
SciTech-EECS-BigDataAIML-NN(神经网络): 模型约定 + MoE(医院)模型(1:Dispatcher(Softmax)+N:Transformers(ReLU)): 先由每条Xi选取"最合适矩阵Mj" + 后用"Mj(最合适矩阵)"变换(左乘)Xi
SciTech-EECS-BigDataAIML-NN(神经网络):
模型约定:
- 输入矩阵(Model Input) \(X\) 都是 Columnwise("列向量\(X_i\)" 组成的 "行数组");
- 变换矩阵\(W\) 都是" Rowwise"的("行向量\(W_j\)" 组成 的"列数组");
- 变换 用 "矩阵乘法" 实现(对\(X\)左乘\(W\)): 变换矩阵\(W\)在"左", 输入矩阵\(X\)在"右".
MoE(医院)模型
1:Dispatcher(Softmax)+N:Transformers(ReLU)):
注意:
-
此处的"Transformer"不是Google的"Attention is all your need"的"Transformer";
而是代指"变换矩阵"。 -
对于"每条输入列向量(病人)"\(X_i\):
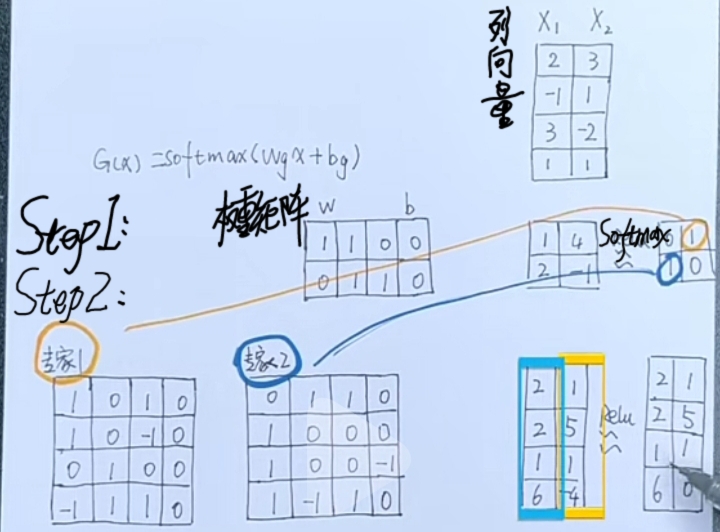
- 到"Dispatcher矩阵(挂号处)"根据\(X_i\)(列向量)选择最合适"变换矩阵(医生)"\(M_j\);\[G(X) = Softmax(W \times X_i + B ) \]
- W: 权重矩阵(变换矩阵\(M_j\) 一一对应 行向量\(W_j\), 即权重矩阵 W 的第 j 行)
- 用“Softmax”激活, 是因为要选择“最合适(总分最高)”的。
- 变换得到的"列向量"的"最大元素"的"行号"就是"最合适医生(\(M_j\))"的"编号(\(j\))"。
- 用"\(j\)(编号)"找到的\(M_j\)(变换矩阵, 医生)"对\(X_i\)(列向量, 病人)作"变换(左乘\(M_j\))":\[MoE(X) = ReLU(M_j \times X_i) \]
- 用“ReLU”激活, 是因为要得出“结果列向量(诊断列表)”。
- 根据结果列向量,可以计算总体Cost(成本),预测,或后续变换。
- 此处只是为说明 MoE(医院🏥模型)的精华。
- 到"Dispatcher矩阵(挂号处)"根据\(X_i\)(列向量)选择最合适"变换矩阵(医生)"\(M_j\);
-
对于"每个变换矩阵(医生)"Mj:
不仅都有 对应的 "变换矩阵"(诊疗处理矩阵, 将 \(X_i\) 左乘 M_j 即变换),
也都要在"Dispatcher矩阵(挂号处)"有对应的"行向量\(W_j\)(注册向量)"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号