S3 日志跨云导入 SLS:技术挑战、解决方案与最佳实践
作者:范中豪(炽凡)
在多云架构日益普及的今天,企业常常面临这样的场景:运行在多云环境中的业务系统会产生大量日志数据,通常存储于对象存储服务中,但为了实现集中化运维、安全合规与统一分析,需要将这些分散的日志数据汇聚至统一的日志平台进行处理与洞察。
典型场景包括:
- 跨云服务日志集中分析: 各类云服务产生的审计日志、网络流日志、负载均衡访问日志等,需在统一平台进行关联分析与故障排查;
- 海外业务数据回流: 分布在境外的业务系统生成的日志需安全、高效地回流至国内,以满足数据合规、安全审计与运营分析需求;
- 多云统一运营管理: 企业采用多云或混合云战略,亟需构建统一的日志采集、分析与告警体系,打破数据孤岛,提升可观测性与响应效率。
针对以上场景,阿里云日志服务 SLS 提供了强大的实时分析能力、灵活的查询语法和完善的告警机制,是日志统一管理的理想选择。接下来,我们以业界广泛采用的对象存储服务 AWS S3 为例,展示如何将异构环境中的对象存储日志高效导入 SLS,实现统一平台上实现日志的实时查询、智能分析、可视化监控与自动化告警,帮助企业更加智能、高效、可靠地进行跨云平台海量日志统一管理。
技术挑战:看似简单的数据搬运背后
挑战一:海量小文件的实时发现难题
许多 AWS 服务(如 CloudTrail、ALB)会持续向 S3 写入小文件,每分钟可能产生成百上千个文件。如何快速发现这些新增文件并及时导入?
核心难点在于: S3 的 ListObjects API 只支持按字典序遍历,不支持按时间过滤。这意味着要找到最新的文件,可能需要遍历整个目录树。
举个例子:假设某个 S3 bucket 中已有上亿个历史文件,每分钟新增 1000+ 文件。如果采用全量遍历,可能需要数分钟才能完成一次扫描,根本无法满足实时性要求;但如果只做增量遍历,又可能因为文件命名不规则而遗漏数据。
挑战二:流量突发的弹性应对
业务流量往往具有明显的波动性。电商大促、营销活动、系统故障都可能导致日志量瞬间暴增。
真实场景: 某电商客户在平时每分钟产生 1GB 日志,但在大促期间会飙升到 10GB 甚至更高。如果导入能力无法快速扩容,就会导致数据积压,影响实时分析和告警的时效性。
更棘手的是,流量波动往往不可预测。系统需要自动感知流量变化,并在几分钟内完成扩容,这对调度系统提出了很高的要求。
挑战三:数据格式的多样性与成本控制
S3 中的日志数据千差万别:
- 压缩格式:gzip、snappy、lz4、zstd 等;
- 数据格式:JSON、CSV、Parquet、纯文本等;
- 数据质量:可能包含脏数据、需要字段提取和转换。
如果先将数据原样导入 SLS,再进行加工处理,会产生额外的存储和计算成本。理想的方案是在导入过程中就完成数据清洗和转换。
我们的解决方案:智能、弹性、全面
在 S3 到 SLS 的迁移场景中,最让运维团队头疼的是“如何又快又稳地搬数据”。传统方案往往面临两难选择:要么快但容易漏,要么稳但慢如蜗牛。
SLS 团队的解决方案是:不做选择题,两个都要。
通过创新的两阶段并行架构:
- 第一阶段(文件发现):多种机制组合出击,实时事件捕获 + 定期全量校验,确保“一个不漏”;
- 第二阶段(数据拉取):专属传输通道全速运转,不受文件扫描拖累;
- 关键创新:两阶段独立运行、并行推进,既快又稳。
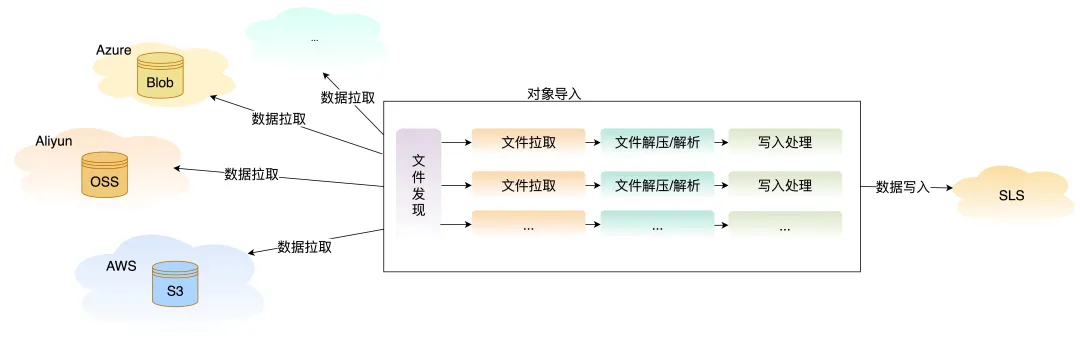
实时文件发现:秒级响应零遗漏
方案一:双模式智能遍历
针对文件发现难题,我们提供了两种互补的遍历模式:
全量遍历模式
- 周期性(如每分钟)对指定目录进行完整扫描;
- 确保不遗漏任何文件,适合对数据完整性要求极高的场景;
- 智能记录已导入文件,避免重复处理。
增量遍历模式
- 基于字典序的增量发现机制;
- 每次从上次扫描的位置继续遍历,快速发现新增文件;
- 适合文件按时间顺序命名的标准场景,可实现分钟级实时导入。
两种模式组合使用: 增量遍历保证实时性,全量遍历兜底保证完整性。
方案二:SQS 事件驱动导入
对于实时性要求极高的场景,我们支持通过 SQS 消息队列来驱动导入流程:
- 配置 S3 事件通知: 当有新文件上传到 S3 时,自动发送事件到 SQS;
- 实时消费消息: 导入服务从 SQS 中获取文件变更通知;
- 精准导入: 直接导入指定的文件,无需遍历。
这种方案可以实现分钟级的导入延迟,特别适合:
- 文件创建顺序不规则的场景;
- 对实时性有严格要求的业务;
- 需要同时监控多个目录的复杂场景。
方案对比:
| 对比维度 | 双模式遍历 | SQS 事件驱动 |
|---|---|---|
| 新文件发现实时性 | 分钟级 | 秒级 |
| 配置复杂度 | 简单 | 需配置 S3 事件 |
| 可靠性 | 高(全量兜底) | 依赖 SQS 可靠性 |
| 适用场景 | 标准日志导入 | 高实时性要求 |
