《Fundamentals of Computer Graphics》第八章 视图
开篇
上一章主要讲了使用变换矩阵和改变坐标系统。有一个次重要的一点就是使用矩阵在物体的三维位置和物体在二维视图的位置之间进行变换。其中三维到二维的映射叫做视图变换(Viewing Transformation),这种映射在物体顺序渲染中很重要,因为这种渲染方式需要我们快速地为场景中的每个物体找到它在图像空间的位置。第四章讲的光线追踪,涵盖了透视视图和正交视图,以及如何为给定的视图生成光线,这章讲的就是这个过程的反向过程,即如何使用矩阵变换来表达任意平行或透视视图。
要注意的是把点从世界映射到图像上只能很好地进行线框(Wireframe)渲染,也就是只能看到被绘制的物体的边缘部分,如下图所示。而且更近的物体可能不会遮蔽更远的物体,就像光线追踪器需要为每个视线找到最近的交点一样,一个能显示物体实体表面的基于物体顺序的渲染器,需要在影响相同像素着色的所有表面中挑选出最近的表面。在这章,我们假设模型只由三维线段组成,后面的章节将会讨论渲染实体表面所需要的机制。
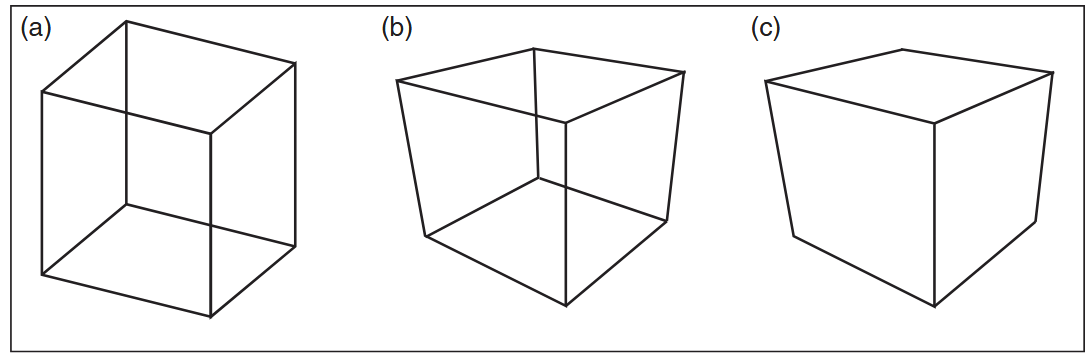
视图变换(Viewing Transformation)
视图变换的作用就是把规范坐标系统的\((x,y,z)\)三维位置映射到以像素为单位的图像中,不过这稍微有点复杂,因为依赖于相机的位置和朝向还有投影类型、视场、图像的分辨率。和其它的很多的复杂变换一样,我们最好把视图变换拆解为几个更简单的变换,许多图形系统通过一序列的三个变换来达到视图变换。
-
一个相机变换或者眼变换:它是一个刚体变换,通过把一个有着便捷朝向的相机放到原点来做到,只取决于位置、朝向或者相机的姿态。
-
一个投影变换:它会变换在相机空间中的点并且让可见的点都落在\(x,y \in [-1,1]\)的归一化坐标空间内,它只取决于投影的类型。
-
一个视口变换(Viewport Transformation)或窗口变换(Windowing Transformation):它把单位的图像矩形映射到期望的像素坐标矩形内,它只取决于输出图像的大小和位置。
为了更好的描述如下图所示的过程的几个阶段,我们给予一些坐标系统名字。
![img]()
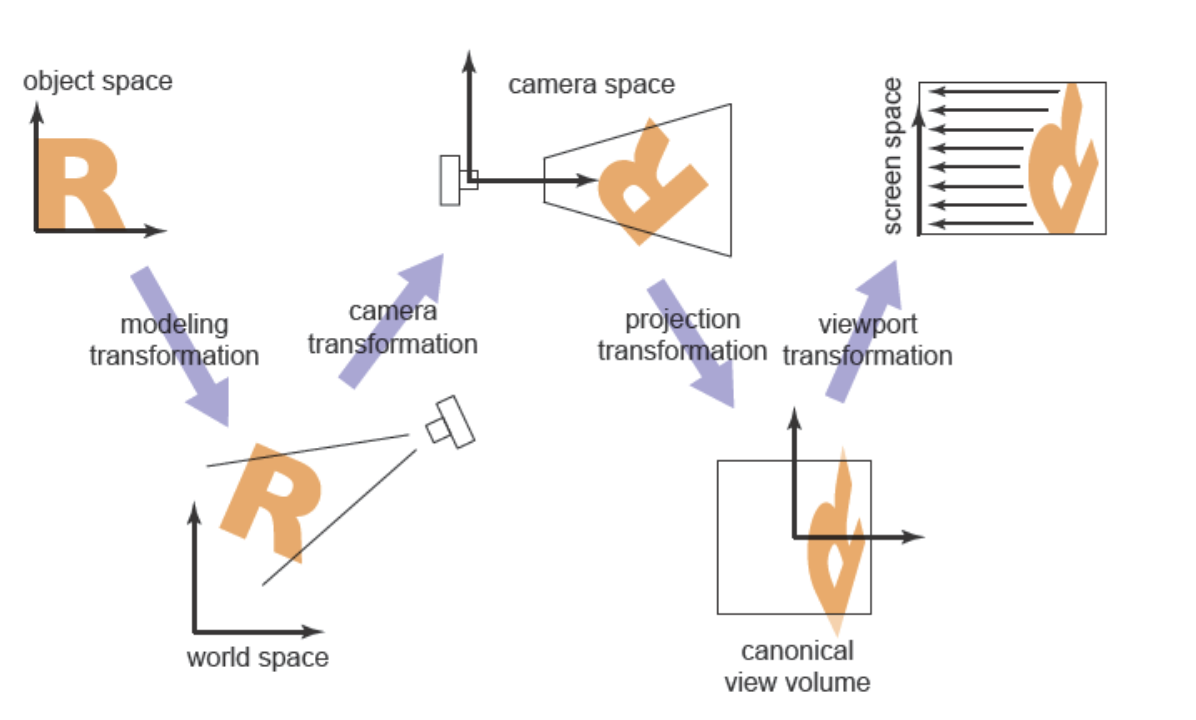
相机变换把规范坐标系内的坐标转换到相机空间(Camera Space)中,投影变换把相机空间中可见的点变换到规范视图体(Canonical View Volume)内,视口变换在最后把规范视图体映射到屏幕空间(Screen Space)。这几个单独的变换都很简单,下面先从正交投影开始,后续会覆盖支持透视投影所需要的改变。
