DeepWalk论文精读:(3)实验
DeepWalk论文精读系列:
(1)解决问题&相关工作:https://www.cnblogs.com/ZhaoLX/p/DeepWalk1.html
(2)核心算法:https://www.cnblogs.com/ZhaoLX/p/DeepWalk2.html
(3)实验:https://www.cnblogs.com/ZhaoLX/p/DeepWalk3.html
(4)总结及不足:https://www.cnblogs.com/ZhaoLX/p/DeepWalk4.html
模块三
1 实验设计
1.1 数据集
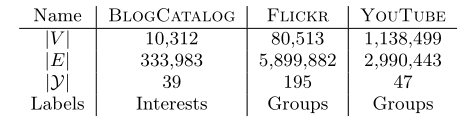
- BLOGCATALOG[39]:博客作者网络。标签为作者感兴趣的主题。
- FLICKR[39]:照片分享网站的用户网络。标签为用户的兴趣群组,如“黑白照片”。
- YOUTUBE[40]:视频分享网站的用户网络。标签为用户喜欢的视频种类,如动漫或摔跤。
1.2 baseline模型
- SpectralClustering[41]:生成节点的表示时,使用图G的拉普拉斯矩阵的第d小的特征向量。使用拉普拉斯矩阵的特征向量代表作者认为图的割对于分类十分有用。
- Modularity[39]:生成节点的表示时,使用图的modularity(模块)矩阵的前d个特征向量。Modularity矩阵的特征向量蕴含了图的模块划分的信息。
- EdgeCluster[40]:使用K-Means方法对图G的邻接矩阵进行聚类。由于当图较大时,spectral decomposition(谱分析)难以实施,所以表现比Modularity方法更好。
- wvRN[24]:关联邻居的带权投票方法。对于节点$v_i$和它的邻居$N_i$,它的概率分布函数由 $\Pr(y_i|N_i)=\frac{1}{Z}\sum_{v_j \in N_i}{w_{ij}\Pr(y_j|N_j)}$ 计算得到。该方法在实际的网络中有着非常出色的表现,所以经常被用作关联分类的baseline[25]。
- Majority:非常简单粗暴的模型,直接取训练集中最经常出现的标签。
在后边进行对比时,基本只与SpectralClustering、EdgeCluster、Modularity、wvRN这四种baseline进行对比。
2 实验
2.1 多标签分类
为说明对比效果,采用了和前述模型相同的数据集合实验步骤。划分训练集和验证集进行实验,重复十次取Macro-F1以及Micro-F1的平均值。
---F1-score:
F1 = 2 * (P*R) / (P+R)
准确率(P) = TP/ (TP+FP) ,衡量是否有误判
召回率(R) = TP/ (TP+FN),衡量是否有遗漏
真阳性(TP): 预测为正, 实际也为正
假阳性(FP): 预测为正, 实际为负
假阴性(FN): 预测为负,实际为正
真阴性(TN): 预测为负, 实际也为负
---Macro-F1 & Micro-F1:
Macro-F1和Micro-F1,宏观F1值和微观F1值,将只适用于Binary分类的F1值推广了,考虑的是在多标签(Multi-label)情况下,分类效果的评估方式。
Micro-F1:先将各类别的TP,FN和FP的数量累加,得到总体的数量,再计算F1。在Micro-F1的计算公式中考虑到了每个类别的数量,所以适用于数据分布不平衡的情况;但同时因为考虑到数据的数量,所以在数据极度不平衡的情况下,数量较多的类会较大的影响到F1的值。
