实验2 熟悉常用的HDFS操作
(二)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
# 进入工作目录
cd /home/hadoop/java_code
# 1. 删除旧文件
rm -f MyFSDataInputStream.java MyFSDataInputStream.class
# 2. 创建修正后的Java文件并编译运行
cat > MyFSDataInputStream.java << 'EOF'
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
public class MyFSDataInputStream extends FSDataInputStream {
private BufferedReader reader;
public MyFSDataInputStream(FSDataInputStream in) {
super(in.getWrappedStream());
try {
this.reader = new BufferedReader(new InputStreamReader(in, "UTF-8"));
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("UTF-8编码不受支持", e);
}
}
// 修改方法名为 readNextLine()
public String readNextLine() throws IOException {
return reader.readLine();
}
@Override
public void close() throws IOException {
if (reader != null) {
reader.close();
}
super.close();
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:8020");
FileSystem fs = FileSystem.get(conf);
Path filePath = new Path("/user/hadoop/test/file1.txt");
if (!fs.exists(filePath)) {
System.err.println("错误:HDFS文件不存在 - " + filePath);
return;
}
FSDataInputStream fsIn = fs.open(filePath);
MyFSDataInputStream myInputStream = new MyFSDataInputStream(fsIn);
System.out.println("===== 开始读取文件内容 =====");
String line;
int lineNumber = 1;
// 使用新方法名
while ((line = myInputStream.readNextLine()) != null) {
System.out.printf("第 %d 行: %s%n", lineNumber++, line);
}
System.out.println("===== 文件读取完成 =====");
System.out.printf("总共 %d 行%n", lineNumber - 1);
myInputStream.close();
fs.close();
} catch (IOException e) {
System.err.println("操作失败: " + e.getMessage());
e.printStackTrace();
}
}
}
EOF
# 3. 编译(如果失败会显示错误,成功则无输出)
javac -cp $(hadoop classpath) MyFSDataInputStream.java
#4.运行
java -cp $(hadoop classpath):. MyFSDataInputStream

(三)查看Java帮助手册或其它资料,用“java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中。
# 1. 进入工作目录
cd /home/hadoop/java_code
# 2. 删除旧文件(如有)
rm -f HdfsUrlReader.java HdfsUrlReader.class
# 3. 一键写入新源码
cat > HdfsUrlReader.java << 'EOF'
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
public class HdfsUrlReader {
public static void main(String[] args) throws Exception {
/* 注册 hdfs:// 协议处理器 */
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
/* 目标文件 URL */
String hdfsUrl = "hdfs://master:8020/user/hadoop/file1.txt";
URL url = new URL(hdfsUrl);
/* 打开流并逐行读取 */
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(url.openStream(), "UTF-8"))) {
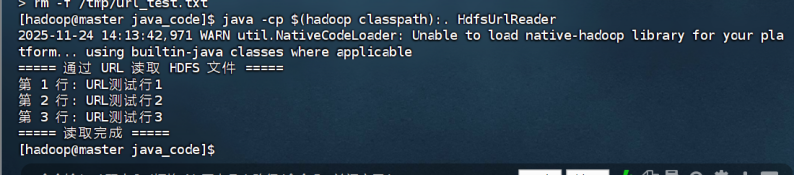
System.out.println("===== 通过 URL 读取 HDFS 文件 =====");
String line;
int lineNo = 1;
while ((line = reader.readLine()) != null) {
System.out.printf("第 %d 行: %s%n", lineNo++, line);
}
System.out.println("===== 读取完成 =====");
}
}
}
EOF
# 4. 编译
javac -cp $(hadoop classpath) HdfsUrlReader.java
# 5. 运行
java -cp $(hadoop classpath):. com.mwh.HdfsUrlReader

 浙公网安备 33010602011771号
浙公网安备 33010602011771号