

机器学习算法
线性回归(Linear Regression)
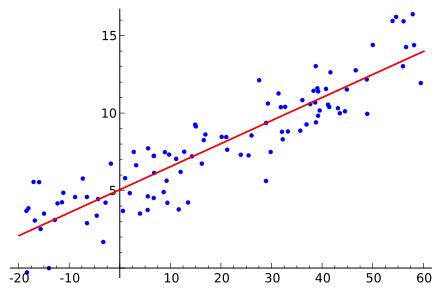
线性回归是一种用于回归问题的算法,它通过学习输入特征与目标值之间的线性关系,来预测一个连续的输出。
应用场景:预测房价、股票价格等。
线性回归的目标是找到一个最佳的线性方程:
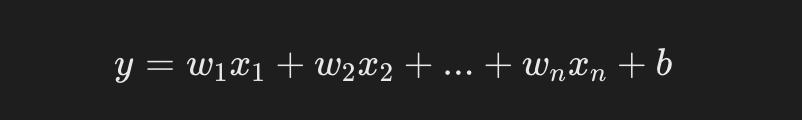
- y 是预测值(目标值)。
- x1,x2,xn 是输入特征。
- w1,w2,wn是待学习的权重(模型参数)。
- b 是偏置项。
from skle.linear_model import LinearRegression from sklearn.model_selection import train_test_split import pandas as pd # 假设我们有一个简单的房价数据集 data = { '面积': [50, 60, 80, 100, 120], '房价': [150, 180, 240, 300, 350] } df = pd.DataFrame(data) # 特征和标签 X = df[['面积']] y = df['房价'] # 数据分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练线性回归模型 model = LinearRegression() model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) print(f"预测的房价: {y_pred}")
逻辑回归(Logistic Regression)
逻辑回归是一种用于分类问题的算法,尽管名字中包含"回归",它是用来处理二分类问题的。
逻辑回归通过学习输入特征与类别之间的关系,来预测一个类别标签。
应用场景:垃圾邮件分类、疾病诊断(是否患病)。
逻辑回归的输出是一个概率值,表示样本属于某一类别的概率。
通常使用 Sigmoid 函数:
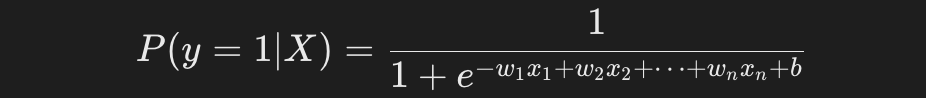
from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 只取前两类做二分类任务 X = X[y != 2] y = y[y != 2] # 数据分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练逻辑回归模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) # 评估模型 print(f"分类准确率: {accuracy_score(y_test, y_pred):.2f}")
支持向量机(SVM)
支持向量机是一种常用的分类算法,它通过构造超平面来最大化类别之间的间隔(Margin),使得分类的误差最小。
应用场景:文本分类、人脸识别等。
使用 SVM 进行鸢尾花分类任务:
from sklearn.svm import SVC from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 数据分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 训练 SVM 模型 model = SVC(kernel='linear') model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) # 评估模型 print(f"SVM 分类准确率: {accuracy_score(y_test, y_pred):.2f}")
决策树(Decision Tree)
决策树是一种基于树结构进行决策的分类和回归方法。它通过一系列的"判断条件"来决定一个样本属于哪个类别。
应用场景:客户分类、信用评分等。
使用决策树进行分类任务:
from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 数据分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 训练决策树模型 model = DecisionTreeClassifier(random_state=42) model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) # 评估模型 print(f"决策树分类准确率: {accuracy_score(y_test, y_pred):.2f}")
K-means 聚类(K-means Clustering)
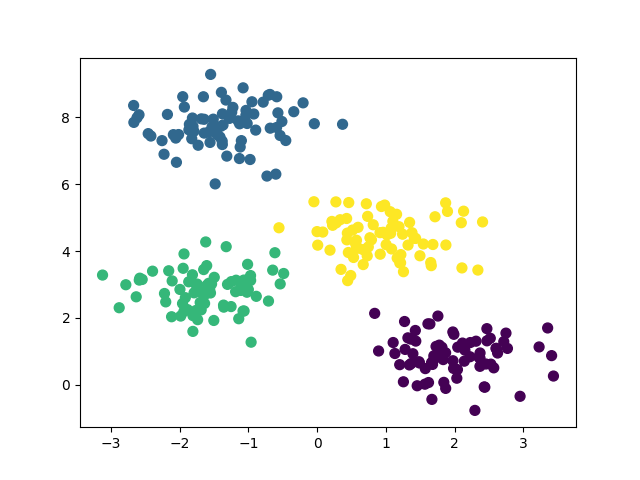
K-means 是一种基于中心点的聚类算法,通过不断调整簇的中心点,使每个簇中的数据点尽可能靠近簇中心。
应用场景:客户分群、市场分析、图像压缩。
使用 K-means 进行客户分群:
from sklearn.cluster import KMeans from sklearn.datasets import make_blobs import matplotlib.pyplot as plt # 生成一个简单的二维数据集 X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0) # 训练 K-means 模型 model = KMeans(n_clusters=4) model.fit(X) # 预测聚类结果 y_kmeans = model.predict(X) # 可视化聚类结果 plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis') plt.show()
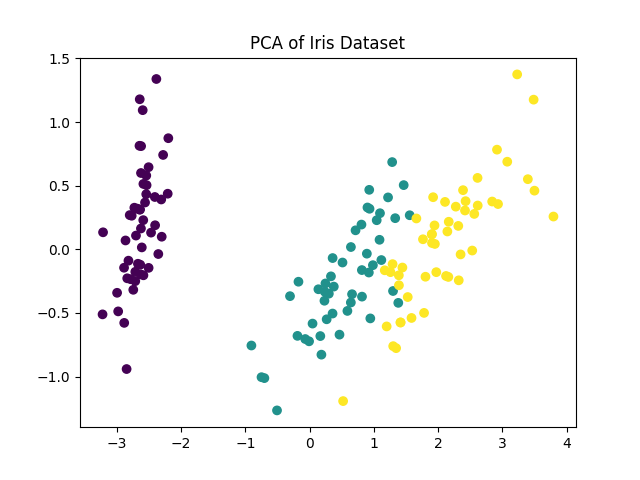
主成分分析(PCA)
PCA 是一种降维技术,它通过线性变换将数据转换到新的坐标系中,使得大部分的方差集中在前几个主成分上。
应用场景:图像降维、特征选择、数据可视化。
使用 PCA 降维并可视化高维数据:
from sklearn.decomposition import PCA from sklearn.datasets import load_iris import matplotlib.pyplot as plt # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 降维到 2 维 pca = PCA(n_components=2) X_pca = pca.fit_transform(X) # 可视化结果 plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis') plt.title('PCA of Iris Dataset') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号