
[学习笔记]流匹配(Flow Matching)
看VLA相关内容,总是在用流匹配啊扩散模型啊生成这个策略那个策略,一会又是向量场一会又是高维空间的,这下是不学不行了,那就来好好看一看这个在AI时代被广泛应用的神仙方法吧。
与强化学习学习路径一样,先直观理解一下原理,然后找一个简单的demo跑起来,对着AI一点一点看代码。通过这几步,大概就能把这个方法看个七七八八了。至于再具体到创新与应用,还有具体的原理啥的,那就是现在不急了。
(碎碎念一下,在大模型出现之后,学习这种东西真的越来越容易了,看不懂的地方问ai,让ai一点一点纠正我的认知,让ai训练我了属于是。)
先贴代码,感谢https://www.youtube.com/watch?v=7cMzfkWFWhI这位博主提供的简单demo,帮助非常大。代码仓库见视频简介。


1 #!/usr/bin/env python 2 # coding: utf-8 3 4 # # Flow Matching (GPU版本) 5 6 # ## Data 7 8 # In[ ]: 9 10 11 import tqdm 12 import math 13 import torch 14 import numpy as np 15 from torch import nn 16 import matplotlib.pyplot as plt 17 from matplotlib.colors import ListedColormap 18 19 20 train = False 21 22 # 检查GPU是否可用 23 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 24 print(f"使用设备: {device}") 25 if torch.cuda.is_available(): 26 print(f"GPU名称: {torch.cuda.get_device_name(0)}") 27 28 # Parameters 29 N = 1000 # Number of points to sample 30 x_min, x_max = -4, 4 31 y_min, y_max = -4, 4 32 resolution = 100 # Resolution of the grid 33 34 # Create the grid 35 x = np.linspace(x_min, x_max, resolution) 36 y = np.linspace(y_min, y_max, resolution) 37 X, Y = np.meshgrid(x, y) 38 39 # Checkerboard pattern 40 length = 4 41 checkerboard = np.indices((length, length)).sum(axis=0) % 2 42 43 # Sample points in regions where checkerboard pattern is 1 44 sampled_points = [] # 目标点,从棋盘中随机采样 45 while len(sampled_points) < N: 46 # Randomly sample a point within the x and y range 47 x_sample = np.random.uniform(x_min, x_max) 48 y_sample = np.random.uniform(y_min, y_max) 49 50 # Determine the closest grid index 51 i = int((x_sample - x_min) / (x_max - x_min) * length) 52 j = int((y_sample - y_min) / (y_max - y_min) * length) 53 54 # Check if the sampled point is in a region where checkerboard == 1 55 if checkerboard[j, i] == 1: 56 sampled_points.append((x_sample, y_sample)) 57 58 # Convert to NumPy array for easier plotting 59 sampled_points = np.array(sampled_points) 60 61 # Plot the checkerboard pattern 62 plt.figure(figsize=(6, 6)) 63 plt.imshow(checkerboard, extent=(x_min, x_max, y_min, y_max), 64 origin="lower", cmap=ListedColormap(["purple", "yellow"])) 65 66 # Plot sampled points 67 plt.scatter(sampled_points[:, 0], 68 sampled_points[:, 1], color="red", marker="o") 