Macro-F1:分布计算每个类别的F1,然后求它们的算术平均(即各类别F1的权重相同)。没有考虑到数据的数量,会平等地看待每一类别,相对地受高precision和高recall类别的影响较大。
所有模型都使用LibLinear[10]的one-vs-rest逻辑回归用于分类。
DeepWalk参数设置为:$\gamma=80, \omega=10, d=128$;
SpectralClustering、Modularity和EdgeCluster的参数设置为:$d=500$(原作者使用的参数)。
作者用$T_R$表示选取训练集的比例,$T_R$越大表明训练集样本越多,带标签的样本越密集。
2.1.1 BlogCatalog
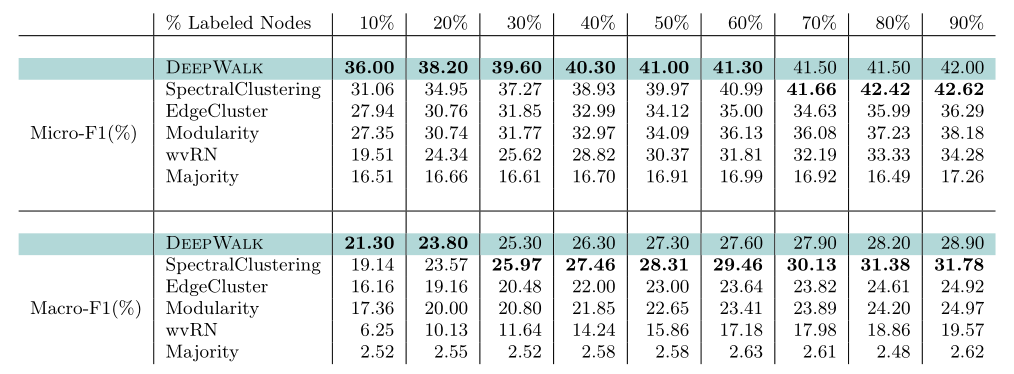
改变有标签节点的百分比/密度,从10%至90%。
和四个baseline相比,效果远好于EdgeCluster、Modularity、wvRN这三个,甚至当仅使用20%的数据训练的效果,就比这三个baseline用90%的数据训练的效果要好。
SpectralClustering的效果和DeepWalk比较接近,但依然可以看出来DeepWalk在有标签的数据少于20%时,Macro-F1的值更高;少于60%时,Micro-F1的值更高。
综上,当图中仅有少量数据有标记时,DeepWalk的效果非常好,这也正是DeepWalk的核心优点。
2.1.2 Flickr
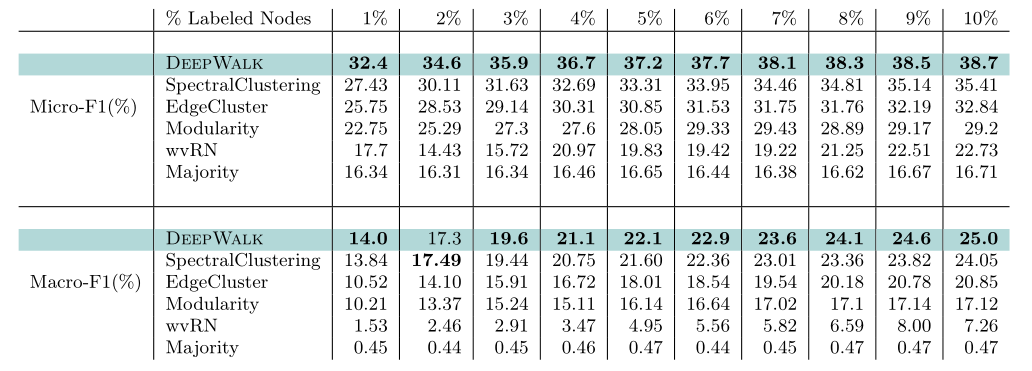
改变有标签节点的百分比/密度,从1%至10%,即节点个数从800到8000。
实验结果与BlogCatalog的一致:在Micro-F1上,各个百分比下都比最好的baseline高至少三个百分点;当仅使用3%的数据训练的效果,就比最好的baseline用10%的数据训练的效果好,换言之,DeepWalk算法在减少60%的有标签数据后,效果依然强于最好的baseline。
在Macro-F1上,效果也很好。有1%的有标签数据时,效果只比最好的baseline好一点;但当有10%的有标签数据时,效果比最好的baseline好了一个百分点。
2.1.3 YouTube
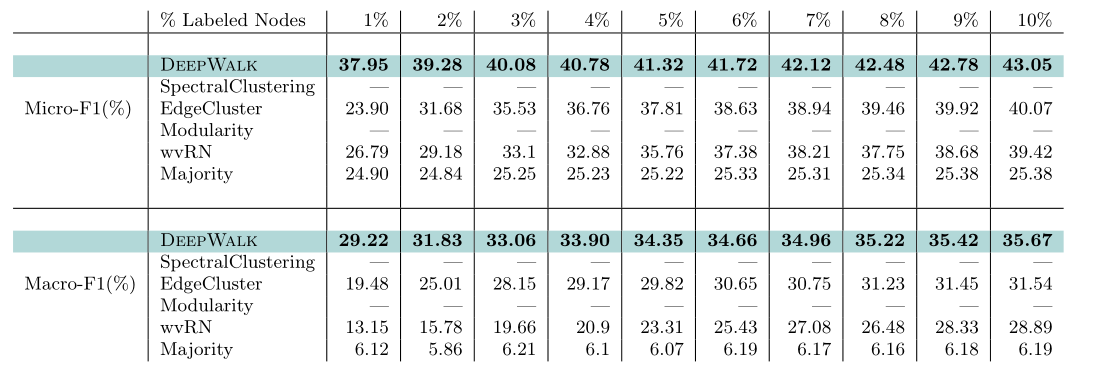
YouTube网络的规模十分庞大,更加接近真实情况下的网络,这也导致SpectralClustering和Modularity两个算法已经无法运行。
改变有标签节点的百分比/密度,从1%至10%。在1%时,DeepWalk在Micro-F1和Macro-F1上分别领先baseline14%和10%的得分,随着有标签数据的增多,和baseline之间的差距在逐渐缩小,但到10%时依然分别保持3%和5%的领先。
综合以上三个实验,我们可以得得出以下结论。在多标签分类的任务上使用DeepWalk有两点好处——
- 可以适用于大规模的图
- 仅需要少量有标记的样本就拥有很高的分类准确率
2.2 参数敏感性
改变模型参数时,观察模型效果的变化情况。作者在Flickr和BlogCatalog数据集上:
固定窗口大小$\omega$=10 和 随机游走序列长度$t$=40,
改变嵌入维度$d$、每个节点作为根节点的次数$\gamma$、训练集比例$T_R$。
