Hadoop集群搭建实验
前言
最近云计算实验需要搭建hadoop集群,顺便实验过程记录下来。使用的虚拟机VMware Workstation 16 Pro,还有三台centos 7 虚拟机。这种使用多台虚拟机的很麻烦,后面推荐选择使用Docker来搭建hadoop集群。
1. 实验目的
了解如何安装、配置和管理有实际意义的Hadoop集群
2. 实验内容
CentOS 7上搭建 hadoop 集群,包含 3 个节点,体验集群分布式,能够正常的访问hadoop的web页面。
准备机器:一台master,两台slave,配置每台机器保证各台机器之间通过机器名可以互访,如:
| ip | node | 描述 |
|---|---|---|
| 192.168.111.101 | node1 | (master) (hadoop1) |
| 192.168.111.102 | node2 | (slave1)(hadoop2) |
| 192.168.111.103 | node3 | (slave2)(hadoop3) |
3.1 单机配置
3.1.1 准备环境
虚拟机:Centos 7
SSH工具:MobaXterm
hadoop:hadoop-2.7.3.tar.gz
jdk:jdk-8u202-linux-x64.tar.gz
创建/software 目录 (mkdir /software), 上传jdk和hadoop
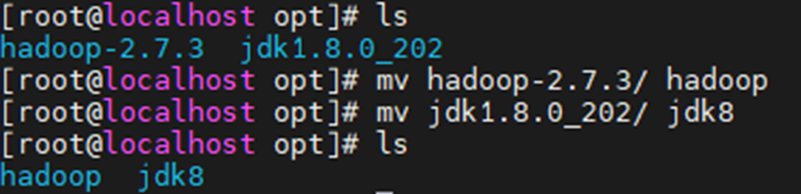
将文件解压到/opt目录下面,并修改名称
tar -xvzf hadoop-2.7.3.tar.gz -C /opt/
tar -xvzf jdk-8u202-linux-x64.tar.gz -C /opt/
3.1.2 修改配置文件
vim /etc/hosts
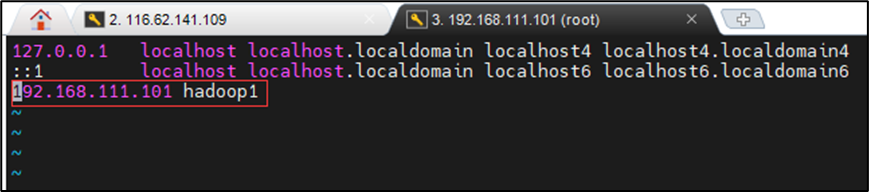
进入opt目录下
