[论文速览] RectifiedFlow@Flow Straight and Fast{colon}Learning to Generate and Transfer Data with Rectified Flow
Pre
title: Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
accepted: ICLR 2023
paper: https://arxiv.org/abs/2209.03003 / https://openreview.net/forum?id=XVjTT1nw5z
code: https://github.com/gnobitab/RectifiedFlow
ref: https://zhuanlan.zhihu.com/p/603740431
ref: https://colab.research.google.com/drive/1CyUP5xbA3pjH55HDWOA8vRgk2EEyEl_P?usp=sharing
ref: https://www.spaces.ac.cn/archives/9497
关键词:Image Generation, ODE(Ordinary Differential Equation), Flow, OT(Optimal Transport), Generative Modeling
阅读理由:十分新颖且简洁优雅的生成模型
Idea
用模型去学习两个分布数据点之间变化的速度 \(v\) ,通过 \(x_{t+1} = x_t + v t, t=0,\ldots,1\) ,以实现将源数据转换为目标数据。而v通过模型进行学习,并通过多次Reflow(用训练好的模型生成配对数据进行第二轮的模型训练,模型参数复制上一轮),可以拉直生成轨迹,加快生成速度。
ps. 速度含方向,是矢量
Motivation&Solution
- 各类无监督学习共同的困难是缺少配对的输入输出数据,它们大多数都希望寻找两个分布的数据点之间的关系
- Diffusion Generative Models(扩散式生成模型)效果很好,但生成速度缓慢,数学推导复杂,依赖随机微分方程(Stochastic Differential Equation (SDE))的知识。

图 DDPM, Rectified Flow数学推导对比
为此作者提出Rectified Flow,一个"简简单单走直线“生成模型,极度简单,一步生成。
- Motivation1: 通常的扩散模型把高斯白噪声转换成想要的数据(比如图片)。本方法可以把任何一种数据(比如猫脸照片)或噪声转换成另外一种数据(比如人脸照片)。不仅可以做生成模型,还可以应用于很多更广泛的迁移学习 (比如domain transfer)任务上。
- Motivation2: 基于简单的常微分方程ODE(Ordinary Differential Equation),不需要变分法或随机微分方程SDE(Stochastic Differential Equation)的知识,概念简单,推理时更快速
- Motivation2: 使用reflow方法实现“一步生成,快速,计算量小(对比扩散模型)
Background
The Transport Mapping Problem 给定两个分布,找一个传输映射T可以将 \(x_0\) 映射到另一个分布的数据点 \(x_1\)。在传统的生成模型中,T参数化为一个神经网络,用GAN类的最小最大化算法或最大似然估计(MLE)进行训练。
然而GAN时常有数值不稳定、模式坍塌的问题,需要大量工程努力跟人类的调整,无法适应不同的的模型架构跟数据集。另一方面,MLE难以处理复杂模型,而且对于大模型计算代价高昂,因为每个训练步都得重复模拟ODE。
上面是MLE训练目标,借此学习ODE \(dZ_{t}=v(Z_{t},t)dt\) , \(\rho^{v,\pi_{0}}\) 是直接从\(Z_0\)估计的\(Z_1\)的密度,它只关注如何匹配目标分布,而这个过程中有许多不同路径的ODEs都能达到相同目标(因此轨迹不直,而且混乱?)