2.2.1 维度敏感性
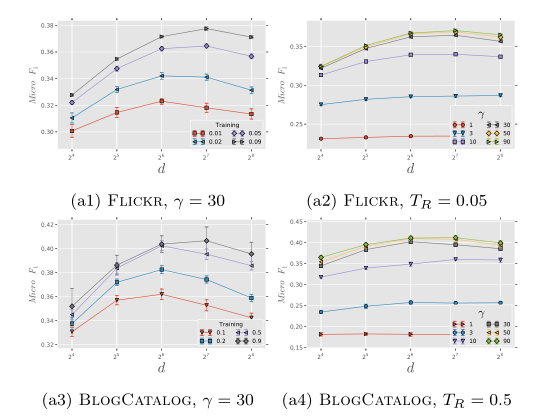
观察a1和a3可以发现,两个数据集上结论高度一致:存在最优的维度,且最优维度的大小和$T_R$的大小有关(注意到,Flickr的1%的训练集大小与BlogCatalog的10%的训练集大小相当)。
观察a2和a4可以发现,模型效果对维度并不十分敏感,在$\gamma$的各个取值上都呈现这个特征。除此之外,还有两个有趣的发现:
- 在$\gamma$小于30时,增加$\gamma$对模型的准确率提升非常模型。但当$\gamma$大于30后,增加$\gamma$对模型准确率的提升就比较有限了。
- 在两个数据集上,不同的$\gamma$参数模型之间的差距非常相似。然而Flickr数据集中边的个数比BlogCatalog的高一个数量级(所以$T_R$的取值分别是0.05和0.5)。
2.2.2 采样频率敏感性
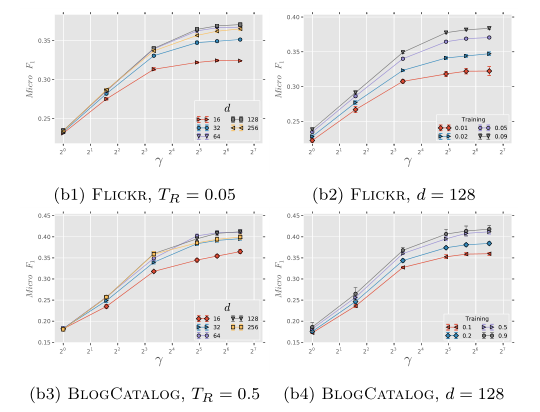
本图和2.2.1中的图高度一致。$\gamma$的增大对于模型效果的提升有着非常巨大的作用,但当$\gamma$大于10后这种作用在逐渐减小。
参考文献
[39] L. Tang and H. Liu. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, pages 817–826, New York, NY, USA, 2009. ACM.
[40] L. Tang and H. Liu. Scalable learning of collective behavior based on sparse social dimensions. In Proceedings of the 18th ACM conference on Information and knowledge management, pages 1107–1116. ACM, 2009.
[41] L. Tang and H. Liu. Leveraging social media networks for classification. Data Mining and Knowledge Discovery, 23(3):447–478, 2011
[24] S. A. Macskassy and F. Provost. A simple relational classifier. In Proceedings of the Second Workshop on Multi-Relational Data Mining (MRDM-2003) at KDD-2003, pages 64–76, 2003.
[25] S. A. Macskassy and F. Provost. Classification in networked data: A toolkit and a univariate case study. The Journal of Machine Learning Research, 8:935–983, 2007.
[10] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9:1871–1874, 2008.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号