SciTech-BigDataAIML-LLM-Transformer Series-Positional Encoding: 位置编码: 统计模型(够多参数够高精度)+"够大数据"凝聚客观规律"预训练+深度NN(学习规律).
词汇
- $\large MI $(Mobile Internet): 移动互联网
- $\large IoT $(Internet of Things): 万物互联网
- \(\large Supervised\ Statistical\ Model\):
\(\large Supervised\ Learning\) 监督学习: 要用"大量训练数据", "学习总结事实规律"(模型参数)。
\(\large Statistical\ Model\) 统计模型: 用概率和统计分析方法建立模型, 对数据进行处理, 确定模型参数。 - $\large WE $(Word Embedding): 词嵌入
- $\large PE $(Positional Encoding): 词位置信息编码
统计模型和大数据的保障源于\(\large MI\)和 \(\large IoT\)
统计模型"预训练大量数据""的本质决定\(\large PE\)
\(\large PE\) 的计算公式和数学证明
1 \(\large PE\) 的计算公式
\(\large pos\ 和\ i\) 都是 \(\large N自然数\), 且由\(\large 0开始编号\); \(\large d\)是\(\large WE\)词向量维度数)
$\large \therefore $
$\large \because $
$\large \therefore $
$\large \Uparrow \therefore $
- 将一 $ Word\ Sequence$ 进行\(Word\ Embedding\),
变换为一 \(Matrix(Word\ Embeded\ Vector\ Sequence)\); - \(Matrix(Word\ Embeded\ Vector\ Sequence)\) 第 \(x(2i或2i+1)\) 维特征上,
$ hypothesis:\ Word_{a} :pos为a的词向量, \ Word_{b} :pos为b的词向量 $ ,
\(PE(a + b , 2i)\) 可表示为:
\(PE(a, 2i)与PE(b, 2i)\) 的 或 \(PE(a, 2i+1)与PE(b, 2i+1)\) 的 \(Linear\ Combination\).
\(PE(a + b, 2i+1)\) 可表示为:
\(PE(a, 2i)与PE(a, 2i+1)\) 的 或 \(PE(b, 2i)与PE(b, 2i+1)\) 的 \(Linear\ Combination\).
0 $\large PE $的问题
-
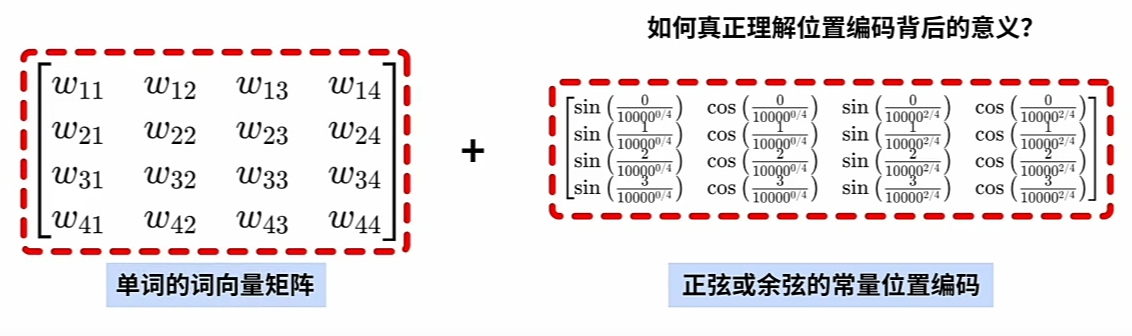
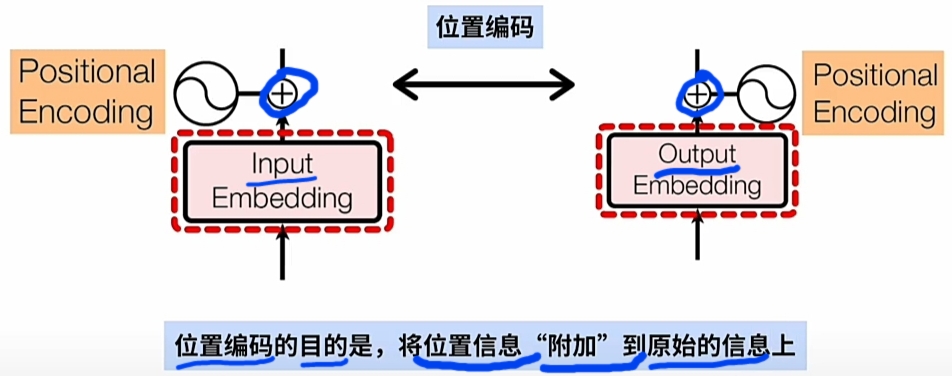
Transformer直接 \(\large WE\ +\ PE\) 实现在\(\large WE\)词嵌入向量 嵌入 \(\large PE\)词位置信息.
