
【Python爬虫】从天气后报网站上爬取近十年来各省会城市的空气质量数据
数据来源网站
天气后报:https://www.tianqihoubao.com/
完整代码
import csv
import random
import time
from datetime import datetime
import requests
from bs4 import BeautifulSoup
class AqiSpider:
def __init__(self, cityname, realname):
self.cityname = cityname
self.realname = realname
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.f = open(f'air_quality.csv', 'a', encoding='utf-8', newline='')
self.writer = csv.DictWriter(self.f,
fieldnames=['city', 'date', 'AQI', 'quality_level', 'AQI_rank', 'PM2.5', 'PM10',
'NO2', 'S02', 'CO', 'O3'])
# self.writer.writeheader()
def send_request(self, year, month):
"""
发送请求
"""
print(self.realname)
url = f"https://www.tianqihoubao.com/aqi/{self.cityname}-"+str(year)+str("%02d"%month)+".html"
response = requests.get(url, headers=self.headers, timeout=60)
time.sleep(random.uniform(1, 3)) # 休眠一段时间,防止频繁请求
# print(response.text)
# print(f"响应状态码:{response.status_code}")
self.parse_response(response.text) # 解析网页
def parse_response(self, response):
"""
解析网页
"""
soup = BeautifulSoup(response, 'lxml')
tr = soup.find_all('tr')
for j in tr[1:]:
td = j.find_all('td')
city = self.realname # 城市
Date = td[0].get_text().strip() # 日期
AQI = td[1].get_text().strip() # AQI
Quality_Level = td[2].get_text().strip() # 空气质量等级
AQI_rank = td[3].get_text().strip() # AQI排名
PM25 = td[4].get_text().strip()
PM10 = td[5].get_text().strip()
NO2 = td[6].get_text().strip()
S02 = td[7].get_text().strip()
CO = td[8].get_text().strip()
