RUM 链路打通实战:打破移动端可观测性黑洞
作者:路锦(小蘭)
背景:移动端的“可观测性黑洞”
在微服务架构蓬勃发展的今天,服务端的可观测性建设已日趋成熟。无论是 Jaeger、Zipkin 还是 SkyWalking,这些分布式链路追踪工具都能够帮助开发者清晰地观察到一个请求从网关进入后,是如何在各个微服务之间层层流转、逐级调用的。然而,当我们试图将这条链路向前延伸至移动端时,却发现一道难以逾越的鸿沟横亘其间。
- 关联困难:移动端和服务端仿佛两座孤岛,各自维护着独立的日志系统。客户端记录着请求发起的时间和结果,服务端保存着完整的调用链路,但两者之间缺乏一条有效的纽带将其串联起来。一旦出现问题,排查人员只能依靠时间戳进行手工比对,既费时又容易出错,遇到高并发场景更是如同大海捞针。
- 定位模糊:我们常常遇到这样的场景:用户投诉说接口超时了,但翻开服务端监控,每一条请求都显示着正常返回的 200 状态码。问题究竟出在用户的网络环境、运营商的链路质量,还是服务端在某个瞬间的抖动?由于移动端与服务端的监控体系相互割裂,我们根本无从判断故障边界,各团队之间也容易陷入相互推诿的困境。
- 复现无门:移动端的网络环境远比服务端复杂——DNS 解析可能受到劫持、SSL 握手可能遭遇兼容性问题、弱网环境下的重试和超时更是家常便饭。这些关键信息在传统方案中往往随着请求结束而烟消云散,当问题间歇性发生时,开发者既无法还原现场,也难以定位根因,只能在用户的反复投诉中束手无策。
