
[学习笔记]qwen3大模型微调实战
学校要求的大作业,微调一个视觉语言大模型,以解决相关问题。
终究还是躲不过跟大模型相爱相杀啊...
不过,简中互联网的资料真的是鱼龙混杂,咱也搞不清这些个框架怎么用,怎么微调,怎么跑
简单记录一下我作为大模型小白(只在线用过deepseek,用ollama部署过deepseek-7b自娱自乐过)
是如何进行大模型微调的
1、环境介绍
首先介绍环境,因为随便一个大模型微调都不是本地显卡能够承受的(我主机12400+30708G,勉强能跑起来2b的模型,但是在寝室跑训练我会被室友达斯的)
所以,使用了阿里提供的云服务器。
这里使用了魔塔社区提供的免费环境,具体配置见下图
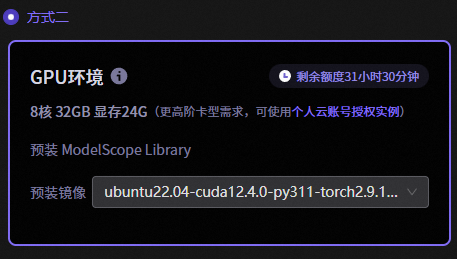
每个账号有36小时的免费使用时长,这个显存大小可以跑起来8b的模型,用来对付大作业足够了。
进入服务器是一个jupyter notebook的页面,主要通过linux命令行来使用,并且配置了vs code作为文本编译器。vs code死忠粉表示极度舒适。
2、工具介绍
大模型选择阿里的qwen3-vl-2B和8B,数据集是老师提供的医疗行业的数据集(后面会把怎么用数据集也写上)
微调工具使用的是ms-swift。ms-swift是魔塔社区提供的微调、运行工具,还是比较好用的。
接下来依次介绍
a.环境安装
(感谢这位博主的博客,非常简单明了以及好用,看了半天简中开发环境里最明了的攻略了:
【多模态】qwen3-vl的强化微调_swift qwen3-vl强化学习-CSDN博客)
前置的cuda啊什么的就不说了,阿里云服务器提供了ubuntu、cuda、torch的完整开发环境。
直接安装ms-swift和transformer
#ms-swift:
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
transformer及其他必须的包:
# 安装transformer==4.57.0和qwen-vl-utils==0.0.14,是qwen3-vl的要求 pip install transformers==4.57.0 qwen-vl-utils==0.0.14 vllm==0.11.0 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
b.大模型下载
微调首先需要一个大模型本体,依旧使用魔塔社区提供的工具下载
新建一个python文件,复制以下代码后运行(记得改路径),具体下什么模型也可以更改:
#模型下载 from modelscope import snapshot_download model_dir = snapshot_download('Qwen/Qwen3-VL-8B-Instruct',cache_dir='预期下载的路径')
c.数据集准备
老师提供的数据集是huggingface上的开源数据集,下载下来是这个格式:

算是三个压缩包吧,分别压缩了test/train/val的数据集。
解压需要一个python脚本(感谢gemini先生提供的脚本):


import os import json import pyarrow as pa import pyarrow.ipc # 定义文件名 files_map = { "train": "slake-train.arrow", "val": "slake-validation.arrow", "test": "slake-test.arrow" } def read_arrow_file_force(filename): """尝试使用多种方式读取 Arrow 文件,绕过 datasets 库的校验""" try: # 尝试方式 1: 作为内存映射文件读取 (常见于 datasets 生成的文件) with pa.memory_map(filename, 'r') as source: try: reader = pa.ipc.open_file(source) return reader.read_all() except: # 尝试方式 2: 作为流读取 source.seek(0) reader = pa.ipc.open_stream(source) return reader.read_all() except Exception as e: print(f"❌ 底层读取失败: {e}") return None def extract_data(tag, arrow_file): print(f"正在暴力读取: {arrow_file} ...") if not os.path.exists(arrow_file): print(f"⚠️ 文件不存在: {arrow_file}") return # 1. 直接读取为 PyArrow Table table = read_arrow_file_force(arrow_file) if table is None: return # 2. 转为 Pandas DataFrame (方便处理) # 如果提示缺少 pandas,请 pip install pandas df = table.to_pandas() output_file = f"{tag}.jsonl" count = 0 # 3. 写入 jsonl with open(output_file, 'w', encoding='utf-8') as f: # 遍历每一行 for index, row in df.iterrows(): # 容错获取字段 question = row.get('question') or row.get('q_en') or row.get('query') answer = row.get('answer') or row.get('a_en') or row.get('response') # 强制转字符串 if answer is None: answer = "" if question is None: question = "" question = str(question) answer = str(answer) if question and answer: data_row = { "query": question, "response": answer, "system": "你是一个医疗问答助手。" } f.write(json.dumps(data_row, ensure_ascii=False) + "\n") count += 1 print(f"✅ 成功提取! 已保存到: {output_file} (共 {count} 条)") if __name__ == "__main__": for tag, filename in files_map.items(): extract_data(tag, filename)
解压完成后的数据集长这样:

如果有图片数据的话,会有一个image文件夹。目前好像大部分的开源数据集都是统一格式,处理数据集这方面还是比较容易的。
万事俱备,只欠东风,准备开始训练。
3.开始微调
a.介绍一下微调方法先
经过了解,有LORA,即将参数分解为两个向量,大大减少计算量的方法
还有LISA,即随机冻结一部分参数,对另外一部分进行LORA
总之,现在大模型的微调方法多种多样,各有优缺点,在本文中就不一一介绍原理和作用了,主要介绍工程实践。
b.lora微调
在ms-swift中,微调只需要一个脚本,运行train.sh就可以了(理论上)
但在实际运用中,还是有各种各样的问题。为了向显存妥协,我们牺牲了太多太多的速度,导致训练有95%以上的时间处在等待数据吞吐的过程中。
LORA训练脚本:
CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=501760 swift sft \#使用一个cuda设备,图片最大像素为MAX_PIXELS(长*宽) --model /mnt/workspace/Qwen/Qwen3-VL-2B-Instruct \#模型地址 --dataset /mnt/workspace/dataset/flaviagiammarino___vqa-rad/train.jsonl \#数据集地址 --val_dataset /mnt/workspace/dataset/flaviagiammarino___vqa-rad/test.jsonl \#验证集地址 --use_dora true \#lora --lorap_lr_ratio 10 \ --target_modules q_proj k_proj v_proj o_proj gate_proj up_proj down_proj \ --freeze_vit true \ --freeze_aligner true \ --freeze_llm true \ --per_device_train_batch_size 8 \#batch_size --per_device_eval_batch_size 8 \ --gradient_accumulation_steps 2 \ --dataloader_num_workers 8 \ --dataloader_pin_memory true \ --split_dataset_ratio 0.1 \ --output_dir /root/dataset/flaviagiammarino___vqa-rad/output \#输出地址 --num_train_epochs 6 \ --save_steps 50 \ --eval_steps 50 \ --save_total_limit 2 \ --logging_steps 5 \ --seed 42 \ --learning_rate 1e-4 \ --init_weights true \ --lora_rank 8 \ --lora_alpha 32 \ --adam_beta1 0.9 \ --adam_beta2 0.95 \ --adam_epsilon 1e-08 \ --weight_decay 0.1 \ --max_grad_norm 1 \ --lr_scheduler_type cosine \ --warmup_ratio 0.05 \ --warmup_steps 0 \ --gradient_checkpointing true
lora占用的显存尤其之大,我们只能冻结vit层、llm层、线性层,要不然根本跑不起来。(这样的话,我也不知道到底训练了个啥)
运行就比较简单了,给权限然后运行就可以(这几天我打这两行命令不知道多少次):
chmod +x train.sh
./train.sh
别看只要给权限然后./train.sh就可以运行,但是运行中出了无数问题。明明是一个版本的ms-swift,相同的命令就是运行不起来,拷打gemini也弄不出来,我也没有找到官方的文档,确实是很折磨的debug过程。
c.LISA
CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=501760 swift sft \ --model /mnt/workspace/Qwen/Qwen3-VL-2B-Instruct \ --dataset /mnt/workspace/dataset/BoKelvin___slake/train.jsonl \ --val_dataset /mnt/workspace/dataset/BoKelvin___slake/test.jsonl \ --train_type full \ --lisa_activated_layers 2 \ --lisa_step_interval 20 \ --freeze_vit true \ --freeze_aligner true \ --freeze_llm false \ --per_device_train_batch_size 16 \ --per_device_eval_batch_size 16 \ --gradient_accumulation_steps 4 \ --dataloader_num_workers 4 \ --split_dataset_ratio 0.1 \ --output_dir /mnt/workspace/dataset/BoKelvin___slake/output \ --num_train_epochs 3 \ --save_steps 50 \ --eval_steps 50 \ --save_total_limit 2 \ --logging_steps 5 \ --learning_rate 2e-5 \ --gradient_checkpointing true
LISA占用的显存要好一些,可以释放LLM层进行微调
运行也跟lora一样,给权限运行即可
4、总结
老师似乎是有些太高估我们了,让我们微调大模型。不过这确实是一个学习的机会。这半年确实是被逼着学了不少,上半年还一窍不通的强化学习在导师学长的压力之下也是大概入门了,自己能写出来flappy_bird的训练过程了。不得不说,那几天光是盯着flappy_bird傻笑我就够开心了。往后的组会也了解了机器人方面的最新方向VLA,通读过几篇论文之后感觉技术发展太快了。这几天又通体了解了一下大模型微调,也是以后大概率会用得上的技能点。确实,读研比本科学到了多得多的东西

 浙公网安备 33010602011771号
浙公网安备 33010602011771号