梯度消失与梯度爆炸
梯度消失和梯度爆炸是训练神经网络时经常会遇到的两个问题,会直接影响网络的训练过程和性能
概述
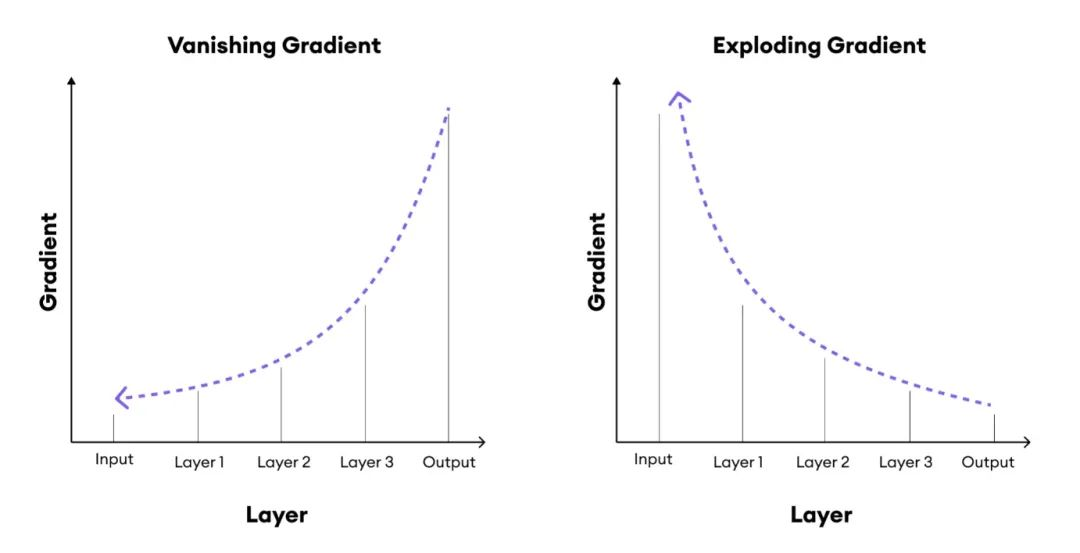
- 梯度消失:指在深层神经网络的反向传播中,随着训练层数增加,梯度值逐渐减小趋近于0
- 梯度爆炸:指在深层神经网络的反向传播中,随着训练层数增加,梯度值逐渐增大到非常大
原因
-
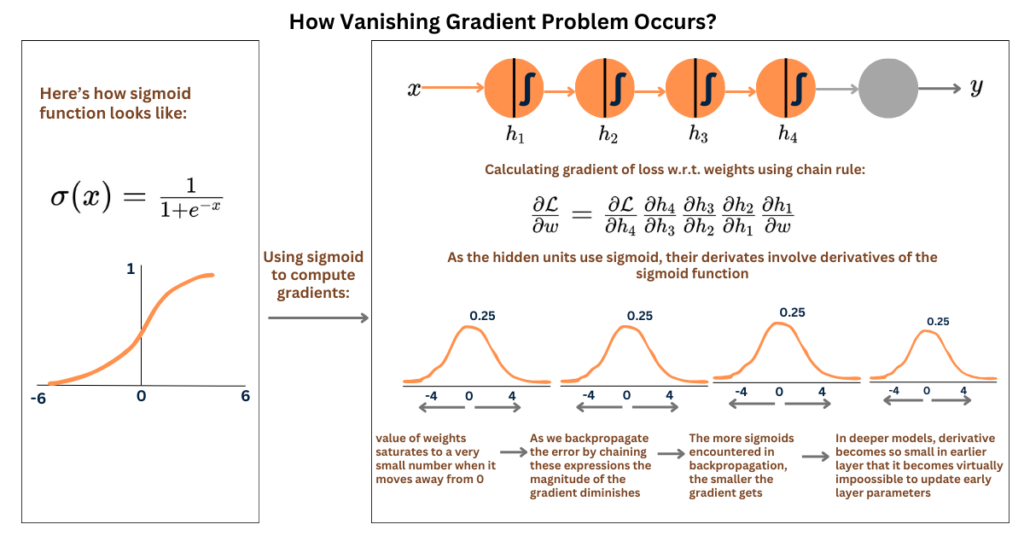
梯度消失:
- 激活函数的选择:如 Sigmoid 和 Tanh
- 链式法则的应用:根据反向传播原理,每一层的梯度都是前一层梯度和该层激活函数导数的乘积。若梯度逐层递减,经过多层传播梯度会越来越小
- 权重初始化过小:在向前传播的过程中,输入信号迅速衰减,导致激活函数的输入值非常小,进而使得梯度在反向传播时迅速减小
- 网络层数过多:梯度需要通过更多的层进行反向传播,每一层都有可能对梯度进行衰减
-
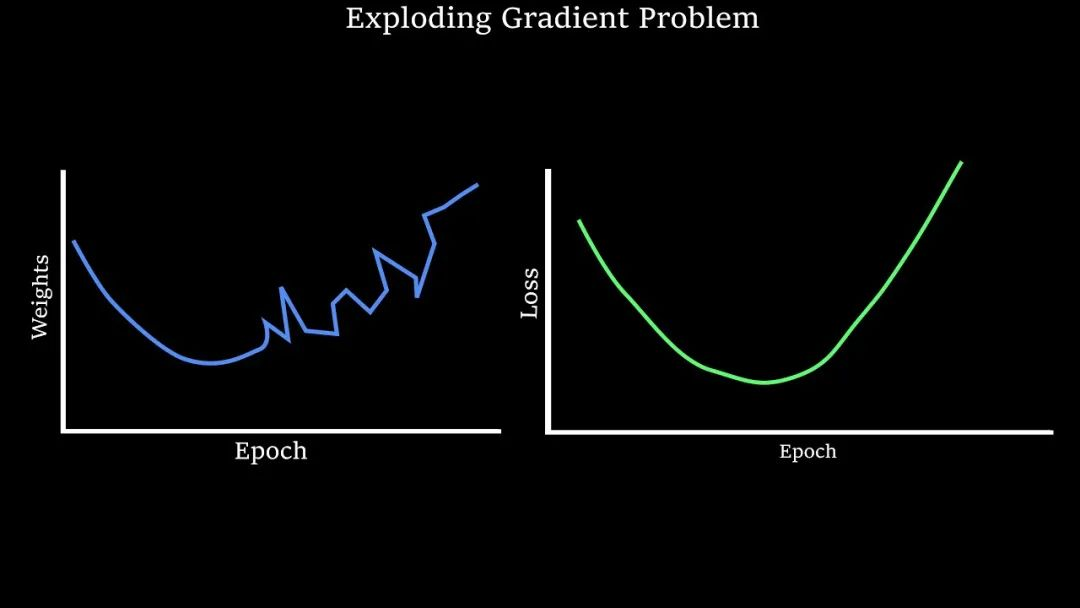
梯度爆炸:
- 权重初始化过大:与权重初始化过小类似
- 网络层数过多:与梯度消失的原理类似
- 学习率设置过高:学习率规定了模型参数更新的步长,过高会导致在训练阶段跳出最优解范围;加剧梯度的波动
解决方法
- 梯度消失:使用ReLU或其变体作为激活函数、采用合适的权重初始化策略、引入批量归一化(Batch Normalization)以及使用残差连接(Residual Connections)
- 梯度爆炸:梯度裁剪、合理初始化权重、调整学习率并选择稳定的优化算法
参考资料:一文彻底搞懂深度学习:梯度消失和梯度爆炸
个人学习用,侵权删

 浙公网安备 33010602011771号
浙公网安备 33010602011771号