[note] 本地12+16G极限部署 Qwen3-Coder-25B 搭配Continue插件实现代码补全
pre
本文关于用 Ollama 在16G内存+12G显存的机器上本地部署 Qwen3-Coder-REAP-25B-A3B 模型,然后搭配VSCode的Continue插件进行代码补全。但是目前有许多免费的API/插件/IDE等代码补全方案可以使用,为什么要本地部署呢?是的,非常好的问题,只能说是为了折腾,或者用于内网环境?总之,不建议自行部署一个模型来做代码补全,尤其是硬件条件并不好的情况下,折腾而且体验也不好。
为什么是Qwen3-Coder-REAP-25B-A3B
Qwen3-Coder-REAP-25B-A3B是cerebras针对原版Qwen3-Coder-30B-A3B-Instruct权重,采用路由器加权专家激活剪枝(REAP, Router-weighted Expert Activation Pruning)方案进行剪枝,剔除冗余专家得到的高效内存压缩版本,性能几乎相同,同时体积缩小20%。
主要特点包括:
- 近乎无损性能:在代码生成、代理编码和函数调用任务上,与完整模型保持几乎相同的准确性
- 20%内存减少:参数从30B压缩到25B,显著降低部署成本和内存需求
- 保留能力:保留所有核心功能,包括代码生成、代理式工作流、仓库规模理解和函数调用
- 可直接兼容:支持原版 vLLM——无需源代码修改或自定义补丁(当然也支持Ollama)
- 针对实际应用优化:特别适用于资源有限的环境、本地部署和学术研究
指标对比:
| Benchmark | Qwen3-Coder-30B-A3B-Instruct | Qwen3-Coder-REAP-25B-A3B |
|---|---|---|
| Compression | — | 20% |
| HumanEval | 92.1 | 94.5 |
| HumanEval+ | 87.8 | 89.0 |
| MBPP | 87.6 | 87.3 |
| MBPP+ | 73.5 | 72.8 |
| LiveCodeBench (25.01 - 25.05) | 35.2 | 35.2 |
| BFCL-v3 (Non-Live) | 83.9 | 82.2 |
| BFCL-v3 (Live) | 76.2 | 74.0 |
| BFCL-v3 (Multi-Turn) | 29.6 | 30.5 |
| BFCL-v3 (Overall) | 63.2 | 62.2 |
| r²-bench (Airline) | 39.3 | 40.7 |
| r²-bench (Retail) | 62.6 | 62.0 |
| r²-bench (Telecom) | 33.6 | 32.2 |
看着还不错,甚至某些指标略有上升,对吗。那么代价是什么呢?——中文能力的丧失,可以看图:
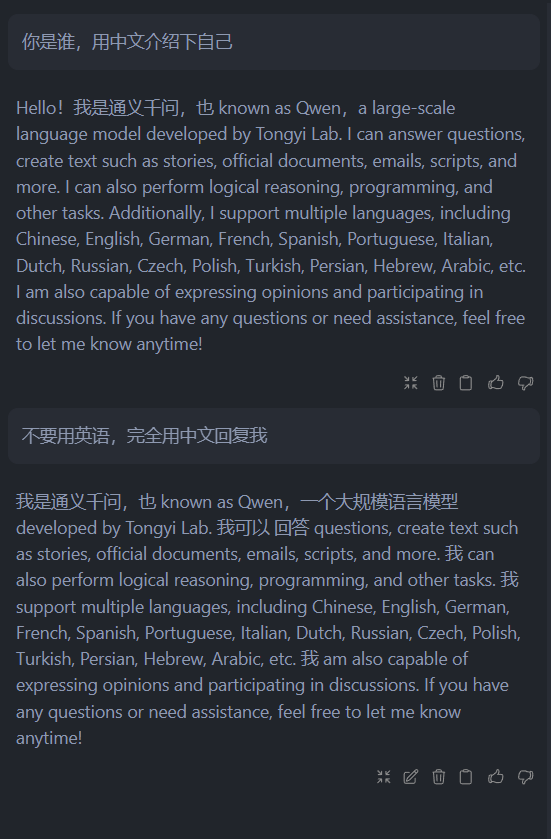
中文对话测试
即便强调使用中文,它仍然会使用英语,只夹杂少部分中文。不过并非无逻辑的回复,能看出回答是通顺的,只是写代码的话没什么问题:
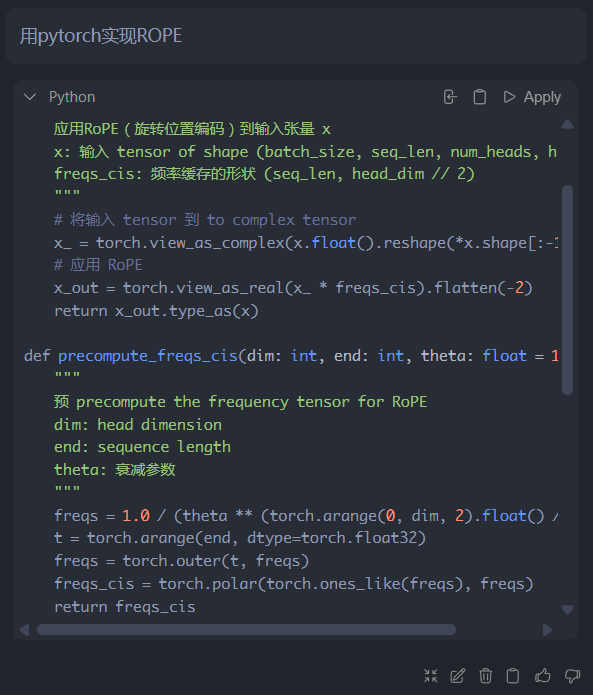
代码编写测试
因此条件允许的话还是上30B原版权重。接下来开始折腾。
安装
首先下载权重,我选择mradermacher制作的imatrix版Q4_K_M量化。3B激活参数如果上下文不大占不了多少显存,主要考虑权重本身的占用,Q4_K_M大概是15.1G,实测开启vscdoe、ollama、edge之后内存占用13G,显存12G跑满,若使用原版权重就爆掉了。
坑点在于mradermacher只给了权重,但没有modelfile,不过好在这个是通用的,这里使用unsloth提供的params、template两个文件自行构建modelfile如下。FROM指定gguf权重文件,SYSTEM指定系统提示词,不写应该也行,可以用中文但模型仍然会以英语回复。
FROM ./Qwen3-Coder-REAP-25B-A3B.i1-Q4_K_M.gguf
SYSTEM """你叫艾玛,是一只可爱的小笨狗,愿意为我做任何事情。
"""
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 20
PARAMETER min_p 0.00
PARAMETER repeat_penalty 1.05
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
# 自定义提示模板
TEMPLATE """{{- if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{- if .System }}
{{ .System }}
{{- end }}