视口变换(Viewport Transformation)
我们假设被看到的物体最后都在规范视图体内,而且期望有个正交相机朝着\(+z\)方向观察。规范视图体是个立方体,它包含着笛卡尔坐标在\([-1,1]\)之内的所有三维点,也就是\((x,y,z) \in [-1,1]^3\),如下图所示。我们把\(x=-1\)投影到屏幕左边,把\(x=1\)投影到屏幕右边,把\(y=-1\)投影到屏幕底边,把\(y=1\)投影到屏幕顶边。如果屏幕左下角的像素的中心坐标为\((0,0)\)且像素边长为一单位,那么对于一个每排\(n_x\)像素和每列\(n_y\)像素的屏幕,我们得把正方形\([-1,1]^2\)映射到矩形\([-0.5,n_x-0.5] \times [-0.5,n_y-0.5]\)。
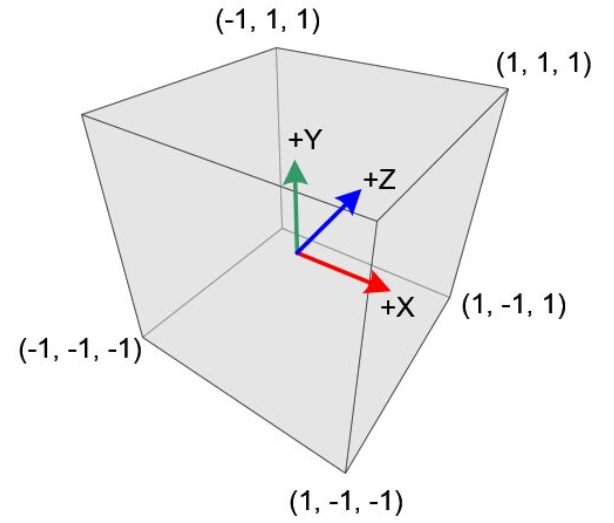
出于初学的目的,我们先假设所有被绘制的线段在被变换后都完全处于规范视图体内。不过,当我们之后讨论裁剪(Clipping)时会取消这个限制。因为视口变换只是映射矩形,所以视口变换可以如下所示
要注意的是式子中的矩阵忽视了\(z\)坐标,因为点沿着投影方向的距离和它所影响的像素位置无关。在正式称之为视口矩阵(Viewport Matrix)前,我们增加一行和一列来支持\(z\)坐标,
当前这个章节不需要这些,不过当我们想让更近的表面遮蔽更远的表面时会用到\(z\)值。
正交投影变换(The Orthographic Projection Transformation)
当然了,被看到物体一般都不会直接处于规范视图体内,我们需要把位于相机空间的视图体内的物体变换到规范视图体中。我们首先确定相机空间中的相机的观察方向为\(-z\)方向并且以\(+y\)为向上方向,对于正交投影来说,相机空间内的视图体为\([l,r] \times [b,t] \times [f,n]\),我们称这个视图体为正交视图体(Orthographic View Volume),它的包围平面为:
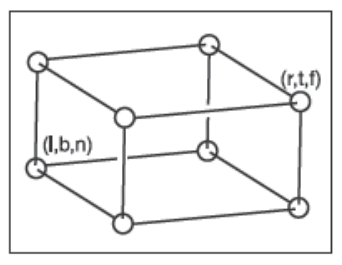
由于我们确定了观察方向为\(-z\)方向并且以\(+y\)为向上方向,这会导致\(n>f\),可能看起来怪怪的。不过考虑到整个正交视图体都有负\(z\)值,\(z=n\)的近平面有着更大的\(z\)值因此离观察者最近,下图是一个正交视图体的直观展示。
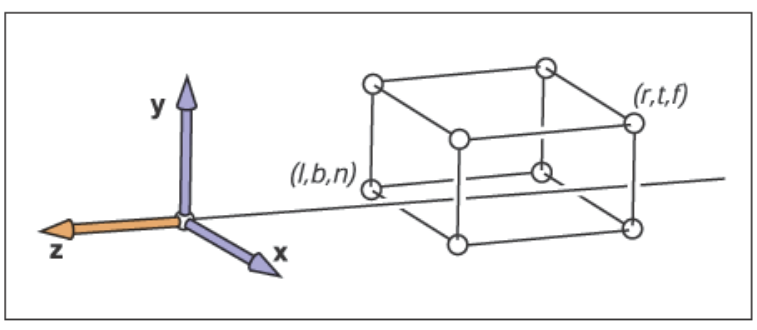