cd hadoop/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/opt/jdk8

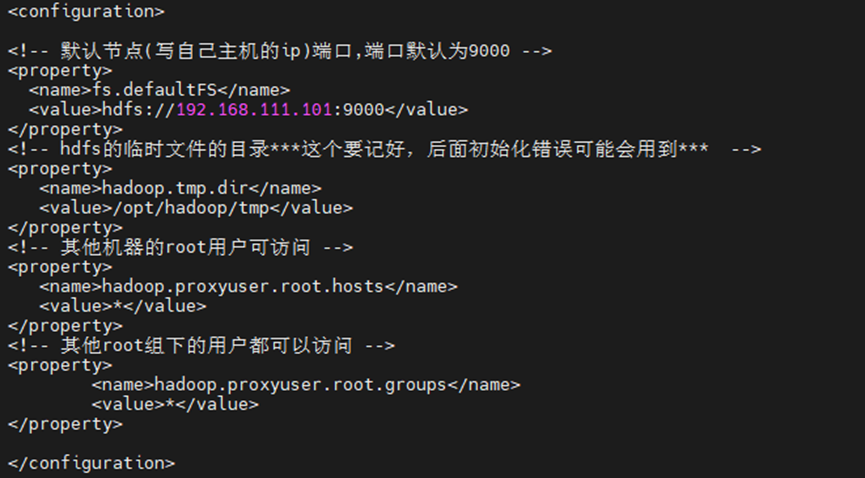
vi core-site.xml
<!-- 默认节点(写自己主机的ip)端口,端口默认为9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.226.101:9000</value>
</property>
<!-- hdfs的临时文件的目录***这个要记好,后面初始化错误可能会用到*** -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 其他机器的root用户可访问 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 其他root组下的用户都可以访问 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
vi hdfs-site.xml
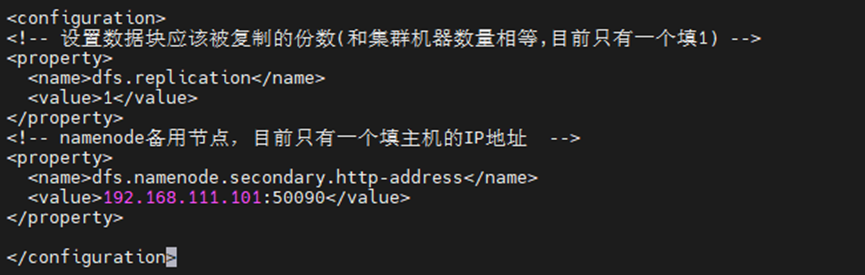
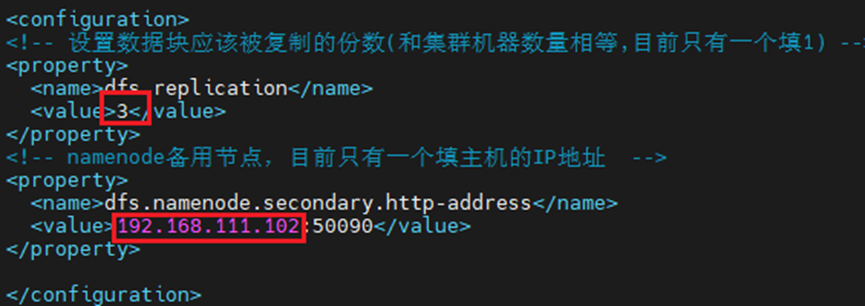
<!-- 设置数据块应该被复制的份数(和集群机器数量相等,目前只有一个填1) -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- namenode备用节点,目前只有一个填主机的IP地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.226.101:50090</value>
</property>
将文件mapred-site.xml.template改名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
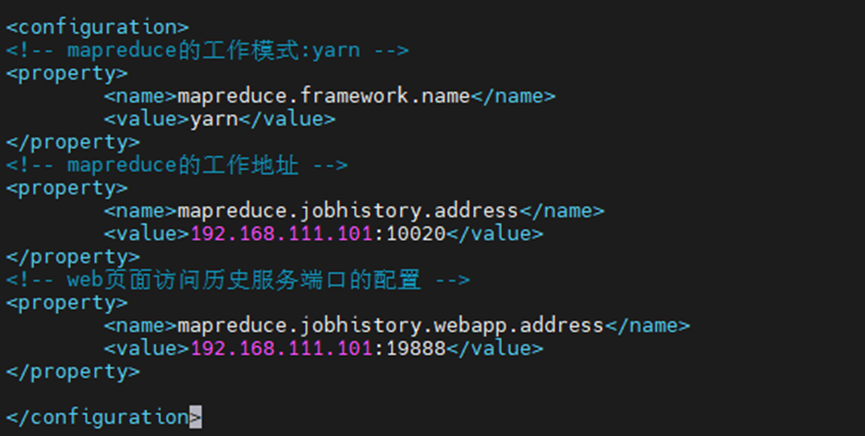
