Spark-2.1.1集群的安装和配置
前言
这篇文章主要是介绍Spark(2.1.1)集群的搭建,基于(hadoop-2.7.3),没有hadoop环境请看我另一篇文章Hadoop集群搭建。
Hadoop和Spark都是并行计算,两者都是用MR模型进行计算
Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束;
Spark用户提交的任务称为application,一个application对应一个SparkContext,app中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGScheduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset,由TaskScheduler分发到各个executor中执行;executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
环境准备
CentOS 7上搭建 hadoop 集群,包含 3 个节点,体验集群分布式,能够正常的访问hadoop的web页面。
准备机器:一台master,两台slave,配置每台机器保证各台机器之间通过机器名可以互访,如:
192.168.111.101 node1 (hadoop1)
192.168.111.102 node2 (hadoop2)
192.168.111.103 node3 (hadoop3)
安装spark
ps:每台机器都需要安装。
将spark压缩包上传到相应目录下。解压spark-2.1.1-bin-hadoop2.7.tgz安装包实现安装
将文件解压到/opt目录下面
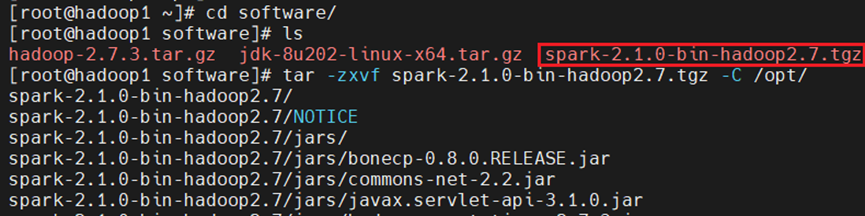
修改目录名:

修改配置
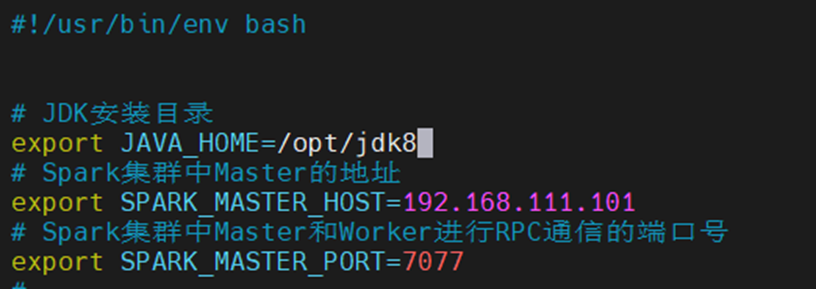
修改spark-env.sh.template文件
进入到spark的配置目录
[root@hadoop1 conf]# cd /opt/spark/conf/
[root@hadoop1 conf]# ll
[root@hadoop1 conf]# cp spark-env.sh.template spark-env.sh
[root@hadoop1 conf]# vim spark-env.sh
