第三次作业:卷积神经网络
第三次作业:卷积神经网络
0x00 绪论
卷积神经网络的应用
- 分类
- 检索
- 检测
- 分割
- 人脸识别
- 人脸表情识别
- 图像生成
- 图像风格转化
- 自动驾驶
传统神经网络vs卷积神经网络
深度学习三部曲
-
搭建神经网络结构
-
找到一个合适的损失函数
交叉熵损失(cross entropy loss)、均方误差(MSE)...
-
找到一个合适的优化函数,更新参数
反向传播(BP)、随机梯度下降...
损失函数
- 给定W,可以由像素映射得到类目得分
- 损失函数是用来衡量吻合度的
- 可以调整参数/权重,使得映射的结果和实际类别吻合
- 常用分类损失
- 交叉熵损失:\(Loss=-\sum\limits_iy_i\ln{y_i^p}\)
- hinge loss:\(L(y,f(x))=max(0,1-yf(x))\)
- ...
- 常用回归损失
- 均方误差:\(MSE=\sum\limits^n_{i=1}\left(y_i-y_i^p\right)^2\)
- 平均绝对值误差(L1损失):\(MAE=\sum\limits^n_{i=1}\left|y_i-y_i^p\right|\)
- ...
对比
- 全连接网络处理图像的问题
- 参数太多多:权重矩阵的参数太多\(\to\)过拟合
- 卷积神经网络的解决方式
- 局部关联,参数共享
0x01 基本组成结构
卷积
一维卷积
- 常用在信号处理中,用于计算信号的延迟累积
- f为滤波器(filter)或卷积核(convolutional kernal)
- 设滤波器f长度为m,它和一个信号序列x的卷积记为\(y_t =\sum\limits_{k=1}^mf_k·x_{t-k+1}\)
卷积是什么
- 卷积是对两个实变函数的一种数学操作
- 在图像处理中,图像是以二维矩阵的形式输入到神经网络的,因此我们需要二维卷积。
涉及到的基本概念
- input:输入
- kernel/filter:卷积核/滤波器
- weights:权重
- receptive field:感受野
- activationmap / feature map:特征度
- depth/channel:深度
- output:输出
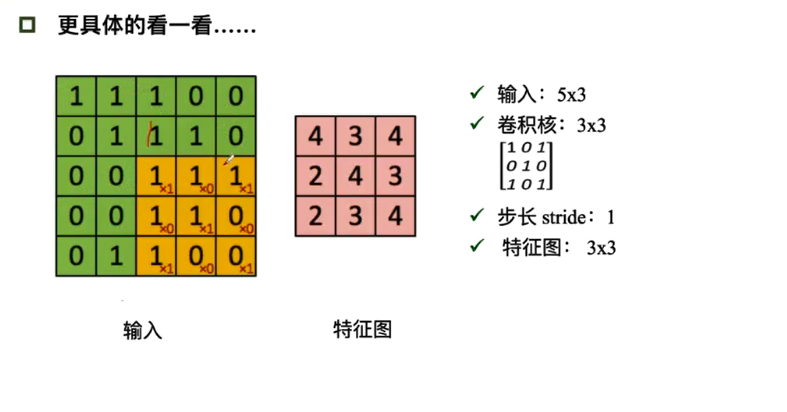
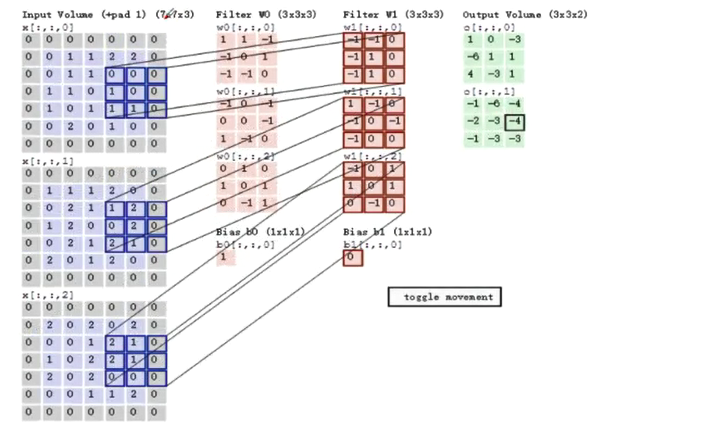
输出特征图的大小:\((N-F)/stride+1\)(未加padding)
有padding时输出的特征图大小\((N+padding*2-F)/stride+1\)
池化(pooling)
- 保留了主要特征的同时减少参数和计算量,防止过拟合,调高模型泛化能力。
- 它一般处于卷积层与卷积层之间,全连接层与全连接层之间。
Pooling的类型
- Max pooling:最大值池化
- Average pooling:平均值池化
全连接(FC Layer)
- 两层之间所有神经元都有权重链接
- 通常在卷积神经网络的尾部
- 参数量通常最大
小结
- 一个典型的卷积网络由卷积层、池化层、全连接层交叉堆叠而成
- 卷积是对两个实变函数的一种数学操作
- 局部关联,参数共享
0x02 卷积神经网络经典结构
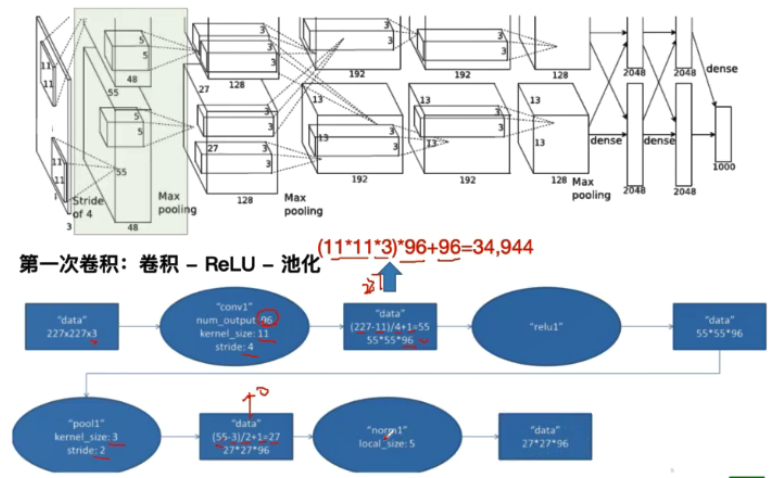
AlexNet
Paper:ImageNet Classification with Deep Convolutional Neural Networks