从正交视图体到规范视图体的变换其实是另外一种窗口变换,因此正交投影变换矩阵为
相机变换(The Camera Transformation)
我们通常可能想在世界空间中的任意位置摆放有着任意朝向的相机,通过相机变换我们就能把位于世界空间中的物体变换到相机空间中,为此我们需要
- \(\mathbf{e}\):眼睛位置
- \(\mathbf{g}\):视线方向
- \(\mathbf{t}\):向上向量(辅助向量)
![img]()
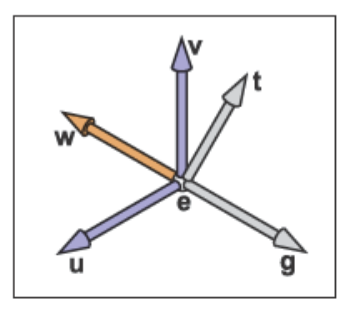
要注意的是这里的向上向量\(\mathbf{t}\)只是一个辅助向量,它会把观察者的头分成两半,而且对于站在地面上的人来说会指向天空。有了这些信息,我们就能构建一个坐标系统,以\(\mathbf{e}\)为原点,以\(\mathbf{uvw}\)为基,如上图所示。利用第二章提到的知识,我们可以这样得到基向量
得到标准正交基后,接下来我们利用上一章提到的坐标系统之间转换的知识,把规范坐标系内的物体变换到相机空间中,变换矩阵为
使用这个矩阵变换后,相机会位于相机空间中的原点,并且以\(+y\)为向上方向,向\(-z\)方向观察,这就对应了上一部分开头对相机做的假设。这里你可能会问为什么会朝着\(-z\)观察,这是因为\(\mathbf{w} = - \mathbf{g}/||\mathbf{g}||\),所以观察方向\(\vec{g}\)在相机空间中为\(-z\)。综上,用于把规范坐标系内的物体投影到屏幕空间的矩阵\(\mathbf{M}\)为
透视投影变换
透视投影变换和正交投影变换一样,都是要把相机空间内的视图体变换到规范视图体,不过透视投影变换的视图体和正交投影变换的六面体不一样。下图是这两者的区别
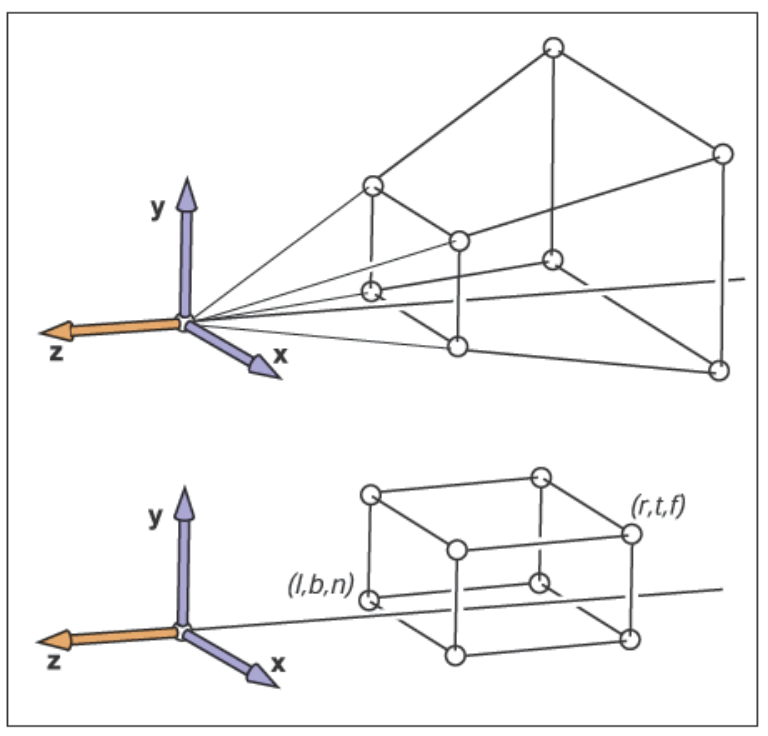
我们称透视投影变换的视图体为视锥台(View Frustum),它是一个视锥体被近平面截去后所获得的一个棱台。在这里,我们假设视锥台是对称的,接下来要做的就是把这种视锥台映射映射到规范视图体\([-1,1]^3\)。
对于视锥台内某点的变换,可能很难想出来。但是我们可以这么想,对于从相机空间的原点出发,并且经过视锥台的任意光线来说,这上面的点在屏幕空间中都会有相同的\(x\)坐标和\(y\)坐标。于是第一步就是找到光线和相机空间中的图像平面的交点。
对于上述这种光线,我们可以把它看作是位置关于\(z\)坐标的函数,即
假设相机空间中的图像平面离相机空间的原点的距离为\(d\),那么光线与图像平面的交点为
