构造交互题目学习笔记
常用结论和方法
抽屉原理:
\(n\) 个物品和 \(m\) 个盒子,将物品装入盒子中。
至少有一个盒子的物品数量 \(\ge \lceil\frac{n}{m}\rceil\)。
摩尔投票法:
问题: 长度为 \(n\) 的数列中存在一个出现次数大于 \(\frac{n}{2}\) 的数,设计一个算法找到它。
只要每次删除两个不同的数,最后留下的那个数(或那些数,但这些数全部相同)就是要求的答案。
拓展: 找到长度为 \(n\) 的数列中的所有出现次数大于等于 \(n\times p\%\) 的数。
记 \(k=\lfloor\frac{100}{p}\rfloor\),每次删 \(k+1\) 个不同的数即可。这样可以保证满足要求的数一定可以保留下来,最后再check即可。
这种记录方式适合用于合并信息。
调整法:
一. 从不优的状态逐渐往目标调整。
相关题目:
UOJ#569.【IOI2020】Stations
P13614 [IOI 2018] highway 高速公路收费
二. 若所求为 \(x\) 恰好为 \(k\),考虑估计出最大值和最小值,证明最值之间可以取到,在从最值调整到 \(k\)。
相关题目:
CF1311E Construct the Binary Tree
构造
构造是什么?
构造一种合法的方案。
构造一组达到最优贡献的方案。
构造一组操作次数最小的方案。
CF1198C Matching vs Independent Set
注意到边独立集每条边会消耗 \(2\) 个点和 \(1\) 条边,而点独立集每个点会消耗 \(1\) 个点和它的所有连边。
那么,点独立集对边的消耗会较大,边独立集对点的消耗较大,启发我们考虑到如果一个图的点无法满足边独立集,可能很容易满足点独立集,毕竟点数是 \(3n\),较为充裕。
考虑一下算法构造一个边独立集:
依次考虑每一条边 \((u,v)\),如果 \(u,v\) 都没有被用过则加入到边独立集中。
显然,此时求出的不一定是最大的边独立集,如果发现求出的边独立集大小 \(\ge n\),直接在中间选出 \(n\) 条边就可以了。
否则,考虑转向求点独立集。此时可以注意到,求边独立集花费了 \(< 2n\) 的点,剩下会有多于 \(n\) 的点不在边独立集中,并且它们的所有邻点都在边独立集中,否则边独立集可以继续扩大。
所以,不在边独立集中的点构成了一个大小 \(> n\) 的点独立集,可以选出 \(n\) 个点作为答案。
CF618F Double Knapsack
首先大致感觉一下,子集和的大小是 \(n^2\) 级别的,子集的数量是 \(2^n\) 的,感觉还是大概率有解的。
由于子集的限制过于开放,考虑加强限制。
这里把子集和改为区间和,容易发现区间数也是 \(O(n^2)\) 的。
那么记 \(a_i,b_i\) 为 \(A,B\) 的前缀和。
要求 \(a_{r_1}-a_{l_1}=b_{r_2}-b_{l_2}\) 的 \(l_1,l_2,r_1,r_2\),且 \(0\le 1_1<r_1\le n\),\(0\le l_2<r_2\le n\)。
移项:
接着,限制一下左右两边的范围,让它们更有可能相同。
不妨令 \(a_n \ge b_n\) ,记 \(p_i\) 为最大的 \(j\) 满足,\(b_j\le a_i\),双指针线性求。
我们考虑左右两边的 \(b\) 都用对应的 \(p_i\)。
有
仔细分析一下,发现 \(0\le a_i-b_{p_i}<n\),总共 \(n\) 个取值,而我们有 \(0\sim n\) 总共 \(n+1\) 个 \(a_i\),根据抽屉原理,可以得出一定会有一对重复,复杂度 \(O(n)\)。
CF1470D Strange Housing
考虑把图给分层,然后只给奇数层的点标记,就可以连通所有的点,但是有一个问题,就是奇数层的点之间可能会有连边,要避免这种情况。
考虑使用 bfs 来分层,在标记完一个点后,把它的所有邻点都记为不可标记状态,之后不再将其标记,并放入队列;之后如果遇到要标记这种结点的情况就不标记,也不在这时放入队列。
CF643G Choosing Ads
使用线段树维护区间覆盖。直接维护数量是不现实的,考虑在 pushup 的过程中得到所有答案。
