AR | ARKANSAS |
| 2020-11-16 | AZ | ARIZONA |
| 2020-11-16 | CA | CALIFORNIA |
| 2020-11-16 | CO | COLORADO |
| 2020-11-16 | CT | CONNECTICUT |
| 2020-11-16 | DE | DELAWARE |
| 2020-11-16 | FL | FLORIDA |
所以看起来pypolars在连接的列中遗漏了空值,但这是因为默认的连接方式是内连接,而不像 pandas 默认的连接方式是左连接。要获得与 pandas 相同的结果,你需要将第 8 行更改为:
df_all_states_history.join(df_states, left_on=”state”, right_on=”Abbreviation”, how=”left”).to_csv(“joined_pl.csv”)
在我的机器上花费了大约 317 毫秒,这意味着:
pypolars 在左连接中快 3 倍
最后的思考
最终,我们发现了pypolars与pandas的性能对比。当然,pandas更成熟,因为它已经有 12 年了,社区仍在继续投入,但如果对pypolars进行更多的合作,这个新兴库会很出色!
你可能会发现这些教程很有用:
保重,下次教程见 😃
和平!
点击这里 获取最新内容到你的邮箱****
资源
个人简介: Ezz El Din Abdullah (ezzeddinabdullah.com) 是 Affectiva 的数据平台工程师。
原文。经许可转载。
相关:
-
在 Python 中合并 Pandas 数据框
-
Pandas 的强化版:使用 Dask 进行端到端的数据科学
-
每种复杂数据框操作的直观解释与可视化
更多相关话题
-
[停止学习数据科学,找到目的,再找到目的...] (https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html)
AI/ML 模型的风险管理框架
原文:
www.kdnuggets.com/2022/03/risk-management-framework-aiml-models.html
来源:商业矢量图由 jcomp 创作 — www.freepik.com(展示管理 AI 风险和生产成功 AI 模型的关键概念)
AI/ML 模型像其他数学和金融模型一样,具有其自身的风险,并需要事先了解以减轻这些风险。本文的意图在风险定义中得到了很好的总结:
风险是指可能发生不利情况的可能性。风险涉及对活动效果/影响的不确定性,这些活动涉及人类重视的东西(例如健康、福祉、财富、财产或环境),通常关注负面、不期望的后果。
风险需要提前充分考虑,从设计阶段开始。不能等到后果显现后再进行损害控制。这就是“风险管理”通过设计前瞻性的方法、拉动杠杆评估最坏情况,并及时采取行动的帮助所在。
来源:作者
管理风险的关键措施包括识别风险来源,并检查它们在当前流程中的处理方式。这种分析可以揭示当前检查可能不足以应对不可预见的风险的差距。
从原则上讲,这一框架涉及对可能出错的情况进行头脑风暴——不能等到自动驾驶汽车在路上陷入是否拯救一个老人还是一个孩子的困境时才采取行动。对于这个问题没有一个理想的答案,但必须在实施解决方案之前考虑最坏情况,并且这个最坏情况必须是可以接受的。
风险本质上是非自包含的,会通过放大所有方面的麻烦而产生连锁反应。清晰的风险定义和测量指标对确保风险被控制在可接受的范围内至关重要。这些指标还通过前后分析证明了风险缓解措施的有效性。
由于技术的迅猛发展,相对于金融和医学等成熟行业,AI 相关的风险在衡量、规划和预先捕捉方面仍相对未知。可以直接学习并导入到 AI 风险管理工具中的几个教训包括:
-
文档
-
数据完整性
-
法规与合规性
-
可解释性
文档
ML 模型可能最终解决的问题与最初设想的可能有所不同。项目开始时对 ML 模型有一定的期望(可理解为魔法)。然而,由于缺乏相关特征或高质量数据提供的统计信号用于模型学习,模型的性能受到限制。进行了一系列实验来校准特征、算法、数据,甚至是问题陈述本身,以评估模型如何最佳地适应确切或调整后的业务任务,并且仍能增加价值。
例如,如果业务需求是优化服务中心的资源分配,以处理全天接收到的大量查询和电话。可以将问题框定为多类分类,其中目标变量,即预期的电话数量,可以分为 3 类——低、中和高。这意味着企业将根据 ML 模型对低、中或高工作量(或预期电话数量)的预测来估算资源。
另一方面,企业可能更感兴趣的是从 ML 模型中获取未来一周的预期工作量,并将应用自己的后处理逻辑来决定资源应该如何分配。
我们已经讨论了两种问题陈述的框架——回归和分类。
虽然没有一种规则适用于所有情况——这需要与业务讨论并进行详细文档记录。假设、数据可用性、数据历史记录、任何仅在实时中可用且在学习阶段未显示给模型的属性都需要详细记录,并与客户签署确认,然后再深入数据建模。
数据完整性
Covid 已经极大地改变了世界运作的动态,使得许多 ML 模型变得无关紧要。没有任何模型/AI 解决方案提供商能够预见到这一点,考虑到这次疫情的黑天鹅效应。但,模型输出偏离预期结果的方式还有无数种,其中一个主要原因是训练数据与推理数据特征之间的漂移。现在,这在开发者的掌控之中,可以使用各种统计方法来控制。其中一个指标是 KS 统计量。
如果你想了解更多关于如何维护数据质量以构建成功的机器学习解决方案的信息,我推荐你事先阅读这篇 文章。文章解释了无缝数据集成和一致性对维护数据管道的重要性,并强调了采纳数据文化的重要性。
声誉、法规和合规风险
人工智能机器人能否获得意识并通过接管世界来危害人类安全?这样的问题主要占据我们的思考,并立即将 AI 变成数字化转型潮流中的反派。
但 AI 只是一个技术本身不能造成伤害,除非它被设计和构建成这样。这引出了一个重要且常被忽视的概念——意图。
引用 Dave Waters的话,“人工智能的潜在好处巨大,危险也是如此。”
来源:人物矢量图由 pch.vector 创作 — www.freepik.com,并结合作者对良好和恶意意图的例子进行输入
AI 有巨大的潜力来改善人类生活,但也带来了自身的风险。
一旦风险出现,就需要遵循法规。是的,法规是必要的,以建立检查和平衡机制,并确保它们提供正确的框架,不妨碍 AI 利益的飞跃,同时控制可能的危害。
不妥协或滥用个人数据且尊重用户隐私的社会友好型应用才能成功并进入市场。像 GDPR 这样的法规旨在赋予个人控制权和权利,以决定他们允许如何使用个人数据。
及时干预和更新这些监管框架可以确保我们的社会继续享受 AI 良好意图带来的好处,同时阻止恶意 AI 产品的出现。
可解释性
AI 模型能否解释预测结果。模型开发者必须在不影响模型准确性的情况下解释算法的内部工作原理。这可以通过两种方式实现——可解释模型或辅助工具。
来源:教育矢量图由 freepik 创作 — www.freepik.com
“可解释性”和“解释性”这两个词常被交替使用。决策树、线性回归等模型由于其固有的预测解释特性,属于可解释模型的范畴。而像深度神经网络这样的黑箱模型则需要借助 LIME 和 SHAP 框架等辅助工具和技术来解释模型输出。
下图展示了数据科学社区应努力实现的真实状态,我们能够解释为什么模型输出特定类别 X 而不是类别 Y。模型何时成功并可以以更大的信心信任?输入数据中的哪些变化会导致预测结果的翻转等。

来源:https://www.darpa.mil/program/explainable-artificial-intelligence
有多种工具可以帮助控制风险,包括但不限于模型可解释性、偏差检测和缓解、模型监控和维护。
我将在即将发表的文章中详细阐述这些内容。敬请关注。
Vidhi Chugh 是一位获奖的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究的交汇点工作,以提供业务价值和见解。她提倡数据中心科学,并在数据治理方面是领先专家,致力于构建值得信赖的 AI 解决方案。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
循环神经网络(RNN):用于序列数据的深度学习
原文:
www.kdnuggets.com/2020/07/rnn-deep-learning-sequential-data.html
评论
循环神经网络(RNN)是一类人工神经网络,可以在深度学习中处理一系列输入,并在处理下一序列的输入时保留其状态。传统神经网络会处理一个输入并移动到下一个,忽略其序列。诸如时间序列的数据具有需要遵循的顺序以便理解。传统的前馈网络无法理解这一点,因为每个输入被假定为彼此独立,而在时间序列设置中,每个输入依赖于先前的输入。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在插图 1 中,我们看到神经网络(隐藏状态)A接收一个x**t并输出一个值h**t。循环展示了信息是如何从一个步骤传递到下一个步骤的。输入是“JAZZ”的各个字母,每个字母按顺序传递给网络 A(即顺序处理)。
循环神经网络可以用于多种方式,例如:
-
检测下一个单词/字母
-
在时间空间中预测金融资产价格
-
体育中的动作建模(预测体育赛事中的下一动作,例如足球、橄榄球、网球等)
-
音乐创作
-
图像生成
RNN 与自回归模型
自回归模型是指将具有时间维度的数据的值回归到先前的值,直到用户指定的某个点。RNN 的工作方式相同,但明显的区别在于 RNN 查看所有数据(即不需要用户指定特定的时间段)。
Yt = β0*** + β1yt-1 + Ɛ***t
上述 AR 模型是一个阶数为 1 的 AR(1) 模型,它以直接前值来预测下一时间段的值 (yt)。由于这是一个线性模型,它需要某些线性回归的假设,特别是因变量和自变量之间的线性假设。在这种情况下,Yt 和 yt-1 必须具有线性关系。此外,还有其他检查,例如自相关检查,需要确定预测 Yt的适当阶数。
循环神经网络无需线性或模型阶数检查。它可以自动检查整个数据集以预测下一序列。如下面的图像所示,一个神经网络包含 3 个隐藏层,具有相等的权重、偏置和激活函数,并用于预测输出。

这些隐藏层可以合并成一个单一的递归隐藏层。递归神经元现在存储所有之前步骤的输入,并将这些信息与当前步骤的输入合并。

循环神经网络的优点
-
它可以建模非线性时间/序列关系。
-
相比于自回归过程,无需指定滞后值来预测下一个值。
循环神经网络的缺点
-
消失梯度问题
-
不适合预测长时间跨度
消失梯度问题
随着更多含激活函数的层被添加,损失函数的梯度趋近于零。梯度下降算法找到网络成本函数的全局最小值。浅层网络不应该受到过小梯度的影响,但随着网络的增大及隐藏层的增加,这可能导致梯度过小,影响模型训练。
神经网络的梯度通过反向传播算法计算,其中你需要找到网络的导数。通过链式法则,逐层计算导数并将其相乘。这就是问题所在。使用像 sigmoid 函数这样的激活函数时,梯度有可能随着隐藏层的增加而减小。
这个问题可能导致模型编译后的结果很糟糕。解决这个问题的简单方法是使用具有 ReLU 激活函数的长短期记忆模型。
长短期记忆模型
长短期记忆网络是一种特殊的递归神经网络,能够处理长期依赖问题,而不会受到梯度不稳定的影响。

上面的图是一个典型的 RNN,只是重复模块包含额外的层,使其与 RNN 区别开来。
这里的区分是水平线称为“单元状态”,它充当信息的传送带。LSTM 将通过使用如上所示的 3 个门来删除或添加单元状态中的信息。这些门由一个 sigmoid 函数和一个逐点乘法操作组成,输出值在 1 和 0 之间,用于描述允许单元状态通过多少成分。值为 1 表示允许所有信息通过,而 0 则表示完全忽略它。
3 个门是:
1. 输入门
- 这个门用于发现哪些值将用于修改记忆,通过使用 sigmoid 函数(分配介于 0 和 1 之间的值),然后使用 tanh 函数为值赋予 -1 到 1 之间的权重。
2. 忘记门
- 忘记门使用 sigmoid 函数来决定哪些值被忽略,通过使用前一个状态 (h**t-1) 和输入 (x**t),为 c**t-1 中的每个值分配一个介于 0 和 1 之间的值。
3. 输出门
- 该块的输入用于决定输出,通过使用 sigmoid 函数分配介于 0 和 1 之间的值,然后乘以 tanh 函数来决定其重要性级别,分配一个介于 -1 和 1 之间的值。
编写 RNN – LSTM
## Libraries
import tensorflow as tf
model = tf.keras.models.Sequential()
Dense = tf.keras.layers.Dense
Dropout = tf.keras.layers.Dropout
LSTM = tf.keras.layers.LSTM
## Dataset
mnist_data = tf.keras.datasets.mnist # mnist is a dataset of 28x28 images of handwritten digits and their labels with 60,000 rows of data
## Create train and test data
(x_train, y_train),(x_test, y_test) = mnist_data.load_data()
x_train = x_train/255.0 # Normalize training data features
x_test = x_test/255.0 # Normalize training data labels
# The images are 28x28 pixels of unassigned integers in the range of 0 to 255\. The above #normalization code is not necessary and can still be passed on to compile.
# However, the #accuracy will be much worse of at around 20% best case scenario and loss at over 90%. The #training time will also increase.
model.add(LSTM(256, activation='relu', return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
optimizer = tf.keras.optimizers.Adam(lr=1e-4, decay=1e-6)
# Compile model
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'],
)
# The specification of loss=’sparse_categorical_crossentropy’ is very important here as our targets are # integers and not one-hot encoded categories.
model.fit(x_train,
y_train,
epochs=4,
validation_data=(x_test, y_test))
Epoch 1/4
60000/60000 [==============================] - 278s 5ms/sample - loss: 0.9960 - acc: 0.6611 - val_loss: 0.2939 - val_acc: 0.9013
Epoch 2/4
60000/60000 [==============================] - 276s 5ms/sample - loss: 0.2955 - acc: 0.9107 - val_loss: 0.1523 - val_acc: 0.9504
Epoch 3/4
60000/60000 [==============================] - 273s 5ms/sample - loss: 0.1931 - acc: 0.9452 - val_loss: 0.1153 - val_acc: 0.9641
Epoch 4/4
60000/60000 [==============================] - 270s 4ms/sample - loss: 0.1489 - acc: 0.9581 - val_loss: 0.1076 - val_acc: 0.9696
原文。经许可转载。
相关内容:
-
LSTM 用于时间序列预测
-
NLP 中的深度学习:ANNs、RNNs 和 LSTMs 解析!
-
理解应用于 LSTM 的反向传播
更多相关内容
使用计算机视觉模型进行道路车道线检测
原文:
www.kdnuggets.com/2017/07/road-lane-line-detection-using-computer-vision-models.html/2
图. 霍夫变换识别图像中的车道线
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
步骤 5:外推各个小线段并构建左侧和右侧车道线
霍夫变换根据霍夫空间中的交点给我们小线段。现在,我们可以利用这些信息来构建一个全局的左车道线和右车道线。
我们通过将小线段分成两组来实现这一点,一组具有正梯度,另一组具有负梯度。由于摄像机视角的深度,车道线在深度方向上会向彼此倾斜,因此它们应该具有相反的梯度。
然后,我们取每组的平均梯度和截距值,并从中构建我们的全局车道线。车道线随后被外推到具有最小 y 轴坐标和具有最大 y 轴坐标的边缘检测像素。
要实现这个算法,我们只需将之前声明的 draw_lines 函数更改为外推这些线条。
---------------------------------------------------------------------------
def draw_lines(img, lines, color=[255, 0, 0], thickness=2):
"""
This function draws `lines` with `color` and `thickness`.
"""
imshape = img.shape
# these variables represent the y-axis coordinates to which
# the line will be extrapolated to
ymin_global = img.shape[0]
ymax_global = img.shape[0]
# left lane line variables
all_left_grad = []
all_left_y = []
all_left_x = []
# right lane line variables
all_right_grad = []
all_right_y = []
all_right_x = []
for line in lines:
for x1,y1,x2,y2 in line:
gradient, intercept = np.polyfit((x1,x2), (y1,y2), 1)
ymin_global = min(min(y1, y2), ymin_global)
if (gradient > 0):
all_left_grad += [gradient]
all_left_y += [y1, y2]
all_left_x += [x1, x2]
else:
all_right_grad += [gradient]
all_right_y += [y1, y2]
all_right_x += [x1, x2]
left_mean_grad = np.mean(all_left_grad)
left_y_mean = np.mean(all_left_y)
left_x_mean = np.mean(all_left_x)
left_intercept = left_y_mean - (left_mean_grad * left_x_mean)
right_mean_grad = np.mean(all_right_grad)
right_y_mean = np.mean(all_right_y)
right_x_mean = np.mean(all_right_x)
right_intercept = right_y_mean - (right_mean_grad * right_x_mean)
# Make sure we have some points in each lane line category
if ((len(all_left_grad) > 0) and (len(all_right_grad) > 0)):
upper_left_x = int((ymin_global - left_intercept) / left_mean_grad)
lower_left_x = int((ymax_global - left_intercept) / left_mean_grad)
upper_right_x = int((ymin_global - right_intercept) / right_mean_grad)
lower_right_x = int((ymax_global - right_intercept) / right_mean_grad)
cv2.line(img, (upper_left_x, ymin_global),
(lower_left_x, ymax_global), color, thickness)
cv2.line(img, (upper_right_x, ymin_global),
(lower_right_x, ymax_global), color, thickness)
---------------------------------------------------------------------------
图. 外推车道线
步骤 6:将外推的线条添加到输入图像中
然后,我们将外推的线条叠加到输入图像上。我们通过根据检测到的车道线坐标将权重值添加到原始图像来实现这一点。
---------------------------------------------------------------------------
def weighted_img(img, initial_img, α=0.8, β=1., λ=0.):
"""
`img` is the output of the hough_lines(), An image with lines drawn on it.
Should be a blank image (all black) with lines drawn on it.
`initial_img` should be the image before any processing.
The result image is computed as follows:
initial_img * α + img * β + λ
NOTE: initial_img and img must be the same shape!
"""
return cv2.addWeighted(initial_img, α, img, β, λ)
# outline the input image
colored_image = weighted_img(houged, image)
---------------------------------------------------------------------------
图. 叠加在输入图像上的车道线
步骤 7:将管道添加到视频中
一旦我们设计并实现了整个车道检测管道,我们就会逐帧应用变换。我们需要一段车辆在车道线上的视频来完成这项工作。
---------------------------------------------------------------------------
from moviepy.editor import VideoFileClip
from IPython.display import HTML
def process_image(image):
# grayscale the image
grayscaled = grayscale(image)
# apply gaussian blur
kernelSize = 5
gaussianBlur = gaussian_blur(grayscaled, kernelSize)
# canny
minThreshold = 100
maxThreshold = 200
edgeDetectedImage = canny(gaussianBlur, minThreshold, maxThreshold)
# apply mask
lowerLeftPoint = [130, 540]
upperLeftPoint = [410, 350]
upperRightPoint = [570, 350]
lowerRightPoint = [915, 540]
pts = np.array([[lowerLeftPoint, upperLeftPoint, upperRightPoint,
lowerRightPoint]], dtype=np.int32)
masked_image = region_of_interest(edgeDetectedImage, pts)
# hough lines
rho = 1
theta = np.pi/180
threshold = 30
min_line_len = 20
max_line_gap = 20
houged = hough_lines(masked_image, rho, theta, threshold, min_line_len,
max_line_gap)
# outline the input image
colored_image = weighted_img(houged, image)
return colored_image
output = 'car_lane_detection.mp4'
clip1 = VideoFileClip("insert_car_lane_video.mp4")
white_clip = clip1.fl_image(process_image)
%time white_clip.write_videofile(output, audio=False)
---------------------------------------------------------------------------
就这样:一个端到端的 Python 车道检测实现!
原文。经许可转载。
个人简介: Vijay Ramakrishnan 是 Mindmeld Inc 的机器学习工程师,该公司是一家 Cisco 于 2017 年收购的对话 AI 公司。曾担任 Qualcomm 的项目经理和 Google 的数据工程师。喜欢扩展机器学习系统、开发自动驾驶技术和对话 AI 产品。
相关内容:
-
理解计算机视觉的 7 个步骤
-
漫画:史上首个自动驾驶深度学习烧烤架
-
获取自动驾驶车辆入门的 5 个免费资源
更多相关话题
计算机视觉路线图
评论
图片由 Ennio Dybeli 在 Unsplash 上拍摄
介绍
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业
2. Google Data Analytics Professional Certificate - 提升您的数据分析水平
3. Google IT Support Professional Certificate - 支持您的组织 IT
计算机视觉(CV)如今是人工智能的主要应用之一(例如:图像识别、目标跟踪、多标签分类)。在本文中,我将带你了解组成计算机视觉系统的一些主要步骤。
计算机视觉系统的标准工作流程表示如下:
-
一组图像进入系统。
-
特征提取器用于对这些图像进行预处理并提取特征。
-
机器学习系统利用提取的特征来训练模型并进行预测。
我们将简要地走过数据在这三种不同步骤中可能经历的一些主要过程。
图像进入系统
在尝试实现计算机视觉系统时,我们需要考虑两个主要组件:图像采集硬件和图像处理软件。部署计算机视觉系统的主要要求之一是测试其鲁棒性。我们的系统实际上应该能够对环境变化(如光照、方向、缩放的变化)保持不变,并能够重复执行其设计任务。为了满足这些要求,可能需要对系统的硬件或软件施加某种形式的约束(例如:远程控制光照环境)。
一旦图像从硬件设备中获取,就有许多可能的方式在软件系统中数值表示颜色(颜色空间)。最著名的颜色空间之一是 RGB(红、绿、蓝)和 HSV(色调、饱和度、明度)。使用 HSV 颜色空间的一个主要优点是,通过仅使用 HS 组件,我们可以使系统对光照变化具有不变性(图 1)。