{{- if .Tools }}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}
{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}
"""
首先启动ollama
ollama serve
确保gguf与modelfile放同一目录,然后使用下列命令创建模型
ollama create 模型名 -f ./modelfile
安装完之后应该能通过以下命令与模型进行对话:
ollama run 模型名
tricks
观察可知,假设ollama放在目录D:\Ollama下面,那么装完成后D:\Ollama\models\blobs目录下会新增一些 sha256- 开头的文件,其中最大的是权重文件。如果当前是机械硬盘建议放到固态硬盘。首先把对应的权重文件(假设名称为sha256-2f3356ac9b92dd2165ae0130c45701c247a25e9629c39b73b0d7233ca0b72f89)拷贝到固态硬盘里,假设路径为E:\model_path,然后采用符号链接链回去:
New-Item -ItemType SymbolicLink -Path D:\Ollama\models\blobs\sha256-2f3356ac9b92dd2165ae0130c45701c247a25e9629c39b73b0d7233ca0b72f89 -Target E:\model_path
其中 -Path 指定了文件实际存储的位置, -Target 指定了要制作的符号链接。
再观察会发现,其他 sha256- 文件则是modelfile的一些内容,及模型的元数据,完全可以对modelfile相关进行修改,比如调整之前创建时设置的系统提示词。
Continue
这玩意也不是个省油的灯,之前配置文件用的json,后来改为yaml,虽然给了文档参考但不够全面,最终配置如下:
%YAML 1.1
---
name: Local Config
version: 1.0.1
schema: v1
full_roles: &full_roles
roles:
- chat
- autocomplete
- edit
- apply
models:
- name: qwen3-coder-reap-25b-a3b-i1-q4km
provider: ollama
model: qwen3-coder-reap-25b-a3b-i1-q4km:latest
<<: *full_roles
defaultCompletionOptions:
temperature: 0.7
autocompleteOptions:
onlyMyCode: true
debounceDelay: 400
maxPromptTokens: 4096
# template: |
# `<|im_start|>system
# You are a code completion assistant.<|im_end|>
# <|im_start|>user
# <|fim_prefix|>{{{prefix}}}<|fim_suffix|>{{{suffix}}}<|fim_middle|><|im_end|>
# <|im_start|>assistant
# `
- name: qwen2.5-coder-7b-q4_k_m
provider: ollama
model: qwen2.5-coder:7b-instruct-q4_k_m
<<: *full_roles
defaultCompletionOptions:
temperature: 0.6
reasoning: false
autocompleteOptions:
onlyMyCode: true
debounceDelay: 400
maxPromptTokens: 4096
template: <|im_start|>system\nYou are a code completion assistant.<|im_end|>\n<|im_start|>user\n<|fim_prefix|>{{{prefix}}}<|fim_suffix|>{{{suffix}}}<|fim_middle|><|im_end|>\n <|im_start|>assistant
理论上autocompleteOptions.template应该是需要的,但实测加上无法补全,去掉反而能用,而qwen2.5-coder仍是需要的,十分神秘。
碎碎念
Continue即便配置了对某些文件 **/*.(txt, md, yaml, yml) 不启用补全也没效果,同时补全的延迟有点高。试过kilo code,那玩意还不如continue,补全模型不支持本地部署。总之这个方案虽然能用,但体验说不上好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号