因此需要VAE用到的近似变分法(approximate variational)或蒙特卡洛推断技术(Monte Carlo inference techniques),又或是使用normalizing flow或自回归模型这种特殊的模型结构,但需要处理表达能力跟计算开销之间的平衡。
近来有了一些进展,比如流模型这种(neural ordinary differential equations (ODEs)),和扩散模型那种(stochastic differential equations (SDEs)),这种连续时间模型(continuous-time models)训练高效。其中最著名的例子是 score-based generative
models 和 DDPM,统称降噪扩散方法,他们没有GAN的那些问题,而且学好的SDEs还能通过 probability flow ODEs 和 DDIM 的方法转换成确定性的ODE模型,以实现更快的推理。
但这类模型比起GAN、VAE他们有个关键的缺点是推理缓慢,而且需要在 involved design space 中大量搜索超参数,而且实践上理论上皆知之甚少。
当前这些方法通常把生成式建模跟域迁移分开对待,需要扩展或定制生成学习技术才能用于解决域迁移问题,而最优传输(OT)可以将其统一在一起。然而当前的OT技术处理高维、大量数据时很慢,而且传输代价跟实际的学习表现并未对齐,代价小的方法未必就表现好。

图1 用于图像生成的reftified flows的轨迹。上面两行是标准高斯噪声-猫脸之间的转换(image generation),下面两行是人脸-猫脸的转换(image transfer)
作者借图1说明rectified flow只用很少的欧拉步(Euler steps)就能产生高质量的图片。此外,该算法也能用于域迁移任务,如I2I翻译和迁移学习。
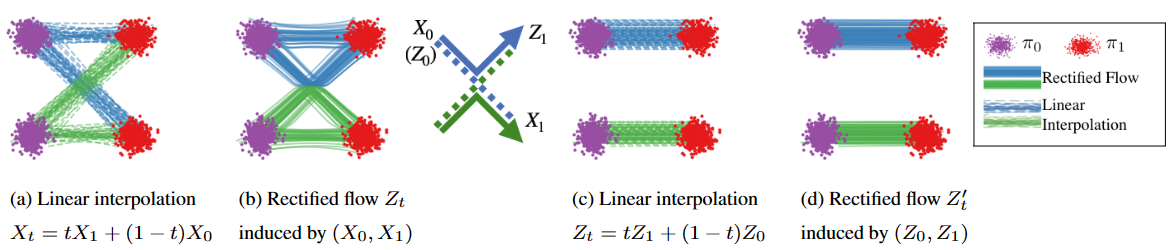
图2 (a)x_0,x_1的线性插值 (b)x_0,x_1的rectified flow Z_t,在交点处重组以避免相交 (c)流Z_t的端点z_0,z_1的线性插值(reflow后) (d)z_0,z_1的rectified flow,近乎直线
Unpaired Image-to-Image translation standard denoising diffusion、PF-ODEs关注生成任务,要做I2I的话可以用两个PF-ODEs将source转换为latent,再把latent换成target,或者用什么energy-guided方法。而rectified flow单纯地把 \(\pi_0\) 的噪声换成source domain就好了
Re-thinking the role of diffusion noise 本文工作展示了如果希望学习ODEs,那么无需利用SDE工具,并比较了二者的差别:
- ODE概念简单且计算更快
- ODE前向反向计算一样容易,SDE很难沿时间反向
- ODE学到的\(Z_0,Z_1\)更确定且传输代价可以用rectified flow降低,提供更好的隐空间做表征或操控输出
- ODE训练不会比SDE更难
- 二者表达边缘分布的能力一样强,但需要更丰富的时间相关结构时,更偏好SDEs
- 流形数据ODE的输出往往落入平滑的低维流形,这是人工智能中结构化数据(如图像和文本)的关键归纳。而SDE会得到平滑的结果,导致计算缓慢,而且有调整超参的负担,它更适合建模高噪声数据,如金融经济领域,或分子模拟那样涉及物理上的扩散过程的领域。
Method(Model)
Overview
扩散模型的演化过程是 \(x_0 \rightarrow x_T\),而ODE扩散模型演化过程如下:
也就是以微分方程的形式定义了数据变化的速度,指示如何进行 \(x_0 \rightarrow x_T\)
给定从两个分布 \(π_0\) 和 \(π_1\) 中的采样,希望找到一个传输映射 T 使得,当 \(Z_0∼π_0\) 时, \(Z_1=T(Z_0)∼π_1\)
映射T通过以下常微分方程(ordinary differential equation (ODE)),或者叫流模型(flow),来隐式定义:
可以想象从 \(π_0\) 里采样出来的 \(Z_0\) 是一个粒子。它从 \(t=0\) 时刻开始连续运动,在 t 时刻以 \(v(Z_t,t)\) 为速度。直到 \(t=1\) 时刻到达 \(Z_1\),且\(Z_1\) 服从分布 \(π_1\) 。这里用神经网络来学习 \(v(Z_t,t)\)
注意上式通常使用Euler法(或其变种)用离散时间进行近似计算:
其中 \(\epsilon\) 是一个步长参数,越小越精确,但生成速度就慢。为了用较大的 \(\epsilon\) 还保持高精度,作者提出“走直线”!