图 1:RGB 与 HSV 颜色空间 [1]
特征提取器
图像预处理
一旦图像进入系统并使用色彩空间表示后,我们可以对图像应用不同的操作符以改善其表示:
-
点操作符:我们使用图像中的所有点来创建原始图像的转换版本(以便明确图像内部的内容,而不改变其内容)。点操作符的一些示例包括:强度归一化、直方图均衡化和阈值化。点操作符通常用于帮助人类视觉更好地可视化图像,但对于计算机视觉系统不一定提供任何优势。
-
组操作符:在这种情况下,我们从原始图像中提取一组点,以在图像的转换版本中创建一个单一的点。这种类型的操作通常通过使用卷积来完成。可以使用不同类型的卷积核与图像进行卷积,以获得我们的转换结果(图 2)。一些示例包括:直接平均、Gaussian 平均和中值滤波。对图像应用卷积操作可以减少图像中的噪声并改善平滑度(尽管这也可能稍微模糊图像)。由于我们使用一组点来创建新图像中的单一新点,新图像的维度必然会低于原始图像。解决此问题的一种方法是应用零填充(将像素值设置为零)或在图像的边界使用更小的模板。使用卷积的主要限制之一是当处理大型模板时的执行速度,解决此问题的一种可能方法是使用傅里叶变换。

图 2: 卷积核
一旦对图像进行了预处理,我们可以应用更高级的技术以尝试通过使用如一阶边缘检测(例如 Prewitt 操作符、Sobel 操作符、Canny 边缘检测器)和霍夫变换等方法来提取图像中的边缘和形状。
特征提取
一旦对图像进行了预处理,可以使用特征提取器从图像中提取 4 种主要的特征形态:
-
全局特征:整个图像作为一个整体进行分析,并从特征提取器中得到一个单一的特征向量。一个简单的全局特征示例是像素值的直方图。
-
网格或块基特征:图像被划分为不同的块,并从每个不同的块中提取特征。提取图像块中特征的主要技术之一是密集 SIFT(尺度不变特征变换)。这种类型的特征主要用于训练机器学习模型。
-
基于区域的特征:图像被分割成不同的区域(例如,使用阈值分割或 K-Means 聚类等技术,然后通过连接组件将其连接成段),并从这些区域中的每一个提取特征。可以使用区域和边界描述技术(如矩和链码)来提取特征。
-
局部特征:在图像中检测到多个单一兴趣点,并通过分析兴趣点邻近的像素来提取特征。可以从图像中提取的两个主要兴趣点类型是角点和斑点,这些可以通过如 Harris & Stephens 检测器和高斯拉普拉斯方法等方法提取。最后,可以通过如 SIFT(尺度不变特征变换)等技术从检测到的兴趣点提取特征。局部特征通常用于匹配图像以构建全景/3D 重建或从数据库中检索图像。
一旦提取了一组判别特征,我们可以利用这些特征来训练机器学习模型进行推断。特征描述符可以通过如OpenCV这样的库在 Python 中轻松应用。
机器学习
在计算机视觉中,分类图像的一个主要概念是视觉词袋(BoVW)。为了构建视觉词袋,我们首先需要通过从一组图像中提取所有特征(例如使用基于网格的特征或局部特征)来创建词汇表。接着,我们可以计算提取的特征在图像中出现的次数,并从结果中构建一个频率直方图。使用频率直方图作为基本模板,我们可以通过比较直方图来最终判断图像是否属于同一类别(见图 3)。
这个过程可以总结为以下几个步骤:
-
我们首先通过使用特征提取算法(如 SIFT 和 Dense SIFT)从图像数据集中提取不同的特征来构建词汇表。
-
其次,我们使用如 K-Means 或 DBSCAN 等算法对我们词汇表中的所有特征进行聚类,并利用聚类中心来总结我们的数据分布。
-
最后,我们可以通过计算词汇表中不同特征在图像中出现的次数来构建每个图像的频率直方图。
新图像可以通过对每个要分类的图像重复相同的过程,然后使用任何分类算法来找出我们词汇表中哪个图像最像我们的测试图像,从而进行分类。

图 3: 视觉词袋 [2]
如今,得益于卷积神经网络(CNNs)和递归人工神经网络(RCNNs)等人工神经网络架构的创建,已经能够构思出一种计算机视觉的替代工作流(见图 4)。
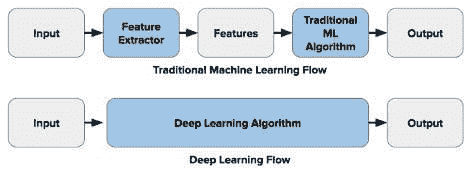
图 4:计算机视觉工作流 [3]
在这种情况下,深度学习算法结合了计算机视觉工作流中的特征提取和分类步骤。使用卷积神经网络时,神经网络的每一层都应用不同的特征提取技术(例如,第 1 层检测边缘,第 2 层在图像中找到形状,第 3 层进行图像分割等……)然后将特征向量提供给全连接层分类器。
机器学习在计算机视觉中的进一步应用包括多标签分类和目标识别等领域。在多标签分类中,我们旨在构建一个能够正确识别图像中有多少对象以及它们属于哪个类别的模型。而在目标识别中,我们则更进一步,旨在识别图像中不同对象的位置。
联系方式
如果你想保持更新我的最新文章和项目,请在 Medium 上关注我 follow me on Medium 并订阅我的 邮件列表。以下是我的一些联系信息:
参考文献
[1] 用作海滩清扫器的模块化机器人,Felippe Roza。Researchgate。访问链接:www.researchgate.net/figure/RGB-left-and-HSV-right-color-spaces_fig1_310474598
[2] OpenCV 中的视觉词袋,Vision & Graphics Group。Jan Kundrac。访问链接:vgg.fiit.stuba.sk/2015-02/bag-of-visual-words-in-opencv/
[3] 深度学习与传统计算机视觉的比较。Haritha Thilakarathne,NaadiSpeaks。访问链接:naadispeaks.wordpress.com/2018/08/12/deep-learning-vs-traditional-computer-vision/
个人简介: Pier Paolo Ippolito 是一位数据科学家,拥有南安普顿大学人工智能硕士学位。他对人工智能进展和机器学习应用(如金融和医学)有浓厚兴趣。可以通过 Linkedin 联系他。
原文。经授权转载。
相关:
-
自然语言处理(NLP)路线图
-
加速计算机视觉:亚马逊提供的免费课程
-
计算机视觉食谱:最佳实践和示例
更多相关内容
自然语言处理(NLP)的路线图
原文:
www.kdnuggets.com/2020/10/roadmap-natural-language-processing-nlp.html
评论
图片由Kelly Sikkema拍摄,来源于Unsplash
介绍
由于过去十年中大数据的发展,组织现在每天面临分析来自各种来源的大量数据的任务。
自然语言处理(NLP)是人工智能研究的一个领域,专注于处理和使用文本和语音数据以创建智能机器并生成洞察。
目前最有趣的 NLP 应用之一是创建能够与人类讨论复杂话题的机器。IBM 项目辩论者迄今为止代表了这一领域最成功的方法之一。
视频 1:IBM 项目辩论者
预处理技术
一些最常用的技术用于准备文本数据以供推理使用:
-
分词: 用于将输入文本分割成其组成单词(标记)。这样,更容易将数据转换为数字格式。
-
停止词去除: 应用于从文本中去除所有介词(例如“an”,“the”等),这些介词只是数据中的噪音源(因为它们不会带来额外的信息)。
-
词干提取: 最终用于去除数据中的所有词缀(例如前缀或后缀)。这样,算法可以更容易地将具有相似含义的词(例如 insight ~ insightful)视为不同的词。
所有这些预处理技术可以通过标准的 Python NLP 库,如NLTK和Spacy,轻松应用于不同类型的文本。
此外,为了推断我们文本的语言语法和结构,我们可以利用如词性(POS)标注和浅层解析等技术(见图 1)。实际上,运用这些技术,我们会明确地将每个单词标记上其词汇类别(基于短语的句法上下文)。
图 1:词性标注示例 [1]。
建模技术
词袋模型
词袋模型是一种用于自然语言处理和计算机视觉的技术,用于创建用于训练分类器的新特征(图 2)。该技术通过构建直方图来计算文档中的所有词汇(不考虑词序和语法规则)。
图 2:词袋模型 [2]
这种技术可能受限的主要问题之一是文本中介词、代词、冠词等的存在。实际上,这些词可能在我们的文本中频繁出现,但不一定对找出文档的主要特征和主题有实际信息。
为了解决这种问题,通常使用一种称为“词频-逆文档频率”(TFIDF)的技术。TFIDF 旨在通过考虑文本中每个词在大量文本样本中的总体出现频率来重新调整词频。使用这种技术,我们将奖励那些在我们的文本中出现但在其他文本中很少出现的词(提升其频率值),而惩罚那些在我们的文本和其他文本中都频繁出现的词(如介词、代词等)。
潜在狄利克雷分配(LDA)
潜在狄利克雷分配(LDA)是一种主题建模技术。主题建模是一个研究领域,专注于发现聚类文档的方法,以便根据内容发现潜在的区分标志(图 3)。因此,主题建模在这个范围内也可以被视为一种降维技术,因为它允许我们将初始数据减少到一个有限的聚类集。
图 3:主题建模 [3]
潜在狄利克雷分配(LDA)是一种无监督学习技术,用于发现可以表征不同文档的潜在主题,并将相似的文档聚集在一起。该算法输入的是被认为存在的主题数N,然后将不同的文档分组到N个彼此紧密相关的文档聚类中。
LDA 与其他聚类技术如 K 均值聚类的区别在于,LDA 是一种软聚类技术(每个文档根据概率分布分配到一个聚类中)。例如,文档可以被分配到聚类 A,因为算法确定该文档 80%的可能性属于该类,同时也考虑到该文档中嵌入的一些特征(剩余的 20%)更有可能属于第二个聚类 B。
词嵌入
词嵌入是将词编码为数值向量的最常见方法之一,然后将这些向量输入到我们的机器学习模型中进行推断。词嵌入旨在可靠地将词转换为向量空间,以便相似的词由相似的向量表示。
图 4:词嵌入 [4]
目前,有三种主要技术用于创建词嵌入:Word2Vec、GloVe和fastText。这三种技术都使用浅层神经网络来创建所需的词嵌入。
如果你有兴趣了解更多关于词嵌入的工作原理,这篇文章是一个很好的起点。
情感分析
情感分析是一种自然语言处理技术,通常用于理解某种文本是否表达了对一个话题的正面、负面或中性情感。这在尝试了解公众对一个话题、产品或公司的总体看法(通过在线评论、推文等)时尤其有用。
在情感分析中,文本中的情感通常表示为介于-1(负面情感)和 1(正面情感)之间的值,称为极性。
情感分析可以被视为一种无监督学习技术,因为我们通常没有为数据提供手工标签。为了克服这一障碍,我们使用了预标记的词典(一个词汇书),这些词典已经创建用来量化大量词在不同上下文中的情感。一些广泛使用的情感分析词典包括TextBlob和VADER。
Transformer
Transformer代表了当前最先进的自然语言处理模型,用于分析文本数据。一些广为人知的 Transformer 模型包括BERT和GTP2。
在 Transformer 出现之前,递归神经网络(RNNs)代表了分析序列化文本数据以进行预测的最有效方法,但这种方法在可靠地利用长期依赖性方面相当困难(例如,我们的网络可能会发现很难理解几个迭代前输入的一个词对当前迭代的有用性)。
Transformers 成功克服了这一限制,得益于一种叫做 Attention 的机制(该机制用于确定文本中需要关注的部分并给予更多权重)。此外,Transformers 使得并行处理文本数据变得更容易,而不是顺序处理(从而提高了执行速度)。
现在可以通过 Hugging Face 库轻松在 Python 中实现 Transformers。
文本预测演示
文本预测是可以通过 Transformers 轻松实现的任务之一,例如 GPT2。在这个示例中,我们将输入 Carlos Ruiz Zafón 的《风之影》中的一句话,然后我们的 Transformer 将生成另外 50 个字符,这些字符应该逻辑上跟随我们的输入数据。
A book is a mirror that offers us only what we already carry inside us. It is a way of knowing ourselves, and it takes a whole life of self awareness as we become aware of ourselves. This is a real lesson from the book My Life.
从上面展示的示例输出中可以看出,我们的 GPT2 模型在为输入字符串创建可续写的内容方面表现得相当出色。
一个示例笔记本可以运行以生成你自己的文本,访问 此链接。
希望你喜欢这篇文章,感谢阅读!
联系方式
如果你想保持更新我的最新文章和项目, 请关注我在 Medium 上 并订阅我的 邮件列表。以下是我的一些联系方式:
参考文献
[1] 使用 NLTK POS 标注器在 Python 中提取自定义关键词,Thinkinfi,Anindya Naskar。访问地址:www.thinkinfi.com/2018/10/extract-custom-entity-using-nltk-pos.html
[2] BoW 和 SoW 词袋模型的比较,ProgrammerSought。访问地址:www.programmersought.com/article/4304366575/;jsessionid=0187F8E68A22612555B437068028C012
[3] 主题建模:NLP 中的讲故事艺术,
TechnovativeThinker。访问地址:medium.com/@MageshDominator/topic-modeling-art-of-storytelling-in-nlp-4dc83e96a987
[4] 词移动嵌入:来自 Word2Vec 的通用文本嵌入,IBM 研究博客。访问链接:www.ibm.com/blogs/research/2018/11/word-movers-embedding/
简介: Pier Paolo Ippolito 是一位数据科学家和南安普顿大学人工智能硕士毕业生。他对 AI 进展和机器学习应用(如金融和医学)有浓厚的兴趣。可以在Linkedin上与他联系。
原文。经授权转载。
相关:
-
加速自然语言处理:来自亚马逊的免费课程
-
NLP 简介及提升技能的 5 个技巧
-
开始使用 PyTorch
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
机器学习算法选择路线图
原文:
www.kdnuggets.com/roadmap-to-machine-learning-algorithm-selection