O3 = td[9].get_text().strip()
print(city, Date, AQI, Quality_Level, AQI_rank, PM25, PM10, NO2, S02, CO, O3)
data_dict = {
'city': self.realname,
'date' :Date,
'AQI': AQI,
'quality_level': Quality_Level,
'AQI_rank': AQI_rank,
'PM2.5': PM25,
'PM10': PM10,
'NO2': NO2,
'S02': S02,
'CO': CO,
'O3': O3
}
# print(Date)
# print(data_dict)
self.save_data(data_dict)
def save_data(self, data_dict):
"""
保存数据
"""
self.writer.writerow(data_dict)
def run(self):
current_year = datetime.now().year
for year in range(2015, 2026):
for month in range(1, 13):
if year == current_year and month > datetime.now().month:
continue # 跳过未来的月份
print(f"正在爬取{year}年{month}月的数据")
self.send_request(year, month)
if __name__ == '__main__':
city_dict = {
'beijing': '北京',
'shanghai': '上海',
'tianjin': '天津',
'chongqing': '重庆',
'shijiazhuang': '石家庄',
'taiyuan': '太原',
'shenyang': '沈阳',
'changchun': '长春',
'haerbin': '哈尔滨',
'nanjing': '南京',
'hangzhou': '杭州',
'hefei': '合肥',
'fuzhou': '福州',
'nanchang': '南昌',
'jinan': '济南',
'zhengzhou': '郑州',
'wuhan': '武汉',
'changsha': '长沙',
'guangzhou': '广州',
'haikou': '海口',
'chengdu': '成都',
'guiyang': '贵阳',
'kunming': '昆明',
'xian': '西安',
'lanzhou': '兰州',
'xining': '西宁',
'huhehaote': '呼和浩特',
'nanning': '南宁',
'lasa': '拉萨',
'yinchuan': '银川',
'wulumuqi': '乌鲁木齐'
}
for k, v in city_dict.items():
AS = AqiSpider(k, v)
AS.run()
运行结果:
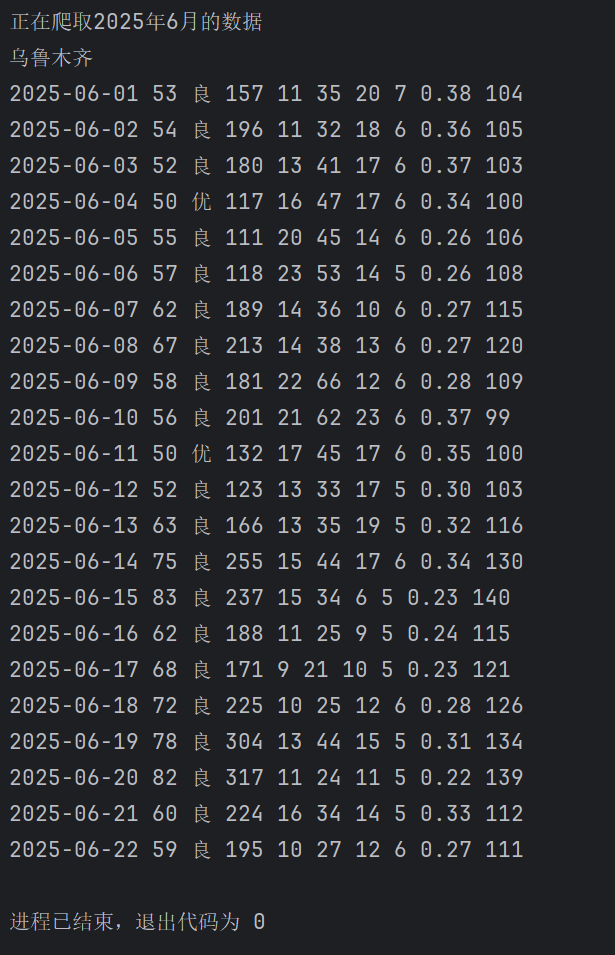
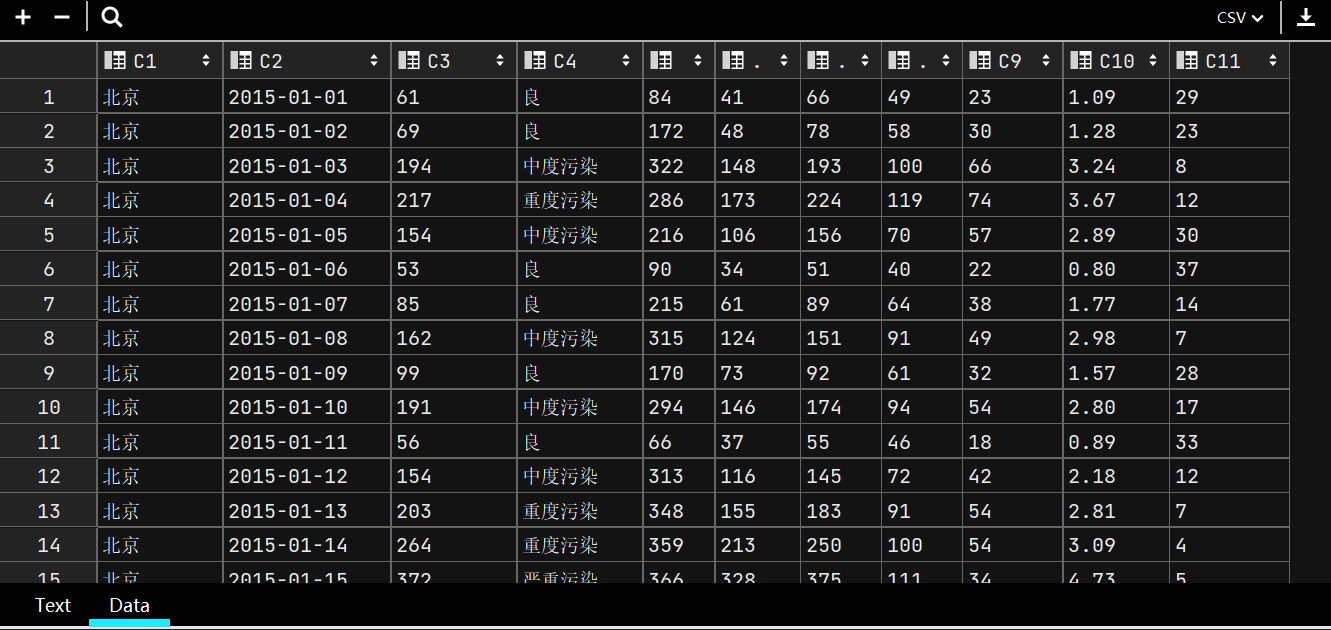
查看csv文件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号