特别注意是每一词\(\large Word\)的\(\large WE\)的\(每一维度\)都要加上\(\large PE\)位置编码信息.
即 \(\large PE\)(位置编码矩阵)的 \(\large Shape\) 与\(\large WE\)(词嵌入编码矩阵) 的\(\large Shape\)是一致的.
![]()
![]()
-
为什么可以直接 $\large WE $ 加上 \(\large PE\) 就有实际的意义?
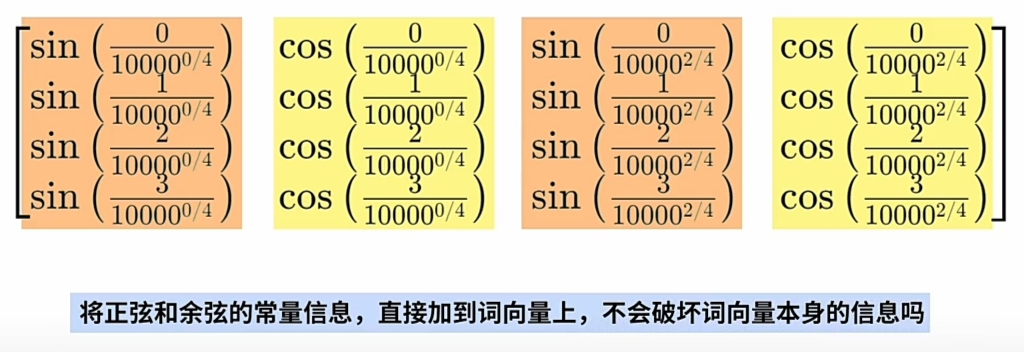
将 $\large WE $ 直接加上 $\large PE $(正弦或余弦的常量位置编码):- 不会破坏$\large WE $(词向量)本身的信息?
- 还能还原出原来\(\large Word\)及其\(\large 序列位置\) 的含义?
![]()

1 什么是 $\large PE $
$\large PE $发生在Transformer的"预训练阶段"对"大量的训练数据"进行统计分析总结数据规律。
Transformer设计“机器翻译任务”的“英译汉模型(统计概率)”为例:
- 要准备好“大量的训练数据”即大量配对互译的“英文句子” 与 “中文句子”。
用一对“Are you okay?”与 “你好吗?”例句为例.
预训练阶段:
-
$\large WE $(Word Embedding) 词嵌入:
-
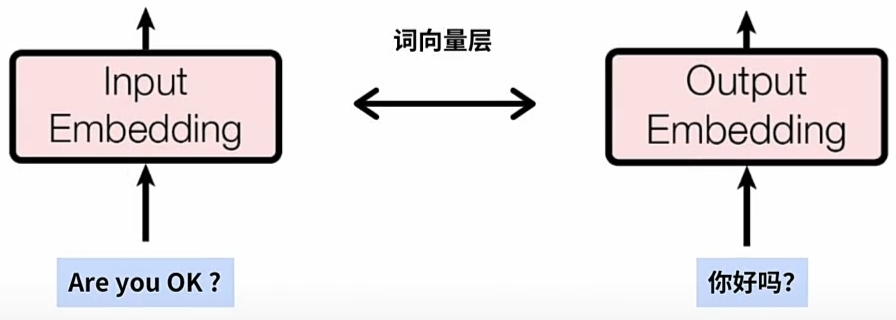
一对 配对的 英文与中文例句 分别送入\(\large Input\)与\(\large Output\)的\(\large Emebdding\)层:
\(\large Emebdding\)层完成后, 每一词 \(\large Word\) 对应 \(\large WE\) 的 一条词(嵌入)向量- "Are you okay?" 通过 \(\large Input\)侧的 \(\large Emebdding\)层, 得到英文例句的 $\large WE $