69 plt.xlabel("X-axis") 70 plt.ylabel("Y-axis") 71 # plt.show() 72 73 74 # In[2]: 75 76 77 t = 0.5 78 noise = np.random.randn(N, 2) # 噪声采样 79 plt.figure(figsize=(6, 6)) 80 plt.scatter(sampled_points[:, 0], 81 sampled_points[:, 1], color="red", marker="o") 82 plt.scatter(noise[:, 0], noise[:, 1], color="blue", marker="o") 83 plt.scatter((1 - t) * noise[:, 0] + t * sampled_points[:, 0], (1 - t) 84 * noise[:, 1] + t * sampled_points[:, 1], color="green", marker="o") 85 # plt.show() 86 87 88 # ## Model 89 90 # In[3]: 91 92 93 class Block(nn.Module): 94 def __init__(self, channels=512): 95 super().__init__() 96 self.ff = nn.Linear(channels, channels) 97 self.act = nn.ReLU() 98 99 def forward(self, x): 100 return self.act(self.ff(x)) 101 102 103 class MLP(nn.Module): 104 def __init__(self, channels_data=2, layers=5, channels=512, channels_t=512, device=device): 105 super().__init__() 106 self.channels_t = channels_t 107 self.device = device 108 109 # 网络层定义 110 self.in_projection = nn.Linear(channels_data, channels) 111 self.t_projection = nn.Linear(channels_t, channels) 112 self.blocks = nn.Sequential(*[ 113 Block(channels) for _ in range(layers) 114 ]) 115 self.out_projection = nn.Linear(channels, channels_data) 116 117 # 将模型移动到指定设备 118 self.to(device) 119 120 def gen_t_embedding(self, t, max_positions=10000): # 编码器,将时间t转换成向量 121 t = t * max_positions 122 half_dim = self.channels_t // 2 123 emb = math.log(max_positions) / (half_dim - 1) 124 emb = torch.arange( 125 half_dim, device=self.device).float().mul(-emb).exp() 126 emb = t[:, None] * emb[None, :] 127 emb = torch.cat([emb.sin(), emb.cos()], dim=1) 128 if self.channels_t % 2 == 1: # zero pad 129 emb = nn.functional.pad(emb, (0, 1), mode='constant') 130 return emb 131 132 def forward(self, x, t): 133 # 确保输入在正确的设备上 134 if x.device != self.device: 135 x = x.to(self.device) 136 if t.device != self.device: 137 t = t.to(self.device) 138 139 x = self.in_projection(x) 140 t_emb = self.gen_t_embedding(t) 141 t_proj = self.t_projection(t_emb) 142 x = x + t_proj 143 x = self.blocks(x) 144 x = self.out_projection(x) 145 return x 146 147 148 # In[ ]: 149 150 151 model = MLP(layers=5, channels=512, device=device) 152 optim = torch.optim.AdamW(model.parameters(), lr=1e-4) 153 