<!-- mapreduce的工作模式:yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce的工作地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.226.101:10020</value>
</property>
<!-- web页面访问历史服务端口的配置 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.226.101:19888</value>
</property>
vi yarn-site.xml
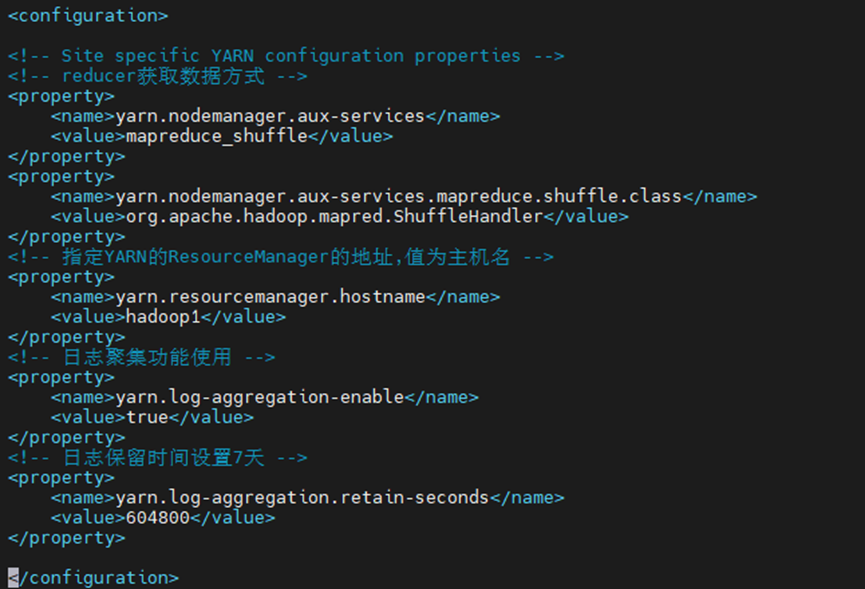
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址,值为主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
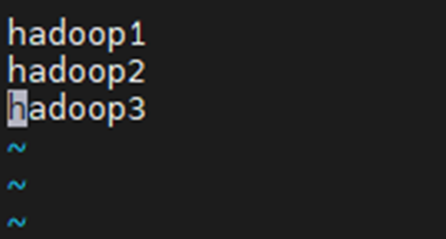
vim slaves
将内容改为主机名hadoop1
修改环境变量
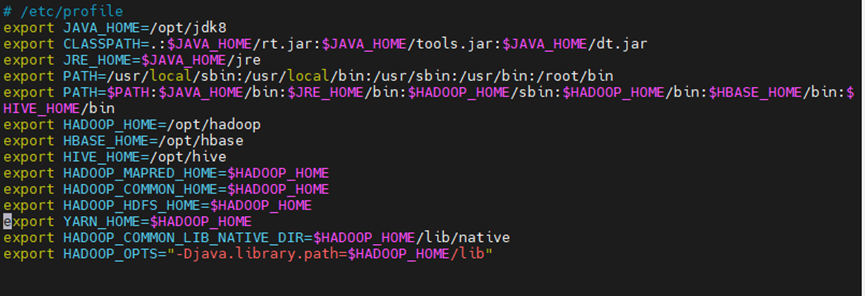
vim /etc/profile
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/rt.jar:$JAVA_HOME/tools.jar:$JAVA_HOME/dt.jar
export JRE_HOME=$JAVA_HOME/jre
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
export HADOOP_HOME=/opt/hadoop
export HBASE_HOME=/opt/hbase
export HIVE_HOME=/opt/hive
