
基于图神经网络的推荐系统综述
论文原文:《Graph Neural Networks in Recommender Systems:A Survey》ACM Computing Surveys ,Accepted on March 2022

论文原文地址:https://dl.acm.org/doi/abs/10.1145/3535101
论文pdf:https://dl.acm.org/doi/pdf/10.1145/3535101
这篇论文由北大及阿里巴巴整合211篇论文后于2022年五月发表在ACM Computing Surveys上,该论文阐述了近些年较火的图神经网络(Graph Neural Network,GNN)在推荐系统中的应用综述,将基于GNN的推荐系统大致分为四类,对每一类典型模型和方法需要解决的问题以及解决方案进行详细阐述和全面回顾。整合了该领域的通用数据集、评估指标和在实际工业中的应用。最后提出了未来该领域的研究方向和开放性问题。
论文整体结构:
在推荐系统中,主要的挑战是从用户/物品的相互作用或者是边缘信息(如有有的话)来学习用户/物品的有效表示。最近,GNN被广泛应用于推荐系统,因为在推荐系统中大多数的信息是基于图结构的而且GNN在图表示学习中表现很优越。这篇文章旨在为近期基于GNN的推荐系统提供了一个综合的回顾。这篇文章将基于GNN的推荐系统模型根据信息使用的类别和推荐系统的任务进行了分类建模。并且系统分析了GNN在不同类型数据应用时面临的问题,同时讨论了在该领域的现存方法是如何解决这些问题的。更进一步的讲,这篇文章阐述了对这个邻域的发展提供了一个新的视角。并讲典型的模型与他们开源的实现共同收录于https://github.com/wusw14/GNN-in-RS。
关键字:推荐系统;图神经网络;综述
1 简介
广泛的讲,在过去的几十年里,推荐系统的主流建模模式已经从邻域方法发展到基于表示学习的框架。其中基于物品邻域的方法直接为用户推荐那些与用户曾经有过联系的用户历史中相似的物品。基于表示学习的方法试图将用户和物品编码为共享空间中的连续向量(即嵌入),从而使它们可以直接比较。目前,深度学习方法已经成为推荐系统中主要的方法,不仅是在学术界还是工业界,因为深度学习方法可以高效的捕获非线性和非琐碎的用户-物品关系,并且可以很容易的聚合海量数据资源。在很多深度学习方法中,基于图的学习是其中的一种,它从图的视角考虑了推荐系统中的信息。受GNN对图结构数据学习能力的启发,近年来出现了大量基于GNN的推荐模型。同时,GNN能广泛应用于推荐系统中的另一个原因是它不同于只能隐式捕获协同过滤信号(即 使用用户-项目交互作为监督信号)的传统方法,GNN可以自然地显式编码关键的协同信号(即 拓扑结构),以改进用户和物品的表示。之前的一些工作主要是基于图的一跳邻居,GNN提供了一个很有力并且很系统的工具来探索多跳邻居的关系,其已经被证明在推荐系统中是很有用的。
不同于其他综述,这篇综述主要从基于GNN的推荐系统的角度出发,总结了基于GNN的推荐系统的进展,讨论了该领域中开放式的问题和未来的研究方向,超过100篇文章入围并分类。
本篇综述的贡献:
•新的分类:基于现存方法,根据使用信息的种类和推荐的任务提出了新的系统的分类模式,将其分为五类,包扩:用户-物品 协同过滤(user-item collaborative filtering)、序列化推荐系统(sequential recommendation)、社交化推荐系统( social recommendation)、基于知识图谱推荐系统(knowledge graph-based recommendation)和其他任务(包括POI推荐系统、多媒体推荐系统等)。
•综合全面的回顾:为每个类别阐述了主要需要解决的问题,以及介绍了经典的模型并阐述他们是如何解决这些问题的。
•未来的研究:讨论了现存方法的局限性并提出未来九个有潜力的研究方向。
2 背景和分类
在详细探究文章前,先为推荐系统和GNN技术提出简要介绍。符号标识如图1

2.1 推荐系统