- "你好吗?" 通过 \(\large Output\)侧的 \(\large Emebdding\)层, 得到中文例句的 $\large WE $
![]()
![]()
-
-
\(\large PE\)(Positional Encoding) 词位置信息编码:
-
\(\large PE\)(Positional Encoding) 词位置信息编码 的goal(目标):
![]()
-
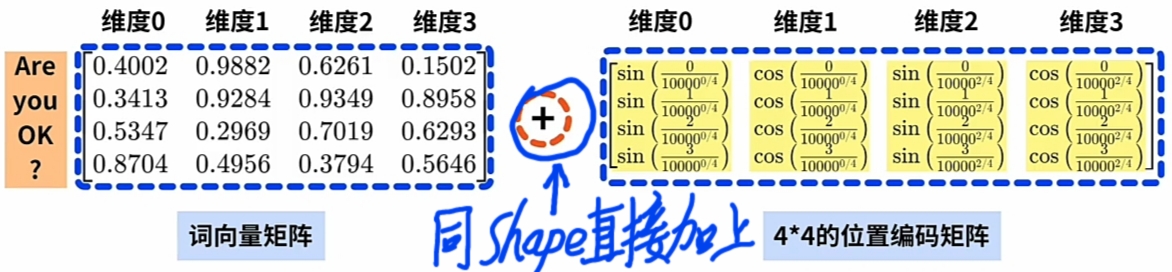
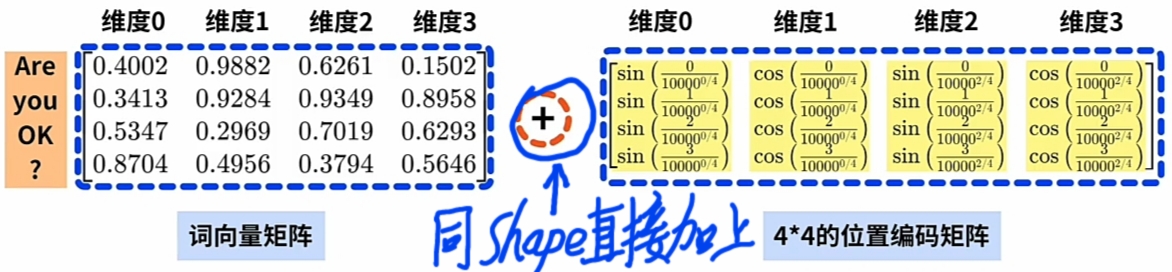
由 \(\large WE\) 矩阵, 计算同 \(\large shape\) 的 $\large PE $矩阵:
参考本文下方的“怎么计算 \(\large PE\)”章节。 -
Transformer直接 \(\large WE\ +\ PE\), 实现在 \(\large WE\) 词向量 嵌入 \(\large PE\) 词位置信息.
![]()
-
-
预训练阶段
2 怎么计算 \(\large PE\)
- $\large PE $计算公式
![]()
-
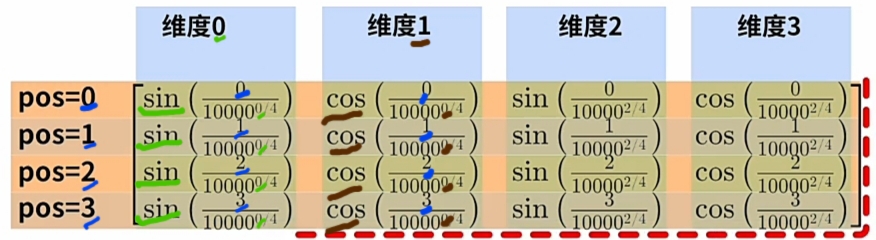
\(\large pos\) 当前Word 在输入Word Sequence 的常量位置(整数值, 由0开始编号):
![]()
-
\(\large d\) 当前Word对应"词向量"的"维度总数(整数值)"
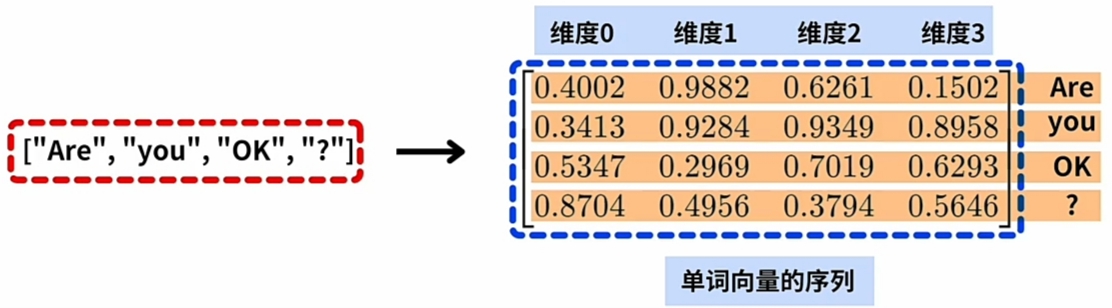
假设"Are you okay?"每一Word对应"词向量"的"维度总数(整数值)" 为 4.