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
添加修改为:
其中hbase、hive等的环境变量暂时用不到,先配上方便以后使用完成后
source /etc/profile
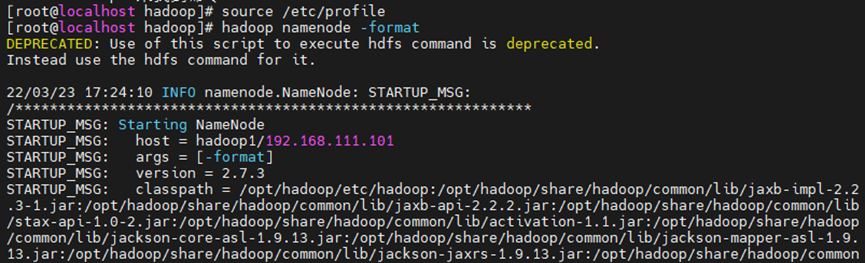
格式化HDFS
hadoop namenode -format
3.1.3 生成私钥
ssh-keygen -t rsa -P ""(注意这里是两个英文双引号)
回车后需要再按一次回车
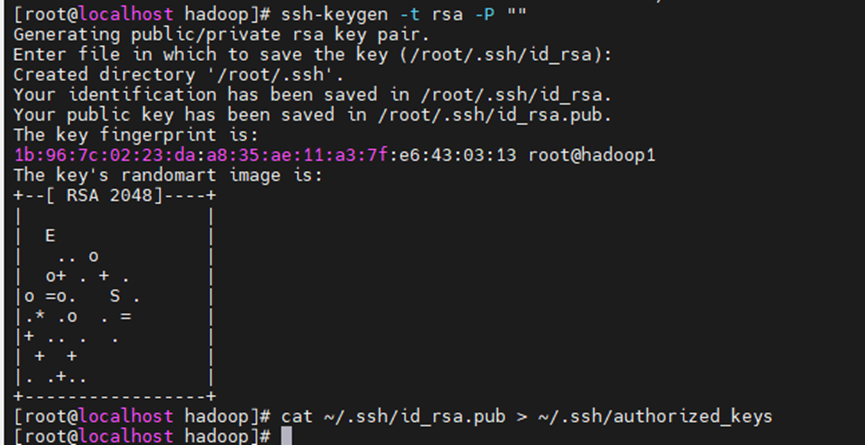
复制到授权密钥
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
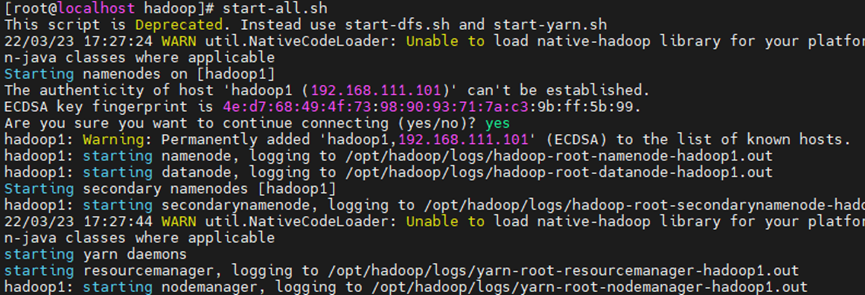
3.1.4 启动服务
start-all.sh
第一次启动需要输入yes确认密钥
jps查看
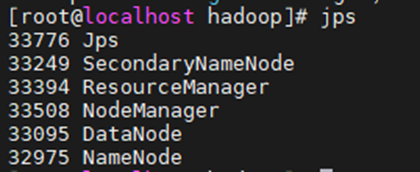
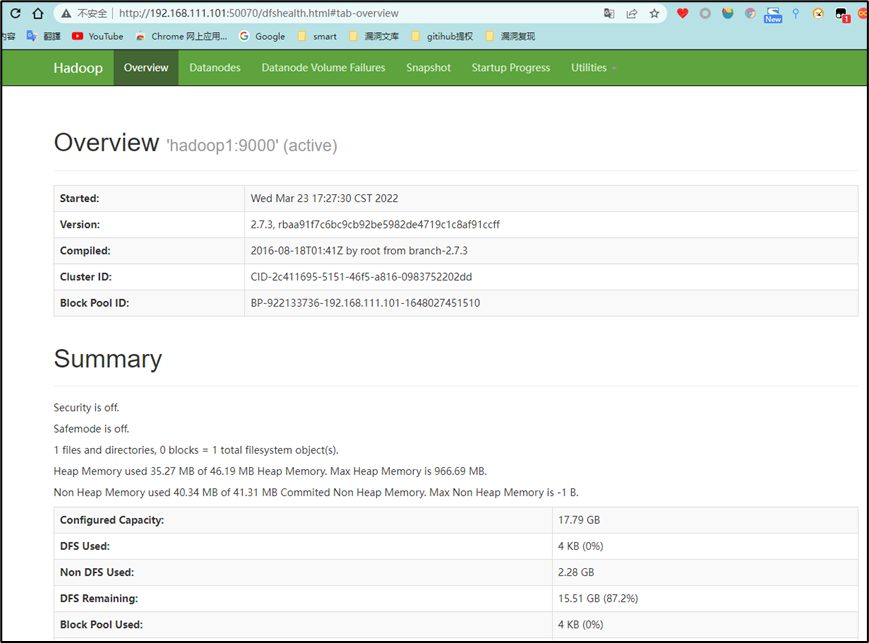
或者通过浏览器来判断服务是否开启成功
hdfs:
192.168.111.101:50070
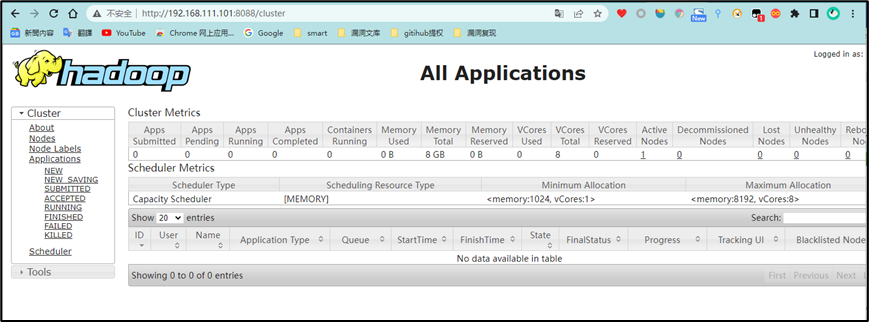
yarn:
192.168.111.101:8088
启动历史服务(开不开没关系)
mr-jobhistory-daemon.sh start historyserver
再次输入jps
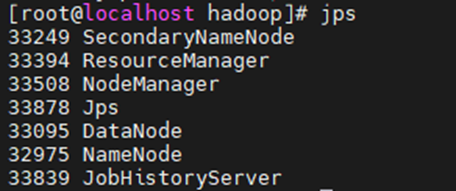
访问:http://192.168.111.101:19888/
3.1.5 关闭服务
stop-all.sh
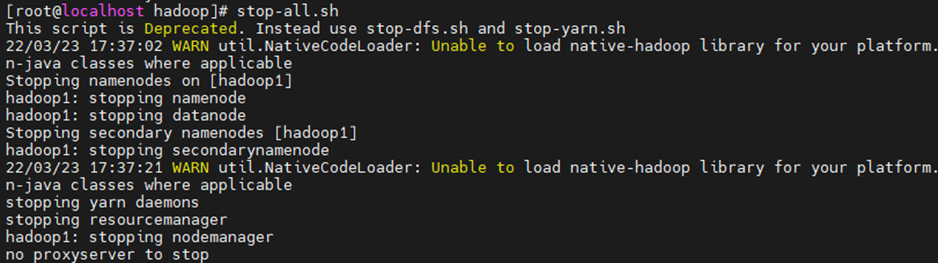
jps查看没有进程表示关闭完成

关闭历史服务
mr-jobhistory-daemon.sh stop historyserver