正是这些痛点的存在,让端到端全链路追踪的需求变得愈发迫切。我们需要一种方案,能够让移动端真正成为分布式链路的起点,让每一次用户操作触发的请求都能够被完整记录、精准关联、一路追踪到最底层的数据库调用。本文将通过一个最佳实践案例,展示如何借助阿里云用户体验监控实现移动端到后端的全链路 Trace 打通,辅助网络请求问题排查。
核心方案:端到端链路打通的技术实现
核心思想
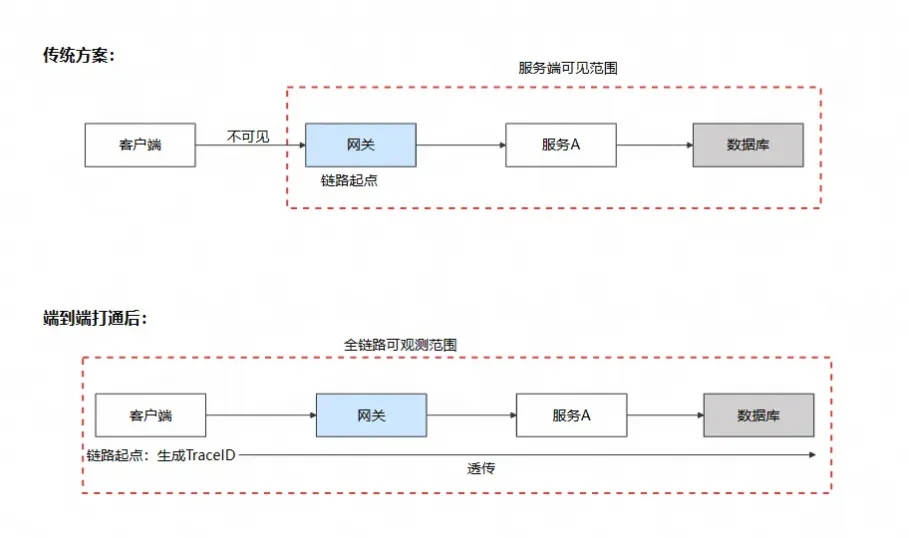
端到端链路打通的本质是:让客户端成为分布式追踪链路的第一跳,使其与服务端链路共享同一个 Trace ID。
在传统架构中,链路追踪的起点是服务端网关——请求进入网关时,APM Agent 为其分配 Trace ID,并在后续的微服务调用中透传。而端到端打通方案则将这个起点前移到了用户的手机上,由移动端 SDK 主动生成 Trace ID 并注入到请求头中,使得整条链路从用户指尖到数据库底层都被同一个标识串联起来。
技术实现的四个关键环节
整个链路打通的实现可以分为四个紧密衔接的环节:
环节一:客户端生成链路标识
当用户触发一次网络请求时,客户端 SDK 在请求真正发出之前介入:
- 拦截请求:通过网络库的拦截机制(如 OkHttp Interceptor)捕获即将发出的请求
- 创建 Span:为这次请求创建一个 Span 对象,生成两个核心标识:
- Trace ID(32 位十六进制):整条链路的唯一身份