AlexNet结构图

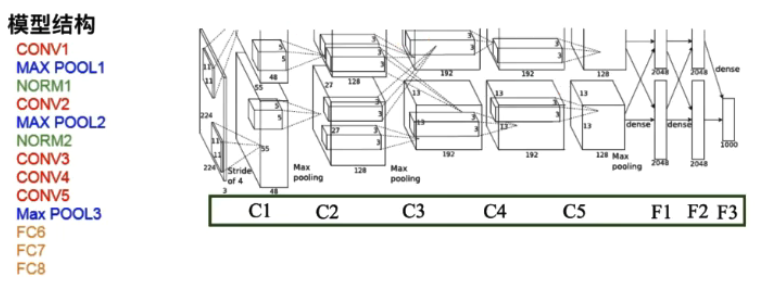
AlexNet成功之处在于:
- 大数据训练:百万级ImageNet图像数据
- 非线性激活函数:ReLU
- 防止过拟合:Dropout,Data augmentation
- 其他:双GPU实现
ReLU
优点:
- 解决了梯度消失的问题(在正区间)
- 计算速度特别快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid
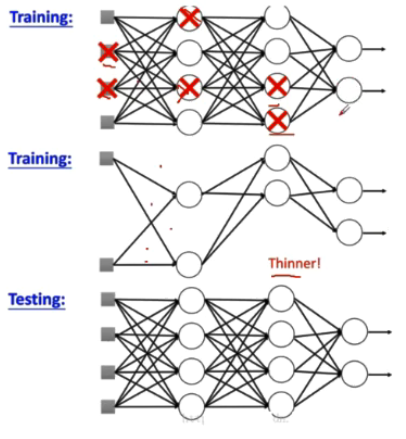
DropOut
训练时随机关闭部分神经元,测试时整合所有神经元
数据增强
-
平移、反转、对称
- 随机crop
- 水平翻转,相当于样本倍增
-
改变RGB通道强度
-
对RGB空间做一个高斯扰动
每个RGB图片的像素\(I_{xy}=\left[I^R_{xy},I^G_{xy},I^B_{xy}\right]^T\)
\(I_{xy}=\left[I^R_{xy},I^G_{xy},I^B_{xy}\right]+\left[p_1,p_2,p_3\right]\left[\alpha_1\lambda_1,\alpha_2\lambda_2,\alpha_3\lambda_3\right]^T\)
-
代码
来自torchvision
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def alexnet(pretrained=False, progress=True, **kwargs):
r"""AlexNet model architecture from the
`"One weird trick..." <https: arxiv.org="" abs="" 1404.5997="">`_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = AlexNet(**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls['alexnet'],
progress=progress)
model.load_state_dict(state_dict)
return model
ZFNet
- 网络结构与AlexNet相同
- 将卷积层1中的感受野大小由11*11改为7*7,步长由4改为2
- 卷积层3,4,5中的滤波器个数由384,384,256改为512,512,1024
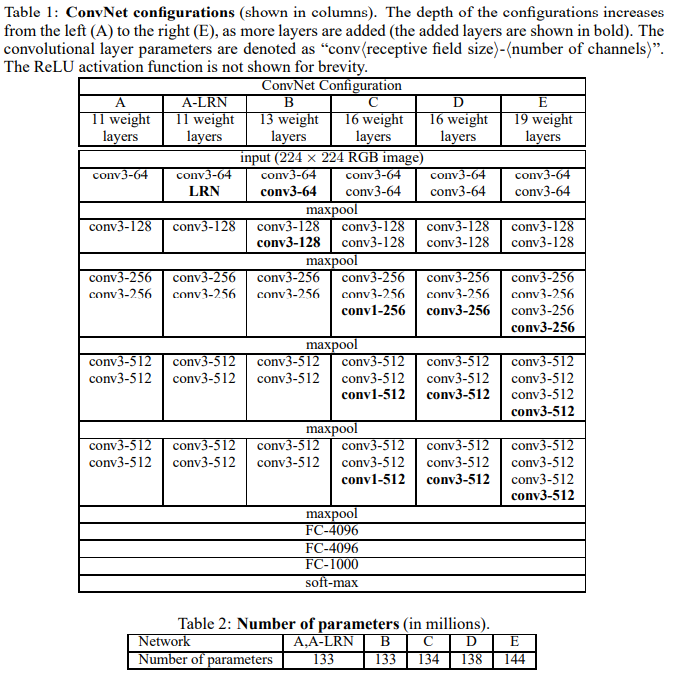
VGG
- 一个更深的网络
Paper:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
结构图:
代码
来自torchvision
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def vgg11(pretrained=False, progress=True, **kwargs):
r"""VGG 11-layer model (configuration "A") from
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)
