使用GPU
使用场景
物理机上GPU卡被挂载到容器中,容器中安装GPU驱动来管理GPU。
约束
k8s对GPU设备的管理只能处理设备个数这一种情况。
GPU产品有AMD和NVIDIA,在k8s中对应amd.com/gpu和nvidia.com/gpu。
GPU数量只能设置在limits,requests默认与limits相同,不支持小数,独占GPU。
GPU插件通过gRPC与kubelet交互
1. 在Pod的limits字段声明nvidia.com/gpu: 1,kube-scheduler完成调度。
2. 针对kubelet的Allocate请求,Device Plugin根据kubelet传递过来的设备ID,把设备路径(例如/dev/nvidia0)和驱动目录(例如/usr/local/nvidia/*)返回给kubelet。
3. kubelet把这些信息放到创建容器的CRI请求中。其中,GPU设备路径是该容器启动时的Devices参数,驱动目录是容器启动时的Volume参数。
查看内核加载的nvidia模块
lsmod | grep ^nvidia2张GPU卡场景
机器上有GPU之后,安装驱动(宿主机)和CUDA(容器镜像,上层应用程序库)才能使用。
只有真实存在GPU卡,才能成功安装GPU驱动。
安装GPU驱动后,有2张GPU卡时,/dev目录下生成5个文件nvidiactl(与nvidia+数字这个文件一起出现)、nvidia-uvm(与nvidia-uvm-tools一起出现)、nvidia-uvm-tools、nvidia0、nvidia1。
谷歌GPU插件github.com/GoogleCloudPlatform/container-engine-accelerators,根据正则表达式^nvidia[0-9]*$,在/dev目录下找GPU设备,nvidia0和nvidia1表示2个GPU设备。
创建假的GPU设备
构造假文件
mknod命令用于创建字符设备文件和块设备文件。
mknod [选项] [文件名称] [文件类型] [主设备号] [次设备号]
ll /dev结果显示b开头和c开头的,即标识了块设备和字符设备。
为了管理设备,设备中都有两个设备号。
主设备号用于区分不同类型的设备,次设备号用于区分同一设备下不同子设备。
例如 通过ls /dev/null -l ,查看null设备:
crw-rw-rw- 1 root root 1, 3 2017-08-16 15:32 null
c开头,所以null设备为字符设备,主设备号为1,次设备号为3
mknod /dev/nvidiactl c 50 0
mknod /dev/nvidia-uvm c 50 1
mknod /dev/nvidia-uvm-tools c 50 2
mknod /dev/nvidia0 c 50 3
mknod /dev/nvidia1 c 50 4编译部署谷歌GPU
cd $GOPATH/src
mkdir -p github.com/GoogleCloudPlatform
cd github.com/GoogleCloudPlatform/
git clone https://github.com/GoogleCloudPlatform/container-engine-accelerators.git
cd container-engine-accelerators
git checkout stable
docker build -t nvidia-gpu:v1.0 .
# 覆盖原有daemonset.yaml
cp $GOPATH/src/k8s.io/kubernetes/cluster/addons/device-plugins/nvidia-gpu/daemonset.yaml ./
# 修改daemonset.yaml中容器镜像为nvidia-gpu:v1.0,去掉nodeAffinity
vim daemonset.yaml
kubectl create -f daemonset.yaml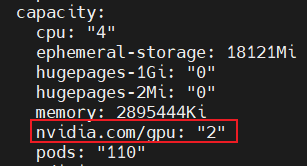
节点kubelet上报有2个GPU。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号