
06 RDD编程
1.读文本文件生成RDD lines
将一行一行的文本分割成单词 words flatmap()
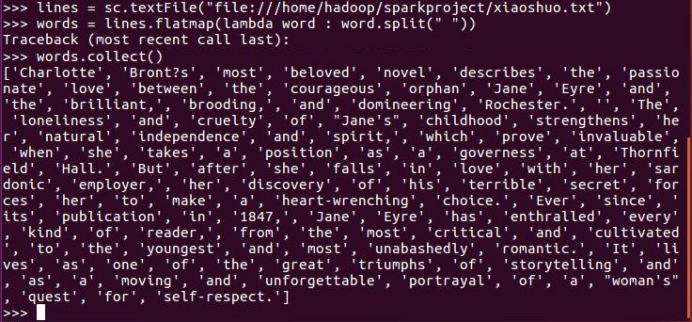
lines = sc.textFile("file:///home/hadoop/sparkproject/xiaoshuo.txt")
words = lines.flatMap(lambda word : word.split(" "))
words.collect()
2.全部转换为小写 lower()

words_lower = words.map(lambda wl : wl.lower())
words_lower.collect()[0]
3.去掉长度小于3的单词 filter()

words_data_filter = words_lower.filter(lambda wd : len(wd)>3)
words_data_filter.collect()[0]
4.去掉停用词

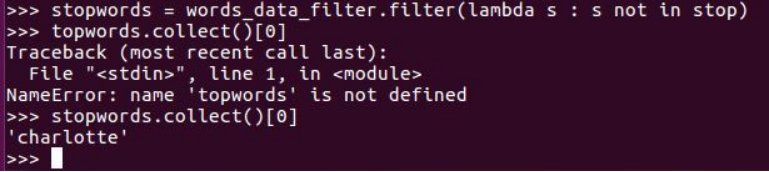
with open("/home/hadoop/sparkproject/stopwords.txt") as f:
... stop = f.read()
stopwords = words_data_filter.filter(lambda s : s not in stop)
stopwords.collect()[0]
5.转换成键值对 map()
stopwords_kv = stopwords.map(lambda x : (x,1))
stopwords_kv.collect()[0]
6.统计词频 reduceByKey()