def vgg11_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 11-layer model (configuration "A") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11_bn', 'A', True, pretrained, progress, **kwargs)
def vgg13(pretrained=False, progress=True, **kwargs):
r"""VGG 13-layer model (configuration "B")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13', 'B', False, pretrained, progress, **kwargs)
def vgg13_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 13-layer model (configuration "B") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13_bn', 'B', True, pretrained, progress, **kwargs)
def vgg16(pretrained=False, progress=True, **kwargs):
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)
def vgg16_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 16-layer model (configuration "D") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
def vgg19(pretrained=False, progress=True, **kwargs):
r"""VGG 19-layer model (configuration "E")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19', 'E', False, pretrained, progress, **kwargs)
def vgg19_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 19-layer model (configuration 'E') with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https: arxiv.org="" pdf="" 1409.1556.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19_bn', 'E', True, pretrained, progress, **kwargs)
GoogleNet
Paper:Going deeper with convolutions
- 网络总体结构:
- 网络包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共有约100个。
- 参数量大概是Alexnet的1/12
- 没有FC层
结构图:
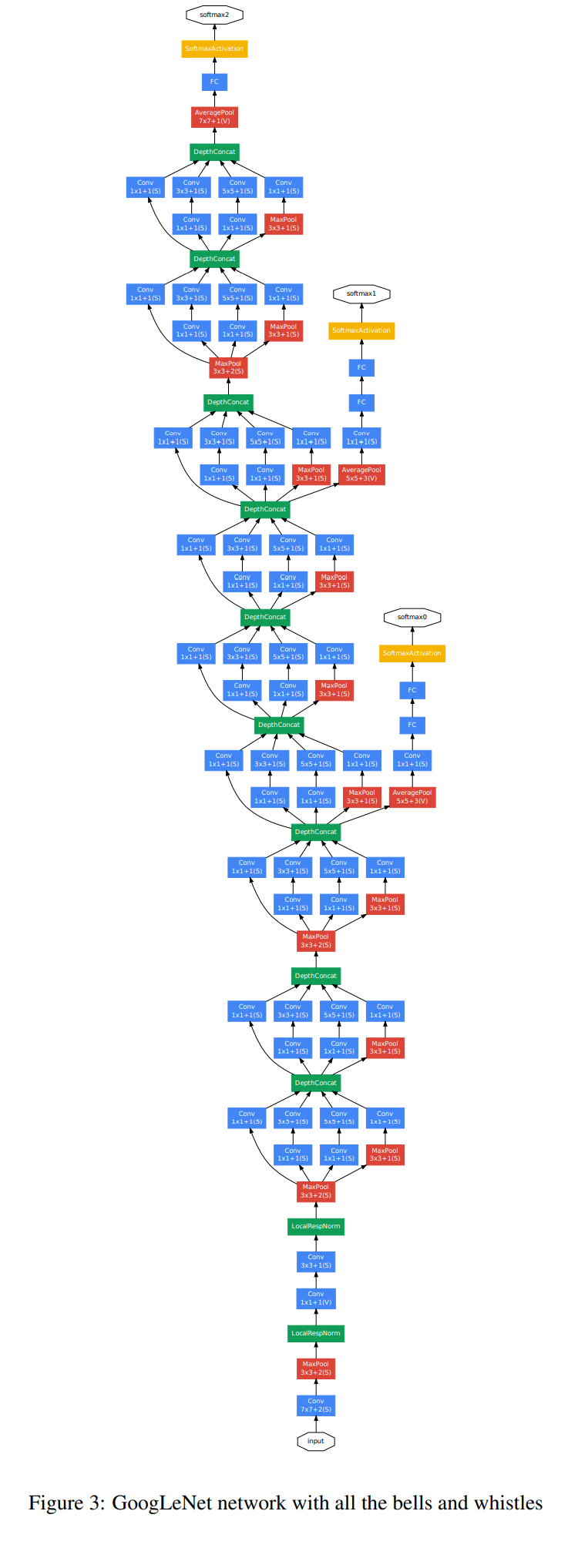
Inception模块
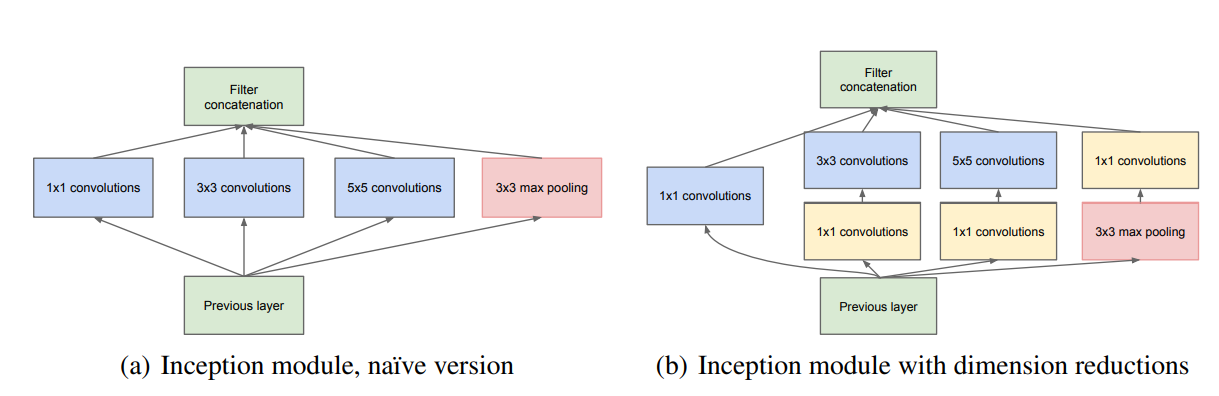