154 # 打印模型参数数量 155 total_params = sum(p.numel() for p in model.parameters()) 156 trainable_params = sum(p.numel() 157 for p in model.parameters() if p.requires_grad) 158 print(f"总参数数量: {total_params:,}") 159 print(f"可训练参数数量: {trainable_params:,}") 160 161 162 # ### Load Pretrained Model for 500k Steps 163 164 # In[ ]: 165 166 167 # If you don't want to train yourself, just load a pretrained model which trained for 500k steps. 168 try: 169 ckpt = torch.load("models/model_500k.pt", map_location=device) 170 model.load_state_dict(ckpt) 171 print("已加载预训练模型") 172 except FileNotFoundError: 173 print("未找到预训练模型,将从头开始训练") 174 175 176 # ## Training 177 178 # In[14]: 179 180 181 # 将数据移动到GPU 182 data = torch.Tensor(sampled_points).to(device) 183 training_steps = 100_000 184 batch_size = 2048 185 pbar = tqdm.tqdm(range(training_steps)) # 进度条 186 losses = [] 187 188 # 训练前清空GPU缓存 189 if torch.cuda.is_available(): 190 torch.cuda.empty_cache() 191 192 if train == True: 193 for i in pbar: 194 # 从数据中随机采样目标点 195 indices = torch.randint(data.size(0), (batch_size,), device=device) 196 x1 = data[indices] 197 198 # 生成噪声点 199 x0 = torch.randn_like(x1, device=device) 200 201 # 计算目标向量 202 target = x1 - x0 203 204 # 随机采样时间 205 t = torch.rand(batch_size, device=device) 206 207 # 线性插值 208 xt = (1 - t[:, None]) * x0 + t[:, None] * x1 209 210 # 前向传播 211 pred = model(xt, t) 212 213 # 计算损失 214 loss = ((target - pred) ** 2).mean() 215 216 # 反向传播 217 loss.backward() 218 optim.step() 219 optim.zero_grad() 220 221 # 更新进度条 222 pbar.set_postfix(loss=loss.item()) 223 losses.append(loss.item()) 224 225 # 定期显示GPU内存使用情况 226 if i % 1000 == 0 and torch.cuda.is_available(): 227 allocated = torch.cuda.memory_allocated(0) / 1024**3 228 reserved = torch.cuda.memory_reserved(0) / 1024**3 229 pbar.set_postfix(loss=loss.item(), 230 gpu_alloc=f"{allocated:.2f}GB", 231 gpu_reserved=f"{reserved:.2f}GB") 232 233 # 训练完成后保存模型 234 torch.save(model, "models/model_trained_gpu.pt") 235 print("模型已保存为 models/model_trained_gpu.pt") 236 237 # In[15]: 238 239 plt.plot(losses) 240 plt.title("Training Loss") 241 plt.xlabel("Steps") 242 plt.ylabel("Loss") 243 plt.show() 244 245 246 # Sampling 247 248 # In[1]: 249 250 251 # 设置评估模式 252 model = torch.load('models/model_trained_gpu.pt') 253 