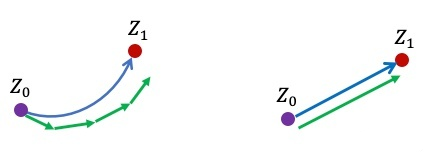
图 蓝色:真实ODE轨迹;绿色:Euler法得到的离散轨迹
作者思路实际上比较简单,假设从两个分布中各自 随机采样,有 \(x_0∼π_0\) 时, \(x_1∼π_1\),也就是说这时的 \(x_0,\; x_1\) 并不配对
简单对它进行线性插值得到 \(x_t\):
那么对它求导实际上就能得到一个简单的ODE:
但这个并不实用,因为它并非“因果”(causal),或者“可前向模拟”的,指它需要 \(x_1\) 来估计。毕竟如果能知道 \(x_1\) 还需要去模拟吗?为此作者提出学习一个可前向模拟的 \(v(Z_{t},t)\) 来逼近这个导数:
论文中作者也证明了网络学习到的 \(v\) 确实能够实现 \(π_0, π_1\) 之间数据的转换
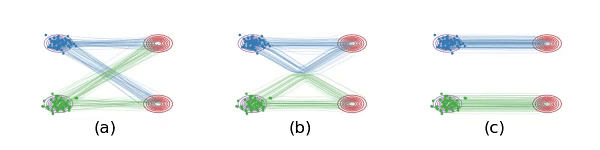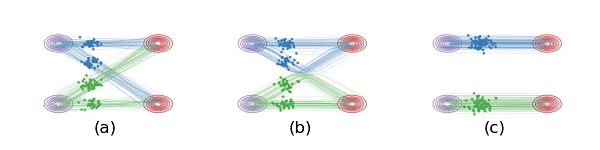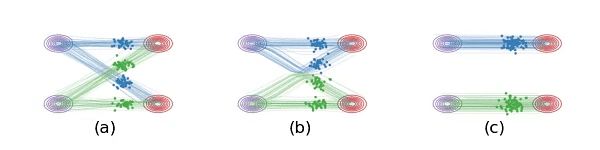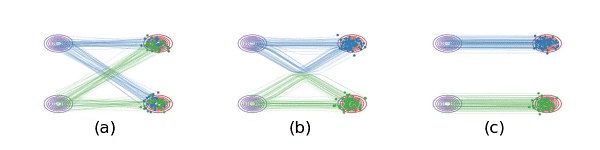
图t1 (a)线性插值时,数据点会相交相交,这是 ${\frac{d}{d t}}x_{t}$ 非因果的原因,粒子在交叉点处有两个选择,不确定。 (b)要求学习的ODE因为必须是因果的,所以不能相交,现在ODE仍然保留了原来的基本路径,但是做重组来避免相交的情况。图(a)和图(b)里的系统在每个时刻的边际分布是一样的,即使总体的路径不一样。
因此作者称他们的方法为 Rectified Flow,”拉直/规整的流”。事实上如上图b,虽然避免了交叉,但轨迹仍然是弯曲的,作者称这代表生成无法一步实现,为此提出了 “Reflow”方法将轨迹进一步拉直。
实际上也非常简单,首先用两个分布中随机采样的非配对数据训练一个flow,称为 1-Rectified Flow,然后用训练好的模型离线地采样: \(x_1 = Flow_1(x_0)\) ,如此得到的 \((x_0,\; x_1)\) 就是比较配对的数据对,用它的参数再去训练一个 2-Rectified Flow:
2-Rectified Flow和1-Rectified Flow在训练过程中唯一的区别就是数据配对不同,上图的c就展示了Reflow的效果,此时 \((x_0,\; x_1)\) 更配对,直线插值交叉数减少,但实际上仔细看还不是特别直。理论上可以重复Reflow多次,可证明该过程其实是在单调地减小最优传输理论中的传输代价(transport cost),而且最终收敛到完全直的状态。

