
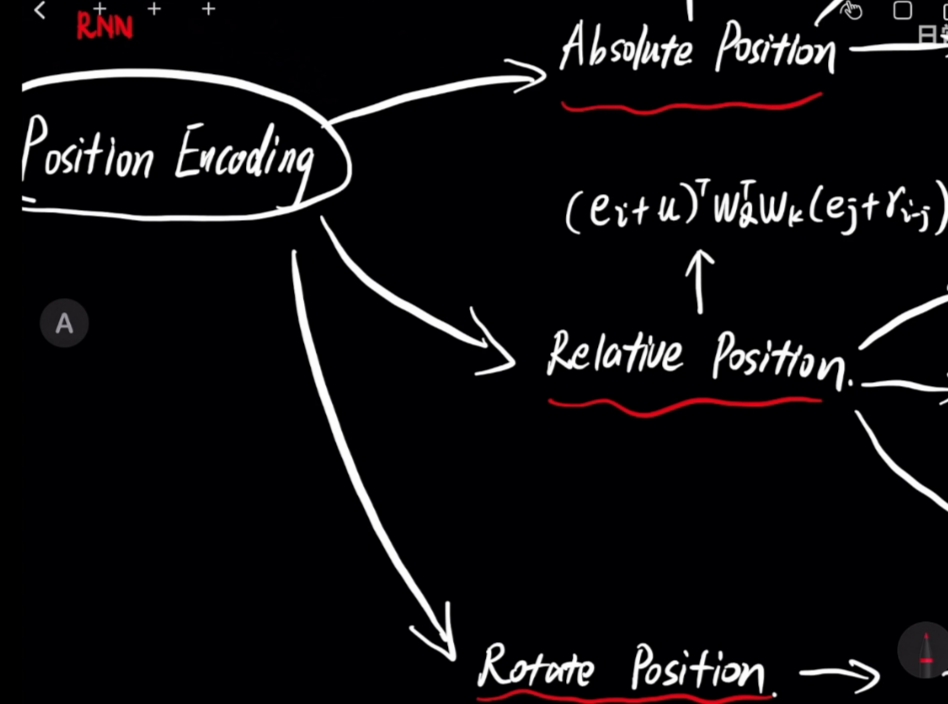
SciTech-BigDataAIML-LLM-PE(Positional Encoding)位置编码: Absolute(绝对)Position + Relative(相对)Position + Rotate(旋转)Position
SciTech-BigDataAIML-LLM
PE(Positional Encoding)位置编码:
- BOW(Bag of Words)词袋模型:丢弃Word位置信息, 只统计Word之间的 Co-occurrence Probability(共现概率)。
- RNN(Recurrent neural networks): 有Word的Position信息。
- Transformer: Positional Encoding, 将Absolute Position位置信息Embedding 嵌入 Word Embedding Vector。
- BERT: Trainable Position Embedding.
- GPT: ?
- Latest: Rotate Position(最新的旋转位置编码)。
数学公式应用:
-
向量的“$\large Dot-Product\ Similarity $”点积相似度:
$\large A_i = \vec{Q^{T}} \cdot \vec{K} = \vec{W_{Q}^T} \vec{Q_{i}^T} \cdot \vec{K} $$\large \vec{Q} = \vec{Q_{i}} \vec{W_{Q}} $
$\large \vec{K} = \vec{K_{i}} \vec{W_{K}} $\(\large \vec{Q_{i}} = \vec{e_{i}} + \vec{p_{i}}\)
\(\large \vec{K_{j}} = \vec{e_{j}} + \vec{p_{j}}\)
\(\large \vec{Q_{i}}\) : Word Vector with "i" as its index.
\(\large \vec{e_{i}}\) : Word Embedding Vector with "i" as its index.
\(\large \vec{p_{i}}\) : Positional Embedding Vector with "i" as its index.
\(\large \vec{A_{ij}}\) : Word Attention Score(Word Vector Similarity) between Word Vector \(\large \vec{Q_{i}}\) and $\large \vec{Q_{j}} $ -
$\large $
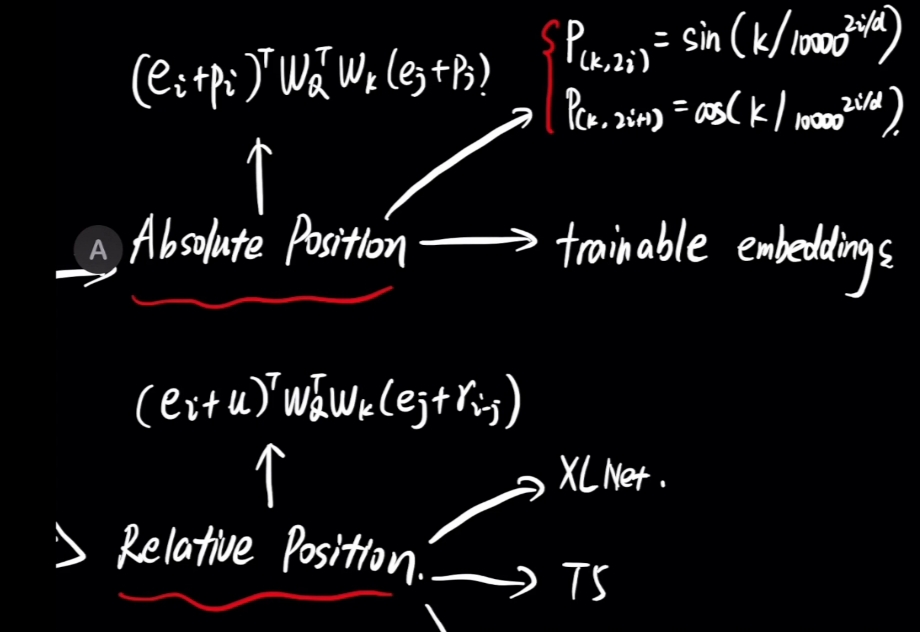
1 Absolute(绝对)Position
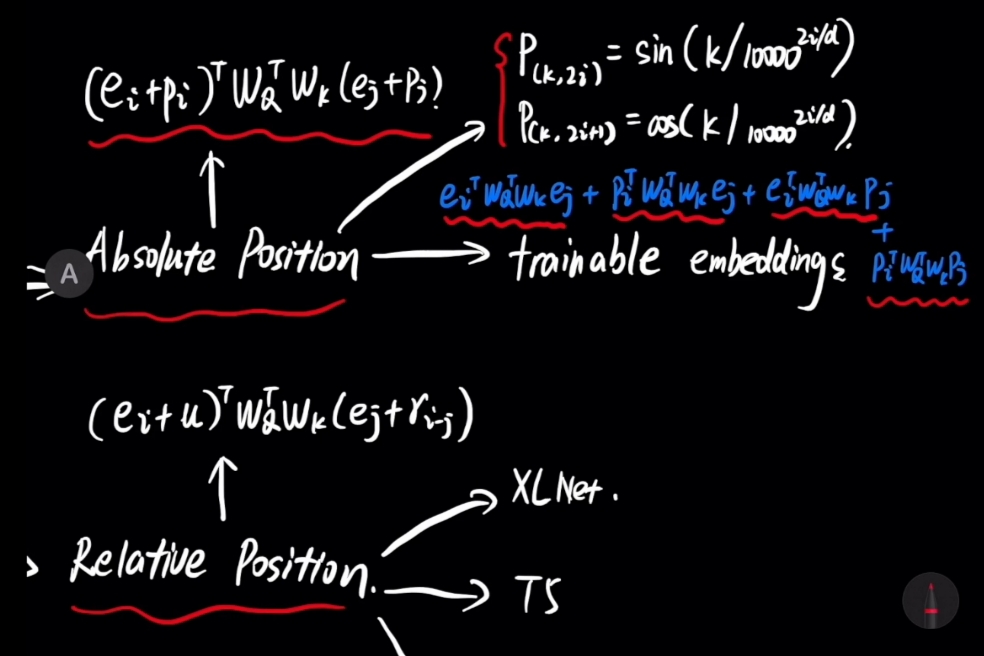