图片由作者创建
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
生成预测模型的重要一步是选择合适的机器学习算法,这一选择可能对模型性能和效率产生显著影响。这种选择甚至可以决定最基本的预测任务的成功:模型是否能够充分从训练数据中学习并推广到新的数据集。这对于数据科学从业者和学生尤为重要,因为他们面临着大量可能的算法选择。本文的目标是帮助揭开选择合适机器学习算法的过程,重点介绍“传统”算法,并提供一些选择最佳算法的指南。
算法选择的重要性
选择最佳、正确或甚至足够的算法可以显著提高模型的预测准确性。你可能会猜到,错误的算法选择可能导致模型性能不佳,甚至可能达不到有用的标准。这带来了巨大的潜在优势:选择与数据和问题的统计特征匹配的“正确”算法,将使模型能够更好地学习并提供更准确的输出,可能还会节省时间。相反,选择错误的算法可能会带来一系列负面后果:训练时间可能更长;训练可能计算开销更大;最糟糕的是,模型可能不够可靠。这可能意味着模型准确性降低,面对新数据时结果不佳,或者无法真正洞察数据所能告诉你的内容。在这些指标中任何一个或全部表现不佳,最终可能浪费资源并限制整个项目的成功。
简而言之 正确选择适合任务的算法直接影响机器学习模型的效率和准确性。
算法选择考虑因素
为任务选择正确的机器学习算法涉及多种因素,每个因素都可能对最终决策产生重大影响。以下是决策过程中的几个方面需要牢记。
数据集特征
数据集的特征对于算法选择至关重要。数据集的大小、包含的数据元素类型、数据是结构化还是非结构化等因素都是顶级因素。试想将一个针对结构化数据的算法应用于非结构化数据问题,你可能不会取得很大进展!大型数据集需要可扩展的算法,而较小的数据集可能用更简单的模型就可以处理。还不要忘记数据的质量——数据是干净的,还是有噪声的,或许是不完整的——因为不同的算法在处理缺失数据和噪声时具有不同的能力和鲁棒性。
问题类型
你要解决的问题类型,无论是分类、回归、聚类还是其他类型,显然会影响算法的选择。每类问题都有适合的特定算法,而许多算法根本无法处理其他问题类型。例如,如果你在处理分类问题,你可能会在逻辑回归和支持向量机之间进行选择,而一个聚类问题可能会使你使用 k-means。你可能不会在试图解决回归问题时从决策树分类算法开始。
性能指标
你打算通过什么方式来衡量模型的性能?如果你设定了特定的指标——例如,分类问题的精确度或召回率,回归问题的均方误差——你必须确保所选算法能够适应。此外,不要忽视其他非传统指标,如训练时间和模型可解释性。尽管某些模型的训练速度较快,但可能会以牺牲准确性或可解释性为代价。
资源可用性
最后,你所拥有的资源可能会大大影响你的算法决策。例如,深度学习模型可能需要大量的计算能力(例如,GPU)和内存,这使得它们在一些资源受限的环境中不那么理想。了解你拥有的资源可以帮助你做出一个能够在需求、资源和完成工作的折中之间做出平衡的决策。
通过周密考虑这些因素,可以做出一个既表现良好又符合项目目标和限制的算法选择。
算法选择初学者指南
以下是一个可以作为实际工具的流程图,用于指导机器学习算法的选择,详细说明了从问题定义阶段到模型完成部署的步骤。通过遵循这一结构化的选择点和考虑事项的顺序,用户可以成功评估将影响选择正确算法的因素。
需要考虑的决策点
流程图标识了许多具体的决策点,其中大部分在上述内容中已经涵盖:
-
确定数据类型:理解数据是结构化还是非结构化形式可以帮助确定选择算法的起点,同时识别单个数据元素类型(整数、布尔值、文本、浮点小数等)也有帮助。
-
数据大小:数据集的大小在决定是使用更简单还是更复杂的模型时起着重要作用,这取决于数据大小、计算效率和训练时间等因素。
-
问题类型:要解决的机器学习问题的具体类型——分类、回归、聚类或其他——将决定可能相关的算法集合,每组算法提供的算法或算法集合将适合目前为止对问题的选择。
-
调整和评估:从选择的算法得出的模型通常会从选择开始,经过参数调整,最后进行评估,每一步都需要确定算法的有效性,任何时刻都可能导致选择另一种算法的决定。
流程图可视化由作者创建(点击放大)
一步一步来
从头到尾,上述流程图概述了从问题定义,到数据类型识别、数据大小评估、问题分类,再到模型选择、调整和后续评估的演变过程。如果评估表明模型令人满意,可能会进行部署;否则,可能需要修改模型或使用不同的算法进行新的尝试。通过使算法选择步骤更简单,选择最有效的算法以适应特定数据和项目规格的可能性更大。
第一步:定义问题并评估数据特征
选择算法的基础在于对问题的精确定义:你想要建模什么以及你要克服哪些挑战。同时,评估数据的特性,如数据的类型(结构化/非结构化)、数量、质量(噪声和缺失值的缺乏)和多样性。这些因素共同影响你能够应用的模型复杂性水平和你必须使用的模型类型。
第 2 步:根据数据和问题类型选择合适的算法
在问题和数据特征被揭示之后,下一步是选择最适合你的数据和问题类型的算法或算法组。例如,像逻辑回归、决策树和 SVM 这样的算法可能对结构化数据的二分类有用。回归可能会提示使用线性回归或集成方法。非结构化数据的聚类分析可能需要使用 K-Means、DBSCAN 或其他类型的算法。你选择的算法必须能够有效处理你的数据,同时满足项目的要求。
第 3 步:考虑模型性能要求
不同项目的性能要求需要不同的策略。这一轮涉及识别对你的企业最重要的性能指标:准确性、精度、召回率、执行速度、可解释性等。例如,在理解模型内部工作机制至关重要的领域,如金融或医学中,可解释性变得非常关键。必须将关于项目中重要特征的数据与各种算法的已知优势相匹配,以确保这些需求得到满足。最终,这种对齐确保了数据和业务的需求得到满足。
第 4 步:构建基线模型
与其追求算法复杂性的最前沿,不如从一个简单的初始模型开始建模。该模型应该易于安装并运行快速,这是基于对更复杂模型性能的估计。这一步对建立早期模型性能估计非常重要,并可能指出数据准备中的大规模问题,或初始时做出的天真假设。
第 5 步:根据模型评估进行精细化和迭代
一旦达到基线水平,依据性能标准对模型进行精细化。这包括调整模型的超参数和特征工程,或者如果前一个模型不符合项目指定的性能指标,则考虑不同的基线。通过这些精细化过程的迭代可能会发生多次,每次模型的调整都可能带来更深入的理解和更好的性能。以这种方式精细化和评估模型是优化其性能以符合设定标准的关键。
这种规划水平不仅减少了选择适当算法的复杂过程,而且还会增加能够引入一个耐用、合理定位的机器学习模型的可能性。
结果:常见机器学习算法
本节概述了一些常用的分类、回归和聚类任务算法。了解这些算法及其使用时机,可以帮助个人做出与其项目相关的决策。
常见分类算法
-
逻辑回归:最适用于二分类任务,逻辑回归是一个有效但简单的算法,当因变量和自变量之间的关系是线性时。
-
决策树:适用于多类和二类分类,决策树模型易于理解和使用,在透明度重要的情况下很有用,可以处理分类数据和数值数据。
-
支持向量机(SVM):适用于高维空间中具有明确类别边界的复杂问题分类。
-
朴素贝叶斯:基于贝叶斯定理,适用于大型数据集,相对于更复杂的模型通常较快,特别是当数据是独立时。
常见回归算法
-
线性回归:最基础的回归模型,当处理数据可以通过最小的多重共线性线性分离时最有效。
-
Ridge 回归:在线性回归中添加正则化,旨在减少复杂性并防止在处理高度相关的数据时过拟合。
-
Lasso 回归:类似于 Ridge,也包括正则化,但通过将不太重要变量的系数归零来强制模型简单化。
常见聚类算法
-
k-means 聚类:当簇的数量和它们明显的非层次分离明显时,使用这个简单的聚类算法。
-
层次聚类:如果您的模型需要层次结构,让层次聚类促进发现和访问更深层次的簇。
-
DBSCAN:如果目标是找到形状变化的簇,标记数据集中明显和远离的簇,或者处理高度噪声的数据,一般来说可以考虑在数据集上实现 DBSCAN。
牢记性能目标,您的算法选择可以根据数据集的特征和目标进行调整,如下所述:
-
在数据较小且类别地理位置明确且容易区分的情况下,实施简单模型——如用于分类的逻辑回归和用于回归的线性回归——是一个好主意。
-
要处理大型数据集或防止数据建模中的过拟合,您可能需要考虑使用更复杂的模型,例如用于回归问题的 Ridge 回归和 Lasso 回归,以及用于分类任务的 SVM。
-
对于聚类目的,如果你面临各种问题,比如恢复基本的鼠标点击聚类、识别更复杂的自上而下或自下而上的层次结构,或处理特别嘈杂的数据,那么应该考虑 k-means、层次聚类和 DBSCAN,这取决于数据集的具体情况。
总结
选择机器学习算法对任何数据科学项目的成功至关重要,同时也是一门艺术。本文讨论了算法选择过程中的许多步骤的逻辑进展,并以最终集成和模型的进一步优化作为结论。每一步都与前一步同样重要,因为每一步都会对指导下的模型产生影响。本文开发的一个资源是一个简单的流程图,用于帮助指导选择。这个想法是将其作为确定模型的模板,至少在开始阶段如此。这将作为未来构建的基础,并为未来尝试构建机器学习模型提供路线图。
这个基本点是正确的:你学习和探索不同方法的越多,你在使用这些方法解决问题和建模数据方面就会变得越好。这要求你不断质疑算法本身的内部机制,并保持对新趋势甚至是领域中新算法的开放态度。为了成为一名优秀的数据科学家,你需要不断学习并保持灵活。
请记住,亲手尝试各种算法并测试它们可以是一个有趣且有回报的经历。通过遵循本讨论中介绍的指南,你可以理解这里涵盖的机器学习和数据分析的各个方面,并为将来出现的问题做好准备。机器学习和数据科学无疑会带来许多挑战,但这些挑战最终会成为帮助你取得成功的经验点。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的主编,以及Machine Learning Mastery的特约编辑,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是使数据科学社区的知识普及化。Matthew 自 6 岁起便开始编程。
进一步阅读
机器学习中的优化:稳健还是全局最小值?
comments
作者:Nikolaos Vasiloglou

在 2014 年,Facebook 最佳论文奖 @UAI 授予 “Universal Convexification via Risk-Aversion” b.y Krishnamurthy Dvijotham; Maryam Fazel; Emanuel Todorov www.auai.org/uai2014/proceedings/individuals/121.pdf。三年后,我们在一次简短的采访中跟进了作者:
NV: 首先祝贺你们获奖。我们知道在凸问题中,找到全局最优解要容易得多。
KD, MF: 谢谢!我们很感激有机会参与这个讨论。
1. NV: 凸化问题是否总是具有与原始问题相同的最小值?
KD, MF: 不,凸化的问题可能具有与原始问题相当不同的最小值。我们论文的动机来源于许多问题(如控制和强化学习)中人们对“稳健”最小值(即当扰动参数时成本不会大幅增加的最小值)的兴趣。我们的方法破坏了非稳健最小值,保留了问题的唯一稳健最小值。
2. NV: 我们已经看到很多对分析所有局部最小值等于全局最小值的非凸问题的兴趣。例如 A. Anandkumar 的团队一直在研究如何保证非凸问题中的最小值。你的工作与这个方向相比如何?
KD: 是的,这些结果非常有趣,并且与我们的工作有潜在的联系。特别是,论文 arxiv.org/abs/1503.03712 和 arxiv.org/pdf/1610.09322.pdf 研究了平滑非凸函数以消除局部最小值的方法,但采用了逐渐的方法(从大量平滑开始,并逐渐减少,同时跟踪全局最小值)。我们的方法是一次性完成的(添加大量噪声/风险规避)以直接凸化问题,但通过逐渐的方式可能可以改进(在允许较弱假设的意义上,保证一个稳健最小值的位置)。我们期待进一步探索这些联系。
MF: 只是补充一下,我们的工作(以及 KD 上面提到的论文)并不专注于所有局部最小值等同于全局最小值的限制情况。
3. NV: 最大的难题是深度学习。你的论文中有一个 MNIST 的例子。你们尝试过其他案例吗?
KD: 我们在 MNIST 上的结果相当初步,确实需要更仔细的调查,并与最新的深度学习算法进行比较。不幸的是,我们没有机会进行更详细的实验——在我们撰写这篇论文后不久,我就离开去做博士后,并将重点转向其他主题。我们计划在接下来的几个月里重新研究这个问题,并撰写这篇论文的扩展版本。然而,文献中出现了几篇其他作者的论文,探讨了向神经网络中添加噪声以改善优化和泛化的类似想法(例如,openreview.net/forum?id=B1YfAfcgl)。
4. NV:深度学习爱好者说 SGD 大多数时候都能工作,并且经过几次重启你就能训练好网络。你对此有何评论?你认为你的方法为何仍然更好?
KD: 我们论文的贡献是一个具体的方法,它精确量化了需要多少噪声/风险厌恶才能使问题凸化。我们不期望这种方法直接与 SGD 竞争,至少对于标准的监督学习问题是这样,尽管它可能会提供一些关于添加多少噪声的见解,以便训练对局部极小值的敏感性更低(MF: 最近,噪声梯度下降和 Langevin 动力学因类似目标而受到关注)。
然而,我们开发这个方法的主要动机是在 RL 和控制问题中,其中鲁棒性本身是一种理想的特质(例如,它是一种确保机器人系统在扰动和干扰下不会违反安全约束的方法)。我们的直觉是,找到鲁棒的极小值实际上更容易,论文中提出的理论对此声明提供了一些严格的理由。
6. NV:你的论文在社区中的反响如何?有没有后续工作?你的方法似乎很直接实现。你认为 TensorFlow 实现(或其他流行的包)会更有助于人们采纳它吗?
KD: 我们收到了来自最近应用类似想法于计算机视觉的论文的一些后续跟进 (link.springer.com/chapter/10.1007/978-3-319-14612-6_4) 和一般非凸优化的论文 (arxiv.org/abs/1602.02191)。然而,由于我们没有继续进行这项工作,这篇论文没有得到广泛宣传。我们希望尽快回到这项工作中,改进算法以使其实际可用,并发布一个开源实现。论文中的基本方法是直接实现的。然而,为了在实践中取得良好的性能,我们认为这种方法需要与近年来从事 SGD 研究的学者们开发的方差减少思想相结合。正如我在前面的问题中所说,我们的观点是这种方法最适用于那些对鲁棒性有直接兴趣的问题,而不是标准的监督学习问题。我们希望在接下来的几个月中,开发一个适用于 RL 问题的实现,使用 OpenAIgym 环境 (gym.openai.com/) 并公开发布。
7. NV: 讲述一下在实际中找到全局最小值的其他成功方法。
KD: 非凸问题的全局优化通常具有挑战性和困难。在优化社区中,已经开发出几种依赖于分支定界的方法,即构建和改进凸松弛,并结合某种搜索策略(例如 BARON: archimedes.cheme.cmu.edu/?q=baron)。对于没有额外结构的问题,这些方法是最佳的。然而,这些算法在任何特定问题上的性能可能会有很大的变化(在最坏的情况下,它们可能类似于暴力搜索)。对于多项式优化问题,Lasserre 层次结构 (homepages.laas.fr/lasserre/book-flyer.pdf) 允许通过逐渐增大的半正定程序的层次来计算全局最优解。理论上,需要解决非常大的半正定程序以找到全局最优解,但在实践中,对于一些多项式优化问题,适当大小的半正定程序足以计算全局最优解。
8. NV: 对于非凸问题,寻找凸包是否值得?与凸包相比,你的算法会慢多少?
KD: 这是一个很好的问题。构造一般非凸函数的凸包问题仍然是 NP 难的,除非在特殊情况下,否则很难解决。在那些构造凸包比较容易的特殊情况下,如果你有兴趣找到原始目标函数的最小值,可以最小化这个凸包。然而,正如之前所述,我们的方法的重点是找到一个鲁棒的最小值,而不是全局最小值,因此凸包是否对这个目标有用并不明显。也可能通过另一种称为莫罗包络的包络来解释我们的方法;我们目前正在研究这些联系。
9. NV: 在你的实验中,你更强调泛化误差而不是全局最小值的接近程度。这是为什么?你的方法实际上解决了这两个问题吗?
KD: 我们的方法可能会产生一个远离全局最小值的最优解,因为它试图找到一个鲁棒的最小值。我们在实验中测试的假设是,也许鲁棒最小值在泛化误差方面优于全局最小值——期望这样是因为在实验中,我们对 SVM(w’x+b)和神经网络的中间神经元的预测添加了噪声。这个想法是,添加这种噪声并尝试最小化噪声上的期望学习损失,试图确保算法的预测不仅对给定输入保持稳定,还对其周围的一系列噪声扰动保持稳定。当然,在我们的论文中,这一点并没有被严格证明,但我们进行的初步实验表明确实如此。我们正在研究将这一点形式化的方法;已知学习算法对扰动的稳定性与泛化能力有关 www.jmlr.org/papers/volume2/bousquet02a/bousquet02a.pdf。
10. NV: 你的方法对输入添加噪声并在期望上进行优化吗?这与贝叶斯方法有联系吗?与加速的蒙特卡洛变体有任何联系吗?另外,你的方法是否提供了学习模型的分布?
KD: 由于我们的方法中注入噪声是有意为之,并非像贝叶斯方法中的概率模型那样产生的,因此没有直接的联系。此外,最后我们没有得到模型参数的后验分布,而只是一个点估计。可能有方法利用蒙特卡洛算法来获得更好的随机梯度样本估计,但我们还没有研究过。我们的方法仅产生模型参数的单一估计,而不是整个分布。
11. NV: 你的方法与 dropout(在提高泛化能力方面)有任何联系吗?
KD,MF: 我们不知道任何直接的联系。
12. NV: ICLR 2017 最佳论文 “理解深度学习需要重新思考泛化” 以如下话语结束: “从我们的实验中得到的另一个见解是,即使得到的模型不能泛化,优化仍然在经验上是容易的。这表明,优化在经验上容易的原因必须与泛化的真实原因不同”。你似乎同时处理了这两个(优化和泛化)。你的方法是否与这篇论文的发现相矛盾?
KD: 我尚未仔细研究这篇论文,但它确实有一个有趣的观察。正如我之前提到的,我们的方法确实表明,找到稳健的最小值比找到全局最小值更容易,并且有一些证据(来自我们的实验和其他学习理论论文)表明稳健性和泛化是相关的。然而,我们的实验相当初步,并使用了非常小的数据集和神经网络。最近的深度学习工作显示,在大数据和大规模神经网络领域,优化问题(局部最小值等)往往会消失——因此,最近的 ICLR 论文所研究的情况可能实际上呈现了一个不同的状态,其中优化和泛化具有不同的定性特征,而不是少量模型参数和小数据集的设置。我不会说这两项研究相互矛盾,但新的 ICLR 工作令人着迷,因为它违背了关于学习和泛化的传统智慧。
原文。已获得许可转载。
个人简介:Nikolaos Vasiloglou 是 UAI 2017 的组织委员会成员,并在构建/开发分布式机器学习系统方面有多年经验。
相关:
-
介绍 Dask-SearchCV:使用 Scikit-Learn 进行分布式超参数优化
-
通过梯度下降学习如何学习
-
5 个你不容忽视的机器学习项目,1 月
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
使用 Gensim 的稳健 Word2Vec 模型与应用 Word2Vec 特征于机器学习任务
原文:
www.kdnuggets.com/2018/04/robust-word2vec-models-gensim.html
评论
编辑注: 本文只是一个更全面、更深入的原文的一部分,原文链接包含了更多内容。
使用 Gensim 构建稳健的 Word2Vec 模型
尽管我们的实现已经相当不错,但在大语料库上并没有得到优化。[**gensim**](https://radimrehurek.com/gensim/) 框架由 Radim Řehůřek 创建,提供了一个健壮、高效且可扩展的 Word2Vec 模型实现。我们将在我们的圣经语料库上利用它。在我们的工作流程中,我们将对规范化的语料库进行分词,然后关注 Word2Vec 模型中的以下四个参数来构建它。
-
**size**: 词嵌入的维度 -
**window**: 上下文窗口大小 -
**min_count**: 最小词频 -
**sample**: 高频词的下采样设置
构建模型后,我们将使用感兴趣的词查看每个词的最相似词。

这里的相似词确实与我们感兴趣的词更相关,这符合预期,因为我们运行了更多次数的模型,这应该带来了更好、更具上下文的嵌入。你注意到任何有趣的关联吗?