Inception_v1(左) Inception_v2(右)
初衷:多卷积核增加特征多样性
Inception V3
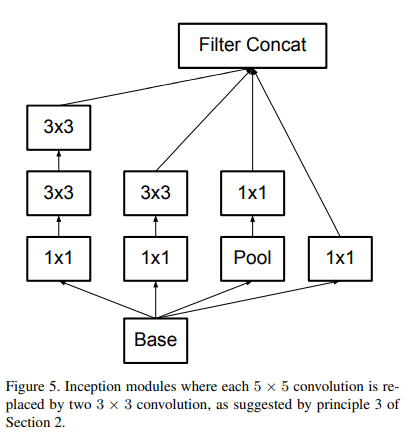
用小卷积核替代大的卷积核
用两个3*3的卷积核代替一个5*5的卷积核,在感受野相同的情况下
- 降低参数量
- 增加非线性激活函数:增加非线性激活函数使网络产生更多独立特征,表征能力更强,训练更快。
Paper:Rethinking the Inception Architecture for Computer Vision
代码
来自torchvision
Inception v2
import warnings
from collections import namedtuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from .utils import load_state_dict_from_url
__all__ = ['GoogLeNet', 'googlenet']
model_urls = {
# GoogLeNet ported from TensorFlow
'googlenet': 'https://download.pytorch.org/models/googlenet-1378be20.pth',
}
_GoogLeNetOutputs = namedtuple('GoogLeNetOutputs', ['logits', 'aux_logits2', 'aux_logits1'])
def googlenet(pretrained=False, progress=True, **kwargs):
r"""GoogLeNet (Inception v1) model architecture from
`"Going Deeper with Convolutions" <http: arxiv.org="" abs="" 1409.4842="">`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
aux_logits (bool): If True, adds two auxiliary branches that can improve training.
Default: *False* when pretrained is True otherwise *True*
transform_input (bool): If True, preprocesses the input according to the method with which it
was trained on ImageNet. Default: *False*
"""
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
if 'aux_logits' not in kwargs:
kwargs['aux_logits'] = False
if kwargs['aux_logits']:
warnings.warn('auxiliary heads in the pretrained googlenet model are NOT pretrained, '
'so make sure to train them')
original_aux_logits = kwargs['aux_logits']