算法1 rectified flow主要算法
按我的理解应该是一开始训练时 \((x_0,\; x_1)\) 之间没有明确配对关系,导致转化过程中可能有多种选择,不确定性高,所需的步数多,生成速度慢。而反复Reflow可以得到配对数据,更有益于模型从中学习。
当然,实际中,因为每次 v 优化得不完美,多次Reflow会积累误差,因此需要进行权衡。不过对生成图片和一些问题来说,像上面的图(c)一样,1次Reflow已经可以得到非常直的轨迹了,配合蒸馏足够达到一步生成的效果了。
Main Results and Properties
Reducing transport costs

上图举简单的例子说明reflow后的距离不会大于之前的
Reflow, straightening, fast simulation
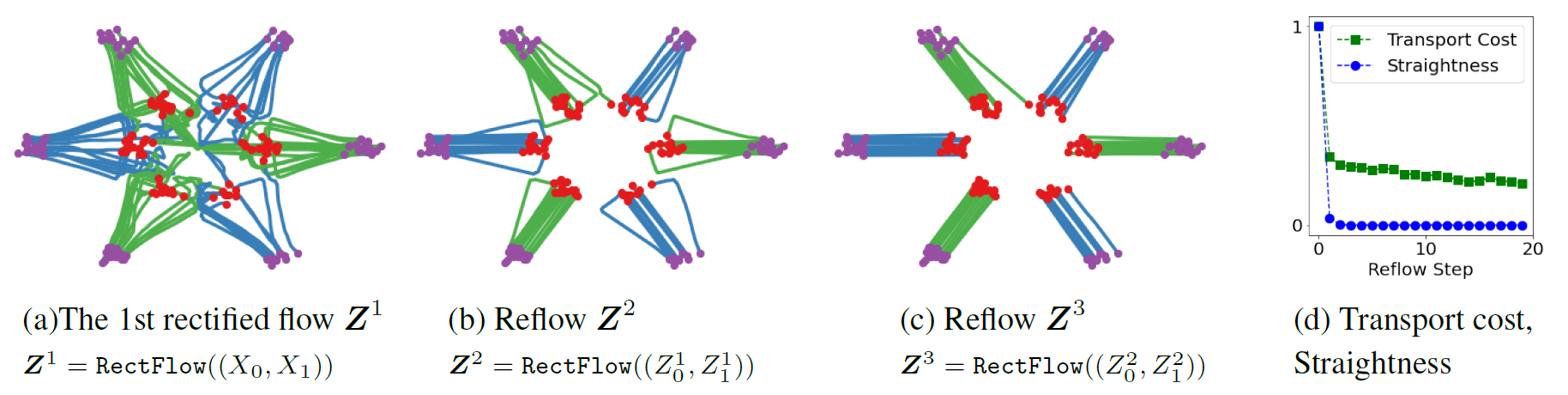
图3 在玩具示例上的reflow轨迹样本
作者试图讲清楚拉直的流是什么意思,比如给了个公式:
\(S(Z) = 0\) 时为直,但还是想知道为什么会不直
Distillation
distillation会忠实地逼近 \((Z^k_o,Z^k_1)\) 对,而rectification则会产生更直的流以及更低传输代价的 \((Z^{k+1}_o,Z^{k+1}_1)\) ,因此distillation只能用于最终阶段
Probability Flow ODEs and DDIM 概率流模型:probability flow ODEs (PF-ODEs),作者说所有PF-ODEs的变种都可以看成是 \(X_{t}=\alpha_{t}X_{1}+\beta_{t}\xi\) 的形式
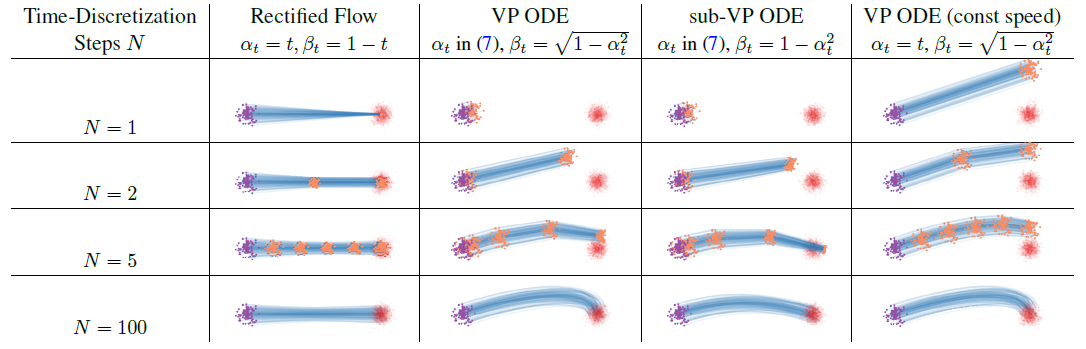
图5 不同方法使用不同时间步N的轨迹,其他方法轨迹曲线,而且速度不均匀,前面慢后面快
Theoretical Analysis
给出了该方法的理论证明,看不懂( ´◔︎ ‸◔︎`)
The Straightening Effect 只有线性插值路径不相交时才说配对是直的(coupling is straight)
Straight vs. Optimal Couplings 拉直是必要的,但不是最优配对的充分条件