推荐系统从用户与物品的交互或静态特征中推断用户的偏好,并进一步推荐用户可能感兴趣的物品。几十年来,它一直是一个热门的研究领域,因为它有很大的应用价值,但这一领域的挑战仍然没有得到很好的解决。形式上,该任务是通过学习到的用户表示$h_{u}^{*}$和项目(物品)表示$h_{i}^{*}$来估计她/他对任何项目(物品)$i \in \mathcal{I}$的偏好。
\begin{equation}y_{u, i}=f\left(h_{u}^{*}, h_{i}^{*}\right)\end{equation}
其中评分函数$f(\cdot)$可以是点积、余弦、多层感知等,$y_{u, i}$表示用户𝑢对项目𝑖的偏好评分,通常以概率的形式表示。
根据用于学习用户/项目表示的信息类型,推荐系统的研究通常可以分为特定类型的任务。用户-项目协同过滤推荐的目标是仅利用用户-项目交互来捕获协同信号,也就是说,用户/项表示是从成对数据中联合学习的。当用户历史行为的时间戳已知或历史行为按时间顺序组织时,可以通过探索用户历史交互中的顺序模式来增强用户表示。根据用户是否匿名以及行为是否被划分为会话,该领域的工作可以进一步分为顺序推荐和基于会话的推荐。基于会话的推荐可以看作是具有匿名和会话假设的顺序推荐的子类型。在本文中,为了简单起见不区分它们,而是将它们统称为更广泛的术语--序列化推荐,因为我们主要关注的是GNN对推荐的贡献,它们之间的差异对于GNN的应用来说是可以忽略的。除了序列信息,另一个研究方向是利用社会关系来增强用户表示,这被归类为社交化推荐。社会推荐基于“有联系的人会相互影响”的社会影响理论,假设有社会关系的用户倾向于具有相似的用户表征。除了增强用户之间的表示之外,许多工作都试图通过利用知识图谱来增强项目之间的表示,知识图谱通过属性表示项目之间的关系。这些工作通常被归类为基于知识图谱的推荐系统,它将项目之间的语义关系整合为协作信号。
2.2 图神经网络技术
图表示为$\mathcal{G}=(\mathcal{V}, \mathcal{E})$,其中$\mathcal{V}$是节点的集合,$\mathcal{E}$是边的集合。$v_{i} \in \mathcal{V}$是一个结点,$e_{i j}=\left(v_{i}, v_{j}\right) \in \mathcal{E}$是一条从$v_{j} $指向$v_{i} $的边。结点𝑣的邻域记为$\mathcal{N}(v)=\{u \in \mathcal{V} \mid(v, u) \in \mathcal{E}\}$。一般来说,图可以分为:
•有向图/无向图
•同构图/异构图:同构图结点和边类型只有一类,异构图可以有多种类别的结点或边
•超图:一条边可以连接任意多个结点
对于图数据,GNN的主要思想是迭代聚合来自邻居的特征信息,并在传播过程中将聚合的信息与当前中心结点表示集成。从网络架构的角度来看,GNN堆叠了多个传播层,这些传播层由聚合和更新操作组成。传播的公式是
\begin{equation}
\begin{aligned}
Aggregation: \quad \mathbf{n}_{v}^{(l)}=\operatorname{Aggregator}\left(\left\{\mathbf{h}_{u}^{l}, \forall u \in \mathcal{N}_{v}\right\}\right) \\
Update: \quad \mathbf{h}_{v}^{(l+1)}=\operatorname{Updater}_{l}\left(\mathbf{h}_{v}^{(l)}, \mathbf{n}_{v}^{(l)}\right)
\end{aligned}
\end{equation}
其中$\mathbf{h}_{u}^{(l)}$指的是结点$u$在第$l^{th}$层的表示,$\text { Aggregator }_l$和$\text { Updater}_l$分别表示第$l^{th}$层的聚合函数和更新函数。在聚合操作过程中,现存的工作对待结点的邻居有的平等地使用均值池化对待,有的则通过注意力机制来区别对待结点每个邻居的重要性。在更新操作过程中,中心节点的表示和聚合的邻域将集成到中心节点的更新表示中。