![]()
-
\(\large i\) 当前"词向量"的"当前维索引(整数值)"的一半
- 每一Word(词), 对应一"词(嵌入)向量";
- 每一"词(嵌入)向量"在"模型训练时"都统一设定为\(\large d\)维;
- 维索引由"0开始编号到\(\large d-1\)".
- 维索引(整数值)为奇数, 用\(\large sin\)正弦, 维索引(整数值)为偶数, 用\(\large cos\)余弦
![]()
-
计算出整个Word Sequence的每个 \(\large WE\) 的 \(\large PE\):
根据 \(\large pos\) 一一计算Word Sequence的每一Word的 \(\large PE\) ; 直到完成整个 \(\large PE\) 矩阵.
![]()
![]()
-
- Transformer“丰富训练数据”的内幕实现:
- 先用 不同\(\large WE\)(词向量) 与 不同 \(\large PE\) (位置编码) 生成combinations(所有组合);
- 实际训练时用生成的\(\large WE\)(词向量) 与 \(\large PE\) (位置编码)的combinations(所有组合);
- 图示:
![]()
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息。
![]()






3 $\large PE $的真正意义
-
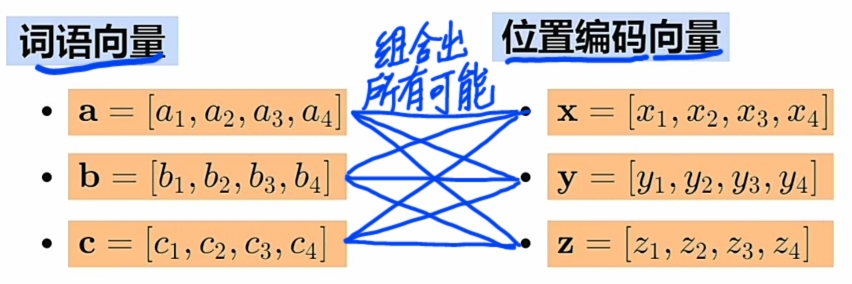
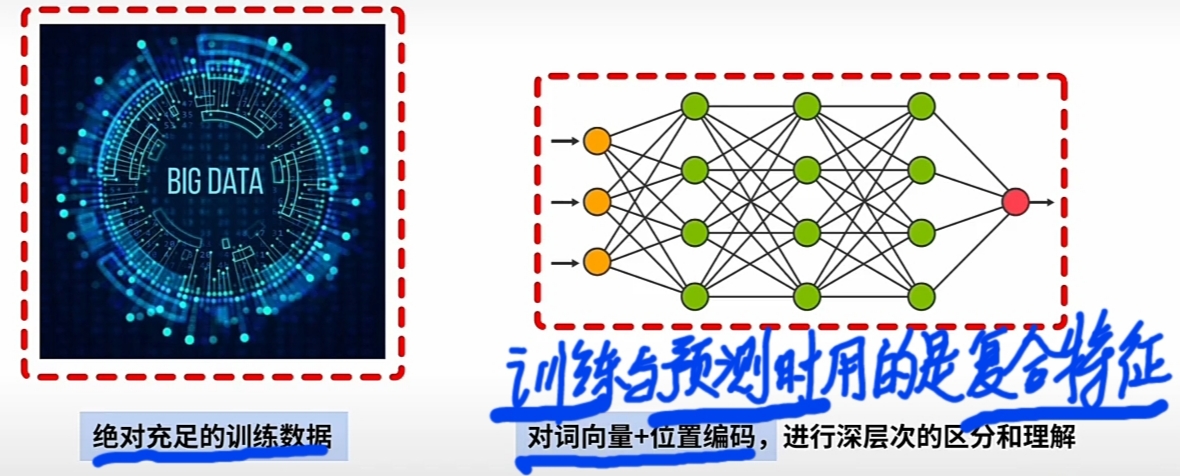
1 极大丰富预训练数据(实际训练用不同的\(\large WE\) 与 不同的\(\large PE\) 的 \(\large combinations\)).
- 使用远大于 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 数量的 \(\large combinations\) 预训练.
