
[学习笔记]强化学习基础入门
前段时间学习了一下强化学习入门,一直没有时间写博客
元旦放假,来补一下博客学习笔记吧。
强化学习跟着学长给的教程简单入门了一下
https://hrl.boyuai.com/chapter/intro
强化学习基础,讲得不错
学了个大概,了解了原理之后回头看框架更加清晰了。
那就从一个新手的角度出发,来介绍一下强化学习,这一强大的方法吧
(去年,我的一个学长发朋友圈说强化学习真难啃,今年也轮到我了,笑)
0.前置知识
首先,马尔可夫过程啊状态啊策略啊这些概念就不再赘述了,直接说一些比较关键的知识点吧。
作为入门,我也就不贴什么公式了,我尽量直观地解释一下各个概念,然后直接上代码,从工程里学习。
首先,价值函数
价值函数分为状态价值函数与动作价值函数,它们有所区别,但它们都是用来评估学习到的模型是否优秀的工具。
区别在于:状态价值函数没有引入策略,也就是说,它是面对一个完全随机的马尔可夫过程评估的,智能体并不参与决策。
动作价值函数引入了策略,即它评估了:当前状态下,如果选择动作A,其余变量都不变的情况下,这个状态的优劣。它将智能体纳入了考虑范围,不再是单纯的随机游动,这也使得动作价值函数是我们在强化学习中主要使用的工具
其次,价值函数的更新
现在,手里有了评价模型的指标,下一步就是要利用这个指标进行学习
学习的目的很简单,在初始时,我们面对一个完全陌生的环境,并不知道评估工具——价值函数在每个状态的取值。
为了利用价值函数,必须先对价值函数进行更新。
更新的方法有很多,比如动态规划、时序差分、蒙特卡洛等。
这里简介一下几种方法
首先是最简单最直观的蒙特卡洛
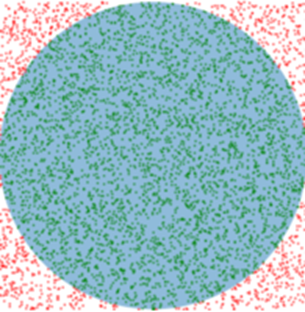
这一张图基本就够了,就是究极采样然后取平均
古典概型和大数定律罢了
但是缺点也很明显,需要大量的遍历,会大大增加计算成本
很自然地想到:如果不遍历整个过程呢?
那么就要提到:动态规划算法了
动态规划,成立地前提就是马尔可夫性质。它的直观理解是:将大问题拆成小问题,然后对小问题逐个击破。(打oi地痛苦经历又一次浮现)
那么,我们想计算第一个节点的价值函数,是不是只需要计算不同路径里的价值函数最大值,也就是它的子节点的价值函数的最大值就行了?
那么,子节点的价值函数是不是也只要计算子子节点的价值函数就行了?
往下迭代,最终就能得到整个过程的价值函数取值了。
但是,这里也带来一个问题,那就是:动态规划需要知道整个地图的发展,不然怎么知道该对比哪些节点呢?就像:你在上帝视角看着迷宫,虽然你不能一眼看出来怎么走,但是可以有一个大致的方向,并且知道智能体附近哪里是能走,哪里是不能走的。
但是在真实环境中,大多数环境并不是如此全知。于是,引出了下一个算法:时序差分
时序差分,可以说是动态规划与蒙特卡洛的融合版。
其思路也很简单,先探索,再利用。
在更新的前期,先随机游动,把迷宫摸个大概
然后开始利用动态规划算法更新价值函数。
具体实现的ε-贪心算法先不介绍了,先有个直观了解。
于是,利用时序差分,就可以更新价值函数,进入正式的强化学习环节了
1.从Q-Learning到DQN
以一个简单的例子入手,我最爱的环境flappy bird

(就是这只小破鸟,那段时间做梦都能梦到它)
首先,分析它的状态。
环境提供了12个数据,小鸟的高度、下一根管子的数据,还有下下一根管子的数据。
先不用管这些数据具体是什么,现在的目的是先对强化学习有一个基础了解。
接下来,按照上面的思路,需要对每一个状态都计算其动作价值函数。
那,我们就要建立一个13维的数组(因为是动作价值函数,所以需要加一个动作维度)
接下来,再更新就好了
这就是Q-Learning。
但是问题来了,13维的数组,你见过吗?反正我是没见过,计算机应该也没见过。
这样的更新显然是让内存无比汗颜的存在。
那么,很自然地想到,有没有什么办法能够节约空间呢?