在这里,文章简要总结了在推荐领域广泛采用的五种典型GNN框架的聚合和更新操作。
\begin{equation}
\text { Aggregation: } \quad \mathbf{n}_{v}^{(l)}=\sum_{j \in N_{v}} d_{v v}^{-\frac{1}{2}} \tilde{a_{v j}} d_{j j}^{-\frac{1}{2}} \mathbf{h}_{j}^{(l)}, \quad \\ \text { Update: } \quad \mathbf{h}_{v}^{(l+1)}=\delta\left(\mathbf{W}^{(l)} \mathbf{n}_{v}^{(l)}\right) \text {, }
\end{equation}
$\delta(\cdot)$是非线性激活函数,如ReLU函数,$\mathbf{W}^{(l)}$是第$l$层可学习的变换矩阵,$\tilde{a_{v j}}$是邻接矩阵$\tilde{a_{v v}}=1$,$d_{j j}=\sum_{k} a_{j k}^{\sim}$。
\begin{equation}
\text { Aggregation: }\quad \mathbf{n}_{v}^{(l)}=\operatorname{Aggregator}\left(\left\{\mathbf{h}_{u}^{l}, \forall u \in \mathcal{N}_{v}\right\}\right) , \\
\text { Update: } \quad \mathbf{h}_{v}^{(l+1)}=\delta\left(\mathbf{W}^{(l)} \cdot\left[\mathbf{h}_{v}^{(l)} \oplus \mathbf{n}_{v}^{(l)}\right]\right) ,
\end{equation}
其中$\text { Aggregator }_l$表示第$l^{th}$层的聚合函数,$\delta(\cdot)$是非线性激活函数,$\mathbf{W}^{(l)}$是可学习的变换矩阵。
\begin{equation} \text { Aggregation: } \quad \mathbf{n}_{v}^{(l)}=\sum_{j \in \mathcal{N}_{v}} \alpha_{v j} \mathbf{h}_{j}^{(l)}, \alpha_{v j}=\frac{\exp \left(\operatorname{Att}\left(h_{v}^{(l)}, \mathbf{h}_{j}^{(l)}\right)\right)}{\sum_{k \in \mathcal{N}_{v}} \exp \left(\operatorname{Att}\left(h_{v}^{(l)}, \mathbf{h}_{k}^{(l)}\right)\right)} , \\ \text { Update: } \quad \mathbf{h}_{v}^{(l+1)}=\delta\left(\mathbf{W}^{(l)} \mathbf{n}_{v}^{(l)}\right) , \end{equation}
其中$\operatorname{Att}(\cdot)$表示注意力函数,其中一类$\operatorname{Att}(\cdot)$是$\text { LeakyReLU }\left(\mathbf{a}^{T}\left[\mathbf{W}^{(l)} \mathbf{h}_{v}^{(l)} \oplus \mathbf{W}^{(l)} \mathbf{h}_{j}^{(l)}\right]\right)$,$\mathbf{W}^{(l)}$负责转化第$l$层反向传播的邻居表示,$a$是一个可学习的参数。