jps查看没有进程表示关闭完成

下次开机重新启动。
cd /opt/Hadoop/etc/Hadoop
source /etc/profile
start-all.sh
3.2 Hadoop集群的搭建
3.2.1 环境准备:
直接复制虚拟机,然后修改一些配置就可以了,在虚拟机关闭的情况下克隆。
同样的方法克隆两个
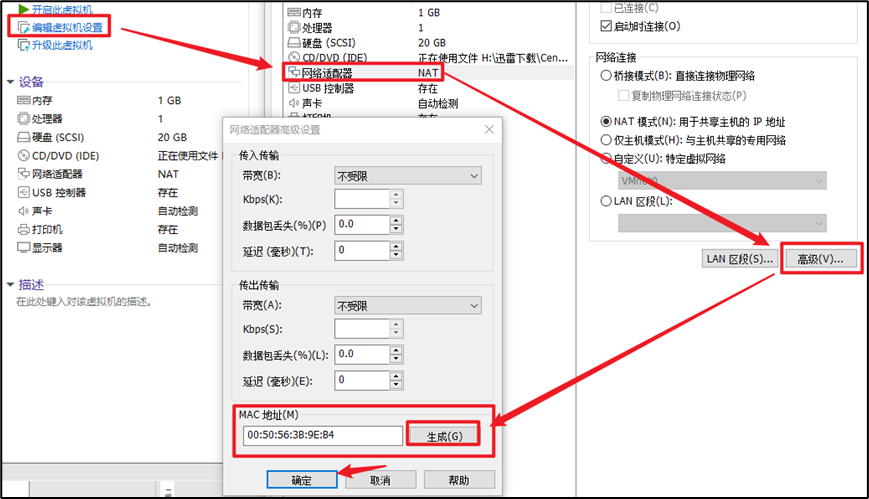
克隆完成之后的虚拟机要先将MAC地址重新生成一下,不然后面Moba连不上
3.2.2 修改虚拟机配置
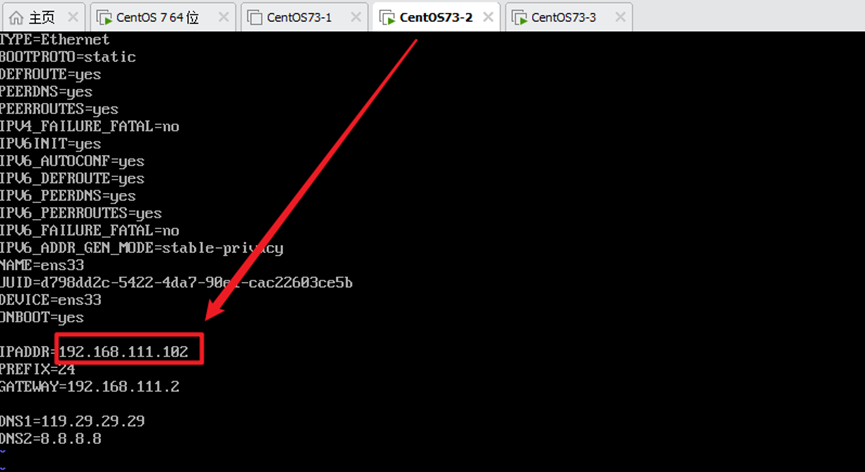
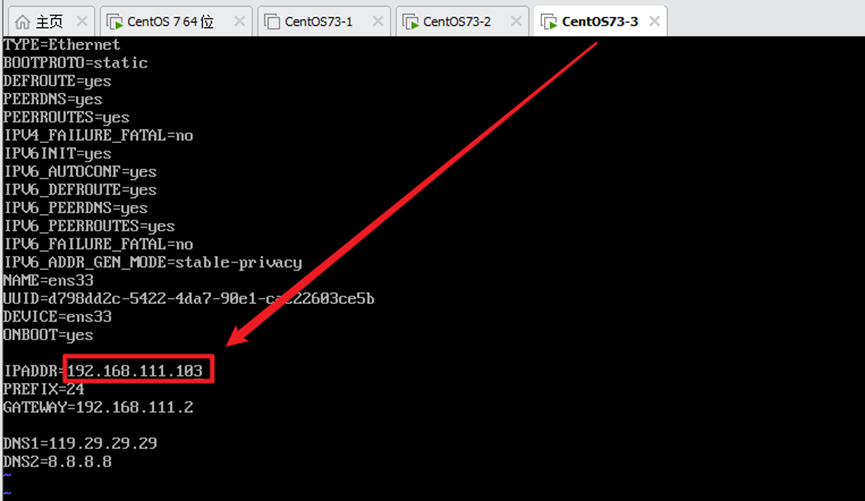
1)修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
两台机器修改IPADDR为102和103
重启网卡
systemctl restart network
修改主机名
102:
hostnamectl set-hostname hadoop2
103:
hostnamectl set-hostname hadoop3
修改完之后并不会立刻改变,可以输入命令exit先断开连接,在重连就可以显示修改后的名字
101/102/103:
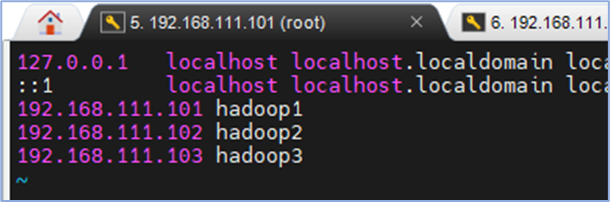
vim /etc/hosts
三个虚拟机同样操作
3.2.3 配置所有机器之间的免密登录
三台虚拟机上先执行之前同样的操作
ssh-keygen -t rsa -P ""
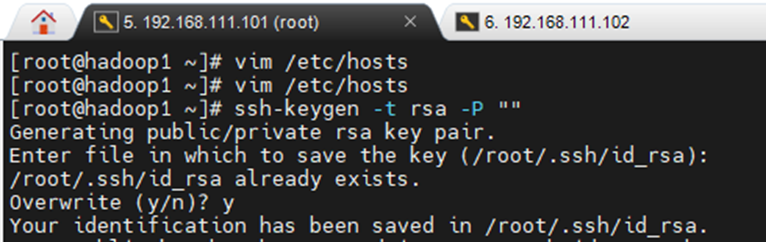
提示是否overwrite的时候输入 y
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
这里要使用一个“>”表示覆盖,重写,两个“>”表示追加
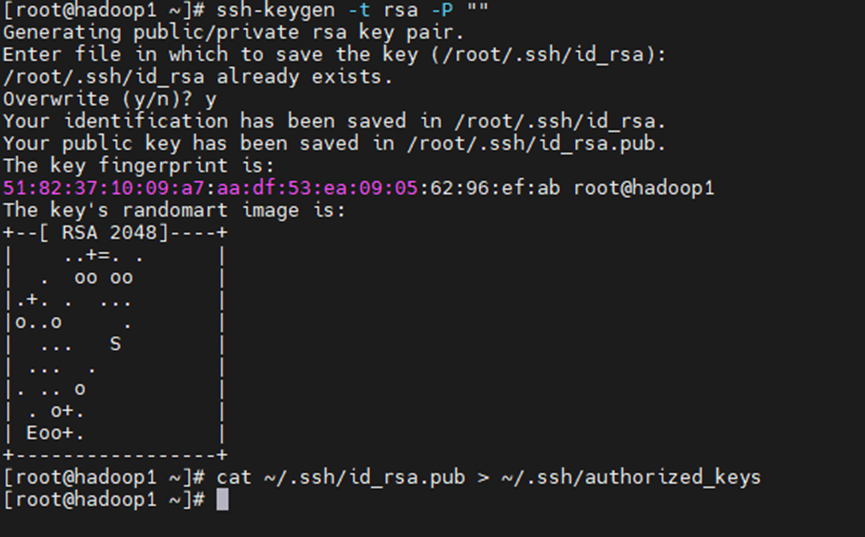