model.eval() 254 torch.manual_seed(42) 255 256 # 生成初始噪声 257 xt = torch.randn(1000, 2, device=device) 258 steps = 1000 259 plot_every = 25 260 261 262 # 采样过程 263 with torch.no_grad(): # 禁用梯度计算以节省内存 264 for i, t in enumerate(torch.linspace(0, 1, steps, device=device), start=1): 265 t_tensor = t.expand(xt.size(0)) 266 pred = model(xt, t_tensor) 267 xt = xt + (1 / steps) * pred 268 269 # 定期可视化 270 if i % plot_every == 0: 271 # 将数据移动到CPU进行可视化 272 xt_cpu = xt.cpu().numpy() 273 plt.figure(figsize=(6, 6)) 274 plt.scatter(sampled_points[:, 0], 275 sampled_points[:, 1], color="red", marker="o", alpha=0.5, label="Target") 276 plt.scatter(xt_cpu[:, 0], xt_cpu[:, 1], color="green", 277 marker="o", alpha=0.5, label="Generated") 278 plt.title(f"Sampling Step {i}/{steps}") 279 plt.legend() 280 plt.savefig(f"sampling_step_{i}.png") 281 # plt.show() 282 283 # 恢复训练模式 284 model.train() 285 print("Done Sampling") 286 287 # 清理GPU内存 288 if torch.cuda.is_available(): 289 torch.cuda.empty_cache() 290 print("GPU内存已清理") 291 292 293 # In[ ]:
0、demo介绍
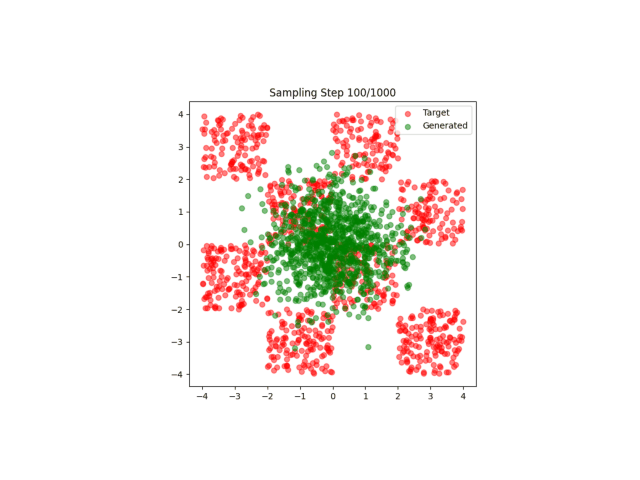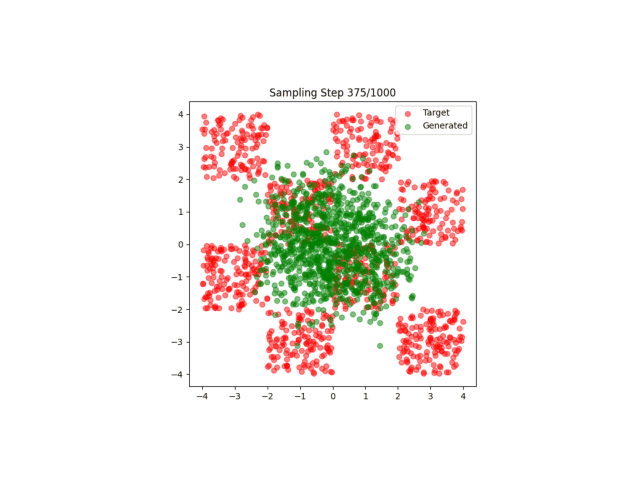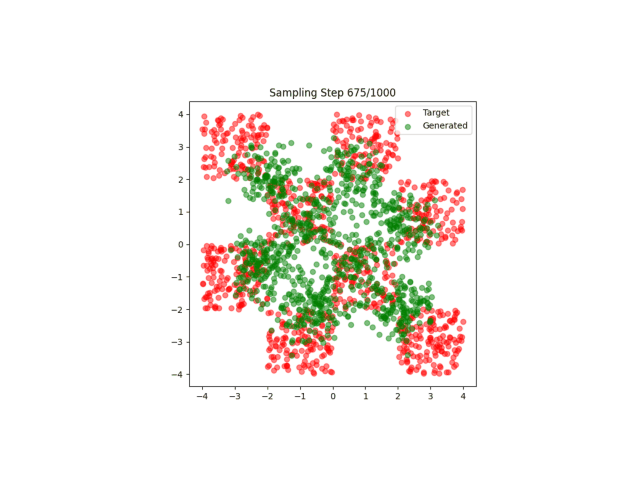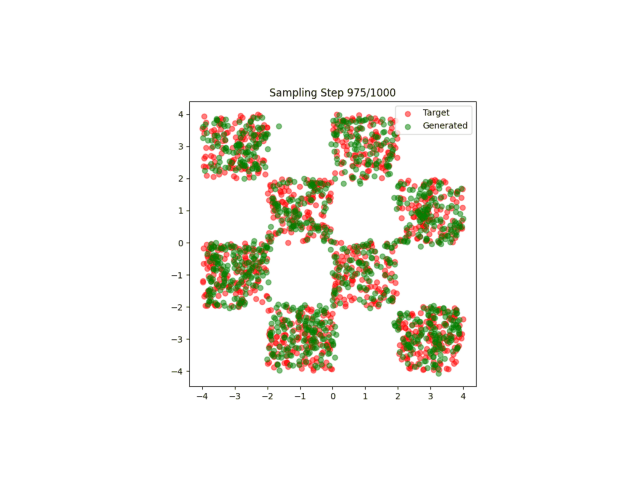
最简单的流匹配应用,匹配点阵。
1、什么是流匹配
简单来说,就是一个随时间变化的向量场,更简单来说就是这个场景中,每个点(注意,是点所在的位置)的速度变化。
当然,在更加复杂的场景中,向量场维度还会继续变化,这就不是入个门需要操心的事了。
在这个简单的demo中,作者使用了一个简单的MLP来拟合随时间分布的向量场。
2、Q&A
来说一下我在学习这个demo时的一些疑惑吧,再次感谢大模型
Q1:都说流匹配中时间很重要,那么怎么规定时间呢?
A1:使用一个时间编码函数,利用三角函数在周期内的性质,总之很多项目都直接拿来用,也就是一个归一化然后计算三角函数作为时间戳的过程
代码如下:
(专业点叫时间嵌入,总之就是一个时间戳,将时间转化为独一无二的编码向量) def gen_t_embedding(self, t, max_positions=10000): # 编码器,将时间t转换成向量 t = t * max_positions half_dim = self.channels_t // 2 emb = math.log(max_positions) / (half_dim - 1) emb = torch.arange( half_dim, device=self.device).float().mul(-emb).exp() emb = t[:, None] * emb[None, :] emb = torch.cat([emb.sin(), emb.cos()], dim=1) if self.channels_t % 2 == 1: # zero pad emb = nn.functional.pad(emb, (0, 1), mode='constant') return emb
Q2:流匹配拟合的是什么?结合这个demo讲一下
A2:流匹配拟合的是一个(x,y,t)时刻的向量场,直观一点理解就是当时刻为t时,每个位置的点应该往哪里跑。这个速度分布是随时间变化的。之前在一些论文和项目里见到余弦时间戳之类的东西,现在明白了。时间戳这个东西在流匹配中是十分重要的,它直接告诉了模型当前时间应该调用哪个向量场。
还有,流匹配是按照(x,y,t)进行分批,即对t进行离散,每个时刻训练一整个二维的向量场,而不是对每个数据点训练不同的向量场,这也是比较容易混淆的点。据说是因为这样更加符合整个系统的物理变化,毕竟流匹配的本质是一个物理过程。
Q3:目标点和噪声点是如何分配的呢?