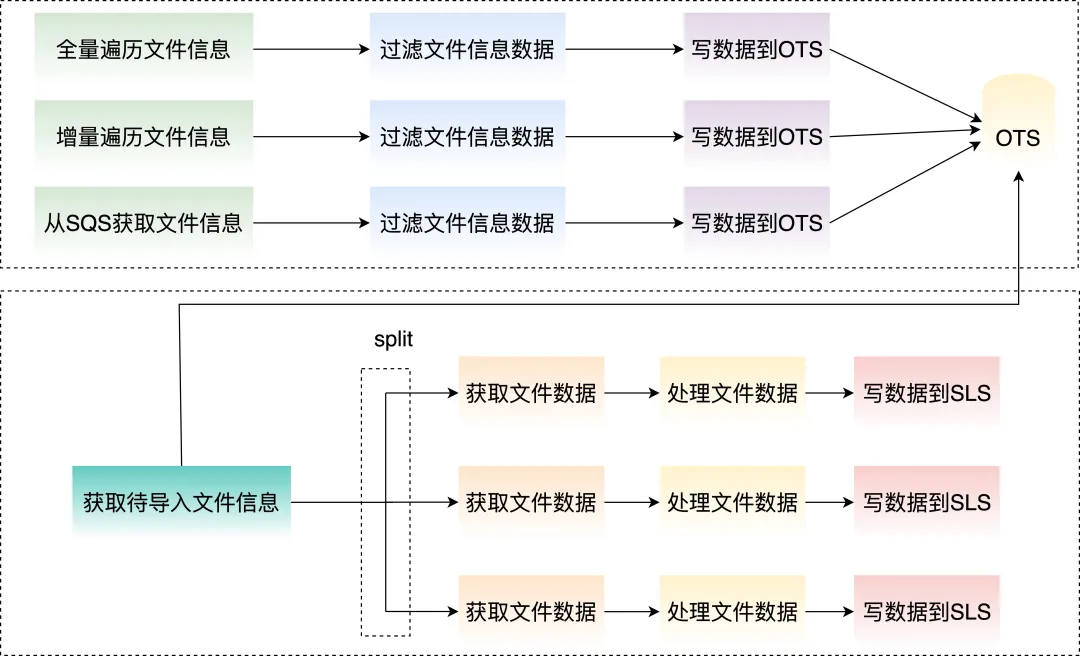
智能弹性伸缩:自动应对流量波动
我们实现了三种弹性机制来应对流量突发:
1. 基于滑动窗口的自适应调整
- 每 5 分钟评估一次待导入的数据量;
- 根据文件元信息(大小、数量)预估所需并发度;
- 自动扩容或缩容,确保导入速度与数据产生速度匹配。
2. 长尾问题优化
- 让不同 task 导入的文件量/文件数据量尽量一致,避免长尾问题带来延迟。
3. 用户提单预先设置并发度
- 支持用户根据业务规律提单设置导入并发度;
- 例如:用户提前预知活动高峰流量,支持提单给 SLS 来提前设置任务并发度。
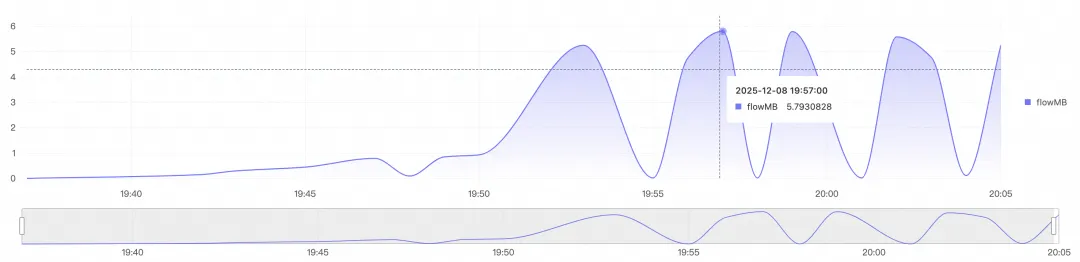
下图展示了在大数据量导入场景下,快速弹性扩缩,快速扩至 300 并发,以近 5.8 GB/s 的速率导入文件数据。
全面的数据处理能力
多格式无缝支持
| 能力类型 | 支持范围 |
|---|---|
| 压缩格式 | zip、gzip、snappy、lz4、zstd、无压缩等 |
| 数据格式 | JSON、CSV、单行文本、跨行文本、Cloudtrail、Json数组等 |
| 字符编码 | UTF-8、GBK |
落盘前处理:省钱又高效
传统方案是“先存储,再加工”,会产生不必要的存储成本。我们支持在数据写入 SLS 之前进行处理:
- 字段提取:从非结构化日志中提取关键字段;
- 数据过滤:丢弃无用日志,减少存储量;
- 字段转换:格式标准化、时间戳转换等;
- 数据脱敏:敏感信息脱敏处理;
- 等等。
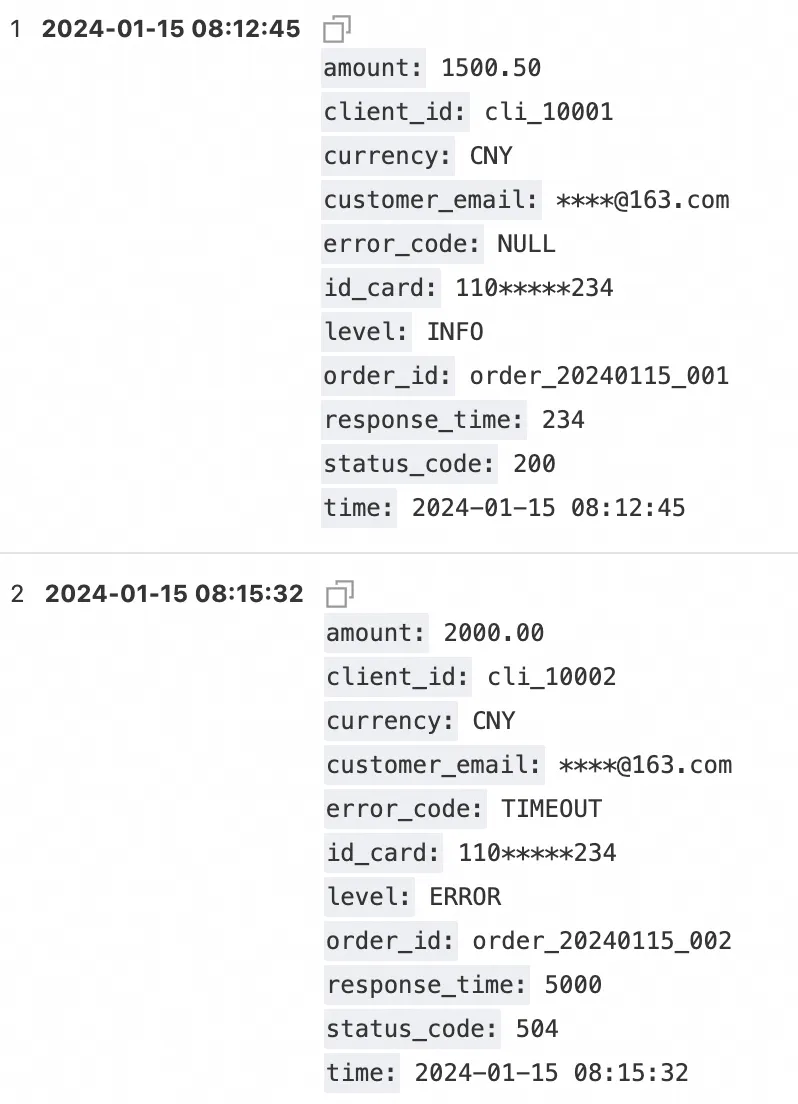
落盘前数据处理样例
源单行文本日志

写入处理器规则
* | parse-csv -delim='\t' content as time,level,order_id,amount,currency,error_code,response_time,status_code,client_id,customer_email,id_card
| project-away content
| extend customer_email = regexp_replace(customer_email, '([\s\S]+)@([\s\S]+)', '****@\2')
