


决策树算法
决策树通过树状结构来表示决策过程,每个内部节点代表一个特征或属性的测试,每个分支代表测试的结果,每个叶节点代表一个类别或值。
决策树的基本概念
- 节点(Node):树中的每个点称为节点。根节点是树的起点,内部节点是决策点,叶节点是最终的决策结果。
- 分支(Branch):从一个节点到另一个节点的路径称为分支。
- 分裂(Split):根据某个特征将数据集分成多个子集的过程。
- 纯度(Purity):衡量一个子集中样本的类别是否一致。纯度越高,说明子集中的样本越相似。
决策树的工作原理
决策树通过递归地将数据集分割成更小的子集来构建树结构。具体步骤如下:
- 选择最佳特征:根据某种标准(如信息增益、基尼指数等)选择最佳特征进行分割。
- 分割数据集:根据选定的特征将数据集分成多个子集。
- 递归构建子树:对每个子集重复上述过程,直到满足停止条件(如所有样本属于同一类别、达到最大深度等)。
- 生成叶节点:当满足停止条件时,生成叶节点并赋予类别或值。
决策树的构建:
标准1:信息增益(Information Gain)

标准2:基尼指数(Gini Index)
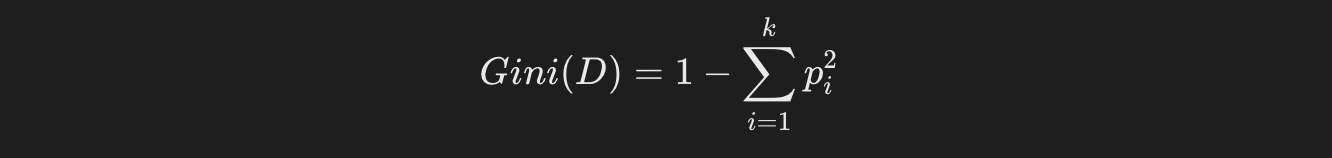
标准3:均方误差(MSE)
决策树的优缺点
优点
- 易于理解和解释:决策树的结构直观,易于理解和解释。
- 处理多种数据类型:可以处理数值型和类别型数据。
- 不需要数据标准化:决策树不需要对数据进行标准化或归一化处理。
缺点
- 容易过拟合:决策树容易过拟合,特别是在数据集较小或树深度较大时。
- 对噪声敏感:决策树对噪声数据较为敏感,可能导致模型性能下降。
- 不稳定:数据的小变化可能导致生成完全不同的树。
使用Python的scikit-learn库来实现一个简单的决策树分类器(预先装好graphviz库)
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.tree import export_graphviz import graphviz # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 将数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建决策树分类器 clf = DecisionTreeClassifier() # 训练模型 clf.fit(X_train, y_train) # 对测试集进行预测 y_pred = clf.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print(f"模型准确率: {accuracy:.2f}") # 导出决策树为dot文件 dot_data = export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) # 使用graphviz渲染决策树 graph = graphviz.Source(dot_data) graph.render("iris_decision_tree") # 保存为PDF文件 graph.view() # 在浏览器中查看


 浙公网安备 33010602011771号
浙公网安备 33010602011771号