使用摩尔投票法拓展。
每个节点维护当前区间的删除过后的剩余的数。由于 \(p\in[20,100]\),\(k=\lfloor\frac{100}{p}\rfloor\),所以不会超过 5 个。
然后在 pushup 时,可以 \(O(k^2)\) 合并。
总复杂度为 \(O(nk^2\log n)\)。
CF1270G Subset with Zero Sum
首先,把 \(i-n\le a_i \le i-1\),改为 \(1\le i-a_i \le n\),这样方便使用。
那么,进一步就把 \(a_i\) 赋值为 \(i-a-i\),所求变为 \(\sum (i-a_i)=0\),拆为 \(\sum i-\sum a_i=0\)。
注意到,这里的 \(i\) 和 \(a_i\) 的范围都是 \([1,n]\),且只要选了 \(i\) ,\(a_i\) 也要参与,最后所有的和为0。
我们考虑构造一组方案使得,每个 \(a\) 都有一个 \(i\) 与之抵消,考虑转为图论问题:从 \(i\) 向 \(a_i\) 连无向边,则图中必有至少一个环,这个环上的点就是一组合法的方案。
那么,只要使用 Tarjan 求边双即可。
CF1404D Game of Pairs
显然,这题是个构造题。
首先从小的情况手玩一下。
\(n=1:\) 只能分为 \((1,2)\),选择 \(S\)。
\(n=2:\) 可以分为 \((1,3),(2,4)\),选择 \(F\)。
\(n=3:\) 选择 \(S\)。
大胆猜想在 \(n\) 为奇数时选 \(S\),在 \(n\) 为偶数时选 \(F\)。
先来分析一下较为简单的 \(n\) 为偶数情况。
观察 \(n=2\),发现是由于最后的和一定是奇数导致无法找出合法方案,启发我们往同余系的方向想。
这里考虑把 \(a_i \equiv a_j \pmod n\) 的一对 \(i,j\) 作为一组,总共有 \(n\) 组,刚好 \(n\) 个同余类。
在 \(n=4\) 时:
\((1,5),(2,6),(3,7),(4,8)\)
容易发现无法找到合法方案。
下面来证明一下所有偶数都满足:
首先,我们假设 \(S\) 选择了每对里较小的数,则 \(sum=1+2+\dots+n=\frac{(n+1)n}{2}\)。
那么假设进行了 \(k\) 次调整(\(k\in[0,n-1]\)),换为较大的数,\(sum=\frac{(n+1+2k)n}{2}\)。
那么,现在就相当于要 \((n+1+2k)\) 为 \(4\) 的倍数,由于 \(n\) 为偶数,显然不可能,得证。
\(n\) 为奇数:
记 \(A\) 代表每个同余类中较小的,\(B\) 代表较大的,那么考虑分别统计一下 \(AB\)(或 \(BA\)) 型,\(AA\) 型,\(BB\) 型的数量,显然由于总共有奇数个同余类,一定有奇数个 \(AB\)(或\(BA\)) 型。
首先,考虑先随便找出一种把所有同余类选一次的方案,那么,如果当前方案不满足,其补集一定满足。
考虑证明:
首先,一定可以找出把所有同余类选一次的方案,考虑忽略 \(AA,BB\) 的数对(不影响性质),那么剩下的 \(AB(BA)\) 就可以构成多个置换环,可以选出方案。
其次,由于 \(AB(BA)\) 只有奇数个,所以补集的 \(sum=n(\frac{n+1}{2}+k)\) 中的 \(k\) 会只因为 \(AB(BA)\) 的变化而改变奇偶性,那么 \(\frac{n+1}{2}+k\) 一定可以取到偶数,使得 \(sum\) 为 \(2n\) 的倍数。
具体做法就是:
视为 \(i\) 和 \(i+n\) 之间有无向边。每次发现一个没有选过的数对,随便选一个,那么之后另一个的同余类就要在其他数对中选,通过边走过去,直接顺着环把这个环上的所有数对全都处理了,然后就可以选出一组方案,再看它和它的补集哪个合法。
总复杂度为 \(O(n)\)。
#include <bits/stdc++.h>
using namespace std;
const int N=500050;
int n,a[N<<1],p[N],sum,used[N<<1];
inline void add(int &x,int y) {x+=y;(x>=2*n)&&(x-=n*2);}