words = sc.parallelize(stopwords_kv.collect())
words1 = words.reduceByKey(lambda a,b : a+b)
7.按字母顺序排序sortByKey()
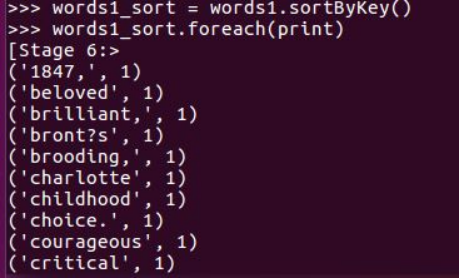
words1_sort = words1.sortByKey()
words1_sort.foreach(print)
8.按词频排序 sortBy()
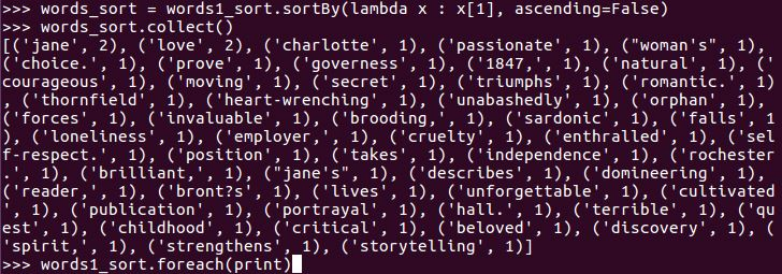
words_sort = words1_sort.sortBy(lambda x : x[1], ascending=False)
words_sort.collect()
9.结果文件保存 saveAsTextFile(out_url)
代码:sort.saveAsTextFile("file:///home/hadoop/sparkproject/output")
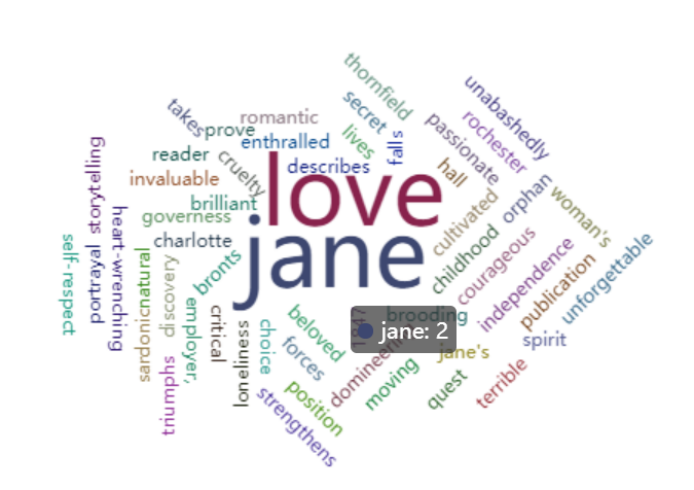
10.词频结果可视化 pyecharts.charts.WordCloud()
from pyecharts.charts import WordCloud
data = [('jane', 2), ('love', 2), ('1847', 1), ('beloved', 1), ('brilliant', 1), ('bronts', 1), ('brooding', 1), ('charlotte', 1), ('childhood', 1), ('choice', 1), ('courageous', 1), ('critical', 1), ('cruelty', 1), ('cultivated', 1), ('describes', 1), ('discovery', 1), ('domineering', 1), ('employer,', 1), ('enthralled', 1), ('falls', 1), ('forces', 1), ('governess', 1), ('hall', 1), ('heart-wrenching', 1), ('independence', 1), ('invaluable', 1), ('jane\'s', 1), ('lives', 1), ('loneliness', 1), ('moving', 1), ('natural', 1), ('orphan', 1), ('passionate', 1), ('portrayal', 1), ('position', 1), ('prove', 1), ('publication', 1), ('quest', 1), ('reader', 1), ('rochester', 1), ('romantic', 1), ('sardonic', 1), ('secret', 1), ('self-respect', 1), ('spirit', 1), ('storytelling', 1), ('strengthens', 1), ('takes', 1), ('terrible', 1), ('thornfield', 1), ('triumphs', 1), ('unabashedly', 1), ('unforgettable', 1), ('woman\'s',1)]
mywordcloud = WordCloud()
mywordcloud.add('', data, shape='circle')
# 渲染图片
mywordcloud.render()
# 指定渲染图片存放的路径
mywordcloud.render('./wordcloud.html')
11.比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
1)易用性
由于 MapReduce 中仅为数据处理提供了两个操作,即Map和Reduce,因此系统开发人员需要解决的一个难题是如何把数据处理的业务逻辑合理有效地封装在对应的两个类中。而通常同样的功能若换成 Spark,其核心代码最短仅需一行。MapReduce 自身并没有交互模式,需要借助 Hive 和 Pig 等附加模块。Spark则提供了一种命令行交互模式,即 Spark Shell,使得用户可以获取到查询和其他操作的即时反馈。
2)效率
Map 中间结果写入磁盘,效率低下,不适合迭代运算。Spark Job 中间输出结果可以保存在内存,不再需要读写 HDFS。
3)任务启动开销
Spark 和 Hadoop MapReduce 都实现了异步并发模型,而 MapReduce 采用的是多进程模型,Spark 采用了多线程模型。
多进程模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间,不适合运行低延迟类型的作业,这是MapReduce广为诟病的原因之一。多线程模型则相反,该模型使得 Spark 很适合运行低延迟类型的作业。
MapReduce不适合迭代处理、交互式处理和流式处理,而Spark可以
二、学生课程分数案例
总共有多少学生?map(), distinct(), count()

开设了多少门课程?

每个学生选修了多少门课?map().countByValue() //map(), countByKey()
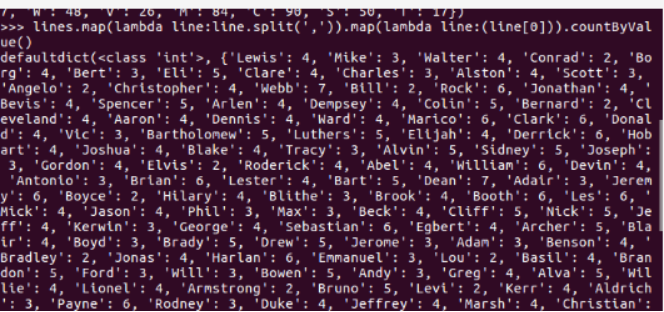
每门课程有多少个学生选?map(), countByValue()