下面复制的时候小心使用
101:将授权密钥发给102,103
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.102
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.103
102:将授权密钥发给101,103
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.101
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.103
103:将授权密钥发给101,102
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.101
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@192.168.111.102
操作的时候需要输入一次yes和一次密码
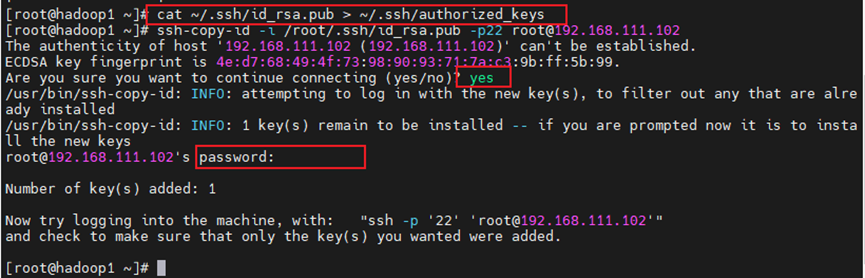
一共操作六次,完成之后测试免密切换。
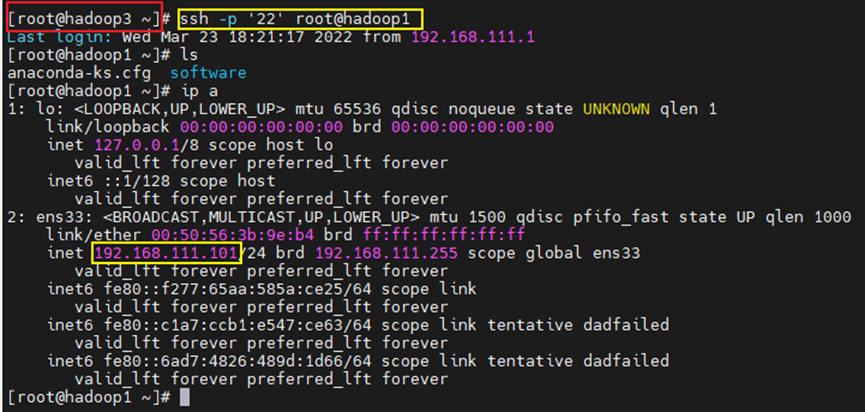
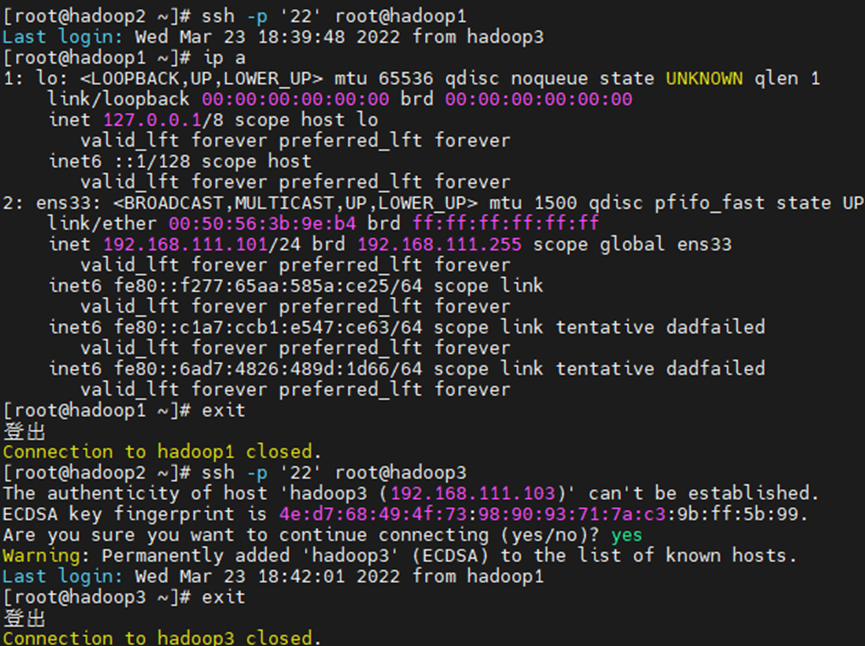
ssh -p 22 root@hadoop2(ssh hadoop2)
第一次连接却要输入yes确认,以后不用 切换用户之后可以使用命令exit登出
3.2.4 修改Hadoop配置文件
101/102/103三台虚拟机都要改:
cd /opt/hadoop/etc/hadoop
vi hdfs-site.xml
Vim slaves
只需修改102/103两台虚拟机:
vim mapred-site.xml
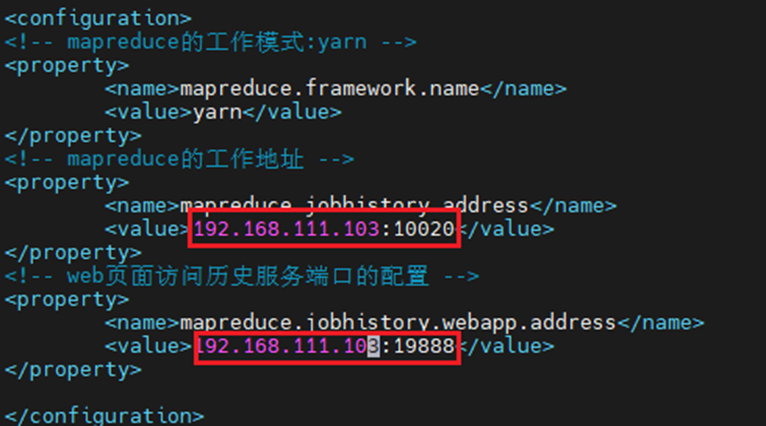
3.2.5 启动集群
先将三台虚拟机下的tmp目录删除