诺亚的儿子被我们的模型识别为最具上下文相似性的实体!
让我们在使用 t-SNE 将维度减少到二维空间后,使用词嵌入向量可视化感兴趣的词及其相似词。
使用 t-SNE 可视化我们的 word2vec 词嵌入
红色圆圈是我画的,用于指出我发现的一些有趣的关联。根据我之前描述的内容,我们可以清楚地看到,基于我们模型的词嵌入,noah 和他的儿子们彼此之间非常接近!
应用 Word2Vec 特征于机器学习任务
如果你记得阅读过之前的文章 Part-3: 传统文本数据方法,你可能看到我使用了一些实际的机器学习任务特征,如聚类。我们将利用其他顶级语料库,尝试实现相同的目标。首先,我们将基于语料库构建一个简单的 Word2Vec 模型,并可视化嵌入。
在我们的玩具语料库上可视化 word2vec 词嵌入
记住,我们的语料库非常小,因此为了获得有意义的词嵌入并让模型获得更多的上下文和语义,更多的数据是有帮助的。那么在这种情况下,什么是词嵌入?它通常是每个词的密集向量,如下例所示,表示词sky。
w2v_model.wv['sky']
Output
------
array([ 0.04576328, 0.02328374, -0.04483001, 0.0086611 ,
0.05173225, 0.00953358, -0.04087641, -0.00427487, -0.0456274 ,
0.02155695], dtype=float32)
现在假设我们想要对来自玩具语料库的八个文档进行聚类,我们需要从每个文档中每个词的文档级嵌入中获取信息。一种策略是计算每个文档中每个词的词嵌入的平均值。这是一种非常有用的策略,你可以将其应用到你自己的问题中。现在让我们在我们的语料库上应用这个方法,获取每个文档的特征。
文档级别的嵌入
现在我们已经获得了每个文档的特征,让我们使用亲和传播算法对这些文档进行聚类。该算法基于数据点之间的“消息传递”概念,不需要显式输入簇的数量,而这是基于分区的聚类算法通常需要的。

根据我们从 word2vec 获得的文档特征进行簇的分配
我们可以看到,我们的算法已经根据 Word2Vec 特征将每个文档归入了正确的组,非常棒!我们还可以通过使用主成分分析 (PCA)将特征维度降到 2-D 并可视化(通过为每个簇进行颜色编码)来可视化每个文档在每个簇中的位置。
可视化我们的文档簇
一切看起来都很有序,因为每个簇中的文档彼此更接近,而与其他簇距离较远。
简介: Dipanjan Sarkar 是 Intel 的数据科学家,作者,Springboard 的导师,作家,体育和情景喜剧迷。
原文。转载经许可。
相关:
-
文本数据预处理:Python 中的操作指南
-
处理文本数据的一般方法
-
处理文本数据科学任务的框架
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
相关主题
ROC 曲线解释
评论
作者:Zolzaya Luvsandorj,iSelect 数据科学家
ROC 曲线下面积是评估监督分类模型的最有用的指标之一。这个指标通常被称为 ROC-AUC。这里,ROC 代表接收者操作特征,AUC 代表曲线下面积。在我看来,AUROCC 是一个更准确的缩写,但可能听起来不如 ROC-AUC 那样悦耳。在正确的语境中,AUC 也可以暗示 ROC-AUC,尽管它也可以指代任何曲线下的面积。

图片由Joel Filipe在Unsplash提供
在这篇文章中,我们将深入了解 ROC 曲线的概念构建,并在 Python 中以静态和交互式格式可视化该曲线。
理解曲线
ROC 曲线展示了在不同阈值下假阳性率(FPR)与真正阳性率(TPR)之间的关系。让我们理解这三个术语的含义。
首先,让我们回顾一下混淆矩阵的样子:
作者提供的图像
复习一下混淆矩阵,让我们来看一下这些术语。
假阳性率
我们可以使用下面的简单公式来计算 FPR:

FPR 告诉我们错误预测的负记录的百分比。
作者提供的图像
真正阳性率
我们可以使用下面的简单公式来计算 TPR:

TPR 告诉我们正确预测的正记录的百分比。这也被称为召回率或灵敏度。
作者提供的图像
阈值
一般来说,分类模型可以预测给定记录属于某一类别的概率。通过将概率值与我们设定的阈值进行比较,我们可以将记录分类到一个类别中。换句话说,你需要定义一个类似于以下的规则:
如果为正的概率大于或等于阈值,则记录被分类为正预测;否则为负预测。
在下面的小例子中,我们可以看到三个记录的概率分数。使用两个不同的阈值(0.5 和 0.6),我们将每个记录分类到一个类别中。如你所见,预测的类别根据我们选择的阈值不同而有所变化。

作者提供的图像
在构建混淆矩阵并计算如 FPR 和 TPR 等比率时,我们需要预测的类别而不是概率分数。
ROC 曲线
现在我们知道了 FPR、TPR 和阈值是什么,理解 ROC 曲线的展示就很简单了。在构造曲线时,我们首先计算许多阈值下的 FPR 和 TPR。一旦我们得到这些阈值的 FPR 和 TPR,我们就将 FPR 绘制在 x 轴上,将 TPR 绘制在 y 轴上,从而得到 ROC 曲线。就是这样!✨
作者提供的图像
ROC 曲线下的面积范围从 0 到 1。一个完全随机的模型其 AUROCC 为 0.5,由下方虚线蓝色三角形对角线表示。ROC 曲线距离该线越远,模型的预测能力越强。
作者提供的图像
现在,到了查看一些代码示例来巩固我们的知识的时候了。
在 Python 中构建静态 ROC 曲线
首先,让我们导入在本帖其余部分中需要的库:
import numpy as np
import pandas as pd
pd.options.display.float_format = "{:.4f}".formatfrom sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, plot_roc_curveimport matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
sns.set(palette='rainbow', context='talk')
现在,我们将构建一个函数,根据正确类别、预测为正类的概率和阈值,来找出假阳性和真阳性的数量:
def get_fp_tp(y, proba, threshold):
"""Return the number of false positives and true positives."""
# Classify into classes
pred = pd.Series(np.where(proba>=threshold, 1, 0),
dtype='category')
pred.cat.set_categories([0,1], inplace=True)
# Create confusion matrix
confusion_matrix = pred.groupby([y, pred]).size().unstack()\
.rename(columns={0: 'pred_0',
1: 'pred_1'},
index={0: 'actual_0',
1: 'actual_1'})
false_positives = confusion_matrix.loc['actual_0', 'pred_1']
true_positives = confusion_matrix.loc['actual_1', 'pred_1']
return false_positives, true_positives
请注意,实际上你将使用分割的数据集(例如训练集、测试集)。但为了简单起见,我们在这篇文章中不会对数据进行分割。
我们将在一个玩具数据集上构建一个简单的模型,并获取记录的正类概率(用值 1 表示):
# Load sample data
X = load_breast_cancer()['data'][:,:2] # first two columns only
y = load_breast_cancer()['target']# Train a model
log = LogisticRegression()
log.fit(X, y)# Predict probability
proba = log.predict_proba(X)[:,1]
我们将使用 1001 个不同的阈值,范围从 0 到 1,每次增加 0.001。换句话说,阈值将类似于 0、0.001、0.002、…、0.998、0.999、1。让我们找出这些阈值的 FPR 和 TPR。
# Find fpr & tpr for thresholds
negatives = np.sum(y==0)
positives = np.sum(y==1)columns = ['threshold', 'false_positive_rate', 'true_positive_rate']
inputs = pd.DataFrame(columns=columns, dtype=np.number)
thresholds = np.linspace(0, 1, 1001)for i, threshold in enumerate(thresholds):
inputs.loc[i, 'threshold'] = threshold
false_positives, true_positives = get_fp_tp(y, proba, threshold)
inputs.loc[i, 'false_positive_rate'] = false_positives/negatives
inputs.loc[i, 'true_positive_rate'] = true_positives/positives
inputs

绘图数据已准备好。让我们来绘制它:
def plot_static_roc_curve(fpr, tpr):
plt.figure(figsize=[7,7])
plt.fill_between(fpr, tpr, alpha=.5)
# Add dashed line with a slope of 1
plt.plot([0,1], [0,1], linestyle=(0, (5, 5)), linewidth=2)
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC curve");
plot_static_roc_curve(inputs['false_positive_rate'],
inputs['true_positive_rate'])
虽然构建自定义函数有助于我们理解曲线及其输入,并更好地控制它们,但我们也可以利用sklearn的优化能力。例如,我们可以使用roc_curve()函数获取 FPR、TPR 和阈值。我们可以使用自定义绘图函数以相同的方式绘制数据:
fpr, tpr, thresholds = roc_curve(y, proba)
plot_static_roc_curve(fpr, tpr)
Sklearn还提供了一个plot_roc_curve()函数,自动完成所有工作。你只需一行代码(添加标题是可选的):
plot_roc_curve(log, X, y)
plt.title("ROC curve"); # Add a title for clarity
在 Python 中绘制交互式 ROC 曲线
使用静态图时,很难看到曲线上不同点对应的阈值。一个选项是检查我们创建的inputs数据框。另一个选项是创建图的交互式版本,这样当我们悬停在图表上时,可以看到 FPR 和 TPR 以及对应的阈值:
def plot_interactive_roc_curve(df, fpr, tpr, thresholds):
fig = px.area(
data_frame=df,
x=fpr,
y=tpr,
hover_data=thresholds,
title='ROC Curve'
)
fig.update_layout(
autosize=False,
width=500,
height=500,
margin=dict(l=30, r=30, b=30, t=30, pad=4),
title_x=.5, # Centre title
hovermode = 'closest',
xaxis=dict(hoverformat='.4f'),
yaxis=dict(hoverformat='.4f')
)
hovertemplate = 'False Positive Rate=%{x}<br>True Positive Rate=%{y}<br>Threshold=%{customdata[0]:.4f}<extra></extra>'
fig.update_traces(hovertemplate=hovertemplate)
# Add dashed line with a slope of 1
fig.add_shape(type='line', line=dict(dash='dash'), x0=0, x1=1, y0=0, y1=1)
fig.show()plot_interactive_roc_curve(df=inputs,
fpr='false_positive_rate',
tpr='true_positive_rate',
thresholds=['threshold'])

交互性非常有用,不是吗?
希望你喜欢学习如何构建和可视化 ROC 曲线。一旦你理解了这条曲线,就很容易理解另一条相关曲线:精确度-召回率曲线。
感谢阅读这篇文章。如果你感兴趣,这里有一些我其他文章的链接:
再见了 ????????
个人简介: Zolzaya Luvsandorj 在 iSelect 担任数据科学家。在以优异的成绩获得多个荣誉奖项完成 BCom 学位后,Zolzaya 曾在一家咨询公司担任数据分析师三年,然后转到现在的职位。她热衷于扩展数据科学、计算机科学和统计学知识,并在博客中用简单的语言解释数据科学概念。
原文。已获许可转载。
相关:
-
直接使用 Pandas 获取互动图表
-
如何创建一个互动的 3D 图表并轻松与任何人分享
-
指标的重要性,第一部分:评估分类模型
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
相关主题
数据工程师的角色正在变化
原文:
www.kdnuggets.com/2019/01/role-data-engineer-changing.html
comments
特里斯坦·汉迪,Fishtown Analytics 的创始人兼总裁