inline int get(int x){return x>n?x-n:x+n;}
void solve(int x){
int y=p[a[x]]-x;if (used[x]||used[y]) return ;
used[x]=1,add(sum,x),solve(get(y));
}
int main(){
scanf("%d",&n);
if (n&1){
printf("Second\n");fflush(stdout);
for (int i=1;i<=n*2;i++) scanf("%d",&a[i]),p[a[i]]+=i;
for (int i=1;i<=n*2;i++) if (!used[i]) solve(i);sum=!!sum;
for (int i=1;i<=n*2;i++) if (used[i]^sum) printf("%d ",i);
}
else {
printf("First\n");fflush(stdout);
for (int i=1;i<=n;i++) printf("%d ",i);
for (int i=1;i<=n;i++) printf("%d ",i);
}
fflush(stdout);return 0;
}
AT_arc122_e Increasing LCMs
考虑倒着放入数。
则对于每次放入的数 \(a_i\) ,要有 \(\operatorname{lcm}\limits_{j\not =i}(\gcd(a_i,a_j))<a_i\),其中 \(a_j\) 表示所有未放入的数。改为 \(\gcd_{j\not =i}(\operatorname{lcm}(a_i,a_j))<a_i\),避免爆了 \(\operatorname{long long}\)。
就这样,每次考虑放入一个数,然后在剩余的数集中找一个满足要求的数即可。
来考虑一下最优性:
那么,考虑加入时每次有多个数满足条件,是否随便一个都可以。由于 \(a_i\) 在当前数集中可以满足此条件,那么选择其他数后,数集缩小了,那么 \(lcm\) 也缩小了,其他数接着放会比当前局面更优。
AT_arc103_d Distance Sums
注意到,\(\min\{D\}\) 就是树的重心,考虑以重心为根进行构造。
由于重心的性质,每个子树的大小不超过 \(\frac{n}{2}\),同时有 \(D_{fa}=D_{u}-(n-2sz_u)\),所以 \(D_{fa}<D_u\)。考虑从大到小来构造,这样就是一个拓扑序。
每次把当前子树向对应 \(D_{fa}\) 的节点上挂,就可以完成构造。
由于之前之确定了节点之间的相对大小,所以还需要验证其中一个节点的 \(D_u\)。
AT_arc117_d [ARC117D] Miracle Tree
考虑将点的编号按 \(E_i\) 从小到大排,只要相邻两个位置满足了,那么其他位置也一定可以间接推出来满足条件。
那么,有 \(E_{p_i}-E_{p_{i-1}}\ge dis(p_i,p_{i-1})\),累加可以得到,\(E_{p_n}-E_{p_1}\ge \sum dis(p_i,p_{i-1})\)。
所以要构造一个序列 \(p\),使得 \(\sum dis(p_i,p_{i-1})\) 最小,我们发现只要 \(p_1\) 和 \(p_n\) 为树的直径的端点即可,接下来就可以自行构造。
CF1311E Construct the Binary Tree
使用调整法。
最大情况是链,最小情况是完全二叉树。
考虑从完全二叉树向链调整。
特殊标记完全二叉树的最左边一条链,然后每次找到未被标记的点中深度最大的一个 \(u\),显然 \(u\) 是一个叶子。
显然,最左边一条链的长度肯定不小于 \(u\) 的深度,那么把 \(u\) 往最左链上接。先考虑接到链的末尾,如果接完后深度和还是不够,就接上,然后继续;否则,计算出 \(u\) 应该接入的位置,由于比 \(u\) 深度大的点都已接入左链,那么此时最左链上比 \(u\) 深度大的部分肯定是只有一个儿子的,能够把 \(u\) 接上。
交互题
AT_arc154_d [ARC154D] A + B > C ?
