DeepWalk论文精读:(2)核心算法
DeepWalk论文精读系列:
(1)解决问题&相关工作:https://www.cnblogs.com/ZhaoLX/p/DeepWalk1.html
(2)核心算法:https://www.cnblogs.com/ZhaoLX/p/DeepWalk2.html
(3)实验:https://www.cnblogs.com/ZhaoLX/p/DeepWalk3.html
(4)总结及不足:https://www.cnblogs.com/ZhaoLX/p/DeepWalk4.html
模块2
1. 核心思想及其形成过程
DeepWalk结合了两个不相干领域的模型与算法:随机游走(Random Walk)及语言模型(Language Modeling)。
1.1 随机游走
由于网络嵌入需要提取节点的局部结构,所以作者很自然地想到可以使用随机游走算法。随机游走是相似性度量的一种方法,曾被用于内容推荐[11]、社区识别[1, 38]等。除了捕捉局部结构,随机游走还有以下两个好处:
- 容易并行,使用不同的线程、进程、机器,可以同时在一个图的不同部分运算;
- 关注节点的局部结构使得模型能更好地适应变化中的网络,在网络发生微小变化时,无需在整个图上重新计算。
1.2 语言模型
语言模型(Language Modeling)有一次颠覆性创新[26, 27],体现在以下三点:
- 从原来的利用上下文预测缺失单词,变为利用一个单词预测上下文;
- 不仅考虑了给定单词左侧的单词,还考虑了右侧的单词;
- 将给定单词前后文打乱顺序,不再考虑单词的前后顺序因素。
这些特性非常适合节点的表示学习问题:第一点使得较长的序列也可以在允许时间内计算完毕;第二、三点的顺序无关使得学习到的特征能更好地表征“临近”这一概念的对称性。
1.3 如何结合
可以结合的原因,是作者观察到:
- 如果不论规模大小,节点的度服从幂律分布,那么在随机游走序列上节点的出现频率也应当服从幂律分布。
- 自然语言中词频服从幂律分布,自然语言模型可以很好地处理这种分布。
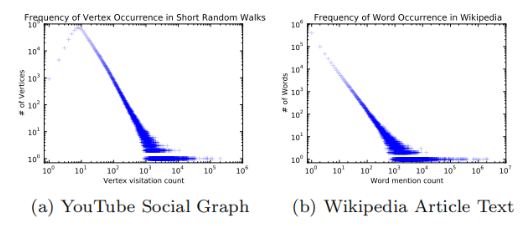
所以作者将自然语言模型中的方法迁移到了网络社群结构问题上,这也正是DeepWalk的一个核心贡献。
2. 具体算法
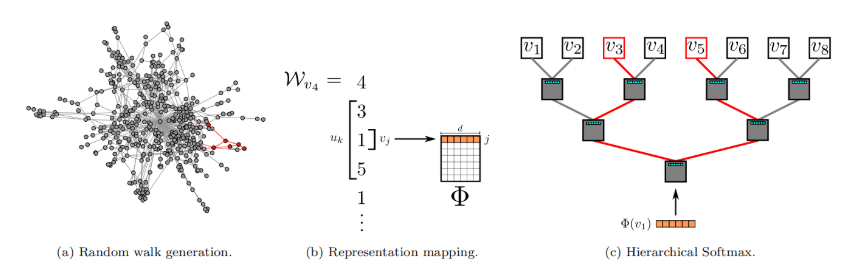
算法由两部分组成:第一部分是随机游走序列生成器,第二部分是向量更新。
2.1 随机游走生成器
DeepWalk用$W_{v_i}$表示以$v_i$为根节点的随机游走序列,它的生成方式是:从$v_i$出发,随机访问一个邻居,然后再访问邻居的邻居...每一步都访问前一步所在节点的邻居,直到序列长度达到设定的最大值$t$。在进行上述过程的时候,可能会发生“掉头”的情况,但实验证明这并没有什么影响。在实际操作中,规定每一个节点都要作为根节点游走$\gamma$次,序列长度为$t$。

Algorithm 1中的3-9(不包括7)展示了随机游走的过程。外循环指定$\gamma$次循环,每次首先打乱全部节点的顺序以加速随机梯度下降(SGD)的收敛速度,内循环中在每一个节点上执行一遍随机游走RandomWalk,得到随机游走序列$W_{v_i}$。
2.2 节点表示更新
在得到了随机游走序列之后,就可以更新节点的表示向量了。作者使用了SkipGram算法,并利用Hierarchichal Softmax进行加速。
2.2.1 SkipGram

Algorithm 2展示了SkipGram算法[26]。第3行为算法核心,其思想是“利用中心节点预测临近节点”。对于一个随机游走序列,每一个节点都可作为中心节点,根据设定的窗口大小$\omega$,选取序列里中心节点前后各$\omega$,共$2\omega$个节点。SkipGram的优化目标是:
$$
minimize \space -\log \Pr(u_k|\Phi(v_j))
$$
即最大化在$v_j$附近出现$u_k$的概率。其中,$u_k$是这$2\omega$个节点中的每一个,$\Phi(v_j) \in \mathbb{R}^d$是将节点映射到它的嵌入表示的函数,也即我们最终要得到的结果。但这样做有一个很大的不足:在学习和计算$\Pr(u_k|\Phi(v_j))$的分布时,由于节点个数非常多,标签个数将会与$|V|$相同,需要非常多个分类器,需要大量的计算资源[3]。为了加速计算,可以使用Hierarchical Softmax近似求解,将在2.2.2中具体介绍。
第4行是利用随机梯度SGD[4]下降更新映射函数(形式为矩阵),其中学习率初始值为2.5%(2.5e-2),在训练中随着见过的节点数量增多而线性地减小。
2.2.2 Hierarchical Softmax
在计算$\Pr(u_k|\Phi(v_i))$时,可以利用Hierarchical Softmax二叉树[29, 30]加速。作者将所有节点作为二叉树的叶子节点,就可以用从根节点到叶子节点的路径来表示每个节点。二叉树若有$|V|$个叶子节点,则深度至多为$\log|V|$。这样就会有:
$$
\Pr(u_k|\Phi(v_j))=\prod_{l=1}^{\lceil\log|V|\rceil}\Pr(b_l|\Phi(v_j))
$$
其中$b_0, b_1, ..., b_{\lceil\log|V|\rceil}$是一系列二叉树中的非叶子节点。这样就可以用较少的分类器完成这个任务,将计算复杂度由$O(|V|)$降低至$O(\log|V|)$。
更进一步,还可以结合节点出现频率,使用霍夫曼编码,为更频繁出现的节点分配稍短的路径,再次降低计算复杂度。
3. 并行化