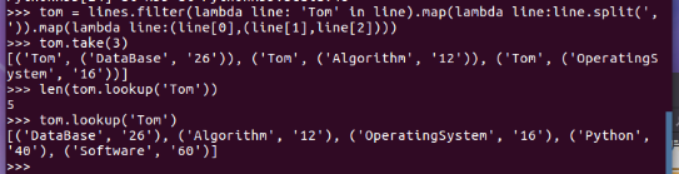
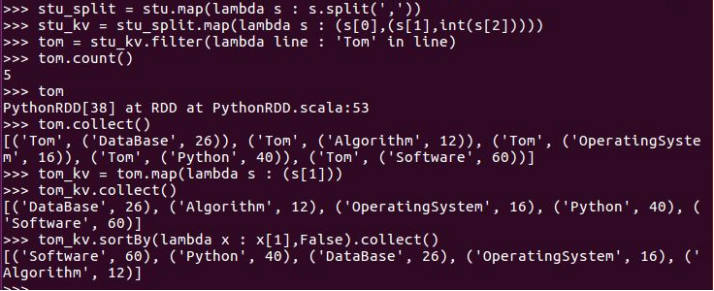
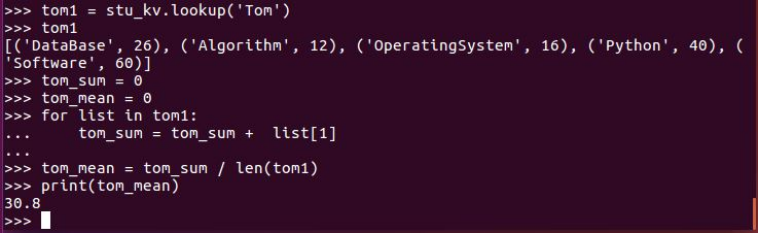
Tom选修了几门课?每门课多少分?filter(), map() RDD

Tom选修了几门课?每门课多少分?map(),lookup() list
Tom的成绩按分数大小排序。filter(), map(), sortBy()
Tom的平均分。map(),lookup(),mean()
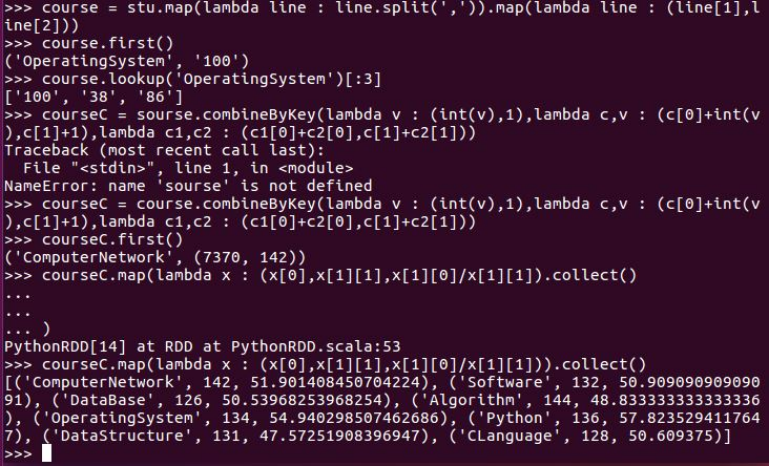
求每门课的选修人数及平均分。combineByKey()
生成(课程,分数)RDD,观察keys(),values()


stu_rdd = stu_split.map(lambda s : (s[1],int(s[2])))
stu_rdd.keys().collect()
stu_rdd.values().collect()
每个分数+5分。mapValues(func)

stu_mapValues = stu_rdd.mapValues(lambda v : v+5)
stu_mapValues.collect()
求每门课的选修人数及所有人的总分。combineByKey()
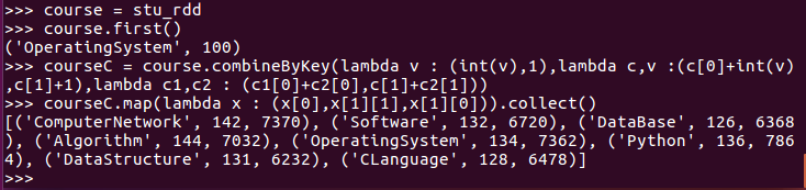
course = stu_rdd
courseC = course.combineByKey(lambda v : (int(v),1),lambda c,v :(c[0]+int(v),c[1]+1),lambda c1,c2 : (c1[0]+c2[0],c[1]+c2[1]))
courseC.map(lambda x : (x[0],x[1][1],x[1][0])).collect()
求每门课的选修人数及平均分,精确到2位小数。map(),round()