诶,神!经!网!络!
众所周知,神经网络具有极强地拟合能力,尤其是对这种连续的多元函数
这简直就是为MLP(多层感知机)量身定制的任务啊!!!
那还愣着干啥,上吧。
于是,Q-Learning就华丽升级为了DQN(Deep Q-Network)
这就是强化学习入门的基本路径了,接下来,就直接上代码吧。
2、DQN
直接上代码吧


1 import flappy_bird_gymnasium 2 import gymnasium 3 import torch 4 import torch.nn as nn 5 import torch.nn.functional as F 6 import numpy as np 7 import gymnasium as gym 8 import time 9 import matplotlib.pyplot as plt 10 11 # Hyper Parameters 12 BATCH_SIZE = 32 13 LR = 0.001 # learning rate 14 EPSILON = 0.9 # greedy policy 15 GAMMA = 0.9 # reward discount 16 TARGET_REPLACE_ITER = 100 # target update frequency 17 MEMORY_CAPACITY = 10000 18 env = gymnasium.make("FlappyBird-v0", render_mode='human', use_lidar=False) 19 # env = gymnasium.make("FlappyBird-v0", use_lidar=False) 20 env = env.unwrapped 21 N_ACTIONS = env.action_space.n 22 N_STATES = env.observation_space.shape[0] # 状态变量数 23 ENV_A_SHAPE = 0 if isinstance(env.action_space.sample( 24 ), int) else env.action_space.sample().shape # to confirm the shape 25 26 27 class Net(nn.Module): 28 def __init__(self, device): 29 super(Net, self).__init__() 30 self.device = device 31 self.fc1 = nn.Linear(N_STATES, 128) 32 self.fc1.weight.data.normal_(0, 0.1) # initialization,服从正态分布N(0,1) 33 self.fc2 = nn.Linear(128, 50) 34 self.fc2.weight.data.normal_(0, 0.1) 35 self.out = nn.Linear(50, N_ACTIONS) 36 self.out.weight.data.normal_(0, 0.1) # initialization 37 38 def forward(self, x): 39 x = self.fc1(x) 40 x = F.relu(x) 41 x = self.fc2(x) 42 x = F.relu(x) 43 actions_value = self.out(x) 44 return actions_value 45 46 47 class DQN(object): 48 49 def __init__(self, device): 50 self.device = device 51 self.eval_net = Net(device).to(device) # 移动到GPU 52 self.target_net = Net(device).to(device) # 移动到GPU 53 54 self.learn_step_counter = 0 # 学习步数初始化 # for target updating 55 self.memory_counter = 0 # 经验存储位置计数器 # for storing memory 56 # initialize memory 57 self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) 58 self.optimizer = torch.optim.Adam( 59 self.eval_net.parameters(), lr=LR) # 使用Adam优化器 60 self.loss_func = nn.MSELoss() # 均方差损失函数 61 62 def choose_action(self, x, epoch): 63 64 x = torch.unsqueeze(torch.FloatTensor(x), 0).to(self.device) # 移动到GPU 65 # input only one sample 66 if np.random.uniform() < EPSILON or epoch > 100: # greedy 67 actions_value = self.eval_net.forward(x) # 前向传播 68 action = torch.max(actions_value, 1)[ 69 1].cpu().data.numpy() # 移回CPU处理 70 action = action[0] if ENV_A_SHAPE == 0 else np.array( 71 action).reshape(ENV_A_SHAPE) # return the argmax index 72 else: # random 73 action = np.random.randint(0, N_ACTIONS) 74 action = action if ENV_A_SHAPE == 0 else np.array( 75 action).reshape(ENV_A_SHAPE) 76 return action 77 78 def store_transition(self, s, a, r, s_): 79 80 if isinstance(s, tuple): 81 s = s[0] 82 if isinstance(s_, tuple): 83 s_ = s_[0] 84 85 transition = np.hstack((s, [a, r], s_)) 86 # replace the old memory with new memory 87 index = self.memory_counter % MEMORY_CAPACITY 88 