kwargs['aux_logits'] = True
kwargs['init_weights'] = False
model = GoogLeNet(**kwargs)
state_dict = load_state_dict_from_url(model_urls['googlenet'],
progress=progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
del model.aux1, model.aux2
return model
return GoogLeNet(**kwargs)
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False, init_weights=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
return x
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 2048
x = F.dropout(x, 0.7, training=self.training)
# N x 2048
x = self.fc2(x)
# N x 1024
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
Inception v3
from collections import namedtuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from .utils import load_state_dict_from_url
__all__ = ['Inception3', 'inception_v3']
model_urls = {
# Inception v3 ported from TensorFlow
'inception_v3_google': 'https://download.pytorch.org/models/inception_v3_google-1a9a5a14.pth',
}
_InceptionOutputs = namedtuple('InceptionOutputs', ['logits', 'aux_logits'])
def inception_v3(pretrained=False, progress=True, **kwargs):
r"""Inception v3 model architecture from
`"Rethinking the Inception Architecture for Computer Vision" <http: arxiv.org="" abs="" 1512.00567="">`_.
.. note::
**Important**: In contrast to the other models the inception_v3 expects tensors with a size of
N x 3 x 299 x 299, so ensure your images are sized accordingly.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
aux_logits (bool): If True, add an auxiliary branch that can improve training.