训练并整合 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 信息。是因为:
![]()
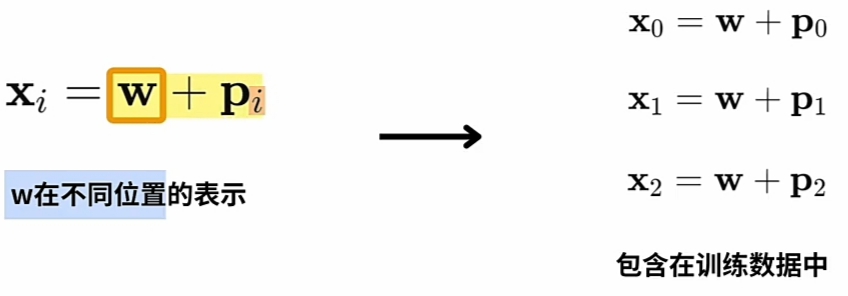
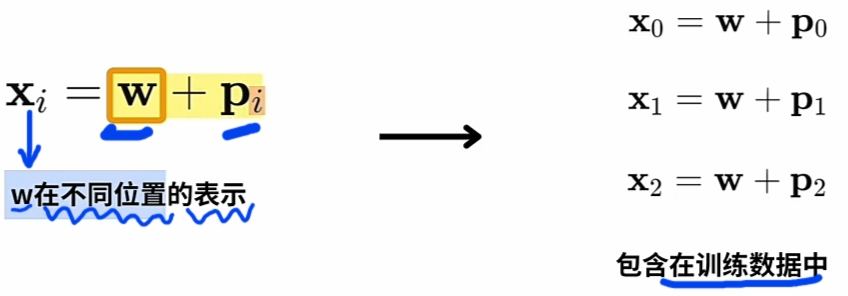
- 假设有: 三个不同\(\large WE\)(词向量) 与 三个不同\(\large PE\), 则实际训练用\(\large combinations\)):
![]()
![]()
![]()
- 使用远大于 \(\large WE\)(词向量)+\(\large PE\)(位置编码) 数量的 \(\large combinations\) 预训练.
-
2 为什么 Transformer 的\(\large PE\)能使“模型”理解“任一不同词”在“不同位置”的语义?
- Transformer的\(\large PE\)是统计概率模型的一部分
统计概率模型本质是:
预训练阶段: 先“统计概率分析”总结出凝聚在“预训练的数据”的“隐藏规律”
预测用阶段: 后“用模型”对“输入数据”应用与调整“预训阶段统计分析总结出的隐藏规律”. - 1 预训练阶段: Transformer Model实际用的是复合\(\large WE\ +\ PE\)的新特征.
预训练阶段, Transformer Model Designer 保障确定复合\(\large WE\ +\ PE\)的新特征是有效的. - 2 预训练阶段: 复合\(\large WE\ +\ PE\)的新特征的有效性
- 3 举例: 预训练数据上的 3个\(\large WE\) 与 3个\(\large PE\) 可组合出9个不同的复合新特征实例.
通过\(\large WE\) 与 \(\large PE\)的\(\large combinations\)极大丰富预训练数据,提高有效性。
![]()
![]()
![]()
![]()
![]()
- Transformer的\(\large PE\)是统计概率模型的一部分
-
3 数学上的“碰撞”特殊情况
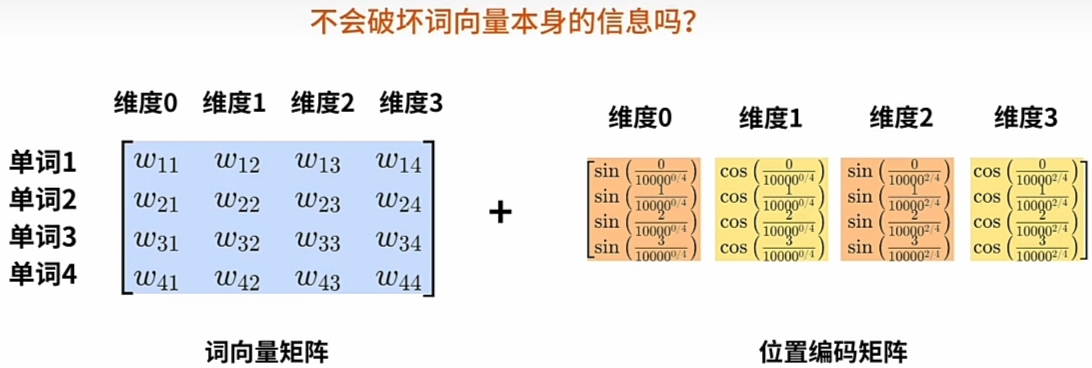
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息, 不会破坏词向量本身的信息?
![]()
- 数学上的“碰撞”特殊情况:
![]()
- $\large WE $(词向量) 都是 "高维向量" 使"所有维度同时碰撞"的概率几乎为0.
![]()
- \(\large PE\)矩阵直接加上到其\(\large WE\)矩阵以嵌入位置信息, 不会破坏词向量本身的信息?







$\large PE $的代码实现


 浙公网安备 33010602011771号
浙公网安备 33010602011771号