Denoising Diffusion Models and Probability Flow ODEs PF-ODEs可以看做是非线性的 rectified flows
一些补充
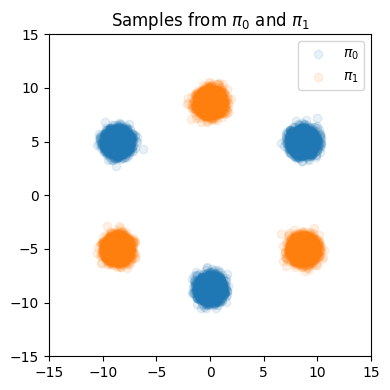
图colab-0 训练数据
图colab-1 1-Rectified Flow, 2-Rectified Flow的loss曲线
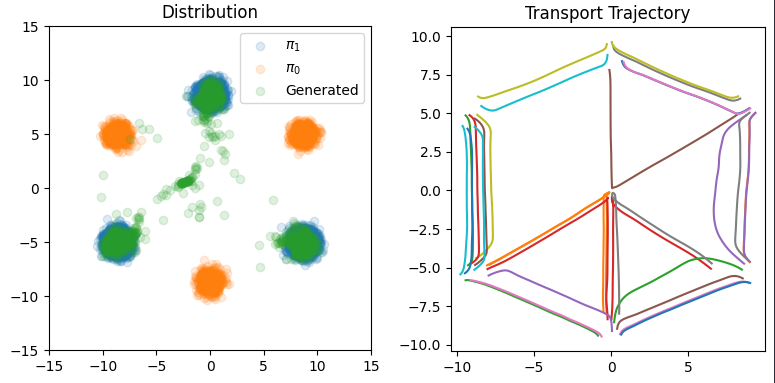
图colab-2 1-Rectified Flow步长N=1000时分布、轨迹可视化
从colab来看,一个分布可以由多个簇构成,所以图2的轨迹可以交叉,因为点不管走上面还是下面都可以,都属于目标分布,只是距离不同。看图colab-2更加直观,两个分布间转换时可以近似直线,也可能呈“>”形,因此作者说当ODE步长很小的时候,性能就很糟糕
图colab-3 1-Rectified Flow步长N=1时的分布、轨迹可视化
可以看到当步长过小时,点刚到中心位置,还没开始转折,全挤在中间了。注意Euler法里面的 \(\epsilon\) 在代码中的实现为步长倒数 \(\epsilon = 1/N\) ,因此N=1时实际上有最大的 \(\epsilon\) ,可能因此导致点“一步前进了太多”。但归根到底,这都是模型轨迹不够直导致的,因此需要拉直“>”轨迹
训练2-Rectified Flow用了训练1-Rectified Flow时5倍的iteration,但学习率不变
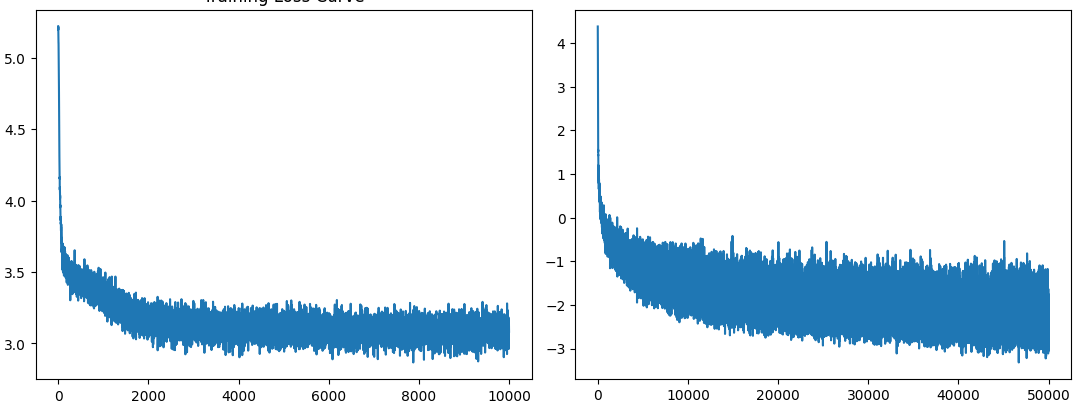
图colab-4 1-Rectified Flow, 2-Rectified Flow的loss曲线
画图colab-4用的实际上是对数平方误差,因此会有负数,而训练用的仍然是没加对数的

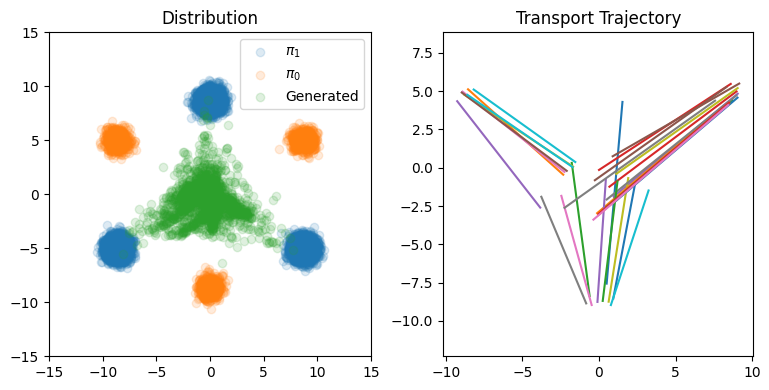
图colab-5 2-Rectified Flow步长N=100时分布、轨迹可视化
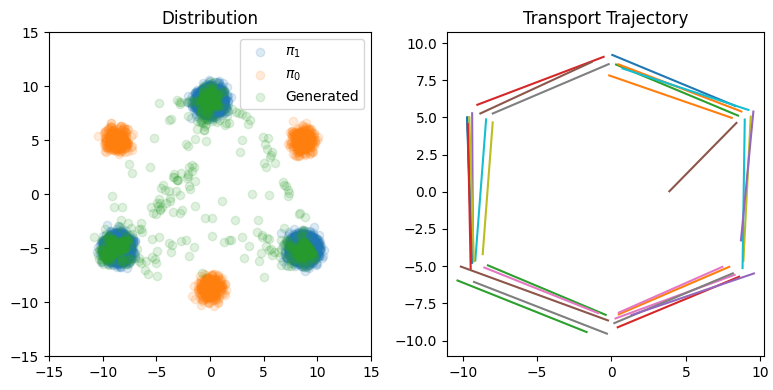
图colab-5 2-Rectified Flow步长N=1时分布、轨迹可视化
确实是直了不少,但还是有一些不够好的地方,作者的colab应该是挑了最好的一次结果展示

图20 隐空间嵌入/图片重建。给定图片,先反向获取其隐编码,然后再重建相应图片。
Experiment
Training Detail
对于欧拉法来模拟流,N步有固定步长1/N。