Default: *True*
transform_input (bool): If True, preprocesses the input according to the method with which it
was trained on ImageNet. Default: *False*
"""
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
if 'aux_logits' in kwargs:
original_aux_logits = kwargs['aux_logits']
kwargs['aux_logits'] = True
else:
original_aux_logits = True
model = Inception3(**kwargs)
state_dict = load_state_dict_from_url(model_urls['inception_v3_google'],
progress=progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
del model.AuxLogits
return model
return Inception3(**kwargs)
class Inception3(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False):
super(Inception3, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.Conv2d_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = BasicConv2d(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = BasicConv2d(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = BasicConv2d(80, 192, kernel_size=3)
self.Mixed_5b = InceptionA(192, pool_features=32)
self.Mixed_5c = InceptionA(256, pool_features=64)
self.Mixed_5d = InceptionA(288, pool_features=64)
self.Mixed_6a = InceptionB(288)
self.Mixed_6b = InceptionC(768, channels_7x7=128)
self.Mixed_6c = InceptionC(768, channels_7x7=160)
self.Mixed_6d = InceptionC(768, channels_7x7=160)
self.Mixed_6e = InceptionC(768, channels_7x7=192)
if aux_logits:
self.AuxLogits = InceptionAux(768, num_classes)
self.Mixed_7a = InceptionD(768)
self.Mixed_7b = InceptionE(1280)
self.Mixed_7c = InceptionE(2048)
self.fc = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
stddev = m.stddev if hasattr(m, 'stddev') else 0.1
X = stats.truncnorm(-2, 2, scale=stddev)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
# N x 3 x 299 x 299
x = self.Conv2d_1a_3x3(x)
# N x 32 x 149 x 149
x = self.Conv2d_2a_3x3(x)
# N x 32 x 147 x 147
x = self.Conv2d_2b_3x3(x)
# N x 64 x 147 x 147
x = F.max_pool2d(x, kernel_size=3, stride=2)
# N x 64 x 73 x 73
x = self.Conv2d_3b_1x1(x)
# N x 80 x 73 x 73
x = self.Conv2d_4a_3x3(x)
