【机器学习】李宏毅机器学习-Keras-Demo-神经网络手写数字识别与调参
参考:
-
原视频:李宏毅机器学习-Keras-Demo
-
调参博文1:深度学习入门实践_十行搭建手写数字识别神经网络
-
调参博文2:手写数字识别---demo(有小错误)
-
代码链接:
编程环境:
-
操作系统:win7 - CPU
-
anaconda-Python3-jupyter notebook
-
tersonFlow:1.10.0
-
Keras:2.2.4
背景:
-
视频里宝可梦大师提供的部分参数设置不能得到好的结果,这里记录一下后续调参
1-载入数据报错的问题:
-
载入数据运行时报错:[WinError 10054] 远程主机强迫关闭了一个现有的连接
-
解决方案详情参考博文:【问题解决方案】Keras手写数字识别-ConnectionResetError: [WinError 10054]
-
后续是:最终仍然报错,没办法只好搭tizi硬着头皮在线载入数据,最后也成了,赞啦~
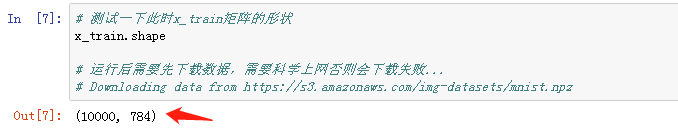
2-测试程序是否正常
-
打印一下某个矩阵的形状,没有报错一切正常
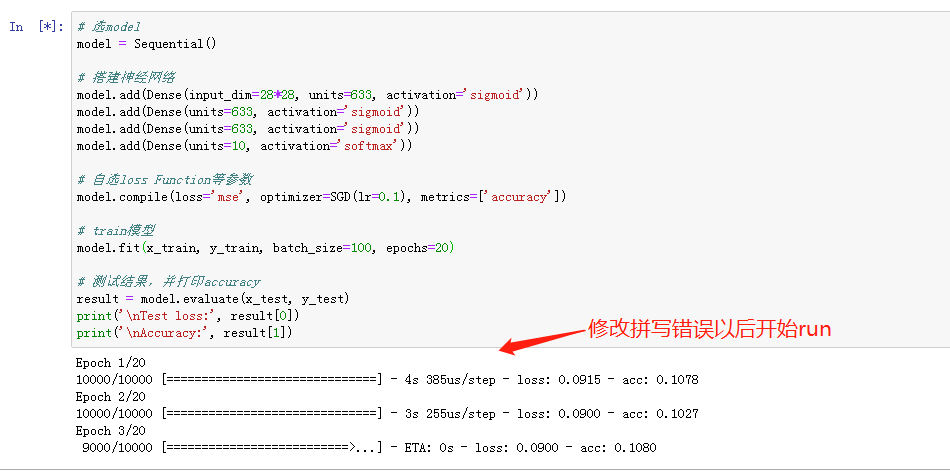
3-运行原始代码
-
按照李宏毅老师视频里讲的全是坑代码运行看看效果

4-对神经网络进行调参
改动地方主要为:
-
激励函数由sigmoid改为relu
-
loss function由mse改为categorical_crossentropy
-
增加了Dropout,防止过拟合
-
改动后的代码为
# 选model
model = Sequential()
# 搭建神经网络
# 改动:4点
# 1-中间层units由633改为700
# 2-激活函数由sigmoid改为relu
# 3-原四个Dense,删去一个中间层,只留三个Dense
# 4-在三个Dense的每两个Dense中间加入Dropout
# batch-epochs=100,20时,三Dense好于四Dense
# batch-epochs=1,2时,三Dense好于四Dense
model.add(Dense(input_dim=28*28, units=700, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=700, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=10, activation='softmax'))
# 自选loss Function等参数
# 改动:1点
# 1-loss function由mse改为categorical_crossentropy
model.compile(loss='mse', optimizer=SGD(lr=0.1), metrics=['accuracy'])
# train模型
# 改动:1点
# 1-参数列表最后加一个validation_split(交叉验证?)
# 2-batch-size=1, epochs=2时,acc变为0.9314(3个Dense),0.9212(4个Dense)
model.fit(x_train, y_train, batch_size=1, epochs=2, validation_split=0.05)
# 测试结果,并打印accuracy
result = model.evaluate(x_test, y_test)
print('\nTest loss:', result[0])
print('\nAccuracy:', result[1])
5-结果分析
-
貌似相同参数,不同train回合,得到的结果还有细微的差别。。。

总结:
-
无论如何,总算DL-hello world达成了,好的开始就是成功的一半,再接再厉!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号