Image Generation 使用DDPM++的U-Net架构,数据集CIFAR-10,图片大小32x32,网络训练使用指数移动平均进行平滑化,比例0.999999,Adam优化器,学习率2e-4,dropout率0.15
Image-to-Image Translation 在不提供配对样本的情况下转换风格,并保持主体目标的identity
令\(h(x)\)表示风格图片x的特征映射,\(X_{t}=tX_{1}+(1-t)X_{0}\),有\(H_t = h(X_t),\; \mathrm{d}H_{t} = \nabla h(X_{t})^{T}(X_{1} - X_{0})\mathrm{d}t\)。要想风格转换正确,可以通过学习到的模型得到\(H'_t = h(Z_t)\),它尽可能地逼近\(H_t\)。因为\(\mathrm{d}H_{t}^{\prime} = \nabla h(Z_{t})^{T}v(Z_{t},t)\mathrm{d}t\),可最小化下列损失:
上式应该是计算\(\mathrm{d}H_{t}、\mathrm{d}H_{t}^{\prime}\)之间的差值,可能是考虑到\(X_{1}-X_{0}-v(X_{t},t)\)已经学习了\(Z_t\)逼近\(X_t\),因此合并了目标一致的\(\nabla h(X_{t})、\nabla h(Z_{t})\)?
从AFHQ, MetFace, CelebAHQ 数据集两两配对作为\(\pi_0, \pi_1\),其中随机挑选80%作为训练数据,其他都是测试数据,图片缩放到512x512
同样用使用DDPM++的U-Net架构,优化用AdamW, \(\beta(0.9,0.999)\),weight decay 0.1,dropout 0.1。batchsize=4,训练1000epoch,使用指数移动平均进行平滑化,比例0.9999,学习率用网格搜索,多个模型跑多个学习率,然后挑训练损失最小模型。
Domain Adaptation 在现实问题中应用机器学习有个关键挑战是训练跟测试数据集之间的域偏移(domain shift):当测试的数据跟训练集差异很大时,机器学习模型的性能会严重下降,但Rectified flow可以解决这个问题。
首先将训练和测试数据映射到预训练模型最后一个隐层的隐式表达,然后在这个表达上构建 rectified flow。同样使用DDPM++模型架构去训练,推理时用均匀分布的100步。所以这个就是将测试数据转换为训练数据所在的域,使其他模型在测试数据上的表现更好?