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我发现自己经常与分析领导者交谈,他们根据过时的思维模式来构建其团队的数据工程师角色。这个错误可能会严重阻碍整个数据团队,我希望看到更多公司避免这种结果。
这篇文章表达了我对何时、如何以及为什么应该将数据工程师纳入团队的看法。它基于我在Fishtown Analytics的经验,与 100 多家风险投资支持的初创公司合作建立他们的数据团队,以及与更广泛的数据社区中的数百家公司进行的对话。
如果你在一家风险投资支持的初创公司管理数据团队,这篇文章是为你写的。
数据工程师的角色正在变化。
软件正在越来越多地自动化数据工程中的无聊部分。
在 2012 年,如果你想在风险投资支持的初创公司中拥有一个复杂的分析实践,你需要一个或多个数据工程师。这些工程师负责从你的操作系统中提取数据,并将其传输到分析师和业务用户可以获取的地方。他们通常会进行一些转换工作,以便数据更易于分析。如果没有数据工程师,分析师和科学家将没有数据可用,因此工程师经常是新数据团队的第一批成员。
到了 2019 年,你可以购买现成的技术来完成大部分工作。在大多数情况下,你和你的数据分析师以及科学家可以在没有任何硬核数据工程经验的情况下构建整个管道。而且你不会构建一些二流、糟糕的管道:现成的工具实际上是解决这些问题的最佳方式。
数据分析师和科学家构建自服务管道的能力是新的——目前大约有 2-3 年的历史。推动这一变化的有三个具体的产品:Stitch、Fivetran 和 dbt。这些产品最初是在 Amazon Redshift 发布之后推出的,当时初创数据团队发现了构建数据仓库的巨大潜力。尽管如此,这些产品要真正变好还是花了几年时间——在 2016 年,我们还处于早期采用者阶段。
目前,基于 Stitch / Fivetran / dbt 构建的管道比基于自定义 Airflow 任务构建的管道要可靠得多。这是一种经验性的说法,而不是理论性的说法:我不是说构建可靠的 Airflow 基础设施是不可能的,我只是说大多数初创公司并没有这样做。在 Fishtown Analytics,我们与 100 多个风险投资支持的数据团队合作,并且一再看到这种情况。我们一直在将人们从自定义构建的管道迁移到现成的基础设施中,几乎每一个案例的效果都是极其积极的。
工程师不应编写 ETL。
2016 年,Jeff Magnusson 写了一篇基础性的博客文章,标题为 工程师不应编写 ETL。这是我知道的第一个有人提到这种变化的帖子。以下是我最喜欢的部分:
数据处理工具和技术在过去五年中经历了巨大的演变。除非你需要处理超过数个 PB 的数据,或每天摄取数百亿的事件,否则大多数技术已经发展到可以轻松满足你的需求的地步。
除非你需要推动这些技术的能力的边界,否则你可能不需要一个高度专业化的工程师团队来构建这些技术上的解决方案。如果你勉强聘请到他们,他们会感到无聊。如果他们感到无聊,他们会离开你,去 Google、Facebook、LinkedIn、Twitter 等——这些地方才真正需要他们的专业知识。如果他们没有感到无聊,可能他们的水平也就只是中等而已。中等水平的工程师确实擅长于构建极其复杂且难以使用的“解决方案”。
我非常喜欢这一部分,因为它不仅突出了为什么你不需要数据工程师来解决大多数 ETL 问题,还说明了为什么你最好不要让他们来解决这些问题。
如果你雇佣一个数据工程师并要求他们构建管道,他们会认为他们的工作就是构建管道。这会导致像 Stitch、Fivetran 和 dbt 这样的工具会被视为对他们存在的威胁,而不是强大的增效器。他们会找到现成管道无法满足你非常定制的数据需求的理由,以及分析师不应构建自己数据转换的理由。他们会编写易碎、难以维护且性能不佳的代码。你将依赖这些代码,因为它在你团队做的其他所有工作之下。
像瘟疫一样避免这种情况。你的数据团队的创新速度将急剧下降,你将花费所有时间思考那些实际上不会为业务带来收入的基础设施问题。
如果不是 ETL,那…什么呢?
那么,你的初创数据团队是否仍然需要数据工程师?确实需要。
即便有新的工具使数据分析师和科学家能够构建自助服务管道,数据工程师仍然是任何高效数据团队中不可或缺的一部分。然而,他们需要专注的任务已发生变化,招聘的顺序也发生了变化。我会在后续部分讨论“何时”招聘的问题;现在,我们来谈谈数据工程师在现代初创数据团队中的责任。
数据工程师仍然是任何高效数据团队中不可或缺的一部分。
与其构建现成的摄取管道和实现基于 SQL 的数据转换,不如让你的数据工程师专注于以下任务:
-
管理和优化核心数据基础设施,
-
构建和维护定制的摄取管道,
-
支持数据团队资源的设计和性能优化,以及
-
构建非 SQL 转换管道。
管理和优化核心数据基础设施
尽管数据工程师不再需要管理 Hadoop 集群或为 VC 支持的初创公司扩展 Vertica 硬件,但在这一领域仍然有真正的工程工作需要做。确保你的数据技术在峰值状态下运行,将会大幅提高性能、降低成本或同时实现两者。通常这涉及到:
-
构建监控基础设施,以便了解数据管道的状态,
-
监控所有作业对集群性能的影响,
-
定期运行维护例程,
-
调整表模式(即分区、压缩、分布)以最小化成本并最大化性能,以及
-
开发无法从现成产品中获得的定制数据基础设施。
这些类型的工作在数据团队的早期阶段常常被忽视,但随着团队和数据集的增长,变得异常重要。在一个项目中,我们通过优化表分区将 BigQuery 的表构建成本从$500/天降至$1/天。 这些工作很重要。
一个在这方面走得很远的公司是 Uber。Uber 的数据工程师开发了一种叫做Queryparser的工具,自动监控所有对其数据基础设施的查询,并收集有关资源使用和利用模式的统计数据。Uber 的数据工程师可以使用元数据来相应地调整基础设施。
数据工程师还常常负责构建和维护运行数据基础设施的 CI/CD 管道。虽然许多数据团队在 2012 年时 VCS、环境管理和测试基础设施极差,但情况正在改变,数据工程师正在引领这一变革。
最后,领先公司的数据工程师通常还会参与构建不存在的工具。例如,Airbnb 的数据工程师开发了 Airflow,因为他们没有有效构建和调度 DAG 的方式。而 Netflix 的数据工程师则负责构建和维护一个复杂的基础设施,用于开发和运行数万份 Jupyter notebooks。
你可以在今天的市场上获得大多数核心基础设施,但仍然需要有人来监控它并确保其性能。如果你真的属于前沿数据组织,你可能还希望在现有工具的基础上推动界限。数据工程师可以在这方面提供帮助。
构建和维护数据摄取管道
虽然数据工程师不再需要手动开发 Postgres 或 Salesforce 数据传输,但现代数据集成供应商提供的现成集成大约只有 100 种。我们合作的大多数公司对其数据源的现成覆盖率在 75%到 90%之间。
实际上,集成通常是分阶段实施的。通常,第一阶段包括核心应用程序数据库和事件跟踪,第二阶段包括如 ESP 和广告平台等营销系统。这两个阶段的解决方案现在完全可以现成获得。一旦你深入到更具领域特定的 SaaS 供应商,你将需要数据工程师来构建和维护这些更专业的数据摄取管道。
例如,电子商务公司通常需要处理大量不同的产品,这些产品涉及 ERP、物流和运输领域。许多产品非常特定于某些行业,并且几乎没有现成的解决方案。预计你的数据工程师需要在可预见的未来构建这些管道。
建立和维护可靠的数据接收管道是困难的。如果你决定投入资源来建立一个,预计会比最初预算的时间更长,而且需要的维护也会更多。达到 V1 很简单,但让管道稳定地向你的数据仓库传送数据却很难。在你确定业务案例之前,不要承诺支持一个自定义的数据接收管道。一旦确定了,投入时间并将其建设得更为稳健。考虑使用 Stitch 的开源 Singer 框架——我们已经使用它构建了约 20 个自定义集成。
支持数据团队资源的设计和性能优化,用于 SQL 转换
在过去五年中,我们在数据工程方面看到的一种变化是 ELT 的兴起:这种 ETL 的新方式是在数据加载到仓库后进行转换,而不是之前。这种变化的具体内容和原因在其他地方有详细介绍;我在这里提到它的原因是 这种转变对 谁 构建这些管道有着巨大的影响。
如果你在编写 Scalding 代码来扫描 S3 中的 TB 级事件数据,并将其聚合到会话级别以便加载到 Vertica 中,你可能需要数据工程师来编写这个作业。但如果你的事件数据已经在 BigQuery 中(由 Google Analytics 360 加载),那么它已经完全可以在高性能、可扩展的环境中访问。不同之处在于 这个环境使用 SQL。这意味着 数据分析师现在可以构建自己的数据转换管道。
这一趋势在 2014 年随着 Looker 的 PDT 功能发布 开始真正兴起。在过去两年中,整个数据团队使用 dbt 构建了 500+ 节点的 DAG,并处理了多个 TB 的数据集。这一模式现在在现代数据团队中根深蒂固,使得分析师能够以前无法实现的方式自助服务。
向 ELT 的转变意味着 数据工程师不必构建大多数数据转换作业。这也意味着没有数据工程师的数据团队仍然可以通过为分析师构建的数据转换工具走得很远。然而,数据工程师在构建这些转换管道中仍然扮演着重要角色。数据工程师应该参与的两个关键领域是:
-
当性能至关重要时。
有时,业务逻辑需要一些特别复杂的转换,数据工程师的参与可以帮助评估特定构建表的方法的性能影响。许多分析师在 MPP 分析数据库的性能优化方面经验不足,这是与更技术性的人进行协作的绝佳机会。
-
当代码变得复杂时。
分析师擅长使用数据回答业务问题,但通常没有训练过如何编写可扩展的代码。很容易在你的数据仓库中开始构建表格,并使整个项目很快失控。让数据工程师参与考虑仓库的整体架构,并对特别棘手的转换进行设计审查,否则你会发现自己需要清理一团麻线。
构建非 SQL 转换管道
虽然 SQL 可以本地完成大多数数据转换需求,但它无法处理所有事情。一种常见需求是通过获取纬度/经度并分配特定区域来进行地理信息增强。目前,这在现代 MPP 分析数据库中尚未广泛支持(尽管这开始发生变化!),因此最佳答案通常是编写一个基于 Python 的管道,将数据仓库中的数据与区域信息进行增强。
Python(或其他非 SQL 语言)的另一个明显用例是算法训练。如果你有一个产品推荐器、需求预测模型或流失预测算法,它从你的数据仓库中获取数据并输出一系列权重,你会希望将其作为 SQL 基于 DAG 末尾的一个节点运行。
目前,大多数运行这些非 SQL 工作负载的公司都使用 Airflow 来协调整个 DAG。dbt 用于 DAG 的基于 SQL 的部分,然后在最后添加非 SQL 节点。这种方法提供了最佳的两全其美的结果,数据分析师可以主要负责基于 SQL 的转换,而数据工程师则负责生产级别的机器学习代码。
我的团队什么时候需要数据工程师?
角色的变化也促使重新思考数据工程师招聘的顺序。以前的公认智慧是你需要先有数据工程师,因为如果没有数据平台,数据分析师和科学家就没有东西可用。今天,数据分析师和科学家应该自助服务,使用现成的工具构建他们的数据栈的第一个版本。在达到规模点时雇佣数据工程师:
-
规模点 #1: 当你的团队中有 3 名数据分析师/科学家时,考虑雇佣你的第一位数据工程师。
-
规模点 #2: 当你有 50 个 活跃 用户使用你的 BI 平台时,考虑雇佣你的第一位数据工程师。
-
规模点 #3: 当你仓库中最大的数据表达到 10 亿行时,考虑雇佣你的第一位数据工程师。
-
规模点 #4: 当你知道在接下来的几个季度中需要构建 3 个或更多定制的数据摄取管道,并且它们都是至关重要的时,考虑雇佣你的第一位数据工程师。
如果你还没有触及到这些点,你的数据分析师和科学家应该可能能够使用现成技术、自外部顾问的支持和你所参与的数据社区(如Locally Optimistic和dbt的 Slack!)进行自助服务。
关键是要认识到数据工程师不提供直接的业务价值——他们的价值在于提高你的数据分析师和科学家的生产力。你的数据分析师和科学家是那些与利益相关者合作、衡量 KPI 以及构建报告和模型的人——他们是每天帮助你的业务做出更好决策的人。雇用数据工程师来作为更广泛团队的增效器:如果增加一名数据工程师能使你的四名数据分析师提高 33%的效率,那这可能是一个好的决定。
数据工程师通过提高你的数据分析师和科学家的生产力来提供业务价值。
当你扩展数据团队时,我通常看到的最佳比例是约 5 名数据分析师/科学家对应 1 名数据工程师。如果你在处理特别大或不寻常的数据集,也许这个比例会有所变化,但这是一个很好的基准。
你应该雇用谁?
随着数据工程师角色的变化,理想候选人的档案也在变化。我的尊敬的同事Michael Kaminsky在我们就此话题交换的邮件中比我更好地表达了这一点,所以我在这里引用他的话:
我对这种转变的看法是数据工程师在团队中的角色发生了变化。它从一个基础设施的建设者变成了支持更广泛数据团队的角色。这实际上是一个相当大的转变,一些数据工程师(希望专注于构建基础设施的)并不总是对这种变化感到兴奋。
我实际上认为这对初创公司来说是非常重要的:他们需要聘请一位对为分析/数据科学团队构建工具充满热情的数据工程师。如果你雇用一位只是想在后台混日子并且不喜欢与技术水平较低的人员合作的数据工程师,你会经历一段糟糕的时期。我寻找的是那些愿意与分析师和数据科学家合作,能够发现“你做的事情似乎很低效,我想要构建一些东西来改善它”的数据工程师。
我完全同意这一观点。今天初创公司的最佳数据工程师是支持型角色,他们几乎参与数据团队所做的所有事情。他们应该对这种合作角色感到兴奋,并有动力让整个团队取得成功。
如果你读到这里,非常感谢你:) 这显然是我非常关心的话题。如果你认为我完全错误,请在评论中告诉我——我很想听听你在数据团队中构建数据工程师角色的经历。
最后,如果你目前考虑招聘数据工程师,我公司实际上进行相当多的数据工程师面试——我们发现这是一种保持行业脉搏的好方法。如果你希望在发出录用通知之前进行最后一次理智检查,我们很乐意为你管道中的候选人进行最终轮面试。请 联系 我们,我们可以安排一个面试。
感谢 Drew Banin。
简介:Tristan Handy 是 Fishtown Analytics 的创始人兼总裁。他为高级分析构建开源工具。
原文。经许可转载。
相关:
-
人工智能和数据科学中的前 10 大角色
-
数据集成和数据工程的区别是什么?
-
数据工程入门指南——第 I 部分
更多相关话题
MLOps 工程师在组织中的角色
原文:
www.kdnuggets.com/2023/04/role-mlops-engineer-organization.html
作者提供的图片
所以你已经构建了一个机器学习模型,并且它在验证数据集上达到了预期的性能。你很高兴能够运用你的数据科学和机器学习技能来构建这个模型。然而,你意识到模型在本地计算机上的 Jupyter notebook 中表现良好,但在实际应用中尚未真正发挥作用(尚未)。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
为了让用户从你的模型中受益,并让企业能够利用机器学习,这些模型必须部署到生产环境中。然而,部署和维护机器学习模型并非没有挑战。在开发环境中表现良好的模型可能在生产环境中表现不佳。这可能是由于数据和概念漂移以及其他导致性能下降的因素造成的。
所以你意识到:为了使机器学习模型有用,你必须超越模型构建。这就是 MLOps 发挥作用的地方。今天,我们将了解 MLOps 以及MLOps 工程师在组织中的角色。
什么是 MLOps?
更多时候,你会看到 MLOps 被定义为将 DevOps 原则应用于机器学习。
软件开发生命周期(SDLC)因 DevOps 实践而发生了积极变化,简化了开发团队与运维团队之间的跨职能协作。如果你认识在 DevOps 领域工作的人,你可能听说过 CI/CD 管道、自动化 CI/CD 管道、应用监控等。
虽然这些概念可以迁移到机器学习应用中,但机器学习系统有其特定的挑战。构建和运营机器学习系统是一个更复杂的过程。
因此,一般来说,你可以将 MLOps 视为一套用于构建、部署和维护机器学习系统的最佳实践。
了解了这些概念后,让我们继续学习 MLOps 工程师在组织中具体做什么。
MLOps 工程师的工作是什么?
我们说过,将 DevOps 实践应用于机器学习系统是可能的。如果这就是 MLOps,那么 MLOps 工程师的职责就是做到这一点!
我们说的是什么意思?一旦数据科学团队构建了模型,MLOps 工程师通过以下方式确保模型的成功运行:
-
自动化机器学习模型部署
-
为 ML 管道设置监控
-
自动化 CI/CD 管道以考虑数据、代码和模型的变化
-
设置自动化模型重新训练
-
确定所需的自动化水平
与 MLOps 相关的一些挑战
设置监控只能帮助识别问题出现的时机。为了获得不同版本模型性能的更详细信息,MLOps 工程师通常使用模型版本控制和实验跟踪。
我们提到过,MLOps 工程师设定了模型重新训练的所需自动化水平。让我们尝试理解与之相关的挑战。
一旦应用程序部署到生产环境,模型所使用的数据(在生产环境中)可能与其训练时的数据有很大不同。因此,这样的模型表现可能较差,我们通常需要重新训练。
MLOps 工程师还需要处理模型重新训练的过程和自动化,包括考虑性能下降、数据变化的频率以及模型重新训练的成本。
等等,我做 MLOps。但我不是 MLOps 工程师。
在一些初创公司中,你可能会有既担任机器学习工程师又担任 MLOps 工程师的角色。而在其他公司中,你可能会有同时担任 DevOps 和后端工程师的角色。
在大科技公司中,MLOps 的工作可能与早期阶段的创业公司中的 MLOps 大相径庭。MLOps 的自动化程度也可能因组织而异。
如果你在一个初创公司工作,负责从模型训练到监控和维护机器学习系统的端到端机器学习管道,你也已经是 MLOps 工程师。
你是否对探索这个具有挑战性的 MLOps 工程师角色感到兴奋?让我们总结一下你需要的技能。
MLOps 技能和工具概述
MLOps 工程师通常具有强大的机器学习、DevOps 和数据工程技能。
图片由作者提供
-
机器学习技能:编程、对机器学习算法和框架的工作知识,以及领域知识
-
软件工程技能:查询和操作数据库、测试 ML 模型、Git 和版本控制、如 FastAPI 等框架
-
DevOps 基础:精通 Docker 和 Kubernetes 等工具
-
实验跟踪:熟悉如 MLflow 等实验跟踪框架
-
编排数据管道:使用 Prefect 和 Airflow 等工具设置和自动化数据管道
-
云基础设施:熟悉云基础设施提供商,如 AWS、GCP,以及像 Terraform 这样的基础设施即代码(IaC)工具
学习 MLOps
如果你对学习 MLOps 感兴趣,这里有一个资源列表可以帮助你入门:
-
DataTalks.Club 的 MLOps Zoomcamp:DataTalks.Club 提供的 MLOps zoomcamp 是一个免费的课程,涵盖了 MLOps 的所有内容——从模型构建到部署和监控的最佳实践。你将通过构建一个项目来整合所学的知识。
-
Coursera 上的 MLOps 专项课程:DeepLearning.AI 提供的生产环境机器学习(MLOps)专项课程。该专项课程(包括四门课程)将教你如何构建生产级机器学习系统。
-
MLOps GitHub 仓库:一个经过筛选的仓库列表,用于提升 MLOps 技能。
总结
在这篇文章中,我们涵盖了组织中 MLOps 工程师的主要职责和关键 MLOps 技能。
如前所述,并非所有从事 MLOps 的工程师都被称为 MLOps 工程师。我们还讨论了 MLOps 自动化的程度以及实际的日常工作可能因组织而异。
和其他角色一样,作为 MLOps 工程师成功需要软技能,如有效的沟通、协作和战略性解决问题。如果你想尝试成为一名 MLOps 工程师,祝你 MLOps 顺利!
Bala Priya C 是一位技术写作专家,喜欢创建长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等,与开发者社区分享她的学习成果。
更多相关主题
开源工具在加速数据科学进展中的作用
原文:
www.kdnuggets.com/2023/05/role-open-source-tools-accelerating-data-science-progress.html