观察交互次数,发现大概是 \(O(n\log n)\) 次询问次数。
先做一步转化,假如询问方式为 \(P_i\ge P_j\) ,可以怎么做?
考虑对这个数组排序,\((i,P_i)\) 记为一个元素,然后按照第二关键字排序,最后就可以得到每个位置的值。
这里的问题在于我们不知道 \(P_i\),但是可以通过询问来实现 \(P_i\) 的比较,所以可以使用一个归并排序来做到 \(n\log n\) 的比较次数。
那么,现在是 \(P_i+P_j>P_k\),如果我们钦定 \(P_j=1\),发现就可以变为 \(P_i\ge P_k\)。
那么,现在还要考虑如何找到 \(1\)。
由于 \(1+1>x\) ,这里的 \(x\) 不能为 \(>1\) 的数,我们考虑利用这个性质来求。
考虑双指针,直接让 \(i\) 从 \(1\) 开始,然后 \(j\) 遍历后面的数,询问 \(P_j+P_j>P_i\),如果成立就跳过,否则,让 \(i=j\)。
最后,\(P_i\) 的值就是 \(1\)。总共询问 \(n-1\) 次。
CF1365G Secure Password
容易想到 \(2\log n\) 的分治做法。
考虑通过标号来做到不漏不多地通过构造13个元素拼凑出所有的位置。
考虑给每个位置标号为不同的 [有 \(6\) 个 \(1\) 的 \(13\) 位二进制数],然后记为 \(p_i\)。由于 \(\binom{13}{6}>1000\),所以够用。
则我们记 \(res_i\) 为所有编号第 \(i\) 为 \(1\) 的位置的异或和,刚好通过询问得到。
那么,\(ans_i\) 为 \(i\) 所有的为 \(0\) 的二进制位的 \(res\) 异或和。
由于 \(i\) 与 \(j\) 的编号不同,而 \(1\) 的总数固定,所以一定会有某一位 \(i\) 是 \(1\),\(j\) 是 \(0\),所以所有非 \(i\) 的位置都会被统计。
CF1562F Tubular Bells
先考虑一下暴力做法。
考虑每次单点求出一个位置。
给出一个做法:对于每个 \(i\),询问所有 \(\operatorname{lcm}(a_i,a_j)\),那么,当 \(n\ge 4\) 时,\(a_i=\gcd(\operatorname{lcm}_{j\not =i}(a_i,a_j))\)。
证明
对于 \(i\) 来说,\(\operatorname{lcm}(i,i\pm 1)=i(i\pm 1)\)。
若 \(i\) 为奇数,\(\operatorname{lcm}(i,i\pm 2)=i(i\pm 2)\);若 \(i\) 为偶数,\(\operatorname{lcm}(i,i\pm 2)=\frac{i}{2}(i\pm 2)\)。
那么,\(i\) 为奇数时,就有与 \(i\) 值域上最近的三个数 \(k_1,k_2,k_3\) 的 \(\operatorname{lcm}(i,j)\) 的 \(\gcd\) 是 \(i\gcd(k_1,k_2,k_3)\),显然就是 \(i\)。
那么,\(i\) 为偶数时,就有与 \(i\) 值域上最近的三个数 \(k_1,k_2,k_3\) (\(k_3\) 为其中的偶数)的 \(\operatorname{lcm}(i,j)\) 的 \(\gcd\) 是 \(i\gcd(k_1,k_2,\frac{1}{2}k_3)\),显然就是 \(i\)。
所以,至少要 \(4\) 个数才可以确定一个点值,不然偶数情况无法确定。
那么,\(n=3\) 的时候,直接先用上述做法后,还要分讨一下,如果是答案是一奇两偶,那么奇数会算大两倍;如果是答案是一偶两奇,就是正确的。
这样就可以做到 \(\frac{n^2}{2}\) 的询问数量,可以解决 \(100\) 以内。
接着,有了暴力做法,就可以考虑一下 \(\ge 100\) 的大区间的做法。
注意到在大区间内,是很容易存在质数的,在 \(10^5\) 范围内,间隔最远的两个质数的差为 \(85\),所以在大的区间内,必有一个质数。只要找到了一个 \(\ge \frac{r}{2}\) 的质数,它就与这个序列的所有其他数互质,就可以用它把整个序列给问出来。
那么,如何来找呢?