2 Relative(相对)Position

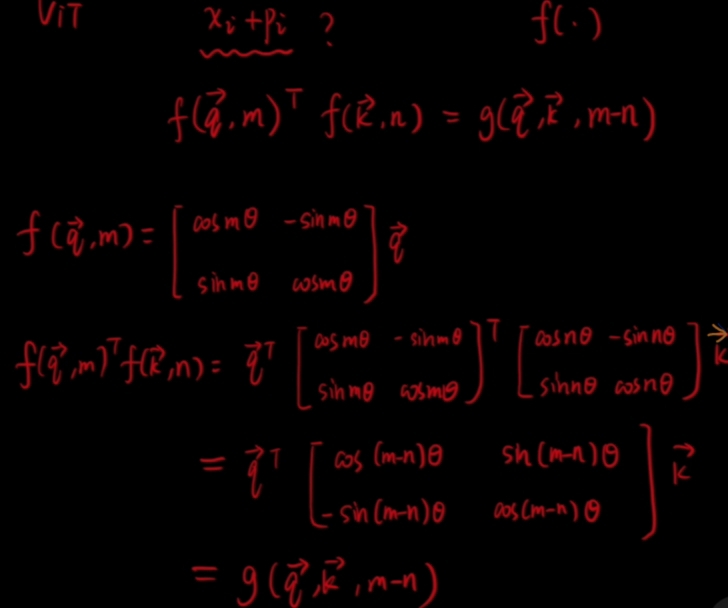

 浙公网安备 33010602011771号
浙公网安备 33010602011771号