- Span ID(16 位十六进制):当前这一跳的唯一身份
- 记录起始时间:精确记录请求发起的时间戳,用于后续计算各阶段耗时
环节二:协议编码与注入
生成链路标识后,需要将其编码为服务端能够理解的格式。这里的关键是选择一套双方都遵守的“通用语言”——W3C Trace Context 或 SkyWalking SW8 协议。
客户端 SDK 将编码后的信息写入 HTTP 请求头,随请求一同发送。
环节三:网络传输与透传
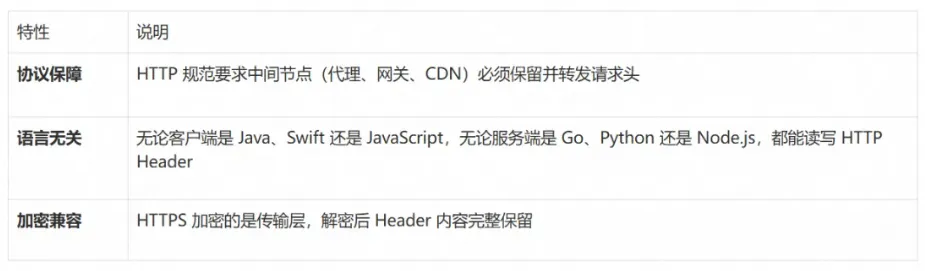
HTTP 协议天然具备请求头的穿透性,这是透传能够实现的技术基础:
环节四:服务端接收与延续
当请求到达服务端时,APM Agent 接管后续处理,完成链路的延续:
- 解析请求头:从
traceparent或sw8头中提取 Trace ID 和 Parent Span ID - 继承链路上下文:将客户端传入的 Trace ID 作为本条链路的身份标识,而非重新生成
- 创建子 Span:为服务端的处理逻辑创建新的 Span,其 Parent Span ID 指向客户端的 Span
- 继续透传:在调用下游服务时,继续在请求头中携带同一个 Trace ID
通过这四个环节的紧密配合,移动端发出的每一个请求都能与服务端的调用链路无缝衔接,形成一条从用户设备到数据库的完整追踪链路。
链路打通协议
为了让不同系统之间能够“说同一种语言”,业界制定了标准化的链路追踪协议。目前主流的协议有两种:
W3C Trace Context 协议
W3C Trace Context 是 W3C 官方标准,具有最广泛的兼容性。
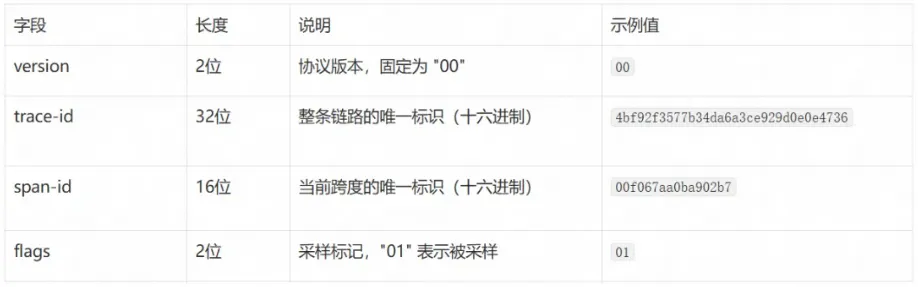
Header 格式:

字段说明:
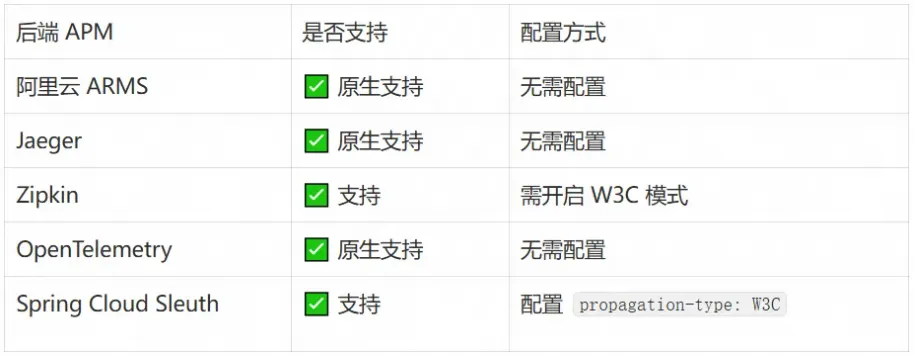
适用场景:
SkyWalking SW8 协议
SW8 是 Apache SkyWalking 的原生协议,包含更丰富的上下文信息。
Header 格式:

字段说明:
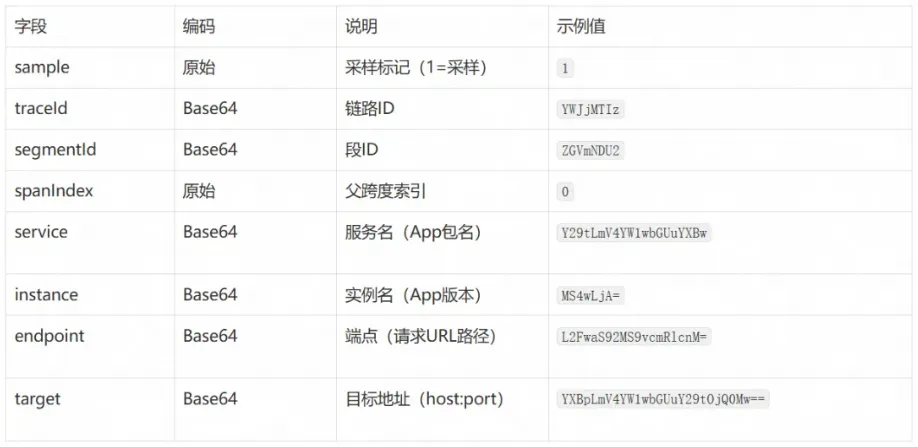
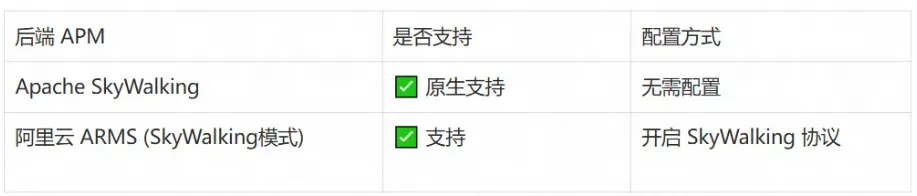
适用场景:
实战案例:一次查询接口超时的全链路排查
理论讲完了,接下来让我们通过一个真实的排查案例,看看端到端链路打通在实际问题定位中是如何发挥作用的。
问题背景
我们基于某开源代码库构造了一个慢请求场景,架构如下图所示:

在日常使用中,我们发现某个页面打开十分缓慢,用户体验极差。初步怀疑是由于 API 请求响应过慢导致,但具体慢在哪里、为什么慢,还需要进一步分析。接下来,我们将借助阿里云用户体验监控的全链路追踪能力,一步步定位问题根因。
第一步:在云监控控制台定位异常请求
首先,我们登录阿里云控制台,进入云监控 2.0 控制台 → 用户体验监控 →您的应用 → API 请求模块。在这里,我们可以看到所有 API 请求的性能统计数据。
