Task-adaptive Neural Process for User Cold-Start Recommendation阅读笔记
动机
本文是2021年WWW上的一篇论文。之前解决推荐系统冷启动问题的工作大部分是通过辅助信息或是元学习,这两种方法都有一些缺点,前者不能保证每个应用场景都能获取足够且高质量的辅助信息,后者由于通常是建立在MAML框架上的,它假设不同用户的推荐是高度相关的,但是事实并非如此。本文提出了TaNP框架解决上述问题。
方法
首先是TaNP的框架图。主要分为三部分,分别是Encoder、Customization module、Adaptive Decoder。这里只讲一下这三部分,想要把整篇文章都读懂还需要看原文。
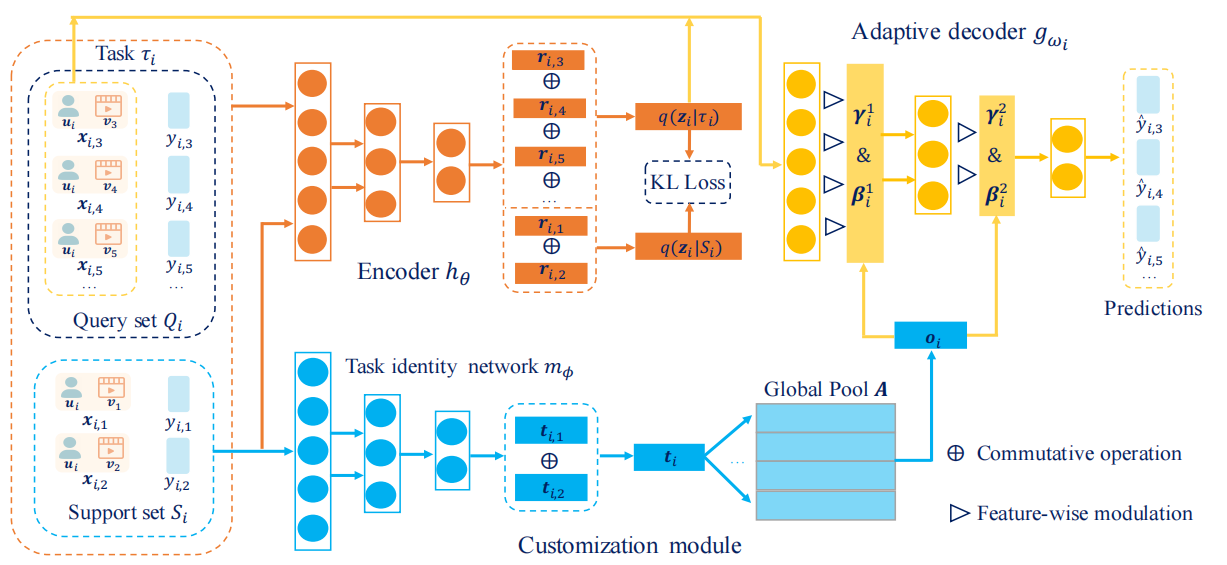
Encoder
这里编码器\(h_\theta\)的作用是根据用户的历史行为学习到隐变量的分布。首先计算任务i中的第j个交互的嵌入
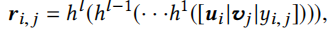
其中\(h(x)=ReLU(Wx+b)\),之后有
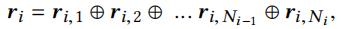
⊕是一种运算符,这里作者使用平均运算符
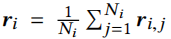
接下来使用重新参数化技巧表示随机变量
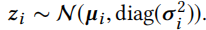
它被正式定义为
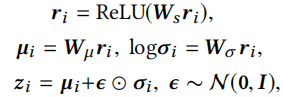
Customization Module
Customization Module用来学习不同任务之间的相关性(推荐系统元学习中把一个用户看作一个任务),包括一个任务标识网络\(m_{\phi}\)和一个全局池A。\(m_{\phi}\)用于根据一个任务的support set生成对应的embedding \(t_i\)
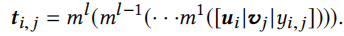
\(m_\phi\)的结构和上述\(h_\theta\)结构相同。\(t_i\)的计算方式和上述\(r_i\)相同。
全局池A表示k个类的中心,每个\(t_i\)都会与A有交互且获得一个软簇分类,利用学生t分布计算得
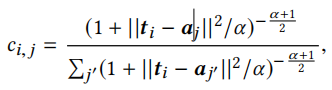
最后的任务嵌入\(o_i\)得
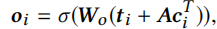