表2 用不同方法做转换后的测试数据的精度
评估时,用一个在训练数据上训练好的分类模型,将它在转换后的测试数据上的精度作为模型的指标。看表2效果还是很好的,跟之前最好方法 Deep CORAL 持平。
Dataset
Image Generation, I2I: CIFAR-10 和高分辨率数据集 LSUN Bedroom, LSUN Church, CelebA HQ, AFHQ Cat
Domain Adaptation: DomainNet, Office-Home
Results
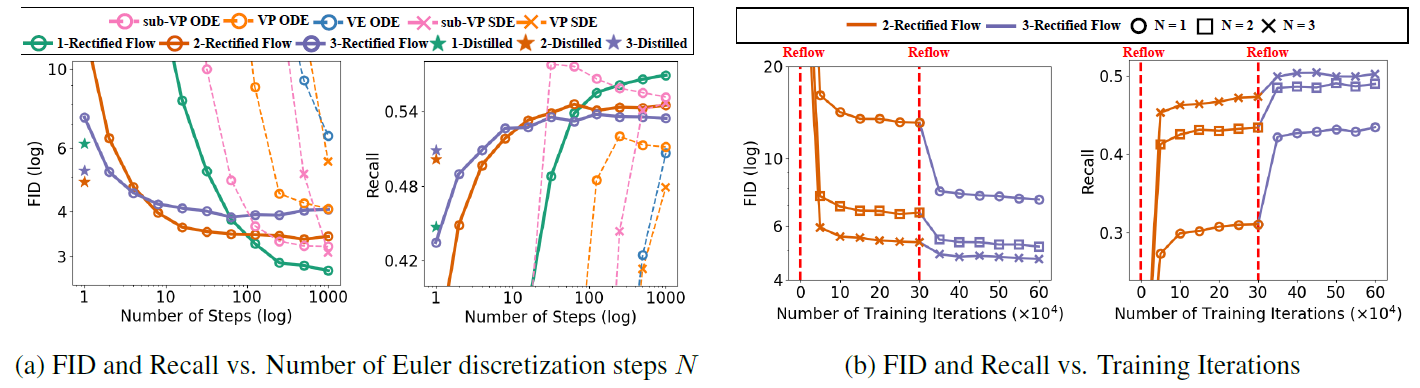
图8 Image Generation,各模型对比,k-distilled指的是从k-rectified flow蒸馏来的单步模型
图10 不同流在AFHQ猫数据集上的样本轨迹
图10外推 \(\hat{z}^t_1 = z_t + (1-t)v(z_t,t)\)。三个模型均使用一样的随机种子,看2-rectifed flow的\(\hat{z}^t_1\)几乎独立于时间,说明它的轨迹几乎是直的。

图12 用1-rectifid flow进行图片编辑的例子.
图12这里把两只猫的图片直接缝合,用ODE将其反向转换为latent code \(z_0\),因为\(z_1\)不自然,\(z_0\)在分布\(\pi_0 = \mathcal{N}(0,1)\)下的概率很小,因此将\(z_0\)移到\(\pi_0\)的高概率区域,得到\(z'_0\)。然后再利用ODE前向获得更真实的图片\(z'_1\)。上下两行获得\(z'_0\)的方式不同,其中\(\alpha \in (0,1)\)

图13 1-rectified flow当N=100时两个域的转换样本

图14 其他实验样本
Conclusion
Critique
标题图片都很吸引人,而且作者还在知乎写了介绍文章,降低了阅读门槛,然而总共41页的论文还是让人望而生畏,而且里面理论部分太专业了,还是不大好懂。理性而论方法很新颖,效果好像也不错,然而这个快似乎只针对推理时,训练时的开销仍然非常大,乃至于checkpoint的运行都不大容易。
Unknown
- 如何理解”非因果 = 轨迹交叉 = ODE解不唯一“?
- 图t1 作者1-rectified flow是(a), 还是(b)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号