图片由作者使用 Midjourney 创建
开源工具无疑已成为数据科学发展历程中不可或缺的催化剂。从提供强大的平台来处理各种分析任务,到点燃帮助塑造当代 AI 领域的创新火花,这些工具在学科中持续留下了深远的影响。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
这些技术的影响最好通过探索它们的过去、欣赏现在并洞察未来来总结。这种碎片化的方法不仅提供了开源技术与数据科学之间关系的见解,还突出了这些工具在塑造该领域发展的相关性。深入挖掘,我们将探讨这些技术在推动数据科学进步中的本质、它们在该领域出现中的作用以及如何创造无数创新机会。
过去:开源工具在数据科学发展中的历史
开源编程语言如 Python 和 R 的出现标志着数据科学革命时代的开始。这些语言提供了灵活高效的数据分析、预测建模和可视化任务的平台。以社区为中心的方法促进了问题解决和知识共享,提高了整体效率,并扩展了数据科学的能力。
在大规模数据管理和分析领域,开源数据处理框架如 Hadoop 和 Spark 扮演了重要角色。这些工具使得从庞大复杂的数据集中提取有价值的见解变得民主化,而这些数据以前是难以处理的。这一转变为大数据分析的新范式铺平了道路,促进了创新,并使组织能够更有效地做出数据驱动的决策。
开源机器学习库的普及,如 TensorFlow、Scikit-learn 和 PyTorch,进一步促进了数据科学的发展。这些库简化了机器学习模型开发和部署中复杂的过程。它们使前沿算法的访问民主化,从而使机器学习变得更加可及,加速了数据科学的整体进展。
当前:开源工具的现有应用
在当前,开源工具对协作开发和定制至关重要。它们的透明性使数据科学家不仅可以使用这些工具,还可以积极参与并改进这些工具,以更好地应对其独特挑战。这种协作解决问题的环境培养了对数据科学问题的创造性方法,并推动了该领域的进一步创新。
开源工具在当前数据科学领域中的教育价值也是不可或缺的资产。它们提供了实践学习的机会和利用广泛用户社区集体智慧的独特机会。这样的共享学习环境加快了新技能的掌握,培养了新一代的数据科学家。
此外,开源工具现在成为了持续进行的人工智能研究与开发的基础。对现代库和框架的开放访问推动了创新,加速了包括深度学习、自然语言处理和强化学习在内的各种人工智能子领域的发展。
未来:开源工具可能带领数据科学走向何方
展望未来,开源工具有望在引导数据科学的未来朝着更加负责任和伦理的人工智能方向上发挥更为重要的作用。它们通过允许对算法进行审查和促进公平、无偏见的人工智能系统的开发,能够推动透明性和问责制。随着理解局限性、减轻偏见和确保负责任使用等挑战的出现,开源社区将共同应对这些问题。这种协作努力不仅会提高数据科学家的技能,还会改进公司和组织决策的方式。
未来也承诺了数据科学进一步民主化的前景,这得益于开源工具。随着这些工具的不断发展,它们将使更多的参与者能够从数据中提取洞察,无论其技术专长如何。
最后,开源工具将对在数据科学工作流程中利用大型语言模型(LLMs)如 GPT-3 或 GPT-4 的潜力发挥核心作用。它们将使数据科学家能够更有效地利用这些先进模型进行自然语言处理、生成技术和进一步的人工智能系统开发。
结论
总结来说,开源工具的迅速发展和广泛应用推动了数据科学领域的显著加速。这些工具为高效的数据分析、机器学习模型的部署以及新兴的研究和开发提供了重要的平台。它们的贡献在过去的走廊中回响,现在在实际应用中得以体现,并对未来充满了巨大的潜力。
我们描绘了这些技术如何促进了数据科学的增长,并改变了其发展方向。开源在数据科学中的持续重要性不可低估;随着我们迈向一个越来越数字化的未来,开源技术作为创新推动者的角色变得更加相关。实际上,它们是数据科学大厦的基础,是 AI 的支柱,也是指引我们进入未来未知领域的指南针。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
相关主题
数据科学中重新抽样技术的作用
原文:
www.kdnuggets.com/2023/02/role-resampling-techniques-data-science.html
作者提供的图片
在处理模型时,你需要记住不同的算法在接收数据时有不同的学习模式。这是一种直观的学习方式,帮助模型学习给定数据集中的模式,这称为训练模型。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
然后,模型将在测试数据集上进行测试,这是模型之前未见过的数据集。你希望达到一个最佳性能水平,使模型在训练数据集和测试数据集上都能产生准确的输出。
你可能也听说过验证集。这是一种将数据集分成两个部分的方法:训练数据集和测试数据集。数据的第一部分将用于训练模型,而第二部分将用于测试模型。
然而,验证集方法存在一些缺点。
模型将学习到训练数据集中的所有模式,但可能错过了测试数据集中相关的信息。这使得模型缺乏可以提高其整体性能的重要信息。
另一个缺点是训练数据集中可能存在异常值或数据错误,模型会学习到这些内容。这成为模型的知识库的一部分,并将在第二阶段测试时应用。
那我们可以做什么来改进这一点?重新抽样。
什么是重新抽样?
重新抽样是一种涉及反复从训练数据集中抽取样本的方法。这些样本随后被用来重新拟合特定的模型,以获取更多关于拟合模型的信息。目的是收集更多关于样本的信息,提高准确性并估计不确定性。
例如,如果你在查看线性回归拟合并希望检查其变异性,你将反复使用训练数据中的不同样本,并对每个样本进行线性回归拟合。这将允许你检查结果如何因不同样本而异,并获取新的信息。
重采样的显著优势在于,你可以反复从同一总体中抽取小样本,直到你的模型达到最佳性能。通过能够重复使用相同的数据集,而不必寻找新数据,你将节省大量时间和金钱。
欠采样和过采样
如果你处理的是高度不平衡的数据集,重采样是一种可以帮助你应对的方法。
-
欠采样是当你从多数类中删除样本,以提供更多平衡。
-
过采样是当你因为收集的数据不足而重复少数类的随机样本。
然而,这些方法也有其缺点。欠采样中的样本删除可能导致信息丢失,而少数类的随机样本重复可能导致过拟合。
在数据科学中,常用的两种重采样方法是:
-
自助法
-
交叉验证
自助法
你可能会遇到不符合典型正态分布的数据集。因此,可以应用自助法来检查数据集中的隐藏信息和分布。
使用自助法时,抽取的样本会被替换,而未包含在样本中的数据则用于测试模型。这是一种灵活的统计方法,可以帮助数据科学家和机器学习工程师量化不确定性。
该过程包括
-
从数据集中反复抽取样本观察值
-
替换这些样本以确保原始数据集保持相同的大小。
-
一个观察值可以出现多次,也可以完全不出现。
你可能听说过集成技术——Bagging。它是 Bootstrap Aggregation 的缩写,将自助法和集成结合起来形成一个集成模型。它创建了多个原始训练数据集,然后将这些数据集汇总以得出最终预测。每个模型都学习前一个模型的错误。
自助法的一个优点是,与上述的训练-测试划分方法相比,它们的方差较低。
交叉验证
当你反复随机划分数据集时,样本可能会出现在训练集或测试集中。这可能不幸地对你的模型造成不平衡的影响,影响预测的准确性。
为了避免这种情况,你可以使用 K 折交叉验证来更有效地划分数据。在这个过程中,数据被分成 k 个相等的集合,其中一个集合定义为测试集,其余集合用于训练模型。这个过程将持续进行,直到每个集合都作为测试集并且所有集合都经过训练阶段。
该过程包括:
-
数据被划分为 k 折。例如,将数据集划分为 10 折——10 个相等的集合。
-
在第一次迭代中,模型在(k-1)个集合上进行训练,并在剩余的一个集合上进行测试。例如,模型在(10-1 = 9)个集合上进行训练,在剩下的 1 个集合上进行测试。
-
这个过程会重复进行,直到所有的折叠都充当了测试阶段的剩余 1 组。
这使每个样本都能得到平衡的表示,确保所有数据都被用来改进模型的学习并测试模型的性能。
结论
在本文中,你将了解什么是重采样,以及如何通过三种不同的方式对数据集进行采样:训练-测试分割、自助法和交叉验证。
这些方法的总体目标是帮助模型以有效的方式吸收尽可能多的信息。确保模型成功学习的唯一方法是对数据集中各种数据点进行训练。
重采样是预测建模阶段的一个重要元素;确保输出准确、高性能的模型和有效的工作流程。
Nisha Arya 是一位数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学相关的理论知识。她还希望探索人工智能如何能够或正在促进人类生命的长寿。作为一名热心的学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
在 LM Studio 中本地运行 LLM
编辑器截图
这已经是一个有趣的 12 个月。大型语言模型(LLMs)成为了所有技术相关事物的前沿。您可以拥有像 ChatGPT、Gemini 等 LLMs。
我们的 Top 3 课程推荐
1. Google 网络安全证书 - 快速迈入网络安全职业快车道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的 IT 组织
这些 LLMs 目前在云端运行,这意味着它们在别人的计算机上运行。如果某物在别处运行,您可以想象它有多昂贵。因为如果便宜的话,为什么不在您自己的计算机上本地运行呢?
但现在情况已经完全改变。您现在可以使用LM Studio运行不同的 LLMs。
LM Studio 是什么?
LM Studio 是一个工具,您可以用来在本地和开源 LLMs 上进行实验。您可以在笔记本电脑上运行这些 LLMs,完全脱机。有两种方式可以发现、下载和在本地运行这些 LLMs:
-
通过应用内的聊天界面
-
兼容 OpenAI 的本地服务器
您只需从HuggingFace仓库下载任何兼容的模型文件,一切搞定!
那么我该如何开始呢?
LM Studio 要求
在您开始深入了解本地发现所有 LLMs 之前,您需要满足以下最低硬件/软件要求:
-
M1/M2/M3 Mac
-
Windows PC 需要支持 AVX2 的处理器(Linux 版本正在测试中)
-
建议使用 16GB 以上的 RAM
-
对于 PC,建议使用 6GB 以上的 VRAM
-
支持 NVIDIA/AMD GPU
如果您具备这些条件,您就可以开始了!
那么,具体步骤是什么?
如何使用 LM Studio
您的第一步是下载适用于 Mac、Windows 或 Linux 的 LM Studio,您可以在这里进行下载。该下载大约有 400MB,因此根据您的互联网连接速度,可能需要一段时间。
您的下一步是选择要下载的模型。一旦 LM Studio 启动,点击放大镜以浏览可用模型选项。再次注意,这些模型可能很大,因此下载可能需要一些时间。
下载模型后,点击左侧的气泡图标,选择你的模型以加载。
准备好闲聊了吗!
就是这样,本地设置 LLM 这么快且简单。如果你想加快响应时间,可以通过右侧启用 GPU 加速来实现。
总结一下
你看,这么快就完成了?很快吧。
如果你担心数据收集,值得知道的是,本地使用 LLM 的主要原因是隐私。因此,LM Studio 正是为了这一点而设计的!
尝试一下,并在评论中告诉我们你的想法!
Nisha Arya 是一位数据科学家、自由技术撰稿人,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程及理论知识。Nisha 涉猎广泛,并希望探索人工智能如何有助于人类寿命的延长。作为一个热心的学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
在 Google Colab 上免费运行 Mixtral 8x7b
原文:
www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free
作者提供的图片
在这篇文章中,我们将深入探讨一种名为 Mixtral 8x7b 的最新开源模型。我们还将学习如何使用 LLaMA C++库来访问它,以及如何在减少计算和内存的条件下运行大型语言模型。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
Mixtral 8x7b 是什么?
Mixtral 8x7b是一个高质量的稀疏专家混合(SMoE)模型,由 Mistral AI 创建,具有开放权重。它在大多数基准测试中超越 Llama 2 70B,推理速度快 6 倍。Mixtral 在大多数标准基准测试中与 GPT3.5 相当或超越,是成本/性能比最佳的开放权重模型。
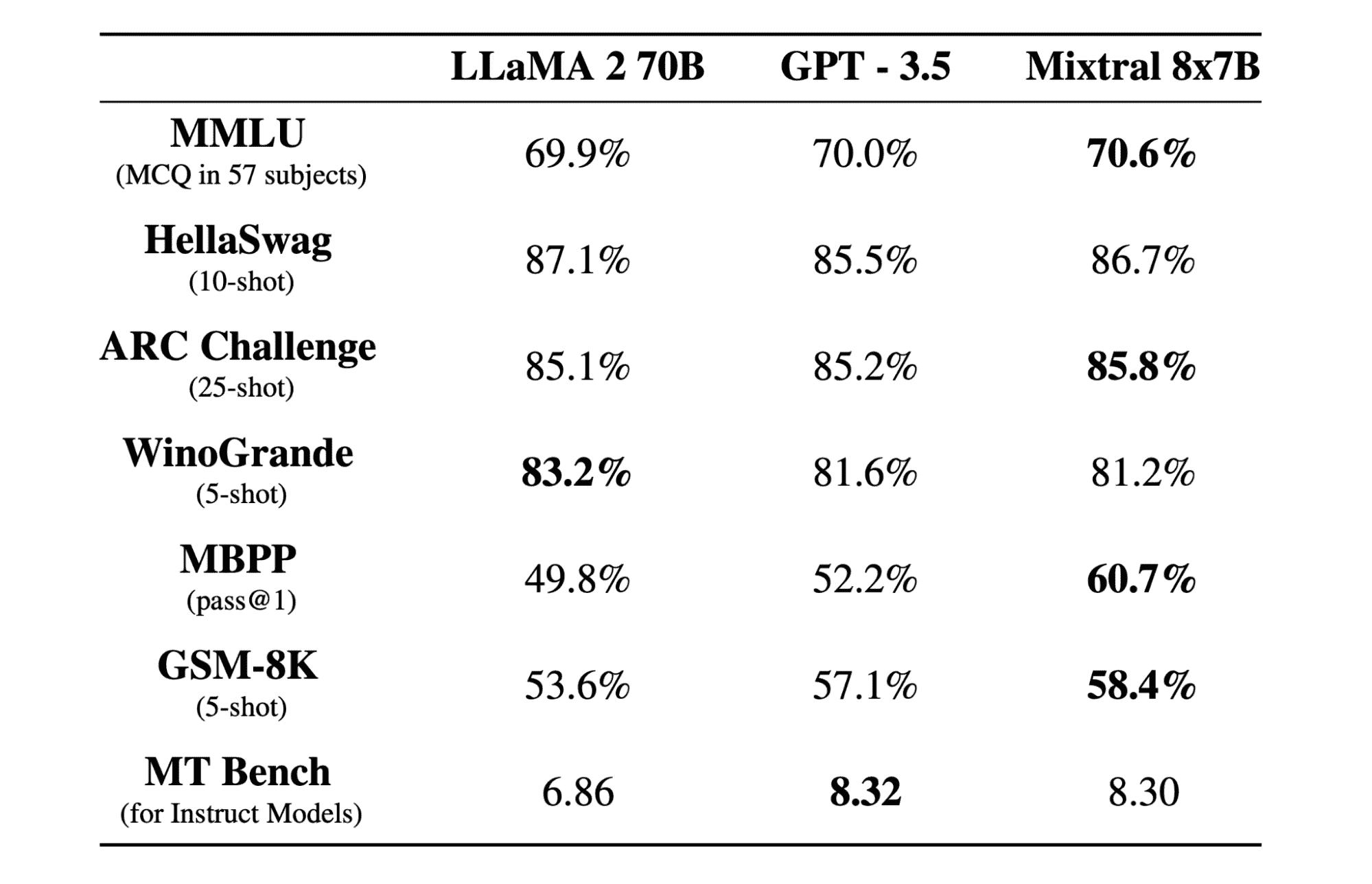
图片来自 Mixtral 专家
Mixtral 8x7B 使用仅解码器的稀疏专家混合网络。这涉及到一个前馈块从 8 组参数中选择,路由网络为每个 token 选择其中两个组,将它们的输出进行加和。这种方法在管理成本和延迟的同时增强了模型的参数数量,使其在效率上等同于一个 12.9B 模型,尽管总参数量为 46.7B。
Mixtral 8x7B 模型在处理 32k tokens 的广泛上下文方面表现出色,并支持包括英语、法语、意大利语、德语和西班牙语在内的多种语言。它在代码生成方面表现强劲,并可以被微调为一个指令跟随模型,在 MT-Bench 等基准测试中取得高分。
使用 LLaMA C++运行 Mixtral 8x7b
LLaMA.cpp 是一个 C/C++ 库,提供了一个高性能接口,用于大型语言模型(LLMs),基于 Facebook 的 LLM 架构。它是一个轻量且高效的库,可用于多种任务,包括文本生成、翻译和问答。LLaMA.cpp 支持广泛的 LLM,包括 LLaMA、LLaMA 2、Falcon、Alpaca、Mistral 7B、Mixtral 8x7B 和 GPT4ALL。它与所有操作系统兼容,可以在 CPU 和 GPU 上运行。
在这一部分,我们将在 Colab 上运行 llama.cpp web 应用程序。通过编写几行代码,你将能够在你的 PC 或 Google Colab 上体验到最新的模型性能。
入门指南
首先,我们将使用以下命令行下载 llama.cpp GitHub 仓库:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
之后,我们将切换到代码库目录,并使用 make 命令安装 llama.cpp。我们为安装了 CUDA 的 NVidia GPU 安装 llama.cpp。
%cd llama.cpp
!make LLAMA_CUBLAS=1
下载模型
我们可以从 Hugging Face Hub 下载模型,通过选择适当版本的 .gguf 模型文件。有关不同版本的更多信息,请参阅 TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF。
图片来源于 TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
你可以使用命令 wget 在当前目录中下载模型。
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
LLaMA 服务器的外部地址
当我们运行 LLaMA 服务器时,它会给我们一个 localhost IP,这对我们在 Colab 上无用。我们需要通过使用 Colab 内核代理端口连接到 localhost 代理。
运行以下代码后,你将获得全球超链接。我们稍后将使用这个链接来访问我们的 webapp。
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/
运行服务器
要运行 LLaMA C++ 服务器,你需要提供服务器命令,指定模型文件的位置以及正确的端口号。确保端口号与我们在前一步为代理端口初始化的端口号匹配非常重要。
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
由于服务器没有在本地运行,可以通过点击前一步中的代理端口超链接访问聊天 webapp。
LLaMA C++ Webapp
在开始使用聊天机器人之前,我们需要对其进行自定义。在提示部分将 "LLaMA" 替换为你的模型名称。此外,修改用户名和机器人名称以区分生成的回复。
通过向下滚动并在聊天区域输入来开始聊天。随意提出其他开源模型无法正确回答的技术问题。
如果你遇到应用程序的问题,可以尝试使用我的 Google Colab 运行它:https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
结论
本教程提供了如何使用 LLaMA C++ 库在 Google Colab 上运行高级开源模型 Mixtral 8x7b 的全面指南。与其他模型相比,Mixtral 8x7b 提供了更出色的性能和效率,成为那些希望尝试大型语言模型但没有广泛计算资源的人的理想解决方案。你可以轻松地在笔记本电脑或免费的云计算平台上运行它。它用户友好,你甚至可以为其他人部署你的聊天应用进行使用和实验。
我希望你发现这个简单的解决方案对运行大型模型有所帮助。我始终在寻找更简单、更好的选项。如果你有更好的解决方案,请告诉我,我会在下次介绍。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在精神健康方面遇到困难的学生。
更多相关内容
在 Jupyter 中运行 R 和 Python
原文:
www.kdnuggets.com/2019/02/running-r-and-python-in-jupyter.html
评论
Jupyter 项目始于 2014 年,作为一种面向交互式和科学计算的倡议。
它包含一个 Python 内核,以便用户可以拥有一个新的交互式 IDE 来使用 Python。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
它基于 IPython 计算环境。2015 年,IRkernel 也被添加了对 R 的支持。这使得用户可以使用 R 和 Python 运行内核。

R 内核安装
如果你使用的是 Windows,下面的方法是可以的。如果你使用的是基于 Unix 的机器(OSX 或 Linux),命令必须在终端中运行。
最好的方法是安装 Anaconda,它会自动安装 Python、R 和 Jupyter Notebooks。
-
在安装 Anaconda 后,打开 Anaconda 提示符并输入
install.packages(c(repr, IRdisplay, evaluate, crayon, pbdZMQ, devtools, uuid, digest), type=source)。务必在终端中执行此命令,以便直接从 R 执行,而不是通过 IDE。 -
在步骤 1 后,运行
devtools::install_github(IRkernel/IRkernel),最后运行IRkernel::installspec(user=FALSE)。 -
进入 Anaconda Navigator,打开 Jupyter Notebook,或者在 Anaconda 提示符中输入
jupyter notebook。在 New 下,你应该能找到 R 内核。点击它以在 Jupyter 环境中开始运行 R。
需要注意的是,由于安装 Anaconda 是安装 Jupyter Notebook 的最简单和最快捷的方式,Anaconda 安装的 R 版本滞后于最新发布版本。你不能像从 R 网站单独安装时那样更新 Anaconda 中的 R。这是因为 Anaconda 中的所有程序都由 Conda 包管理器管理,Anaconda 需要更新其默认的 R 版本,然后用户才能安装。因此,在 Jupyter Notebooks 中运行 R 时,某些包可能由于包更新频率比 R 更新频率更高而无法正常工作(尽管这很少见)。
在 Jupyter 中运行 R
现在我们已经在 Jupyter 中安装了 R,我们可以像在任何 R IDE 中一样开始使用 R 代码。
-
在上述步骤 3 之后,您将被带到一个新标签页,R 内核已准备好:
![新的 R 内核]() 新的 R 内核
新的 R 内核 -
接下来,为您的内核命名,以便以后能够识别它。只需点击显示“无标题”的地方,您就可以给它命名。之后,您就可以开始在 Jupyter 中使用 R 了。
-
在第一个代码块中执行
library(tidyverse), data(mtcars), options(warnings=-1).options(warnings=-1)将抑制任何警告信息,因此仅在运行代码块后使用它。按下 Windows 中的 Ctrl+Enter 或 Mac 中的 Cmd + Enter 来运行代码块。![第一个代码]() 第一个代码块
第一个代码块 -
glimpse(mtcars)提供数据集的概览,包括数据类型和维度,而summary(mtcars)生成数据集所有特征的总结统计。![一瞥和总结]() mtcars 的一瞥和总结
mtcars 的一瞥和总结 -
options(repr.plot.width=5, repr.plot.height=5)设置全局选项,使绘图的大小按指定的尺寸。如果需要调整不同图的大小,可以将相同的代码行添加到不同的块中,这将导致从该块执行的图进行调整。![Jupyter 中的 ggplot]() Jupyter 中的 ggplot
Jupyter 中的 ggplot
 新的 R 内核
新的 R 内核 第一个代码块
第一个代码块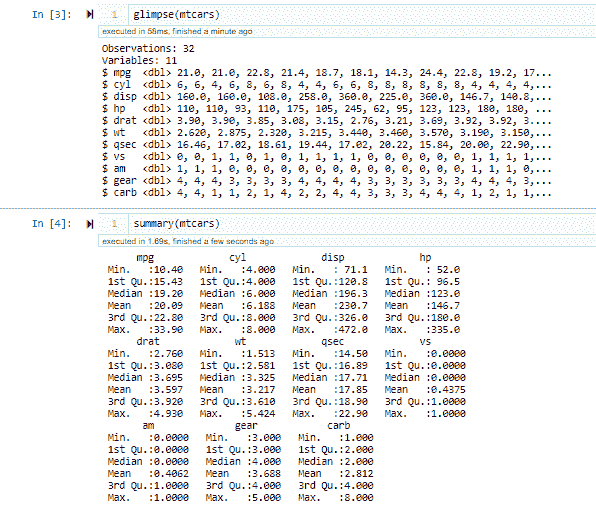 mtcars 的一瞥和总结
mtcars 的一瞥和总结 Jupyter 中的 ggplot
Jupyter 中的 ggplotPython 内核
现在,Python 在 Jupyter 中变得更加直接。按照上述步骤安装 Anaconda 后,Python 内核是默认安装的。当您打开 Jupyter Notebook 时,转到 新建 --> Python,您将进入 Jupyter 中的 Python 环境。
如果您已经在 R 内核(或其他任何内核)中,请转到 文件 --> 新建笔记本 --> Python 3
 切换到 Python 内核
切换到 Python 内核
这将带您到浏览器中的新标签页,Python 环境已准备好。现在,您可以同时在 Jupyter 中运行 R 和 Python。您可以同时运行它们,也可以一个接一个地运行(根据您的需求)。
 Jupyter 中的 Python 内核
Jupyter 中的 Python 内核
结论
这将帮助您开始在 Jupyter 中使用 R 和 Python。您可以像平常一样使用 R。在 Jupyter 中还有更多内容可以探索。即将推出的教程将重点介绍如何使用 Markdown 和 nb-extensions 在 Jupyter 中进行报告。
相关:
相关主题
在 Google Colab 上运行 Redis
原文:
www.kdnuggets.com/2022/01/running-redis-google-colab.html
Google Colab 是一个流行的基于浏览器的环境,用于在托管的 Jupyter 笔记本上执行 Python 代码和训练机器学习模型,包括免费访问 GPU!这是数据科学家和机器学习(ML)工程师学习和快速开发 Python 中的 ML 模型的绝佳平台。Redis 是一个内存中的开源数据库,越来越多地用于机器学习——从缓存、消息传递和快速数据摄取,到语义搜索和 在线特征存储。实际上,NoSQL 数据库——尤其是 Redis——被 Zynga 应用数据科学总监 Ben Weber 列为 2020 年他作为数据科学家学到的 8 种新工具之一。
在 Colab 上使用 Redis 进行机器学习
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
由于 Redis 在数据科学和机器学习中的使用越来越广泛,能够直接从 Google Colab 笔记本中运行 Redis 非常方便!然而,在 Google Colab 上运行 Redis 与在本地机器或使用 Docker 上的设置有所不同。下面我将向你展示如何通过两个简单的步骤,在 Colab 笔记本上直接从浏览器运行 Redis。