\begin{equation}\text { Aggregation: } \quad \mathbf{n}_{v}^{(l)}=\frac{1}{\left|\mathcal{N}_{v}\right|} \sum_{j \in \mathcal{N}_{v}} \mathbf{h}_{j}^{(l)}, \quad \text { Update: } \quad \mathbf{h}_{v}^{(l+1)}=\mathrm{GRU}\left(\mathbf{h}_{v}^{(l)}, \mathbf{n}_{v}^{(l)}\right)\end{equation}
GGNN在所有节点上多次执行循环函数,当它应用于大型图时,可伸缩性可能会面临问题。
其中 $\delta(\cdot)$是非线性激活函数,如ReLU, $\mathbf{W}^{(l)}$为第$𝑙$层的可学习变换矩阵,$\mathbf{E}$为超图邻接矩阵,$ \mathbf{D}_{e}$和$\mathbf{D}_{v}$分别代表边的度矩阵和结点的度矩阵,他们都是对角矩阵。
2.3 为什么要用图神经网络应用于推荐
最主要的直观性原因是在很多领域GNN已经被证明在图数据的表示学习上非常有效,并且很多推荐系统中的数据都是基于图结构。如图1
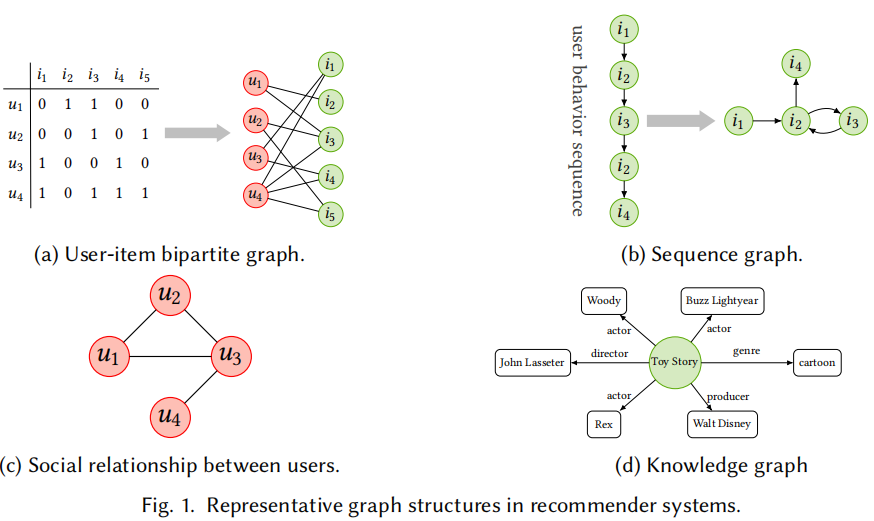
用户-物品交互数据可以被表示为一个用户与物品结点的二部图,其中边表示对应的用户和物品的交互信息。另外,一系列的物品可以被转换为序列图,其中每个物品可以与一个或多个后续物品连接。与原始序列数据相比,序列图在物品与物品之间的关系上具有更大的灵活性。除此之外,一些侧面信息也自然地具有图形结构,如社会关系图和知识图谱。
此外,GNN可以显式编码用户-项目交互的关键协同信号,通过传播过程增强用户/项目表示。对于一些传统的方法,GNN对于从用户-物品交互关系中建模多跳连接是更灵活和更方便的,并且在推荐系统中捕获多跳邻居下的协同过滤信号被证明是很高效的。
2.4 基于GNN推荐系统的分类
根据使用信息的种类和推荐的任务提出了新的系统的分类模式,将其分为:用户-物品 协同过滤(user-item collaborative filtering)、序列化推荐系统(sequential recommendation)、社交化推荐系统( social recommendation)、基于知识图谱推荐系统(knowledge graph-based recommendation)和其他任务(包括POI推荐系统、多媒体推荐系统等)。分类的依据如下:图的结构在很大程度上取决于信息的类型。例如:社交网络可以自然地看作是一个同构图,用户-物品交互关系可以被认为是一个二分图或者是两个同构图(即 用户-用户和物品-物品图)。另外,信息类别在设计高效的GNN结构中扮演了重要角色,比如聚合和更新操作以及网络的深度。例如,知识图谱含有多种类别的实体和关系,因此需要在传播过程中考虑为异构图。而且,推荐系统的任务和被使用信息的类型是高度相关的。例如,社交网络通过利用社交网络信息来构建推荐,知识图谱通过利用物品与物品之间的语义关系来增强物品的表示。因此这篇文章不光从推荐系统的角度,也考虑了GNN的角度来进行上述分类。
3 用户-物品 协同过滤(user-item collaborative filtering)
针对用户-物品交互数据,用户-物品协同过滤的基本思想实质上是利用用户交互过的物品增强用户表示,利用用户与物品交互过的物品丰富物品表示。图2说明了将GNN应用于用户-项交互信息的流程。
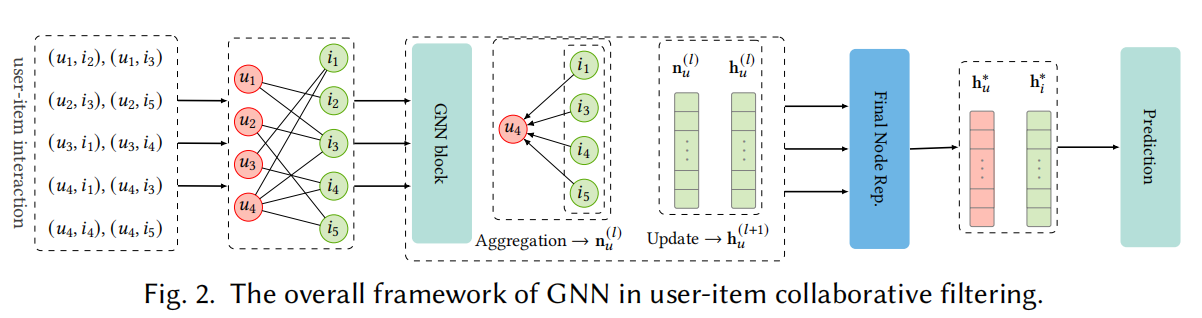
为了充分利用GNN方法从用户-项目交互中捕获协同信号,有四个主要问题需要处理:
•图结构 图结构对于传播信息的范围和类型是必不可少的。原始的二部图由一组用户/项目节点和它们之间的交互组成。是在异构二部图上应用GNN还是构造基于两跳邻居的同构图?考虑到计算效率,如何对图传播的代表性邻居采样,而不是对整个图进行操作?