通过对“缓慢占比”进行排序,我们很快发现了问题所在:
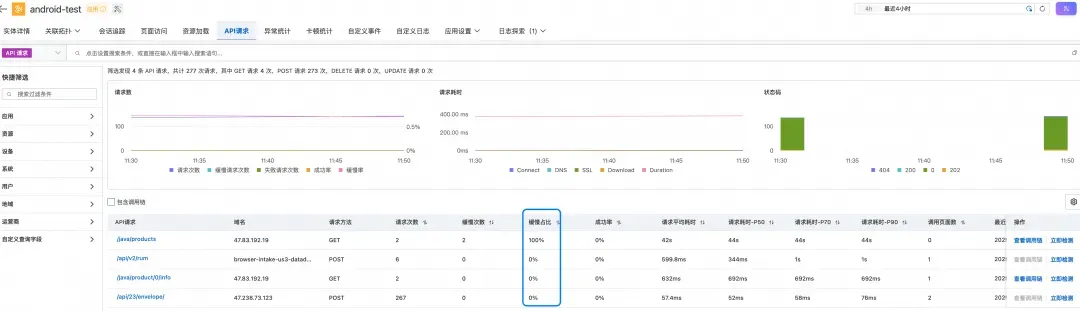
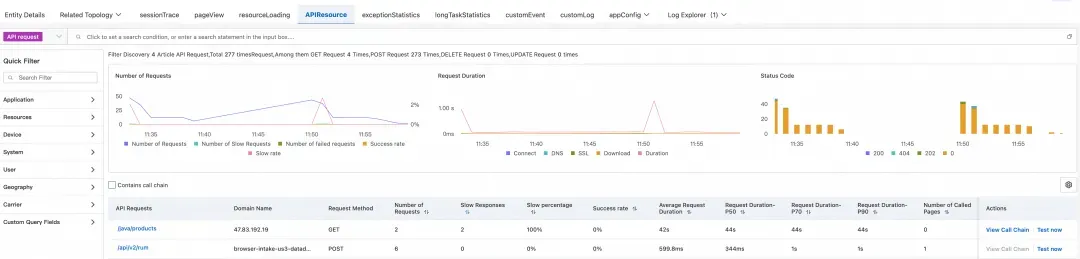
从监控数据可以清晰地看到,API /java/products 的响应时间异常——平均耗时高达 40 多秒!这个耗时远远超出了正常范围,难怪用户会感觉页面打开缓慢。
找到了可疑的 API,接下来我们需要进一步分析它的调用链,搞清楚这 40 多秒究竟消耗在了哪个环节。
第二步:查看调用链,追踪服务端链路
点击对应 API 的“查看调用链”按钮,系统会跳转到当前请求的 Trace 详情页面。
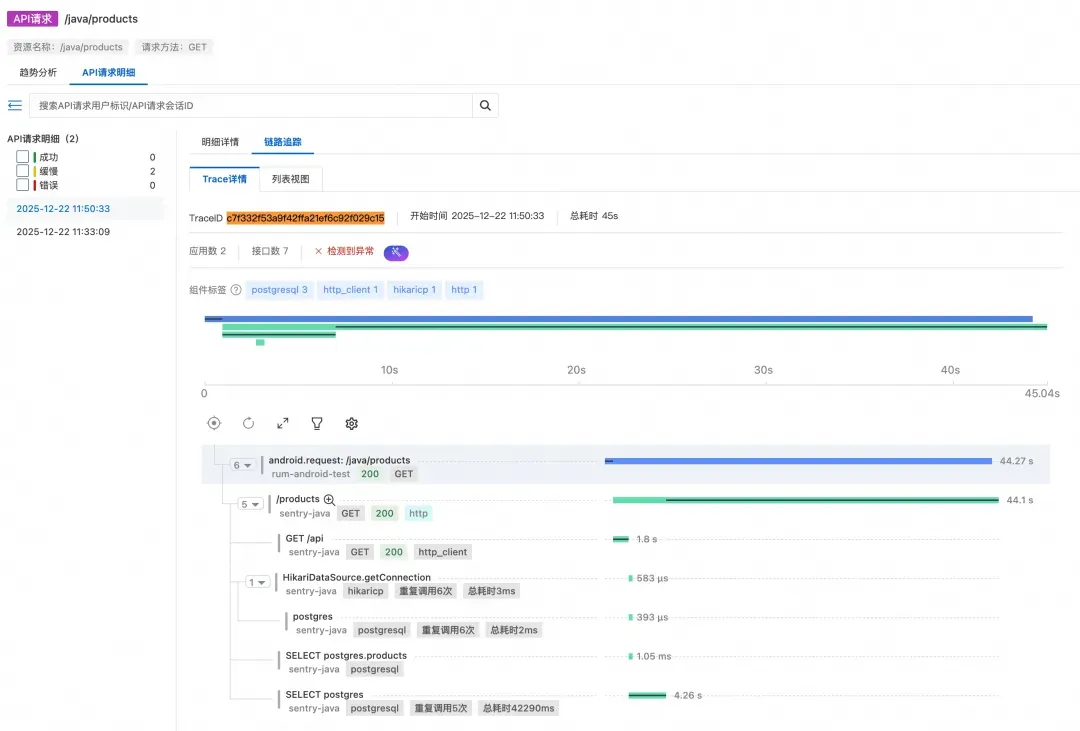
这里就是端到端链路打通的核心价值所在——我们可以直接看到从移动端到后端的完整调用链路,无需在多个系统之间来回切换。
从链路瀑布图中可以清晰地看到:
- 移动端发起请求后,链路完整地延续到了后端服务
- 耗时主要发生在后端服务的
/products接口 - 该接口处理耗时超过 40 秒才返回数据
为了方便后续在后端应用监控中进行更深入的分析,我们记录下当前的 Trace ID:c7f332f53a9f42ffa21ef6c92f029c15。
第三步:查看后端服务Trace分析
