数据处理的全过程---(获取数据-清洗数据-数据建模-数据可视化)
获取数据:
已有的数据
1. 大家能想到的应该是我们数据库已有的数据
2.数据整理的各种表格数据
3.其他
我们没有的数据
1.爬虫
2.利用大数据的生态圈的工具进行搜集(其实也是在做同样的事情 )
那我们看看爬虫和finbi结合从无数据到数据展示的全过程:
数据的获取:
爬虫:(相关的开源库和框架---请关注本博客的相关动态,也会一一发布相关的信息)这里选择的是爬虫框架scrapy
细节方面:1.mysql redis mogondb 三者结合 或者单独使用 将数据进行保存
2.对爬去目标网站的提取内容的处理(字符串提取 正则表达式的应用 css选择器的使用 extract和extract_first的区别 和get get_all)
3.python的基础语法 和数据库相关知识的应用(最后数据存储有以下几种:1.保存到本地文件中 2.保存到本地或者服务器数据库中 3.利用大数据生态圈中Hadoop及其他插件做存储)
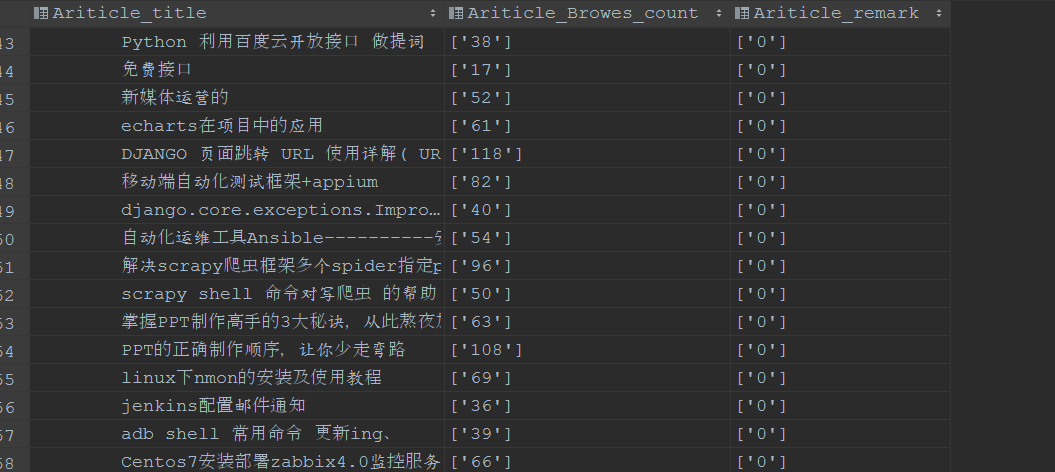
4.如果多个spider 需要考虑在一个scrapy中运行多个spider
5.后期数据量变大 或者服务器部署了其他应用 需要考虑分布式来做高可用
6.数据展示方面和处理 (展示用finbi 不限于这一种 处理用到的数学知识(也可以考虑大数据生态圈中的相关技术) Python扩展件对数据的处理 )
7.太多了.........
今天先说:finBI
FinBI如果商用是需要收费的(作为技术出生的你 我相信你是有办法的---------- 调皮)
首页就是这个样子了!!这里不解释怎么操作 提供一种可以实现可话的选择
它的操作文档和使用说明书:https://help.finebi.com/doc-view-62.html
重点在于:数据建模
1.我想要通过数据了解什么
2.除了这个维度能不能通过其他维度持有更多的信息
3.怎样计算使的信息更加准确
4.如果是运营人员使用的工具(维度非常重要)
5.其他