| extend id_card = regexp_replace(id_card, '(\d{3,3})(\d+)(\d{3,3})', '\1*****\3')
| extend __time__ = cast(to_unixtime(cast(time as TIMESTAMP)) as bigint) - 28800
落盘日志样例
方案价值:不只是数据搬运
可靠性保障
- 文件级状态追踪:每个文件的导入状态清晰可查;
- 自动重试机制:临时失败自动重试,无需人工干预;
- 完整性校验:支持文件级别的导入确认;
- 监控告警:导入延迟、失败率等关键指标实时监控。
成本优化
- 按需弹性:根据实际流量自动调整资源,避免延迟增长;
- 写入前处理:减少无效数据存储,降低存储成本;
- 增量导入:只导入新增和变更的文件,避免重复导入。
开箱即用
- 可视化配置:无需编写代码,通过控制台即可完成配置;
- 预设模板:针对 CloudTrail、JsonArray 等常见日志提供开箱即用的配置模板;
- 完善文档:详细的配置说明和最佳实践指南。
最佳实践建议
场景一:AWS 服务日志导入(推荐双模式遍历)
典型日志: CloudTrail、VPC Flow Logs、S3 访问日志,文件名顺序递增场景
推荐配置:
- 配置检查新文件周期为一分钟;
- 自动启用增量遍历,保证实时性;
- 自动启用全量遍历,保证完整性;
- 配置写入处理器,提取关键字段。
效果: 可实现 2-3 分钟的端到端延迟,数据完整性 100%
场景二:应用日志实时分析(推荐 SQS 方案)
典型场景: 应用程序实时日志,文件生成速率以及文件名无规则,但需要快速告警
推荐配置:
- 配置 S3 事件通知到 SQS;
- 使用 SQS 驱动导入。
效果: 可实现 2 分钟内的端到端延迟,满足实时告警需求
总结
从 S3 到 SLS 的数据导入,看似简单的数据搬运工作,实则是一个需要精心设计的系统工程。我们通过双模式智能遍历解决了文件发现难题,通过三种弹性机制实现了流量突发的自动应对,通过写入处理器降低了客户成本。
这不仅仅是一个数据导入工具,更是一套完整的跨云日志集成解决方案。无论是标准的云服务日志,还是复杂的应用程序日志,我们都能提供高效、可靠、经济的导入能力。
立即开始:访问 SLS 控制台,选择“数据导入 > S3 导入”,三步即可完成配置,开启您的跨云日志分析之旅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号