•邻居聚合 如何聚合来自邻居节点的信息?具体来说,是区分邻居的重要性,是对中心节点与邻居的密切程度进行建模,还是对邻居之间的相互作用进行建模?
•信息更新 如何聚合中心结点表示及其邻居的聚合表示?
•最终结点表示 预测用户对物品的偏好需要总体的用户/物品表示。是使用最后一层的结点表示,还是使用所有层的结点表示的组合作为最终的结点表示?
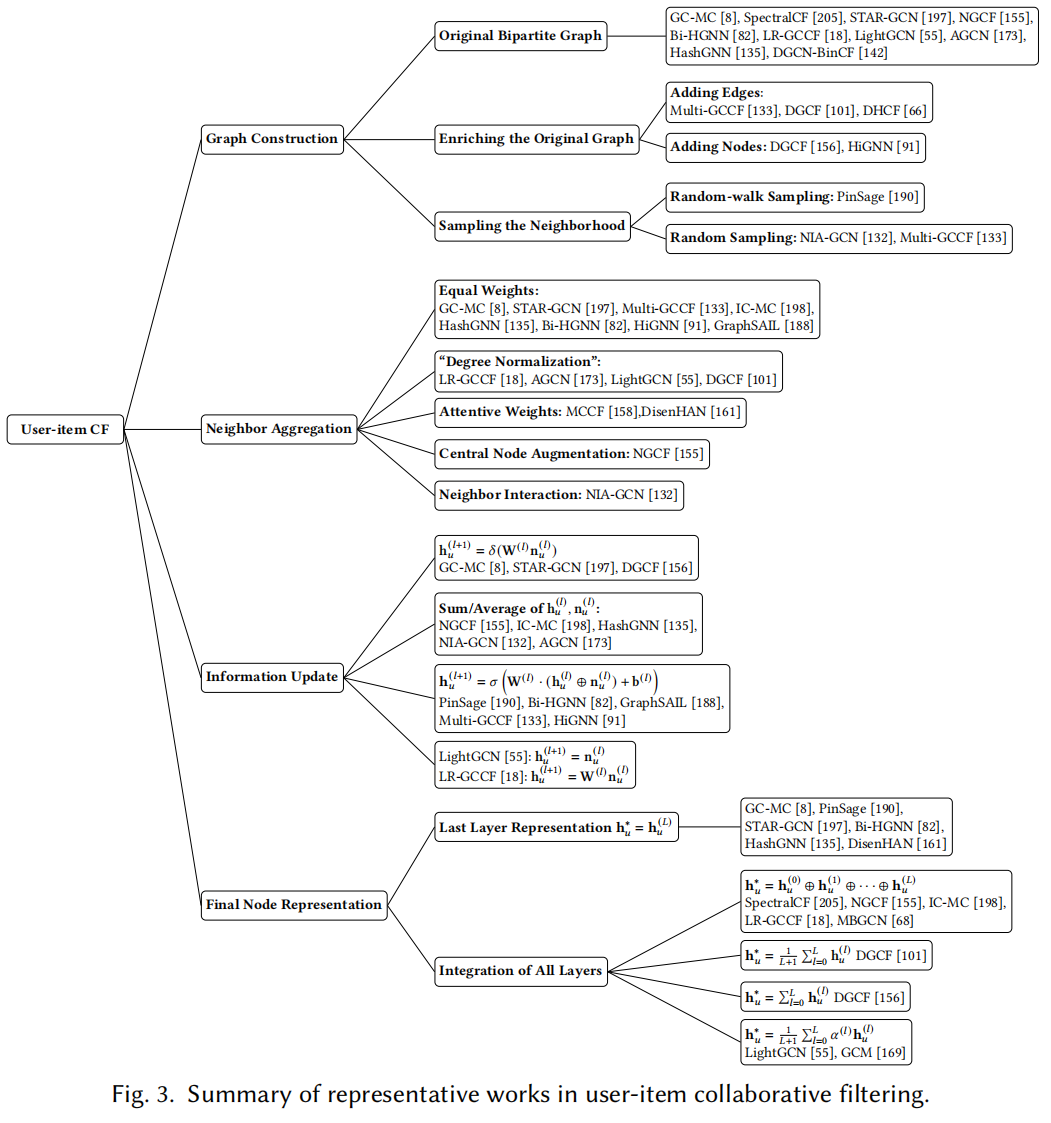
3.1 图构建
很多工作直接使用原始二部图,但有效性和高效性不能保证。一是有效性,原始的图结构可能不足以学习用户/项目表示;另一个是高效性,聚集结点的全部邻域信息需要很高的计算成本,特别是对于大规模的图。
对于有效性,可以通过增加边来丰富图结构信息。此处有很多方法,比如加入二跳邻居和超边来获得用户-用户和物品-物品的信息,通过这种方式,用户和物品之间的接近性信息可以显式地合并到用户-物品交互中;引入超边构建超图,捕获显式混合的高阶相关性;引入虚有的结点增强用户-物品交互性;创建新的粗化的图通过聚合相似的用户/物品并且将聚合后的中心作为新的结点,为乐趣显示捕获用户和物品之间的多层关系。
针对第二个问题,提出了采样策略,使GNN高效且可扩展到大规模基于图的推荐任务。其中有通过随机游走采样的方法,有通过权衡计算量和原图信息采取固定大小的方法。模型的性能取决于采样策略,更有效的邻域构建采样策略值得进一步研究。
3.2 邻居聚合
均值聚合是其中一种最直接的聚合操作,它平等的对待每一个邻居,
\begin{equation}\mathbf{n}_{u}^{(l)}=\frac{1}{\left|\mathcal{N}_{u}\right|} \mathbf{W}^{(l)} \mathbf{h}_{i}^{(l)}\end{equation}
均值池化易于实现,但当邻居的重要性显著不同时可能不合适。在传统GCN的基础上,有些文章采用了“度归一化”。它根据图的结构为节点分配权重,
\begin{equation}\mathbf{n}_{u}^{(l)}=\sum_{i \in \mathcal{N}_{u}} \frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}} \mathbf{W}^{(l)} \mathbf{h}_{i}^{(l)}\end{equation}
有些方法使用内积操作来增加用户关心的产品特性或用户对产品特性的偏好。以用户节点为例,聚合邻居表示计算如下:
\begin{equation}\mathbf{n}_{u}^{(l)}=\sum_{i \in \mathcal{N}_{u}} \frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}}\left(\mathbf{W}_{1}^{(l)} \mathbf{h}_{i}^{(l)}+\mathbf{W}_{2}^{(l)}\left(\mathbf{h}_{i}^{(l)} \odot \mathbf{h}_{u}^{(l)}\right)\right)\end{equation}
3.3 信息更新
根据是否保留节点本身的信息,现有的方法可以分为两个方向。一种是完全丢弃用户或物品节点的原始信息,使用邻居的聚合表示作为新的中心节点表示,这可能忽略了内在的用户偏好或内在的物品属性。另一种是考虑结点本身信息表示和其邻居信息表示来更新结点表示。最直接的方法是用求和或均值池化操作将这两种表示线性组合。受GraphSAGE的启发,一些模型采用带有非线性变换的拼接操作将这两种表示整合如下:
\begin{equation}\mathbf{h}_{u}^{(l+1)}=\sigma\left(\mathbf{W}^{(l)} \cdot\left(\mathbf{h}_{u}^{(l)} \oplus \mathbf{n}_{u}^{(l)}\right)+\mathbf{b}^{(l)}\right)\end{equation}
LightGCN和LR-GCCF观察到非线性激活对全局表示的作用不大。它们通过删除非线性来简化更新操作,从而保持甚至提高性能并提高计算效率。
3.4 最终结点表示
一种主流的方法是使用最后一层的节点向量作为最终表示,即$\mathbf{h}_{u}^{*}=\mathbf{h}_{u}^{(L)}$。但是,在不同层中获得的表示强调通过不同连接传递的消息.具体来说,较低层次的表征更多地反映了个体特征,而较高层次的表征更多地反映了邻居特征。为了利用不同层的输出所表达的联系,最近的研究采用了不同的方法来集成来自不同层的消息。