图片由作者使用 Colab 标志创建(图片来源:Medium)和 Redis 标志(合理使用)
在 Colab 上安装和运行 Redis
步骤 1:安装
要安装 Redis 和 Redis Python 客户端:
%pip install redis-server redis
备注:
*虽然 Jupyter Notebooks 支持多种语言,但 Colab 仅支持 Python。要在 Python 中使用 Redis,你需要一个 Redis Python 客户端。在本教程中,我们演示了 redis-py 的使用,这是一个 Redis Python 客户端,我们使用 [%pip install](https://ipython.readthedocs.io/en/7.23.0/interactive/magics.html#magic-pip) redis 命令进行安装。
**你可以在 Jupyter Notebook 或 Google Colab 中运行 shell 命令,通过在命令前加上 ! 字符或 % 来使用魔法命令。有关数据科学家的有用魔法命令列表,请参见文章 - Jupyter Notebook 中的 8 个魔法命令。
步骤 2:启动 Redis 服务器
要启动 Redis 服务器,请运行:
import redis_server
!$redis_server.REDIS_SERVER_PATH --daemonize yes
注意:
另外,你可以通过 Python 子进程在不使用 shell 命令的情况下启动 Redis 服务器:
import subprocess import redis_server subprocess.Popen([redis_server.REDIS_SERVER_PATH])
就这样!就是这么简单。
连接到 Redis 服务器和 Redis 命令函数
现在让我们来看看我们需要哪些命令来验证 Redis 是否在运行、连接到它并读取和写入数据。
验证 Redis 是否在运行
如果你想验证 Redis 是否启动并运行,你可以连接到服务器并运行 "PING 命令"。我们使用 Python 客户端 redis-py 创建一个连接,然后对服务器进行 'ping':
import redis
client = redis.Redis(host = 'localhost', port=6379)
client.ping()
如果你得到 True,那么你就可以开始了!
Redis 命令的示例代码
一旦连接到 Redis,你可以通过 Redis 命令函数 读取和写入数据。在这个示例中,我们将 Redis 用作 键值数据库(也称为键值存储)。下面的代码片段将值 bar 分配给 Redis 键 foo,读取它并返回:
client.set('foo', 'bar')
client.get('foo')
总结
在这篇博客文章中,我们展示了如何在 Google Colab 上运行 Redis 数据库,全部通过你的浏览器完成!我们首先安装了 Redis 和 Redis Python 客户端,然后启动了 Redis 服务器,并通过创建连接来验证它是否正在运行。最后,我们看到如何使用 Redis 命令函数从 Redis 数据库中读取和写入数据。如果你想自己尝试命令,这里有一个 Redis 与 Colab 笔记本 的链接,其中包含了本教程中的代码。
Nava Levy 是 Redis 的数据科学和 MLOps 开发者倡导者。她在以色列国防军的研发部门开始了她的技术职业生涯,随后很幸运地能够与云计算、大数据以及深度学习/机器学习/人工智能技术一起工作,并成为这些技术浪潮中的一员。Nava 还是 MassChallenge 加速器的导师以及 LerGO——一个基于云的教育科技创业公司的创始人。她在空闲时间喜欢骑自行车、四球杂技,以及阅读奇幻和科幻书籍。
更多相关主题
Rust Burn 深度学习库

图片由作者提供
什么是 Rust Burn?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
Rust Burn 是一个完全用 Rust 编程语言编写的新深度学习框架。创建一个新框架而不是使用现有的框架如 PyTorch 或 TensorFlow 的动机是构建一个多功能的框架,能够很好地服务于各种用户,包括研究人员、机器学习工程师和底层软件工程师。
Rust Burn 的关键设计原则是灵活性、性能和易用性。
灵活性 来自快速实现前沿研究思想和进行实验的能力。
性能 通过优化实现,例如利用 Nvidia GPU 上的 Tensor Cores 等硬件特性。
易用性 来自简化训练、部署和在生产中运行模型的工作流程。
关键特性:
-
灵活且动态的计算图
-
线程安全的数据结构
-
直观的抽象以简化开发过程
-
在训练和推理过程中具有极快的性能
-
支持多种后端实现,适用于 CPU 和 GPU
-
完全支持训练过程中的日志记录、度量和检查点
-
小而活跃的开发者社区
入门
安装 Rust
Burn 是一个强大的深度学习框架,基于 Rust 编程语言。它需要对 Rust 有基本了解,但一旦掌握,你将能够利用 Burn 提供的所有功能。
使用官方 指南 安装它。你也可以查看 GeeksforGeeks 提供的安装 Rust 的指南,其中包括 Windows 和 Linux 的截图。
图片来源于 安装 Rust
安装 Burn
要使用 Rust Burn,你首先需要在系统上安装 Rust。Rust 正确设置后,你可以使用 cargo 创建一个新的 Rust 应用程序,cargo 是 Rust 的包管理器。
在当前目录下运行以下命令:
cargo new new_burn_app
进入这个新目录:
cd new_burn_app
接下来,添加 Burn 作为依赖项,并包括启用 GPU 操作的 WGPU 后端功能:
cargo add burn --features wgpu
最后,编译项目以安装 Burn:
cargo build
这将安装 Burn 框架及其 WGPU 后端。WGPU 使 Burn 能够执行低级 GPU 操作。
示例代码
元素级加法
要运行以下代码,你必须打开并替换 src/main.rs 中的内容:
use burn::tensor::Tensor;
use burn::backend::WgpuBackend;
// Type alias for the backend to use.
type Backend = WgpuBackend;
fn main() {
// Creation of two tensors, the first with explicit values and the second one with ones, with the same shape as the first
let tensor_1 = Tensor::<backend>::from_data([[2., 3.], [4., 5.]]);
let tensor_2 = Tensor::<backend>::ones_like(&tensor_1);
// Print the element-wise addition (done with the WGPU backend) of the two tensors.
println!("{}", tensor_1 + tensor_2);
}</backend></backend>
在主函数中,我们创建了两个带 WGPU 后端的张量并执行了加法。
要执行代码,你必须在终端中运行 cargo run。
输出:
现在你应该能够查看添加的结果。
Tensor {
data: [[3.0, 4.0], [5.0, 6.0]],
shape: [2, 2],
device: BestAvailable,
backend: "wgpu",
kind: "Float",
dtype: "f32",
}
注意: 以下代码来自 Burn 书籍的示例:入门指南。
位置-wise 前馈模块
这是一个展示如何轻松使用框架的例子。我们声明了一个位置-wise 前馈模块及其前向传递,使用了这个代码片段。
use burn::nn;
use burn::module::Module;
use burn::tensor::backend::Backend;
#[derive(Module, Debug)]
pub struct PositionWiseFeedForward<B: Backend> {
linear_inner: Linear<B>,
linear_outer: Linear<B>,
dropout: Dropout,
gelu: GELU,
}
impl <b: backend="">PositionWiseFeedForward<B> {
pub fn forward<const d:="" usize="">(&self, input: Tensor<B, D>) -> Tensor<B, D> {
let x = self.linear_inner.forward(input);
let x = self.gelu.forward(x);
let x = self.dropout.forward(x);
self.linear_outer.forward(x)
}
}</const></b:>
上述代码来自 GitHub 仓库。
示例项目
要了解更多示例并运行它们,请克隆 github.com/burn-rs/burn 仓库,并运行以下项目:
-
MNIST:在 CPU 或 GPU 上使用各种后端训练模型。
-
MNIST 推理网页:在浏览器中进行模型推理。
-
文本分类:从头开始在 GPU 上训练一个变换器编码器。
-
文本生成:从头开始在 GPU 上构建和训练自回归变换器。
预训练模型
要构建你的 AI 应用程序,你可以使用以下预训练模型并用你的数据集进行微调。
-
SqueezeNet: squeezenet-burn
-
Llama 2: Gadersd/llama2-burn
-
Whisper: Gadersd/whisper-burn
-
稳定扩散 v1.4: Gadersd/stable-diffusion-burn
结论
Rust Burn 代表了深度学习框架领域的一个激动人心的新选择。如果你已经是 Rust 开发者,你可以利用 Rust 的速度、安全性和并发性来推动深度学习研究和生产的可能性。Burn 旨在在灵活性、性能和可用性之间找到适当的妥协,以创建一个独特的、多用途的框架,适用于各种用例。
尽管仍处于早期阶段,Burn 显示出解决现有框架痛点和满足领域内各种从业者需求的潜力。随着框架的成熟和社区的扩展,它有可能成为一个与成熟选项并驾齐驱的生产级框架。其新颖的设计和语言选择为深度学习社区提供了新的可能性。
资源
-
GitHub:
github.com/burn-rs/burn
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,以帮助那些面临心理健康问题的学生。
更多相关信息
数据科学和商业智能中的职位薪资
原文:
www.kdnuggets.com/2015/09/salaries-roles-data-science-business-intelligence.html
Geethika Bhavya Peddibhotla,发表于 2015 年 9 月 9 日,来源于 商业智能、数据科学、数据科学技能、数据科学家、薪资、趋势 评论By Bhavya Geethika & Shashank Iyer.
根据 Glassdoor 的国家平均薪资数据,以下是分析职位进展、增长和技能的热门角色。[数据科学家]( http://www.glassdoor.com/Salaries/data-scientist-salary-SRCH_KO0 ,14.htm) 排名第一。25 个数据科学与商业智能相关职位列表。
数据科学与商业智能领域的热门职位按国家平均薪资(美元) 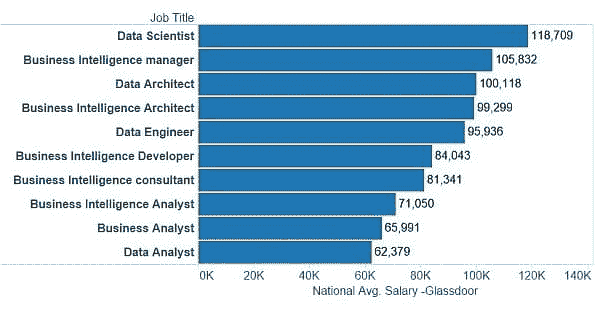
职位进展 - 给定一个职位名称,那个职位的人会接下哪些其他职位?
基于 Glassdoor API 的职位进展数据分析如下 - 它展示了中位薪资增长最高的前 3 个职位进展。Glassdoor API 职位进展目前仅支持美国数据。
下一个职位是指一个人在当前职位基础上可能会接下的角色。这里的职位数量指的是“下一个职位”在全国的职位数量。

方法:对于热门职位标题作为查询,Glassdoor API 将返回美国的相关职位,这些职位是该职位通常会接下的职位 - 基于频率百分比。我们通过先按频率筛选出最热门的职位,然后按中位薪资增长进行排序,从而汇总了这些数据。
职位趋势: Indeed.com 搜索了数百万个列在成千上万网站上的职位。下面的职位趋势图展示了 Indeed 找到的包含给定职位名称作为搜索词的职位百分比。
BI 开发人员和 BI 分析师的职位是过去几年中最常列出的职位,这一职位趋势似乎在 2015 年有所增加。

图 3:Indeed.com BI 职位的年度百分比变化。
数据分析师和数据架构师的职位在过去几年中列出的最多。数据科学家职位的发布量在过去四年中有所上升,这一趋势似乎在 2015 年将继续。

图 4:Indeed.com 的数据科学职位年百分比变化。
商业分析师职位的发布量相对较高,因此单独列出。

图 5:Indeed.com 的商业分析师职位年百分比变化。
影响薪资的技能(payscale.com):
-
数据科学家:机器学习、软件开发、hadoop、java、数据挖掘/数据仓库、数据分析、python 和面向对象编程。查看:成为数据科学家需要掌握的 9 项技能
-
商业智能经理:SAP BI、人员管理、数据仓库、数据挖掘、Cognos、Microstrategy、BI、SQL、大数据分析、项目管理。
-
数据架构师:数据管理、Oracle DB、数据挖掘/数据仓库、BI 和数据建模。
-
商业智能架构师:SQL Server 报告服务(SSRS)、项目管理、数据建模、BusinessObjects、SQL Server 集成服务(SSIS)、商业智能、数据挖掘、数据仓库、Cognos、SQL、数据仓库
-
商业智能开发人员:数据建模、数据仓库、ETL(提取、转换、加载)、SQL、PL/SQL、Oracle、BI、Transact-SQL、BusinessObjects
-
商业智能顾问:项目管理、SAS、数据仓库、BusinessObjects、MicroStrategy、BI、Cognos、SQL
-
商业智能分析师:数据建模/数据仓库、项目管理、BusinessObjects、BI、Cognos、商业分析、数据挖掘、SQL。
-
商业分析师:需求分析、商业分析、项目管理、Oracle、Sharepoint Server
-
数据分析师:数据挖掘/数据仓库、数据建模、SAS、SQL、统计分析、数据库管理与报告、数据分析
分享你对雇主在数据科学和商业智能职位中所寻求技能的看法。
相关:
-
2015 年分析和大数据的两个最重要趋势
-
真正的数据科学家请站出来!
-
50+ 数据科学和机器学习备忘单
更多相关话题
顶级数据科学职位的薪资分解
原文:
www.kdnuggets.com/2021/11/salary-breakdown-top-data-science-jobs.html
评论

由Thought Catalog拍摄的照片,来源于Unsplash [1]。
目录
-
介绍
-
机器学习工程师
-
自然语言处理工程师
-
数据工程师
-
数据科学家
-
概要
-
参考文献
介绍
当查看数据科学家的薪资和数据科学角色时,很明显,数据科学中存在不同、更具体的方面。这些方面与独特的职位相关,特别是机器学习操作、自然语言处理、数据工程以及数据科学本身。当然,还有比这些更具体的职位,但这些可以给你一个大致的了解,如果你获得其中一个职位的话。我选择这四个角色也是因为它们可以很好地分开,几乎就像有一个聚类算法发现了彼此之间最不同的职位,但这些职位也在同一个领域。接下来,我将讨论平均基本工资的低高范围、相应的资历水平、用于确定这些数字的估计数量,以及每个角色所需的技能和经验。
机器学习工程师

由Possessed Photography拍摄的照片,来源于Unsplash [2]。
机器学习工程师往往将已研究和构建的数据科学模型应用于生产环境,通常涉及软件工程以及机器学习算法知识。可以想象,薪资水平相当不错。这个估计来自[glassdoor]( https://www.glassdoor.com/Salaries/machine-learning-engineer-salary-SRCH_KO0 ,25.htm) [3]。
基于大约
1,900份提交的薪资数据,范围广泛如下:
-
低 — ~ $86,000
-
平均 — ~$128,000
-
高 — ~$190,000
如你所见,任何职位都有一个范围,经验越多,薪资越高也就不足为奇。除了工作经验年限之外,你工作的州、所用的技能以及公司也会影响最终薪资 — 对于所有这些职位也同样适用。为了获得更多细节,我们可以查看不同的资历等级,以便了解级别提升与薪资之间的关系:
-
机器学习工程师 L2 ~ $128,000
-
高级机器学习工程师 L3 ~ $153,000
-
机器学习领军人物 L4 ~ $166,000
下面是一些个人经验中你可以在机器学习职位中使用的技能:
-
SQL/Python/Java (有时)
-
算法知识 — 无监督与监督分类、时间序列、回归以及将它们封装在一起的流行库
-
部署平台和工具 — AWS、Google Cloud、Azure、Docker、Flask、MLFlow 和 Airflow — 部署模型并与数据科学家合作组成自动化流程
自然语言处理工程师

图片来自 Patrick Tomasso 在 Unsplash [4].
通常被称为 NLP 工程师,这个角色通常专注于将数据科学模型或机器学习算法应用于文本数据。一些 NLP 工作的例子包括对大量文本进行主题建模、语义分析以及聊天机器人代理。虽然如此,你也可以预期有相当不错的薪资 — 然而,这个薪资水平可能会低于机器学习工程师,因为这个角色的包容性较差,更多地集中于数据科学中的某一特定主题。这个估算来源于 [glassdoor]( https://www.glassdoor.com/Salaries/nlp-engineer-salary-SRCH_KO0 ,12.htm) [5]。
基于大约
*20*份提交的薪资,有一个广泛的范围如下:
需要注意的是,报告的薪资金额相对较低,因此对这个范围要持保留态度,但尽管如此,对这个薪资仍然有很高的信心。
-
低 — ~ $80,000
-
平均 — ~$115,000
-
高 — ~$166,000
所有这些金额都低于机器学习岗位,但与大多数其他职位相比仍然相当高。
下面是一些个人经验中你可以在自然语言处理工程师职位中使用的技能:
-
NLTK — 自然语言工具包库
-
TextBlob
-
spaCy
-
文本清理和处理(去除标点符号、去除停用词、隔离词根、词干提取和词形还原)
-
语义分析 — 一个例子是分析客户的正面和负面评价
-
主题建模 — 一个例子是发现大量文本中的共同话题,比如客户评论的相同内容,但不仅仅是好的或坏的评论,而是可以分析以改进产品的评论主题:“差质量”与 90%的负面评论相关。
-
分类 — 使用像随机森林这样的算法,将传统的数值特征与描述等文本特征结合起来,创建一个将数据分组的模型 —— 比如客户细分
数据工程师

照片由 Caspar Camille Rubin 拍摄,来源于 Unsplash [6]。
也许更常见的角色,并且更与数据科学相关的是数据工程。然而,这个角色依然对数据科学工作至关重要,有时数据科学家需要了解大部分数据工程师的知识,因此我会将其包括在本分析中。一些数据工程的例子包括创建一个 ETL 任务,存储最终用于数据科学模型的数据,以及自动存储模型结果,进行查询优化。这个估算也来自于 [glassdoor]( https://www.glassdoor.com/Salaries/data-engineer-salary-SRCH_KO0 ,13.htm) [7]。
根据大约 ~
6,800提交的薪资,以下是广泛的范围:
-
低 — ~ $76,000
-
平均 — ~$111,000
-
高 — ~$164,000
这个范围更接近自然语言处理工程师的角色,但它可能与实际的日常工作中的职位最为不同。还需要注意的是,这个职位涉及的估算更多。
以下是一些个人经验中可以在数据工程师职位中运用的技能:
-
ETL — 提取、转换和加载
-
ELT — 提取、加载和转换
-
获取将被存储在数据库或数据湖中的数据,这些数据可以用于数据分析、机器学习算法训练,并用于存储数据科学模型的结果
-
SQL 查询优化 — 为公司节省时间和金钱
数据科学家

