250个LLM 评估基准大盘点!从推理到多模态,一文看懂LLM考试大纲
原文:https://mp.weixin.qq.com/s/ihKJVqs3TWXVQcqnsjZ9Og
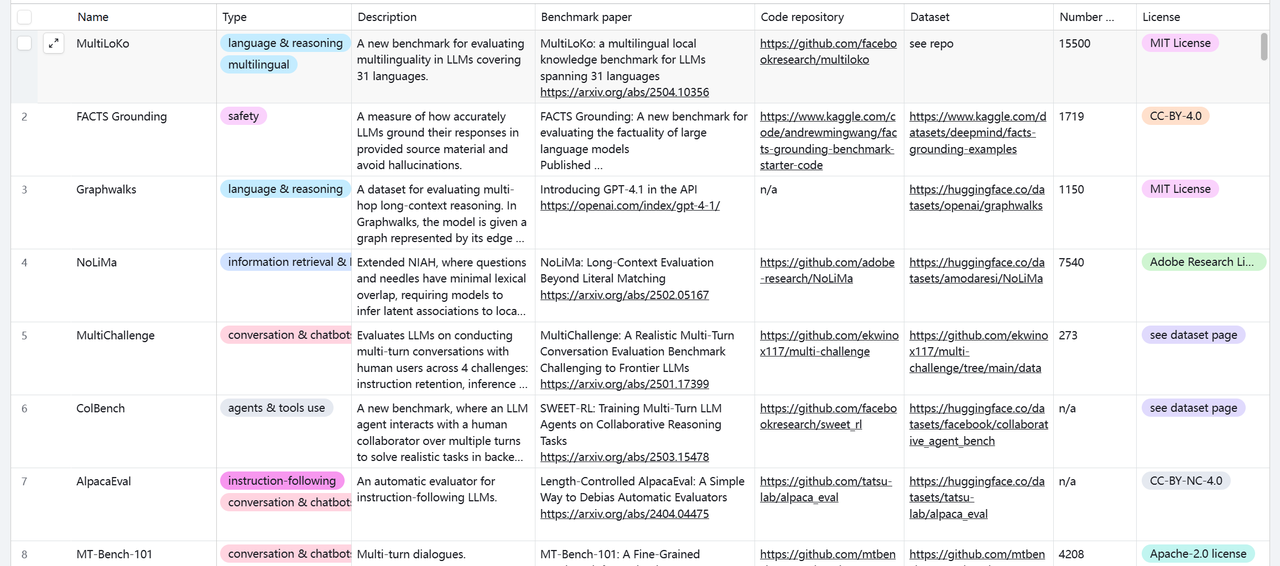
选不对 LLM,业务落地全是坑!面对五花八门的大模型,你是否还在纠结:推理题太简单测不出差距?编程评估没标准?上线才发现安全不达标?核心痛点在于:缺乏系统化的评估标准。今天,给大家分享一个宝藏资源:250个 LLM 评估基准与数据集,覆盖推理、编程、对话、Agent 工具调用等多个维度,支持标签化分类筛选,帮你快速摸清模型底细,拒绝盲目选型。
这个数据集最强大的地方在于,它把虚无缥缈的模型能力拆解成了6大垂直领域。无论你的业务场景是什么,都能找到对应的考卷,关注这里https://mp.weixin.qq.com/s/ihKJVqs3TWXVQcqnsjZ9Og,后台回复llm_eval领取下面资料。
1. LLM 评测 6 大核心维度
- 知识、语言与推理类:LLM的基础功底测试,核心考察模型对信息的理解、逻辑推断能力,以及事实知识的检索准确性。比如让模型理解复杂文本的深层含义,或根据已知信息推导结论,都属于这类测试的范畴。
- 聊天机器人与对话类:专为对话场景设计,重点看模型生成的回复是否连贯、符合语境,能不能精准应对用户的问题,同时保证内容准确且有吸引力
- 编程类:码农们最关心的板块,主要测试模型在代码生成、调试、优化等任务上的表现,不管是写简单的脚本,还是复杂的项目模块,都能通过这类基准测试看出模型的编程实力。
- 安全性类:这是LLM落地的底线测试。考察模型如何处理对抗性输入(比如恶意诱导的问题),能否有效减轻自身的偏见,以及避免生成有毒、有害或违规的内容。对企业来说,安全性不达标,再强的能力也不能上线。
- 多模态类:针对全能型LLM设计,测试模型处理图像、视频、音频、结构化数据等多种信息类型的能力。比如让模型根据图片内容生成描述,或结合音频和文本做总结,都可以通过这类基准来评估。
- 代理与工具调用类:进阶版能力测试,评估模型在复杂工作流中,能否主动调用外部工具,比如搜索引擎、计算器、API,以及作为AI Agent独立完成一系列任务的表现。这直接决定了模型能否胜任自动化办公、智能助手等复杂场景。
2. 两个关键维度,帮你快速筛
基准测试有250个数据集,怎么快速选出适合自己的?不用慌,表格中提供了两个核心参考维度,帮你少走弯路:
被引次数:简单说,就是这个基准测试被其他研究者引用的次数。引用次数越高,说明这个基准在学术界和工业界的认可度越高,越适合作为标准参考。比如一款被引上千次的编程类基准,肯定比一款鲜有人知的测试更有说服力。
新旧标识:为了方便大家追踪最新动态,2024年及以后发表的基准测试都被标注为New。如果你想了解行业最新的评估方法,或者测试最新发布的模型,直接筛选New标签就能精准定位。
现在LLM技术更新太快了,想精准评估模型性能、选对适配业务的工具,需要一套完整的数据集。这个包含250个基准测试的数据集,相当于给大家提供了一套LLM能力体检手册,不管是选模型、做研究,还是优化现有系统,都能帮你找到精准的评估依据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号