\begin{equation}\text{Mean-pooling:} \quad \mathbf{h}_{u}^{*}=\frac{1}{L+1} \sum_{l=0}^{L} \mathbf{h}_{u}^{(l)} , \\ \text{Sum-pooling:} \quad \mathbf{h}_{u}^{*}=\sum_{l=0}^{L} \mathbf{h}_{u}^{(l)} , \\ \text{Weighted-pooling:} \quad \mathbf{h}_{u}^{*}=\frac{1}{L+1} \sum_{l=0}^{L} \alpha^{(l)} \mathbf{h}_{u}^{(l)} , \\ \text{Concatenation:} \quad \mathbf{h}_{u}^{*}=\mathbf{h}_{u}^{(0)} \oplus \mathbf{h}_{u}^{(1)} \oplus \cdots \oplus \mathbf{h}_{u}^{(L)} , \\ \end{equation}
其中,$\alpha^{(l)}$是一个可学习的参数。注意到,均值池化和求和池化可以被视为加权池化的两种特殊情况。与均值池化和求和池化相比,加权池化可以更灵活地区分不同层的贡献。在这四种方法中,前三种都属于线性操作,只有拼接操作保留了所有层的信息。
3.5 总结
•图构建 最直接的方法是直接使用原始的用户-项目二部图。如果有些节点在原图中邻居很少,那么通过增加边或增加节点来丰富图的结构是很有效果的。在处理大规模图时,为了提高计算效率,有必要对邻域进行抽样。抽样是有效性和效率之间的权衡,更有效的抽样策略值得进一步研究。
•邻居聚合 当邻居更多的是异构时,采取注意力机制聚合邻居优于权值相等和度归一化的方法;否则,为便于计算,后两种方法更可取。显式建模邻居之间的影响或中心节点与邻居之间的密切性可能带来更好的效果,但需要在更多的数据集上进行验证。
•信息更新 与丢弃原始节点相比,使用原始结点表示和聚合邻居表示更新结点更可取。最近的研究表明,通过去除变换和非线性操作来简化传统的GCN,可以获得比原始GCN更好的性能。
•最终结点表示 要获得总体的用户/物品表示,利用所有层的表示要比直接使用最后一层表示更可取。就整合来自所有层的表示而言,加权池化提供了更大的灵活性,而将各层表示拼接操作保留了来自所有层的信息。
图3总结了针对每个主要问题的典型策略,并列出了相应的代表性作品。
4 序列化推荐系统(sequential recommendation)
序列化推荐系统基于用户最近的活动预测用户的下一个偏好,试图在连续的项目中建模顺序模式,并为用户生成准确的推荐。
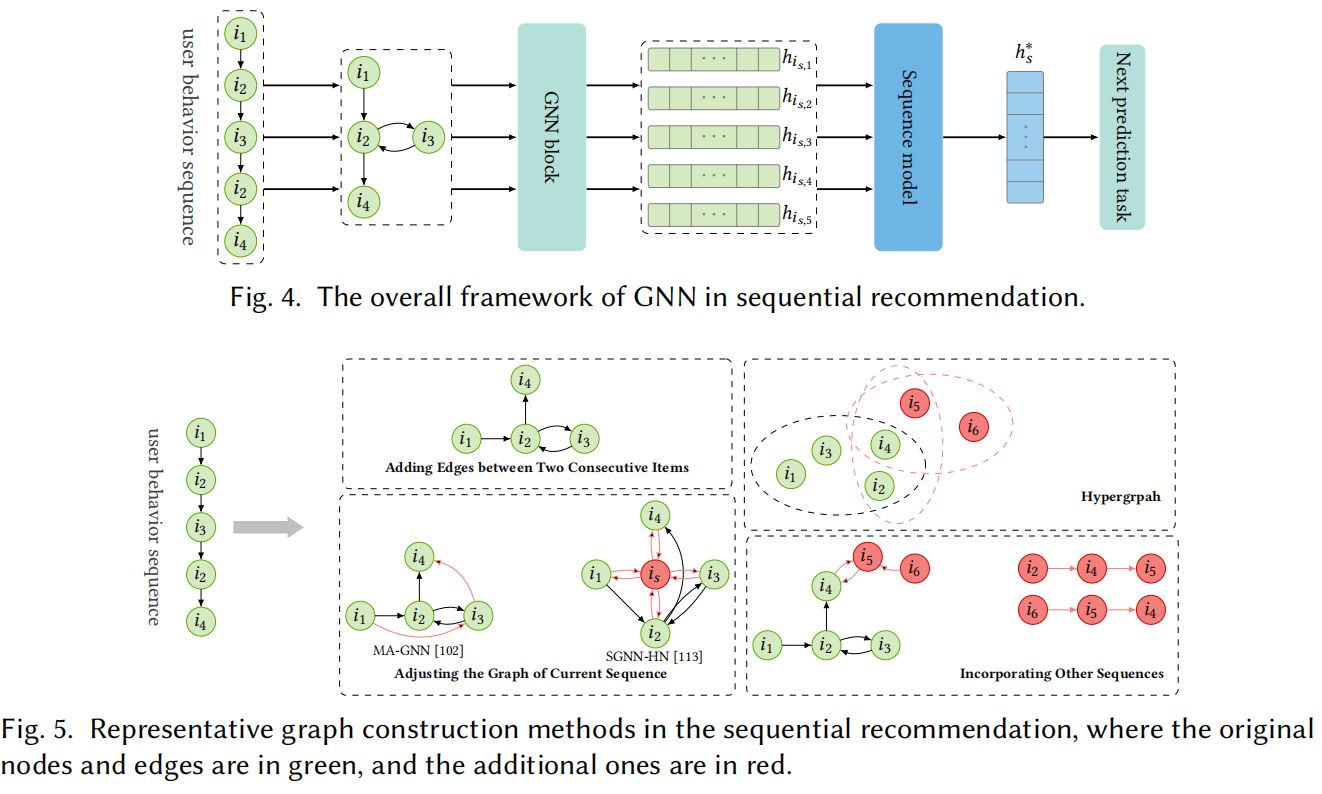