cd /opt/hadoop/
rm -rf tmp/

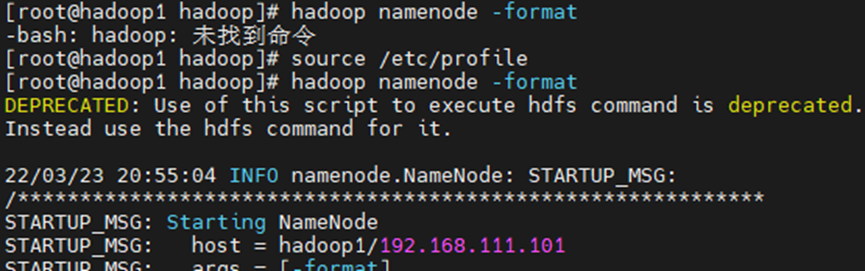
101机器初始化hdfs
hadoop namenode -format
如果出现无法找到命令,就重新激活一下配置文件
在101机器下启动服务
start-all.sh
mr-jobhistory-daemon.sh start historyserver
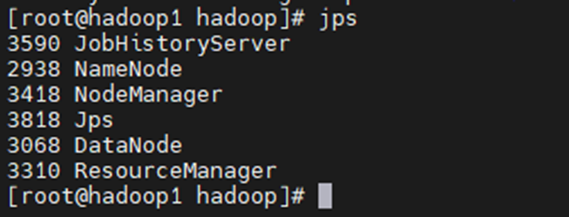
启动后分别输入jps查看启动进程
101:
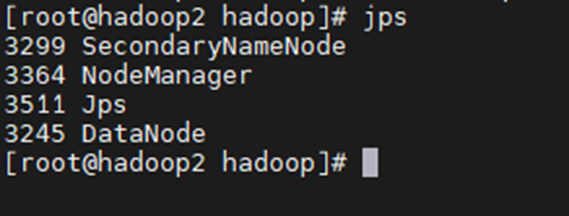
102:
103:
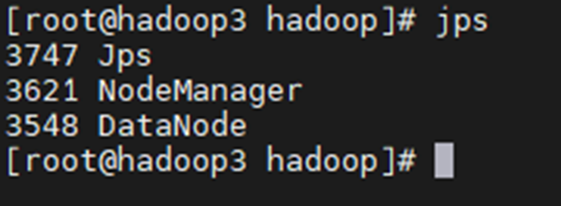
3.3 Hadoop运行wordcount
3.3.1 HDFS简介
HDFS是hadoop原生态的文件系统,HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
3.3.2 HDFS命令
1.帮助命令
一切命令都从帮助开始,命令是记不完的,只有学会使用帮助,才能免却记忆的痛苦。
hdfs dfs -help
2.查看命令
列出文件系统目录下的目录和文件
-h 以更友好的方式列出,主要针对文件大小显示成相应单位K、M、G等
-r 递归列出,类似于linux中的tree命令
hdfs dfs -ls [-h] [-r] <path>
3.查看文件内容
hdfs dfs -cat <hdfsfile>
查看文件末尾的1KB数据
hdfs dfs -tail [-f] <hdfsfile>
4.创建命令
新建目录
hdfs dfs -mkdir <path>
创建多级目录
hdfs dfs -mkdir -p <path>
新建一个空文件
hdfs dfs -touchz <filename>
上传本地文件到hdfs
-f 如果hdfs上已经存在要上传的文件,则覆盖