如前文所述,随机序列中节点出现频率服从幂律分布,长尾中包含了大量的不经常出现的节点,所以对于$\Phi$的更新应当是十分稀疏的。因此,作者使用了非同步的随机梯度下降(ASGD)方法,并行计算以提高收敛速度[36],使得可以用于大规模的机器学习[8]。
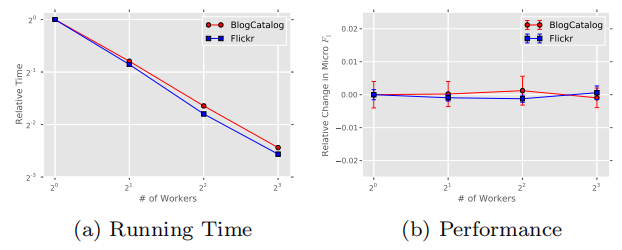
在BlogCatalog和Flickr两个网络上的实验结果也表明:增加并行任务的个数,可以可以线性地减少训练时间,但不会降低准确性。
4. 算法变体
4.1 Streaming
Streaming无需知道整个图的结构,将随机游走序列直接传递到表示学习部分,并直接更新模型。但由于不知道整个图的信息,所以学习过程需要做如下调整:
- 不能使用衰减的学习率,但可以指定一个较小的固定的学习率。
- 无法构建Hierarchical Softmax二叉树,除非知道或可以预测节点个数的数量级。
4.2 Non-random walks
某些网络是客户与一些元素互动的副产品,比如网站导航的层级结构。当一个网络中进行随机游走的序列是非随机的,比如只能按照导航的层级结构进行游走时,可以直接将这种结构传递给模型。这样,不仅可以捕捉到网络结构信息,还可以知道路径遍历的频率。
作者认为,自然语言模型就是Non-random walks的一个特例。句子可以被看作是在整个词汇网络中非随机、有目的的游走序列。
Non-random walks可以和Streaming结合,当网络持续变化难以获得网络整体信息,或网络规模过大难以处理全部信息时,使得DeepWalk算法依旧可行。
参考文献
1. 核心思想
[11] F. Fouss, A. Pirotte, J.-M. Renders, and M. Saerens. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. Knowledge and Data Engineering, IEEE Transactions on, 19(3):355–369, 2007.
[1] R. Andersen, F. Chung, and K. Lang. Local graph partitioning using pagerank vectors. In Foundations of Computer Science, 2006. FOCS’06. 47th Annual IEEE Symposium on, pages 475–486. IEEE, 2006.
[38] D. A. Spielman and S.-H. Teng. Nearly-linear time algorithms for graph partitioning, graph sparsification, and solving linear systems. In Proceedings of the thirty-sixth annual ACM symposium on Theory of computing, pages 81–90. ACM, 2004.
[26] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781, 2013.
[27] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
2.2.1 SkipGram
[3] Y. Bengio, R. Ducharme, and P. Vincent. A neural probabilistic language model. Journal of Machine Learning Research, 3:1137–1155, 2003.
[4] L. Bottou. Stochastic gradient learning in neural networks. In Proceedings of Neuro-Nˆımes 91, Nimes, France, 1991. EC2.
2.2.2 Hierarchical Softmax
[29] A. Mnih and G. E. Hinton. A scalable hierarchical distributed language model. Advances in neural information processing systems, 21:1081–1088, 2009
[30] F. Morin and Y. Bengio. Hierarchical probabilistic neural network language model. In Proceedings of the international workshop on artificial intelligence and statistics, pages 246–252, 2005.
3. 并行化
[36] B. Recht, C. Re, S. Wright, and F. Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems 24, pages 693–701. 2011.
[8] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. Le, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Ng. Large scale distributed deep networks. In P. Bartlett, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1232–1240. 2012.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号