A3:随机分配,一一对应,在代码的这里体现:
1 indices = torch.randint(data.size(0), (batch_size,), device=device) 2 x1 = data[indices]#从唯一目标中提取一组点 3 4 # 生成噪声点 5 x0 = torch.randn_like(x1, device=device)#随机生成一组点,与x1同型列表,一一对应
对于每一轮训练,都重新生成一组点,让模型更加拟合随机分布的点。
Q4:为什么要使用激活函数:
A4:其实在之前我也不明白什么非线性特征是什么意思,直到这一次实验结果的出现:
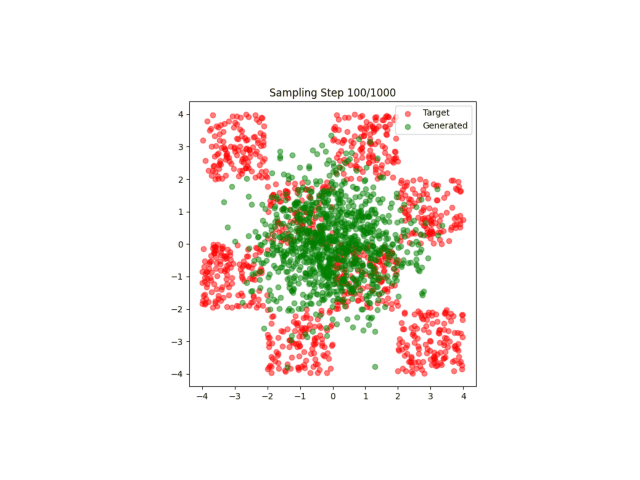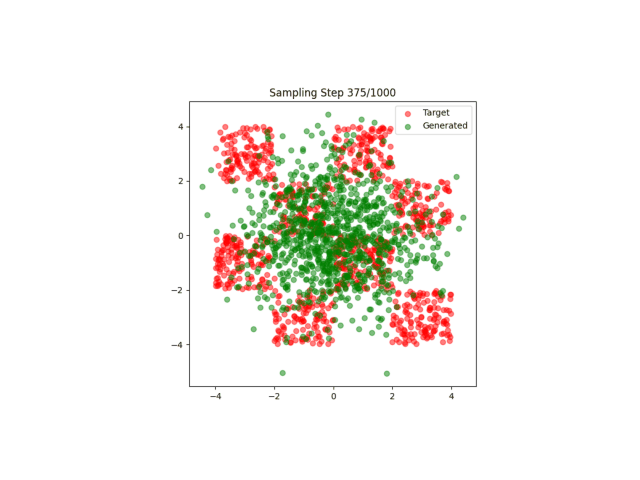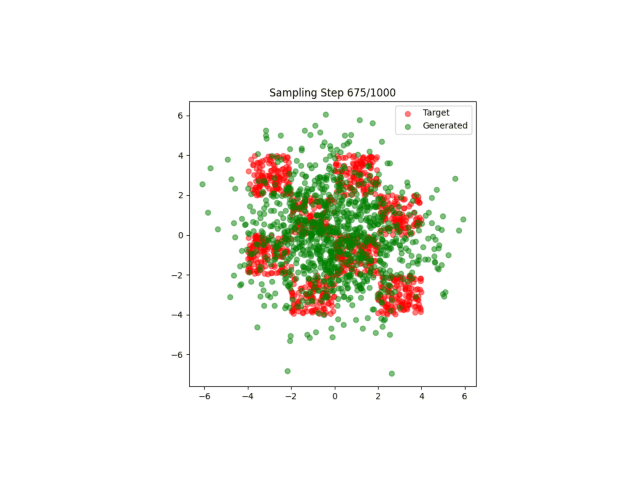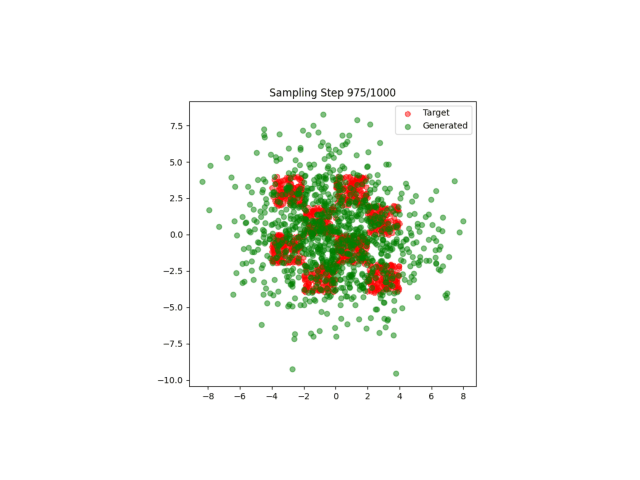
这太神奇了,仅仅是一个非线性特征的区别就导致了模型完全不收敛!
但是我依旧不是很明白非线性特征的含义...
(这让我想起了曾经打oi时候的一道题,学长说我已经完成了离散化操作,但是我就是不明白怎么就离散化了)
Q5:为什么loss曲线是震荡的,而不是像机器视觉那样收敛?
A5:流匹配的loss震荡是因为:(写到最后懒得写了,让ai总结一下吧)
-
目标向量随机:每个batch的
target = x₁ - x₀都重新随机采样 -
条件期望本质:模型学习的是给定
(xₜ,t)时x₁-x₀的条件期望,而非固定值 -
固有方差:即使最优模型,具体样本的
x₁-x₀也会偏离期望值
额大概问题就是这样,虽然搞懂它们拷打ai两三个小时,但是写出来好像就这么点
最后再贴一个详细注释版的代码吧,有什么问题都在代码里了
1 #!/usr/bin/env python 2 # coding: utf-8 3 4 # # Flow Matching (GPU版本) 5 6 # ## Data 7 8 import tqdm 9 import math 10 import torch 11 import numpy as np 12 from torch import nn 13 import matplotlib.pyplot as plt 14 from matplotlib.colors import ListedColormap 15 16 17 train = False # 训练模式为否 18 19 # 检查GPU是否可用 20 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 往GPU上顶 21 print(f"使用设备: {device}") 22 if torch.cuda.is_available(): 23 print(f"GPU名称: {torch.cuda.get_device_name(0)}") 24 25 # Parameters 26 # 这里都是生成棋盘和点阵的,不重要,我也没细看,从82行开始网络训练 27 N = 1000 # Number of points to sample 28 x_min, x_max = -4, 4 29 y_min, y_max = -4, 4 30 resolution = 100 # Resolution of the grid 31 32 # Create the grid 33 x = np.linspace(x_min, x_max, resolution) 34 y = np.linspace(y_min, y_max, resolution) 35 X, Y = np.meshgrid(x, y) 36 37 # Checkerboard pattern 38 length = 4 39 checkerboard = np.indices((length, length)).sum(axis=0) % 2 40 41 # Sample points in regions where checkerboard pattern is 1 42 sampled_points = [] # 目标点,从棋盘中随机采样 43 while len(sampled_points) < N: 44 # Randomly sample a point within the x and y range 45 x_sample = np.random.uniform(x_min, x_max) 46 y_sample = np.random.uniform(y_min, y_max) 47 48 # Determine the closest grid index 49 i = int((x_sample - x_min) / (x_max - x_min) * length) 50 j = int((y_sample - y_min) / (y_max - y_min) * length) 51 52 # Check if the sampled point is in a region where checkerboard == 1 53 if checkerboard[j, i] == 1: 54 sampled_points.append((x_sample, y_sample)) 55 56 # Convert to NumPy array for easier plotting 57 sampled_points = np.array(sampled_points) 58 59 # Plot the checkerboard pattern 60 plt.figure(figsize=(6, 6)) 61 plt.imshow(checkerboard, extent=(x_min, x_max, y_min, y_max), 62 origin="lower", cmap=ListedColormap(["purple", "yellow"])) 63 64 # Plot sampled points 65 plt.scatter(sampled_points[:, 0], 66 sampled_points[:, 1], color="red", marker="o") 67 plt.xlabel("X-axis") 68 plt.ylabel("Y-axis") 69 # plt.show() 70 71 72 t = 0.5 73 noise = np.random.randn(N, 2) # 噪声采样 74 plt.figure(figsize=(6, 6)) 75 plt.scatter(sampled_points[:, 0], 76 sampled_points[:, 1], color="red", marker="o") 77 plt.scatter(noise[:, 0], noise[:, 1], color="blue", marker="o") 78 plt.scatter((1 - t) * noise[:, 0] + t * sampled_points[:, 0], (1 - t) 79 * noise[:, 1] + t * sampled_points[:, 1], color="green", marker="o") 80 # plt.show() 81 82 # 从下面开始才是网络和训练推理 83 # ## Model 84 85 86 class Block(nn.Module): 87 def __init__(self, channels=512): 88 super().__init__() 89 self.ff = nn.Linear(channels, channels) # 定义一个全连接层 90 self.act = nn.ReLU() # 简单模型,使用简单的ReLU激活函数即可 91 92 def forward(self, x): 93 return self.act(self.ff(x)) # 前向传播 94 95 96 class MLP(nn.Module): 97 def __init__(self, channels_data=2, layers=5, channels=512, channels_t=512, device=device): 98 super().__init__() 99 self.channels_t = channels_t 100 self.device = device 101 102 # 网络层定义 103 self.in_projection = nn.Linear(channels_data, channels) 104 self.t_projection = nn.Linear(channels_t, channels) 105 self.blocks = nn.Sequential(*[ # 对每个层进行激活 106 Block(channels) for _ in range(layers) 107 ]) 108 self.out_projection = nn.Linear(channels, channels_data) 109 110 # 将模型移动到指定设备 111 self.to(device) 112 113 def gen_t_embedding(self, t, max_positions=10000): # 编码器,将时间t转换成向量 114 t = t * max_positions 115 half_dim = self.channels_t // 2 116 emb = math.log(max_positions) / (half_dim - 1) 117 emb = torch.arange( 118 half_dim, device=self.device).float().mul(-emb).exp() 119 emb = t[:, None] * emb[None, :] 120 emb = torch.cat([emb.sin(), emb.cos()], dim=1) 121 if self.channels_t % 2 == 1: # zero pad 122 emb = nn.functional.pad(emb, (0, 1), mode='constant') 123 return emb 124 125 def forward(self, x, t): # 前向传播 126 # 确保输入在正确的设备上 127 if x.device != self.device: 128 x = x.to(self.device) 129 if t.device != self.device: 130 t = t.to(self.device) 131 132 x = self.in_projection(x) 133 t_emb = self.gen_t_embedding(t) 134 t_proj = self.t_projection(t_emb) 135 x = x + t_proj # 将时间嵌入和输入进行相加,统一喂给之后的MLP 136 x = self.blocks(x) 137 x = self.out_projection(x) 138 return x 139 140 141 model = MLP(layers=5, channels=512, device=device) 142 optim = torch.optim.AdamW(model.parameters(), lr=1e-4) 143 144 # 打印模型参数数量 145 total_params = sum(p.numel() for p in model.parameters()) 146 trainable_params = sum(p.numel() 147 for p in model.parameters() if p.requires_grad) 148 print(f"总参数数量: {total_params:,}") 149 print(f"可训练参数数量: {trainable_params:,}") 150 151 152 # ### Load Pretrained Model for 500k Steps 153 154 # If you don't want to train yourself, just load a pretrained model which trained for 500k steps. 155 try: 156 ckpt = torch.load("models/model_500k.pt", map_location=device) 157 model.load_state_dict(ckpt) 158 print("已加载预训练模型") 159 except FileNotFoundError: 160 print("未找到预训练模型,将从头开始训练") 161 162 163 # ## Training 164 165 166 # 将数据移动到GPU 167 data = torch.Tensor(sampled_points).to(device) 168 training_steps = 100_000 169 batch_size = 2048 170 pbar = tqdm.tqdm(range(training_steps)) # 进度条 171 losses = [] 172 173 # 训练前清空GPU缓存 174 if torch.cuda.is_available(): 175 torch.cuda.empty_cache() 176 177 if train == True: 178 for i in pbar: 179 # 从数据中随机采样目标点 180 indices = torch.randint( 181 data.size(0), (batch_size,), device=device) # 从数据中随机采样目标点 182 x1 = data[indices] # 目标点 183 # 生成噪声点 184 x0 = torch.randn_like(x1, device=device) # 噪声点 185 # 计算目标向量 186 target = x1 - x0 # 计算与目标点的向量,也就是需要的速度方向 187 # 随机采样时间 188 t = torch.rand(batch_size, device=device) # 