hdfs dfs -put [-f] <local src> <hdfs dst>
3.3.3 wordcount实践
- 准备一个英语小短文文本winepress.txt
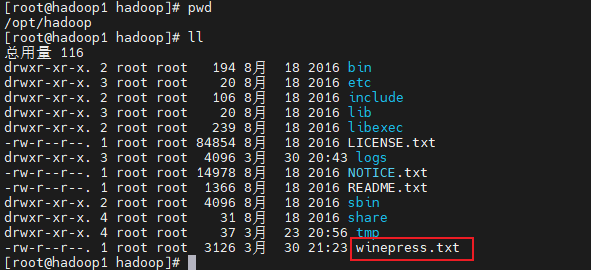
- 在HDFS中创建input目录
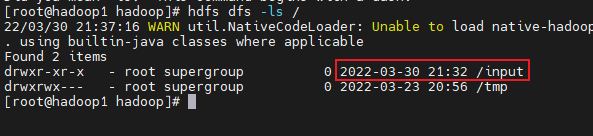
就在刚才hadoop 目录下,输入命令:hdfs dfs -mkdir /input ,之后可以用命令看:hdfs dfs -ls / 创建input目录成功
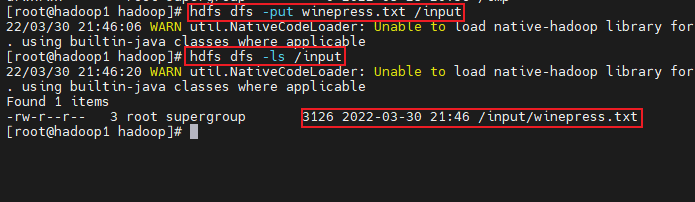
- 将winepress.txt放到input目录下
hdfs dfs -put winepress.txt /input #上传文件到指定目录
hdfs dfs -ls /input #查看目录下的文件
- 通过hadoop自带示例程序wordcount计算出其中各字母出现的次数便可
在系统文件中找到相应的hadoop-mapreduce-examples-2.7.3.jar 。
首先在hadoop/etc的同级目录找到一个叫做share的目录,再向下寻找mapreduce

执行语句统计字数:
[root@hadoop1 hadoop]# hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
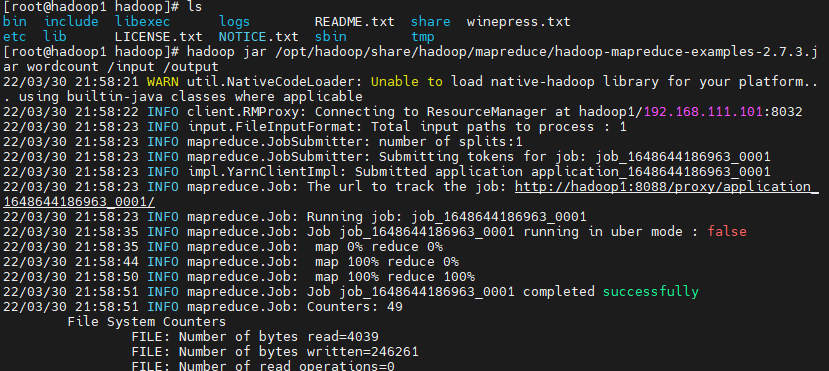
查看执行完毕的文件
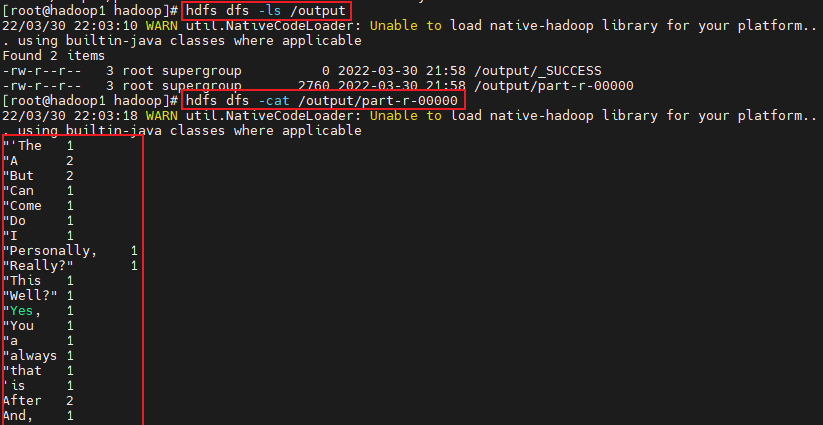
[root@hadoop1 hadoop]# hdfs dfs -ls /output
[root@hadoop1 hadoop]# hdfs dfs -cat /output/part-r-00000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号