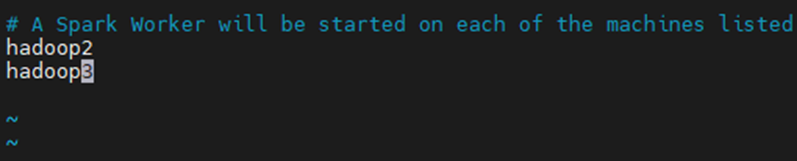
修改slaves.template文件:
[root@hadoop2 conf]# cp slaves.template slaves
[root@hadoop2 conf]# vim slaves
删除原来的localhost,增加另外两个节点的名称:
启动服务
再spark项目文件下启动(注意路径问题,很可能启动到hadoop项目):
[root@hadoop1 ~]# cd /opt/spark/sbin/
[root@hadoop1 sbin]# ./start-all.sh
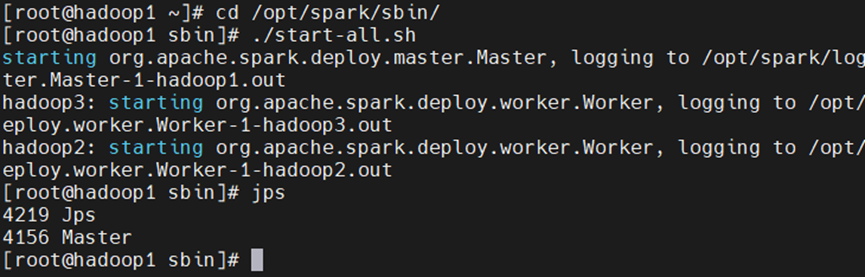
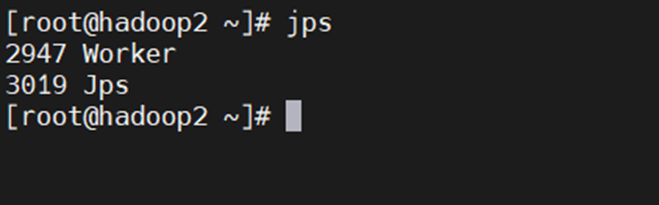
102查看相关服务:
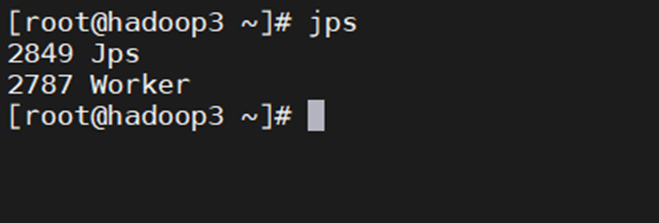
103查看相关服务:
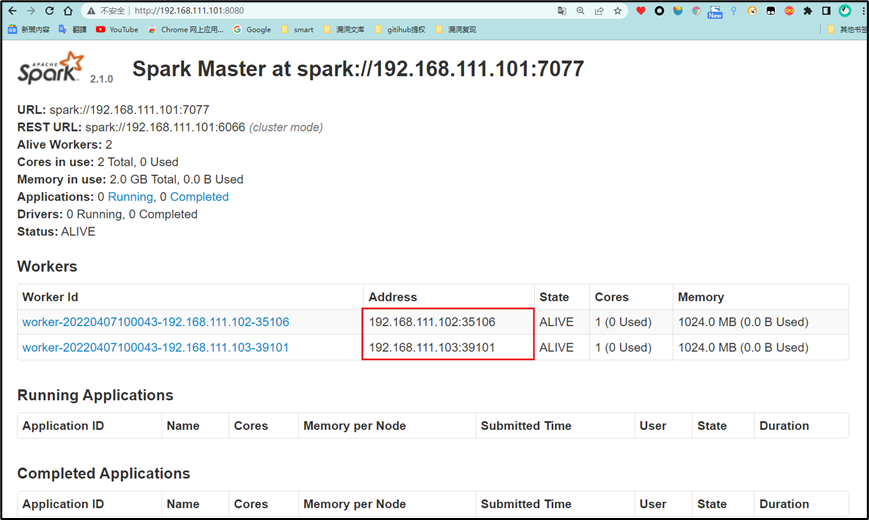
打开浏览器访问:http://192.168.111.101:8080/
案例测试
Spark 中存在大量的测试案例,比如 SparkPi(蒙特·卡罗求 Pi)
[root@hadoop1 bin]# ./spark-submit --class org.apache.spark.examples.SparkPi --master local /opt/spark/examples/jars/spark-examples_2.11-2.1.0.jar 100

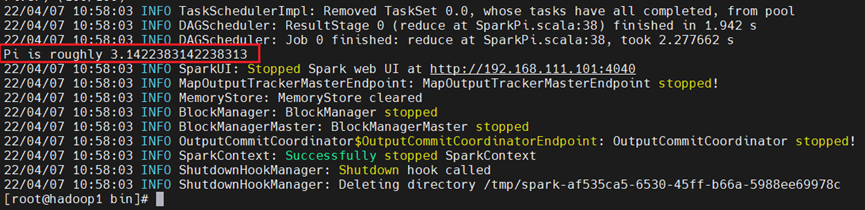
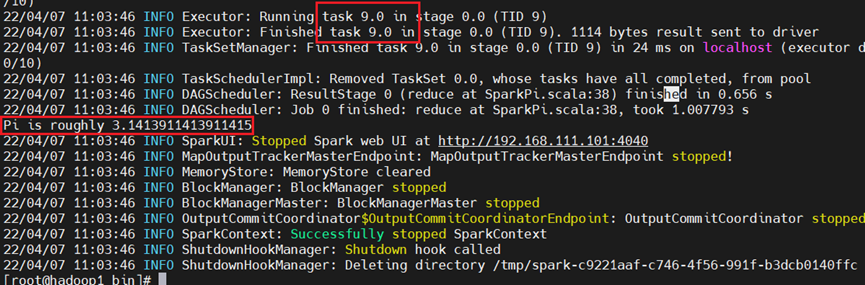
再计算10次,注意观察两次的结果,明显是有区别的!
./spark-submit --class org.apache.spark.examples.SparkPi --master local /opt/spark/examples/jars/spark-examples_2.11-2.1.0.jar 10
Hadoop适合处理离线的静态的大数据;
Spark适合处理离线的流式的大数据;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号