这里\(t_i\)可以看作用户意图,A可以看作用户意图的解耦。
加入无监督聚类损失\(L_u\)辅助聚类,\(L_u\)定义为
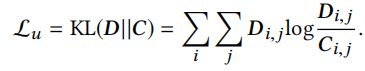
D为
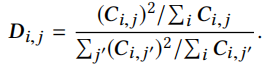
Adaptive Decoder
这里解码器根据用户表示\(u_i\),物品表示\(v_j\)以及隐变量\(z_i\)来共同预测推荐结果。这里作者提出了FiLM和Gating-FiLM两种方法。
FiLM为
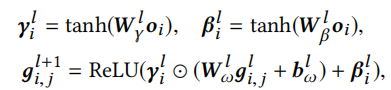
其中
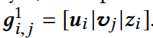
Gating-FiLM为
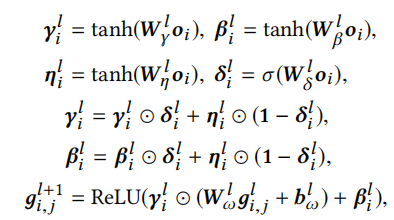
损失函数
回归问题的损失函数为
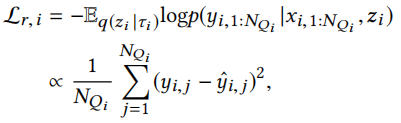
二分类问题的损失函数为
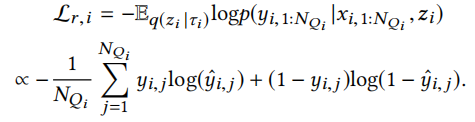
总的损失函数为
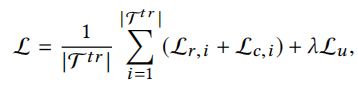
其中
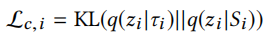
训练过程如下

实验结果
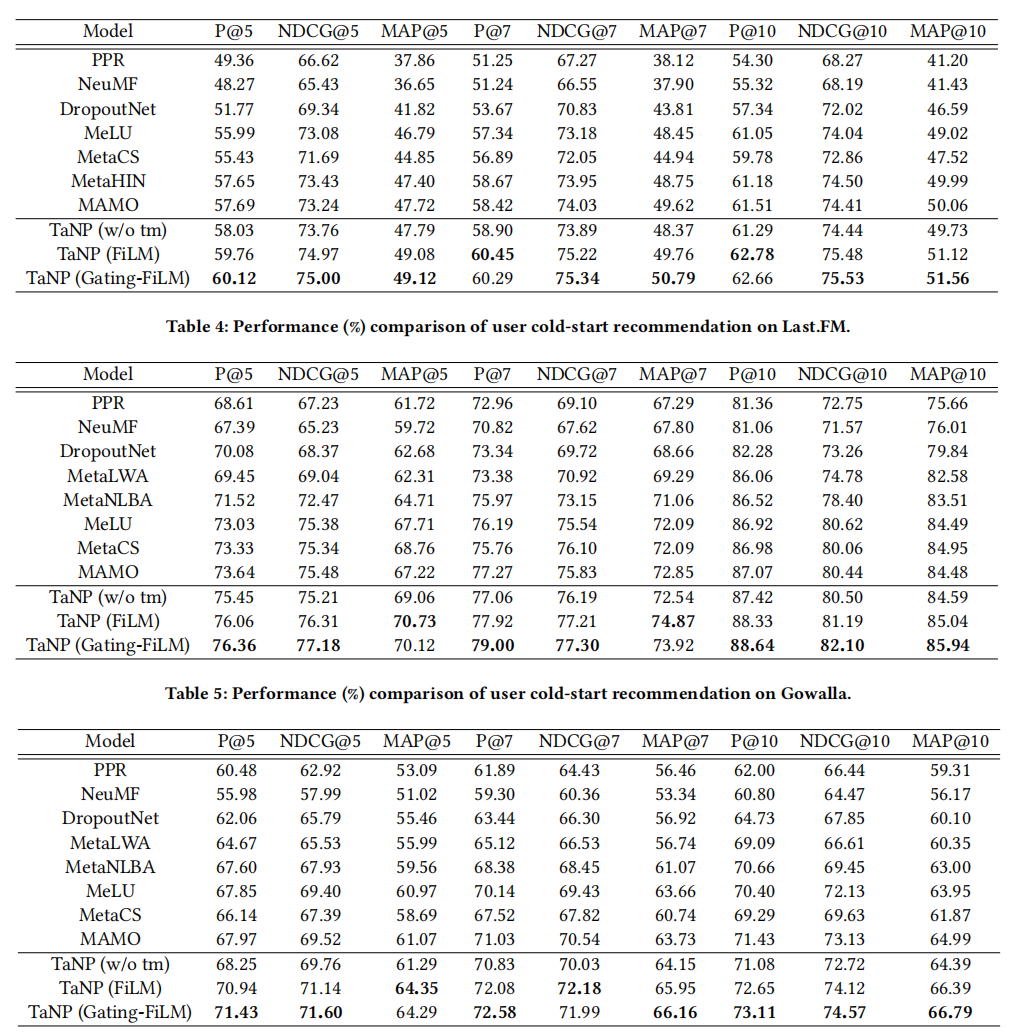
在三个数据集上,本文提出的TaNP优于其他所有基准模型。
总结
根据我个人的理解,本文将用户划分为老用户和新用户两部分,每部分用户再将其交互数据划分为支持集和查询集两部分,新用户没有查询集和标签。本文假设每个任务都和一个随机实例化过程有关,我们可以将其近似为一个固定长度向量\(z_i\)。首先根据老用户的数据近似计算出隐变量\(z_i\)的后验分布\(q(z_i|S_i)\)和\(q(z_i|\tau_i)\),这里有一个KL散度约束使得上述两个分布尽可能相似。之后在老用户的支持集上解耦用户意图,并生成最终的任务嵌入向量。最后通过解码器预测推荐结果,计算损失并更新参数。在预测阶段,新用户通过编码器采样得到\(z_i\),再通过Customization Module获取任务的嵌入表示,最终通过解码器预测结果。本文公式很多较为复杂,我还没完全读透,许多部分还需要再读。我认为尤其是涉及到变分推断这部分的内容需要再细读,因为之前也看过一篇文章有用到变分推断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号