有点treap的意思 189 # 线性插值 190 xt = (1 - t[:, None]) * x0 + t[:, None] * x1 # 对两点之间的点进行插值,数据增强了属于是 191 # 前向传播 192 pred = model(xt, t) 193 # 计算损失 194 loss = ((target - pred) ** 2).mean() # 预测向量场与真实向量场的均方差,作为loss 195 # 反向传播 196 loss.backward() 197 optim.step() 198 optim.zero_grad() 199 # 更新进度条 200 pbar.set_postfix(loss=loss.item()) 201 losses.append(loss.item()) 202 203 # 定期显示GPU内存使用情况 204 if i % 1000 == 0 and torch.cuda.is_available(): 205 allocated = torch.cuda.memory_allocated(0) / 1024**3 206 reserved = torch.cuda.memory_reserved(0) / 1024**3 207 pbar.set_postfix(loss=loss.item(), 208 gpu_alloc=f"{allocated:.2f}GB", 209 gpu_reserved=f"{reserved:.2f}GB") 210 # 训练完成后保存模型 211 torch.save(model, "models/model_trained_gpu.pt") 212 print("模型已保存为 models/model_trained_gpu.pt") 213 214 plt.plot(losses) 215 plt.title("Training Loss") 216 plt.xlabel("Steps") 217 plt.ylabel("Loss") 218 plt.show() 219 220 221 # Sampling 222 223 # 设置评估模式 224 model = torch.load('models/model_trained_gpu.pt') 225 model.eval() 226 torch.manual_seed(42) 227 228 # 生成初始噪声 229 xt = torch.randn(1000, 2, device=device) 230 steps = 1000 231 plot_every = 25 232 233 234 # 采样过程 235 with torch.no_grad(): # 禁用梯度计算以节省内存 236 for i, t in enumerate(torch.linspace(0, 1, steps, device=device), start=1): 237 # 接下来就是可视化和推理过程了,没啥好看的,不注释了 238 t_tensor = t.expand(xt.size(0)) 239 pred = model(xt, t_tensor) 240 xt = xt + (1 / steps) * pred 241 242 # 定期可视化 243 if i % plot_every == 0: 244 # 将数据移动到CPU进行可视化 245 xt_cpu = xt.cpu().numpy() 246 plt.figure(figsize=(6, 6)) 247 plt.scatter(sampled_points[:, 0], 248 sampled_points[:, 1], color="red", marker="o", alpha=0.5, label="Target") 249 plt.scatter(xt_cpu[:, 0], xt_cpu[:, 1], color="green", 250 marker="o", alpha=0.5, label="Generated") 251 plt.title(f"Sampling Step {i}/{steps}") 252 plt.legend() 253 plt.savefig(f"sampling_step_{i}.png") 254 # plt.show() 255 256 # 恢复训练模式 257 model.train() 258 print("Done Sampling") 259 260 # 清理GPU内存 261 if torch.cuda.is_available(): 262 torch.cuda.empty_cache() 263 print("GPU内存已清理")
(完)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号