# N x 192 x 71 x 71
x = F.max_pool2d(x, kernel_size=3, stride=2)
# N x 192 x 35 x 35
x = self.Mixed_5b(x)
# N x 256 x 35 x 35
x = self.Mixed_5c(x)
# N x 288 x 35 x 35
x = self.Mixed_5d(x)
# N x 288 x 35 x 35
x = self.Mixed_6a(x)
# N x 768 x 17 x 17
x = self.Mixed_6b(x)
# N x 768 x 17 x 17
x = self.Mixed_6c(x)
# N x 768 x 17 x 17
x = self.Mixed_6d(x)
# N x 768 x 17 x 17
x = self.Mixed_6e(x)
# N x 768 x 17 x 17
if self.training and self.aux_logits:
aux = self.AuxLogits(x)
# N x 768 x 17 x 17
x = self.Mixed_7a(x)
# N x 1280 x 8 x 8
x = self.Mixed_7b(x)
# N x 2048 x 8 x 8
x = self.Mixed_7c(x)
# N x 2048 x 8 x 8
# Adaptive average pooling
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 2048 x 1 x 1
x = F.dropout(x, training=self.training)
# N x 2048 x 1 x 1
x = torch.flatten(x, 1)
# N x 2048
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits:
return _InceptionOutputs(x, aux)
return x
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionD(nn.Module):
def __init__(self, in_channels):
super(InceptionD, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)
class InceptionE(nn.Module):
def __init__(self, in_channels):
super(InceptionE, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# N x 768 x 17 x 17
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# N x 768 x 5 x 5
x = self.conv0(x)
# N x 128 x 5 x 5
x = self.conv1(x)
# N x 768 x 1 x 1
# Adaptive average pooling
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 768 x 1 x 1
x = torch.flatten(x, 1)
# N x 768
x = self.fc(x)
# N x 1000
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
ResNet
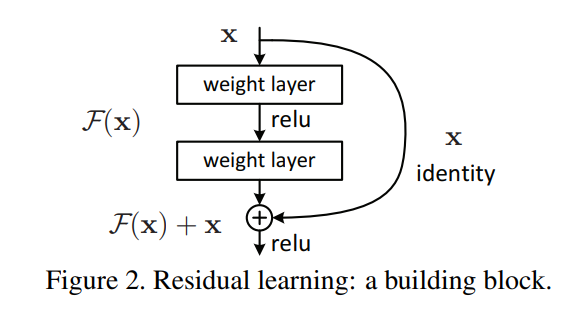
残差学习网络
- 残差的思想:去掉相同的主体部分,从而突出微小的变化。
- 可以被用来训练非常深的网络
Paper:Deep Residual Learning for Image Recognition
残差模块
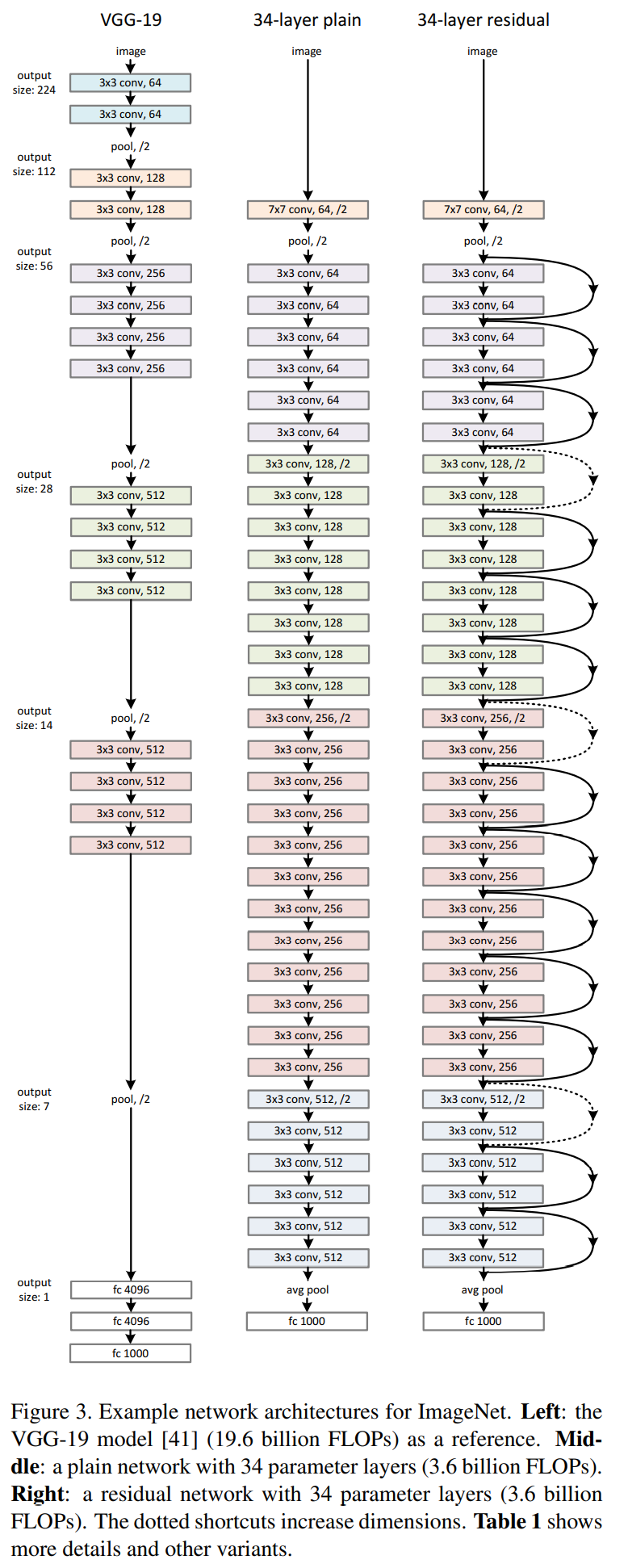
与VGG对比
不同深度网络结构
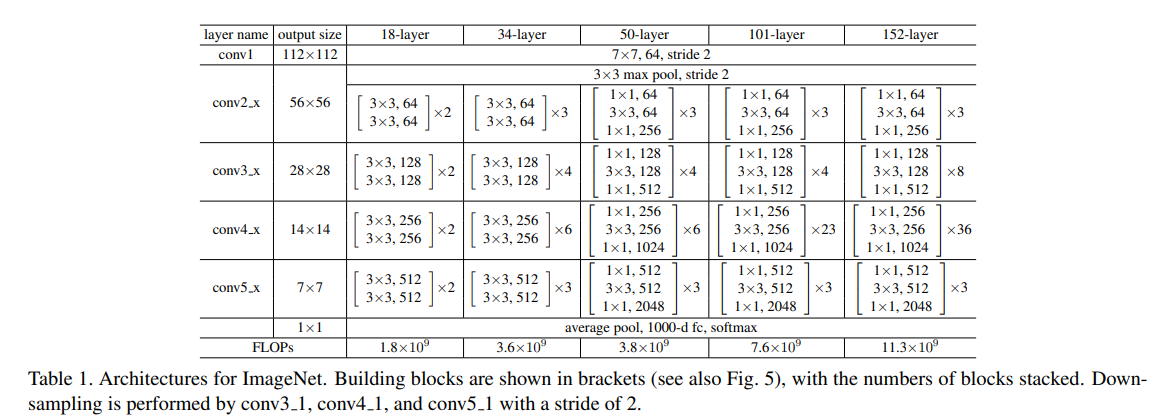
网络更深时采用bottleneck(右)
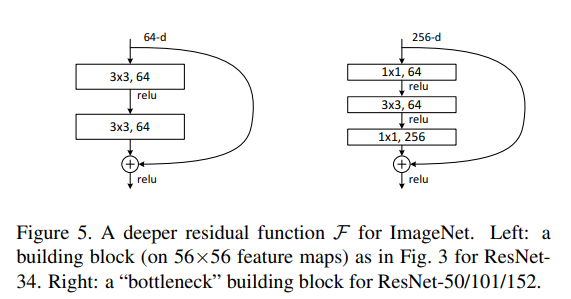
代码
来自torchvision
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