courseC.map(lambda x : (x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect()
求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
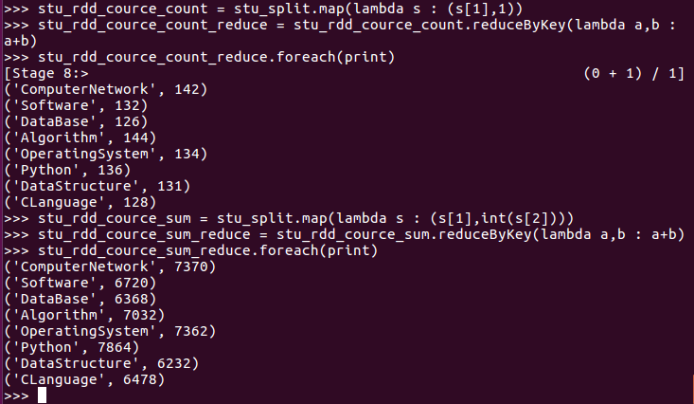
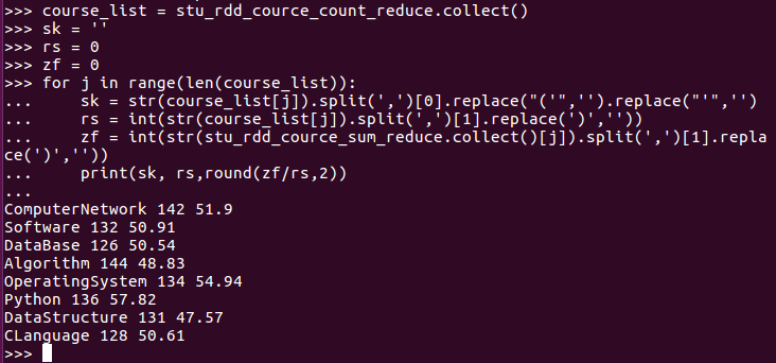
course_list = stu_rdd_cource_count_reduce.collect()
sk = ''
rs = 0
zf = 0
for j in range(len(course_list)):
sk = str(course_list[j]).split(',')[0].replace("('",'').replace("'",'')
rs = int(str(course_list[j]).split(',')[1].replace(')',''))
zf = int(str(stu_rdd_cource_sum_reduce.collect()[j]).split(',')[1].replace(')',''))
print(sk, rs,round(zf/rs,2))
结果可视化。 pyecharts.charts,Bar()
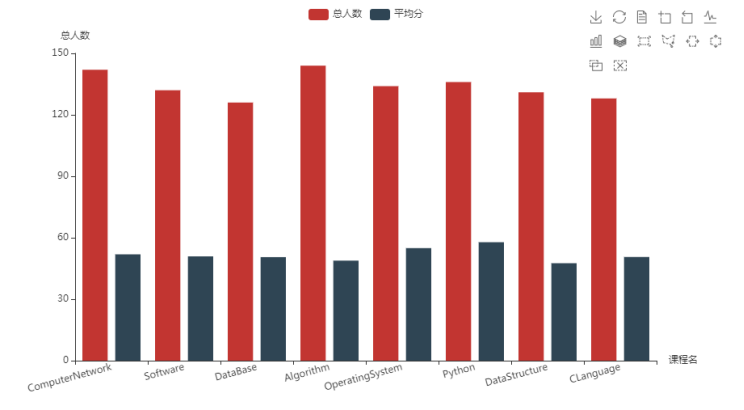
import pyecharts.options as opts
from pyecharts.charts import Bar
x = ['ComputerNetwork', 'Software', 'DataBase', 'Algorithm', 'OperatingSystem', 'Python', 'DataStructure', 'CLanguage']
y = [
[142, 132, 126, 144, 134, 136, 131, 128],
[51.9, 50.91, 50.54, 48.83, 54.94, 57.82, 47.57, 50.61]
]
bar = (
Bar()
.add_xaxis(x)
.add_yaxis(series_name='总人数', y_axis=y[0])
.add_yaxis(series_name='平均分', y_axis=y[1])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='课程', pos_left='right'))
.set_global_opts(toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(name="总人数"),
xaxis_opts=opts.AxisOpts(name="课程名"),axislabel_opts=opts.LabelOpts(rotate=15))
)
bar.render()
bar.render('./bar.html')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号