考虑随机化算法。由于在 \(10^5\) 范围内,平均素数密度为 \(\frac{1}{\ln 10^5}=0.08\),所以随机找是有很大概率找到这个数的。
考虑进行 \(250\) 次随机选数,每次使用 \(20\) 次询问来判定,如果该数和随机的 \(20\) 个数的 \(\operatorname{lcm}\) 都有一个较大的质因子,那么,这个数就很有可能是质数。最终取最大的即可。
CF1364E X-OR
考虑找到 \(0\) 的位置。
由于总共有 \(4269\) 次,而 \(n\le 2048\),所以可以有 \(2221\) 次机会来找到 \(0\)。
类似上题做法,考虑 \(0\) 的性质。
即 \(0\) 的 \(\operatorname{popcount}\) 的个数最少。
考虑不断去找比 \(\operatorname{popcount}\) 当前数更小的数,注意到如果 \((x|y)=x\),即 \(y\) 是 \(x\) 的子集,那么 \(y\) 的 \(\operatorname{popcount}\) 就比 \(x\) 的小。
那么,上述判定中需要知道 \((x|y)\),可以从查询得到,那么 \(x\) 要怎么得到呢?
考虑通过随机化的方法来得到一个点值,随机 \(20\) 个位置,把它们与当前位置的按位或都按位与起来,可以将结果作为点值,出错概率为 \(11\times 10^{-20}\)。
这样就可以从前往后扫,然后不断用 \(\operatorname{popcount}\) 更小的数来代替 \(x\),最后 \(x\) 一定为 \(0\)。
这样最劣需要 \(12\times 20 + 2n\) 次,即 \(4336\) 次。
但是,只要我们随机打乱数组下标,就可以防止被卡,通过此题。
AT_agc044_d Guess the Password
-
首先对字符集里的所有字符 \(c\) 都进行一次询问,内容为 \(128\) 个 \(c\) 拼接在一起,那么容易得到每种字符的出现次数,以及总长 \(sum\)。
-
构建一个答案串 \(S\),初始为空,然后考虑依次插入每种字符。由于相对位置是可以二分的,如果 \(S[0,mid-1]\) 和 \(k\) 个 \(c\) 拼接的字符串的询问结果为 \(sum-mid-k\),那么 \(mid\) 之后一定有 \(k\) 个 \(c\),找到最大的满足要求的位置,就是倒数第 \(k\) 个 \(c\) 要插入的位置。
-
次数为 \(O(|\sum|+L\log L)\)。另外,二分时有单调性,利用单调性缩减范围可过。
P13614 [IOI 2018] highway 高速公路收费
我们可以先把所有边赋为 \(A\),那么把一条边换为 \(B\) 可以看作把它删掉,这两者产生的效果相同,即要么最短路都不变,要么最短路都变化了。
那么,想找到具体的询问数值对应哪一条最短路是困难的,但是得到一条必经边是容易的。考虑在边的编号上二分,找到一个最大的前缀使得删除这些边不会改变最短路。把下一条边记为 \((u,v)\),\((u,v)\) 显然就是一条必经边。
再根据最短路的性质,假设最短路为 \(S\to u\to v\to T\),那么 \(dis_{S,u}<dis_{S,v}\),\(dis_{T,u}>dis_{T,v}\)。