'wide_resnet50_2', 'wide_resnet101_2']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def resnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" <https: arxiv.org="" pdf="" 1512.03385.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
def resnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" <https: arxiv.org="" pdf="" 1512.03385.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" <https: arxiv.org="" pdf="" 1512.03385.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet101(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" <https: arxiv.org="" pdf="" 1512.03385.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
**kwargs)
def resnet152(pretrained=False, progress=True, **kwargs):
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" <https: arxiv.org="" pdf="" 1512.03385.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
**kwargs)
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-50 32x4d model from
`"Aggregated Residual Transformation for Deep Neural Networks" <https: arxiv.org="" pdf="" 1611.05431.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-101 32x8d model from
`"Aggregated Residual Transformation for Deep Neural Networks" <https: arxiv.org="" pdf="" 1611.05431.pdf="">`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-50-2 model from
`"Wide Residual Networks" <https: arxiv.org="" pdf="" 1605.07146.pdf="">`_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" <https: arxiv.org="" pdf="" 1605.07146.pdf="">`_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
0x03 学习心得&问题总结
学习心得
利用全连接网络处理图像,参数量过大,并且容易出现过拟合的现象。
卷积神经网络通过将卷积层、池化层和全连接层交叉堆叠,减少了参数量,并且引入池化层能够在保留主要特征的同时减少参数和计算量,提高模型的泛化能力。从AlexNet开始,到VGG,再到GoogleNet和ResNet,卷积神经网络通过增加多卷积核或者引入跳连式结构等方法,不断增加网络的宽度和深度,用于提高网络的表征能力。同时用多层小卷积核代替大卷积核的方式,在感受野相同的情况下减少了参数量。
问题
DropOut通过在训练时随机临时删掉网络中隐藏神经元的方法,缓解了小数据集训练时过拟合的现象。那为何不在网络设置的时候直接减少隐层神经元的数量,是因为DropOut相比之下有一些别的优点吗?</https:></https:></https:></https:></https:></https:></https:></https:></https:></http:></http:></https:></https:></https:></https:></https:></https:></https:></https:></https:>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号