接下来,我们进入应用监控 → 找到对应的后端应用 → 调用链分析,使用刚才记录的 Trace ID 进行查询。
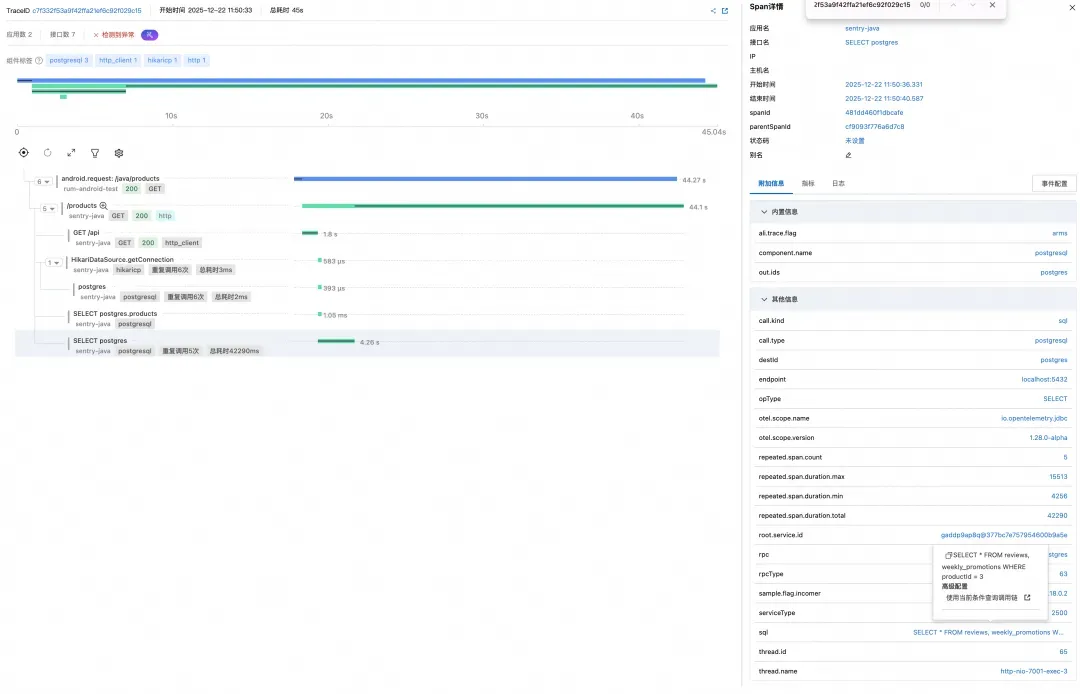
从后端链路数据可以还原出 /products 接口的执行链路:
- HikariDataSource.getConnection,重复 6 次,总耗时 3ms。含义:获取数据库连接(从连接池拿)一共 6 次,总共才 3ms,不是瓶颈。
- postgres,重复 6 次,总耗时 2ms。这是一些非常快的 Postgres 操作/小查询,同样不是瓶颈。
- SELECT postgres.products,重复执行了1 + 5 次,总耗时 42290ms ≈ 42.3s。这行才是关键:同一个 SQL(查 products 相关)一共执行了 5 次,总耗时 42.3s,平均每次大约 8 秒。
- 也就是说:主要时间都花在执行这个 SQL 上,而不是连库 / 建连接 / 网络。
第四步:深入分析慢 SQL
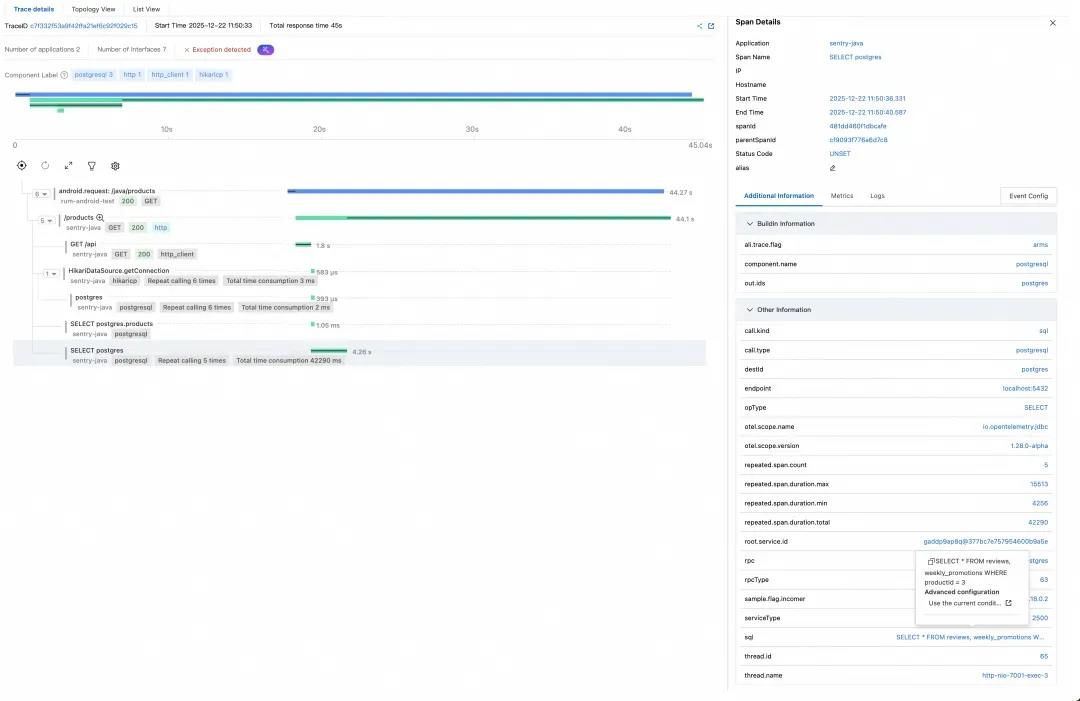
点击链路中的最后一个 Span,我们可以在右侧详情面板中看到具体执行的 SQL 语句:
-- 第一次查询:获取全量产品数据
SELECT * FROM products
-- 对每个产品执行 N 次查询(N+1 问题)
SELECT * FROM reviews, weekly_promotions WHERE productId = ?