照片由 Daria Nepriakhina 拍摄,来源于 Unsplash [8]。
最后但同样重要的是数据科学家的角色。虽然这个角色看似最为通用,但实际上也可以很具体,通常主要包括模型构建过程——有时还需具备数据工程师和机器学习工程师的操作要求,并且有时——但也不常见——可能涉及自然语言处理的专长(通常如果重点是 NLP,那么数据科学家会以此为职称——但并非总是如此)。这个角色的变动性也更大,因此我们也可以预期较宽的范围。这个特定的估计也来源于[glassdoor]( https://www.glassdoor.com/Salaries/data-scientist-salary-SRCH_KO0 ,14.htm)[9]。
基于约 ~
*16,200*提交的薪资数据,以下范围非常广泛:
-
低 — ~ $81,000
-
平均 — ~$115,000
-
高 — ~$164,000
出乎意料地低于预期,这个角色与本分析中的大多数角色相当。话虽如此,它可能是对异常值最真实且最稳健的,因为它的薪资数据提交量远远最多。
这里是一些个人经验中你可以期望在数据科学职位中使用的技能:
-
SQL, Python, R
-
Jupyter Notebooks
-
可视化——Tableau、库和包、Google Data Studio、Looker 等……
-
定义问题陈述、获取数据集、特征工程、模型比较、模型部署以及结果讨论
-
示例项目——创建一个分类器,根据多个特征对公司产品进行分组,从各种来源获取数据,使用 SQL 和 Python,部署模型并解释结果及其对公司的影响
概述
尽管这些角色有很多相似点和不同点,但它们的薪资范围也如此。四个薪资中有近三者相似,只有一个明显不同。那个角色是机器学习工程师——为什么会这样? 我理解是,这个角色需要了解大多数数据科学概念,尤其是它们的输出,以及涉及到的部署软件工程——这需要了解和运用大量知识,因此,既包含软件工程又包含数据科学的角色薪资自然较高。除了每个数据科学角色的薪资分解——或与数据科学类似的角色,还有你可以期望使用的技能,以便更好地了解该角色及其与薪资金额的关系。
总结一下,我们分析了以下四个职位,以及你可以期望使用的技能:
* Machine Learning Engineer
* Natural Language Processing Engineer
* Data Engineer
* Data Scientist
我希望你觉得我的文章既有趣又有用。如果你同意这些数据和范围,请在下面评论——为什么或者为什么不?你认为某个角色特别偏离现实吗?你还能想到哪些数据科学角色,其薪资结构会有所不同?还有哪些因素会影响角色的薪资?
这些薪资数据报告来自美国,因此以美元计价。我与这些公司没有关联。
请随时查看我的个人资料和其他文章,也可以通过 LinkedIn 与我联系。
参考资料
[1] 图片由 Thought Catalog 拍摄,发布在 Unsplash,(2018)
[2] 图片由 Possessed Photography 拍摄,发布在 Unsplash,(2018)
[3] Glassdoor, Inc., [机器学习工程师薪资]( https://www.glassdoor.com/Salaries/machine-learning-engineer-salary-SRCH_KO0 ,25.htm),(2008–2021)
[4] 图片由 Patrick Tomasso 拍摄,发布在 Unsplash,(2016)
[5] Glassdoor, Inc., [自然语言处理工程师薪资]( https://www.glassdoor.com/Salaries/nlp-engineer-salary-SRCH_KO0 ,12.htm),(2008–2021)
[6] 图片由 Caspar Camille Rubin 拍摄,发布在 Unsplash,(2017)
[7] Glassdoor, Inc., [数据工程师薪资]( https://www.glassdoor.com/Salaries/data-engineer-salary-SRCH_KO0 ,13.htm),(2008–2021)
[8] 图片由 Daria Nepriakhina 拍摄,发布在 Unsplash,(2017)
[9] Glassdoor, Inc., [数据科学家薪资]( https://www.glassdoor.com/Salaries/data-scientist-salary-SRCH_KO0 ,14.htm),(2008–2021)
个人简介: Matthew Przybyla 是 Favor Delivery 的高级数据科学家,以及一名自由技术作家,专注于数据科学。
原文。经许可转载。
相关内容:
-
数据科学家与数据工程师薪资对比
-
数据科学家与机器学习工程师 – 他们的技能有哪些?
-
2021 年数据科学家最需要的技能
更多相关内容
使用 Facebook 的 Prophet 进行销售预测
原文:
www.kdnuggets.com/2018/11/sales-forecasting-using-prophet.html
评论
销售预测是许多以销售为驱动的组织中最常见的任务之一。这项活动使组织能够以一定的信心充分规划未来。在本教程中,我们将使用 Prophet,这是 Facebook 开发的一个包,展示如何实现这一点。此包在 Python 和 R 中均可用。我们假设读者对在 Python 中处理 时间序列 数据有基本的理解。
攻击计划
-
介绍与安装
-
模型拟合
-
未来预测
-
获取预测
-
绘制预测
-
绘制预测组件
-
交叉验证
-
获取性能指标
-
可视化性能指标
-
结论
介绍与安装
有很多开源预测工具,但没有一种能够解决所有预测问题。Prophet 最适合处理几个月的每小时和每周数据。使用 Prophet 时,年度数据是最理想的。根据 Facebook 研究:
从根本上说,Prophet 程序是一个 加性回归模型,具有四个主要组件:
1. 分段线性或逻辑增长曲线趋势。Prophet 通过从数据中选择变化点来自动检测趋势变化。
2. 使用 傅里叶级数 建模的年度季节性组件。
3. 使用虚拟变量的每周季节性组件。
4. 用户提供的重要节假日列表。
可以使用 pip 在 Python 中安装 Prophet,如下所示。Prophet 依赖于名为 pystan. 的 Python 模块。我们在安装 Prophet 时,此模块将自动安装。
我们在本教程中使用的数据集可以在这里下载。一旦下载数据集,请确保删除文件末尾的一些不必要的行,因为它们可能会干扰分析。对于这个单变量分析Prophet 期望数据集包含两列,分别命名为ds和y。ds是日期列,而y是我们进行预测的列。
让我们开始导入 Pandas 进行数据处理,以及 Prophet 进行预测。接下来,我们加载数据集并查看其头部。
模型拟合
由于我们之前使用过Scikit-learn,因此使用 Prophet 对我们来说将是一件轻而易举的事。这是因为 Prophet 和 Scikit-learn 的 API 实现非常相似,如下所示。我们首先创建一个 Prophet 类的实例,然后将其拟合到我们的数据集上。
进行未来预测
下一步是准备我们的模型进行未来预测。这可以通过使用Prophet.make_future_dataframe方法并传入我们希望预测的天数来实现。我们使用periods属性来指定这个值。这还包括历史日期。我们将使用这些历史日期将预测值与ds列中的实际值进行比较。

获取预测结果
我们使用predict方法来进行未来的预测。这将生成一个包含yhat列的数据框,该列将包含预测结果。
如果我们查看预测数据框的head,会发现它有很多列。然而,我们主要关注ds, yhat, yhat_lower和yhat_upper。yhat是我们的预测值,yhat_lower是我们预测的下限,yhat_upper*是我们预测的上限。
让我们继续查看预测数据框的尾部和头部。
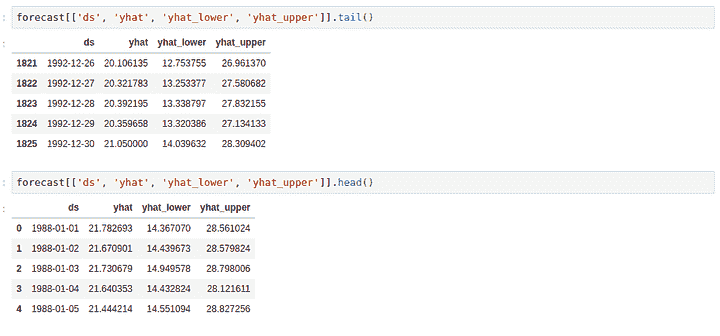
绘制预测结果
Prophet 具有一个内置功能,允许我们绘制刚刚生成的预测结果。这可以通过使用mode.plot()方法并将我们的预测结果作为参数传递来实现。图中的蓝线表示预测值,而黑点表示我们数据集中的数据。
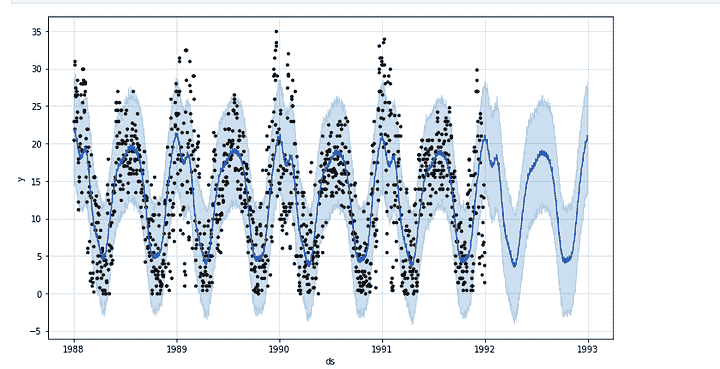
绘制预测组件
plot_components 方法绘制了时间序列数据的趋势、年度和每周季节性。
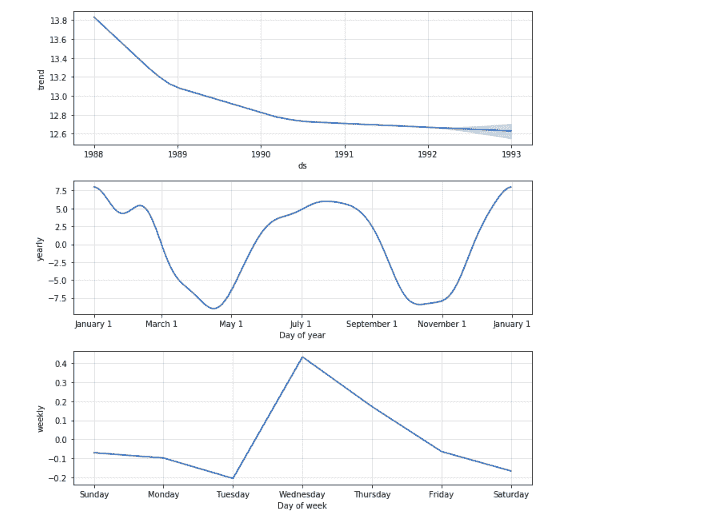
交叉验证
接下来,让我们使用历史数据测量预测误差。我们将通过将预测值与实际值进行比较来完成此操作。为了执行此操作,我们选择数据历史中的截止点,并用该截止点之前的数据拟合模型。然后,我们将实际值与预测值进行比较。交叉验证方法允许我们在 Prophet 中执行此操作。此方法使用以下参数,如下所述:
-
预测范围预测范围
-
初始初始训练期的大小
-
周期截止日期之间的间隔
交叉验证方法的输出是一个数据框,其中包含y真实值和yhat预测值。我们将使用此数据框来计算预测误差。

获取性能指标
我们使用performance_metrics工具计算均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)以及yhat_lower和yhat_upper估计值的覆盖率。

可视化性能指标
性能指标可以使用plot_cross_validation_metric工具进行可视化。让我们下面可视化 RMSE。
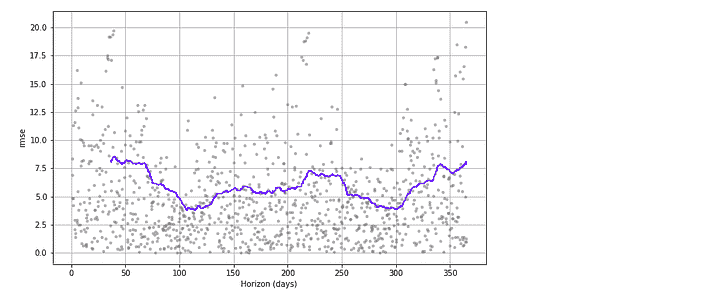
结论
正如我们所见,Prophet 在时间序列预测中非常强大和有效。然而,正如我们之前提到的,还有一些其他预测工具。工具的选择是基于数据集的性质逐案决定的。人们可以始终比较这些工具,并使用那些能提供最佳预测且误差最小的工具。这些方法包括ARIMA、Holt-Winters 方法、Holt 的线性趋势、简单指数平滑和移动平均等。您可以从官方文档或阅读Prophet 论文了解更多关于 Prophet 的信息。
简介:Derrick Mwiti 是一名数据分析师、作家和导师。他致力于在每个任务中取得优异成果,并且是 Lapid Leaders Africa 的导师。
相关内容:
-
使用 Keras 长短期记忆(LSTM)模型预测股票价格
-
Keras 深度学习入门
-
PyTorch 深度学习入门
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
相关主题
如何从机器学习中的巨大数据集中正确选择样本
原文:
www.kdnuggets.com/2019/05/sample-huge-dataset-machine-learning.html

在机器学习中,我们常常需要用一个非常大的数据集来训练模型。数据集的规模越大,它的统计意义和包含的信息就越多,但我们很少问自己:这么大的数据集真的有用吗?或者我们能否用一个更小、更易管理的数据集达到令人满意的结果?选择一个适度小的数据集,并包含足够的信息,真的可以让我们节省时间和金钱。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
让我们做一个简单的心理实验。假设我们在一个图书馆里,想要逐字学习但丁·阿利吉耶里的 神曲。
我们有两个选择:
-
获取我们找到的第一个版本并开始学习
-
尽可能多地获取不同版本并从中学习
正确的答案很明确。为什么我们要从不同的书籍中学习,当仅一本书就足够呢?
机器学习也是如此。我们有一个学习东西的模型,和我们一样,它也需要一些时间。我们想要的是学习现象所需的最小信息量,以免浪费时间。信息冗余对我们没有任何商业价值。
但是我们如何确保我们的版本没有损坏或不完整呢?我们必须与其他版本的集合进行某种形式的高水平比较。例如,我们可以检查 canti 和 cantiche 的数量。如果我们的书有三本 cantiche,每本都有 33 个 canti,也许它是完整的,我们可以安全地从中学习。
我们正在做的是从一个样本(单一的 神曲 版本)中学习,并检查其统计意义(与其他书籍的宏观比较)。
相同的概念也可以应用于机器学习。我们可以通过对大量记录的总体进行子采样,保持所有统计信息不变,而不是直接从庞大的总体中学习。
统计框架
为了得到一个小而易于处理的数据集,我们必须确保不会丧失相对于总体的统计显著性。数据集过小无法提供足够的信息进行学习,而数据集过大则可能需要耗费大量时间进行分析。那么,我们如何在大小和信息之间找到合适的折中呢?
从统计角度来看,我们希望样本保持总体的概率分布在合理的显著性水平下。换句话说,如果我们查看样本的直方图,它必须与总体的直方图相同。
实现这一目标有许多方法。最简单的方法是随机抽取一个具有均匀分布的子样本,并检查其是否显著。如果它具有合理的显著性,我们就保留它。如果不显著,我们将再取一个样本并重复这一过程,直到获得良好的显著性水平。
多变量与多个单变量
如果我们有一个由N个变量组成的数据集,它可以聚合成一个N变量的直方图,任何我们从中提取的子样本也可以是这样。
尽管这一操作在学术上是正确的,但在实际操作中可能非常困难,特别是当我们的数据集混合了数值变量和分类变量时。
所以我更喜欢一种更简单的方法,这通常会引入一个可接受的近似值。我们将考虑每个变量独立于其他变量。如果样本列的每一个单变量直方图与总体列的相应直方图可比,我们可以假设样本是不偏倚的。
样本和总体之间的比较是这样进行的:
-
从样本中选取一个变量
-
比较它的概率分布与总体中同一变量的概率分布
-
对所有变量重复此过程
你们中的一些人可能认为我们忽略了变量之间的相关性。在我看来,这不完全正确,如果我们均匀地选择样本。众所周知,均匀选择子样本在数量足够大的情况下,会产生与原始总体相同的概率分布。像自助法这样强大的重采样方法就是基于这一概念的(有关更多信息,请参见我的上一篇文章)。
比较样本和总体
正如我之前所说的,对于每个变量,我们必须将其在样本中的概率分布与在总体中的概率分布进行比较。
分类变量的直方图可以使用Pearson’s chi-square test 进行比较,而数值变量的累计分布函数可以使用Kolmogorov-Smirnov test 进行比较。
两个统计测试都基于原假设,即样本具有与总体相同的分布。由于一个样本由许多列组成,我们希望所有列都具有显著性,因此如果至少一个测试的 p 值低于通常的5% 置信水平,我们可以拒绝原假设。换句话说,我们希望每一列都通过显著性测试,以接受样本为有效。
R 示例
让我们从理论进入实践。像往常一样,我将使用 R 语言中的一个例子。我将展示统计测试如何给我们警告,当采样不正确时。
数据模拟
让我们模拟一些(巨大的)数据。我们将创建一个包含 100 万条记录和 2 列的数据框。第一列有 500,000 条记录,取自正态分布,而另一列的 500,000 条记录取自均匀分布。这个变量是明显有偏倚的,它将帮助我解释统计显著性的概念。
另一个字段是通过使用前 10 个字母创建的因子变量,这些字母均匀分布。
以下是创建这样一个数据集的代码。
set.seed(100)
N = 1e6
dataset = data.frame(
# x1 variable has a bias. The first 500k values are taken
# from a normal distribution, while the remaining 500k
# are taken from a uniform distribution
x1 = c(
rnorm(N/2,0,1) ,
runif(N/2,0,1)
),
# Categorical variable made by the first 10 letters
x2 = sample(LETTERS[1:10],N,replace=TRUE)
)
创建一个样本并检查其显著性
现在我们可以尝试从原始数据集中创建一个包含 10,000 条记录的样本,并检查其显著性。
记住:数值变量必须通过Kolmogorov-Smirnov 检验,而分类变量(即 R 中的因素)需要Pearson’s chi-square 检验。
对于每个测试,我们会将其 p 值存储在一个命名列表中以便最终检查。如果所有的 p 值都大于 5%,我们可以说样本没有偏倚。
sample_size = 10000
set.seed(1)
idxs = sample(1:nrow(dataset),sample_size,replace=F)
subsample = dataset[idxs,]
pvalues = list()
for (col in names(dataset)) {
if (class(dataset[,col]) %in% c("numeric","integer")) {
# Numeric variable. Using Kolmogorov-Smirnov test
pvalues[[col]] = ks.test(subsample[[col]],dataset[[col]])$p.value
} else {
# Categorical variable. Using Pearson's Chi-square test
probs = table(dataset[[col]])/nrow(dataset)
pvalues[[col]] = chisq.test(table(subsample[[col]]),p=probs)$p.value
}
}
pvalues
p 值如下:

它们中的每一个都大于 5%,所以我们可以说样本在统计上是显著的。
如果我们取前 10,000 条记录而不是随机选择,会发生什么?我们知道数据集中 X1 变量的前半部分与总体的分布不同,因此我们期望这样的样本不能代表整个总体。
如果我们重复测试,这些是 p 值:

如预期的那样,由于总体的偏倚,X1 的 p 值过低。在这种情况下,我们必须不断生成随机样本,直到所有 p 值都大于允许的最小置信水平。
结论
在这篇文章中,我展示了一个合适的样本在统计上可以显著地代表整个群体。这可能对机器学习有所帮助,因为一个小数据集可以让我们更快地训练模型,而信息量与较大的数据集相同。
然而,一切都与我们选择的显著性水平密切相关。对于某些问题,提高置信水平或丢弃那些不显示合适 p 值的变量可能会很有用。像往常一样,训练前的适当数据发现可以帮助我们决定如何正确地进行样本。
原文。经授权转载。
资源
詹卢卡·马拉托是一位作家和博主,但最重要的是一位充满热情的读者。詹卢卡写作奇幻、恐怖和科幻小说和短篇故事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号