由此,分别跑 \(u,v\) 为源点的最短路,通过 \(S,T\) 性质的不同,把所有点分为两个集合,一个距离 \(u\) 更近,一个距离 \(v\) 更近。
此时,分别在两个集合中操作。以 \(S\) 所在集合为例,求出该集合从 \(u\) 出发的 bfs 序,那么考虑在上面二分,每次删除一个后缀的点,即删除它们的所有连边,然后看最短路是否发生变化,就可以二分出两个点。
次数为 \(\log m+2\log n+O(1)\),要求是 \(50\),但这里算出来是 \(53\),由于 \(2\log n\) 中 \(n\) 是不满的,所以可以通过。
CF1930H Interactive Mex Tree
好吧,我也不知道这是交互还是伪装成交互的构造了。
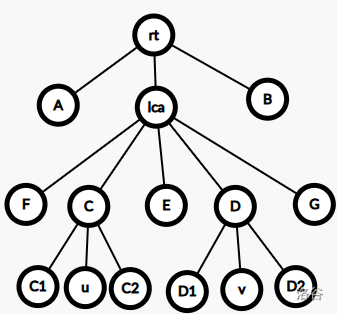
好吧,居然有图,我太强了。
由于是排列,所以可以把 \(\operatorname{mex}\) 转为补集的 \(\min\)。
在此图中,我们就是要用 \(5\) 个区间来覆盖 \(rt,A,B,C1,C2,D1,D2,E,F,G\) 这 \(10\) 个区域。
那么,先尝试使用 \(dfs\) 入栈序作为 \(p_1\)。
假设从左到右遍历这些边,这些部分在 \(dfs\) 序上连续的有 \([rt,A]\),\([F]\),\([C1]\),\([C2,E],[D1],[D2,G,B]\)。
发现要用 \(6\) 次才行。
那么,考虑使用第二个序列。尝试使用出栈序来刻画。
这些部分在 \(dfs\) 出栈序上连续的有 \([A,F,C1]\),\([C2]\),\([E,D1]\),\([D2]\),\([G]\),\([B,rt]\)。
权衡利弊得到最终策略:
入栈序:\([D2,G,B]\),\([C2,E]\),\([rt,A]\)。
出栈序:\([A,F,C1]\),\([E,D1]\)。
实现:求 LCA,和 LCA 的两个儿子,另外,弄清楚出栈序和入栈序中 \(A,B,C1,C2,D1,D2,E,F,G,rt\) 对应的范围。
Plus:
还有可能 \(u\) 是 \(v\) 的祖先。
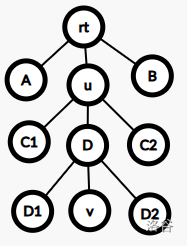
入栈连续的有 \([rt,A]\),\([C1]\),\([D1]\),\([D2,C2,B]\)。
出栈连续的有 \([A,C1,D1]\),\([D2]\),\([C2]\),\([B,rt]\)。
选择入栈 \([D2,C2,B]\),\([rt,A]\)。
选择出栈 \([A,C1,D1]\)。
通信题
UOJ#569.【IOI2020】Stations
如果直接按照 dfs序的入栈序来标号,我们发现 \(>\max\{c\}\) 的部分是无法区分的,有可能向父亲走,也有可能向最后一个儿子走。
发现使用出栈序也是类似的问题,但其实如果知道了 \(s\) 的出栈序,再结合开始的做法就可以判断了。考虑在奇数层记录入栈序,偶数层记录出栈序,那么结合上述两种做法,先判断一下 \(s\) 是出栈序还是入栈序,再分讨来做。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号