self.memory[index, :] = transition 89 self.memory_counter += 1 90 91 def learn(self): 92 # target parameter update 93 if self.learn_step_counter % TARGET_REPLACE_ITER == 0: 94 self.target_net.load_state_dict( 95 self.eval_net.state_dict()) # 更新目标网络,从eval中拷贝参数 96 self.learn_step_counter += 1 # 计数器 97 98 # sample batch transitions 99 sample_index = np.random.choice( 100 MEMORY_CAPACITY, BATCH_SIZE) # 从2000个经验中选取32个索引 101 b_memory = self.memory[sample_index, :] # 从内存中取得经验 102 103 b_s = torch.FloatTensor(b_memory[:, :N_STATES]).to( 104 self.device) # 数据转换类型 105 # 采样的经验,状态 106 b_a = torch.LongTensor( 107 b_memory[:, N_STATES:N_STATES+1].astype(int)).to(self.device) 108 # 采样的经验,动作 109 b_r = torch.FloatTensor( 110 b_memory[:, N_STATES+1:N_STATES+2]).to(self.device) 111 # 采样的经验,奖励 112 b_s_ = torch.FloatTensor( 113 b_memory[:, -N_STATES:]).to(self.device) # 负索引,表示从后往前 114 # 采样的经验,下一个状态 115 116 # q_eval w.r.t the action in experience 117 q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1) 118 # 前向传播,并获得索引为[1],[b_a]的值 119 # detach from graph, don't backpropagate 120 q_next = self.target_net(b_s_).detach() 121 q_target = b_r + GAMMA * \ 122 q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1) 123 loss = self.loss_func(q_eval, q_target) # 计算loss 124 125 self.optimizer.zero_grad() # 梯度归零 126 loss.backward() # 反向传播计算梯度,求loss对每个变量的梯度 127 self.optimizer.step() # 由梯度下降法优化参数 128 129 130 # print(N_ACTIONS) 131 # print(N_STATES) 132 print('\nCollecting experience...') 133 print(N_STATES) 134 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 135 dqn = DQN(device) 136 137 x = [] 138 y = [] 139 time.sleep(2) 140 for i_episode in range(4000): 141 s, _ = env.reset() 142 ep_r = 0 143 while True: 144 # Next action: 145 # (feed the observation to your agent here) 146 # env.render() 147 148 action = dqn.choose_action(s, i_episode) 149 # Processing: 150 s_, reward, terminated, _, info = env.step(action) 151 # ep_r += reward 152 last_pop_top = s_[1] 153 last_pop_bot = s_[2] 154 last_pop_pos = (last_pop_top+last_pop_bot)/2 155 156 pip_x = s_[0] 157 158 # next_pop_top = s_[4] 159 # next_pop_bot = s_[5] 160 # next_pop_pos = (next_pop_top+next_pop_bot)/2 161 162 pos_actor = s_[9] 163 vec_actor = s_[10] 164 # print(pip_x) 165 # print(abs(pos_actor-last_pop_pos)) 166 # print(abs(pos_actor-next_pop_pos)) 167 # print(last_pop_top, last_pop_bot) 168 # break 169 170 r = reward*2 - abs(pos_actor-last_pop_pos) 171 ep_r += r 172 173 dqn.store_transition(s, action, r, s_) 174 175 if dqn.memory_counter > MEMORY_CAPACITY: 176 # print("learn!!!") 177 # 如果存储达到了一定量,则利用经验进行学习 178 dqn.learn() 179 # Checking if the player is still alive 180 if terminated: 181 x.append(ep_r) 182 y.append(i_episode) 183 print('Ep: ', i_episode, 184 '| Ep_r: ', round(ep_r, 2)) 185 break 186 s = s_ 187 188 plt.plot(y, x, color="green") 189 plt.show() 190 env.close()
到这,强化学习入门就差不多了,具体往后还有一些Double DQN啊、策略梯度啊什么的,那就不在这里赘述了
希望能够帮到一些像我一样看强化学习头疼的人
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号