问题的根因逐渐浮出水面:
- 第一次查询:
SELECT * FROM products获取所有产品,这一步耗时尚可 - N 次循环查询:对于每一个产品,又单独执行了一次
SELECT * FROM reviews, weekly_promotions WHERE productId = ?
这是一个典型的 N+1 查询问题!更糟糕的是,weekly_promotions 是一个特意设计的“慢视图”(sleepy view),每次查询都会执行较重的操作。当产品数量较多时,这些查询累积起来就造成了 42 秒的惊人耗时。
我们记录下当前的线程名称:http-nio-7001-exec-3,以便进一步查看 Profile 数据进行验证。
第五步:查看 Profile 数据验证结论
为了进一步确认我们的分析结论,我们进入应用诊断 → 持续性能剖析,查看后端服务的 Profile 数据。
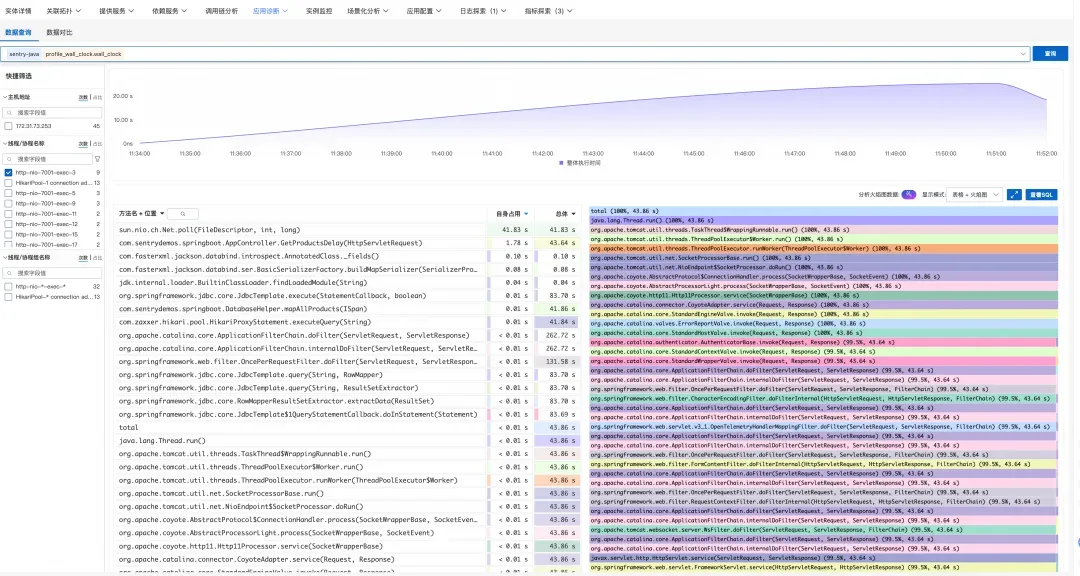
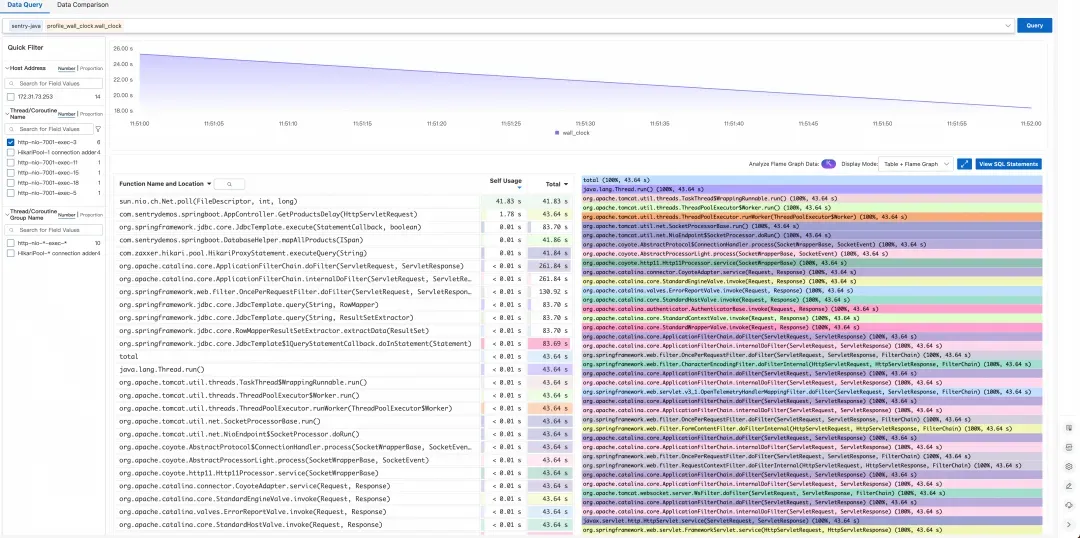
筛选对应的线程后,我们看到了服务执行时间的分布情况:
sun.nio.ch.Net.poll(FileDescriptor, int, long)耗时占比接近 100%- 这表明线程大部分时间都在等待 Postgres socket 返回数据
Profile 数据与调用链分析的结论完全吻合——问题确实出在数据库查询上,线程一直在等待慢 SQL 的执行结果。
第六步:定位根因
综合以上分析,我们可以清晰地定位到问题的根因:
问题根因:N+1 查询 + 慢视图
- 代码逻辑存在 N+1 查询问题:
- 第一次查询:
SELECT * FROM products(1 次) - 对每个 product 循环查询:
SELECT * FROM reviews, weekly_promotions WHERE productId = ?(N 次)
- 第一次查询:
- weekly_promotions 是一个“慢视图”,查询本身就很耗时
- 两者叠加,导致接口总耗时超过 40 秒
总结
全链路端到端打通解决了移动端与服务端之间的“可观测性黑洞”问题。通过在移动端注入标准化的 Trace Header,实现:
- 统一追踪:移动端请求和服务端链路使用同一个 TraceID,一键关联;
- 精准定位:从用户手机到数据库,每一跳的耗时清晰可见;
- 快速定界:告别“移动端说服务端慢,服务端说网络差”的扯皮;
- 数据驱动:基于真实链路数据优化,而非猜测。
阿里云 RUM 针对 Android 端实现了对应用性能、稳定性、和用户行为的无侵入式监控采集 SDK,可以参考接入文档体验使用。除了 Android 外,RUM 也支持 Web、小程序、iOS、鸿蒙等多种平台监控分析,相关问题可以加入“RUM 用户体验监控支持群”(钉钉群号: 67370002064)进行咨询。
参考链接:
[1] Android 接入文档:
[2] Java 应用监控说明文档:
[3] 持续性能剖析说明文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号