Kimball 维度建模:数据仓库领域最实用的“用户友好”方法论
在数据仓库和商业智能(BI)领域,Ralph Kimball 被誉为“维度建模之父”。他提出的 Kimball 维度建模 方法论,以其简单易懂、高性能、快速落地的特点,成为全球无数企业和数据团队的首选架构。
不同于 Bill Inmon “先建企业级数据仓库,再建数据集市”的自上而下思路,Kimball 倡导自下而上的构建方式:从具体的业务过程出发,先快速交付能解决实际业务问题的数据集市,最终通过一致性维度拼成企业级数据仓库。
今天,我们就来全面、深入地拆解 Kimball 维度建模,并结合真实业务案例帮你更好地理解和应用。
一、Kimball 建模的核心哲学
以业务过程为驱动,以用户理解和查询性能为目标。
Kimball 认为,数据仓库的最终用户是业务分析师和报表开发人员,而不是数据库专家。因此模型必须像星空一样清晰直观,让非技术人员也能快速看懂。
核心理念:
自下而上(Bottom-Up):先解决一个业务痛点,再逐步扩展。 快速迭代交付:避免大而全的前期规划,直接产出可用数据集市。 用户导向:模型设计围绕“业务人员怎么看、怎么用”来展开。
二、经典的四步设计过程(附案例)
以一家大型电商平台为例,我们来走一遍完整的 Kimball 维度建模四步法。
1. 选择业务过程(Select the Business Process)
选择一个清晰的业务活动。例如:
订单支付过程(最常见的高价值过程)
2. 声明粒度(Declare the Grain)—— 最关键的一步
粒度决定一切。
正确做法:订单中的每一行商品(一行记录代表“2025年4月5日,用户ID=123 在上海门店购买了1件 iPhone16,单价 5999 元”)。
错误做法:按“每天订单汇总”或“每月销售额汇总”作为粒度(这样会丢失大量分析灵活性)。
案例粒度声明:
本事实表的粒度为:每个订单的每个商品行(Order Line Level)。
3. 确定维度(Identify the Dimensions)
回答经典的“Who、What、Where、When、Why、How”问题。
针对电商订单支付过程,常用维度包括:
日期维度(Date Dimension) 产品维度(Product Dimension) 客户维度(Customer Dimension) 门店/渠道维度(Store/Channel Dimension) 支付方式维度(Payment Method Dimension) 促销活动维度(Promotion Dimension)
4. 确定事实(Identify the Facts)
事实表中保存可度量、可聚合的数值指标:
订单金额(Order Amount) 实际支付金额(Paid Amount) 商品数量(Quantity) 折扣金额(Discount Amount) 运费(Shipping Fee) 退款金额(Refund Amount)(如果需要)
三、事实表与维度表的结构(电商案例)
事实表示例:订单事实表(Fact_Order)
| 代理键 | 维度外键 | 度量值 |
|---|---|---|
| order_key | date_key product_key customer_key store_key promotion_key |
order_amount paid_amount quantity discount_amount |
事实表特点:
行数巨大(亿级甚至十亿级) 列数较少 几乎全是外键 + 数值事实
维度表示例:产品维度表(Dim_Product)(Type 2 SCD)
