
SciTech-BigDataAIML-RagFlow: 一文读懂RAGFlow:从 0 到 1教你搭建RAG知识库
https://ragflow.io/docs/dev/
https://www.thoughtailab.com/article/ragflow-project-intro
RAG(Retrieval-Augmented Generation, 检索增强生成)
GM(Generative Model, 生成式模型)
Deepseek火爆,引出 如何高效地 "整合海量数据与生成式模型" 成为技术领域的一大热点。
传统的 生成模型 在回答复杂问题时, 常常依赖于 "预训练数据" 的广度与深度。
而 RAG(Retrieval-Augmented Generation, 检索增强生成)则有效结合了"检索"与"生成"的优势,
为各类应用场景提供了更为灵活、高效的解决方案。
一、RAGFlow概述
-
RAGFlow的定义
RAGFlow是一种融合了 "数据检索" 与 "GM(Generative Model, 生成式模型)" 的 hybrid新型系统架构,其核心思想是结合 "大规模检索系统" 与 "先进的GM(Generative Model, 如Transformer、GPT系列), 响应查询时,既利用 "海量数据的知识库",又生成"符合上下文语义的自然语言应复"。该系统主要包含两个关键模块:数据检索模块 和 生成模块。
- 数据检索模块: 负责在海量数据快速定位、收集 与 过滤 结果信息,
- 生成模块:则基于 检索结果 用 GM(生成式Model) 生成 "高质量应答或文本内容"。
在实际应用,RAGFlow能够在客户服务、问答系统、智能搜索、内容推荐等领域发挥重要作用。通过 "检索与生成" 的双重保障,显著提升系统的响应速度和准确性。
-
特点
高效整合海量数据:借助先进的检索算法, 系统能够在大数据中迅速找到有关信息,并用于生成应答.
增强生成质量:生成模块引入外部数据能够克服模型记忆限制, 提供更丰富和准确信息.
应用场景广泛:包括但不限于: 在线问答系统、智能客服、知识库问答、个性化推荐等。 -
RAGFlow应用场景
在在线客服系统,RAGFlow能够利用用户的历史咨询记录、产品文档以及FAQ等数据,
实时检索出关联度最高的信息,并通过生成模块整合成自然、连贯的应答,大幅提升客户满意度。 -
RAGFlow系统架构
317212466-d6ac5664-c237-4200-a7c2-a4a00691b485
RAGflow 项目介绍
RAGflow 是基于 "深度文档理解" 构建的开源 RAG(Retrieval-Augmented Generation)引擎。
它可以为各种不同规模的项目, 提供一套精简通用的 RAG 工作流程,结合 LLM(大语言模型) 针对用户的各类不同的复杂格式数据, 提供 "可靠的问答" 和 "有理有据的引用"。
本文将详细介绍 RAGflow 项目,并提供快速入门指南,
同时也会从源码层面对 RAGflow 项目进行简要解析,对 RAGflow 项目有全面的了解。
- RAGflow 核心功能介绍
RAGflow 是一个集成化、模块化的 RAG 框架,
它结合了最新的 检索技术、LLM(大型语言模型)、支持多种类型的数据格式解析、多样的切片&索引构建策略,
以提高 "生成内容的质量和关联性",同时还支持基于 Graph 的 Agent 工作流构建,
端到端提供检索增强问答等能力。
具体来说,RAGflow 的核心功能包括:- 高质量的文档提取:支持多种格式的文档,确保准确的信息抽取
- 基于模板,支持各类切片模式:灵活适应不同场景的数据分割需求
- 可视化,检索内容支持溯源,切片透明:提高系统的可解释性和可信度
- 支持多种类型的数据源:适应各种数据环境,提高系统的通用性
- 支持多种模型对接:兼容不同的语言模型,满足多样化的应用需求
- 提供各类API:便于集成到现有系统中,提高开发效率
- 多路召回,融合重排序:提高检索精度和相关性
- 支持Graph定制工作流:实现复杂的智能交互和决策流程
- 系统架构
RAGflow 整体的系统架构图如下:
![]()
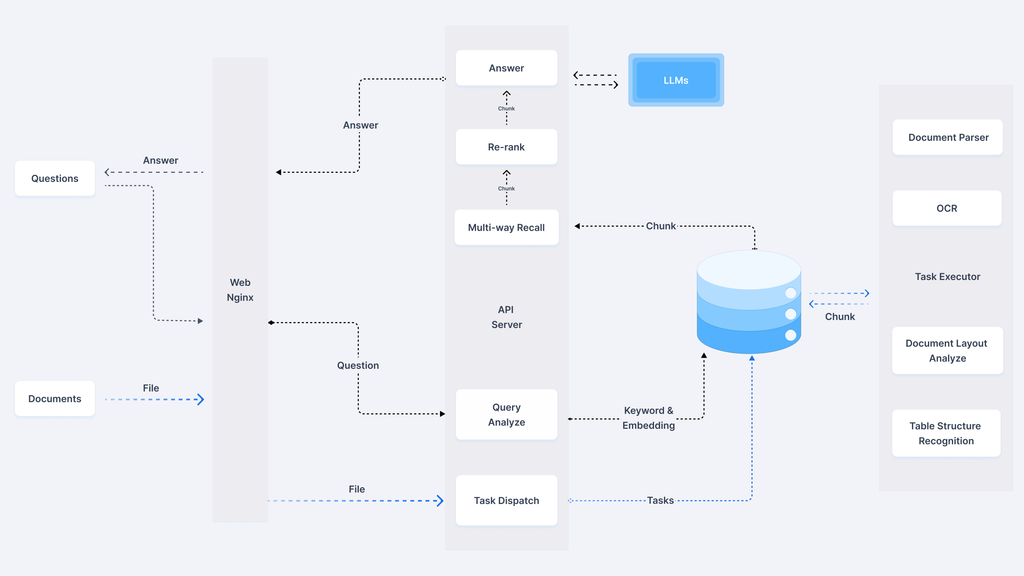
二、环境准备与系统搭建
-
环境需求
在搭建RAGFlow系统前,需要确保开发与运行环境满足以下要求:- 硬件配置:采用多核CPU、充足内存(16GB+) 及 支持高并发访问的存储设备;
如需部署大规模检索服务,可考虑使用分布式存储集群。 - 操作系统:推荐使用Linux发行版(如CentOS、Ubuntu)以便于Shell脚本自动化管理;
同时也支持Windows环境,但在部署自动化脚本时可能需要适当调整。 - 开发语言与工具:主要使用Java进行系统核心模块开发,同时结合Shell脚本实现自动化运维。
- 依赖环境:
需要安装Java 8及以上版本,同时配置Maven或Gradle进行依赖管理;
对于数据检索部分,可采用ElasticSearch、Apache Solr等开源检索引擎;
生成模块则依赖于预训练模型,可以借助TensorFlow或PyTorch进行实现。
- 硬件配置:采用多核CPU、充足内存(16GB+) 及 支持高并发访问的存储设备;
-
服务器配置
• CPU >= 4 核
• RAM >= 16 GB
• Disk >= 50 GB
• Docker >= 24.0.0 & Docker Compose >= v2.26.1 -
安装
修改 max_map_count : 确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
如果 vm.max_map_count 的值小于 262144,可以进行重置:
你的改动会在下次系统重启时被重置。如果希望做永久改动,
还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再更新一遍:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号