我们令交点为\((x_1,y_1,-d)\)。获得与图像平面的交点后,接着就能通过一次平移变化把交点的\(x\)、\(y\)坐标变换到屏幕空间中的\(x\)、\(y\)坐标。又因为从屏幕空间变换到规范视图体只是一次逆的平移变换加上一次逆的缩放变换,于是这个时候能得出一个结论:我们只需要一次缩放变换就能把交点的\(x\)、\(y\)坐标变换到在规范视图体内的\(x\)、\(y\)坐标。假设被渲染的图像的宽和高分别为\(w\)和\(h\),那么交点的\(x\)、\(y\)坐标的变换公式分别为
那么对于光线上任意一点\((x_2,y_2,z_2)\),我们先把它线性缩放到图像平面上,缩放因子为\(-d/z_2\),接着再进行线性变换。于是有如下公式
在实践中,我们通常不会用到图像平面相关的信息,取而代之的是和近平面或FOV相关的信息。假设近平面的坐标为\(z=n\),且它的左边和右边分别有\(x=l\)和\(x=r\),它的底边和顶边分别有\(y=b\)和\(y=t\)。利用相似关系我们可以得到
因此,对于视锥台内任意一点\(\mathbf{p}(x_p,y_p,z_p)\)来说,它的\(x\)坐标和\(y\)坐标的变换公式分别为
到这里就完成了\(x_p\)和\(y_p\)的变换,这个时候你可能会想当然地认为\(z_p\)的变换会利用近平面和远平面进行线性变换,且公式如下
然而实际情况却不是这样,通过翻阅用于不同图形API的数学库,你会发现这些数学库用到的透视投影矩阵都会非线性地映射\(z\)坐标到\([0,1]\)。GLM中的右手透视投影perspectiveRH_NO用到的变换如下
当\(z=n\)时,\(z^\prime=-1\)。当\(z=f\)时,\(z^\prime=1\)。而DirectXMath中的右手透视投影XMMatrixPerspectiveFovRH用到的变换如下
当\(z=n\)时,\(z^\prime=0\)。当\(z=f\)时,\(z^\prime=1\)。这里要说明一下,因为Direct3D用到的规范视图体的\(z\in [0,1]\),所以配套的DirectXMath数学库使用的是这种变换。这种非线性映射实际上是为了更好地分配精度,来让近处的深度精度更高,从而不易观察出瑕疵。而对于我们的情况来说,可以直接使用GLM中的perspectiveRH_NO函数所用到的变换。因此\(x_p\)、\(y_p\)、\(z_p\)的变换分别为