| product_key(代理键) | product_id(自然键) | product_name | category | subcategory | price | start_date | end_date | is_current |
|---|---|---|---|---|---|---|---|---|
| 10001 | P001 | iPhone 16 | 手机 | 智能手机 | 5999 | 2025-09-01 | 9999-12-31 | Y |
| 10002 | P001 | iPhone 16 | 手机 | 智能手机 | 5799 | 2025-03-01 | 2025-08-31 | N |
缓慢变化维(SCD)处理:
当产品价格或分类变化时,采用 Type 2:新增一行记录,保留历史版本。
四、星型模型 vs 雪花模型(强烈推荐星型)
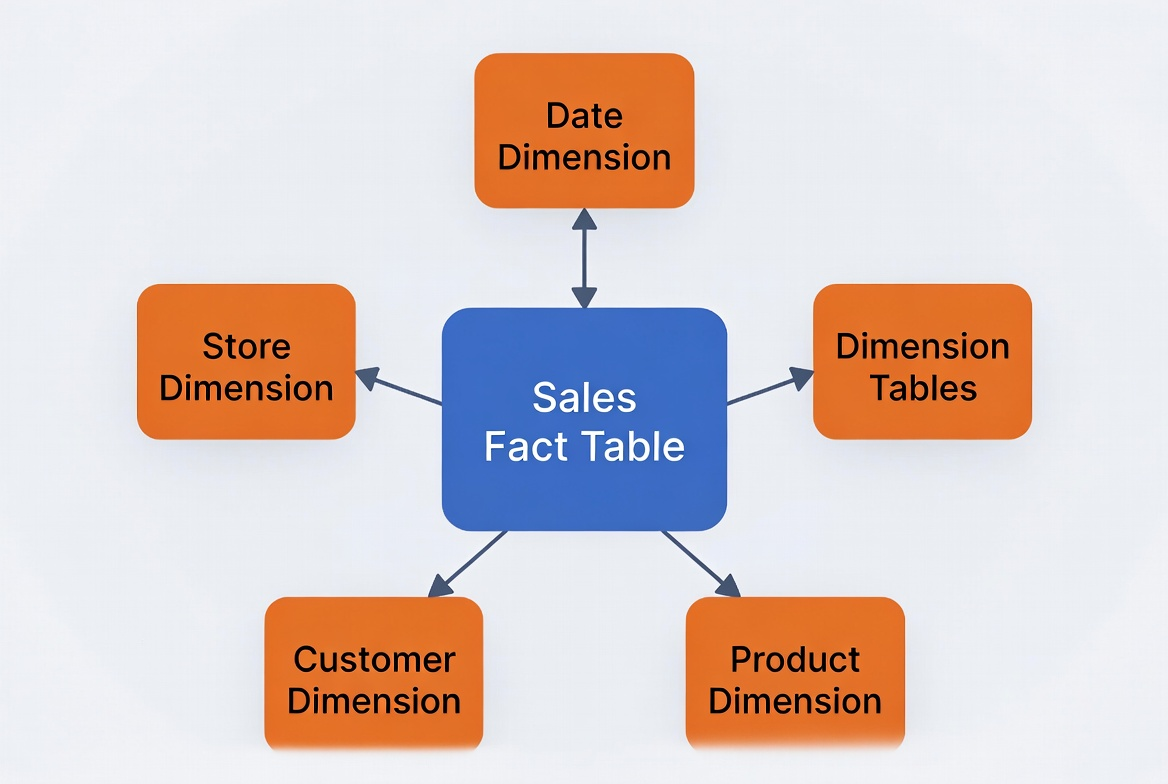
Kimball 强烈推荐星型模型:
Join 操作少 → 查询速度快 模型直观 → 业务人员容易理解 在 ClickHouse、Doris、DuckDB 等现代 OLAP 引擎上性能表现极佳
雪花模型虽然更“规范化”,但会显著增加 Join 次数,在大数据环境下往往得不偿失。
五、企业级总线架构:避免数据孤岛
当你为“销售”“库存”“物流”“营销”分别构建多个数据集市后,如何保证它们能相互关联分析?
解决方案:
一致性维度(Conformed Dimensions):全公司共享同一份“产品维度”“客户维度”“日期维度”。 总线矩阵(Bus Matrix):
电商企业总线矩阵示例:
| 业务过程 \ 维度 | 日期 | 产品 | 客户 | 门店 | 促销 | 供应商 |
|---|---|---|---|---|---|---|
| 订单支付 | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 库存快照 | ✓ | ✓ | ✓ | ✓ | ||
| 物流发货 | ✓ | ✓ | ✓ | ✓ | ||
| 营销活动 | ✓ | ✓ | ✓ | ✓ |
通过总线矩阵,你可以清晰看到哪些维度需要做成一致性维度,从而实现跨事实表的 Drill-across 分析(例如:分析“某个促销活动在不同门店的销售转化率和库存周转率”)。
六、实际落地建议(来自真实项目经验)
优先选择高价值业务过程:从销售额、订单、用户行为等核心过程入手。 坚持原子粒度:不要为了省事而过早汇总,未来你会后悔。 严格管理一致性维度:建议建立维度治理团队或主数据管理系统(MDM)。 在大数据平台上的演进: Hive / Spark:传统星型模型 ClickHouse / Doris:宽表 + 星型混合(预聚合 + 维度表) Lakehouse(Databricks / Iceberg):维度建模思想依然有效,可结合 Delta Lake 实现高效 SCD
总结
Kimball 维度建模不是追求数据库理论上的“完美”,而是追求“报表出得快、业务用得好”。
它像一把实用主义利器:在过去二十多年里,帮助无数企业从混乱的数据泥潭中走出来,快速构建起支持决策的数据体系。
在 2026 年的今天,虽然技术栈从传统数仓演进到 Lakehouse、大模型辅助建模,但 Kimball 的核心思想——以业务为驱动、以用户理解为目标、坚持星型/宽表设计,依然是数据仓库领域最经得起时间考验的方法论。
推荐阅读:
《The Data Warehouse Toolkit》(Kimball 经典著作) 《The Kimball Group Reader》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号