图4展示了顺序推荐中GNN的总体框架。要充分利用GNN与序列化的推荐系统中,主要有三个问题需要处理:
• 图构建 要将GNN应用于顺序推荐,需要将序列数据转化为序列图。是否应该为每个序列单独构造子图?在多个连续物品之间添加边是否比只在两个连续项之间添加边更好?
• 信息传递 要为了捕获转移模式,哪一个传播机制是更合适的?是否需要区分链接物品的系列顺序?
• 序列偏好 为了获得用户在时间上的偏好,应该整合序列物品的表示。是否应该应用注意力机制的池化操作还是利用RNN结构来增强连续时间上的信息?
4.1 图构建
不同于用户-物品交互本质上具有二部图结构,用户的顺序行为自然地以时间顺序表示,即序列,而不是序列图。在原二部图的基础上构建图是可选的,主要受可扩展性或异质性问题的驱动,而基于用户的顺序行为构建序列图是将GNN应用于顺序推荐的必要条件。图5展示了一些用户顺序行为的代表性图构建的策略。
为每个序列构建有向图,将序列中的每个项视为节点,并在连续单击的两个项之间添加边是很直接的方法。然而,在大多数情况下,用户序列的长度是短的,例如在预处理的Yoochoose1/4数据集上的平均长度是5.71。从简单和短的由很少数目的结点和边构建的序列图、甚至一些结点可能只含有一个邻居,它们包含了太少的信息来反映用户动态的偏好并且不能在图学习过程中充分利用GNN。为了应对这一挑战,最近的研究提出了几种丰富原有序列图结构的策略,可分为两大主流。
一种主流方法是利用额外的序列来丰富项目之间的转换。附加序列可以是其他类型的行为序列,同一用户的历史序列,或者整个数据集中的部分/全部序列。例如,HetGNN利用所有的行为序列,在相同序列的两个连续项之间构造边,其行为类型作为边类型。A-PGNN处理用户已知的情况,从而将用户的历史序列与当前序列结合起来,丰富项与项之间的连接。GCE-GNN和date - mdi利用所有会话中的项转换来辅助当前序列中的转换模式。TASRec更加重视最近的转换,以增强最近的转换。DGTN只将相似的会话添加到当前会话中,其假设是相似的序列更可能反映相似的转换模式。这些方法在原始图中引入了更多的信息,与单一序列图相比,提高了性能。
另一种主流的方法是调整当前序列的图结构。例如,假设当前节点对多个连续项有直接影响,
太长啦,越到后来越觉得变成了一个翻译工作,建议读原文吧,原文更清晰明确,而且也详述了各方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号