观察上三式会发现这三个分量的变换都得除以\(z_p\),但是我们的\(4\times4\)矩阵不能直接完成这件事。于是这个时候得利用齐次坐标,我们先赋予\(\mathbf{p}\)齐次坐标到\(\mathbf{p}(x_p,y_p,z_p,1)\)。对于以上三个分量的变换,我们先不考虑\(1/z_p\)对变换的影响,即为每个分量的变换计算除了\(1/z_p\)之外的部分,另外我们还让变换后的齐次坐标\(w^{new}_p\)等于\(z_p\),这样就把\(\mathbf{p}(x_p,y_p,z_p,1)\)变换到了四维空间内,这个变换如下所示
我们称等式右侧的矩阵为透视投影变换矩阵,变换后的\(\mathbf{p}^{new}\)的四个分量分别为
最后我们利用\(w^{new}_p\)进行一次透视除法也称为齐次化(Homogenize),从而得到\(\mathbf{p}^{\prime}=\mathbf{p}^{new}/w^{new}_p\)。
透视变换的一些属性(Some Properties of the Perspective Transform)
透视变换的一个重要的属性就是直线被变换后依旧是直线,平面被变换后依旧是平面。下面我们证明这一点,现有相机空间内的两点\(\mathbf{q}\)、\(\mathbf{Q}\),我们用参数\(t\in[0,1]\)描述线段\(\mathbf{qQ}\)
令这两个点在四维空间内的坐标分别为\(\mathbf{r}\)和\(\mathbf{R}\),使用透视矩阵\(\mathbf{M}\)变换可得
齐次化后的三维线段为
经过暴力运算后可重写成
而\(f(t)\)为
视场(Field-of-View)
视场即FOV(Field-of-View),它是透视投影变换部分提到的边缘视线与观察方向\(\vec{g}\)之间的夹角的两倍,我们令它为\(\theta\)。之前的部分提到的透视变换矩阵为
\(y\)的缩放因子为
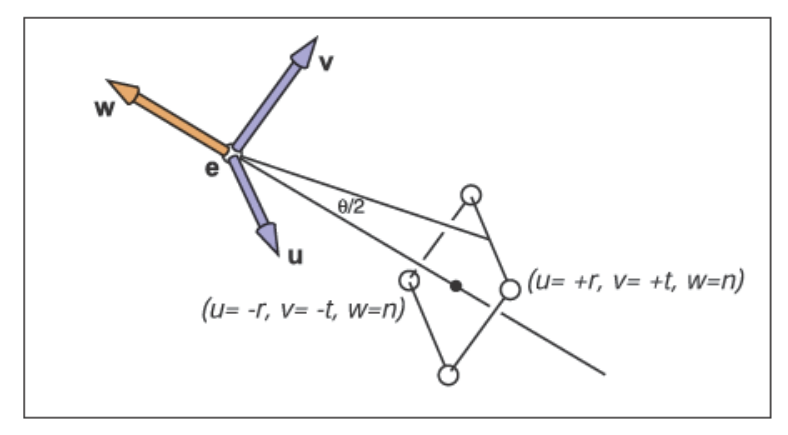
由上图易得\(\theta\)和它的关系为
因此我们可以通过视场\(\theta\)、近平面和远平面的\(z\)值的绝对值\(|n|\)和\(|f|\)、输出图像的宽高比\(\mathrm{AspectRatio}\)得到透视变换矩阵。下面分别列举GLM(perspectiveRH_NO)和DirectXMath(XMMatrixPerspectiveFovRH)用到的右手透视变换矩阵\(\mathbf{M}\)。
本文来自博客园,作者:TiredInkRaven,转载请注明原文链接:https://www.cnblogs.com/TiredInkRaven/p/18917149

 浙公网安备 33010602011771号
浙公网安备 33010602011771号